1. Introduction
Estimating the abundance of land-based breeding aggregations of seabirds and pinnipeds is a key part of population monitoring and marine resource management efforts [
1]. However, remote locations of breeding colonies, inaccessible or hazardous beach landings, and narrow periods of time for conducting standardized counts of adults or offspring can constrain the collection of census data using traditional ground-based counting techniques. Additionally, large aggregations can complicate manual counts and may require extended visitation at breeding locations to achieve reliable estimates. One alternative to manual ground counts is the use of small, unoccupied aerial systems (UAS) that can systematically survey breeding aggregations using airborne cameras.
Advances in UAS technology [
2,
3,
4] have facilitated the development of safe, reliable platforms for research [
5], particularly in polar environments [
6]. Moreover, surveys conducted with small UAS can offer relatively low-disturbance methods [
7] for quickly obtaining full photographic coverage of large breeding colonies in remote and inaccessible areas [
8,
9]. However, with the use of UAS, the burden of analysis shifts from on-site counting efforts to the review and annotation of images. The cryptic nature of pinnipeds and seabirds in polar areas and the high-contrast environment (e.g., bright snow or ice on dark substrates) can introduce uncertainty when identifying species or life stages from photographs. Additionally, UAS images collected at the scales necessary to count large, often dispersed breeding aggregations can create large data streams that are unmanageable for manual image analysis. Moreover, a manual process of identifying and counting individuals or species within photographs can be difficult to replicate across multiple observers. Automated image analysis is therefore appealing as it can provide a structured and replicable process to advance the use of small UAS aerial surveys for rapid census work.
The development of machine learning (ML) algorithms, particularly deep learning classification models that are rooted in convolutional neural networks [
10], provides accessible opportunities to automate image analysis in support of UAS-based predator monitoring. Prior efforts to develop automated methods for the detection of penguins and pinnipeds in polar settings from aerial surveys have yielded varying degrees of success [
11,
12]. However, continual improvement in automated image classification algorithms [
13], development of open-access tools that support a broader implementation of machine learning techniques [
14,
15], and the expanding use of automated and semi-automated methods to detect and classify a wide range of organisms in aerial images [
16,
17,
18] support further exploration.
A key factor affecting the utility of UAS-derived images for animal detection is the choice of sensor used to image targets. The utility of traditional color (RGB) imagery can depend on light levels, contrast of targets with background substrate (e.g., ice, snow, rock, vegetation), and shadows that may mask targets. Alternatively, infrared (IR) thermal imaging may improve the detection of warm targets against colder backgrounds irrespective of light levels, potentially reducing image complexity and improving target detectability [
17,
19,
20,
21,
22]. For example, Hyun et al. [
22] report that thermal sensors were advantageous for detecting large elephant seals in a maritime Antarctic setting. To assess the benefits of IR images relative to RGB images for automating the detection of smaller Antarctic organisms, we used a single camera with integrated IR and RGB sensors. The paired images facilitate the direct comparison of the different spectra for automating animal detection in the northern Antarctic Peninsula, where targets may occur on substrates that include snow, ice, water, rock, cobble, guano, moss, and grasses.
Here, we evaluate IR and RGB sensors for using deep learning convolutional neural networks (CNN) to automate the detection of target penguins (
Pygoscelis spp.) and Antarctic fur seals (
Arctocephalus gazella) in images collected by a small UAS. Such direct comparisons of sensor types for use in developing automated detection algorithms is, to our knowledge, not commonly considered in UAS applications. We used the Video and Image Analytics for Marine Environments software (VIAME v0.16.1;
https://www.viametoolkit.org, accessed on 8 September 2021), a publicly available computer vision application for building and deploying image analysis tools [
15,
23], to build separate detection models from paired IR and RGB images. We ask specifically whether models developed from IR images performed better than models from corresponding RGB images. Finally, we introduce a method to assess model performance with a custom R [
24] package, vvipr (Verify VIAME predictions v0.3.2;
https://github.com/us-amlr/vvipr; accessed on 14 September 2022), that allows users to adjust thresholds for identifying valid model predictions, visualize the overlaps of model predictions and truth (expert) annotations, and rapidly calculate aggregate model performance metrics using a standardized, repeatable process. We developed vvipr as a GUI-based web application with the R package shiny [
25] to make it accessible to non-R users. We describe the core functionalities of vvipr here.
2. Materials and Methods
2.1. Aerial Surveys
We conducted aerial surveys at Cape Shirreff, Livingston Island, Antarctica (60.79 °W, 62.46 °S) during the 2019–2020 austral summer. Aerial surveys were flown over breeding aggregations of chinstrap (Pygoscelis antarcticus) and gentoo (P. papua) penguins in December 2019 and over aggregations of Antarctic fur seals consisting of pups (<3 months old) and non-pups (≥1 year old) at Cape Shirreff and the neighboring San Telmo Islands in December 2019 and February 2020. All aerial surveys occurred under the Marine Mammal Protection Act Permit No. 20599 granted by the Office of Protected Resources/National Marine Fisheries Service, the Antarctic Conservation Act Permit No. 2017-012, NMFS-SWFSC Institutional Animal Care and Use Committee Permit No. SWPI 2017-03, and all domestic and international UAS flight regulations.
