

UAV Confrontation and Evolutionary Upgrade Based on Multi-Agent Reinforcement Learning

Abstract
1. Introduction
- Fully centralized methods: the fully centralized methods treat the decisions of multiple agents as those of a super-agent, aggregating the states of all agents into a global super-state and connecting the actions of all agents as a joint action. While advantageous for the super-agent as the environment remains static, ensuring the convergence of individual agent algorithms, this method struggles to scale well with a large number of agents or a large environment due to the curse of dimensionality [18].
- Fully decentralized methods: the fully decentralized methods assume each agent learns independently in its own environment without considering changes in other agents, such as independent proximal policy optimization (IPPO) algorithm [19]. Each agent applies a single-agent reinforcement learning algorithm directly. This method exhibits good scalability with increasing agent numbers without encountering training termination due to the curse of dimensionality. However, the environment using this method is non-stationary, jeopardizing the convergence of training.
- Centralized Training Decentralized Execution (CTDE): CTDE utilizes global information, which individual agents cannot observe during training, to achieve better training performance. However, during execution, this global information is not used, and each agent takes actions solely based on its own policy, thus achieving decentralized execution. CTDE algorithms effectively use global information to enhance the quality and stability of training, while only using local information during policy model inference, making the algorithm scalable to a certain extent.
2. Model Constraints and Path Planning
2.1. Drone Dynamic Model
- Yaw Angle Constraint: the drone can only turn on a horizontal plane that is less than or equal to the specified maximum yaw angle:In the above formula, , where denotes the maximum yaw angle.
- Pitch Angle Constraint: the drone can only rise in a vertical plane that is less than or equal to the specified maximum pitch angle:In the above formula, , where denotes the maximum pitch angle.
- The Trajectory Segment Length Constraint represents the shortest distance that the drone can fly along the current flight direction before changing its flight attitude.In the above formula, , where denotes the minimum segment length of the trajectory.
