1. Introduction
Real-world systems are often modelled using integral/differential equations, which are then numerically solved to predict the system behaviour and evolution. This process can be time-consuming, as numerical simulations sometimes take months, and finding the
correct model parameters is often challenging. However, with significant advancements in Neural Networks (NNs) that can learn patterns, real-world systems are increasingly being modelled using a combination of integral/differential models and NNs or even NNs alone [
1,
2,
3,
4].
Neural Ordinary Differential Equations (Neural ODEs) were introduced in 2018 [
5] (see also [
6,
7]) as a continuous version of the discrete Residual Neural Networks and claimed to offer a continuous modelling solution for real-world systems that incorporate time-dependence, mimicking the dynamics of a system using only discrete data. Once trained, the Neural ODEs result in a
hybrid ODE (part analytical, part NN-based) that can be used for making predictions by numerically solving the resulting ODEs. The numerical solution of these
hybrid ODEs is significantly simpler and less time-consuming compared to the numerical solution of complex governing equations, making Neural ODEs an excellent choice for modelling time-dependent, real-world systems [
8,
9,
10]. However, the simplicity of ODEs sometimes limits their effectiveness in capturing complex behaviours characterised by intricate dynamics, non-linear interactions, and memory. To address this, Neural Fractional Differential Equations (Neural FDEs) were recently proposed [
11,
12].
Neural FDEs, as described by Equation (
1), are an NN architecture designed to fit the solution
to given data
(for example, experimental data) over a specified time range
. The Neural FDE combines an analytical part,
, with an NN-based part,
, leading to the initial value problem
Here,
denotes the Caputo fractional derivative [
13,
14], defined for
(and considering a generic scalar function
) as
where
is the Gamma function.
In this study, we focus on the Caputo fractional derivative, although several other definitions of fractional derivative exist in the literature, such as the Riemann–Liouville definition,
Unlike the Riemann–Liouville derivative, solving differential equations with the Caputo definition does not require specifying fractional order initial conditions. Moreover, if
is constant, its Caputo derivative is zero, while the Riemann–Liouville fractional derivative is not. These two definitions are closely related, and under certain continuity conditions on
, it can be shown (see [
15], Lemma 2.12) that
Therefore, if
, the two definitions are equivalent.
An important feature of Neural FDEs is their ability to learn not only the optimal parameters of the NN but also the order of the derivative (when , we obtain a Neural ODE). This is achieved using only information from the time-series dataset , where each , is associated with a time instant .
In [
12], the
value is learnt from another NN
with parameters
. Therefore, if
represents the loss function, we can train the Neural FDE by solving the minimisation problem (5). The parameters
and
are optimised by minimising the error between the predicted
and ground-truth
values (in this work, we consider that the solution outputted by the solver is the predicted output, although this might not always be the case (e.g., image classification)):
The popular Mean Squared Error (MSE) loss function was considered in [
12] and also in this work. Here,
refers to any numerical solver used to obtain the numerical solution
for each instant
.
Since Neural FDEs are a recent research topic, there are no studies on the uniqueness of the parameter
and its interaction with the NN
. In [
12], the authors provided the values of
learnt by Neural FDEs for each dataset; however, a closer examination reveals that these values differ significantly from the ground-truth values, which were derived from synthetic datasets. The authors attributed this discrepancy to the approximation capabilities of NNs, meaning that, during training,
adapts to any given
(this is a complex interaction since, in [
12],
is also learnt by another NN). Additionally,
must be initialised in the optimisation procedure, and yet, no studies have investigated how the initialisation of
affects the learned optimal
and the overall performance of Neural FDEs.
In this work, we address these key open questions about the order of the fractional derivative in Neural FDEs. We show that Neural FDEs are capable of modelling data dynamics effectively, even when the learnt value of deviates significantly from the true value. Furthermore, we perform a numerical analysis to investigate how the initialisation of affects the performance of Neural FDEs.
This paper is organised as follows: In
Section 2, we provide a brief overview of FDEs and Neural FDEs, highlighting the theoretical results regarding the existence and uniqueness of solutions. We also discuss how the solution depends on the given data.
Section 3 presents a series of numerical experiments on the non-uniqueness of the learnt
values. The paper ends with the discussion and conclusions in
Section 4.
2. Neural Networks and Theory of Fractional Initial Value Problems
As shown in the introduction, a Neural FDE is composed of two NNs:
An NN with parameters
, denoted as
, that models the right-hand side of an FDE,
where
is the state of the system at time step
