1. Introduction
With the advancement in quadcopter technology, quadcopters have quickly become a popular flying platform across various application fields. Their simple design, adaptability in control, and ability to perform vertical flight maneuvers have made them widely adopted. They are not limited only to traditional military reconnaissance and geographic mapping, but also play an important role in logistics and transportation, environmental monitoring, agricultural management, and emergency rescue [
1,
2,
3]. However, due to the limitations of a quadcopter’s batteries, quadcopters cannot sustain prolonged flight and must land frequently. Ensuring a safe and stable landing in various conditions is thus a critical challenge in enhancing the autonomy of quadcopter missions. Particularly in dynamic environments, autonomously identifying and accurately locking onto a landing point without human intervention presents a significant challenge for quadcopter systems. Therefore, intelligent recognition systems and precise autonomous guidance strategies are crucial. They not only ensure the safety of quadcopter landings but also directly impact the success rate of the mission [
4,
5].
In the early days, many scientists used traditional guidance strategies based only on GNSS [
6,
7]. However, GNSS signals are often blocked or interfered with in complex or restricted environments, leading to significant positioning errors. As a result, GNSS alone cannot meet the requirements for the high-precision fixed-point landings of quadcopters. With the advancement in image recognition technology, vision-based and image processing techniques have gradually emerged, offering a more accurate and reliable solution. This approach improves the precision of quadcopter landings while minimizing dependence on external positioning systems, fostering the further development of autonomous quadcopter mission capabilities. Landing based on drone vision is usually affected by two factors: target recognition accuracy and landing control stability.
For target recognition, while traditional edge detection algorithms can identify the outlines of landing targets in simple environments, they have significant limitations in more complex environments. Edge detection algorithms are highly susceptible to changes in lighting, noise interference, and background complexity, which can lead to reduced target recognition accuracy [
8,
9,
10]. Additionally, in our previous experiments, during high-altitude flight, the landing target appears too small in the field of view, making it challenging for the edge detection algorithm to identify it accurately [
11]. In such cases, traditional edge recognition algorithms struggle to effectively identify larger secondary targets, such as dynamic objects like vehicles, and are unable to perform pre-tracking and positioning to assist with landing. Mainstream approaches are now categorized into one-stage and two-stage detection methods as a response to the rapid development of object detection technologies and the challenges in target recognition. First, the two-stage methods, for example, Faster R-CNN [
12], offer high accuracy but are slow and computationally intensive. In contrast, one-stage methods, including well-known approaches like YOLO and SSD, significantly improve detection speed by integrating target positioning and classification tasks, making them particularly suited for real-time scenarios [
13,
14,
15,
16]. With advancements in algorithm and architecture optimization, YOLO’s accuracy has been significantly improved, even surpassing two-stage methods in some scenarios, making it the preferred solution for complex target detection tasks. Lee et al. developed a deep learning-driven solution for automatic landing area positioning and obstacle detection for quadcopters. However, this approach is susceptible to false detections due to perspective changes and the presence of obstacles [
17]. Leijian Yu et al. integrated the improved SqueezeNet architecture into YOLO to detect landing landmarks and make it robust to different lighting conditions. However, it was not tested in dynamic and complex environments [
18]. BY Suprapto et al. used Mean-Shift and Tiny YOLO VOC to detect falling targets, but the Mean-Shift method had a poor detection effect on moving objects and, although Tiny YOLO VOC had high detection speed and accuracy, its detection performance would decrease at higher altitudes [
19]. Ying Xu et al. developed an advanced A-YOLOX algorithm, incorporating an attention mechanism to enhance the autonomous landing capabilities of quadcopters, particularly improving the recognition of small and mid-sized objects as well as adapting to varying lighting conditions. However, the article mentioned that the control algorithm still needs to be further optimized to enhance the safety of landing [
20]. Tilemahos Mitroudas et al. compared the YOLOv7 and YOLOv8 algorithms in a quadcopter safe landing experiment and found that the performance improvement of YOLOv8 made detection and data more reliable [
21]. Kanny Krizzy D. Serrano et al. compared four generations of algorithms from YOLOv5 to YOLOv8 to ensure the safe landing of quadcopters, and found that YOLOv8 achieved the highest average accuracy, outperforming other YOLO architecture models [
22]. During the dynamic landing of UAVs, factors such as complex background environment, changes in lighting conditions, and local blur of targets will affect the accuracy of target recognition, and the difficulty in detecting small targets at high altitudes further exacerbates this challenge. Therefore, improving the performance of the recognition algorithm, enhancing the ability to extract key features, enabling UAVs to accurately focus on the target area under complex background conditions and improving the compatible detection capabilities of multi-scale targets are of great significance to improving the success rate in the stable landing of UAVs.
In conclusion, once the target is identified, it is essential to implement a controller that guarantees the stability throughout the landing procedure [
20]. Lin et al. proposed a visual servo-based landing controller (PBVS) for landing on a mobile platform. The controller has low computational complexity and strong robustness, but it relies on the camera’s field of view and has high requirements for parameter adjustment [
23]. Wu et al. proposed a RL-PID controller that can automatically adjust the PID parameters during the landing process, but its landing accuracy is greatly affected by environmental changes [
24]. Alireza Mohammadi et al. employed the extended Kalman filter for position estimation using UAV vision, while utilizing an MPC controller to achieve dynamic landing. But, the calculation complexity was high and it was more dependent on the model [
25]. In addition to the methods mentioned, various controllers like PID control [
26,
27], backstepping control [
23,
28], and adaptive control [
29,
30] have also been used for quadcopter landing. Among them, the sliding mode controller excels in dynamic landing due to its strong robustness and adaptability to uncertainty and disturbances. It can effectively handle environmental changes and uncertainties in system models [
31,
32,
33], and therefore can help improve landing accuracy and stability during landing to a certain extent. Therefore, this paper selects a sliding mode controller to enhance the stability of the UAV in dealing with disturbances during landing.
Based on the previous discussion, to achieve the precise dynamic landing of quadcopters, the landing target detection system in this paper is built upon the advanced YOLOv8 OBB algorithm. Additionally, RMSMC is utilized during the landing process to ensure both stability and accuracy in landing control. The primary contributions of this paper include the following:
To ensure precise positioning of the landing point, we enhanced the YOLOv8 OBB algorithm and deployed the optimized model on the quadcopter. By combining pixel error conversion with attitude angle compensation, we were able to obtain accurate distance errors, enabling the quadcopter to precisely identify the landing point. The accuracy and feasibility of this method were validated through experiments.
The performance and accuracy of the landing system were verified through flight tests. The results show that the improved YOLOv8 OBB algorithm improves mAP@0.5 by 3.1% and mAP@0.5:0.95 by 2.61% on the VisDrone/DroneVehicle datasets, and mAP@0.5 by 0.5% and mAP@0.5:0.95 by 2.1% on private datasets, compared with the latest version of YOLOv8 OBB. In addition, when the proposed controller is deployed, the maximum position tracking error is kept within 0.23 m and the maximum landing error is kept within 0.12 m. The experimental video can be found at
https://doi.org/10.6084/m9.figshare.28600868.v1 (accessed on 26 March 2025).
The structure of this paper is as follows:
Section 2 and
Section 3 provide an overview of the system architecture, including the design of the vision algorithm and controller.
Section 4 describes the experimental setup and presents the results. Finally,
Section 5 concludes the paper and outlines future work.
