
Comparative Analysis of ANN-MLP, ANFIS-ACOR and MLR Modeling Approaches for Estimation of Bending Strength of Glulam



Abstract
:1. Introduction
2. Materials and Methods
2.1. Materials
2.2. Methods
2.2.1. Modifying Starch and Making Starch Adhesive
2.2.2. Making the UF-OS Adhesive
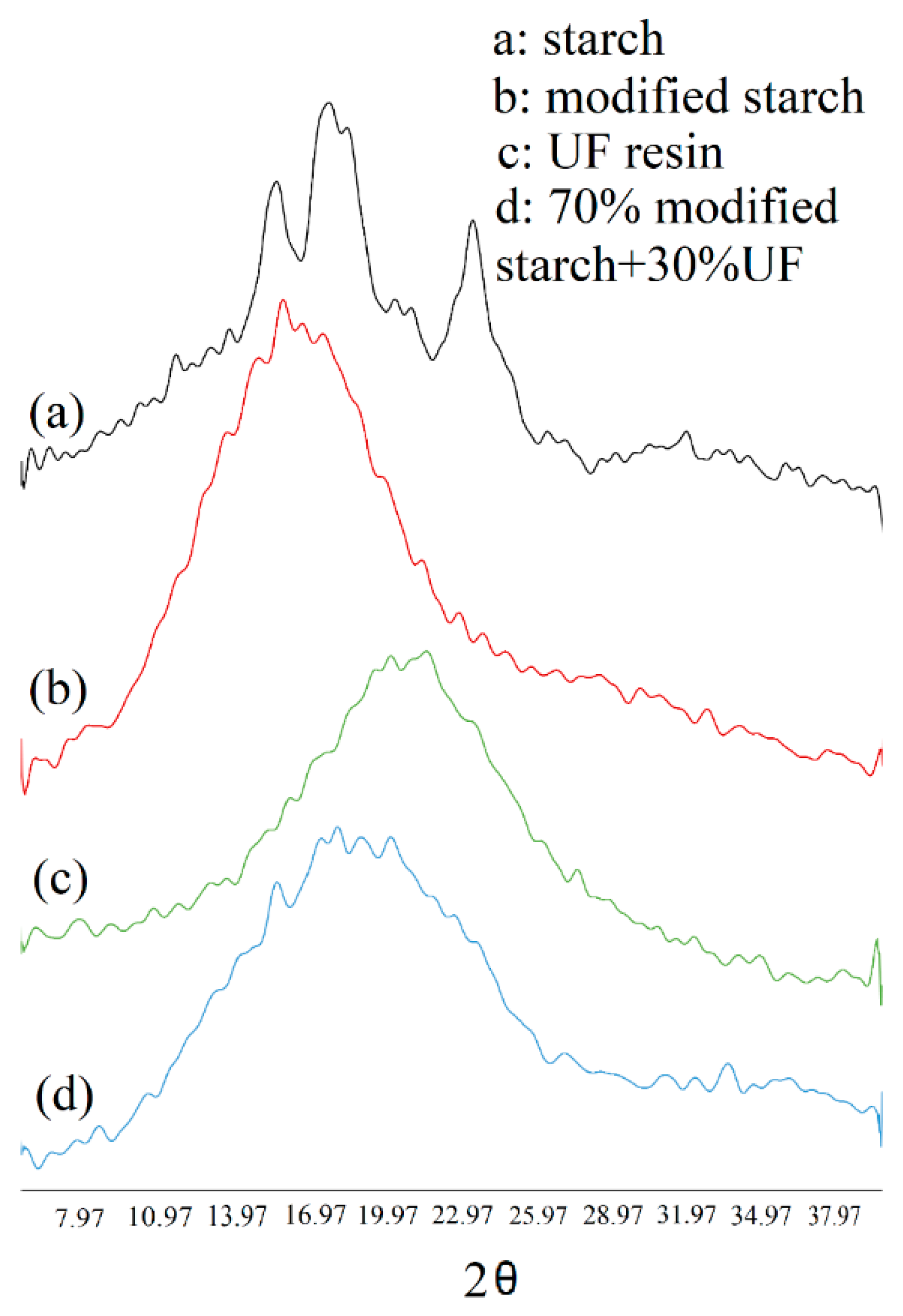
2.2.3. XRD Analysis
2.2.4. Making Glulam
2.3. Statistical Analysis
2.3.1. The Multiple Linear Regression (MLR) Method
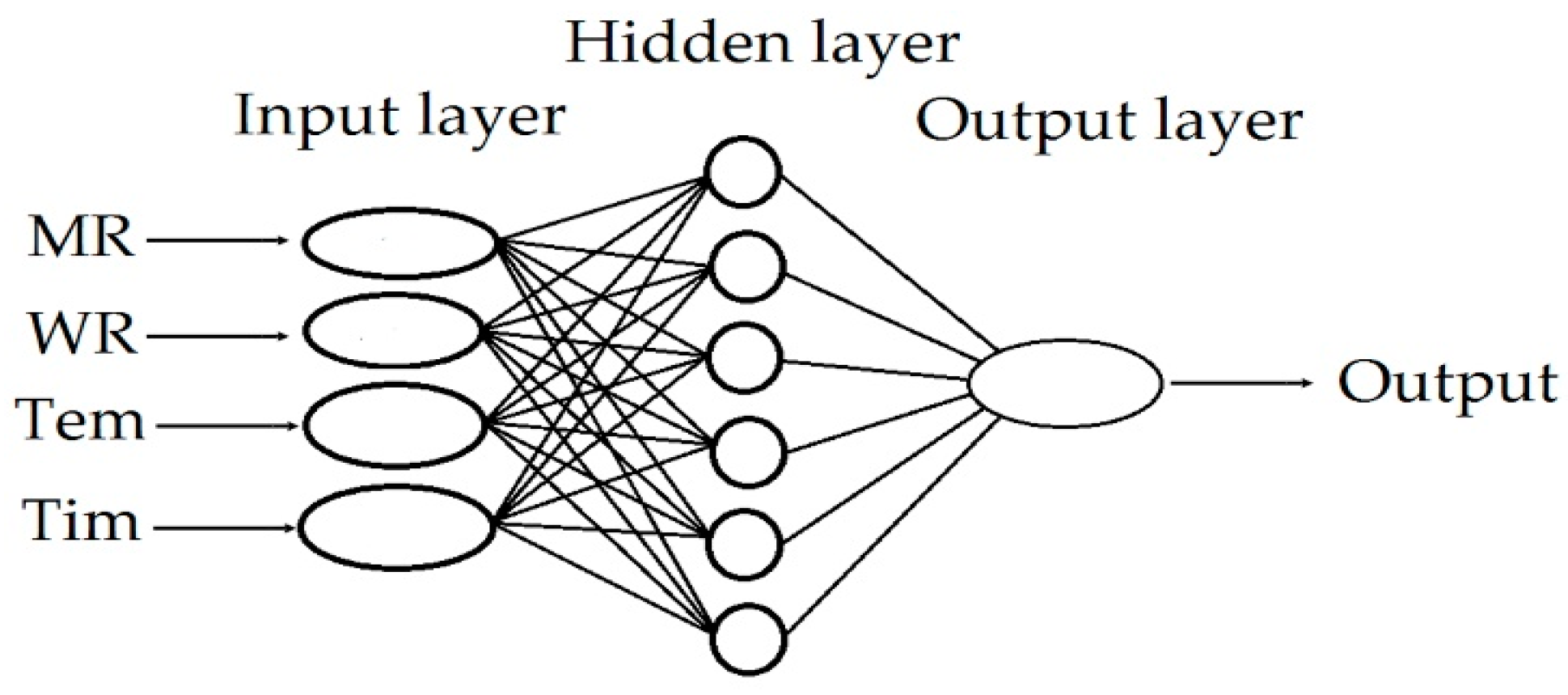
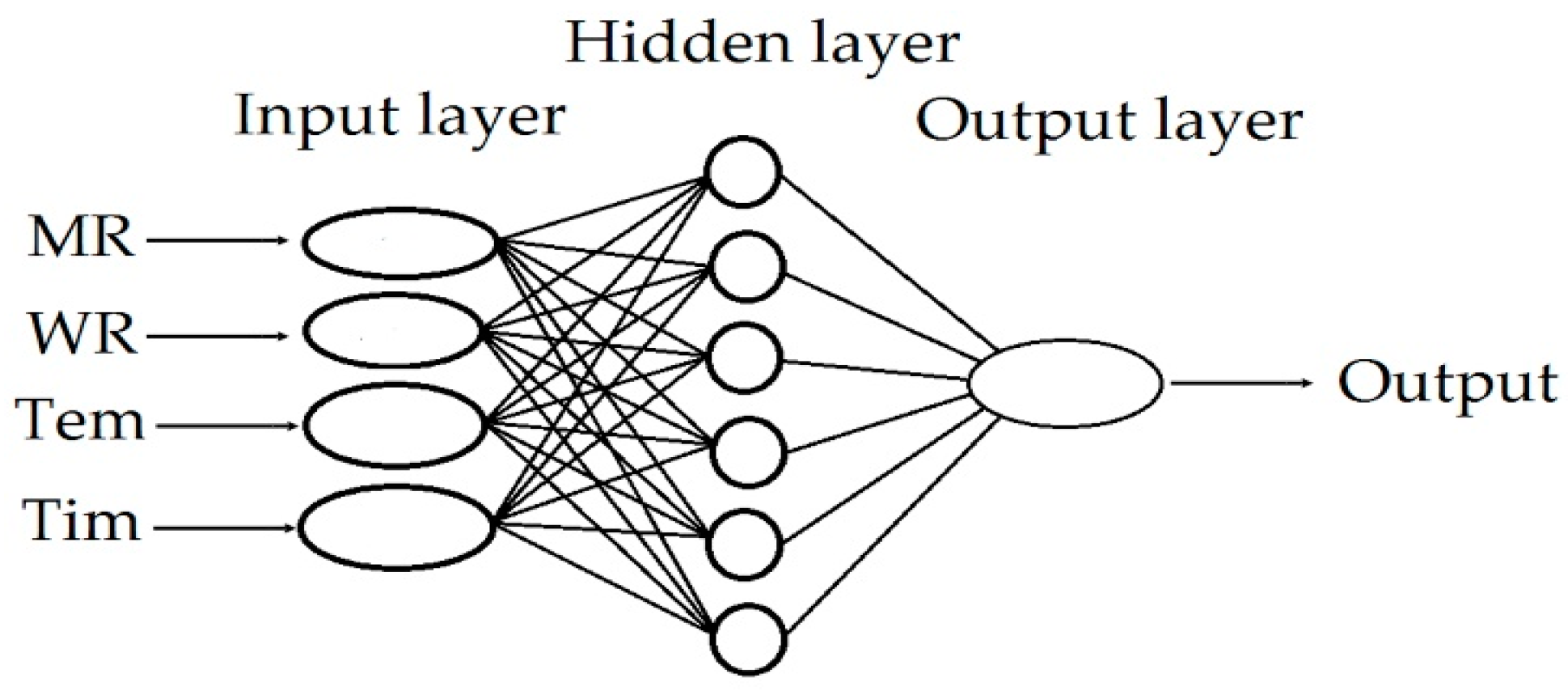
2.3.2. The Artificial Neural Network–Multilayer Perceptron (MLP-ANN) Methods
2.3.3. The Adaptive Neuro-Fuzzy Inference System–Ant Colony Optimization (ANFIS-ACOR) Methods
2.3.4. The Evaluation Criteria
2.3.5. Combination of the ANN with the GA Algorithm
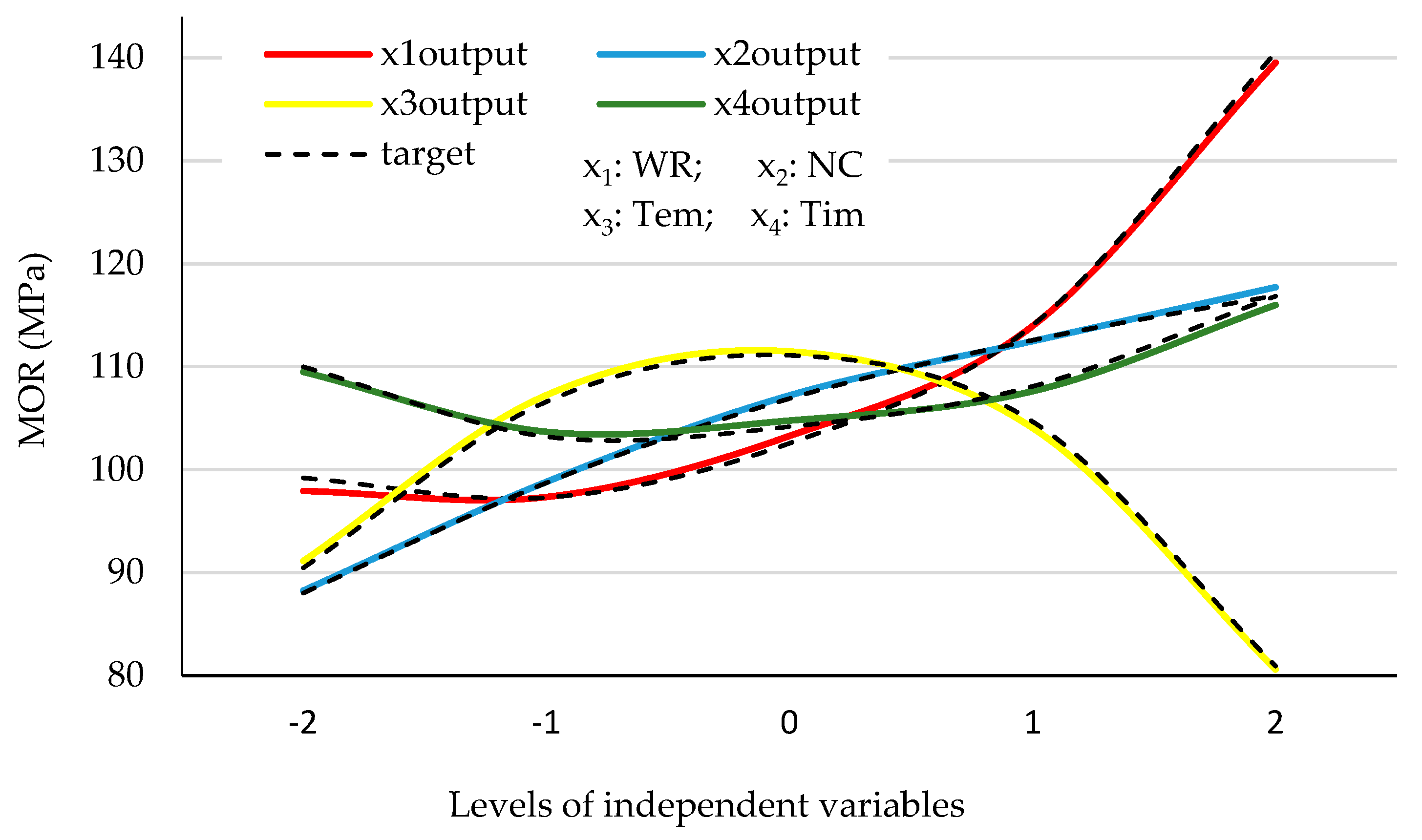
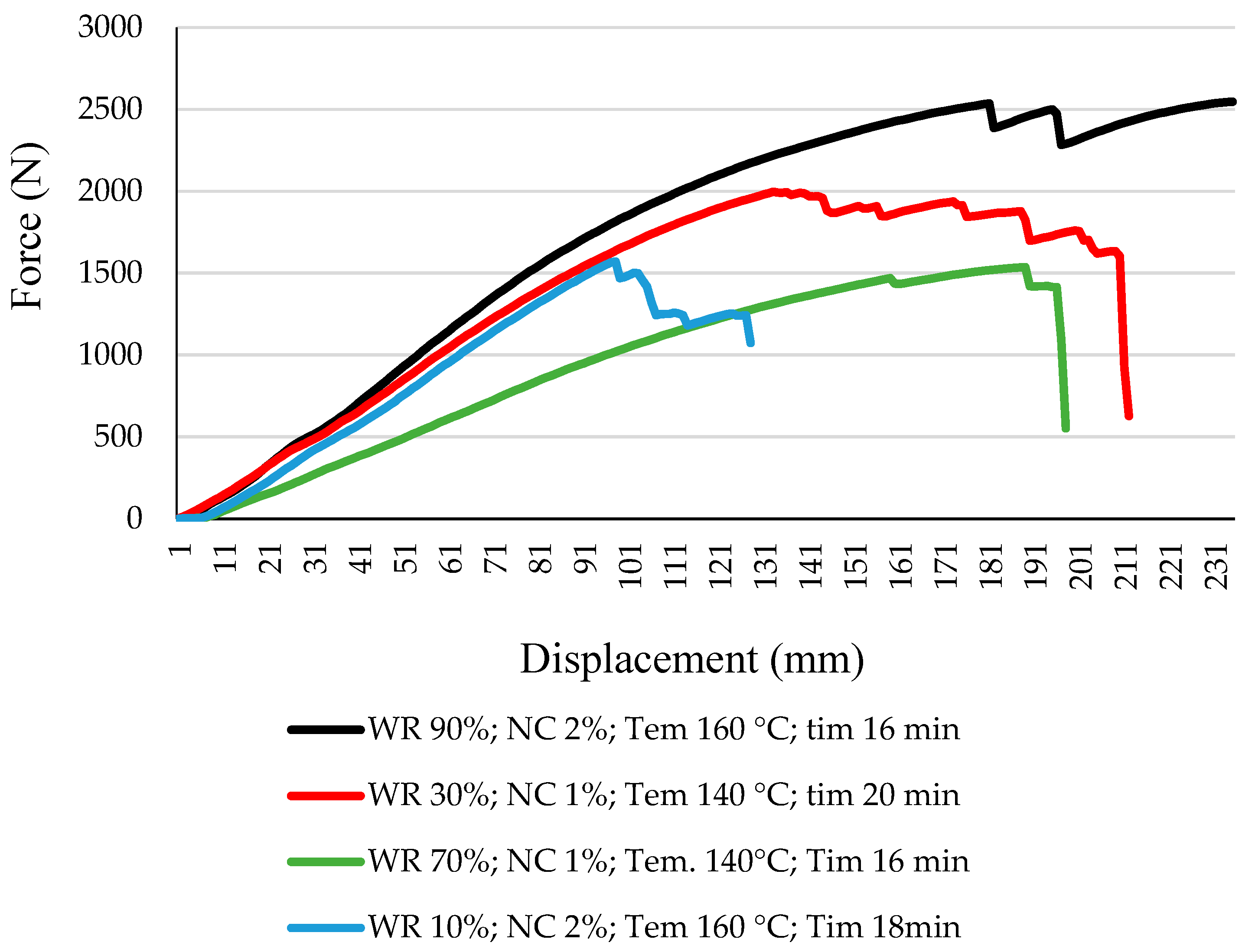
3. Results and Discussion
Selection of the Best Modeling Method
4. Conclusions
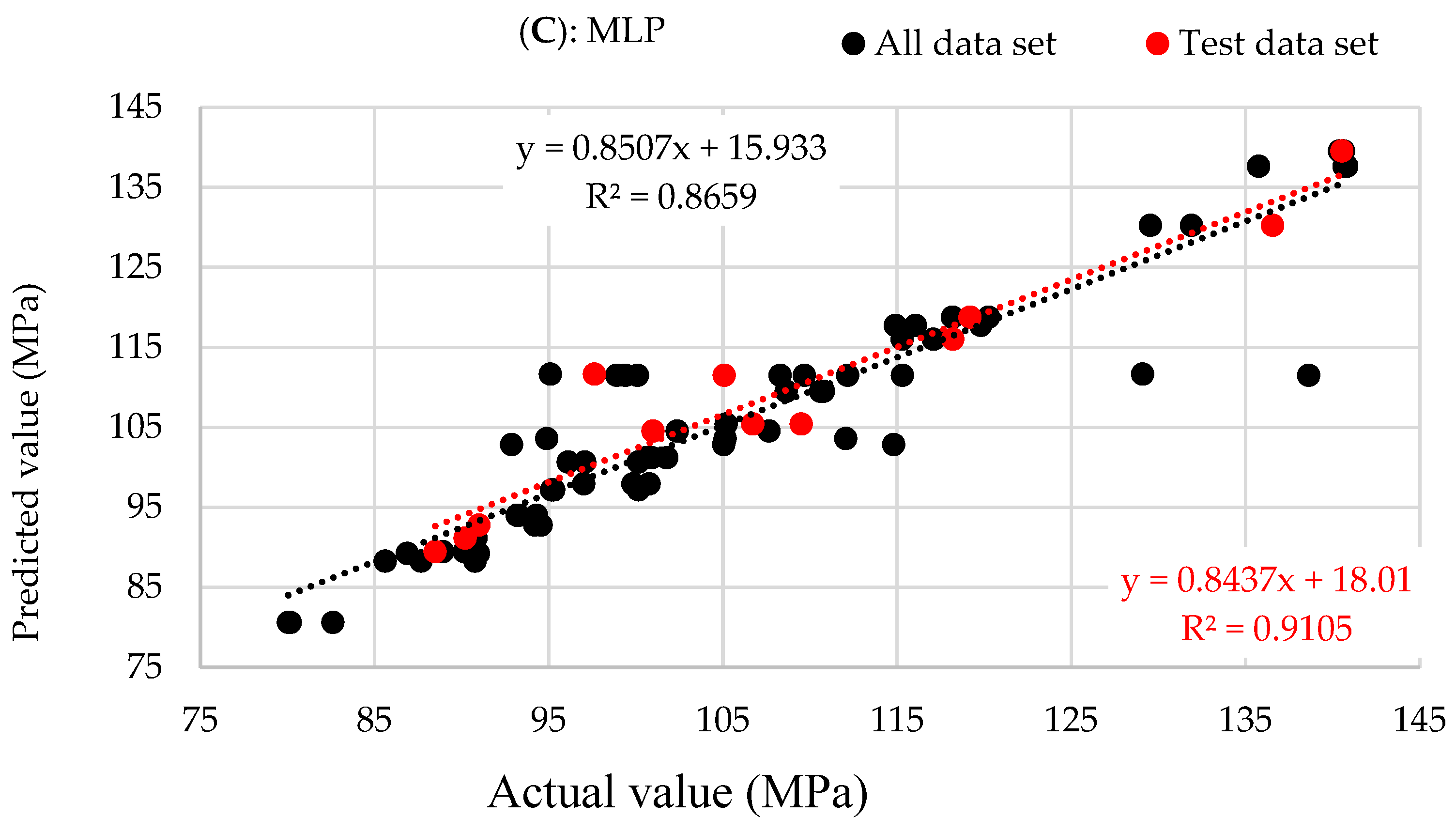
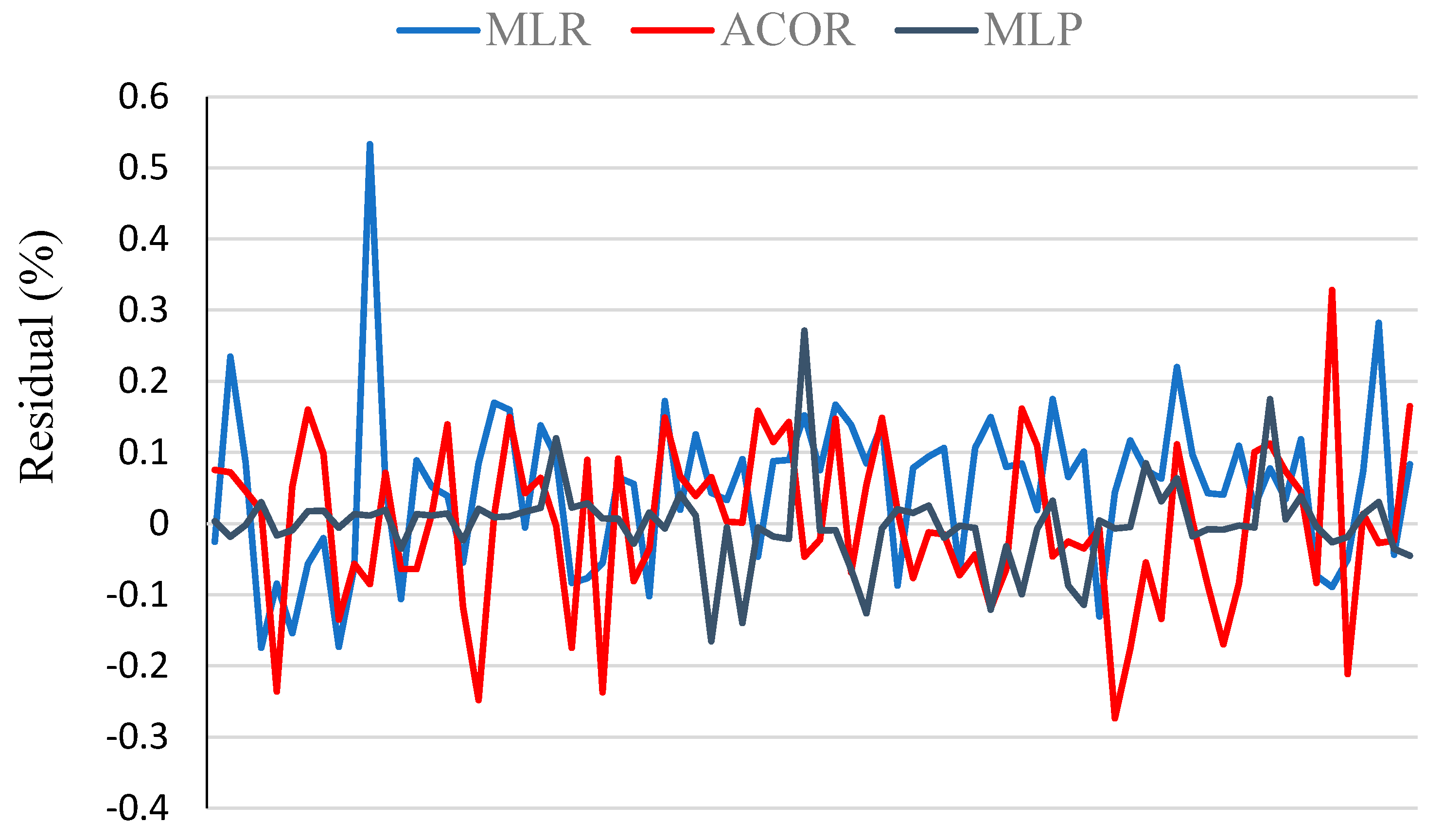
- The ANN-MLP model had the best ability to offer an accurate prediction compared to the other two methods;
- After determining the ANN-MLP as the most precise method in estimating the response, and combining it with the GA, the interactive effects of the variables were derived using the multiple objective and nonlinear constraint functions, respectively, on the actual and estimated values. It was observed that the difference between the functions’ factors was very slight, indicating the accurate estimation of the combined ANN-GA method used to evaluate the mechanical properties of the laminated products;
- Based on the XRD analysis, it can be observed that the chemical treatment of starch and its addition to the UF resin changes the crystallization and the chemical reactivity significantly;
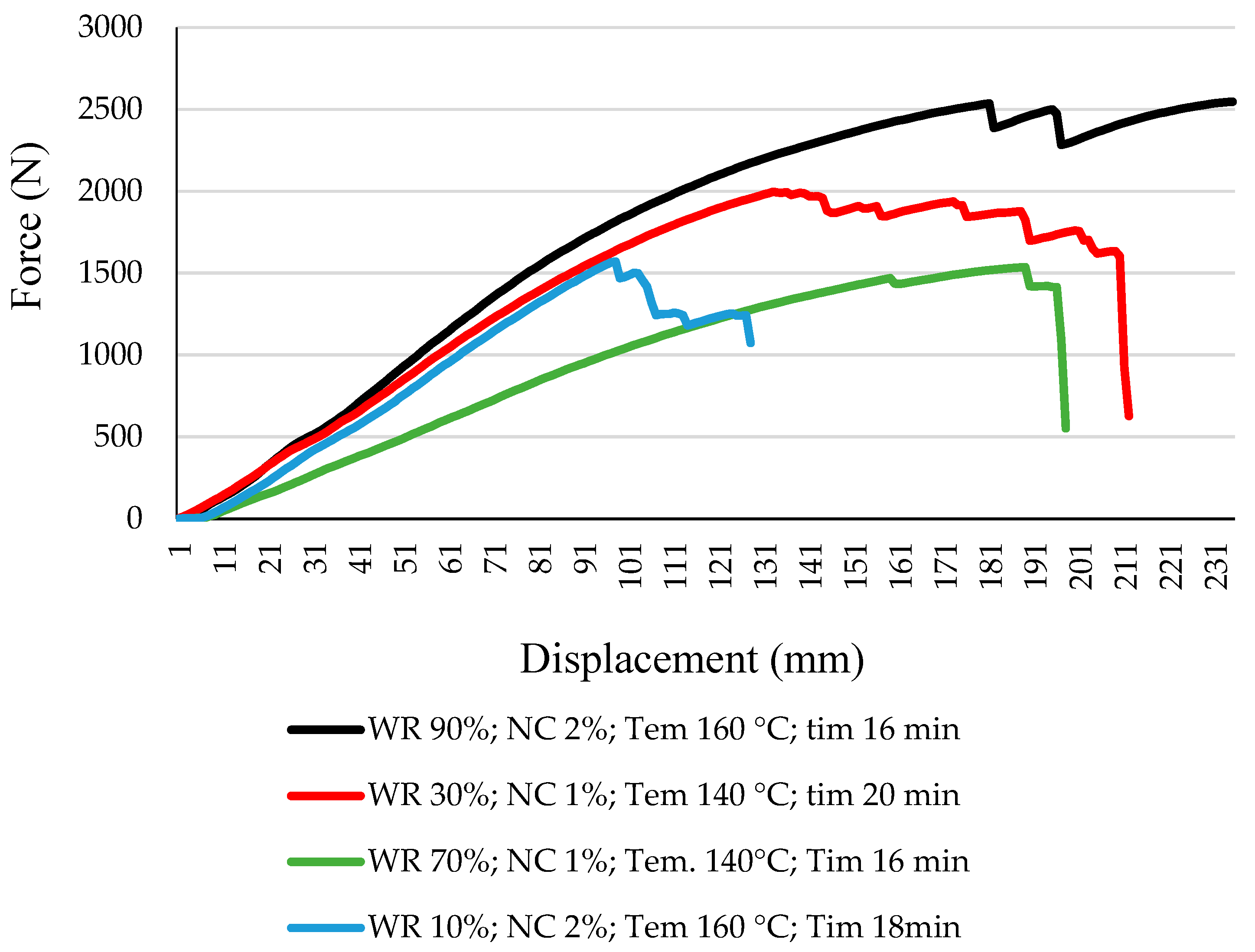
