4.1. Observation Space and Action Space
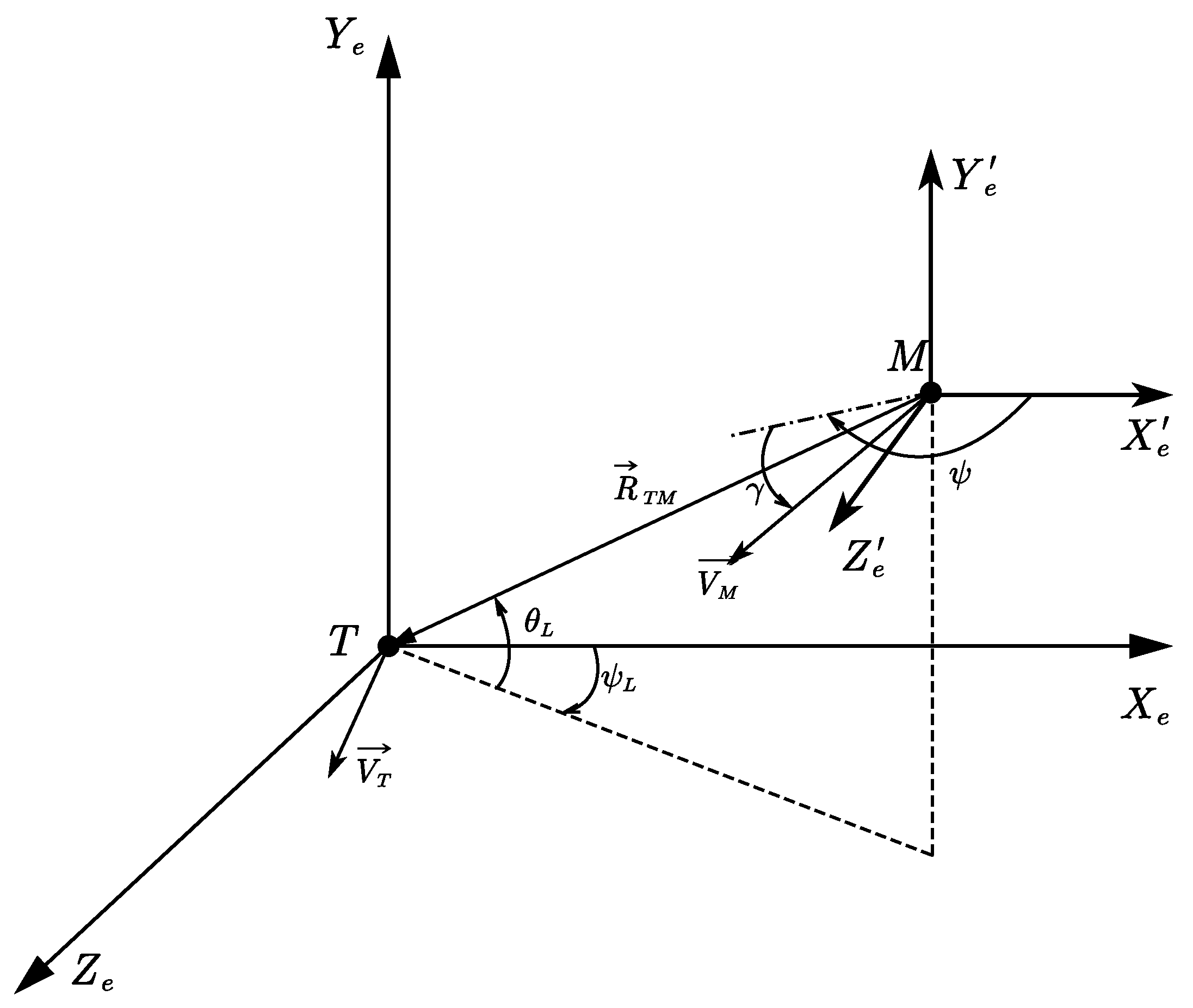
For the guidance and control problems, the observation vector must fully describe the information about the relative state of the vehicle and target. Therefore, the observation vector was designed as follows:
where
denotes the LOS uni vector,
denotes the estimated value of the time-to-go
,
is the estimated arrival time error, and
. Moreover, the observation noise was considered, that is,
where
denotes the
n-dimensional independent Gaussian distributed random variables with mean 1.0 and standard deviation
, and
n is the dimension of the observation.
The majority of existing time-to-go estimation methods employ constant velocity and PNG guidance assumptions. However, the velocity is not constant during the terminal flight phase, and the guidance methods used do not necessarily adhere to the principles of PNG. Therefore, existing time-to-go estimation methods cannot be applied directly in vehicles with time-varying velocity. For this reason, we propose a straightforward but effective iterative approach to estimate the time-to-go. First, the initial guess for the remaining flight time estimate can be expressed as:
Here, we utilized Assumption 3, as
, and thus
. Based on the assumption that the derivative of the vehicle’s velocity with respect to time is constant, the predicted value of the terminal velocity can be calculated as follows:
It is important to note that, since the deviations in aerodynamic parameters and atmospheric density cannot be determined in advance, it is not feasible to calculate
using Equation (
7d) in practice. However, in real-world applications,
can be directly obtained from the output of an accelerometer.
Then, the average velocity over the entire flight process can be obtained using the following equation:
Therefore,
in Equation (
23) can be replaced with the average velocity
, thereby obtaining a new estimate for the time-to-go, expressed as
In general, is not directly equal to . However, after a few iterations of the above process, the estimate of time-to-go converges quickly.
