





Enhancing the Scale Adaptation of Global Trackers for Infrared UAV Tracking


Abstract
1. Introduction
- (1)
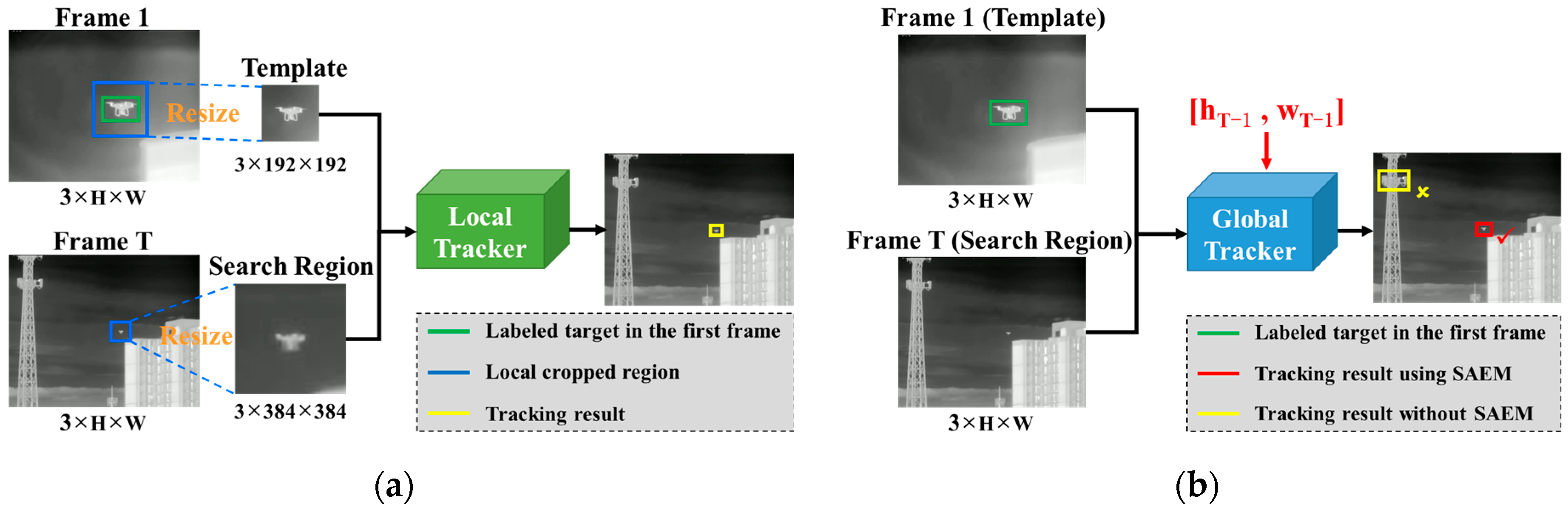
- Infrared UAV tracking is susceptible to occlusion, thermal crossover, and interference in complex scenarios such as trees, buildings, heavy clouds, and strong clutter.
- (2)
- Due to the rapid movement of the UAV target or the instability of the infrared camera platform, the position of the UAV target will change drastically between two adjacent frames or even move out of view.
- (3)
- The target scale variation is dramatic when the camera adjusts its focal length or the target moves rapidly closer or farther away, especially in the UAV-to-UAV task [5].
- (1)
- We propose a plug-and-play scale adaptation enhancement module, which can implicitly resize the target template to enhance the scale adaptation of existing global trackers for the infrared UAV tracking task.
- (2)
- During training, we design an auxiliary branch to supervise the learning of SAEM and add Gaussian noise to the input size to enhance its robustness. During online tracking, an adaptive threshold is proposed to accurately judge target disappearance and prevent SAEM from being affected by incorrect input size.
- (3)
- We propose a one-stage anchor-free global tracker with a simpler structure, which can track UAVs in real time.
2. Related Work
2.1. Single Object Tracking
2.2. Global Tracker
2.3. Infrared UAV Tracking
2.4. Scale-Arbitrary Image Super-Resolution
3. Methodology
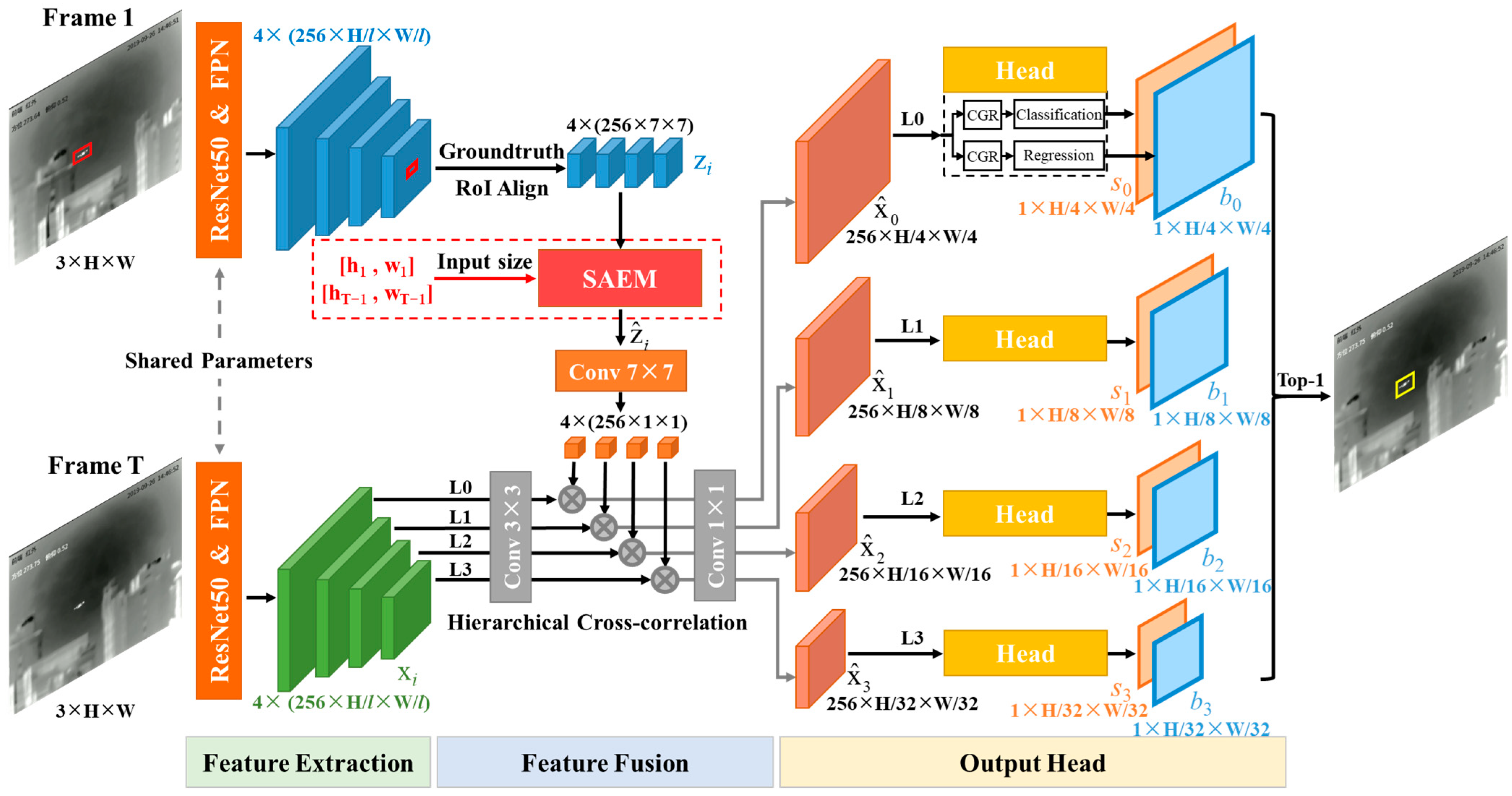
3.1. One-Stage Anchor-Free Global Tracker
3.1.1. Feature Extraction
3.1.2. Feature Fusion
3.1.3. Output Head
3.2. Enhancing the Scale Adaptation of Global Tracker
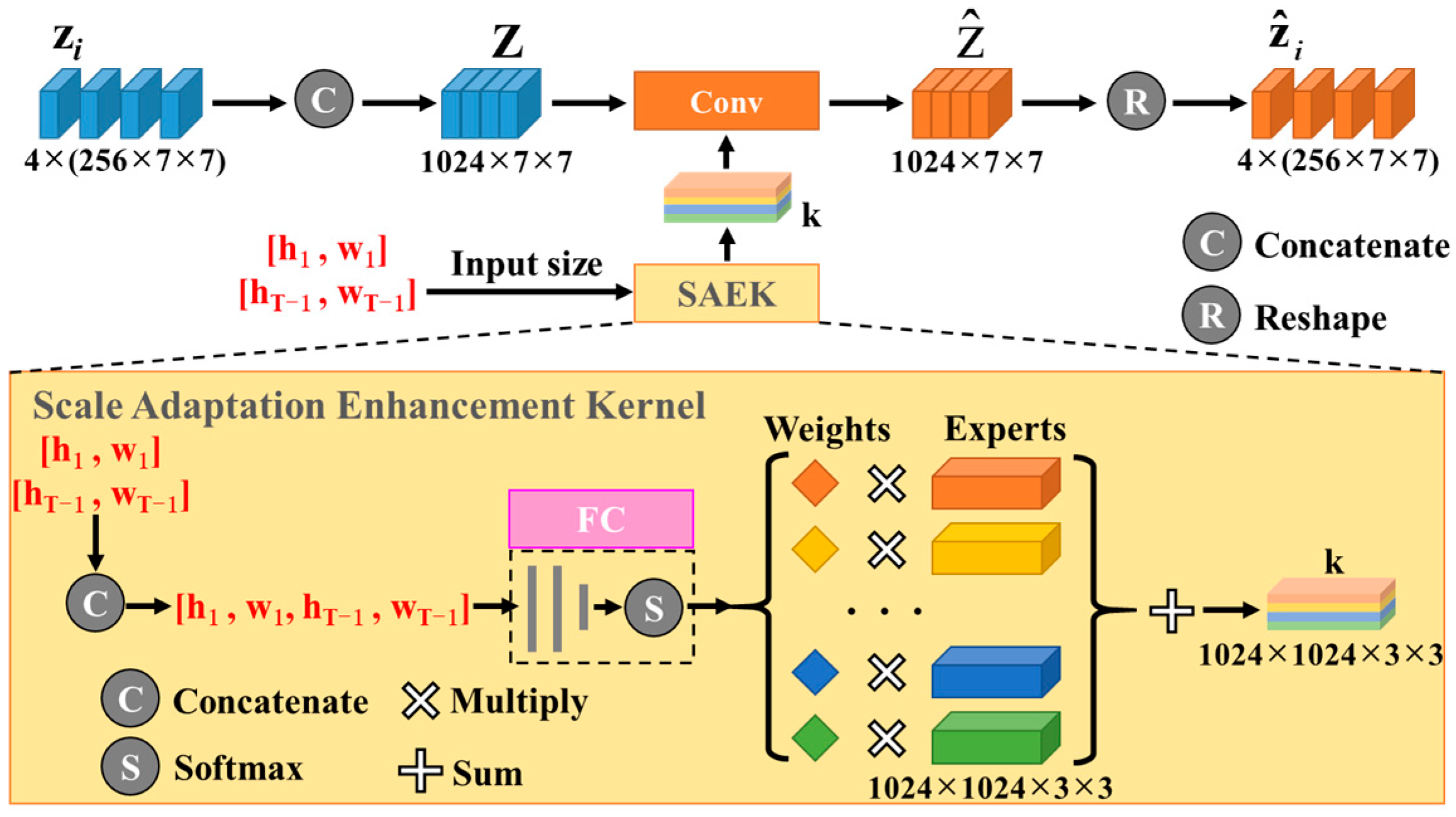
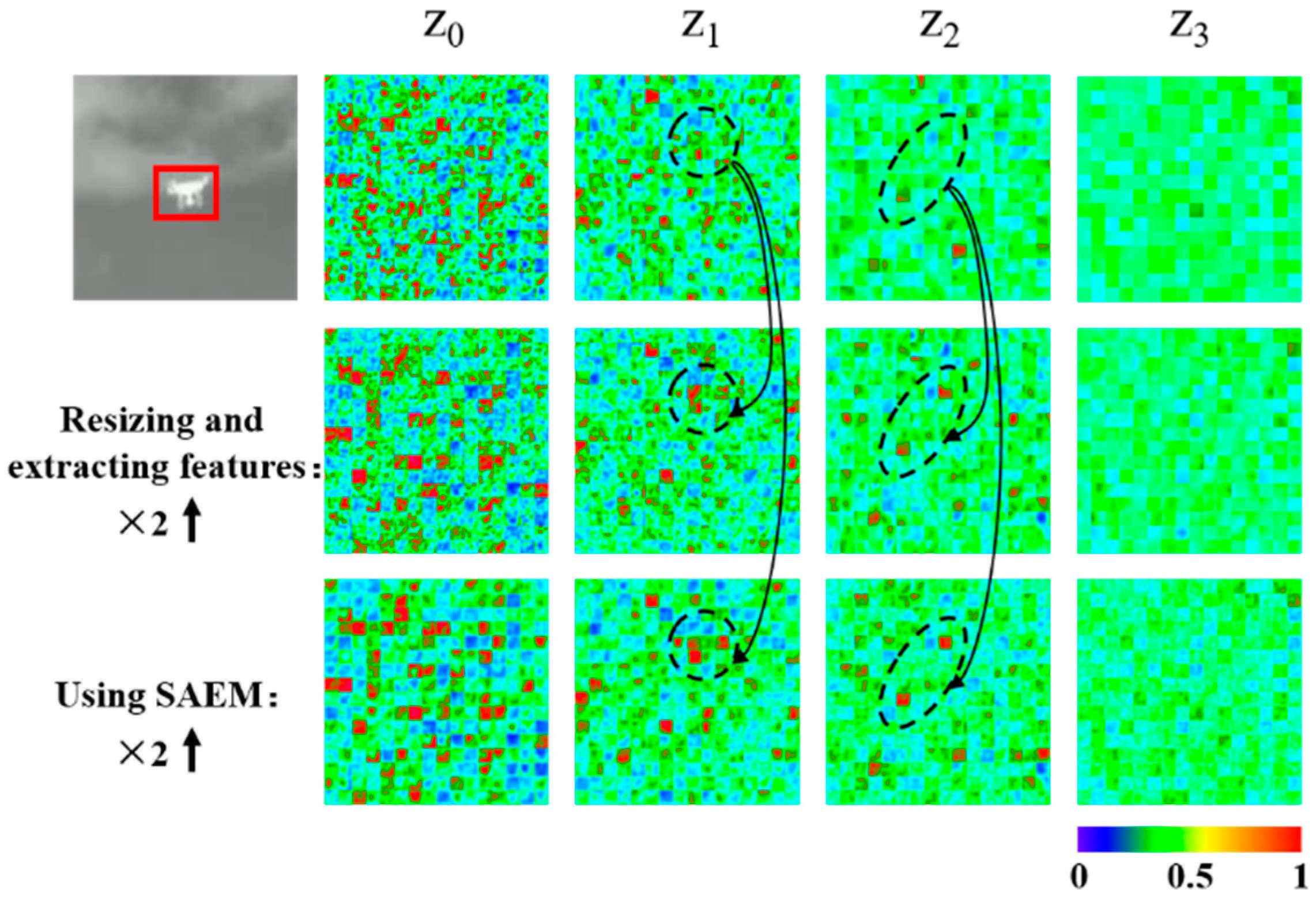
3.2.1. Scale Adaptation Enhancement Module
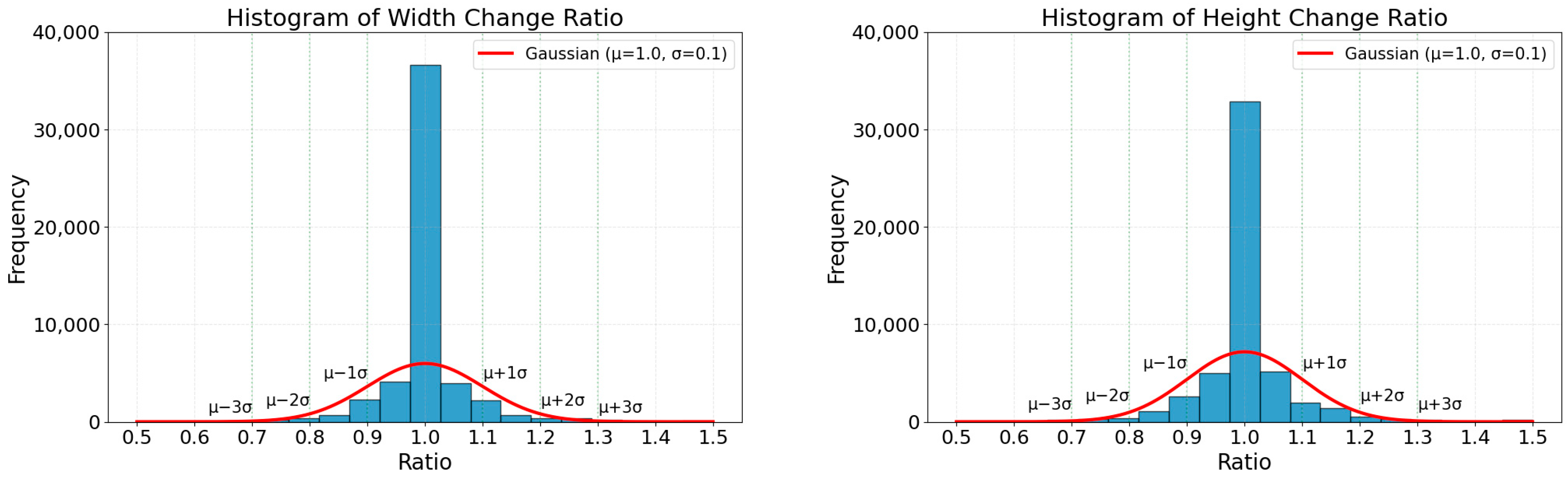
3.2.2. Supervision and Gaussian Noise
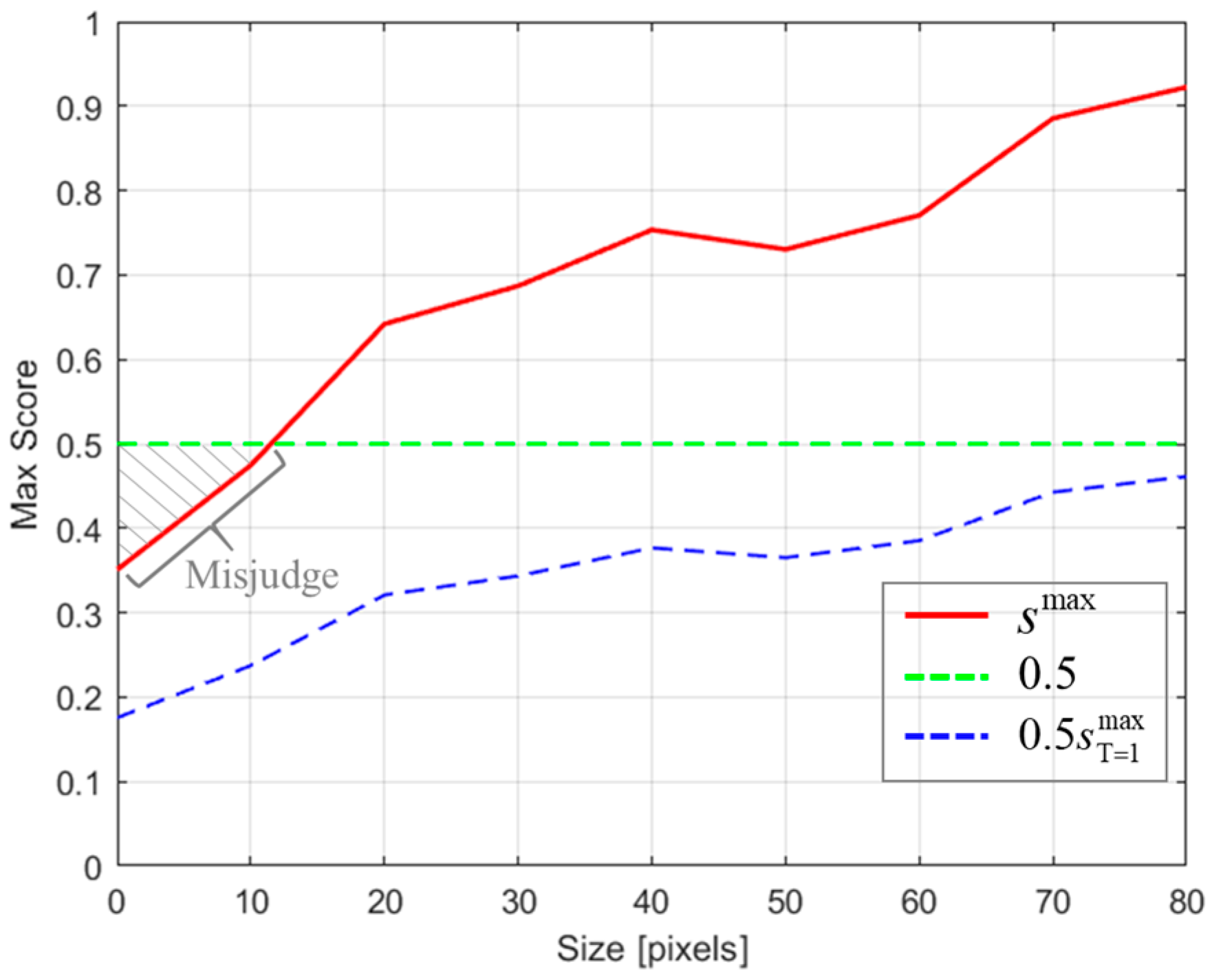
3.2.3. An Adaptive Threshold for Judging Target Disappearance
4. Experiment
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Quantitative Evaluation
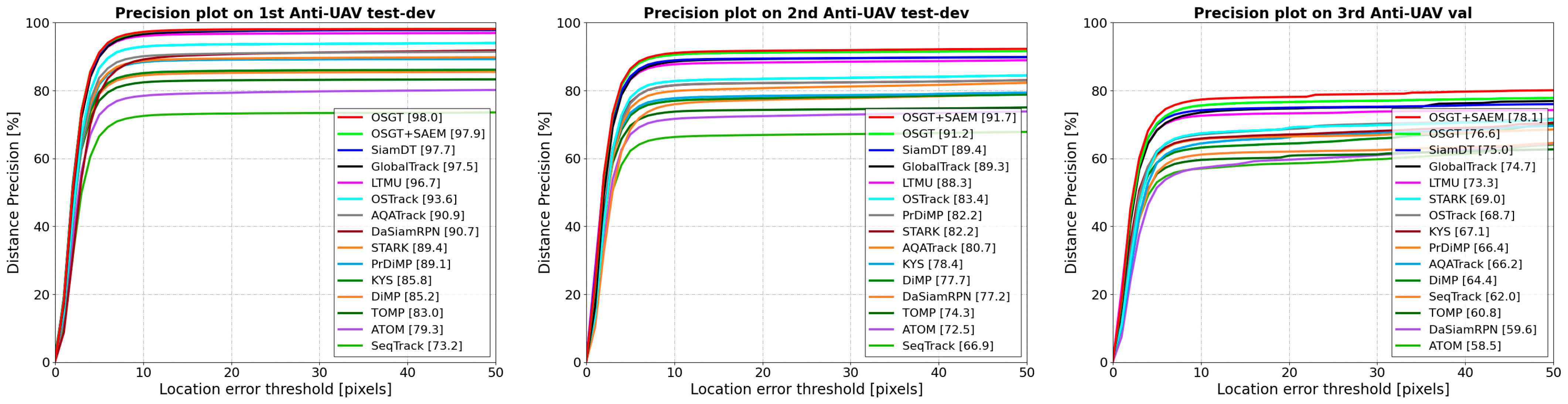
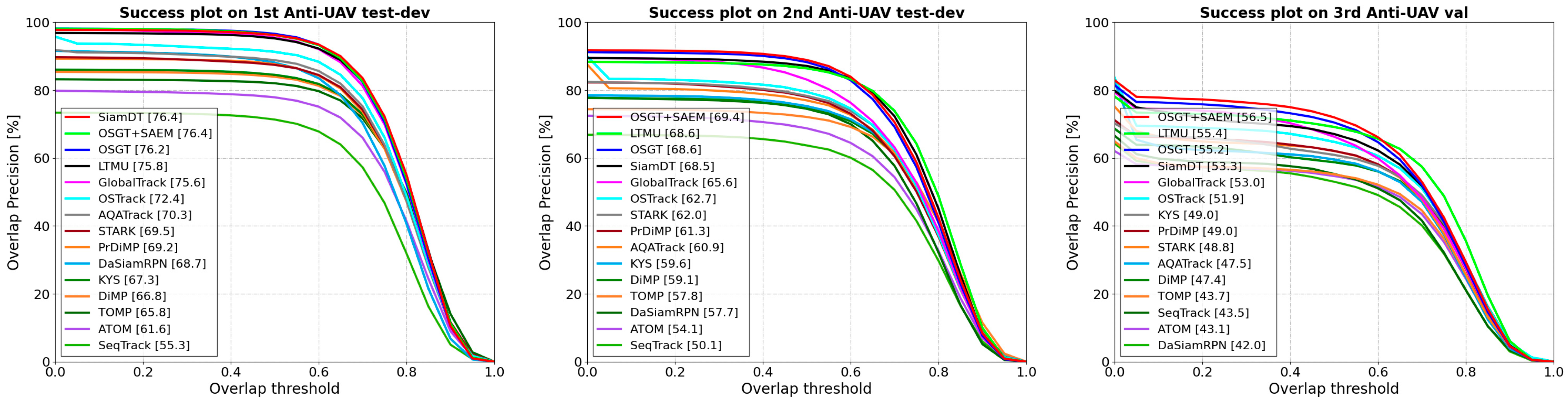
4.3.1. Comparison Results on Anti-UAV Challenge Datasets
