




Data Fusion Analysis and Synthesis Framework for Improving Disaster Situation Awareness


Abstract
:1. Introduction
2. Background and Related Work
2.1. Situation Awareness
2.2. The Disaster Situation Awareness Problem
2.3. UAVs and Data Fusion Techniques
2.4. Advanced Air Mobility and Enhancing Disaster Situation Awareness
3. Problem Statement and Approach
- There is a lack of a model-based framework where, with the help of model management tools, a large category of data sources and geographical elements can be defined.
- A domain model of data sources for earthquake detection is missing.
- There is a lack of analysis tools to evaluate various prospective data source fusion alternatives for the purpose of achieving higher effectiveness.
- A toolset for automated synthesis is lacking, which can help in finding out the best data fusion alternative for a given set of constraints.
3.1. Research Questions
- What is a suitable architectural style of the desired model-based framework? How can this architecture be extended to deal with the (future) UASs?
- How to define a domain model of the data sources suitable for detecting the effects of earthquakes?
- How to compute the combined effectiveness, cost, and timing values as a result of data fusion? The algorithms for computation must be changeable and re-definable to satisfy different needs.
- What kind of algorithms can be defined for automated synthesis of the optimal data fusion?
3.2. Method
- Based on software engineering principles, architectural styles [42] are adopted.
- The proposed framework is inspired from model-driven engineering techniques [43]. Within this context, a domain analysis work is carried out and the ‘feature-model’ notation is adopted for representing the domain of data sources.
- From programming techniques and algorithm design, design patterns [44] are adopted. Patterns provide flexibility to the proposed framework. In addition, object-oriented programming and querying techniques are adopted for relating the candidate data sources to the elements of a geographical area. As for algorithms, data fusion formulas and optimization algorithms are implemented for data fusion synthesis and for computing the effectiveness, cost, and timing values of the fused data sources.
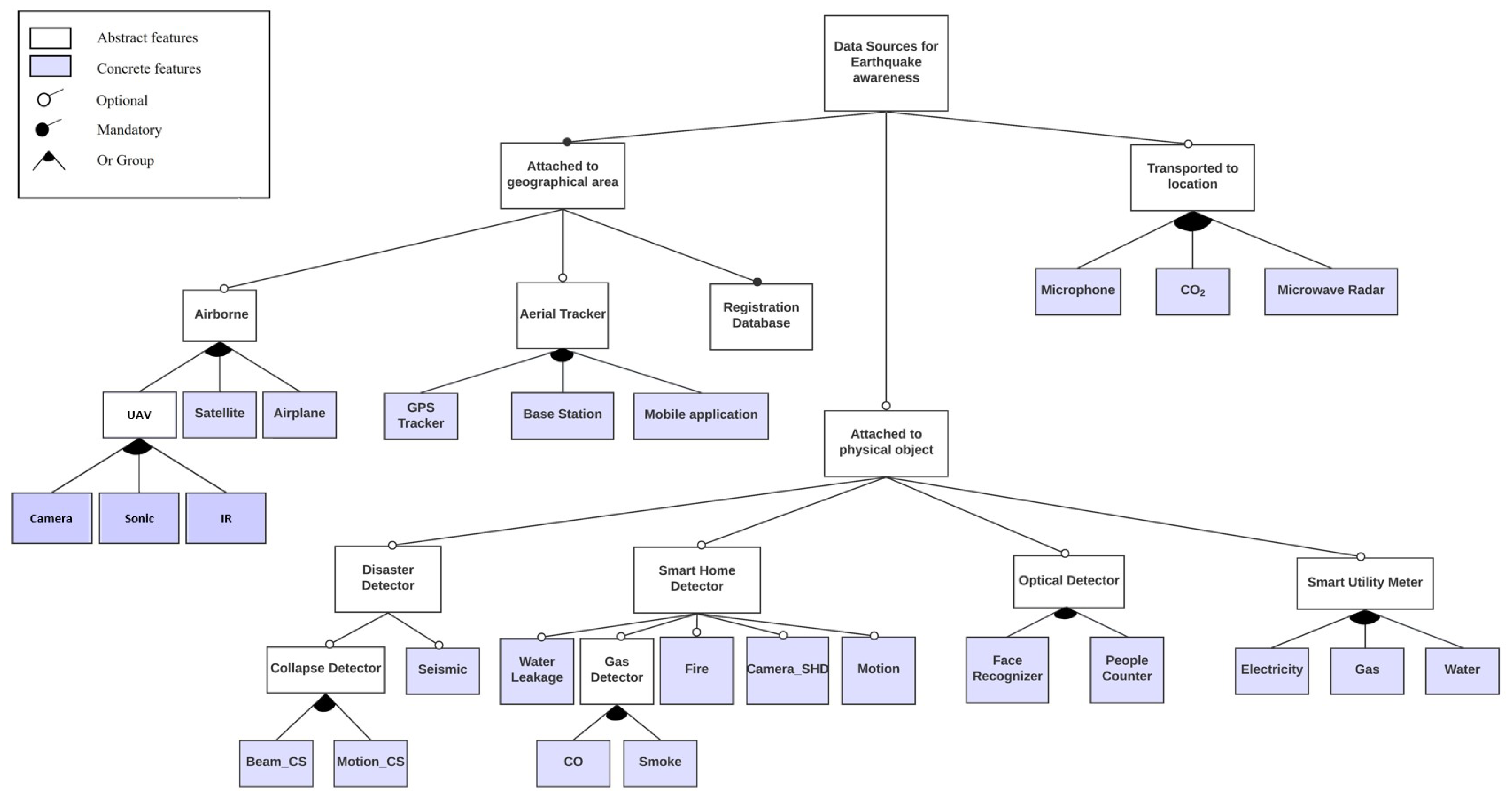
4. Domain Model for Data Sources
4.1. A General View of the Domain
- Starting from the root node, select the compulsory features, if any.
- Decide if the optional features must be selected, if any.
- By obeying the defined semantics, refine the features which are grouped together by the logical operators of the feature model (for example OR, Alternative OR), if any.
- Continue with this process from the abstract features towards the concrete ones until no optional and/or abstract feature is left unresolved.
