

MobileAmcT: A Lightweight Mobile Automatic Modulation Classification Transformer in Drone Communication Systems
 and
and
Abstract
1. Introduction
- Proposed TCC1 and TCC2 Modules: In the MobileAmcT model, we have proposed two novel Token and Channel Conv (TCC) modules, TCC1 and TCC2, designed to efficiently capture local features of signals at different levels. These modules are based on the MetaFormer [36] general architecture, integrating the concepts of Token Mixer and Channel Mixer. By combining lightweight convolution and channel attention mechanisms, the TCC modules are structured uniquely to significantly enhance the efficiency and accuracy of local feature extraction while maintaining the model’s lightweight nature.
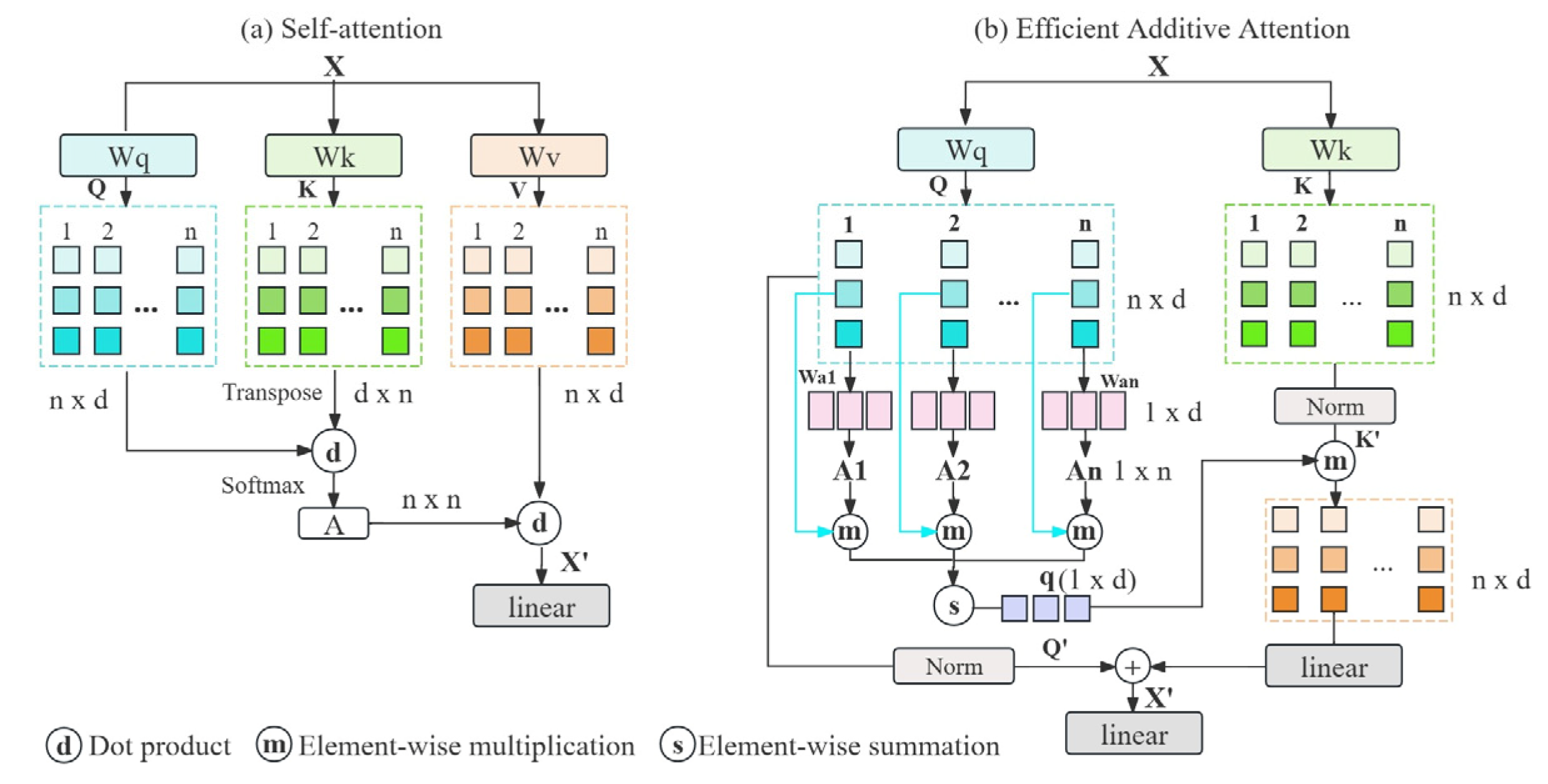
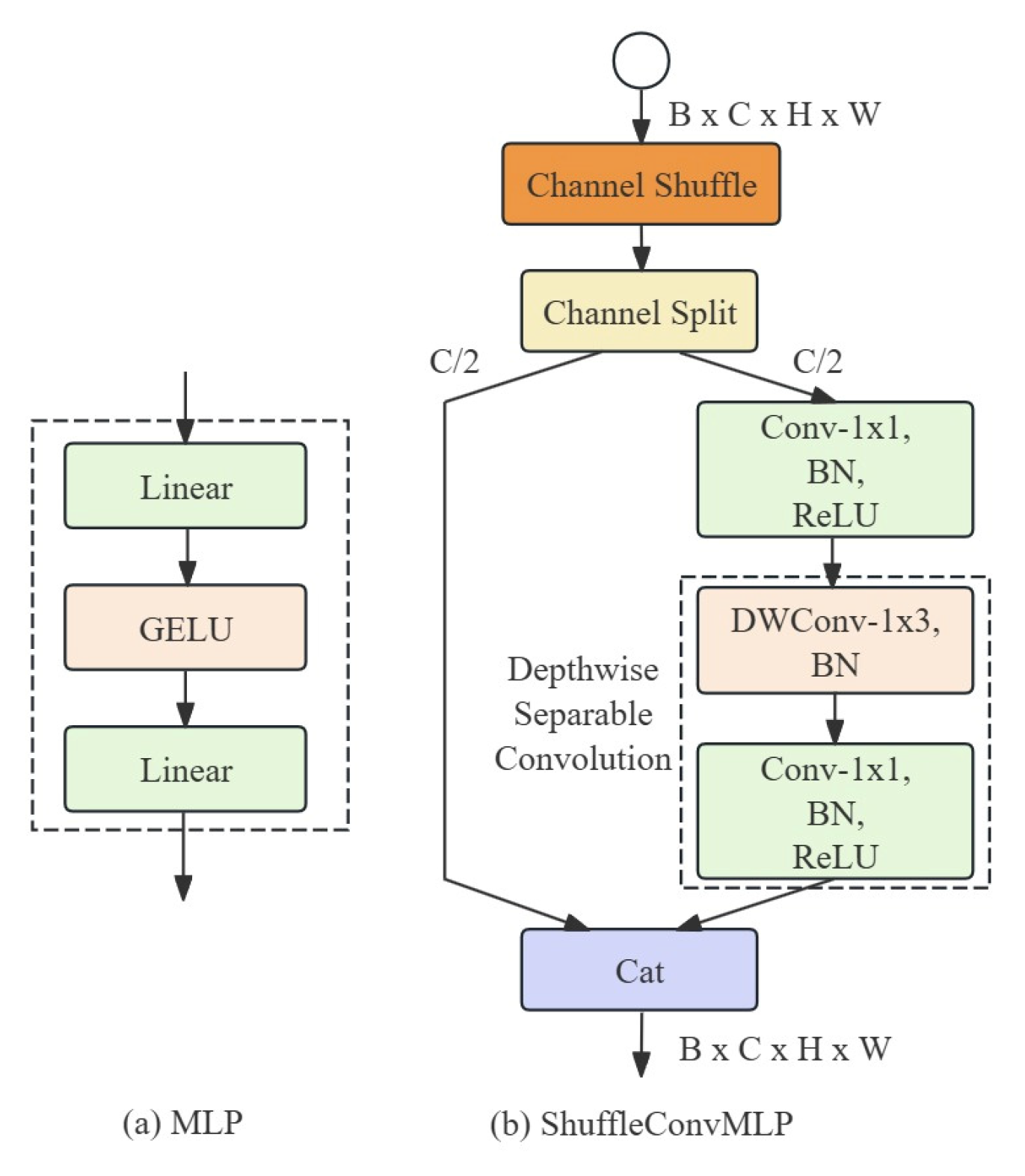
- Innovative EfficientShuffleFormer Module: The EfficientShuffleFormer module in the MobileAmcT model combines Efficient Additive Attention and ShuffleConvMLP to provide efficient global feature representation and fusion capabilities while keeping the model lightweight. Efficient Additive Attention reduces computational complexity by