4.3.2. Comparison Results on Anti-UAV410 Dataset
4.3.3. Inference Performance Comparison
4.4. Qualitative Evaluation
4.5. Model Analysis
4.5.1. Ablation Study
4.5.2. Different Backbone Networks
4.5.3. Different Multi-Level Settings
4.5.4. Effectiveness of SAEM
4.5.5. Compatibility of SAEM
4.5.6. Number of Experts in SAEM
4.5.7. Different Input Forms in SAEM
4.5.8. Using Different Thresholds to Judge the Target Disappearance
4.5.9. Comparison Results of Different Template Update Methods
4.5.10. Tracking Failure Cases
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jiang, N.; Wang, K.; Peng, X.; Yu, X.; Wang, Q.; Xing, J.; Li, G.; Guo, G.; Ye, Q.; Jiao, J.; et al. Anti-UAV: A Large-scale Benchmark for Vision-based UAV Tracking. IEEE Trans. Multimed. 2023, 25, 486–500. [Google Scholar] [CrossRef]
- Yang, H.; Liang, B.; Feng, S.; Jiang, J.; Fang, A.; Li, C. Lightweight UAV Detection Method Based on IASL-YOLO. Drones 2025, 9, 325. [Google Scholar] [CrossRef]
- Ye, Z.; You, J.; Gu, J.; Kou, H.; Li, G. Modeling and Simulation of Urban Laser Countermeasures Against Low-Slow-Small UAVs. Drones 2025, 9, 419. [Google Scholar] [CrossRef]
- Javed, S.; Danelljan, M.; Khan, F.; Khan, M.; Felsberg, M.; Matas, J. Visual Object Tracking with Discriminative Filters and Siamese Networks: A Survey and Outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 6552–6574. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Ye, D.H.; Kolsch, M.; Wachs, J.P.; Bouman, C.A. Fast and Robust UAV to UAV Detection and Tracking from Video. IEEE Trans. Emerg. Top. Comput. 2021, 10, 1519–1531. [Google Scholar] [CrossRef]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar]
- Ye, B.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework. In Proceedings of the European Conference on Computer Vision (ECCV 2022), Tel Aviv, Israel, 23–27 October 2022; pp. 341–357. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. Globaltrack: A Simple and Strong Baseline for Long-term Tracking. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11037–11044. [Google Scholar]
- Fang, H.; Wang, X.; Liao, Z.; Chang, Y.; Yan, L. A Real-Time Anti-Distractor Infrared UAV Tracker with Channel Feature Refinement Module. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 1240–1248. [Google Scholar]
