
An Objective Metallographic Analysis Approach Based on Advanced Image Processing Techniques


 ,
, 
 and
and 
Abstract
1. Introduction
- White cast iron shows that all of the carbon is combined in the form of cementite. This type of manufacturing offers great hardness and fragility. Furthermore, it provides great resistance to wear and abrasion [4].
- In gray cast iron [5], in contrast to what happens in white cast iron, the carbon is in the form of sheets. This type of cast iron has good resistance to compression, and its mechanical properties are suitable for a large number of activities.
- Lastly, in nodular cast iron (also known as ductile iron or spheroidal graphite) [6], carbon crystallizes in the form of spherical nodules, inhibiting the creation of cracks by releasing the matrices of stress points. This type of cast iron has much more hardness and resistance to fatigue. For this reason, it is especially useful for elements that require high resistance, such as safety components for the automotive industry.
- The classification is based solely on mathematical formulae, leaving out the ones that do not meet the criteria. The software extracts some characteristics from images using computer vision and they apply formulas defined in the regulations they include.
- Subjectivity is still present even if measurements were objectively made.
- The software implements regulations that, perhaps, are not needed for the customer or by a certification procedure. For instance, AmGuss only includes DIN EN ISO 945 and ASTM-A247. Sometimes customers ask for custom calculations that are not possible using this software.
- The analysis software mainly focuses on analyzing the image to extract features and characteristics, but they do not accurately determine the final quality of the iron that was manufactured. Hence, new functionality needs to be added to them.
- In the end, these solutions are not believed to be deployed for real-time analyses in manufacturing plants.
2. Materials and Methods
2.1. Methodology and Evaluation Methods
- Identification of the problem and the challenges to overcome. The purpose of this first step is to extract the background and context of the problem to be solved. In other words, we work to become aware of what we are attempting to solve.
- Acquisition of knowledge. The second step involves the acquisition of knowledge at a high level, providing the general vision necessary to start the investigation. Later, when we are working on a much more specific topic about the challenge to be faced, we will study that topic in a more specific way.
- Division in challenges. Based on the idea of the divisions already mentioned, in this step, we define the challenges faced. In our work, the following challenges were identified: (i) data extraction, (ii) handling nodule sizes, (iii) handling nodule shapes, and (iv) metal quality classification. For each of them, the following sub-phases were carried out:
- (a)
- Acquisition of specific knowledge. Once the topic was defined, in this stage, we increased the knowledge to solve this problem. Many times, this acquisition was directly related to the exploration and learning of the production process that we were optimizing.
- (b)
- Definition of the experiment and the techniques used. At this point, the specific research and experiments were defined for each of the challenges faced.
- (c)
- Evaluation. At this stage, we carried out the defined experiment and obtained the results of the approximation that was defined.
- (d)
- Analysis. Once the previous stage was complete, an analysis process was carried out on the data collected during the specific experimentation designed.
- (e)
- Interpretation of the results. When a solution for each identified challenge was created, we combined all of them, coming up with a final interpretation based on all of those results.
2.2. Data Extraction
- Nodule shapes. Taking into account the given results by third-party software, one new script was generated to segment the images and extract each nodule. Once it was done, the results were automatically classified into different folders. On the one hand, some of them were labeled and inserted in different folders related to the nodule shape, and on the other hand, in a special folder with nodules without classification. The aforementioned review task focused on validating the extracted information, as well as classifying the non-processed nodules.
