1. Introduction
Condition-based monitoring (CBM) is defined as the act of monitoring the condition of a machine or a process [
1], while prognostics and health management (PHM) is defined as an algorithmic way of detecting, predicting, monitoring and assessing operation problems and health changes of systems [
2] as well as taking decisions on them. Both are used to monitor machinery, such as pumps [
3], bearings and gears [
4,
5], electronics [
6], plane parts [
6] and machine tools (Computer Numerical Control (CNC)) [
2,
7]. This field of research is backed by a strong interest of the industry towards
Smart Manufacturing, also called
Industry 4.0, which aims at the autonomous management of production through virtualization of the production chain [
8]. This is mainly achieved through the effective leverage of advances in the Internet of Things (IoT) [
9] and Big Data analytics [
10] technologies. Moreover, when used for monitoring purposes, CBM and PHM can be used to optimize the part production process, reduce costs and increase yields.
CBM and PHM research is split in two main research categories, namely model-based approaches [
1,
11] and data-oriented approaches [
1,
12]. Model-based approaches need expert knowledge of the system to be built and are dedicated to that system, as presented in [
11], where a finite element model of the system for prognostic and health management is developed. Data-oriented approaches are more abstract. They use data acquired on the system and knowledge of the outcome to build a model representing the phenomenon [
12]. For example, Zhang et al. [
13] show how a deep convolutional neural network trained on a vibration temporal signal can predict bearing faults. They only use the input data, vibration over time, and output information, and a vector of size 10 used as a voting method, to classify the four bearings’ states. These methods are of great interest since they can be updated easily without expert knowledge of the machine and can be trained to work on more than one system, as long as good quality contextual data are available.
Additionally, process monitoring research still focuses on design, as highlighted by the review of Imad et al. [
14], Hopkins and Hosseini [
15]. Lu et al. [
16] review the deployment of the STEP-NC standard for a CNC system programming interface that enables bi-directional communication between machine tool controllers, computer-aided design (CAD)/Computer-Aided Manufacturing (CAM) software, monitoring software, etc. Unfortunately, Lu et al. [
16] reveal that most CNC controller vendors are not compliant with the standard. The authors also state that STEP-NC could be used for cloud manufacturing frameworks, such as the ones presented by Caggiano [
17] or Siddhartha et al. [
18], but manufacturers seem reluctant to the use of this open standard citing legacy machine compatibility problems for older machines and the high cost of early adoption, hindering development in this field. CNC manufacturers, as well as the machining industry, are slowly integrating more digital options in their systems, but it is not yet clear whether they will transition to open technologies that will help research in the CBM and PHM fields or to closed source solutions sold by the CNC manufacturers themselves when it comes to machine condition and process monitoring. This makes building a decision making system challenging since CNC manufacturers tend to use their own closed-source system for accessing the CNC controller’s functionalities.
This paper proposes a data-driven automated system for normal behavior signal determination applied to the manufacturing process of complex aerospace parts with a low sampling rate, limited to
by our industrial partner who could not change this setting. The technology used in our approach is kernel density estimation functions [
19]. The advantages of solutions using a low sampling rate are the speed of numerical computations and the small amount of data storage required to keep historical data for testing or even further improvements of the algorithms. First, the paper discusses previous work in this field. Then, the data used in this study for process monitoring research, which were acquired by industry, are detailed. The data are complex and demonstrate the challenges faced by companies transitioning towards
Industry 4.0 for process monitoring. We then present an explanation of the processing needed for normal behavior determination by using kernel density estimation functions and the results. A discussion on how the method can be used for monitoring and its limitations ensues. Finally, a practical implementation of this technology is presented and discussed at the end of this paper.
2. Materials and Methods
In the field of CBM and PHM, research is performed on high frequency acquisition rates. Jin et al. [
20] proposed a method for bearing fault prognosis using a derivation of wavelet transform as a health index and tested on a dataset acquired at 25.6 kHZ. Rafiee et al. [
21] proposed a method based on neural networks for gearbox condition monitoring and tested their approach on a dataset acquired at 16,384
. Bhuiyan et al. [
22] studied acoustic emission, and the lowest acquisition rate studied was 50 kHZ. Rivero et al. [
23] proposed a method based on time domain analysis of cutting power and axial cutting force. The proposed approach was able to predict variability in the acquired signal corresponding to tool wear. The frequency used for the signal acquisition was in the range of 500–1500 kHZ. Zhang et al. [
24] used kernel density estimation (KDE) and and Kullback–Leibler divergence to monitor rotating machinery. Their work was shown to outperform both support-vector machine and neural network-based approaches on data sampled at 20 kHZ. Lee et al. [
25] used KDE to monitor tool wear using by using T2-statistics and Q-statistics with control charts. They used NASA’s milling dataset [
26] for which data were acquired at a minimum of 100 kHZ. It is hard to find, in the scientific literature, methods of monitoring CNC machine tools’ behaviors on low sampling rate data.
