3.1. Data Collection and Sensor Integration
This methodology section details the system and sensors utilized for data collection, focusing on the integration of IMU and LiDAR sensors to correct tilt-induced distortions and reduce noise without delving into experimental specifics. This framework incorporates two primary data streams: LiDAR-generated point clouds and rotational data captured by the IMU from the boat. These two data streams are fused to mitigate the effects of tilt and dynamic fluctuations caused by water movement, ensuring precise and stable spatial data collection. LiDAR provides high-resolution spatial information for object detection, while the IMU captures the orientation data needed to correct for the boat’s roll, pitch, and yaw.
Each sensor is modeled mathematically to describe how measurements relate to the system state. The IMU model is expressed as
where
represents the IMU measurements,
is a nonlinear function linking the state to the IMU output, and
denotes the measurement noise.
Similarly, the LiDAR sensor is modeled as
where
represents the LiDAR measurements,
is the function mapping the state to LiDAR observations, and
accounts for noise.
To effectively fuse the IMU and LiDAR data, it is essential to align the timestamps between these sensors to ensure synchronization of the measurements. Timestamp misalignment is addressed through interpolation of IMU data to match LiDAR timestamps, defined as follows:
where
I denotes the interpolation function that adjusts the IMU data to the corresponding LiDAR measurement timestamps.
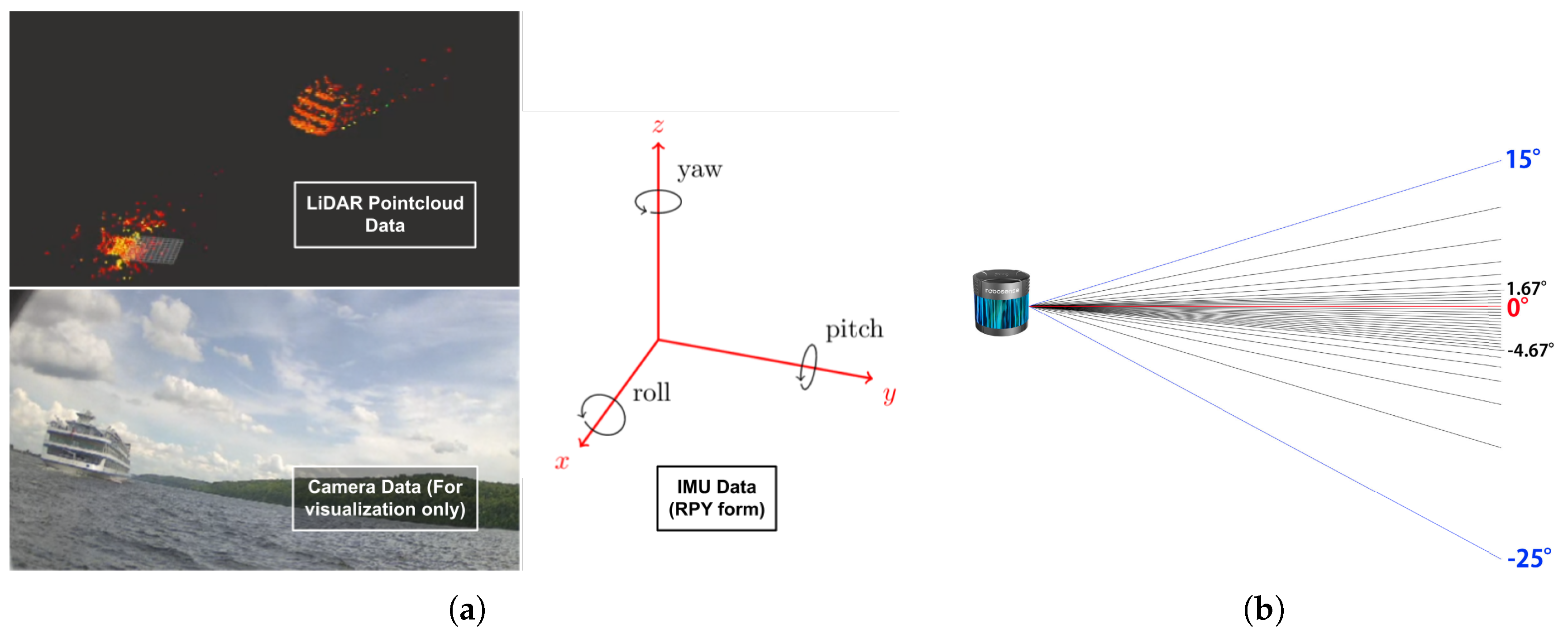
Figure 2a illustrates data acquired from the LiDAR, camera, and IMU sensors. It is noteworthy that the camera-captured images serve solely for visualization and debugging purposes, and do not contribute to the data processing pipeline.
