
End-to-End Nano-Drone Obstacle Avoidance for Indoor Exploration





Abstract
1. Introduction
- In order to reduce drone memory usage, this paper explores running depth estimation networks on single-channel grayscale images. The experimental results on the KITTI dataset show that self-supervised depth estimation using grayscale images is feasible. A single grayscale image saves two-thirds of the storage space compared to using a single RGB image.
- The remaining space is still insufficient for the storage and inference of small models such as Lite-Mono [17]. Therefore, a lightweight depth estimation framework DDND is proposed that has few parameters (310 K). To compensate for the limited learning capacity of the small network, knowledge distillation is introduced and a Channel-Aware Distillation Transformer (CADiT) is proposed to make the student model explore important information in different feature channels from the teacher, thus enhancing the knowledge distillation. The effectiveness of the method is validated on the KITTI dataset.
- The proposed model is deployed on the nano-drone platform Crazyflie, and it runs at 1.24 FPS on a GAP8 processor to avoid obstacles in real environments. The code will be released on the project website https://github.com/noahzn/DDND (accessed on 17 January 2024).
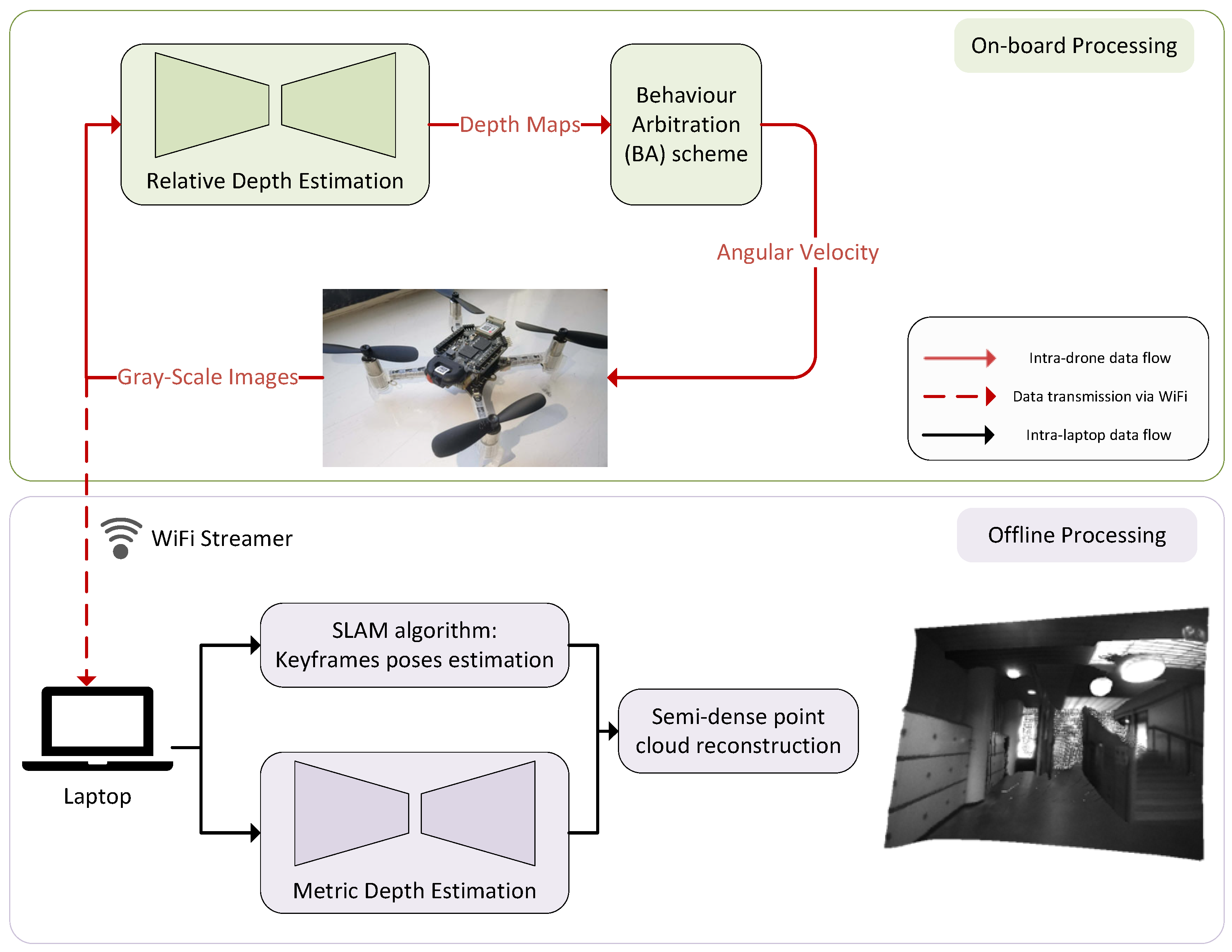
- Since a map of the environment is useful for rescue missions and considering that it is not possible to run reconstruction algorithms onboard nano-drones, this paper implements data communication from the drone to a laptop and presents a pipeline for offline reconstruction of the environment.
