2.2.2. Network Architecture
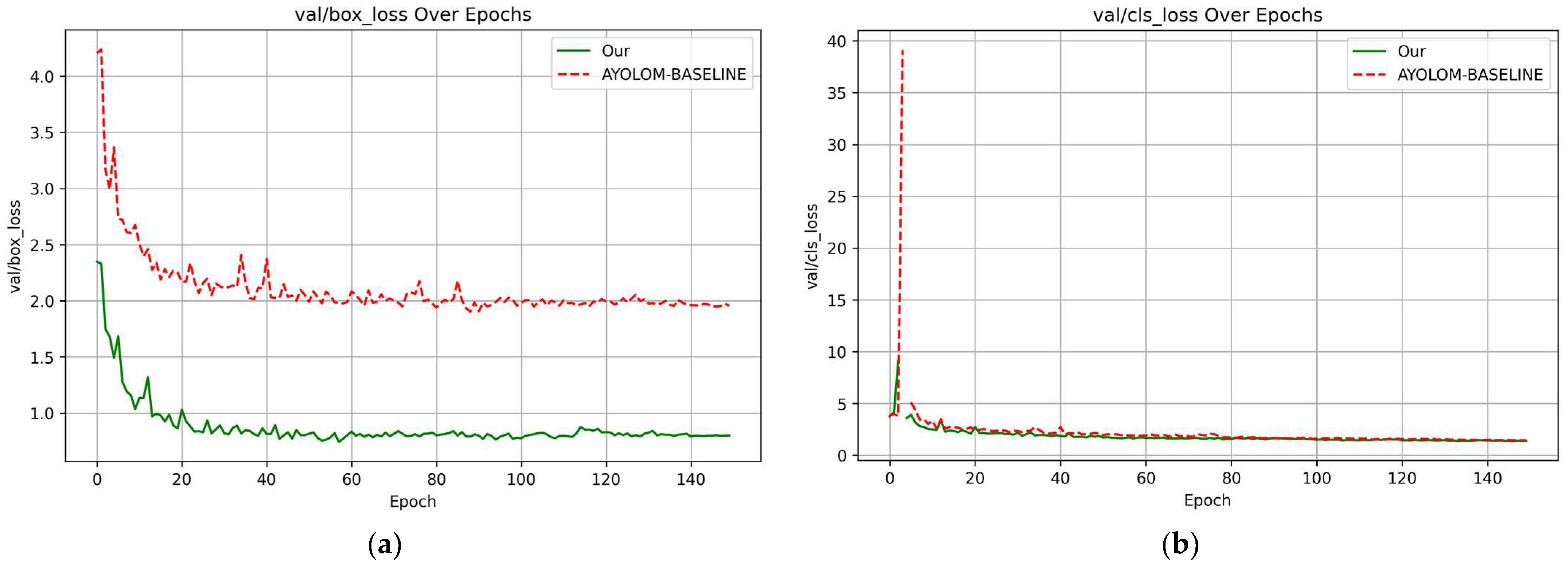
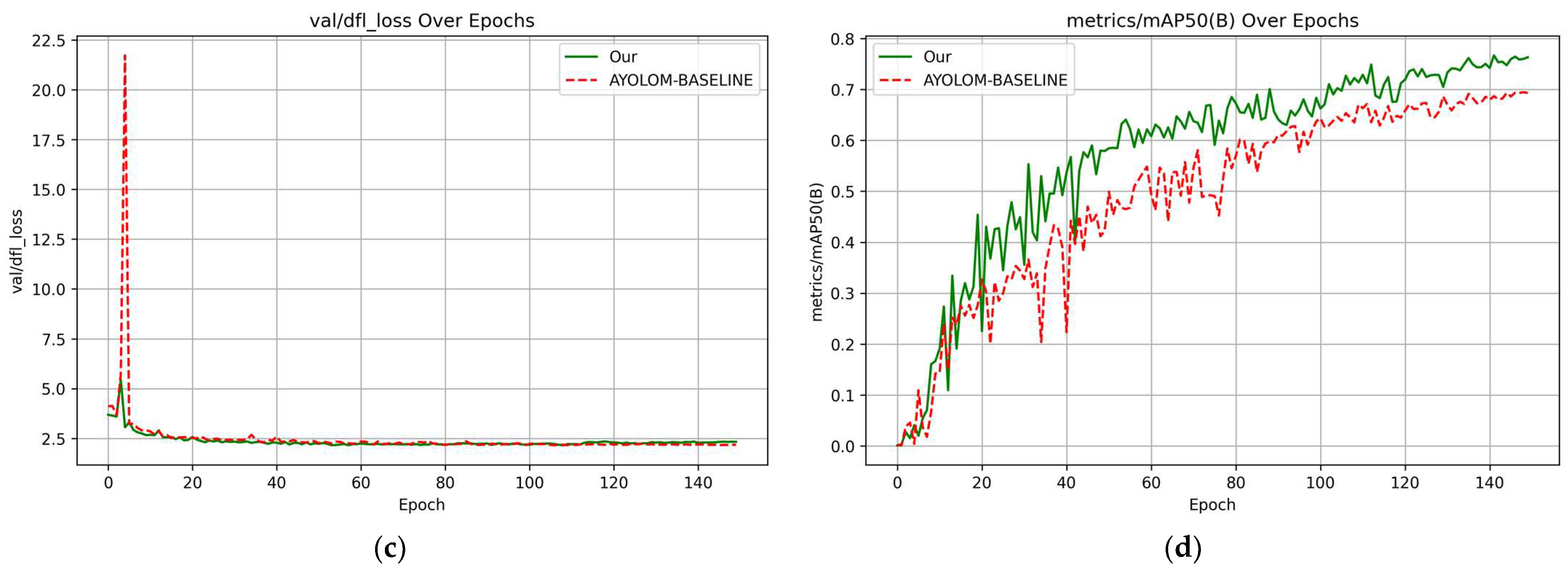
The PowerLine-MTYOLO framework is designed for simultaneous power line segmentation and defect detection, processing a single input image and producing two outputs—one for segmentation and another for object detection. While these two branches operate independently at inference time, their joint training confers multiple benefits. First, the segmentation task reinforces the model’s spatial understanding of cable structures, which indirectly enhances the quality of features shared with the detection branch, leading to more accurate anomaly localization (as shown in
Section 3.2). This is particularly relevant, since both tasks focus on the same physical component (the cable), albeit in different states (normal vs. defective). Conversely, the anomaly detection branch also benefits from the segmentation process. Learning to detect localized defects sharpens the model’s attention on critical regions—often near cable boundaries—thereby improving the segmentation precision and reducing confusion with background elements. This reciprocal learning mechanism encourages a richer and more discriminative feature space. Second, although segmentation is not directly involved for anomaly detection during inference, it remains crucial for many practical UAV-based applications. For instance, segmentation maps can support autonomous navigation by enabling a drone to follow the cable path in real time, while simultaneously detecting anomalies. This dual-output design therefore provides both technical synergy and operational flexibility.
As illustrated in
Figure 2, the model structure follows the general layout of A-YOLOM, with key modifications tailored for power line inspection.
The input image, with dimensions of 640 × 640 × 3, is first processed by the backbone (see
Figure 2, top), which progressively extracts multi-scale features through a cascade of convolutional and residual blocks. Specifically, the image passes through successive Conv → C2f layers with increasing channel depths and downsampling strides, enabling the model to capture both low-level spatial textures and high-level semantic structures. Each Conv block consists of a convolutional layer followed by batch normalization and a SiLU activation function. These operations yield feature maps at five spatial resolutions (P1 to P5), where P5 corresponds to the deepest layer with the smallest spatial resolution and highest semantic abstraction. At the deepest level (P5), we replace the original SPPF block from YOLOv8 with our custom Shared Dilation Pyramid Module (SDPM). This module increases the effective receptive field by applying multiple depthwise separable convolutions with different dilation rates, thereby enriching the feature representations without adding substantial computational burden. This replacement is highlighted in yellow in
Figure 2, just above the backbone’s output.