IMU data, represented as quaternions, are converted to Roll (
), Pitch (
), and Yaw (
) angles for a more intuitive representation of the boat’s orientation with respect to the
,
, and
axes. These angles are derived using the formulas shown below.
These transformations allow us to account for the boat’s tilt and provide the necessary corrections to the point cloud data based on the boat’s orientation relative to the , , and axes.
For enhanced analysis and calibration, we also consider the angular velocities (
,
,
) and linear accelerations (
,
,
) derived from the IMU data. The angular velocities are calculated as follows:
where
,
, and
are the angular velocity components measured by the IMU.
To transform the linear accelerations from the body frame to the inertial frame, we employ the rotation matrix
R derived from the quaternion [
23,
24,
25,
26]. The transformation is described by
where the rotation matrix
R is provided by
To enhance the accuracy of our sensor data interpretation, we integrate Kalman filtering techniques. This approach helps to mitigate noise and improve the estimation of the boat’s state by combining the LiDAR and IMU data streams. The state estimation vector
and the process model can be represented as follows:
where
is the state transition matrix,
is the control input matrix,
is the control vector, and
represents the process noise. The initial state vector
is defined as follows:
where
is the initial estimate of the state vector. This estimate is often derived from prior data or domain knowledge about the system.
The measurement update equation is provided by
where
is the measurement matrix and
is the measurement noise.
To achieve optimal sensor fusion, a weighting scheme is applied based on the relative noise characteristics of each sensor. The measurement covariance matrices
and
quantify the uncertainty in IMU and LiDAR data, respectively. The Kalman gain
, which determines the contribution of each sensor to the state update, is computed as follows:
where
is the prior error covariance and
combines the measurement noise from both IMU and LiDAR.
By implementing this fusion algorithm, we are able to combine the spatial accuracy of LiDAR with the orientation precision of the IMU, correcting for tilt and dynamic fluctuations caused by the water. The resulting data fusion enhances the precision and stability of the spatial measurements.
3.2. Preprocessing
Preprocessing is a vital step in enhancing the quality of point cloud data. It involves correcting for orientation errors, reducing noise, and stabilizing the data to accurately reflect the environment. This section outlines the mathematical methods used for these tasks. To align the point cloud data with the world coordinate system, we need to account for the boat’s orientation relative to the LiDAR sensor. This orientation correction involves applying a rotation matrix R derived from te roll (), pitch (), and yaw () angles obtained from the IMU.
The transformation of a point
from the LiDAR frame to the world frame
is provided by
where the rotation matrix
is defined as
and the individual rotation matrices are
Following orientation correction, the next task is noise reduction, which is crucial for eliminating artifacts such as ripples caused by water. We implement a height-based filtering approach to remove points below a specified threshold.
The filtered point cloud
is provided by
Here, is typically set to zero or a small positive value to exclude points representing the water surface.
Point cloud stabilization is performed to compensate for dynamic changes due to the boat’s movement, ensuring that the data reflect a stable reference frame. This is achieved by applying a homogeneous transformation matrix derived from the IMU data.
The stabilized point cloud
is obtained by
The homogeneous transformation matrix
is
where
is the
rotation matrix representing orientation correction and
is the translation vector, which is typically zero if no translation is applied.
To clarify the covariance matrices used in our preprocessing, Equation (
16) transforms point cloud data from the LiDAR frame (
) to the world frame (
) using the rotation matrix
. Equation (
22) stabilizes the point cloud data using the inverse of the transformation matrix
.
The covariance matrices are defined as follows:
The accuracy of object detection and tracking in LiDAR systems depends heavily on the quality of the point cloud data. However, raw point cloud data often contain noise and orientation distortions due to environmental factors and the movement of the boat. To address these issues, a preprocessing step is applied to the data, which includes correcting orientation errors, removing noise, and stabilizing the data to ensure reliable object detection.
