
Decentralized UAV Swarm Control: A Multi-Layered Architecture for Integrated Flight Mode Management and Dynamic Target Interception



Abstract
1. Introduction
2. Related Work and Problem Definition
Contributions
- A new hybrid layered control architecture for intercepting swarms: A three-layer control system is developed to address advanced swarm control problems. This architecture establishes a highly flexible and scalable framework for swarm activities across different scales, ensuring robust control in dynamic and unpredictable environments.
- A new decentralized target allocation algorithm: A dynamic target selection algorithm is designed to enable distributed target allocation for each ownship with capabilities for prompt responses in emergency situations.
- An integrated method for enhancing safe flight operations: A strategy for random waypoint generation is created for adaptable return mode processes, and a control signal optimizer is employed to enhance the security of physical UAV applications.
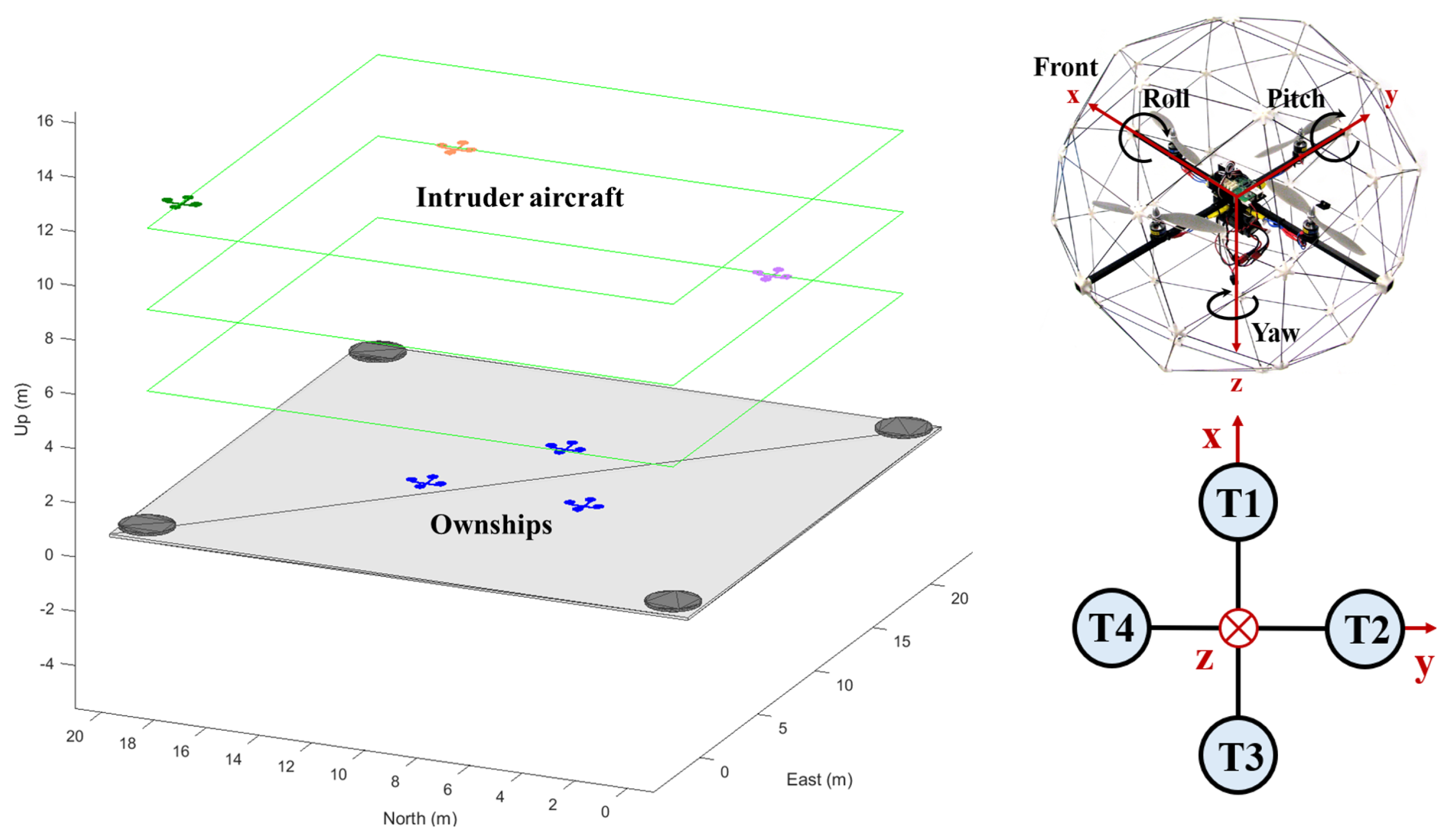
3. Methodology
3.1. Inner Loop Control
3.1.1. Linear Velocity and Position Update
3.1.2. Angular Velocity and Attitude Update
3.2. Outer Loop Control
3.2.1. SAC-FIS Controller for Mobile Intruder Interception
- : The Euclidean distance between the ownship and selected target ship.
