1. Introduction
In recent years, with the rapid development of UAV technology, multi-UAV systems have become increasingly widely used in military and civilian fields. Especially in the military, the coordinated operation of multiple drones can significantly improve combat efficiency and effectiveness. However, the target allocation problem in multi-aircraft cooperative operations becomes a typical nonlinear polynomial problem because the decision space increases exponentially with the task size. Solving such problems is crucial to improving the combat efficiency of drone groups, but it also faces substantial technical challenges.
Currently, target allocation algorithms for multi-UAV cooperative operations are divided into two basic types: centralized and distributed. The centralized goal allocation algorithm makes global optimization decisions through central nodes to ensure the accuracy and efficiency of decision-making. In this mode, the central node receives situation information from other UAVs during the iterative process and runs the target allocation algorithm to determine the optimal target combination scheme. Such algorithms usually use global or local optimization problem models and can be further subdivided into two categories. The first category is traditional optimization methods used for minor problems, such as exhaustive methods, integer linear programming [
1], and graph theory analysis [
2], focusing on accurate solutions to ensure that the absolute optimal solution to the problem is found; the second category includes heuristic and meta-heuristic methods such as genetic algorithms and their derivative algorithms [
3,
4], particle swarm optimization [
5], and artificial immune algorithms [
6]. These algorithms are known for their flexibility and scalability; they can effectively handle larger-scale problems and obtain approximately global or local optimal solutions within an acceptable time range. It is suitable for complex and dynamically changing decision-making environments. Although the centralized target allocation algorithm has been widely used, its dependence on the central node leads to extended execution time and reduced response speed. At the same time, the data processing of the central node can easily cause information bottlenecks and single points of failure, affecting system robustness.
Distributed algorithms improve the robustness and scalability of the system through decentralized decision-making, but how to ensure the consistency and optimization effect of decisions is the critical problem that needs to be solved. In response to these challenges, researchers in the academic community have proposed various solutions. For example, the Consensus-Based Bundle Algorithm (CBBA) [
7,
8,
9] by Choi et al. effectively solves the target allocation problem of multi-agents by combining auctions and consensus mechanisms. However, it has shortcomings in the allocation of single targets by multi-agents. Since then, various improved algorithms based on the CBBA framework have been proposed. Li et al. [
10] proposed a multi-target consensus-based auction algorithm (MTCBBA) specifically for target allocation in multi-agent collaborative beyond-visual-range air combat. However, the algorithm has poor adaptability in dynamic environments and relies on collaborative mechanisms, which limits its application in large-scale complex air combat environments. Zhao et al. [
11] developed a multi-UAV dynamic target allocation algorithm based on communication network node clustering (CU-CBBA). The node grouping and clustering strategy effectively improved the limitations of CBBA in the communication network structure, but its high computational complexity resulted in a significant allocation delay. These studies have significantly promoted the development of distributed target allocation algorithms, but issues such as dynamic environment adaptability and target importance evaluation are still the main challenges facing this field.
With the continuous advancement of technology, more and more scholars have begun to adopt reinforcement learning methods to solve the problem of target allocation for multi-UAV collaboration. Through the adaptive learning mechanism, drones can select the optimal attack target in a complex environment. For example, Li et al. [
12] proposed a target allocation model based on the Actor–Critic structure to solve the problem of multi-agent collaborative target allocation. In addition, Ma et al. [
13] constructed a collaborative target allocation model based on multi-agent reinforcement learning and achieved the allocation of optimal targets by combining local strategy scoring with centralized strategy reasoning. These reinforcement learning algorithms show significant speed advantages when dealing with large-scale and complex continuous-state spaces. However, current reinforcement learning algorithms have shortcomings in target importance evaluation, which may limit their effectiveness in improving air victory rate and drone survivability.
At present, the attention mechanism has been widely used in many fields, such as target detection, semantic communication, autonomous navigation, and multi-UAV collaborative task allocation, and has dramatically improved the efficiency of air combat. Therefore, this paper fully considers the problems faced by traditional air combat target allocation algorithms and the unique advantages of the attention mechanism for target importance assessment. A target allocation algorithm based on threat assessment and attention mechanism is proposed, a high-precision air combat simulation environment is constructed, 8vs8 multi-UAV collaborative confrontation is carried out, and it is compared with the current mainstream target allocation algorithm to verify the effectiveness of the algorithm. The main contributions of this paper are summarized as follows:
- (1)
A proximal strategy optimization algorithm integrating a threat assessment and attention mechanism is proposed. The algorithm considers the prior knowledge of air combat target allocation, introduces threat assessment and attention mechanism under the reinforcement learning framework, and solves the challenges of traditional algorithms in target importance assessment.
- (2)
Based on this, a dynamic reward function based on drone hit rate and missile benefit ratio is constructed to improve the algorithm’s convergence speed and enhance its robustness and scalability in different battlefield environments and mission types.
- (3)
A highly realistic air combat simulation scene is constructed using Unity3D, covering air combat elements such as aerodynamics, thermal imaging, radar systems, and missiles. A multi-aircraft air combat scene simulation is carried out in this environment, and the performance is compared with the rule-based finite state machine and the traditional target allocation algorithm to verify the effectiveness of the proposed method.
2. Related Work
2.1. Proximal Policy Optimization
In reinforcement learning, the Proximal Policy Optimization (PPO) algorithm [
14,
15] belongs to the policy gradient algorithm. Its principle is to parameterize the policy and represent the policy through a parameterized linear function or neural network. An essential core of the PPO algorithm is importance sampling, which evaluates the difference between the new and old policies. A large or small importance sampling ratio will limit the new policy and prevent the new and old policies from deviating too far. The new and old policy ratios are shown in the Equation (1), where
represents the probability that the current policy selects action under
a given state
s, and
represents the old policy, that is, the probability that the policy at the time of the last policy update selects an action under a given state.
represents the action taken by the agent at time
t, and
represents the state of the agent at time
t.
Another core is gradient clipping. The objective function expression of the PPO algorithm is shown in Equation (2):
Among them, is the policy parameter; is the advantage value of action in-state estimated using generalised advantage estimation. The function acts as a clipping mechanism, mainly used for gradient clipping, to ensure the stability of the action probability distribution. When the policy is updated, the adjustment is limited to between and , which effectively prevents large deviations during the policy update process and makes the policy change within a limited range.
The PPO algorithm uses an Actor–Critic architecture. In order to enhance the agent’s exploration ability, a policy entropy is usually added to the loss function of the actor network and multiplied by a preset coefficient—the entropy coefficient. This coefficient is typically set to 0.01. The introduction of policy entropy is intended to encourage the agent to explore a broader range of action spaces, thereby avoiding premature convergence to suboptimal policies. The entropy of the policy is defined as shown Equation (3).
The critic network uses TD-Error to update the network parameter
, which is defined as shown in the Equation (4), where
represents the immediate reward obtained by the agent in the environment at time t, which measures the feedback of the environment after executing the action
in the current state
.
is a discount factor, usually between 0 and 1, which controls the importance of the agent to future rewards. If
is closer to 1, the agent will pay more attention to long-term rewards; if
is closer to 0, the agent will pay more attention to immediate rewards.
and
represent the value estimates of state
at time t and time t + 1, respectively.
2.2. Attention Mechanism
The self-attention mechanism [
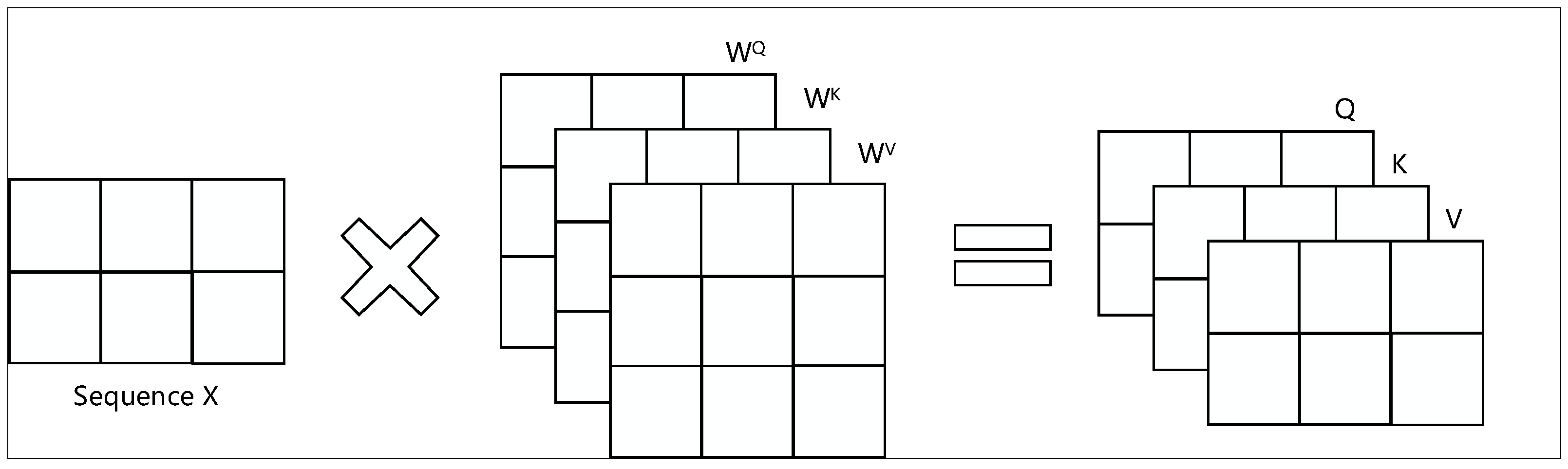
16] uses the inherent information of the features to perform attention interactions. By introducing the self-attention mechanism, the neural network solves the problem of model information overload and improves the accuracy and robustness of the network. The calculation of the self-attention mechanism is divided into two steps: first, it calculates the attention weights between each vector in the input sequence; then, these weights are used to perform a weighted average calculation on the sequence. In this way, the self-attention mechanism can identify the connection between the parts of the sequence and improve the ability to identify critical information. Compared with the traditional attention mechanism, self-attention only depends on the input features and does not require external parameters or structures, making the calculation more efficient.
