1. Introduction
Unmanned Underwater Vehicles (UUVs) are widely utilized in diverse fields, such as oceanic exploration, environmental surveillance, underwater rescue missions, and military applications. The enhancement of their autonomy and cooperative capabilities is crucial for the efficiency of underwater missions [
1,
2,
3,
4]. In multi-UUV systems, efficient task allocation and path planning are essential not only for the performance of individual units, but also for ensuring global system optimization and high-quality task execution. However, the underwater environment is complex and variable, with challenges such as limited communication conditions and dynamic environmental disturbances, which impose higher demands on the cooperative capabilities of UUVs [
5,
6]. Therefore, researching efficient methods for task allocation and path planning is of significant theoretical value and engineering importance for improving the autonomous collaborative capabilities of UUVs and enhancing mission execution reliability.
In task allocation for UUV mission planning, conventional methods involve the Hungarian algorithm and centralized linear programming techniques. Recently, with the rapid development of swarm intelligence optimization algorithms and neural network techniques, researchers have increasingly introduced intelligent optimization theories to provide new solutions for swarm task allocation. For instance, Wu et al. put forward a dynamic expanding consensus bundle algorithm based on a consensus algorithm. Extensive results demonstrated that this approach enables fast and efficient conflict-free dynamic task allocation for UUVs [
7]. Yu et al. addressed the challenges of target search under limited underwater communication and dynamic environmental changes by proposing a cooperative search task planning method for UUVs based on modified k-means clustering and a dynamic consensus-based bundle algorithm (DCBBA-TICC) [
8]. This method evaluates the reliability of acoustic communication links using the frame error rate and optimizes communication relay positions using the particle swarm optimization (PSO) algorithm. Li et al. introduced a multi-objective bi-level task planning approach to address the issue of dispatching UUVs to visit a series of targets [
9]. Simulated annealing and a genetic algorithm were utilized to optimize task allocation and path planning simultaneously. However, as the number of UUVs increases, it becomes challenging to address load balancing between different levels. Yang et al. modeled the task of detecting potential underwater threats as a traveling salesman problem (TSP) with specified starting and ending points, and applied the ant colony optimization (ACO) algorithm to find a solution [
10]. However, this approach did not fully consider complicated obstacles in UUV motion planning. To improve task efficiency and quality, Li et al. proposed a balanced task planning strategy for multi-route patrol and detection missions, aiming to reduce mission time while enhancing task performance [
11].
Path planning aims to generate a short, safe, and feasible trajectory for unmanned underwater vehicles (UUVs) to reach their target locations [
12,
13]. To mitigate the effect of navigation errors on UUV path planning, Ma et al. introduced a hybrid approach combining quantum principles with particle swarm optimization [
14]. This approach considers navigation errors and generates a time-optimal and safe trajectory, effectively mitigating the adverse effects of navigation inaccuracies. Li et al. proposed a combined strategy that merges an enhanced A* path planning algorithm with model predictive control (MPC) [
15]. This method integrates path planning with trajectory tracking, greatly enhancing the real-time path planning performance of UUVs. Yu et al. proposed a cylinder-heuristic rapidly exploring random tree (termed Cyl-HRRT*) algorithm [
16]. This approach enhances the likelihood of sampling feasible states by biasing the search toward cylindrical subsets, thereby yielding more optimal paths for autonomous underwater vehicles (AUVs). To solve the problem of three-dimensional path planning for UUVs, Chen et al. proposed a hybrid algorithm that combines particle swarm optimization with ant colony optimization (PSO-ACO) [
17]. Li et al. developed the PQ-RRT* algorithm (Potential-Quick Rapidly-exploring Random Tree Star) to overcome the challenges of path planning for UUVs in complicated environments [
18]. Experimental results show that this algorithm improves the convergence speed and path quality of UUV path planning, and effectively balances the efficiency and optimality of search. Experimental results show that this combined approach improves the global search efficiency and reduces search time. In recent years, deep reinforcement learning has shown unique advantages in path planning due to its autonomous learning and decision-making optimization capabilities [
19,
20,
21]. For instance, Wang et al. addressed issues such as large oscillations and low learning efficiency in traditional actor-critic reinforcement learning algorithms during the initial training phases, and put forward a multi-actor-critic reinforcement learning approach for path planning of AUVs [
21]. The simulation results demonstrate that the proposed method enhances adaptive learning capabilities in dynamic scenarios and increases the effectiveness of AUV obstacle avoidance.
Motivated by the above work, we put forward a task allocation and path planning approach for UUVs. By integrating an Improved Grey Wolf Algorithm (IGWA) into the task allocation process, the proposed approach enhances the efficiency of UUVs in reaching their target locations. Furthermore, an improved GR-RRT* algorithm is introduced to address path planning challenges in complicated underwater environments. The simulation results confirm the effectiveness and flexibility of the proposed method. The key contributions of our work are as follows:
An Improved Grey Wolf Optimization (IGWA) algorithm is proposed for task allocation in multi-UUV systems, providing an optimized foundation for subsequent path planning.