2. Visual Identification System Design
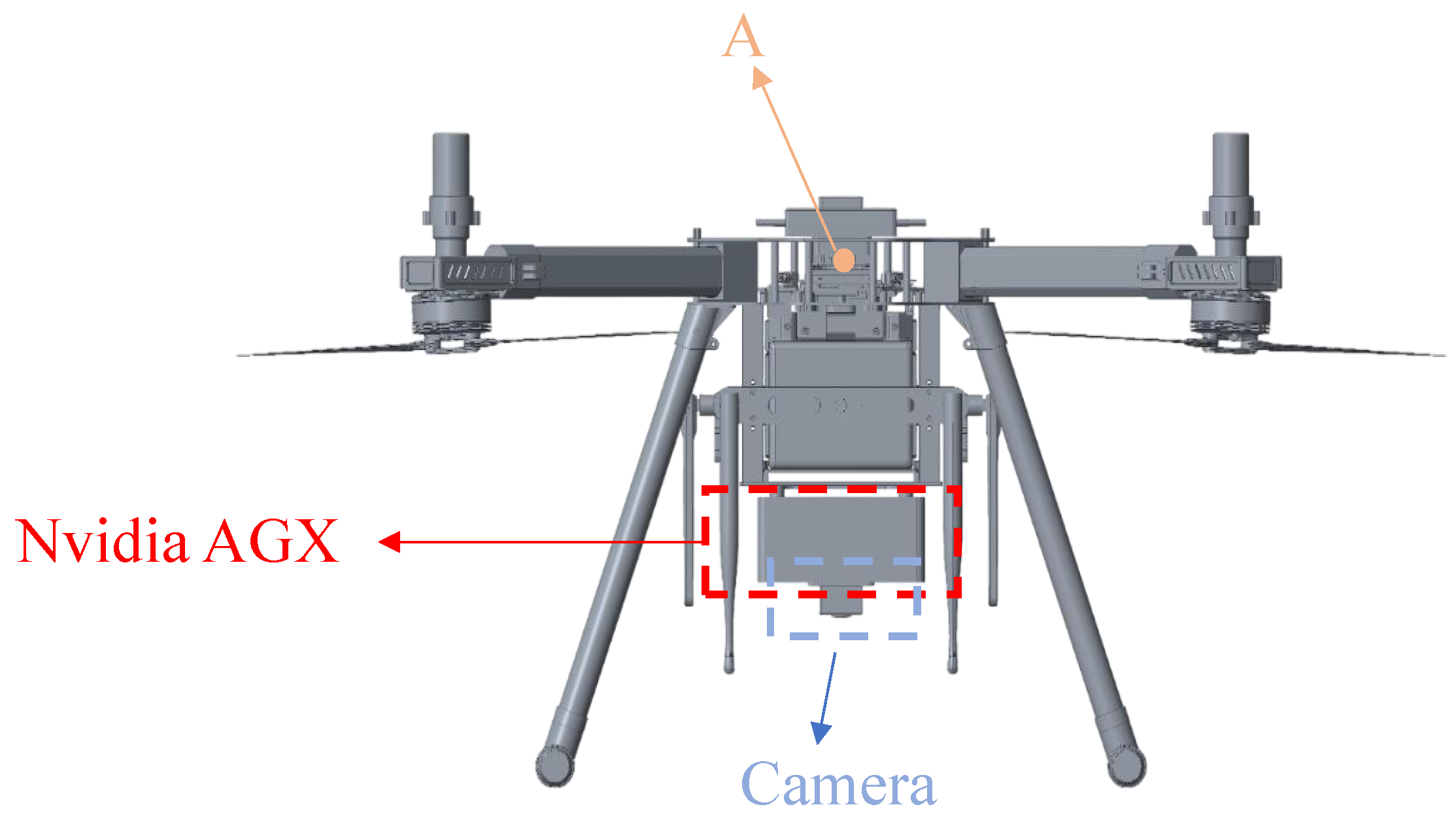
The quadcopter used in this system was independently developed by our team, as shown in
Figure 1.
Figure 2 illustrates the system structure. First, quadcopters are used to collect the necessary experimental data. Then, the landing target recognition model is trained on an external computer before being deployed to the onboard Nvidia AGX platform. The overall system workflow is as follows: the image captured by the camera in real time is transmitted to the Nvidia AGX for recognition processing. Specifically, Nvidia AGX calculates the pixel error, converts it into the actual distance error based on the recognition results, and feeds this information back to the flight control system. Finally, the quadcopter adjusts its position using position and altitude control to ensure that the landing point remains centered beneath the quadcopter. The bottom layer of the system consists of the camera driver and quadcopter sensors. The framework layer includes open-source libraries such as Robot Operating System (ROS), PyTorch, and OpenCV. The application layer handles the flight control and dynamic landing of the quadcopter.
2.1. YOLOv8 OBB Algorithm
To improve landing adaptability, this paper adopts the YOLOv8 OBB algorithm, which incorporates the target’s rotation angle as part of the landing recognition process. YOLOv8 OBB integrates an oriented bounding box (OBB) mechanism into the YOLOv8 framework to enhance detection of objects with strong directional features. To enhance the input data, some advanced augmentation methods, including cropping accompanied by certain rotation operations, are applied, achieving a 3.1% accuracy improvement on the COCO dataset. During training, the model stabilizes learning by refining the data augmentation strategy in the final epochs, enabling efficient training from scratch without requiring pre-trained models. Structurally, YOLOv8 and YOLOv8 OBB share the same backbone (EfficientNet) and neck, which combines a feature pyramid network (FPN) with a spatial attention module (SAM).
YOLOv8 OBB builds upon YOLOv8 by modifying the output layer to include an oriented bounding box detection head, enhancing rotated object detection accuracy and speeding up convergence, albeit with slightly higher computational demands. To optimize performance and efficiency, it uses a 1 × 1 convolution in the output layer for dimensionality reduction and employs a 5 × 5 convolution in subsequent layers to control parameter expansion, ensuring high-precision detection is preserved.
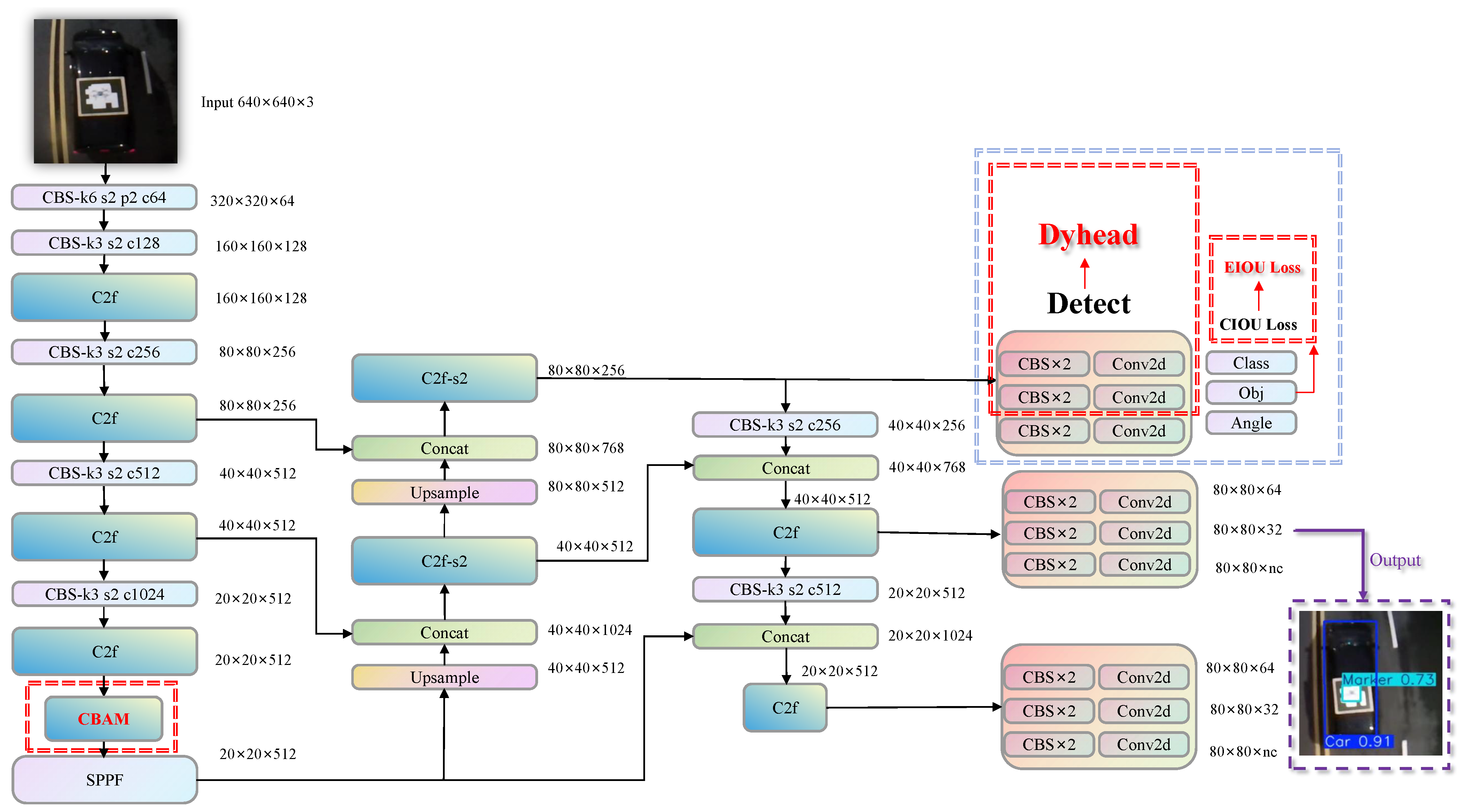
2.2. Improved YOLOv8 OBB Algorithm
The accuracy of landing target recognition is crucial to ensure the safety and precision of the landing process. Factors such as complex backgrounds and lighting changes can significantly affect recognition performance, and the difficulty in detecting small targets at high flight altitudes further increases the challenge. To enhance recognition accuracy, this paper improves the baseline YOLOv8 OBB model by integrating three key components: the Convolutional Block Attention Module (CBAM) [
34], Dyhead [
35], and EIoU loss.