This is a problem, since our industrial partner acquires data from its machines at a limited sampling rate of .
KDE functions are used to approximate the probability density function of random variables [
27]. The function is very fast to compute and can reliably model multi-modal distributions [
27]. KDE was used by the authors in the data exploration phase and was proven to reliably model the underlying dataset.
For all the abovementioned reasons, this paper focuses on a condition monitoring method that can be used on low sampling rate data by using KDE functions.
2.1. Dataset
Our industrial partner acquires data on there shop floors from all machines that produce data and from three main sources. First, the controller of the machines; second, a spindle assisted program that monitors the use time of tools; and third, the advance spindle technology software for their machines, which gives information about the spindle state, such as spindle power, spindle torque, axial force min, axial force max, etc. They save all of this information at a rate of , whether the machines are running or not. This is a hard limitation of their system. This study focuses on our industrial partner’s titanium production line. This choice was motivated by the fact that more data are available through the controller of the machines used on these production lines and it was in the interest of our industrial partner to make this research since their cost of operation is high and any down time results in high loss in revenue.
Figure 1 shows that, for each part produced, there are multiple operations needed on the raw material (pre-forged titanium). All of these operations are represented by programs. Those programs can run multiple times on the machines each time the part needs to be produced. Then all programs are divided into sub-programs that represent the geometrical features of the part. Additionally, each sub-program, and by extension program, uses different tools to produce the different features of the part. Finally, while in production, sensors are used to monitor the whole process.
2.2. Sensors
The sensors used were installed on the machines by the CNC manufacturer. In terms of sensors,
Table 1 shows the different categories of data acquired by the machine’s controller. This data contain all necessary information to identify the running CNC program, tools and sub-programs. This information is saved in a database following the structure shown by
Figure 2. This is necessary for data analysis since different operations and different tools result in very different signals acquired.
One of the major challenges with the built data base is that the data are not synchronized. As explained, a CNC machining program is comprised of multiple sub-programs that can directly be associated with geometrical features of the part to be machined, see
Figure 2. These sub-programs are generated by computer-aided design (CAD) software (CATIA, Solid Work, etc.). At the change of each sub-program, the machining process may use a different tool, or the new sub-program may correspond to a new geometry. Moreover, even if the same tool model is used between two sub-programs, G-Code programmers may ask for a tool change, also called the use of a sister tool, to ensure the quality of the cutting process. These must all be taken into account when building a model for process monitoring using data acquired in production settings. Finally, for all changes of sub-programs, there is a possibility of inducing a delay due to uncertainty between the loading time of the next sub-program and the variability of tool change times. Those delays cause problems since the goal is to treat the data acquired as time series that can be statistically compared with each other. Each delay must be removed and all time series must be properly synchronized with each other. This means that the timestamp of the acquisition cannot be used for accurate comparison.
