1. Introduction
Digitalization, often called as Industry 4.0, is radically changing the way manufacturing is conducted [
1]. At the core of Industry 4.0, increasing amounts of data about products and production processes are collected and analyzed [
2]. These big datasets present an opportunity for advanced data analytics to obtain new insights about the production process, provide better decision support, and enhance the quality and sustainability of manufacturing activities while reducing costs [
3]. Aside from the aforementioned opportunities from a business perspective, some main drivers of this digital transformation can also be environmental and regulatory [
4]. To harness these benefits, the manufacturing industry has started to increasingly invest in research on artificial intelligence (AI) and data-driven approaches and their applications in manufacturing [
5,
6]. Machine learning (ML), a subset of AI and a currently dominant method for implementing AI, can address the following three important aspects of (industrial) data [
4]: (1) ML approaches can learn nonlinear and complex relationships; (2) these approaches address the problem of generalization (i.e., once the model is trained, it can capture possible hidden relationships, enabling better predictions on unseen data in the future); and (3) these approaches do not impose any restrictions on the input variables and their distributions.
However, with increasing complexity (e.g., deep learning), ML models become more difficult to explain and, hence, are often referred to as black-box models [
7]. This increase in complexity has led to the formulation of new requirements for algorithmic decision making, such as fairness, accountability, and transparency (FAT) principles [
8]. The increasing complexity, as well as the limited explainability and interpretability, of complex ML models, makes it increasingly difficult to address the FAT principles, thus hindering the latter’s applications in industrial and mission-critical scenarios. Furthermore, a significant amount of these methods are based on associational patterns and correlation, which do not provide an insight into the causal relationships [
9]. Knowledge of such causal relationships (i.e., generative causal mechanisms) in an underlying system is paramount in manufacturing domains [
10]. Explainable AI (xAI) is an attempt to address these issues; however, it is focused on the understanding and interpretation of the AI models rather than the causal behavior of the underlying systems [
11].
Since the initial work of Fisher (1970) [
12] and Granger (1969) [
13] and the causal reasoning language and framework introduced by Pearl (2011) [
14], a strong computer science foundation has been developed in the domain of causal discovery due to large volumes of data and the necessity for automatic causal search algorithms. Nonetheless, causal discovery from observational data is a challenging issue with ongoing research efforts. Notably, initial successful applications have been noted in various fields of research, such as medicine [
15], genetics [
16], natural sciences [
17], ecology [
18], astronomy [
19], and neuroscience [
20]. Due to these developments, several literature reviews can be found on causal discovery method concepts and benchmarks [
21,
22], as well as their applications in earth system sciences [
23] or biomedical informatics [
24]. However, due to their specific nature and progression complexity, the insights from these reviews cannot be transferred to manufacturing. It is worth mentioning that individual application studies of causal discovery have been conducted in manufacturing, but no comprehensive overview about how causal discovery can be applied in the manufacturing context is available. To address the dearth of research on this subject, this paper aims to investigate the state and development of research on causal discovery in the manufacturing context.
This paper is organized as follows.
Section 2 provides a background on causal discovery.
Section 3 introduces the methodology used to conduct the literature review.
Section 4 describes the findings from the literature review.
Section 5 provides open points and agenda for further research, and
Section 6 presents the conclusion
2. Background
The digitalization and increased utilization of data-driven technologies in manufacturing are the major driving forces and enablers of Industry 4.0 [
25]. Digital transformation enables manufacturers to increasingly collect and analyze industrial data from different stages of the manufacturing cycle, from the low-level production engineering processes to the holistic perspective of the lifecycle management processes. Technologies and concepts such as Cyber–Physical Systems, Internet of Things, Blockchain, Additive Manufacturing, and AI have been identified as the core technologies of Industry 4.0 [
26].
AI is one of the key components of Industry 4.0 that has the potential to improve industrial processes by reducing maintenance costs, avoiding equipment failures, and improving business operations [
1]. AI is an overarching term that encompasses a wide range of fields, such as ML, computer vision, natural language processing, planning, and expert systems. ML methods have begun to find applications in manufacturing systems such as automated visual inspections, fault detection, and maintenance; they have also established strong theoretical foundations [
27]. However, their black-box characteristics and increasing requirements for transparency constitute significant barriers to their adoption in manufacturing [
28]. On the one hand, ML models are faced with acceptance risks in safety-critical decision making [
10]. On the other hand, by nature, some of the tasks in manufacturing domains, such as reliability assessment, are focused on describing and testing causal theories about the system rather than predictive models based on observational data alone [
29]. Notably, these factors and the previously mentioned limiting aspects of traditional ML can be addressed through causal discovery, which goes beyond statistical dependency and focuses on cause-and-effect relationships [
30].
An advantage of having knowledge about causal relationships rather than statistical associations is that the former enables the prediction of the effects of actions that perturb the observed system [
31] and can drive a knowledge discovery process in the context of detection of underlying driving forces in a manufacturing process. Furthermore, the development of new data-driven causal discovery algorithms enables the utilization of vast amounts of collected manufacturing data [
32,
33,
34].
Traditionally, there have been several different approaches to causal discovery. The gold standard of causal discovery has typically been to perform planned or randomized experiments [
35]. However, there are many practical considerations that limit the applicability of such experiments in manufacturing, especially in scenarios where process stability is crucial. Causality has also been the focus of the control theory and system dynamics [
36]. In the engineering domain, a plethora of methodologies for causality analysis and root cause analysis have been developed, including Fault Tree Analysis, Failure Modes and Effects Analysis, 5Why, and the Fishbone diagram. However, these methods are knowledge driven and, as such, introduce bias. Thus, they often require knowledge of possible failures, are difficult to run in a live system, and do not utilize the vast amounts of available manufacturing data. Furthermore, with the development of more personalized and customizable products at scale and with highly complex production systems and production processes, knowledge- and domain-driven causality analyses become unfeasible. Hence, significant research efforts have been focused on developing generic algorithms for causal discovery from observational data [
30].