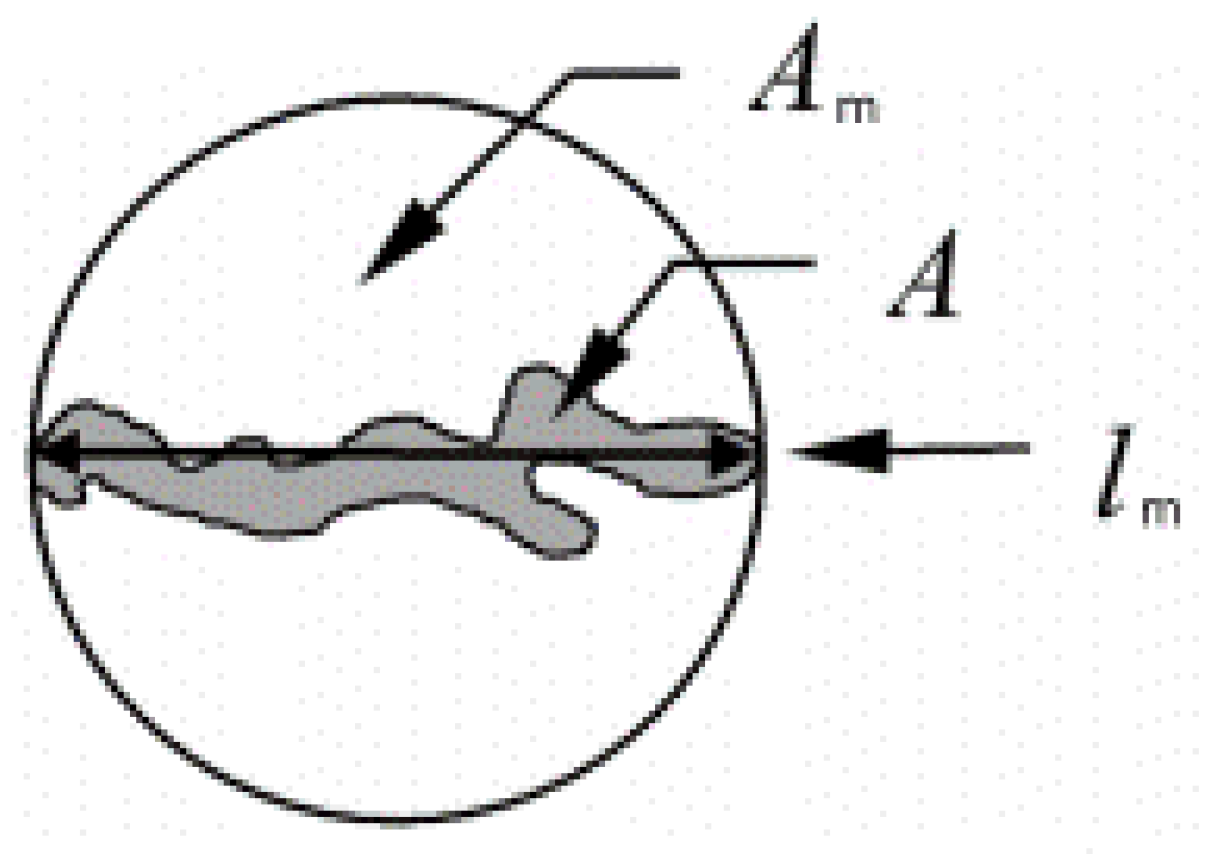
- Metal Quality. The graphite distribution together with the nodule density was used to determine the quality of the solidified metal. The higher graphite density with a smaller graphite size distribution indicates that the metal has enough expansion capacity to avoid the austenitic contraction that occurs at the end of solidification. In this way, higher densities and graphite distributions with smaller graphites present less danger in terms of internal sanity defect apparitions. On the contrary, if there is a sample with a low graphite density with a distribution of coarser graphites, this indicates that at the end of solidification the precipitated graphites are insufficient at preventing the metallic contraction of the austenite, leading to micro-shrinkage. The analysis was conducted by extracting the diameter of the nodules using ImageJ [11], to divide them into different groups, ranging from 5 to 60 µm. The results were plotted in a histogram-type graph to definitively be interpreted by experts; they were evaluated and a label was assigned to the metallography. In the end, the resultant dataset consisted of labeled images referencing five different groups: (i) optimal, (ii) good, (iii) regular, (iv) bad, and (v) pessimal; from a higher density and smaller size to the contrary. The labeling criteria were carried out by using a comparison method. Accurately, the labeled dataset was processed by extracting individual nodules and measuring them. Secondly, the average graphite diameters were calculated and divided into the groups explained in Section 2.5. Third, the average values between the metallography belonging to the same group were calculated to establish a centroid of each possible classification label. Finally, each metallography was compared to all centroids using cosine similarity [37] as the measurement. The biggest similarity was the label to be applied to our metallography.