3.3. Clustering Algorithm
Clustering is a vital step in maritime object detection where environmental factors such as water movement and sensor noise add complexity. This manuscript focuses on Euclidean distance-based (k-means) clustering and DBSCAN algorithms due to their robustness in handling spatial data and noise tolerance, which is essential in dynamic maritime environments. However, it is acknowledged that other clustering techniques, such as hierarchical clustering or Gaussian mixture models (GMM), could also be considered depending on the dataset’s structure and application.
The primary rationale for selecting these clustering methods is that k-means clustering is computationally efficient for large datasets, while DBSCAN is particularly well suited to nonlinear shapes and can handle noise, which is a common challenge in maritime environments. Although hierarchical clustering and GMM are viable options, k-means and DBSCAN were prioritized for their computational simplicity and noise-handling capabilities, which are well suited to real-time processing and environmental variability.
3.3.1. Euclidean Distance-Based Clustering
Euclidean distance-based clustering approaches [
27] such as k-means group datapoints based on their proximity. The Euclidean distance between points
and
is provided by
In k-means clustering, the objective is to minimize the within-cluster sum of squares (WCSS):
where
represents the
k-th cluster,
is a point in cluster
, and
is the centroid of cluster
. The centroid
is updated iteratively as follows:
while the convergence criterion for k-means is
where
N is the total number of points and
t denotes the iteration number.
K-means clustering, as shown in Algorithm 1, is particularly useful in maritime environments due to its efficiency in handling large volumes of data and its ability to cluster objects based on spatial proximity. However, it is sensitive to noise, which is why DBSCAN is introduced as a complementary approach.
| Algorithm 1: K-means clustering |
| | Input: Data points , Number of clusters K |
| | Output: Cluster centroids , Cluster assignments |
| 1: | Initialize centroids randomly |
| 2: | repeat |
| 3: | for each data point do |
| 4: | | Assign to the nearest centroid |
| 5: | end |
| 6: | for each cluster do |
| 7: | | Update centroid using (26) |
| 8: | end |
| 9: | Evaluate convergence using (27) |
3.3.2. DBSCAN Algorithm
The Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm [
28] clusters data based on density as shown in Algorithm 2. Its key parameters include the maximum distance
and minimum number of points MinPts required to form a dense region.
A point
is classified as a core point if
Clusters are defined starting from core points as follows:
A point
is density-reachable from a core point
if and only if:
is density-reachable from
if and only if
where
denotes the Euclidean distance between points
and
and where
is the predefined distance threshold. Thus, a cluster
includes all points
within the
-neighborhood of any core point
in
.
The distance matrix used in the DBSCAN algorithm can be formalized as follows:
In this matrix,
represents the Euclidean distance between points
and
. If this distance exceeds the threshold
, then the distance is set to
∞, indicating that the points are not density-reachable from each other.
| Algorithm 2: DBSCAN clustering |
| | Input: Data points , , MinPts |
| | Output: Clusters and noise |
| 1: | for each point do |
| 2: | | if is not yet visited then |
| 3: | | | Mark as visited |
| 4: | | | if is a core point then |
| 5: | | | | Create a new cluster |
| 6: | | | | ExpandCluster (Algorithm 3)(, cluster) |
| 7: | | | end |
| 8: | | | else |
| 9: | | | | Mark as noise |
| 10: | | | end |
| 11: | | end |
| 12: | end |
| Algorithm 3: ExpandCluster Subroutine |
![Drones 08 00561 i001]() |
DBSCAN was chosen over alternatives such as hierarchical clustering and GMM because it can efficiently cluster noisy data without the need for prior knowledge of the number of clusters, which can vary in real-world maritime applications. Additionally, hierarchical clustering is computationally more expensive, while GMM assumes a Gaussian distribution that may not fit the irregularities of maritime object data.
3.3.3. Advanced Considerations
For enhanced clustering performance [
29], several advanced techniques and mathematical formulations are employed.
Mahalanobis Distance for Clustering
The Mahalanobis distance accounts for the correlation between variables:
where
is the covariance matrix. This distance metric adjusts for the shape of the data distribution. Spectral clustering involves computing the Laplacian matrix
where
is the degree matrix and
is the weight matrix. The eigenvalues of
are used to partition the data into clusters.
The normalized Laplacian matrix is provided by
where
is the identity matrix.