Causal discovery is concerned with the problem of identifying causal relationships from data, that is, identifying as much as possible the causal structure given statistical quantities, such as a probability distribution or its features [
37]. Other than causal discovery, in the context of traditional causality research, related terms can often be found in the literature. These include causal modeling, causal inquiry, causal (structure) learning, causal inferences, causal effect, and causal mining. According to the literature [
21,
37,
38], three key terms (problems) are distinguished: (1) causal discovery; (2) causal inference; and (3) statistical inference. All mentioned terms can be classified under one of these three categories. Causal discovery is focused on learning the causal structure; causal inference assumes a complete or partially known causal structure and is concerned with the identification and estimation of causal effects; and statistical inference is concerned with the inference from the data to the generating distribution or properties of generating distribution [
37].
Causal discovery aims to identify a causal structure, namely, the causal relationships between the observed variables. Generally, this problem can be defined as finding the structure of a set of variables in which some pairs of these variables are somehow related. Graphs are practical representations of such problems; hence, the results of causal discovery are most commonly represented as causal graphs. A previous study [
31] defined causal graph G as a structure that contains variables X
1, …, X
p as nodes, and a directed edge from X
i to X
j if and only if X
i is a direct cause of X
j with respect to X
1, …, X
p.
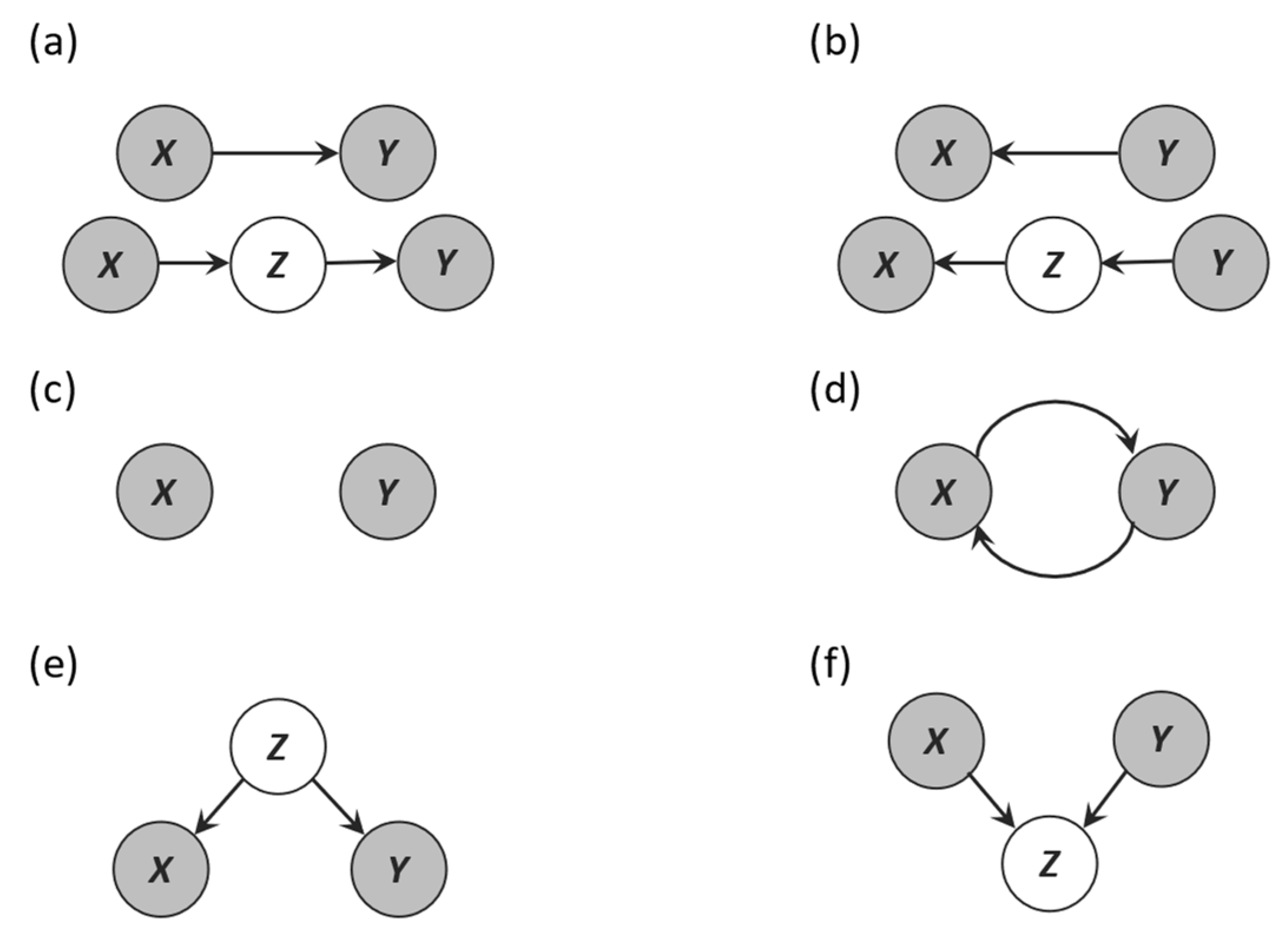
Often, in causal discovery literature, this definition contains a stronger assumption that requires this causal graph to be acyclic, leading to a structure called Directed Acyclic Graph (DAG). In the case of two variables X and Y, there are several possible causal relationships between them, as depicted in
Figure 1. In
Figure 1a, variable X causes variable Y, while in
Figure 1b, variable Y causes variable X. This structure is also referred to as a “chain.”
