Analysis of Machine Learning Algorithms for Opinion Mining in Different Domains


Abstract
1. Introduction
2. Literature Review
3. Datasets
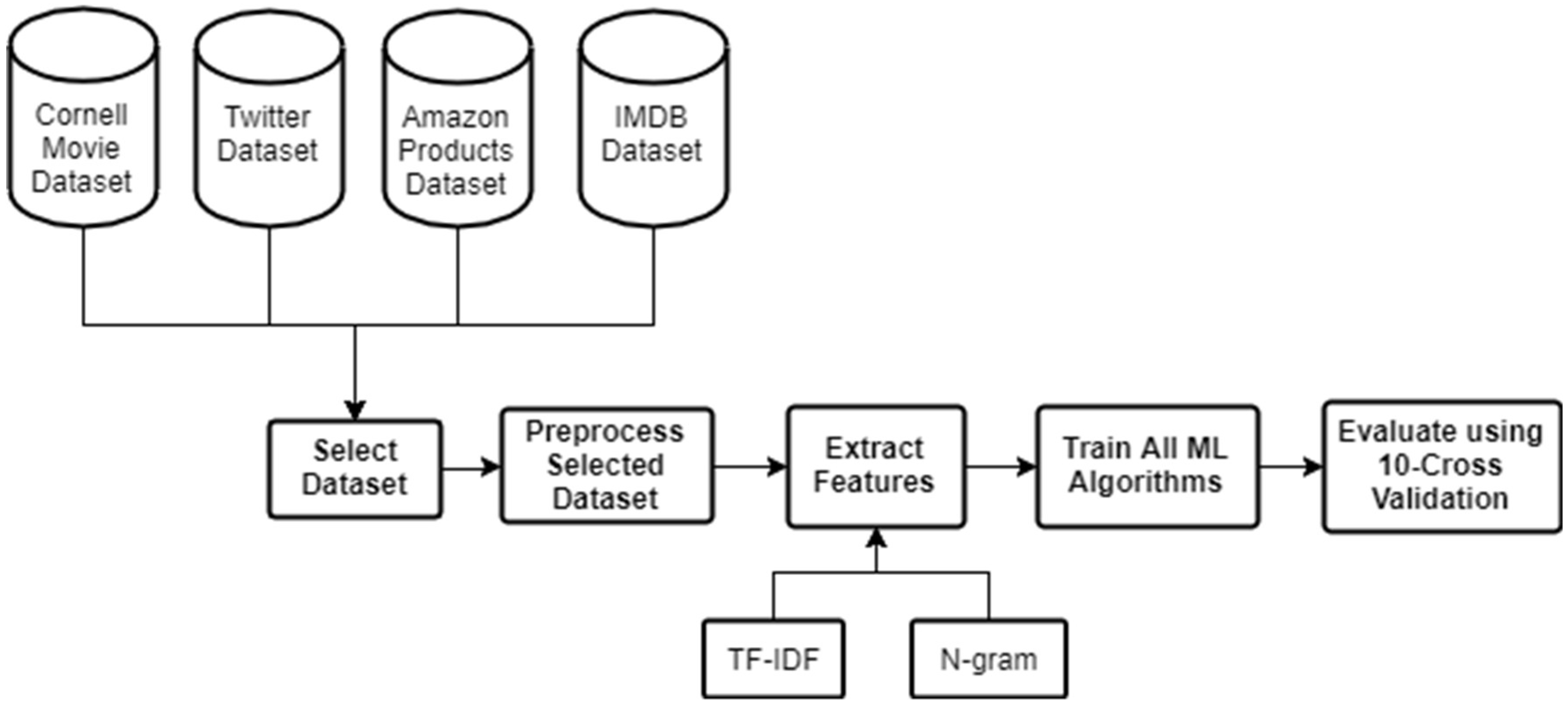
4. The Proposed Methodology
4.1. Datasets Pre-Processing
4.2. Feature Extraction
4.2.1. Term Frequency–Inverse Document Frequency Algorithm
4.2.2. N-Gram Algorithm
4.3. Machine Learning Classification
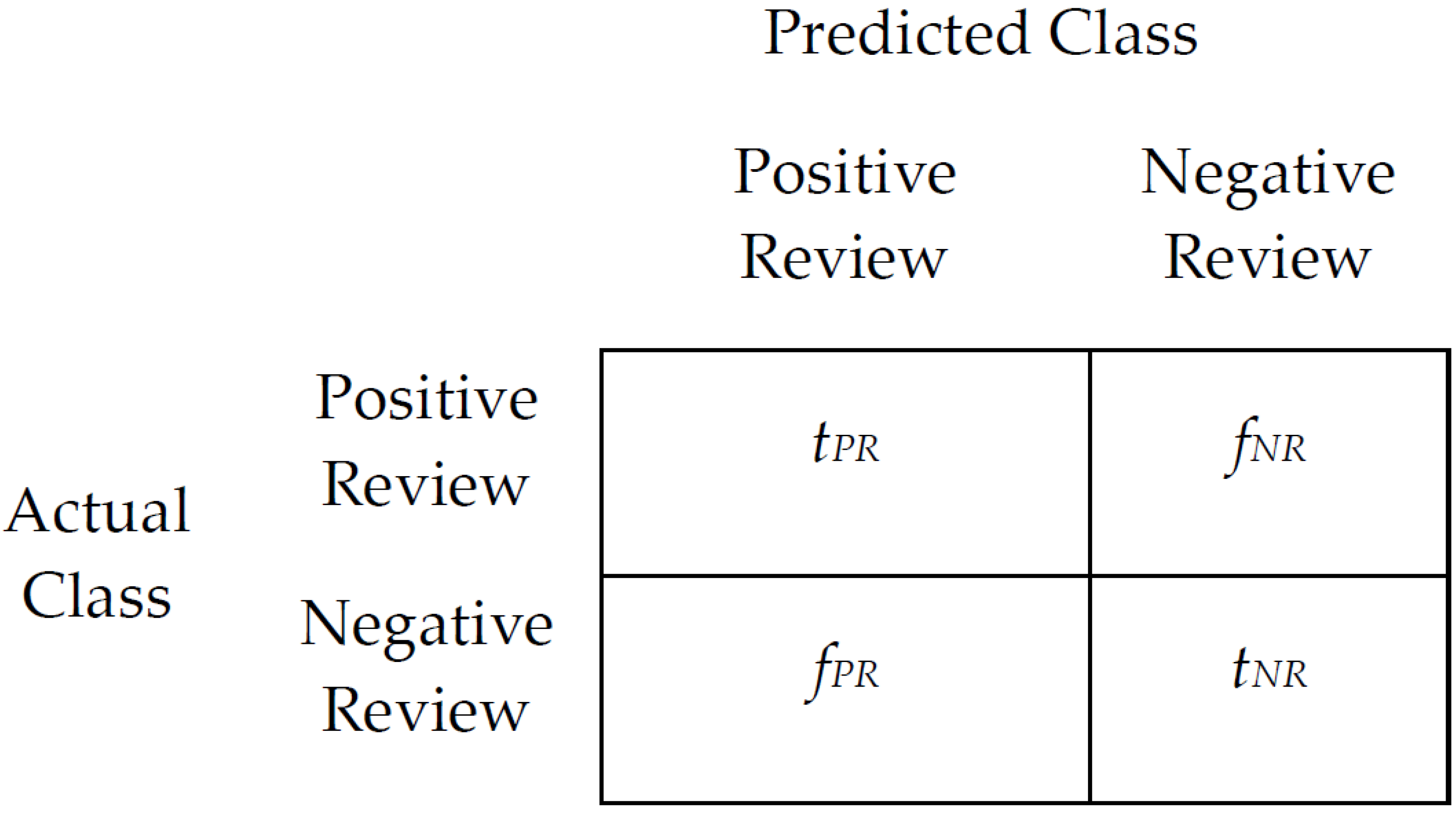
4.4. Evaluation
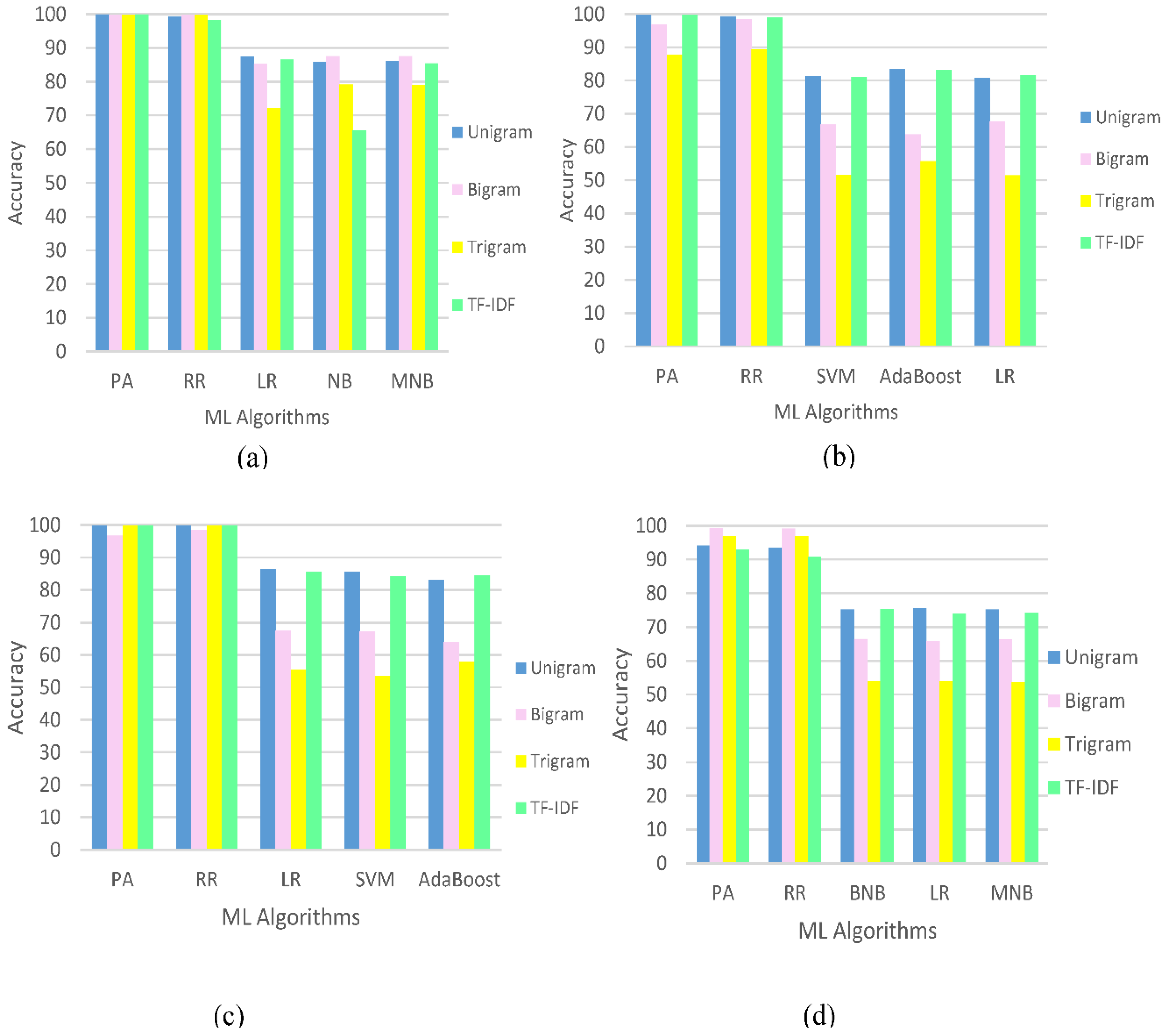
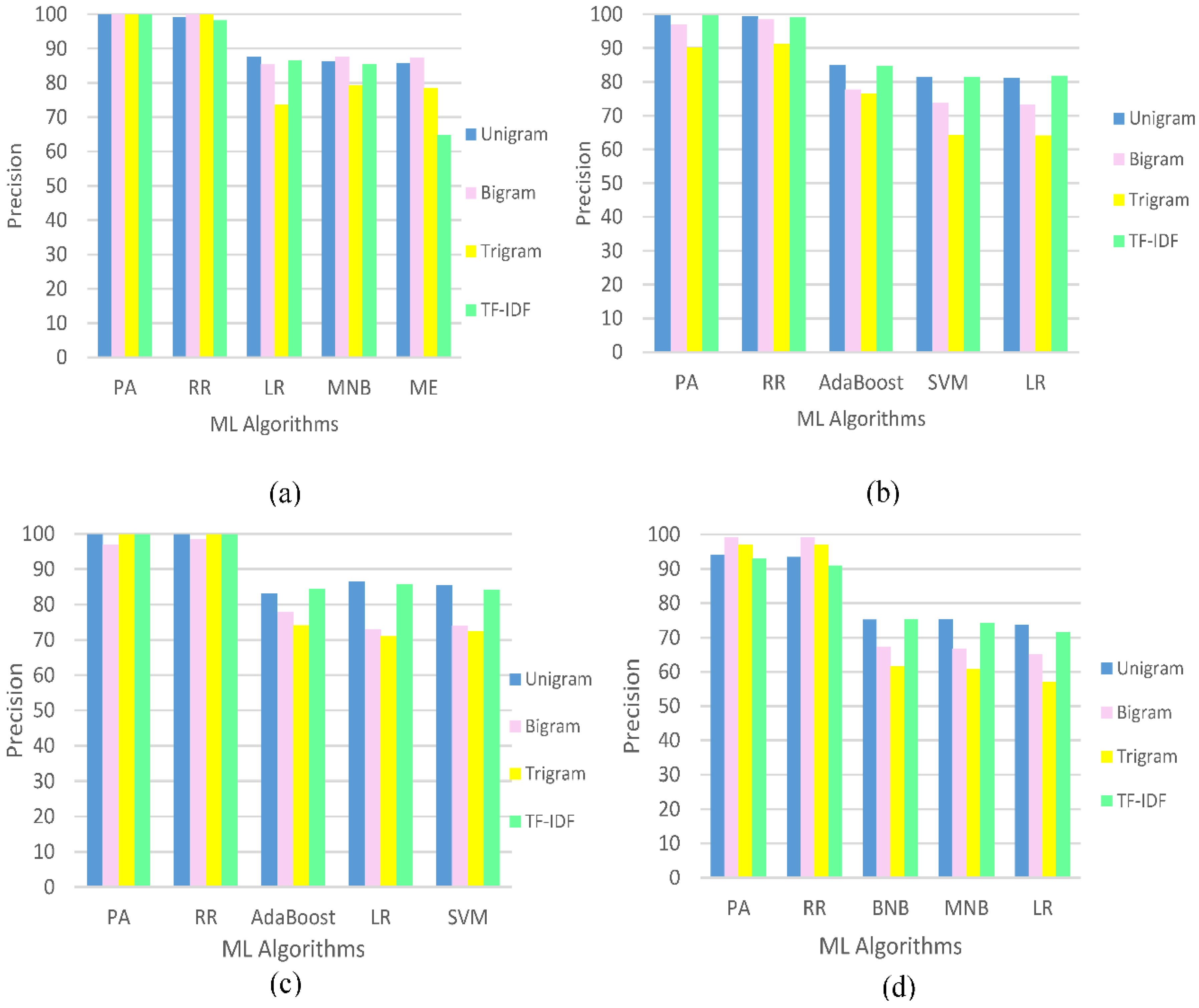
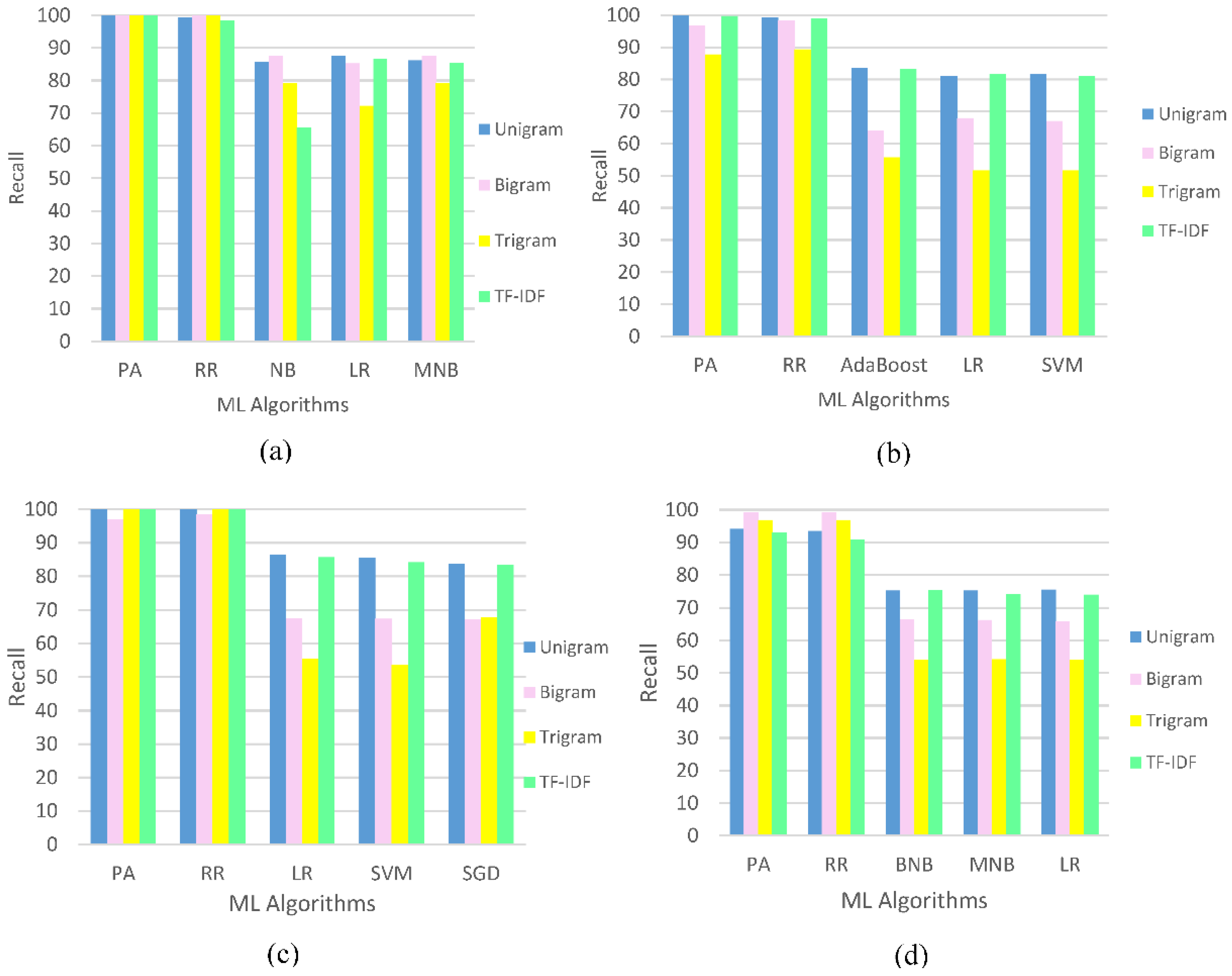
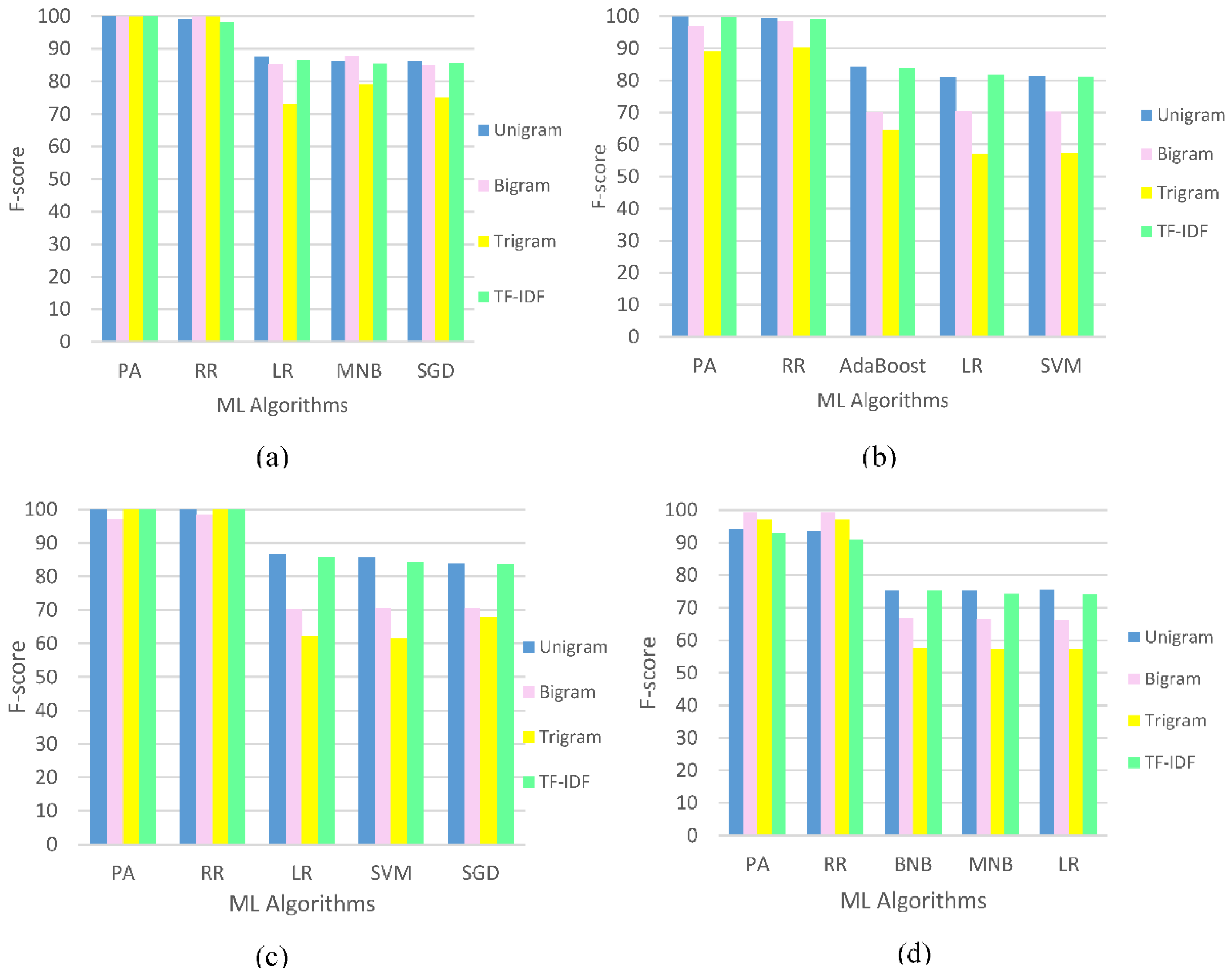
5. Results and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Gamal, D.; Alfonse, M.; El-Horbaty, E.S.; Salem, A.B. A comparative study on opinion mining algorithms of social media