- Flight Height Constraint represents the height of the drone that the drone can safely fly.In the above formula, represents the maximum height, while represents the minimum height.
- The Total Trajectory Length Constraint is the total trajectory length of the drone less than or equal to the specified threshold.In the above formula, represents the maximum total trajectory length.
2.2. Disturbance Flow Field Method
3. Simulation Scenario and Algorithm Design
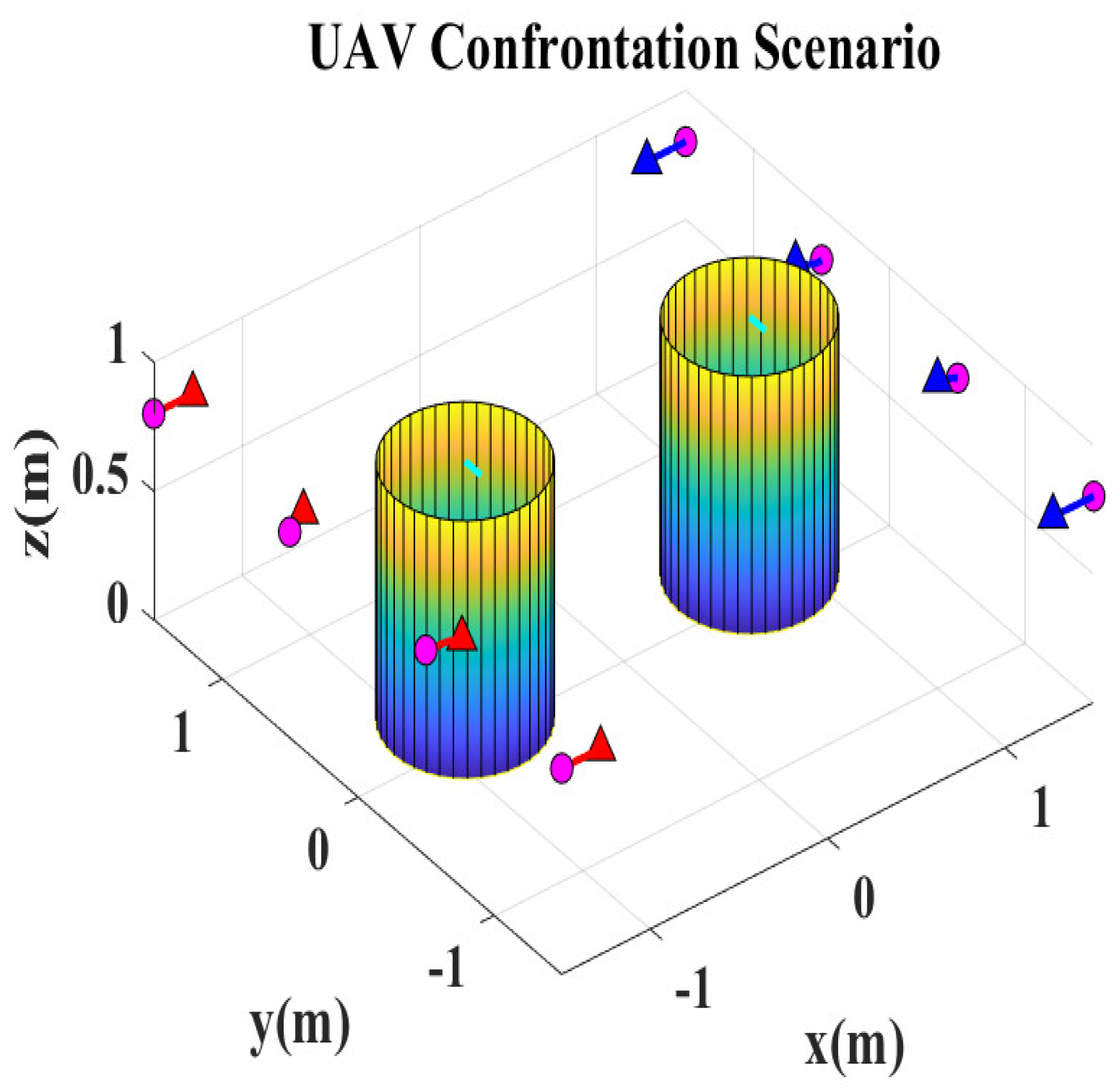
3.1. UAV Confrontation Scenario
3.2. Reinforcement Learning Algorithm Based on Actor-Critic
- State Space: The state space represents the state information of the constructed multi-agent adversarial environment, including both the agents’ own information and environmental information. It may include parameters such as the positions and velocities of the agents, the positions and velocities of adjacent agents, and the positions and velocities of obstacles.
- Action Space: The action space represents the actions that both agents of the multi-agent environment can take. In this case, the action space is represented by the actions performed by the agents. Based on the environmental conditions in the adversarial environment, agents may perform actions such as detecting and attacking.
- Reward Function: The reward function provides feedback to the agents after taking actions, guiding them toward better strategies and evaluating the system’s behaviors. It evaluates the goodness or badness of the system’s actions.
3.3. Semi-Static MADDPG Algorithm Based on UAV Confrontation Scenario
3.3.1. Observation Space and Action Space
3.3.2. Algorithm Design
- Policy Network: the policy network of agent i takes the local observation information as input, which includes the agent’s own position information, the destination position information, and the position and velocity information of the nearest neighbor. The input observation information is processed by a three-layer neural network of input layer, hidden layer and output layer, and outputs the optimal action .
- Value Function Network: the value network of agent i takes the joint observation information of its team’s agents and the joint action information as input. The joint information is processed by a three-layer neural network of input layer, hidden layer and output layer, and outputs the state-action function value .