- Wang, Z.; Hu, Y.; Yang, J.; Zhou, G.; Liu, F.; Liu, Y. A Contrastive-Augmented Memory Network for Anti-UAV Tracking in TIR Videos. Remote Sens. 2024, 16, 4775. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, J. A Scale Adaptive Kernel Correlation Filter Tracker with Feature Integration. In Proceedings of the European Conference on Computer Vision (ECCV 2015), Zurich, Switzerland, 6–12 September 2015; pp. 254–265. [Google Scholar]
- Danelljan, M.; Hager, G.; Khan, F.S.; Felsberg, M. Discriminative Scale Space Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1561–1575. [Google Scholar] [CrossRef]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-Aware Anchor-Free Tracking. In Proceedings of the European Conference on Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; pp. 771–787. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 8122–8131. [Google Scholar]
- Hu, X.; Mu, H.; Zhang, X.; Wang, Z.; Tan, T.; Sun, J. Meta-SR: A Magnification-Arbitrary Network for Super-Resolution. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1575–1584. [Google Scholar]
- Wang, L.; Wang, Y.; Lin, Z.; Yang, J.; An, W.; Guo, Y. Learning a Single Network for Scale-Arbitrary Super-Resolution. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 4781–4790. [Google Scholar] [CrossRef]
- Huang, B.; Chen, J.; Xu, T.; Wang, Y.; Jiang, S.; Wang, Y.; Wang, L.; Li, J. SiamSTA: Spatio-temporal Attention based Siamese Tracker for Tracking UAVs. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 1204–1212. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Li, S.; Zhao, S.; Cheng, B.; Zhao, E.; Chen, J. Robust Visual Tracking via Hierarchical Particle Filter and Ensemble Deep Features. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 179–191. [Google Scholar] [CrossRef]
- Hare, S.; Golodetz, S.; Saffari, A.; Vineet, V.; Cheng, M.-M.; Hicks, S.L.; Torr, P.H.S. Struck: Structured Output Tracking with Kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2096–2109. [Google Scholar] [CrossRef] [PubMed]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the Circulant Structure of Tracking-by-Detection with Kernels. In Proceedings of the European Conference on Computer Vision (ECCV 2012), Florence, Italy, 7–13 October 2012; pp. 702–715. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; pp. 4277–4286. [Google Scholar]