4.2. Data Sources Which Can Be Attached to Geographical Areas
4.3. Data Sources Which Can Be Attached to Physical Objects
4.4. Data Sources Which Can Be Transported to Certain Locations
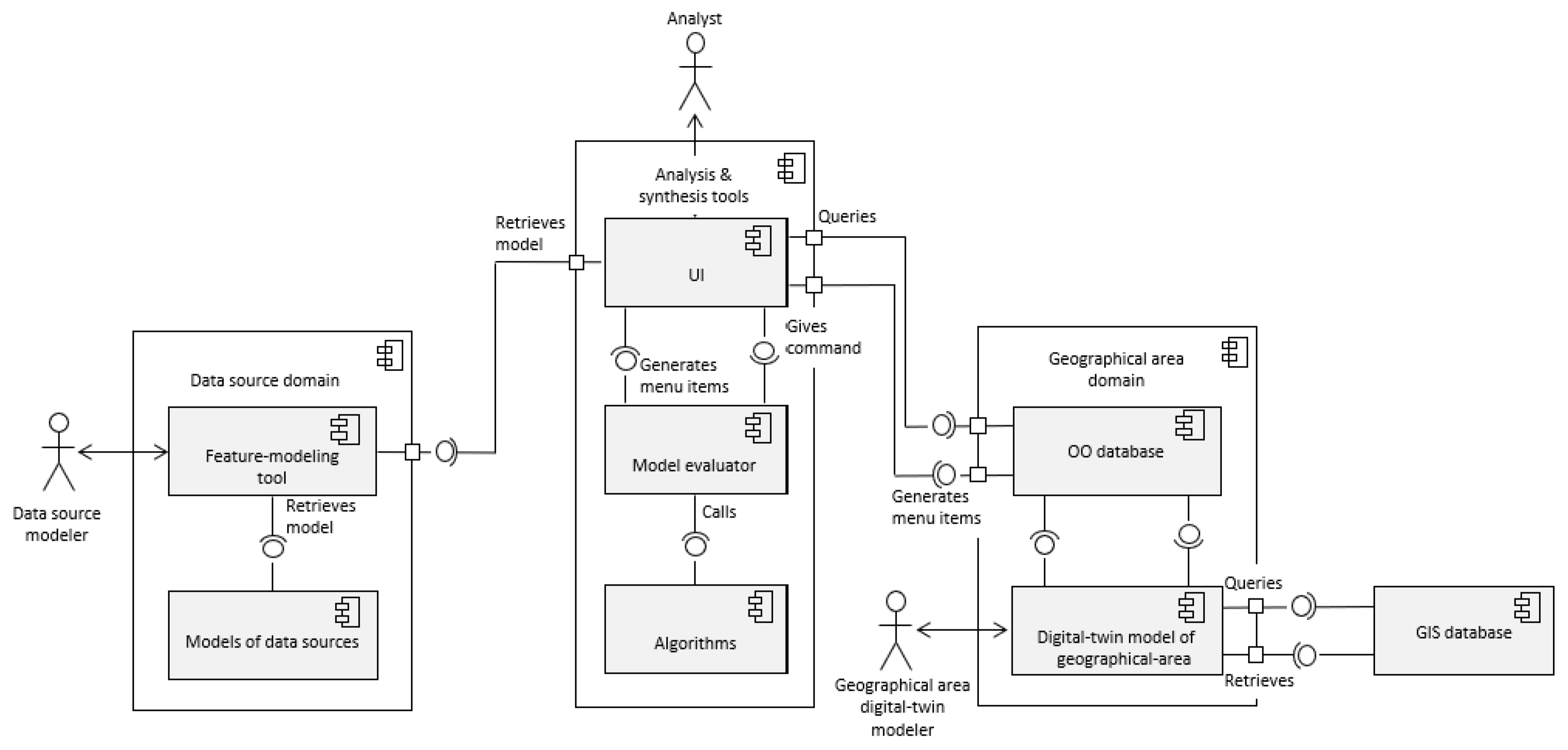
5. Architecture of the Framework
The Analysis Process
- Let us assume that a number of instances of class Residence has been created which represents a selected set of actual residences of an urban area under consideration. In this process, the constant attributes of these instances have been initialized as well.
- Additionally, for the instances of class Residence, a set of dedicated ‘command-query objects’ has been defined and stored in the attribute queries.
- At this stage, these instances are now ready for use to analyse a model of a prospective sensor fusion system. First, a fusion model must be defined.
- With the help of the user interface (UI), the analyst observes these queries, which are displayed at the UI as menu items. An implementation of Command pattern [44] provides a dynamic menu generation mechanism.
- To simulate the attachment of the prospective data sources, an appropriate query is selected by activating the corresponding menu item. The data source objects are also selected by using the feature-modeling tool as defined in Section 4.
- With the help of an object-oriented database, and depending on its definition, the selected query item is executed over one or more instances of class Residence.
- While executing the query, the database calls on the necessary ‘setter methods’ of the corresponding instances. To this aim, class Residence provides the necessary method interface.
- Depending on the query, the selected data source objects are stored in one or more instances of class Residence.
- 9.
- When the data source objects are stored in an instance of class Residence, the method calculateEffectiveness() is called on ‘self’.
- 10.
- This method retrieves the properties of the stored data source objects, and by using the formulas presented in this article, it computes the values of the derived attributes.
- 11.
- If a new set of data source objects is stored, the derived attributes are computed in the same way again.
- 12.
- Now assume that the analyst executes another menu item for attaching a UAV as a data source on the corresponding geographical area.
- 13.
- In our system, a geographical area is represented as an instance of class GeographicArea. The method notifyAttach() is automatically called on the corresponding instances of class Residence, when a data source, such as a UAV is attached to the corresponding geographical area. An implementation of Observer pattern [44] provides an ‘event propagation’ mechanism.
- 14.
- When called, this method reads the characteristics of this new data source, registers its identity, and calculates the derived attributes again. Similarly, the method notifyDetach() is used when the corresponding data source is removed from the geographical area.
- Face recognizer: This is attached to the corresponding physical instance.
- Collapse detector: This is attached to the corresponding physical instance.
- UAV camera: This is attached to the corresponding geographical area.