replacing traditional matrix multiplication with element-wise multiplication. ShuffleConvMLP utilizes channel shuffling and depthwise separable convolution techniques to enhance the model’s ability to handle diverse features and capture fine-grained information, thereby improving the efficiency of the feedforward network.
- Enhanced Classification Accuracy and Computational Efficiency: Extensive experiments on the public RadioML2016.10a dataset validate the superior performance of the MobileAmcT model. Compared to existing representative methods, MobileAmcT exhibits high classification accuracy across different SNR environments while significantly reducing the model’s parameter count and computational requirements. The parameters were reduced by up to 82.5%, and classification accuracy was improved by up to 13.6%. Additionally, through ablation experiments, this study systematically evaluates the critical impact and innovative value of core components such as the TCC modules and EfficientShuffleFormer on the overall performance of AMC tasks, showcasing the model’s potential for applications in resource-constrained environments.
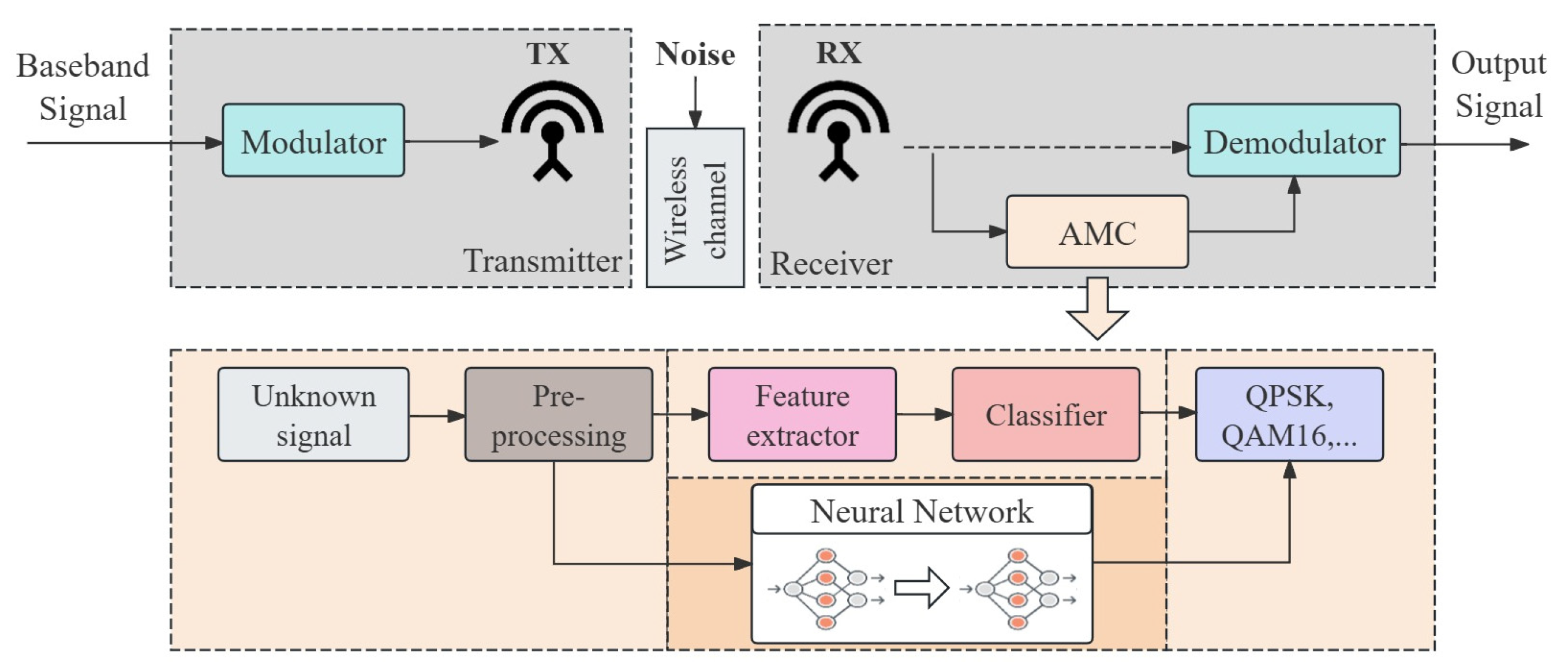
2. AMC System Architecture and Signal Model
2.1. AMC System Architecture
2.2. Signal Model
3. Our Proposed MobileAmcT Model
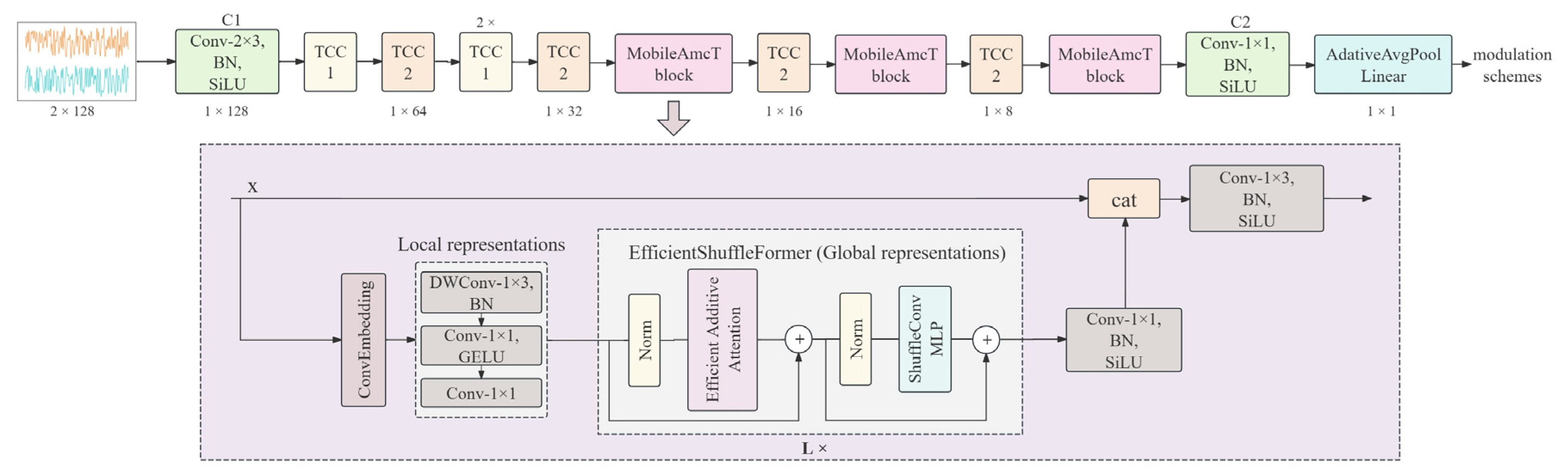
3.1. Model Framework
- Firstly, the model processes the input signal through the initial convolutional layer C1, which uses 2 × 3 convolutional kernels with a stride of 1, and integrates batch normalization (BN) and the SiLU activation function. This layer extracts low-level features from the signal and facilitates information exchange between I/Q channels.
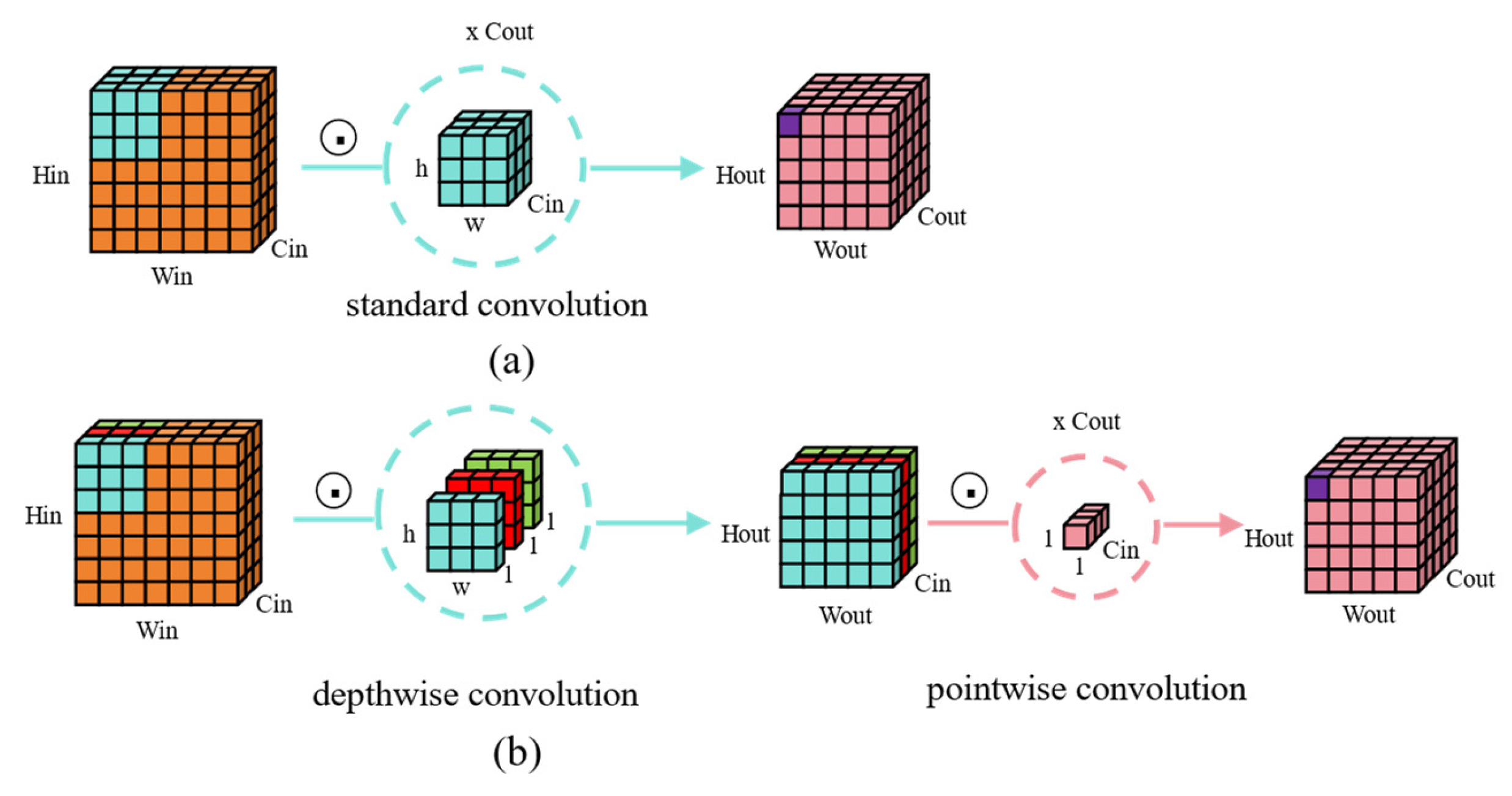
- Secondly, the intermediate TCC modules are divided into TCC1 and TCC2 modules. The TCC1 module combines depthwise convolution and channel attention mechanisms, focusing on efficient local feature extraction. This module efficiently extracts deep features through depthwise convolution and enhances feature representation using the channel attention mechanism. The TCC2 module further performs feature fusion and downsampling, extending the spatial range of features and enabling the model to effectively capture and process signal features at different scales.