- Xie, X.; Xi, J.; Yang, X.; Lu, R.; Xia, W. STFTrack: Spatio-Temporal-Focused Siamese Network for Infrared UAV Tracking. Drones 2023, 7, 296. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-Aware Siamese Networks for Visual Object Tracking. In Proceedings of the European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; pp. 103–119. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ATOM: Accurate Tracking by Overlap Maximization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; pp. 4655–4664. [Google Scholar]
- Bhat, G.; Danelljan, M.; Van Gool, L.; Timofte, R. Learning Discriminative Model Prediction for Tracking. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6181–6190. [Google Scholar] [CrossRef]
- Yan, B.; Peng, H.; Fu, J.; Wang, D.; Lu, H. Learning Spatio-Temporal Transformer for Visual Tracking. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 10428–10437. [Google Scholar]
- Mayer, C.; Danelljan, M.; Bhat, G.; Paul, M.; Paudel, D.P.; Yu, F.; Van Gool, L. Transforming model prediction for tracking. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 8731–8740. [Google Scholar]
- Cui, Y.; Song, T.; Wu, G.; Wang, L. MixFormerV2: Efficient Fully Transformer Tracking. arXiv 2023, arXiv:2305.15896. [Google Scholar]
- Wei, X.; Bai, Y.; Zheng, Y.; Shi, D.; Gong, Y. Autoregressive Visual Tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 9697–9706. [Google Scholar]
- Xie, J.; Zhong, B.; Mo, Z.; Zhang, S.; Shi, L.; Song, S.; Ji, R. Autoregressive Queries for Adaptive Tracking with Spatio-Temporal Transformers. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 19300–19309. [Google Scholar]
- Voigtlaender, P.; Luiten, J.; Torr, P.H.S.; Leibe, B. Siam R-CNN: Visual Tracking by Re-Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 6577–6587. [Google Scholar] [CrossRef]
- Huang, B.; Dou, Z.; Chen, J.; Li, J.; Shen, N.; Wang, Y.; Xu, T. Searching Region-Free and Template-Free Siamese Network for Tracking Drones in TIR Videos. IEEE Trans. Geosci. Remote Sens. 2023, 62, 5000315. [Google Scholar] [CrossRef]
- Huang, B.; Li, J.; Chen, J.; Wang, G.; Zhao, J.; Xu, T. Anti-UAV410: A Thermal Infrared Benchmark and Customized Scheme for Tracking Drones in the Wild. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 2852–2865. [Google Scholar] [CrossRef] [PubMed]
