Deep Learning-Based Damage Detection from Aerial SfM Point Clouds


Abstract
:1. Introduction and Related Work
2. Datasets
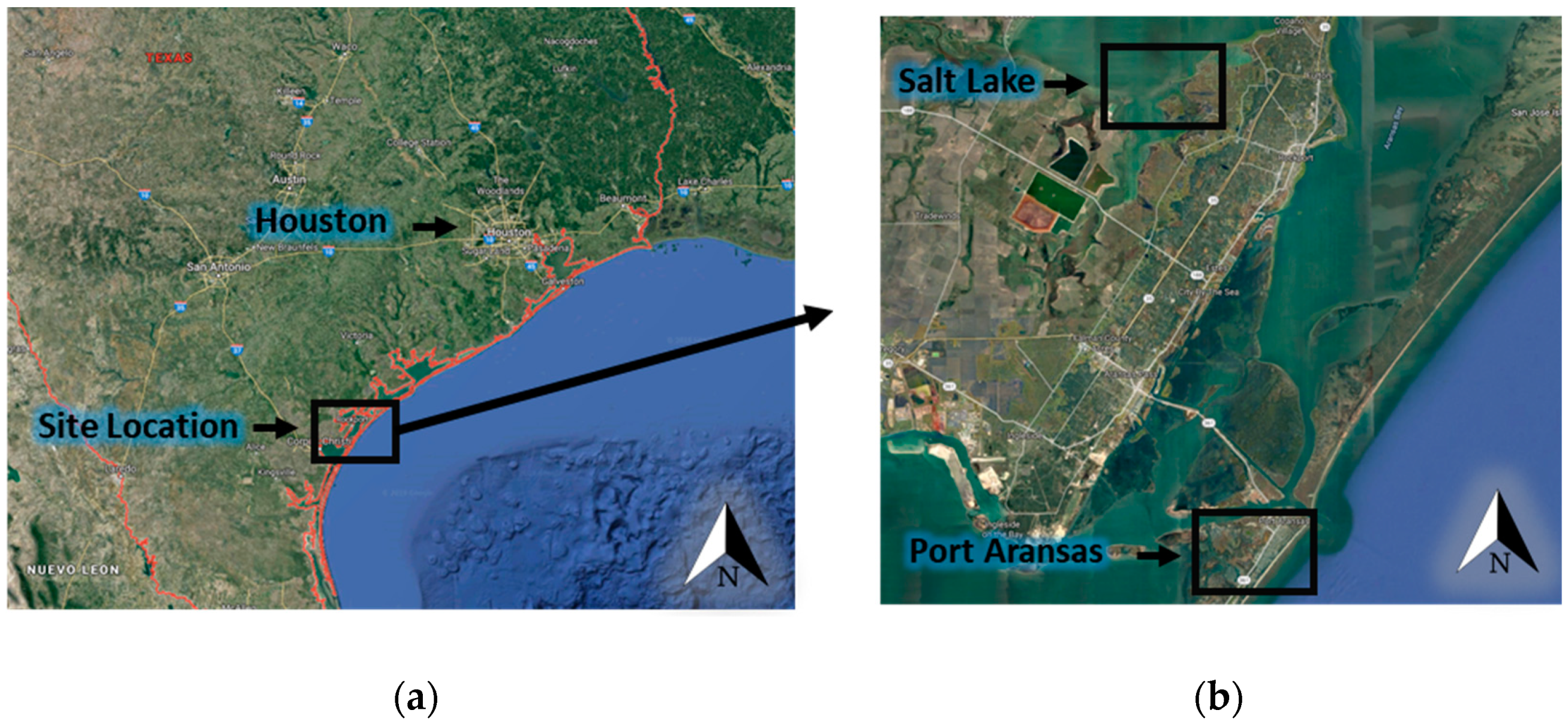
2.1. Introduction to Hurricane Harvey
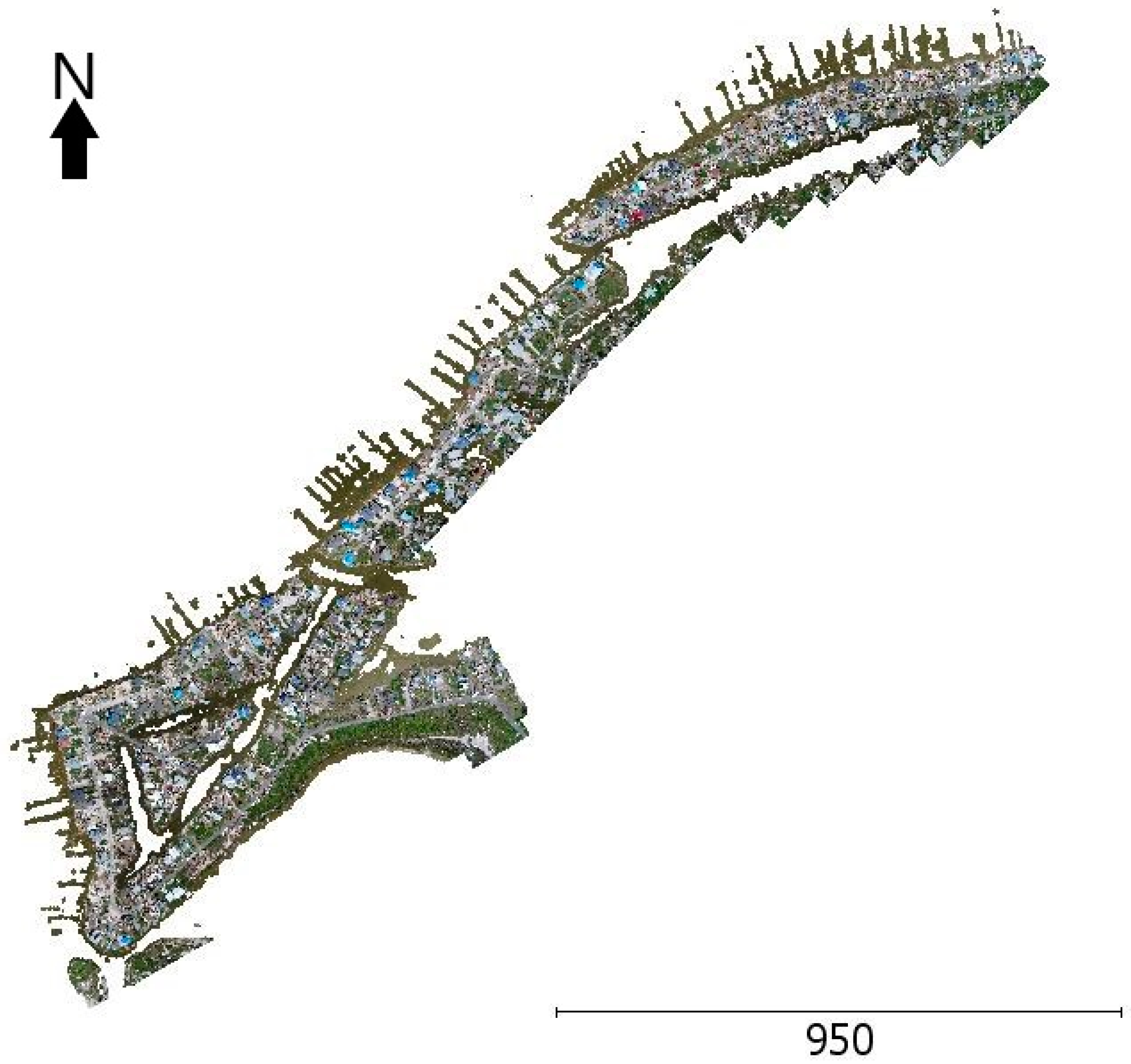
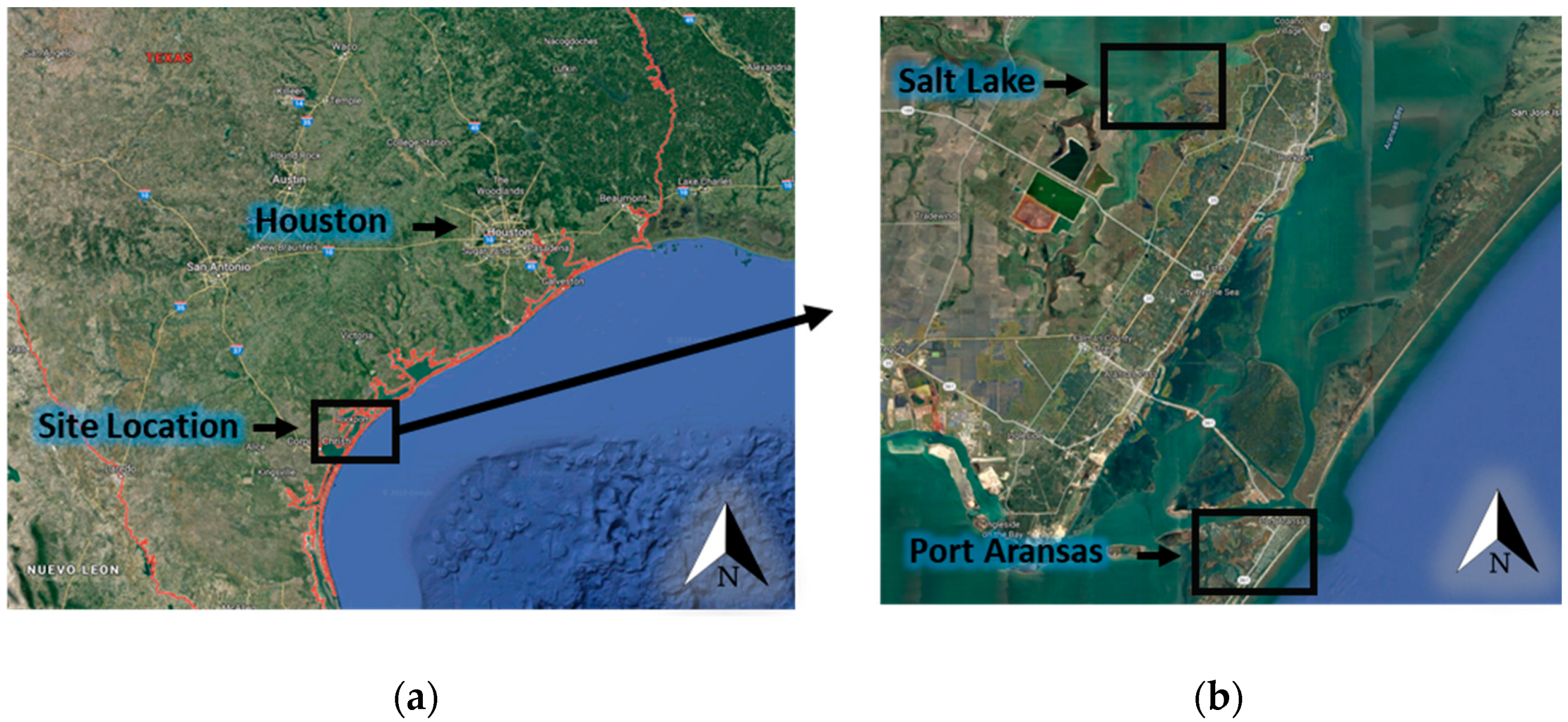
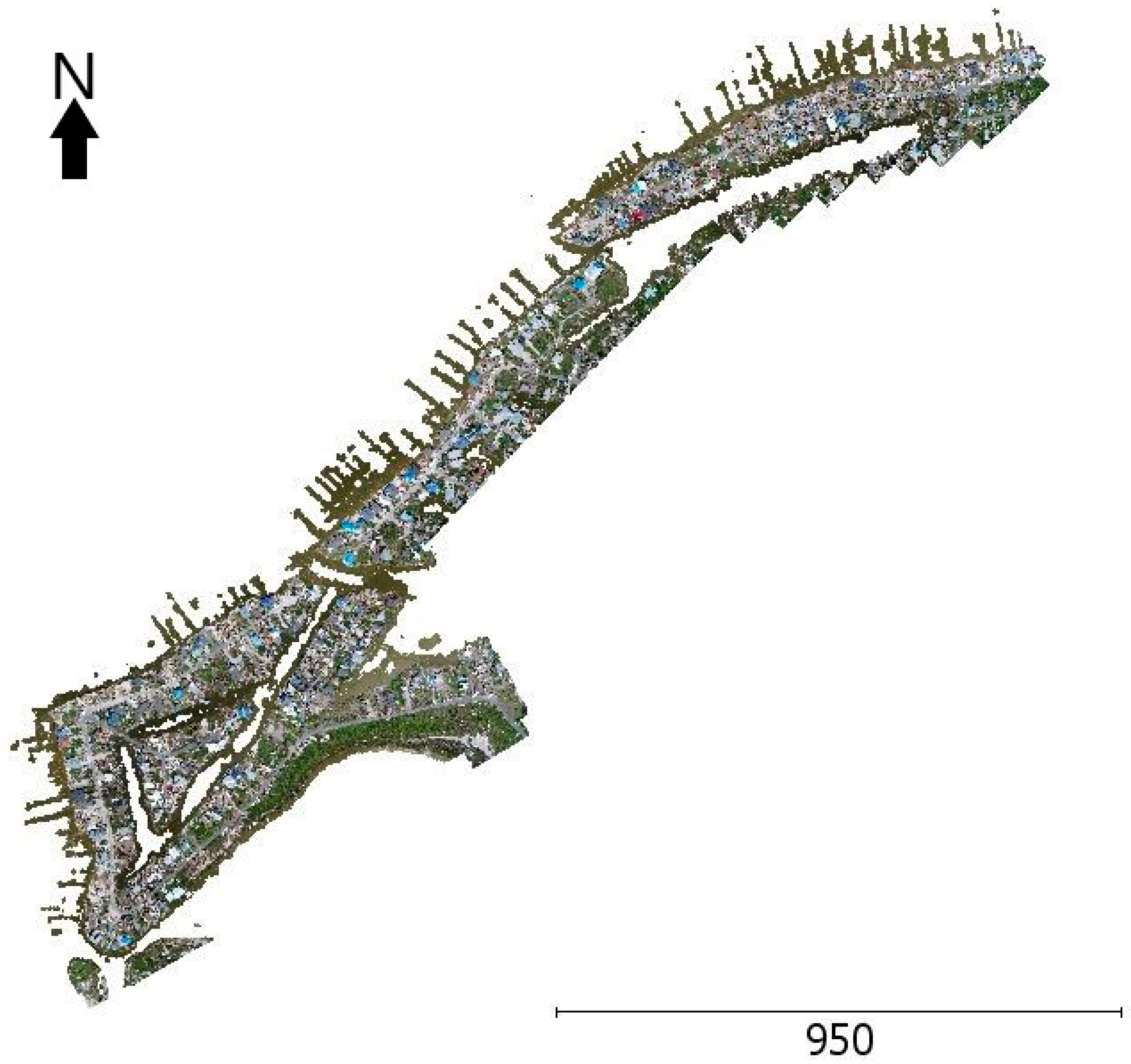
2.2. Data Collection Details
2.3. Dataset Classes
3. Methodology
3.1. Data Preparation and Occupancy Grid Model
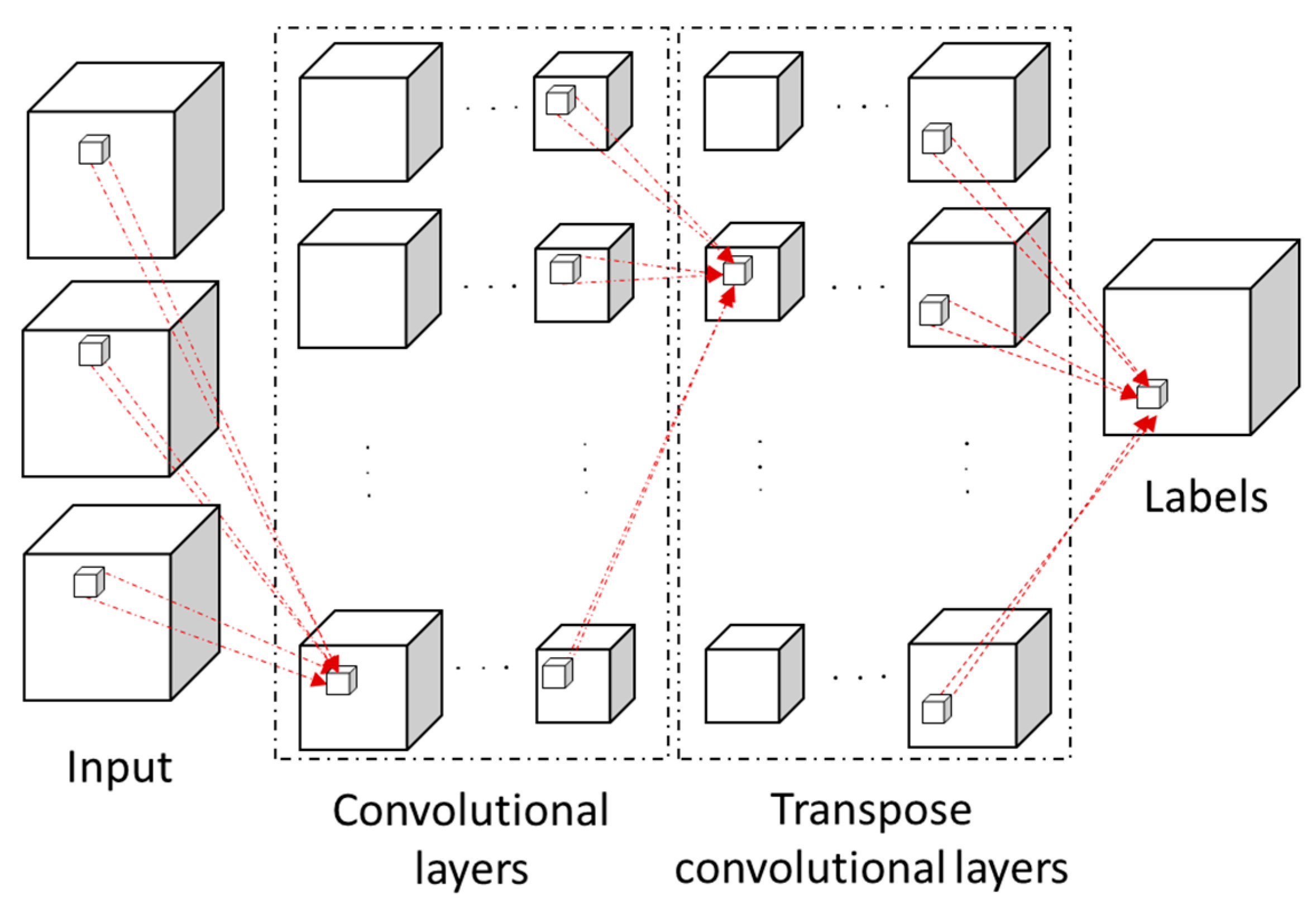
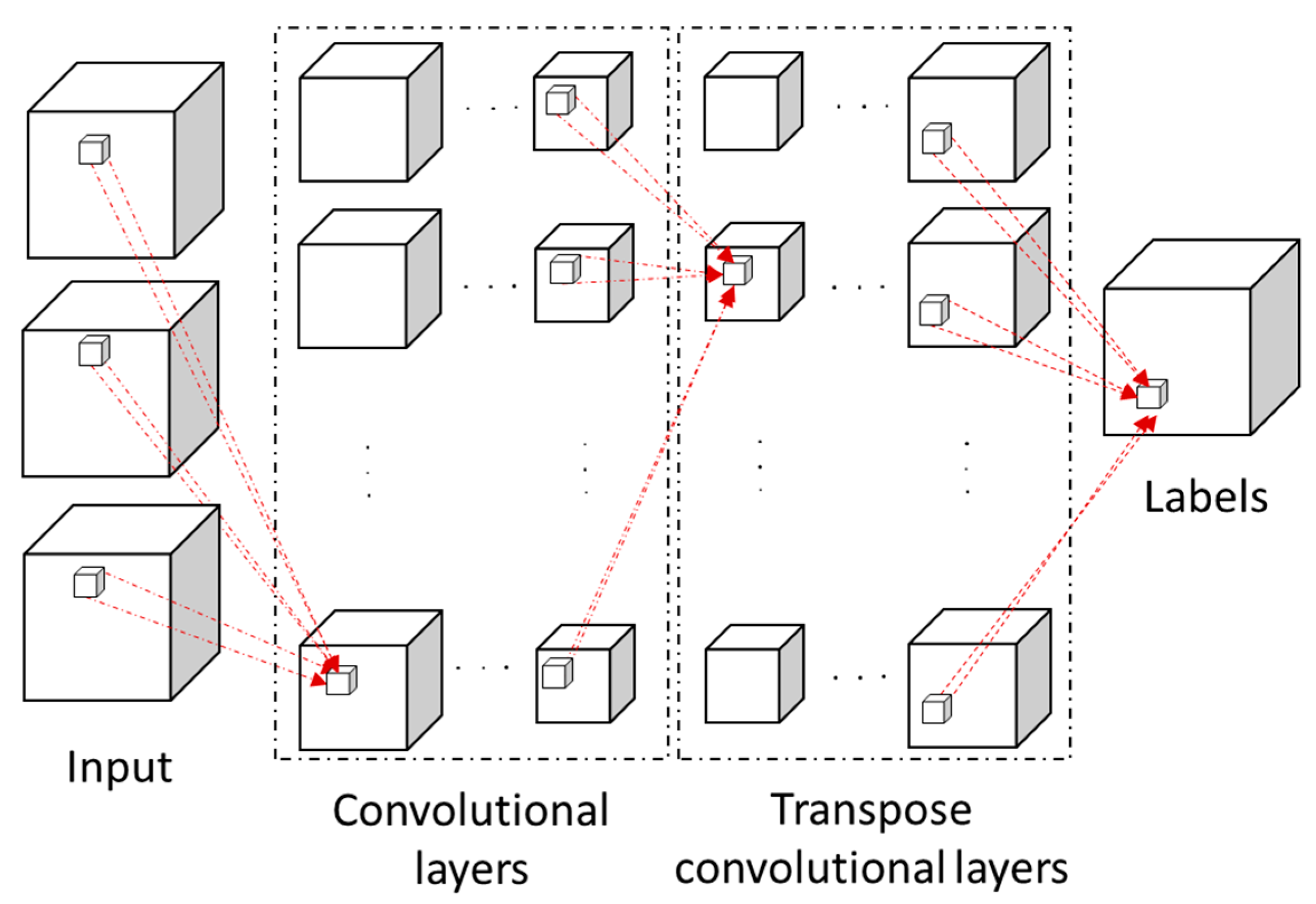
3.2. Three-Dimensional Fully Convolutional Network
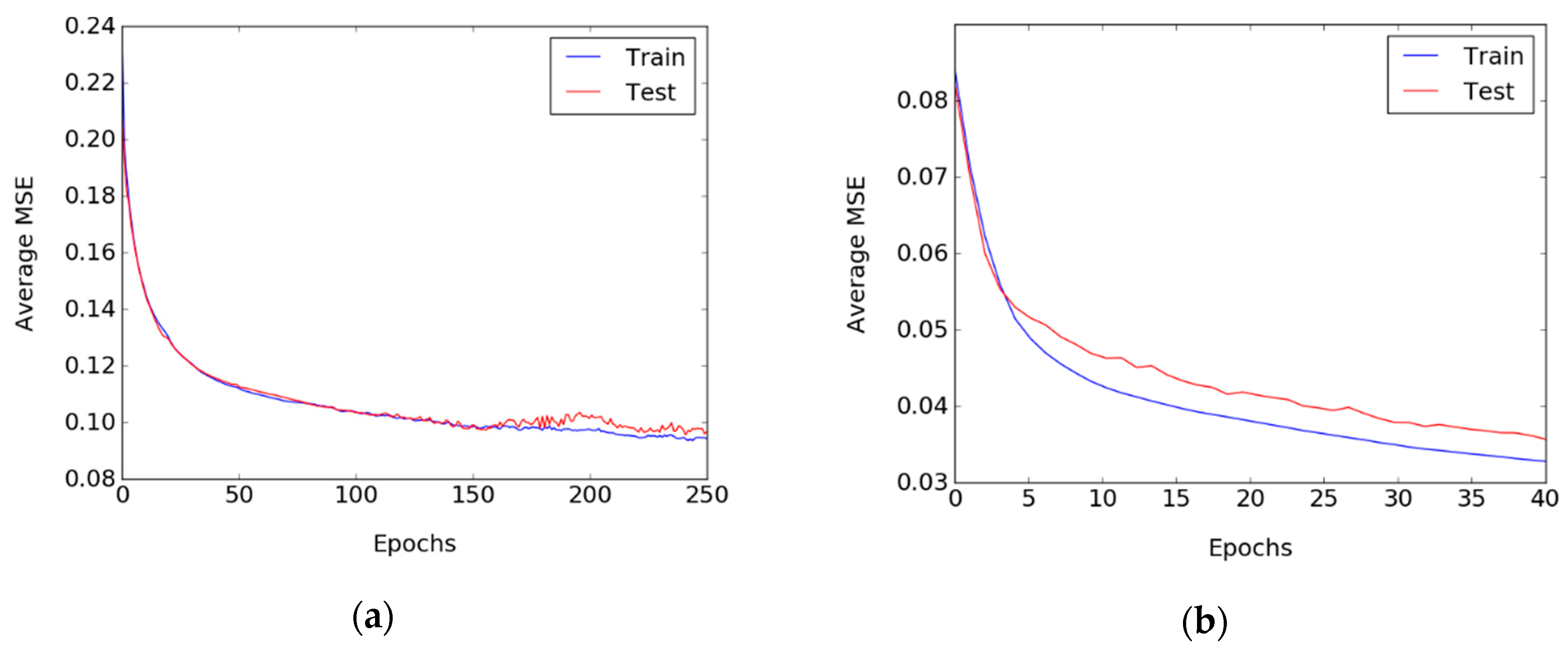
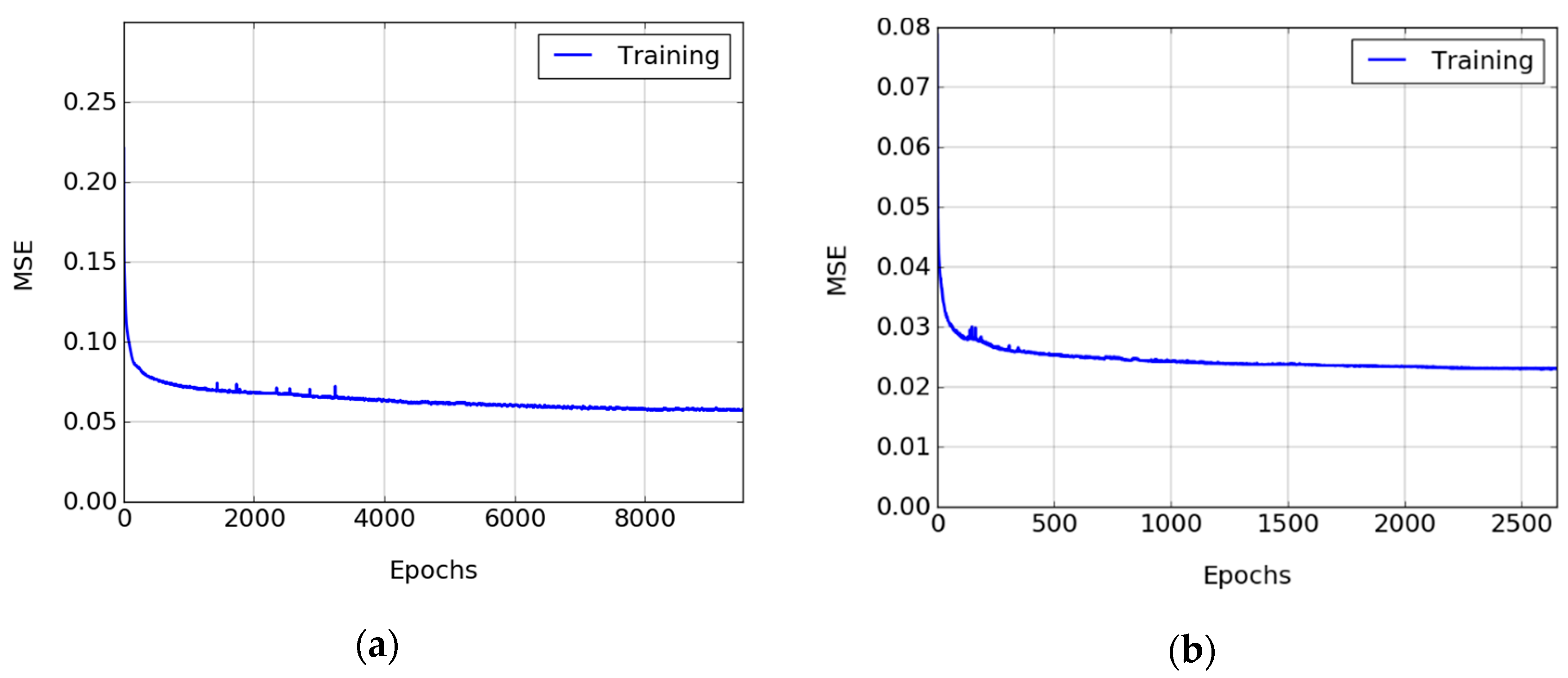
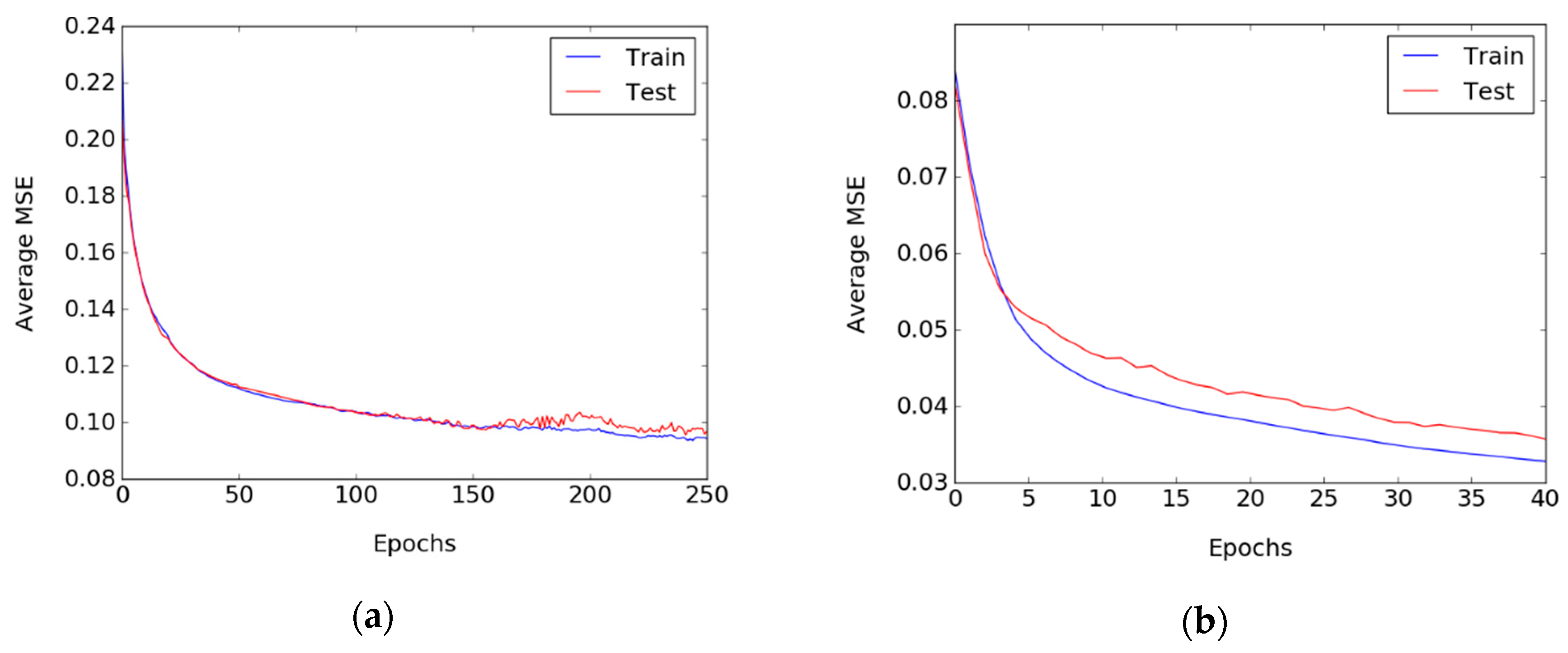
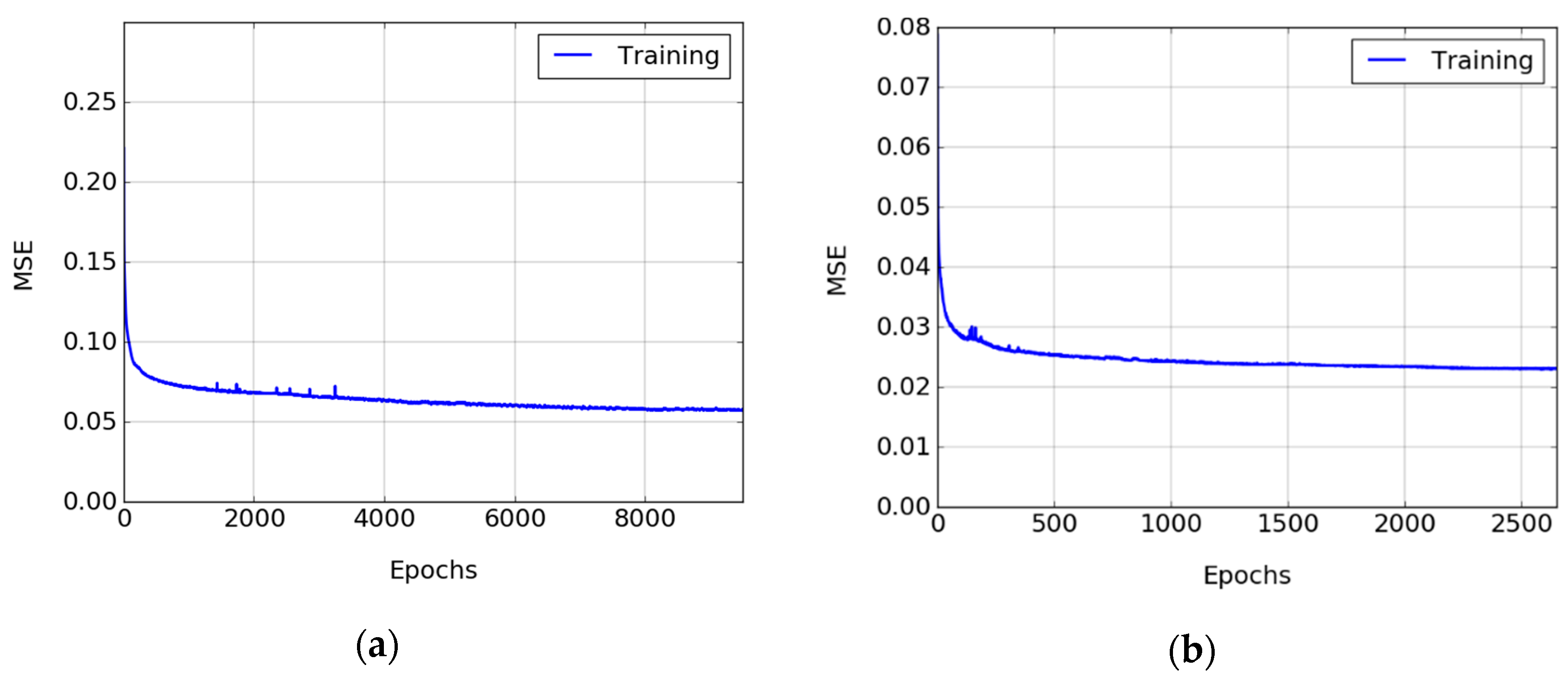
3.3. Training Process
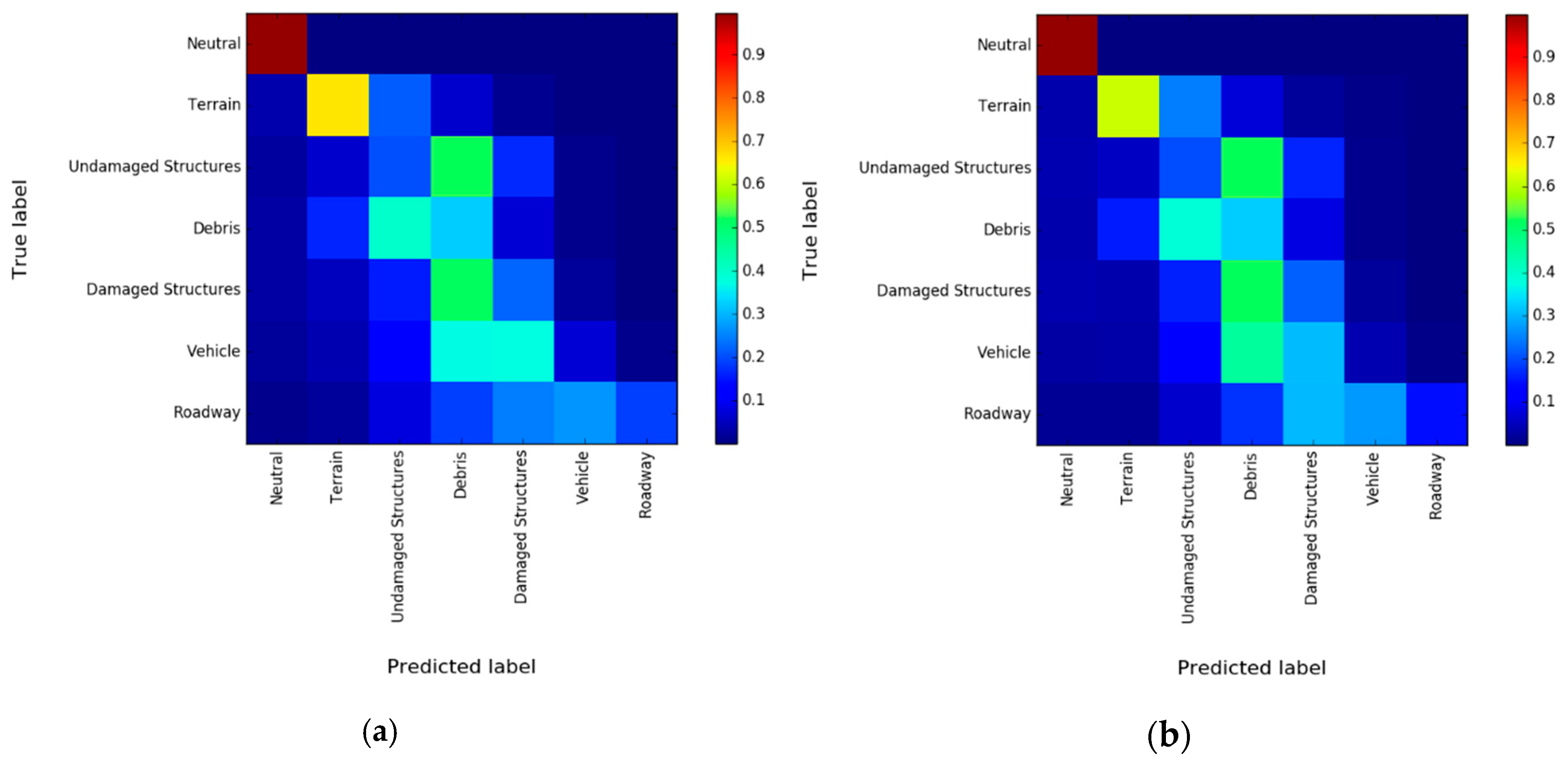
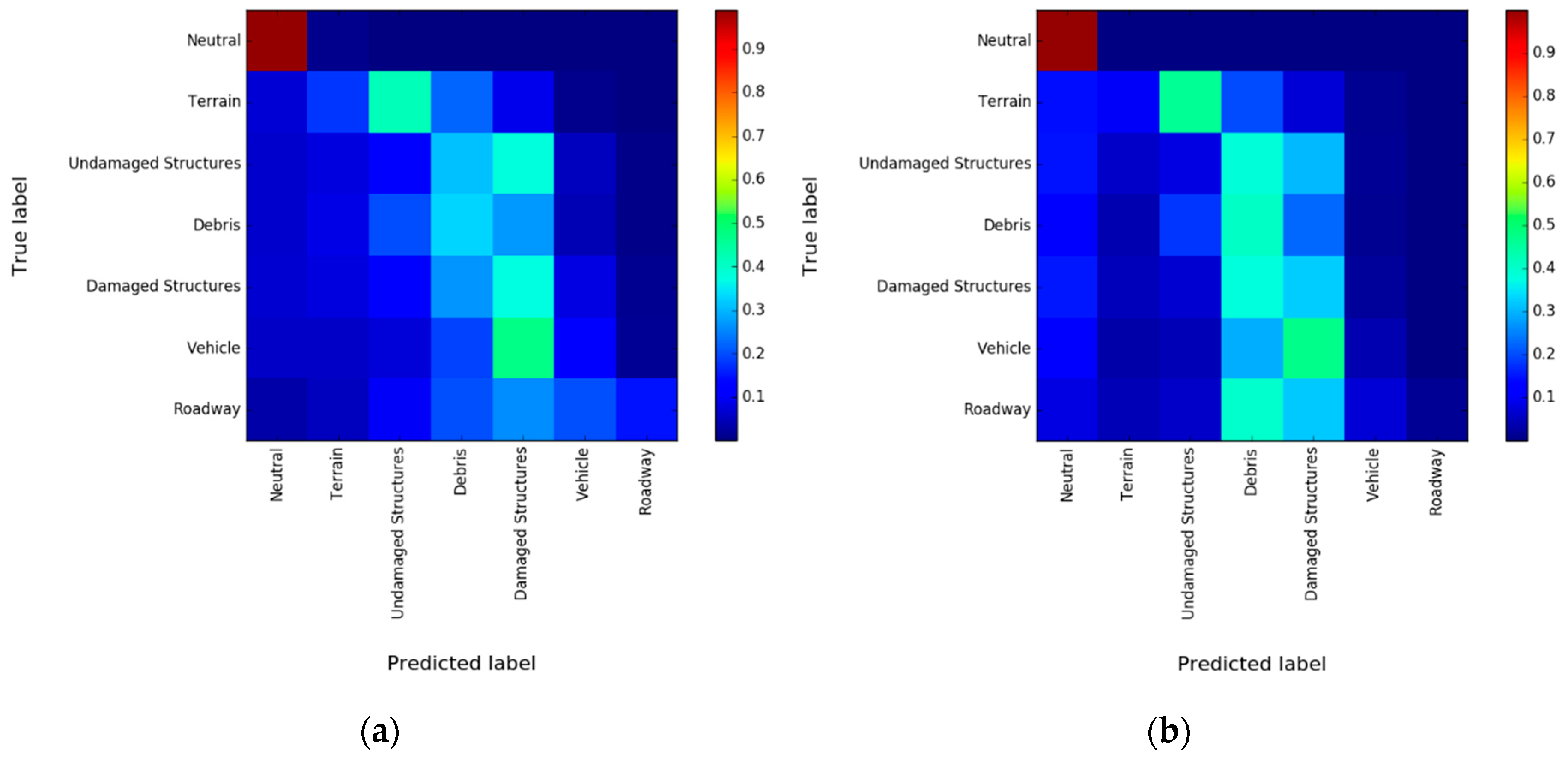
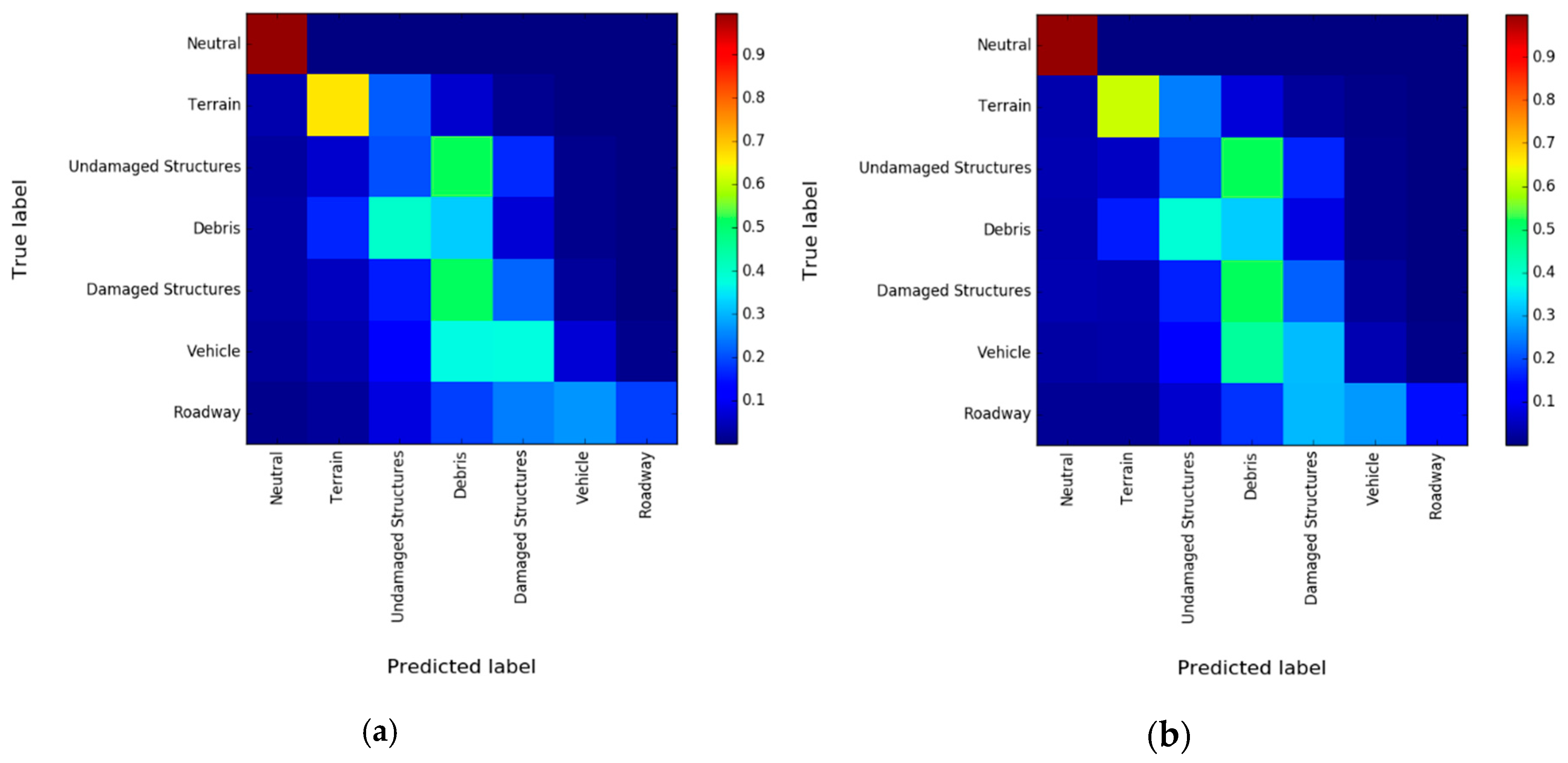
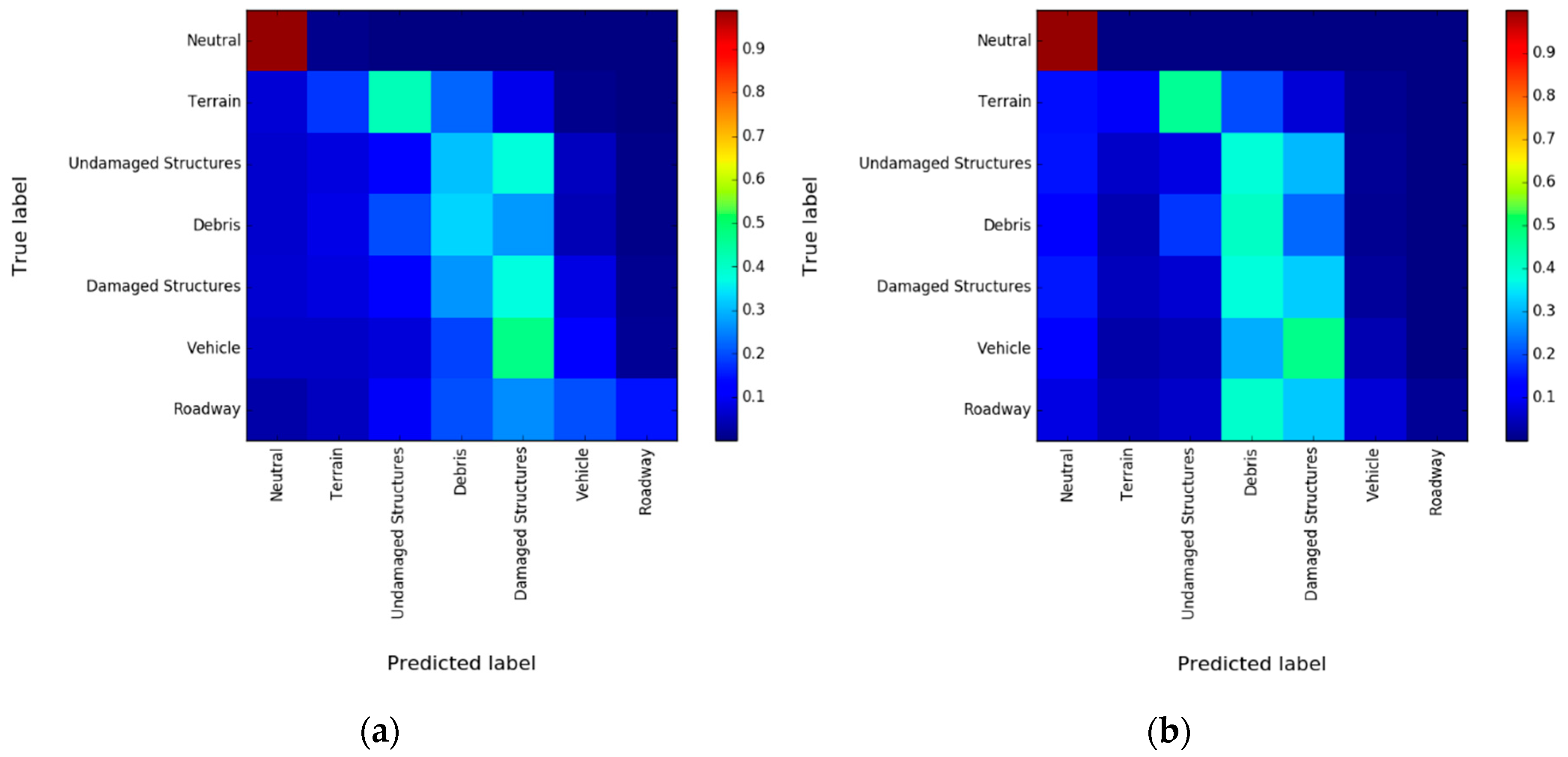
3.4. Experimental Results and Discussion
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Nozhati, S.; Ellingwood, B.R.; Mahmoud, H. Understanding community resilience from a PRA perspective using binary decision diagrams. Risk Anal. 2019. [Google Scholar] [CrossRef]
- Brunner, D.; Lemoine, G.; Bruzzone, L. Earthquake damage assessment of buildings using VHR optical and SAR imagery. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2403–2420. [Google Scholar] [CrossRef]
