1. Introduction
Concrete diagnosis is essential to enable structural engineers to make informed decisions about reconstructing or repairing buildings [
1]. For this purpose, the main challenge is the on-site evaluation of the concrete’s properties, particularly the compressive strength (
), which is essential to assess the structure’s safety under test [
1,
2]. It is well known that destructive testing (DT) is the most reliable method for determining this quantity. However, DT is characterized by the need to perform laboratory concrete compressive strength tests and by the unavoidable local damage effect on the structure under test (which sometimes needs to be repaired after testing) [
3]. Non-destructive testing (NDT) techniques provide a complementary approach to obtaining information on the condition of a given structure. The rebound hammer (RH) and the ultrasonic pulse velocity (UPV) tests are the NDT methods most commonly used for this aim [
3,
4,
5].
Despite this, the main problem with using NDT measurements is that these methods do not directly provide the
values. Instead, they provide the pulse velocity
(i.e., the velocity of the compression stress waves) for the UPV technique and the rebound index
R for the RH technique (a term directly related to the energy absorbed by the concrete during the impact with the rebound hammer) [
2,
3]. Since the theoretical governing equations relating
and/or
R with
are unknown,
and/or
R must be mapped to
by identifying a proper mathematical model, known as a conversion model [
3]. This model establishes a suitable relationship between
and NDT measurements, appropriately tailored using experimentally collected DT and NDT data [
1,
6]. There are two distinct approaches to formulating a conversion model in the literature. The first is through direct identification, based on an extensive campaign of measurements employed to derive a customized functional form selected from a univariate or multivariate parametric model [
1,
6], or obtained through a machine learning approach [
7,
8,
9] such as artificial neural networks (ANNs) [
10,
11,
12], support vector machines (SVMs) [
13], and ensemble learning methods [
14,
15].
On the contrary, the conversion model can be derived using one of the many pre-existing conversion models available from previous literature studies, an approach notably indicated in all cases where minimizing the number of DT measurements is necessary [
1,
3,
6]. If this approach is followed, the selected model must undergo an appropriate mathematical calibration phase to reliably evaluate the
for the concrete structure under test (because there is no universal conversion model, i.e., one that is valid regardless of the case being studied [
6]). This phase is implemented using the shifting or multiplying factor method, which provides a multiplicative or an additive calibration constant to improve the predictive performance of the conversion model [
3,
6]. The overall modeling procedure described above may involve only the ultrasonic velocity
or the rebound index
R, or it may include both quantities (aiming to overcome the limitations related to each of the NDT techniques), giving rise to the so-called SonReb conversion model [
1,
2,
3,
11,
16].
In this paper, considering the scenario where the assessment of the concrete structure must be conducted while trying to minimize the number of DTs (i.e., the number of cores), we investigate the performance of Gaussian process regression (GPR) to calibrate pre-existing SonReb conversion models. GPR, a powerful nonparametric Bayesian approach to regression problems, has been successfully employed in various scientific and engineering fields [
17]. It has shown promising results in predicting the compressive strength (
) of concrete buildings, serving as a viable alternative to ANNs and other nonparametric approaches [
18,
19,
20].
The basis for using GPR as a calibration technique is rooted in the parallel between calibrating a pre-existing conversion model and multi-fidelity surrogate modeling [
21]. To understand this parallelism, it is necessary to describe what this type of modeling consists of briefly. In the multi-fidelity surrogate modeling technique, the results provided by the low-fidelity surrogate model—a mathematical model capable of reasonably describing the physical problem under study with low computational precision, but using a short CPU time—are made more accurate using an appropriate mathematical model properly trained to compensate for the error committed by the low-fidelity surrogate model [
21,
22]. This correction model is trained on a dataset that consists of a small set of samples of the independent variables related to the physical model at hand and by the set of the difference between the predictions made (on the set of the independent variables used as an input), by the physical–mathematical model accurately describing the phenomenon under analysis, but characterized by an expensive CPU time, the so-called high-fidelity model, and by the predictions made by the low-fidelity model (in other words, the correction model is trained to model the existing error between the high-fidelity and low-fidelity predictions made on the same set of independent variables). The goal is to formulate a two-block mathematical model, consisting of the low-fidelity surrogate model and the error-correction model, capable of providing accurate predictions comparable to those of the exact mathematical model of the physical or engineering problem under study, but characterized by a lower CPU time. In the above context, GPR is intensively used to build this type of correction block, providing excellent results using minimal high-fidelity samples [
22,
23].
Based on what has been said so far, if we think of a given uncalibrated conversion model used to predict CS as a low-fidelity surrogate model and the related DT measurements used to evaluate CS (data whose number must be minimal for different practical reasons) as the high-fidelity model, it is possible to conceive of the calibration procedure as an attempt to construct a two-stage multi-fidelity surrogate model capable of providing accurate predictions of
[
21,
24]. Accordingly, considering its ability to handle nonlinear relationships and uncertainties, we propose and investigate the performance of GPR regression as an error-correction block for the uncalibrated pre-existing conversion models proposed in the literature [
25].