- Reward Function: in the multi-agent adversarial scenario, agents in the same team collaborate to accomplish the same task, while agents from different teams engage in adversarial relationships with each other. Therefore, agents in the same team form a cooperative relationship and can share a common reward value. Each agent is required to complete collision avoidance and adversarial tasks before reaching the target point.The reward function for agent i at a given time t is composed of the following three parts:(a) Collision Penalty: if agent i collides with obstacle j, the agent receives the following penalty:If agent collides with agent , the agent receives the following penalty:(b) Detect and Attack Reward: if agent i detects an opponent’s agent, it obtains a reward value and attacks the opponent’s agent, which has a certain probability of hitting the opponent’s agent. If agent i successfully attacks the opponent’s agent, agent i obtains a reward value .(c) Remaining Distance Penalty: if agent i fails to reach the target point in the current time, the agent receives the following penalty:where represents the distance from the center of agent i to the destination of agent i, and represents the distance from the starting point of agent i to the destination of agent i. is the mission completion distance, if , the agent’s task is declared complete. The constants , , and are predefined.The final reward obtained by agent i is as followsUnder this reward function setting, agents are effectively able to complete collision avoidance and attack tasks while aiming for their target points. However, to achieve the goal of adversarial engagement between the two sides, each agent also needs to avoid enemy attacks as much as possible. Therefore, the above reward is the task reward, and the ultimate objective of the team is to maximize its own task reward while minimizing the other side’s adversarial reward .
3.3.3. Algorithm Process
| Algorithm 1 Semi-static MADDPG algorithm based on UAV confrontation scenario |
| Input: discount factor ; learning rate ; random noise ; number of training rounds E; number of training steps T; number of drones per party N; Output: Policy network or
|
| Algorithm 2 Original MADDPG algorithm based on UAV confrontation scenario |
| Input: discount factor ; learning rate ; random noise ; number of training rounds E; number of training steps T; number of drones per party N; Output: Policy network and
|
4. Experimental Results
4.1. Comparison Algorithm
4.2. Simulation Environment
4.3. Result Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Han, S.; Ke, L.; Wang, Z. Multi-Agent Confrontation Game Based on Multi-Agent Reinforcement Learning. In Proceedings of the 2021 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 15–17 October 2021; IEEE: New York, NY, USA, 2021; pp. 157–162. [Google Scholar]
- Xiang, L.; Xie, T. Research on UAV swarm confrontation task based on MADDPG algorithm. In Proceedings of the 2020 5th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 25–27 December 2020; IEEE: New York, NY, USA, 2020; pp. 1513–1518. [Google Scholar]
- Yang, X.; Xue, X.; Yang, J.; Hu, J.; Yu, T. Decomposed and Prioritized Experience Replay-based MADDPG Algorithm for Multi-UAV Confrontation. In Proceedings of the 2023 International Conference on Ubiquitous Communication (Ucom), Xi’an, China, 7–9 July 2023; IEEE: New York, NY, USA, 2023; pp. 292–297. [Google Scholar]
