
Data-Driven Prediction of Polymer Nanocomposite Tensile Strength Through Gaussian Process Regression and Monte Carlo Simulation with Enhanced Model Reliability

 , , ,
, , , 
Abstract
1. Introduction
2. Background Theory
Recent Advances in Probabilistic and Reliability-Based Modeling of Composite Materials
3. Materials and Methodology
3.1. Database
- Type of polymer matrix and its density (e.g., PE, PP, PLA, Epoxy, PU, etc.);
- Mechanical properties of the polymer matrix: Young’s modulus and tensile strength;
- Physical characteristics of the nanofillers: density, average length, and average diameter/thickness (applicable to CNTs, graphene, nanoclays, oxides, etc.);
- Mechanical properties of nanofillers: Young’s modulus;
- Incorporation parameters: nanofiller weight fraction, processing method, and nanofiller surface modification method.
3.2. Machine Learning Method: Gaussian Process Regression
Overview of Gaussian Process Regression
- is the observed output (tensile strength);
- is the latent function;
- ε∼N(0, ) is Gaussian noise with zero mean and variance .
- is the Euclidean distance between two input vectors;
- is the signal variance;
- is the characteristic length scale;
- controls the relative weighting of large-scale and small-scale variations.
- Coefficient of Determination (R):
- Root Mean Square Error (RMSE):
- Mean Absolute Error (MAE):
- Mean Absolute Percentage Error (MAPE):
- Willmott’s Index of Agreement (IA):
3.3. Monte Carlo Method for Random Sampling
4. Results and Discussion
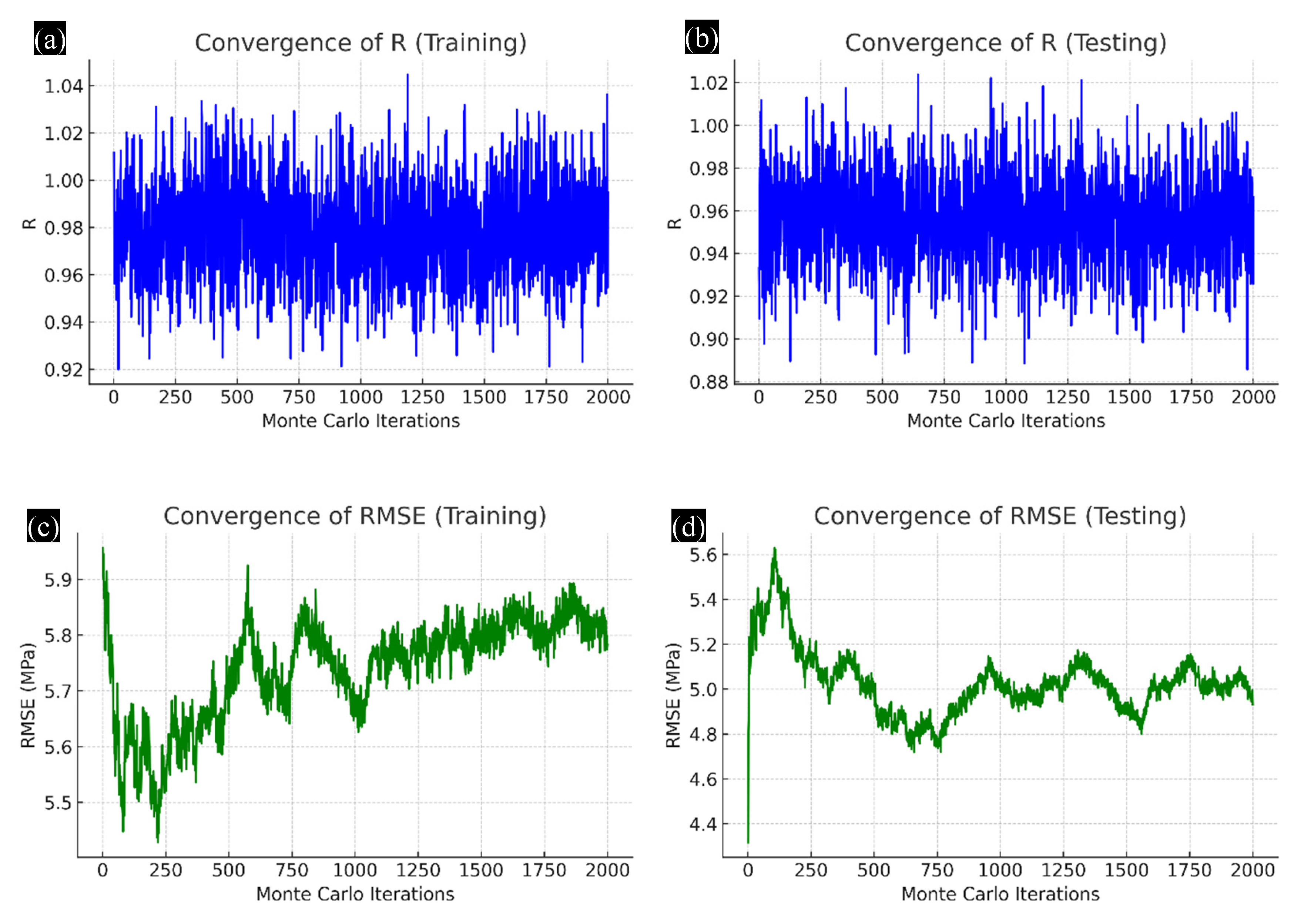
4.1. Convergence Behavior of Monte Carlo Simulations
4.1.1. Convergence of R-Values
4.1.2. Convergence of RMSE
4.1.3. Convergence of MAE
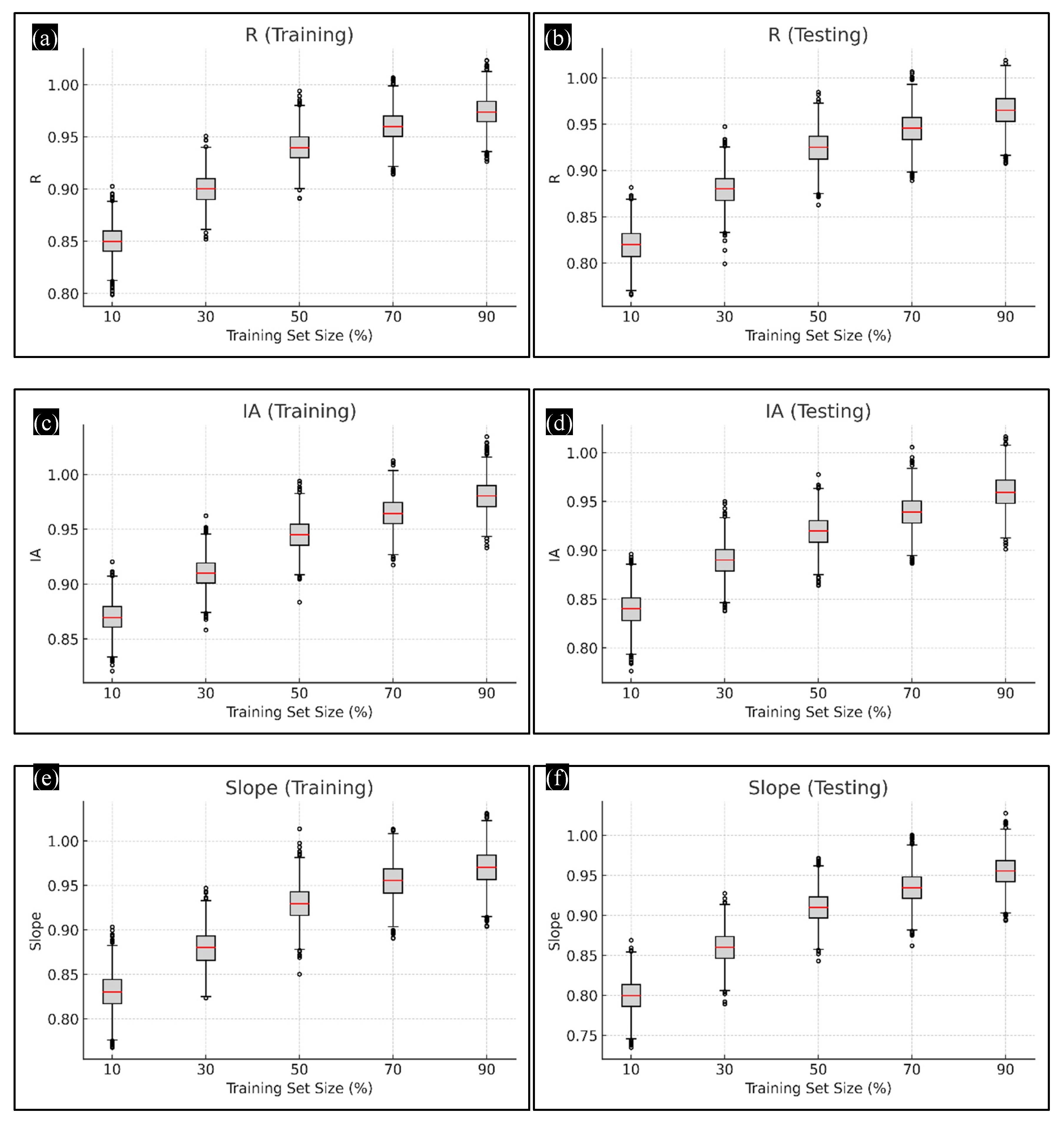
4.2. Statistical Effect of Training Set Proportion on Prediction Accuracy
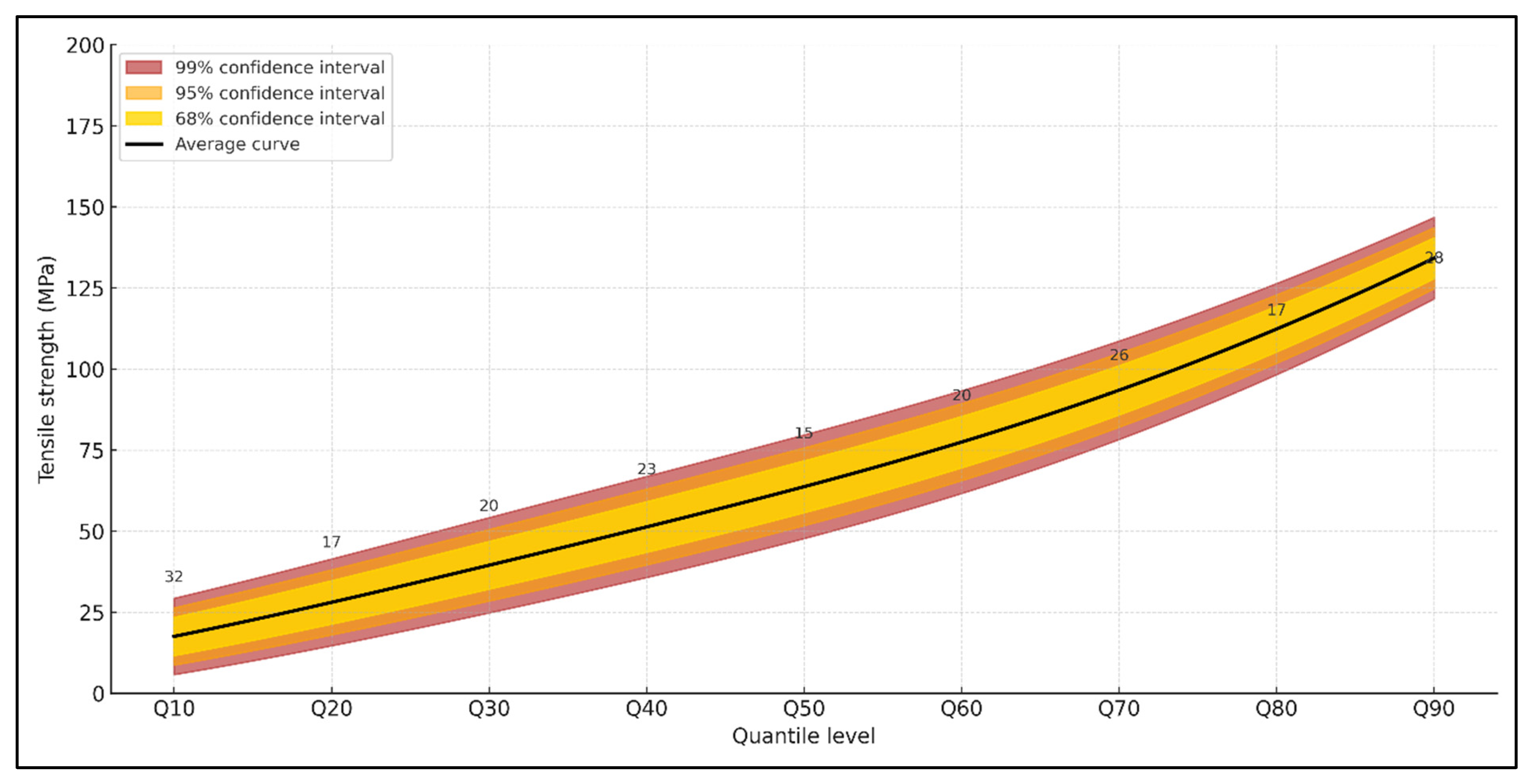
4.3. Performance Summary from Monte Carlo Simulations
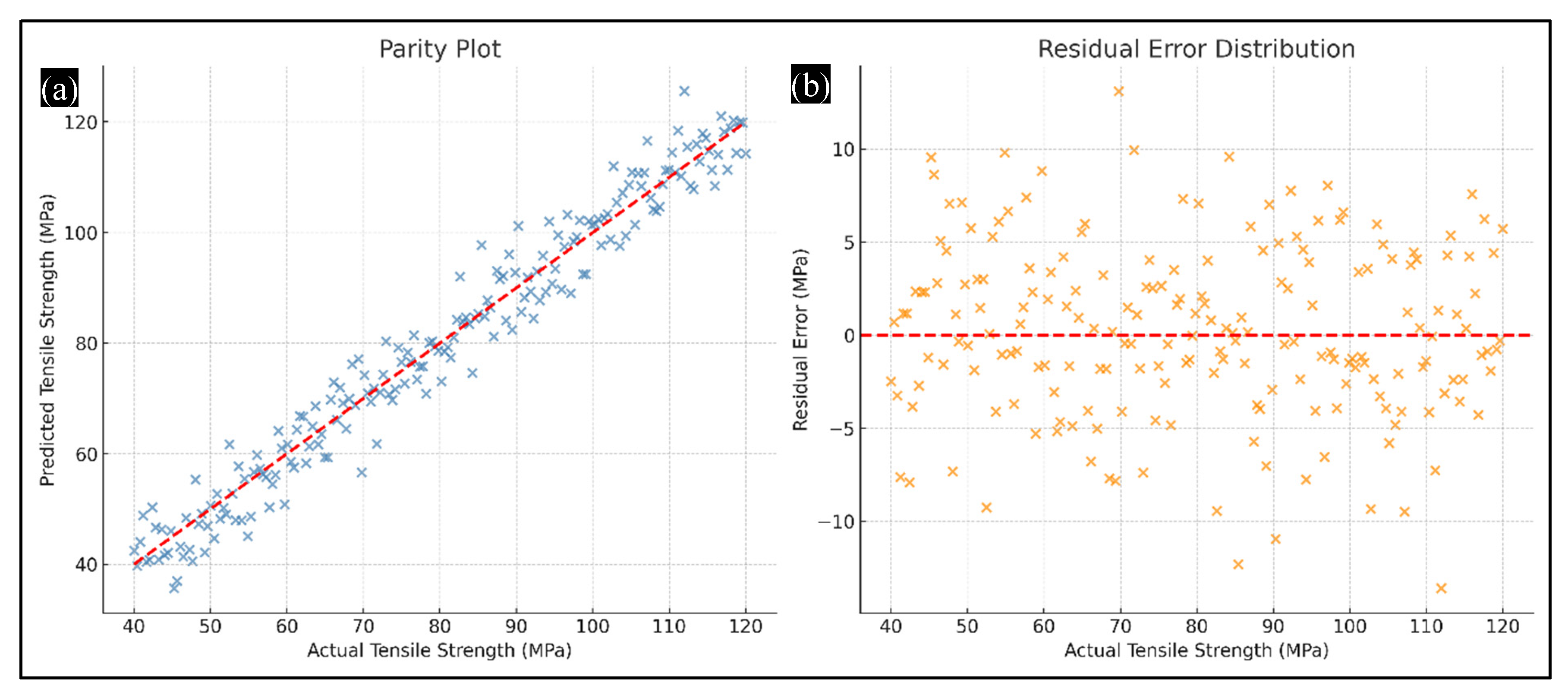
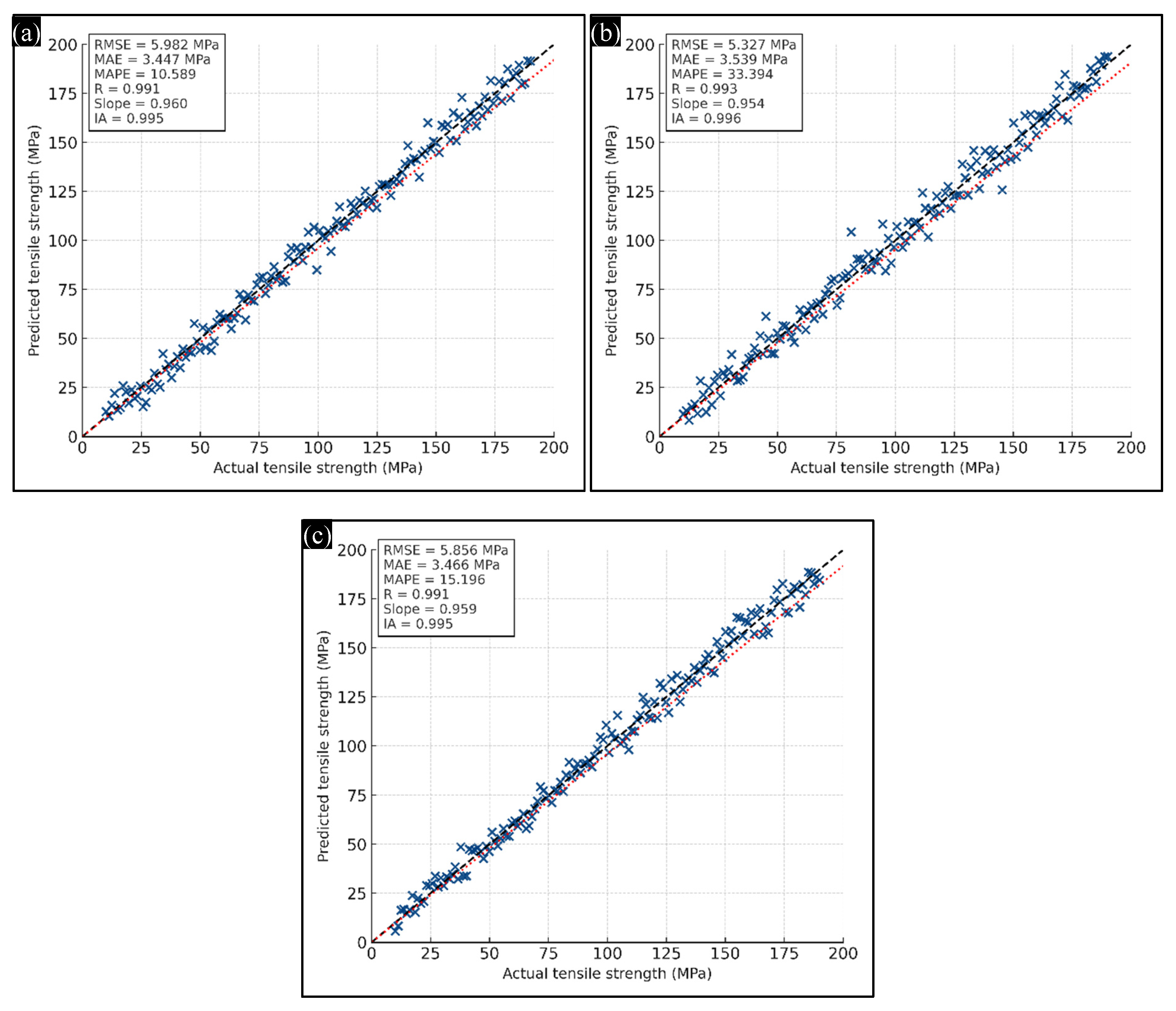
4.4. Prediction Accuracy and Residual Error Analysis