- : The ownship’s Euler angles in ZYX order, represented as .
- : The ownship’s linear velocities; .
- : The ownship’s angular velocities, represented as p, q, r.
- : The coordinate differences between the ownship and selected target ship in the XYZ directions, represented as , , and .
- : The selected target ship’s linear velocities.
- : The ownship’s angular velocities about the earth coordinate system’s X and Y axes, represented by and .
- : The roll (), pitch (), yaw (), and thrust () actions.
- : Inputs of the FIS, consisting of the ownship–target angle () and sampled readings from the 3D LiDAR, including the front distance () and lateral distance error ().
- : The speed vector’s projection onto the direction (vector) formed between the ownship and the selected target ship.
- : The component of the speed vector that is perpendicular to the vector formed between the ownship and the selected target ship.
- : The number of successfully intercepted intruders.
3.2.2. PID Control for Safe Returning
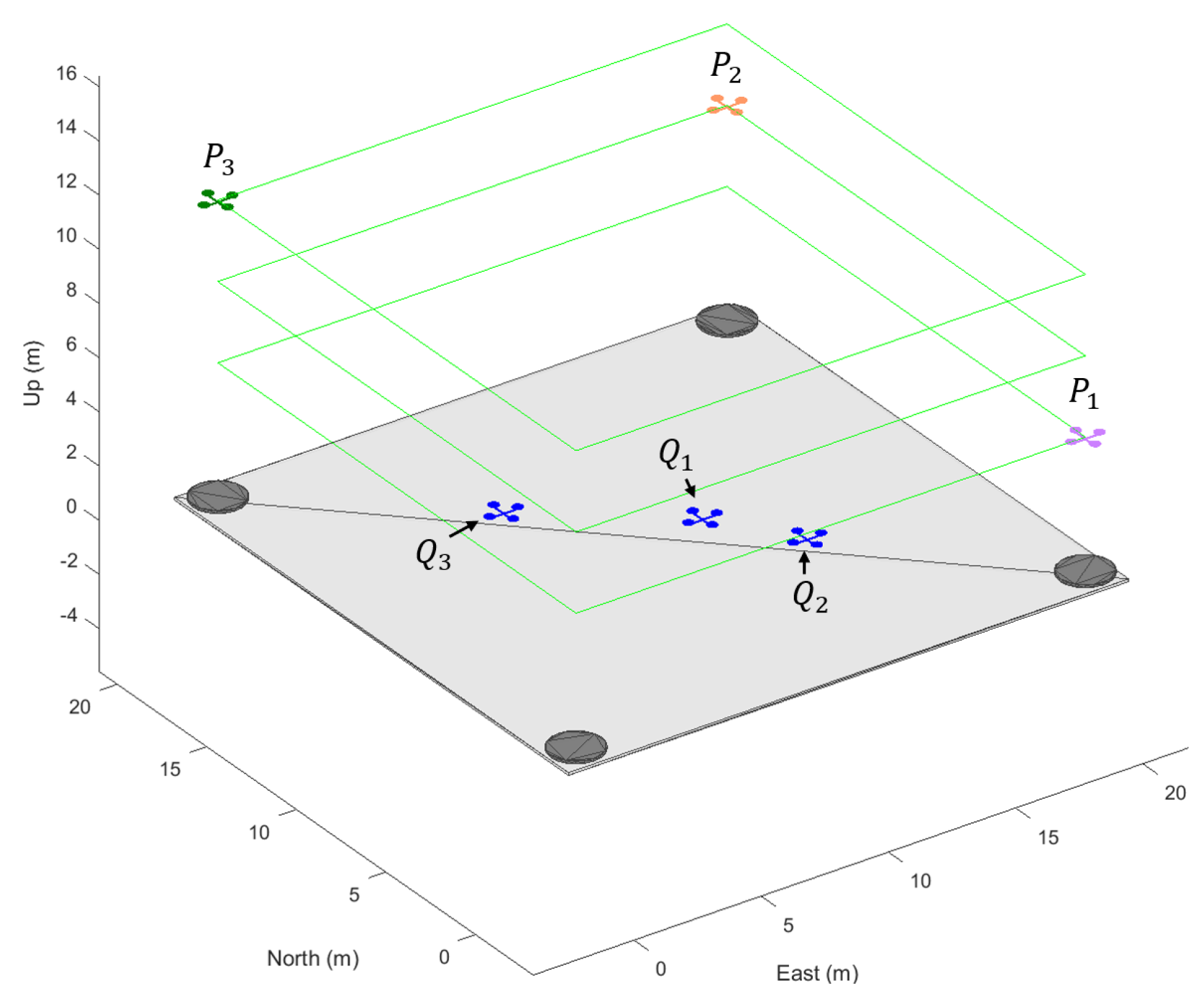
3.3. Decentralized Swarm Control
3.3.1. Dynamic Target Selection Algorithm
3.3.2. Conditions for Triggering Safe Return Mode
- The ownship successfully neutralizes its current target and no unassigned intruder aircraft remain in the environment.
- The ownship encounters an emergency situation, e.g., a collision or .

| Algorithm 1: Dynamic Target Selection Algorithm for Multiple Ownships and Intruders |
|
3.3.3. Termination Conditions
- Each ownship is positioned more than 30 m away from its assigned target ship:
- The duration surpasses the predefined maximum time threshold:
- All intruders have been successfully intercepted and all ownships have been safely disarmed on the drone hub (note that if any ownship lands outside the drone hub, it is considered a failed mission):
- Each individual ownship has collided with an obstacle, identified by a minimal LiDAR reading (from the 3D point cloud) dropping below 0.75 m (note: in this study, the distance from the center of an ownship to its edge should not exceed 0.4 m):