By integrating these advanced mathematical techniques and clustering methodologies, the ability of the algorithm to accurately segment and identify clusters in complex datasets is significantly enhanced. Further performance analysis and evaluation results are discussed in
Section 4.
3.5. Hungarian Matching Algorithm
Due to the movement of the boat, a discontinuity problem arises. As shown in
Figure 2b, the LiDAR has a vertical range of about −25° to 15°, meaning that objects outside this range will not have data representations from the LiDAR. Although the −25° to 15° range is sufficient to capture most objects, discontinuity appears when the boat tilts, causing the LiDAR’s horizontal line (0°) to tilt as well. Consequently, the same object may not be detected across consecutive frames. This results in objects having different numbers of points between frames, or even no points in certain frames, making it impractical to rely solely on clustering algorithms. Thus, we need to track objects to ensure that when point cloud data are missing for any given frame, we can fill the gap using data from prior frames. Here, the Hungarian Matching Algorithm (HM) [
38,
39,
40] is utilized to match objects detected in prior frames with those in the current frame.
The matched data (from prior frames and the current frame) for the same object serve as input for the Kalman filter [
41,
42,
43], which enhances the object’s measurements (position, orientation, dimensions). If an object in the prior frame does not match any object in the current frame, the Kalman filter algorithm predicts the object’s position in the current frame based on prior frame data.
The Hungarian Algorithm matches objects from prior frames with objects in the current frame, framing this as an assignment problem where we have n objects from prior frames and m objects from the current frame.
Assume that we have three objects from prior frames and four objects from the current frame. To achieve our goal, we establish a weight matrix with dimensions
, where the rows represent objects from the prior frame and the columns represent objects from the current frame, as shown in Equation (
50).
Note: The size of
W varies depending on the number of objects in the objects bank and the number of objects in the current frame’s objects array. Equation (
50) uses a
matrix for demonstration.
represents the ith object from the prior frames’ objects bank .
represents the jth object from the current frame’s objects array .
These weights represent the relationship between objects in prior frames and objects in the current frame. Each weight in this matrix indicates the similarity between each pair of objects; the smaller the weight, the higher the similarity and the greater the probability of a match. These weights are derived from the distance between the two objects and the ratio of their point counts, as shown in Equation (
51):
where:
is the Euclidean distance between objects and .
is the volume of object from the prior frames’ list .
is the volume of object from the current frame’s list .
Next, the
W matrix shown in Equation (
50) is fed into the Hungarian Algorithm to assign objects from prior frames to objects in the current frame.
To further refine the weight calculation, we incorporate more advanced mathematical models.
Let
and
be the sets of points belonging to objects
and
, respectively. We define the point set distance
as the average Euclidean distance between points in
and their nearest neighbors in
:
where
is the Euclidean distance between points
p and
q.
Additionally, we incorporate the shape similarity
which measures the similarity of the point distribution of objects
and
. This can be quantified using the overlap ratio of their convex hulls:
where
and
are the convex hulls of
and
, respectively.
Thus, the weight
can be refined as follows:
where
and
are weighting factors that respectively balance the contributions of shape similarity and volume ratio.
Finally, the refined W matrix is fed into the Hungarian Algorithm to assign objects from the prior frames to objects in the current frame, ensuring robust object tracking and reducing the discontinuity caused by the boat’s tilting motion.
While the Hungarian Algorithm is effective for object tracking, there are several limitations that should be discussed. First, in scenarios with high object density, the algorithm may struggle to differentiate between multiple objects with similar characteristics. This is particularly problematic in cluttered environments, where overlapping or closely spaced objects can result in ambiguous matches. In such cases, incorporating additional object descriptors such as texture or color information (if available) could improve performance.
Another limitation is the computational complexity of the Hungarian Algorithm, which is
for an
assignment problem. This can become a bottleneck as the number of objects increases, especially in real-time applications where the algorithm must operate within strict time constraints. For larger datasets, alternative approaches with lower complexity, such as the Jonker–Volgenant algorithm [
44] or auction algorithms [
45], may provide more efficient solutions.
Moreover, the algorithm’s reliance on geometric and volumetric data may result in incorrect matches in cases where objects have similar volumes and shapes. In such scenarios, integrating machine learning models trained on object-specific features or temporal information (e.g., motion trajectories) could improve matching accuracy.