Figure 1 shows the principle of the self-attention mechanism.
Where
x represents the input sequence data, and its detailed calculation formula is shown in the Equation (5).
Calculating the self-attention mechanism involves three matrices: the query matrix Q, the fundamental matrix K, and the value matrix V. They are obtained by multiplying the input with the corresponding weight matrix. First, calculate the product of the transformed rank of Q and K, divide the above result by the square root of the dimension of Q and K, and then multiply the result by the value matrix to get the value of self-attention.
The multi-head attention mechanism enables the model to focus on information from multiple subspaces at different positions and merge this information to increase the weight of important information. Its calculation process involves the output of multiple attention heads, and key features are strengthened by splicing this information. The specific calculation formula can be expressed as Equations (6) and (7), where
represents the matrix used to calculate the linear transformation of each attention head instance.
In current research, intelligent drones have significantly improved their efficiency in target detection, semantic communication, autonomous navigation, and multi-drone collaborative task allocation by integrating attention mechanisms. In 2023, Zhang et al. [
17] developed a global–local feature guidance module that uses attention mechanisms to focus on specific target areas, thereby significantly improving the accuracy of drone image target detection. In addition, the graph attention exchange network proposed by Yun et al. [
18] in 2021 effectively solved the problem of ultra-reliable low-latency air-to-ground communication between mobile ground users. The research of Liu et al. [
19] enhanced the application effect of drones in autonomous navigation through the attention mechanism. At the same time, Wu et al. [
20] introduced an attention mechanism based on the ISOM algorithm, taking into account the flight distance and task execution time of drones, and further improved the efficiency of multi-drone collaborative task execution.
In designing the multi-UAV collaborative target allocation module, this paper applies the attention mechanism to assign weights to targets, thereby participating in the intelligent decision-making process of drones. This mechanism enables drones to focus on enemy aircraft with more significant potential threats, guiding the intelligent agent to implement the air combat strategy of “first enemy detection, first enemy strike”.
3. Methods
3.1. Algorithm Structure Design
Air combat decision-making is an essential challenge in the field of drone air combat games, among which target assignment is a critical link in the decision-making process. At present, decision-making theory based on the OODA [
21] (observation, orientation, decision, action) cycle is widely used in this field. UAVs make tactical decisions by assimilating battlefield environment information and combining their status for strategic maneuvers.
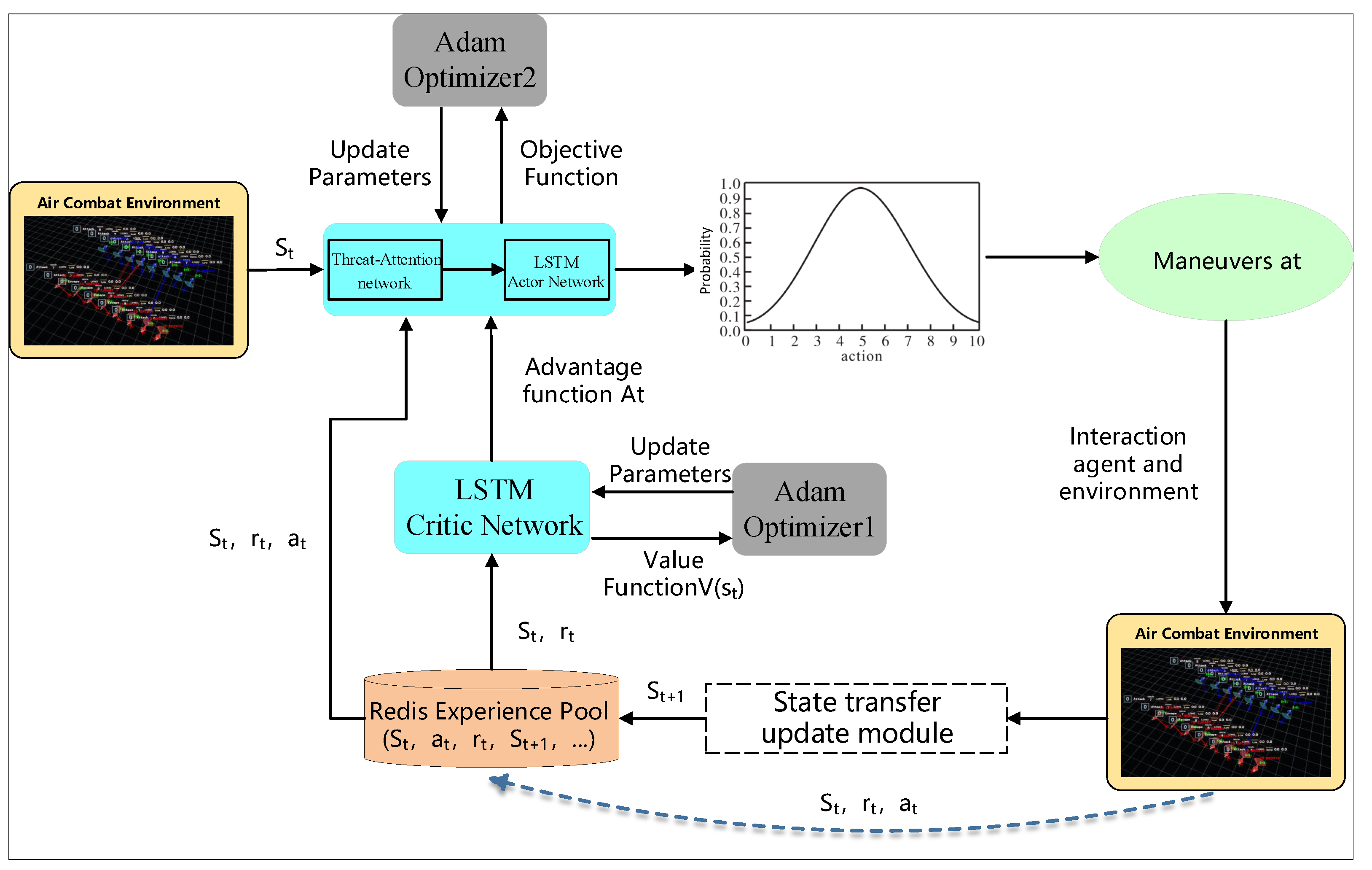
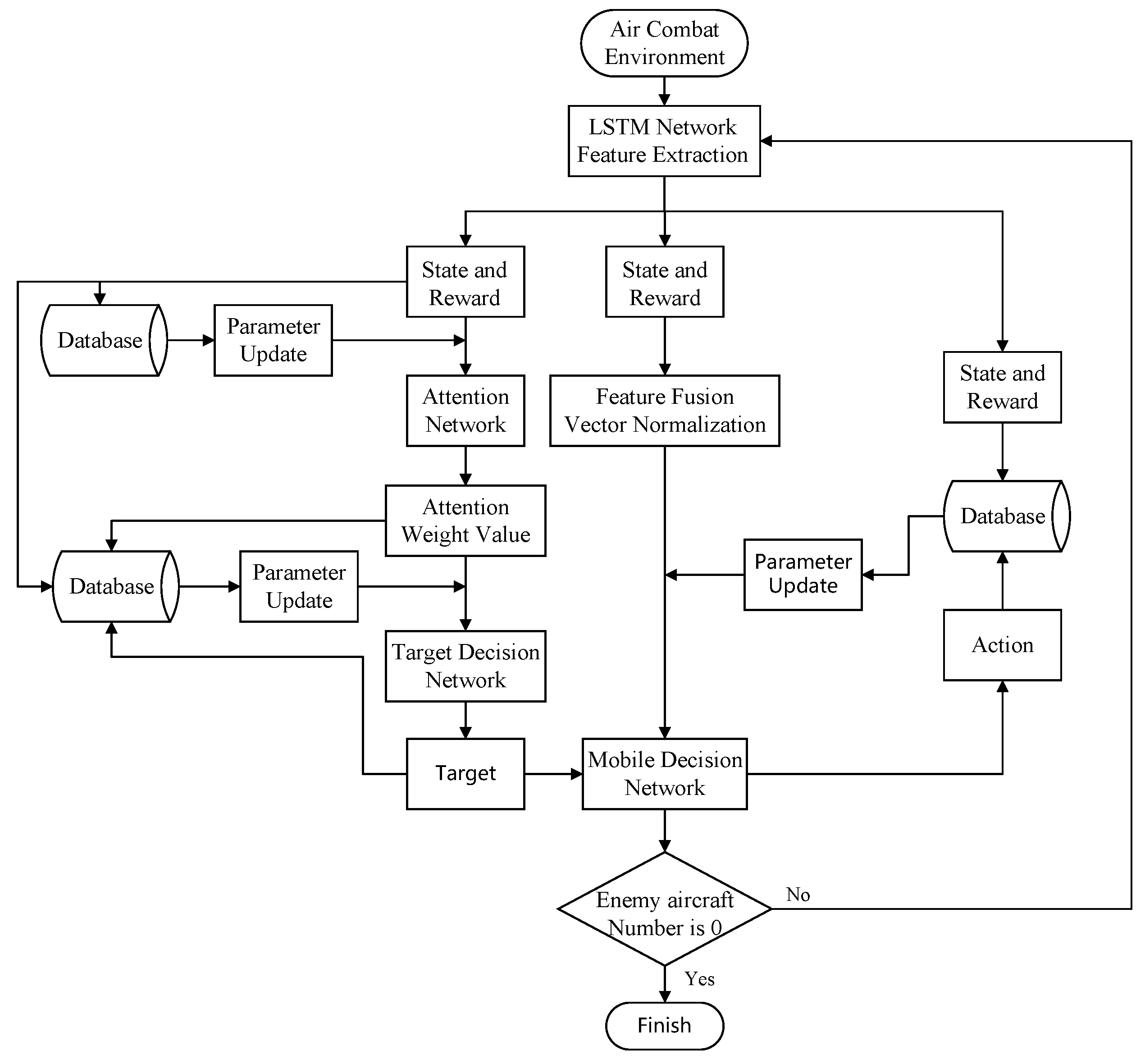
Due to the complexity and continuity of air combat, this paper introduces a multi-UAV collaborative decision-making solution based on the Long Short-Term Memory Network-Proximal Policy Optimization algorithm (LSTM-PPO), that is, using LSTM to extract features from the front-end packaged state and using the PPO algorithm to select actions. The TAPPO algorithm is used to optimize target allocation in the drone decision-making process, thereby improving the survival rate of air combat. The algorithm framework mainly includes the TAPPO-Actor maneuver decision network, LSTM-Critic network, experience buffer, and state transfer module. The detailed framework is shown in
Figure 2.