Once extracted, the multi-scale features are distributed into two distinct necks: a detection path on the left and a segmentation path on the right. The detection branch follows the classical PANet-style neck architecture adopted by YOLOv8, designed to promote rich multi-scale feature fusion across shallow and deep layers. The process begins with upsampling operations (e.g., P5 → P4, P4 → P3), which are applied to align the spatial resolutions of deep feature maps with those from earlier stages of the backbone. This alignment is crucial to enable the concatenation of semantically rich (deep) features with spatially precise (shallow) ones. Upsampling does not add new information per se, but it ensures that all feature maps involved in the fusion share the same spatial dimensions. After concatenation, each fused output undergoes a C2f refinement block, which allows the network to reprocess and compress the combined features, improving both representation power and computational efficiency. These refined feature maps are then downsampled again (e.g., P3 → P4, P4 → P5) using strided convolutions. This downsampling serves not only to restore deeper resolutions but also to ensure bidirectional flow of information, making it possible to capture both fine details from shallow layers and semantic abstractions from deep ones. This process yields a hierarchically aggregated feature space, where object features of varying sizes and complexities are coherently integrated. Finally, these multi-scale representations (from P3, P4, and P5) are passed to the Hierarchical Attention Detection (HAD) head, which performs bounding-box regression and object classification. By operating at multiple resolutions, the detection head is inherently more robust to variations in object size, shape, and context—particularly relevant in UAV-based inspection, where defects may appear at any scale.
In parallel, the segmentation branch adopts a decoder-style architecture, mirroring the feature aggregation logic but focused on spatial reconstruction. Starting from the deepest level (P5), it performs progressive upsampling (P5 → P1) and integrates skip connections from corresponding backbone outputs (P4, P3, …, P1), preserving high-resolution spatial cues throughout the decoding process. Each upsampled and fused stage is refined by a C2f block, improving spatial coherence and suppressing artifacts. In addition, the segmentation neck uniquely leverages the adaptive concatenation module [
21] inherited from A-YOLOM, which enables dynamic feature aggregation during training. Rather than systematically merging feature maps from skip connections and the main path, this module applies a sigmoid-activated gating mechanism to decide whether the auxiliary input should be concatenated. If the gate is inactive, only the main branch is propagated; otherwise, the concatenated tensor is compressed via a 1 × 1 convolution. This selective fusion process is repeated throughout the segmentation pathway, as shown by the “Adaptive Concat” blocks in
Figure 2. It effectively acts as a form of learnable dropout, allowing the network to suppress noisy or redundant spatial information and enhancing the robustness of the segmentation output. This refined multi-scale path is then directed to the Edge-Enhanced Refinement (EFR-Seg) head, which specializes in reconstructing cable masks with high boundary fidelity and structural consistency.