statuses. In Proceedings of the Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 5–7 December 2017; pp. 385–390. [Google Scholar]
- Petz, G.; Karpowicz, M.; Fürschuß, H.; Auinger, A.; Stříteský, V.; Holzinger, A. Opinion mining on the web 2.0—Characteristics of user generated content and their impacts. In Lecture Notes in Computer Science LNCS 7947; Springer: Berlin/Heidelberg, Germany, 2013; pp. 35–46. [Google Scholar] [CrossRef]
- Zhang, Z.; Ye, Q.; Zhang, Z.; Li, Y. Sentiment classification of Internet resturant reviews written in Catonese. Expert Syst. Appl. 2011, 38, 7674–7682. [Google Scholar] [CrossRef]
- Petz, G.; Karpowicz, M.; Fürschuß, H.; Auinger, A.; Stříteský, V.; Holzinger, A. Computational approaches for mining user’s opinions on the web 2.0. Inf. Process. Manag. 2015, 51, 510–519. [Google Scholar] [CrossRef]
- Tripathy, A.; Agrawal, A.; Rath, S.K. Classification of sentiment reviews using n-gram machine learning approach. Expert Syst. Appl. 2016, 57, 117–126. [Google Scholar] [CrossRef]
- Khoo, C.S.; Johnkhan, S.B. Lexicon-based sentiment analysis: Comparative evaluation of six sentiment lexicons. J. Inf. Sci. 2018, 44, 491–511. [Google Scholar] [CrossRef]
- Dey, L.; Haque, S.M. Opinion mining from noisy text data. Int. J. Doc. Anal. Recognit. IJDAR 2009, 12, 205–226. [Google Scholar] [CrossRef]
- Bouazizi, M.; Ohtsuki, T. Sentiment analysis: From binary to multi-class classification: A pattern-based approach for multi-class sentiment analysis in Twitter. In Proceedings of the IEEE International Conference Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–6. [Google Scholar]