- Yan, B.; Zhao, H.; Wang, D.; Lu, H.; Yang, X. ‘Skimming-Perusal’ Tracking: A Framework for Real-Time and Robust Long-Term Tracking. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2385–2393. [Google Scholar]
- Dai, K.; Zhang, Y.; Wang, D.; Li, J.; Lu, H.; Yang, X. High-Performance Long-Term Tracking with Meta-Updater. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 6297–6306. [Google Scholar] [CrossRef]
- Qian, K.; Zhu, D.; Wu, Y.; Shen, J.; Zhang, S. TransIST: Transformer Based Infrared Small Target Tracking Using Multi-Scale Feature and Exponential Moving Average Learning. Infrared Phys. Technol. 2025, 145, 105674. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, X.; Zhang, P. A Unified Approach for Tracking UAVs in Infrared. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Virtual, 11–17 October 2021; pp. 1213–1222. [Google Scholar]
- Liu, S.; Huang, W.; Chen, X. Is Brain-inspired Intelligence a New Dawn for Infrared Imaging Missile Anti-interference Strategies? Chin. J. Aeronaut. 2025, 38, 103462. [Google Scholar] [CrossRef]
- Wu, H.; Li, W.; Li, W.; Liu, G. A Real-Time Robust Approach for Tracking UAVs in Infrared Videos. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Virtual, 14–19 June 2020; pp. 4448–4455. [Google Scholar] [CrossRef]
- Yu, Q.; Ma, Y.; He, J.; Yang, D.; Zhang, T. A Unified Transformer Based Tracker for Anti-UAV Tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 18–22 June 2023; pp. 3035–3045. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Virtual, 11–17 October 2021; pp. 1833–1844. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, G.; Li, J.; Jin, L.; Fan, N.; Wang, M.; Wang, X.; Yong, T.; Deng, Y.; Guo, Y.; et al. The 2nd Anti-UAV Workshop & Challenge: Methods and Results. arXiv 2021, arXiv:2108.09909. [Google Scholar]
- Danelljan, M.; Van Gool, L.; Timofte, R. Probabilistic Regression for Visual Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 7181–7190. [Google Scholar] [CrossRef]
- Bhat, G.; Danelljan, M.; Van Gool, L.; Timofte, R. Know Your Surroundings: Exploiting Scene Information for Object Tracking. In Proceedings of the European Conference on Computer Vision (ECCV 2020), Virtual, 23–28 August 2020; pp. 205–221. [Google Scholar]