This dual-neck configuration allows the model to simultaneously exploit shared backbone features for detection and segmentation, while tailoring each branch to the specific spatial and semantic demands of its task.
During training, both branches are supervised simultaneously using their respective loss functions. These losses are backpropagated jointly through the necks and the shared backbone, allowing the model to optimize feature representations that serve both tasks. This multi-objective learning encourages the network to extract spatially precise features (helpful for segmentation) while also being sensitive to localized anomalies (critical for detection).
Additional technical details and the design of our novel modules introduced in PowerLine-MTYOLO are discussed in the following sections.
Feature extraction is a crucial step in power line segmentation and broken strand detection, where maintaining structural continuity is essential. Traditional approaches, such as Spatial Pyramid Pooling-Fast (SPPF), rely on max pooling to extract multi-scale features.
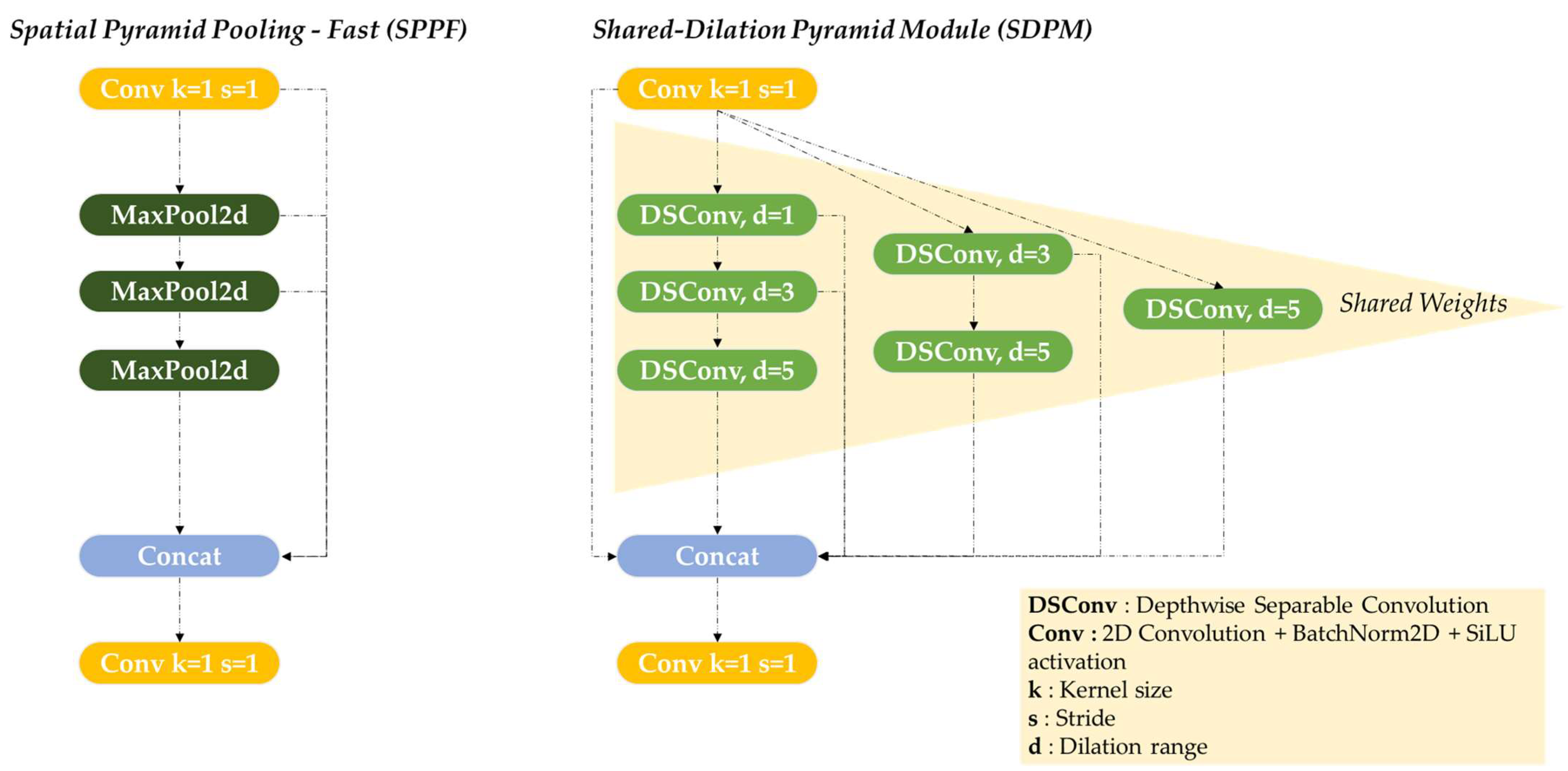
However, max pooling removes fine spatial details, which can disrupt the segmentation of thin and elongated structures like power lines. To address this limitation, we introduce the Shared Dilation Pyramid Module (SDPM), illustrated in
Figure 3, which replaces SPPF with a dilation-based multi-path approach tailored to the characteristics of power lines.
