1. Introduction
Due to its distributed and highly flexible nature, UAV swarms can effectively leverage their numerical advantages to conduct reconnaissance and strike missions across multiple regions and targets. However, the experience of modern warfare shows that high-value targets are often hidden behind the front line and in a relatively deep position in order to protect themselves from direct enemy attacks or to better fulfill their strategic functions [
1]. Employing intelligent stealth UAV swarms in penetration and search tasks is an effective approach. However, real battlefield environments are highly dynamic, characterized by constantly changing target behaviors, electromagnetic conditions, and weather patterns. The current simulation environment makes it difficult to update these dynamic changes in real time, which may lead to adaptability issues for the trained algorithms in practical applications.
In the SEAD mission, the UAV swarm enters the target reconnaissance and strike area, executes the final search task, and completes the closed loop of the whole task. High-value enemy targets are usually located in the deep area of the enemy. Compared with the conventional mission environment, the SEAD mission environment is in a strong refusal state. On the one hand, due to the distance between the fleet and the rear command center, it is difficult for rear command personnel to obtain real-time dynamic information in a timely manner. Without considering satellite communication support, it is also challenging to exert real-time control over the UAV swarm. At the same time, the UAV swarm will face various enemy countermeasures in the process of performing established combat missions. Typical countermeasures, like electromagnetic interference or air defense firepower, are difficult challenges of swarm’s autonomous task ability, and a practical problem that restricts the application of swarms [
2,
3,
4,
5].
The traditional air combat confrontation theory is based on the principle of “win by energy”, with both sides’ aircraft aiming to achieve higher relative altitude, better attack angles, and more favorable relative battle positions [
6]. However, the swarm is mainly in the form of “group-attack verse group-defense”, and the comparative advantages between single machines are difficult to be transform into the combat effectiveness of the group. Swarms should aim to “win by intelligence”, and realize “gathering of intelligence” through orderly division of labor and coordinated operations [
7]. Facing the complex rejection environment, the formation, battle position and strategy of each UAV in the swarm are very complex, which would exceed people’s conceptual design ability and is difficult to achieve directly. It is an effective method to use artificial intelligence [
8,
9].
In recent years, researchers have increasingly applied multi-agent deep reinforcement learning (MARL) to various applications in UAV swarms, such as combat, formation, obstacle avoidance, and navigation [
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27]. For example, to achieve efficient swarm coordination and combat strategies through intelligent algorithms, Yang et al. (2024) proposed a Decomposed Prioritized Experience Replay-based Multi-Agent Deep Deterministic Policy Gradient (DP-MADDPG) algorithm for drone swarm combat [
28]. This algorithm integrates decomposition mechanisms and Prioritized Experience Replay (PER) into the traditional MADDPG framework, overcoming the technical challenges of converging to local optima and dominant strategies, thereby improving the success rate of drone combat. Deng et al. (2024) introduced an Evolutionary Multi-Agent Twin Delayed Deep Deterministic Policy Gradient (E-MATD3) algorithm, which combines evolutionary algorithms with multi-agent reinforcement learning to effectively address the issue of strategy cycling in traditional self-play training [
29]. The E-MATD3 algorithm employs an attention-based network architecture to adapt to dynamic changes in the number of drones in aerial combat and uses death masking to avoid weight bias caused by drone crashes. Aschu et al. (2024) proposed a multi-agent deep reinforcement learning (MADRL) approach for local path planning in a UAV swarm, specifically targeting the precise landing task in a 3D environment [
30]. This method addresses the challenges faced by traditional control and planning methods in drone swarm landing scenarios. Kumari et al. (2024) developed a method for reliable identification and tracking of individual drones within a swarm using stereo vision cameras and multi-agent reinforcement learning [
31]. This method effectively deals with the high density and dynamic behavior of UAV swarms, providing technical support for precise tracking within the swarm. Although these algorithms have their own advantages, the Deep Deterministic Policy Gradient (DDPG) algorithm better meets the task planning requirements of UAV swarms in complex battlefield environments, with its efficiency and accuracy in continuous action space [
32,
33,
34,
35,
36,
37,
38]. In addition, the experience replay mechanism and target network design of the DDPG algorithm enable it to have higher sample efficiency and convergence speed when dealing with complex tasks. These characteristics make the DDPG algorithm well-suited for autonomous task planning of UAV swarms, effectively improving task success rates and swarm survivability.