We introduce a circle chaotic mapping mechanism into the GWA method to mitigate the issue of uneven initial population distribution. Additionally, a differential evolution mechanism is incorporated to enhance local search capability and prevent premature convergence.
A modified RRT*-based path planning algorithm is developed, featuring a goal-guided sampling strategy that ensures obstacle avoidance while reducing excessive sampling, thereby improving planning efficiency.
The structure of the paper is as follows: In
Section 2, the scenario tasks are briefly introduced and a simulation environment model is established. In
Section 3, the improved task allocation method and path planning algorithm are introduced. In
Section 4, the simulation results under various simulation environments and the real boat experimental results are analyzed. Finally, a summary is given in
Section 5.
3. Task Allocation Approach for UUVs
The problem of assigning tasks to UUVs can be characterized as follows: Within a specified mission context, numerous UUVs having distinct performance attributes are delegated to carry out various tasks. At the same time, it is essential to make sure that every task is carried out by a UUV. Meanwhile, it must be ensured that each task is executed by a UUV. Nevertheless, in the actual task allocation process, some factors will affect the allocation results, such as the ocean environment, path cost, task success rate and UUV damage probability. Thus, it is essential to develop an optimization model for task allocation to ensure an efficient allocation solution. In this way, it ensures that each UUV is allocated an appropriate target, thereby maximizing the overall benefits and minimizing the operational costs for the entire UUVs. Drawing inspiration from the hunting behavior of wolves, we employ the GWA algorithm to allocate tasks for UUVs, aiming to derive the optimal task distribution solution.
Specifically, we use a five-tuple model to construct the task allocation model. In this model, T represents the task set, U represents the UUV set, C represents the constraints in task allocation, O represents the objective function in task allocation, and E represents the marine environmental factors. In order to ensure that each UUV can achieve efficient allocation efficiency, the following aspects need to be comprehensively considered during the task allocation process to ensure the flexibility and feasibility of the assigned tasks.
3.1. Constraints
In terms of AUV task distribution, it is necessary to ensure that each task is executed by only one UUV, and each UUV is assigned one task. Assuming
M UUVs and
N targets, the constraint can be mathematically formulated as follows:
In Formula (1),
represents a binary decision variable, indicating whether
is assigned to perform the task. If
, it means that
is assigned to perform the task, and if
, it means that UUV
i is not assigned to perform the task. Formula (2) represents the UUV and target allocation result.
3.2. Target Benefit
In UUV task allocation, target utility computation serves as a fundamental metric for assessing the effectiveness of the allocation strategy. This utility not only includes the direct result of the task but also embodies task execution efficiency and the optimal allocation of resources. Given the differences in the performance of each UUV, the success probability and benefits of the same task will be different when it is performed by different unmanned boats. Assume that
represents the probability that the UUV
completes the task target
, and
represents the benefit that the
can obtain by executing the task target
. Moreover,
represents the value of UUV, and
represents the value of the target. The value of UUV lies mainly in its ability to perform tasks, while the target value quantifies the priority of the task goals and the demand for resource allocation. Therefore, the total task benefit function of all UUVs can be expressed as:
where
,
, and
are normalized weight coefficients.
3.3. Comprehensive Loss
In the process of UUVs performing mission objectives, they can not only obtain benefits, but also incur certain damage costs, which mainly include the range cost, damage cost, and resource cost. However, to simplify the complexity of the model in this work, the time cost and damage cost are not taken into consideration. This study only focuses on the range cost and environmental cost incurred by a UUV when performing different tasks.
Specifically, the UUV’s voyage cost can be understood as the UUV’s navigation loss caused by the complex environment, which is determined by the total distance from the UUV to the target. We adopt the Euclidean distance between two points to approximate the voyage between them.
i is the UUV number,
j is the target number, and the voyage cost function is expressed as:
In addition, the environmental cost indicates that in the actual mission execution process, marine environmenta factors will affect the navigation of the UUV to a certain extent, and the fixed cost calculation formula may be too idealized and difficult to generalize to the real mission scenario. Therefore, in order to simulate the uncertainty in the actual mission execution, it is necessary to add noise to simulate the random disturbance in reality, so that the task allocation is more robust, thereby improving the feasibility of the algorithm in real applications. Environmental impacts on the UUV are simulated by adding noise characterized by a normal distribution, and the environmental cost function is expressed as:
where
and
=50.
Based on the above functions for different cost costs, we design the cost function for the multi-UUV task allocation problem as follows:
where
and
are normalized weight coefficients.
3.4. Objective Function
When assigning UUVs to target tasks, the goal is to lay a solid foundation for subsequent path planning, with the allocation strategy comprehensively considering multiple factors. On one hand, it is crucial to minimize the loss value, ensuring that the wear and tear on UUVs during task execution is kept to a minimum. On the other hand, the strategy should emphasize maximizing the benefit value to ensure the effectiveness of the allocation scheme. Therefore, the allocation process requires a strategy that balances both loss and benefit, aiming to minimize the cost incurred during the approach phase. The specific formulation of the objective function
F is described as follows:
It should be emphasized that task allocation and path planning are closely interconnected rather than independent processes. The designated target location for a UUV directly influences the difficulty of its path planning, while the feasibility of the planned path should also be considered during task assignment.