The SDPM is designed to capture both fine details and large-scale contextual information by leveraging depthwise separable convolutions (DSConv) [
22] with increasing dilation rates and a kernel size of 3 (as explained in
Figure 4).
Since power lines are long structures in images, effective segmentation requires not only local precision but also an extended receptive field to understand the broader context. Dilated convolutions enable this expansion, where a small dilation rate focuses on capturing local fine details, while larger dilation rates progressively explore a wider spatial context, ensuring that the network can model the continuity of long cables effectively. To achieve this, the SDPM follows a three-path hierarchical structure with residual connections. Each path extracts features at different scales, ensuring a progressive increase in receptive field without losing critical information.
The first path starts with a small dilation (d = 1), preserving local details before progressively increasing dilation (d = 3, 5). The second path begins at d = 3, capturing intermediate-scale structures before reaching d = 5 to integrate broader context. The third path processes features at d = 5 from the outset, ensuring that long-range dependencies are incorporated early in the feature extraction process. This structured expansion allows the model to match the elongated nature of power lines, ensuring both precise segmentation and contextual continuity. Also, residual connections are integrated across paths, allowing feature information from earlier dilation stages to be retained as the receptive field expands. These connections help mitigate feature degradation, ensuring that finer details are not lost in deeper layers.
In addition to its hierarchical structure, the SDPM employs a shared-weight convolutional mechanism, which reduces redundancy while preserving a diverse range of spatial features. Instead of using separate convolutional kernels for each dilation level, the SDPM shares parameters across different receptive fields, resulting in a more lightweight and efficient representation. In our implementation, the shared-weight mechanism consists of applying the same depthwise convolution kernel across multiple dilation levels using F.conv2d, with a fixed weight tensor shared among paths. The reference kernel used for sharing is the base depthwise convolution filter (not the point-wise convolution; see
Figure 4). For example, for dilation rates 1, 3, and 5, the same filter W is reused at different scales: F.conv2d (input, weight = W, dilation = d). This design enables efficient multi-scale feature extraction without introducing redundant parameters. Finally, the extracted multi-scale features are concatenated and refined through a final 1 × 1 convolution block (Conv2D + BatchNorm + SiLU), which ensures smooth feature integration before passing them to the neck.
- 2.
Edge-Enhanced Refinement (EFR-Seg) Head:
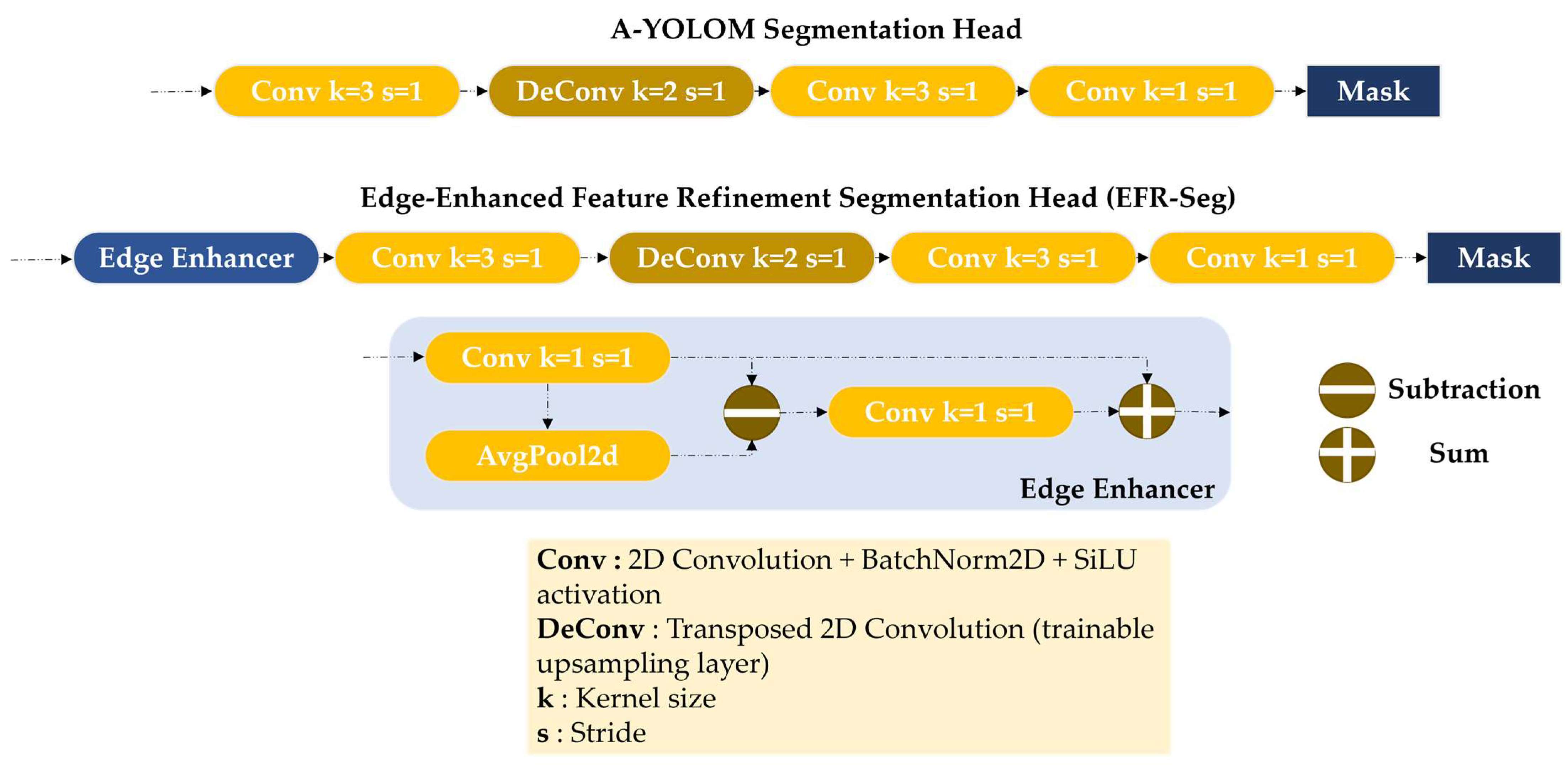
Accurate power line segmentation is a challenging task due to the thin, elongated nature of cables, which can be difficult to distinguish from the background. In prior architectures, A-YOLOM’s segmentation head provided a lightweight approach to mask generation but lacked specialized mechanisms for enhancing edge precision. To address this, we introduce the Edge-Enhanced Refinement (EFR) segmentation head, illustrated in
Figure 5, which retains the efficiency of the original A-YOLOM segmentation head while integrating an Edge Enhancer block at the input to refine boundary information.
The primary goal of the EFR segmentation head is to improve edge awareness in power line segmentation without significantly increasing the computational complexity. Traditional edge detection techniques, such as Sobel filters [