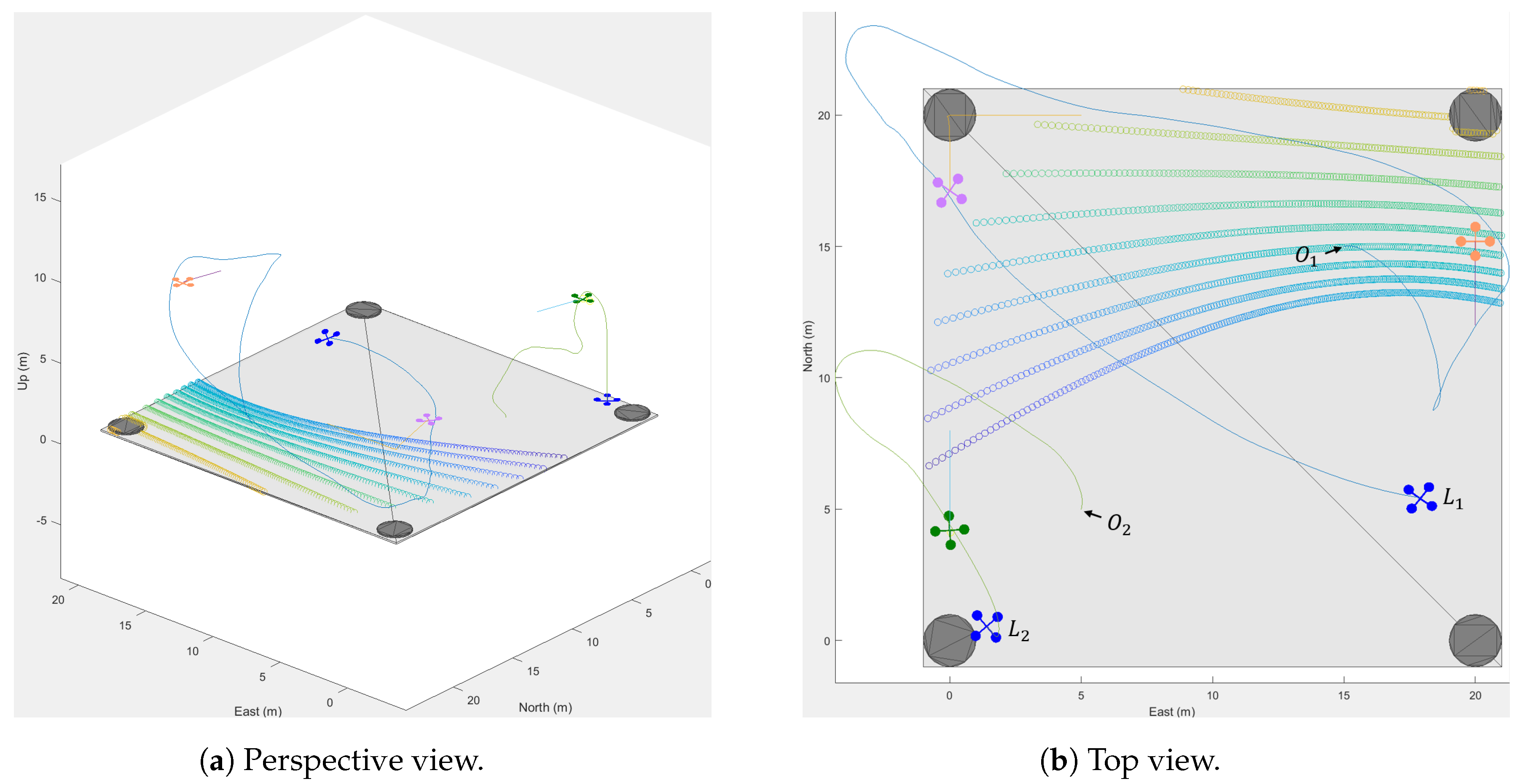
4. Results
4.1. Equal Number of Ownships and Intruder Aircraft ()
4.2. Fewer Ownships than Intruder Aircraft ()
4.3. Equal Number of Ownships and Intruder Aircraft ( with Emergency Situations)
4.4. Control System Feasibility Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xu, X.; Zhao, H.; Yao, H.; Wang, S. A blockchain-enabled energy-efficient data collection system for UAV-assisted IoT. IEEE Internet Things J. 2020, 8, 2431–2443. [Google Scholar] [CrossRef]
- Feng, W.; Wang, J.; Chen, Y.; Wang, X.; Ge, N.; Lu, J. UAV-aided MIMO communications for 5G Internet of Things. IEEE Internet Things J. 2018, 6, 1731–1740. [Google Scholar] [CrossRef]
- Phang, S.K.; Chiang, T.H.A.; Happonen, A.; Chang, M.M.L. From Satellite to UAV-based Remote Sensing: A Review on Precision Agriculture. IEEE Access 2023, 11, 127057–127076. [Google Scholar] [CrossRef]
- Song, X.; Yang, R.; Yin, C.; Tang, B. A cooperative aerial interception model based on multi-agent system for uavs. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; pp. 873–882. [Google Scholar]
- Evdokimenkov, V.N.; Kozorez, D.A.; Rabinskiy, L.N. Unmanned aerial vehicle evasion manoeuvres from enemy aircraft attack. J. Mech. Behav. Mater. 2021, 30, 87–94. [Google Scholar] [CrossRef]
- Wu, J.; Li, D.; Shi, J.; Li, X.; Gao, L.; Yu, L.; Han, G.; Wu, J. An Adaptive Conversion Speed Q-Learning Algorithm for Search and Rescue UAV Path Planning in Unknown Environments. IEEE Trans. Veh. Technol. 2023, 72, 15391–15404. [Google Scholar] [CrossRef]
- Dong, J.; Ota, K.; Dong, M. UAV-based real-time survivor detection system in post-disaster search and rescue operations. IEEE J. Miniaturization Air Space Syst. 2021, 2, 209–219. [Google Scholar] [CrossRef]
- Campion, M.; Ranganathan, P.; Faruque, S. UAV swarm communication and control architectures: A review. J. Unmanned Veh. Syst. 2018, 7, 93–106. [Google Scholar] [CrossRef]