- It was determined that as a result of increasing the consumption of the modified starch in the resin, together with relatively increasing the nano-ZnO in the adhesive, the behavior of the stress–strain curve improved due to the change in the ductility level.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Li, Z.; Gu, Z.; Hong, Y.; Cheng, L. Preparation, characterization and properties of starch-based wood adhesive. Carbohydr. Polym. 2012, 88, 699–706. [Google Scholar] [CrossRef]
- Sandhu, K.S.; Singh, N.; Kaur, M. Characterizations of the different corn types and their grain fractions: Physicochemical, thermal, morphological, and rheological properties of starches. J. Food Eng. 2004, 64, 119–127. [Google Scholar] [CrossRef]
- Kaur, B.; Ariffin, F.; Bhat, R.; Karim, A.A. Progress in starch modification in the last decade. Food Hydrocoll. 2012, 26, 398–404. [Google Scholar] [CrossRef]
- Wang, Y.; Xiong, H.; Wang, Z.; Din, A.U.; Chen, L. Effects of different durations of acid hydrolysis on the properties of starch-based wood adhesive. Int. J. Biol. Macromol. 2017, 103, 819–828. [Google Scholar] [CrossRef]
- Papadopoulos, A.N.; Taghiyari, H.R. Innovation wood surface treatments based on nanotechnology. Coatings 2019, 9, 866. [Google Scholar] [CrossRef]
- Wang, X.; Ding, Y.; Summers, C.J.; Wang, Z.L. Large-scale synthesis of six-nanometer-wide ZnO nanobelts. J. Phys. Chem. B 2004, 108, 8773–8777. [Google Scholar] [CrossRef]
- Dhoke, S.K.; Bhandari, R.; Khanna, A. Effect of nano-ZnO addition on the silicone-modified alkyd-based waterborne coatings on its mechanical and heat-resistance properties. Prog. Org. Coat. 2014, 64, 39–46. [Google Scholar] [CrossRef]
- Gul, W.; Shah, S.R.A.; Khan, A.; Pruncu, C.I. Characterization of zinc oxide-urea formaldehyde nano resin and its impact on the physical performance of medium-density fiberboard. Polymers 2021, 13, 371. [Google Scholar] [CrossRef]
- da Silva, A.P.S.; Ferreira, B.S.; Favarim, H.R.; Silva, M.F.F.; Silva, J.V.F.; Azambuja, M.A.; Campos, C.I. Physical properties of medium density fiberboard produced with the addition of ZnO nanoparticles. Bioresources 2019, 14, 1618–1625. [Google Scholar] [CrossRef]