t;
An NN with parameters
(or a learnable parameter), referred to as
, that models
,
As shown in
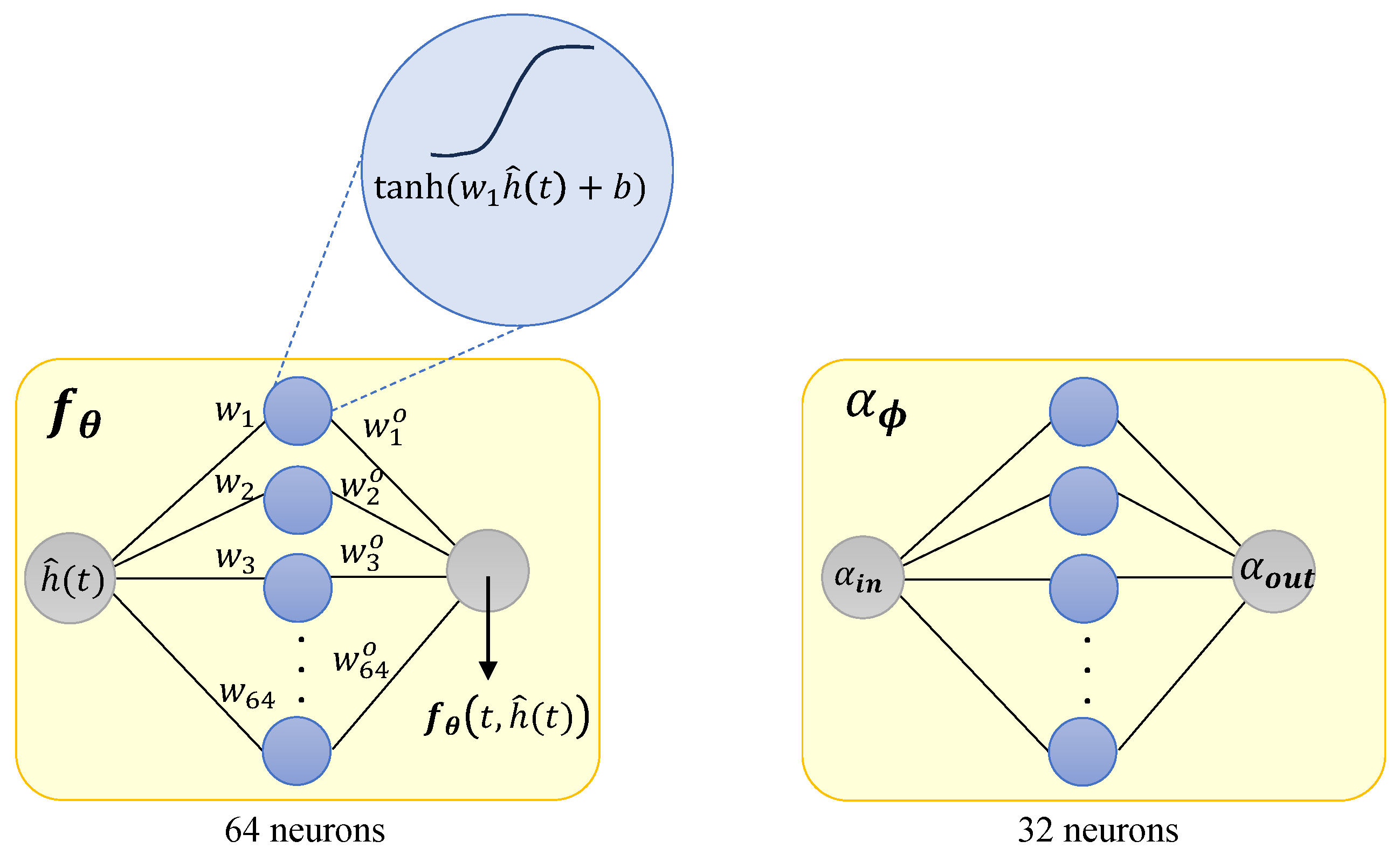
Figure 1 in this work, we constructed
with 3 layers: an input layer with 1 neuron and a hyperbolic tangent (tanh) activation function; a hidden layer with 64 neurons and tanh; and an output layer with 1 neuron. For learning
, we considered an NN
with 3 layers: an input layer with 1 neuron and a hyperbolic tangent (tanh) activation function; a hidden layer with 32 neurons and tanh; an output layer with 1 neuron and a sigmoid activation function (that helps keep the value of
within the interval
). For ease of understanding, we consider
to be a scalar in
Figure 2 and in Equations (8) and (9). We use
instead of
because it is assumed that
is being evaluated during the training of the Neural FDE, where a numerical solution is needed (
is a numerical approximation of
[
12]). After training, we obtain the final/optimal Neural FDE model and use again the notation
.
In the NN
(
Figure 1), the values
and
for
are the weights of the hidden and output layers, respectively, and
b is the bias,
, where 64 is an arbitrary number. The output of the NN
can be written as
An important feature is that there is no activation function in the output layer of , allowing the NN to approximate any function . If we opt to use, for example, a tanh in the output layer, it would constrain the fractional derivative to vary only from −1 to 1, thus limiting the fitting capabilities of the Neural FDE. This limitation can be mitigated by normalising the given data .
Remark 1. In Figure 1 and Equation (8), we observe h as a function of t. However, the NN depicted on the left side of Figure 1 does not use t as an input. Instead, the NN is called at each iteration of the numerical solver that addresses a discretised version of Equation (1). This solver defines all time instants through a mesh over the interval [12], and consequently, each evaluation of is always associated with a specific time instant. Since, for a differentiable function
with continuous derivative on
, we have that (using the mean value Theorem),
and
(
), we can say that tanh is 1-Lipschitz, that is,
Define
as
which is a weighted sum of 64 tanh functions. Then,
is
L-Lipschitz, with
(
). This property is important to guarantee the uniqueness of the solution of (
1).
2.1. Fractional Differential Equations
We now provide some theoretical results that are fundamental in understanding the expected behaviour of the Neural FDE model. Consider the following fractional initial value problem:
For ease of understanding, we restrict the analyses to the case where
is a scalar function and
.
2.1.1. Existence and Uniqueness
The following Theorem [
14,
15] provides information on the existence of a continuous solution to problem (10):
Theorem 1. Let , , , and . Define , and let the function be continuous. Furthermore, we define and Then, there exists a function solving the initial value problem (10). Note that this continuous solution may be defined in a smaller interval
compared to the interval
, where the function
is defined (
). From Theorem 1, we can infer that high values of
(see Equation (
1)) decrease the interval within which we can guarantee a continuous solution. However, these conclusions should be approached with caution. As shown later, we only access discrete values of the function
in the numerical solution of (1). Note that
also affects the size of the interval. Its contribution can be either positive or negative, depending on the values of
Q and
M.
The following Theorem establishes the conditions for which we can guarantee the uniqueness of the solution
[
14,
15]:
Theorem 2. Let , , and . Define the set , and let the function be continuous and satisfy a Lipschitz condition with respect to the second variable: where is a constant independent of t, , and . Then, there exists a uniquely defined function solving the initial value problem (10). As shown above, the function on the right-hand side of the Neural FDE model is Lipschitz (see Equation (9)). Therefore, we can conclude that the solution to Equation (1) is unique.
2.1.2. Analysing the Behaviour of Solutions with Perturbed Data
Other results of interest for Neural FDEs pertain to the dependencies of the solution on
and
. In Neural FDEs, both
and
are substituted by NNs that vary with each iteration of the Neural FDE training [
12].
Let
be the solution of the initial value problem
where
is a perturbed version of
f, which satisfies the same hypotheses as
Theorem 3. Let If ε is sufficiently small, there exists some such that both functions z (Equation (10)) and u (Equation (11)) are defined on , and we have where is the solution of (10). This Theorem provides insight into how the solution of (1) changes in response to variations in the NN . While the variations in both the solution and the function are of the same order for small changes of the function, it is crucial to carefully interpret these results given the NN as defined by Equation (9).
When training the Neural ODE, one must solve the optimisation problem (5), where the weights and biases are adjusted until an optimal Neural FDE model is obtained (training 1). If a second, independent training (training 2) of the Neural FDE is conducted with the same stopping criterion for the optimisation process, a new Neural FDE model with different weights and biases may be obtained.