First, a CBAM is incorporated following the last layer of the backbone to capture spatial information while preserving precise positional data. This integration improves the model’s focus on critical areas within complex scenes, enabling accurate landings across diverse environments. Second, the Dyhead module is employed to dynamically refine feature representations across multiple scales and directions, enhancing the receptive field and robustness to objects of varying orientations and sizes. This further improves recognition accuracy and model stability. Additionally, in the dynamic quadcopter landing task, where large vehicles are identified before smaller landing spots, the original CIoU loss is replaced with EIoU loss. This adjustment enhances accuracy, ensuring the quadcopter reliably identifies landing targets even in challenging environments. Together, these modifications significantly improve detection performance, particularly in dense and directionally complex scenes. The improved YOLOv8 OBB structure is illustrated in
Figure 3.
2.3. Convolutional Block Attention Module
In the realm of object detection, the attention module is commonly employed to improve the model’s ability to focus on important features, boosting both selectivity and sensitivity. Common attention mechanisms include compressed excitation network (SENet) [
36], coordinated attention (CA) [
37], efficient channel attention (ECA) [
38], and CBAM [
34]. SENet improves the importance of features by compressing feature maps along spatial dimensions using global average pooling to generate global descriptors, followed by a scaling step that amplifies key features and reduces the influence of less relevant ones. ECA improves the attention of the channel by replacing SENet’s fully connected layer with a 1 × 1 convolution, eliminating dimensionality reduction and reducing parameters while maintaining efficiency and accuracy. CBAM extends SENet by incorporating spatial attention alongside channel attention, enabling more precise feature processing. In the dynamic landing task, the integration of CBAM can significantly improve the recognition accuracy of vehicles and landing targets by adaptively refining feature representations through channel and spatial attention mechanisms [
39]. The channel attention module prioritizes the most informative features by reweighting feature maps, while the spatial attention module focuses on key spatial regions to improve the detection of small targets or partially occluded targets. Moreover, its lightweight design minimizes computational overhead, making CBAM particularly suitable for resource-constrained UAV systems that require real-time processing. In addition, it can enhance feature discrimination capabilities under different lighting conditions and complex backgrounds to ensure robust performance, which is critical for the safety and reliability of UAV dynamic landing operations.
To improve recognition accuracy, CBAM optimizes convolutional neural networks for better recognition accuracy by leveraging both channel and spatial attention features. It first employs a channel attention module, using global average and maximum pooling to generate importance weights that emphasize critical features. Next, the spatial attention module processes the feature map using pooling followed by convolution operations, concentrating on key spatial regions.
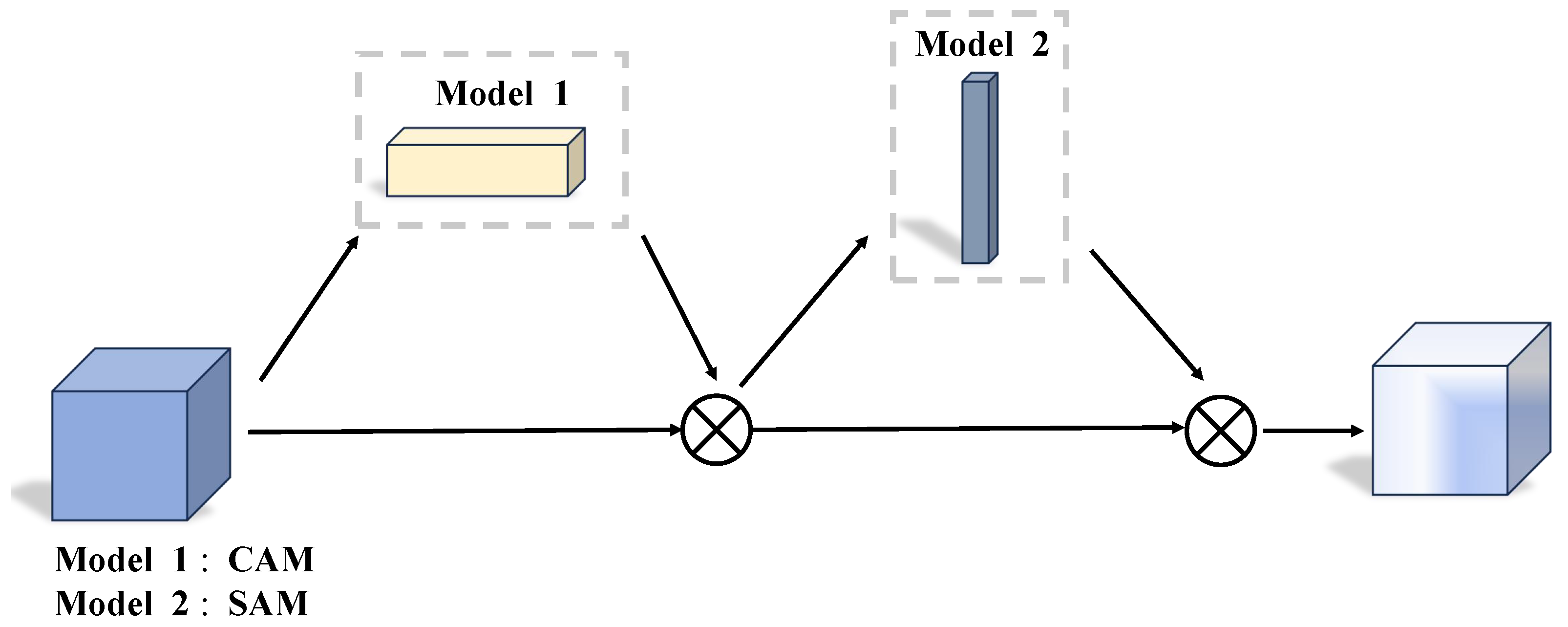
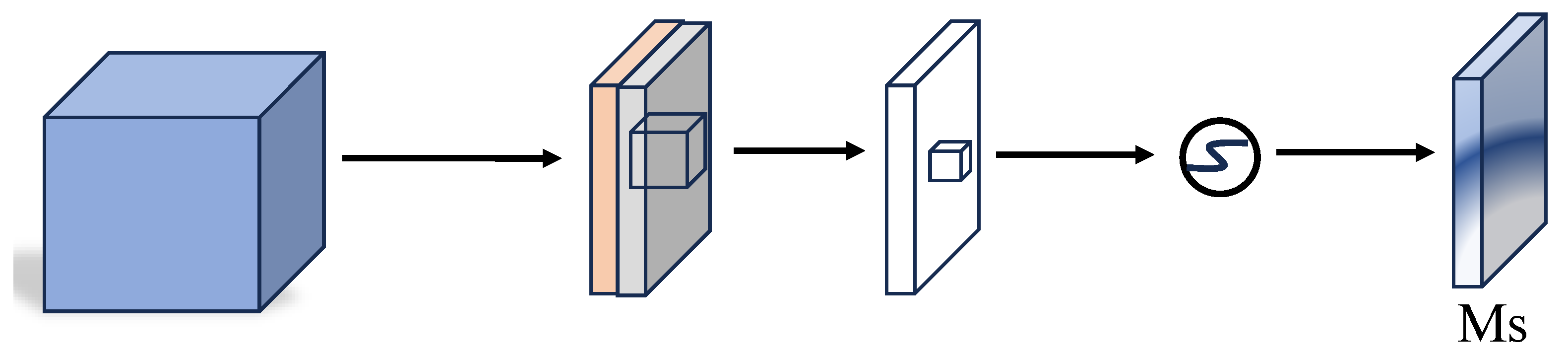
In summary, CBAM is made up of two parts: the channel attention module (CAM) and the spatial attention module (SAM), with their outputs fused through element-wise multiplication to generate the final result. The overall structure is shown in
Figure 4:
Figure 5 depicts the design of the channel attention module (CAM). The feature map
F is first processed using both global average and maximum pooling operations. The pooled results are subsequently fed into a multi-layer perceptron (MLP) to generate the channel attention weights
. These weights are then applied to the original feature map
F to emphasize the most relevant feature channels, and the final output is obtained by applying a sigmoid activation.