2.3. Data Processing
As shown in
Table 1, one of the signals acquired by the machine tools’ controllers is the
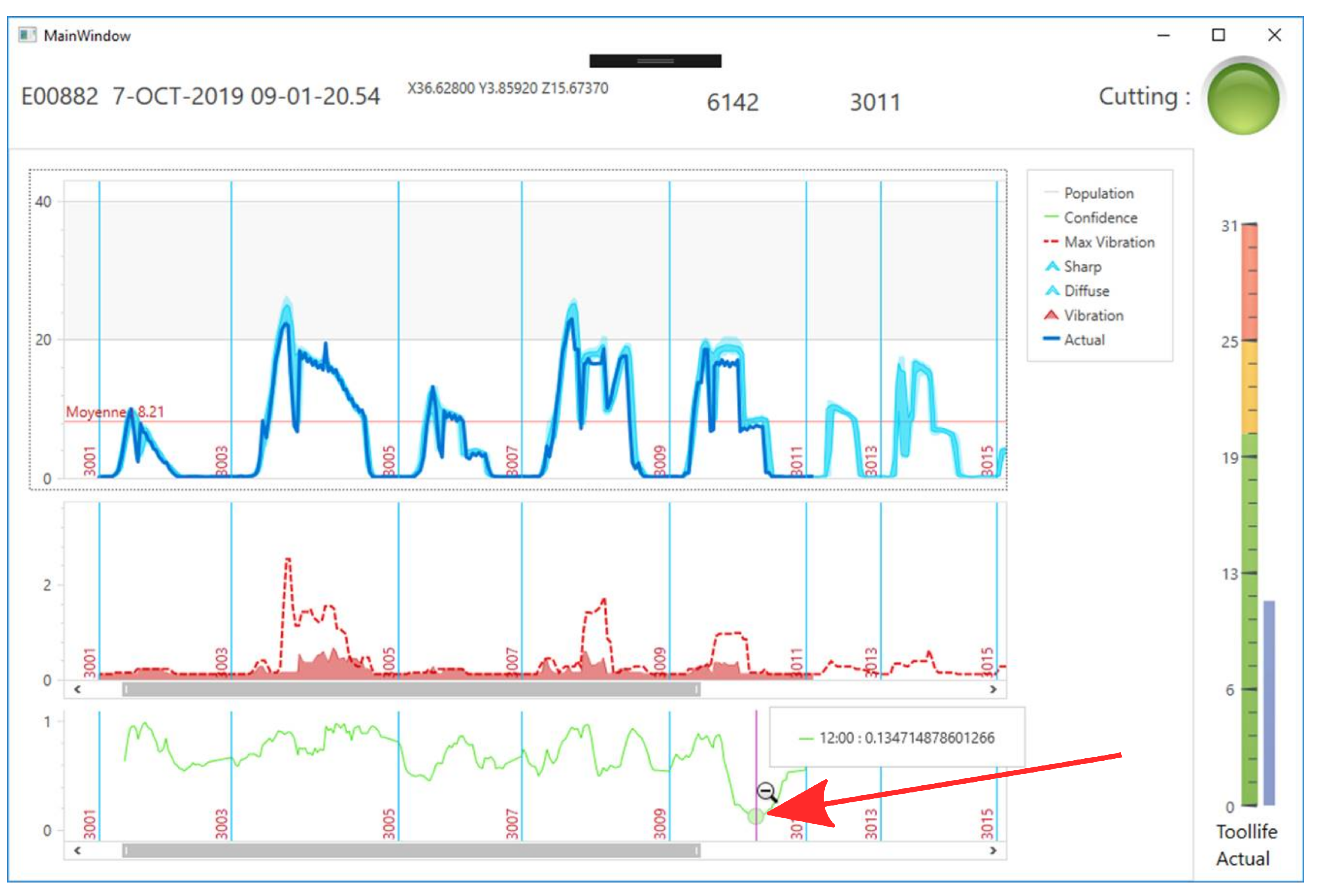
Spindle Load. The spindle load is given in % and represents the force needed to keep the tool rotating at the desired speed with respect to the maximum amount of force the motor can exert. On 28 February 2018, a catastrophic breakage occurred and a part was scrapped. The spindle load signal acquired for this particular event compared with historical production of the same part is shown in
Figure 3. It is clear visually that the signal acquired was off with respect to historical runs; see red circle and arrow. Other signals, such as the vibration registered for the same event, were also off; however, this research will focus solely on the spindle load.
2.4. Data Synchronization
Figure 4 shows the raw spindle load data acquired for 18 runs of the same process. The run number is a label that represents a CNC program, a tool and the time it was run. The label number 127 represents a run made on 2018-10-13T21:08:57-04:00 while the program number 356 was run on 2018-11-16T8:58:31-05:00. By analyzing this figure, where data where synchronized using Algorithm 1 to reduce variations within all runs, it is still hard to determine if all data points correspond perfectly to the position in time to which they were attributed due to noise in the data acquisition. For comparison,
Figure 5 shows a single run of this program, the run labeled 127.
| Algorithm 1: Program run synchronization |
 |
Nonetheless, the data in
Figure 4 and
Figure 5 are concentrated in a band. There is a starting upward phase where the spindle load is increasing rapidly while the CNC machine is trying to keep the tool’s rotation at the desired speed while it starts cutting titanium. Then there is a series of ups and downs until the end of the operation. Such a behavior can be automatically extracted and quantified using the techniques presented in this paper.