- Thirdly, the core part of the model—the MobileAmcT Block—leverages lightweight convolution combined with the EfficientShuffleFormer to simultaneously handle local and global features. This module integrates the outputs of various layers through feature fusion techniques, forming a comprehensive feature representation, which significantly enhances the model’s performance in automatic modulation classification tasks.
- Finally, the information fusion convolutional layer C2 uses pointwise convolution to linearly combine the features from each channel, increasing the number of feature map channels and facilitating the capture of complex patterns. Finally, the adaptive global pooling layer and the fully connected layer work together to output the final classification results.
3.2. Key Module Design
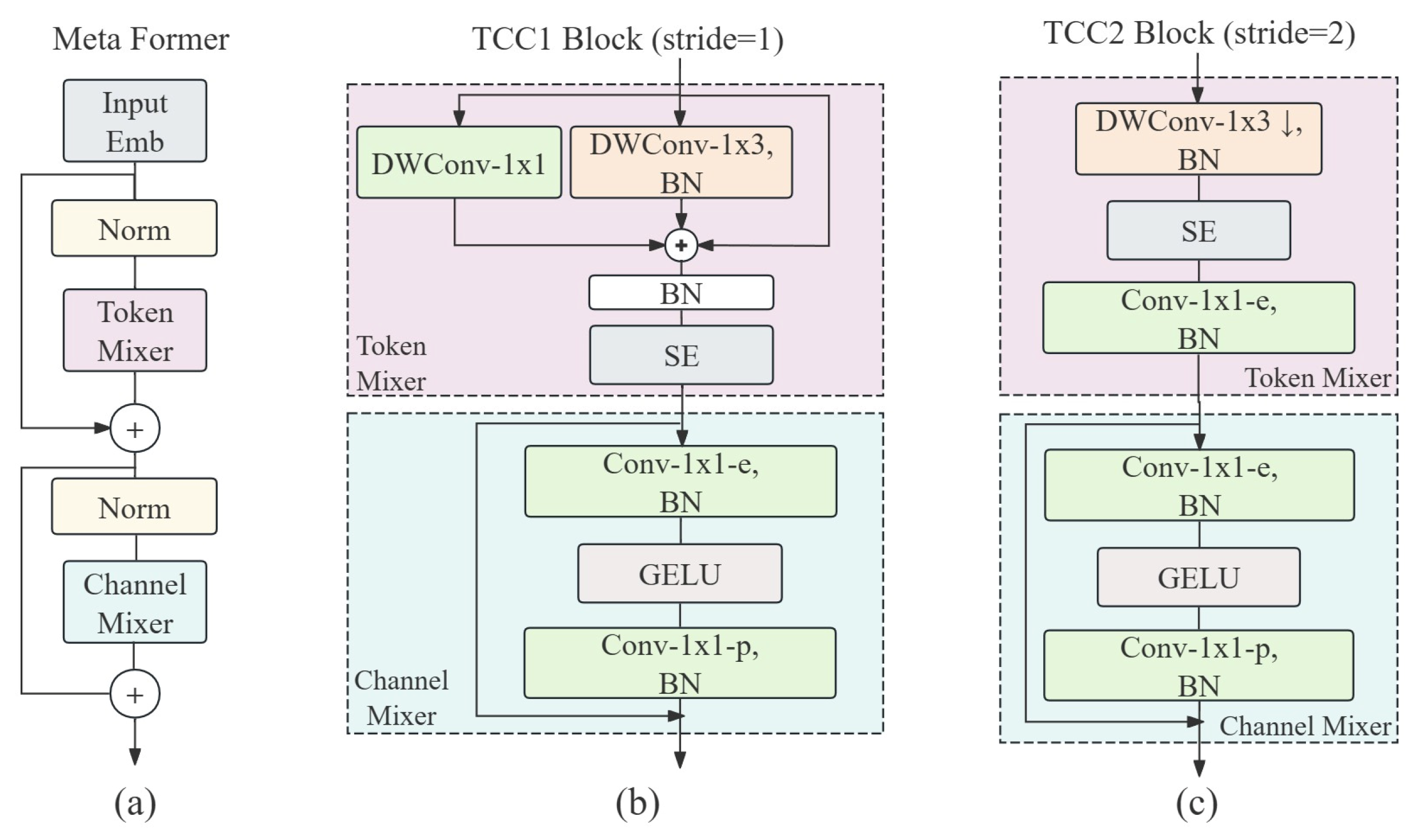
3.2.1. TCC1 and TCC2 Modules
- TCC1 Module
- 2.