- Q1 ATTACH_ENTRANCE WHEREphysical_object == ‘Residence’ AND data_source == ‘FaceRecognizer’
- Q2 ATTACH_BASEMENT WHEREphysical_object == ‘Residence’ AND data_source == ‘CollapseDedector’
- Q3 ATTACH_ENTRANCE WHEREphysical_object == ‘Residence’ AND data_source == ‘FaceRecognizer’AND physical_object.id == ‘instance’
- Q4 ATTACH_ENTRANCE WHEREphysical_object == ‘Residence’ AND data_source == ‘FaceRecognizer’AND physical_object.robustness_factor ‘<3’
- Q5 ATTACH WHEREphysical_object == ‘GeographicRegion’AND physical_object.coordinates == ‘coordinates’AND data_source == ‘UAV-camera’)
6. Objectives and the Effects of Data Fusion
6.1. Quality Objectives of Data Fusion
- Objective 1: The accuracy of estimating the effects of disasters is represented as a probabilistic variable. This value must be sufficiently high for a given purpose;
- Objective 2: The accuracy of estimating the horizontal coordinates of a (living) person after a disaster as a probabilistic variable. This value must be sufficiently high for a given purpose;
- Objective 3: The accuracy of estimating the vertical coordinates of a (living) person after a disaster as a probabilistic variable; this value must be sufficiently high for a given purpose.
- Objective 4: The estimated cost value of a data fusion per element which is represented as a probabilistic distribution function. This value must not exceed the budgeting constraints;
- Objective 5: The estimated timing value of a data fusion per element which is represented as a probabilistic distribution function. This value must not exceed the deadline constraints.
6.2. Calculating the Effect of Data Fusion
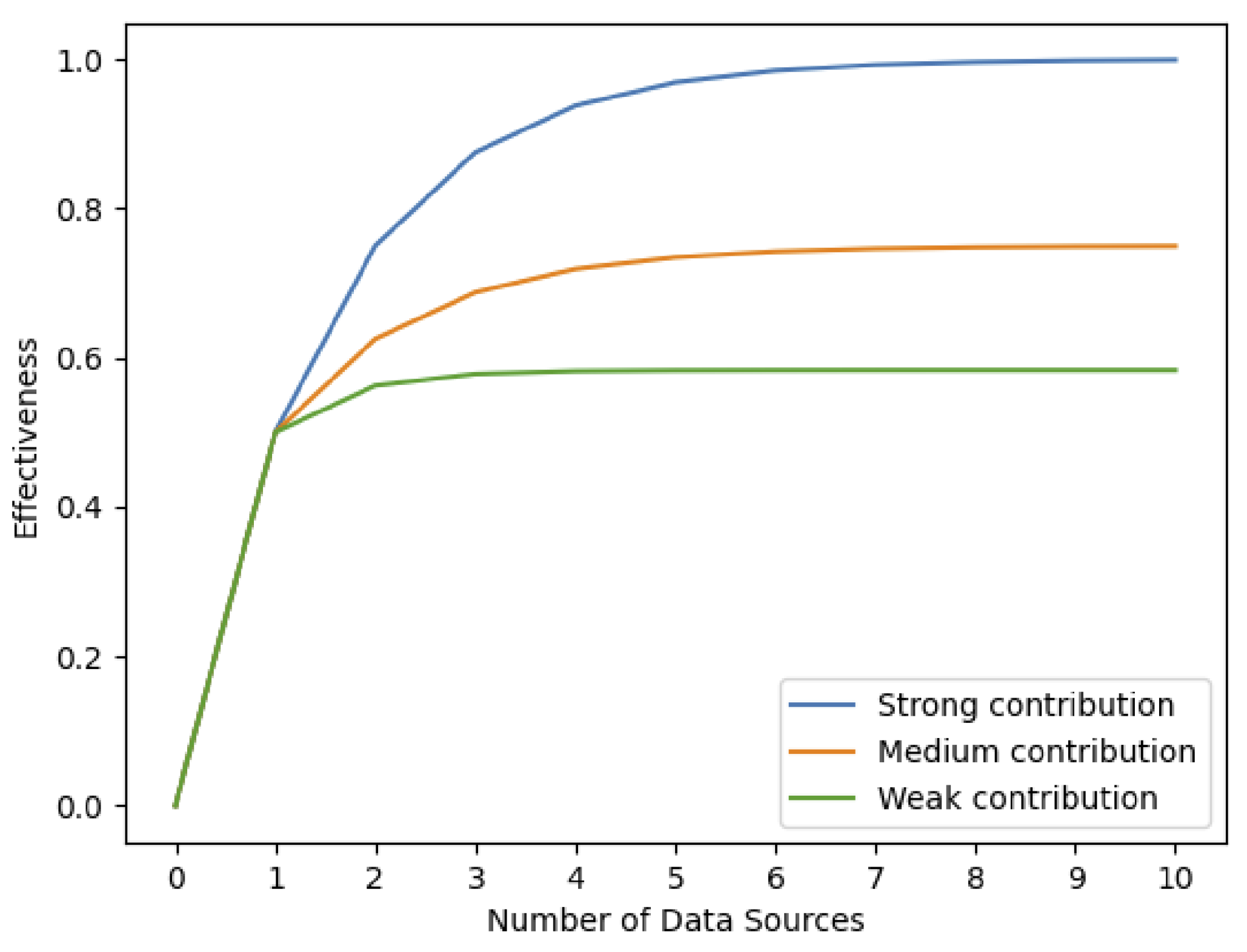
- Effectiveness of fusion of data sources with no contribution to each other. In this case, the effectiveness value of the data source with the highest value is considered. For example, in Appendix B Table A4, it is estimated that the data sources of UAV cameras, motion-based collapse detectors, seismic detectors, and cameras of the face recognizers have no contribution to a GPS tracker.
- Effectiveness of fusion of data sources with some contribution two each other. The effectiveness value of the fusion must be computed.
- Weak contribution: Per effectiveness objective, the selected N data sources are ranked according to their effectiveness value from , where 1 represents the data source with the highest effectiveness value and N is the lowest. The effectiveness of data fusion of the element which is denoted as with respect to objective which is denoted as is calculated using the following formula:where, is the estimated effectiveness value of the data fusion computed as a series of contributions of the ranked data sources, is the effectiveness value of the first data source in ranking, and are the effectiveness values of the and data sources in ranking, respectively.
- A UAV-camera is dispatched to the geographical area.
- There is a base station in the geographical area.
- One collapse detector is installed at the ground floor.
- There exists a registration database.
- There is a face recognizer at the entrance of the building.
- The camera of the face recognizer is used also as a collapse detector.
- Collapse detector (0.7).
- UAV-camera (0.7).
- The camera of the face recognizer (0.65).
- Base station (0).
- Registration database (0).
- Face recognizer (0).
- Face recognizer (0.75).
- Registration database (0.55).
- Collapse detector (0).
- UAV-camera (0).