The maneuver decision network selects appropriate maneuver strategies according to the current situation and the target. It interacts with the environment to generate the state and reward at the next moment. The state transfer module packages the current state, maneuver strategy, reward, and state at the next moment into a sequence of 16 steps and sends it to the experience pool. When the experience pool threshold is reached, the experience is used to participate in the agent training.
The TAPPO algorithm introduces threat assessment and a multi-head attention mechanism, based on the PPO algorithm, to solve the defects of the traditional target allocation algorithm in target importance assessment.
When the agent selects a target, the network must focus on the local critical target. This paper uses the drone state and the threat parameter vector of the enemy drone to implement the attention mechanism through four attention heads and an additive model. Define
as N input features, and each
represents the feature vector of a potential target. Given
q and
x, choose to calculate the i-th attention distribution as the target weight value.
is defined as Equation (8):
Here,
is an attention evaluation function, which is used to calculate the matching degree between a given query
q (the threat feature currently being focused on) and each target
. The calculation model is an additive model, and the
is defined as Equation (9).
In the weight matrices,
and
are defined as trainable neural network parameters,
v is the global state information feature vector, and the global information is used to participate in the attention network to evaluate the attention value of each target machine. By applying
sampling to each bit of the attention value, the corresponding target weight value is generated. The pseudo code for TAPPO algorithm is as
Figure 3 and
Figure 4:
3.2. Network Structure Design
The LSTM-PPO algorithm [
22] is used in the maneuver decision to achieve multi-UAV collaborative confrontation. The algorithm uses the Actor–Critic distributed network framework and the LSTM network for state encoding and feature extraction. In a single step, the agent fully considers the current state information and goals, outputs reward-maximizing maneuvers, and achieves the optimal solution for multi-UAV collaborative confrontation.
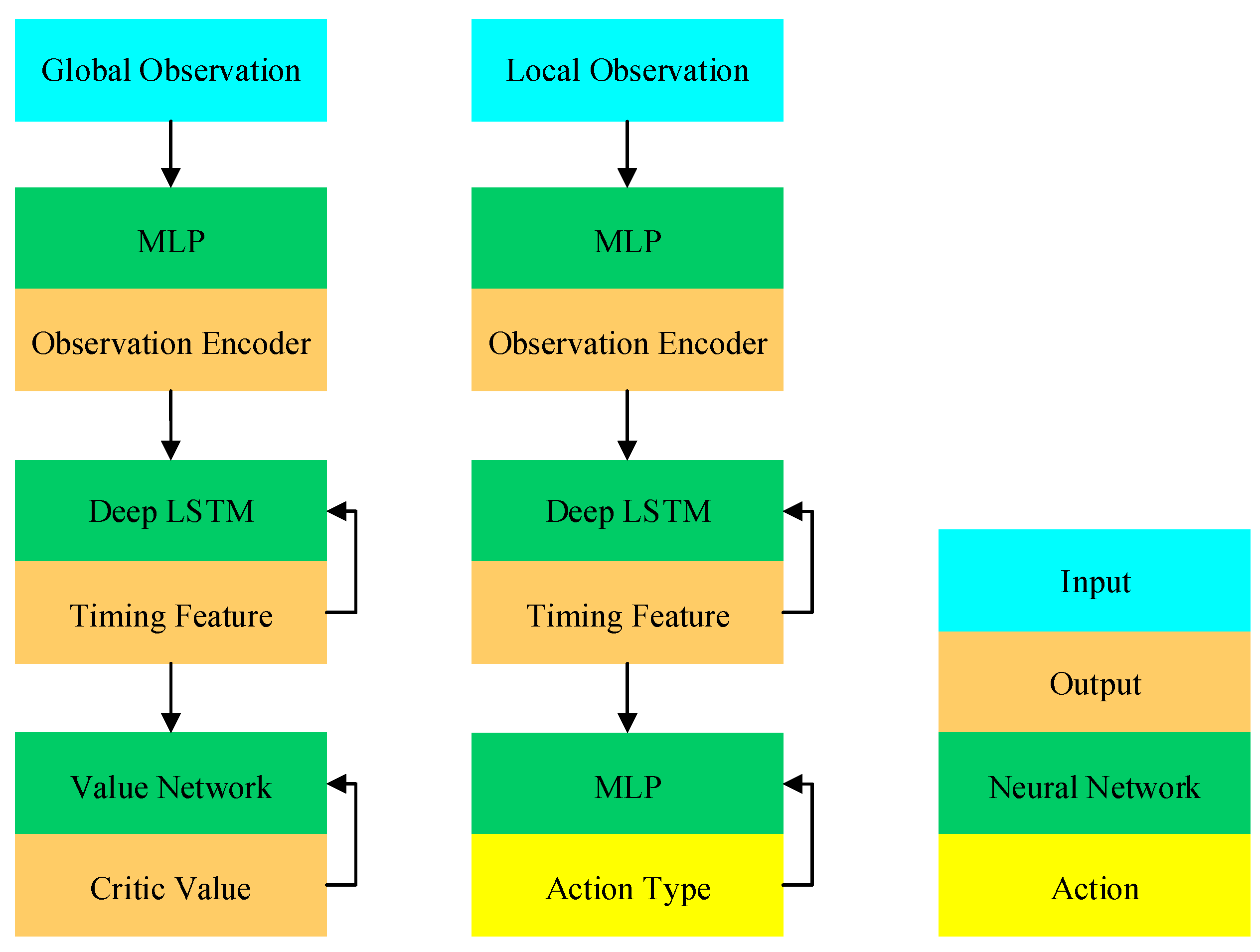
As shown in
Figure 5, when designing the network structure, we designed different observation spaces for the Actor and Critic networks and partially observable state spaces to encourage the agent to give full play to the exploration advantages of the PPO algorithm, thereby improving the scalability and robustness of the algorithm. However, the air battlefield changes rapidly. In order to avoid the problem of state lock in the new state faced by the agent, the agent keeps repeating a maneuver in a new state. We propose a deep 2048-cell LSTM network to process real-time data. This design makes full use of historical state information, helps to break the state lock phenomenon, and improves the adaptability and decision-making effect of the agent in complex environments.
The Critic network adopts the design of a global observation space, which can guide the agent to find the optimal strategy and accelerate convergence. The global observation space enables the Critic network to comprehensively consider the information of the entire environment, including the state and goals of all agents, thereby providing a more comprehensive and accurate reward signal.
Global optimization in air combat is the process of an intelligent agent looking for the optimal strategy in the observed state space. This process defines a probability distribution function to complete the mapping from action to state. To optimize this distribution to maximize the air combat victory rate, this paper introduces the TAPPO algorithm for threat assessment and target allocation, aiming to improve the survival rate and victory rate in air combat.
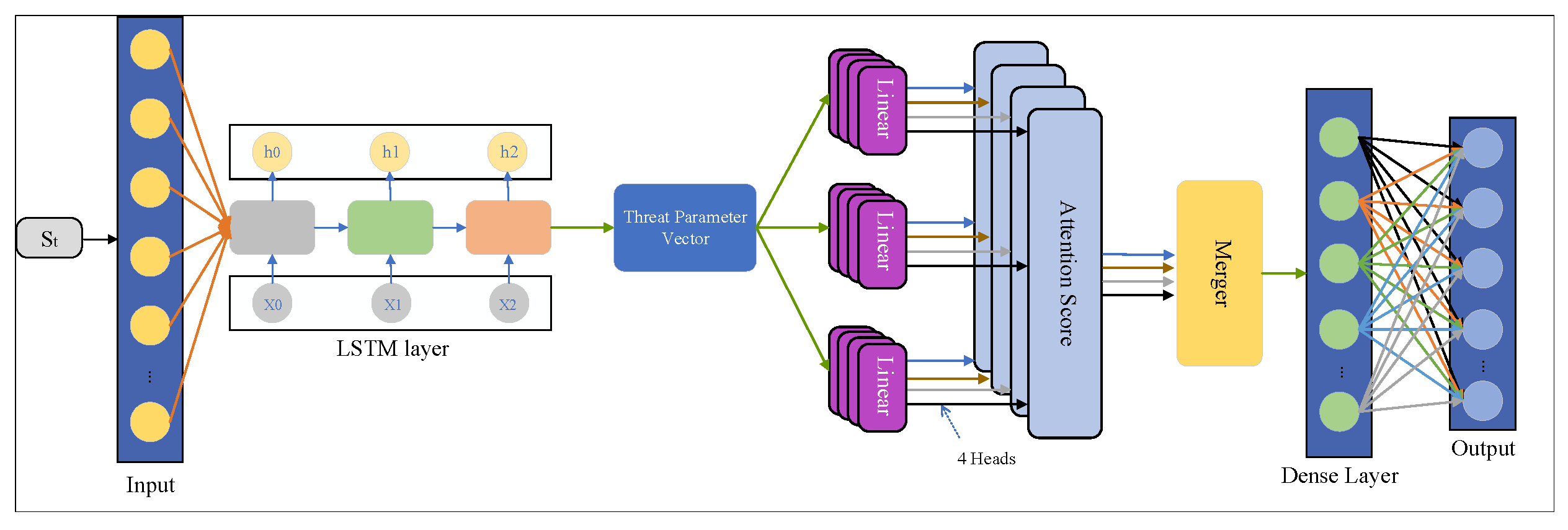
We improve the PPO algorithm and introduce a threat value and multi-head attention mechanism based on PPO intelligent decision-making to achieve target allocation. The Actor network structure of the TAPPO algorithm is shown in
Figure 6.