We flew an APH-28 hexacopter (Aerial Imaging Solutions, LLC, Old Lyme, CT, USA) for all surveys and used a bespoke ground station that receives real-time flight information and video data from the aircraft. The APH-28 weighs 1.6 kg, can be powered by up to three batteries (6-cell 440 mAmp lithium-polymer), and has a payload capacity of 1.8 kg with an estimated flight endurance of 30 min. We used the FLIR Duo Pro R camera system (Teledyne FLIR LLC., Wilsonville, OR, USA) as payload to image the animal aggregations. The camera system contains independent thermal (IR, 0.33 megapixel) and color (RGB, 6 megapixel) sensors that, upon triggering, capture simultaneous IR and RGB images of the same target area. We used this integrated camera system to enable direct comparisons of models developed from the different sensors.
We conducted visual-line-of-sight aerial surveys, flying between 30 and 90 m above ground level (AGL). Survey grids for each flight covered target aggregations of animals and the camera triggered when the aircraft paused at each waypoint.
2.2. Image Sets for Analysis
From all images collected during the flights, we selected a subset of images that met three criteria. First, we selected only IR and RGB images that contained targets (penguins or fur seals). Second, we retained only the pairs of IR and RGB images that exhibited minimal blurring from sensor movement or aircraft vibrations. Although blurring occurs normally in UAS aerial survey work, the extent of blurring in much of the IR imagery was atypical and unfit for model training (
Figure S1). Third, we rejected IR and RGB pairs if the images contained individuals present in previously selected images (i.e., overlapping images). In this way, we sought to ensure each image pair represented a unique set of in-focus individuals for model training and testing. Extensive blurring of poorly resolved targets resulted in the rejection of most images obtained during the survey flights. In total, we retained 20 image pairs containing penguins and, initially, 23 image pairs containing fur seals. Upon annotation, we discarded two images from the fur seal IR analysis due to inconsistent blurring of individuals but retained the corresponding RGB images for the RGB analysis (
Table 1).
2.3. Image Annotation
We manually annotated each image set with the annotation tools provided in the desktop version of VIAME software (version 0.16.1) or in the online instance of VIAME-Web (
https://viame/kitware.com/, accessed on 1 November 2021). We used rectangular bounding boxes to identify target classes, centering the bounding box on the target and extending the edges to surround all visible features of the target. For the penguin model, we could not distinguish chinstrap and gentoo penguins in the IR images, so we simply annotated individuals as generic ‘penguins’ for all analyses. For the fur seal model, we identified individuals as pups or non-pups based on the relative size of imaged targets (all images) and coloration (RGB images only).
In addition to the target classes for detection, we also included annotations of non-target features to test whether the additional information might help constrain the detection of penguin or fur seal targets. These non-target features included rocks, abandoned nests, guano stains, or other identifiable objects in the images that shared visual characteristics of the target classes. For example, in the penguin image set, we added non-target annotations for 212 “warm” and 172 “cold” background areas in the IR images and, correspondingly, 276 “light” and 296 “dark” background features in the RGB images. For the fur seal image set, we included 42 annotations of an “other” class that identified non-targets with visual characteristics similar to fur seal pup targets in the RGB imagery only. The image annotations thus define seven classification models that we trained and tested (
Table 2) to compare model performance.
2.4. Model Training and Testing
We randomly split the collection of paired IR and RGB images into two image sets for independent model training and model testing. For penguins, we set aside 70% of the images for training and 30% for model testing (
Table 1). Due to the reduced number of targets in the fur seal images relative to the penguin images, we assigned at least 80% of the fur seal images to the training set (
Table 1).
Using the training images and annotation sets (
Table 2), we trained seven independent classification models based on the YOLOv3 CNN model [
13] as implemented in its default configuration in VIAME v0.16.1 [
15,
23]. The default YOLOv3 model was trained originally on the COCO dataset [
26]. The use of the YOLOv3 model is consistent with prior work to automate detection of other organisms [
17,
21]. Note that the IR images are single-channel 8-bit images, whereas the RGB images are 3-channel 24-bit images. The implementation of YOLOv3 in VIAME typically requires a 3-channel input images. However, the model automatically replicates the single-channel IR image to achieve the necessary 3-channel input without material change to the information available for model training. Once trained, we confronted each model with its corresponding set of novel test images (
Table 1) to generate predictions for each target class. The predictions provide a bounding box to identify the location of the target, a label to identify the class of the target, and a confidence level on the prediction ranging from 0 to 1. The confidence level represents an estimate of the degree to which a prediction differs from the target class (i.e., it is not a probability of correct identification).