The influence of task allocation on path planning: If a UUV is assigned to a target that is far from its initial position and surrounded by obstacles, it may lead to an increase in the time consumption of path planning or a deterioration in the quality of the path. Therefore, in the objective function of task allocation, in addition to considering the target value and distance, the pre-assessment indicators of path planning can be implicitly introduced as constraints.
Path planning feedback on task allocation: For certain targets for which it is difficult to plan feasible paths, the task allocation needs to be adjusted, and they should be assigned to UUVs with stronger obstacle avoidance capabilities or better initial positions.
Although the IGWA algorithm in this paper indirectly considers some spatial factors by integrating the cost function, an explicit linkage mechanism between task allocation and path planning has not yet been established. The in-depth modeling of this coupling relationship will be an important direction for future research. For example, by constructing a joint optimization framework, the difficulty of path planning can be predicted during the task allocation stage, and the allocation strategy can be dynamically adjusted to achieve global collaborative optimization.
3.5. Improved Grey Wolf Algorithm
The Grey Wolf Algorithm (GWA) [
22] is a swarm intelligence optimization method inspired by the cooperative behavior of grey wolves during hunting. To further strengthen its ability to achieve the global optimal solution, the algorithm requires continued refinement and improvement. Therefore, we improved the Grey Wolf Algorithm from two key aspects. First, we replace the original random initialization of the wolf group method with initialization using Circle chaotic mapping [
23]. Compared with random number generation, chaotic mapping shows superior characteristics in the optimization search process, especially in solving the global optimal solution problem. The advantage of chaotic mapping is that it can fully cover the search space to avoid missing potential solution areas, effectively avoid local optimal traps to expand the scope of solution space exploration. At the same time, this mechanism maintains the optimization direction to a certain extent, thereby accelerating the convergence process of the algorithm.
Specifically, the expression formula of Circle mapping is as follows:
where
denotes the state variable of the current iteration,
denotes the state variable of the next iteration,
and
are control parameters.
In the realm of differential evolution and related optimization algorithms, parameter selection is of the utmost importance. The parameter a in the Circle mapping formula plays a crucial role in determining the basic step—like movement of the state variable from one iteration to the next. A value of provides a moderate offset that helps in balancing global exploration. It is large enough to encourage the algorithm to explore new regions of the search space, yet not so large as to cause erratic and unproductive jumps.
Parameter b influences the oscillatory component of the mapping through its role in the function term. This relatively small value means that the sinusoidal perturbation has a subdued impact. It allows for a gentle modulation of the state variable’s progression, facilitating local exploitation. By choosing , the algorithm can fine-tune its search around promising areas while still maintaining enough randomness to avoid becoming trapped in local optima. Overall, these parameter values work in tandem to enhance the algorithm’s ability to balance exploration and exploitation, improving its effectiveness in optimization tasks.