- Zuo, J.; Liu, Z.; Chen, J.; Li, Z.; Li, C. A Multi-agent Cluster Cooperative Confrontation Method Based on Swarm Intelligence Optimization. In Proceedings of the 2021 IEEE 2nd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Nanchang, China, 26–28 March 2021; IEEE: New York, NY, USA, 2021; pp. 668–672. [Google Scholar]
- Hu, C. A confrontation decision-making method with deep reinforcement learning and knowledge transfer for multi-agent system. Symmetry 2020, 12, 631. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, F.; Guo, J.; Hong, C.; Chen, M.; Wang, E.; Zhao, Y. UAV swarm confrontation based on multi-agent deep reinforcement learning. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Heifei, China, 25–27 July 2022; IEEE: New York, NY, USA, 2022; pp. 4996–5001. [Google Scholar]
- Chi, P.; Wei, J.; Wu, K.; Di, B.; Wang, Y. A Bio-Inspired Decision-Making Method of UAV Swarm for Attack-Defense Confrontation via Multi-Agent Reinforcement Learning. Biomimetics 2023, 8, 222. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Li, Z.; Huang, K.; Wang, R.; Cheng, G.; Li, T. Evolutionary reinforcement learning algorithm for large-scale multi-agent cooperation and confrontation applications. J. Supercomput. 2024, 80, 2319–2346. [Google Scholar] [CrossRef]
- Ren, A.Z.; Majumdar, A. Distributionally robust policy learning via adversarial environment generation. IEEE Robot. Autom. Lett. 2022, 7, 1379–1386. [Google Scholar] [CrossRef]
- Liu, D.; Zong, Q.; Zhang, X.; Zhang, R.; Dou, L.; Tian, B. Game of Drones: Intelligent Online Decision Making of Multi-UAV Confrontation. IEEE Trans. Emerg. Top. Comput. Intell. 2024, 8, 2086–2100. [Google Scholar] [CrossRef]
- Gupta, J.K.; Egorov, M.; Kochenderfer, M. Cooperative multi-agent control using deep reinforcement learning. In Proceedings of the Autonomous Agents and Multiagent Systems: AAMAS 2017 Workshops, Best Papers, São Paulo, Brazil, 8–12 May 2017; Revised Selected Papers 16. Springer: Berlin/Heidelberg, Germany, 2017; pp. 66–83. [Google Scholar]
- Yang, P.; Freeman, R.A.; Lynch, K.M. Multi-agent coordination by decentralized estimation and control. IEEE Trans. Autom. Control 2008, 53, 2480–2496. [Google Scholar] [CrossRef]
- Littman, M.L. Markov games as a framework for multi-agent reinforcement learning. In Machine Learning Proceedings 1994; Elsevier: Amsterdam, The Netherlands, 1994; pp. 157–163. [Google Scholar]
- Zhang, K.; Yang, Z.; Başar, T. Multi-agent reinforcement learning: A selective overview of theories and algorithms. In Handbook of Reinforcement Learning and Control; Springer: Berlin/Heidelberg, Germany, 2021; pp. 321–384. [Google Scholar]
- Buşoniu, L.; Babuška, R.; De Schutter, B. Multi-agent reinforcement learning: An overview. In Innovations in Multi-Agent Systems and Applications-1; Springer: Berlin/Heidelberg, Germany, 2010; pp. 183–221. [Google Scholar]
- Tan, M. Multi-agent reinforcement learning: Independent vs. cooperative agents. In Proceedings of the Tenth International Conference on Machine Learning, Amherst, MA, USA, 27–29 June 1993; pp. 330–337. [Google Scholar]
- Foerster, J.; Assael, I.A.; De Freitas, N.; Whiteson, S. Learning to communicate with deep multi-agent reinforcement learning. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Hernandez-Leal, P.; Kartal, B.; Taylor, M.E. A survey and critique of multiagent deep reinforcement learning. Auton. Agents Multi-Agent Syst. 2019, 33, 750–797. [Google Scholar] [CrossRef]