- Khalil, H.; Rahman, S.U.; Ullah, I.; Khan, I.; Alghadhban, A.J.; Al-Adhaileh, M.H.; Ali, G.; ElAffendi, M. A UAV-Swarm-Communication Model Using a Machine-Learning Approach for Search-and-Rescue Applications. Drones 2022, 6, 372. [Google Scholar] [CrossRef]
- Shrit, O.; Martin, S.; Alagha, K.; Pujolle, G. A new approach to realize drone swarm using ad-hoc network. In Proceedings of the 2017 16th Annual Mediterranean Ad Hoc Networking Workshop (Med-Hoc-Net), Budva, Montenegro, 28–30 June 2017; pp. 1–5. [Google Scholar]
- Khalil, H.; Ali, G.; Rahman, S.U.; Asim, M.; El Affendi, M. Outage Prediction and Improvement in 6G for UAV Swarm Relays Using Machine Learning. Prog. Electromagn. Res. 2024, 107, 33–45. [Google Scholar] [CrossRef]
- Li, H.; Sun, Q.; Wang, M.; Liu, C.; Xie, Y.; Zhang, Y. A baseline-resilience assessment method for UAV swarms under heterogeneous communication networks. IEEE Syst. J. 2022, 16, 6107–6118. [Google Scholar] [CrossRef]
- Qin, B.; Zhang, D.; Tang, S.; Xu, Y. Two-layer formation-containment fault-tolerant control of fixed-wing UAV swarm for dynamic target tracking. J. Syst. Eng. Electron. 2023, 34, 1375–1396. [Google Scholar] [CrossRef]
- Altshuler, Y.; Yanovski, V.; Wagner, I.A.; Bruckstein, A.M. Multi-agent cooperative cleaning of expanding domains. Int. J. Robot. Res. 2011, 30, 1037–1071. [Google Scholar] [CrossRef]
- Beni, G.; Wang, J. Swarm intelligence in cellular robotic systems. In Robots and Biological Systems: Towards a New Bionics? Springer: Berlin/Heidelberg, Germany, 1993; pp. 703–712. [Google Scholar]
- Kada, B.; Khalid, M.; Shaikh, M.S. Distributed cooperative control of autonomous multi-agent UAV systems using smooth control. J. Syst. Eng. Electron. 2020, 31, 1297–1307. [Google Scholar] [CrossRef]
- Perez-Carabaza, S.; Besada-Portas, E.; Lopez-Orozco, J.A.; de la Cruz, J.M. Ant colony optimization for multi-UAV minimum time search in uncertain domains. Appl. Soft Comput. 2018, 62, 789–806. [Google Scholar] [CrossRef]