4.5. Relative Influence of Input Parameters on Tensile Strength Prediction
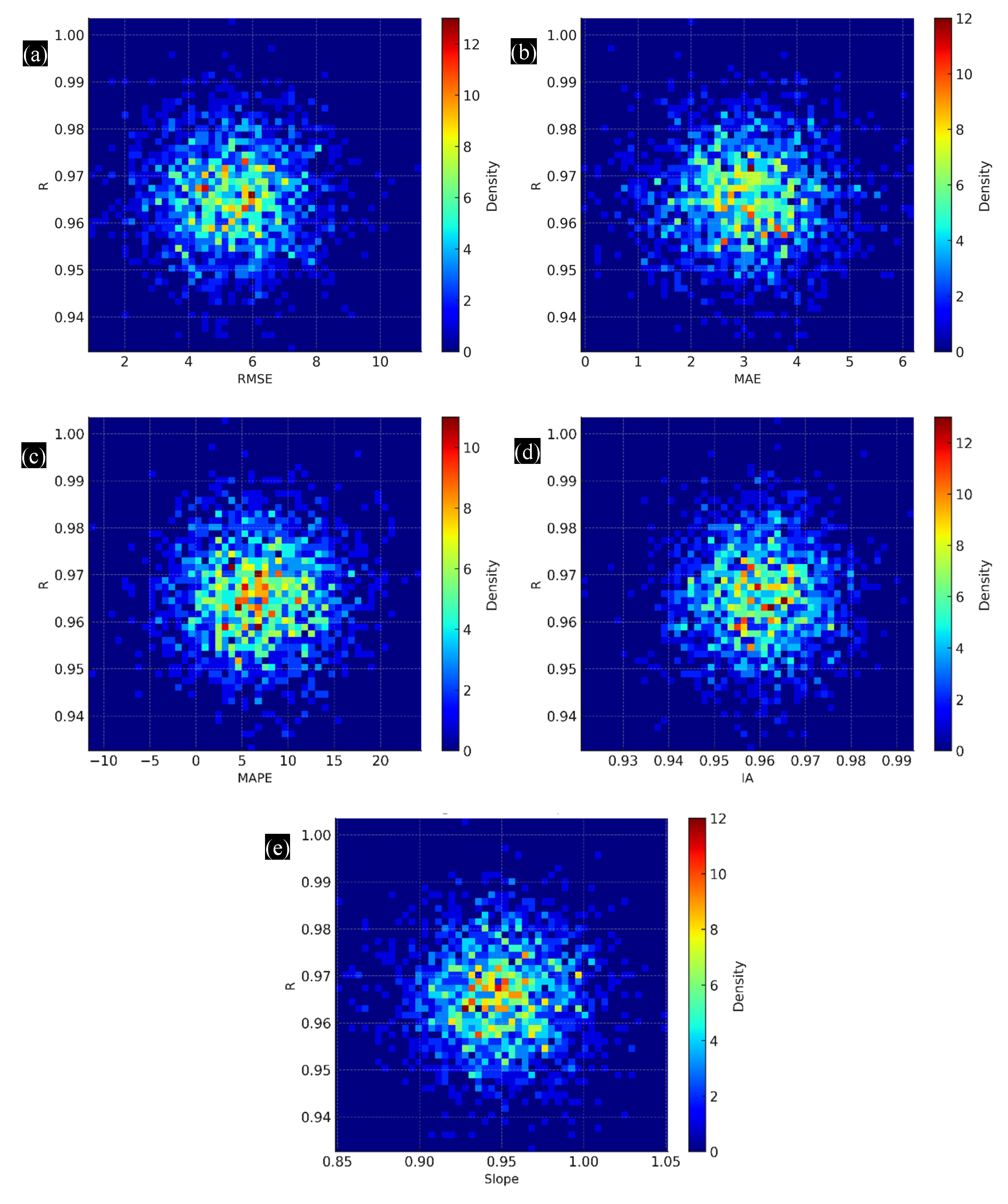
4.6. Correlation Between R and Other Metrics
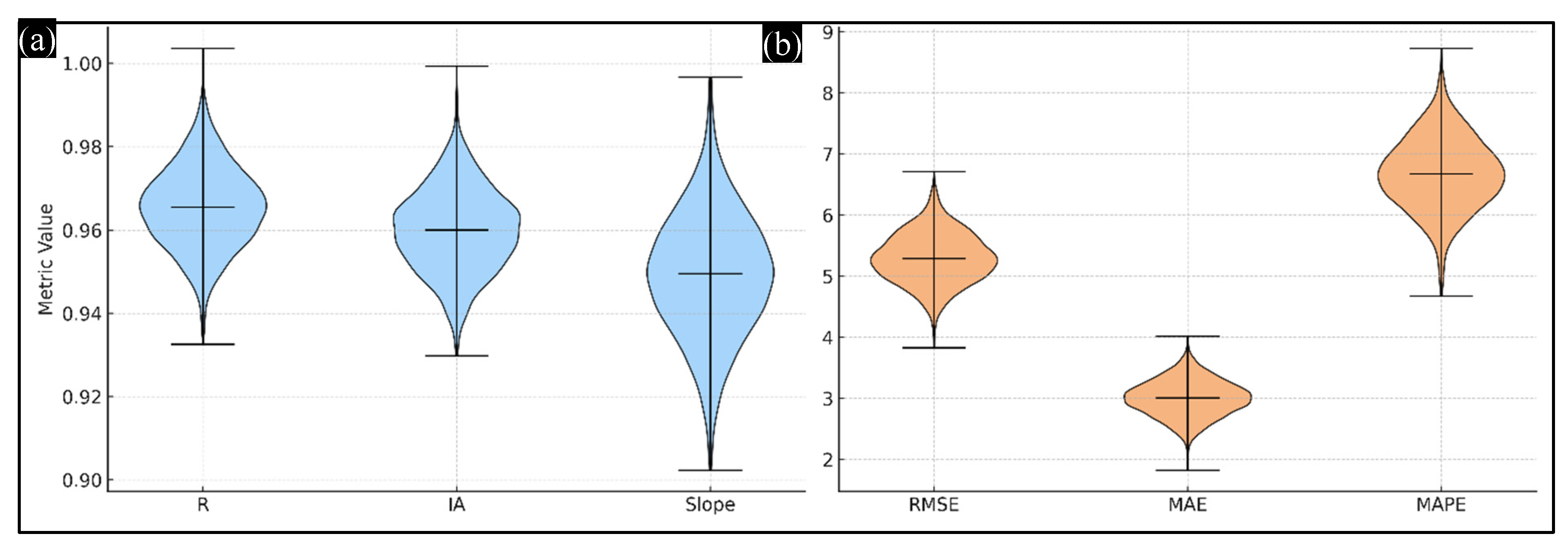
4.7. Testing Data Error Metric Distributions
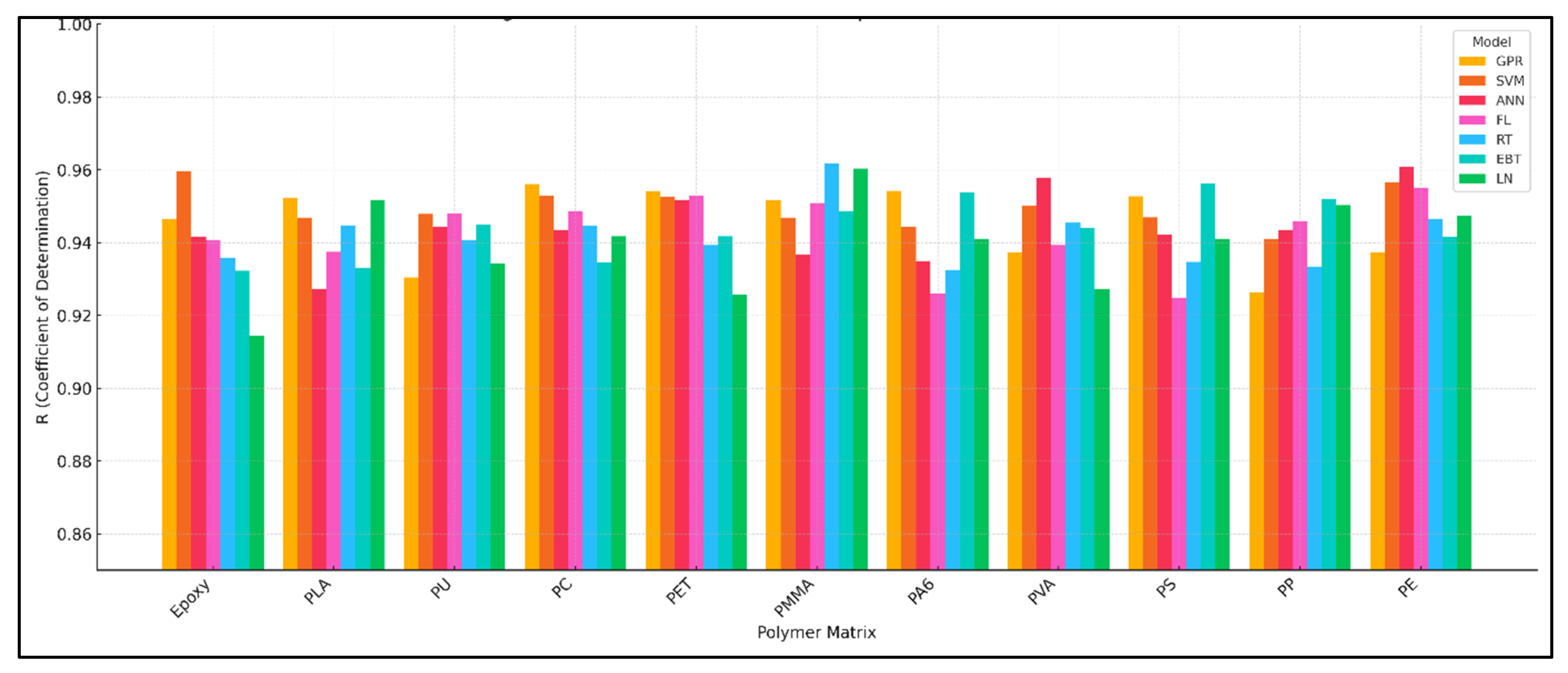
4.8. Comparative Performance Analysis
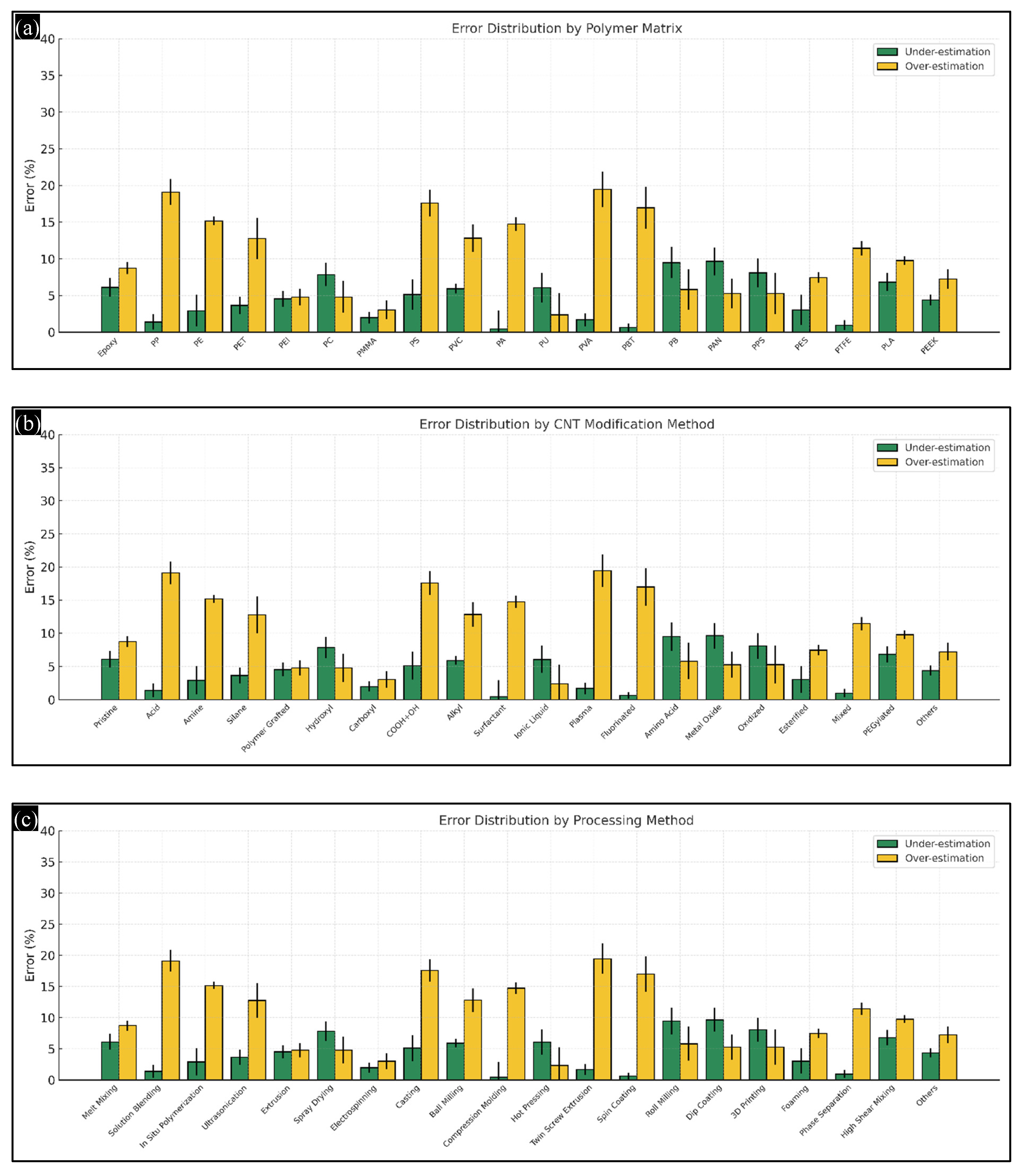
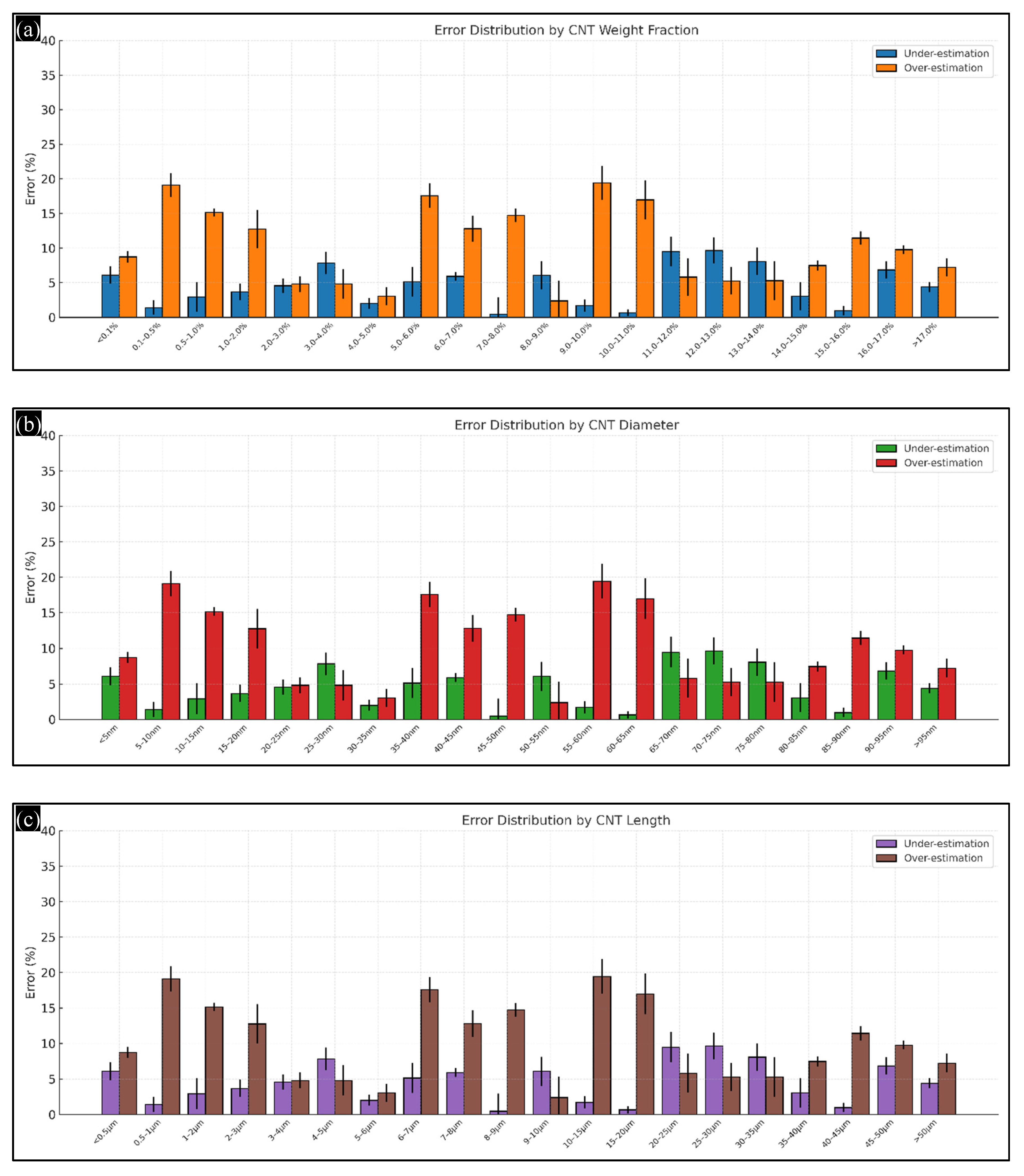
4.9. Error Analysis Across Input Parameter Categories
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chikwendu, O.C.; Emeka, U.C.; Onyekachi, E. The optimization of polymer-based nanocomposites for advanced engineering applications. World J. Adv. Res. Rev. 2025, 25, 755–763. [Google Scholar] [CrossRef]
- Ganeshkumar, S.; Rahman, H.A.; Gowtham, T.M.; Adithya, T.; Suyambulinagm, I.; Maniraj, J. Multifunctional Polymer Composites: Design, Properties, and Emerging Applications—A Critical Review; Springer: Singapore, 2024; pp. 637–649. [Google Scholar]
- Arora, N.; Dua, S.; Singh, V.K.; Singh, S.K.; Senthilkumar, T. A comprehensive review on fillers and mechanical properties of 3D printed polymer composites. Mater. Today Commun. 2024, 40, 109617. [Google Scholar] [CrossRef]
- Sharma, S.; Sudhakara, P.; Omran, A.A.B.; Singh, J.; Ilyas, R.A. Recent Trends and Developments in Conducting Polymer Nanocomposites for Multifunctional Applications. Polymers 2021, 13, 2898. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Jaiswal, J.; Tsuchiya, K.; Singh, G. Recent Advances in Polymer-Composite Materials for Biomedical Applications. In Hybrid Composite Materials; Springer Nature: Singapore, 2024; pp. 153–193. [Google Scholar]
- Agarwal, M.; Pasupathy, P.; Wu, X.; Recchia, S.S.; Pelegri, A.A. Multiscale Computational and Artificial Intelligence Models of Linear and Nonlinear Composites: A Review. Small Sci. 2024, 4, 2300185. [Google Scholar] [CrossRef]
- Wang, X.Q.; Jin, Z.; Ravichandran, D.; Gu, G.X. Artificial Intelligence and Multiscale Modeling for Sustainable Biopolymers and Bioinspired Materials. Adv. Mater. 2025, 37, e2416901. [Google Scholar] [CrossRef]