In conclusion, while the Hungarian Matching Algorithm, see Algorithm 5, offers a solid foundation for object tracking, its performance may degrade in high-density and cluttered environments or when objects share similar features. Exploring more advanced matching techniques and integrating alternative data sources can help mitigate these challenges.
| Algorithm 5: Hungarian matching algorithm for object tracking |
![Drones 08 00561 i003]() |
3.7. Seal Pipeline
In this section, we describe the Seal Pipeline and its capabilities for maritime object detection.
Our work adopts a multimodal sensing approach by combining LiDAR and IMU data to achieve robust object detection and tracking in maritime environments. While LiDAR provides precise 3D point cloud data, relying on a single modality has inherent challenges, especially in detecting objects that may be difficult for a particular sensor to capture due to environmental or sensor limitations. This issue has been thoroughly discussed in previous works such as [
47], where the authors recommended the integration of complementary sensors to overcome the limitations of individual systems. An example is the narrow detection range of LiDAR, which can miss narrow objects such as lampposts or other small obstructions. Similarly, in [
48] the authors demonstrated the effectiveness of sensor fusion by combining LiDAR, ultrasonic sensors, and wheel speed encoders in their autonomous mobile robot design to enhance detection accuracy and robustness.
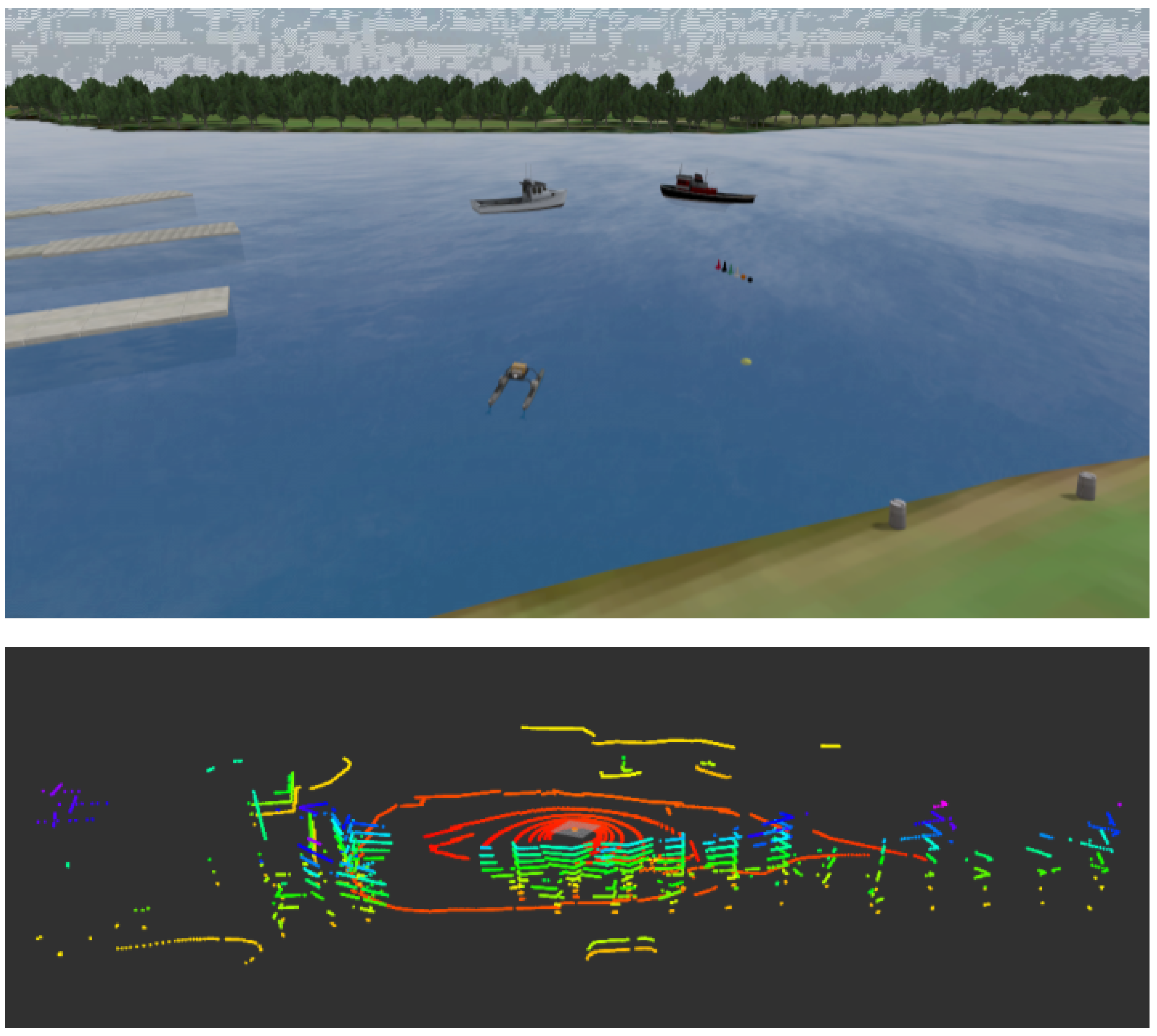
In our Seal Pipeline, as shown in
Figure 1, we apply these principles by integrating LiDAR and IMU data to compensate for motion-induced fluctuations, particularly the roll, pitch, and yaw of the boat. The IMU inputs stabilize the detection system, ensuring accurate object tracking even in the dynamic maritime environment. Although ultrasonic rangefinders have been effectively combined with LiDAR for autonomous land vehicles, as shown by [
47,
48], we propose that similar multimodal approaches could enhance maritime applications. Future extensions of our system will explore the inclusion of additional sensing modalities, such as ultrasonic sensors or radar, to improve detection under challenging conditions where LiDAR and IMU may not suffice, ultimately creating a more resilient object detection pipeline.
This combination of modalities reflects the broader trend, highlighted by Wiseman and Premnath et al. [
47,
48], of using ancillary systems alongside LiDAR to ensure comprehensive environmental awareness and enhanced safety in both land and maritime contexts.