- Gao, S.; Zhou, C.; Ma, C.; Wang, X.; Yuan, J. AiATrack: Attention in Attention for Transformer Visual Tracking. In Proceedings of the European Conference on Computer Vision (ECCV 2022), Tel Aviv, Israel, 23–27 October 2022; pp. 146–164. [Google Scholar]
- Chen, X.; Peng, H.; Wang, D.; Lu, H.; Hu, H. SeqTrack: Sequence to Sequence Learning for Visual Object Tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 14572–14581. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scheme | Search Region | Efficiency | Scale Adaptation | Occlusion or Moving out of View | Fast Target or Camera Motion |
|---|---|---|---|---|---|
| Local tracker | Local patch | High |  |  | |
| Global tracker | Whole frame | Low | | | |
| Methods | Publication | 1st Anti-UAV test-dev | 2nd Anti-UAV test-dev | 3rd Anti-UAV val | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUC | OP50 | P | PNorm | AUC | OP50 | P | PNorm | AUC | OP50 | P | PNorm | ||
| ATOM [25] | CVPR 2019 | 61.6 | 77.9 | 79.3 | 78.9 | 54.1 | 68.8 | 72.5 | 69.5 | 43.1 | 54.7 | 58.5 | 57.6 |
| DiMP [26] | ICCV 2019 | 66.8 | 84.0 | 85.2 | 84.9 | 59.1 | 74.6 | 77.7 | 75.3 | 47.4 | 58.8 | 64.4 | 62.1 |
| PrDiMP [48] | CVPR 2020 | 69.2 | 87.7 | 89.1 | 88.7 | 61.3 | 78.1 | 82.2 | 79.0 | 49.0 | 62.1 | 66.4 | 64.2 |
| KYS [49] | ECCV 2020 | 67.3 | 84.5 | 85.8 | 85.5 | 59.6 | 75.3 | 78.4 | 76.0 | 49.0 | 60.9 | 67.1 | 63.5 |
| STARK [27] | ICCV 2021 | 69.5 | 87.4 | 89.4 | 88.5 | 62.0 | 78.3 | 82.2 | 79.1 | 48.8 | 62.1 | 69.0 | 64.0 |
| TOMP [28] | CVPR 2022 | 65.8 | 82.0 | 83.0 | 82.8 | 57.8 | 72.1 | 74.3 | 72.9 | 43.8 | 55.2 | 60.8 | 57.8 |
| OSTrack [7] | ECCV 2022 | 72.4 | 91.3 | 93.6 | 92.7 | 62.7 | 79.5 | 83.4 | 79.9 | 51.9 | 64.8 | 68.7 | 67.2 |
| SeqTrack [51] | CVPR 2023 | 55.3 | 71.4 | 73.2 | 72.9 | 50.1 | 63.7 | 66.9 | 65.2 | 43.5 | 55.3 | 62.0 | 57.9 |
| AQATrack [31] | CVPR 2024 | 70.3 | 88.9 | 90.9 | 89.9 | 60.9 | 77.0 | 80.7 | 78.0 | 47.5 | 59.6 | 66.2 | 62.3 |
| DaSiamRPN [24] | ECCV 2018 | 68.7 | 88.1 | 90.7 | 87.9 | 57.7 | 74.5 | 77.2 | 74.8 | 42.0 | 53.0 | 59.6 | 55.7 |
| GlobalTrack [8] | AAAI 2020 | 75.6 | 95.5 | 97.5 | 96.4 | 65.5 | 83.1 | 89.3 | 85.2 | 53.0 | 66.3 | 74.7 | 70.5 |
