


Toward High-Resolution UAV Imagery Open-Vocabulary Semantic Segmentation


Abstract
1. Introduction
- We propose a novel cost volume-based framework that effectively adapts CLIP to achieve high-resolution semantic segmentation. To our best knowledge, this is the first work designed for high-resolution UAV images for OVSS tasks.
- To strengthen the network’s perception ability to the high-resolution UAV images, we design the detail-enhanced encoder and detail-aware decoder, which aggregate multi-scale features to refine the segmentation results.
- We conduct extensive experiments to compare HR-Seg with existing OVSS methods. HR-Seg achieves the best performance, demonstrating the effectiveness of our method.
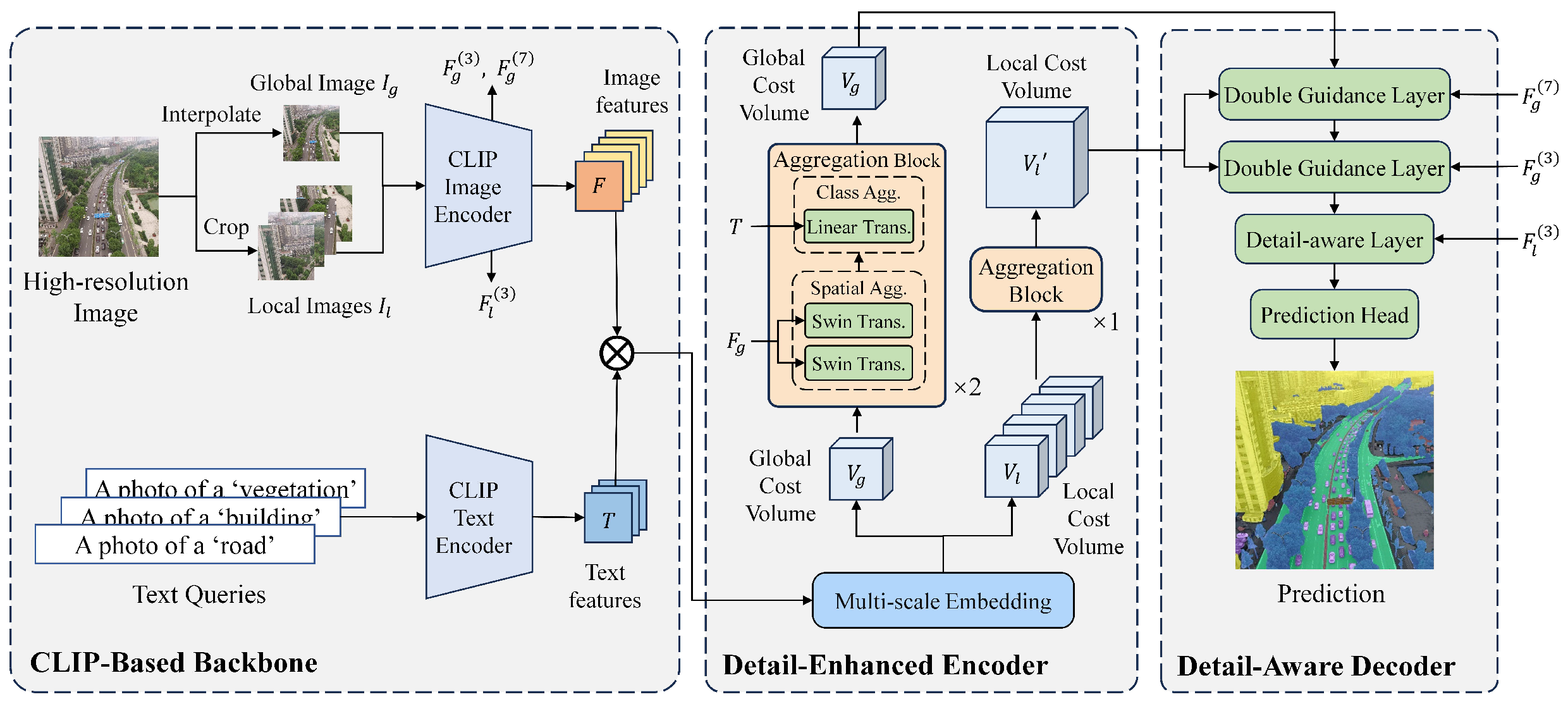
2. Method
2.1. Detail-Enhanced Encoder
2.1.1. Multi-Scale Embedding Block
2.1.2. Aggregation Block
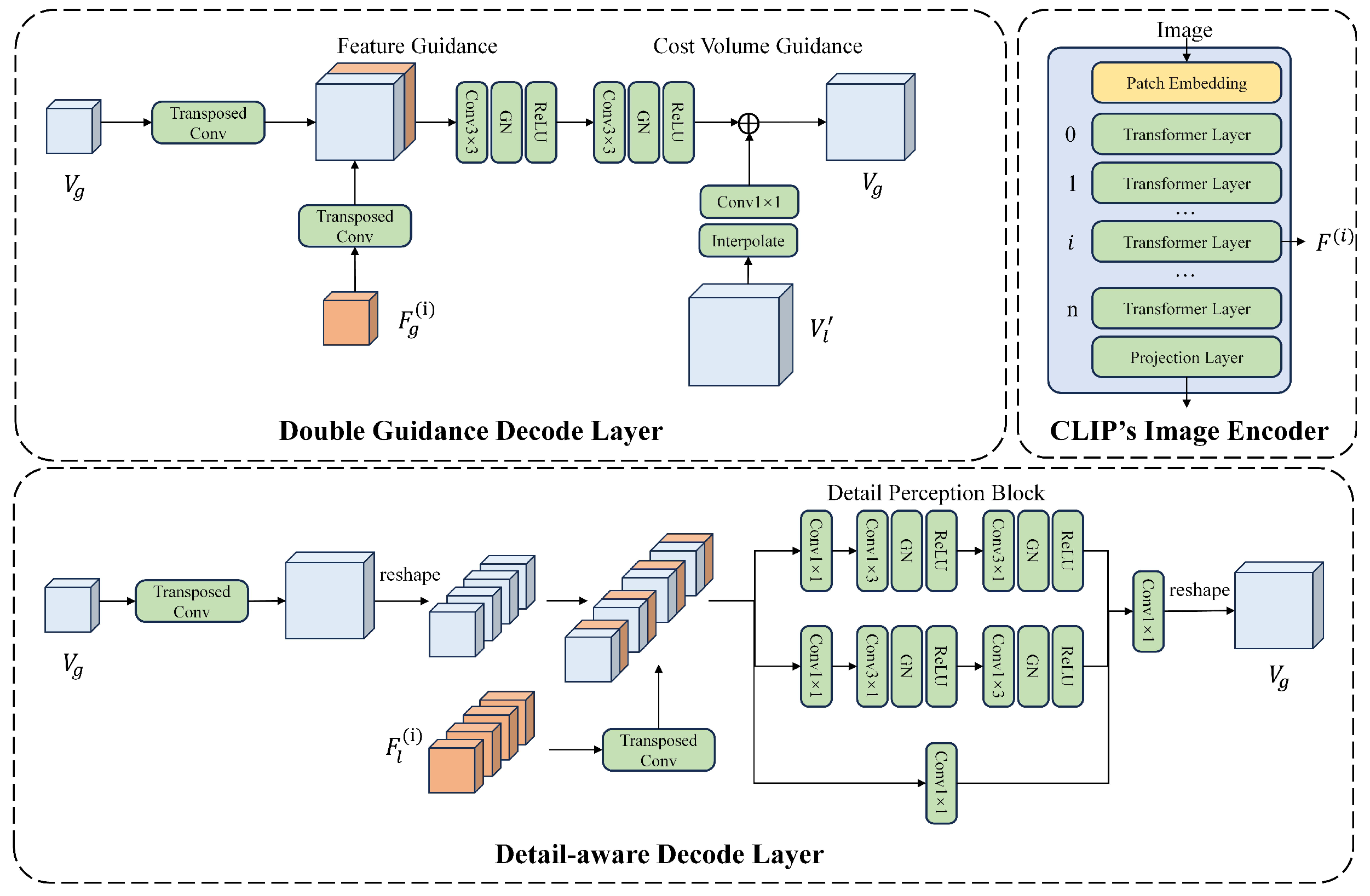
2.2. Detail-Aware Decoder
2.2.1. Double Guidance Decode Layer
2.2.2. Detail-Aware Decode Layer
3. Results and Discussion
3.1. Datasets and Evaluation Metrics
3.2. Implementation Details
3.3. Main Results
3.4. Ablation Studies
3.5. Error Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. More Evaluation Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| iSAID [33]: |
| “ship”, “storage tank”, “baseball diamond”, “tennis court”, “basketball court”, “Ground Track Field”, “Bridge”, “Large Vehicle”, “Small Vehicle”,“Helicopter”, “Swimming pool”, “Roundabout”, “Soccer ball field”, “plane”, “Harbor” |
| NightCity [34]: |
| “road”, “sidewalk”, “building”, “wall”, “fence”, “pole”, “traffic light”, “traffic sign”, “vegetation”, “terrain”, “sky”, “person”, “rider”, “car”, “truck”, “bus”, “train”, “motorcycle”, “bicycle” |
| Method | Image Size | iSAID [33] | NightCity [34] | ||
|---|---|---|---|---|---|
| mIoU | mACC | mIoU | mACC | ||
| SAN [18] | 640 × 640 | 10.31 | 21.86 | 4.96 | 13.27 |
| Cat-Seg [19] | 384 × 384 | 24.48 | 43.07 | 17.50 | 33.74 |
| SED [20] | 768 × 768 | 22.31 | 39.89 | 14.98 | 34.07 |
| GSnet [21] | 384 × 384 | 23.71 | 42.44 | 14.33 | 29.50 |
| Ebseg [30] | 640 × 640 | 15.65 | 29.05 | 6.01 | 14.80 |
| HR-Seg (ours) | 1152 × 1152 | 25.67 | 45.70 | 16.26 | 29.40 |




References