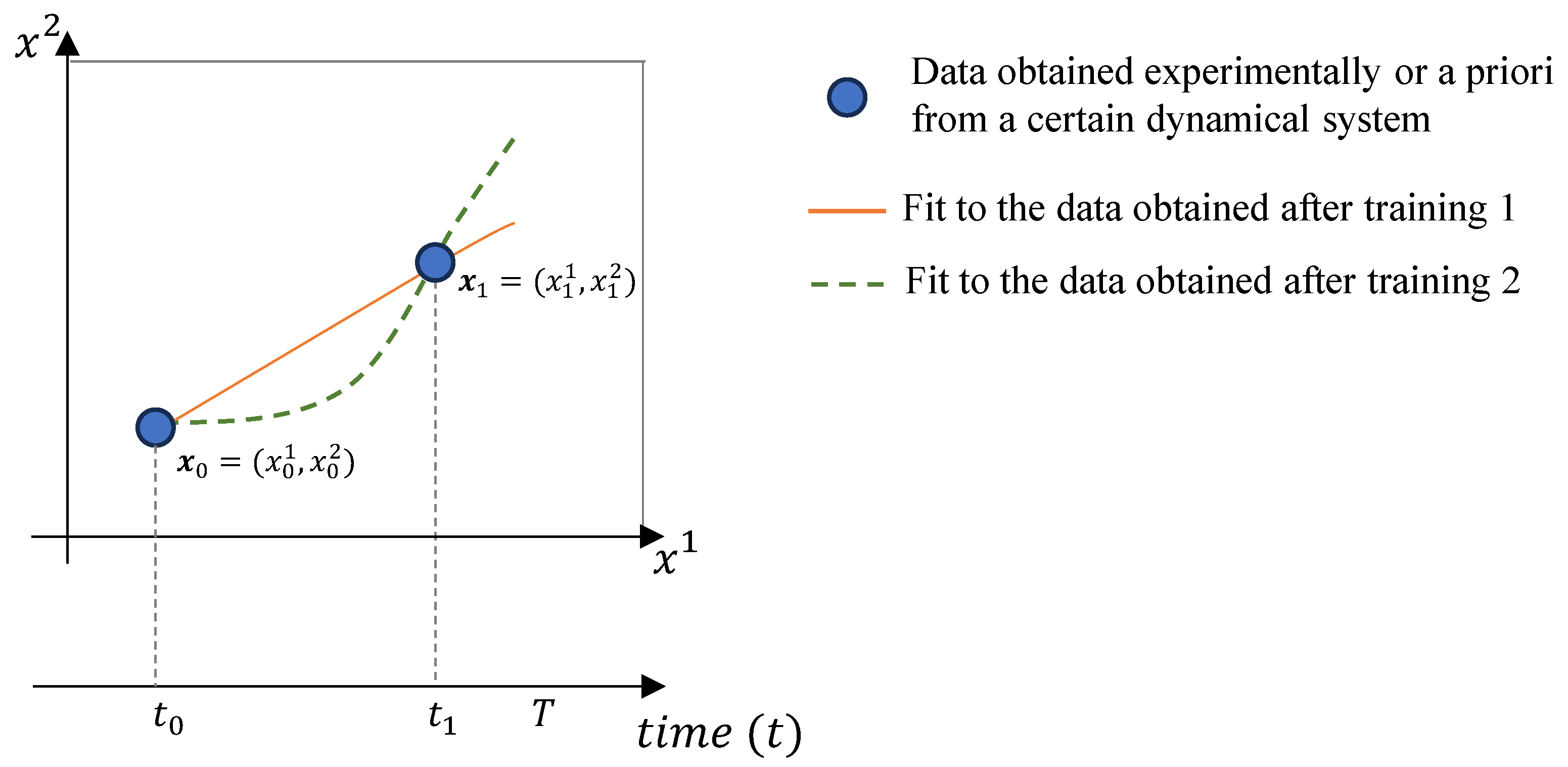
The NN learns model parameters based on a set of ordered data, meaning the number of elements in the set significantly influences the difference between
and
, as in Theorem 3. This effect is illustrated in
Figure 2, where a training dataset of only two observations can be fitted by two distinct functions.
Therefore,
Figure 2 tells us that when modelling with Neural FDEs, it is important to have some prior knowledge of the underlying physics of the data. This is crucial because the number of data points available for the training process may be beyond our control. For instance, the data can originate from real experiments where obtaining results is challenging.
Regarding the influence of the order of the derivative on the solution, we have the following [
14,
15]:
Theorem 4. Let be the solution of the initial value problem where is a perturbed α value. Let . Then, if ε is sufficiently small, there exists some such that both the functions u and z are defined on , and we have that where is the solution of (10). Once again, for small changes in
, the variations in both the solution and the order of the derivative are of the same order. This property is explored numerically and with more detail later in this work when solving (5). It is important to note that the NN
is not fixed in our problem (
1) (its structure is fixed, but the weights and bias change along the training optimisation procedure). However, Theorem 4 assumes that the function
is fixed. Therefore, Theorem 4 gives us an idea of the changes in our solution but does not allow the full understanding of its variation along the optimisation procedure.
2.1.3. Smoothness of the Solution
For the classical case, in Equation (10), we have (under some hypotheses on the interval ) that if , then is k times differentiable.
For the fractional case, even if
, it may happen that
. This means that the solutions may not behave well, and solutions with singular derivatives are quite common. See [
16] for more results on the smoothness properties of solutions to fractional initial value problems.
These smoothness properties (or lack of smoothness) make it difficult for numerical methods to provide fast and accurate solutions for (
1), thus making Neural FDEs more difficult to handle compared to Neural ODEs. It should be highlighted that during the learning process, the NN
always adjusts the Neural FDE model to the data, independent of the
amount of error obtained in the numerical solution of the FDE.
4. Conclusions
In this work, we present the theory of fractional initial value problems and explore its connection with Neural Fractional Differential Equations (Neural FDEs). We analyse both theoretically and numerically how the solution of a Neural FDE is influenced by two factors: the NN , which models the right-hand side of the FDE, and the NN that learns the order of the derivative.