Figure 1c shows the graphical representation of the absence of a causal relationship between variables X and Y, while
Figure 1d shows a feedback relationship wherein X causes Y and Y causes X.
Figure 1e shows the hidden confounding variable Z that explains the dependence between variables X and Y. This structure is also known as a “fork”. Finally,
Figure 1f shows a structure referred to as a “collider” wherein both variables X and Y cause Z, but there is no causal effect or association between variables X and Y.
A graphical representation of a causal structure facilitates the development of different evaluation metrics for learning causal relations. Two approaches to evaluation can be found in the literature: distances between the learned causal graph and the ground truth and accuracy of discovered causal relations. The first approach is focused on measures such as the Frobenius norm [
39] and structural Hamming distance (SHD) [
40], relying on counting the changes needed for the learned graph, so it becomes ground truth. By contrast, methods that rely on the accuracy of discovered causal relationships are premised on the fact that the discovery of a causal relationship can be interpreted as a binary classification (i.e., a causal relationship between two nodes exists or a causal relationship between two nodes does not exist). Hence, this group contains traditional classification accuracy measures, such as precision, recall, and false-positive rate, which can be used to create receiver operating characteristic (ROC) curves [
41].
Causal discovery methods are typically categorized into four groups based on the underlying mechanism used for detecting causality. These are constraint-based methods, score-based methods, hybrid models, and methods based on functional causal models [
21,
38]. Furthermore, in the context of time-series data, several other methods can be identified, particularly methods based on Granger causality and conditional independence, as well as methods based on structural equation models and deep learning [
22].
In practice, the development of generalized causal discovery methods requires tackling the challenges that come with real-world datasets and problems such as non-stationarity or heterogeneity of data. To address these problems, researchers have developed different assumptions that are required for different causal discovery methods to work. Some of these assumptions are causal Markov assumption, faithfulness assumption, Markov equivalence classes, and distribution equivalence (see [
35] and [
21] for more details).
Notably, despite these challenges and assumptions, causal discovery has been successfully applied in several manufacturing use cases. However, the true potential of causal discovery in manufacturing is still vague due to the lack of structured reviews of the field.
3. Methodology
The goal of this literature review is to investigate the current developments and state of research on causal discovery in manufacturing. Moreover, this review aims to identify the motivations, common application scenarios and approaches, as well as impacts and common challenges of causal discovery implementation in manufacturing. For this purpose, a structured literature review (SLR), as described by Webster and Watson [
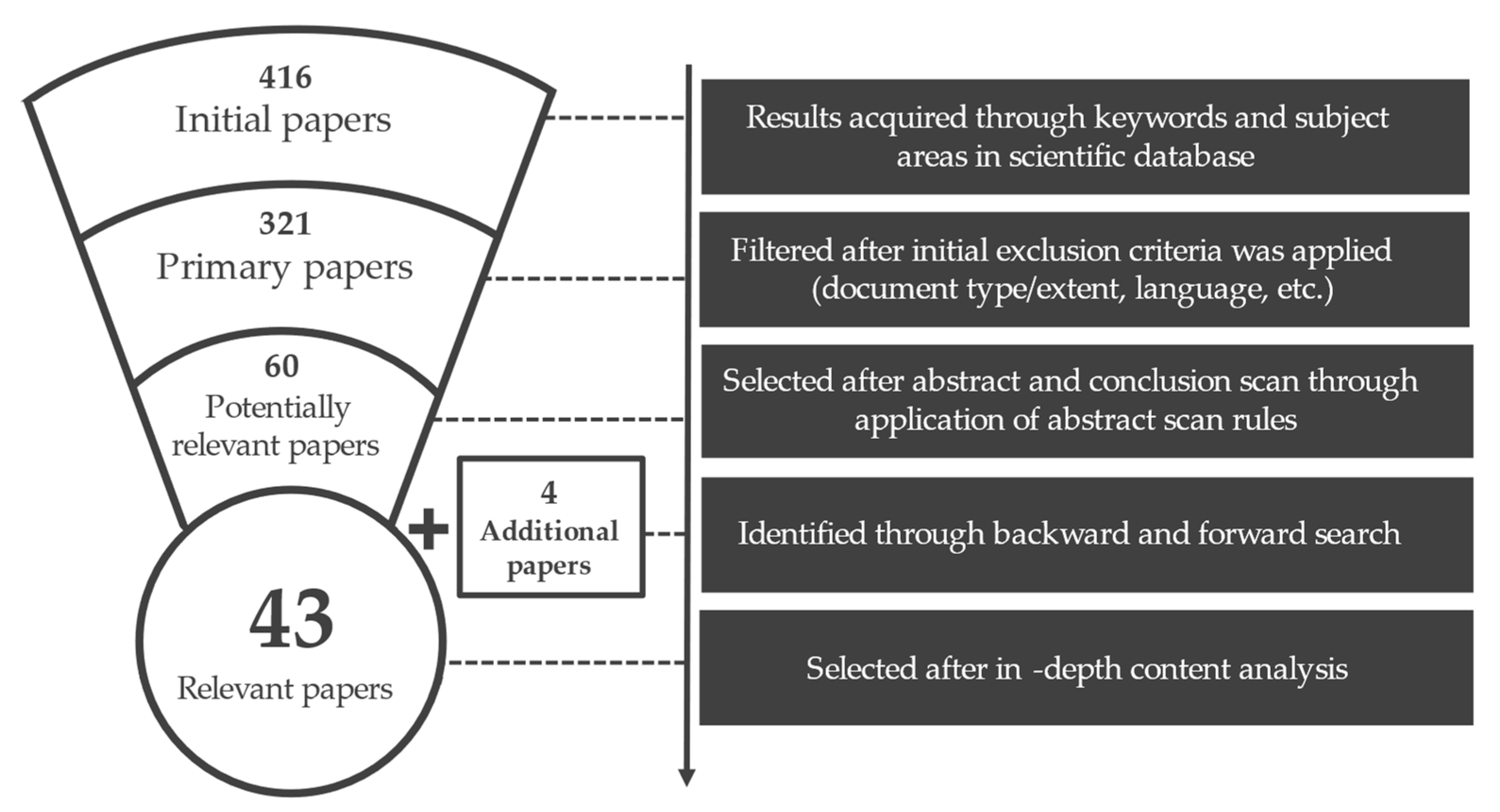
42], was undertaken. The initial body of literature was acquired from the Scopus database of scientific literature. Two key limitation factors were used for conducting the initial search, namely, keywords and research domains (conferences and journals). All scientific works published until the end of 2020 were considered in this review.
