

Hierarchical Reinforcement Learning for Viewpoint Planning with Scalable Precision in UAV Inspection

 , ,
, , 
Abstract
1. Introduction
- (1)
- A novel UAV viewpoint planning method is proposed. By leveraging hierarchical reinforcement learning, the viewpoint planning task is decomposed into high-level and low-level strategies.
- (2)
- A reward function designed to improve observation precision is proposed. Within the reinforcement learning framework, a reward function is constructed that comprehensively considers the precision of the observation, the coverage ratio, and the number of waypoints.
- (3)
- The effectiveness of the proposed method is validated. Experimental evaluations on various inspection object models demonstrate that the proposed method reduces the number of waypoints by at least 70% across multiple inspection tasks while increasing the average observation resolution to 1.51 pixels/mm, significantly enhancing the efficiency and precision of inspection tasks.
2. Related Work
2.1. Greedy Algorithms
2.2. Heuristic Algorithms
2.3. Differentiable Continuous Planning
2.4. Reinforcement Learning-Based Methods
2.5. UAV Path and Coverage Planning
2.6. Summary
3. Approach
3.1. Problem Formulation
- (1)
- Excessive number of waypoints. Traditional methods often require a large number of waypoints to achieve full coverage of the inspection object’s surface. This not only results in low inspection efficiency, but also increases task complexity and execution risks.
- (2)
- Ensuring observation precision. The surface of the inspected object may contain small defects, which can be difficult to detect in captured images if the observation precision is inadequate.
- (3)
- Complexity of viewpoint planning. Viewpoint planning is inherently complex due to the tightly coupled optimization of waypoint selection and camera pose and zoom value. The tightly coupled optimization leads to a combinatorial explosion in the decision space, making it an NP-hard problem.
3.2. Visibility Modeling
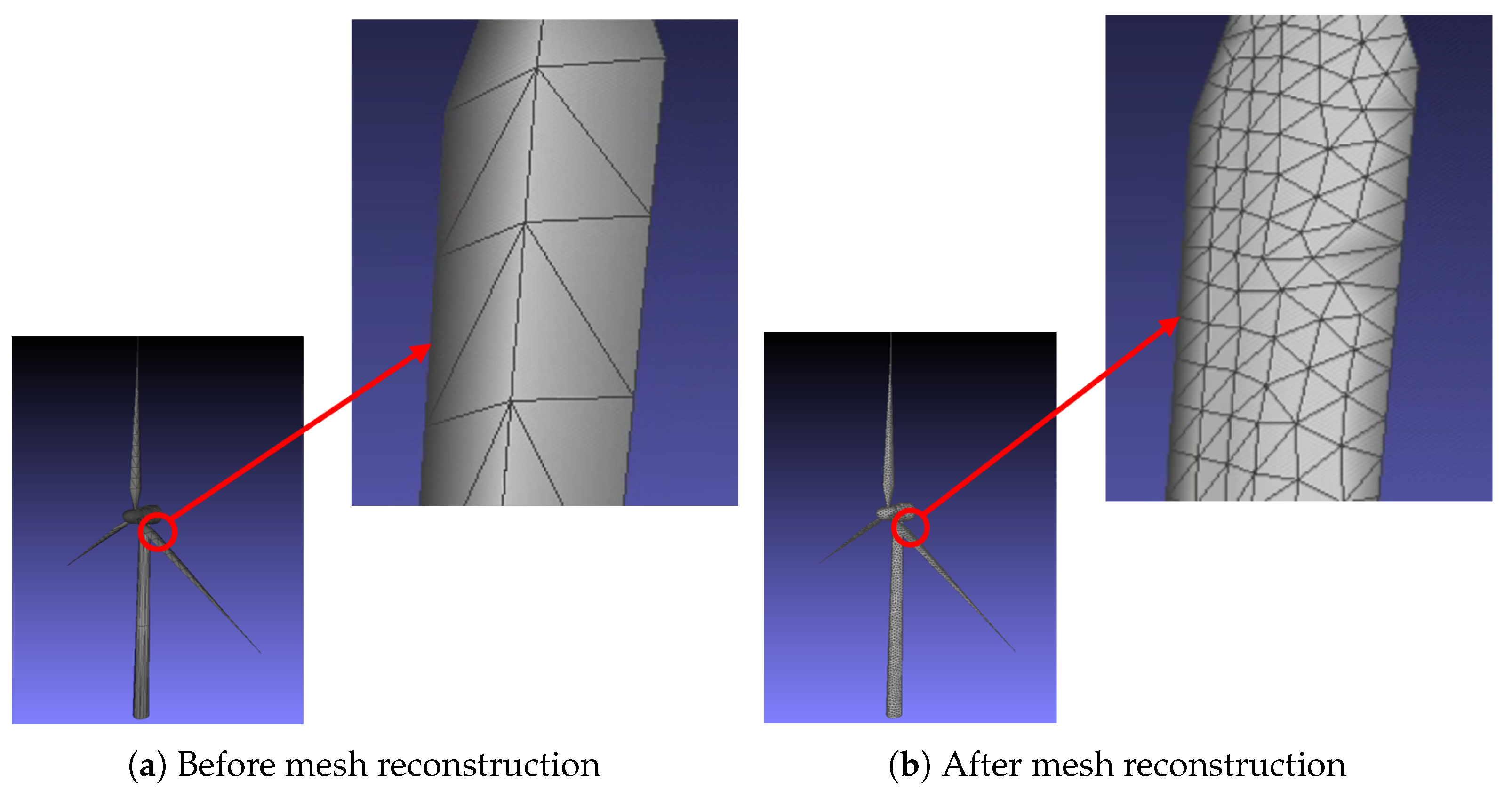
3.2.1. Remeshing of Inspection Targets
3.2.2. Viewpoint Sampling
3.2.3. SubsubsectionVisibility Computation Between Viewpoints and Surface Grids
- Field of View (FOV) Constraint: Determines whether a grid lies within the camera’s field of view.
- Incidence Angle Constraint: Evaluates the angle between the direction of the view and the grid surface norm, ensuring that it does not exceed a predefined threshold .
- Occlusion Detection: Verifies the absence of obstructions along the line of sight between the viewpoint and the center of the grid, ensuring that no other grids block visibility.