2.5. Kernel Density Estimation
This section discusses how kernel density estimation (KDE) functions can be used to automatically capture the pattern in historical runs, and exemplified by the runs in
Figure 4. Since CNC machine tools are highly repeatable machines [
28], it is expected that two runs of the same program should yield very similar results (i.e., be repeatable). For such a repeatable processes, knowing the region in space where the data should be can be used for monitoring purposes.
KDE is used to estimate the probability density of a dataset, in order to find where most of the data is situated in a certain space. For this study, the “space” is the spindle load.
Equation (
1) [
27] is the KDE function estimated by the points (
x) in our dataset and where
is the estimated probability density function,
K is the kernel used for the estimation,
n is the number of points in the dataset and
h is the bandwidth, which serves as a smoothing parameter. To automate the bandwidth selection, the method proposed by Sheather and Jones [
29] was used.
Equation (
2) represents a Gaussian kernel where
u is the sample data for which it is estimated.
Since the goal is to compare the current part production process with the known normal behavior run of the same production program, we can use KDE on the measured signals to estimate what values are the most probable. Computing an estimation of the probability density function of spindle loads yields an idea regarding which values are most commonly measured to test if the program run replicates the same behavior.
2.6. Normal Behavior Computation
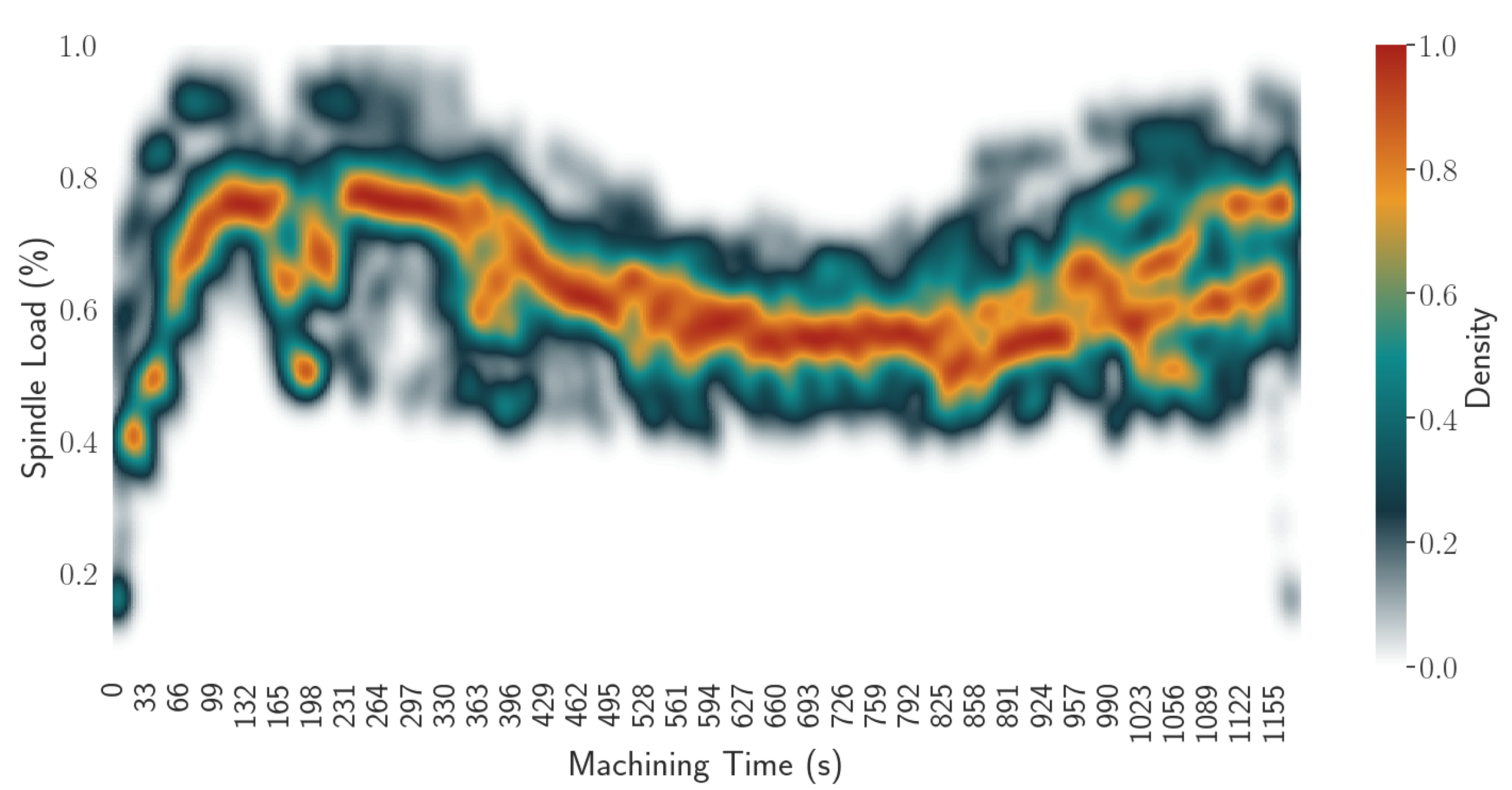
To determine the normal behavior of a program, the KDE is computed on the spindle load signal for bins of 3 s corresponding to the sampling rate of our data acquisition system (see Algorithm 2). This gives the region in space where the largest amount of data can be found for each time bin, i.e., the density function of spindle load for each time bin.