With regard to the keywords, the authors wanted to focus on data-driven causal discovery in Industry 4.0 scenarios. Hence, two main keyword groups were used. The first group of keywords aimed to capture the causal discovery focus of the literature, while the second group focused on manufacturing-related problems. As stated in the previous Section, different causality-related terms were used interchangeably in the literature, so several keywords alongside “causal discovery” were utilized (e.g., causal structure, causal inference, causal modeling, causal analysis, etc.). The second group of keywords focused on the manufacturing-related context in the literature, including manufacturing, industrial, production, fault detection, and process control. Due to active research of causal discovery in other fields, such as medicine, economy, social sciences, and biology, several keywords were used as exclusion criteria. Keywords such as “health”, “FMRI”, and “market uncertainty” were used to exclude literature that did not focus on the industrial applications of causal discovery.
With regard to publication outlets, due to the interdisciplinary nature of research within the manufacturing domain, no specific conferences and journals were selected as they were abstracted to their respective subject areas. Literature searches were restricted to subject areas of engineering, computer science, mathematics, and decision sciences. These subject areas were selected because they encompass scientific work around the topic of causal discovery in manufacturing. A total of 160 publication outlets were aggregated with these subject areas. Only full papers (i.e., conference papers and journals) published and written in English were added, resulting in a total of 321 papers.
To identify the relevant papers that focused on causal discovery in manufacturing, an abstract and conclusion scan was performed on the previously collected literature. To detect the out-of-scope literature, three criteria that a manuscript should satisfy were formulated. First, the literature had to be focused on the application of causal discovery method, the development of a causal discovery method, or the development of a causal discovery tool. Second, the literature had to be focused on a manufacturing process or used manufacturing data for evaluation to be considered for further analysis. Finally, the methods for causal discovery presented in the literature should be data driven. Literature focused on traditional knowledge-driven and model-driven approaches or other engineering approaches of detecting causal structure are beyond the scope of this literature review. These criteria were applied to the 321 papers identified in the previous steps. Additionally, backward and forward searches were conducted [
42] using the Google Scholar platform to identify additional studies. Finally, 60 papers were found to be relevant for qualitative content analysis [
43]. These papers were analyzed in detail, providing a good overview and insight into the current state of research. However, when the literature was scrutinized in detail, some papers that were beyond the scope of this research were identified.
A total of 17 papers were excluded due to reasons such as focusing on scenarios that were not related to manufacturing [
44], using previously developed causal discovery models [
45], or applying model-driven approaches to build a causal structure [
46]. Finally, 43 papers were analyzed, interpreted, and summarized in a concept-centric way [
42].
Figure 2 depicts the overall procedure applied.
Through in-depth content analysis, the research papers were coded using their topics and focus areas. Metadata were extracted from the respective papers, which included the application tasks, initiatives for research, application domains, extents of application, data properties, and limitations. During the analysis, common topics, application tasks, and application domains emerged. These were used as the bases for structuring the literature groups with the same focus (e.g., focus on fault detection, focus on root cause analysis, etc.). Within each group, key characteristics such as motivation, methods, data characteristics, and application cases of causal discovery were identified. These characteristics, together with other insights, are summarized in the next section.
4. Results
In the following subsections, the results of the literature review are discussed. Through an in-depth analysis of the literature identified using the previously described process, several key application areas were established. The identified application areas utilized causal discovery in a similar fashion and focused on solving similar tasks. Four application areas were identified and discussed in their respective subsections: (1) fault detection, analysis, and management; (2) root cause analysis; (3) causality as a facilitator; and (4) domain and conceptual work. For each of the application areas mentioned above, four major aspects of causal discovery in the industrial context were identified: motivation, application, methods and concepts, and impacts and challenges. The respective application areas are introduced and analyzed through these aspects, with each representing a subsection. Motivation to use causal discovery in this specific application area gives an introduction of the reasons for the utilization of such methods over traditional ML or model-driven approaches. The Application subsection presents the tasks and use cases of causal discovery methods and how they are applied. The Methods and concepts subsection introduces the algorithms and domain concepts found in the literature, focusing on the previously mentioned application area. Finally, the Impacts and challenges subsection provides insights on the most significant effects of the utilization of causal discovery methods, together with the challenges of implementing such methods, found in the reviewed literature.