It is worth noting that in the above analysis, we implicitly used two assumptions:
is constant, and the leading angle
is also constant. These assumptions may introduce errors in the final estimate. However, the estimation error of the time-to-go will also gradually converge to zero as the distance between the UAV and the target continues to decrease. The time-to-go estimation approach is shown in Algorithm 1.
| Algorithm 1 Improved time-to-go estimation algorithm |
Input: Error tolerance , maximum number of iterations , distance , leading angle , velocity and the rate of change in velocity Output: Estimated value of time-to-go
- 1:
Let , - 2:
while
do - 3:
Let - 4:
Estimated the final velocity of vehicle - 5:
Obtain the mean velocity - 6:
Obtain the new estimated value of time-to-go - 7:
- 8:
if then - 9:
Break - 10:
end if - 11:
end while - 12:
return The estimated value of time-to-go .
|
The proposed time-to-go estimation algorithm has the following advantages: First, it does not rely on any specific guidance law, making it applicable to a broader range of scenarios. In contrast, traditional analytical prediction formulas [
8,
9,
10] can only predict the remaining flight time for trajectories derived from PNG. Second, compared to numerical integration methods, the proposed method benefits from its simple iterative process, offering superior real-time performance.
To avoid the excessive overload of the vehicle during flight, the action space was formed as an acceleration command, that is,
where
and
are the required acceleration of the vehicle in the horizontal and vertical planes, respectively.
There are two principal reasons for adopting the acceleration command as the action. Firstly, the overload of the vehicle can be easily made to satisfy the constraints by applying a clip operation to the output of the policy . Secondly, although taking the command angular rates as action is an end-to-end solution, which makes the problem formulation more concise, it may prove challenging in terms of achieving convergence on the policy of the agent.
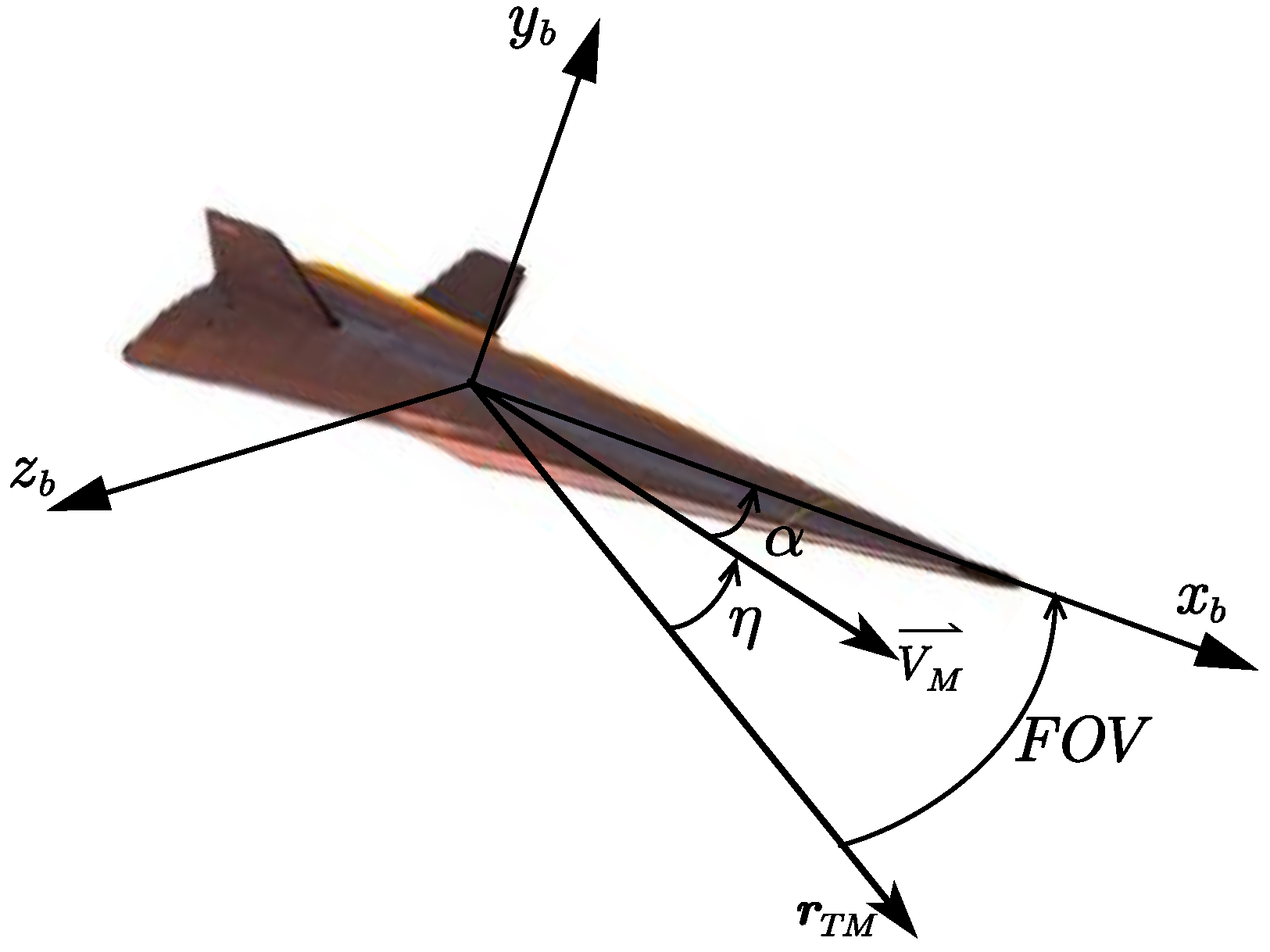
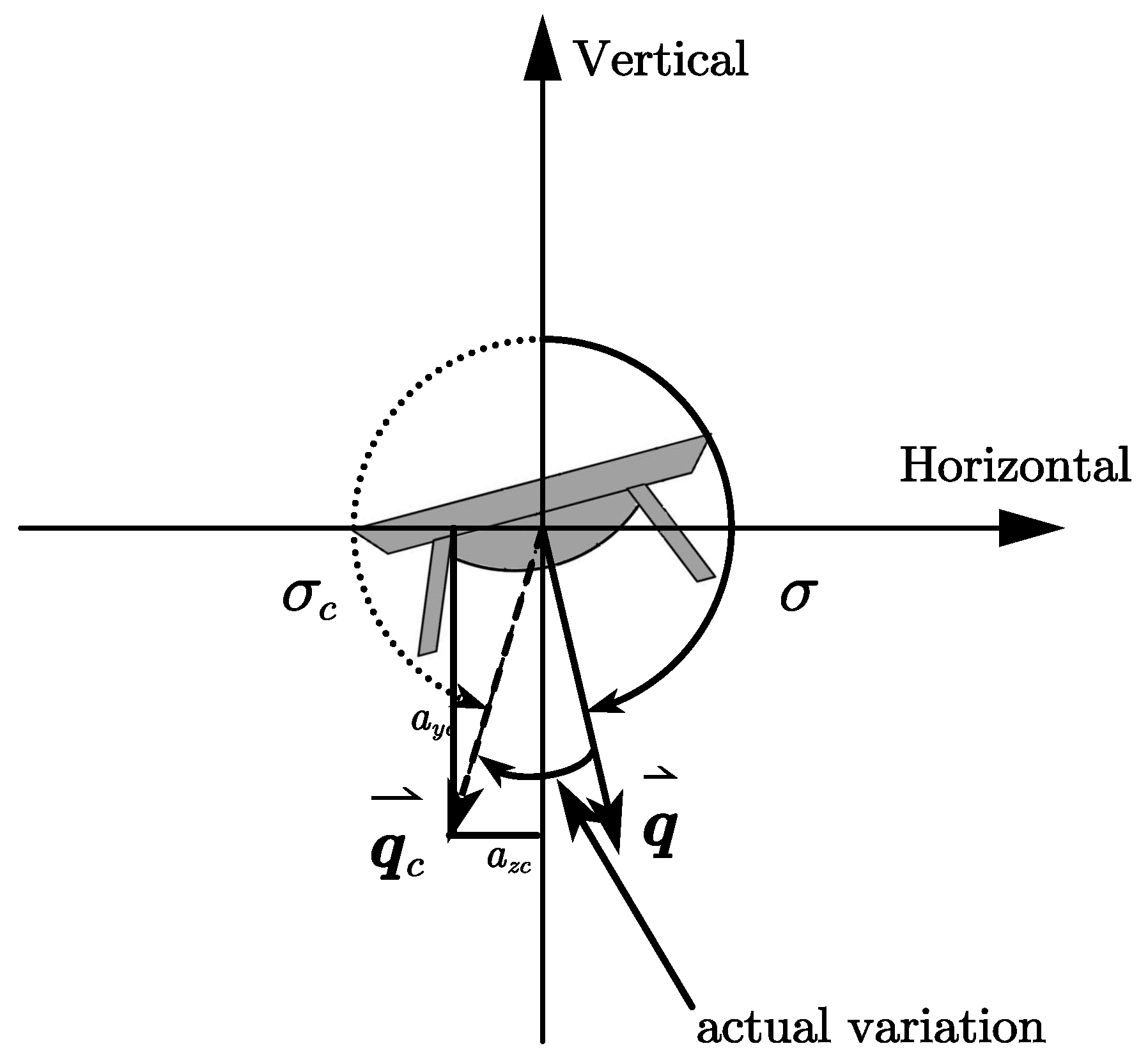
Although a method for calculating the angle of attack and bank angle commands was proposed in ref. [
35], applying that method implies that when the sign of the required lift changes, the sign of the bank angle must also change accordingly. When the sign of the bank angle change occurs for larger orders of magnitude of the bank angle, it leads to the occurrence of undesired transient processes. To circumvent this challenging problem, we adopted an unlimited bank angle scheme which was employed in [
12] (as illustrated in
Figure 4). Consequently, a simple and effective computational approach is given.
Based on the action of the agent, the commands
can be obtained by solving the following equation:
where
and
represent the minimum and maximum values of the vehicle’s angle of attack, respectively.