- Silva, L.C.L.; Lima, F.O.; Chahud, E.; Christoforo, A.L. Heat transfer and physical-mechanical properties analysis of particleboard produced with Zno nanoparticles addition. Bioresources 2019, 14, 9904–9915. [Google Scholar] [CrossRef]
- Kargarfard, A.; Jahan-Latibari, A. The effect of press temperature on properties of medium density fiberboard produced from Eucalyptus camendulensis fibers. Int. J. Lignocellul. Prod. 2014, 1, 142–150. [Google Scholar]
- Qiao, Z.; Qiao, Z.; Lv, S.; Gu, J.; Tan, H.; Shi, J.; Zhang, Y. Influence of acid hydrolysis on the properties of maize starch adhesive. Pigment Resin Technol. 2017, 46, 148–155. [Google Scholar] [CrossRef]
- Ozturk, H.; Demir, A.; Demirkir, C. Optimization of pressing parameters for the best mechanical properties of wood veneer/polystyrene composite plywood using artificial neural network. Eur. J. Wood Wood Prod. 2022, 80, 907–922. [Google Scholar] [CrossRef]
- Ozsahin, S.; Aydin, I. Prediction of the optimum veneer drying temperature for good bonding in plywood manufacturing by means of artificial neural network. Wood Sci. Technol. 2014, 48, 59–70. [Google Scholar] [CrossRef]
- Nazerian, M.; Razavi, S.A.; Partovinia, A.; Vatankhah, E.; Razmpour, Z. Comparison of different modeling methods toward predictive capability evaluation of the bonding strength of wood laminated products. Proc. Inst. Mech. Eng. Part E J. Process Mech. Eng. 2022, 236, 991–1003. [Google Scholar] [CrossRef]
- Ozsahin, S. Optimization of process parameters in oriented strand board manufacturing with artificial neural network analysis. Eur. J. Wood Prod. 2013, 71, 769–777. [Google Scholar] [CrossRef]
- Yapici, F.; Senyer, N.; Esen, R. Comparison of the multiple regression, ANN, and ANFIS models for production of MOE value of OSB panels. Wood Res. 2016, 61, 741–754. [Google Scholar]
- Nazerian, M.; Naderi, F.; Partovinia, A.; Papadopoulos, A.N.; Younesi-Kordkheili, H. Developing adaptive neuro-fuzzy inference system-based models to predict the bending strength of polyurethane foam-cored sandwich panels. Proc. Inst. Mech. Eng. L J. Mater. Des. Appl. 2022, 236, 3–22. [Google Scholar] [CrossRef]