4.1. Fault Detection, Analysis, and Management
Motivation: Causal discovery can facilitate the detection of the generative mechanisms of an underlying system. Knowledge of these mechanisms is especially important in complex production scenarios, where building a first-principle model (physical, chemical, mathematical, etc.) representation can be difficult or even impossible due to the high amount of participating components and the nonlinear and dynamic nature of the relationships. This is especially prominent in the process monitoring domain, where the occurrence of a disturbance or the process fault can propagate to other units through process and feedback flows. The collected historical process data provide a great opportunity for the application of data-driven methods, as they have the ability to learn and capture complex, nonlinear process dynamics that are otherwise difficult to learn for humans. However, in these scenarios, traditional ML approaches that are based on association (correlation) are not enough to detect directionality and develop propagation paths that impact the overall control performance [
47]. According to [
48], a complete procedure of process monitoring involves four main steps: fault detection, fault identification, fault diagnosis, and process recovery.
Application: The task of fault detection entails determining when an undesired process behavior has occurred and to go one step further by focusing on the identification of the monitored variable most relevant to this process behavior. However, alarm floods constitute one of the commonly occurring obstacles that hinder successful fault detection and identification. In [
49], the authors demonstrated the successful application of causal discovery methods in the analysis and reduction of alarm floods from the process data in a bottle-filling module. Rodrigo et al. (2016) combined alarm log data, process data, and connectivity information to improve the accuracy of the alarm flood reduction in an ethylene plant [
50]. Another perspective on alarm flooding was presented in a Dimethylformamide recovery plant [
51], where causal discovery methods were extended with a similarity measure to reduce the number of nuisance alarms effectively. In addition, Hund and Schroeder (2020) focused on the task of reliability assessment through causal discovery in a battery performance manufacturing scenario [
29].
Fault diagnosis in process monitoring entails determining which fault occurred (i.e., the root cause of the observed out-of-control status) and provides essential input to the process recovery [
48]. Plant-wide disturbance is one of the contexts wherein such steps are necessary. In the literature, online and offline fault diagnosis types are discussed in terms of the temporal perspective and process operator engagement. In online applications, the point of being knowledgeable of the causal structure is to reduce the reaction time by (1) providing narrowed and focused information about the causes or (2) providing the reasoning for the underlying system conditions [
52]. The former finds application in providing causes for rapidly degrading system components [
53] or sub-systems where a fault has occurred [
54], among others. Meanwhile, offline applications focus on the impacts of production attributes on fault events so that the process can be designed in such a way that these faults are prevented in future operations. Offline fault diagnosis has been applied in the analysis of heating–cooling device failure [
55], hot strip mill processes [
56], or plant-wide oscillations in chemical production facilities [
47,
57,
58]. One of the common tasks in fault diagnosis is root cause analysis, but due to the extensive volume of literature in this area, these results will be discussed separately in
Section 4.2.
Methods and concepts: In the area of fault detection, analysis, and management, no best practice approach or method could be identified. A previous study [
49] compared the performance of three methods in learning the causal structure of the alarm flood in a bottle-filling module, namely, Grow Shrink, Hill-Climbing, and Max-Min Hill-Climbing [
49]. Rodrigo et al. (2016) employed transfer entropy in the alarm log, process, and connectivity data in one of the steps of their general approach for alarm flood reduction [
50]. Furthermore, in [
51], the authors based their data similarity analysis approach on Granger causality, which was also used in [
52]. Bayesian networks saw application in reliability management [
53] and were one of the methods evaluated by Yadav et al. (2017) alongside association rule mining, direct estimation, and propensity score-matching methods for the analysis of rare events [
55]. In [
54,
57], Kernel Density Estimation was applied for the detection of causal structure in their framework for distributed system monitoring and fault detection. Meanwhile, the Structural Causal Modeling (SCM) framework was used for battery performance and reliability assessment in the works of Hund and Schroeder (2020) [
29].
Impactsand challenges: The impact of causal discovery is primarily reported in the context of process improvement, which was identified as one of the key initiatives behind the application of causal discovery methods within the literature that focused on fault detection, analysis, and management. Rather than using smaller use case examples and numerical studies, most of the literature focusing on fault detection, analysis, and management featured case studies that focused on a deep understanding of process behavior or the development of causality-based or causality-enhanced tools to improve process operation. Out of the reviewed literature, only two articles used industrial benchmark datasets in their evaluation [
47,
52]. In this regard, it can be concluded that in the transition from model-driven methods to data-driven methods, the domain experts in manufacturing are the ones primarily utilizing causal discovery methods. This is apparent in view of the disadvantages of traditional, associational, or knowledge-based models. Some of these disadvantages were noted in the literature: inability to deduce the cause-and-effect relationship from the correlation [
47,
49,
55], poor performance in imbalanced data scenarios [
49,
55], or relying too much on the domain input [
49,
51]. On the other hand, some authors [
47,
52] focused their efforts on the intrinsic challenges of industrial data, such as nonstationarity and multicollinearity. Overall, from the analyzed literature in this application area, it is evident that causal discovery applications are scattered, with no systematic application or integration into continuous process improvement.
4.2. Root Cause Analysis
Motivation: Industrial process are rapidly developing, and from the Industry 4.0 perspective, they are usually composed of multiple process units and a large number of feedback control loops. In such complex systems, process units are strongly interconnected. Thus, undesired conditions in one unit can potentially have plant-wide effects. These conditions deteriorate the product quality, increase operational costs, and can lead to hazardous situations [
59]. In these scenarios, effective root cause analysis of these undesired conditions is crucial for restoring the process to its normal operating condition in a timely manner [
32]. Finding a true propagation path of these undesired conditions (faults) is a major challenge. Existing research shows two major approaches for root cause analysis: traditional knowledge-based (also model-based and analytical model-based) approaches and data-driven (ML) approaches [
32,
33,
34]. Data-driven approaches do not depend on the maturity and the extent of the knowledge base or the experience of the domain experts; they can also capture complex process dynamics, a task that is, in some cases, not possible with the analytical approaches. Data-driven approaches such as causal discovery can augment the research on cause-and-effect relationships and, through causal maps, provide an effective way to localize root causes and guide further investigations.