- The camera of the face recognizer (0).
- Base station (0).
- Face recognizer: 12.5 K.
- Collapse detector: 5.5 K.
- UAV-camera: This cost value is not included.
- Base station: This cost value is not included.
- Registration database: This cost value is not included.
- Face recognizer: 0.55.
- Collapse detector: 0.55.
- Registration database: 0.55.
- Base station: 10.5.
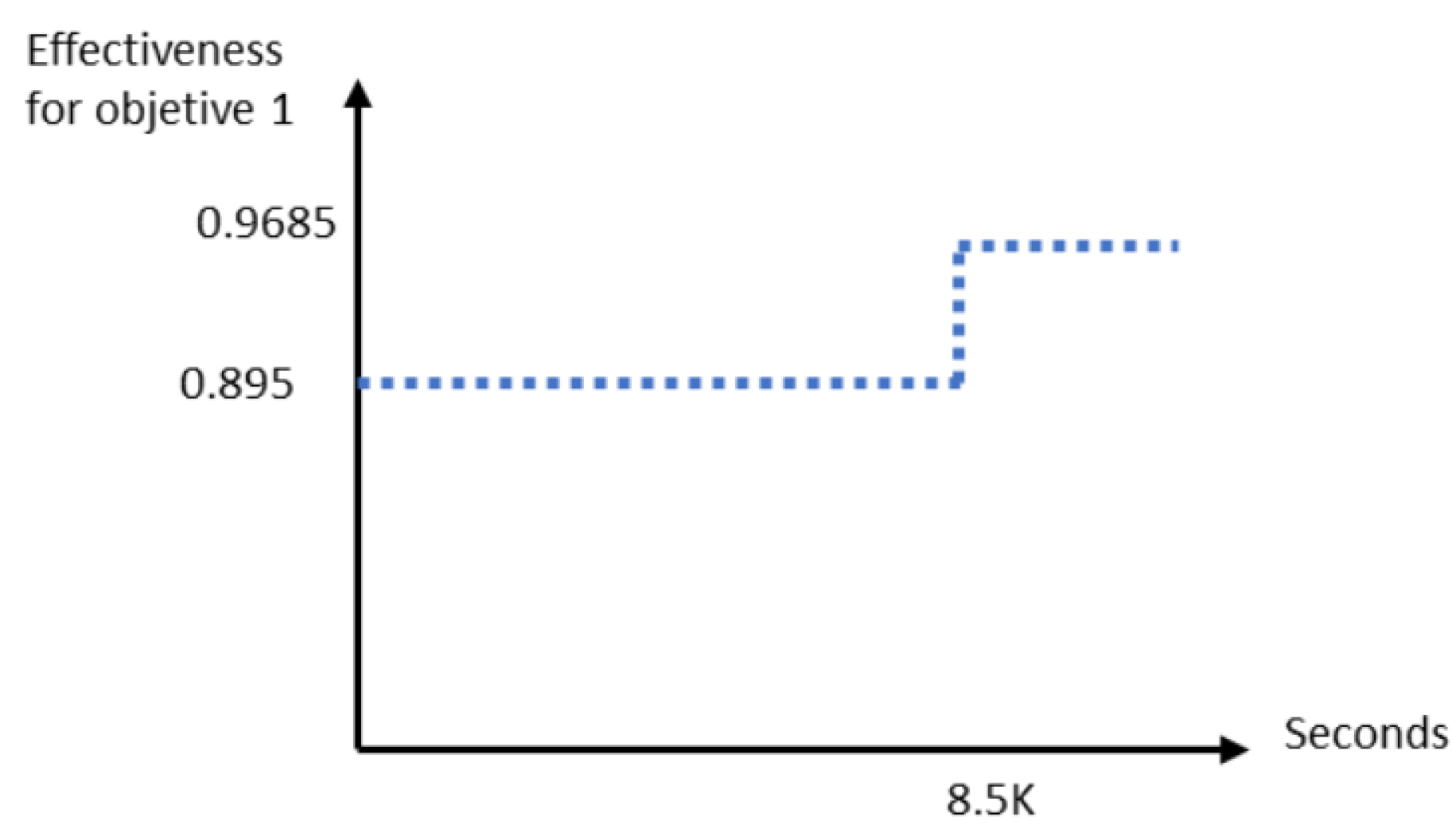
- UAV-camera: 8.5 K.
7. Algorithms for Synthesizing the Optimal Data Fusion Configuration
- Forming a model of a geographical area with a set of data sources attached.
- Calculating the effectiveness, cost, and timing properties of the model.
7.1. Best-Fit
- The cost limit is 15 K in unit of currency.
- The time limit is 3.6 K in seconds.
| Algorithm 1 CALCULATE_BEST_FIT(instance, time_limit, cost_limit) returns list of data sources |
|
- Smart home ();
- Face recognizer ();
- Collapse detector ();
- Camera of face recognizer();
- Seismic detector ();
- People counter ().
7.2. Optimal-Fit
| Algorithm 2 CALCULATE_OPTIMAL_FIT(instance, time_limit, cost_limit) returns list of data sources |
|
- The cost limit is 15 K in unit of currency.
- The time limit is 3.6 K in seconds.
- GPS trackers ();
- Mobile phone apps ();
- Base station ();
- Registration database ();
- UAV-camera ().
- GPS Trackers Mobile Phones, Base Stations, Registration Database;
- Mobile Phone apps GPS Trackers, Base Stations, Registration Database;
- Base Stations GPS Trackers, Mobile Phones, Registration Database.
8. Generalization of the Analysis and Synthesis Approach to UAS-Based Data Fusion
- UAV must be introduced as an element of a geographical model. If necessary, a new class must be introduced in CityGML.
- A set of queries must be defined for UAVs so that data sources can be attached for fusion. In this case, an instance of a UAV can function as a data source and and as a fusion node (element of a geographical area).
- In addition to cost and timing values, a new quality attribute weight must be introduced.
- The analysis and synthesis algorithms must take care of this new attribute as well.
- UAVs may cooperate together during their mission by sharing some of their tasks.
- To analye and synthesize models with cooperating UAVss, the computation of the efficiency values must take care of a group of elements. In addition, time-dependent properties of UAVs must be taken into account. The analysis and synthesis algorithms must be defined accordingly, possibly by using network-based evaluation models.