2.3. Handling Nodule Sizes
2.4. Handling Nodule Shapes
- Type III (Figure 2a): this group encompassed the first three types of the ISO classification, the ones considered elongated or amorphous, far from the perfect circular-shaped graphites.
- Type V (Figure 2b): considered as both Types IV and V, and far more similar to circles than the first group, but still presented the deformities.
- Type VI (Figure 2c): the last types of graphites were very circular and proportional; they were considered the ideal shapes.
2.5. Metal Quality Classification
- K-nearest neighbor (KNN): This is a supervised classification algorithm that uses the Euclidean distance to measure how close the learned values are in relation to the ones that need to be classified. The method was tested with numbers between 1 and 8 to see how the model reacted to different values in order to evaluate accuracy.
- Bayesian network classifier: This is a graphical probabilistic model for the multivariate analysis based on the Bayes theorem. Various search algorithms were used to determine which was the best, due to behavioral variations: (i) K2, (ii) hill climber, (iii) LAGD hill climber, (iv) tree augmented naïve, and (v) simulated annealing.
- Artificial neural networks (ANNs): These are a collection of interconnected units called neurons that are distributed between layers. They compute the outputs based on the input values and non-linear activation functions. The networks used consist of multilayer perceptrons, input, a single hidden layer, and an output layer, which use backpropagation for training. The input had 12 different values, representing the classes mentioned, 8 neurons on the hidden layer, and 5 outputs representing the classification. Two of them were used and the differences between them involved the tolerances and the usage of conjugate gradient descent.
- Support vector machine (SVM): Data represented in an n-dimensional space are divided into two regions by a hyperplane to attempt to maximize the margin between distinct classes. In order to diversify the surfaces created, multiple kernels such as (i) poly kernel, (ii) normalized poly kernel, (iii) radial basis function kernel, and (iv) Pearson VII were used.
- Decision trees: These are logical construct diagrams based on successive rules or conditions that represent solutions for problems. Different tree sizes were tested; numbers ranged from 50 to 500 in batches of 50. Apart from that, another distinct method based on the C4.5 algorithm was used.
3. Results
3.1. Nodule Size Results
3.2. Nodule Shape Results
3.3. Metallurgical Quality Results
4. Discussion
4.1. Nodule Shape Results Discussion
4.2. Metallurgical Quality Results Discussion
5. Conclusions
- Presented an approach to manage the characterization of metallographic images.
- Provided a deep learning-based method to classify nodule characteristics.
- Introduced a multiple-level classifier (classification pipeline) to improve the type of classification.
- Completed the feature extraction by determining the quality of metal made thanks to the employment of an ANN classification.
- Proposed a new way of classification, which is easy to manage and make different classifications based on different conditions.
- Defined how it could be created via a small software prototype that is able to handle all metallographic analyses in offline and online manners.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Metal Casting Market Size, Share & Trends Analysis Report By Material (Aluminum, Iron, Steel), By Application (Automotive & Transportation, Building & Construction, Industrial), By Region, And Segment Forecasts, 2020–2025; Market Analysis Report GVR-3-68038-298-3; Grand View Research: San Francisco, CA, USA, 2019.
- Pattnaik, S.; Karunakar, D.B.; Jha, P.K. Developments in investment casting process—a review. J. Mater. Process. Technol. 2012, 212, 2332–2348. [Google Scholar] [CrossRef]
- Beeley, P. Foundry Technology; Elsevier: Amsterdam, The Netherlands, 2001. [Google Scholar]
- Ngqase, M.; Pan, X. An overview on types of white cast irons and high chromium white cast irons. J. Phys. Conf. Ser. 2020, 1495, 012023. [Google Scholar]
- Collini, L.; Nicoletto, G.; Konečná, R. Microstructure and mechanical properties of pearlitic gray cast iron. Mater. Sci. Eng. A 2008, 488, 529–539. [Google Scholar] [CrossRef]
- Özdemir, N.; Aksoy, M.; Orhan, N. Effect of graphite shape in vacuum-free diffusion bonding of nodular cast iron with gray cast iron. J. Mater. Process. Technol. 2003, 141, 228–233. [Google Scholar] [CrossRef]
- ISO 945-1:2008; Part 1: Clasificación del Grafito por anáLisis Visual. Standard, International Organization for Standardization: Geneva, CH, USA, 2012.