Application: Due to their ability to detect causal direction, causal discovery methods are especially useful in manufacturing applications of root cause analysis. Several approaches have focused on combining process topology and connectivity information to improve accuracy and reduce the computational load of root cause analysis in industrial board and board machine case studies [
59,
60,
61,
62,
63]. Other studies demonstrated the application of causal discovery methods in the detection of disturbance propagation paths in fluid catalytic cracking units [
64], mineral concentrator plants [
65], and semiconductor production facilities [
66]. Kühnert and Beyerer (2014) evaluated several data-driven causal discovery approaches for root cause analysis in chemical-stirred tank reactor and laboratory plant case studies [
67]. The aforementioned case studies were done in laboratory plants as they bring the benefits of knowing the ground truth of the process and enable precise measurements. Similarly, several other studies focused on benchmark data to verify new methods for finding the propagation paths and root causes. Tennessee-Eastman process control data [
68] were commonly found, comprising the de facto, standard dataset for the evaluation of root cause analysis methods. This dataset was developed for the evaluation of process control technology and provides established ground truth and observational data from an industrial process. Tennessee-Eastman process data have been used for the evaluation of methods developed in several studies [
32,
33,
34,
69,
70,
71].
Methods and concepts: From the perspective of methods and approaches, the literature on the application of causal discovery methods in the context of root cause analysis for process improvement focused on established methods such as transfer entropy [
59,
60,
65,
70,
71,
72], Granger causality [
13,
32,
61,
62,
67], or Bayesian networks [
34]. Aside from the application of existing methods, several studies have focused on the improvement of current approaches for data-driven root cause analysis. Two main improvement directions can be identified: algorithmic improvements and improvements through additional information. Algorithmic improvements are focused on applications of principal component analysis [
64], extension to multivariate scenarios [
32], or improvements in the causality analysis models [
33,
69,
71]. On the contrary, the latter approaches focus on the integration of Granger causality and transfer entropy approaches with process schematic data in adjacency (connectivity) matrix form [
59,
60,
61,
62,
63]. Modern approaches, such as deep learning combined with graph processing techniques, have been applied in the context of root cause analysis in [
66].
Impactsand challenges: In root cause analysis use cases, the impact of causal discovery is significant as based on the nature of the task, it relies on the detection of cause-and-effect relationships. This can also be deduced from the substantial share of literature focusing on algorithmic improvements of already established methods. The aforementioned fault detection, analysis, and management literature focused on general process improvements and mostly consisted of larger case studies that delve into different aspects of the production processes or finished products. However, in root cause analysis, a commonly identified characteristic in the literature is that the case studies and use cases are based on already well-established and known benchmark data and are designed to test the applicability of the developed approaches, methods, and designs. This indicates that causal discovery methods found usage in root cause analysis, yet current efforts are not focusing on the evaluation of these methods in production scenarios but are addressing the recognized challenges of existing approaches. Some of the existing challenges found in the literature are data stationarity [
32,
59,
60,
61,
62,
69], distribution assumptions [
34,
71], small datasets [
71], nonlinearity [
33,
69], computational time [
59,
60,
64], scaling the analysis process [
60], or inclusion of prior knowledge [
59,
67]. The lack of application of root cause analysis in real production scenarios can be associated with the mentioned challenges along with the overall complexity in the application of these methods. The complexity of the application of these methods can be addressed through user guidance in the verification of specific method assumptions (distribution, scale, stationarity, etc.), inclusion of prior knowledge, and overall analysis process, among others.
4.3. Causality as a Facilitator
Motivation: Causal discovery or knowledge of the cause-and-effect relationships can play a supporting role in a multi-stage approach in an industrial setting. In this context, causality is used in a supporting role to improve other data-driven processes (e.g., acceptance of ML models or as a baseline for the optimization of the production process). Furthermore, causality can provide new insights and increase the transparency of modern ML (often black-box) approaches. The latter has the potential of increasing their acceptance, especially in mission-critical or regulated-use cases. Many different applications of causal discovery in a facilitator role were identified in the literature. Some of the most prominent ones are the use of causal discovery in improving some characteristics of existing ML models or improving the acceptance of ML models overall.
Application: The application of causal discovery for the improvement of existing ML models in scheduling scenarios was demonstrated in [
73]. In their work, the authors built a causal model of a coke oven gas to detect the production variables with the most effects on the final outcome. This multi-step optimization framework built on this causal model showed better accuracy than human operators with varying levels of experience. Furthermore, the authors [
74] showed how causality could be used to provide causal input for a prediction model. The causal model is built from observational alarm data, which are used to find the different paths that an industrial alarm can propagate. These propagation paths are then fed into a prediction model and finally applied in a fault rule mining context.