- Comba, L.; Biglia, A.; Sopegno, A.; Grella, M.; Dicembrini, E.; Ricauda Aimonino, D.; Gay, P. Convolutional Neural Network Based Detection of Chestnut Burrs in UAV Aerial Imagery. In AIIA 2022: Biosystems Engineering Towards the Green Deal; Ferro, V., Giordano, G., Orlando, S., Vallone, M., Cascone, G., Porto, S.M.C., Eds.; Springer International Publishing: Cham, Switzerland, 2023; pp. 501–508. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015, Proceedings, Part III 18; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Mu, Y.; Ou, L.; Chen, W.; Liu, T.; Gao, D. Superpixel-Based Graph Convolutional Network for UAV Forest Fire Image Segmentation. Drones 2024, 8, 142. [Google Scholar] [CrossRef]
- Huang, L.; Tan, J.; Chen, Z. Mamba-UAV-SegNet: A Multi-Scale Adaptive Feature Fusion Network for Real-Time Semantic Segmentation of UAV Aerial Imagery. Drones 2024, 8, 671. [Google Scholar] [CrossRef]
- Zhang, W.; Li, M.; Wang, H. Mamba: A Flexible Framework for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1234–1245. [Google Scholar]
- Xian, Y.; Choudhury, S.; He, Y.; Schiele, B.; Akata, Z. Semantic Projection Network for Zero- and Few-Label Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8248–8257. [Google Scholar]
- Bucher, M.; Vu, T.-H.; Cord, M.; Pérez, P. Zero-shot semantic segmentation. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 466–477. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.-T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.-H.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Zhou, C.; Loy, C.C.; Dai, B. Extract free dense labels from clip. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 696–712. [Google Scholar]
- Li, B.; Weinberger, K.Q.; Belongie, S.; Koltun, V.; Ranftl, R. Language-driven semantic segmentation. arXiv 2022, arXiv:2201.03546. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision Transformers for Dense Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12179–12188. [Google Scholar]
- Li, B.; Wu, F.; Weinberger, K.Q.; Belongie, S. Positional Normalization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 1620–1632. [Google Scholar]
- Xu, M.; Zhang, Z.; Wei, F.; Lin, Y.; Cao, Y.; Hu, H.; Bai, X. A Simple Baseline for Open-Vocabulary Semantic Segmentation with Pre-Trained Vision-Language Model. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 736–753. [Google Scholar]