Although the current parameter configuration has achieved performance improvement through empirical methods, the quantitative impact of these parameters on population diversity and convergence speed is still not fully clear. Therefore, it is planned to design orthogonal experiments in subsequent work to provide a theoretical basis for the adaptive parameter adjustment of the algorithm in different task scenarios.
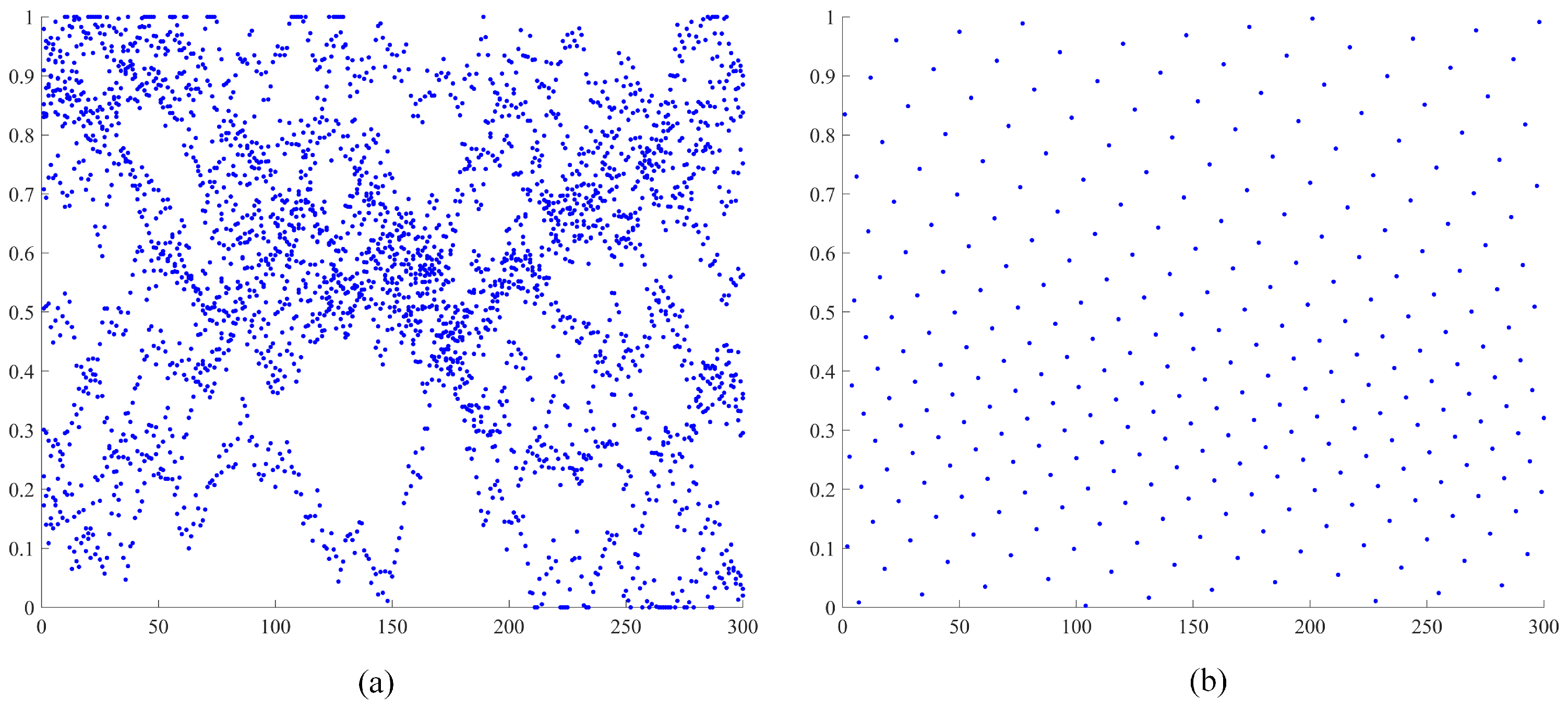
As illustrated in
Figure 2, the traditional Grey Wolf Algorithm relies on random initialization of the wolf pack, which may lead to uneven distribution of initial individuals, potentially limiting the algorithm’s global search capability. By incorporating Circle chaotic mapping during initialization, a more diverse and evenly distributed initial population is generated, enhancing both the algorithm’s global exploration ability and optimization efficiency.
In the position update process of the Grey Wolf Optimization Algorithm, individuals with lower fitness continue to follow the original update mechanism, while those with higher fitness are updated using the differential evolution strategy (randk). This approach helps balance the algorithm’s global exploration and local exploitation capabilities, ultimately enhancing overall optimization performance. As a population-based global optimization method, differential evolution generates new candidate solutions through mutation and crossover operations, effectively improving the algorithm’s search depth. Specifically, the integration of differential evolution strengthens the Grey Wolf Optimization Algorithm through the following mutation and crossover mechanisms:
Mutation operation: Differential operations among individuals in the population introduce randomness, expand the search space, and enhance global exploration capability. In this way, it helps to solve the problem of grey wolves escaping from local optimality. As a key stage in the differential evolution algorithm, differential mutation generates new candidate solutions by utilizing individuals from the current population. It promotes information exchange among population members and guides the search process toward the global optimum. The specific operation is to randomly select three different individuals
,
,
and generate a new mutation vector
, which is expressed as follows:
where
F is the scaling factor, typically
.
Crossover operation: Crossover generates new candidate solutions by combining traits from multiple high-quality individuals, enhancing the algorithm’s local exploitation capability. This operation maintains diversity within the search space. The mutated individuals undergo crossover with the current population to produce candidate solutions. The crossover probability CR (
) determines whether the solution from the mutated individual is accepted, promoting a balance between exploration and exploitation. Binomial crossover is usually used to generate the vector
, which is described as follows:
In this context, CR stands for the crossover probability, which regulates the mixing proportion between the mutation vector and the original solution. The symbol
signifies the
jth dimensional component of the test vector created after crossover,
represents the
jth dimensional component of the mutation vector, and
indicates the value of the original individual in the
jth dimension.