- Wong, Y.J.; Mustapha, K.B.; Shimizu, Y.; Kamiya, A.; Arumugasamy, S.K. Development of surrogate predictive models for the nonlinear elasto-plastic response of medium density fibreboard-based sandwich structures. Int. J. Lightweight Mater. Manuf. 2021, 4, 302–314. [Google Scholar] [CrossRef]
- Korai, H.; Watanabe, K. Predicting the strength reduction of particleboard subjected to various climatic conditions in Japan using artificial neural networks. Eur. J. Wood Prod. 2017, 75, 385–396. [Google Scholar] [CrossRef]
- Watanabe, K.; Korai, H.; Matsushita, Y.; Hayashi, T. Predicting internal bond strength of particleboard under outdoor exposure based on climate data: Comparison of multiple linear regression and artificial neural network. J. Wood Sci. 2015, 61, 151–158. [Google Scholar] [CrossRef]
- Akyuz, I.; Ozsahin, S.; Tiryaki, S.; Aydın, A. An application of artificial neural networks for modeling formaldehyde emission based on process parameters in particleboard manufacturing process. Clean Technol. Environ. Policy 2017, 19, 1449–1458. [Google Scholar] [CrossRef]
- Yang, J.G.; Weng, S.Y.; Zhao, H. Applied Textbook of Artificial Neural; Network, Zhejiang University Press: Hangzhou, China, 2001. [Google Scholar]
- Nazerian, M.; Akbarzade, M.; Ghorbanezdad, P.; Papadopoulos, A.N.; Vatankhah, E.; Foti, D.; Koosha, M. Optimal modified starch content in UF resin for glulam based on bonding strength using artificial neural network. J. Compos. Sci. 2022, 6, 279. [Google Scholar] [CrossRef]
- Nazerian, M.; Razavi, S.A.; Partovinia, A.; Vatankhah, E.; Razmpour, Z. Prediction of the bending strength of a laminated veneer lumber (LVL) using an artificial neural network. Mech. Compos. Mater. 2020, 56, 649–664. [Google Scholar] [CrossRef]
- EN 310; Wood Based Panels, Determination of Modulus of Elasticity in Bending and Bending Strength. European Committee for Standardization: Brusselles, Belgium, 1993.