The network structure of the TAPPO algorithm mainly consists of two parts: Actor and Critic. In this structure, the Actor-network receives an n×m-dimensional state space as the input, where n represents the number of enemy aircraft and m represents the dimension of the threat value. We designed a 128-dimensional neural network as the input layer and used LSTM to extract the threat parameters of the enemy drone at the current moment. The threat parameters in this paper include seven dimensions: altitude, position, speed, pitch angle, roll angle, yaw angle, and the current state of the aircraft.
This paper adopts a four-head attention mechanism to increase model integration and generalization capabilities. The high-dimensional and continuous characteristics of the air combat environment make historical state information crucial. In order to solve the defect that multiplicative attention cannot handle long-distance dependencies, this paper introduces an additive model in each attention head, uses the Equation (8) to calculate the attention score of each enemy aircraft, participates in the probability selection calculation of the Network, and adjusts the action probability distribution of the PPO algorithm. Finally, the actor-network outputs a p-dimensional action space probability distribution, where p represents the dimension of the friendly aircraft.
Similar to the actor network, the Critic network is also an essential part of the TAPPO algorithm. However, unlike the Actor output action probability distribution, the output of the Critic network is a single value function used to evaluate the predicted value of the current state. The predicted value can help the agent judge the pros and cons of the current goal selection, optimizing the decision-making process and improving the selection of subsequent actions. The Critic network enhances the system’s ability to adapt to environmental changes, allowing the agent to learn and adjust strategies more effectively.
3.3. Decision-Making Process Design
This study used the Unity simulation platform to build a realistic air combat scenario simulation environment. Our method is to use the current state information of the drone as input, extracting features through the extended short-term memory network and then processing these features through an attention network to optimize the importance evaluation of the information. Based on these attention-weighted features, the target allocation network generates a target probability matrix to guide the drone in selecting targets.
The maneuver decision network determines the appropriate maneuver strategy based on the current state information and target selection results to maximize the target reward. The drone’s state information, the reward obtained, the attention weight, the target probability matrix, and the selected maneuver actions are stored in three independent experience buffers for updating the parameters of each network.
The system receives the drone’s state information at each moment and calculates the target allocation and maneuver decisions through the reinforcement learning algorithm, which will act in the simulation environment in real-time. If the number of enemy aircraft is reduced to zero, it is considered that our side wins. This process will continue until the training goal is reached or the simulation ends, as shown in
Figure 7.
3.4. Air Combat Model Design
This paper models multi-UAV cooperative target allocation and intelligent decision-making as a partially observable Markov decision process problem, which consists of a five-tuple
, where
represents the air combat state information at the current time t,
represents the action taken by the agent at the current time t,
represents the reward feedback given by the system,
P is used as the state transfer function, and the discount factor
is used to determine the importance of future rewards. The agent performs action according to the current state
and interacts with the environment to produce the state
at the next moment. The system feeds back the agent reward rt, and the agent expects the return to be maximized.
is defined as the Equation (10):
In POMDP, the task of the agent is to learn the mapping from state to action, which is defined as a policy. The core goal of POMDP is to find an optimal policy that maximizes the expected cumulative discounted return, defined as Equation (11).
The state space, action space, and reward function of the multi-UAV collaborative target allocation problem under reinforcement learning are as follows. These are used to evaluate the agent’s single-step decision-making performance under the reinforcement learning framework.
3.4.1. State Space Design
and
represent the state spaces of the friendly and enemy drones, respectively. Both spaces consist of sets of related drone and missile parameters. The drone state includes position
P, height
H, and speed
V. Missile-related information involves missile type
, launch state
, and remaining number
. In the enemy state space,
is additionally introduced. This parameter quantifies the current threat level of the enemy target.
and
are defined Equations (12) and (13).
The attitude of the drone is controlled by the pitch angle
, roll angle
, and yaw angle
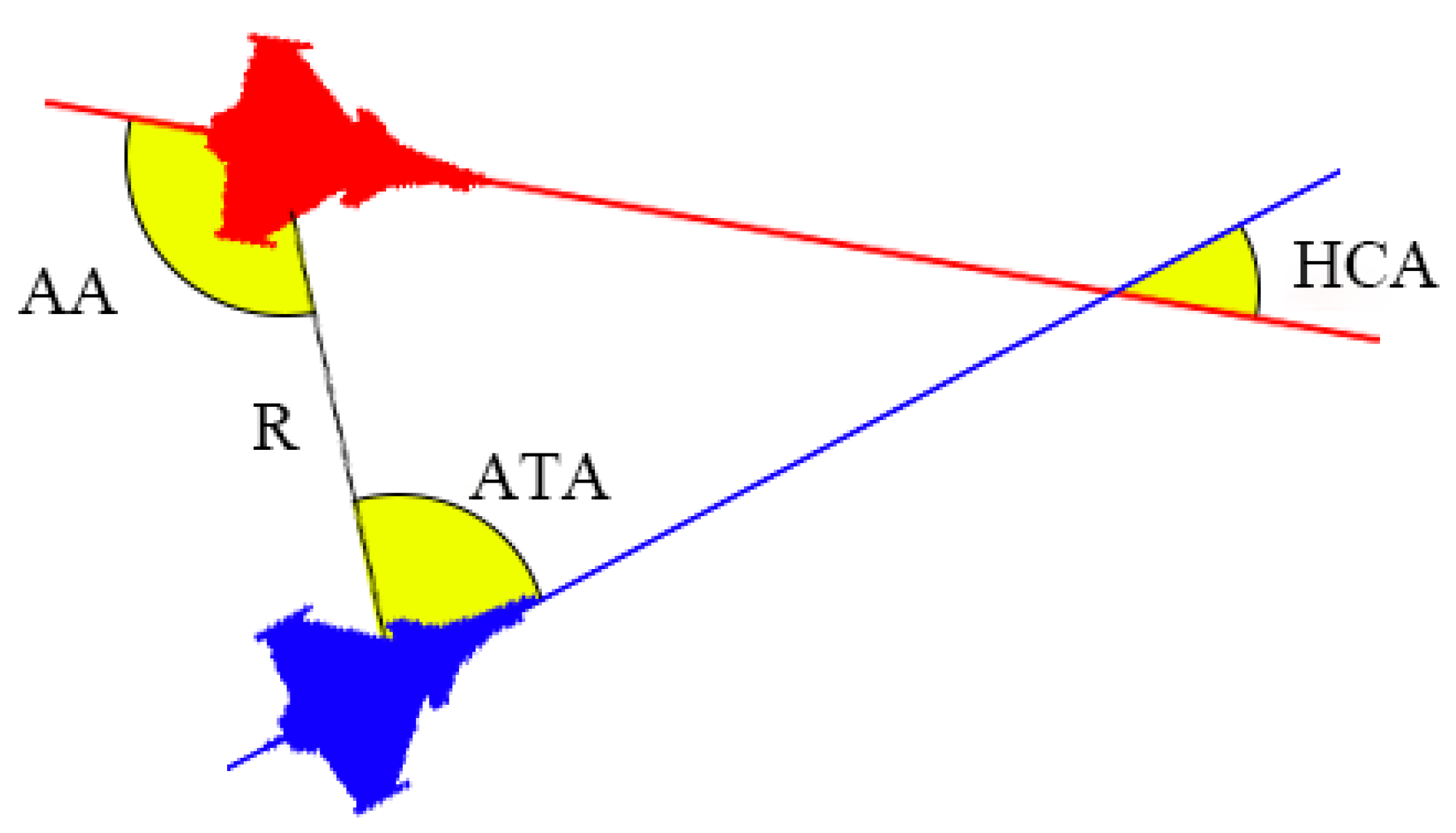
. In addition, the McGrew [
23] method is used to describe the azimuth information of the drone. Specifically, the line of aspect angle (AA) is defined as the angle between the speed direction of our aircraft and the line connecting the two drones; the antenna train angle (ATA) represents the angle between the speed direction of the enemy aircraft and the line connecting the two drones; the horizontal crossing angle (HCA) is the angle between the speed directions of the two drones. At the same time,
R represents the distance between the enemy and our drones. The representation of the drone azimuth information is shown in
Figure 8.
In summary, the state space is represented by
and is defined as the Equation (14):
3.4.2. Action Space Design
Action Space Design of TAPPO Algorith
In the reinforcement learning framework, the agent adjusts its decision-making strategy by performing actions and receiving corresponding rewards to select the most optimal action at future decision points to maximize the cumulative reward. Therefore, the action space is crucial to achieve an efficient learning process and is defined as Equation (15)
Among them, represents the probability that the agent selects the i-th drone as the attack target, and n represents the number of enemy drones on the current battlefield.
3.4.3. Reward Function Design
TAPPO Algorithm Reward Function Design
In multi-UAV coordinated air combat, the agent aims to shoot down the assigned enemy aircraft through appropriate maneuvers to maximize the reward. The target assignment process mainly focuses on the target threat level and the current drone status. The reward function is defined as the formula
Among them,
represents the reward obtained by taking an action in the current state,
quantifies the threat level of the target aircraft at the current moment, and
reflects the current combat status of our drone. The definitions of
and
are shown in Equation (17).
The agent prioritizes targets with higher threat values during the target assignment process. The reward function quantifies the threat level of the enemy drone. It consists of three parts: speed reward , height reward , and distance reward .
reflects the relative difference in speed between the enemy and ourselves. Set and to represent the speed of our and enemy aircraft, respectively. In the model, the faster the enemy aircraft is, the higher the threat level, and increases accordingly to prompt the agent to prioritize faster targets.
considers the height difference between the enemy and our drones. When the enemy and the enemy are at significantly different altitude levels, the side at the lower altitude is usually at a tactical disadvantage. Therefore, the size of increases or decreases with the height difference, reflecting the combat advantages of different tactical positions.
is designed based on the distance difference
between enemy and friendly drones. As the distance decreases, the hit rate of both sides increases, and the threat value becomes more extensive, thus increasing the distance reward.
As shown in Equation (18), this article proposes a reward mechanism based on the current state of the agent. Agents with higher hit rates and significant missile gains will receive higher reward returns. Missile_Launches quantifies the value of launched missiles, and target_hits represents the number of successful target hits. At the same time, Remaining_Missiles and Remaining_Targets quantify the number of remaining missiles and targets, respectively. The hit rate and missile benefit ratio are introduced as critical factors in the quantitative reward function to encourage the agent to select targets based on its current situation, thereby improving the model’s adaptability and robustness in complex air combat scenarios.