2. Related Work
2.1. Obstacle Avoidance of Nano-Drones
2.2. Efficient Monocular Self-Supervised Depth Estimation
2.3. Knowledge Distillation for Depth Estimation
3. Method
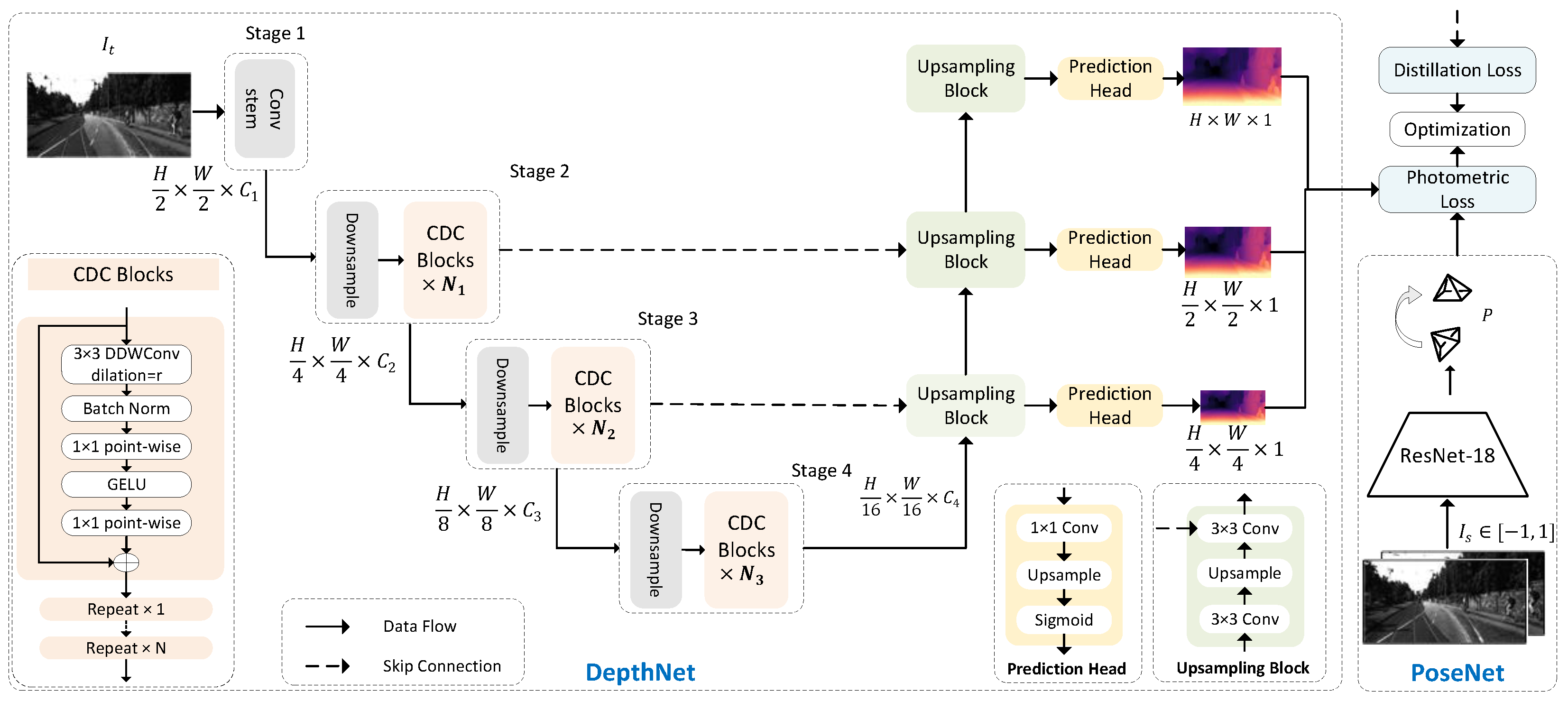
3.1. Network Structures
3.2. SSDE Training Scheme
3.2.1. Photometric Loss
3.2.2. Smoothness Loss
3.3. Knowledge Distillation Scheme
3.3.1. Matching Intermediate Features using the Channel Aware Distillation Transformer (CADiT)
3.3.2. Matching Outputs
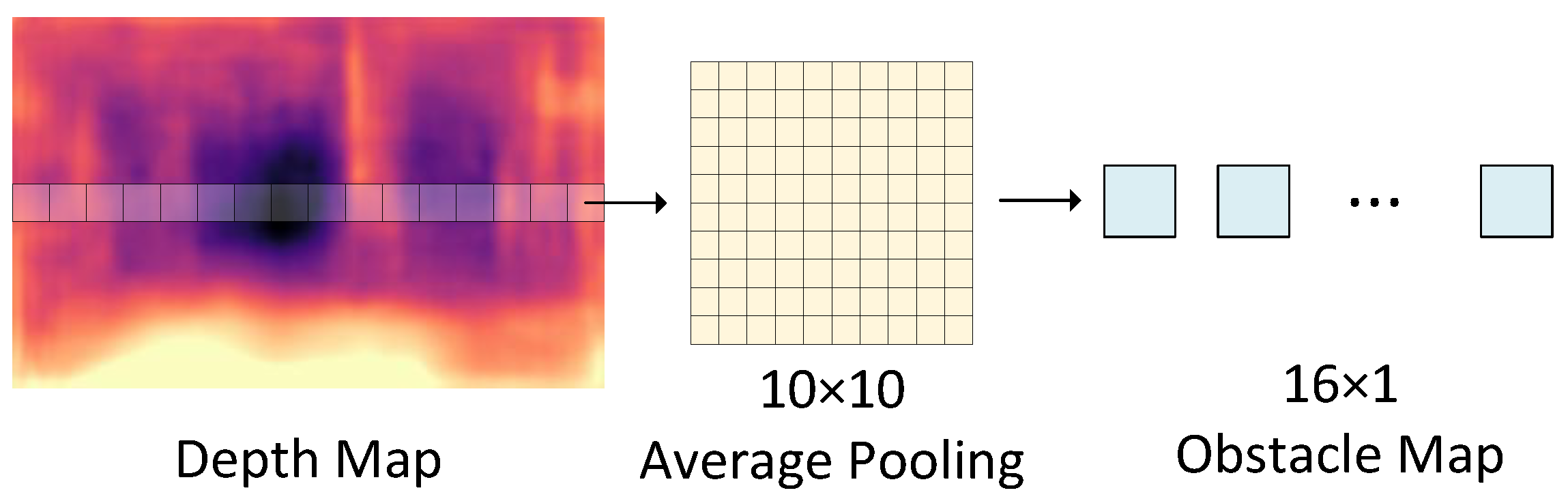
3.4. Drone Controlling
4. Experiments
4.1. Drone Platform
4.2. Datasets
4.2.1. KITTI
4.2.2. Gray Campus Indoor
4.3. Implementation Details
4.3.1. Network Training
4.3.2. Model Quantization and Deployment
4.4. Results on Grayscale KITTI
4.5. Qualitative Results on Gray Campus Indoor
4.6. Ablation Study on KD Losses
4.7. Test in Real Environments
4.8. Inference Speed Analysis
4.9. Failure Cases
5. The Scene Reconstruction Pipeline
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Paliotta, C.; Ening, K.; Albrektsen, S.M. Micro indoor-drones (mins) for localization of first responders. In Proceedings of the ISCRAM, Blacksburg, VA, USA, 23–26 May 2021. [Google Scholar]
- Smolyanskiy, N.; Gonzalez-Franco, M. Stereoscopic first person view system for drone navigation. Front. Robot. AI 2017, 4, 11. [Google Scholar] [CrossRef]
- Schmid, K.; Tomic, T.; Ruess, F.; Hirschmüller, H.; Suppa, M. Stereo vision based indoor/outdoor navigation for flying robots. In Proceedings of the IROS, Tokyo, Japan, 3–8 November 2013; pp. 3955–3962. [Google Scholar]
- Chiella, A.C.; Machado, H.N.; Teixeira, B.O.; Pereira, G.A. GNSS/LiDAR-based navigation of an aerial robot in sparse forests. Sensors 2019, 19, 4061. [Google Scholar] [CrossRef] [PubMed]
- Moffatt, A.; Platt, E.; Mondragon, B.; Kwok, A.; Uryeu, D.; Bhandari, S. Obstacle detection and avoidance system for small uavs using a lidar. In Proceedings of the ICUAS, Athens, Greece, 1–4 November 2020; pp. 633–640. [Google Scholar]
- Park, J.; Cho, N. Collision avoidance of hexacopter UAV based on LiDAR data in dynamic environment. Remote Sens. 2020, 12, 975. [Google Scholar] [CrossRef]
- Akbari, A.; Chhabra, P.S.; Bhandari, U.; Bernardini, S. Intelligent exploration and autonomous navigation in confined spaces. In Proceedings of the IROS, Las Vegas, NV, USA, 25–29 October 2020; pp. 2157–2164. [Google Scholar]