- ISO 945-2:2011; Part 2: Graphite Classification by Image Analysis. Standard, International Organization for Standardization: Geneva, CH, USA, 2011.
- ISO 945-4:2019; Part 4: Test Method for Evaluating Nodularity in Spheroidal Graphite Cast Irons. Standard, International Organization for Standardization: Geneva, CH, USA, 2019.
- Reason, J. Human Error; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Schneider, C.A.; Rasband, W.S.; Eliceiri, K.W. NIH Image to ImageJ: 25 years of image analysis. Nat. Methods 2012, 9, 671–675. [Google Scholar] [CrossRef]
- Gesellschaft zur Förderung Angewandter Informatik. AmGuss. Available online: https://www.gfai.de/entwicklungen/bildverarbeitung/amguss (accessed on 15 October 2021).
- Leica. Leica Application Suite X (LAS X). Available online: https://www.leica-microsystems.com/products/microscope-software/p/leica-las-x-ls/ (accessed on 26 December 2022).
- Espinosa, L.F.; Herrera, R.J.; Polanco-Tapia, C. Segmentation of anatomical elements in wood microscopic images using artificial vision techniques. Maderas Cienc. Technol. 2015, 17, 735–748. [Google Scholar]
- Gómez, F.J.P. Application of Artificial Vision Algorithms to Images of Microscopy and Spectroscopy for the Improvement of Cancer Diagnosis. Ph.D. Thesis, Universitat Politècnica de València, Valencia, Spain, 2018. [Google Scholar]
- von Chamier, L.; Laine, R.F.; Henriques, R. Artificial intelligence for microscopy: What you should know. Biochem. Soc. Trans. 2019, 47, 1029–1040. [Google Scholar] [CrossRef]
- Batool, U.; Shapiai, M.I.; Tahir, M.; Ismail, Z.H.; Zakaria, N.J.; Elfakharany, A. A systematic review of deep learning for silicon wafer defect recognition. IEEE Access 2021, 9, 116572–116593. [Google Scholar] [CrossRef]
- Tin, T.C.; Tan, S.C.; Lee, C.K. Virtual Metrology in Semiconductor Fabrication Foundry Using Deep Learning Neural Networks. IEEE Access 2022, 10, 81960–81973. [Google Scholar] [CrossRef]
- Rodrigues, D.d.A.; Santos, G.P.d.; Fernandes, M.C.; Santos, J.C.d.; Freitas, F.N.C.; Rebouças Filho, P.P. Classificaçâo automatica do tipo de ferro fundido utilizando reconhecimento de padrões em imagens de microscopia. Matéria (Rio Jan.) 2017, 22. [Google Scholar] [CrossRef][Green Version]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Hamerly, G.; Elkan, C. Learning the k in k-means. Adv. Neural Inf. Process. Syst. 2003, 16, 281–288. [Google Scholar]
- Pearl, J. Reverend Bayes on Inference Engines: A Distributed Hierarchical Approach; Cognitive Systems Laboratory, School of Engineering and Applied Science, University of California: Los Angeles, CA, USA, 1982. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berkeley, CA, USA, 2013. [Google Scholar]
- Krogh, A. What are artificial neural networks? Nat. Biotechnol. 2008, 26, 195–197. [Google Scholar] [CrossRef] [PubMed]