Figure 6 illustrates this density with a heat map where the color represents the density score for each time bin (abscissa) and each spindle value (ordinate) computed on the 15 historical runs shown in
Figure 4.
Figure 6’s color map goes from 0 to 1 because it was normalized with respect to the maximum density score of each time bin (see Algorithm 3). In accordance with
Figure 4, the white region shows where the KDE computation estimates that the density score is 0 and all of the colored region is where data were found. Furthermore, the estimated density for each time bin and spindle load value gives an insight of what represents a normal behavior of a machining program. The closer to 1 is the density score for a spindle load value and time bin combination, the more it is considered normal.
| Algorithm 2: Computation of KDEs for each time bin |
 |
| Algorithm 3: Heat map computation |
 |
4. Discussion
Using the probability distribution estimated with the KDE function, the probability of a sensor’s data point acquired while in production being part of the estimated distribution can be computed. To do this, we used the estimated probability density function to compute the density score for the signal received and divided. If the score was above
, the point was deemed part of the normal behavior (
of the historical runs of the machining program). Graphically, this means that the data received will appear in the blue region of
Figure 7. The closer the score is to 1, the closer the point will appear near the colored regions of
Figure 6 and the more normal that point is for this point in time of this particular machining program. If the series is outside of the blue region for an extended amount of time, the probability of that machining process being abnormal is high. A variation of this approach is being tested by our industrial partner and is described in
Appendix A.
4.1. Limitations
To use KDE for monitoring, a historical database is needed. This is a limitation of this method and a challenge for small- and medium-sized companies who may lack the means to acquire and store such information about their production. For example, it is hard for our industrial partner to store more than two months of data because of database storage capacity.
Another limitation is that there is a minimum amount of data needed before this method can be deemed accurate. The amount of historical run for accurate density estimation was not studied and may be discussed in another paper. Additionally, some production processes are very noisy, and thus it is expected they would require more historical data for accurate normal behavior computation.
4.2. Contributions
The main contributions of this research are two-fold.
A methodology is presented to extract normal behavior from known good historical runs of a CNC program that works for low sampling rate data; see
Section 2.6.
The paper shows how the results can be used to monitor new runs of the same CNC program and detect out-of-ordinary data points in real time; see
Section 3.2.
In addition to the aforementioned contributions, the paper addresses the need for synchronization of time-based data for accurate comparison and explains how it was achieved in this study.
5. Conclusions
This research was carried out with the goal of monitoring the condition of machine tools using spindle load signals acquired with low sampling rates. The chosen method needed to be fast to compute, applicable on multimodal distributions and be able to reliably model the underlying distribution of the dataset.
Kernel density estimation functions were used on historical data for signal distribution estimation. A threshold for the normalized kernel density estimations was computed to extract the region in space where the data are deemed normal.
For process monitoring on incoming data, kernel density estimation functions where used to compute where in the density distribution are the data found, and using a defined threshold of three data points outside of the normal region, the condition of the process (normal or anomalous) was determined.
In the future, alternative approaches, such as unsupervised learning approaches, principal component analysis, kernel principal component analysis or deep clustering should be compared to this technique. This approach provides a new insight into what is happening on the production floor, to detect abnormality and flag machined parts for examination. Since most of this technique is automated, it relieves engineers of the burden to choose threshold values for signals acquired on processes that may be too high or too low since the normal behavior computed is automatic, dynamic and aims at representing the data without human bias.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}