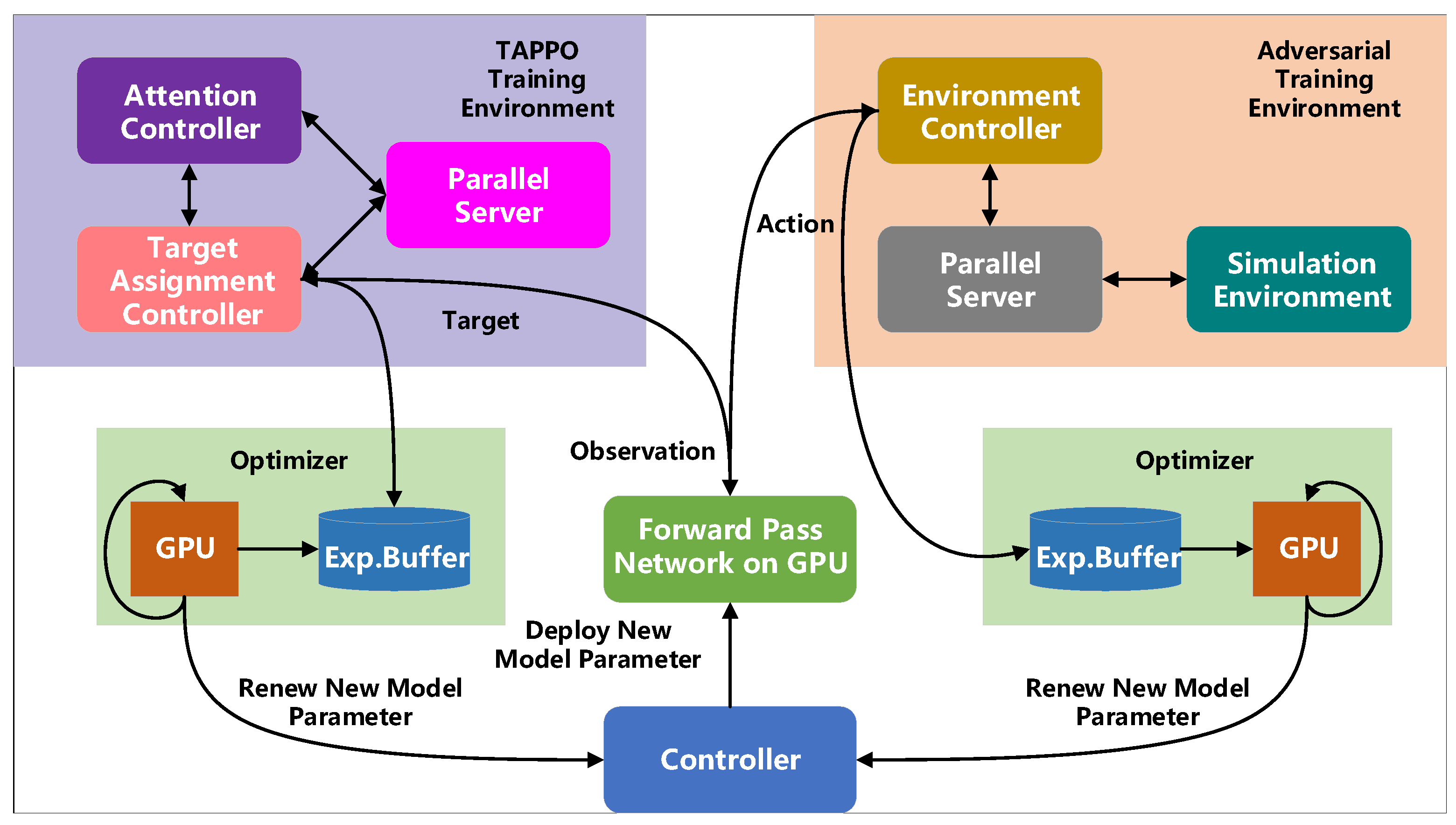
3.5. Training System Design
The training system consists of six parts, as shown in
Figure 9. Unity is used to implement air combat simulation to sample much training data. We use multiple GPUs to open multiple simulation environments in parallel, and the agent continuously interacts with the environment to improve the convergence speed. The agent receives the state observation value transmitted by the air combat environment and sends the observation data to the TAPPO training module and the agent adversarial training module.
The TAPPO algorithm uses the current observation information to extract the threat value parameters, calculates and updates the weight matrix of the attention network, obtains the target attention weight vector that participates in the calculation of the actor network, and adjusts the target selection probability distribution. The agent samples the target probability matrix to obtain the target. The adversarial training module receives the target allocation results, makes maneuver decisions, and interacts with the environment based on the current state, generating the state and reward of the next moment.
The model training data set mainly consists of drone state information, action information, reward information, and a selection probability matrix. The training module packages the generated data into a sequence containing the current state, reward, and next moment. At the same time, the TAPPO module also generates a target probability distribution matrix as one of the sequence parameters. These data are packaged into 16 actions and transmitted to the experience pool asynchronously. When the experience pool reaches the threshold, the system extracts 120 experience samples from it for the training of the intelligent agent. These 120 experiences comprise 80% old data and 20% new experience, aiming to break the correlation between data and improve data utilization.
4. Experiment
4.1. Experimental Environment
This paper designs an 8vs8 air combat simulation confrontation in an air combat simulation environment based on digital twin technology, aiming to evaluate the effectiveness and superiority of the proposed algorithm. In order to comprehensively evaluate the performance of the algorithm, a comparative experiment was conducted to compare the performance of the existing mainstream target allocation algorithm and the TAPPO algorithm in terms of win rate, loss rate, and draw rate under the same conditions. By designing an ablation experiment, it is verified that the improvement proposed in this paper is meaningful. Finally, the results of target allocation under disadvantageous conditions are quantified and statistically analyzed to verify the scalability and robustness of the algorithm.
4.2. Experimental Configuration
This study was experimentally verified through an air combat simulation platform independently developed by the research team. The platform integrates digital twin technology and supports complex battlefield decision-making scenario simulations through advanced target allocation functions, including dynamic target priority setting and multi-target tracking functions, to achieve more accurate target allocation tests (as shown in the figure). The experimental simulation uses an F22 fighter equipped with six AIM-120 medium-range missiles, relying on a radar guidance system for guidance. The aircraft supports a complete missile guidance chain.
In terms of hardware configuration, the experimental environment uses a 5950X + 3070 TI host as the front end, and multiple independent battlefields are managed and scheduled through multi-threading and multi-processing to achieve parallel air combat scene simulation. At the same time, the TCP/IP protocol is used to ensure efficient data exchange between the front-end and back-end models. The back end has an 8-way 3090 graphics processor responsible for real-time data extraction from the experience pool. It uses the neighbouring strategy to optimize the calculation of gradients and mean square errors and continuously updates the Actor and Critic networks in the TAPPO algorithm to ensure the optimization and adaptability of the algorithm in dynamic target allocation scenarios.
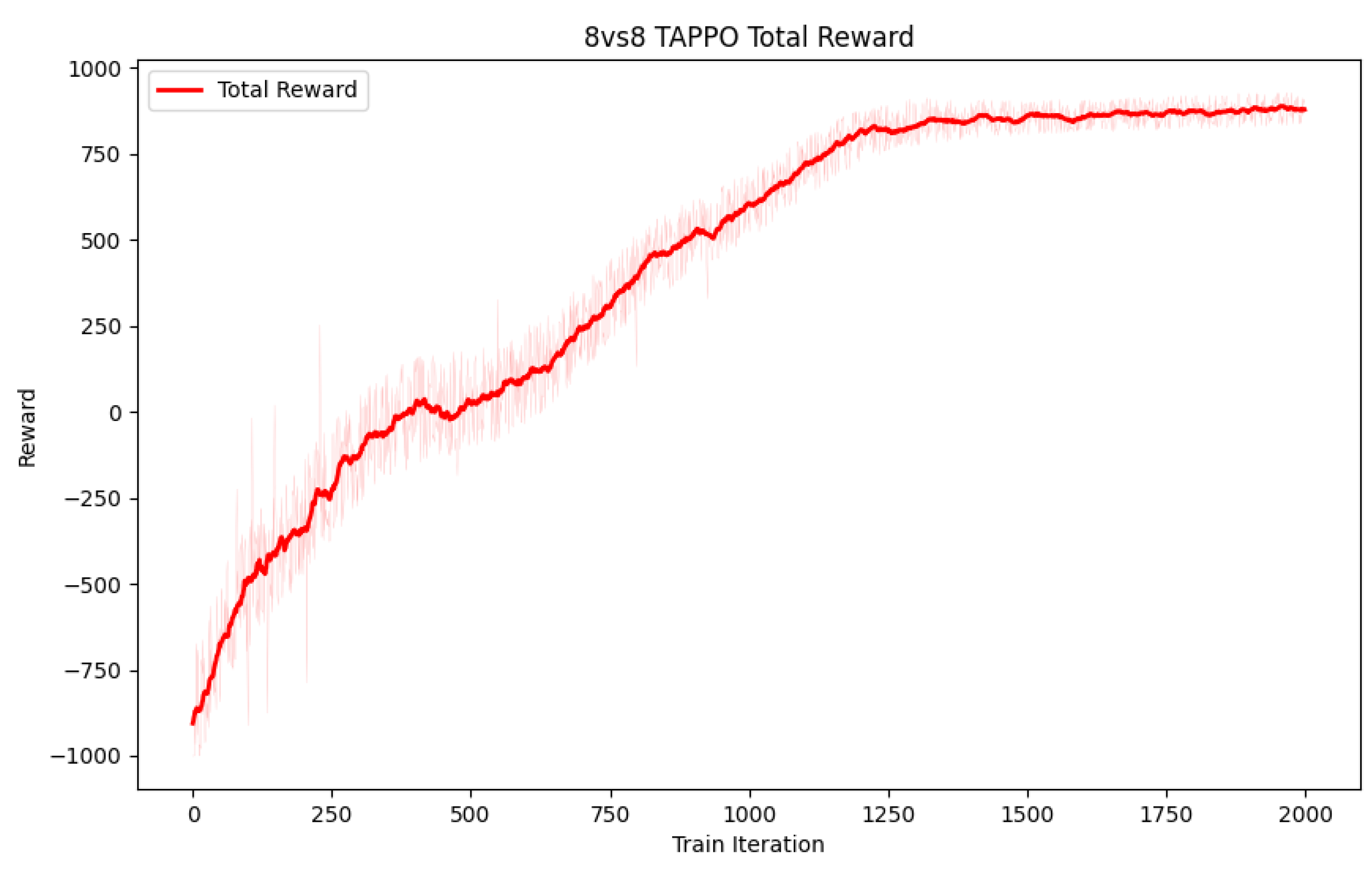
4.3. 8vs8 Multi-UAV Collaborative Confrontation Results
This paper designs an 8vs8 multi-UAV collaborative confrontation. The red side is a reinforcement learning agent based on the TAPPO target allocation algorithm, and the blue side is a finite state machine based on an expert system. Nearly 2000 iterations are counted, and eight allocations are made in each iteration. Each reward is normalized, as shown in
Figure 10. The reward function changes from negative to positive, showing the agent’s gradual learning process.
