Research on the UAV Sound Recognition Method Based on Frequency Band Feature Extraction


Abstract
1. Introduction
2. Method and Model Establishment
2.1. Sound Field Model of UAV Sound Signal
2.2. Frequency Band Feature Extraction Method of UAV Sound
2.2.1. Pre-Processing of Sound Signal
2.2.2. Short Time Fourier Transform of Sound Signal
2.2.3. Frequency Band Feature Extraction Algorithm
2.2.4. Cepstral Domain Analysis
2.3. Convolutional Neural Network for Feature Recognition of UAV Sound
3. Experiment and Analysis
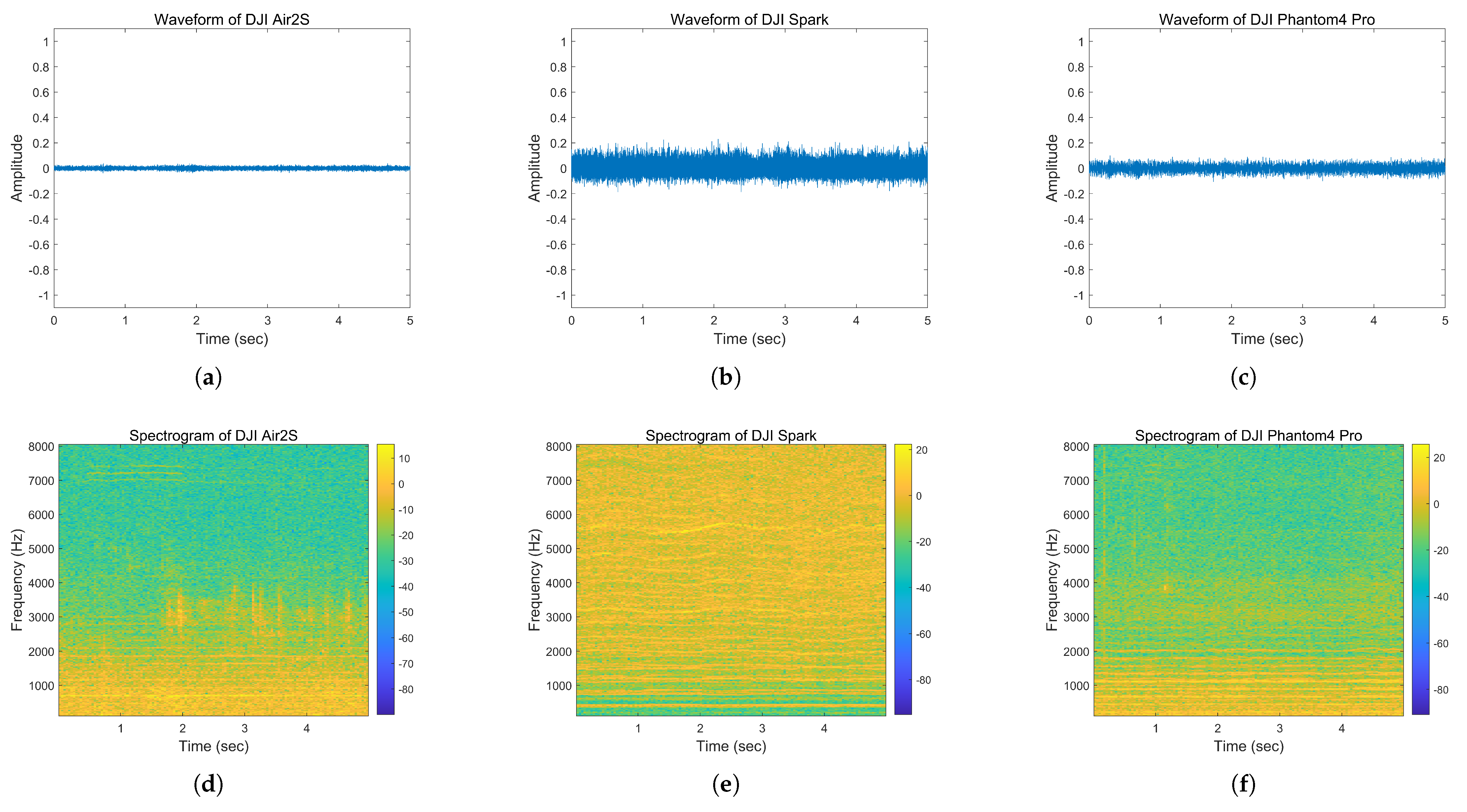
3.1. Experimental Data Collection
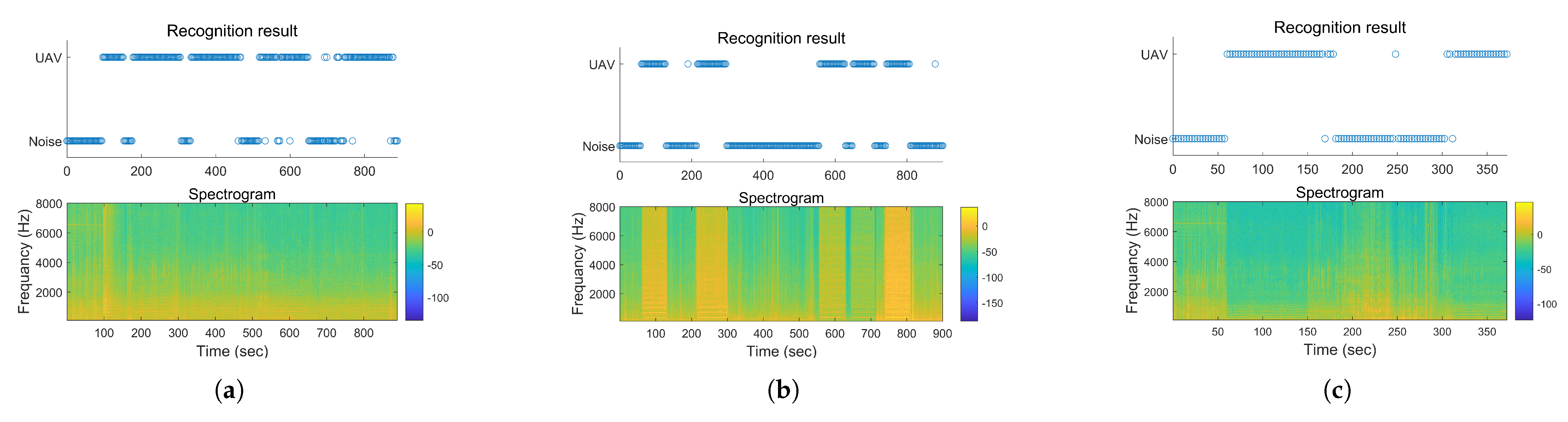
3.2. Experimental Data Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rahman, M.H.; Abrar, M.; Aziz, M.A.; Tabassum, R.; Baik, J.I.; Song, H.K. A Comprehensive Survey of Unmanned Aerial Vehicles Detection and Classification Using Machine Learning Approach: Challenges, Solutions, and Future Directions. Remote Sens. 2024, 16, 879. [Google Scholar] [CrossRef]
- Shi, X.; Yang, C.; Xie, W.; Liang, C.; Shi, Z.; Chen, J. Anti-Drone System with Multiple Surveillance Technologies: Architecture, Implementation, and Challenges. IEEE Commun. Mag. 2018, 56, 68–74. [Google Scholar] [CrossRef]
- Sherman, M.; Shao, S.; Sun, X.; Zheng, J. Counter UAV Swarms: Challenges, Considerations, and Future Directions in UAV Warfare. IEEE Wirel. Commun. 2024, 32, 190–196. [Google Scholar] [CrossRef]
- Wang, C.; Tian, J.; Cao, J.; Wang, X. Deep Learning-Based UAV Detection in Pulse-Doppler Radar. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5105612. [Google Scholar] [CrossRef]
- Cai, Z.; Wang, Y.; Jiang, Q.; Gui, G.; Sha, J. Toward Intelligent Lightweight and Efficient UAV Identification with RF Fingerprinting. IEEE Internet Things J. 2024, 11, 26329–26339. [Google Scholar] [CrossRef]
- Wang, Q.; Yang, P.; Yan, X.; Wu, H.C.; He, L. Radio Frequency-Based UAV Sensing Using Novel Hybrid Lightweight Learning Network. IEEE Sens. J. 2024, 24, 4841–4850. [Google Scholar] [CrossRef]
- Zhao, R.; Li, T.; Li, Y.; Ruan, Y.; Zhang, R. Anchor-Free Multi-UAV Detection and Classification Using Spectrogram. IEEE Internet Things J. 2023, 11, 5259–5272. [Google Scholar] [CrossRef]