23] or gradient-based methods [
24], explicitly compute edges but often suffer from noise sensitivity and are not inherently trainable within deep networks. Instead of using such conventional methods, we introduce an Edge Enhancer module, which learns edge-aware features in a pixel-wise manner using trainable convolutions. That said, several recent strategies have indeed sought to embed edge awareness within deep learning pipelines using trainable modules. Notably, works such as HED [
25], PiDiNet [
26], and AERNet [
27] propose learnable edge refinement mechanisms, often based on multi-scale side outputs, deep supervision, or attention-based decoding blocks.
While these methods achieve strong results, they tend to introduce considerable architectural complexity and parameter overhead. In contrast, our design deliberately emphasizes simplicity, efficiency, and seamless integration, as it relies solely on an average pooling operation and two lightweight 1 × 1 convolutions. Moreover, in
Section 3.6, we conduct a comparative ablation against several of these strategies—including both non-learnable and learnable alternatives—to support this discussion.
The core purpose of the Edge Enhancer module is to function as a lightweight, learnable edge detector by isolating high-frequency components within the feature map and amplifying boundary-specific signals to support downstream segmentation. Importantly, the design philosophy behind this module is not to replace or suppress the original features but to softly enrich them. It preserves the full semantic content of the input and selectively adds edge-focused cues on top. As a result, even if the added signal is not perfectly accurate, the underlying information remains unaffected, making the enhancer non-destructive, safe, and effective in guiding the network’s attention toward fine structures such as thin cables.
Placing the Edge Enhancer at the entry point of the segmentation branch encourages the network to learn edge sensitivity from the earliest layers, reinforcing contour features throughout the entire mask generation process.
Specifically, as shown in
Figure 5 and
Figure 6, the Edge Enhancer module is defined by the following operations:
1 × 1 Convolution: A point-wise convolution is applied to extract localized features from each pixel independently. This operation preserves spatial granularity and highlights local activations that are potentially associated with edges, analogous to examining the intensity of individual pixels without blending adjacent information. As illustrated in
Figure 6 (image #1), this step emphasizes signal contrast in localized regions, especially around cable discontinuities.
3 × 3 Average Pooling: The output is then passed through an average pooling layer to produce a smoothed version of the feature map. Compared to max pooling, average pooling is less sensitive to noise and better at capturing broad contextual patterns. Conceptually, this acts like applying a soft-focus lens, suppressing fine details while retaining low-frequency background structures. This smoothing effect is visualized in
Figure 6 (image #2), where high-frequency noise is reduced, leaving a softened contour representation. To ensure shape compatibility during the subtraction, we apply a 3 × 3 average pooling operation with stride = 1 and padding = 1, which maintains the same spatial resolution as the input. While pooling operations are typically used to reduce spatial dimensions, in this case, it serves as a smoothing filter to extract low-frequency components without altering the feature map size.