- Barnaghi, P.; Ghaffari, P.; Breslin, J.G. Opinion mining and sentiment polarity on twitter and correlation between events and sentiment. In Proceedings of the Second international Conference Big Data Computing Service and Applications (BigDataService), Oxford, UK, 29 March–1 April 2016; pp. 52–57. [Google Scholar]
- Liu, S.M.; Chen, J.-H. A multi-label classification based approach for sentiment classification. Int. J. Expert Syst. Appl. 2015, 42, 1083–1093. [Google Scholar] [CrossRef]
- Joshi, N.S.; Itkat, S.A. A survey on feature level sentiment analysis. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 5422–5425. [Google Scholar]
- Deng, Z.-H.; Luo, K.-H.; Yu, H.-L. A study of supervised term weighting scheme for sentiment analysis. Expert Syst. Appl. 2014, 41, 3506–3513. [Google Scholar] [CrossRef]
- Hima, S.; Gladston, R.S. Analysis of machine learning techniques for opinion mining. Int. J. Adv. Res. 2015, 3, 375–381. [Google Scholar]
- Joshi, V.C.; Vekariya, V.M. An approach to sentiment analysis on Gujarati tweets. Int. J. Adv. Comput. Sci. Technol. 2017, 10, 1487–1493. [Google Scholar]
- Liu, B. Sentiment analysis and subjectivity. Int. J. Handb. Nat. Lang. Process. 2010, 2, 627–666. [Google Scholar]
- Wawre, S.V.; Deshmukh, S.N. Sentiment classification using machine learning algorithms. Int. J. Sci. Res. IJSR 2016, 5, 1–3. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011. [Google Scholar]
- Movie Review Data. Available online: http://www.cs.cornell.edu/people/pabo/movie-review-data/ (accessed on 2 August 2018).