- Tong, P.; Yang, X.; Yang, Y.; Liu, W.; Wu, P. Multi-UAV Collaborative Absolute Vision Positioning and Navigation: A Survey and Discussion. Drones 2023, 7, 261. [Google Scholar] [CrossRef]
- Maddula, T.; Minai, A.A.; Polycarpou, M.M. Multi-target assignment and path planning for groups of UAVs. In Recent Developments in Cooperative Control and Optimization; Springer: Boston, MA, USA, 2004; pp. 261–272. [Google Scholar]
- Arafat, M.Y.; Moh, S. Localization and clustering based on swarm intelligence in UAV networks for emergency communications. IEEE Internet Things J. 2019, 6, 8958–8976. [Google Scholar] [CrossRef]
- Venturini, F.; Mason, F.; Pase, F.; Chiariotti, F.; Testolin, A.; Zanella, A.; Zorzi, M. Distributed reinforcement learning for flexible and efficient uav swarm control. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 955–969. [Google Scholar] [CrossRef]
- Weng, L.; Liu, Q.; Xia, M.; Song, Y.D. Immune network-based swarm intelligence and its application to unmanned aerial vehicle (UAV) swarm coordination. Neurocomputing 2014, 125, 134–141. [Google Scholar] [CrossRef]
- Tang, D.; Shen, L.; Hu, T. Online camera-gimbal-odometry system extrinsic calibration for fixed-wing UAV swarms. IEEE Access 2019, 7, 146903–146913. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Chen, Y.J.; Chang, D.K.; Zhang, C. Autonomous tracking using a swarm of UAVs: A constrained multi-agent reinforcement learning approach. IEEE Trans. Veh. Technol. 2020, 69, 13702–13717. [Google Scholar] [CrossRef]
- Qie, H.; Shi, D.; Shen, T.; Xu, X.; Li, Y.; Wang, L. Joint optimization of multi-UAV target assignment and path planning based on multi-agent reinforcement learning. IEEE Access 2019, 7, 146264–146272. [Google Scholar] [CrossRef]