- Mesh orientation: whether the surface norm of the triangular mesh is oriented toward the camera.
3.3. Hierarchical Reinforcement Learning-Based Viewpoint Planning
- High-level waypoint planning strategy: Responsible for selecting the optimal waypoint position from the set of candidate waypoints to achieve full surface coverage of the inspection target with as few waypoints as possible.
- Low-level pose and zoom planning strategy: At a given waypoint, multiple image captures are performed to cover the local region. This strategy optimizes the viewpoint pose and the focal length f to meet the precision requirements of inspection data acquisition.
3.3.1. High-Level Waypoint Position Planning
- State Space: The state of the high-level strategy includes the set of covered meshes , the set of remaining uncovered meshes , and the sequence of selected waypoint positions .
- Action Space: The action of the high-level strategy is to select a new waypoint position from the candidate waypoint set P, where:
- State Transition: After executing the high-level action , the low-level strategy begins to execute at the selected waypoint position for a duration of time step . Upon completion of the low-level strategy, the high-level state transitions to:where:is the new set of covered grids added by the low-level policy at the current waypoint.
- Policy Learning: The high-level policy is trained using the SMDP Q-learning algorithm, with the update rule:where is the learning rate and is the discount factor.
3.3.2. Low-Level Pose and Zoom Planning
- State Space: The state of the low-level policy includes the set of covered meshes at the current waypoint, the set of meshes that are visible but not yet covered at the current waypoint, and the set of selected viewpoint combinations at the current waypoint.
- Action Space: During the visibility modeling phase, the viewpoint parameters are discretized. The action A of the low-level policy involves selecting a new viewpoint combination from the discretized set of poses and focal lengths at the current waypoint :Here, is the set of selectable viewpoint combinations at the current waypoint.
- State Transition: After executing a low-level action , a capture is performed, and the state is updated as follows:Here, represents the set of newly covered grid cells captured by the selected viewpoint at time t.
- Termination Condition: The low-level strategy terminates when either local full coverage is achieved or the maximum number of time steps is reached. Local full coverage is defined as the complete coverage of all visible grid cells at the current waypoint, while the maximum time step constraint corresponds to the predefined maximum number of captures allowed at a single waypoint.