Figure 6 illustrates the design of the SAM. The module takes as input the feature map produced by the CAM, from which two separate feature maps are generated using global maximum and average pooling operations to capture spatial importance. These pooled maps are then concatenated along the channel axis and passed through a convolutional layer to compute the spatial attention map
. This attention map is then element-wise multiplied with the input feature map, producing the final output of the SAM.
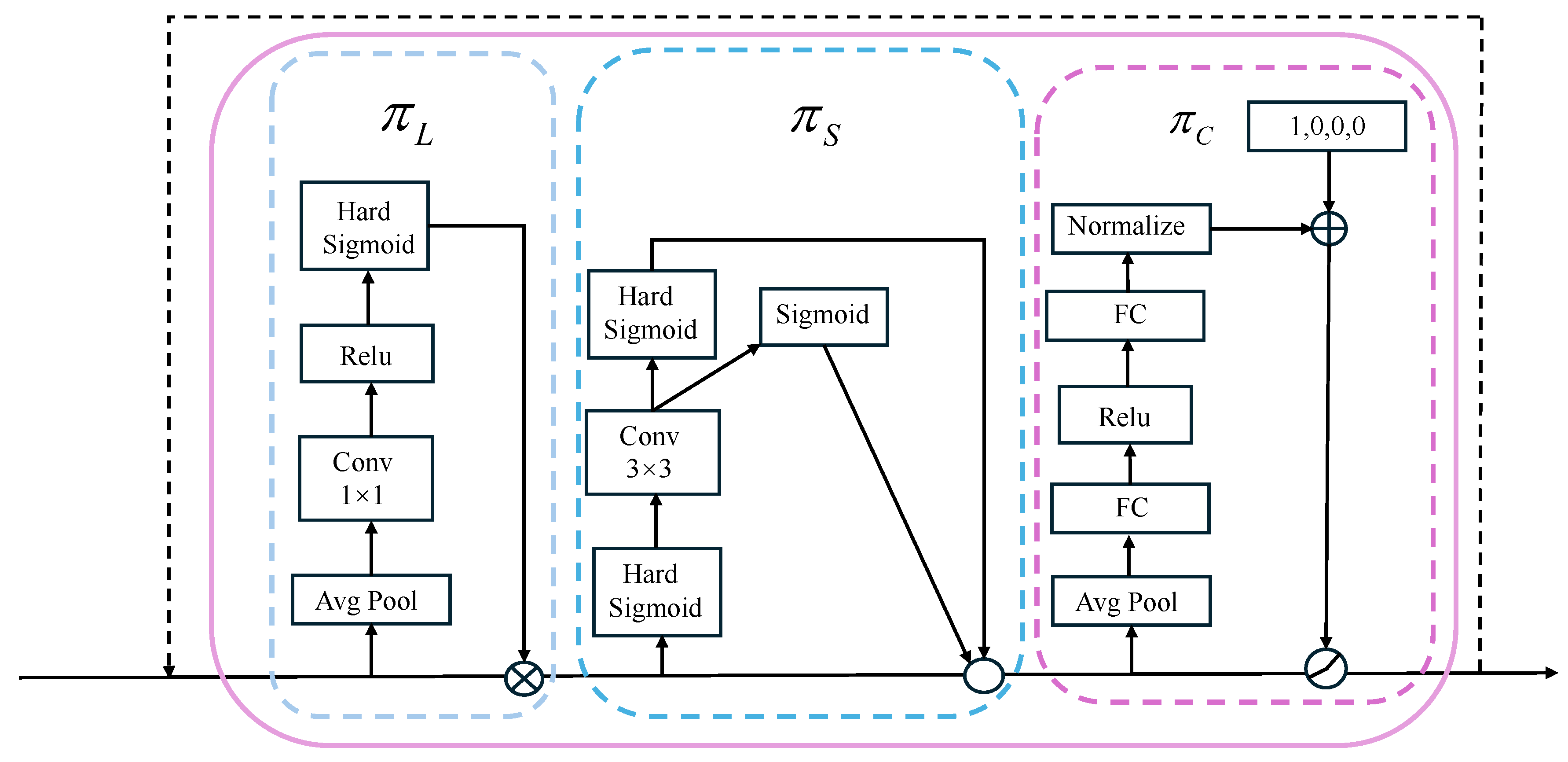
2.4. Dynamic Head
In dynamic landing tasks, when the flight altitude is high, the landing target is usually smaller, and the detection difficulty increases accordingly. In recent years, Dyhead, as a novel dynamic detection head framework, has significantly improved the performance of small target detection and object detection in complex scenes [
40]. Dyhead improves the capability of the detection head by incorporating several self-attention layers, which allows for better feature representation and enhanced focus on important regions within the input data, combining the scale, space, and task perception mechanisms of different feature layers, spatial positions, and task-related channels to achieve more efficient feature representation. More importantly, this optimization does not increase significant computational overhead. Its architecture is shown in
Figure 7:
In
Figure 7, from left to right, the first is
, which is the scale-aware attention mechanism and can be expressed as follows:
In Equation (
1),
refers to a tensor with four dimensions representing the feature pyramid. The first dimension,
L, corresponds to the total number of levels, while
H and
W capture the height and width of the spatial structure, respectively. Finally,
C denotes the quantity of channels within each feature map. For computational efficiency, the tensor is reshaped into a three-dimensional structure
, where
S is the total spatial dimension of each layer, calculated as the product of height and width
. The operation
performs a linear mapping, which is approximated using a
convolution layer. Additionally, the hard sigmoid activation
is defined as
and is applied to map the output values to the range [0, 1]. This simple yet efficient nonlinear activation function helps reduce the computational burden while improving performance by providing a smooth, bounded output.
The second one is
, which is the spatial perception attention, and its equation can be written as follows:
Method involves two main steps: sparse attention learning and cross-layer feature aggregation at the same spatial position. First, the method performs sparse sampling at k positions, where each position is denoted as . A self-learned spatial offset, , shifts the sampling position from to . This modification enables the model to concentrate more accurately on the discriminative regions within the feature map. Additionally, is a scalar representing the importance of the feature at the adjusted position , and is learned through the training process. At the intermediate layer of , the feature activations are used to generate both and .
By leveraging these learned spatial offsets and importance scalars, the method enables the model to selectively attend to the most relevant areas within the input feature maps. It can allocate varying significance to each spatial position, thereby improving the overall detection performance by focusing on critical areas of the feature map.
Finally,
represents the attention mechanism tailored to the task at hand, and its equation can be expressed as follows:
Equation (
3) divides the feature map into two key terms to separately capture and adjust different contributions or interactions,
represents the portion of the feature map linked to the
c-th channel. The vector
represents an extended function designed to learn and regulate the activation threshold. The function
is implemented in several stages. Initially, average pooling is applied across the
dimensions to reduce the feature’s size. The pooled features undergo two fully connected layers for learning intricate patterns, followed by normalization to standardize the outputs. Finally, the outputs are mapped to the interval
through the application of the sigmoid function, which enables the model to dynamically adjust the activation level of the features based on the learned threshold.
2.5. Optimization of Loss Function
In the YOLO task, an appropriate loss function is chosen to guide model convergence and ensure task completion. The Probabilistic IoU (ProbIoU) used in YOLOv8 OBB is an effective method for measuring the overlap between oriented bounding boxes (OBBs). Based on the Hellinger distance, ProbIoU assesses the similarity between two OBBs by calculating their covariance matrices and the differences in their center coordinates. Specifically, ProbIoU can be computed using the following equation:
In Equation (
4),
represents the Bhattacharyya distance, a metric that quantifies the geometric similarity between two oriented bounding boxes (OBBs). This distance is calculated by considering the covariance matrices of the two oriented bounding boxes (OBBs), represented by
for the first OBB and
for the second OBB. Additionally, the difference in their center coordinates, given by
and
, is also factored in. The covariance matrices describe the orientation, shape, and spread of each OBB, while the differences in center coordinates capture their relative positions. The resulting value of
provides a measure of how closely the two OBBs align geometrically. This distance is then used to compute the Probabilistic IoU (ProbIoU), which assesses the overlap between the OBBs. Ultimately, the final result of the ProbIoU is determined by the following:
While ProbIoU is effective in assessing the overlap between bounding boxes, the introduction of Complete IoU (CIoU) significantly improves the accuracy of the evaluation. CIoU extends ProbIoU by adding an aspect ratio consistency term, which is expressed in the following equation:
Here, the aspect ratio consistency term
v is defined as follows:
The weight
is then used to adjust the influence of the aspect ratio on the final IoU value; this can be obtained from the following:
This enhancement allows CIoU to capture the geometric relationships between OBBs more comprehensively, thereby improving the detection performance.