2.5. Model Evaluation
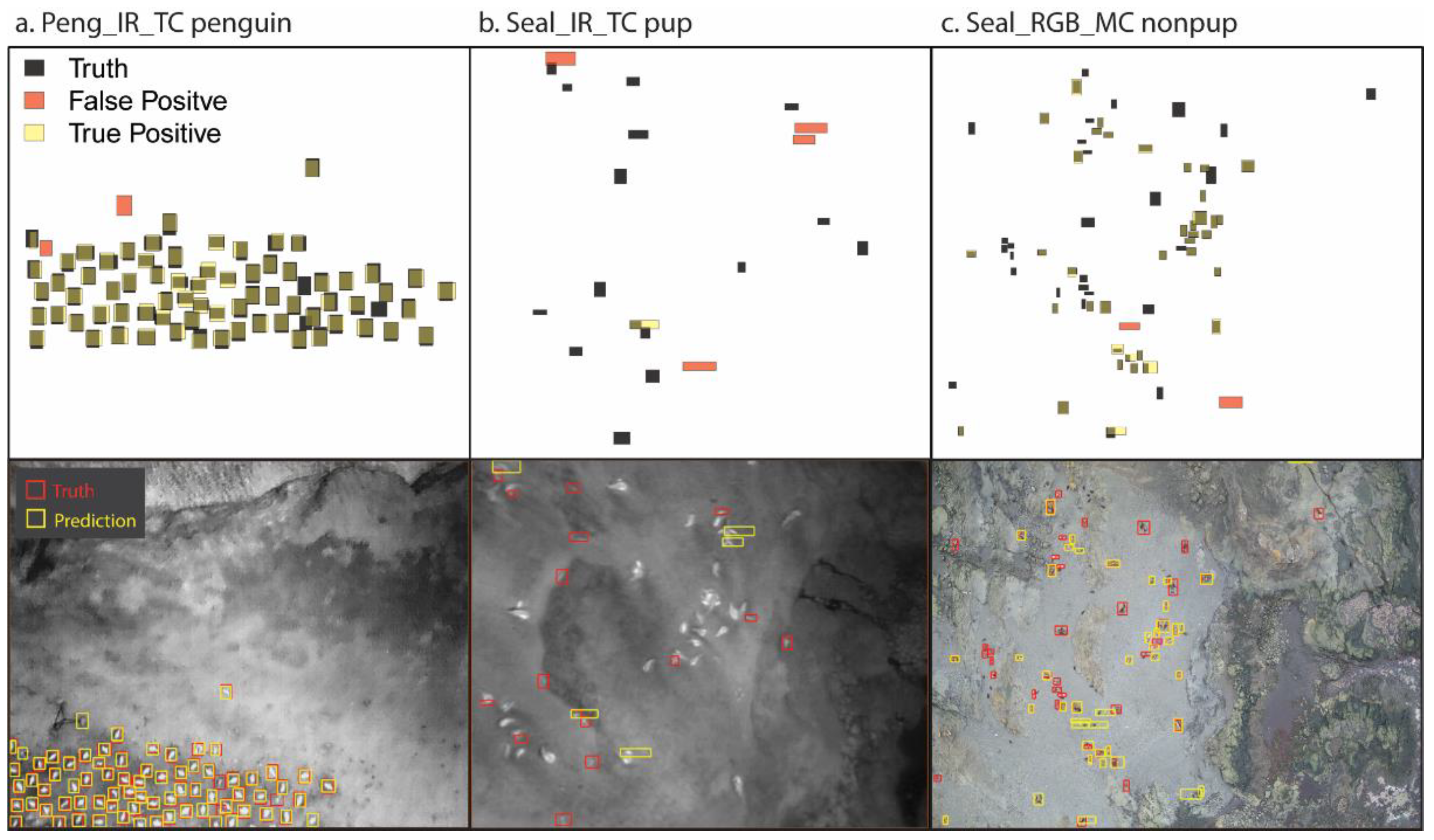
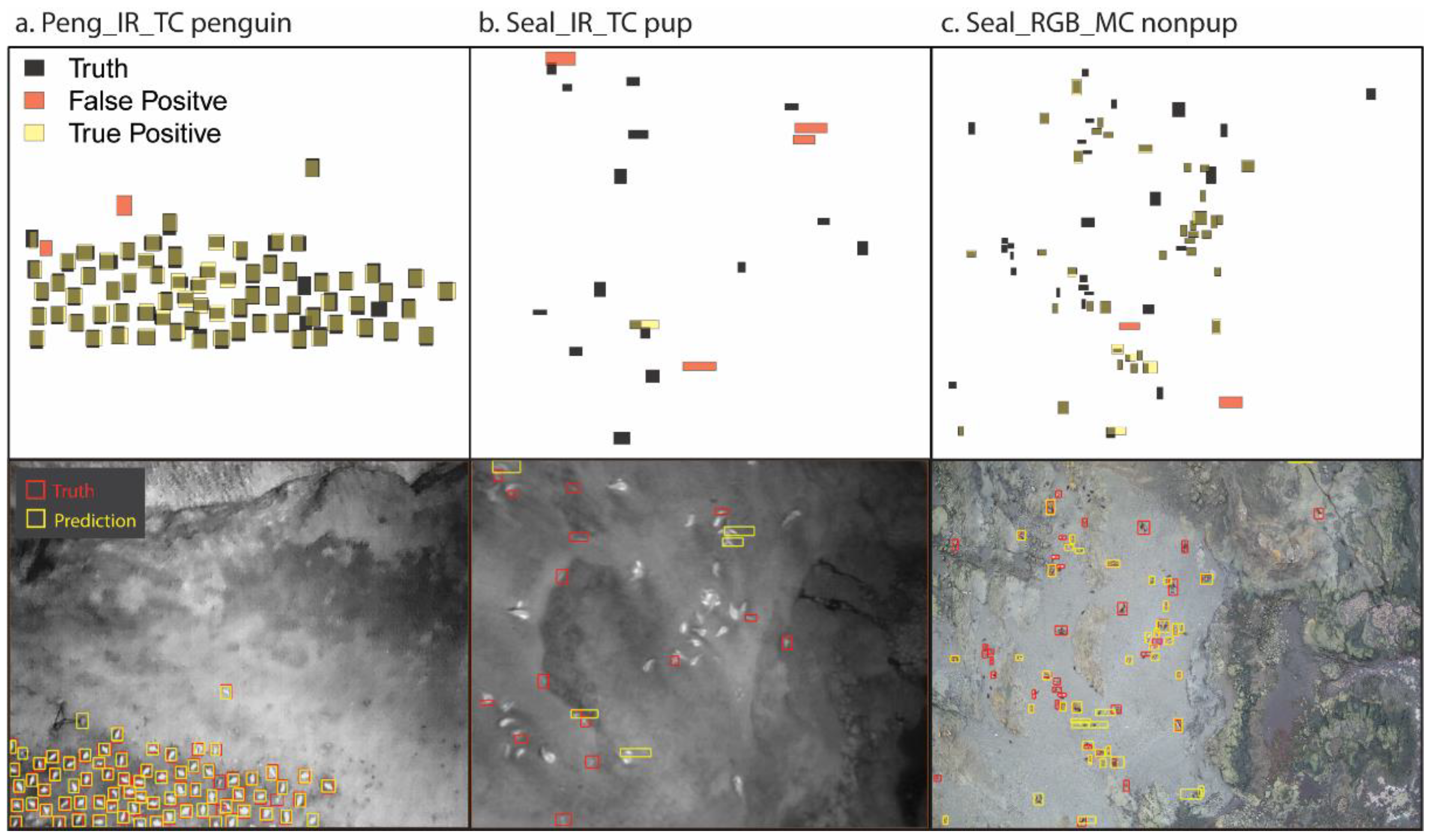
We used vvipr to evaluate the performance of each model by comparing the model predictions on the test images (
Table 2) to the corresponding truth annotations for the test images. The method of vvipr is chiefly concerned with identifying false positives (FP) in the model predictions, from which counts of false negatives (FN) and true positives (TP) can be estimated, given known counts of truth annotations and total model detections, using the ‘uniroot’ optimization [
27] in R [
24]. From the total counts of FP, FN, and TP, we computed five standard performance metrics to characterize aggregate model performance: accuracy, precision, recall, F1, and mean average precision (mAP) of each model. The performance metrics are defined as:
Accuracy represents the ratio of the number of correct predictions relative to the total number of observations. Precision represents the ratio of the number of correct predictions relative to the total number of predictions. Recall represents the ratio of the number of correct predictions relative to the total number of possible correct predictions. The F1 score is a weighted average of Precision and Recall. These four metrics represent aggregate measures of model performance for all target classes and are based on the model evaluation thresholds identified by a sensitivity analysis (see below). The mAP represents the mean of the class-specific average precision that is calculated over a range (e.g., 10% to 90%) of overlap thresholds.
When assessed together, this suite of metrics provides a useful benchmark to assess model performance. We used a benchmark value of 0.9 as a target performance goal. This benchmark is an arbitrary choice, representing a threshold that is lower than the traditional 5% error for manual counts of individual nests in a colony of Antarctic seabirds [
28] but similar to the model performance achieved in another application of automated classification of penguins from UAS images [
11].