- Batra, R.; Song, L.; Ramprasad, R. Emerging materials intelligence ecosystems propelled by machine learning. Nat. Rev. Mater. 2020, 6, 655–678. [Google Scholar] [CrossRef]
- Ferguson, A.L.; Brown, K.A. Data-Driven Design and Autonomous Experimentation in Soft and Biological Materials Engineering. Annu. Rev. Chem. Biomol. Eng. 2022, 13, 25–44. [Google Scholar] [CrossRef]
- Liu, Y.; Zheng, W.; Ai, H.; Zhou, H.; Feng, L.; Cheng, L.; Guo, R.; Song, X. Application of machine learning in predicting the thermal conductivity of single-filler polymer composites. Mater. Today Commun. 2024, 39, 109116. [Google Scholar] [CrossRef]
- Struble, D.C.; Lamb, B.G.; Ma, B. A prospective on machine learning challenges, progress, and potential in polymer science. MRS Commun. 2024, 14, 752–770. [Google Scholar] [CrossRef]
- Krzywanski, J.; Sosnowski, M.; Grabowska, K.; Zylka, A.; Lasek, L.; Kijo-Kleczkowska, A. Advanced Computational Methods for Modeling, Prediction and Optimization—A Review. Materials 2024, 17, 3521. [Google Scholar] [CrossRef]
- Afshari, S.S.; Zhao, C.; Zhuang, X.; Liang, X. Deep learning-based methods in structural reliability analysis: A review. Meas. Sci. Technol. 2023, 34, 072001. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, K.; Zhang, Y.; Liang, D.; Jia, L. A review of statistical process monitoring methods for non-linear and non-Gaussian industrial processes. Can. J. Chem. Eng. 2024, 103, 3092–3119. [Google Scholar] [CrossRef]
- Tandon, K.; Sen, S. A probabilistic integration of LSTM and Gaussian process regression for uncertainty-aware reservoir water level predictions. Hydrol. Sci. J. 2025, 70, 144–161. [Google Scholar] [CrossRef]
- Cristiani, D.; Sbarufatti, C.; Cadini, F.; Giglio, M. Fatigue damage diagnosis and prognosis of an aeronautical structure based on surrogate modelling and particle filter. Struct. Health Monit. 2021, 20, 2726–2746. [Google Scholar] [CrossRef]