- Knuth, D. Art of Computer Programming, The: Volume 3: Sorting and Searching; Addison-Wesley: Reading, MA, USA, 1968. [Google Scholar]
- Qassim, H.; Verma, A.; Feinzimer, D. Compressed residual-VGG16 CNN model for big data places image recognition. In Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2018; pp. 169–175. [Google Scholar] [CrossRef]
- Narendra, T.; Sankaran, A.; Vijaykeerthy, D.; Mani, S. Explaining deep learning models using causal inference. arXiv 2018, arXiv:1811.04376. [Google Scholar]
- Constante, P.; Gordon, A.; Chang, O.; Pruna, E.; Acuna, F.; Escobar, I. Artificial Vision Techniques to Optimize Strawberry’s Industrial Classification. IEEE Lat. Am. Trans. 2016, 14, 2576–2581. [Google Scholar] [CrossRef]
- Draghici, S. A neural network based artificial vision system for licence plate recognition. Int. J. Neural Syst. 1997, 8, 113–126. [Google Scholar] [CrossRef]
- Sata, A.; Ravi, B. Bayesian inference-based investment-casting defect analysis system for industrial application. Int. J. Adv. Manuf. Technol. 2017, 90, 3301–3315. [Google Scholar] [CrossRef]
- Damacharla, P.; Ringenberg, A.R.M.V.J.; Javaid, A.Y. TLU-Net: A Deep Learning Approach for Automatic Steel Surface Defect Detection. arXiv 2021, arXiv:2101.06915. [Google Scholar]
- Posner, E.A.; Spier, K.E.; Vermeule, A. Divide and conquer. J. Leg. Anal. 2010, 2, 417–471. [Google Scholar] [CrossRef]
- Mackey, L.; Jordan, M.; Talwalkar, A. Divide-and-conquer matrix factorization. Adv. Neural Inf. Process. Syst. 2011, 24. [Google Scholar]
- Horowitz, E.; Zorat, A. Divide-and-conquer for parallel processing. IEEE Trans. Comput. 1983, 32, 582–585. [Google Scholar] [CrossRef]
- Düntsch, I.; Gediga, G. Confusion matrices and rough set data analysis. J. Phys. Conf. Ser. 2019, 1229, 012055. [Google Scholar]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE). Geosci. Model Dev. Discuss. 2014, 7, 1525–1534. [Google Scholar]
- Wang, P.; Wang, J.; Wei, G.; Wei, C. Similarity measures of q-rung orthopair fuzzy sets based on cosine function and their applications. Mathematics 2019, 7, 340. [Google Scholar] [CrossRef]
- Bradski, G.; Kaehler, A. Learning OpenCV: Computer Vision with the OpenCV Library; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2008. [Google Scholar]
- Pohudina, O.; Kritskiy, D.; Bykov, A.; Szalay, T. Method for identifying and counting objects. In Integrated Computer Technologies in Mechanical Engineering; Springer: Cham, Switzerland, 2020; pp. 161–172. [Google Scholar]
- Ni, J.; Khan, Z.; Wang, S.; Wang, K.; Haider, S.K. Automatic detection and counting of circular shaped overlapped objects using circular hough transform and contour detection. In Proceedings of the 2016 12th World Congress on Intelligent Control and Automation (WCICA), Guilin, China, 12–15 June 2016; pp. 2902–2906. [Google Scholar]