- Xie, Y.L.; Jiang, P.; Xiao, X. Grouping Parallel Detection Method of UAV Based on Multi Features of Image Transmission Signal. Radioengineering 2021, 30, 556–568. [Google Scholar] [CrossRef]
- Li, R.; Wang, Q.; Wang, S.; Mao, J.; Zhang, Z.; Cui, X. CT-YoloTrad: Fast and accurate recognition of point-distributed coded targets for UAV images incorporating CT-YOLOv7. Phys. Scr. 2024, 99, 085032. [Google Scholar] [CrossRef]
- Zhou, G.; Liu, X.; Bi, H. Recognition of UAVs in Infrared Images Based on YOLOv8. IEEE Access 2025, 13, 1534–1545. [Google Scholar] [CrossRef]
- Guo, L.; Yang, R.; Zhong, Z.; Zhang, R.; Zhang, B. Target recognition method of small UAV remote sensing image based on fuzzy clustering. Neural Comput. Appl. 2021, 34, 12299–12315. [Google Scholar] [CrossRef]
- Shi, Z.; Shi, G.; Zhang, J.; Wang, D.; Xu, T.; Ji, L.; Wu, Y. Design of UAV Flight State Recognition System for Multisensor Data Fusion. IEEE Sens. J. 2024, 24, 21386–21394. [Google Scholar] [CrossRef]
- Utebayeva, D.; Ilipbayeva, L.; Matson, E.T. Practical Study of Recurrent Neural Networks for Efficient Real-Time Drone Sound Detection: A Review. Drones 2022, 7, 26. [Google Scholar] [CrossRef]
- Anwar, M.Z.; Kaleem, Z.; Jamalipour, A. Machine Learning Inspired Sound-Based Amateur Drone Detection for Public Safety Applications. IEEE Trans. Veh. Technol. 2019, 68, 2526–2534. [Google Scholar] [CrossRef]
- Jiao, Q.; Wang, X.; Wang, L.; Bai, H. Audio features based ADS-CNN method for flight attitude recognition of quadrotor UAV. Appl. Acoust. 2023, 211, 109540. [Google Scholar] [CrossRef]
- Lee, H.; Han, S.; Byeon, J.I.; Han, S.; Myung, R.; Joung, J.; Choi, J. CNN-Based UAV Detection and Classification Using Sensor Fusion. IEEE Access 2023, 11, 68791–68808. [Google Scholar] [CrossRef]
- Liu, L.; Sun, B.; Li, J.; Ma, R.; Li, G.; Zhang, L. Time-Frequency Analysis and Recognition for UAVs Based on Acoustic Signals Collected by Low-Frequency Acoustic-Electric Sensor. IEEE Sens. J. 2024, 24, 19601–19613. [Google Scholar] [CrossRef]
- Li, J.; Zhao, J.; Ren, J.; Gao, X.; Li, Z. A multi-scale integrated learning model with attention mechanisms for UAV audio signal detection. Signal Image Video Process. 2025, 19, 344. [Google Scholar] [CrossRef]