- Li, L.; Li, Z.; Zhang, R.; Ma, J.; Lei, L. Collapsed buildings extraction using morphological profiles and texture statistics—A case study in the 5.12 Wenchuan earthquake. In Proceedings of the 2010 IEEE International Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 25–30 July 2010; pp. 2000–2002. [Google Scholar]
- LeCun, Y. Generalization and network design strategies. In Connectionism in Perspective; Elsevier: Amsterdam, The Netherlands, 1989; Volume 19. [Google Scholar]
- Ji, M.; Liu, L.; Buchroithner, M. Identifying Collapsed Buildings Using Post-Earthquake Satellite Imagery and Convolutional Neural Networks: A Case Study of the 2010 Haiti Earthquake. Remote Sens. 2018, 10, 1689. [Google Scholar] [CrossRef]
- Li, Y.; Hu, W.; Dong, H.; Zhang, X. Building Damage Detection from Post-Event Aerial Imagery Using Single Shot Multibox Detector. Appl. Sci. 2019, 9, 1128. [Google Scholar] [CrossRef]
- Hansen, J.; Jonas, D. Airborne Laser Scanning or Aerial Photogrammetry for the Mine Surveyor; AAM Survey Inc.: Sydney, Australia, 1999. [Google Scholar]
- Javadnejad, F.; Simpson, C.H.; Gillins, D.T.; Claxton, T.; Olsen, M.J. An assessment of UAS-based photogrammetry for civil integrated management (CIM) modeling of pipes. In Pipelines 2017; ASCE: Reston, VA, USA, 2017; pp. 112–123. [Google Scholar]
- Wood, R.L.; Gillins, D.T.; Mohammadi, M.E.; Javadnejad, F.; Tahami, H.; Gillins, M.N.; Liao, Y. 2015 Gorkha post-earthquake reconnaissance of a historic village with micro unmanned aerial systems. In Proceedings of the 16th World Conference on Earthquake (16WCEE), Santiago, Chile, 9–13 January 2017. [Google Scholar]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Science & Business Media: Berlin, Germany, 2010. [Google Scholar]