- Policy Learning: The low-level strategy is trained using the Q-learning algorithm, with the update rule given as:where is the learning rate and is the discount factor.
3.3.3. Reward Function Design
- :
- Coverage reward coefficient, controlling the weight of this component in the total reward.
- :
- Newly covered grid area by the current viewpoint, i.e., the area of grids visible from the current viewpoint that have not been covered by any previous viewpoints.
- :
- Total surface area of the inspection object. In the calculation process, a specific numerical value for is not required because only the coverage ratio needs to be calculated in this study. After remeshing, the coverage ratio can be determined by the ratio of the number of newly added covered grids to the total number of surface grids.
- :
- Waypoint penalty coefficient, representing the fixed penalty incurred for adding one more waypoint.
- :
- Observation precision reward term.
- Coverage Reward: The coverage reward guides the algorithm to select better viewpoints, thereby achieving more comprehensive coverage of the surface meshes, and is defined as:
- Waypoint Penalty: The waypoint penalty aims to encourage the agent to achieve full coverage with as few waypoints as possible. A fixed negative reward is applied for each additional waypoint. The waypoint penalty is defined as:
- Observation Precision Reward: The observation precision reward guides the algorithm to select viewpoints that meet the observation precision requirements. Specifically, the number of pixels corresponding to a texture of size d mm on the surface of the inspection object in the camera imaging plane should not be less than the predefined value D.
4. Experiments and Analysis
- CCPP Method [30]: A viewpoint planning approach designed for robot path planning, aiming at optimizing a set of viewpoints to cover target regions or objects while satisfying specific constraints.
- Non-Hierarchical Reinforcement Learning Method [17]: This method employs the Deep Q-Network (DQN) algorithm without utilizing the multi-shot per waypoint strategy (i.e., single-shot per waypoint). The reward function does not include the observation precision reward term .
- Hierarchical Reinforcement Learning Method Without observation precision Reward: A hierarchical reinforcement learning approach where the observation precision reward term is removed from the reward function. This serves to verify the influence of the proposed reward function on the observation precision of viewpoint planning.
4.1. Visualization of Viewpoint Planning Results
4.2. Waypoint Number Comparison
4.3. Verification of Observation Precision Reward
4.4. Multiple Observation Precision Comparison
4.5. Analysis of Algorithm Capabilities
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AOR | Average observation resolution |
| CAD | Computer-Aided Design |
| CCPP | Coverage-Constrained Path Planning |
| DQN | Deep Q-Network |
| FOV | Field of View |
| GNSS | Global Navigation Satellite System |
| HRL-SPVP | Hierarchical Reinforcement Learning for Viewpoint Planning with Scalable Precision |
| IER | Isotropic Explicit Remeshing |
| MDP | Markov Decision Process |
| NP-hard | Non-deterministic Polynomial-time hard |
| RGB-D | Red-Green-Blue plus Depth |
| SMDP | Semi-Markov Decision Process |
| TB | Turbine Blade |
| UAV | Unmanned Aerial Vehicle |
| VP | Viewpoint |
| WP | Waypoint |
| WRR | Waypoint Reduction Rate |
References
- Su, C.; Jin, J.; Mao, Y.; Ding, S.; Wang, E.; Cai, M. A Method for Automatic View Planning of Unknown Complex Surfaces. Mach. Tool Hydraul. 2022, 50, 103–111. [Google Scholar]