denotes the required lift force, whose expressions are given by the following equations:
Equation (
28) is essentially a single-variable root-finding problem. In this paper, the Newton–Raphson method was employed to solve Equation (
28). However, alternative methods such as the secant method or Brent’s method can also achieve rapid solutions for Equation (
28).
Then, the commanded bank angle
can be obtained by the following equation with the unlimited bank angle control scheme:
Finally, the commanded angular rate can be obtained by the following equations
where
is the guidance period.
The adoption of an unlimited bank angle control scheme is motivated by two primary reasons: First, to satisfy the requirement for dive attacks, the high-speed UAV must generate a negative lifting force. If the bank angle is restricted to the range , the negative lift force can only be achieved through the negative angles of attack. However, for non-axisymmetric high-speed UAVs, the aerodynamic effects of negative and positive angles of attack often differ significantly, which increases control complexity. Second, when the high-speed UAV approaches the target, oscillations in guidance commands inevitably occur. When the sign of the required lateral acceleration changes, the unlimited bank angle control scheme allows the bank angle to adjust by a small magnitude. In contrast, if the bank angle is restricted to , a sign change in would require large variations in the bank angle, severely compromising the flight stability of high-speed UAVs.
4.2. Reward Function and Termination Conditions
The most significant challenge in using DRL to address the UAV with time-varying velocity guidance problem is developing an effective reward function in a sparse reward environment. If the reward signal is given only if the vehicle arrives at the target and satisfies the process and terminal constraints, it is probable that, with a limited number of episodes, the policy of the agent may encounter difficulty in identifying and exploiting positive samples.
The potential-based reward shaping (PBRS) method was proposed in [
36] to avoid the challenge of a sparse reward environment. Inspired by PBRS, a compound reward function was designed that provided cues to the agent within each time step, thereby motivating the vehicle to reach the target. The shaping reward was designed for keeping the LOS angular rate of the vehicle as small as possible, that is,
where
,
is a positive constant, and
is the LOS angular rate’s scaling factor.
Then, we also need to keep the arrival time error within tolerance. The reward signal on arrival time error is
where
is a positive constant, and
is the arrival time error’s scaling factor.
Meanwhile, in order to achieve a dive attack, an overly smooth path angle is undesirable behavior. Therefore, a penalty signal must be applied to the dive angle error, that is,
where
is a positive constant, and
is the dive angle error’s scaling factor.