- Haykin, S. Neural Networks; Prentice Hall: New York, NY, USA, 1994; Volume 2. [Google Scholar]
- Mazloom, M.S.; Rezaei, F.; Hammati-Sarapardeh, A.; Husein, M.M.; Zendehboudi, S.; Bemani, A. Artificial intelligence based methods for asphaltenes adsorption by nanocomposites: Application of group method of data handling, least squares support vector machine, and artificial neural networks. Nanomaterials 2020, 10, 890. [Google Scholar] [CrossRef]
- Calp, M.H. A hybrid ANFIS-GA approach for estimation of regional rainfall amount. Gazi Univ. J. Sci. 2019, 32, 145–162. [Google Scholar]
- Luk, K.C.; Ball, J.E.; Sharma, A. A study of optimal model lag and spatial inputs to artificial neural network for rainfall forecasting. J. Hydrol. 2000, 227, 56–65. [Google Scholar] [CrossRef]
- Desai, K.M.; Survase, S.A.; Saudagar, P.S.; Lele, S.S.; Singhal, R.S. Comparison of artificial neural network (ANN) and response surface methodology (RSM) infermentation media optimization: Case study of fermentative production of scleroglucan. Biochem. Eng. J. 2008, 41, 266–273. [Google Scholar] [CrossRef]
- Abdullah, A.H.D.; Putri, O.D.; Fikriyyah, A.K.; Nissa, R.C.; Hidayat, S.; Septiyanto, R.F.; Karina, M.; Satoto, R. Harnessing the excellent mechanical, barrier and antimicrobial properties of zinc oxide (ZnO) to improve the performance of starch-based bioplastic. Polym. Plast. Technol. Mater. 2020, 59, 1259–1267. [Google Scholar] [CrossRef]
- Nafchi, A.M.; Moradpour, M.; Saeidi, M.; Alias, A.K. Effects of nanorod-rich ZnO on rheological, sorption isotherm, and physicochemical properties of bovine gelatin films. LWT Food Sci. Technol. 2014, 58, 142–149. [Google Scholar] [CrossRef]
- Ma, X.; Chang, P.R.; Yang, J.; Yu, J. Preparation and properties of glycerol plasticized-pea starch/zinc oxide-starch bionanocomposites. Carbohyd. Polym. 2009, 75, 472–478. [Google Scholar] [CrossRef]
- Lubis, M.A.R.; Park, B.D. Modification of urea-formaldehyde resin adhesives with oxidized starch using blocked pMDI for plywood. J. Adhes. Sci. Technol. 2018, 32, 2667–2681. [Google Scholar] [CrossRef]
- Zhao, X.F.; Peng, L.Q.; Wang, H.; Wang, Y.B.; Zhang, H. Environment-friendly urea-oxidized starch adhesive with zero formaldehyde emission. Carbohydr. Polym. 2018, 181, 1112–1118. [Google Scholar] [CrossRef]
- Liu, F.; Sun, B.; Jiang, X.; Aldeyab, S.S.; Zhang, Q.; Zhu, M. Mechanical properties of dental resin/composite containing urchin-like hydroxyapatite. Dent. Mater. 2014, 30, 1358–1368. [Google Scholar] [CrossRef]
- Venkatesan, R.; Rajeswari, N. ZnO/PBAT nanocomposite films: Investigation on the mechanical and biological activity for food packaging. Polym. Adv. Technol. 2017, 28, 20–27. [Google Scholar] [CrossRef]
- Taubert, A.; Wegner, G. Formation of uniform and monodisperse zincite crystals in the presence of soluble starch. J. Mater. Chem. 2002, 12, 805–807. [Google Scholar] [CrossRef]
- Ozdemir, F.A.; Demirata, B.; Apak, R. Adsorptive removal of methylene blue from simulated dyeing wastewater with melamine-formaldehyde-urea resin. J. Appl. Poly. Sci. 2009, 112, 3442. [Google Scholar] [CrossRef]
- Sun, X.; Chai, Z. Urea–formaldehyde resin monolith as a new packing material for affinity chromatography. J. Chromatogr. A 2002, 943, 209. [Google Scholar] [CrossRef]
- Jin, X.; Deng, M.; Kaps, S.; Zhu, X.; Holken, I.; Mess, K.; Adelung, R.; Mishrae, Y.K. Study of tetrapodal znO-PDMS composites: A comparison of fillers shapes in stiffness and hydrophobicity improvements. PLoS ONE. 2014, 10, e106991-9. [Google Scholar] [CrossRef]