- Tan, Y.; Li, S.; Liu, H.; Chen, P.; Zhou, Z. Automatic inspection data collection of building surface based on BIM and UAV. Autom. Constr. 2021, 131, 103881. [Google Scholar] [CrossRef]
- Jing, W.; Deng, D.; Wu, Y.; Shimada, K. Multi-UAV coverage path planning for the inspection of large and complex structures. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 1480–1486. [Google Scholar]
- Bolognini, M.; Fagiano, L. A scalable hierarchical path planning technique for autonomous inspections with multicopter drones. In Proceedings of the 2021 European Control Conference (ECC), Strasbourg, France, 28 June–1 July 2021; pp. 787–792. [Google Scholar]
- Song, Y.S.; Arshad, M.R. Coverage path planning for underwater pole inspection using an autonomous underwater vehicle. In Proceedings of the 2016 IEEE International Conference on Automatic Control and Intelligent Systems (I2CACIS), Langkawi, Malaysia, 21–23 November 2016; pp. 230–235. [Google Scholar]
- Gospodnetić, P.; Mosbach, D.; Rauhut, M.; Hagen, H. Viewpoint placement for inspection planning. Mach. Vis. Appl. 2022, 33, 2. [Google Scholar] [CrossRef]
- Blaer, P.S.; Allen, P.K. Data acquisition and view planning for 3-D modeling tasks. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October 29–2 November 2007; pp. 417–422. [Google Scholar]
- Kaba, M.D.; Uzunbas, M.G.; Lim, S.N. A reinforcement learning approach to the view planning problem. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6933–6941. [Google Scholar]
- Mavrinac, A.; Chen, X. Modeling coverage in camera networks: A survey. Int. J. Comput. Vis. 2013, 101, 205–226. [Google Scholar] [CrossRef]
- Mavrinac, A.; Chen, X.; Alarcon-Herrera, J.L. Semiautomatic model-based view planning for active triangulation 3-D inspection systems. IEEE/ASME Trans. Mechatron. 2014, 20, 799–811. [Google Scholar] [CrossRef]
- Liang, L.; Wei, Y.X.; Li, Y.X.; Jia, Y.J. A Flower Pollination Algorithm Based on Nonlinear Cross-Generation Differential Evolution and Its Application Study. Acta Electron. Sin. 2023, 51, 2445–2456. [Google Scholar]
- Zhang, X.; Chen, X.; Farzadpour, F.; Fang, Y. A visual distance approach for multicamera deployment with coverage optimization. IEEE/ASME Trans. Mechatron. 2018, 23, 1007–1018. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, J.; Wang, Y.; Feng, S.; Peng, T.; Yang, H.; Zou, J. A CNN-based adaptive surface monitoring system for fused deposition modeling. IEEE/ASME Trans. Mechatron. 2020, 25, 2287–2296. [Google Scholar] [CrossRef]
- Wu, H.; Xu, X.S.; Bai, X.J. Multi-directional viewpoints planning of UAV inspection based on continuous differentiable sampling. Comput. Integr. Manuf. Syst. 2024, 30, 1161–1170. [Google Scholar]
- Landgraf, C.; Meese, B.; Pabst, M.; Martius, G.; Huber, M.F. A reinforcement learning approach to view planning for automated inspection tasks. Sensors 2021, 21, 2030. [Google Scholar] [CrossRef]
- Respall, V.M.; Devitt, D.; Fedorenko, R.; Klimchik, A. Fast sampling-based next-best-view exploration algorithm for a MAV. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 89–95. [Google Scholar]
- Wang, Y.; Peng, T.; Wang, W.; Luo, M. High-efficient view planning for surface inspection based on parallel deep reinforcement learning. Adv. Eng. Inform. 2023, 55, 101849. [Google Scholar] [CrossRef]