| LTMU [36] | CVPR 2020 | 75.8 | 95.3 | 96.7 | 96.2 | 68.6 | 86.4 | 88.3 | 88.1 | 55.4 | 69.2 | 73.3 | 72.3 |
| SiamSTA # [17] | ICCVW 2021 | 72.6 | — | 96.9 | — | 65.5 | — | 88.8 | — | — | — | — | — |
| SiamDT [34] | PAMI 2024 | 76.4 | 96.2 | 97.7 | 97.2 | 68.5 | 87.1 | 89.4 | 89.1 | 53.3 | 67.1 | 75.0 | 70.3 |
| OSGT | — | 76.2 | 96.6 | 98.0 | 97.3 | 68.6 | 88.3 | 91.2 | 89.8 | 55.2 | 70.5 | 76.6 | 75.2 |
| OSGT+SAEM | — | 76.4 | 96.2 | 97.9 | 97.3 | 69.4 | 88.9 | 91.7 | 90.5 | 56.5 | 72.0 | 78.1 | 76.4 |
| Methods | PrDiMP [48] | STARK [27] | AiATrack [50] | OSTrack [7] | MixFormer [29] | GlobalTrack [8] | CAMTracker # [10] | SiamDT # [34] | OSGT | OSGT +SAEM |
| Publication | CVPR 2020 | ICCV 2021 | ECCV 2022 | ECCV 2022 | CVPR 2023 | AAAI 2020 | RS 2024 | PAMI 2024 | — | — |
| SA | 54.69 | 57.15 | 59.56 | 60.15 | 59.65 | 66.45 | 67.10 | 68.19 | 67.03 | 68.98 |
| Methods | DaSiamRPN | GlobalTrack | LTMU | SiamDT | OSGT | OSGT+SAEM |
| Speed (GPU) | 22.7 | 22.3 | 1.5 | 9.1 | 30.9 | 27.3 |
| Speed (CPU) | 2.0 | 2.0 | — | 0.5 | 3.2 | 2.2 |
| OSGT | SAEM | Supervision | Gaussian Noise | AUC | OP50 | P | PNorm |
|---|---|---|---|---|---|---|---|
| 55.2 | 70.5 | 76.6 | 75.2 | |||
| | 52.7 | 69.3 | 76.8 | 75.3 | ||
| | | 51.9 | 68.1 | 76.8 | 74.5 | |
| | | 55.9 | 71.5 | 77.0 | 75.6 | |
| | | | 56.5 | 72.0 | 78.1 | 76.4 |
| Metrics | Darknet | SwinTransformer | ResNeXt50 | ResNet50 |
|---|---|---|---|---|
| AUC | 50.1 | 54.4 | 55.3 | 55.2 |
| OP50 | 62.9 | 68.7 | 69.8 | 70.5 |
| P | 69.5 | 75.8 | 77.6 | 76.6 |
| PNorm | 66.9 | 72.5 | 75.4 | 75.2 |
| Metrics | GlobalTrack | GlobalTrack +SAEM | SiamDT | SiamDT +SAEM | OSGT | OSGT +SAEM |
|---|---|---|---|---|---|---|
| AUC | 53.0 | 54.4 (1.4 ↑) | 53.3 | 55.3 (2.0 ↑) | 55.2 | 56.5 (1.3 ↑) |
| OP50 | 66.3 | 68.2 (1.9 ↑) | 67.1 | 69.5 (2.4 ↑) | 70.5 | 72.0 (1.5 ↑) |
| P | 74.7 | 76.1 (1.4 ↑) | 75.0 | 76.1 (1.1 ↑) | 76.6 | 78.1 (1.5 ↑) |
| PNorm | 70.5 | 73.1 (2.6 ↑) | 70.3 | 72.8 (2.5 ↑) | 75.2 | 76.4 (1.2 ↑) |
| Experts | Params. | FLOPs | Time | AUC | OP50 | P | PNorm | Speed |
|---|---|---|---|---|---|---|---|---|
| 4 | 1.35 K | 2.58 K | 1.72 ms | 55.6 | 70.6 | 76.9 | 74.6 | 28.5 |
| 8 | 1.48 K | 2.86 K | 2.53 ms | 55.8 | 71.4 | 76.9 | 76.0 | 27.9 |
| 12 | 1.61 K | 3.14 K | 3.31 ms | 56.5 | 72.0 | 78.1 | 76.4 | 27.3 |