- Crandall, D.; Owens, A.; Snavely, N.; Huttenlocher, D. Discrete-continuous optimization for large-scale structure from motion. In CVPR 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 3001–3008. [Google Scholar] [Green Version]
- Liebowitz, D.; Criminisi, A.; Zisserman, A. Creating architectural models from images. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 1999; pp. 39–50. [Google Scholar]
- Wood, R.; Mohammadi, M. LiDAR scanning with supplementary UAV captured images for structural inspections. In Proceedings of the International LiDAR Mapping Forum, Denver, CO, USA, 23–25 February 2015. [Google Scholar]
- Lattanzi, D.; Miller, G. Review of robotic infrastructure inspection systems. J. Infrastruct. Syst. 2017, 23, 04017004. [Google Scholar] [CrossRef]
- Atkins, N.T.; Butler, K.M.; Flynn, K.R.; Wakimoto, R.M. An integrated damage, visual, and radar analysis of the 2013 Moore, Oklahoma, EF5 tornado. Bull. Am. Meteorol. Soc. 2014, 95, 1549–1561. [Google Scholar] [CrossRef]
- Burgess, D.; Ortega, K.; Stumpf, G.; Garfield, G.; Karstens, C.; Meyer, T.; Smith, B.; Speheger, D.; Ladue, J.; Smith, R. 20 May 2013 Moore, Oklahoma, tornado: Damage survey and analysis. Weather Forecast. 2014, 29, 1229–1237. [Google Scholar] [CrossRef]
- Womble, J.A.; Wood, R.L.; Mohammadi, M.E. Multi-Scale Remote Sensing of Tornado Effects. Front. Built Environ. 2018, 4, 66. [Google Scholar] [CrossRef]