Due to the significant jitter in the reinforcement learning training process, the curve is challenging to observe. To effectively visualize the general trend of the curve, this paper performs an exponential moving average on the original data. The light curve represents the original data, and the dark curve represents the data after sliding average processing.
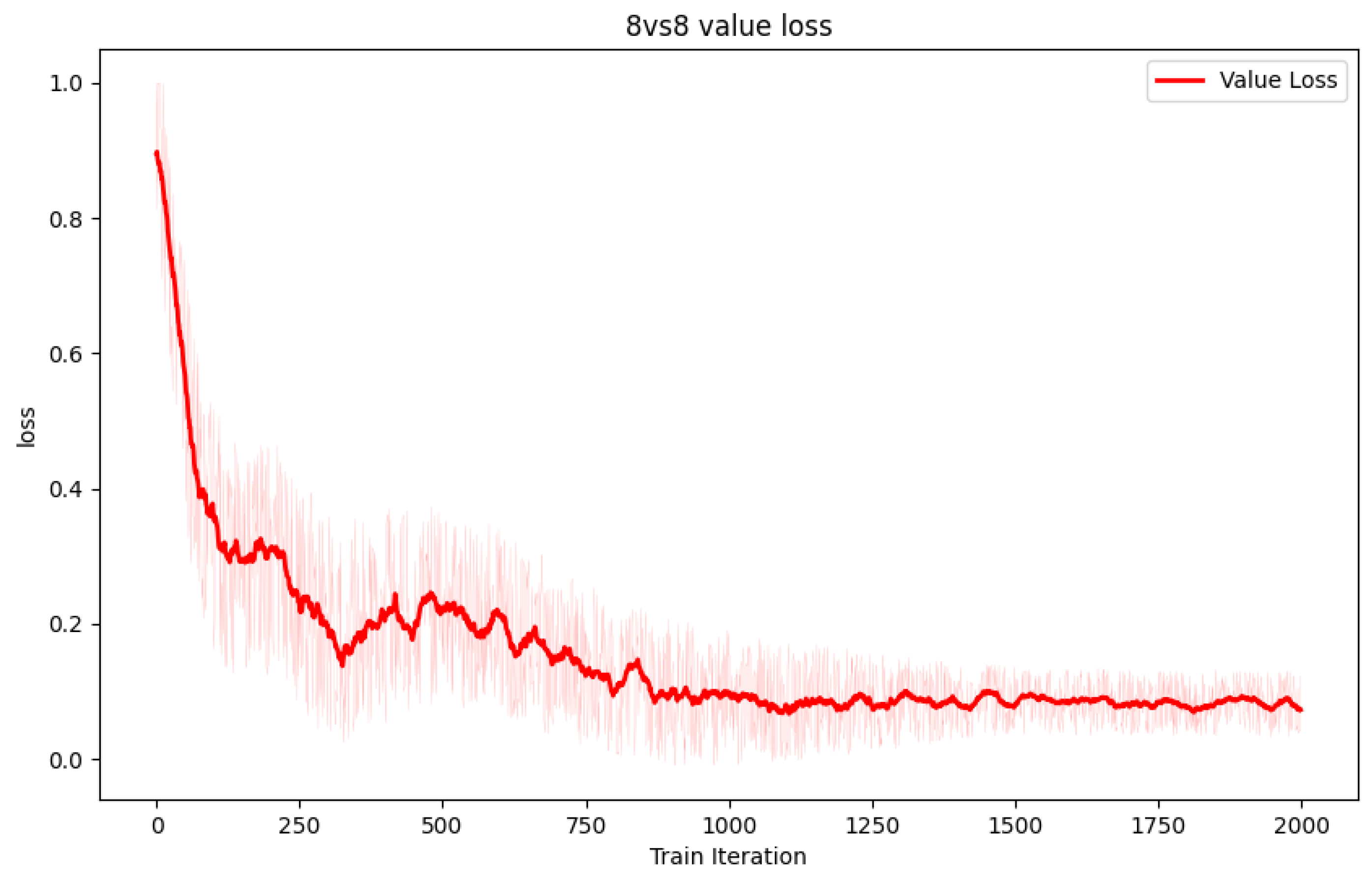
Observing the loss function of the value network in
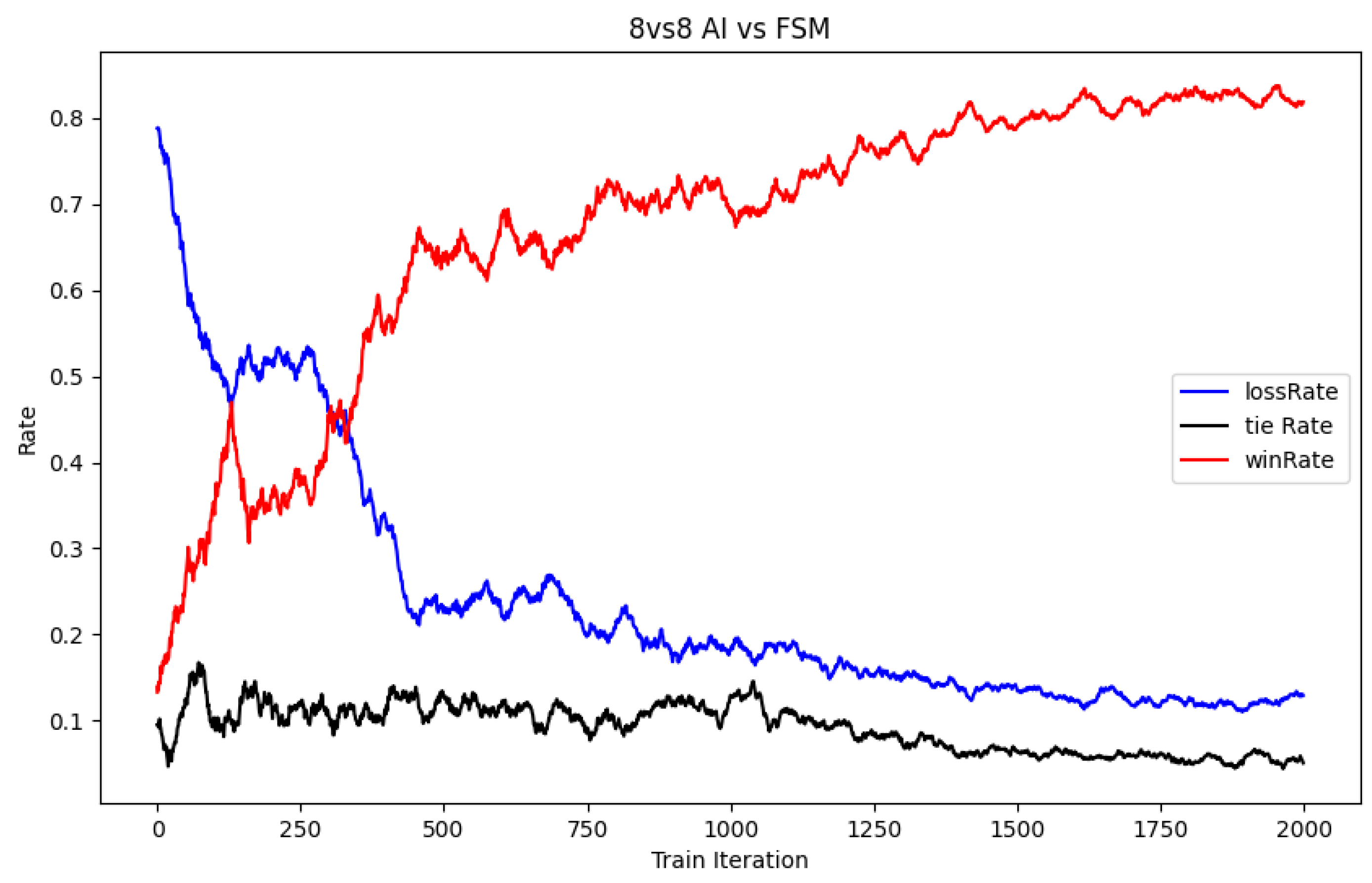
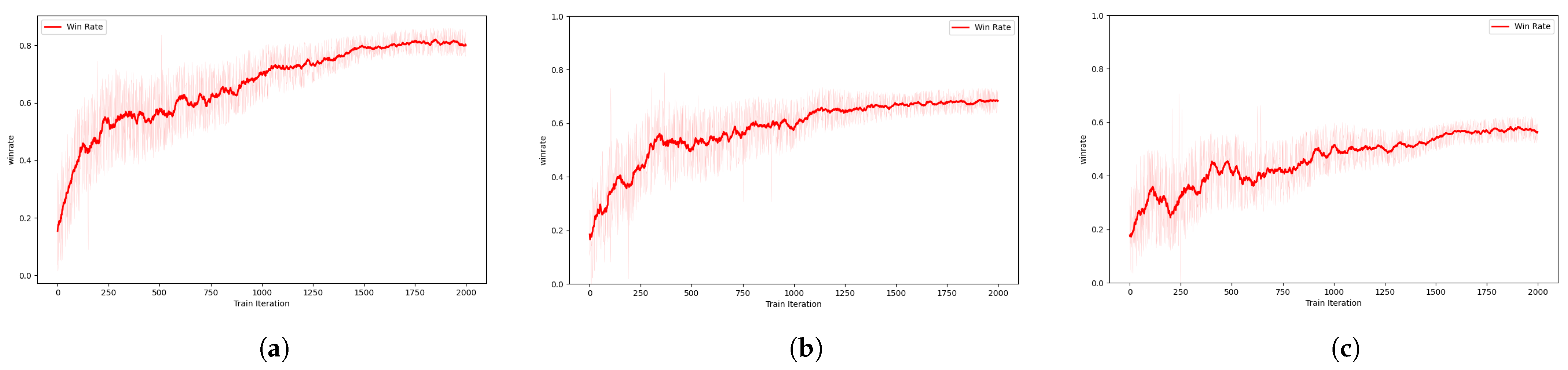
Figure 11, we can see that the current agent has reached a convergence state. In order to evaluate the real-time performance of the agent, we counted the real-time winning rate against enemy aircraft in the last 2000 iterations. According to
Figure 12, the real-time winning rate of the agent reached 86%. Due to the random initialization of the red and blue aircraft positions during initialization, some enemy aircraft are initially far away, making it impossible for the radar to detect them immediately, so achieving a 100% winning rate is not comfortable.