4. Improved Path Planning Algorithm for UUVs
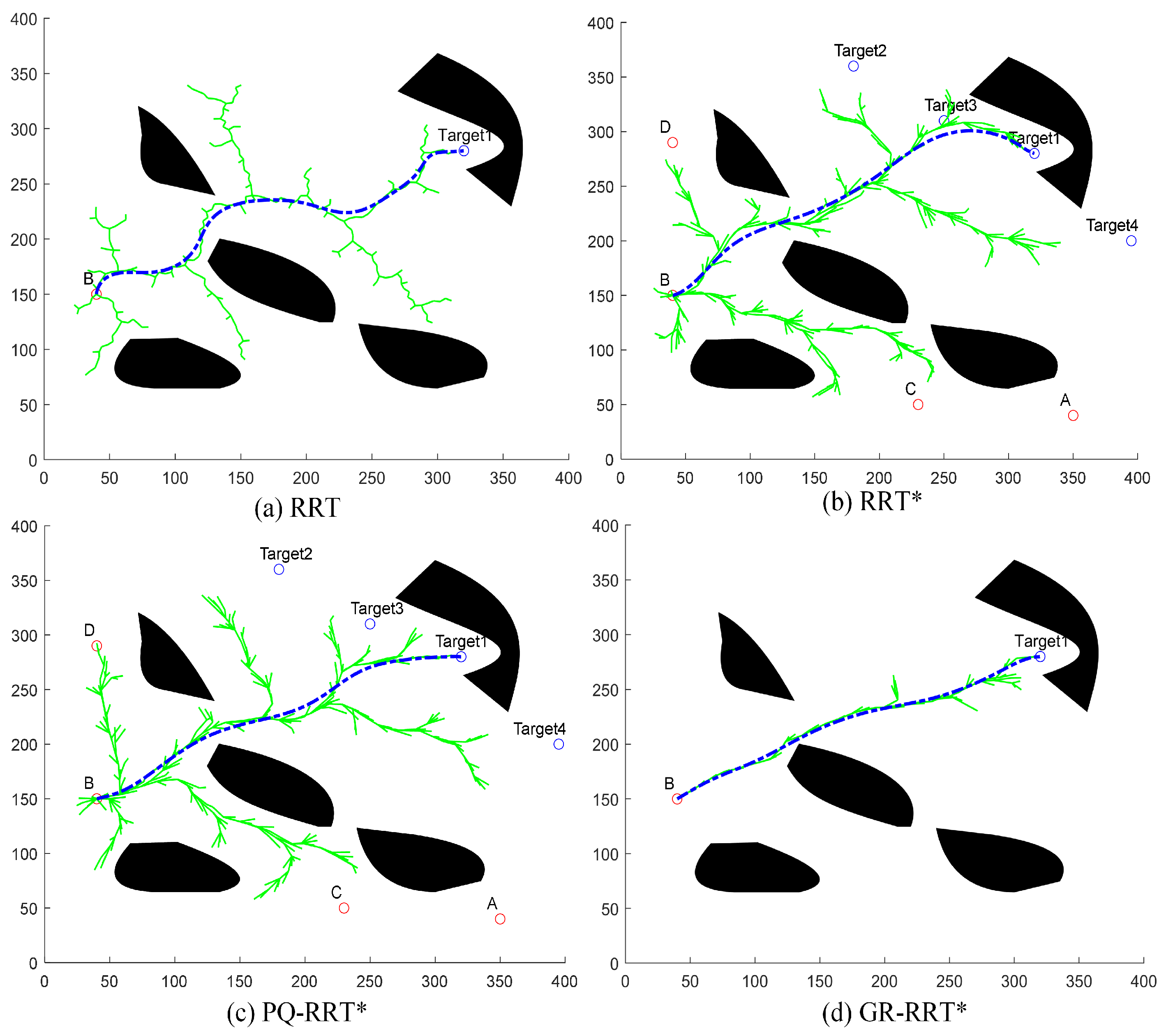
We propose an improved version of the RRT* algorithm in this section [
24], termed Goal-Region Guided RRT (GR-RRT*), designed to achieve more efficient path planning. Traditional RRT* algorithms generate sampling points uniformly across the entire map, ensuring global search coverage. However, the presence of numerous redundant points significantly reduces convergence efficiency. To address this issue, our algorithm introduces an innovative goal-oriented regional sampling strategy. Specifically, instead of distributing random sampling points uniformly across the entire space, sampling is restricted to a dynamically adjusted region around the target point, following a normal distribution. This approach effectively reduces the number of redundant samples and directs the search process toward the target region, enhancing convergence speed.
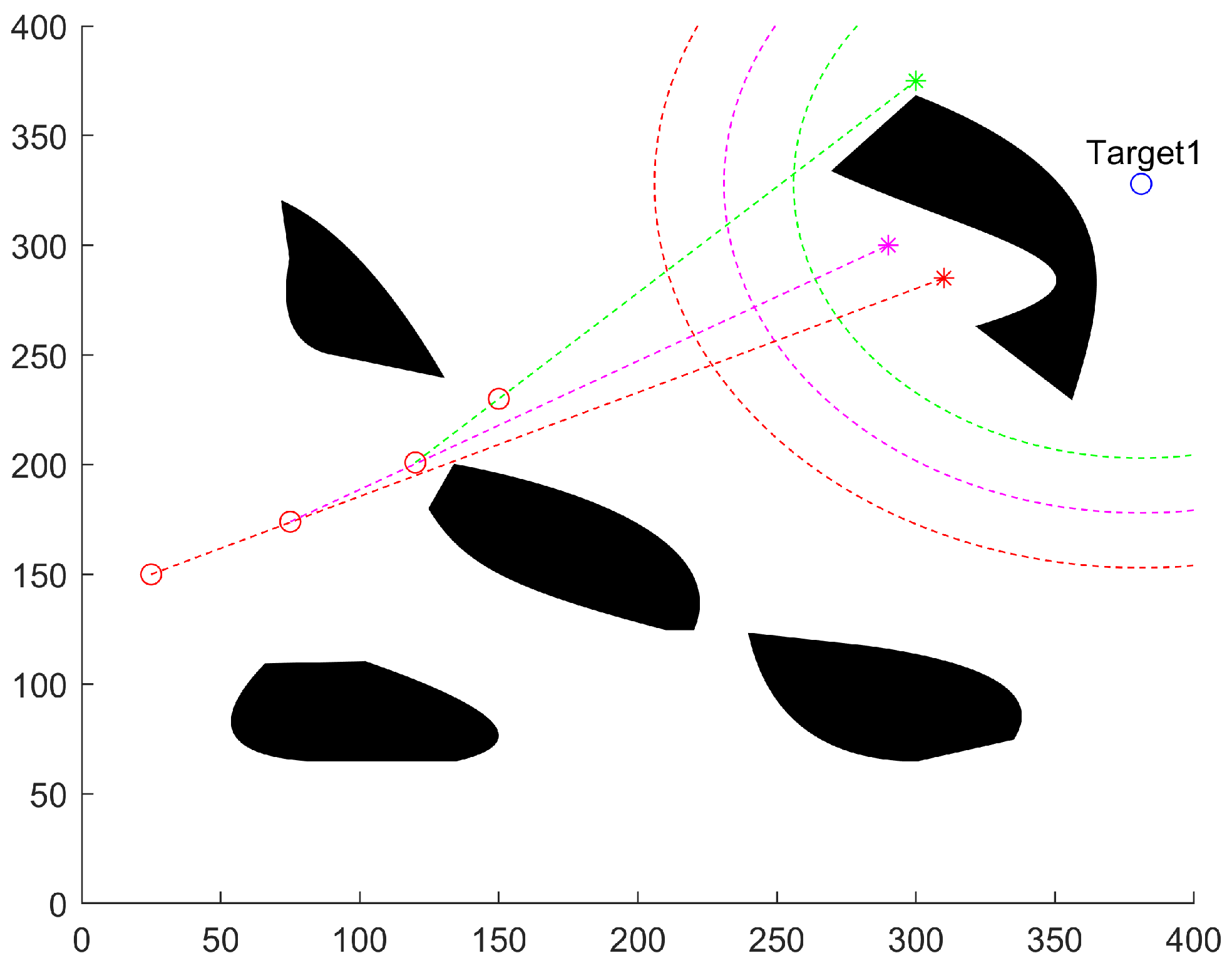
As illustrated in
Figure 3, the dynamic evolution of the sampling region can be observed through three sampling iterations. When the existing nodes are far from the target point, the sampling region remains relatively large to ensure the random tree explores the environment thoroughly, avoids obstacles, and prevents premature convergence to suboptimal paths. As nodes gradually approach the target, the sampling region contracts, accelerating fine-tuned exploration and final convergence. This adaptive sampling mechanism ensures a balance between exploration and exploitation, improving both search efficiency and path quality compared to traditional RRT* algorithms.
The research in this paper focuses on 2D UUV path planning, where the proposed algorithm generates random sampling points around the target point, modeled as a 2D normal distribution problem. If random variables follow a bivariate normal distribution, the probability density function is expressed as:
where
is the generation probability of the sampling point at
position in the map. The variances are
,
, and
(set to 0) is the correlation coefficient of two variables.
and
are the location information of the target point.
and
are related to the surrounding environment of the target point and the shortest distance from all nodes to the target point. In Formula (12),
represents the minimum distance from all the existing nodes to the target point,