This paper focuses on two key issues:
- (1)
building a standard framework of simulation environments for intelligent stealth swarms in a rejection environment, and form a simulation environment with high standardization and generalization ability with scientific and reasonable logic and combined with swarm characteristics;
- (2)
based on the existing simulation environment, aiming at typical SEAD tasks, use a reinforcement learning algorithm to realize autonomous tasks of intelligent swarms.
The rest of the paper is organized as follows.
Section 2 introduces the scenario where a UAV swarm autonomously completes the task of searching and striking ground targets through reinforcement learning.
Section 3 designs a simulation and verification platform of autonomous task confrontation empowered by artificial intelligence.
Section 4 sets reward functions for mission UAVs and control rules for ground targets. Through analysis of simulation results, it is proven that a reinforcement learning algorithm enables the UAV swarm to display higher levels of intelligence.
Section 5 presents the conclusions.
2. Problem Model in Mission Scenario
The mission scenario is shown in
Figure 1. Our stealth UAV swarm has broken through the enemy’s dense defense circle and entered the target search area. At this stage, the mission UAV obtains the real-time position and motion information of enemy high-value targets through radar or Electro-Optical (EO) load, and performs the search mission. Enemy ground vehicles adopt scattered avoidance mode, keep moving and scattered avoidance, which increases the difficulty of the mission. In highly dynamic and highly time-sensitive scenarios, maximizing the ability to strike all enemy mobile ground targets within a limited strike window time places extremely high demands on the autonomous task planning capability of our mission swarm.
The mission UAVs are controlled by a reinforcement learning algorithm, with each UAV acting as an independent agent. The internal limiting factor is the absence of centralized cooperative command and dispatch, while the swarm’s intelligence relies on the emergent intelligence provided by the artificial intelligence algorithm. There are two external limiting factors. First, there is electromagnetic interference in the environment, and there are distance constraints and noise interference in the communication and observation between UAVs, that is, friendly UAVs can only obtain each other’s state information within a certain communication range, and can only observe the state information of an enemy UAV swarm within a certain radar or EO visual distance, and random noise is added to the communication information and observation information. Second, the target has maneuverability, adopts expert strategy control, and has the ability of global observation and spontaneous decentralized defense, which restricts the UAV swarm’s ability to carry out the established tasks.
The goal of the control framework and simulation training is to enhance the intelligence level of the mission UAV swarm and develop its group awareness. When hitting ground targets, swarms can connect target allocation, mission planning and maneuver control, and quickly close the killing chain of “target-discovery to swarm-maneuver”. In this process, the task itself and the algorithm itself are deeply analyzed. Through the combination of control framework and related algorithms, the swarm has the ability of terminal autonomous confrontation. Through simulation experiments, the feasibility of the method is verified.
3. Construction of Simulation Model
According to the task requirements of stealth swarm, the simulation and verification platform of autonomous task confrontation empowered by artificial intelligence is designed. The simulation platform is structured into six levels, from bottom to top: mission level, kinematics model level, intelligent algorithm level, sensor information fusion level, command and control level, and effectiveness evaluation level.
Figure 2 depicts the design of the adversarial simulation verification platform.
3.1. Mission Level
In the mission level, confrontation scenes are set, and the characteristics of all parties can be refined and added to the simulation environment model according to different task backgrounds, so as to realize various task scenes such as air combat confrontation, air–sea confrontation or air–ground attack.
The mission level is the foundation of the UAV swarm countermeasure simulation platform, and its core purpose is to build a highly realistic virtual combat scene, simulating the elements and attributes in the actual battlefield. Researchers can use this level to customize various battlefield conditions.
Through careful design, the simulation platform can provide users with a highly realistic and customizable battlefield environment, so as to facilitate various tactical drills and strategy tests. This not only greatly enhances the practicability and educational significance of simulation, but also provides an ideal experimental platform for tactical research and technical development of UAV swarms.
3.2. Kinematics Model Level
Setting the dynamic models of the two sides can change the maneuverability of the two sides, realize the confrontation tests with different speed ratios and overload ratios, and simulate the multi-domain manned or unmanned platforms such as air, sea, and land by setting different types of dynamic kinematics models.