However, while CIoU enhances accuracy, it primarily focuses on the aspect ratio and does not fully capture the relationship between the bounding box’s width, height, and its confidence. To address this limitation, we replace CIoU with the EIoU loss function in ProbIoU. EIoU incorporates not just the center distance, but also the differences in area and size of the bounding box, enhancing both the stability and precision of target box regression.
The EIoU loss function is defined as follows:
where
is the expression of the overall loss, which consists of three losses:
,
, and
. Specifically,
represents the loss function that quantifies the disparity in distance between the predicted center points and the corresponding ground truth center points of the bounding boxes.
evaluates the degree of overlap between the predicted and actual bounding boxes by considering the ratio of their intersection to the total area covered by both.
penalizes discrepancies in shape between the estimated and true bounding boxes by ensuring their aspect ratios are closely aligned. The integration of these three components enables a more thorough refinement of the bounding box’s alignment, proportions, and dimensions, thereby enhancing the precision and robustness of the detection process.
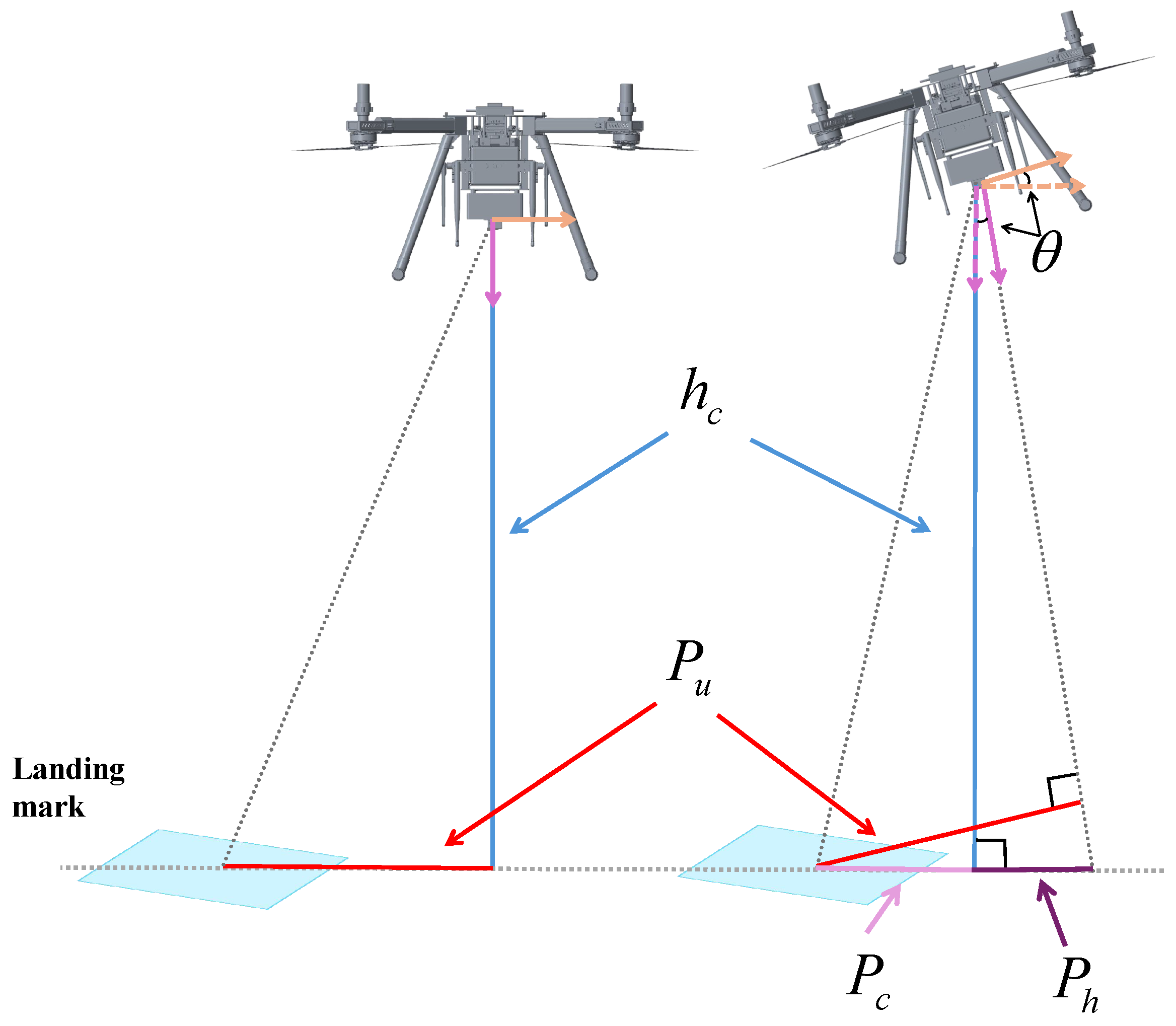
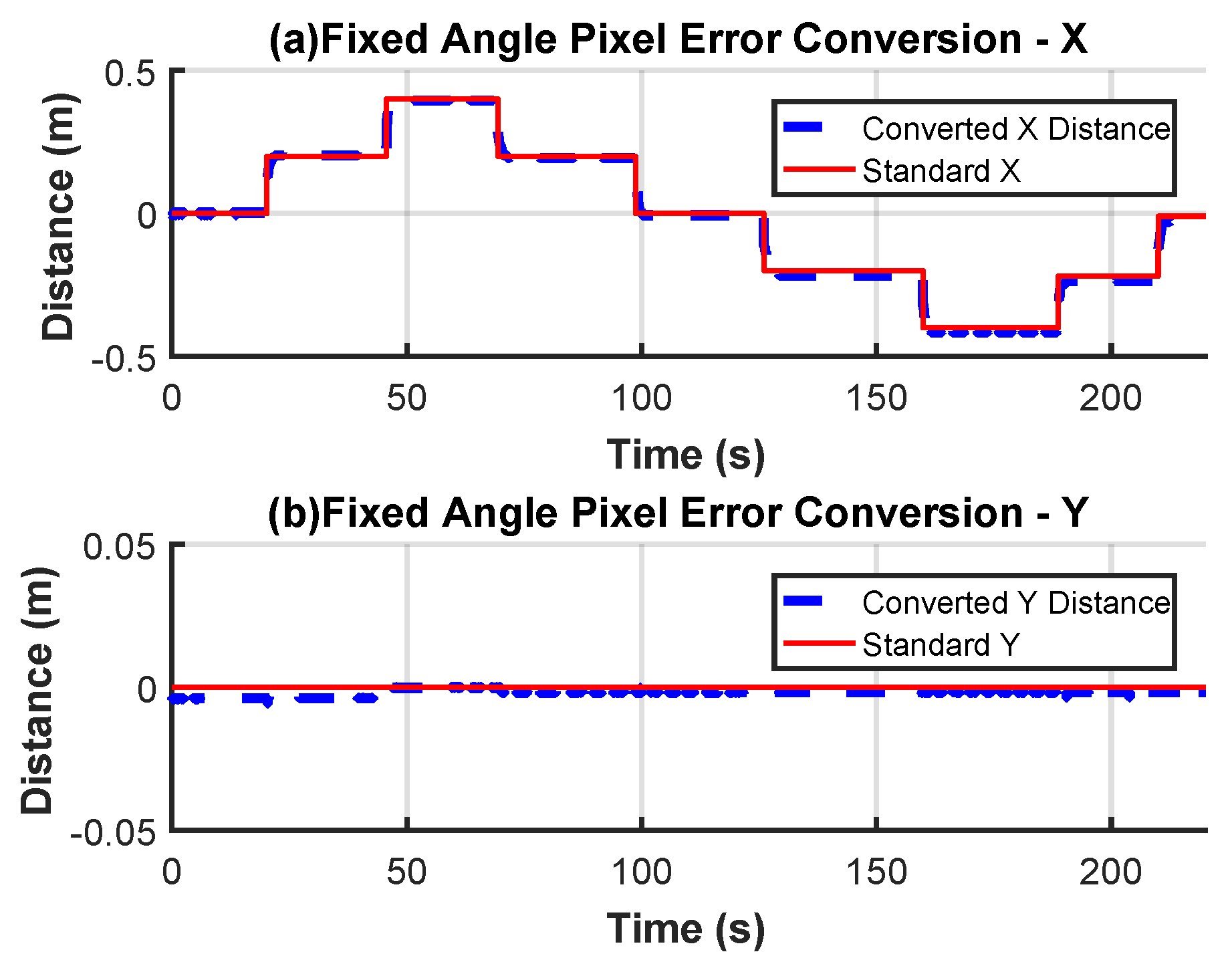
2.6. Pixel Error Converted to Actual Distance Error
During the process of mobile target recognition and landing, the visual system detects the moving landing target as a pixel error, which must be converted into a distance error before it can be provided to the flight control system for flight control. This conversion involves using parameters such as camera focal length, pinhole imaging model, imaging relationship, and camera–target distance to convert the pixel error in the image coordinate system into the true distance error in the world coordinate system. The relevant camera parameters used in this article are shown in
Table 1.