- Yang, T.; Li, P.; Zhang, H.; Li, J.; Li, Z. Monocular vision SLAM-based UAV autonomous landing in emergencies and unknown environments. Electronics 2018, 7, 73. [Google Scholar] [CrossRef]
- von Stumberg, L.; Usenko, V.; Engel, J.; Stückler, J.; Cremers, D. From monocular SLAM to autonomous drone exploration. In Proceedings of the ECMR, Paris, France, 6–8 November 2017; pp. 1–8. [Google Scholar]
- Tulldahl, M.; Holmberg, M.; Karlsson, O.; Rydell, J.; Bilock, E.; Axelsson, L.; Tolt, G.; Svedin, J. Laser sensing from small UAVs. In Proceedings of the Electro-Optical Remote Sensing XIV, San Francisco, CA, USA, 1–3 February 2020; Volume 11538, pp. 87–101. [Google Scholar]
- Kouris, A.; Bouganis, C.S. Learning to fly by myself: A self-supervised cnn-based approach for autonomous navigation. In Proceedings of the IROS, Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Loquercio, A.; Maqueda, A.I.; Del-Blanco, C.R.; Scaramuzza, D. Dronet: Learning to fly by driving. IEEE Robot. Autom. Lett. 2018, 3, 1088–1095. [Google Scholar] [CrossRef]
- Gandhi, D.; Pinto, L.; Gupta, A. Learning to fly by crashing. In Proceedings of the IROS, Vancouver, BC, Canada, 24–28 November 2017; pp. 3948–3955. [Google Scholar]
- Yang, X.; Chen, J.; Dang, Y.; Luo, H.; Tang, Y.; Liao, C.; Chen, P.; Cheng, K.T. Fast depth prediction and obstacle avoidance on a monocular drone using probabilistic convolutional neural network. IEEE Trans. Intell. Transport. Syst. 2019, 22, 156–167. [Google Scholar] [CrossRef]
- Chakravarty, P.; Kelchtermans, K.; Roussel, T.; Wellens, S.; Tuytelaars, T.; Van Eycken, L. CNN-based single image obstacle avoidance on a quadrotor. In Proceedings of the ICRA, Singapore, 29 May–3 June 2017; pp. 6369–6374. [Google Scholar]
- Zhang, Z.; Xiong, M.; Xiong, H. Monocular depth estimation for UAV obstacle avoidance. In Proceedings of the CCIOT, Changchun, China, 6–7 December 2019; pp. 43–47. [Google Scholar]
- Zhang, N.; Nex, F.; Vosselman, G.; Kerle, N. Lite-mono: A lightweight cnn and transformer architecture for self-supervised monocular depth estimation. In Proceedings of the CVPR, Vancouver, BC, Canada, 18–22 June 2023; pp. 18537–18546. [Google Scholar]