The evaluation of the models for
Accuracy,
Precision,
Recall, and
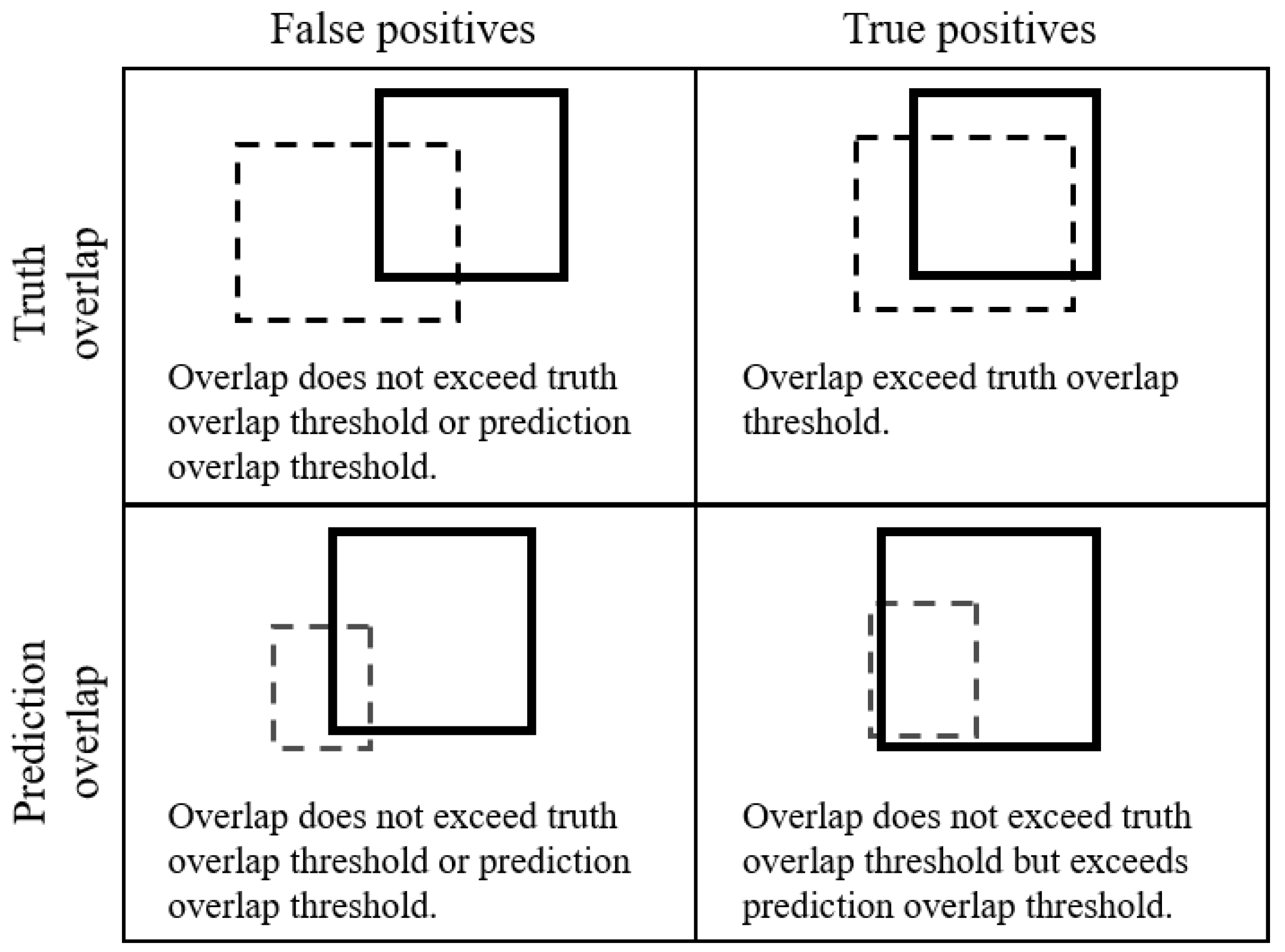
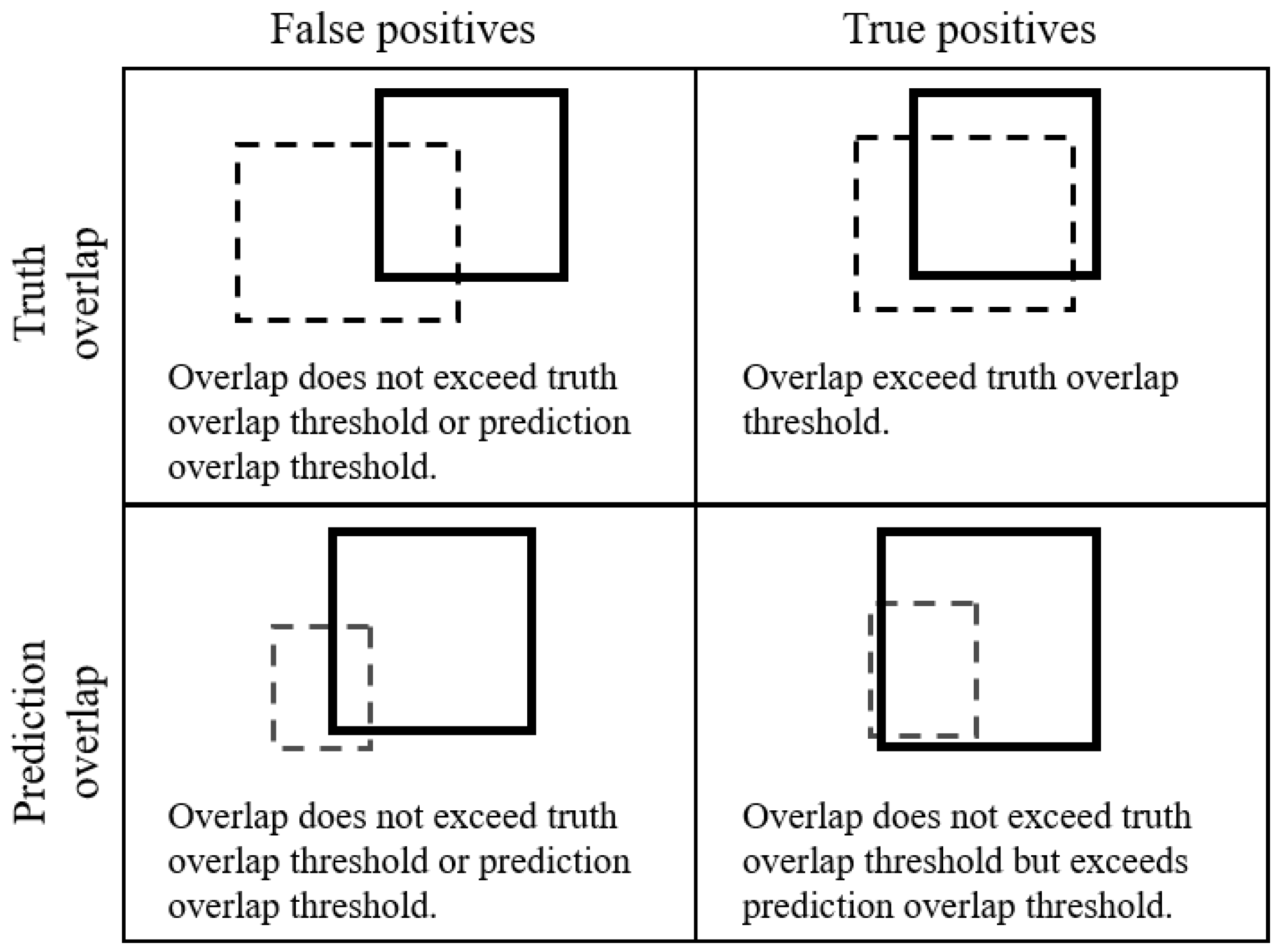
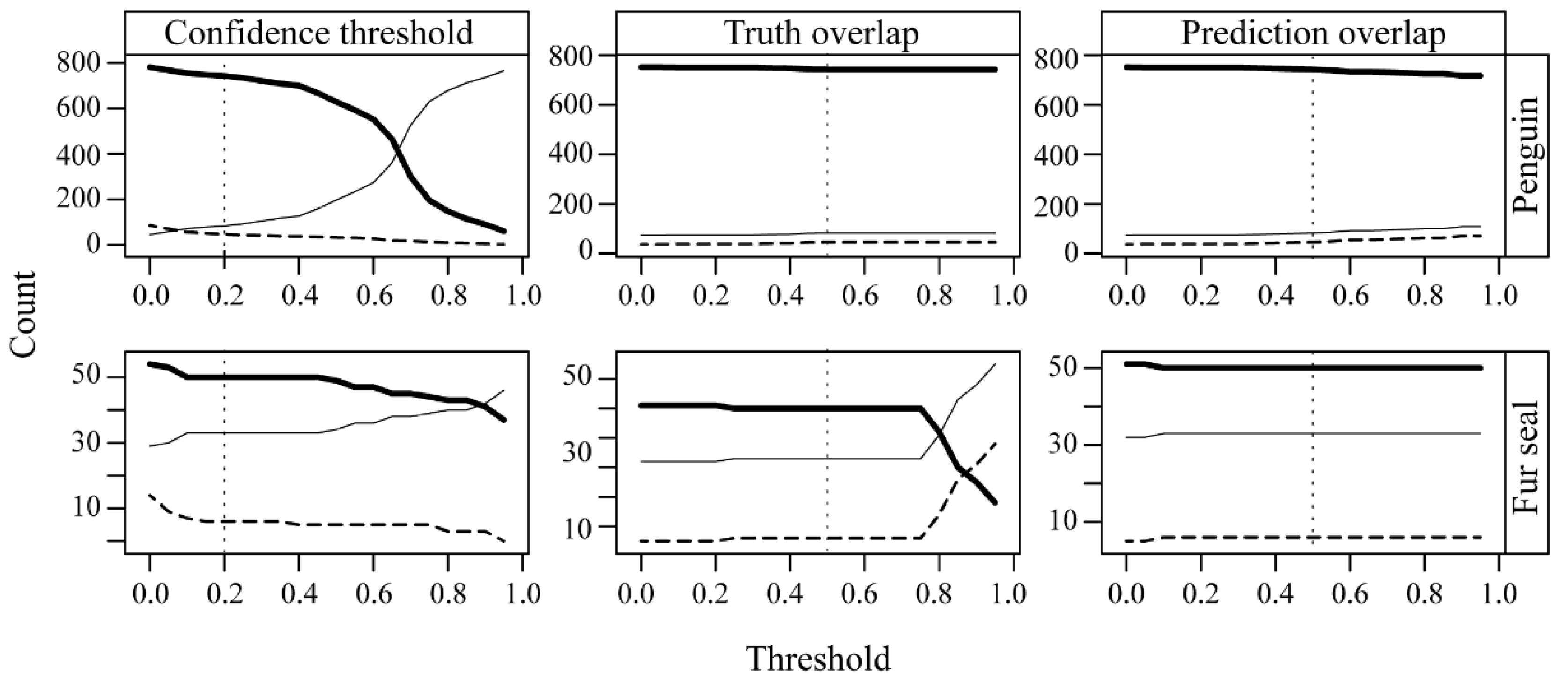
F1 required the selection of appropriate confidence and overlap thresholds for accepting predictions as correct. These thresholds are implemented in vvipr as (1) the confidence threshold for initial filtering of model predictions; (2) the minimum proportion of the geometric area of a truth annotation that is overlapped by a prediction (truth overlap); and (3) the minimum proportion of the geometric area of the prediction that overlaps a truth annotation (prediction overlap). The confidence threshold optionally filters out low-confidence predictions prior to analysis. The “truth overlap” parameter optionally requires that the prediction overlaps the area of the truth annotation to the degree specified. The “prediction overlap” optionally allows for the retention of predictions in special cases where the total area of the prediction is small relative to the area of the truth annotation but overlaps the truth annotation to the degree specified.