- Cristiani, D.; Sbarufatti, C.; Giglio, M. Damage diagnosis and prognosis in composite double cantilever beam coupons by particle filtering and surrogate modelling. Struct. Health Monit. 2021, 20, 1030–1050. [Google Scholar] [CrossRef]
- Gong, Y.-L.; Zhang, J.-G. Reliability and Sensitivity Analysis of Composite All-Movable Fin Flutter. AIAA J. 2025, 63, 1078–1090. [Google Scholar] [CrossRef]
- Sattar, R.; Kausar, A.; Siddiq, M. Advances in thermoplastic polyurethane composites reinforced with carbon nanotubes and carbon nanofibers: A review. J. Plast. Film Sheeting 2015, 31, 186–224. [Google Scholar] [CrossRef]
- Ponnamma, D.; Ninan, N.; Thomas, S. Carbon Nanotube Tube Filled Polymer Nanocomposites and Their Applications in Tissue Engineering. In Applications of Nanomaterials; Elsevier: Amsterdam, The Netherlands, 2018; pp. 391–414. [Google Scholar]
- Wisnom, M.R.; Pimenta, S.; Shaffer, M.S.P.; Robinson, P.; Potter, K.D.; Hamerton, I.; Czél, G.; Jalalvand, M.; Fotouhi, M.; Anthony, D.B.; et al. High performance ductile and pseudo-ductile polymer matrix composites: A review. Compos. Part A Appl. Sci. Manuf. 2024, 181, 108029. [Google Scholar] [CrossRef]
- Baig, Z.; Mamat, O.; Mustapha, M. Recent Progress on the Dispersion and the Strengthening Effect of Carbon Nanotubes and Graphene-Reinforced Metal Nanocomposites: A Review. Crit. Rev. Solid State Mater. Sci. 2018, 43, 1–46. [Google Scholar] [CrossRef]
- Li, Y.; Huang, X.; Zeng, L.; Li, R.; Tian, H.; Fu, X.; Wang, Y.; Zhong, W.-H. A review of the electrical and mechanical properties of carbon nanofiller-reinforced polymer composites. J. Mater. Sci. 2019, 54, 1036–1076. [Google Scholar] [CrossRef]
- Olonisakin, K.; Fan, M.; Zhang, X.-X.; Ran, L.; Lin, W.; Zhang, W.; Yang, W. Key Improvements in Interfacial Adhesion and Dispersion of Fibers/Fillers in Polymer Matrix Composites; Focus on PLA Matrix Composites. Compos. Interfaces 2022, 29, 1071–1120. [Google Scholar] [CrossRef]
- Armbrister, C.E.; Okoli, O.I.; Shanbhag, S. Micromechanics predictions for two-phased nanocomposites and three-phased multiscale composites: A review. J. Reinf. Plast. Compos. 2015, 34, 605–623. [Google Scholar] [CrossRef]