Understanding the reasoning behind the predictions made from ML models is crucial for their acceptance, especially in industrial scenarios [
75]. This issue was addressed by Vukovic et al. (2020) [
4] by focusing on improving the acceptance of ML by means of visual analytics and forecasting model analysis. In their approach, the authors developed a causal model through interviews with domain experts. Another approach was presented in [
76], where artificial neural network-based causal analysis was conducted to improve transparency and discover dominant design variables before the optimization process. Predictions can also be made from the quantification of the relationship between two variables. This quantification is evident both from impact and direction determined through causal discovery. Based on this, Chen et al. (2018) [
77] applied network parameter learning and evidence inference technique for transparent alarm prediction from the causal model in the context of industrial process monitoring. Another group of authors [
30] applied causal modeling for knowledge discovery and used these insights alongside engineering knowledge to facilitate effective process control. In their work, the authors developed an approach for combining both observational data-driven and domain-driven causal discovery processes. Even though most of the identified applications base their approaches either on observational, process data or, as in some of the previous examples, rely on domain expert input, in the case of Du et al. (2009) [
78], process data were not used at all. The authors based their complete causality analysis on domain expertise through data collected from a questionnaire, which enables transparent knowledge discovery and causal inference.
Besides improving the characteristics of ML models and their acceptance, causal discovery has also been used as an inference model. A previous study [
79] featured the applications of causal discovery in wireless sensor networks, where a causal inference model was built with a three-layer Bayesian network. This network was part of a larger network diagnostic model in a fault diagnosis agent architecture. Furthermore, optimal sensor allocation in wireless sensor networks was a central topic discussed by Jing and Jionghua (2008) [
80]. In their approach, causal discovery was used to define a baseline causal structure of a manufacturing process which was later used in determining which physical variables should be sensed to minimize total sensing cost and satisfy the detectability requirement. Moreover, John et al. (2019) made causal discovery an integral part of their framework, where it was used to improve both the performance and acceptance of ML models [
81]. First, several causal discovery methods were applied to improve long-term predictions through the identification of parameters that are causally related to the target variable and, second, the system variables with the most impacts on the system performance were identified for further optimization.
Methods and concepts: In the literature focusing on causality as a facilitator, Bayesian networks were identified as the most commonly used approach [
30,
78,
79,
80,
81] for modeling causality. The application of Bayesian networks in the context of improving acceptance is expected due to it being a graphical model and a transparent representation of a probabilistic model. However, some authors applied empirical approaches and traditional ML approaches for detecting causality, such as ML model analysis [
76], causal modeling based on domain knowledge [
4], LASSO, and relative importance-based methods [
81]. A previous study [
77] developed a novel multivariate causality model, while Jin et al. (2018) applied the average causal effect method combined with Least Square Support Vector Machine and Particle Swarm Optimization to optimize scheduling in a coke oven gas system [
73].
Impacts and challenges: In their supporting roles, there are two major impacting aspects of causal discovery. The first is observed through their utilization in contexts where knowledge of causal mechanisms is necessary for the utilization of other data-driven approaches. This is evident in an approach presented in [
80], where a causal model was used as a ground truth for the application of optimization algorithms for sensor allocation, or in [
77], where a causal model was used for the transparent prediction of alarms. The second aspect is focused on the utilization of causal discovery methods for the improvement of acceptance of traditional data-driven approaches (i.e., achieving FAT AI). Some examples of such applications are given in [
4] and [
81]. This aspect is also apparent in empirical causal discovery approaches that were applied to gain insights of the production process through ML [
4,
30,
76]. In these application scenarios, utilizing causal explanations could serve as a starting point for the integration of transparency of traditional ML and domain knowledge that could be used to gain causal insights. The challenges encountered in these use cases were mostly focused on missing efficient causal discovery algorithms that scale well, performance optimization procedures instead of exhaustive search [
76,
77], and the need for significant preprocessing and verification of data before the causal discovery approaches can be utilized [
30,
80].
4.4. Domain and Conceptual Work
Motivation: Transferring causal discovery methods to manufacturing and generally applying newly developed methods from a purely conceptual environment into practice are highly demanding endeavors. Establishing numerical examples and simulations, such as the ones mentioned in
Section 4.2, facilitated the development of new algorithmic solutions. However, these approaches often come with a set of assumptions that do not match the real-life complexity in the industry. Some of the common assumptions found in the literature are data stationarity [
32,
52,
59,
60,
61,
62,
69], normal distribution [
34,
71], linear relationships [
33,
69], causal sufficiency [
30], and faithfulness [
9].
Manufacturing data are predominantly collected through industrial sensor systems that are prone to transmit inaccurate readings. Other than sensor noise, anomalies in manufacturing data can occur from communication errors, process disturbances, instrument degradation, among others. [
82]. As a consequence, the aforementioned assumptions cannot be validly made. The presence of confounding variables due to unmeasured process variables implies that the causal sufficiency assumption is broken. Furthermore, in a manufacturing process that consists of complex physical or chemical processes, dominant disturbances may not follow a well-defined probability distribution [
68], and a linear relationship between variables cannot be assumed. As these assumptions cannot always be made, it is necessary to develop robust causal discovery approaches that scale well [
21].
Application: To address some of these problems, some authors focused on algorithmic improvements and the development of new methods, such as hybrid models based on Bayesian networks and evidential reasoning rule models. These bodies of literature aimed to bridge the gap between purely conceptual work and application studies through the development of methods that are robust enough to be applied in manufacturing. Several families of causal discovery methods have attracted research focus: graphical models, information theory-based models, and other approaches.
Methods and concepts: In the family of graphical models, some authors [
83] developed a new data-driven approximate causal inference model using the evidential reasoning rule which generalizes Bayesian inference. Furthermore, the notion of Soft Intervention was introduced in the work of Kuehnert et al. (2011) [
9], where a hybrid (constraint- and score-based) model based on a Bayesian network was developed to improve the accuracy of the causal model. Another large family of causal discovery approaches comprises information theory-based approaches. As discussed in the previous sections, one of the most prominent methods in this group is transfer entropy. Naghoosi et al. (2013) [
84] based their approach for causality analysis on transfer entropy with the additional application of mutual information to reduce the computational complexity of the naïve approach. Other approaches found in the literature focused on data stationarity and exogenous variables. A previous study [
85] made use of system identification techniques to improve causality detection in contexts in which not all variables were known. The benefits of system identification techniques were evaluated using routine operating data from a thermoelectric power plant.