Subtraction Operation: The smoothed feature map is subtracted from the original point-wise features, isolating high-frequency content where significant changes occur. These differences typically correspond to edges or transitions, effectively functioning as a trainable edge extractor. As shown in
Figure 6 (image #3), the difference map clearly highlights structural discontinuities such as broken cable strands and object contours.
Sigmoid-Activated Convolution: A subsequent convolution layer followed by a sigmoid activation refines the edge map. The sigmoid non-linearity scales responses between 0 and 1, allowing the network to softly highlight important edge features. In this context, the sigmoid output acts as a soft attention mask, where values closer to 1 indicate a high likelihood of edge presence (e.g., cable boundary), while values near 0 suggest non-edge or background regions. This enables the model to emphasize relevant contours without applying rigid thresholds, promoting smooth and adaptive boundary refinement. This refined edge mask is presented in
Figure 6 (image #4), where enhanced contours begin to emerge. However, since this visualization is produced by applying the Edge Enhancer only once, without any training, the convolutional layer has not yet learned to distinguish cable-specific boundaries from other visual transitions. As a result, the highlighted edges include both relevant and irrelevant structures (like vegetation), illustrating the raw potential of the module prior to task-specific learning.
Residual Addition: Finally, the refined edge response is added back to the original input, preserving the semantic richness of the features while amplifying their edge-localized characteristics. As shown in
Figure 6 (image #5), the edge-focused information appears in pink when overlaid on the original RGB image, providing a clear visualization of the enhancement effect.
The enhanced feature map is then passed through a lightweight yet effective decoding pipeline to produce the final binary segmentation mask. First, the Edge Enhancer output is processed by a 3 × 3 convolution block with stride = 1 (i.e., without spatial downsampling), which extracts a compact set of semantic features while preserving spatial detail. This is followed by a transpose convolution layer (also known as deconvolution), which upsamples the feature map by a factor of 2 while learning how to reconstruct higher-resolution structures. Compared to naïve interpolation (e.g., bilinear), transpose convolution learns trainable filters for upsampling, enabling it to better preserve edge alignment and structure—particularly beneficial for thin cables. Next, another 3 × 3 convolution block is applied to refine the upsampled features and enhance spatial consistency. Finally, the output is passed through a 1 × 1 convolution block that reduces the channel dimensions to match the number of segmentation classes (typically two: cable vs. background). The resulting activation map is then passed through a sigmoid function to obtain a probability mask.
- 3.
Hierarchical Attention Detection (HAD) Head:
Anomaly detection in power line inspection requires an efficient yet accurate prediction head to jointly estimate bounding boxes and classify objects while maintaining computational efficiency. Traditional architectures, such as A-YOLOM, rely on separate branches for classification and bounding-box regression. While independent processing improves specialization, it significantly increases the computational cost and memory consumption, making it less suitable for real-time applications such as UAV-based power line monitoring. To address this limitation, we introduce the Hierarchical Attention Detection (HAD) head, as illustrated in
Figure 7, which replaces the original detection head in A-YOLOM.
The key motivation behind the HAD head is parameter reduction through branch fusion. By merging the classification and bounding-box branches, HAD minimizes redundant computations, resulting in a lighter architecture with fewer parameters. Unlike A-YOLOM, which uses two entirely separate sub-networks for classification and bounding-box regression, our model leverages a shared feature extraction stage (Hierarchical Attention Bottleneck) that outputs a unified feature map. This shared feature map is then passed through two lightweight, parallel 1 × 1 convolutional layers—one for class prediction and one for bounding-box offset regression—which operate on the same input. This architectural choice drastically reduces computational redundancy, as both tasks utilize the same underlying features, and the branching only occurs at the final convolutional stage. Furthermore, the predictions are concatenated along the channel dimension before decoding, eliminating the need for separate spatial feature flows. In other words, unlike A-YOLOM, where the detection head (
Figure 7, top) processes the same input features through two entirely different branches (each with its own intermediate layers, including four convolutional layers with a kernel size of 3, resulting in a significantly higher number of parameters), our approach avoids this duplication, saving parameters and computation while preserving prediction quality. However, this fusion presents a significant challenge: combining these two tasks can degrade accuracy, as bounding-box regression and classification require distinct feature representations. To mitigate this issue, HAD introduces a Hierarchical Attention Bottleneck (HAB), which enhances feature expressiveness by selectively refining spatial and channel-wise information.
Inspired by the Shared Dilation Pyramid Module (SDPM), HAD utilizes DSConv with sequential dilations to process multi-scale contextual features efficiently. Instead of handling dilation separately at different stages, HAD follows a progressive dilation strategy with shared weights, allowing the model to capture fine details while gradually expanding the receptive field.
To further improve feature selection, we integrate Squeeze-and-Excitation (SE) attention [
28] after each DSConv operation. While DSConv primarily focuses on spatial feature refinement, the introduction of SE attention mechanisms ensures that the model also prioritizes critical channel-wise information. This is particularly important in deep neural networks, where a large number of feature maps are generated near the final layers. By dynamically reweighting the channel responses, SE attention helps compensate for the potential loss of discriminative information caused by branch fusion.
Specifically, as shown in
Figure 7, the HAD head follows a carefully designed sequence of operations to jointly produce bounding-box and classification predictions in an efficient manner. It starts with a 1 × 1 convolutional projection layer that reduces the number of channels and standardizes feature representations, ensuring a compact and normalized input space for subsequent processing.