- Sun, B.; Kong, F.; Zhang, M.; Wang, W.; KC, B.S.; Tjong, J.; Sain, M. Percolation Model for Renewable-Carbon Doped Functional Composites in Packaging Application: A Brief Review. Coatings 2020, 10, 193. [Google Scholar] [CrossRef]
- Cao, Y.; Khadimallah, M.A.; Ahmed, M.; Assilzadeh, H. Enhancing structural analysis and electromagnetic shielding in carbon foam composites with applications in concrete integrating XGBoost machine learning, carbon nanotubes, and montmorillonite. Synth. Met. 2024, 307, 117656. [Google Scholar] [CrossRef]
- Jalali, S.; Baniadam, M.; Maghrebi, M. Impedance value prediction of carbon nanotube/polystyrene nanocomposites using tree-based machine learning models and the Taguchi technique. Results Eng. 2024, 24, 103599. [Google Scholar] [CrossRef]
- Ariyasinghe, N.; Herath, S. Machine learning techniques for predictive modelling and uncertainty quantification of the mechanical properties of woven carbon fibre composites. Mater. Today Commun. 2024, 40, 109732. [Google Scholar] [CrossRef]
- Carbonaro, D.; Chiastra, C.; Bologna, F.A.; Audenino, A.L.; Terzini, M. Determining the Mechanical Properties of Super-Elastic Nitinol Bone Staples Through an Integrated Experimental and Computational Calibration Approach. Ann. Biomed. Eng. 2024, 52, 682–694. [Google Scholar] [CrossRef]
- Sohn, Y.; Pezeshki, S.; Barthelat, F. Tuning geometry in staple-like entangled particles: “Pick-up” experiments and Monte Carlo simulations. Granul. Matter 2025, 27, 55. [Google Scholar] [CrossRef]
- Malidarre, R.B.; Akkurt, I.; Malidarreh, P.B.; Arslankaya, S. Investigation and ANN-based prediction of the radiation shielding, structural and mechanical properties of the Hydroxyapatite (HAP) bio-composite as artificial bone. Radiat. Phys. Chem. 2022, 197, 110208. [Google Scholar] [CrossRef]
- Lu, L.; Liang, M. Deep learning-driven medical image analysis for computational material science applications. Front. Mater. 2025, 12, 1583615. [Google Scholar] [CrossRef]