- Ding, J.; Xue, N.; Xia, G.-S.; Dai, D. Decoupling zero-shot semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11583–11592. [Google Scholar]
- Liang, F.; Wu, B.; Dai, X.; Li, K.; Zhao, Y.; Zhang, H.; Zhang, P.; Vajda, P.; Marculescu, D. Open-vocabulary semantic segmentation with mask-adapted clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7061–7070. [Google Scholar]
- Zhou, Z.; Lei, Y.; Zhang, B.; Liu, L.; Liu, Y. Zegclip: Towards Adapting Clip for Zero-Shot Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 11175–11185. [Google Scholar]
- Xu, M.; Zhang, Z.; Wei, F.; Hu, H.; Bai, X. Side adapter network for open-vocabulary semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 2945–2954. [Google Scholar]
- Cho, S.; Shin, H.; Hong, S.; Arnab, A.; Seo, P.H.; Kim, S. Cat-seg: Cost aggregation for open-vocabulary semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 4113–4123. [Google Scholar]
- Xie, B.; Cao, J.; Xie, J.; Khan, F.S.; Pang, Y. SED: A Simple Encoder-Decoder for Open-Vocabulary Semantic Segmentation. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 3426–3436. [Google Scholar]
- Ye, C.; Zhuge, Y.; Zhang, P. Towards open-vocabulary remote sensing image semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Edmonton, AB, Canada, 10–14 November 2025; Volume 39, pp. 9436–9444. [Google Scholar]
- Cao, Q.; Chen, Y.; Ma, C.; Yang, X. Open-vocabulary remote sensing image semantic segmentation. arXiv 2024, arXiv:2409.07683. [Google Scholar]
- Li, K.; Liu, R.; Cao, X.; Bai, X.; Zhou, F.; Meng, D.; Wang, Z. Segearth-ov: Towards training-free open-vocabulary segmentation for remote sensing images. arXiv 2024, arXiv:2410.01768. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-attention with linear complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar]
- Chen, Y.; Wang, Y.; Lu, P.; Chen, Y.; Wang, G. Large-Scale Structure from Motion with Semantic Constraints of Aerial Images; Springer International Publishing: Cham, Switzerland, 2018; pp. 347–359. [Google Scholar]
- Cai, W.; Jin, K.; Hou, J.; Guo, C.; Wu, L.; Yang, W. Vdd: Varied drone dataset for semantic segmentation. J. Vis. Commun. Image Represent. 2025, 109, 104429. [Google Scholar] [CrossRef]