- TCC2 Module
3.2.2. MobileAmcT Block
Local Representation Learning
Global Representation Learning
4. Experimental Results and Analysis
4.1. Experimental Settings
4.1.1. Experimental Platform and Hyperparameter Settings
4.1.2. Experimental Dataset
4.2. Comparison with Model Parameter Setting
4.3. Evaluating Modules in MobileAmcT Model
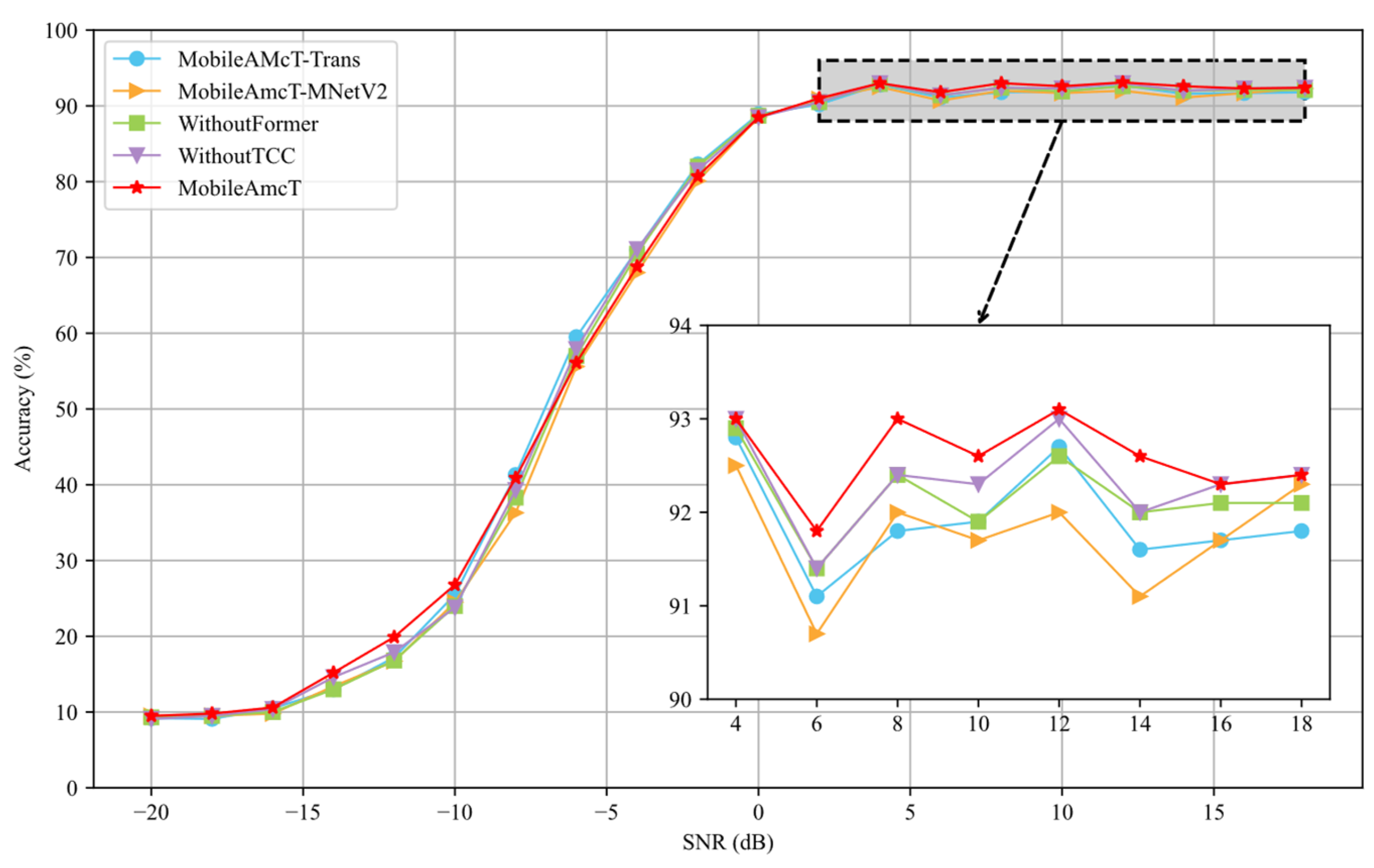
4.3.1. Importance Analysis of Global Feature Extraction Module (MobileAmcT-Trans)
4.3.2. Suitability Analysis of Local Feature Extraction Module (MobileAmcT-MNetV2)
4.3.3. Impact Verification of Global Feature Extraction Module (WithoutFormer)
4.3.4. Performance Impact of Local Feature Extraction Module (WithoutTCC)
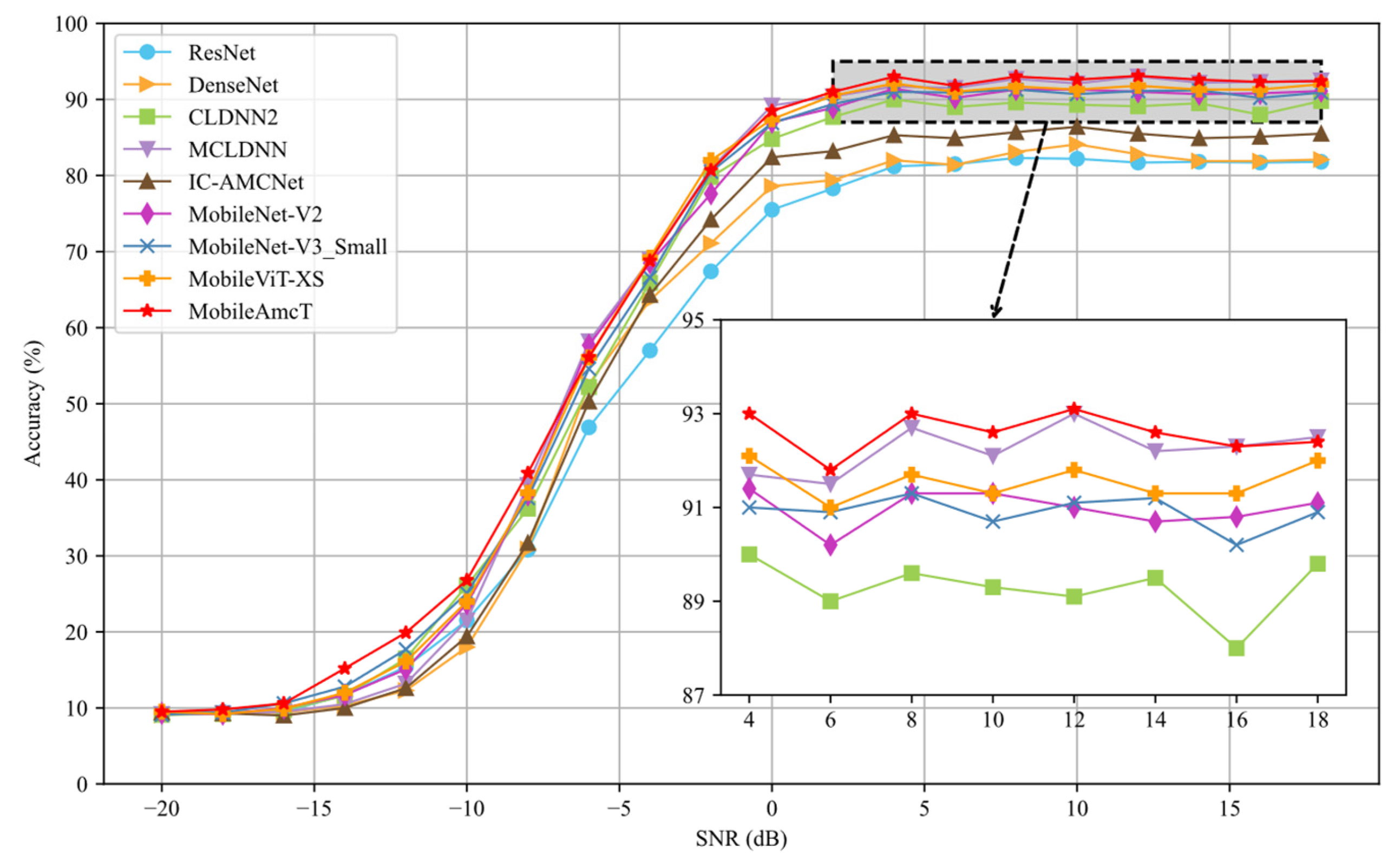
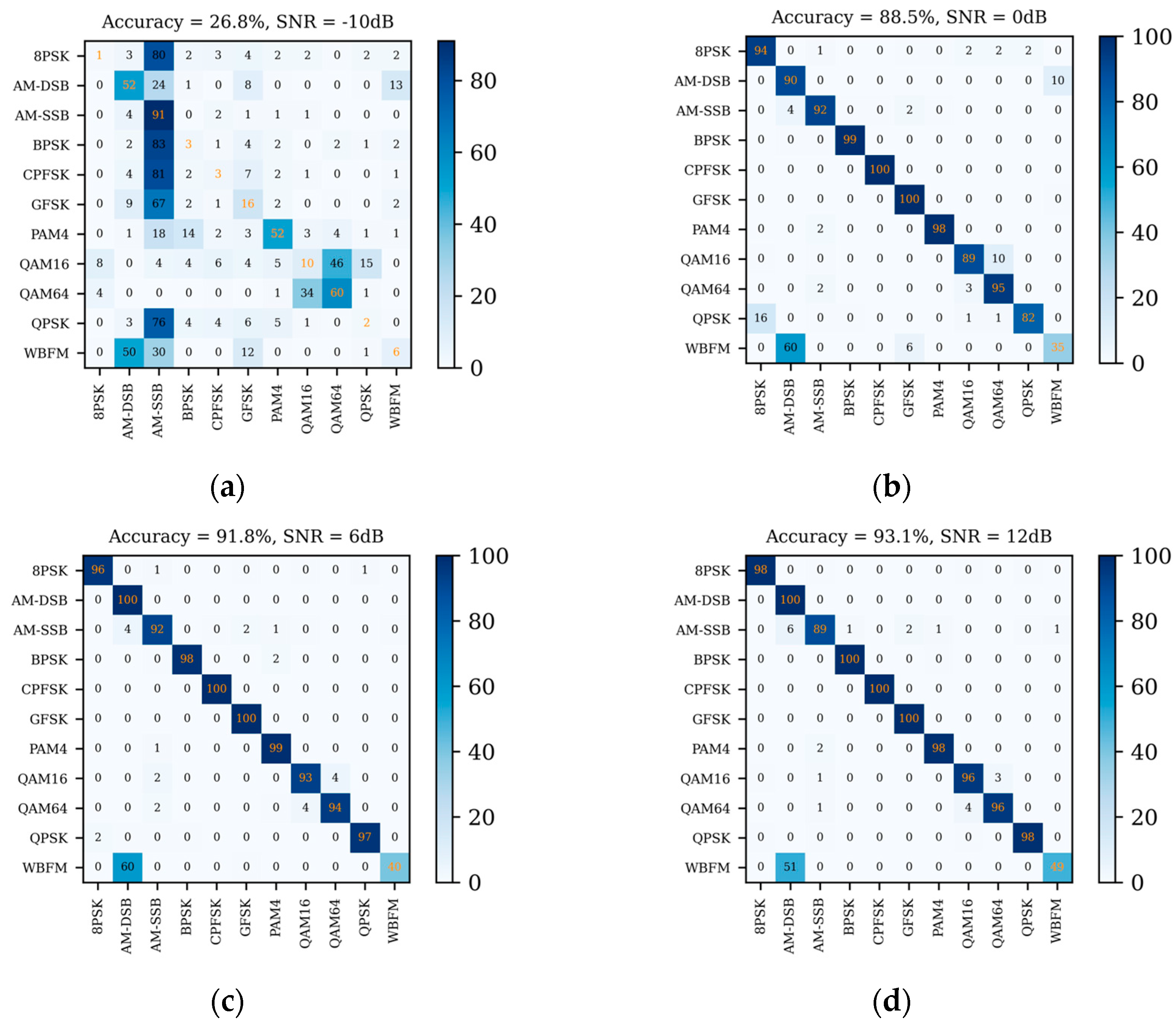
4.4. Performance Comparison between Different Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, M.; Liao, G.; Zhao, N.; Song, H.; Gong, F. Data-driven deep learning for signal classification in industrial cognitive radio networks. IEEE Trans. Ind. Inform. 2020, 17, 3412–3421. [Google Scholar] [CrossRef]
- Ma, J.; Liu, H.; Peng, C.; Qiu, T. Unauthorized broadcasting identification: A deep LSTM recurrent learning approach. IEEE Trans. Instrum. Meas. 2020, 69, 5981–5983. [Google Scholar] [CrossRef]
- Chang, S.; Huang, S.; Zhang, R.; Feng, Z.; Liu, L. Multitask-learning-based deep neural network for automatic modulation classification. IEEE Internet Things J. 2021, 9, 2192–2206. [Google Scholar] [CrossRef]
- Dobre, O.A.; Abdi, A.; Bar-Ness, Y.; Su, W. Survey of automatic modulation classification techniques: Classical approaches and new trends. IET Commun. 2007, 1, 137–156. [Google Scholar] [CrossRef]
- Tadaion, A.; Derakhtian, M.; Gazor, S.; Aref, M. Likelihood ratio tests for PSK modulation classification in unknown noise environment. In Proceedings of the Canadian Conference on Electrical and Computer Engineering, Saskatoon, SK, Canada, 1–4 May 2005; pp. 151–154. [Google Scholar]
- Xu, J.L.; Su, W.; Zhou, M. Likelihood-ratio approaches to automatic modulation classification. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2010, 41, 455–469. [Google Scholar] [CrossRef]
- Xie, L.; Wan, Q. Cyclic feature-based modulation recognition using compressive sensing. IEEE Wirel. Commun. Lett. 2017, 6, 402–405. [Google Scholar] [CrossRef]
- Li, T.; Li, Y.; Dobre, O.A. Modulation classification based on fourth-order cumulants of superposed signal in NOMA systems. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2885–2897. [Google Scholar] [CrossRef]
- Gardner, W.A.; Spooner, C.M. Cyclic spectral analysis for signal detection and modulation recognition. In Proceedings of the MILCOM 88, 21st Century Military Communications-What’s Possible? Conference Record. Military Communications Conference, San Diego, CA, USA, 23–26 October 1988; pp. 419–424. [Google Scholar]