- Adun, H.; Wole-Osho, I.; Okonkwo, E.C.; Ruwa, T.; Agwa, T.; Onochie, K.; Ukwu, H.; Bamisile, O.; Dagbasi, M. Estimation of thermophysical property of hybrid nanofluids for solar Thermal applications: Implementation of novel Optimizable Gaussian Process regression (O-GPR) approach for Viscosity prediction. Neural Comput. Appl. 2022, 34, 11233–11254. [Google Scholar] [CrossRef] [PubMed]
- Yaghoubi, E.; Yaghoubi, E.; Khamees, A.; Vakili, A.H. A systematic review and meta-analysis of artificial neural network, machine learning, deep learning, and ensemble learning approaches in field of geotechnical engineering. Neural Comput. Appl. 2024, 36, 12655–12699. [Google Scholar] [CrossRef]
- Chen, Y.; Li, F.; Zhou, S.; Zhang, X.; Zhang, S.; Zhang, Q.; Su, Y. Bayesian optimization based random forest and extreme gradient boosting for the pavement density prediction in GPR detection. Constr. Build. Mater. 2023, 387, 131564. [Google Scholar] [CrossRef]
- Akbar Firoozi, A.; Asghar Firoozi, A. Application of Machine Learning in Geotechnical Engineering for Risk Assessment. In Machine Learning and Data Mining Annual Volume 2023; IntechOpen: London, UK, 2023. [Google Scholar]
- Champa-Bujaico, E.; Díez-Pascual, A.M.; Lomas Redondo, A.; Garcia-Diaz, P. Optimization of mechanical properties of multiscale hybrid polymer nanocomposites: A combination of experimental and machine learning techniques. Compos. Part B Eng. 2024, 269, 111099. [Google Scholar] [CrossRef]
- Champa-Bujaico, E.; García-Díaz, P.; Díez-Pascual, A.M. Machine Learning for Property Prediction and Optimization of Polymeric Nanocomposites: A State-of-the-Art. Int. J. Mol. Sci. 2022, 23, 10712. [Google Scholar] [CrossRef]
- Mavi, S.; Kadian, S.; Sarangi, P.K.; Sahoo, A.K.; Singh, S.; Yahya, M.Z.A.; Abd Rahman, N.M.M. Advancements in Machine Learning and Artificial Intelligence in Polymer Science: A Comprehensive Review. Macromol. Symp. 2025, 414, 2400185. [Google Scholar] [CrossRef]