- Rollins, K.; Ledezma, C.; Montalva, G.A. Geotechnical aspects of April 1, 2014, M 8.2 Iquique, Chile earthquake. In GEER Association Reports No. GEER-038; Geotechnical Extreme Event Reconnaissance: Berkeley, CA, USA, 2014. [Google Scholar]
- Vu, T.T.; Ban, Y. Context-based mapping of damaged buildings from high-resolution optical satellite images. Int. J. Remote Sens. 2010, 31, 3411–3425. [Google Scholar] [CrossRef]
- Olsen, M.J. In situ change analysis and monitoring through terrestrial laser scanning. J. Comput. Civ. Eng. 2013, 29, 04014040. [Google Scholar] [CrossRef]
- Rehor, M.; Bähr, H.; Tarsha-Kurdi, F.; Landes, T.; Grussenmeyer, P. Contribution of two plane detection algorithms to recognition of intact and damaged buildings in lidar data. Photogramm. Rec. 2008, 23, 441–456. [Google Scholar] [CrossRef]
- Shen, Y.; Wang, Z.; Wu, L. Extraction of building’s geometric axis line from LiDAR data for disaster management. In Proceedings of the 2010 IEEE International Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 25–30 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1198–1201. [Google Scholar]
- Aixia, D.; Zongjin, M.; Shusong, H.; Xiaoqing, W. Building Damage Extraction from Post-earthquake Airborne LiDAR Data. Acta Geol. Sin. Engl. Ed. 2016, 90, 1481–1489. [Google Scholar] [CrossRef]
- He, M.; Zhu, Q.; Du, Z.; Hu, H.; Ding, Y.; Chen, M. A 3D shape descriptor based on contour clusters for damaged roof detection using airborne LiDAR point clouds. Remote Sens. 2016, 8, 189. [Google Scholar] [CrossRef]
- Axel, C.; van Aardt, J.A. Building damage assessment using airborne lidar. J. Appl. Remote Sens. 2017, 11, 046024. [Google Scholar] [CrossRef]