- Peralta, D.; Casimiro, J.; Nilles, A.M.; Aguilar, J.A.; Atienza, R.; Cajote, R. Next-best view policy for 3D reconstruction. In Proceedings of the Computer Vision—ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV; Springer International Publishing: Cham, Switzerland, 2020; pp. 558–573. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Kirtas, M.; Tsampazis, K.; Passalis, N.; Tefas, A. Deepbots: A webots-based deep reinforcement learning framework for robotics. In Proceedings of the Artificial Intelligence Applications and Innovations: 16th IFIP WG 12.5 International Conference, AIAI 2020, Neos Marmaras, Greece, 5–7 June 2020; Proceedings, Part II; Springer International Publishing: Cham, Switzerland, 2020; pp. 64–75. [Google Scholar]
- Jing, W.; Goh, C.F.; Rajaraman, M.; Gao, F.; Park, S.; Liu, Y.; Shimada, K. A computational framework for automatic online path generation of robotic inspection tasks via coverage planning and reinforcement learning. IEEE Access 2018, 6, 54854–54864. [Google Scholar] [CrossRef]
- Zeng, X.; Zaenker, T.; Bennewitz, M. Deep reinforcement learning for next-best-view planning in agricultural applications. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 2323–2329. [Google Scholar]
- Gao, S.H.; Li, J.H.; Li, J.F.; Liu, B.Y. Research on UAV Path Planning Algorithm for Fairness Data Collection and Energy Supplement. Acta Electron. Sin. 2024, 52, 3699–3710. [Google Scholar]
- Duan, S.H.; He, H.; Xu, C.; Yin, N.; Wang, R. DS-MCTS: A Deep Sequential Monte-Carlo Tree Search Method for Source Navigation in Unknown Environments. Acta Electron. Sin. 2022, 50, 1744–1752. [Google Scholar]
- Lin, H.-Y.; Chang, K.-L.; Huang, H.-Y. Development of Unmanned Aerial Vehicle Navigation and Warehouse Inventory System Based on Reinforcement Learning. Drones 2024, 8, 220. [Google Scholar] [CrossRef]
- Liu, X.; Piao, M.; Li, H.; Li, Y.; Lu, B. Quality and Efficiency of Coupled Iterative Coverage Path Planning for the Inspection of Large Complex 3D Structures. Drones 2024, 8, 394. [Google Scholar] [CrossRef]
- Almasi, P.; Xiao, Y.; Premadasa, R.; Boyle, J.; Jauregui, D.; Wan, Z.; Zhang, Q. A General Method for Pre-Flight Preparation in Data Collection for Unmanned Aerial Vehicle-Based Bridge Inspection. Drones 2024, 8, 386. [Google Scholar] [CrossRef]
- Kim, P.; Youn, J. Drone Path Planning for Bridge Substructure Inspection Considering GNSS Signal Shadowing. Drones 2025, 9, 124. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, D.M.; Liu, X.; Tang, C.; Guo, J.; Zhang, X.; Wonka, P. Isotropic surface remeshing without large and small angles. IEEE Trans. Vis. Comput. Graph. 2018, 25, 2430–2442. [Google Scholar] [CrossRef]
- Shang, Z.; Bradley, J.; Shen, Z. A co-optimal coverage path planning method for aerial scanning of complex structures. Expert Syst. Appl. 2020, 158, 113535. [Google Scholar] [CrossRef]
- Jing, W.; Polden, J.; Lin, W.; Shimada, K. Sampling-based view planning for 3D visual coverage task with unmanned aerial vehicle. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 1808–1815. [Google Scholar]
- Jing, W.; Shimada, K. Model-based view planning for building inspection and surveillance using voxel dilation, Medial Objects, and Random-Key Genetic Algorithm. J. Comput. Des. Eng. 2018, 5, 337–347. [Google Scholar] [CrossRef]
- Jung, S.; Song, S.; Youn, P.; Myung, H. Multi-layer coverage path planner for autonomous structural inspection of high-rise structures. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar]
- Glorieux, E.; Franciosa, P.; Ceglarek, D. Coverage path planning with targetted viewpoint sampling for robotic free-form surface inspection. Robot. Comput.-Integr. Manuf. 2020, 61, 101843. [Google Scholar] [CrossRef]