- McGuire, K.; De Wagter, C.; Tuyls, K.; Kappen, H.; de Croon, G.C. Minimal navigation solution for a swarm of tiny flying robots to explore an unknown environment. Sci. Robot. 2019, 4, eaaw9710. [Google Scholar] [CrossRef]
- Duisterhof, B.P.; Li, S.; Burgués, J.; Reddi, V.J.; de Croon, G.C. Sniffy bug: A fully autonomous swarm of gas-seeking nano quadcopters in cluttered environments. In Proceedings of the IROS, Prague, Czech Republic, 27 September–1 October 2021; pp. 9099–9106. [Google Scholar]
- Niculescu, V.; Müller, H.; Ostovar, I.; Polonelli, T.; Magno, M.; Benini, L. Towards a Multi-Pixel Time-of-Flight Indoor Navigation System for Nano-Drone Applications. In Proceedings of the I2MTC, Ottawa, ON, Canada, 16–19 May 2022; pp. 1–6. [Google Scholar]
- Vanhie-Van Gerwen, J.; Geebelen, K.; Wan, J.; Joseph, W.; Hoebeke, J.; De Poorter, E. Indoor drone positioning: Accuracy and cost trade-off for sensor fusion. IEEE Trans. Veh. Technol. 2021, 71, 961–974. [Google Scholar] [CrossRef]
- Briod, A.; Zufferey, J.C.; Floreano, D. Optic-flow based control of a 46g quadrotor. In Proceedings of the IROS Workshop, Tokyo, Japan, 3–8 November 2013. [Google Scholar]
- Bouwmeester, R.J.; Paredes-Vallés, F.; de Croon, G.C. NanoFlowNet: Real-time Dense Optical Flow on a Nano Quadcopter. arXiv 2022, arXiv:2209.06918. [Google Scholar]
- McGuire, K.; De Croon, G.; De Wagter, C.; Tuyls, K.; Kappen, H. Efficient optical flow and stereo vision for velocity estimation and obstacle avoidance on an autonomous pocket drone. IEEE Robot. Autom. Lett. 2017, 2, 1070–1076. [Google Scholar] [CrossRef]
- Palossi, D.; Loquercio, A.; Conti, F.; Flamand, E.; Scaramuzza, D.; Benini, L. A 64-mw dnn-based visual navigation engine for autonomous nano-drones. IEEE Internet Things J. 2019, 6, 8357–8371. [Google Scholar] [CrossRef]
- Zhilenkov, A.A.; Epifantsev, I.R. System of autonomous navigation of the drone in difficult conditions of the forest trails. In Proceedings of the EIConRus, Moscow, Russia, 29 January–1 February 2018; pp. 1036–1039. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]
- Jung, H.; Park, E.; Yoo, S. Fine-grained semantics-aware representation enhancement for self-supervised monocular depth estimation. In Proceedings of the ICCV, Montreal, QC, Canada, 11–17 October 2021; pp. 12642–12652. [Google Scholar]