9. Discussion
- Data sets and incorrect assumptions of the effectiveness, cost, and timing values of data sources: The data sets used in the examples of this article are based on the characteristics of the data sources in Appendix A and Appendix B. Each value is expressed as a probabilistic variable of uniform distribution within a certain range.Although carefully defined, these values may differ considerably from some of the commercially available data sources in the market. Moreover, with the advancement of technology, new products are introduced frequently. It is therefore advisable to consider concrete products instead of their abstract representations. In case of adoption of concrete products, the accuracy of the estimations can be improved by consulting to the catalogues, and if necessary, by carrying out dedicated experiments. If sufficient data are available, machine learning techniques can be adopted to improve these values as well. Nevertheless, the methods and techniques introduced in this article do not depend on the data values presented in Appendix A and Appendix B; the data values are used for illustration purposes and in the examples only.
- Inaccurate data fusion formulas: The data fusion formulas presented in Section 6.2 are based on the following assumptions: (a) The relevancy factor of a data fusion for the objectives 1 to 3 is a probabilistic variable defined in the range of 0 to 1. (b) Attaching a new data source cannot degrade the effectiveness factors of the already attached data sources. (c) If a newly added data source contributes to the considered objective, the effectiveness function is a monotonously increasing function asymptotically approaching 1 or a value less than 1. We consider these assumptions reasonable.The formulas used for weak, medium, and strong contributions can be adapted to the needs, or new formulas can be introduced as plug-ins. A limitation to this approach is that data fusion is assumed to be realized at a geographical element only. In Section 8, more general fusion possibilities are discussed.New formulas can be defined in various ways, as long as they do not violate the assumptions made. The contribution factors of the data sources to each other as presented in Appendix B can be improved by experimentation. In addition, if sufficient data are available, machine learning techniques can be adopted to improve these values.
- Extensibility of the framework: Due to evolution of the needs and technologies, it may be necessary to introduce new elements and/or data sources. The model-based architectural style as described in Section 5 provides flexibility. For example, to introduce a new geographical element, the following actions must be carried out: (1) A new class representing the element must be introduced in the GIS model, possibly by subclassing the existing classes. (2) The attributes of the instances of the class must be initialized including the command objects for the relevant queries. The menu items of the user interface can be automatically generated from the command objects by using the Command design pattern [44]. If a new data source is to be introduced, the following steps must be carried out: (1) The feature-model must be edited to introduce the new feature, which represents the new data source. (2) A new set of command objects must be added to the relevant element instances to enable attaching of the new data source, if necessary. (3) The tables used in computing the effectiveness, cost, and timing values must be updated. Changes to computations can be introduced as plug-ins.
- Complexity of automatic synthesis of data fusion: If the number of possible data sources which can be attached to a selected element is large and if this element offers a large number of alternatives for data sources, the search space of the optimization algorithm can be too large to handle.In this article, we adopt a heuristic rule based on the following: First, data sources are ranked according to their effectiveness values. Second, the search space is formed by starting from the alternatives with the highest effectiveness values. Gradually, other alternatives are considered according to their ranking order. The process continues until the whole search space is constructed or the cost and/or timing constraints are violated. It is also possible to limit the size of the search space while constructing it.The heuristic rule reduces the state space considerably. This algorithm may not find the optimal fusion if many data sources with fewer effectiveness values give in total a better result than a few but more effective data sources. However, in practice due to physical restrictions, it may be impractical to attach too many data sources at a given geographical area even if their total effectiveness value is high. The adopted heuristic rule is therefore considered preferable for most cases.The algorithms presented in this article adopts a single objective optimization strategy, meaning that the quality attribute effectiveness is the main objective of the search for the optimal solution. The other attributes, cost and timing values, are the restricting constraints. One can also adopt multi-objective-based optimization algorithms, such as Pareto optimization [61], to consider all relevant quality factors. From the perspective of this article, the effectiveness of earthquake damage detection is the main objective and the other two attributes are only taken into account as limiting constraints.