Figure 1 illustrates schematically how the overlap of predictions and truth annotations can vary and how vvipr treats such overlaps (
Figure 1).
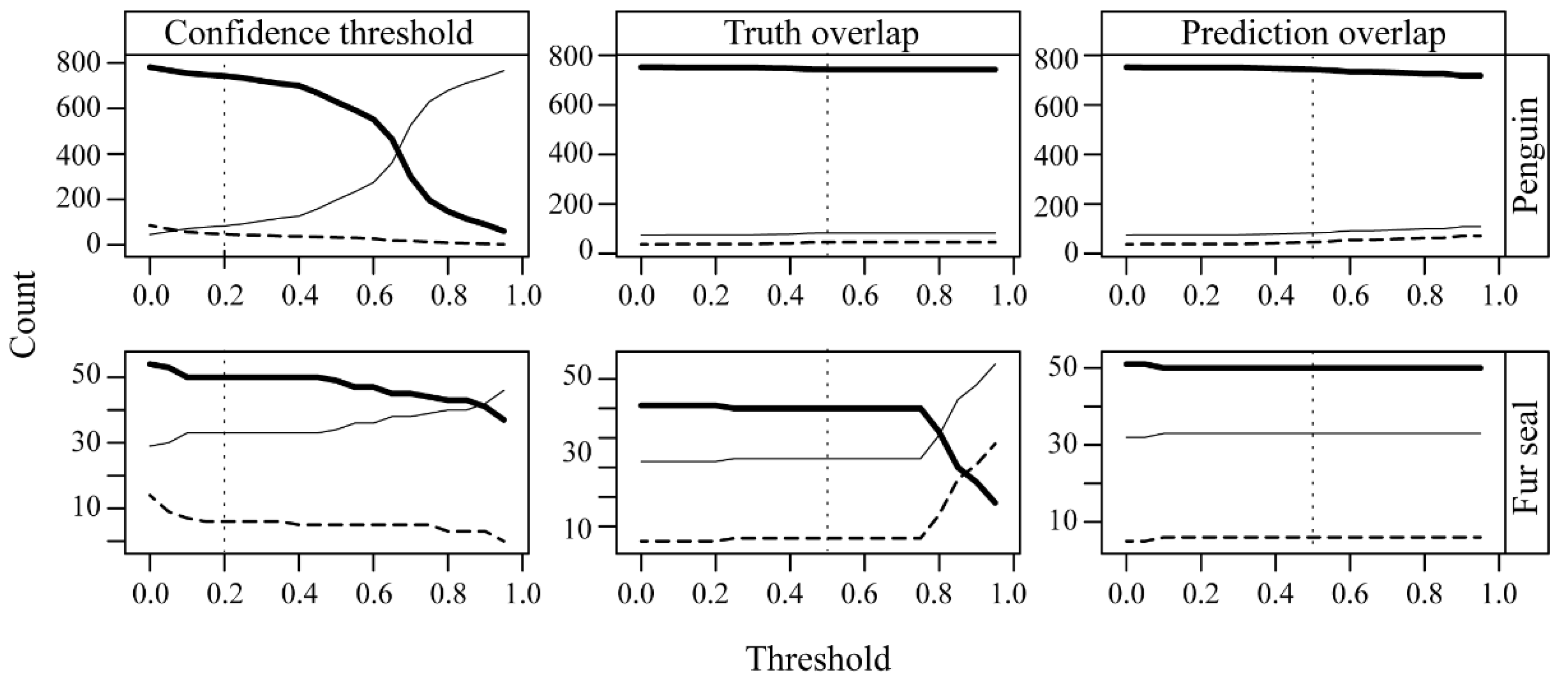
Appropriate thresholds for the confidence level, truth overlap level, and prediction overlap level for this data set required justification. We therefore conducted a sensitivity analysis to assess how the counts of FP, FN, and TP varied across the range of potential confidence threshold, truth overlap, and prediction overlap values to identify inputs for analysis.