- Vetrivel, A.; Gerke, M.; Kerle, N.; Nex, F.; Vosselman, G. Disaster damage detection through synergistic use of deep learning and 3D point cloud features derived from very high resolution oblique aerial images, and multiple-kernel-learning. ISPRS J. Photogramm. Remote Sens. 2018, 140, 45–59. [Google Scholar] [CrossRef]
- Weinmann, M.; Urban, S.; Hinz, S.; Jutzi, B.; Mallet, C. Distinctive 2D and 3D features for automated large-scale scene analysis in urban areas. Comput. Graph. 2015, 49, 47–57. [Google Scholar] [CrossRef]
- Hackel, T.; Wegner, J.D.; Schindler, K. Fast semantic segmentation of 3d point clouds with strongly varying density. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef]
- Prokhorov, D. A convolutional learning system for object classification in 3-D LIDAR data. IEEE Trans. Neural Netw. 2010, 21, 858–863. [Google Scholar] [CrossRef]
- Weng, J.; Zhang, N. Optimal in-place learning and the lobe component analysis. In Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings, Vancouver, BC, Canada, 16–21 July 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 3887–3894. [Google Scholar]
- Maturana, D.; Scherer, S. 3d convolutional neural networks for landing zone detection from lidar. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 3471–3478. [Google Scholar]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3d. net: A new large-scale point cloud classification benchmark. arXiv 2017, arXiv:1704.03847. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lombardo, F.; Roueche, D.B.; Krupar, R.J.; Smith, D.J.; Soto, M.G. Observations of building performance under combined wind and surge loading from hurricane Harvey. In AGU Fall Meeting Abstracts; American Geophysical Union: Washington, DC, USA, 2017. [Google Scholar]
- Roueche, D.B.; Lombardo, F.T.; Smith, D.J.; Krupar, R.J., III. Fragility Assessment of Wind-Induced Residential Building Damage Caused by Hurricane Harvey, 2017. In Forensic Engineering 2018: Forging Forensic Frontiers; American Society of Civil Engineers: Reston, VA, USA, 2018; pp. 1039–1048. [Google Scholar]
- Wurman, J.; Kosiba, K. The role of small-scale vortices in enhancing surface winds and damage in Hurricane Harvey (2017). Mon. Weather Rev. 2018, 146, 713–722. [Google Scholar] [CrossRef]
- Blake, E.S.; Zelinsky, D.A. National Hurricane Center Tropical Cyclone Report: Hurricane Harvey (AL092017); National Hurricane Center: Silver Spring, MD, USA, 2018. [Google Scholar]
- NHC Costliest U.S. Tropical Cyclones Tables Updated; National Hurricane Center: Silver Spring, MD, USA, 2018. [Google Scholar]
- Kijewski-Correa, T.; Gong, J.; Womble, A.; Kennedy, A.; Cai, S.C.S.; Cleary, J.; Dao, T.; Leite, F.; Liang, D.; Peterman, K.; et al. Hurricane Harvey (Texas) Supplement—Collaborative Research: Geotechnical Extreme Events Reconnaissance (GEER) Association: Turning Disaster into Knowledge. Dataset 2018. [Google Scholar] [CrossRef]
- The American Society of Civil Engineers (ASCE). Minimum Design Loads and Associated Criteria for Buildings and Other Structures; ASCE: Reston, VA, USA, 2016. [Google Scholar]