- Hazza, A.; Shoaib, M.; Alshebeili, S.A.; Fahad, A. An overview of feature-based methods for digital modulation classification. In Proceedings of the 2013 1st International Conference on Communications, Signal Processing, and Their Applications (ICCSPA), Sharjah, United Arab Emirates, 12–14 February 2013; pp. 1–6. [Google Scholar]
- Zheng, S.; Zhou, X.; Zhang, L.; Qi, P.; Qiu, K.; Zhu, J.; Yang, X. Towards next-generation signal intelligence: A hybrid knowledge and data-driven deep learning framework for radio signal classification. IEEE Trans. Cogn. Commun. Netw. 2023, 9, 564–579. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, M.; Yang, J.; Gui, G. Data-driven deep learning for automatic modulation recognition in cognitive radios. IEEE Trans. Veh. Technol. 2019, 68, 4074–4077. [Google Scholar] [CrossRef]
- Huang, S.; Lin, C.; Xu, W.; Gao, Y.; Feng, Z.; Zhu, F. Identification of active attacks in Internet of Things: Joint model-and data-driven automatic modulation classification approach. IEEE Internet Things J. 2020, 8, 2051–2065. [Google Scholar] [CrossRef]
- Zheng, Q.; Zhao, P.; Li, Y.; Wang, H.; Yang, Y. Spectrum interference-based two-level data augmentation method in deep learning for automatic modulation classification. Neural Comput. Appl. 2021, 33, 7723–7745. [Google Scholar] [CrossRef]
- Wang, Y.; Gui, G.; Ohtsuki, T.; Adachi, F. Multi-task learning for generalized automatic modulation classification under non-Gaussian noise with varying SNR conditions. IEEE Trans. Wirel. Commun. 2021, 20, 3587–3596. [Google Scholar] [CrossRef]
- Ma, K.; Zhou, Y.; Chen, J. CNN-based automatic modulation recognition of wireless signal. In Proceedings of the 2020 IEEE 3rd International Conference on Information Systems and Computer Aided Education (ICISCAE), Dalian, China, 27–29 September 2020; pp. 654–659. [Google Scholar]
- Zeng, Y.; Zhang, M.; Han, F.; Gong, Y.; Zhang, J. Spectrum analysis and convolutional neural network for automatic modulation recognition. IEEE Wirel. Commun. Lett. 2019, 8, 929–932. [Google Scholar] [CrossRef]
- Daldal, N.; Yıldırım, Ö.; Polat, K. Deep long short-term memory networks-based automatic recognition of six different digital modulation types under varying noise conditions. Neural Comput. Appl. 2019, 31, 1967–1981. [Google Scholar] [CrossRef]
- Zheng, Q.; Tian, X.; Yu, Z.; Wang, H.; Elhanashi, A.; Saponara, S. DL-PR: Generalized automatic modulation classification method based on deep learning with priori regularization. Eng. Appl. Artif. Intell. 2023, 122, 106082. [Google Scholar] [CrossRef]
- Hong, D.; Zhang, Z.; Xu, X. Automatic modulation classification using recurrent neural networks. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 695–700. [Google Scholar]
- Sümen, G.; Çelebi, B.A.; Kurt, G.K.; Görçin, A.; Başaran, S.T. Multi-Channel Learning with Preprocessing for Automatic Modulation Order Separation. In Proceedings of the 2022 IEEE Symposium on Computers and Communications (ISCC), Rhodes, Greece, 30 June–3 July 2022; pp. 1–5. [Google Scholar]