The error conversion process uses camera parameters, including the focal length
and pixel size (
). For the Y-axis, the pixel error
is converted to the image width error
in meters using the following:
Here,
and
are the pixel counts of the original and processed images, and
is the physical pixel size.
To convert the image width error into the actual distance error in the geographic coordinate system, a proportional relationship between the original and processed images is used to scale the pixel size. Using the pinhole imaging model, we can obtain the following:
Here,
(corrected distance) is obtained by subtracting the vehicle height from the radar-measured distance if the straight-line error exceeds 0.7 m.
is the camera’s focal length, and
v is the image height. Based on the principle of similar triangles, Equation (
12) is established:
where
is the distance between the quadcopter and the landing target, and its ratio to the image error
equals the ratio of
to
v.
According to Equations (11)–(12), we can obtain the final true distance error in the world coordinate system
:
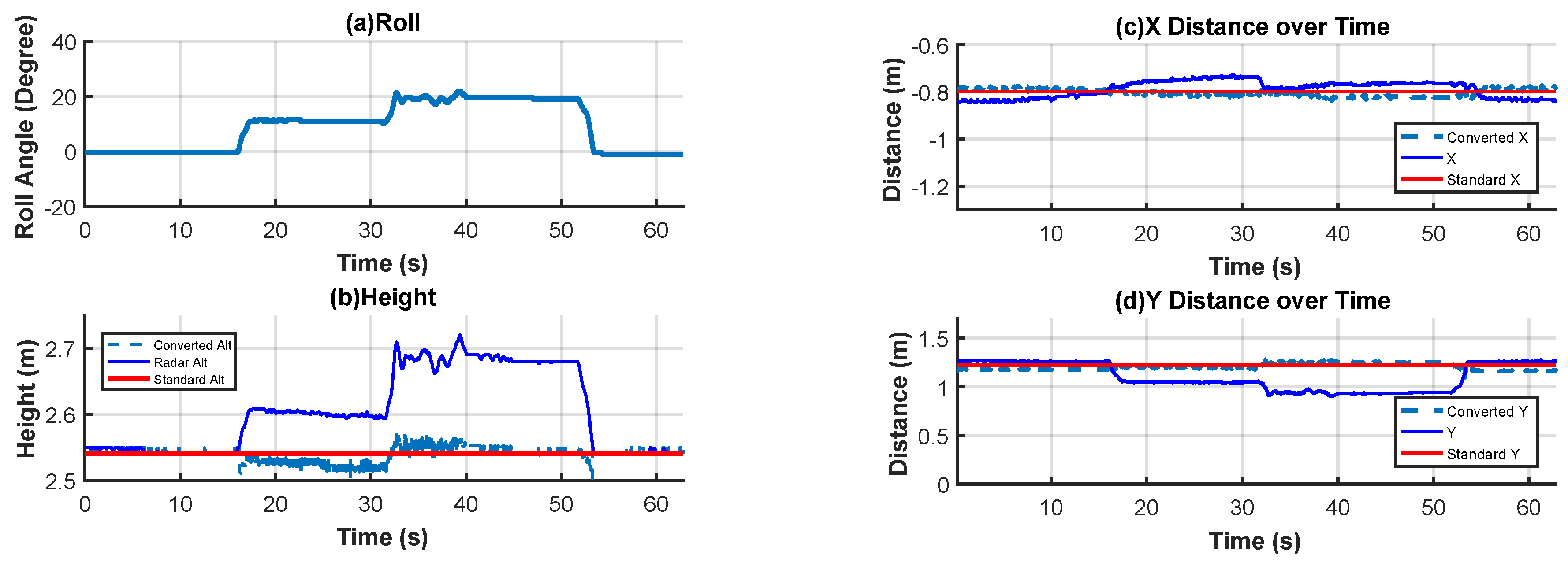
Since the camera used in this study is not equipped with a gimbal, the attitude angle generated during the quadcopter’s flight will impact the accuracy of the conversion in the above equation. Therefore, compensation is necessary to ensure that the pixel error can be accurately converted to the actual distance error, even when the quadcopter has an attitude angle. The conversion relationship is illustrated in
Figure 8:
Figure 8.
Compensation by attitude angle.
Figure 8.
Compensation by attitude angle.
Here,
is the compensated distance error,
is the quadcopter’s current attitude angle, and
is the auxiliary calculated distance. Using Equations (10)–(14), the actual distance error available to the controller is successfully obtained using the detected pixel error.
3. Control System Design
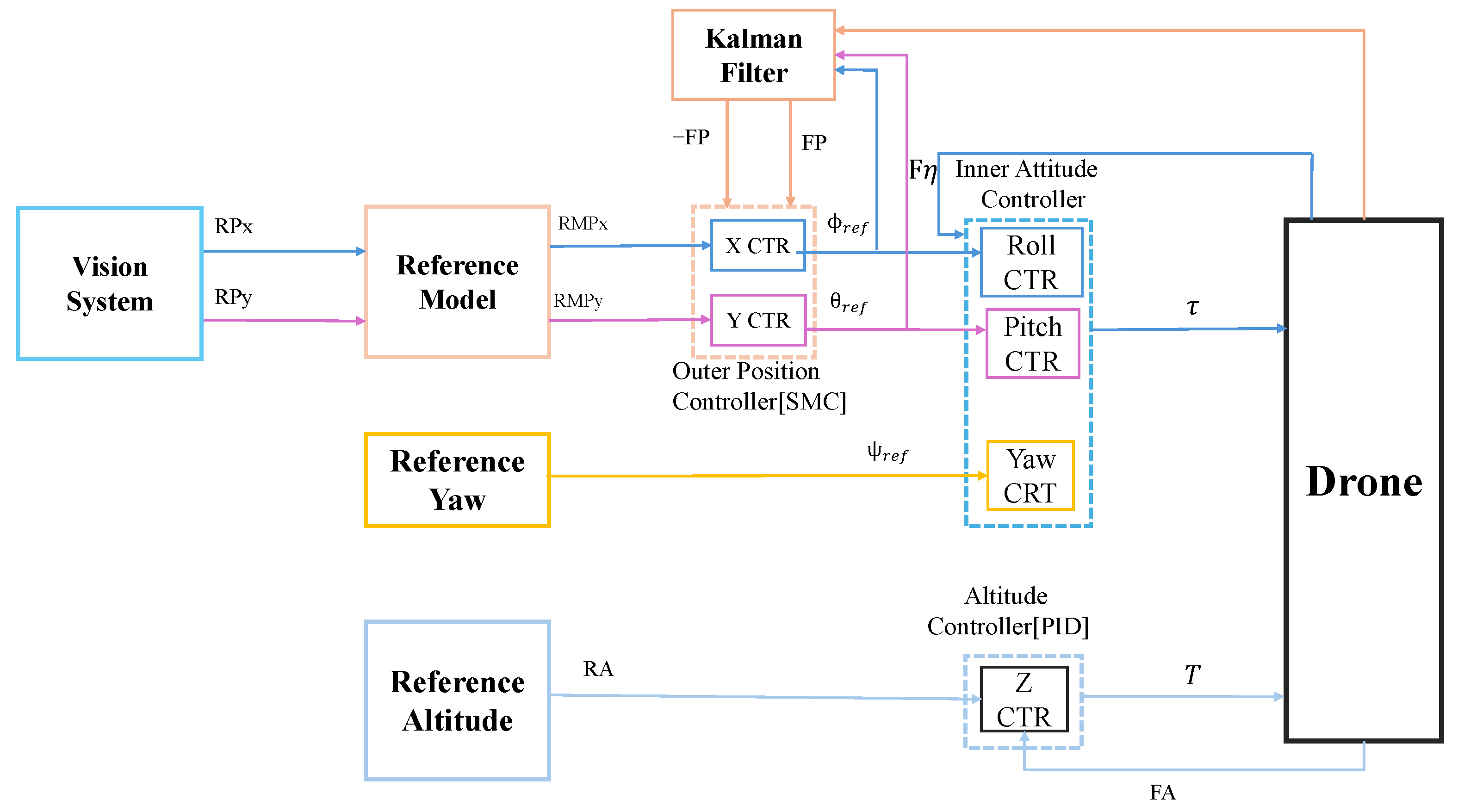
In a dynamic quadcopter visual landing system, identifying the landing target is crucial, but ensuring stable and reliable tracking during landing is equally important. To handle inevitable disturbances, the system incorporates sliding mode control, valued for its robustness against external interference. However, its application often generates large control outputs to counter deviations, potentially causing abrupt attitude changes during landing. To address this, a reference model is introduced to ensure smooth and safe state transitions, enhancing control safety without sacrificing performance. A Kalman filter is also employed to improve stability through accurate state estimation. Combining these, a sliding mode controller integrated with a reference model and Kalman filter is proposed, achieving safe and precise control during dynamic visual landing. The complete controller layout is shown in
Figure 9.