- Zhuang, P.; Xing, L.; Liu, Y.; Guo, S.; Qiao, Y. Marine Animal Detection and Recognition with Advanced Deep Learning Models. In Proceedings of the CLEF (Working Notes), Dublin, Ireland, 11–14 September 2017. [Google Scholar]
- Buscombe, D.; Ritchie, A.C. Landscape classification with deep neural networks. Geosciences 2018, 8, 244. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Moen, E.; Bannon, D.; Kudo, T.; Graf, W.; Covert, M.; Valen, D.V. Deep learning for cellular image analysis. Nat. Methods 2019, 16, 1233–1246. [Google Scholar] [CrossRef]
- Guo, Q.; Zhong, Y.; Dong, T.; Gao, P.; Guo, Y.; Li, J. Effects of vermicular graphite rate on the oxidation resistance and mechanical properties of vermicular graphite iron. J. Alloys Compd. 2018, 765, 213–220. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Rifkin, R.; Klautau, A. In defense of one-vs-all classification. J. Mach. Learn. Res. 2004, 5, 101–141. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Fragassa, C.; Babic, M.; dos Santos, E.D. Machine Learning Approaches to Predict the Hardness of Cast Iron. Tribol. Ind. 2020, 42, 1–9. [Google Scholar] [CrossRef]
- Wisnu, H.; Afif, M.; Ruldevyani, Y. Sentiment analysis on customer satisfaction of digital payment in Indonesia: A comparative study using KNN and Naïve Bayes. J. Phys. Conf. Ser. 2020, 1444, 012034. [Google Scholar]
- Santos, I.; Nieves, J.; Bringas, P.G.; Zabala, A.; Sertucha, J. Supervised learning classification for dross prediction in ductile iron casting production. In Proceedings of the 2013 IEEE 8th Conference on Industrial Electronics and Applications (ICIEA), Melbourne, VIC, Australia, 19–21 June 2013; pp. 1749–1754. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Gola, J.; Webel, J.; Britz, D.; Guitar, A.; Staudt, T.; Winter, M.; Mücklich, F. Objective microstructure classification by support vector machine (SVM) using a combination of morphological parameters and textural features for low carbon steels. Comput. Mater. Sci. 2019, 160, 186–196. [Google Scholar] [CrossRef]
- Patricio Peña, M.; Orellana, J.M. Red neuronal para clasificación de riesgo en cooperativas de ahorro y crédito. Congr. Cienc. Tecnol. 2018, 13, 121–124. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Penrose, L.S. The elementary statistics of majority voting. J. R. Stat. Soc. 1946, 109, 53–57. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Team Sheet | ||
|---|---|---|
| CIRC. [0,0.7] | AR. [2, ∞) | |
| Type III | CIRC. [0,0.5) | AR. (1.5, 2) |
| CIRC. [0,0.35) | AR. [1, 1.5] | |
| CIRC. [0.35,0.77) | AR. [1, 1.5] | |
| Type V | CIRC. [0.5,1] | AR. (1.5, 2) |
| CIRC. [0.7,1] | AR. [2, ∞) | |
| Type VI | CIRC. [0.77,1] | AR. (1, 1.5] |
| Type III | Type V | Type VI | |
|---|---|---|---|
| Original | 35,000 | 60,000 | 107,000 |
| Augmented | 140,000 | 140,000 | 140,000 |
| a | b | ||||