- Oleyaei, S.A.; Zahedi, Y.; Ghanbarzadeh, B.; Moayedi, A.A. Modification of physicochemical and thermal properties of starch films by incorporation of TiO2 nanoparticles. Int. J. Biol. Macromol. 2016, 89, 256–264. [Google Scholar] [CrossRef] [PubMed]
- Ebrahimi, S.; Ghafoori-Tabrizi, K.; Rafii-Tabar, H. Molecular dynamics simulation of the adhesive behavior of collagen on smooth and randomly rough TiO2 and Al2O3 surfaces. Comput. Mater. Sci. 2013, 71, 172–178. [Google Scholar] [CrossRef]
- Shi, J.; Wang, Y.; Liu, L.; Bai, H.; Wu, J.; Jiang, C.; Zhou, Z. Tensile fracture behaviors of T-ZnOw/polyamide 6 composites. Mater. Sci. Eng. A Struct. Mater. 2009, 512, 109–116. [Google Scholar] [CrossRef]
- Niu, L.N.; Fang, M.; Jiao, K.; Tang, L.H.; Xiao, Y.H.; Shen, L.J.; Chen, J.H. Tetrapod-like zinc oxide whisker enhancement of resin composite. J. Dent. Res. 2010, 89, 746–750. [Google Scholar] [CrossRef]
- Mozaffar, A.K.; Sayed Marghoob, A.; Ved Prakash, M. Development and characterization of a wood adhesive using bagasse lignin. Int. J. Adhes. Adhes. 2004, 24, 485–493. [Google Scholar]
- Zhang, S.D.; Zhang, Y.R.; Wang, X.L.; Wang, Y.Z. High Carbonyl Content Oxidized Starch Prepared by Hydrogen Peroxide and Its Thermoplastic Application. Starch 2009, 61, 646–655. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Unit | Coded Values of Variables | Actual Values of Variables | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| WR | % | −2 | −1 | 0 | 1 | 2 | 10 | 30 | 50 | 70 | 90 |
| NC | % | 0 | 1 | 2 | 3 | 4 | |||||
| Tem | °C | 120 | 140 | 160 | 180 | 200 | |||||
| Tim | min | 14 | 16 | 18 | 20 | 22 | |||||
| Treatment | WR (%) | NC (%) | Tem (°C) | Tim (min.) | Treatment | WR (%) | NC (%) | Tem (°C) | Tim (min) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 30 | 1 | 180 | 16 | 40 | 30 | 1 | 140 | 16 |
| 2 | 70 | 3 | 140 | 20 | 41 | 10 | 2 | 160 | 18 |
| 3 | 30 | 3 | 140 | 20 | 42 | 50 | 2 | 160 | 18 |
| 4 | 70 | 1 | 140 | 16 | 43 | 50 | 2 | 160 | 18 |
| 5 | 50 | 4 | 160 | 18 | 44 | 50 | 2 | 160 | 22 |
| 6 | 50 | 2 | 120 | 18 | 45 | 50 | 2 | 200 | 18 |
| 7 | 30 | 1 | 180 | 20 | 46 | 70 | 3 | 180 | 20 |
| 8 | 30 | 3 | 180 | 20 | 47 | 50 | 0 | 160 | 18 |
| 9 | 50 | 0 | 160 | 18 | 48 | 70 | 1 | 140 | 16 |
| 10 | 30 | 1 | 180 | 20 | 49 | 50 | 2 | 120 | 18 |
| 11 | 90 | 2 | 160 | 18 | 50 | 70 | 1 | 180 | 20 |
| 12 | 10 | 2 | 160 | 18 | 51 | 50 | 2 | 160 | 18 |
| 13 | 30 | 1 | 140 | 20 | 52 | 70 | 1 | 140 | 20 |
| 14 | 30 | 3 | 140 | 20 | 53 | 30 | 3 | 180 | 16 |
| 15 | 50 | 2 | 160 | 14 | 54 | 50 | 2 | 120 | 18 |
| 16 | 30 | 3 | 180 | 20 | 55 | 70 | 3 | 140 | 20 |
| 17 | 30 | 1 | 180 | 20 | 56 | 70 | 1 | 180 | 16 |
| 18 | 50 | 4 | 160 | 18 | 57 | 50 | 2 | 160 | 18 |
| 19 | 90 | 2 | 160 | 18 | 58 | 70 | 3 | 180 | 20 |
| 20 | 90 | 2 | 160 | 18 | 59 | 30 | 1 | 180 | 16 |
| 21 | 70 | 3 | 180 | 16 | 60 | 30 | 3 | 140 | 16 |
| 22 | 50 | 2 | 160 | 22 | 61 | 70 | 1 | 180 | 16 |
| 23 | 30 | 3 | 180 | 16 | 62 | 30 | 1 | 140 | 20 |
| 24 | 30 | 3 | 180 | 16 | 63 | 70 | 3 | 180 | 16 |
| 25 | 10 | 2 | 160 | 18 | 64 | 30 | 3 | 180 | 20 |
| 26 | 30 | 1 | 140 | 16 | 65 | 30 | 1 | 180 | 16 |
| 27 | 70 | 1 | 140 | 20 | 66 | 50 | 2 | 160 | 14 |
| 28 | 50 | 4 | 160 | 18 | 67 | 70 | 1 | 180 | 20 |
| 29 | 70 | 1 | 180 | 16 | 68 | 50 | 2 | 200 | 18 |
| 30 | 70 | 3 | 180 | 16 | 69 | 70 | 3 | 140 | 16 |
| 31 | 30 | 3 | 140 | 20 | 70 | 70 | 1 | 180 | 20 |
| 32 | 50 | 2 | 160 | 22 | 71 | 70 | 1 | 140 | 20 |
| 33 | 70 | 3 | 140 | 16 | 72 | 50 | 2 | 200 | 18 |
| 34 | 70 | 3 | 180 | 20 | 73 | 50 | 0 | 160 | 18 |
| 35 | 70 | 3 | 140 | 16 | 74 | 70 | 1 | 140 | 16 |
| 36 | 30 | 1 | 140 | 16 | 75 | 50 | 2 | 160 | 14 |
| 37 | 50 | 2 | 160 | 18 | 76 | 70 | 3 | 140 | 20 |