The Seal Pipeline is designed to process LiDAR and IMU data for detecting and tracking objects such as sailing ships and riverbanks in a maritime environment. The pipeline consists of six stages: data acquisition, preprocessing, clustering, bounding box generation, object matching, and Kalman filtering for tracking. Each stage is crucial to ensure accurate and stable object detection and tracking, especially in challenging conditions such as dynamic water surfaces and fluctuating object visibility.
3.7.1. Data Acquisition
In the first step, data are acquired from both IMU and LiDAR sensors:
IMU data: Provide roll, pitch, and yaw (RPY) values, which are crucial for stabilizing the LiDAR data.
LiDAR data: Capture 3D point clouds of the surrounding environment, including both static objects (e.g., riverbanks) and dynamic objects (e.g., ships).
The point cloud data from the LiDAR sensor are often subject to fluctuations due to the motion of the boat, while the IMU provides real-time information about the boat’s orientation. Both data streams are synchronized and processed in the following steps.
3.7.2. Preprocessing
Preprocessing refines the raw point cloud data, and consists of the following:
LiDAR stabilization: The IMU data (specifically the RPY values) are used to stabilize the LiDAR point cloud. As the boat moves and tilts, the point cloud shifts in the opposite direction. To compensate, the RPY values are converted into a 3 × 3 rotation matrix, which is applied to the point cloud. This transformation shifts the point cloud from a moving frame of reference (boat) to a fixed frame, ensuring that objects remain in their correct positions regardless of the boat’s motion.
Water surface filtration: Points from the water surface can introduce noise. This step removes such points by setting height thresholds, ensuring that only valid points representing objects are retained for further processing.
3.7.3. Clustering
After preprocessing, individual points are grouped into clusters representing distinct objects:
Euclidean clustering: Points are grouped based on spatial proximity, which is suitable for environments where objects are well-separated.
DBSCAN: Tightly packed or partially occluded objects are handled by clustering based on point density, which is more effective when dealing with noisy data.
However, objects may not be consistently detected from frame to frame due to fluctuations in the number of points detected for each object.