- Yin, Z.; Shi, J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1983–1992. [Google Scholar]
- Poggi, M.; Aleotti, F.; Tosi, F.; Mattoccia, S. On the uncertainty of self-supervised monocular depth estimation. In Proceedings of the CVPR, Seattle, WA, USA, 16–18 June 2020; pp. 3227–3237. [Google Scholar]
- Yang, N.; Stumberg, L.v.; Wang, R.; Cremers, D. D3vo: Deep depth, deep pose and deep uncertainty for monocular visual odometry. In Proceedings of the CVPR, Seattle, WA, USA, 16–18 June 2020; pp. 1281–1292. [Google Scholar]
- Yan, J.; Zhao, H.; Bu, P.; Jin, Y. Channel-wise attention-based network for self-supervised monocular depth estimation. In Proceedings of the 3DV, Online, 1–3 December 2021; pp. 464–473. [Google Scholar]
- Bae, J.; Moon, S.; Im, S. Deep Digging into the Generalization of Self-supervised Monocular Depth Estimation. In Proceedings of the AAAI, Washington, DC, USA, 7–14 February 2023. [Google Scholar]
- Lyu, X.; Liu, L.; Wang, M.; Kong, X.; Liu, L.; Liu, Y.; Chen, X.; Yuan, Y. Hr-depth: High resolution self-supervised monocular depth estimation. In Proceedings of the AAAI, Online, 2–9 February 2021; Volume 35, pp. 2294–2301. [Google Scholar]
- Wofk, D.; Ma, F.; Yang, T.J.; Karaman, S.; Sze, V. Fastdepth: Fast monocular depth estimation on embedded systems. In Proceedings of the ICRA, Montreal, QC, Canada, 20–24 May 2019; pp. 6101–6108. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhou, Z.; Fan, X.; Shi, P.; Xin, Y. R-msfm: Recurrent multi-scale feature modulation for monocular depth estimating. In Proceedings of the ICCV, Montreal, QC, Canada, 11–17 October 2021; pp. 12777–12786. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep mutual learning. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4320–4328. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Komodakis, N.; Zagoruyko, S. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In Proceedings of the ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Shu, C.; Liu, Y.; Gao, J.; Yan, Z.; Shen, C. Channel-wise knowledge distillation for dense prediction. In Proceedings of the ICCV, Montreal, QC, Canada, 11–17 October 2021; pp. 5311–5320. [Google Scholar]