|---|---|---|---|---|---|
| Type III | Type V | Type V | Type VI | ||
| Original | 35,000 | 60,000 | Original | 60,000 | 107,000 |
| Base | 35,000 | 35,000 | Base | 60,000 | 60,000 |
| Augmented | 140,000 | 140,000 | Augmented | 300,000 | 300,000 |
| a | ||||
|---|---|---|---|---|
| Predicted | ||||
| Type III | Type V | Type VI | ||
| Type III | 94.64 | 5.36 | 0 | |
| Actual | Type V | 0.58 | 72.83 | 26.59 |
| Type VI | 0 | 3.3 | 95.88 | |
| b | ||||
| Predicted | ||||
| Type III | Type V | Type VI | ||
| Type III | 89.29 | 10.71 | 0 | |
| Actual | Type V | 3.47 | 75.72 | 20.81 |
| Type VI | 0 | 1.56 | 98.44 | |
| Classifier | Accuracy (%) | MAE | RMSE |
|---|---|---|---|
| Bayesian Network (K2) | 85.07 ± 3.29 | 0.06 ± 0.01 | 0.22 ± 0.02 |
| Bayesian Network (Hill Climber) | 85.07 ± 3.29 | 0.06 ± 0.01 | 0.22 ± 0.02 |
| Bayesian Network (LAGD Hill Climber) | 87.87 ± 3.04 | 0.06 ± 0.01 | 0.19 ± 0.02 |
| Bayesian Network (Tree Augmented Naïve) | 88.13 ± 3.26 | 0.06 ± 0.01 | 0.19 ± 0.02 |
| Bayesian Network (Simulated Annealing) | 88.5 ± 3.23 | 0.06 ± 0.01 | 0.19 ± 0.03 |
| Naïve Bayes | 85.99 ± 3.07 | 0.06 ± 0.01 | 0.21 ± 0.02 |
| SVM (Poly Kernel) | 92.78 ± 2.33 | 0.24 ± 0 | 0.32 ± 0 |
| SVM (Normalized Poly Kernel) | 91.28 ± 2.47 | 0.24 ± 0 | 0.32 ± 0 |
| SVM (RBF Kernel) | 56.28 ± 2.51 | 0.27 ± 0 | 0.3 6± 0 |
| SVM (Puk) | 95.08 ± 1.95 | 0.03 ± 0 | 0.32 ± 0 |
| ANN (MLP+Conjugate gradient descent, 500 ep.) | 97.84 ± 1.38 | 0.02 ± 0 | 0.09 ± 0.02 |
| ANN (MLP, 500 ep.) | 96.76 ± 1.61 | 0.05 ± 0.01 | 0.1 ± 0.02 |
| KNN (K = 1) | 87.85 ± 2.89 | 0.05 ± 0.01 | 0.22 ± 0.03 |
| KNN (K = 2) | 86.48 ± 3.18 | 0.05 ± 0.01 | 0.19 ± 0.02 |
| KNN (K = 3) | 90.62 ± 2.68 | 0.05 ± 0.01 | 0.17 ± 0.02 |
| KNN (K = 4) | 89.95 ± 2.76 | 0.05 ± 0.01 | 0.17 ± 0.02 |
| KNN (K = 5) | 90.98 ± 2.54 | 0.06 ± 0.01 | 0.17 ± 0.02 |
| KNN (K = 6) | 90.49 ± 2.68 | 0.06 ± 0.01 | 0.17 ± 0.02 |
| KNN (K = 7) | 91 ± 2.66 | 0.06 ± 0.01 | 0.17 ± 0.02 |
| KNN (K = 8) | 90.51 ± 2.84 | 0.06 ± 0.01 | 0.17 ± 0.02 |
| Tree (J48) | 87.36 ± 3.26 | 0.05 ± 0.01 | 0.22 ± 0.03 |
| Random forest (n = 50) | 92.95 ± 2.36 | 0.06 ± 0.01 | 0.15 ± 0.01 |
| Random forest (n = 100) | 93.01 ± 2.32 | 0.06 ± 0.01 | 0.15 ± 0.01 |
| Random forest (n = 150) | 93.07 ± 2.33 | 0.06 ± 0.01 | 0.15 ± 0.01 |
| Random forest (n = 200) | 93.12 ± 2.24 | 0.06 ± 0.01 | 0.15 ± 0.01 |
| Random forest (n = 250) | 93.12 ± 2.12 | 0.06 ± 0.01 | 0.15 ± 0.01 |
| Random forest (n = 300) | 93.06 ± 2.21 | 0.06 ± 0.01 | 0.15 ± 0.01 |
| Random forest (n = 350) | 93.15 ± 2.17 | 0.06 ± 0.01 | 0.15 ± 0.01 |
| Random forest (n = 400) | 93.16 ± 2.15 | 0.06 ± 0.01 | 0.15 ± 0.01 |
| Random forest (n = 450) | 93.14 ± 2.25 | 0.06 ± 0.01 | 0.15 ± 0.01 |
| Random forest (n = 500) | 93.16 ± 2.31 | 0.06 ± 0.01 | 0.15 ± 0.01 |
| a | b | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Predicted | Predicted | ||||||||||||