- Kotzias, D.; Denil, M.; de Freitas, N.; Smyth, P. From group to individual labels using deep features. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 597–606. [Google Scholar]
- Twitter Sentiment Analysis Training Corpus (Dataset). Available online: http://thinknook.com/twitter-sentiment-analysis-training-corpus-dataset-2012-09-22/ (accessed on 2 August 2018).
- The MIT License (MIT). Available online: http://vineetdhanawat.mit-license.org/ (accessed on 2 August 2018).
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. In Proceedings of the Association for Computational Linguistics (ACL)-02 Conference on Empirical Methods in Natural Language Processing, Stroudsburg, PA, USA, 6–7 July 2002; Volume 10, pp. 79–86. [Google Scholar]
- Pang, B.; Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004. [Google Scholar]
- Derczynski, L.; Maynard, D.; Aswani, N.; Bontcheva, K. Microblog-genre noise and impact on semantic annotation accuracy. In Proceedings of the 24th ACM Conference on Hypertext and Social Media, Paris, France, 1–3 May 2013; ACM: New York, NY, USA, 2013; pp. 21–30. [Google Scholar]
- Petz, G.; Karpowicz, M.; Fürschuß, H.; Auinger, A.; Winkler, S.M.; Schaller, S.; Holzinger, A. On text preprocessing for opinion mining outside of laboratory environments. In Active Media Technology, Lecture Notes in Computer Science, LNCS 7669; Huang, R., Ghorbani, A., Pasi, G., Yamaguchi, T., Yen, N., Jin, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 618–629. [Google Scholar] [CrossRef]
- Derczynski, L.; Ritter, A.; Clark, S.; Bontcheva, K. Twitter part-of-speech tagging for all: Overcoming sparse and noisy data. In Proceedings of the International Conference Recent Advances in Natural Language Processing RANLP 2013, Hissar, Bulgaria, 7–13 September 2013; pp. 198–206. [Google Scholar]
- O’Keefe, T.; Koprinska, I. Feature selection and weighting methods in sentiment analysis. In Proceedings of the 14th Australasian Document Computing Symposium, Sydney, Australia, 4 December 2009. [Google Scholar]
- Tamilselvi, A.; ParveenTaj, M. Sentiment analysis of micro blogs using opinion mining classification algorithm. Int. J. Sci. Res. IJSR 2013, 2, 196–202. [Google Scholar]
- Kao, A.; Poteet, S.R. (Eds.) Natural Language Processing and Text Mining; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Aggarwal, C.C.; Zhai, C. (Eds.) Mining Text Data; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Srivastava, A.N.; Sahami, M. Text Mining: Classification, Clustering, and Applications; (Chapman and Hall/CRC): The CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Scikit-Learn Machine Learning in Python. Available online: https://scikit-learn.org/ (accessed on 17 July 2018).
- Natural Language Toolkit. Available online: https://www.nltk.org/ (accessed on 17 July 2018).
- Wan, Y.; Gao, Q. An ensemble sentiment classification system of twitter data for airline services analysis. In Proceedings of the International Conference on Data Mining Workshops (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 1318–1325. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | IMDB | Cornell Movies | Amazon | Tweets | |
|---|---|---|---|---|---|
| Term | |||||
| Positive | 12,500 | 1000 | 500 | 75 K | |
| Negative | 12,500 | 1000 | 500 | 75 K | |
| Total | 25 K | 2000 | 1000 | 150 K | |