The transformed features then pass through the HAB, which forms the core of the HAD head. This module applies a sequence of three depthwise separable convolutions (DSConv), each with a kernel size of 3 × 3, and progressively increasing dilation rates of 1, 3, and 5, respectively. This strategy allows the network to extract both fine-grained and large-scale contextual information while maintaining a low parameter count. Importantly, the convolutional weights are shared across dilation levels, enhancing computational efficiency and ensuring consistent feature encoding across different receptive fields.
After each DSConv block, the features are refined through a Squeeze-and-Excitation (SE) attention module. Each SE block uses a reduction ratio of 16, implemented via two 1 × 1 convolutions: the first reduces the number of channels, and the second restores it, followed by a sigmoid gating function. This mechanism dynamically reweights the feature channels based on their global relevance, reinforcing the most informative components while suppressing less relevant ones.
In the final stage, the attention-enhanced features are passed through two parallel 1 × 1 convolutions—one head predicts the class probabilities, and the other outputs the bounding-box offsets. These predictions are concatenated and post-processed using specialized loss functions: bounding-box regression is supervised using our proposed Shape-Aware Wise IoU loss, enhanced with Distribution Focal Loss (DFL) for finer localization, while Binary Cross-Entropy (BCE) is used for classification supervision. The formulation and rationale of these loss functions are further explained in the next section.
2.2.3. Loss Functions
Accurate bounding-box regression is crucial for detecting broken strands and cable anomalies in power line inspection. To evaluate the quality of a predicted bounding box, most modern detectors rely on the Intersection-over-Union (IoU) metric, which measures the ratio of the overlapping area to the union area between the predicted and ground-truth boxes. A higher IoU score indicates better alignment and coverage, and this metric serves as the basis for many loss functions in object detection. Traditional IoU-based loss functions, such as CIoU and DIoU, primarily optimize for overlap and center distance alignment but do not account for shape differences explicitly. This limitation becomes particularly problematic in power line defect detection, where defects exhibit high aspect ratio variations (refer to the
Section 2.3). Such variations make it difficult for standard IoU losses to properly guide the model in refining bounding-box predictions, leading to misaligned or imprecise bounding boxes around defects.
To address these challenges, we introduce the Shape-Aware Wise IoU loss, which builds upon Shape IoU [
29] by integrating adaptive scaling mechanisms from Wise IoU [
30]. This formulation aims to enhance the model’s ability to capture elongated structures while maintaining stable gradient flow for optimization. Shape IoU extends traditional IoU by introducing a shape distance term and a shape-aware penalty function, ensuring that the bounding boxes align not only in position but also in aspect ratio, making it more suited for objects with non-uniform shapes such as cables or broken strands. However, Shape IoU alone is insufficient, as its static penalty structure does not adapt to dynamic localization challenges during training. For instance, broken cables are often small, thin, and partially occluded, making their appearance highly variable across scenes. In such cases, a fixed penalty may either under-emphasize subtle misalignments or overly penalize reasonable predictions, leading to unstable convergence. By integrating the adaptive focusing mechanism from Wise IoU, our Shape-Aware Wise IoU loss dynamically adjusts the penalty strength based on the confidence and quality of the prediction—encouraging tighter localization when the model is confident, and being more forgiving when uncertainty is high. In summary, this approach can be likened to fitting a custom-shaped sticker onto an object: traditional IoU focuses on ensuring that the sticker is centered and covers most of the surface, whereas Shape-Aware Wise IoU ensures that the sticker also matches the object’s shape—whether long and narrow or square. The “wise” part adapts how strictly the fit is judged, depending on how difficult the object is to locate.