| 38 | 30 | 1 | 140 | 20 | 77 | 30 | 3 | 140 | 16 |
| 39 | 50 | 2 | 160 | 18 | 78 | 30 | 3 | 140 | 16 |
| Treatment | Actual Value (MPa) | MLR Value (MPa) | ACOR Value (MPa) | MLP Value (MPa) | Treatment | Actual Value (MPa) | MLR Value (MPa) | ACOR Value (MPa) | MLP Value (MPa) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 94.31 | 96.89 | 86.77134 | 93.97804 | 40 | 88.48 | 80.98 | 89.13896 | 89.45788 |
| 2 | 135.75 | 112.3 | 103.4225 | 137.6192 | 41 | 97.02 | 80.34 | 125.6724 | 97.93634 |
| 3 | 105.19 | 96.64 | 104.9268 | 105.3898 | 42 | 105.08 | 91.23 | 105.7902 | 111.5015 |
| 4 | 100.16 | 117.6 | 89.13896 | 97.16088 | 43 | 98.9 | 90.45 | 106.6536 | 111.5015 |
| 5 | 116.06 | 124.5 | 103.7676 | 117.7255 | 44 | 115.29 | 101.34 | 85.90795 | 115.9854 |
| 6 | 90.2 | 105.62 | 103.4225 | 91.1306 | 45 | 82.61 | 91.34 | 104.9268 | 80.60807 |
| 7 | 90.97 | 96.64 | 124.809 | 89.23929 | 46 | 120.26 | 112.45 | 100.5366 | 118.7506 |
| 8 | 94.57 | 96.64 | 91.16155 | 92.78109 | 47 | 90.77 | 81.34 | 92.02495 | 88.25368 |
| 9 | 87.68 | 105 | 108.6761 | 88.25368 | 48 | 95.17 | 84.56 | 106.6536 | 97.16088 |
| 10 | 90.55 | 96.6 | 105.7902 | 89.23929 | 49 | 90.83 | 97.56 | 109.0212 | 91.1306 |
| 11 | 140.63 | 87.3 | 108.6761 | 139.5276 | 50 | 100.59 | 89.98 | 92.02495 | 101.2069 |
| 12 | 99.83 | 94.25 | 108.1578 | 97.93634 | 51 | 99.4 | 84.44 | 102.9042 | 111.5015 |
| 13 | 100.99 | 111.6 | 105.7902 | 104.5311 | 52 | 108.29 | 100.34 | 102.5591 | 111.4828 |
| 14 | 106.71 | 97.85 | 92.02495 | 105.3898 | 53 | 92.87 | 84.44 | 120.4188 | 102.8141 |
| 15 | 110.61 | 105.45 | 89.13896 | 109.4889 | 54 | 90.36 | 88.45 | 124.809 | 91.1306 |
| 16 | 94.21 | 90.34 | 85.90795 | 92.78109 | 55 | 140.81 | 123.34 | 122.7864 | 137.6192 |
| 17 | 86.88 | 92.34 | 106.6536 | 89.23929 | 56 | 94.89 | 88.33 | 122.7864 | 103.5971 |
| 18 | 119.81 | 111.34 | 122.4414 | 117.7255 | 57 | 100.1 | 89.99 | 119.5554 | 111.5015 |
| 19 | 140.4 | 123.44 | 111.0438 | 139.5276 | 58 | 119.18 | 132.23 | 105.7902 | 118.7506 |
| 20 | 140.54 | 124.56 | 125.6724 | 139.5276 | 59 | 93.28 | 88.88 | 122.4414 | 93.97804 |
| 21 | 131.9 | 132.45 | 111.0438 | 130.2227 | 60 | 100.16 | 88.47 | 107.8127 | 100.6346 |
| 22 | 118.2 | 104.4 | 86.77134 | 115.9854 | 61 | 112.06 | 104.56 | 102.5591 | 103.5971 |
| 23 | 114.8 | 105.55 | 88.79393 | 102.8141 | 62 | 107.65 | 101.34 | 108.6761 | 104.5311 |
| 24 | 105.05 | 113.4 | 107.8127 | 102.8141 | 63 | 136.56 | 114.56 | 85.90795 | 130.2227 |
| 25 | 100.77 | 108.45 | 108.1578 | 97.93634 | 64 | 90.99 | 81.34 | 119.5554 | 92.78109 |
| 26 | 90.15 | 95.68 | 103.7676 | 89.45788 | 65 | 93.19 | 88.94 | 102.9042 | 93.97804 |
| 27 | 112.16 | 105.67 | 120.4188 | 111.4828 | 66 | 108.63 | 104.56 | 107.8127 | 109.4889 |
| 28 | 114.9 | 109.34 | 109.0212 | 117.7255 | 67 | 100.92 | 89.99 | 109.0212 | 101.2069 |
| 29 | 105.13 | 115.34 | 122.7864 | 103.5971 | 68 | 80.05 | 77.67 | 108.1578 | 80.60807 |
| 30 | 129.54 | 112.34 | 125.6724 | 130.2227 | 69 | 129.1 | 121.34 | 91.16155 | 111.6252 |
| 31 | 109.5 | 107.56 | 122.4414 | 105.3898 | 70 | 101.78 | 98.34 | 103.4225 | 101.2069 |
| 32 | 117.09 | 104.56 | 105.7902 | 115.9854 | 71 | 115.3 | 103.45 | 100.5366 | 111.4828 |
| 33 | 95.1 | 90.76 | 86.77134 | 111.6252 | 72 | 80.17 | 87.5 | 102.9042 | 80.60807 |
| 34 | 118.18 | 114.89 | 104.9268 | 118.7506 | 73 | 85.62 | 94.56 | 105.7902 | 88.25368 |
| 35 | 97.63 | 88.57 | 88.79393 | 111.6252 | 74 | 95.29 | 100.34 | 103.7676 | 97.16088 |
| 36 | 88.92 | 93.56 | 124.809 | 89.45788 | 75 | 110.77 | 103.45 | 88.79393 | 109.4889 |
| 37 | 109.67 | 100.9 | 120.4188 | 111.5015 | 76 | 140.66 | 112.45 | 111.0438 | 137.6192 |