- Wang, L.Z.H.; Zhao, J.B. Viewpoint planning of surface structured light scanning for complex surface parts. Chin. Opt. 2023, 16, 113–126. [Google Scholar]
- Zhou, B.; Zhang, Y.; Chen, X.; Shen, S. FUEL: Fast UAV Exploration Using Incremental Frontier Structure and Hierarchical Planning. IEEE Robot. Autom. Lett. 2021, 6, 779–786. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, S.; Zhang, X.; Zhang, X.; Liu, J. Near-Optimal 3-D Visual Coverage for Quadrotor Unmanned Aerial Vehicles Under Photogrammetric Constraints. IEEE Trans. Ind. Electron. 2022, 69, 1694–1704. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Episodes | |||||
|---|---|---|---|---|---|---|
| HRL-SPVP | 10 | 1 | 0.1 | 0.99 | 0.01 | 2000 |
| DQN | 10 | 1 | — | 0.99 | 0.01 | 2000 |
| HRL w/o | 10 | 1 | — | 0.99 | 0.01 | 2000 |
| Model | Algorithm | WP | WRR (%) |
|---|---|---|---|
| TB Inverted Y-type | CCPP | 83 | 83.1 |
| DQN | 61 | 77.0 | |
| HRL-SPVP | 14 | - | |
| TB Horizontal | CCPP | 76 | 81.6 |
| DQN | 59 | 76.3 | |
| HRL-SPVP | 14 | - | |
| TB Upright Y-type | CCPP | 75 | 81.3 |
| DQN | 48 | 70.8 | |
| HRL-SPVP | 12 | - | |
| SolarPlant | CCPP | 278 | 97.8 |
| DQN | 162 | 96.3 | |
| HRL-SPVP | 6 | - | |
| Big Ben | CCPP | 225 | 90.2 |
| DQN | 146 | 84.9 | |
| HRL-SPVP | 22 | - | |
| Hoa Hakananai’a | CCPP | 194 | 91.2 |
| DQN | 83 | 79.5 | |
| HRL-SPVP | 17 | - |
| Model | HRL-SPVP | WP | VP | AOR (pixel/mm) |
|---|---|---|---|---|
| TB Inverted Y-type | w/o | 10 | 67 | 0.58 |
| 14 | 156 | 1.52 | ||
| Big Ben | w/o | 17 | 109 | 0.55 |
| 22 | 232 | 1.51 | ||
| Hoa Hakananai’a | w/o | 12 | 78 | 0.53 |
| 17 | 173 | 1.51 |
| Model | OP | WP | VP | AOR (pixel/mm) |
|---|---|---|---|---|
| TB Inverted Y Type | 5 mm | 10 | 74 | 0.68 |
| 3 mm | 11 | 107 | 1.05 | |
| 2 mm | 14 | 156 | 1.52 | |
| Big Ben | 5 mm | 18 | 129 | 0.71 |
| 3 mm | 21 | 175 | 1.06 | |
| 2 mm | 22 | 232 | 1.51 | |
| Hoa Hakananai’a | 5 mm | 12 | 96 | 0.69 |
| 3 mm | 14 | 131 | 1.04 | |
| 2 mm | 17 | 173 | 1.51 |
| Algorithm | Zoom | Multi-Shot per Waypoint | Full Coverage | Yaw Angle | Pitch Angle |
|---|---|---|---|---|---|
| HRL-SPVP | ✓ | ✓ | ✓ | ✓ | ✓ |
| MD-VPP [14] | – | ✓ | ✓ | ✓ | ✓ |
| DQN [17] | – | – | ✓ | ✓ | ✓ |
| CCPP [30] | – | – | ✓ | ✓ | ✓ |
| Sampling-based [31] | – | – | ✓ | ✓ | ✓ |
| Medial-objects [32] | – | – | ✓ | ✓ | ✓ |
| ML-CPP [33] | – | – | – | ✓ | – |
| Targetted sampling [34] | – | – | ✓ | ✓ | ✓ |
| Improved Grid Method [35] | – | – | ✓ | ✓ | ✓ |
| FUEL [36] | – | – | ✓ | ✓ | ✓ |
| Near-Optimal 3D [37] | – | – | ✓ | ✓ | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Li, H.; Yu, J.; Wu, Y.; Bai, X.; Pu, M.; Sun, L.; Li, Y.; Liu, J. Hierarchical Reinforcement Learning for Viewpoint Planning with Scalable Precision in UAV Inspection. Drones 2025, 9, 352. https://doi.org/10.3390/drones9050352
Wu H, Li H, Yu J, Wu Y, Bai X, Pu M, Sun L, Li Y, Liu J. Hierarchical Reinforcement Learning for Viewpoint Planning with Scalable Precision in UAV Inspection. Drones. 2025; 9(5):352. https://doi.org/10.3390/drones9050352
Chicago/Turabian StyleWu, Hua, Hao Li, Junwei Yu, Yanxiong Wu, Xiaojing Bai, Mengyang Pu, Li Sun, Yihuan Li, and Juncheng Liu. 2025. "Hierarchical Reinforcement Learning for Viewpoint Planning with Scalable Precision in UAV Inspection" Drones 9, no. 5: 352. https://doi.org/10.3390/drones9050352
APA StyleWu, H., Li, H., Yu, J., Wu, Y., Bai, X., Pu, M., Sun, L., Li, Y., & Liu, J. (2025). Hierarchical Reinforcement Learning for Viewpoint Planning with Scalable Precision in UAV Inspection. Drones, 9(5), 352. https://doi.org/10.3390/drones9050352