- Lyu, Y.; Vosselman, G.; Xia, G.-S.; Yilmaz, A.; Yang, M.Y. UAVid: A semantic segmentation dataset for UAV imagery. ISPRS J. Photogramm. Remote Sens. 2020, 165, 108–119. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Shan, X.; Wu, D.; Zhu, G.; Shao, Y.; Sang, N.; Gao, C. Open-vocabulary semantic segmentation with image embedding balancing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 28412–28421. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment Anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; pp. 4015–4026. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- Zamir, S.W.; Arora, A.; Gupta, A.; Khan, S.; Sun, G.; Khan, F.S.; Zhu, F.; Shao, L.; Xia, G.-S.; Bai, X. iSAID: A Large-Scale Dataset for Instance Segmentation in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 28–37. [Google Scholar]
- Tan, X.; Xu, K.; Cao, Y.; Zhang, Y.; Ma, L.; Lau, R.W.H. Night-Time Scene Parsing with a Large Real Dataset. IEEE Trans. Image Process. 2021, 30, 9085–9098. [Google Scholar] [CrossRef] [PubMed]


| Evaluation on VDD [27] | ||||||||||
| Method | ClIP Variant | Image Size | mIoU | mACC | IoU | |||||
| wall | road | veg. | vehicle | roof | water | |||||
| SAN [18] | ViT-B/16 | 640 × 640 | 86.28 | 91.38 | 70.83 | 87.11 | 96.64 | 69.98 | 94.76 | 98.36 |
| Cat-Seg [19] | ViT-B/16 | 384 × 384 | 88.08 | 93.77 | 75.46 | 88.64 | 97.15 | 73.45 | 95.36 | 98.40 |
| SED [20] | ConvNeXt-B | 768 × 768 | 88.19 | 93.84 | 76.40 | 88.73 | 97.21 | 72.84 | 95.70 | 98.26 |
| GSnet [21] | ViT-B/16 | 384 × 384 | 88.16 | 93.38 | 75.61 | 89.43 | 97.39 | 72.74 | 95.46 | 98.34 |
| Ebseg [30] | ViT-B/16 | 640 × 640 | 88.45 | 92.43 | 74.61 | 89.10 | 97.28 | 75.34 | 95.59 | 98.76 |
| HR-Seg | ViT-B/16 | 1152 × 1152 | 89.38 | 93.81 | 76.58 | 90.75 | 97.74 | 76.42 | 95.88 | 98.89 |
| Evaluation on UDD5 [26] | ||||||||||
| Method | ClIP Variant | Image Size | mIoU | mACC | IoU | |||||
| veg. | building * | road | vehicle | |||||||
| SAN [18] | ViT-B/16 | 640 × 640 | 63.72 | 73.01 | 85.37 | 83.47 | 44.37 | 41.70 | ||
| Cat-Seg [19] | ViT-B/16 | 384 × 384 | 59.07 | 79.81 | 75.80 | 80.86 | 53.11 | 26.49 | ||
| SED [20] | ConvNeXt-B | 768 × 768 | 64.53 | 83.05 | 88.48 | 90.05 | 62.51 | 17.07 | ||
| GSnet [21] | ViT-B/16 | 384 × 384 | 59.31 | 81.63 | 81.67 | 83.34 | 56.45 | 15.77 | ||