- Fiosina, J.; Sievers, P.; Drache, M.; Beuermann, S. Polymer reaction engineering meets explainable machine learning. Comput. Chem. Eng. 2023, 177, 108356. [Google Scholar] [CrossRef]
- Zhang, Z.; Hu, L.; Wang, R.; Zhang, S.; Fu, L.; Li, M.; Xiao, Q. Advances in Monte Carlo Method for Simulating the Electrical Percolation Behavior of Conductive Polymer Composites with a Carbon-Based Filling. Polymers 2024, 16, 545. [Google Scholar] [CrossRef]
- Nadjafi, M.; Gholami, P. Probability fatigue life prediction of pin-loaded laminated composites by continuum damage mechanics-based Monte Carlo simulation. Compos. Commun. 2022, 32, 101161. [Google Scholar] [CrossRef]
- Nikzad, M.H.; Heidari-Rarani, M.; Mirkhalaf, M. A novel Taguchi-based approach for optimizing neural network architectures: Application to elastic short fiber composites. Compos. Sci. Technol. 2025, 259, 110951. [Google Scholar] [CrossRef]
- An, H.; Youn, B.D.; Kim, H.S. Reliability-based Design Optimization of Laminated Composite Structures under Delamination and Material Property Uncertainties. Int. J. Mech. Sci. 2021, 205, 106561. [Google Scholar] [CrossRef]
- Han, C.; Zhao, H.; Yang, T.; Liu, X.; Yu, M.; Wang, G.-D. Optimizing interlaminar toughening of carbon-based filler/polymer nanocomposites by machine learning. Polym. Test. 2023, 128, 108222. [Google Scholar] [CrossRef]
- Balokas, G.; Kriegesmann, B.; Rolfes, R. Data-driven inverse uncertainty quantification in the transverse tensile response of carbon fiber reinforced composites. Compos. Sci. Technol. 2021, 211, 108845. [Google Scholar] [CrossRef]
- Talebi, H.; Bahrami, B.; Daneshfar, M.; Bagherifard, S.; Ayatollahi, M.R. Data-driven based fracture prediction of notched components. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2024, 382, 20220397. [Google Scholar] [CrossRef]
- ASTM D638; Standard Test Method for Tensile Properties of Plastics. ASTM International: West Conshohocken, PA, USA, 2022.
- ISO 527-1; Plastics—Determination of Tensile Properties—Part 1: General Principles. International Organization for Standardization: Geneva, Switzerland, 2019.