From Equations (
28) and (
29), it can be derived that the required lift
and the commanded acceleration
are positively correlated. This implies that as
increases,
also increases, resulting in a higher commanded angle of attack
. Consequently, the drag coefficient
increases, leading to greater energy loss. Therefore, to minimize the energy consumption of the vehicle guidance policy, we introduced a negative reward signal to penalize excessive vehicle commanded acceleration, that is,
where
is the output of the policy.
Finally, for terminal conditions that satisfy the constraints, it is necessary to provide an appropriate bonus signal:
where
is a positive constant, and
is the impact velocity scaling factor.
Combining Equations (
32), (
33), (
35), and (
36), the reward signal for each time step can be obtained as follows:
Equation (7a–h) was solved by employing the fourth-order Adams prediction-correction numerical integration method with a time step, and the initial four steps were integrated using the Runge–Kutta method. In addition, to ensure sufficient accuracy, the time step was reduced by a factor of 100 when the distance was less than .
Given the mission profile and operational constraints, the terminal criteria were formally established as follows:
The height of the vehicle is less than zero;
The FOV constraints or the overload constraints are violated;
The vehicle is flying in a direction that is away from the target;
The vehicle has arrived at the target successfully.
It is of significant importance to note that the current episode will be terminated if the constraints are violated. In such an instance, the agent will not receive a terminal reward. This incentive is sufficient to encourage the agent to learn to satisfy the constraints; therefore, no negative reward is required when the constraint is violated.
4.3. Policy Optimization
In light of the satisfactory performance of GRU in long-term historical memory, a GRU layer was introduced into the actor network and the critic network with the objective of enhancing the generalization ability of the policy under different task conditions. This integration enabled the policy to adapt to varying tasks through the updating of the hidden states of the GRUs.
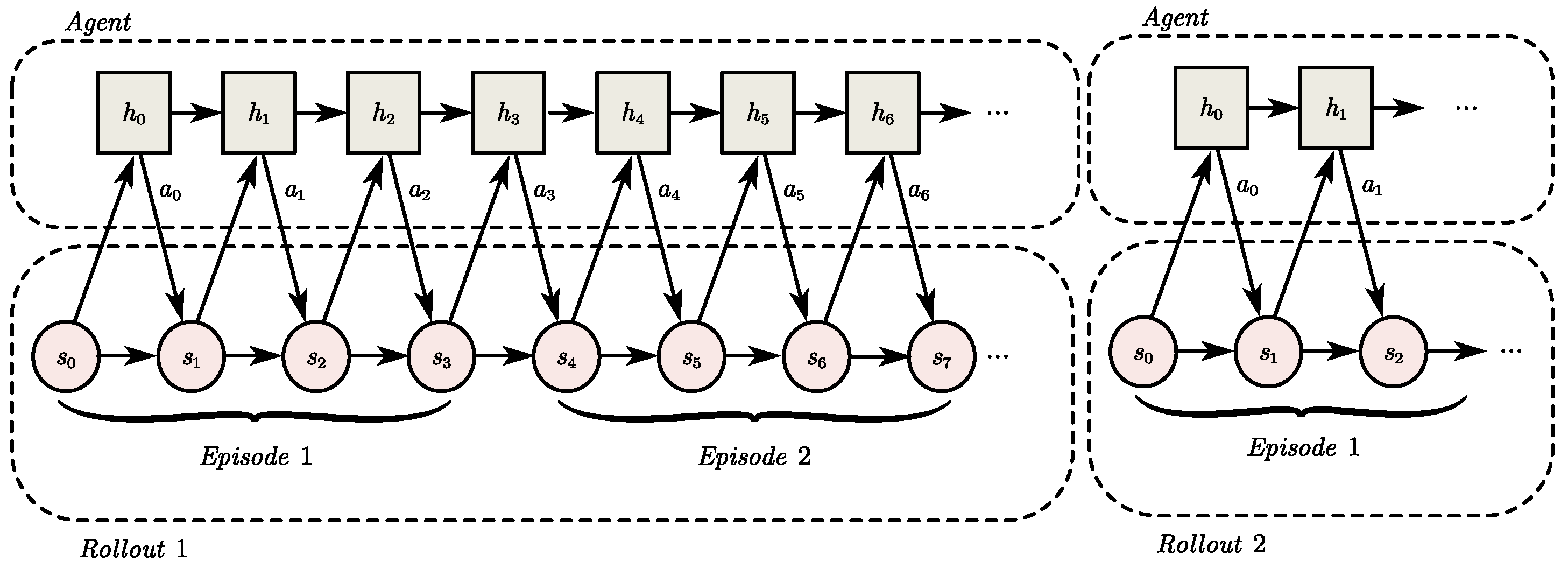
It should be noted that when GRU layers are introduced into policy and value networks, the way to update the hidden state of the GRU layer during the rollout collection process has a significant impact on the training effect. Inspired by [
33,
37], the hidden state was reset before the start of each rollout. However, the hidden state of each episode in the same rollout was inherited from the previous episode. The interaction protocol between the learning agent and its operational environment is illustrated in
Figure 5. It should be noted that the length of each episode may vary, although this is not explicitly shown in
Figure 5. Through this design, the aim was to encourage the agent to update the parameters of the GRU layer so that updates to its hidden state could be used to describe an embedded representation of the current environment or task. This provided the agent with multi-level input features for rapid adaptation to different environments and tasks, thereby enhancing the adaptability and generalization performance of the final network.
The PPO algorithm has two versions of the objective function. The first is the clipped surrogate objective, whose expression is shown in Equation (
2). The second involves incorporating the KL divergence into the objective function as a penalty, and the penalty coefficient is adaptively adjusted so that the KL divergence can reach a specific target value
during each policy update.