| ML Classifier | Dataset | IMDB | Cornell Movies | Amazon | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Feature Extraction | Unigram | Bigram | Trigram | TF-IDF | Unigram | Bigram | Trigram | TF-IDF | Unigram | Bigram | Trigram | TF-IDF | Unigram | Bigram | Trigram | TF-IDF | |
| NB | Acc. | 85.76 | 87.56 | 79.16 | 65.56 | 69.76 | 60.76 | 70.36 | 52.46 | 79.66 | 58.66 | 50.56 | 67.06 | 74.66 | 65.96 | 53.76 | 70.16 |
| Prc. | 85.96 | 87.56 | 79.16 | 65.96 | 78.56 | 70.76 | 70.36 | 52.16 | 79.66 | 67.36 | 64.66 | 67.66 | 74.86 | 66.46 | 60.96 | 70.36 | |
| Rcl. | 85.76 | 87.56 | 79.16 | 65.56 | 69.76 | 62.36 | 70.26 | 52.16 | 79.66 | 60.76 | 52.26 | 66.96 | 74.66 | 65.96 | 54.16 | 70.16 | |
| F-S | 85.86 | 87.56 | 79.16 | 65.76 | 73.86 | 66.26 | 70.36 | 52.16 | 79.66 | 63.86 | 57.86 | 67.36 | 74.76 | 66.26 | 57.36 | 70.26 | |
| BNB | Acc. | 86.16 | 83.66 | 62.56 | 84.86 | 78.46 | 61.46 | 50.26 | 79.56 | 79.46 | 62.46 | 50.26 | 80.26 | 75.26 | 66.46 | 53.96 | 75.36 |
| Prc. | 85.06 | 85.56 | 76.86 | 85.16 | 79.86 | 73.66 | 45.06 | 81.16 | 79.46 | 71.06 | 64.66 | 80.66 | 75.26 | 67.36 | 61.66 | 75.36 | |
| Rcl. | 84.76 | 83.66 | 62.66 | 84.86 | 78.46 | 62.86 | 50.16 | 79.56 | 79.66 | 63.76 | 51.76 | 80.36 | 75.26 | 66.46 | 53.96 | 75.36 | |
| F-S | 84.86 | 84.56 | 68.96 | 84.96 | 79.16 | 67.86 | 47.46 | 80.36 | 79.56 | 67.16 | 57.56 | 80.56 | 75.26 | 66.86 | 57.56 | 75.36 | |
| MNB | Acc. | 86.16 | 87.56 | 79.06 | 85.46 | 82.06 | 62.26 | 70.26 | 81.66 | 79.46 | 59.66 | 50.56 | 79.06 | 75.26 | 66.26 | 53.76 | 74.26 |
| Prc. | 86.26 | 87.56 | 79.26 | 85.46 | 81.96 | 73.86 | 70.36 | 81.66 | 79.56 | 68.06 | 64.66 | 79.56 | 75.36 | 66.86 | 60.86 | 74.26 | |
| Rcl. | 86.16 | 87.56 | 79.16 | 85.46 | 82.06 | 63.96 | 70.26 | 81.66 | 79.46 | 61.76 | 52.26 | 79.16 | 75.26 | 66.26 | 54.16 | 74.26 | |
| F-S | 86.26 | 87.66 | 79.16 | 85.46 | 82.06 | 68.56 | 70.36 | 81.66 | 79.56 | 64.76 | 57.86 | 79.36 | 75.36 | 66.56 | 57.26 | 74.26 | |
| AdaBoost | Acc. | 80.36 | 65.26 | 57.96 | 80.46 | 83.06 | 64.06 | 57.96 | 84.46 | 83.56 | 63.76 | 55.76 | 83.26 | 64.46 | 52.76 | 51.16 | 64.46 |
| Prc. | 80.56 | 72.86 | 68.26 | 80.56 | 83.06 | 77.86 | 74.16 | 84.46 | 84.96 | 77.76 | 76.46 | 84.66 | 64.66 | 67.86 | 62.66 | 69.66 | |
| Rcl. | 80.36 | 65.26 | 57.96 | 80.36 | 83.06 | 64.06 | 57.96 | 84.46 | 83.56 | 63.96 | 55.76 | 83.26 | 64.46 | 52.76 | 51.16 | 64.46 | |
| F-S | 80.46 | 68.76 | 62.76 | 80.46 | 83.06 | 70.36 | 65.06 | 84.46 | 84.26 | 70.16 | 64.46 | 83.96 | 66.96 | 59.36 | 56.36 | 66.96 | |
| ME | Acc. | 85.66 | 87.16 | 78.56 | 64.36 | 68.16 | 57.96 | 69.56 | 52.36 | 77.26 | 56.76 | 51.66 | 64.86 | 74.76 | 65.96 | 53.86 | 70.46 |
| Prc. | 85.86 | 87.26 | 78.56 | 64.86 | 77.76 | 70.06 | 69.76 | 52.36 | 77.86 | 67.76 | 64.16 | 67.46 | 74.96 | 66.56 | 61.36 | 70.56 | |
| Rcl. | 85.66 | 87.16 | 78.56 | 64.36 | 68.56 | 58.06 | 69.56 | 52.36 | 77.26 | 56.76 | 51.66 | 64.86 | 74.76 | 65.96 | 53.86 | 70.46 | |
| F-S | 85.76 | 87.26 | 78.56 | 64.56 | 72.86 | 63.46 | 69.66 | 52.36 | 77.56 | 61.76 | 57.26 | 66.16 | 74.86 | 66.26 | 57.36 | 70.46 | |
| SGD | Acc. | 86.16 | 84.96 | 74.26 | 85.56 | 83.66 | 67.06 | 67.86 | 83.46 | 79.36 | 67.26 | 51.36 | 78.86 | 74.96 | 65.66 | 52.96 | 73.16 |
| Prc. | 86.16 | 84.96 | 75.66 | 85.66 | 83.76 | 74.06 | 67.96 | 83.56 | 79.26 | 74.36 | 64.06 | 79.06 | 75.16 | 66.46 | 63.26 | 73.16 | |
| Rcl. | 86.16 | 84.96 | 74.26 | 85.56 | 83.76 | 67.16 | 67.86 | 83.46 | 79.16 | 67.56 | 51.56 | 78.76 | 74.96 | 65.66 | 52.96 | 73.16 | |