The paper is organized as follows:
Section 2 illustrates the materials and methods employed in this work. More precisely, in
Section 2.1, we recall some basics of the conversion models and list the conversion models used in this study. In
Section 2.3, we briefly discuss the foundation of GPR theory and elucidate the rationale behind our approach to compensation. The choice to use GPR is mainly due to its ability to model the nonlinear input–output relationship occurring in complex devices and systems more effectively than other SM techniques. In
Section 2.4, an account of the statistical parameters used to evaluate the performance of the proposed approach is given. Numerical results are shown in
Section 3. Finally, in
Section 4, some considerations are drawn.
3. Numerical Results
This section presents numerical results relevant to the performance of the proposed GPR-based calibration approach compared to the standard shift and multiplicative calibration techniques. The numerical simulations were performed using the
Matlab Statistics and Machine Learning Toolbox 2023b©, using the built-in functions
and
to train and implement the GPR additive compensation term
from (
22). Algorithm 1 presents a
Matlab© pseudocode of a possible implementation of this procedure (details on how to use the
and
functions can be found in [
28]). Given that a considerable number of SonReb conversion models are available [
2,
6], we decided to use the models adopted in recent literature for developing nonparametric models for CS evaluation [
10,
13,
14]. These models are reported in
Table 1. The experimental dataset used for our simulations, composed of 197 tuples of the form
, is based on data from the work of Logothetis [
29] (a dataset whose integrity and adequacy have been discussed in detail in [
10]), which is reported in
Appendix A. The ranges of the variation of these data are
Km/s
Km/s,
, and
MPa
MPa, respectively. The simulations were conducted by randomly dividing our dataset into two sets (the training set and the test set) considering the following cases:
,
,
,
,
,
, and
. This was performed to assess the influence of the number of cores in the training set on the quality of the predictions offered by the conversion models once calibrated.
Table 2,
Table 3,
Table 4 and
Table 5 show the errors associated with the predictions of the calibrated conversion models for all the error metrics defined in
Section 2.4.2 (marked with the symbol ″) as a function of the number of cores used to train the GPR calibration term
and to evaluate the calibration factors
and
. The same tables also show the errors associated with the predictions of the uncalibrated conversion models (marked with the symbol ′).
| Algorithm 1 Matlab GPR calibration procedure pseudocode. |
- 1:
Input: ; ; - 2:
Output: - 3:
- 4:
; - 5:
; - 6:
; - 7:
; - 8:
; - 9:
|
It is noteworthy that all the models considered, when adequately calibrated, performed better in terms of error metrics just with the use of only four cores, regardless of the method used, compared to the Logothetis model without any calibration (we recall that the Logothetis model has better predictive capabilities than all the other uncalibrated conversion models because it was derived precisely from the experimental data used in our numerical simulations). Regarding our proposed methodology, we observed that it gives significantly better error metrics for ten of the thirteen models considered, specifically #1, #2, #5–#9, and #11–#13. For the conversion models #3, #4, and #10, the error metric results are comparable to those of the multiplication calibration technique. However, GPR calibration results improve as the number of cores increases, albeit in an unpredictable manner, and are ultimately better than multiplicative calibration, though only slightly, with the use of 20 cores.
With specific reference to the A20 metric, which indicates the number of predicted
values that match the experimental
values with a deviation of
%, and considering the case of the minimum number of cores used to evaluate the calibration terms (
), we can observe that our method is characterized by a worst-case value of
%, as opposed to worst-case values of
% and
% obtained in the case of the shift factor and multiplying factor calibration, respectively (concerning model #12). Particularly noteworthy, regarding the same error metric, is the result obtained for conversion model #1, which, from a value of A20 equal to
% in the uncalibrated case, reaches a value of
% in the calibrated case with our proposed approach (against values of
% and
% obtained with
and
, respectively).