- De Witt, C.S.; Gupta, T.; Makoviichuk, D.; Makoviychuk, V.; Torr, P.H.; Sun, M.; Whiteson, S. Is independent learning all you need in the starcraft multi-agent challenge? arXiv 2020, arXiv:2011.09533. [Google Scholar]
- Sunehag, P.; Lever, G.; Gruslys, A.; Czarnecki, W.M.; Zambaldi, V.; Jaderberg, M.; Lanctot, M.; Sonnerat, N.; Leibo, J.Z.; Tuyls, K.; et al. Value-decomposition networks for cooperative multi-agent learning. arXiv 2017, arXiv:1706.05296. [Google Scholar]
- Rashid, T.; Samvelyan, M.; De Witt, C.S.; Farquhar, G.; Foerster, J.; Whiteson, S. Monotonic value function factorisation for deep multi-agent reinforcement learning. J. Mach. Learn. Res. 2020, 21, 1–51. [Google Scholar]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Foerster, J.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual multi-agent policy gradients. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Cai, H.; Luo, Y.; Gao, H.; Chi, J.; Wang, S. A Multiphase Semistatic Training Method for Swarm Confrontation Using Multiagent Deep Reinforcement Learning. Comput. Intell. Neurosci. 2023, 2023, 2955442. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Piao, H.; Yang, Z.; Zhao, Y.; Zhan, G.; Zhou, D.; Meng, G.; Chen, H.; Chen, X.; Qu, B.; et al. Multi-agent hierarchical policy gradient for air combat tactics emergence via self-play. Eng. Appl. Artif. Intell. 2021, 98, 104112. [Google Scholar] [CrossRef]
- Khatib, O. Real-time obstacle avoidance for manipulators and mobile robots. Int. J. Robot. Res. 1986, 5, 90–98. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Yao, P.; Wang, H.; Su, Z. UAV feasible path planning based on disturbed fluid and trajectory propagation. Chin. J. Aeronaut. 2015, 28, 1163–1177. [Google Scholar] [CrossRef]
- Konda, V.; Tsitsiklis, J. Actor-critic algorithms. Adv. Neural Inf. Process. Syst. 1999, 12. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Bellman, R. Dynamic programming. Science 1966, 153, 34–37. [Google Scholar] [CrossRef] [PubMed]
- Filar, J.; Vrieze, K. Competitive Markov Decision Processes; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Altman, E. Constrained Markov Decision Processes; Routledge: London, UK, 2021. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definitions |
|---|---|
| The indexes of drones | |
| The indexes of obstacles | |
| The position of drone i | |
| The position of obstacle i | |
| The destination of drone i | |
| The velocity of drone i | |
| The velocity of obstacle i | |
| The geometric radius of drone | |
| The geometric radius of cylindrical obstacle | |
| H | The geometric height of cylindrical obstacle |
| The detection angle of drone | |
| The detection radius of drone | |
| The blood of drone i | |
| The roll angle of drone i | |
| The yaw angle of drone i | |
| The pitch angle of drone i | |
| The state | |
| z | The observation |
| a | The action |
| r | The reward |
| S | The state space |
| Z | The observation space |
| A | The action space |
| The discount factor |
| Parameter Name | Parameter Value |
|---|---|
| Policy network layers | 3 |
| Policy network hidden layer dimensions | 256 |
| Policy network learning rate | 0.001 |
| Value network layers | 3 |
| Value network hidden layer dimensions | 512 |
| Value network learning rate | 0.001 |
| Total training period | 100 |
| Maximum number of steps per cycle | 5000 |
| Parameter update cycle | 5 |
| Update batch size | 32 |