| 16 | 1.74 K | 3.42 K | 4.11 ms | 56.2 | 72.0 | 77.5 | 75.2 | 26.6 |
| Experts | [1, 5) | [5, 10) | [10, 15] |
|---|---|---|---|
| 4 | 46.4/71.0/73.0/55.4 | 21.3/35.0/41.8/42.8 | 55.4/74.0/79.8/65.5 |
| 8 | 46.2/70.5/72.0/57.1 | 20.9/35.2/40.6/41.7 | 54.6/72.5/76.1/63.5 |
| 12 | 45.8/70.4/72.2/54.6 | 23.3/37.8/43.7/45.1 | 60.0/83.1/89.8/75.4 |
| 16 | 46.3/71.6/73.0/57.5 | 23.0/37.8/43.8/40.1 | 58.0/78.8/81.8/67.5 |
| Input Forms | AUC | OP50 | P | PNorm |
|---|---|---|---|---|
| Ratio form | 56.2 | 72.0 | 77.4 | 75.6 |
| Concatenation form | 56.5 | 72.0 | 78.1 | 76.4 |
| Threshold | AUC | OP50 | P | PNorm |
|---|---|---|---|---|
| 0.0 | 55.4 | 70.5 | 77.0 | 74.3 |
| 0.5 | 56.0 | 71.1 | 78.4 | 76.2 |
| 56.5 | 72.0 | 78.1 | 76.4 |
| Template Update Methods | AUC | OP50 | P | PNorm | Speed |
|---|---|---|---|---|---|
| None | 55.2 | 70.5 | 76.6 | 75.2 | 30.9 |
| Temporal appearance update | 54.9 | 70.2 | 76.4 | 74.7 | 29.9 |
| Explicit scale update | 56.2 | 71.4 | 77.7 | 76.0 | 23.3 |
| Implicit scale update (SAEM) | 56.5 | 72.0 | 78.1 | 76.4 | 27.3 |
| Methods | AUC | OP50 | P | PNorm |
|---|---|---|---|---|
| OSTrack | 4.3/23.9 | 8.0/37.9 | 9.5/39.9 | 11.9/23.7 |
| LTMU | 16.3/29.0 | 30.2/41.5 | 36.4/40.9 | 30.6/30.5 |
| GlobalTrack | 4.6/36.8 | 8.7/61.6 | 12.0/62.8 | 16.1/42.9 |
| SiamDT | 6.0/18.6 | 10.3/30.1 | 16.1/30.5 | 15.7/20.4 |
| OSGT+SAEM | 18.2/41.2 | 30.0/62.8 | 29.1/63.0 | 28.0/45.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, Z.; Zhang, W.; Pan, E.; Liu, D.; Yu, Q. Enhancing the Scale Adaptation of Global Trackers for Infrared UAV Tracking. Drones 2025, 9, 469. https://doi.org/10.3390/drones9070469
Feng Z, Zhang W, Pan E, Liu D, Yu Q. Enhancing the Scale Adaptation of Global Trackers for Infrared UAV Tracking. Drones. 2025; 9(7):469. https://doi.org/10.3390/drones9070469
Chicago/Turabian StyleFeng, Zicheng, Wenlong Zhang, Erting Pan, Donghui Liu, and Qifeng Yu. 2025. "Enhancing the Scale Adaptation of Global Trackers for Infrared UAV Tracking" Drones 9, no. 7: 469. https://doi.org/10.3390/drones9070469
APA StyleFeng, Z., Zhang, W., Pan, E., Liu, D., & Yu, Q. (2025). Enhancing the Scale Adaptation of Global Trackers for Infrared UAV Tracking. Drones, 9(7), 469. https://doi.org/10.3390/drones9070469