10. Future Work
11. Results and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Estimated Parameters of Data Sources
Appendix A.1. Data Sources Attached to Geographical Areas

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Source | Obj1 * min. | Obj1 * max. | Obj2 * min. | Obj2 * max. | Obj3 * min. | Obj3 * max. | Obj4 ⌃ min. | Obj4 ⌃ max. | Obj5 + min. | Obj5 + max. |
|---|---|---|---|---|---|---|---|---|---|---|
| UAV (Camera) | 0.5 & | 0.9 & | 0 | 0 | 0 | 0 | - | - | 1.8 K | 18 K |
| GPS trackers | 0 | 0 | 0.4 | 0.9 | 0.4 | 0.9 | 8 K | 20 K | 0.01 | 0.5 |
| Mobile phones | 0 | 0 | 0.4 | 0.9 | 0.4 | 0.9 | - | - | 0.01 | 0.5 |
| Base stations | 0 | 0 | 0.3 | 0.8 | 0.3 | 0.8 | - | - | 1 | 20 |
| Registration database | 0 | 0 | 0.3 | 0.8 | 0.1 ** | 0.8 ** | - | - | 0.1 | 1 |
Appendix A.2. Data Sources Attached to Physical Objects
| Data Source | Obj1 * min. | Obj1 * max. | Obj2 * min. | Obj2 * max. | Obj3 * min. | Obj3 * max. | Obj4 ⌃ min | Obj4 ⌃ max. | Obj5 + min. | Obj5 + max. |
|---|---|---|---|---|---|---|---|---|---|---|
| Motion-based collapse detector | 0.6 | 0.8 | 0 | 0 | 0 | 0 | 1 K | 10 K | 0.1 | 1 |
| Seismic detector | 0.2 ** | 0.6 ** | 0 | 0 | 0 | 0 | 500 | 2 K | 0.01 | 0.5 |
| Smart-home detectors | 0.8 ⌃⌃ | 0.9 ⌃⌃ | 0.4 | 0.9 | 0.4 | 0.9 | 1 | 4 K | 0.01 | 0.2 |
| Face recognizer | 0 | 0 | 0.6 ++ | 0.9 ++ | 0.6 ++ | 0.9 ++ | 5 K | 20 K | 0.1 | 1 |
| Camera of the face recognizer | 0.5 | 0.8 | 0 | 0 | 0 | 0 | 0 | 0 | 0.1 | 1 |
| People counter & | 0 | 0 | 0.1 | 0.3 | 0.1 | 0.3 | 500 | 1 K | 1 | 10 |
Appendix A.3. Data Sources Transported to the Locations of Disaster Areas
| Data Source | Obj1 * min. | Obj1 * max. | Obj2 * min. | Obj2 * max. | Obj3 * min. | Obj3 * max. | Obj4 ⌃ min | Obj4 ⌃ max. | Obj5 + min. | Obj5 + max. |
|---|---|---|---|---|---|---|---|---|---|---|
| Microphone | 0 | 0 | 0.05 | 0.1 | 0.1 | 0.4 | 1 K | 10 K | 600 | 3.6 K |
| Carbon dioxide meter | 0 | 0 | 0.1 | 0.4 | 0.05 | 0.1 | 500 | 2 K | 600 | 3.6 K |
| Microwave radar | 0 | 0 | 0.8 | 0.9 | 0.8 | 0.9 | 2 M | 4 M | 600 | 3.6 K |
Appendix B. Estimated Parameters of the Effectiveness of Fusion of Multiple Sources
| (a) | (b) | (c) | (d) | (e) | (f) | (g) | (h) | (i) | (j) | (k) | (l) | (m) | (n) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UAV-camera (a) | 1 + | 0 | 0 | 0 | 0 | 2 | 1 | 2 ⌃ | 0 | 2 | 0 | 0 | 0 | 0 |
| GPS trackers (b) | 0 | 0 | 2 | 2 | 2 * | 0 | 0 | 2 * | 2 * | 0 | 1 | 1 | 2 | 2 |
| Mobile phones (c) | 0 | 2 | 0 | 2 | 2 * | 0 | 0 | 2 * | 2 * | 0 | 1 | 1 | 2 | 2 |
| Base stations (d) | 0 | 2 | 2 | 1 | 2 | 0 | 0 | 2 * | 2 * | 0 | 1 | 1 | 2 | 2 |
| Registration database (e) | 0 | 2 * | 2 * | 2 | 0 | 0 | 0 | 0 | 2 * | 0 | 0 | 1 | 2 | 2 |
| Motion-based collapse detector (f) | 2 | 0 | 0 | 0 | 0 | 2 | 2 | 0 | 0 | 2 | 0 | 0 | 0 | 0 |
| Seismic detector (g) | 1 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 |
| Smart home detectors (h) | 2 ⌃ | 2 * | 2 * | 2 * | 0 | 0 | 0 | 2 | 2 * | 0 | 0 | 0 | 0 | 0 |
| Face recognizer (i) | 0 | 2 * | 2 * | 2 * | 2 * | 0 | 0 | 2 * | 0 | 0 | 0 | 2 | 2 | 2 |
| Camera of the face recognizer (j) | 2 | 0 | 0 | 0 | 0 | 2 | 2 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| People counter (k) | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| Microphone (l) | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 2 | 0 | 0 | 2 | 2 | 2 |
| Carbon dioxide meter (m) | 0 | 2 | 2 | 2 | 2 | 0 | 0 | 0 | 2 | 0 | 0 | 2 | 2 | 2 |
| Microwave radar (n) | 0 | 2 | 2 | 2 | 2 | 0 | 0 | 0 | 2 | 0 | 0 | 2 | 2 | 2 |
References
- Endsley, M.R. Toward a Theory of Situation Awareness in Dynamic Systems. Hum. Factors 1995, 37, 32–64. [Google Scholar] [CrossRef]
- da Costa, T.A.G.; Meneguette, R.I.; Ueyama, J. Providing a greater precision of Situational Awareness of urban floods through Multimodal Fusion. Expert Syst. Appl. 2022, 188, 115923. [Google Scholar] [CrossRef]
- Hock, P.; Wakiyama, K.; Oshima, C.; Nakayama, K. Drone monitoring system for disaster areas. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Prague, Czech Republic, 13–17 July 2019; pp. 1686–1690. [Google Scholar]
- Goyal, R.; Cohen, A. Advanced Air Mobility: Opportunities and Challenges Deploying eVTOLs for Air Ambulance Service. Appl. Sci. 2022, 12, 1183. [Google Scholar] [CrossRef]
- Niranjan, D.; Rakesh, N. Early detection of building collapse using iot. In Proceedings of the 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA). IEEE, Coimbatore, India, 15–17 July 2020; pp. 842–847. [Google Scholar]
- Smit, L.; Stander, A.; Ophoff, J. An analysis of base station location accuracy within mobile-cellular networks. Int. J. Cyber Secur. Digit. Forensics (IJCSDF) 2012, 1, 272–279. [Google Scholar]
- Pan, S.; Ye, X.; Zhang, Y.; Zhang, F. Microwave photonic array radars. IEEE J. Microwaves 2021, 1, 176–190. [Google Scholar] [CrossRef]
- Fagel, M.J.; Mathews, R.C.; Murphy, J.H. Principles of Emergency Management and Emergency Operations Centers (EOC); CRC Press: Boca Rotan, FL, USA, 2021. [Google Scholar]