| Algorithm | R-Wins (1–100) | B-Wins (1–100) | R-Wins (61–100) | B-Wins (61–100) | Win-Lose Conversion (1–100) | Win-Lose Conversion (61–100) |
|---|---|---|---|---|---|---|
| MADDPG(1) | 56 | 44 | 27 | 13 | 50 | 17 |
| S-MADDPG(1) | 67 | 33 | 27 | 13 | 45 | 19 |
| MADDPG(4) | 61 | 39 | 28 | 12 | 52 | 18 |
| S-MADDPG(4) | 57 | 43 | 25 | 15 | 50 | 24 |
| MADDPG(5) | 60 | 40 | 28 | 12 | 48 | 15 |
| S-MADDPG(5) | 53 | 47 | 18 | 22 | 48 | 21 |
| MADDPG(8) | 48 | 52 | 19 | 21 | 48 | 18 |
| S-MADDPG(8) | 49 | 51 | 21 | 19 | 56 | 25 |
| MADDPG(16) | 43 | 57 | 16 | 24 | 42 | 17 |
| S-MADDPG(16) | 64 | 36 | 23 | 17 | 43 | 16 |
| Algorithm | Optimal Reward (1–100) | Average Reward Difference (1–100) | Average Reward Difference (61–100) | Average Training Time (1–100) |
|---|---|---|---|---|
| MADDPG(1) | −717.11 | 196.26 | 230.26 | 21.34 s |
| S-MADDPG(1) | −720.81 | 115.17 | 94.56 | 17.48 s |
| MADDPG(4) | −684.06 | 145.80 | 172.29 | 18.80 s |
| S-MADDPG(4) | −606.71 | 124.28 | 111.02 | 12.89 s |
| MADDPG(5) | −780.49 | 238.24 | 160.94 | 25.73 s |
| S-MADDPG(5) | −643.44 | 122.87 | 75.75 | 11.96 s |
| MADDPG(8) | −720.3 | 163.92 | 173.81 | 21.78 s |
| S-MADDPG(8) | −622.31 | 118.44 | 104.77 | 11.79 s |
| MADDPG(16) | −653.81 | 224.60 | 159.50 | 24.31 s |
| S-MADDPG(16) | −652.47 | 137.81 | 86.26 | 11.37 s |
| Algorithm | R-Wins (1–100) | B-Wins (1–100) | R-Wins (61–100) | B-Wins (61–100) | Win-Lose Conversion (1–100) | Win-Lose Conversion (61–100) |
|---|---|---|---|---|---|---|
| MADDPG(1) | 54 | 46 | 20 | 20 | 41 | 15 |
| S-MADDPG(1) | 61 | 39 | 27 | 13 | 45 | 15 |
| MADDPG(4) | 63 | 37 | 17 | 23 | 32 | 20 |
| S-MADDPG(4) | 59 | 41 | 21 | 19 | 50 | 20 |
| MADDPG(5) | 51 | 49 | 16 | 24 | 59 | 25 |
| S-MADDPG(5) | 57 | 43 | 21 | 19 | 42 | 16 |
| MADDPG(8) | 68 | 32 | 24 | 16 | 39 | 15 |
| S-MADDPG(8) | 49 | 51 | 22 | 18 | 47 | 19 |
| MADDPG(16) | 64 | 36 | 27 | 13 | 45 | 15 |
| S-MADDPG(16) | 55 | 45 | 25 | 15 | 49 | 20 |
| Algorithm | Optimal Reward (1–100) | Average Reward Difference (1–100) | Average Reward Difference (61–100) | Average Training Time (1–100) |
|---|---|---|---|---|
| MADDPG(1) | −671.86 | 389.20 | 389.20 | 32.71 s |
| S-MADDPG(1) | −700.08 | 176.78 | 245.39 | 16.12 s |
| MADDPG(4) | −751.39 | 331.60 | 272.17 | 32.94 s |
| S-MADDPG(4) | −564.36 | 159.77 | 126.71 | 13.15 s |
| MADDPG(5) | −636.11 | 383.92 | 324.83 | 33.07 s |
| S-MADDPG(5) | −635.35 | 132.46 | 132.19 | 12.09 s |
| MADDPG(8) | −660.59 | 196.80 | 188.15 | 26.83 s |
| S-MADDPG(8) | −619.53 | 164.82 | 161.87 | 15.51 s |
| MADDPG(16) | −584.09 | 365.022 | 362.74 | 32.83 s |
| S-MADDPG(16) | −559.92 | 159.52 | 132.30 | 16.30 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, X.; Dong, Z.; Ding, J. UAV Confrontation and Evolutionary Upgrade Based on Multi-Agent Reinforcement Learning. Drones 2024, 8, 368. https://doi.org/10.3390/drones8080368
Deng X, Dong Z, Ding J. UAV Confrontation and Evolutionary Upgrade Based on Multi-Agent Reinforcement Learning. Drones. 2024; 8(8):368. https://doi.org/10.3390/drones8080368
Chicago/Turabian StyleDeng, Xin, Zhaoqi Dong, and Jishiyu Ding. 2024. "UAV Confrontation and Evolutionary Upgrade Based on Multi-Agent Reinforcement Learning" Drones 8, no. 8: 368. https://doi.org/10.3390/drones8080368
APA StyleDeng, X., Dong, Z., & Ding, J. (2024). UAV Confrontation and Evolutionary Upgrade Based on Multi-Agent Reinforcement Learning. Drones, 8(8), 368. https://doi.org/10.3390/drones8080368