3.7.4. Bounding Box Generation via PCA
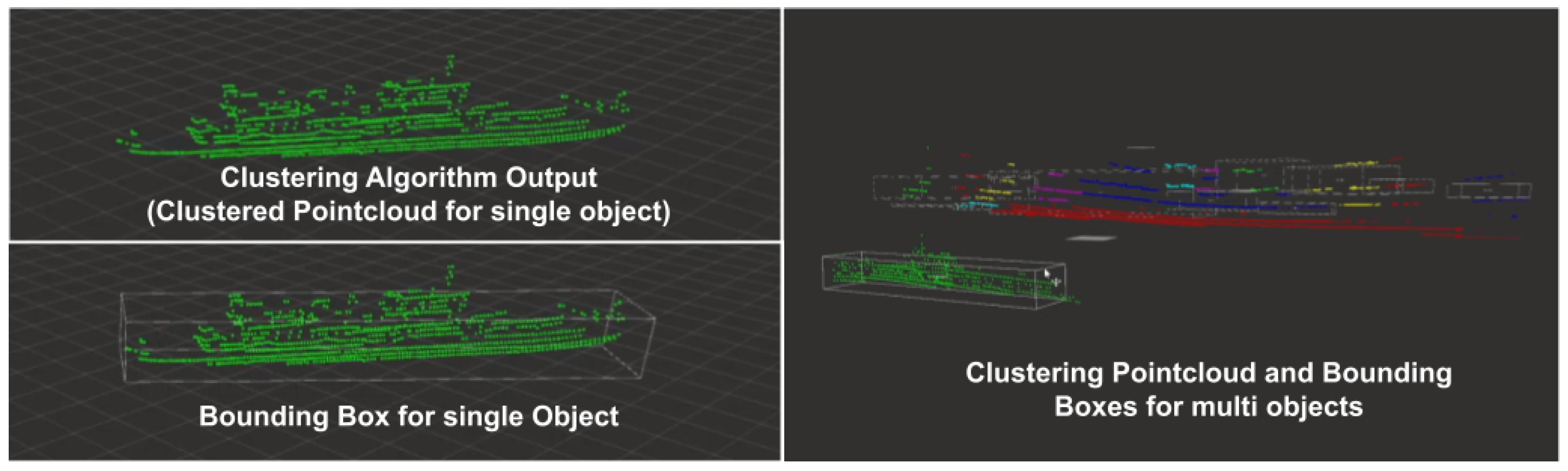
For each cluster, a bounding box is generated using PCA:
This bounding box provides the object’s position, size, and orientation. However, as the number of points varies across frames, the bounding box may fluctuate, which can affect detection stability.
3.7.5. Object Matching Using the Hungarian Algorithm
The Hungarian algorithm is employed to maintain object continuity between frames:
Transformation to world coordinates: Objects are transformed from boat-relative coordinates to world coordinates using the IMU’s transformation matrix, allowing for accurate velocity and orientation calculations.
Gating: A gating mechanism is applied to limit potential object matches within a specific radius. Objects within this radius are considered for matching with prior frame objects.
Matching: The Hungarian algorithm matches current frame objects with previous frame objects using a cost function based on the Euclidean distance and size ratio difference, ensuring that dynamic objects are tracked consistently.
3.7.6. Kalman Filtering for Object Tracking
Kalman filtering is the final stage in the pipeline, providing smooth tracking and prediction of object states:
Inputs: The filter uses the matched object pairs from the Hungarian algorithm and the transformation matrix from the IMU.
State estimation: Using these inputs, the Kalman filter estimates the current state (position, velocity, and orientation) and predicts future states, enabling smooth transitions between frames.
Handling object disappearance: When objects are not detected for a few frames (e.g., due to occlusion), the Kalman filter predicts their positions based on prior data, ensuring robust tracking until they reappear.