| Optimal | Good | Type VI | Bad | Pessimal | Optimal | Good | Type VI | Bad | Pessimal | ||||
| Optimal | 99.36 | 0.63 | 0 | 0 | 0 | Optimal | 100 | 0 | 0 | 0 | 0 | ||
| Good | 3 | 96 | 0 | 0 | 1 | Good | 1 | 98 | 0 | 1 | 0 | ||
| Actual | Regular | 0 | 0.96 | 98.54 | 0 | 0.48 | Actual | Regular | 0 | 0.48 | 98.54 | 0 | 0.96 |
| Bad | 0 | 0 | 1.1 | 97.24 | 1.57 | Bad | 0 | 0 | 1.18 | 97.63 | 1.57 | ||
| Pessimal | 0 | 0 | 0 | 2.7 | 97.29 | Pessimal | 0.67 | 0 | 0 | 2.03 | 97.29 | ||
| c | d | ||||||||||||
| Predicted | Predicted | ||||||||||||
| Optimal | Good | Type VI | Bad | Pessimal | Optimal | Good | Type VI | Bad | Pessimal | ||||
| Optimal | 92.72 | 1.21 | 0 | 0 | 6.06 | Optimal | 90.38 | 4.49 | 0 | 0 | 5.13 | ||
| Good | 5.43 | 90.22 | 4.35 | 0 | 0 | Good | 6.25 | 78.13 | 15.62 | 0 | 0 | ||
| Actual | Regular | 0 | 3.74 | 91.58 | 4.44 | 0.23 | Actual | Regular | 0.24 | 4.6 | 90.8 | 4.36 | 0 |
| Bad | 0 | 0 | 5.43 | 88.37 | 6.2 | Bad | 0 | 0 | 7.17 | 89.64 | 3.19 | ||
| Pessimal | 0.78 | 0 | 0.78 | 3.1 | 95.35 | Pessimal | 7.05 | 0 | 1.92 | 5.13 | 85.9 | ||
| e | f | ||||||||||||
| Predicted | Predicted | ||||||||||||
| Optimal | Good | Type VI | Bad | Pessimal | Optimal | Good | Type VI | Bad | Pessimal | ||||
| Optimal | 94.97 | 1.89 | 0 | 0 | 3.14 | Optimal | 91.19 | 3.14 | 0 | 0 | 5.66 | ||
| Good | 1.98 | 88.12 | 9.9 | 0 | 0 | Good | 2.97 | 89.1 | 7.92 | 0 | 0 | ||
| Actual | Regular | 0 | 0 | 97.81 | 1.7 | 0.48 | Actual | Regular | 0 | 0.72 | 95.62 | 3.4 | 0.24 |
| Bad | 0 | 0 | 1.99 | 94.42 | 3.58 | Bad | 0 | 0 | 5.58 | 92.03 | 2.39 | ||
| Pessimal | 0.66 | 0 | 0 | 5.33 | 94 | Pessimal | 1.33 | 0 | 0.66 | 4.66 | 93.33 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sarrionandia, X.; Nieves, J.; Bravo, B.; Pastor-López, I.; Bringas, P.G. An Objective Metallographic Analysis Approach Based on Advanced Image Processing Techniques. J. Manuf. Mater. Process. 2023, 7, 17. https://doi.org/10.3390/jmmp7010017
Sarrionandia X, Nieves J, Bravo B, Pastor-López I, Bringas PG. An Objective Metallographic Analysis Approach Based on Advanced Image Processing Techniques. Journal of Manufacturing and Materials Processing. 2023; 7(1):17. https://doi.org/10.3390/jmmp7010017
Chicago/Turabian StyleSarrionandia, Xabier, Javier Nieves, Beñat Bravo, Iker Pastor-López, and Pablo G. Bringas. 2023. "An Objective Metallographic Analysis Approach Based on Advanced Image Processing Techniques" Journal of Manufacturing and Materials Processing 7, no. 1: 17. https://doi.org/10.3390/jmmp7010017
APA StyleSarrionandia, X., Nieves, J., Bravo, B., Pastor-López, I., & Bringas, P. G. (2023). An Objective Metallographic Analysis Approach Based on Advanced Image Processing Techniques. Journal of Manufacturing and Materials Processing, 7(1), 17. https://doi.org/10.3390/jmmp7010017