Figure 9 depicts the control system architecture, which includes an outer loop for position control and an inner loop for attitude control. The outer loop generates the desired Roll and Pitch targets based on the quadcopter’s position, which are then fed into the inner control loop to compute required torque to achieve the desired attitude and motion, ensuring stable flight behavior. The establishment of the model can refer to our previous study [
11].
3.1. Reference Model Design
The dynamics of the system are described by using the Newton–Euler formulation:
where
and
are the position and velocity,
m is the mass, and
g is the gravitational acceleration with unit vector
.
is the total thrust,
and
denote attitude and angular velocity,
is the inertia matrix, and
is the control torque.
Then, the three-axis virtual input quantities are introduced as defined in the following equations:
The position movement equations are simplified as in the following equations:
Finally, the general form of the position equations can then be rewritten as follows:
where the input matrix is defined as
, the output matrix is
, and the
A is given by the following:
In the entire control process, ensuring the safety and stability of the quadcopter is crucial. To achieve this, the quadcopter must be able to track the target in a stable manner, with minimal abrupt changes in the target value. Therefore, the design of the transition process for the tracking state plays a key role. In light of this, this paper proposes the design of a reference model to facilitate the smooth and comprehensive state transitions required during the control process.
The reference model is designed with the key consideration that
must ensure the model’s stability and
should be controllable.
Here,
,
,
are the reference state matrix, reference input matrix, and reference output matrix, respectively, and
denotes the reference state associated with
X, where the target values of position and velocity are expressed as
. The structure of the matrix
is as follows:
This matrix is crucial as it governs the change in the reference state. By designing the parameters and , the tracking speed of the transition state can be adjusted. And .
3.2. Design of Sliding Mode Controller
In order to enable the quadcopter to land stably and safely at the center of the moving target, we designed a sliding mode controller to help achieve this goal. Following the design of the Kalman filter and reference model, obtaining the reference transition state, and estimating the system states, the RMSMC can be designed. The difference between the quadcopter’s current state and the transition state given by the reference is defined as
, and the time derivative of the error,
, can be computed as follows:
Then, the sliding surface can be designed as follows:
where
is the weight vector that can be adjusted for each state error. Therefore, by differentiating Equation (
27), we obtain the following:
Once the sliding mode condition is met, the system reaches the sliding surface, meaning that, at this point,
. Assuming
and
, the equivalent control input
is given by the following:
In addition, to minimize the chattering caused by the sliding mode, a smooth function is used in this paper to replace the traditional sign function:
Among them,
∂ is a parameter that can be adjusted artificially, which is related to the disturbance size. Therefore, the nonlinear output is defined as
where
is the nonlinear gain. The final controller output is shown in the following equation:
To confirm the stability of the designed RMSMC, the Lyapunov function can be defined as follows:
To find the time derivative of
V, we proceed as follows:
By incorporating the derivative of the sliding mode surface, we obtain the following equation:
Simplify the expression by expanding and rearranging terms:
Simplify further to the following:
Substitute
; we can obtain:
Simplify further to the following:
Since both m and ∂ are set to positive values and can be adjusted, it follows that . Therefore, by the LaSalle invariance principle, the sliding mode controller designed above is asymptotically stable.
5. Discussion
The improved dynamic landing system proposed in this paper has demonstrated effectiveness in key aspects such as target detection, pixel conversion, and dynamic landing control. Comprehensive experimental results show that, for the baseline YOLOv8 OBB model, challenges commonly encountered during the landing process—such as difficulties in identifying small targets and the presence of complex, high-background environments—were addressed by integrating the CBAM attention mechanism, the DyHead detection head, and the EIoU loss function. These enhancements led to a steady improvement in recognition accuracy across both public and private datasets, validating the effectiveness of each module in boosting model performance and target detection accuracy within the experimental setting.
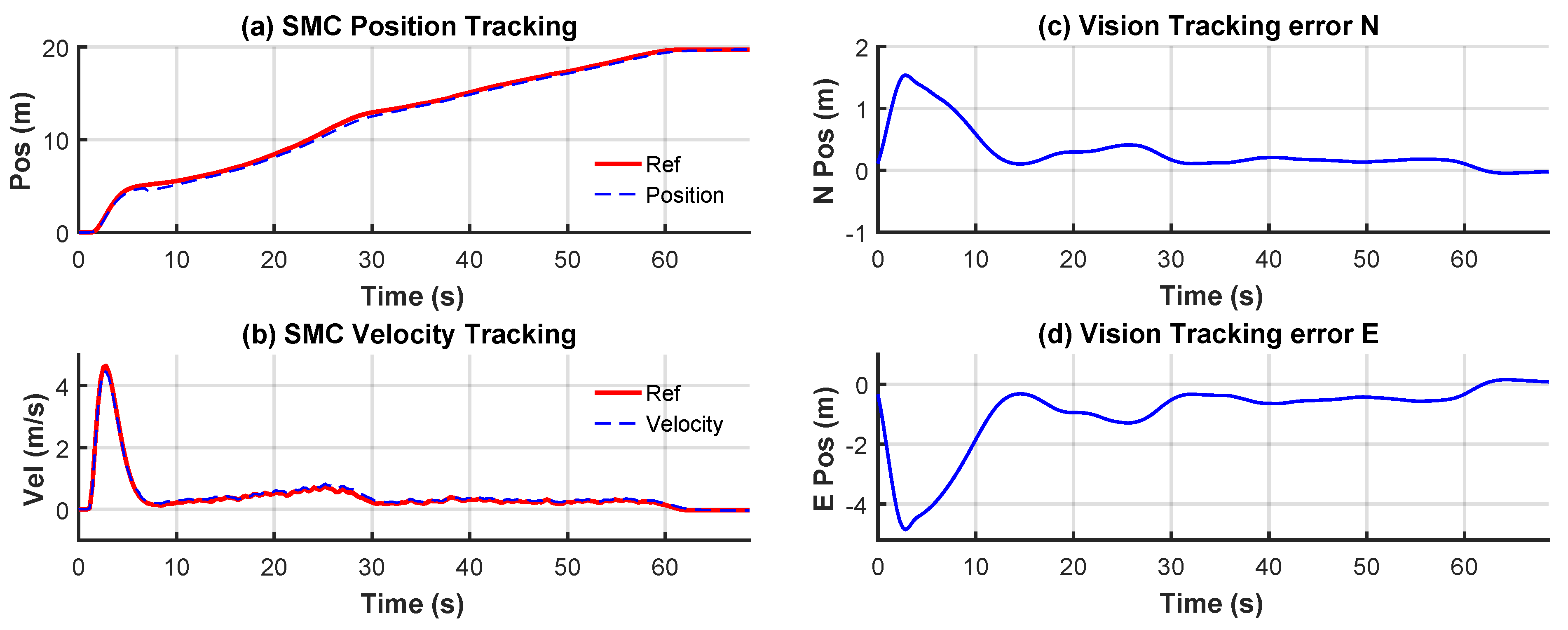
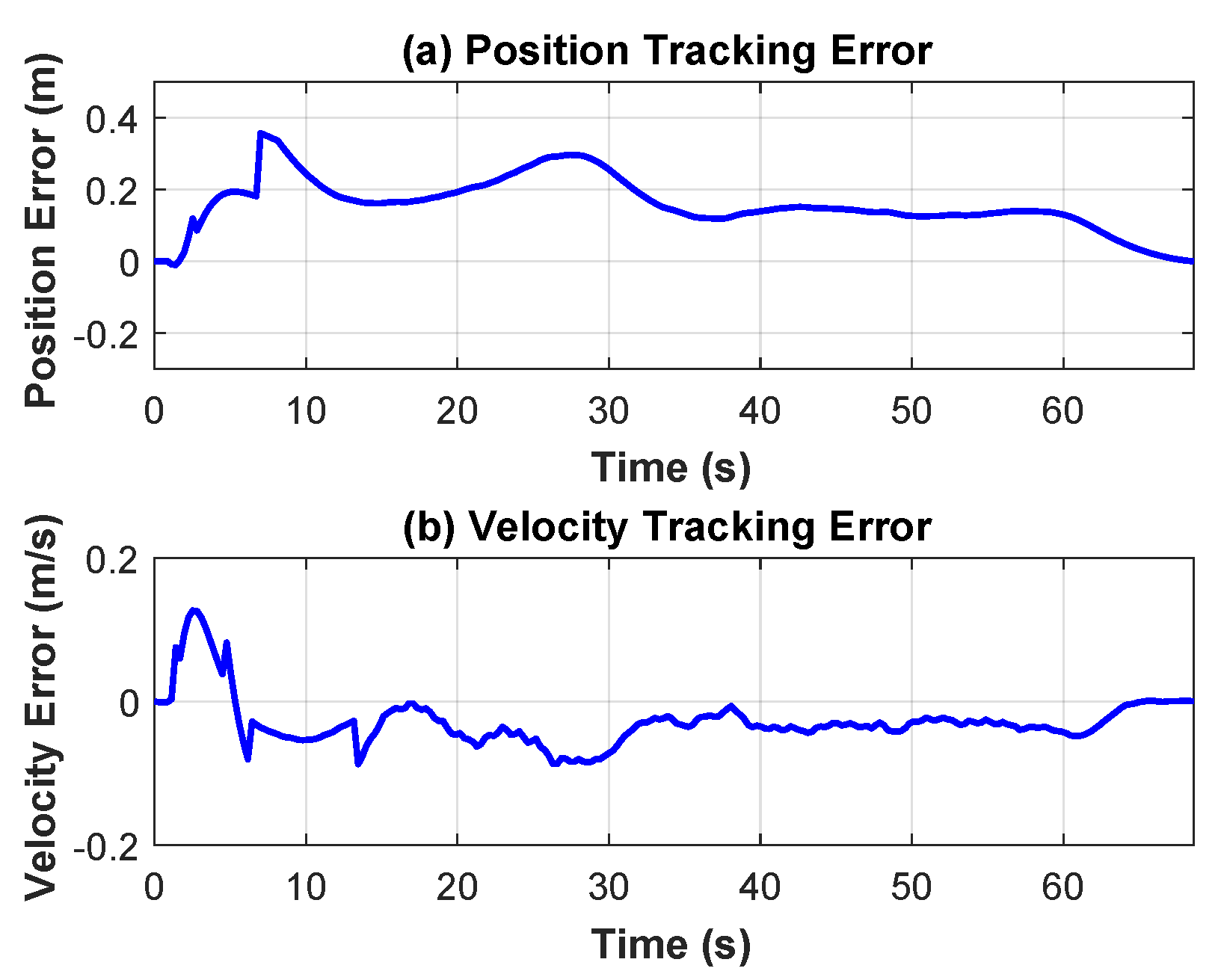
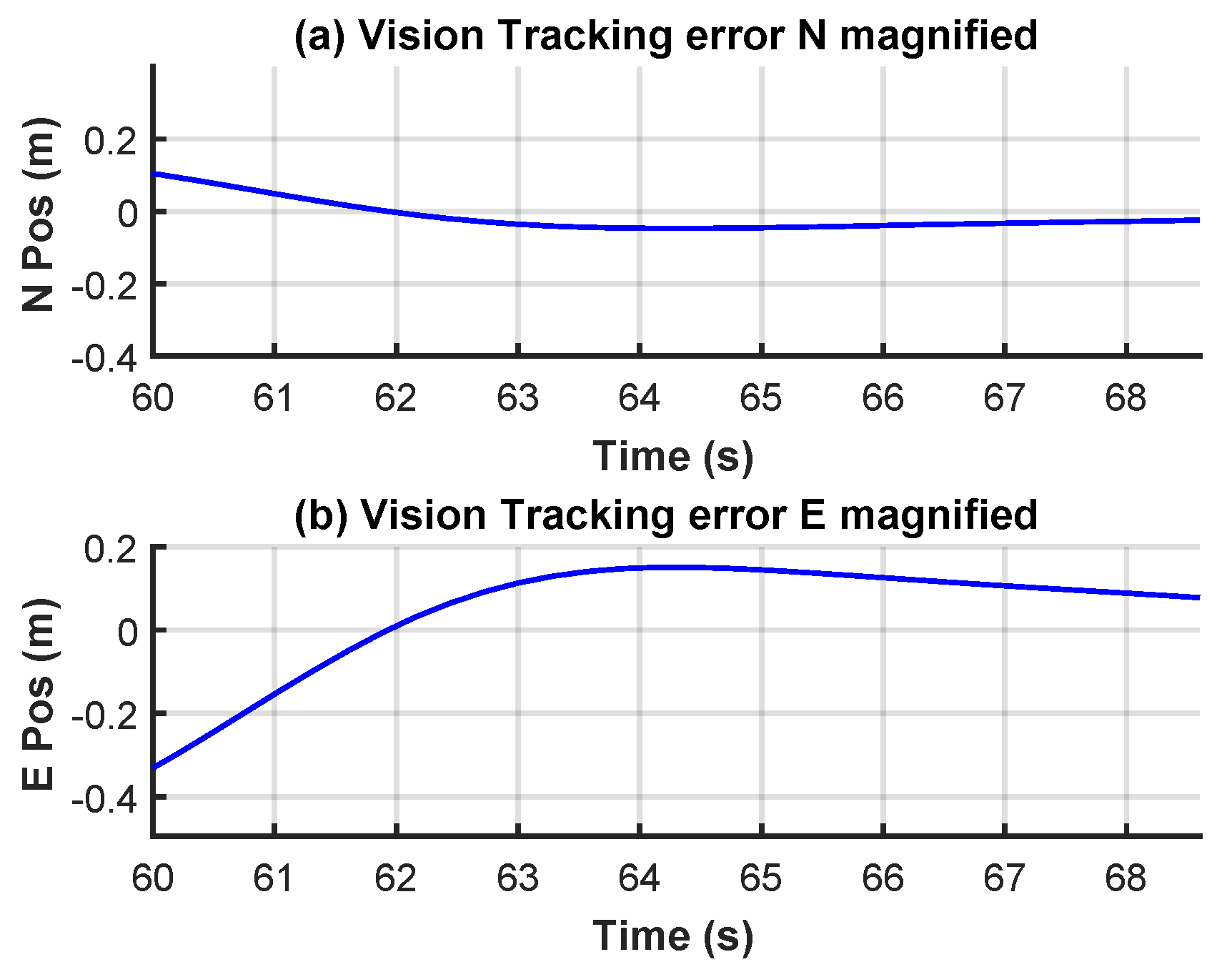
Additionally, for landing guidance in the control process, experiments on pixel error conversion and attitude angle compensation revealed that the proposed conversion algorithm and compensation strategy not only significantly reduced measurement errors under fixed height and varying attitudes but also provided precise position information for subsequent dynamic control. Furthermore, dynamic landing experiments employing a sliding mode controller demonstrated that the system maintained low maximum position and velocity errors while tracking the reference position, ensuring the successful completion of the landing task.
In conclusion, this study enhanced the accuracy and stability of UAV target detection and visual tracking by optimizing the landing recognition algorithm and implementing a sliding mode controller based on a reference model. However, future work should further explore the adaptability and robustness of the proposed approach in larger-scale environments with dynamic and unpredictable conditions.
6. Conclusions
This paper designs and implements a dynamic quadcopter landing system with drone vision and sliding mode control. Landing target detection uses the improved YOLOv8 OBB algorithm. CA, Dyhead, and EIoU Loss are added to the original model to improve the accuracy of the detection. Then, the detected pixel error is converted to the actual position error. At the same time, the attitude compensation is corrected. Furthermore, in order to ensure the stability and rapidity of tracking, a position sliding mode controller based on the reference model is designed, verified, and applied to help the quadcopter track the landing target. Finally, the practicality of the proposed system is ultimately validated through real-world flight experiments. The results demonstrate that the improved YOLOv8 OBB demonstrates an improvement in the mAP0.5:0.95 index by 2.23 percentage points. The position tracking error is always below 0.2 m, and the final landing error is 0.11 m, which proves that the system in this paper can complete accurate dynamic landing.
However, it should be noted that, although the RMSMC has a resistance to disturbances, no additional artificially generated interference was added in this experiment. In future research, we will add additional interference factors, such as continuous wind interference or a swaying landing surface.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}