Formally, the Shape-Aware Wise IoU loss is given by
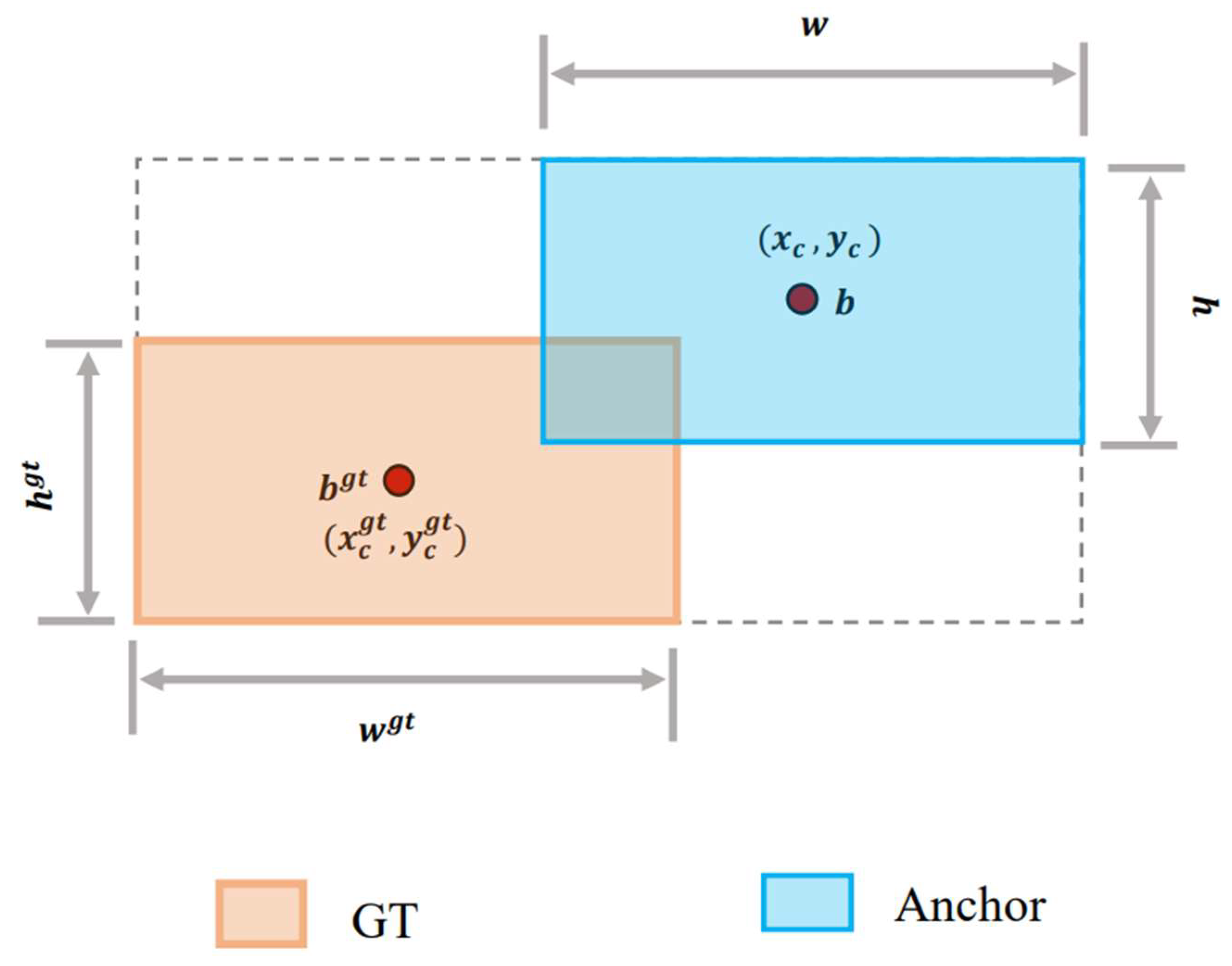
The term
penalizes the spatial displacement between the centers of the predicted box (Anchor) and the ground-truth box (GT), as shown in
Figure 8. This displacement is weighted according to the aspect ratio of the GT box:
where
- ○
(,): Center of the predicted (Anchor) box.
- ○
(,): Center of the GT box.
- ○
: Squared diagonal length of the smallest enclosing box (convex hull) covering both GT and Anchor. The values
and
correspond to the width and height of this enclosing box, respectively, and are computed as follows:
The squared diagonal of this convex box is then
captures the difference in aspect ratios and sizes between GT and prediction, using an exponential decay to down-weight minor differences and emphasize significant ones:
where
acts as a monotonic scaling factor (adaptive focusing mechanism) that dynamically adjusts the contribution of each prediction to the total loss. This mechanism is inspired by Wise IoU’s philosophy of “confidence-aware regularization” and is crucial for maintaining stable optimization across diverse anomaly scales. Intuitively, increases when the predicted box quality (IoU) exceeds the average, encouraging the model to fine-tune and localize confident predictions even more precisely. Conversely, if the IoU is low (poor prediction or ambiguous object), β becomes smaller, reducing the penalty and preventing the model from being misled by difficult or noisy samples—such as small, broken cables that may only partially appear in the frame or exhibit low visual salience. Here, refers to the average IoU over all predictions in the current batch. It serves as a dynamic baseline that normalizes each individual IoU score, allowing the loss to adapt in real time to the difficulty level of each image or sample. This encourages the network to focus more on confident predictions when performance is high and down-weight uncertain predictions when performance is low.
Figure 8.
Geometric interpretation of the Shape IoU formulation.
Figure 8.
Geometric interpretation of the Shape IoU formulation.
These geometric relationships are visually illustrated in
Figure 8 to aid interpretation and understanding.
Finally, following the same structure as A-YOLOM, the final loss function for PowerLine-MTYOLO combines all task-specific losses into a weighted sum, expressed as follows:
where
The weighting factors were used to balance the contributions of classification, bounding-box regression, and segmentation losses during training. We adopted default values commonly recommended by the literature to ensure fair and reproducible comparisons with prior work. These weights were empirically calibrated to maintain stable training dynamics and prevent any task from dominating the optimization process. Specifically, we used for classification loss (BCE), = 7.5 for bounding-box regression (Shape-Wise IoU), = 1.5 for Distribution Focal Loss (DFL), = 8.0 for Tversky Loss, and = 24.0 for Focal Loss.
These values were chosen to ensure a balanced contribution across tasks—detection and segmentation—even in the presence of class imbalance or small-scale objects, as is often the case in power line inspection.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}