- Uddin, Z.; Altaf, M.; Bilal, M.; Nkenyereye, L.; Bashir, A.K. Amateur Drones Detection: A machine learning approach utilizing the acoustic signals in the presence of strong interference. Comput. Commun. 2020, 154, 236–245. [Google Scholar] [CrossRef]
- Wang, W.; Fan, K.; Ouyang, Q.; Yuan, Y. Acoustic UAV detection method based on blind source separation framework. Appl. Acoust. 2022, 200, 109057. [Google Scholar] [CrossRef]
- Ferreira, A.E.; Alarcão, D. Real-time blind source separation system with applications to distant speech recognition. Appl. Acoust. 2016, 113, 170–184. [Google Scholar] [CrossRef]
- Zhou, J.; Bao, C.; Zhang, X.; Xiong, W.; Jia, M. Design of a robust MVDR beamforming method with Low-Latency by reconstructing covariance matrix for speech enhancement. Appl. Acoust. 2023, 211, 109464. [Google Scholar] [CrossRef]
- Liu, H.; Fan, K.; He, B.; Wang, W. Unmanned Aerial Vehicle Acoustic Localization Using Multilayer Perceptron. Appl. Artif. Intell. 2021, 35, 537–548. [Google Scholar] [CrossRef]
- Pawase, C.J.; Chang, K. 5G-NR Physical Layer-Based Solutions to Support High Mobility in 6G Non-Terrestrial Networks. Drones 2023, 7, 176. [Google Scholar] [CrossRef]
- Chen, B.; Ling, X.; Cao, W.; Wang, J.; Ding, Z. Analysis of Channel Uncertainty in Trusted Wireless Services via Repeated Interactions. IEEE J. Sel. Areas Commun. 2025, 1. [Google Scholar] [CrossRef]
- Ling, X.; Le, Y.; Chen, S.; Wang, J.; Zhou, X. Blockchain-Enabled Decentralized Services and Networks: Assessing Roles and Impacts. IEEE J. Sel. Areas Commun. 2025, 1. [Google Scholar] [CrossRef]
- Ling, X.; Le, Y.; Wang, J.; Huang, Y.; You, X. Trust and Trustworthiness in Information and Communications Technologies. IEEE Wirel. Commun. 2025, 32, 84–92. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index of band | Frequency Band (Hz) | Weight |
|---|---|---|
| 0 | [0, 100] | 0.1 |
| 1 | (100, 3000] | 4 |
| 2 | (3000, 6000] | 2 |
| 3 | (6000, 12,000] | 1 |
| 4 | (12,000, 24,000] | 0.15 |
| Layer Level | Layer Name | Layer Type |
|---|---|---|
| 1 | input | 2-D data input layer |
| 2 | conv1 | 2-D data convolutional layer |
| 3 | bn1 | Batch normalization layer |
| 4 | relu1 | Activation layer |
| 5 | maxpool1 | 2-D data max pooling layer |
| 6 | conv2 | 2-D data convolutional layer |