| Ebseg [30] | ViT-B/16 | 640 × 640 | 67.16 | 82.36 | 83.94 | 88.14 | 65.03 | 31.51 | ||
| HR-Seg | ViT-B/16 | 1152 × 1152 | 73.67 | 86.24 | 87.68 | 92.63 | 67.35 | 47.03 | ||
| Evaluation on UAVid [28] | ||||||||||
| Method | ClIP Variant | Image Size | mIoU | mACC | IoU | |||||
| road | building * | tree * | low veg. * | car * | human * | |||||
| SAN [18] | ViT-B/16 | 640 × 640 | 32.82 | 51.84 | 43.62 | 63.27 | 11.69 | 34.99 | 43.34 | 0.00 |
| Cat-Seg [19] | ViT-B/16 | 384 × 384 | 48.80 | 62.98 | 72.15 | 79.87 | 45.98 | 47.79 | 46.67 | 0.36 |
| SED [20] | ConvNeXt-B | 768 × 768 | 40.20 | 54.92 | 73.99 | 89.66 | 0.71 | 34.46 | 41.73 | 0.67 |
| GSnet [21] | ViT-B/16 | 384 × 384 | 41.94 | 59.00 | 72.21 | 80.84 | 15.61 | 37.07 | 45.61 | 0.30 |
| Ebseg [30] | ViT-B/16 | 640 × 640 | 50.76 | 64.17 | 72.52 | 86.32 | 43.95 | 45.24 | 56.54 | 0.00 |
| HR-Seg | ViT-B/16 | 1152 × 1152 | 55.23 | 67.04 | 74.59 | 90.57 | 57.52 | 52.21 | 53.39 | 3.09 |
| Input Size | GPU Memory | Inference Speed | mIoU | ||
|---|---|---|---|---|---|
| VDD | UDD5 | UAVid | |||
| 7809 M | 0.07 s | 85.66 | 55.71 | 37.54 | |
| 15,451 M | 0.13 s | 89.38 | 73.67 | 55.23 | |
| 20,103 M | 0.23 s | 89.07 | 72.93 | 52.63 |
| Method | Additional Backbone | Image Size | Parameters | GPU Memory | Inference Speed |
|---|---|---|---|---|---|
| SAN [18] | - | 640 × 640 | 157.84 M | 11,621 M | 0.04 s |
| Cat-Seg [19] | - | 384 × 384 | 154.29 M | 8535 M | 0.11 s |
| SED [20] | - | 768 × 768 | 180.76 M | 2403 M | 0.02 s |
| GSnet [21] | DINO [32] | 384 × 384 | 243.99 M | 9581 M | 0.26 s |
| Ebseg [30] | SAM [31] | 640 × 640 | 261.83 M | 14,511 M | 0.15 s |
| HR-Seg (ours) | - | 1152 × 1152 | 155.89 M | 15,451 M | 0.12s |
| Method | Image Size | Fusion Method | Components | mIoU | |||||
|---|---|---|---|---|---|---|---|---|---|
| MSEB | DEE | DGL | DAL | VDD | UDD5 | UAVid | |||
| Cat-Seg [19] | 384 × 384 | - | - | - | - | - | 88.08 | 59.07 | 48.80 |
| Cat-Seg* [19] | 768 × 768 | - | - | - | - | - | 88.18 | 50.41 | 42.46 |
| Baseline | 384 × 384 | - | 83.98 | 60.49 | 47.92 | ||||
| A | 384 × 384 | - | ✓ | 84.24 | 58.87 | 47.14 | |||
| B | 1152 × 1152 | CVF | ✓ | 87.95 | 70.16 | 49.99 | |||
| C | 1152 × 1152 | CVF | ✓ | ✓ | 88.32 | 71.48 | 51.97 | ||