A three-dimensional global coordinate system is established with the ground in the center of the simulation area as the origin, and the position of each UAV in the UAV swarm in space is represented by (
X,
Y,
Z). In the simulation, in order to truly reflect the UAV motion state, according to the real state of the pilot operating the aircraft, the pilot’s throttle lever and control lever operation mode are simulated, and a throttle channel and two heading angle channels are set up to establish a second-order three-degrees-of-freedom control model. Compared with the three-dimensional six-degrees-of-freedom equation, using the second-order three-degrees-of-freedom control model can reduce the calculation dimension of three degrees of freedom, save the computing consumption in the emergence of swarm intelligence, and pay more attention to the research problem itself.
The throttle channel controls the flight speed V to change the running speed of the aircraft by changing the acceleration a. The two angle channels control the pitching angle γ and yaw angle Ψ, respectively, and change the running direction of the aircraft by changing the pitching angular acceleration and yaw angular acceleration . In order to limit aircraft overload, boundary constraints are set for three control quantities.
The action space of the mission UAV is three-dimensional, and the output control quantities are
,
a ∈ [
,
],
∈ [
,
],
∈ [
,
]. The attributes of the relevant parameters in the kinematic model are given in
Table 1.
3.3. Intelligent Algorithm Level
Researchers can determine the kernel-driven algorithm of the agent, preset the DDPG algorithm to control task swarm, use expert rules to control defensive swarm, and have algorithm secondary development interface on this level, which can improve the established algorithm according to simulation results and expectations.
The intelligent algorithm level is the core component of the UAV swarm countermeasure simulation platform, in which UAVs are endowed with an advanced autonomous decision-making ability and behavior control. The purpose of this level is to simulate the intelligent behavior of UAVs in a complex battlefield environment, so that they can independently complete key tasks such as path planning, obstacle avoidance, target recognition, and tracking.
In terms of function realization, the intelligent algorithm level uses advanced artificial intelligence technologies such as reinforcement learning to provide powerful data processing and decision support for UAVs. Through machine learning algorithms, UAVs can learn and optimize their behavior pattern from historical data. Reinforcement learning can continuously improve the decision-making quality of UAVs through interactive learning with the environment, so that they can make more reasonable choices when facing unknown challenges.
Furthermore, the role of intelligent algorithms must account for the cooperative work among UAVs. It is essential to achieve information sharing and coordinated task execution within the swarm through decentralized intelligent decision-making algorithms, thereby enhancing the overall operational efficacy of the UAV swarm.
3.4. Sensor Information Fusion Level
At this level, the communication within the UAV swarm and the observation of local targets are considered, corresponding to the state space of UAV action, communication interaction, and radar/EO observation information fusion that are carried out; multiple parameters are reserved; and the limited degree of the environment relative to the task swarm is regulated.
Figure 3 illustrates the state space composition of the mission UAV. The state space of mission UAV
i consists of three parts, namely, its own state information
, communication information
, and radar observation information
Ri, which are expressed as follows:
Self-state information
includes three spatial positional quantities and three speed quantities, which are expressed as follows:
The communication information
includes three spatial position quantities and three speed quantities of all friendly UAVs except itself, and the communication radius is
dO. When the friendly side is not within the communication radius, the information would be empty, which is represented as follows:
Radar observation information
Ri includes three spatial position quantities and three speed quantities of defensive targets, and the observation radius is
dR. When the enemy is not within the observation radius limit, the information would be empty, which is expressed as follows:
3.5. Command and Control Level
In the command and control level of the UAV swarm countermeasure simulation platform, the setting of intelligent control attributes is crucial for realizing tactical decision-making and action coordination. This level primarily serves to establish the control strategies for UAVs in adversarial engagements, which are mainly divided into two categories: reinforcement learning control and expert decision control.
The purpose of the Reinforcement Learning Agent (RLA) is to enable the mission UAV swarm to autonomously learn and optimize its behavior strategy in the countermeasure environment. The reinforcement learning agent learns the optimal strategy by interacting with the environment, that is, by executing actions, receiving feedback, and updating its decision model, it gradually improves its performance. Reinforcement learning is especially suitable for dynamic and uncertain environments, which can adapt to the enemy’s strategic changes and realize adaptive tactical decision-making.
The expert strategy manipulates the defensive swarm by using an expert system or preset tactical rules, thereby simulating the decision-making process of human experts. Expert strategy is based on a set of fixed rules or heuristic methods to guide UAV behavior, and these rules are usually formulated by domain experts according to experience. Expert strategy can simulate the decision-making of human commanders, provide a predictable and interpretable control mode, and facilitate the analysis and evaluation of tactical effectiveness.