- Zhang, Z.; Luo, H.; Wang, C.; Gan, C.; Xiang, Y. Automatic modulation classification using CNN-LSTM based dual-stream structure. IEEE Trans. Veh. Technol. 2020, 69, 13521–13531. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.; Yang, C. Modulation recognition with graph convolutional network. IEEE Wirel. Commun. Lett. 2020, 9, 624–627. [Google Scholar] [CrossRef]
- Tonchev, K.; Neshov, N.; Ivanov, A.; Manolova, A.; Poulkov, V. Automatic modulation classification using graph convolutional neural networks for time-frequency representation. In Proceedings of the 2022 25th International Symposium on Wireless Personal Multimedia Communications (WPMC), Herning, Denmark, 30 October–2 November 2022; pp. 75–79. [Google Scholar]
- Zheng, Q.; Zhao, P.; Wang, H.; Elhanashi, A.; Saponara, S. Fine-grained modulation classification using multi-scale radio transformer with dual-channel representation. IEEE Commun. Lett. 2022, 26, 1298–1302. [Google Scholar] [CrossRef]
- Kong, W.; Yang, Q.; Jiao, X.; Niu, Y.; Ji, G. A transformer-based CTDNN structure for automatic modulation recognition. In Proceedings of the 2021 7th International Conference on Computer and Communications (ICCC), Chengdu, China, 10–13 December 2021; pp. 159–163. [Google Scholar]
- Chen, Y.; Dong, B.; Liu, C.; Xiong, W.; Li, S. Abandon locality: Frame-wise embedding aided transformer for automatic modulation recognition. IEEE Commun. Lett. 2022, 27, 327–331. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv preprint 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Dong, X.; Yuan, L.; Liu, Z. Mobile-former: Bridging mobilenet and transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5270–5279. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- O’shea, T.J.; West, N. Radio machine learning dataset generation with gnu radio. In Proceedings of the GNU Radio Conference, Boulder, CO, USA, 12–16 September 2016; Volume 1. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10819–10829. [Google Scholar]
- Mehta, S.; Rastegari, M. Separable self-attention for mobile vision transformers. arXiv preprint 2022, arXiv:2206.02680. [Google Scholar]
- Wang, A.; Chen, H.; Lin, Z.; Han, J.; Ding, G. Repvit: Revisiting mobile cnn from vit perspective. arXiv 2023, arXiv:2307.09283. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Graham, B.; El-Nouby, A.; Touvron, H.; Stock, P.; Joulin, A.; Jégou, H.; Douze, M. Levit: A vision transformer in convnet’s clothing for faster inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12259–12269. [Google Scholar]
- Yang, H.; Yin, H.; Molchanov, P.; Li, H.; Kautz, J. Nvit: Vision Transformer Compression and Parameter Redistribution. Available online: https://openreview.net/forum?id=LzBBxCg-xpa (accessed on 21 March 2023).