- Zhou, Z.; Zhuge, C.; Guan, X.; Liu, W. Channel distillation: Channel-wise attention for knowledge distillation. arXiv 2020, arXiv:2006.01683. [Google Scholar]
- Wang, Y.; Li, X.; Shi, M.; Xian, K.; Cao, Z. Knowledge distillation for fast and accurate monocular depth estimation on mobile devices. In Proceedings of the CVPR, Nashville, TN, USA, 19–25 June 2021; pp. 2457–2465. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the CVPR, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Fan, C.; Jiang, H.; Guo, X.; Gao, Y.; Lu, X.; Lam, T.L. Boosting Light-Weight Depth Estimation Via Knowledge Distillation. arXiv 2021, arXiv:2105.06143. [Google Scholar]
- Pilzer, A.; Lathuiliere, S.; Sebe, N.; Ricci, E. Refine and distill: Exploiting cycle-inconsistency and knowledge distillation for unsupervised monocular depth estimation. In Proceedings of the CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 9768–9777. [Google Scholar]
- Cho, J.H.; Hariharan, B. On the efficacy of knowledge distillation. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4794–4802. [Google Scholar]
- Stanton, S.; Izmailov, P.; Kirichenko, P.; Alemi, A.A.; Wilson, A.G. Does knowledge distillation really work? NeurIPS 2021, 34, 6906–6919. [Google Scholar]
- Lin, S.; Xie, H.; Wang, B.; Yu, K.; Chang, X.; Liang, X.; Wang, G. Knowledge distillation via the target-aware transformer. In Proceedings of the CVPR, New Orleans, LA, USA, 21–23 June 2022; pp. 10915–10924. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Althaus, P.; Christensen, H.I. Behaviour coordination for navigation in office environments. In Proceedings of the IROS, Lausanne, Switzerland, 30 September–4 October 2002; Volume 3, pp. 2298–2304. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the ICCV, Santiago, Chile, 13–16 December 2015; pp. 2650–2658. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the CVPR, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Bhat, S.F.; Birkl, R.; Wofk, D.; Wonka, P.; Müller, M. Zoedepth: Zero-shot transfer by combining relative and metric depth. arXiv 2023, arXiv:2302.12288. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Platform | Open-Source | MCU | Camera | AI Chip |
|---|---|---|---|---|
| Crazepony2 | Yes | STM32F303 | Yes | - |
| ArduBee | Yes | STM32H743VIT6 | Yes | - |