3.6. Efficiency Evaluation Level
In the UAV swarm countermeasure simulation platform, the core function of the efficiency evaluation level is to judge the outcome. It is based on a series of key indicators to determine the tactical results of opposing sides. Mission completion is the primary index to judge the outcome, which measures the efficiency and success rate of UAV swarm in performing tasks such as target strike, reconnaissance, and surveillance. Survival rate is also very important. It evaluates the durability of swarms by the damage rate of UAVs and the survival time of battlefields. Resource consumption is also a factor that cannot be ignored, which relates to the efficiency of the use of key materials such as fuel and ammunition, and reflects the continuous combat capability of swarm. Reaction time is used to assess the response speed of UAV swarms to enemy threats. This directly affects the timeliness of tactics and the reduction of enemy attack opportunities, so it is also a key component of judging the outcome. In addition, the judgment of winning or losing should follow a series of preset rules and conditions, such as specific mission objectives and battlefield rules of engagement, which provide clear standards for judgment. A real-time monitoring and feedback mechanism ensures the dynamic and adaptive nature of victory and defeat judgments, allowing commanders to adjust tactics and strategies based on real-time data. In the end, judging the outcome is a process of comprehensively considering various factors. By comprehensively analyzing task completion, survival rate, resource consumption, reaction time, etc., scientific and objective evaluation results are obtained, which provide support for tactical decision-making and strategy optimization.
The operating logic of the complete simulation system is as follows:
Firstly, the mission level defines the mission scenario and objectives, providing initial conditions for the kinematics model level. Then, the kinematics model level generates the dynamic behavior of the UAV and target based on mission requirements, providing data for the sensor information fusion level. The sensor information fusion level processes sensor data to provide environmental perception information for the intelligent algorithm level. The intelligent algorithm level generates decision instructions based on sensor information, providing decision support for the command and control level. The command and control level generates specific control commands based on the instructions of intelligent algorithms, and feeds them back to the dynamic model level to update the behavior of the UAV. Finally, the efficiency evaluation level assesses the completion status of missions and system efficiency, providing feedback to the mission level for adjusting subsequent mission settings.
The simulation environment is built on the local host, the software environment is compiled by python, the GPU is GeForce RTX 4070Ti 12G, the CPU is Intel 13,900 K, and the memory is DDR5 32G. The parameter settings related to the simulation environment are shown in
Table 2, where the red side refers to the mission UAV and the blue side refers to the ground target.
4. Implementation of Autonomous Task Planning
Unmanned aerial vehicle (UAV) task planning refers to the process of formulating flight routes for UAVs and conducting task allocation and overall management based on the tasks that the UAVs need to complete, the number of UAVs, and the types of mission payloads they carry. UAV swarm task planning, in addition to considering the requirements of the task itself, must also take into account the constraints of coordination and consistency among UAVs in executing the task together. It is necessary to design collaborative flight routes for the UAV swarm according to the task planning indicators, so as to achieve the optimal or nearly optimal overall combat effectiveness. In this paper, the tasks that the mission UAVs need to complete include collision avoidance among UAVs, search and strike of ground targets, and maintaining a suitable flight altitude.
To achieve autonomous task planning for the mission UAVs, it is necessary to set up a reward function in the DDPG algorithm to control the mission UAVs and use expert rules to control ground targets after establishing the simulation platform. By analyzing the simulation results, the impact of the reinforcement learning algorithm on mission UAV swarm can be obtained. In this section, we introduce the principle of the DDPG algorithm and set reward functions for mission UAVs and expert rules for ground targets. Finally, we analyze the simulation results.
4.1. Principle of DDPG
In the intelligent algorithm level, in order to test the effectiveness of the overall simulation framework, this paper chooses the widely used deep deterministic strategy gradient algorithm (DDPG). The DDPG algorithm is an advanced reinforcement learning technology that is specially designed to deal with complex problems with continuous action space. The DDPG algorithm combines deep learning and the deterministic strategy gradient method, and solves the limitation of traditional reinforcement learning methods in continuous action space by using neural network to approximate strategy and value function.
The core principle of the DDPG algorithm is based on the strategy gradient method in reinforcement learning, which optimizes the strategy by directly increasing the gradient of the strategy function. Different from traditional value-based methods, the strategy gradient method directly models the decision-making process of actions, allowing effective exploration and utilization in continuous action space. The DDPG algorithm uses empirical playback mechanism and stores historical interaction data in playback buffer. The learning process randomly selects samples from this buffer, which helps the algorithm learn more efficiently from experience and reduces the time series dependence of data.