4.4. Comparative Experiment
In order to verify the efficiency and effect of the TAPPO algorithm in multi-aircraft coordinated air combat target allocation, a comparative experiment was designed and conducted to compare the TAPPO algorithm with the MTCBBA, genetic algorithm (GA) [
25], and Hungarian algorithm [
26]. We verified their winning rate, floating point operations per second (FLOPs), real-time performance, and algorithm scalability. All algorithms counted the above four indicators under the same experimental conditions. Each algorithm was run on the air combat simulation platform for 2000 iterations to ensure the reliability of the data.
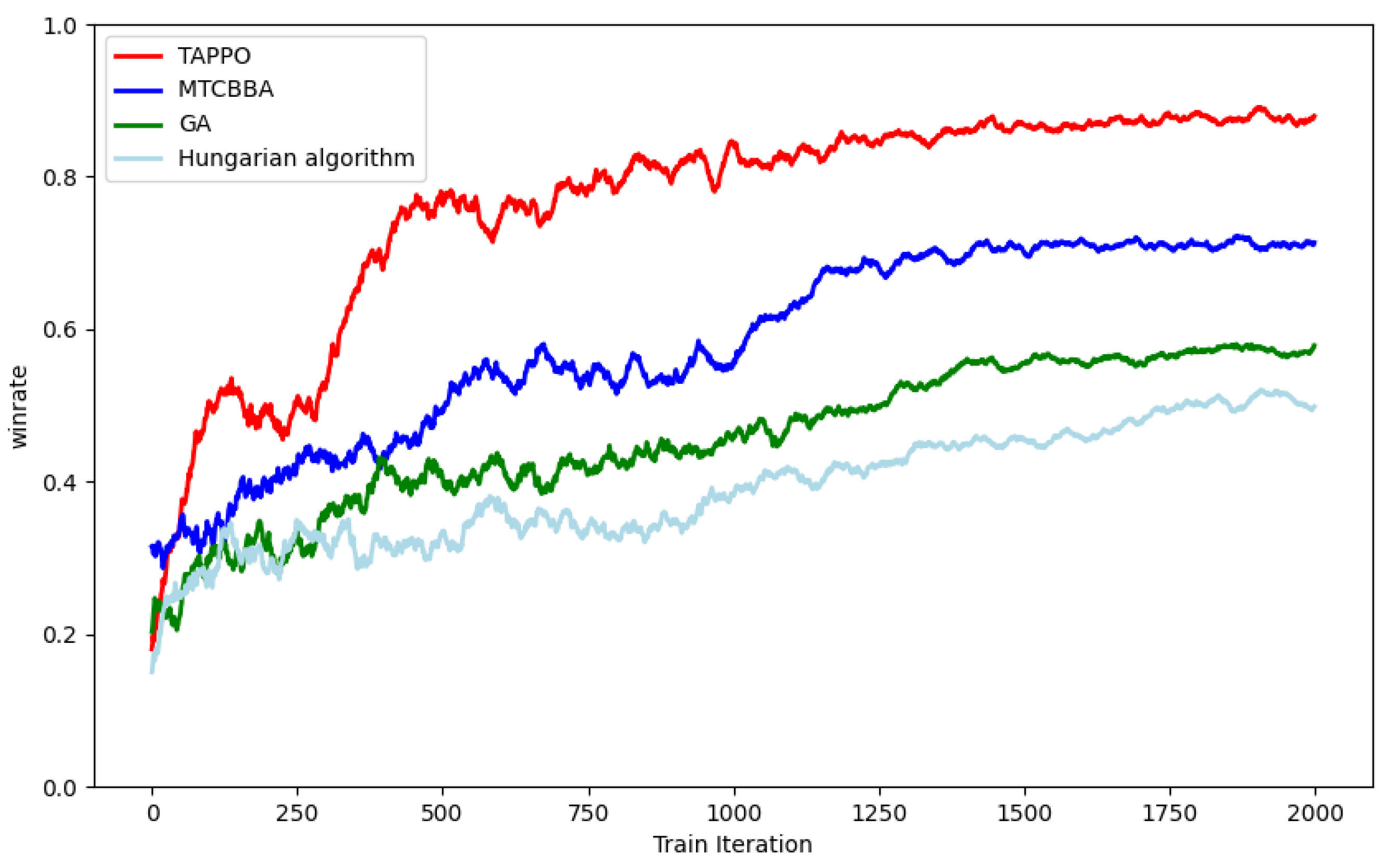
As shown in
Figure 13, the Hungarian algorithm is mainly suitable for static or relatively simple assignment scenarios. In a dynamically changing air combat environment, its lack of adaptability leads to low decision-making efficiency and a low winning rate. GA has excellent global search capabilities and can find the optimal target allocation solution. However, in continuous and complex high-dimensional dynamic air combat scenarios that require fast response, the genetic algorithm requires more iterations to converge to the optimal solution. This increases decision-making time and reduces decision-making efficiency. Although both the TAPPO algorithm and the MTCBBA algorithm reach convergence in about 1200 rounds, the MTCBBA algorithm places too much emphasis on cost–benefit optimization during design rather than maximizing threat response. This strategy cannot effectively ensure the maximum survival rate of our aircraft in air combat. In contrast, the TAPPO algorithm takes advantage of the multi-head attention mechanism to enable the agent to prioritize the enemy aircraft that pose the greatest threat to our aircraft as the target, thereby significantly improving the survival probability of friendly aircraft and improving air combat efficiency.
FLOPs are usually used to measure the computational intensity of algorithms, models, or systems, especially in scenarios involving many floating-point operations. As shown in
Table 3, we counted the FLOPs of a single algorithm run and found that the FLOPs of MTCBAA, genetic algorithm, and Hungarian algorithm were relatively low, indicating that these algorithms are suitable for dealing with smaller-scale target allocation problems. In contrast, the FLOPs of the TAPPO algorithm proposed in this paper far exceed other mainstream target allocation algorithms, which reflects that the TAPPO algorithm can perform more complex and detailed calculations. When dealing with high-dimensional continuous air combat environments, the TAPPO algorithm can provide more accurate target allocation decisions and show stronger robustness. Therefore, the TAPPO algorithm is particularly suitable for dealing with multi-aircraft cooperative target allocation problems with complex state spaces and large scales.
As shown in
Table 4, we conducted a statistical analysis of the time of nearly 200 target allocations. Genetic algorithms require global search and try to find the optimal solution through continuous iterations. Each iteration requires evaluation and selection of multiple candidate solutions. Therefore, in complex air combat scenarios, this process is time-consuming. In addition, its high FLOPs lead to long calculation and allocation times. Although the MTCBBA algorithm has low FLOPs, it emphasizes cost-effective optimization, which also takes much time to optimize. The Hungarian algorithm can quickly complete task allocation due to its greedy strategy.
Although the TAPPO algorithm has a high FLOPs value, it has a lower target allocation time due to the introduction of deep neural networks and the increased calculation speed. This shows that although our algorithm is suitable for large-scale and complex state spaces, it is equal to mainstream reinforcement learning algorithms in terms of real-time performance.