is the distance from the starting point to the target point,
and
represent the initial variances. Their values are empirically determined, with adjustments made based on the surrounding environment of the target point. The initial variances should be set to ensure that the resulting high-probability region adequately covers obstacles near the target, facilitating effective exploration and improving path planning robustness.
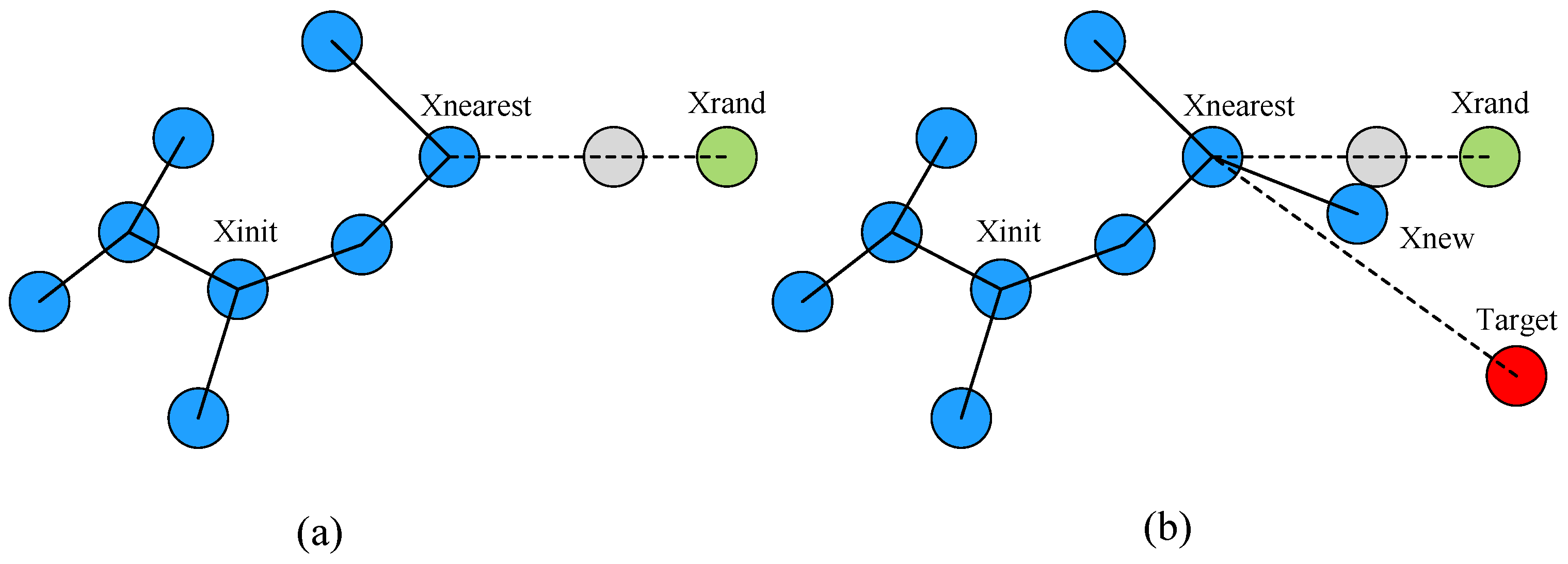
To address the limitations of traditional RRT* algorithms, which select the nearest node to the random sampling point and generate new nodes based solely on their positional relationship, we incorporate the concept of attractive potential from the Artificial Potential Field (APF) approach to improve planning efficiency.
In contrast to the traditional APF method, the enhanced GR-RRT* algorithm focuses solely on the gravitational effect of the target point, disregarding the repulsive influence of obstacles. This design can not only effectively avoid falling into the local minimum area or the problem of unreachable target during path planning, but also significantly accelerate the convergence speed of the algorithm. The conceptual diagram of this idea is shown in
Figure 4b, which clearly shows the guiding effect of the gravity of the target point on the direction of new node generation. By introducing this goal-oriented gravitational mechanism, the algorithm can significantly reduce redundant searches and improve overall planning efficiency while ensuring path quality.
Specifically, the new node calculation formula based on the above concept graph idea is as follows:
where
and
represent the location information of the new node, and
is the distance from the new node to
. As shown in Formula (14), when the distance
between the sampling point and its nearest point is longer than or equal to the fixed step size, the value of
L is the step size. On the contrary, the value of
L is
.
and
represent the angle between
and
, and
and
.
K is the migration parameter of the new node.
The pseudo-code of the algorithm GR-RRT* is shown in Algorithm 1, and the functions of some key functions are explained as follows:
RandPoint represents the sampling point generation function, which generates points around the target based on a bivariate normal distribution with a given initial variance;