| 7 | bn2 | Batch normalization layer |
| 8 | relu2 | Activation layer |
| 9 | fc1 | Full connected layer |
| 10 | relu3 | Activation layer |
| 11 | fc2 | Full connected layer |
| 12 | softmax | Softmax function |
| 13 | classification | Output of classification |
| Sound Type | Sample Volume (s) | Distance (m) | Feature Samples |
|---|---|---|---|
| DJI AIR 2S | 1167 | 5–20, 40–100 | 389 |
| DJI Spark | 1002 | 30–70 | 334 |
| DJI Phantom4 | 591 | 70–120 | 197 |
| Ambient noise | 1350 | Not applicable | 450 |
| Feature | UAV | Accuracy | Precision | Recall |
|---|---|---|---|---|
| mfcc | air2s | 95.9% | 96.1% | 96.1% |
| spark | 96.5% | 96.4% | 96.5% | |
| phantom4 | 93.9% | 94.1% | 94.0% | |
| gfcc | air2s | 93.3% | 93.5% | 91.4% |
| spark | 95.1% | 95.5% | 94.8% | |
| phantom4 | 93.9% | 94.2% | 93.8% | |
| ufbf | air2s | 97.1% | 97.2% | 97.2% |
| spark | 99.3% | 99.4% | 99.2% | |
| phantom4 | 95.1% | 95.7% | 95.0% |
| Feature | UAV | Accuracy | Precision | Recall |
|---|---|---|---|---|
| mfcc | air2s | 89.5% | 98.1% | 85.0% |
| spark | 92.7% | 85.3% | 96.3% | |
| phantom4 | 84.7% | 76.6% | 98.3% | |
| gfcc | air2s | 85.5% | 94.4% | 81.7% |
| spark | 87.7% | 82.6% | 83.3% | |
| phantom4 | 91.1% | 85.5% | 98.3% | |
| ufbf | air2s | 91.2% | 91.7% | 94.6% |
| spark | 94.7% | 89.0% | 97.2% | |
| phantom4 | 96.8% | 95.2% | 98.3% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, J.; Fan, A.; Fan, K.; Pan, W.; Zeng, L. Research on the UAV Sound Recognition Method Based on Frequency Band Feature Extraction. Drones 2025, 9, 351. https://doi.org/10.3390/drones9050351
Zhong J, Fan A, Fan K, Pan W, Zeng L. Research on the UAV Sound Recognition Method Based on Frequency Band Feature Extraction. Drones. 2025; 9(5):351. https://doi.org/10.3390/drones9050351
Chicago/Turabian StyleZhong, Jilong, Aigen Fan, Kuangang Fan, Wenjie Pan, and Lu Zeng. 2025. "Research on the UAV Sound Recognition Method Based on Frequency Band Feature Extraction" Drones 9, no. 5: 351. https://doi.org/10.3390/drones9050351
APA StyleZhong, J., Fan, A., Fan, K., Pan, W., & Zeng, L. (2025). Research on the UAV Sound Recognition Method Based on Frequency Band Feature Extraction. Drones, 9(5), 351. https://doi.org/10.3390/drones9050351