In general, it is more straightforward to achieve convergence when utilizing the clipped surrogate objective. However, this approach inevitably requires a longer training process. In contrast, it is challenging to achieve convergence when employing the adaptive KL penalty coefficient. Therefore, in order to strike a balance between the speed and stability of the training process, the two aforementioned methods were combined in a novel manner, whereby the clipped factor
and the learning rate
of the policy network were adaptively adjusted in order to achieve the target value of the KL divergence
, that is,
In the training phase, the experience data were fully utilized through the conduct of
E update epochs, The training process involved a range of generic operations, including ratio calculation, the computation of various losses, and gradient clipping. The adaptive PPO (APPO) algorithm is shown in Algorithm 2.
| Algorithm 2 Adaptive PPO (APPO) algorithm |
Input: Target value of the KL divergence , number of epochs M Output: The optimized parameters of actor , and critic w
- 1:
Initialize network parameters, including the actor , and critic w - 2:
for epoch = do - 3:
Initialize replay buffer R and reset the hidden states of the RNNs - 4:
for episodes = do - 5:
Reset the environment; - 6:
while not done do - 7:
Obtain the current observation - 8:
The observation is fed to the actor to obtain the action - 9:
Execute one step in the environment - 10:
Store into R - 11:
end while - 12:
end for - 13:
Calculate discounted returns G and advantages - 14:
for opt = do - 15:
Calculate policy network loss, value network loss, and KL divergence - 16:
Update - 17:
Adjust the clipped factor and the learning rate - 18:
end for - 19:
end for - 20:
return The optimized parameters
|






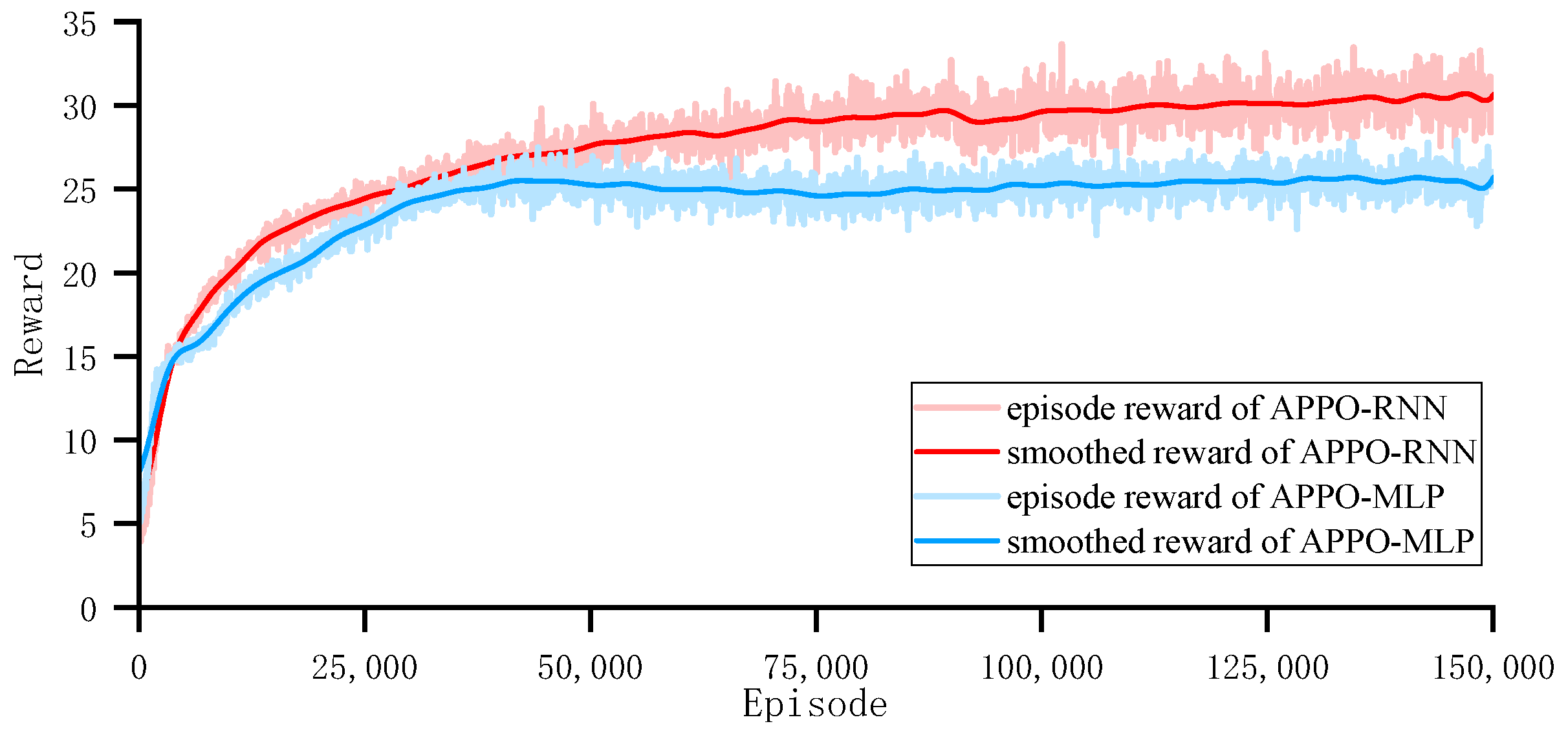
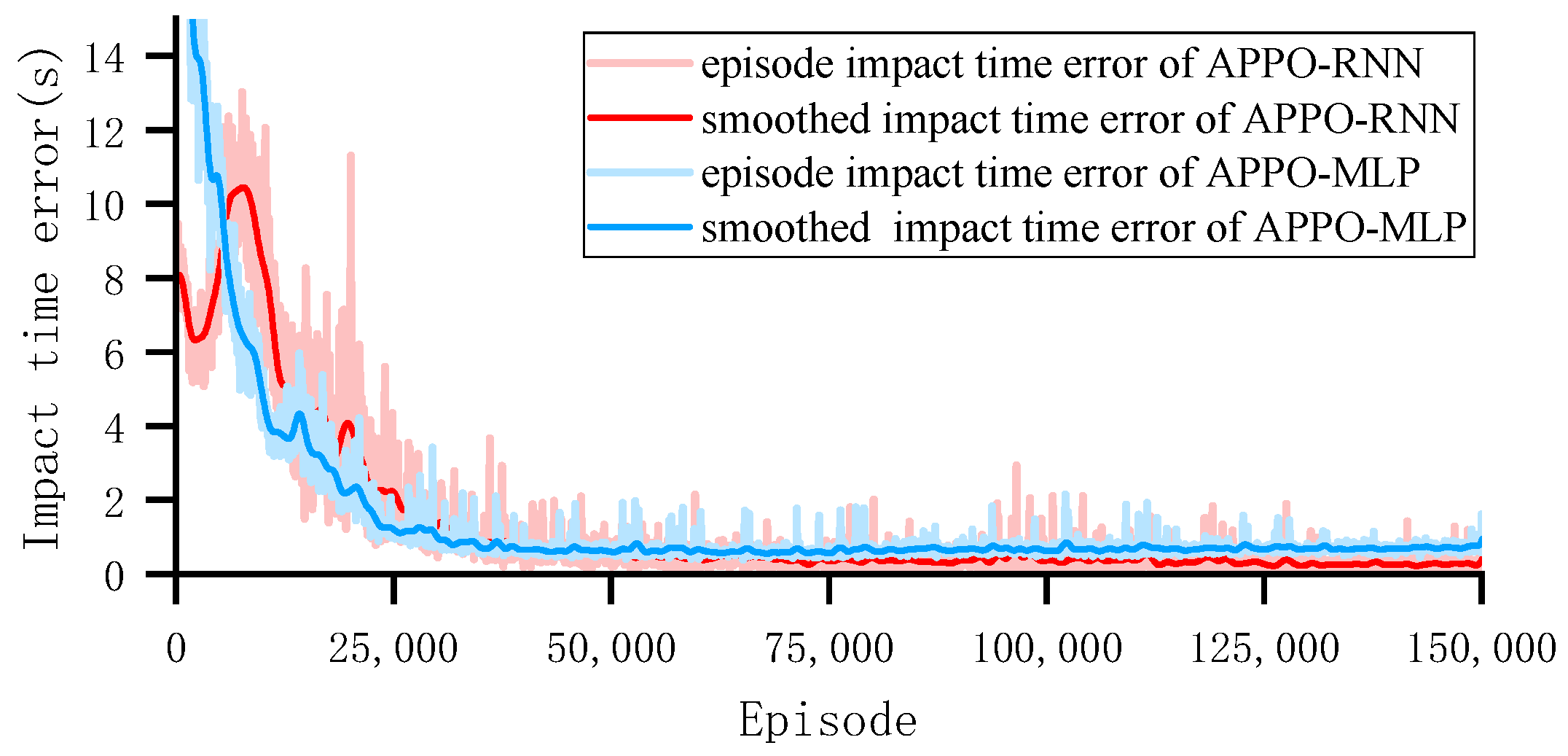
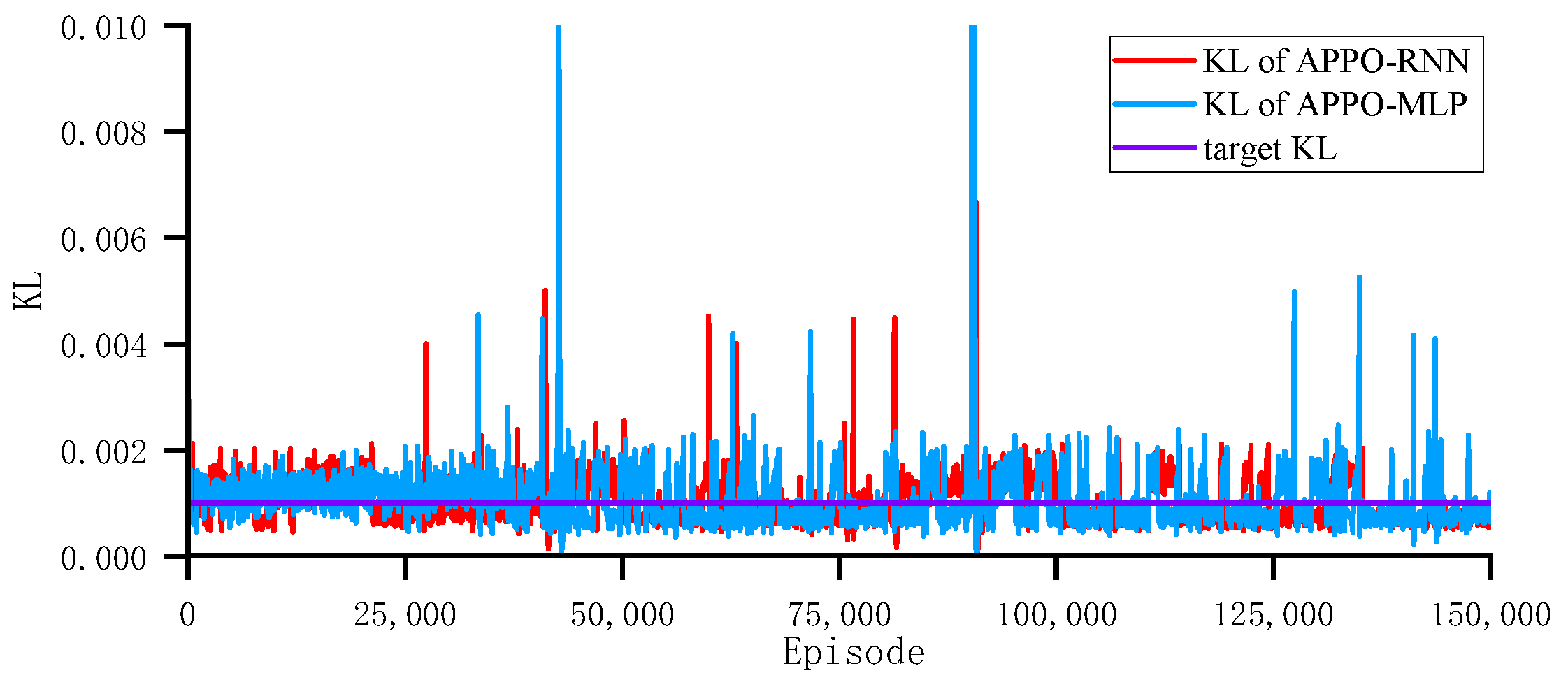
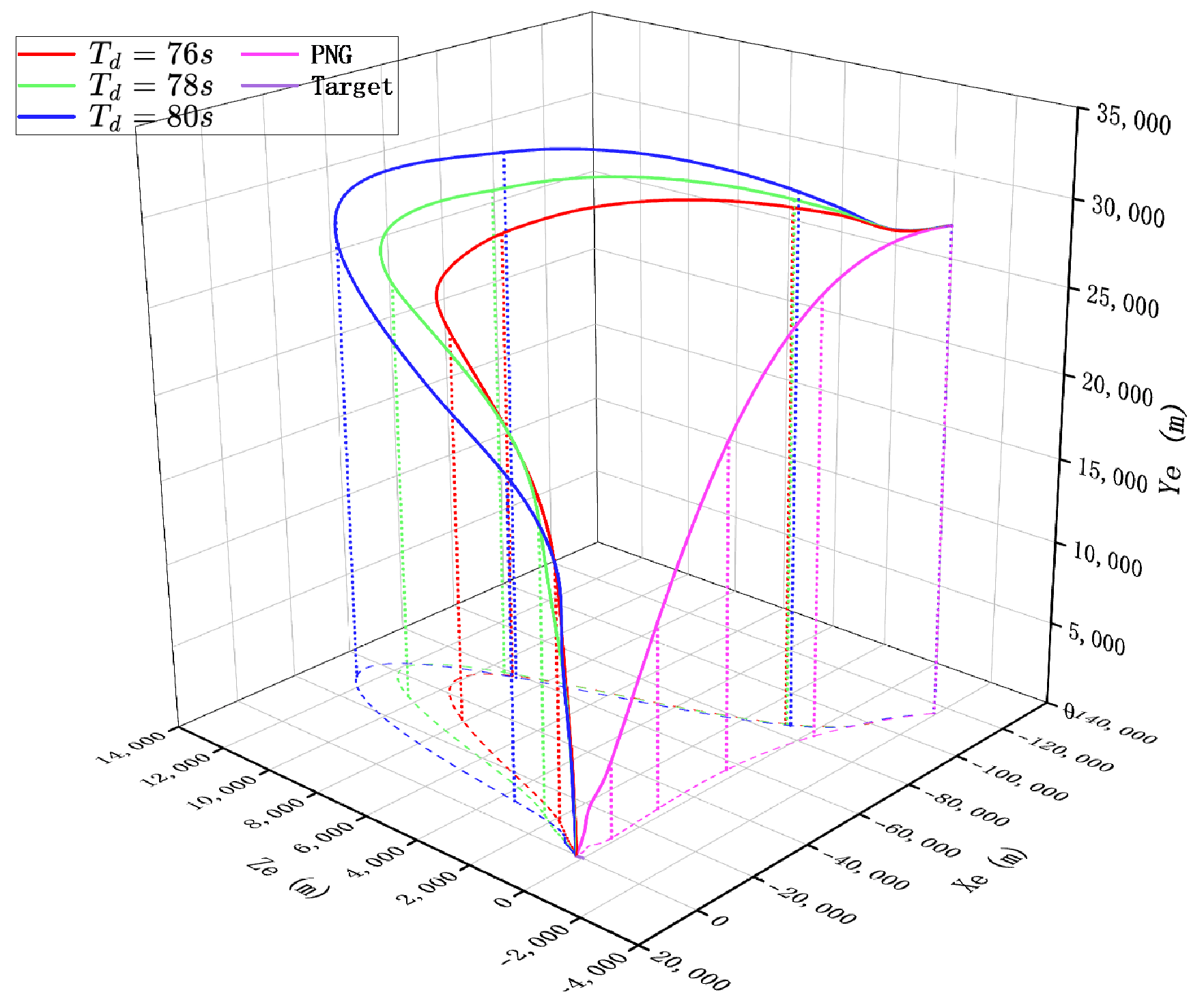
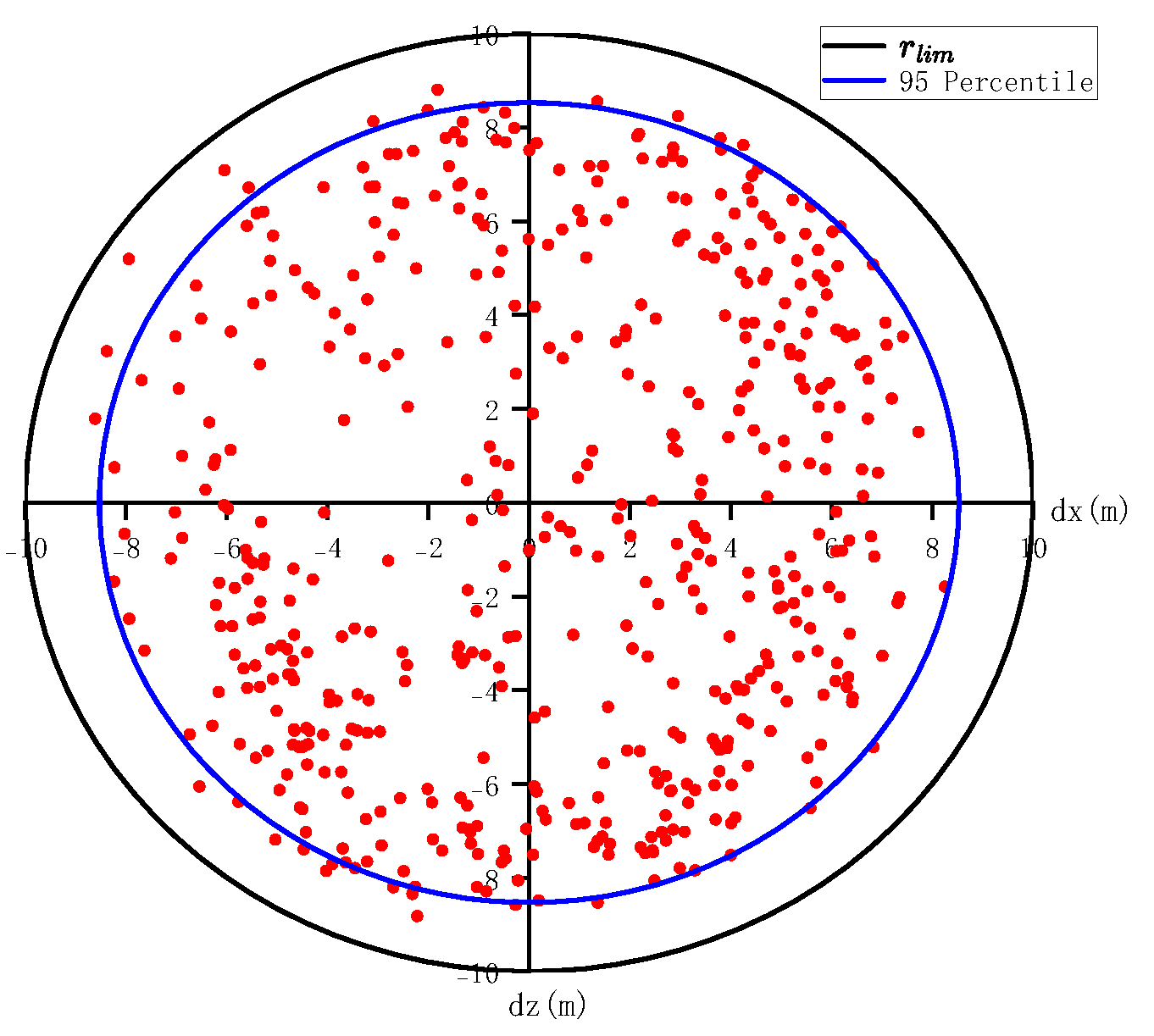
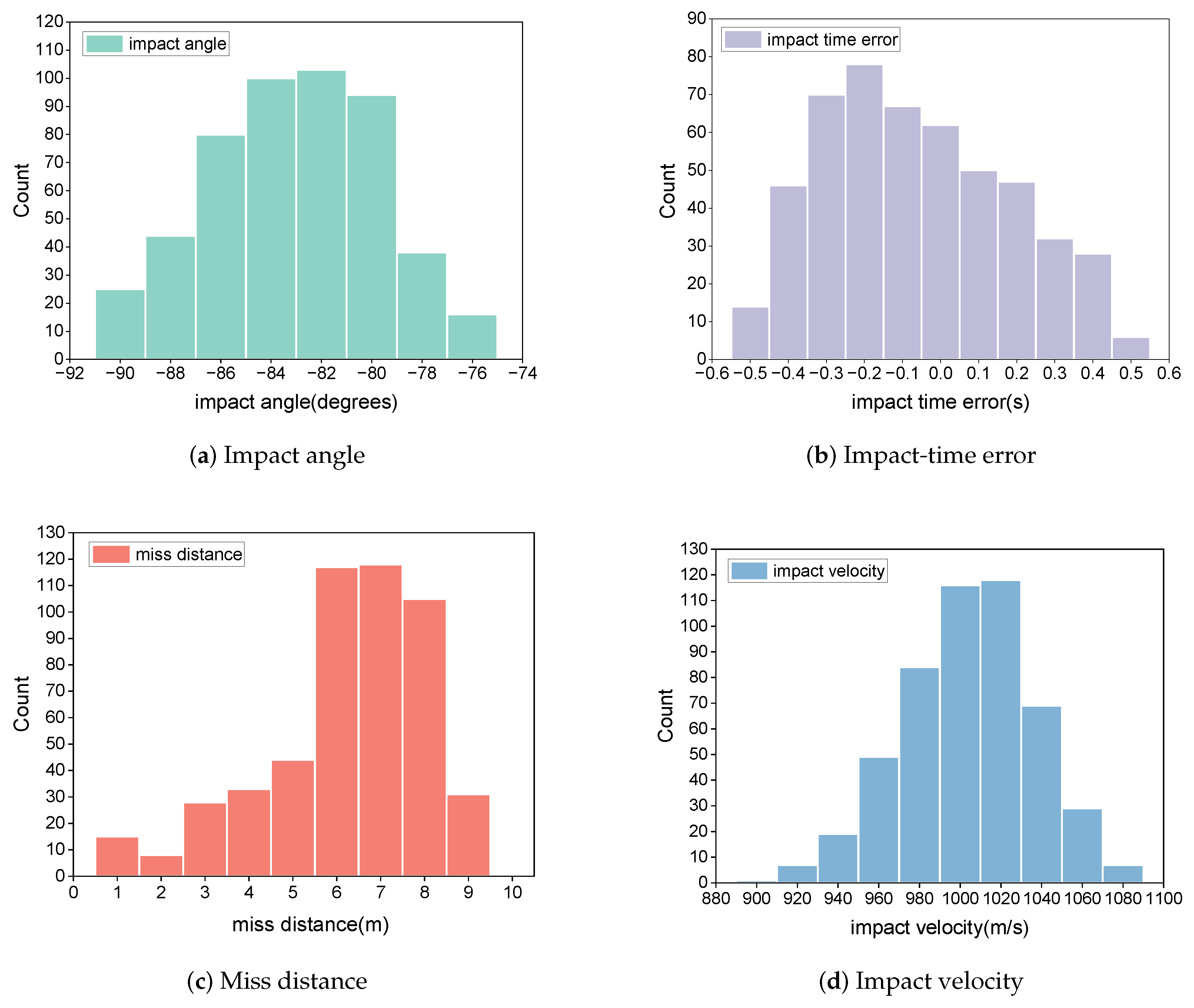

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}