- Zhang, K.; Yang, Z.; Başar, T. Multi-agent reinforcement learning: A selective overview of theories and algorithms. In Handbook of Reinforcement Learning and Control; Springer: Cham, Switzerland, 2021; pp. 321–384. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter, A.O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Li, B.; Liang, S.; Gan, Z.; Chen, D.; Gao, P. Research on multi-UAV task decision-making based on improved MADDPG algorithm and transfer learning. Int. J. -Bio-Inspired Comput. 2021, 18, 82–91. [Google Scholar] [CrossRef]
- Rizk, Y.; Awad, M.; Tunstel, E.W. Decision making in multiagent systems: A survey. IEEE Trans. Cogn. Dev. Syst. 2018, 10, 514–529. [Google Scholar] [CrossRef]
- Amorim, W.P.; Tetila, E.C.; Pistori, H.; Papa, J.P. Semi-supervised learning with convolutional neural networks for UAV images automatic recognition. Comput. Electron. Agric. 2019, 164, 104932. [Google Scholar] [CrossRef]
- Yuan, F.; Liu, Y.J.; Liu, L.; Lan, J. Adaptive neural network control of non-affine multi-agent systems with actuator fault and input saturation. Int. J. Robust Nonlinear Control 2024, 34, 3761–3780. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Y.; Wu, Z.; Xu, J. Deep reinforcement learning for UAV swarm rendezvous behavior. J. Syst. Eng. Electron. 2023, 34, 360–373. [Google Scholar] [CrossRef]
- Xia, B.; Mantegh, I.; Xie, W. UAV Multi-Dynamic Target Interception: A Hybrid Intelligent Method Using Deep Reinforcement Learning and Fuzzy Logic. Drones 2024, 8, 226. [Google Scholar] [CrossRef]
- Xia, B.; Mantegh, I.; Xie, W.F. Intelligent Method for UAV Navigation and De-confliction–Powered by Multi-Agent Reinforcement Learning. In Proceedings of the 2023 International Conference on Unmanned Aircraft Systems (ICUAS), Warsaw, Poland, 6–9 June 2023; pp. 713–722. [Google Scholar]
- Xia, B.; He, T.; Mantegh, I.; Xie, W. AI-Based De-confliction and Emergency Landing Algorithm for UAS. Proceedings of the STO-MP-AVT-353 Meeting; NATO Science & Technology Organization: Brussels, Belgium, 2022; p. 12. Available online: https://www.sto.nato.int/publications/pages/results.aspx?k=bingze&s=Search%20All%20STO%20Reports (accessed on 1 January 2020).