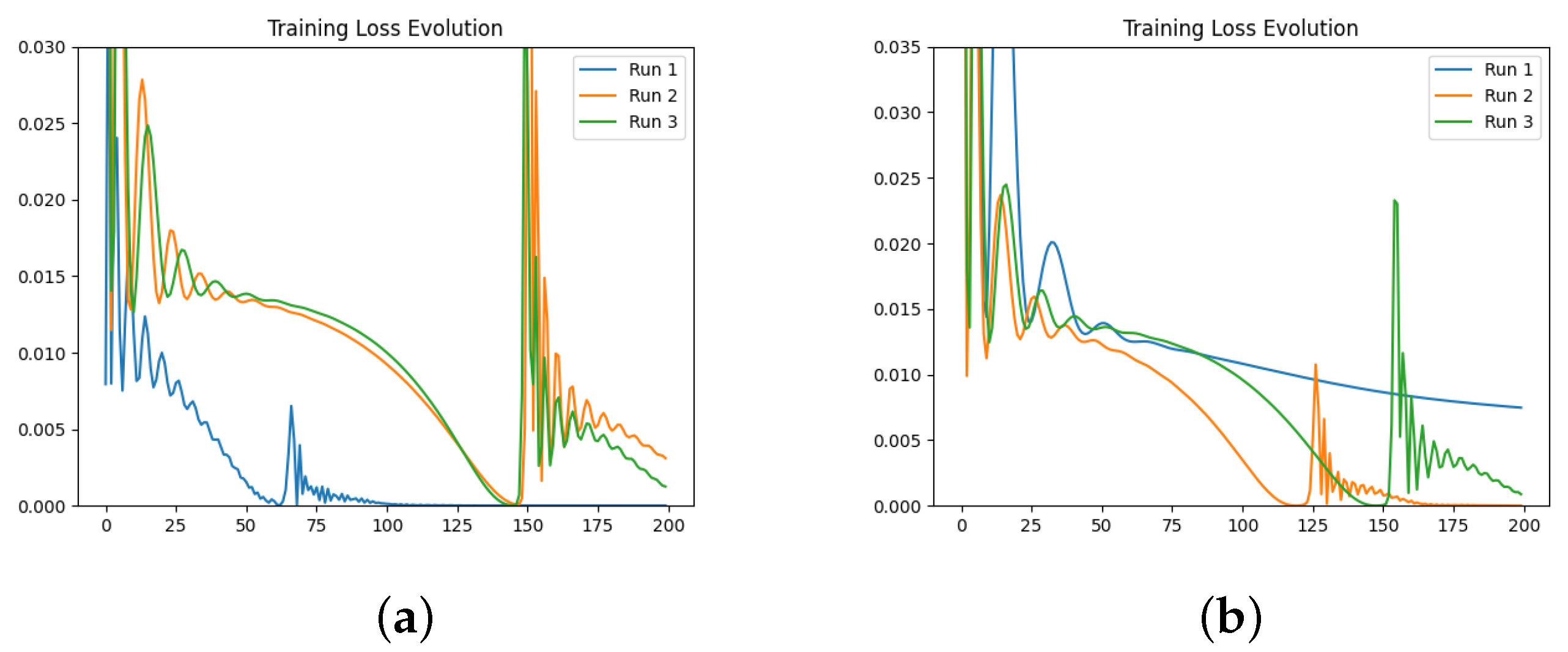
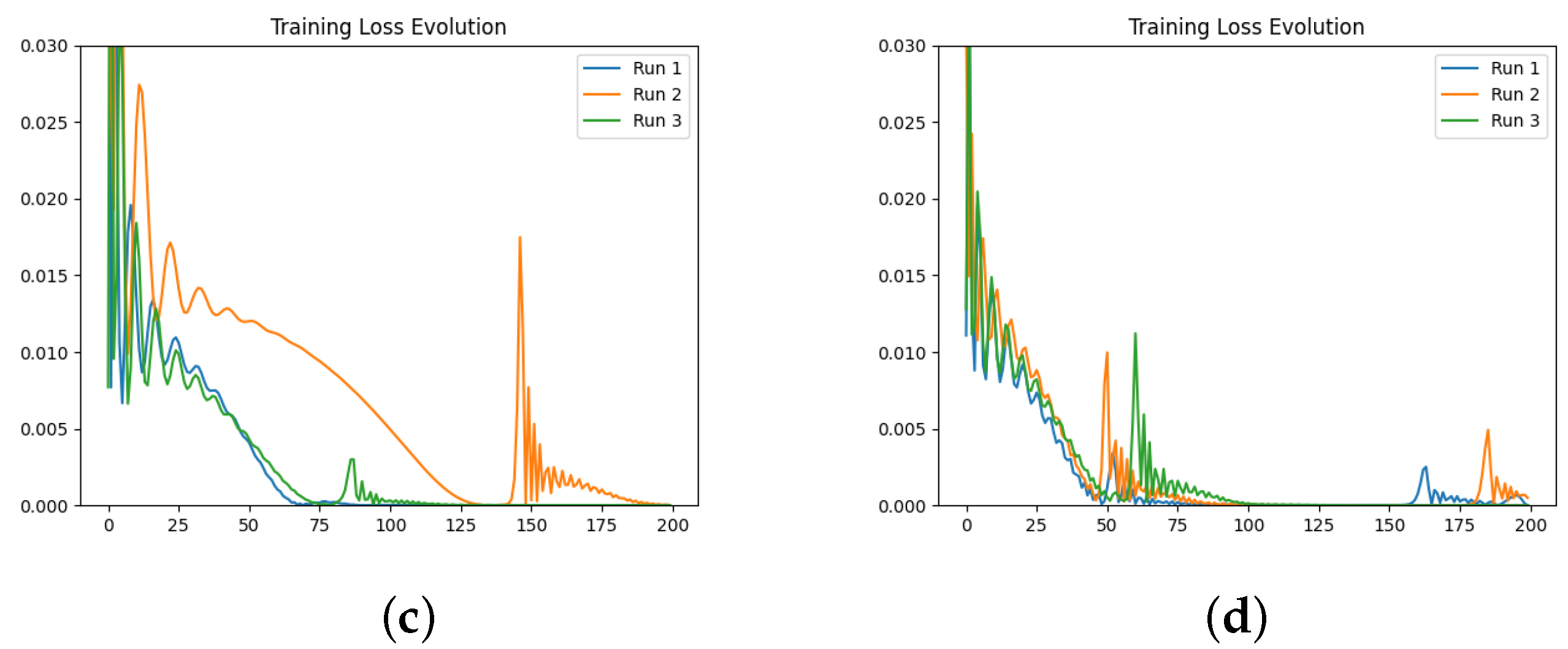
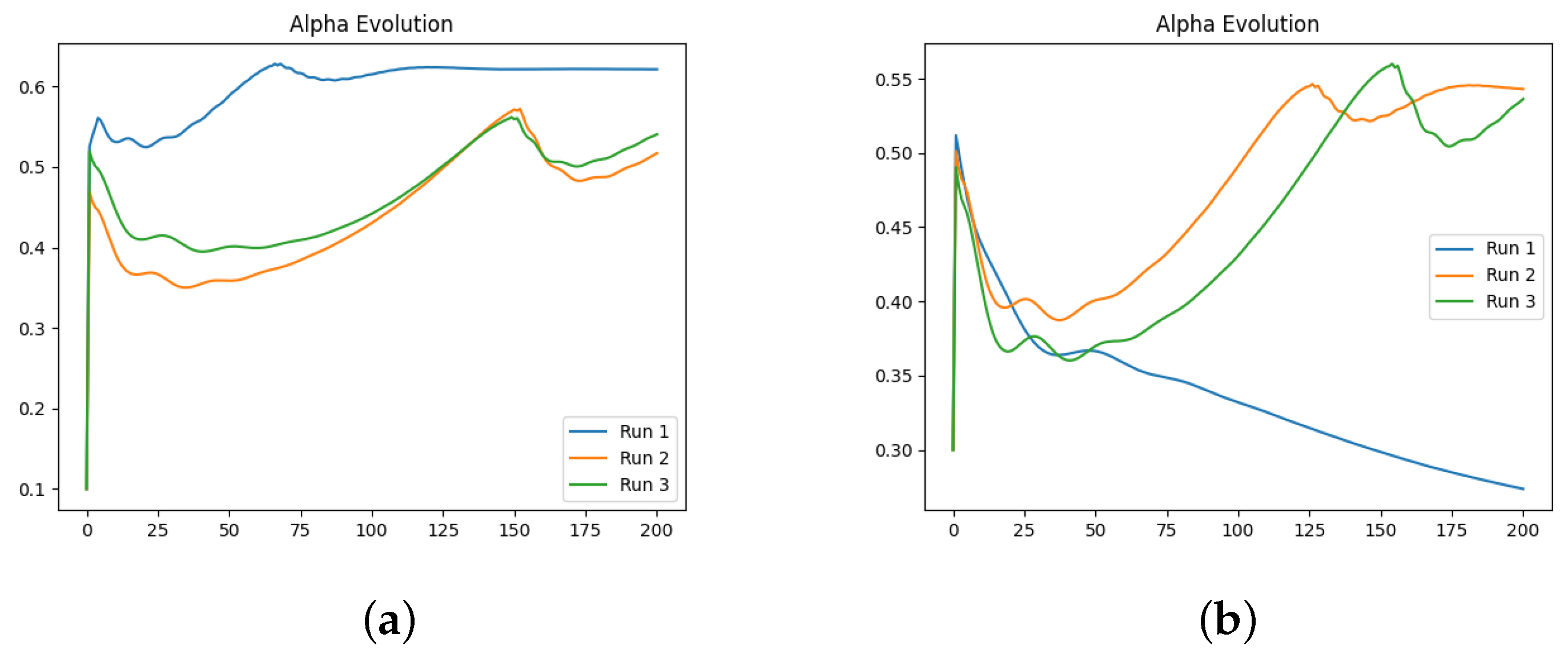
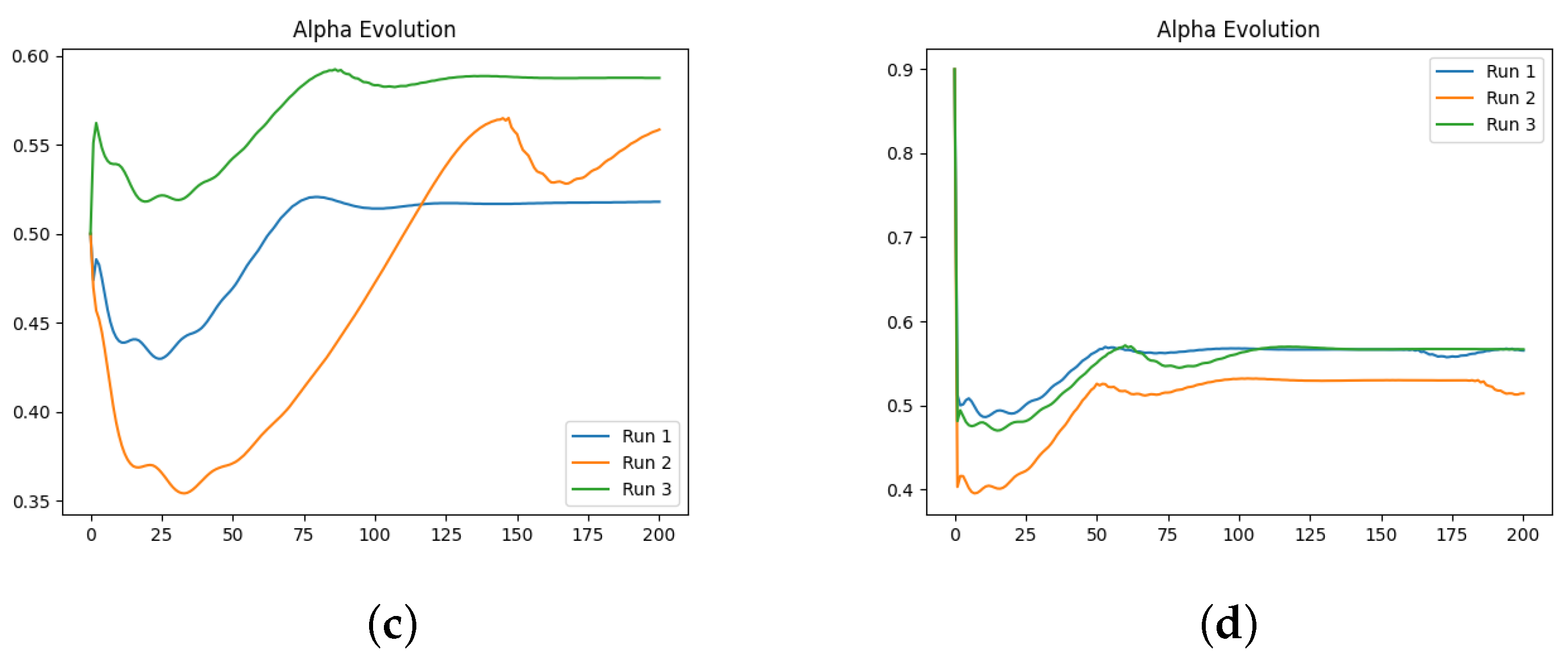
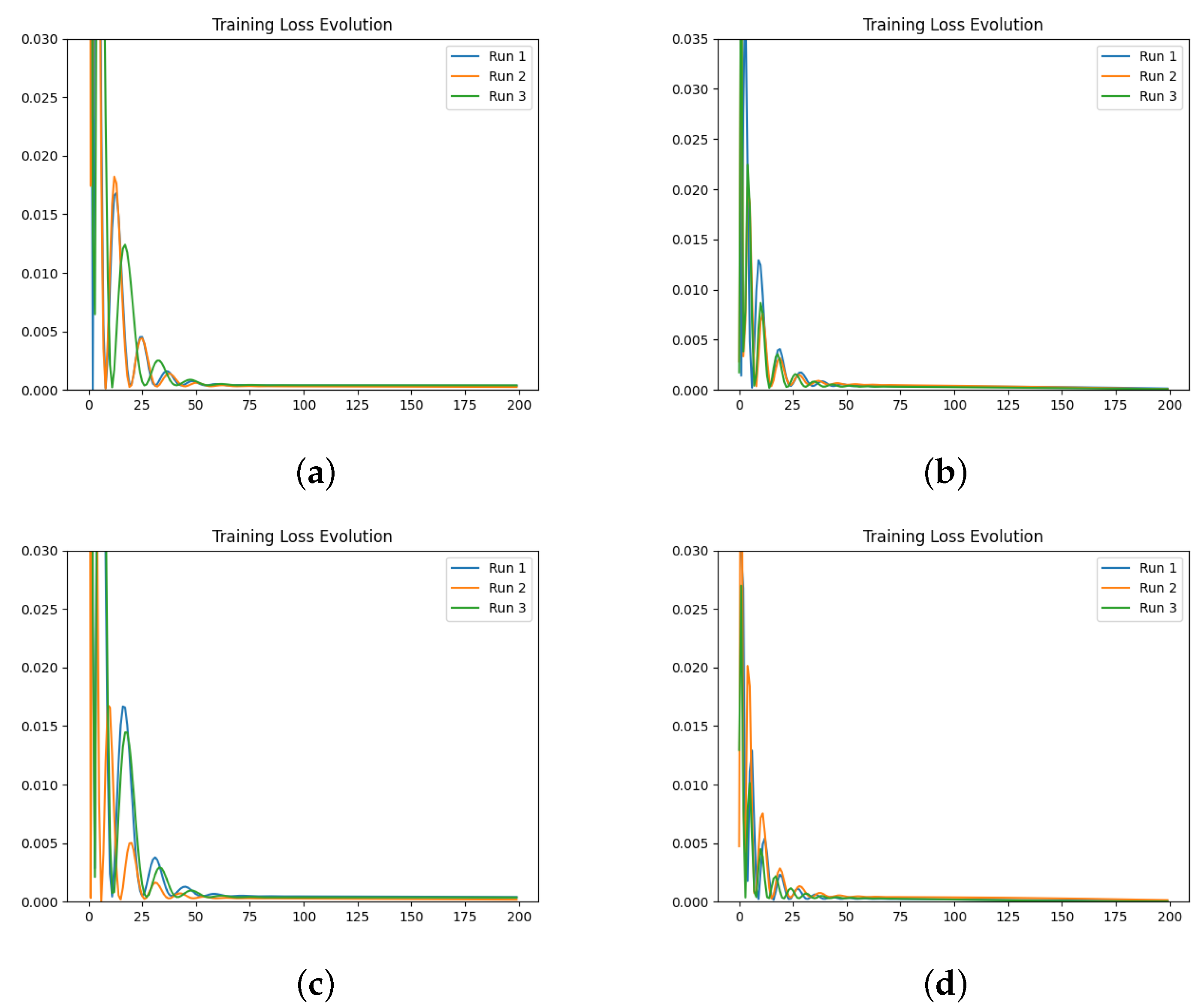
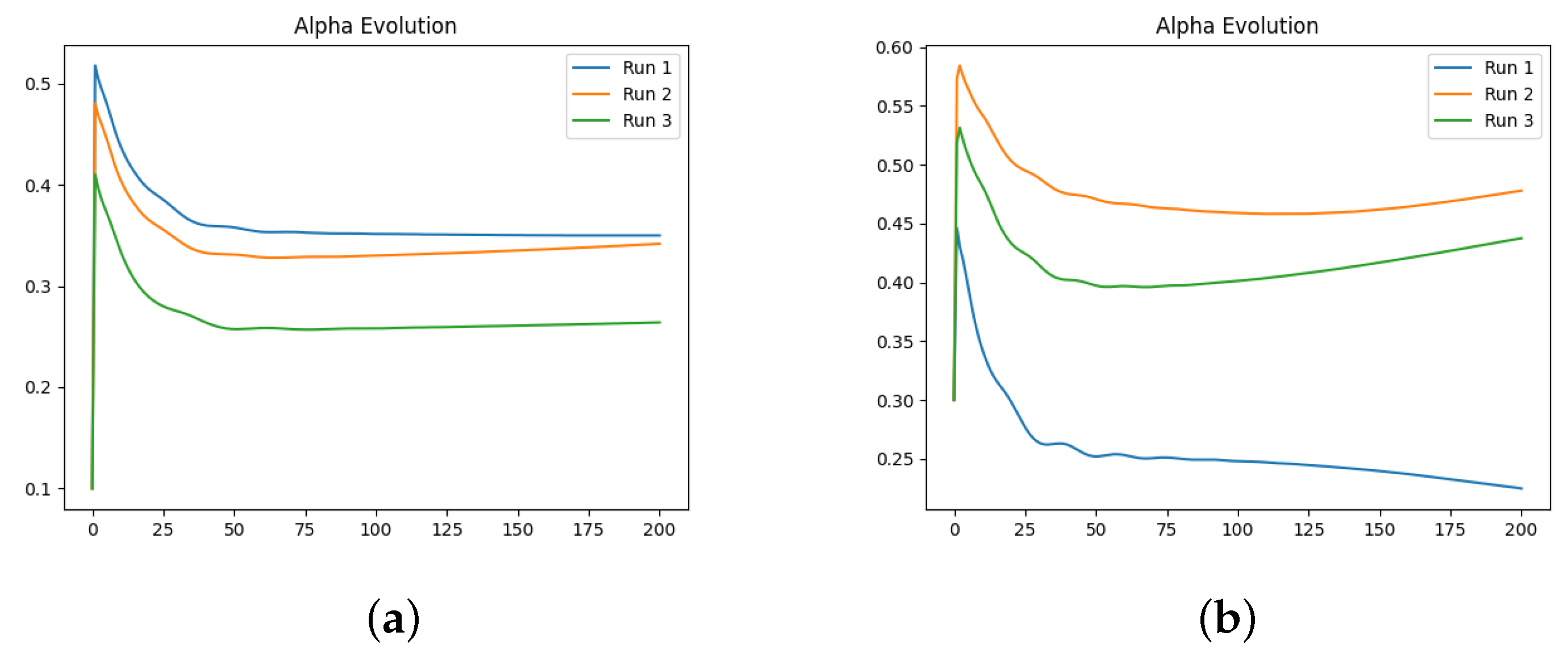
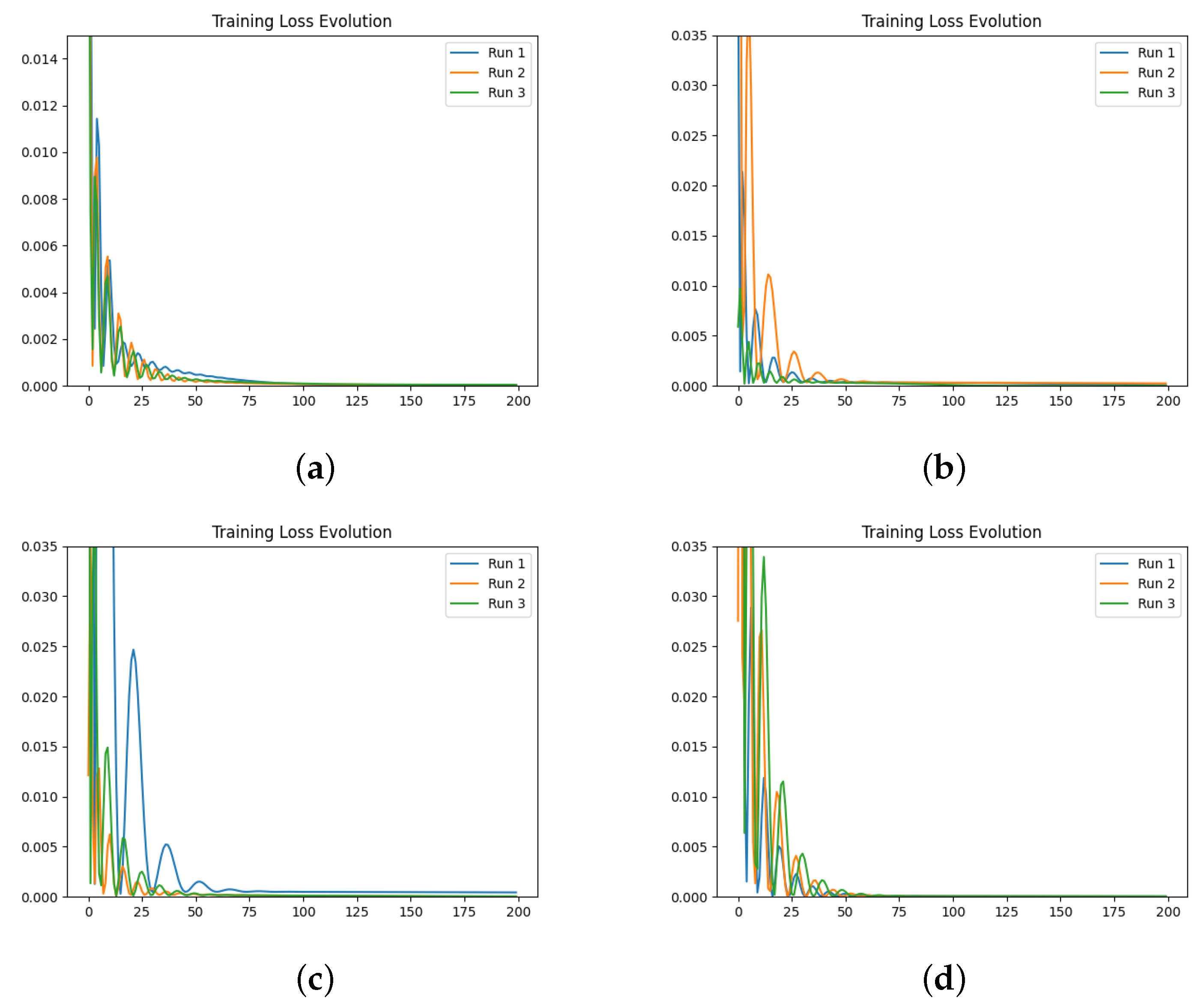
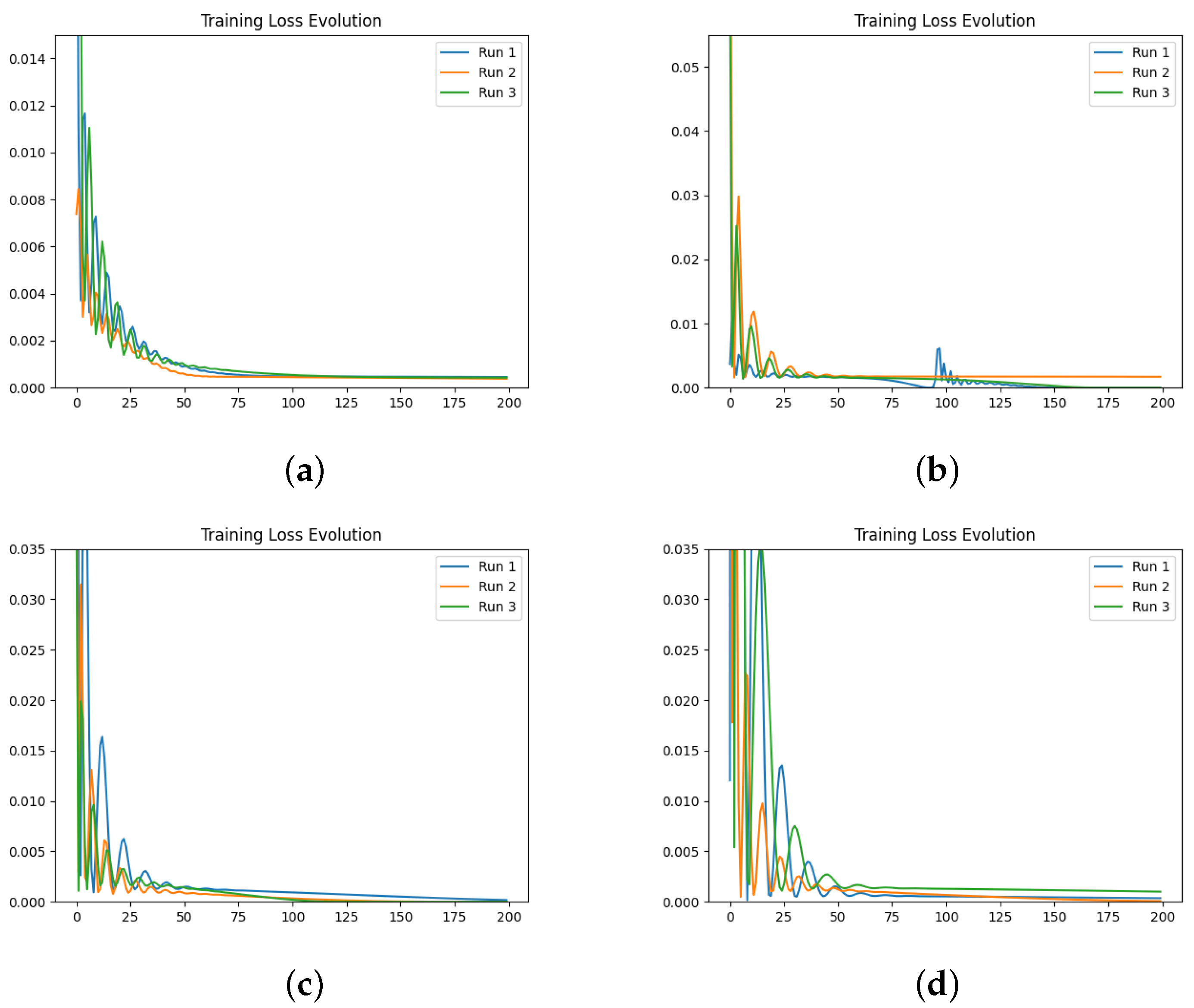
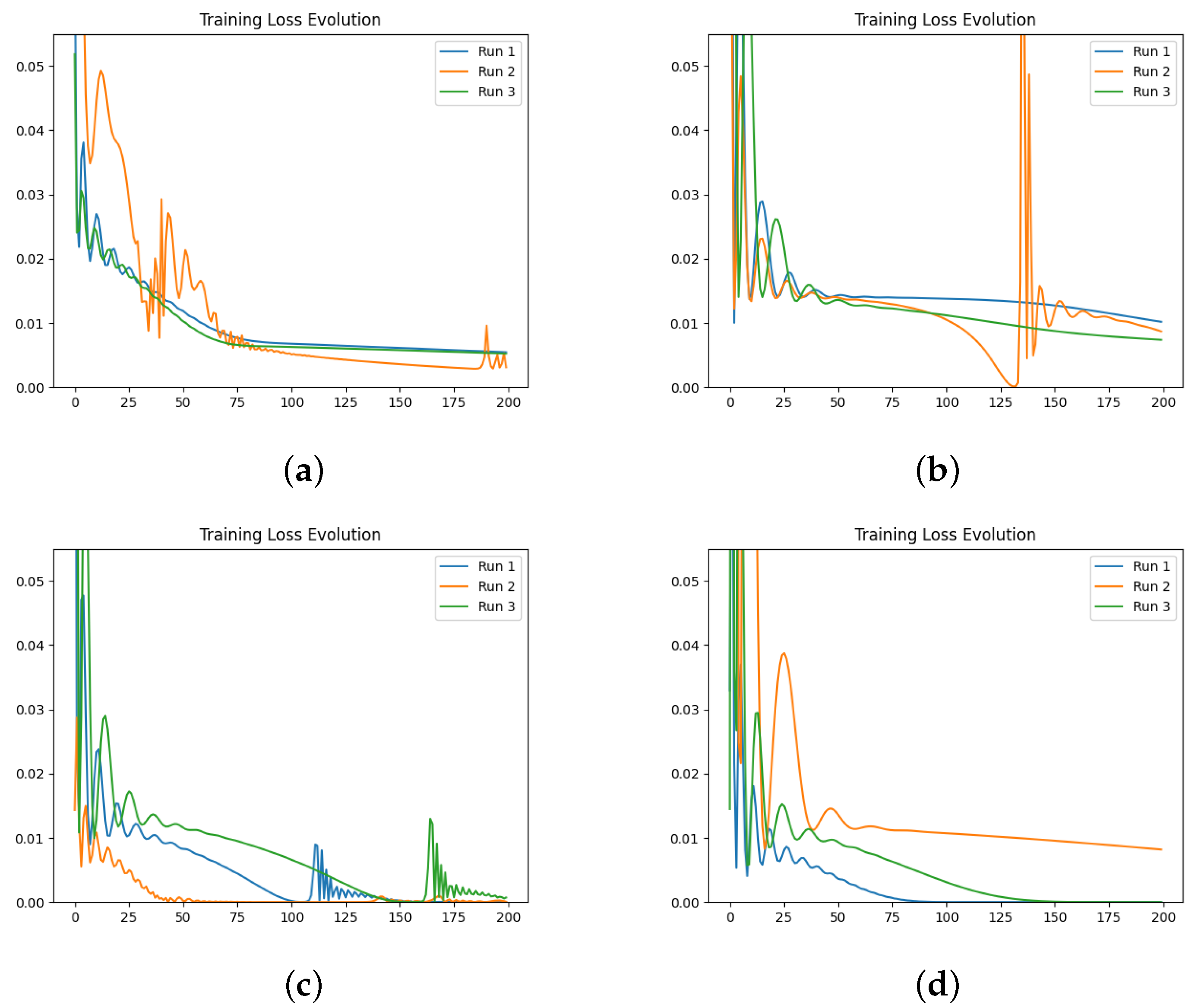
We also investigate the numerical evolution of the order of the derivative () and training loss across several iterations, considering different initialisations of the value. For this experiment, with a fixed number of iterations at 200, we created three synthetic