- Shaker, A.; Maaz, M.; Rasheed, H.; Khan, S.; Yang, M.-H.; Khan, F.S. Swiftformer: Efficient additive attention for transformer-based real-time mobile vision applications. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 17425–17436. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Liu, X.; Yang, D.; El Gamal, A. Deep neural network architectures for modulation classification. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October–1 November 2017; pp. 915–919. [Google Scholar]
- West, N.E.; O’shea, T. Deep architectures for modulation recognition. In Proceedings of the 2017 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Baltimore, MD, USA, 6–9 March 2017; pp. 1–6. [Google Scholar]
- Xu, J.; Luo, C.; Parr, G.; Luo, Y. A spatiotemporal multi-channel learning framework for automatic modulation recognition. IEEE Wirel. Commun. Lett. 2020, 9, 1629–1632. [Google Scholar] [CrossRef]
- Hermawan, A.P.; Ginanjar, R.R.; Kim, D.S.; Lee, J.-M. CNN-based automatic modulation classification for beyond 5G communications. IEEE Commun. Lett. 2020, 24, 1038–1041. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Contents |
|---|---|
| Modulation types | 8PSK, BPSK, CPFSK, GFSK, PAM4, 16QAM, AM-DSB, AM-SSB, 64QAM, QPSK, WBFM |
| Sample length | 2 × 128 |
| SNR (dB) | −20:2:18 |
| Number | 220,000 |
| Standard deviation of the sampling rate offset | 0.01 Hz |
| Maximum sample rate offset | 50 Hz |
| Carrier frequency offset standard deviation | 0.01 Hz |
| Maximum carrier frequency offset | 500 Hz |
| No. of sine waves in frequency selective fading | 8 |
| Sampling rate | 200 kHz |
| MobileAmcT-S | MobileAmcT-M | MobileAmcT-L | ||
|---|---|---|---|---|
| Parameter Settings | L | 2, 4, 3 | 2, 4, 3 | 2, 4, 3 |
| D | 48, 64, 80 | 64, 80, 96 | 96, 120, 144 | |
| 8, 8, 16, 16, 24, 24, 32, 32, 48, 48, 256 | 16, 16, 24, 24, 48, 48, 64, 64, 80, 80, 320 | 32, 32, 48, 48, 64, 64, 80, 80, 96, 96, 384 | ||
| Parameters | 310,752 | 575,064 | 1,146,440 | |
| FLOPs | 4,717,248 | 8,899,328 | 18,516,160 | |
| Average Accuracy | 62.58% | 62.93% | 62.38% | |
| Model Variation | Average Accuracy | Parameters | FLOPs |
|---|---|---|---|
| MobileAmcT-Trans | 62.65% | 1,135,016 | 8,454,032 |
| MobileAmcT-MNetV2 | 61.84% | 540,352 | 8,578,176 |
| WithoutFormer | 62.35% | 290,856 | 4,748,672 |
| WithoutTCC | 62.64% | 521,120 | 66,596,608 |
| MobileAmcT | 62.93% | 575,064 | 8,899,328 |
| Dataset | Model | Average Accuracy | Parameters | FLOPs |
|---|---|---|---|---|
| RadioML2016.10a | ResNet [43] | 54.35% | 3,098,283 | 248,425,410 |
| DenseNet [43] | 55.20% | 3,282,603 | 342,797,250 | |
| CLDNN2 [44] | 60.16% | 517,643 | 117,635,426 | |
| MCLDNN [45] | 61.91% | 406,070 | 35,773,612 | |
| IC-AMCNet [46] | 56.96% | 1,264,011 | 29,686,722 | |
| MobileNet-V2 [47] | 61.23% | 2,194,475 | 24,250,880 | |
| MobileNet-V3_Small [48] | 61.38% | 1,636,483 | 19,411,840 | |
| MobileViT-XS [32] | 61.84% | 1,639,952 | 27,083,296 | |
| MobileAmcT (proposed) | 62.93% | 575,064 | 8,899,328 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fei, H.; Wang, B.; Wang, H.; Fang, M.; Wang, N.; Ran, X.; Liu, Y.; Qi, M. MobileAmcT: A Lightweight Mobile Automatic Modulation Classification Transformer in Drone Communication Systems. Drones 2024, 8, 357. https://doi.org/10.3390/drones8080357
Fei H, Wang B, Wang H, Fang M, Wang N, Ran X, Liu Y, Qi M. MobileAmcT: A Lightweight Mobile Automatic Modulation Classification Transformer in Drone Communication Systems. Drones. 2024; 8(8):357. https://doi.org/10.3390/drones8080357
Chicago/Turabian StyleFei, Hongyun, Baiyang Wang, Hongjun Wang, Ming Fang, Na Wang, Xingping Ran, Yunxia Liu, and Min Qi. 2024. "MobileAmcT: A Lightweight Mobile Automatic Modulation Classification Transformer in Drone Communication Systems" Drones 8, no. 8: 357. https://doi.org/10.3390/drones8080357
APA StyleFei, H., Wang, B., Wang, H., Fang, M., Wang, N., Ran, X., Liu, Y., & Qi, M. (2024). MobileAmcT: A Lightweight Mobile Automatic Modulation Classification Transformer in Drone Communication Systems. Drones, 8(8), 357. https://doi.org/10.3390/drones8080357