Nearest represents the function that finds the node closest to the sampling point among all current nodes;
Newpoint represents the new node generation function, which generates a new node by incorporating the target’s attractive influence according to the node generation strategy;
CollisionFree represents the collision-checking function, which determines whether the newly generated node collides with any obstacles;
Near represents the neighboring node search function, which identifies nodes within a given radius
R around the new node;
ChooseParent represents the parent re-selection function, which selects the node with the lowest path cost among neighboring nodes as the new node’s parent;
Rewire represents the rewiring function, which updates the paths from other nodes to the new node to ensure all nodes maintain the minimum path cost; and
Distance represents the distance calculation function, which computes the Euclidean distance between two nodes.
| Algorithm 1 GR-RRT* algorithm (init, target, obstacle, ) |
- 1:
T.init(); - 2:
for to N do - 3:
if dynamic environment then - 4:
Obstacle handling; - 5:
end if - 6:
Randpoint(target, ); - 7:
; - 8:
Newpoint, target, K, StepSize); - 9:
if CollisionFree(obstacle, ) then - 10:
Near, Neighbor R); - 11:
ChooseParent; - 12:
T.addNode; - 13:
TRewire(T, ); - 14:
if , target error then - 15:
Success(); - 16:
T.addNode(target); - 17:
end if - 18:
end if - 19:
end for - 20:
Optimization; - 21:
return(T);
|
6. Conclusions
In this study, we propose an efficient task allocation and path planning approach specifically designed for UUVs. First, task allocation is optimized by considering factors such as the target value, distance, and UUV capability constraints, ensuring a rational and effective distribution of tasks across the UUVs. The Improved Grey Wolf Algorithm (IGWA) is used for task allocation, which combines circular chaotic mapping to increase population diversity and differential evolution mechanism. In this way, the overall efficiency of task allocation is improved. Second, for UUV path planning, an enhanced RRT* algorithm is employed. A guiding strategy is implemented, where the sampling probability near target points follows a variable two-dimensional Gaussian distribution, effectively reducing redundant sampling and improving planning efficiency.