- Womble, J.A.; Wood, R.L.; Eguchi, R.T.; Ghosh, S.; Mohammadi, M.E. Current methods and future advances for rapid, remote-sensing-based wind damage assessment. In Proceedings of the 5th International Natural Disaster Mitigation Specialty Conference, London, ON, Canada, 1–4 June 2016. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Cogn. Model. 1988, 5, 1. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Mei, S.; Yuan, X.; Ji, J.; Zhang, Y.; Wan, S.; Du, Q. Hyperspectral image spatial super-resolution via 3D full convolutional neural network. Remote Sens. 2017, 9, 1139. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Toronto, ON, Canada, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]
- Sedaghat, N.; Zolfaghari, M.; Amiri, E.; Brox, T. Orientation-boosted voxel nets for 3d object recognition. arXiv 2016, arXiv:1604.03351. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instance | # of Instances | Percentage of Total (%) |
|---|---|---|
| Damaged structures | 242 | 13.4 |
| Debris | 386 | 21.3 |
| Roadway | 57 | 3.2 |
| Terrain | 719 | 39.8 |
| Undamaged structures | 148 | 8.2 |
| Vehicle | 256 | 14.2 |
| Total | 1808 | 100 |
| Instance | # of Instances | Percentage of Total (%) |
|---|---|---|
| Damaged structures | 162 | 10.0 |
| Debris | 255 | 15.7 |
| Roadway | 87 | 5.3 |
| Terrain | 665 | 40.9 |
| Undamaged structures | 235 | 14.4 |
| Vehicle | 223 | 13.7 |
| Total | 1627 | 100 |
| Instance | Model-100 (%) | Model-64 (%) | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | IOU | Precision | Recall | IOU | |