| DJI Tello | No | Not Specified | Yes | Intel® Movidius™ VPUs |
| Crazyflie 2.1 | Yes | STM32F405 | Yes | GAP8 |
| Method | Depth Error (↓) | Depth Accuracy (↑) | # Params. | |||||
|---|---|---|---|---|---|---|---|---|
| Abs Rel | Sq Rel | RMSE | RMSE Log | |||||
| Lite-Mono (RGB) [17] | 0.107 | 0.765 | 4.561 | 0.183 | 0.886 | 0.963 | 0.983 | 3.1 M |
| Lite-Mono [17] | 0.110 | 0.848 | 4.713 | 0.187 | 0.881 | 0.961 | 0.982 | 3.1 M |
| DDND w/o KD | 0.157 | 1.259 | 5.593 | 0.229 | 0.796 | 0.930 | 0.973 | 0.31 M |
| DDND | 0.147 | 1.149 | 5.394 | 0.221 | 0.813 | 0.936 | 0.974 | 0.31 M |
| No. | KD Settings | Depth Error (↓) | Depth Accuracy (↑) | |||||
|---|---|---|---|---|---|---|---|---|
| Abs Rel | Sq Rel | RMSE | RMSE Log | |||||
| 1 | E: n/a, D: n/a | 0.157 | 1.259 | 5.593 | 0.229 | 0.796 | 0.930 | 0.973 |
| 2 | E: n/a, D: L1 | 0.155 | 1.186 | 5.502 | 0.231 | 0.790 | 0.929 | 0.973 |
| 3 | E: L2, D: L1 | 0.154 | 1.305 | 5.653 | 0.229 | 0.803 | 0.932 | 0.972 |
| 4 | E: CD, D: n/a | 0.155 | 1.242 | 5.649 | 0.228 | 0.797 | 0.930 | 0.973 |
| 5 | E: CD, D: L1 | 0.152 | 1.208 | 5.561 | 0.226 | 0.807 | 0.934 | 0.973 |
| 6 | E: n/a, D: CADiT+L1 | 0.149 | 1.172 | 5.472 | 0.226 | 0.807 | 0.933 | 0.974 |
| 7 | E: CADiT, D: n/a | 0.149 | 1.236 | 5.528 | 0.223 | 0.815 | 0.936 | 0.973 |
| 8 | E: CADiT, D: L1 | 0.147 | 1.149 | 5.394 | 0.221 | 0.813 | 0.936 | 0.974 |
| Resolution | Speed (FPS) | |
|---|---|---|
| NVIDIA TITAN Xp | GAP8 | |
| 434.78 | 1.24 | |
| 431.53 | 0.22 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, N.; Nex, F.; Vosselman, G.; Kerle, N. End-to-End Nano-Drone Obstacle Avoidance for Indoor Exploration. Drones 2024, 8, 33. https://doi.org/10.3390/drones8020033
Zhang N, Nex F, Vosselman G, Kerle N. End-to-End Nano-Drone Obstacle Avoidance for Indoor Exploration. Drones. 2024; 8(2):33. https://doi.org/10.3390/drones8020033
Chicago/Turabian StyleZhang, Ning, Francesco Nex, George Vosselman, and Norman Kerle. 2024. "End-to-End Nano-Drone Obstacle Avoidance for Indoor Exploration" Drones 8, no. 2: 33. https://doi.org/10.3390/drones8020033
APA StyleZhang, N., Nex, F., Vosselman, G., & Kerle, N. (2024). End-to-End Nano-Drone Obstacle Avoidance for Indoor Exploration. Drones, 8(2), 33. https://doi.org/10.3390/drones8020033