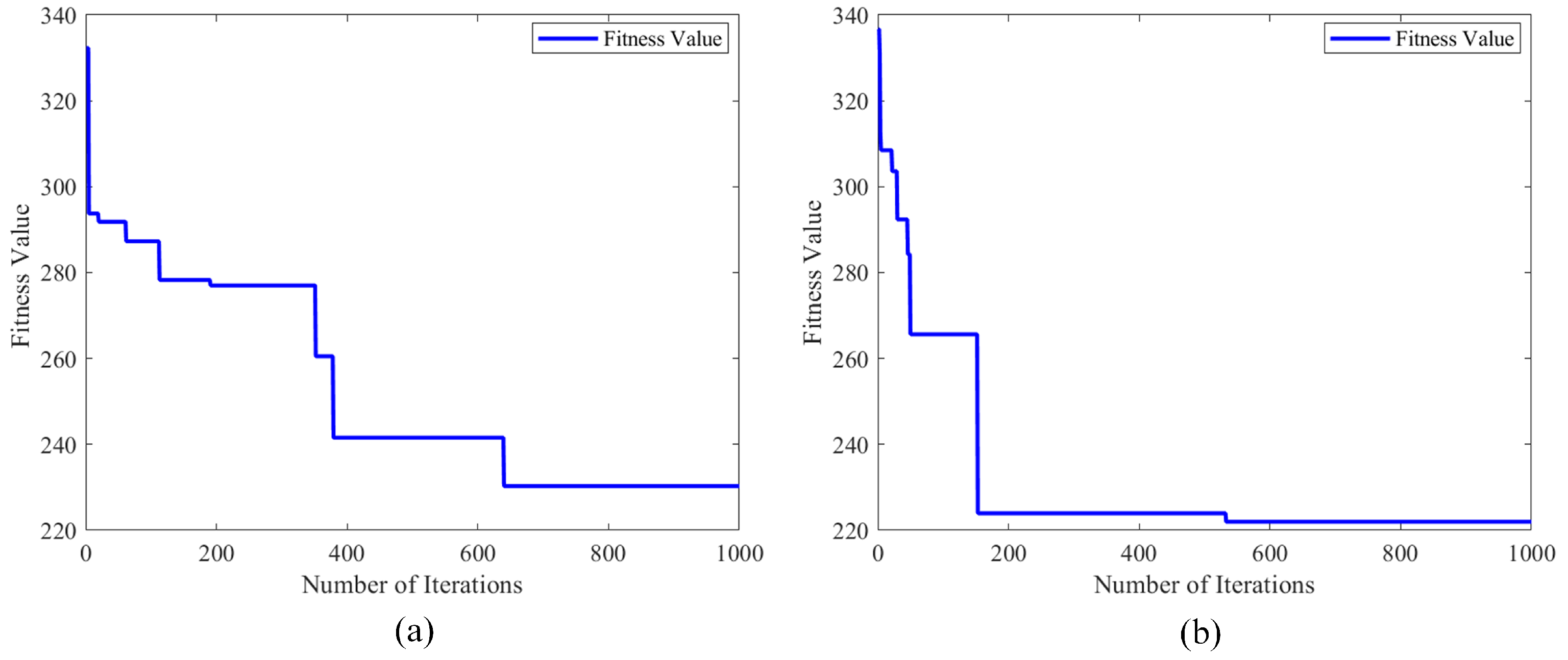
To evaluate the effectiveness of the proposed strategies, a series of simulation experiments were conducted. The results show: (1) The enhanced IGWA algorithm achieves dual optimization through the initialization of Circle chaotic mapping and the differential evolution mechanism; compared with the original GWA, its optimal fitness value decreased from 230.3 to 221.0, the average fitness value improved from 233.9 to 226.7, and the total cost of task allocation decreased by 7.2%. This indicates that integrating the Circle chaotic initialization and the differential evolution mechanism into GWA can significantly enhance its global optimization ability and convergence efficiency. (2) The improved GR-RRT* algorithm introduces a goal-oriented algorithm to alleviate the blind search behavior caused by purely random sampling in the traditional RRT algorithm. It breaks through the limitations of traditional RRT through the goal-guided two-dimensional Gaussian sampling strategy and the gravitational superposition mechanism, reducing the generation of redundant nodes by 58%. This enhancement not only significantly improves the path planning efficiency but also significantly shortens the overall path length.
However, our work has certain limitations. For example, it assumes that obstacles in the ocean environment are static. In practical operational scenarios, the marine environment may change dynamically, and obstacle positions may shift over time. Furthermore, the existing studies are limited to two-dimensional planar environments and fail to fully consider the three-dimensional characteristics of real marine scenes. In the future, our research can explore the following directions: (1) Adaptive extension of algorithms in dynamic three-dimensional environments: Incorporating reinforcement learning into path planning strategies to adaptively adjust paths based on real-time environmental features, enhancing algorithm stability in dynamic and complex environments; (2) Distributed optimization of the multi-UUV three-dimensional cooperative mechanism: Expanding multi-UUV cooperative planning mechanisms by integrating game theory or distributed cooperative control strategies to enable information sharing and task reallocation among multiple agents, thereby improving the efficiency and robustness of path planning in cooperative search and other cluster tasks.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}