| D | 1152 × 1152 | CVF | ✓ | ✓ | 88.41 | 70.70 | 50.32 | ||
| E | 1152 × 1152 | FF | ✓ | ✓ | 90.37 | 67.86 | 49.42 | ||
| F | 1152 × 1152 | CVF | ✓ | ✓ | ✓ | 89.55 | 70.60 | 54.81 | |
| G | 1152 × 1152 | CVF | ✓ | ✓ | ✓ | ✓ | 89.38 | 73.67 | 55.23 |
| Number of Blocks | mIoU | |||
|---|---|---|---|---|
| Global Aggregation Branch | Local Aggregation Branch | VDD | UDD5 | UAVid |
| 1 | 1 | 89.42 | 71.11 | 54.10 |
| 2 | 89.46 | 71.94 | 54.16 | |
| 3 | 89.37 | 73.79 | 51.72 | |
| 2 | 1 | 89.38 | 73.67 | 55.23 |
| 2 | 89.38 | 72.93 | 52.91 | |
| 3 | 89.43 | 72.62 | 53.79 | |
| 3 | 1 | 89.43 | 72.44 | 54.65 |
| 2 | 89.66 | 71.50 | 52.80 | |
| 3 | 89.22 | 72.35 | 52.61 | |
| Kernel Combination | mIoU | |||||
|---|---|---|---|---|---|---|
| 7 × 7 | 5 × 5 | 3 × 3 | 1 × 1 | VDD | UDD5 | UAVid |
| ✓ | 89.55 | 70.60 | 54.81 | |||
| ✓ | 89.39 | 69.17 | 54.05 | |||
| ✓ | 89.54 | 73.28 | 53.42 | |||
| ✓ | 89.34 | 73.19 | 52.75 | |||
| ✓ | ✓ | 89.46 | 72.93 | 55.10 | ||
| ✓ | ✓ | 89.51 | 71.43 | 55.13 | ||
| ✓ | ✓ | 89.45 | 72.63 | 54.75 | ||
| ✓ | ✓ | 89.36 | 71.79 | 53.76 | ||
| ✓ | ✓ | 89.57 | 71.58 | 53.99 | ||
| ✓ | ✓ | 89.65 | 73.53 | 54.93 | ||
| ✓ | ✓ | ✓ | ✓ | 89.38 | 73.67 | 55.23 |
| Decode Component | mIoU | |||
|---|---|---|---|---|
| Double guidance decode layer | Detail-aware decode layer | VDD | UDD5 | UAVid |
| double convolution layer | double convolution layer | 89.62 | 72.89 | 54.81 |
| double convolution layer | detail perception block | 89.38 | 73.67 | 55.23 |
| detail perception block | detail perception block | 89.42 | 71.06 | 54.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Xie, Y.; Wei, Y. Toward High-Resolution UAV Imagery Open-Vocabulary Semantic Segmentation. Drones 2025, 9, 470. https://doi.org/10.3390/drones9070470
Chen Z, Xie Y, Wei Y. Toward High-Resolution UAV Imagery Open-Vocabulary Semantic Segmentation. Drones. 2025; 9(7):470. https://doi.org/10.3390/drones9070470
Chicago/Turabian StyleChen, Zimo, Yuxiang Xie, and Yingmei Wei. 2025. "Toward High-Resolution UAV Imagery Open-Vocabulary Semantic Segmentation" Drones 9, no. 7: 470. https://doi.org/10.3390/drones9070470
APA StyleChen, Z., Xie, Y., & Wei, Y. (2025). Toward High-Resolution UAV Imagery Open-Vocabulary Semantic Segmentation. Drones, 9(7), 470. https://doi.org/10.3390/drones9070470