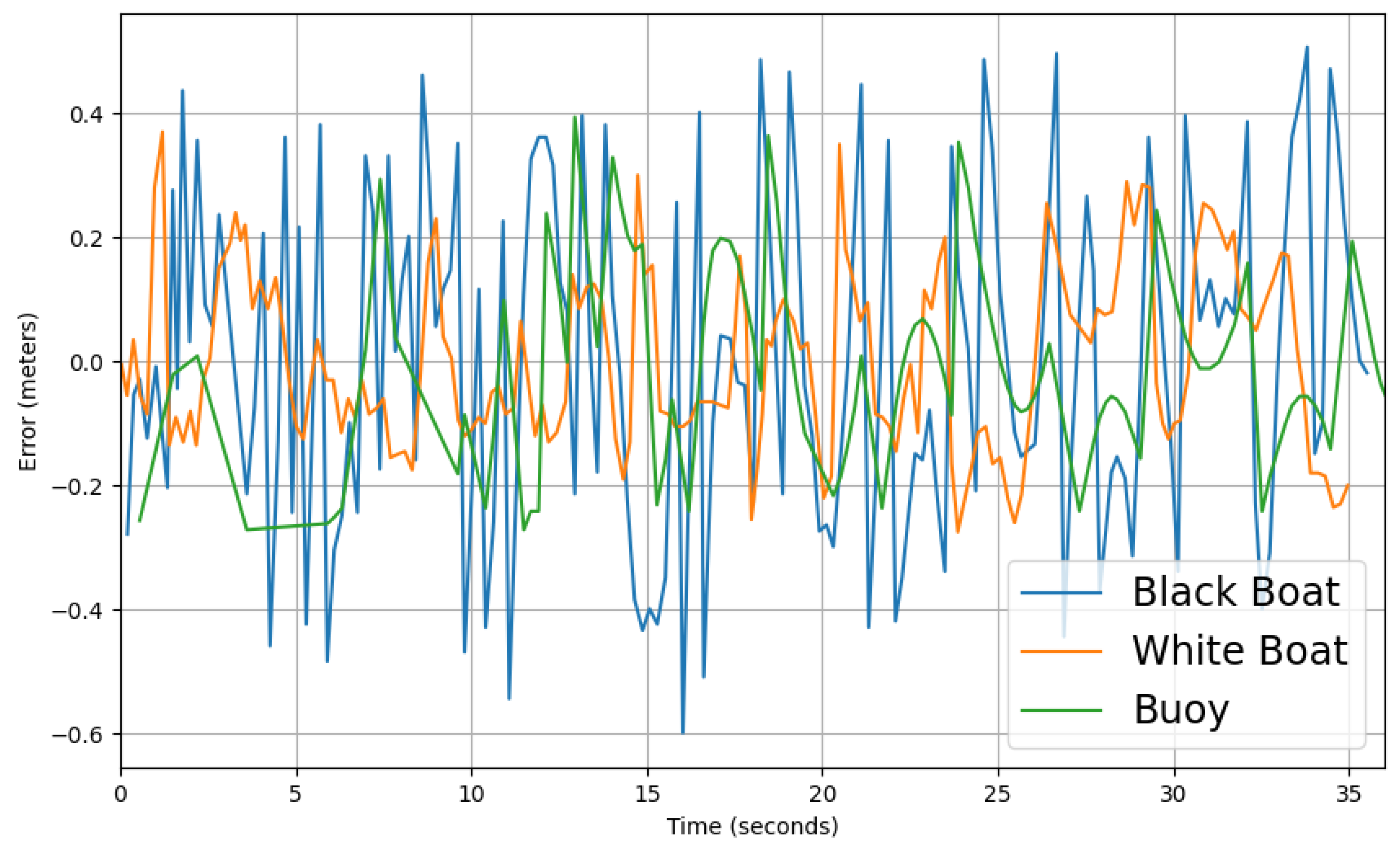
Transforming objects into world coordinates is a critical step, as without it the tracks’ positions, velocities, and orientations would be incorrect. The Kalman filter helps to mitigate the dynamic nature of object detection, providing consistent and reliable estimates of object trajectories.
3.7.7. Computational Complexity Analysis
Each stage in the pipeline has its own computational complexity, with the most computationally expensive stages being clustering and object matching. The overall complexity of the system can be expressed as follows:
where:
3.7.8. Potential Shortcomings and Enhancements
Occlusion: One notable limitations is handling object occlusion. When objects occlude each other, tracking can become challenging, resulting in lost or misaligned tracks. A future enhancement could involve leveraging depth information or advanced multi-object tracking methods to address occlusions.
Dynamic environments: The current pipeline relies heavily on consistent point detection for each object. In cases where objects drastically change in appearance, tracking may be affected. Enhancing the Kalman filter or incorporating particle filters may improve robustness in dynamic scenarios.
High-density scenes: As the number of objects increases, the cubic complexity of the Hungarian algorithm may become a bottleneck. Future work may focus on optimizing or parallelizing the object matching step to handle larger numbers of objects.
In conclusion, while the Seal Pipeline provides a solid framework for detecting and tracking objects in dynamic maritime environments, there is potential for improvement in both accuracy and performance which can be explored in future work.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}