The DDPG algorithm adopts a deterministic policy, which means that in a given state, the policy will produce a deterministic action instead of a random action. This simplifies the strategy optimization process and allows more precise action control. The DDPG algorithm includes two neural networks: actor network and critic network. The actor network is responsible for generating strategies, that is, selecting actions. The critic network evaluates the quality of the current strategy and provides guidance on the direction of strategy improvement.
The DDPG algorithm, based on the Actor–Critic framework, is classified as an off-policy algorithm. The actions in the DDPG algorithm are deterministic, which is more conducive to decision-making in continuous action spaces. The DDPG algorithm features a replay buffer to store samples generated from the agent’s interactions with the environment. In the experiment, the size of the buffer is set to 106, the corresponding discount factor is set to 0.95, and the network model will begin to randomly sample and update when the number of interactions between the agent and the environment reaches 103. The policy and value networks in the DDPG algorithm correspond to the actor and critic, respectively. In the experiment, both the policy and value networks consist of hidden layers with five fully connected layers, each with 128 neurons, and the activation function is ReLU. The learning rate for network training is set to 3 × 10−4, and the batch size for stochastic gradient descent is 1024. When setting the hyperparameters, the target network update interval is d = 1 s, and the soft update rate τ = 0.5 s.
4.2. Reinforcement Learning Reward Function
A well-designed reward function can motivate UAV swarms to adopt more effective action strategies, thereby achieving autonomous task planning. The reward for the mission UAV swarm consists of two parts.
Within time T, after the mission UAV swarm hits all targets, it is judged that the mission swarm wins the round, and after the round ends, the swarm gains the shared sparse reward Ra1. If the mission UAV swarm does not destroy all targets within time T, the round ends and the swarm gains a shared reward of 0. This is the reward for the first part.
The second part refers to the mission UAV obtaining dense rewards through the relative motion with the ground target, which are divided into collision avoidance reward Rb1, search reward Rb2, and flight altitude reward Rb3 in simulation. For the swarm SEAD mission, the core command and control points are patrolling, detection, locking, striking, and safe collision avoidance. The collision avoidance reward is Rb1, which is primarily for the safe progression of the swarm and also to promote dispersion, thereby increasing search efficiency. Detection, locking, and striking are combined into Search Reward Rb2; Rb2 is a time-dependent quantity. To encourage the swarm to adopt a more aggressive strategy, these three actions are linked in sequence. The reward is only obtained after completing the three consecutive operations. Set the low-altitude patrolling reward as Flight Altitude Reward Rb3.
The reward
Rb of intelligent UAV swarms consists of three parts,
Collision Avoidance Reward
Rb1. In order to avoid the internal collision of the swarm in complex confrontation, set the collision avoidance reward
Rb1. The formula is as follows:
The safe distance dsafe, is set here. When the relative distance dA–A between the mission UAV and the adjacent UAV is less than dsafe, dsafe = 200, it will gain a continuous negative reward, and when the relative distance between the mission UAV is greater than dsafe, it will gain a reward of 0. Rb1 is set up to guide mission drones to keep a safe distance between them.
Search Reward
Rb2. In the scenario setting, the UAV swarm uses radar to search the ground. When the relative distance between the target and the UAV
dtA−D is less than the UAV’s radar detection range
dfind,
dfind = 1500, the search and positioning process starts, and the UAV starts to calculate the reward. If the target remains found for five time steps, the positioning is judged to be effective, and the UAV successfully searches for the target, obtaining the cumulative reward. If the target escapes, the location fails, restart the search process, and the reward is empty and recalculated.
Flight Altitude Reward. The reward
Rb3 for fixed height patrol is limited by safe height. Because the detection distance of UAVs in a preset mission is limited, when this item is not added, a UAV will reduce its flight height to the limit in exchange for the maximum ground detection coverage. Therefore, this item is added to limit the flying height
hA−G of UAV,s
hA−G = 800, so as to encourage UAVs to keep patrolling and searching more actively.