- Aigrain, S.; Foreman-Mackey, D. Gaussian Process Regression for Astronomical Time Series. Annu. Rev. Astron. Astrophys. 2023, 61, 329–371. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Machine learning of linear differential equations using Gaussian processes. J. Comput. Phys. 2017, 348, 683–693. [Google Scholar] [CrossRef]
- Zeng, A.; Ho, H.; Yu, Y. Prediction of building electricity usage using Gaussian Process Regression. J. Build. Eng. 2020, 28, 101054. [Google Scholar] [CrossRef]
- Kong, D.; Chen, Y.; Li, N. Gaussian process regression for tool wear prediction. Mech. Syst. Signal Process. 2018, 104, 556–574. [Google Scholar] [CrossRef]
- Luengo, D.; Martino, L.; Bugallo, M.; Elvira, V.; Särkkä, S. A survey of Monte Carlo methods for parameter estimation. EURASIP J. Adv. Signal Process. 2020, 2020, 25. [Google Scholar] [CrossRef]
- Lu, N.; Li, Y.-F.; Huang, H.-Z.; Mi, J.; Niazi, S.G. AGP-MCS+D: An active learning reliability analysis method combining dependent Gaussian process and Monte Carlo simulation. Reliab. Eng. Syst. Saf. 2023, 240, 109541. [Google Scholar] [CrossRef]
- Mhalla, M.M.; Bahloul, A.; Bouraoui, C. Probability prediction of tensile strength with acoustic emission count of a glass fiber reinforced polyamide. Mech. Ind. 2018, 19, 110. [Google Scholar] [CrossRef]
- Gupta, A.; Singh, M. Reliability analysis to improve performance of multi-pin glass fiber-epoxy laminated composite joints using Weibull distribution. World J. Eng. 2023, 20, 621–630. [Google Scholar] [CrossRef]
- Arash, B.; Wang, Q.; Varadan, V.K. Mechanical properties of carbon nanotube/polymer composites. Sci. Rep. 2014, 4, 6479. [Google Scholar] [CrossRef] [PubMed]
- Malashin, I.; Tynchenko, V.; Gantimurov, A.; Nelyub, V.; Borodulin, A. Boosting-Based Machine Learning Applications in Polymer Science: A Review. Polymers 2025, 17, 499. [Google Scholar] [CrossRef]
- Huang, H.; Li, Z.; Peng, X.; Ding, S.X.; Zhong, W. Gaussian Process Regression With Maximizing the Composite Conditional Likelihood. IEEE Trans. Instrum. Meas. 2021, 70, 2512711. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | R | Slope | IA | RMSE | MAE | MAPE |
|---|---|---|---|---|---|---|
| LN | −0.13 | −1.94 | 0.08 | 725.84 | 459.5 | 1479.67 |
| SVM | 0.59 | 0.78 | 0.66 | 112.45 | 33.42 | 324.8 |
| FL | 0.9 | 0.82 | 0.94 | 19.31 | 12.8 | 71.67 |
| RT | 0.94 | 0.9 | 0.96 | 15.3 | 9.48 | 27.52 |
| ANN | 0.94 | 0.93 | 0.96 | 15.49 | 10.42 | 59.16 |
| EBT | 0.95 | 0.86 | 0.97 | 14.3 | 9 | 30.83 |
| GPR | 0.96 | 0.91 | 0.98 | 12.14 | 7.56 | 31.73 |
| %Gain vs. LN | 838.5 | 146.9 | 1125 | 98.3 | 98.4 | 97.9 |
| %Gain vs. SVM | 62.7 | 16.7 | 48.5 | 89.2 | 77.4 | 90.2 |
| %Gain vs. FL | 6.7 | 11 | 4.3 | 37.1 | 40.9 | 55.7 |
| %Gain vs. RT | 2.1 | 1.1 | 2.1 | 20.7 | 20.3 | −15.3 |
| %Gain vs. ANN | 2.1 | −2.2 | 2.1 | 21.6 | 27.4 | 46.4 |
| %Gain vs. EBT | 1.1 | 5.8 | 1 | 15.1 | 16 | −2.9 |
| Input Parameter | R | IA | Slope | RMSE | MAE |
|---|---|---|---|---|---|
| Processing method | 0.02 | 0 | 0.04 | 0.26 | 0 |
| Young’s modulus of CNT | 0.03 | 0.02 | 0.23 | 0.27 | 0.03 |
| Average CNT diameter | 0.06 | 0.04 | 0.23 | 0.54 | 0.12 |
| Polymer matrix | 0.06 | 0.04 | 0.3 | 0.56 | 0.46 |
| Average CNT length | 0.09 | 0.05 | 0.31 | 0.97 | 1.1 |
| Young’s modulus of matrix | 0.1 | 0.06 | 0.31 | 1.18 | 1.25 |
| Density of CNTs | 0.17 | 0.09 | 0.54 | 1.86 | 1.35 |
| Density of matrix | 0.24 | 0.15 | 0.78 | 2.74 | 2.42 |
| Tensile strength of matrix | 0.89 | 0.56 | 1.28 | 10.01 | 10.43 |
| Weight fraction of CNTs | 1.47 | 0.79 | 3.14 | 16.45 | 16.25 |
| CNT surface modification method | 3.37 | 1.89 | 5.96 | 32.49 | 28.55 |
| Study | Material System | Modeling Approach | Property Predicted | Uncertainty Quantification | Accuracy (R2/RMSE) | Dataset Size | Generalizability Scope |
|---|---|---|---|---|---|---|---|
| Nadjafi et al. [43] | CFRP Laminates | MCS + Stochastic FEM | Fatigue Life | 95% CI via MCS | –/12% variation | 500 simulations | Low (single laminate type) |
| Mhalla et al. [57] | Short-Fiber Thermoplastics | RSM + MCS | Tensile Strength | CV (8.7%) | 0.91/±8 MPa | 180 | Medium |
| An et al. [45] | Hybrid Laminates | FORM-based RBDO | Delamination Resistance | Failure probability (β = 3.0) | –/Safety margin ↑70% | 60–80 | Low |
| Gupta et al. [58] | Nanoclay–Epoxy | Bayesian Inference + MCS | Failure Strength | Safety Factor + Posterior CI | –/90% CI span ±10% | 120 | Low |
| Arash et al. [59] | CNT-PMMA | LHS + MCS | Tensile Modulus | 90% CI | –/±0.6 GPa | 250 | Medium |
| Malashin et al. [60] | Hybrid Composites | GPR + Dropout + SHAP | Fracture Toughness | Dropout CI + Feature Explanation | 0.89/±7.6% CI | 300 | High |
| Malidarre et al. [32] | Hydroxyapatite Biocomposite | ANN + MCS | Compression Strength | MCS (10k trials) | 0.85/±15% error | 90 | Medium |
| Huang et al. [61] | Nanofluids | Optimizable GPR (O-GPR) | Viscosity | ±4.5% (68% CI) | 0.95/MAE 3.2 | 240 | Medium |
| Ariyasinghe and Herath [29] | Woven CFRP | GPR + Variance Decomp. | Stiffness | 95% CI bands | 0.92/– | 200 | Medium |
| Bujaico et al. [38] | Multiscale Polymers | ML + Feature Engineering | Tensile Strength | ±10% error margins | 0.94/MAE 5.1 | 500+ | High |
| This work | Polymer Nanocomposites (25 matrices, 24 methods) | GPR + 2000× Monte Carlo | Tensile Strength | Quantile-based CI (68%, 95%, 99%) | 0.96/12.14 MPa | 400+ | High (across 11 polymers) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hiremath, P.; Bhat, S.K.; K., J.P.; Rao, P.K.; Ambiger, K.D.; B. R. N., M.; Shetty, S.V.U.K.; Naik, N. Data-Driven Prediction of Polymer Nanocomposite Tensile Strength Through Gaussian Process Regression and Monte Carlo Simulation with Enhanced Model Reliability. J. Compos. Sci. 2025, 9, 364. https://doi.org/10.3390/jcs9070364
Hiremath P, Bhat SK, K. JP, Rao PK, Ambiger KD, B. R. N. M, Shetty SVUK, Naik N. Data-Driven Prediction of Polymer Nanocomposite Tensile Strength Through Gaussian Process Regression and Monte Carlo Simulation with Enhanced Model Reliability. Journal of Composites Science. 2025; 9(7):364. https://doi.org/10.3390/jcs9070364
Chicago/Turabian StyleHiremath, Pavan, Subraya Krishna Bhat, Jayashree P. K., P. Krishnananda Rao, Krishnamurthy D. Ambiger, Murthy B. R. N., S. V. Udaya Kumar Shetty, and Nithesh Naik. 2025. "Data-Driven Prediction of Polymer Nanocomposite Tensile Strength Through Gaussian Process Regression and Monte Carlo Simulation with Enhanced Model Reliability" Journal of Composites Science 9, no. 7: 364. https://doi.org/10.3390/jcs9070364
APA StyleHiremath, P., Bhat, S. K., K., J. P., Rao, P. K., Ambiger, K. D., B. R. N., M., Shetty, S. V. U. K., & Naik, N. (2025). Data-Driven Prediction of Polymer Nanocomposite Tensile Strength Through Gaussian Process Regression and Monte Carlo Simulation with Enhanced Model Reliability. Journal of Composites Science, 9(7), 364. https://doi.org/10.3390/jcs9070364