- Ryan, M. Planning in the emergency operations center. Technol. Forecast. Soc. Chang. 2013, 80, 1725–1731. [Google Scholar] [CrossRef]
- Moran, B.; Cohen, F.; Wang, Z.; Suvorova, S.; Cochran, D.; Taylor, T.; Farrell, P.; Howard, S. Bounds on multiple sensor fusion. ACM Trans. Sens. Netw. (TOSN) 2016, 12, 1–26. [Google Scholar] [CrossRef]
- Munir, A.; Aved, A.; Blasch, E. Situational Awareness: Techniques, Challenges, and Prospects. AI 2022, 3, 55–77. [Google Scholar] [CrossRef]
- Sanfilippo, F. A multi-sensor fusion framework for improving situational awareness in demanding maritime training. Reliab. Eng. Syst. Saf. 2017, 161, 12–24. [Google Scholar] [CrossRef]
- Dragos, V. Semantic Frameworks to Enhance Situation Awareness for Defence and Security Applications. Master’s Thesis, Habilitation à diriger des Recherches, Université de Paris, Paris, France, 2021. [Google Scholar]
- Pal, A.; Wang, J.; Wu, Y.; Kant, K.; Liu, Z.; Sato, K. Social Media Driven Big Data Analysis for Disaster Situation Awareness: A Tutorial. IEEE Trans. Big Data 2023, 9, 1–21. [Google Scholar] [CrossRef]
- Park, C.Y.; Laskey, K.B.; Salim, S.; Lee, J.Y. Predictive situation awareness model for smart manufacturing. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Lim, T.Y. Designing the next generation of mobile tourism application based on situation awareness. In Proceedings of the 2012 Southeast Asian Network of Ergonomics Societies Conference (SEANES), Langkawi, Malaysia, 9–12 July 2012; pp. 1–7. [Google Scholar] [CrossRef]
- Golestan, K.; Soua, R.; Karray, F.; Kamel, M.S. Situation awareness within the context of connected cars: A comprehensive review and recent trends. Inf. Fusion 2016, 29, 68–83. [Google Scholar] [CrossRef]
- Xu, C.; Zhang, K.; Jiang, Y.; Niu, S.; Yang, T.; Song, H. Communication Aware UAV Swarm Surveillance Based on Hierarchical Architecture. Drones 2021, 5, 33. [Google Scholar] [CrossRef]
- Krytska, Y.; Skarga-Bandurova, I.; Velykzhanin, A. IoT-based situation awareness support system for real-time emergency management. In Proceedings of the 2017 9th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Bucharest, Romania, 21–23 September 2017; Volume 2, pp. 955–960. [Google Scholar] [CrossRef]
- Park, C.Y.; Laskey, K.B.; Costa, P.C.G.; Matsumoto, S. Multi-Entity Bayesian Networks learning for hybrid variables in situation awareness. In Proceedings of the 16th International Conference on Information Fusion, Istanbul, Turkey, 9–12 July 2013; pp. 1894–1901. [Google Scholar]
- Baumgartner, N.; Gottesheim, W.; Mitsch, S.; Retschitzegger, W.; Schwinger, W. BeAware!—Situation awareness, the ontology-driven way. Data Knowl. Eng. 2010, 69, 1181–1193. [Google Scholar] [CrossRef]
- Oliveira, A.C.; Botega, L.C.; Saran, J.F.; Silva, J.N.; Melo, J.O.; Tavares, M.F.; Neris, V.P. Crowdsourcing, data and information fusion and situation awareness for emergency management of forest fires: The project DF100Fogo (FDWithoutFire). Comput. Environ. Urban Syst. 2019, 77, 101172. [Google Scholar] [CrossRef]
- Ouzounov, D.; Pulinets, S.; Hattori, K.; Taylor, P. Pre-Earthquake Processes: A Multidisciplinary Approach to Earthquake Prediction Studies; John Wiley & Sons: Hoboken, NJ, USA, 2018; Volume 234. [Google Scholar]
- Restas, A. Drone applications for supporting disaster management. World J. Eng. Technol. 2015, 3, 316. [Google Scholar] [CrossRef]
- Kaku, K. Satellite remote sensing for disaster management support: A holistic and staged approach based on case studies in Sentinel Asia. Int. J. Disaster Risk Reduct. 2019, 33, 417–432. [Google Scholar] [CrossRef]
- Daud, S.M.S.M.; Yusof, M.Y.P.M.; Heo, C.C.; Khoo, L.S.; Singh, M.K.C.; Mahmood, M.S.; Nawawi, H. Applications of drone in disaster management: A scoping review. Sci. Justice 2022, 62, 30–42. [Google Scholar] [CrossRef]
- Shakhatreh, H.; Sawalmeh, A.H.; Al-Fuqaha, A.; Dou, Z.; Almaita, E.; Khalil, I.; Othman, N.S.; Khreishah, A.; Guizani, M. Unmanned aerial vehicles (UAVs): A survey on civil applications and key research challenges. IEEE Access 2019, 7, 48572–48634. [Google Scholar] [CrossRef]
- Rejeb, A.; Abdollahi, A.; Rejeb, K.; Treiblmaier, H. Drones in agriculture: A review and bibliometric analysis. Comput. Electron. Agric. 2022, 198, 107017. [Google Scholar] [CrossRef]
- Molina, A.A.; Huang, Y.; Jiang, Y. A Review of Unmanned Aerial Vehicle Applications in Construction Management: 2016–2021. Standards 2023, 3, 95–109. [Google Scholar] [CrossRef]
- Ye, X.W.; Ma, S.Y.; Liu, Z.X.; Ding, Y.; Li, Z.X.; Jin, T. Post-earthquake damage recognition and condition assessment of bridges using UAV integrated with deep learning approach. Struct. Control. Health Monit. 2022, 29, e3128. [Google Scholar] [CrossRef]
- Półka, M.; Ptak, S.; Kuziora, Ł. The use of UAV’s for search and rescue operations. Procedia Eng. 2017, 192, 748–752. [Google Scholar] [CrossRef]
- Rostami, M.; Farajollahi, A.; Parvin, H. Deep learning-based face detection and recognition on drones. J. Ambient. Intell. Humaniz. Comput. 2022, 1–15. [Google Scholar] [CrossRef]
- Data Acquisition Project IAGOS-CARIBIC. Available online: https://www.iagos.org/iagoscaribic/ (accessed on 25 August 2023).