4.3. Expert Rule Model
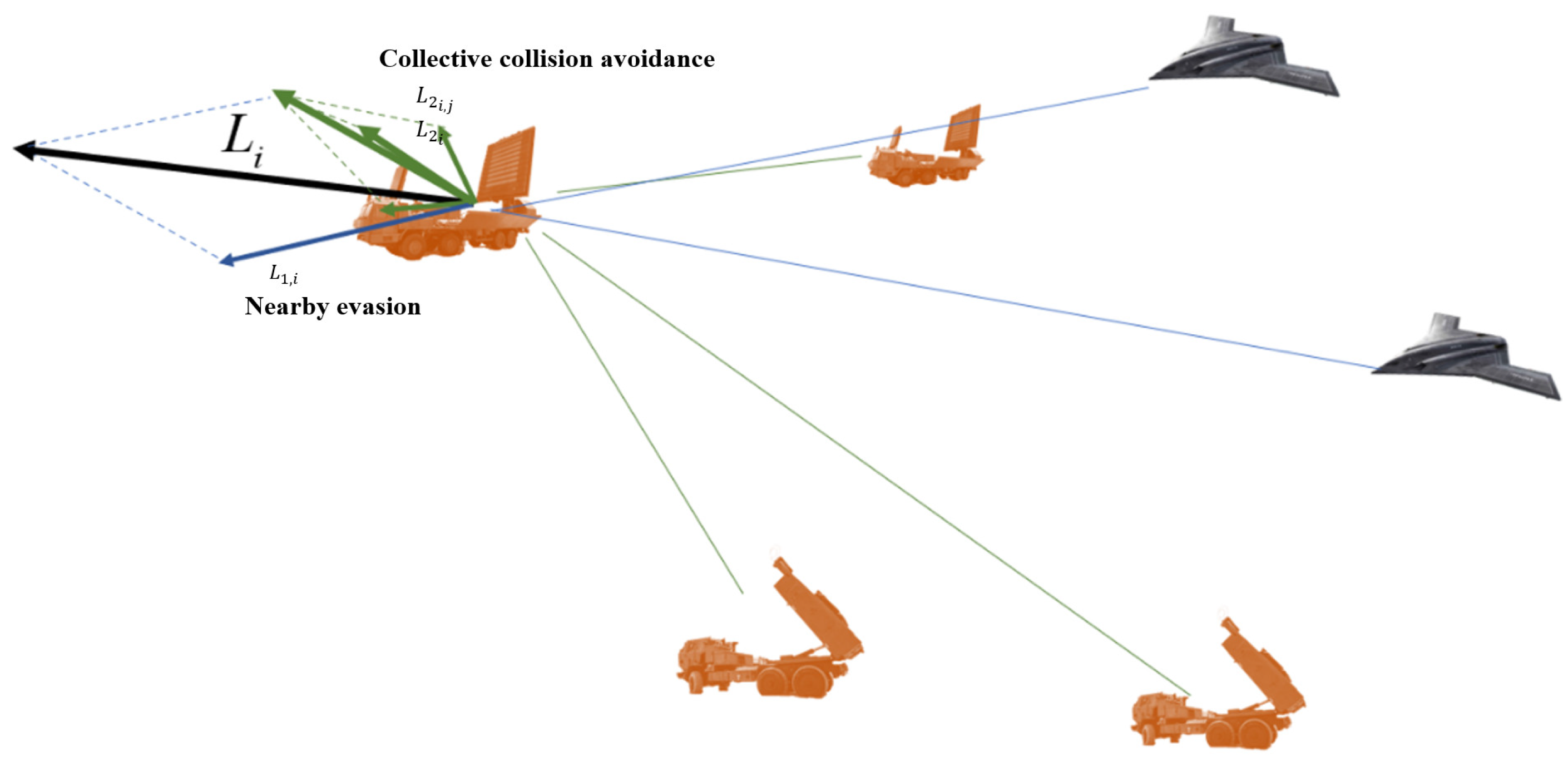
In order to fully stimulate the intelligent emergence of the mission UAV swarm, expert strategy is considered to control ground targets. Similar to the design of the reward function, the expert rules were also crafted with battlefield rules in mind. We employed the artificial potential field method to control the movement of ground targets. In this method, ground targets are treated as points within a potential field, and the relationships between targets and targets, as well as among targets themselves, are translated into potential field forces based on the battlefield situation.
There are two main expert strategies, namely, “nearby avoidance” and “collective collision avoidance”, which are transformed into potential field vectors to control the defensive UAV movement in turn. In
Figure 4, there is a simple example of the evasion strategy for a ground target.