| F-S | 86.16 | 84.96 | 74.96 | 85.66 | 83.76 | 70.46 | 67.86 | 83.56 | 79.26 | 70.76 | 57.16 | 78.96 | 75.06 | 66.06 | 57.66 | 73.16 | |
| SVM | Acc. | 85.76 | 85.26 | 73.36 | 84.56 | 85.56 | 67.26 | 53.56 | 84.16 | 81.36 | 66.76 | 51.66 | 81.16 | 73.66 | 64.86 | 53.86 | 71.46 |
| Prc. | 85.76 | 85.26 | 74.36 | 84.56 | 85.56 | 74.06 | 72.36 | 84.16 | 81.36 | 73.76 | 64.16 | 81.36 | 73.66 | 65.36 | 60.96 | 71.46 | |
| Rcl. | 85.76 | 85.26 | 73.26 | 84.56 | 85.56 | 67.36 | 53.56 | 84.16 | 81.56 | 67.06 | 51.66 | 81.06 | 73.66 | 64.86 | 53.86 | 71.46 | |
| F-S | 85.76 | 85.26 | 73.86 | 84.56 | 85.56 | 70.56 | 61.56 | 84.16 | 81.46 | 70.26 | 57.26 | 81.26 | 73.66 | 65.16 | 57.16 | 71.46 | |
| LR | Acc. | 87.46 | 85.26 | 72.16 | 86.56 | 86.46 | 67.46 | 55.36 | 85.66 | 80.86 | 67.66 | 51.46 | 81.56 | 75.56 | 65.86 | 53.96 | 74.06 |
| Prc. | 87.56 | 85.36 | 73.66 | 86.56 | 86.46 | 72.96 | 71.06 | 85.66 | 81.16 | 73.16 | 64.06 | 81.76 | 75.56 | 66.46 | 61.06 | 74.06 | |
| Rcl. | 87.46 | 85.26 | 72.16 | 86.56 | 86.46 | 67.56 | 55.46 | 85.66 | 81.06 | 67.96 | 51.66 | 81.56 | 75.56 | 65.86 | 53.96 | 74.06 | |
| F-S | 87.56 | 85.36 | 72.96 | 86.56 | 86.46 | 70.16 | 62.26 | 85.66 | 81.06 | 70.46 | 57.16 | 81.66 | 75.56 | 66.16 | 57.26 | 74.06 | |
| PA | Acc. | 99.96 | 99.86 | 99.86 | 99.96 | 99.96 | 96.76 | 99.96 | 99.96 | 99.86 | 96.76 | 87.76 | 99.76 | 94.16 | 99.26 | 96.86 | 92.96 |
| Prc. | 99.96 | 99.86 | 99.86 | 99.96 | 99.96 | 96.96 | 99.96 | 99.96 | 99.76 | 96.96 | 90.26 | 99.76 | 94.16 | 99.26 | 97.06 | 92.96 | |
| Rcl. | 99.96 | 99.86 | 99.86 | 99.96 | 99.96 | 96.86 | 99.96 | 99.96 | 99.86 | 96.86 | 87.76 | 99.76 | 94.16 | 99.26 | 96.86 | 92.96 | |
| F-S | 99.96 | 99.86 | 99.86 | 99.96 | 99.96 | 96.96 | 99.96 | 99.96 | 99.86 | 96.86 | 88.96 | 99.76 | 94.16 | 99.26 | 96.96 | 92.96 | |
| RR | Acc. | 99.16 | 99.86 | 99.86 | 98.26 | 99.96 | 98.46 | 99.96 | 99.96 | 99.36 | 98.46 | 89.26 | 99.06 | 93.46 | 99.16 | 96.86 | 90.86 |
| Prc. | 99.16 | 99.86 | 99.86 | 98.26 | 99.96 | 98.56 | 99.96 | 99.96 | 99.36 | 98.46 | 91.16 | 99.06 | 93.46 | 99.16 | 97.06 | 90.96 | |
| Rcl. | 99.16 | 99.86 | 99.86 | 98.26 | 99.96 | 98.46 | 99.96 | 99.96 | 99.36 | 98.46 | 89.36 | 99.06 | 93.46 | 99.16 | 96.86 | 90.86 | |
| F-S | 99.16 | 99.86 | 99.86 | 98.26 | 99.96 | 98.46 | 99.96 | 99.96 | 99.36 | 98.46 | 90.26 | 99.06 | 93.46 | 99.16 | 96.96 | 90.96 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gamal, D.; Alfonse, M.; M. El-Horbaty, E.-S.; M. Salem, A.-B. Analysis of Machine Learning Algorithms for Opinion Mining in Different Domains. Mach. Learn. Knowl. Extr. 2019, 1, 224-234. https://doi.org/10.3390/make1010014
Gamal D, Alfonse M, M. El-Horbaty E-S, M. Salem A-B. Analysis of Machine Learning Algorithms for Opinion Mining in Different Domains. Machine Learning and Knowledge Extraction. 2019; 1(1):224-234. https://doi.org/10.3390/make1010014
Chicago/Turabian StyleGamal, Donia, Marco Alfonse, El-Sayed M. El-Horbaty, and Abdel-Badeeh M. Salem. 2019. "Analysis of Machine Learning Algorithms for Opinion Mining in Different Domains" Machine Learning and Knowledge Extraction 1, no. 1: 224-234. https://doi.org/10.3390/make1010014
APA StyleGamal, D., Alfonse, M., M. El-Horbaty, E.-S., & M. Salem, A.-B. (2019). Analysis of Machine Learning Algorithms for Opinion Mining in Different Domains. Machine Learning and Knowledge Extraction, 1(1), 224-234. https://doi.org/10.3390/make1010014