| 38 | 102.38 | 93.45 | 100.5366 | 104.5311 | 77 | 97.07 | 101.45 | 102.5591 | 100.6346 |
| 39 | 138.63 | 123.44 | 119.5554 | 111.5015 | 78 | 96.12 | 87.78 | 91.16155 | 100.6346 |
| Source | Test Data Set | Training Data Set | All Data Set | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | SSE | R2 | RMSE | MAE | SSE | R2 | RMSE | MAE | SSE | |
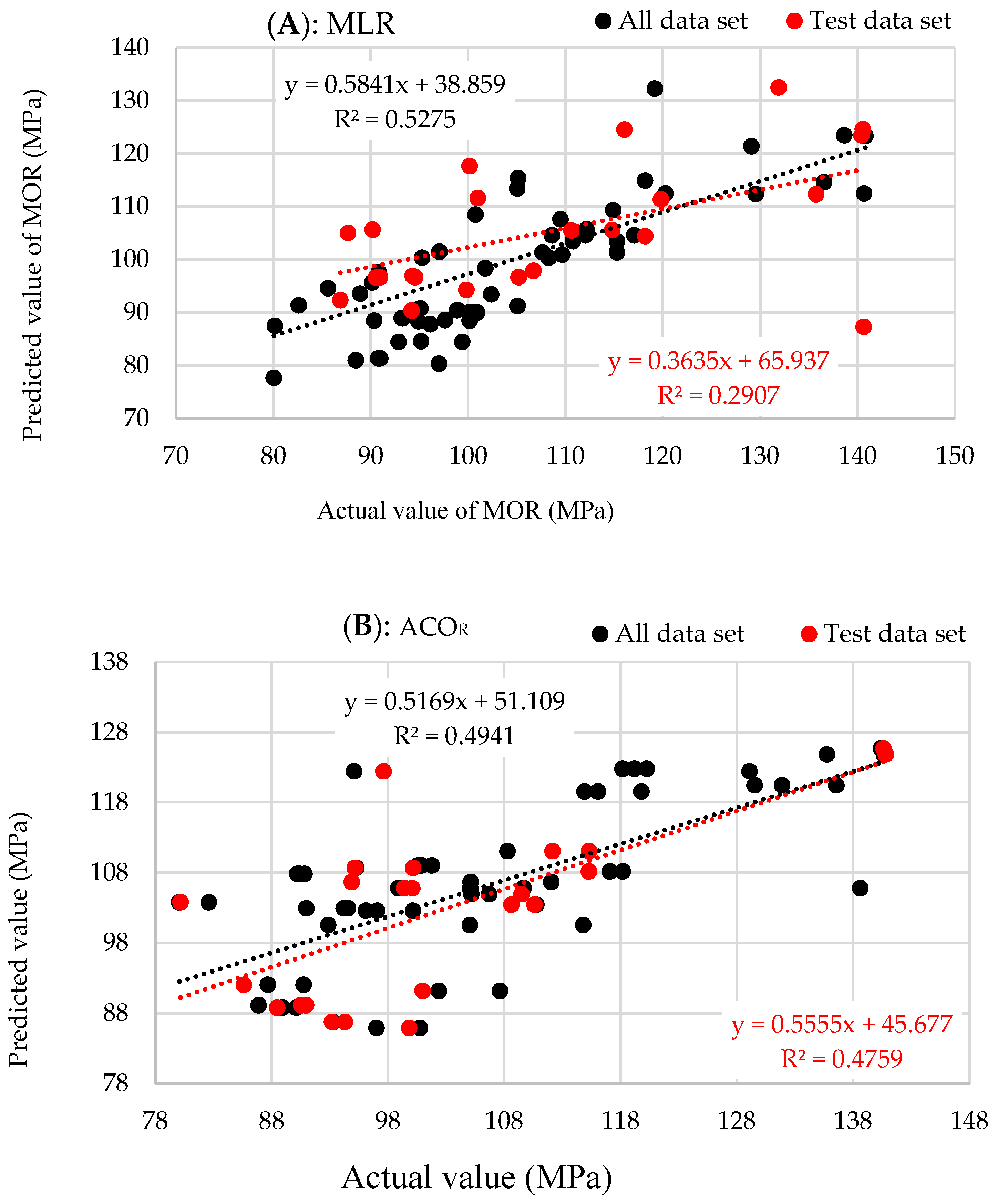
| MLR | 0.2907 | 12.87 | 10.17 | 3811 | 0.6065 | 10.55 | 8.64 | 6125 | 0.5275 | 12.15 | 9.8 | 11528 |
| ACOR | 0.4759 | 10.88 | 8.80 | 2723 | 0.4934 | 11.52 | 9.12 | 7309 | 0.4941 | 19.82 | 16.09 | 30665 |
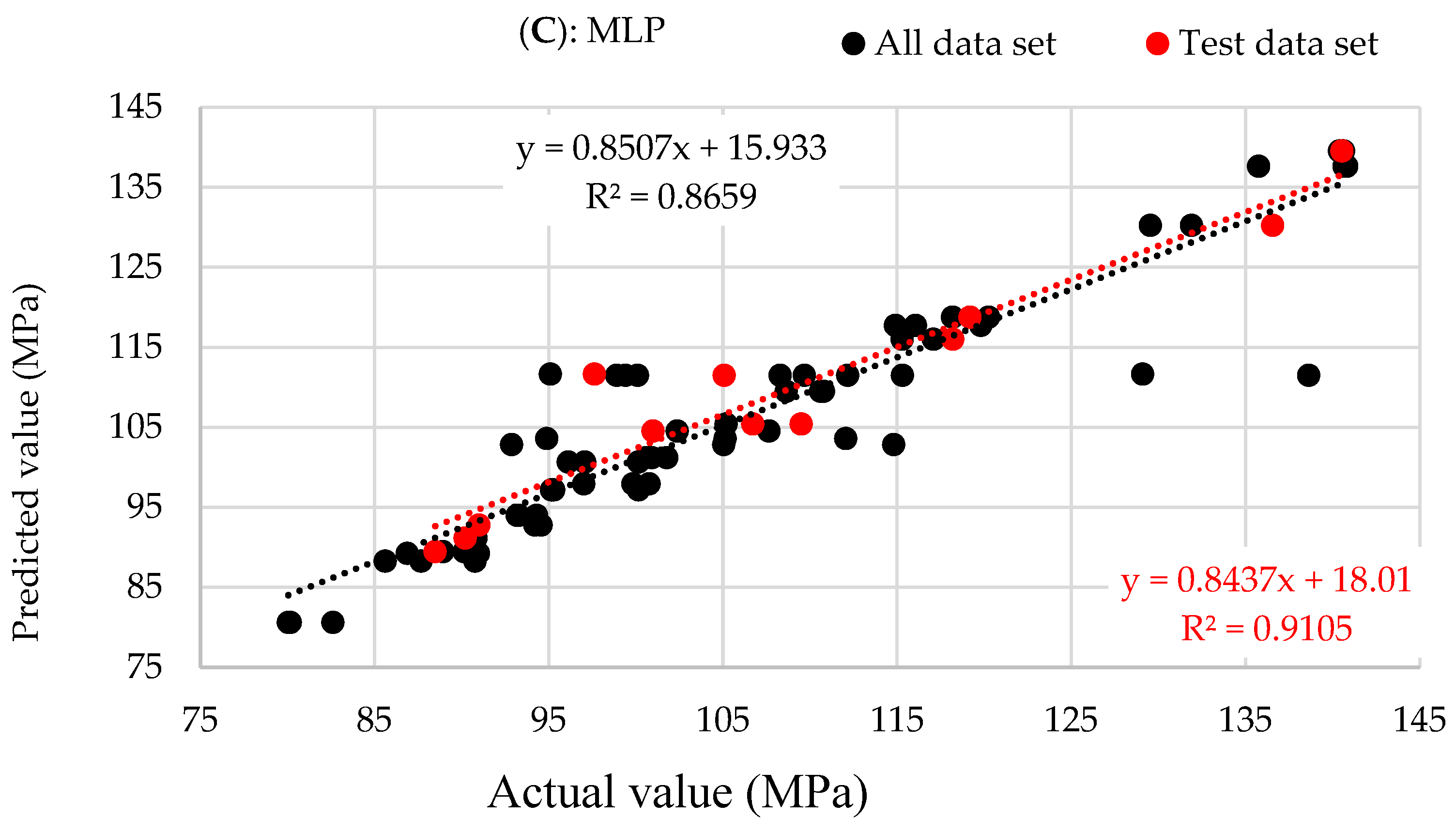
| MLP | 0.9105 | 5.16 | 3.59 | 319 | 0.8589 | 6.31 | 3.58 | 2152 | 0.8659 | 5.83 | 3.44 | 2660 |
| Source | Function | Equation | SSE | R2 | Adj. R2 | RMSE |
|---|---|---|---|---|---|---|
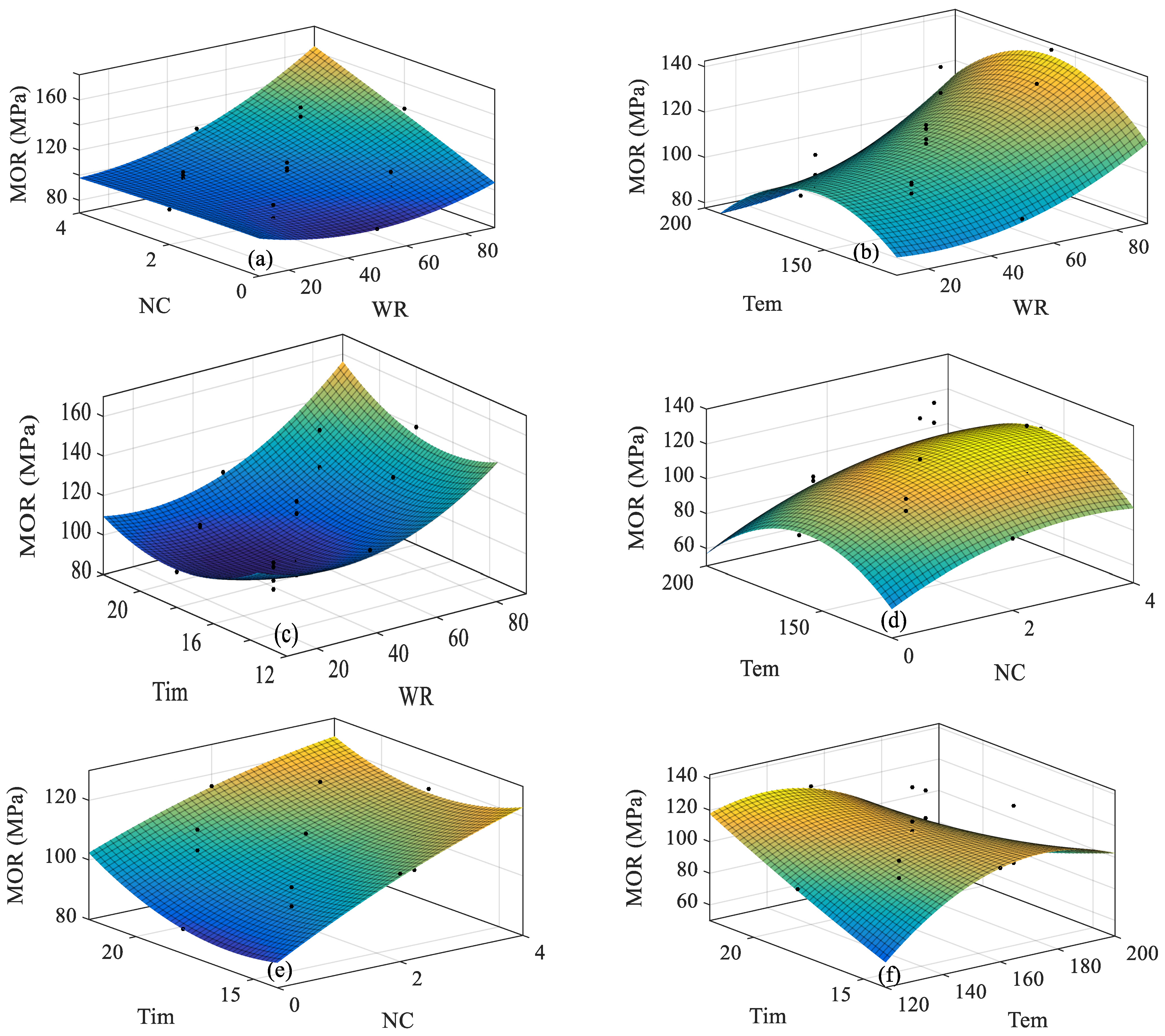
| Actual value | F(x1x2) | 102 + 9.018x1 + 7.025x2 + 4.243x12 + 3.613x1x2 − 0.1053x22 | 8341 | 0.5785 | 0.5493 | 10.76 |
| F(x1x3) | 108.3 + 9.0181x1 − 1.433x3 + 2.932x12 + 1.192x1x3 − 5.608x32 | 9001 | 0.4944 | 0.4593 | 11.79 | |
| F(x1x4) | 97.87 + 9.018x1 + 2.204x4 + 5.099x12 + 1.357x1x4 + 3.49x42 | 9119 | 0.4344 | 0.3952 | 12.47 | |
| F(x2x3) | 114.8 + 7.025x2 − 1.433x3 − 2.774x22 + 0.7229x2x3 − 6.967x32 | 7242 | 0.3726 | 0.329 | 13.13 | |
| F(x2x4) | 104.4 + 7.025x3 + 2.204x4 − 0.6079x32 − 0.3608x3x4 + 2.132x42 | 5454 | 0.2192 | 0.165 | 14.65 | |
| F(x3x4) | 110.7+ −1.433x3 + 2.204x4 − 6.111x32 − 6.386x3x4 + 0.8215x42 | 4204 | 0.2824 | 0.2325 | 14.04 | |
| Estimated value | F(x1x2) | 102.8 + 2.425x1 − 0.7444x2 + 3.709x12 − 1.766x1x2 − 0.2929x22 | 1481 | 0.9444 | 0.9119 | 4.34 |
| F(x1x3) | 102.4 + 2.425x1 − 1.057x3 + 3.705x12 − 0.7738x1x3 + 0.07066x32 | 1494 | 0.816 | 0.8361 | 10.38 | |
| F(x1x4) | 103 + 2.425x1 − 2.111x4 + 3.654x12 + 3.395x1x4 − 0.5224x42 | 1494 | 0.816 | 0.8035 | 11 | |
| F(x2x3) | 108.4 − 0.7444x2 − 1.057x3 − 1.457x22 + 4.731x2x3 − 1.18x32 | 1513 | 0.787 | 0.7213 | 9.5 | |
| F(x2x4) | 109 − 0.7444x2 − 2.111x4 − 1.598x22 −2.724x2x4 − 1.773x42 | 1548 | 0.9173 | 0.9012 | 8.66 | |
| F(x3x4) | 108.6 − 1.057x3 − 2.111x4 − 1.235x32 − 0.8525x3x4 − 1.686x42 | 1584 | 0.7021 | 0.6631 | 4.83 |
| Source | Function | MOR (MPa) | x1 | x2 | x3 | x4 |
|---|---|---|---|---|---|---|
| MLP | F(x1x2) | 110.89 | −0.045 (49.1%) | 1.385 (3.385%) | 1.957 (199.4°C) | 1.987 (19.974) |
| F(x1x3) | 83.54 | |||||
| F(x1x4) | 115.50 | |||||
| F(x2x3) | 91.68 | |||||
| F(x2x4) | 124.76 | |||||
| F(x3x4) | 86.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nazerian, M.; Akbarzadeh, M.; Papadopoulos, A.N. Comparative Analysis of ANN-MLP, ANFIS-ACOR and MLR Modeling Approaches for Estimation of Bending Strength of Glulam. J. Compos. Sci. 2023, 7, 57. https://doi.org/10.3390/jcs7020057
Nazerian M, Akbarzadeh M, Papadopoulos AN. Comparative Analysis of ANN-MLP, ANFIS-ACOR and MLR Modeling Approaches for Estimation of Bending Strength of Glulam. Journal of Composites Science. 2023; 7(2):57. https://doi.org/10.3390/jcs7020057
Chicago/Turabian StyleNazerian, Morteza, Masood Akbarzadeh, and Antonios N. Papadopoulos. 2023. "Comparative Analysis of ANN-MLP, ANFIS-ACOR and MLR Modeling Approaches for Estimation of Bending Strength of Glulam" Journal of Composites Science 7, no. 2: 57. https://doi.org/10.3390/jcs7020057
APA StyleNazerian, M., Akbarzadeh, M., & Papadopoulos, A. N. (2023). Comparative Analysis of ANN-MLP, ANFIS-ACOR and MLR Modeling Approaches for Estimation of Bending Strength of Glulam. Journal of Composites Science, 7(2), 57. https://doi.org/10.3390/jcs7020057