Nearby evasion
L1 means that when a ground target faces an invading swarm, it compares the relative position of each swarm with itself in sequence, aiming at removing the UAV with the strike path as quickly as possible. In the potential field, the potential field vector function is as follows:
where
L1,i represents the escape vector of the
i-th ground target,
Pi,j represents the relative position vector between the
i-th ground target and the
j-th mission UAV, and the relative position vector
Pi,j is transformed into the evasion vector
of ground target
i-th relative to UAV
j-th, and
NUAV represents the number of mission UAV. The larger the value of
β is, the more likely the ground target is to quickly escape from the mission UAV. In the simulation, the value of
β was set to 0.8.
Collective collision avoidance
L2 means that when any target escapes, it keeps safe collision avoidance with all other ground targets. The potential field vector function is as follows:
When the hit ground target moves, the relative position vector Pi,k between itself and other targets is calculated in real time, and the relative position vector Pi,k is transformed into the avoidance vector of ground target i-th relative to ground target k-th. NTarget represents the number of ground targets. Finally, all the collision avoidance vectors except i-th relative to itself form the collision avoidance control vector L2,I; α is the collision avoidance inclination adjustment parameter of i-th. The larger the value of α is, the more conservative the ground targets are and the more inclined they are to maintain safe boundaries with each other. In the simulation, the value of α was set to 0.5.
The nearest-evasion potential field vector L1,i and the collective-collision-avoidance potential field vector L2,i together constitute the control vector Li of the i-th target.
4.4. Simulation Results Analysis
Set up a UAV swarm to search and strike ground escape targets, with three UAVs and eight targets, respectively. The generation location and initial motion direction of ground escape targets are random. Within time T, after the mission UAV detects and eliminates all ground targets, it is determined that the mission swarm has won the turn.
Figure 5a illustrates the winning rate of the mission UAV in the 3v8 scenario, while
Figure 5b shows the corresponding reward. Due to the uncertainty of the initial position, motion trajectory, and avoidance strategy of ground targets in each round of training, we used the results corresponding to every 100 rounds of training when drawing the win rate curve and reward value curve. They can demonstrate the effectiveness of the algorithm for UAV training. By analyzing
Figure 5a, we can see that the winning rate increases with the number of rounds, reaching over 95% in 10,000 rounds. Although there are fluctuations, the independent adjusted winning rate is still high. The average reward also increases with the number of training rounds.
Figure 6 shows the strike process of the mission UAVs on the ground targets in the 3v8 scenario. The red dots represent the mission UAVs and their trajectories, and the blue dots represent the ground targets and their trajectories. When the mission UAV strikes the ground target, the blue dot will disappear and only the trajectory of the ground target will remain. According to the different ground target distribution and trajectory, the UAV swarm can independently complete the mission planning.
After training, the agent is demonstrated by the expert system. At this time, the UAV swarm shows a higher level of intelligence, and has independently evolved the patrol strike tactics. Three UAVs deploy their formation from the initial position, travel in a straight queue in the unknown area, and complete the locking strike after finding the target. Based on the new target position, plan the strike path. The three aircraft cooperated with each other to complete the attack on all eight targets within the specified time.
5. Conclusions
This article successfully realizes the simulation scenario and architectural design for a UAV swarm executing SEAD tasks. In this process, the action strategy of the unmanned aerial vehicle fleet is dynamically generated by reinforcement learning algorithms, while the defense measures for ground targets are controlled by expert rule systems. The simulation results show that the proposed simulation scenario and system architecture are technically feasible, and the artificial intelligence algorithm has demonstrated significant effectiveness in SEAD tasks.
Although preliminary results have been achieved, there is still room for further expansions and improvements in the construction of simulation scenarios and the optimization of algorithms. For example, we can add more complex factors such as changing environmental conditions, more advanced enemy defense systems, and more complex collaboration mechanisms within the drone fleet to improve the realism and challenge of the simulation. In addition, reinforcement learning algorithms themselves also need further optimization to improve their adaptability and robustness in dynamic and uncertain environments. To further improve the adaptability and intelligence level of UAV swarms, Federated Learning and Multi Agent Reinforcement Learning (MARL) techniques can be introduced. Federated learning can achieve knowledge sharing and model updating among drones without sharing raw data, thereby improving the overall intelligence level of the swarm. Multi agent reinforcement learning can better handle the collaborative and competitive relationships between drones, achieving more efficient cluster decision-making.
Through these studies, we aim to further enhance the performance of UAV swarms in SEAD missions, thereby providing robust technical support for future unmanned combat systems.


 and
and 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}