5. Research Agenda for Causal Discovery in Manufacturing
Throughout the analysis and synthesis of previous literature, several key areas for further research were identified. These key areas of the research agenda are based on the different challenges observed in the current state-of-the-art and questions raised by several authors.
Integration of causality in continuous process improvement was identified as one of the key observations from the literature focusing on fault detection and management and causality in a facilitator role (
Section 4.1 and
Section 4.3). These findings imply that causal discovery is used in a scattered way in some specific, small-use cases. It is evident from the analyzed literature that there is a lack of management of causal discovery in process improvement. At the moment, causal discovery is mostly used on-demand for detection and analysis. Hence, further studies should aim to tackle the topic of systematic integration of causal discovery in continuous process improvement.
User guidance is another promising topic requiring more attention in future research [
49,
83]. This is especially prominent in root cause analysis applications of causal discovery (
Section 4.2). It was identified that such applications require in-depth knowledge of data-processing techniques, statistics, and causal discovery methods in general. Tasks such as verifying specific assumptions, data distribution, and selecting appropriate causal discovery methods are limiting factors in the adoption of these methods by domain experts. Future work needs to be carried out to establish whether user guidance might be the catalyst for the widespread adoption of these methods in industrial scenarios.
In the
reduction of adoption barriers, following the notion of user guidance, other approaches can be taken to reduce the adoption barriers of causal discovery in manufacturing. Integration of prior knowledge was utilized in several papers to increase the accuracy and general performance of causal discovery methods. However, the integration of prior knowledge can also be expanded to the role of one measure to reduce the adoption barriers, as it can serve as a contact point between computer scientists and domain experts [
56,
67]. In-depth analysis of an industrial process through causal discovery requires resources and, as indicated in
Section 4.1 and
Section 4.3, takes time. Causal explanations in the domain of explainable AI (xAI) are not causality per se (interpretation of probabilistic ML models) but can lead to causal insight when integrated with domain knowledge. Hence, they can serve as a lightweight causality approach in the reduction of adoption barriers of AI in general and as the initial step in efforts to enhance the acceptance of data-driven approaches in manufacturing. Of course, xAI does not imply causation but can be used alongside an in-depth causality analysis of a system.
Achieving FAT AI is another area of research requiring further attention. As indicated in
Section 4.3, it is evident that knowing the causal relationships in a system can increase transparency, accountability, and fairness in algorithmic decision making. At the moment, significant research efforts are focused on xAI [
86] due to the rising requirements for the increased transparency of black-box models. However, as stated in the previous sections (e.g.,
Section 4.1 and
Section 4.2), in (mission-) critical scenarios or other sensitive cases, in-depth evidence and a general understanding of the process are necessary. It is recommended that future research should be undertaken to improve understanding of the distinction and interplay between lightweight xAI approaches and causal discovery-based approaches. Furthermore, causal explanations comprise another area of research whose importance is discussed in
Section 4.3.
Tackling the requirements of real industrial settings is a final research area that is postulated to be a focus of future work. As indicated in
Section 4.2 and
Section 4.4, a significant number of causal discovery methods rely on certain assumptions. These assumptions are often not valid in real-world industrial scenarios, with low data quality, messy data collection processes, or complex and interdependent processes. Therefore, further algorithmic improvements are needed to customize the current method assumptions and pave the way for the widespread adoption of causal discovery methods in practice [
32,
56,
60,
77].
6. Conclusions
In the context of Industry 4.0, ever-increasing amounts of data are collected and analyzed. Companies use this opportunity to harness the benefits of advanced data analytics and different data-driven methods. Compared with traditional knowledge- or model-driven methods, ML methods, in particular, provide numerous benefits. Raising the complexity of these methods increases their predictive performance, but it also hinders their acceptance in industrial scenarios where fairness, accountability, and transparency requirements are crucial. Causal discovery aims to address these challenges and other previously discussed bottlenecks, finally contributing to the adoption of the Industry 4.0 paradigm as a whole.
In this paper, a comprehensive structured literature review was conducted. Our key contributions are as follows: (1) we highlighted key areas of application of causal discovery in manufacturing; (2) we outlined the most significant aspects of each application area of causal discovery in manufacturing; and (3) based on the in-depth analysis of the literature, a research agenda was proposed.
The identified key areas of application are fault detection, analysis and management, root cause analysis, causality in a facilitator role, and domain and conceptual work. For each of these areas, common application scenarios, methods, and challenges were presented. Additionally, the application challenges of causal discovery in manufacturing were identified.
Compared with other areas of research, such as medicine, economy, earth sciences, and social sciences, where it has an established role in scientific work, manufacturing has not identified the full potential of causal discovery. This was evident from the key takeaways from the literature. The key takeaways from the literature underscored that causality should be integrated into continuous process improvement procedures, as it is currently on the level of on-demand, scattered use. Furthermore, a user guidance topic was proposed to make it easier for domain experts to apply causal discovery in various domains. Further research on the reduction of adoption barriers and the achievement of FAT AI was proposed to augment the possibility of widespread adoption. Finally, several authors indicated that algorithmic improvements are necessary, as some of the presented assumptions cannot be made in the current complex production environments.



{kind=link}
{kind=link}