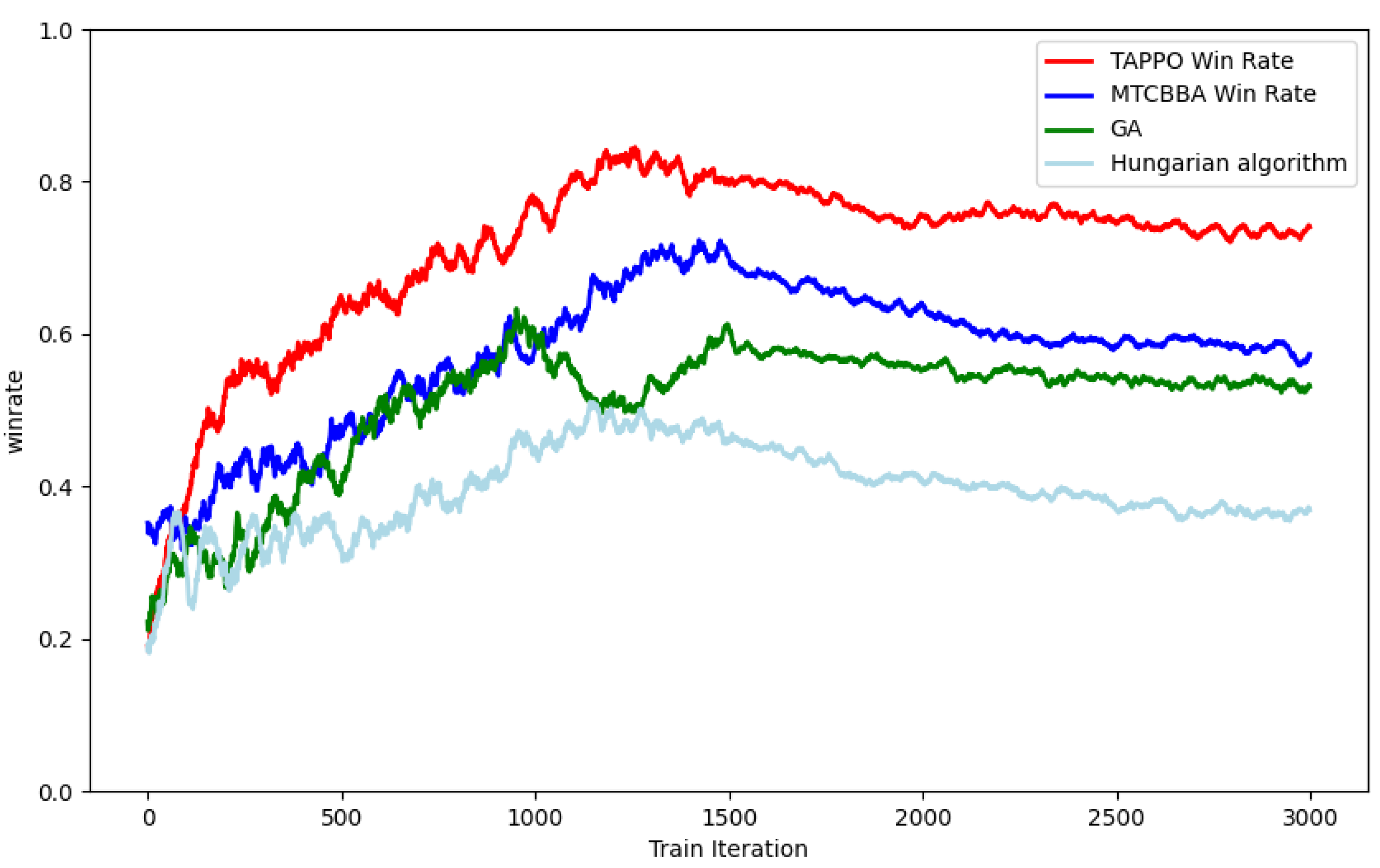
In order to verify the scalability of each algorithm, we conducted experiments in an 8vs8 air combat simulation environment. After each algorithm converged, we added two enemy aircraft to the environment and recorded the winning rate over nearly 1000 battles. The winning rate results are shown in
Figure 14.
As can be seen from
Figure 14, the scalability of the TAPPO algorithm is significantly better than the other three mainstream algorithms. As the Hungarian algorithm is not good at processing continuous and complex state spaces, its winning rate dropped significantly after adding enemy aircraft. The performance of the GA and MTCBBA algorithms also declined when facing new enemy aircraft, but not to the same extent as the Hungarian algorithm. In contrast, the TAPPO algorithm can still maintain a high winning rate when the number of enemy aircraft increases, which shows that the algorithm has high scalability.
By comparing the four indicators, the TAPPO algorithm has advantages in processing large-scale continuous dynamic spaces, achieving a winning rate far exceeding that of other mainstream algorithms in air combat, verifying the effectiveness and superiority of the algorithm.
4.5. Ablation Experiment
Given the problems existing in the traditional target allocation algorithm, this paper makes two improvements to the PPO algorithm. An ablation experiment was conducted to evaluate the impact of different mechanisms on the algorithm’s performance. In each experiment, one improvement was removed, and the winning rate in the 8vs8 multi-UAV collaborative confrontation was compared, as shown in
Table 5.
The comparison results of the ablation experiment algorithms are shown in
Figure 15. As can be seen from the figure, the effects of removing different improvements on the performance of the algorithms are significantly different. Regarding the win rate of the empty game, the win rates of Our-noR and Ours-noAT are higher than those of the PPO method. Regarding convergence speed, the models trained using the Our-noR and Our-noAT methods also converge faster than those using the PPO method. It is particularly noteworthy that Our-noR has the highest win rate, indicating that the key to evaluating the importance of the target lies in the use of attention mechanisms and threat values. The Our-noTA algorithm has the fastest convergence speed, while the Our-noR converges slower, which shows that the reward function accelerates the algorithm’s convergence.
Based on the target allocation experiment of the improved PPO algorithm, the target assignment of the improved PPO algorithm is generally superior to that of the PPO algorithm in terms of convergence speed and winning rate. The experimental results verify the effectiveness of the algorithm.
4.6. Disadvantage Combat Experiment
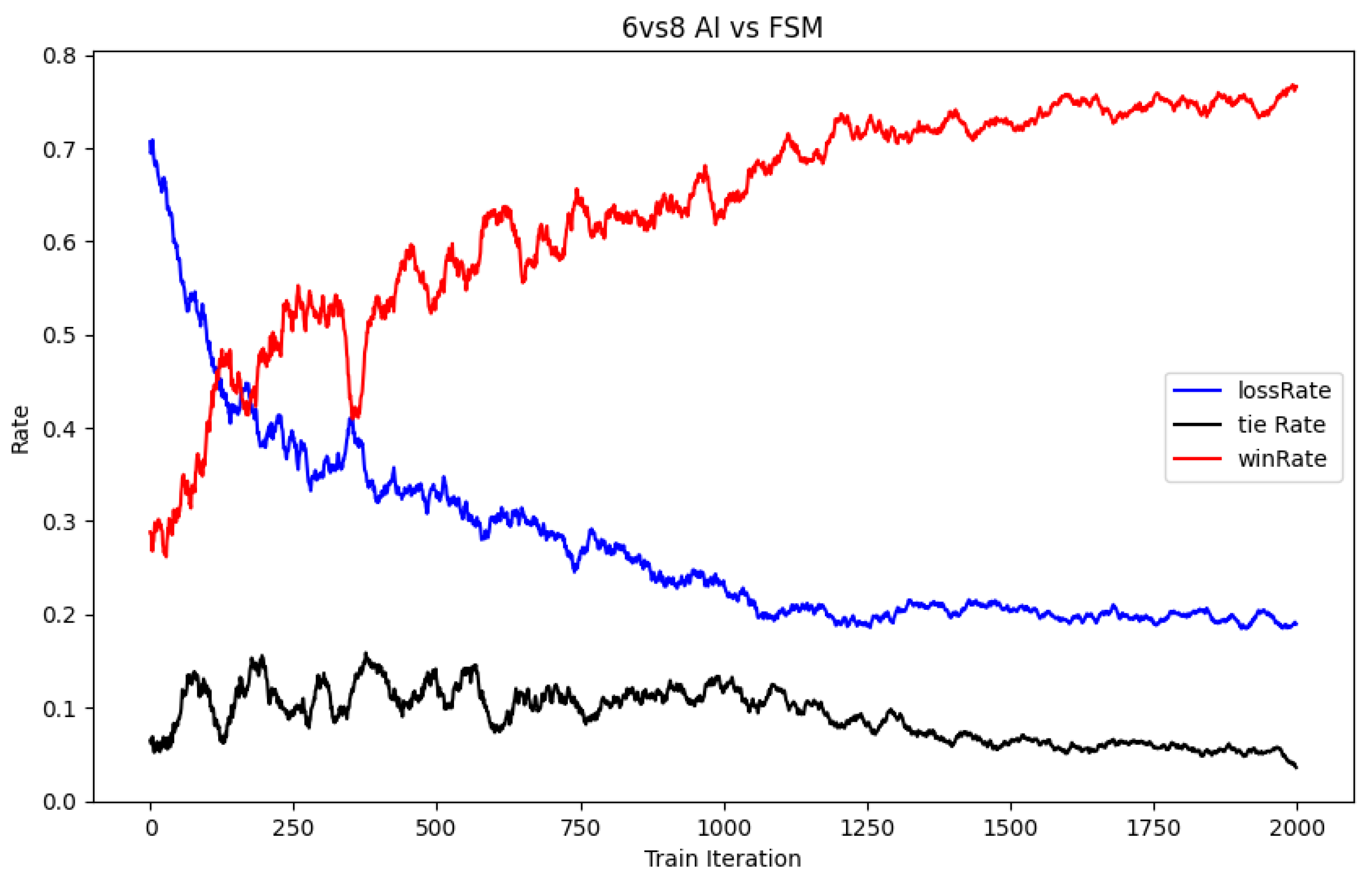
To verify the scalability and robustness of the algorithm at different scales, this paper designed a 6-to-8 multi-UAV collaborative confrontation target allocation experiment, as shown in
Figure 16. Under the same experimental conditions, it can be observed that the winning rate has dropped by nearly ten percentage points compared to the 8-to-8 experiment, which is mainly due to the decrease in the winning rate due to the disadvantage in quantity. After the algorithm converged, the results of the last ten target allocations were counted, and all solutions were optimal.
4.7. Discussion and Future Work
By combining the attention mechanism, the TAPPO algorithm effectively realizes the importance of assessment and target selection in a multi-target environment. The results show that the algorithm can significantly optimize the allocation of combat resources by assigning appropriate attention weights to each enemy aircraft and combining PPO for intelligent decision-making, thereby improving the aircraft’s survivability and winning rate. Compared with traditional target allocation methods, the TAPPO algorithm has significant advantages in allocation efficiency and complexity.
In the rapidly evolving field of air combat technology, this study not only enriches the research on automated target allocation systems in theory, but also opens up new perspectives and strategies for practical military applications. Especially in modern electronic warfare environments, the algorithm may significantly improve the response speed and accuracy of military decision-making and effectively respond to the challenges of quickly processing a large amount of target information and making real-time decisions.
Despite the excellent performance of the TAPPO algorithm, we also noticed that it has some limitations. First, the algorithm’s execution is highly dependent on high-quality real-time data input, and any delays or errors in front-end and back-end data transmission may seriously affect the accuracy of decision-making. Secondly, although the algorithm has optimized computational efficiency, it is still urgent to reduce the FLOPs of the algorithm and reduce the algorithm’s target allocation time. In future research, we will seek to solve these problems and further improve the generalization and computational capabilities of the algorithm.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}