- Campbell, J.; Wynne, R. History and Scope of Remote Sensing; Guilford Publications: New York, NY, USA, 2011. [Google Scholar]
- Mastelic, T.; Lorincz, J.; Ivandic, I.; Boban, M. Aerial imagery based on commercial flights as remote sensing platform. Sensors 2020, 20, 1658. [Google Scholar] [CrossRef] [PubMed]
- Ivanov, R.; Pajic, M.; Lee, I. Resilient multidimensional sensor fusion using measurement history. In Proceedings of the 3rd International Conference on High Confidence Networked Systems, Berlin/Heidelberg, Germany, 15–17 April 2014; pp. 1–10. [Google Scholar]
- Gupta, A.; Fernando, X. Simultaneous Localization and Mapping (SLAM) and Data Fusion in Unmanned Aerial Vehicles: Recent Advances and Challenges. Drones 2022, 6, 85. [Google Scholar] [CrossRef]
- Aerial orthoimage generation for UAV remote sensing: Review. Inf. Fusion 2023, 89, 91–120. [CrossRef]
- Nakamura, E.F.; Loureiro, A.A.; Frery, A.C. Information fusion for wireless sensor networks: Methods, models, and classifications. ACM Comput. Surv. (CSUR) 2007, 39, 9-es. [Google Scholar] [CrossRef]
- Bauranov, A.; Rakas, J. Designing airspace for urban air mobility: A review of concepts and approaches. Prog. Aerosp. Sci. 2021, 125, 100726. [Google Scholar] [CrossRef]
- Kochenderfer, M.; Wheeler, T. Algorithms for Optimization; MIT Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Bass, L.; Clements, P.; Kazman, R. Software Architecture in Practice; SEI Series in Software Engineering; Addison-Wesley Professional: Boston, MA, USA, 2003. [Google Scholar]
- Brambilla, M.; Cabot, J.; Wimmer, M. Model-Driven Software Engineering in Practice, 2nd ed.; Synthesis Lectures on Software Engineering, Morgan & Claypool Publishers: San Rafael, CA, USA, 2017. [Google Scholar]
- Gamma, E.; Helm, R.; Johnson, R.; Vlissides, J.M. Design Patterns: Elements of Reusable Object-Oriented Software, 1st ed.; Addison-Wesley Professional Computing Series; Pearson Education: Boston, MA, USA, 1994. [Google Scholar]
- Kang, K.C.; Cohen, S.G.; Hess, J.A.; Novak, W.E.; Peterson, A.S. Feature-Oriented Domain Analysis (FODA) Feasibility Study; Technical Report; Carnegie Mellon University, Software Engineering Institute: Pittsburgh, PA, USA, 1990. [Google Scholar]
- Epstein, R.L.; Carnielli, W.A. The Semantic Foundations of Logic Volume 1: Propositional Logics; Kluwer Academic Publishers: Dordrecht, The Netherlands; Boston, MA, USA; London, UK, 1990. [Google Scholar]
- Wojtusiak, J.; Mogharab Nia, R. Location prediction using GPS trackers: Can machine learning help locate the missing people with dementia? Internet Things 2021, 13, 100035. [Google Scholar] [CrossRef]
- Kondylakis, H.; Katehakis, D.G.; Kouroubali, A.; Logothetidis, F.; Triantafyllidis, A.; Kalamaras, I.; Votis, K.; Tzovaras, D. COVID-19 Mobile Apps: A Systematic Review of the Literature. J. Med. Internet Res. 2020, 22, e23170. [Google Scholar] [CrossRef]
- Havskov, J.; Alguacil, G. Seismic Sensors. In Instrumentation in Earthquake Seismology; Springer International Publishing: Cham, Switzerland, 2016; pp. 13–100. [Google Scholar] [CrossRef]
- Chong, G.; Zhihao, L.; Yifeng, Y. The research and implement of smart home system based on Internet of Things. In Proceedings of the 2011 International Conference on Electronics, Communications and Control (ICECC), Ningbo, China, 9–11 September 2011; pp. 2944–2947. [Google Scholar] [CrossRef]
- Kortli, Y.; Jridi, M.; Al Falou, A.; Atri, M. Face Recognition Systems: A Survey. Sensors 2020, 20, 342. [Google Scholar] [CrossRef] [PubMed]
- Fisk, W.J.; Sullivan, D. Optical People Counting for Demand Controlled Ventilation: A Pilot Study of Counter Performance; Technical Report; Lawrence Berkeley National Lab. (LBNL): Berkeley, CA, USA, 2009. [Google Scholar]
- Toledo, F. Smart Metering Handbook; PennWell Corporation: Tulsa, OK, USA, 2013. [Google Scholar]
- Zhang, D.; Sessa, S.; Kasai, R.; Cosentino, S.; Giacomo, C.; Mochida, Y.; Yamada, H.; Guarnieri, M.; Takanishi, A. Evaluation of a Sensor System for Detecting Humans Trapped under Rubble: A Pilot Study. Sensors 2018, 18, 852. [Google Scholar] [CrossRef] [PubMed]
- Kutzner, T.; Chaturvedi, K.; Kolbe, T. CityGML 3.0: New Functions Open Up New Applications. PFG—J. Photogramm. Remote. Sens. Geoinf. Sci. 2020, 88, 43–61. [Google Scholar] [CrossRef]
- Arslan, R.; Aksit, M. Chapter 5—Extending the Geographic Information System CityGML with Event-Based Digital Twins for Emergency Management. In Management and Engineering of Critical Infrastructures, 1st ed.; Tekinerdogan, B., Aksit, M., Catal, C., Hurst, W., AlSkaif, T., Eds.; Academic Press: Cambridge, MA, USA, 2023. [Google Scholar]
- Ivanov, S.; Nikolskaya, K.; Radchenko, G.; Sokolinsky, L.; Zymbler, M. Digital Twin of City: Concept Overview. In Proceedings of the 2020 Global Smart Industry Conference (GloSIC), Chelyabinsk, Russia, 17–19 November 2020; pp. 178–186. [Google Scholar] [CrossRef]
- Badal, P.S.; Sinha, R. Risk-targeted importance factors for prescriptive seismic design of critical buildings. Earthquake Engng Struct Dyn. 2023, 1–23. [Google Scholar] [CrossRef]
- Effectiveness—Dictionary.cambridge.org. Available online: https://dictionary.cambridge.org/dictionary/english/effectiveness (accessed on 10 May 2023).
- Damarla, T. Hidden Markov model as a framework for situational awareness. In Proceedings of the 2008 11th International Conference on Information Fusion, Cologne, Germany, 30 June–3 July 2008; pp. 1–7. [Google Scholar]
- de Roo, A.; Sozer, H.; Aksit, M. An architectural style for optimizing system qualities in adaptive embedded systems using Multi-Objective Optimization. In Proceedings of the 2009 Joint Working IEEE/IFIP Conference on Software Architecture & European Conference on Software Architecture, Cambridge, UK, 14–17 September 2009; pp. 349–352. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aksit, M.; Say, H.; Eren, M.A.; de Camargo, V.V. Data Fusion Analysis and Synthesis Framework for Improving Disaster Situation Awareness. Drones 2023, 7, 565. https://doi.org/10.3390/drones7090565
Aksit M, Say H, Eren MA, de Camargo VV. Data Fusion Analysis and Synthesis Framework for Improving Disaster Situation Awareness. Drones. 2023; 7(9):565. https://doi.org/10.3390/drones7090565
Chicago/Turabian StyleAksit, Mehmet, Hanne Say, Mehmet Arda Eren, and Valter Vieira de Camargo. 2023. "Data Fusion Analysis and Synthesis Framework for Improving Disaster Situation Awareness" Drones 7, no. 9: 565. https://doi.org/10.3390/drones7090565
APA StyleAksit, M., Say, H., Eren, M. A., & de Camargo, V. V. (2023). Data Fusion Analysis and Synthesis Framework for Improving Disaster Situation Awareness. Drones, 7(9), 565. https://doi.org/10.3390/drones7090565