- Xia, B.; Mantegh, I.; Xie, W. Integrated emergency self-landing method for autonomous uas in urban aerial mobility. In Proceedings of the 2021 21st International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 12–15 October 2021; pp. 275–282. [Google Scholar]
- Quanser Qball-X4 User Manual. Available online: https://users.encs.concordia.ca/~realtime/coen421/doc/Quanser%20QBall-X4%20-%20User%20Manual.pdf (accessed on 1 January 2020).
- Cui, J.S.; Zhang, F.R.; Feng, D.Z.; Li, C.; Li, F.; Tian, Q.C. An improved SLAM based on RK-VIF: Vision and inertial information fusion via Runge-Kutta method. Def. Technol. 2023, 21, 133–146. [Google Scholar] [CrossRef]
- Runge-Kutta 4th Order Method (RK4). Available online: https://primer-computational-mathematics.github.io/book/c_mathematics/numerical_methods/5_Runge_Kutta_method.html (accessed on 1 January 2020).
- Talaeizadeh, A.; Pishkenari, H.N.; Alasty, A. Quadcopter fast pure descent maneuver avoiding vortex ring state using yaw-rate control scheme. IEEE Robot. Autom. Lett. 2021, 6, 927–934. [Google Scholar] [CrossRef]
- Di Rito, G.; Galatolo, R.; Schettini, F. Self-monitoring electro-mechanical actuator for medium altitude long endurance unmanned aerial vehicle flight controls. Adv. Mech. Eng. 2016, 8, 1687814016644576. [Google Scholar] [CrossRef]
- Cordeiro, T.F.K.; Ishihara, J.Y.; Ferreira, H.C. A Decentralized Low-Chattering Sliding Mode Formation Flight Controller for a Swarm of UAVs. Sensors 2020, 20, 3094. [Google Scholar] [CrossRef] [PubMed]
- Bauer, P.; Bokor, J. LQ Servo control design with Kalman filter for a quadrotor UAV. Period. Polytech. Transp. Eng. 2008, 36, 9–14. [Google Scholar] [CrossRef]
- Liu, Y.; Duan, C.; Liu, L.; Cao, L. Discrete-Time Incremental Backstepping Control with Extended Kalman Filter for UAVs. Electronics 2023, 12, 3079. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Previous Work | The Current Study |
|---|---|---|
| Control Framework | 1. SAC-FIS controller for single-ownship systems [35]. 2. A single outer loop controller for one specific operation, such as target tracking or collision avoidance [35,36,37]. 3. None. | 1. Extended the well-trained SAC-FIS agents for multi-ownship systems 2. Integrated multiple learning-based and rule-based control algorithms. 3. Established a practical cooperative protocol. |
| Algorithm Implementation | 1. Target selection algorithm for single-ownship systems [35]. 2. Pre-planned waypoint navigation and landing algorithm [38]. 3. None. | 1. Extended to a decentralized multi-ownship coordination and dynamic target selection algorithm. 2. Development of a seamless flight mode transitioning strategy with randomly generated safe landing sites. 3. Optimized control signals for safe physical drone operations. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, B.; Mantegh, I.; Xie, W. Decentralized UAV Swarm Control: A Multi-Layered Architecture for Integrated Flight Mode Management and Dynamic Target Interception. Drones 2024, 8, 350. https://doi.org/10.3390/drones8080350
Xia B, Mantegh I, Xie W. Decentralized UAV Swarm Control: A Multi-Layered Architecture for Integrated Flight Mode Management and Dynamic Target Interception. Drones. 2024; 8(8):350. https://doi.org/10.3390/drones8080350
Chicago/Turabian StyleXia, Bingze, Iraj Mantegh, and Wenfang Xie. 2024. "Decentralized UAV Swarm Control: A Multi-Layered Architecture for Integrated Flight Mode Management and Dynamic Target Interception" Drones 8, no. 8: 350. https://doi.org/10.3390/drones8080350
APA StyleXia, B., Mantegh, I., & Xie, W. (2024). Decentralized UAV Swarm Control: A Multi-Layered Architecture for Integrated Flight Mode Management and Dynamic Target Interception. Drones, 8(8), 350. https://doi.org/10.3390/drones8080350