datasets for a fractional initial value problem with ground-truth values of 0.3, 0.5, and 0.99. We tested four different initialisations for : 0.1, 0.3, 0.5, and 0.99. The results indicate that both the initial value and the ground-truth have minimal impact on the Neural FDE training process. Initially, the values increase sharply and then slowly decrease towards a plateau. In some cases, around 100 iterations, the values begin to rise again. This behaviour results from the complex interaction between the two NNs, and it is particularly irregular for and . The loss values achieved are low across all cases.
We then repeated the experiments, fixing the value, meaning there was no initialisation of , and the only parameters changing in the minimisation problem were those of the NN . The results confirm that the final training loss values are generally similar across different fixed values of . Even when the fixed matches the ground-truth of the dataset, the final loss remains comparable to other fixed values.
In a final experiment, we modified the stopping criteria of our Neural FDE training from a maximum number of iterations to a loss threshold. This ensures that the Neural FDEs are trained until the loss threshold is achieved, demonstrating that they can reach similar loss values regardless of the value. We conclude that struggles to adjust its parameters to fit the FDE to the data for any given derivative order. Consequently, Neural FDEs do not require a unique value for each dataset. Instead, they can use a wide range of values to fit the data, suggesting that is a universal approximator.
Comparing the loss values obtained across all three experiments, we conclude that there is no significant performance gain in approximating using a NN compared to fixing it. However, learning may require more iterations to achieve the same level of fitting performance. This is because allowing to be learnt provides the Neural FDE with greater flexibility to adapt to the dynamics of the data under study.
If we train the model using data points obtained from an unknown experiment, then the flexibility of the Neural FDE proves to be an effective method for obtaining intermediate information about the system, provided the dataset contains sufficient information. If the physics involved in the given data is known, it is recommended to incorporate this knowledge into the loss function. This additional information helps to improve the extrapolation of results.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}