4. Discussion
Despite small sample sizes for annotation and model training, we successfully trained automated image analysis algorithms to detect and classify penguin and pinniped targets from IR and RGB images. Although general detectors based on convolutional neural networks often require tens of thousands of annotations to train [
29], successful animal detection models have been developed from pre-trained CNN models using several hundreds of annotations [
11,
17,
18], consistent with our sample sizes. Nonetheless, due to the limited availability of training data from our UAS flights, we caution that the models remain inadequate for implementing colony-wide censuses. However, the models are adequate to evaluate the potential benefits of IR images relative to RGB images for automating detection of penguins and fur seals in aerial imagery collected by UAS. We concluded that the available IR and RGB images provided generally equivalent information for automating the detection of penguins and fur seals. We also determined that the annotation of non-target features provided no clear advantage for the detection and correct classification of target classes in the trained models.
We expected that an IR sensor would allow for improved model performance for detecting and classifying penguin and pinniped targets relative to models using a traditional RGB sensor. A prior demonstration with high-accuracy detections of pinnipeds based on IR sensors [
16] and the expectation of a relatively strong contrast of warm targets against a cold polar substrate [
22] support this expectation. However, the nature of the physical environment, the size of targets, and the capability of the sensor itself appear to have limited its utility in this study. For example, thermal sensors have shown promise for accurate target detections in applications where vegetation or darkness obscures animals [
30] or with relatively large targets [
16,
22]. However, in our study colonies, vegetation and daylight during the summer breeding season do not preclude visual detections. Moreover, the lower resolution of the IR sensor relative to the RGB sensor resulted in greater blurring and reduced our ability to differentiate species and life stages, particularly for small-bodied penguins that present an area ≈0.07 m
2 when prone. The combination of these limitations precluded the identification of a clear advantage of one sensor over the other for use in automating target detection in this study.
We note that the major constraint on model training in this study was the poor image quality from the IR sensor that severely limited sample sizes. The reasons for reduced image quality are unclear but may have resulted from unanticipated interactions between the APH-28 platform, the IR sensor, and the cold and windy local environmental conditions that ultimately resulted in image blur. Though it is not our intent to review the performance of the IR sensor, we note that other IR sensors [
16] do not appear to have limited detectability of targets in other applications. Despite the fact that thermal cameras remain a viable and important option for further testing, traditional RGB sensors provide an effective option for future efforts to operationalize automated image analysis pipelines. Namely, the generally higher resolution to resolve small targets, wider commercial availability for proper mating with rapidly changing UAS platforms, and intuitiveness of traditional RGB sensors and their outputs are tangible advantages to consider.
The results from our experimental approach to compare models based on target-only annotations with models that included additional, non-target annotations suggested no strong difference in model performance. We expected that the addition of non-target annotations would constrain the detection of target classes and improve model performance. Counterintuitively, the addition of non-target classes in our annotations generally led to models with similar or reduced performance. This negative result suggests a potentially time-saving step for analyses, where the annotation of non-target classes may be avoided, provided target annotations are complete.
Finally, we note that verifying model predictions and assessing model performance represents a key step in developing automated workflows. Though manual verification of model predictions is possible, it can be cumbersome, time consuming, and difficult (if not impossible) to consistently apply the same set of conditions for analysis, especially across different observers. We developed an R package, vvipr (v0.3.2;
https://github.com/us-amlr/vvipr; accessed on 14 September 2022) to increase the transparency and repeatability of the model verification process for VIAME model outputs, while providing flexibility to adjust model performance thresholds as required by different projects. For non-R users, vvipr also includes a stand-alone shiny [
25] web application that enables the rapid estimation of model performance and visualization of how each model prediction is evaluated. Standardizing the process for model assessment is especially useful for evaluating multiple competing models to identify candidates for further development or deployment and for assessing appropriate thresholds for identifying true and false positives among the set of predictions. We contend that the iterative process to correctly assign a status of false positive, false negative, or true positive to model predictions vastly benefits from a standard, repeatable process to ensure performance metrics are computed across models consistently.
5. Conclusions
We aimed to compare the efficacy of IR and RGB sensors for use in developing automated classification methods. Our experimental approach helped directly assess the relative strengths of IR versus RGB images for the automation of species detection and classification from aerial drone surveys. In general, the relatively high performance of the penguin models provides encouraging results for implementing machine learning techniques to improve data acquisition from drone surveys of seabirds and pinnipeds in the near future. More specifically, we conclude that the IR images provided no clear advantages for target detection relative to the RGB images. Considering the need to distinguish species and life stages in aerial imagery for accurate population assessments, RGB images appear to offer a greater opportunity for further model development at this time.
Developing a robust automated classification model for deployment on novel images remains an important task. There are several important issues to address in relation to such a development. First, increasing sample sizes relative to those reported here will allow improved model training and validation on a broad suite of field conditions likely encountered during UAS surveys. Second, similar to the comparison of sensor types reported here, a comparison of machine learning approaches (e.g., YOLO [
13], Faster R-CNN [
31], Mask R-CNN [
32], and fuzzy decision trees [
33]) will be useful for identifying tradeoffs among alternative models. Fortunately, several object detector algorithms are implemented within VIAME to facilitate such exploration [
15]. Finally, we note that multi-spectral sensors are increasingly available for use in small UAS applications [
34]. Harnessing additional information from such sensors may improve the utility of imagery for automating classification beyond simple RGB or IR images alone.




 ,
, 

{kind=link}
{kind=link}
{kind=link}