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12 and
Figure 13 show the plot of the experimental versus predicted
for all the conversion models listed in
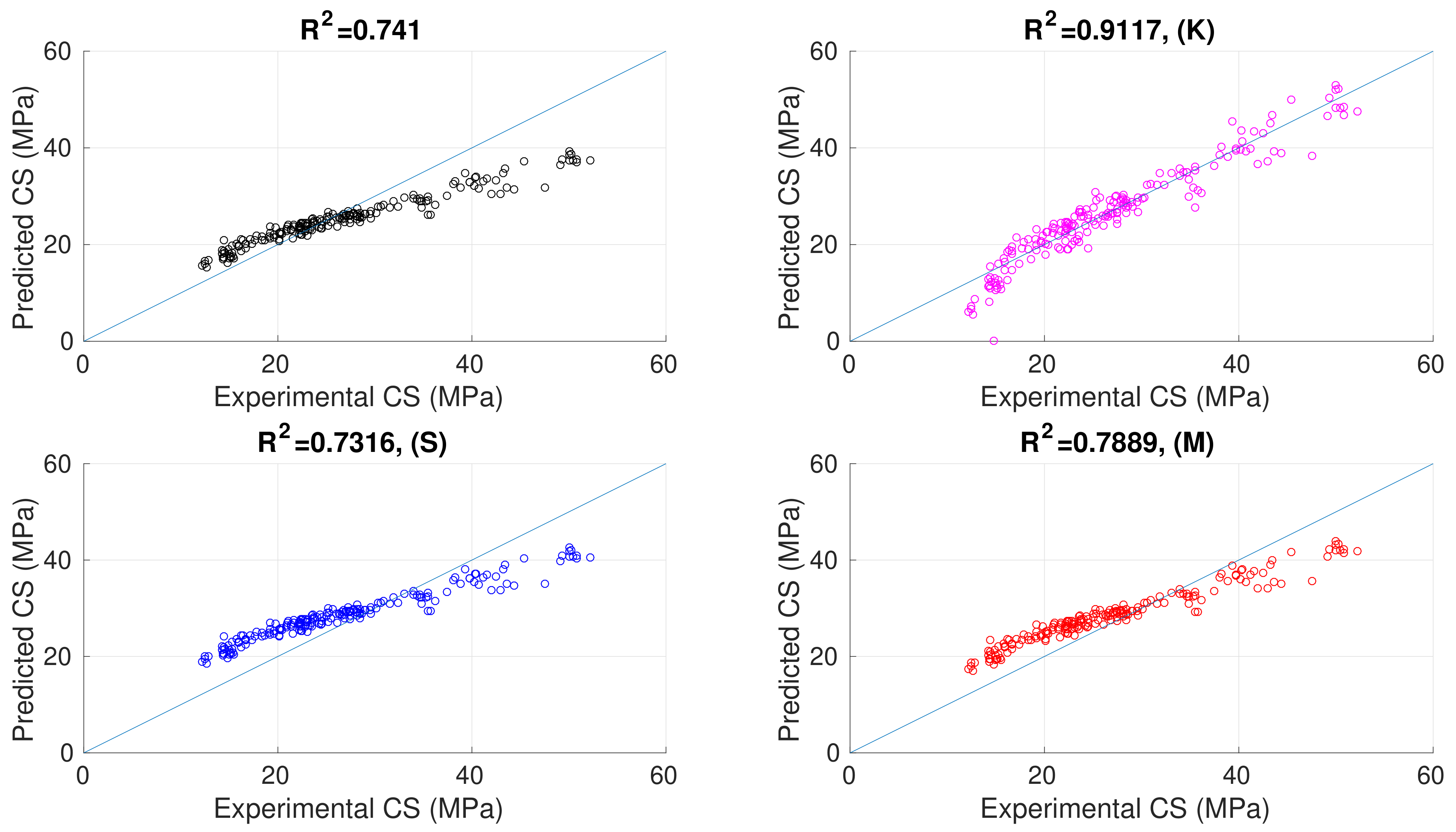
Table 1. All the figures relate to the case of four cores used to evaluate and train all the calibration methods considered. Each figure is organized as follows: The upper right corner shows the plot related to the uncalibrated model predictions. The top left of the figure shows the plot associated with the GPR-calibrated model predictions. At the bottom left and bottom right, the figure shows the plots related to the shifted-factor- and multiplying-factor-calibrated model predictions, respectively.
Finally, the corresponding value of the correlation coefficient
is given for each case to which the figure refers. The results shown in
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12 and
Figure 13 confirm all the considerations we made by analyzing the results reported in
Table 2,
Table 3,
Table 4 and
Table 5, i.e., the GPR calibration procedure we propose allows all the conversion models we considered to improve the quality of the predicted CS values. This improvement can be easily deduced by observing how the data are located close to the line of best fit, i.e., the predicted
values better fit the experimental ones.
In summary, taking into account that each error metric provides a different lens under which to evaluate the performance of the models considered [
42,
43], the fact that all the metrics referring to the GPR calibration are, regardless of the number of samples considered, simultaneously better in the majority of cases compared to those offered by standard calibration techniques for the same number of samples confirms its effectiveness in providing a more precise and accurate calibrated conversion model compared to the conversion models calibrated in the standard way [
44]. This result is undoubtedly due to the fact that the standard calibration methods provide constant calibration coefficients, one multiplicative and the other additive, which, once determined, are independent of the pair
used as the input to the conversion model. In contrast, the GPR calibration technique provides a calibration that is a function of this pair, leading to better prediction results based on our numerical experiments, thanks to its ability to handle nonlinear relationships and uncertainties [
25,
28].







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}