| Neutral | 100 | 100 | 100 | 100 | 100 | 99 |
| Terrain | 81 | 61 | 54 | 73 | 66 | 54 |
| Undamaged structures | 5 | 21 | 4 | 5 | 20 | 4 |
| Debris | 25 | 33 | 17 | 26 | 33 | 17 |
| Damaged structures | 28 | 22 | 14 | 31 | 22 | 15 |
| Vehicle | 4 | 4 | 2 | 7 | 7 | 4 |
| Roadway | 91 | 14 | 14 | 92 | 19 | 18 |
| Instance | Model-100 (%) | Model-64 (%) | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | IOU | Precision | Recall | IOU | |
| Neutral | 100 | 100 | 100 | 100 | 99 | 99 |
| Terrain | 32 | 10 | 8 | 32 | 18 | 13 |
| Undamaged structures | 4 | 8 | 3 | 2 | 11 | 2 |
| Debris | 4 | 41 | 4 | 3 | 33 | 3 |
| Damaged structures | 15 | 32 | 12 | 16 | 37 | 13 |
| Vehicle | 2 | 4 | 1 | 2 | 12 | 2 |
| Roadway | 83 | 2 | 2 | 89 | 15 | 14 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammadi, M.E.; Watson, D.P.; Wood, R.L. Deep Learning-Based Damage Detection from Aerial SfM Point Clouds. Drones 2019, 3, 68. https://doi.org/10.3390/drones3030068
Mohammadi ME, Watson DP, Wood RL. Deep Learning-Based Damage Detection from Aerial SfM Point Clouds. Drones. 2019; 3(3):68. https://doi.org/10.3390/drones3030068
Chicago/Turabian StyleMohammadi, Mohammad Ebrahim, Daniel P. Watson, and Richard L. Wood. 2019. "Deep Learning-Based Damage Detection from Aerial SfM Point Clouds" Drones 3, no. 3: 68. https://doi.org/10.3390/drones3030068
APA StyleMohammadi, M. E., Watson, D. P., & Wood, R. L. (2019). Deep Learning-Based Damage Detection from Aerial SfM Point Clouds. Drones, 3(3), 68. https://doi.org/10.3390/drones3030068