
Accelerated Gradient Descent Driven by Lévy Perturbations




Abstract
1. Introduction
- By dividing the Lévy perturbation into small jumps and large jumps, a general framework for analyzing PAGDs is given;
- Convergence performance of PAGDs are analyzed under small perturbations and large perturbations respectively;
- By introducing the concept of attraction domain for local minima, Makovian transition properties are proven for PAGDs.
2. Preliminaries
2.1. Accelerated Gradient Descent
2.2. Perturbed Gradient Descent
2.3. Stable Process and Lévy Perturbations
3. PAGDs Driven by Lévy Perturbations
Convergence Analyses for Small Perturbations
4. Convergence Properties for PAGD (13)
4.1. Convergence Properties for PAGD (13)
4.2. Convergence Properties for PAGD (14)
4.3. Conclusive Remarks
- The results here can be extended to many other kinds of optimization algorithms, such as the conventional PGD driven by Lévy perturbations. Moreover, our results will be more precise than that in [19] by using the attraction domain as the state space rather than using the local minimum points.
- For conventional PGD, the attraction domain for a local minimum point of is the interval constructed by its two adjacent maximum points. Then the probability of and can be calculated as shown in [19].
- Here, is set sufficiently small to guarantee the establishment of Theorem 1 and Assumption 1. For practical usage, one can set the small jumps as zero to derive the truncated Lévy perturbations and guarantee the establishment of Theorem 1. If is chosen such that is much larger than the convergence time to a small neighbourhood of a local minimum point, then the results in Theorems 2 and 3 still hold for PAGDs driven by truncated Lévy perturbations.
5. Extensions to Vector Case
6. Illustrative Examples
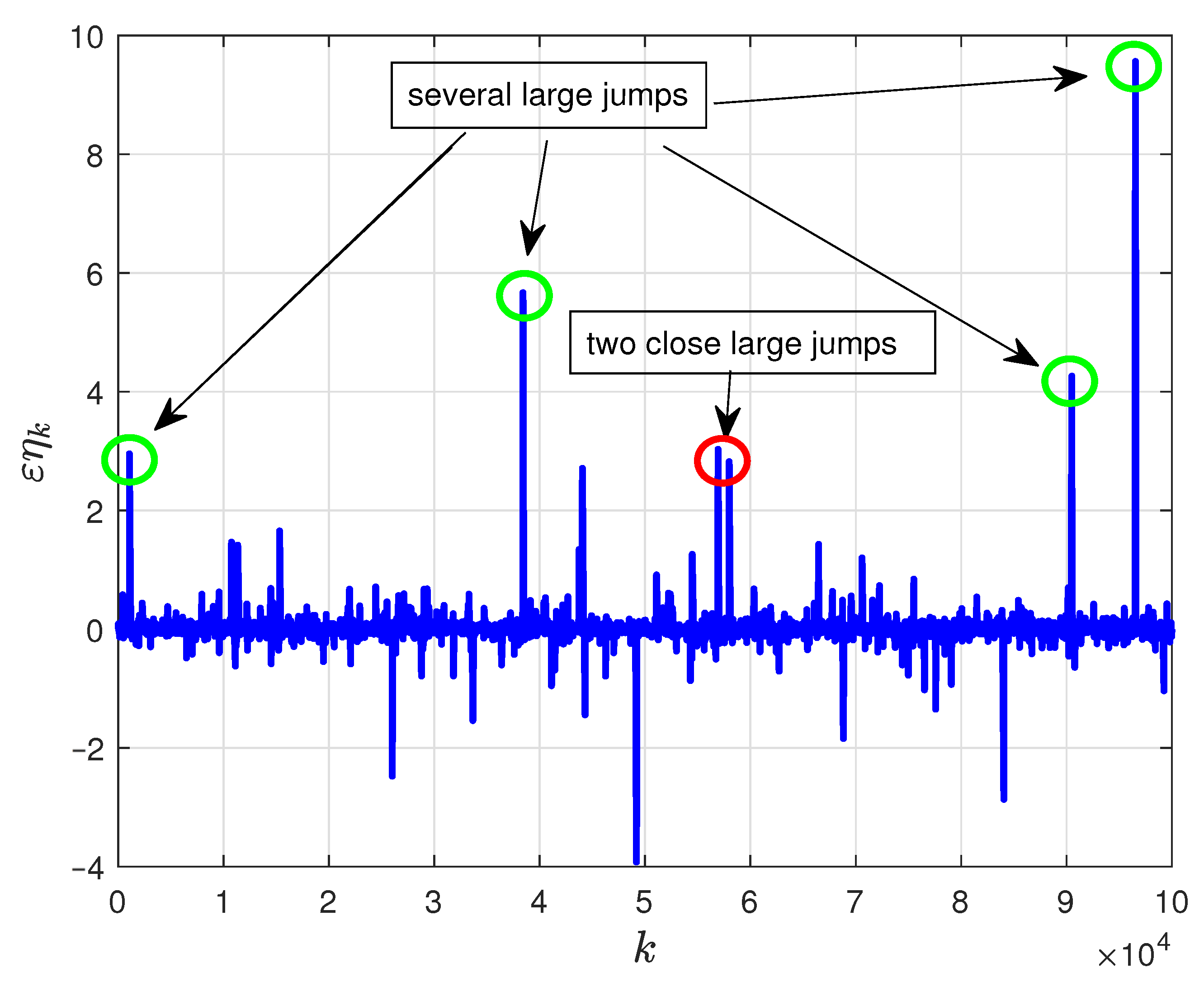
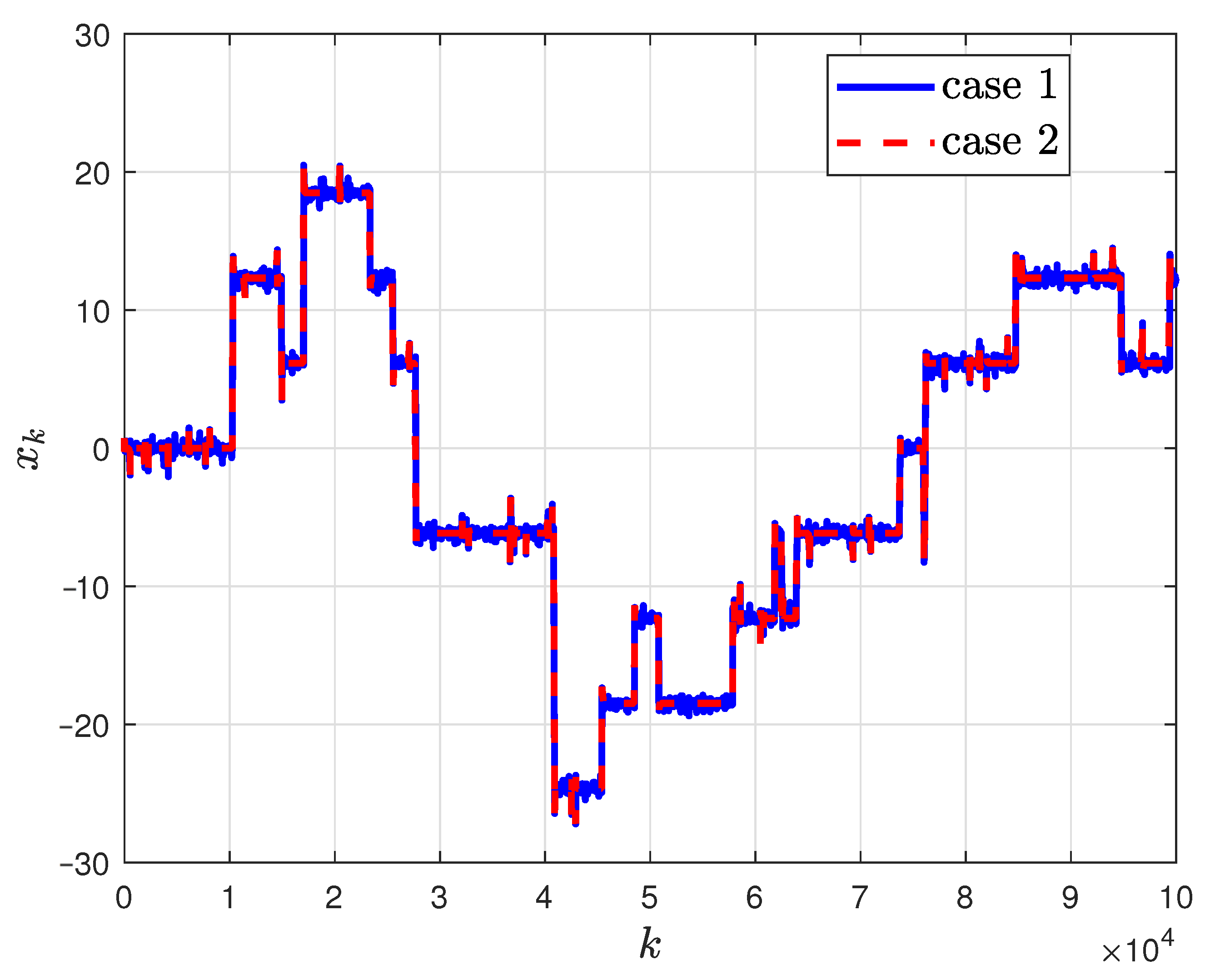
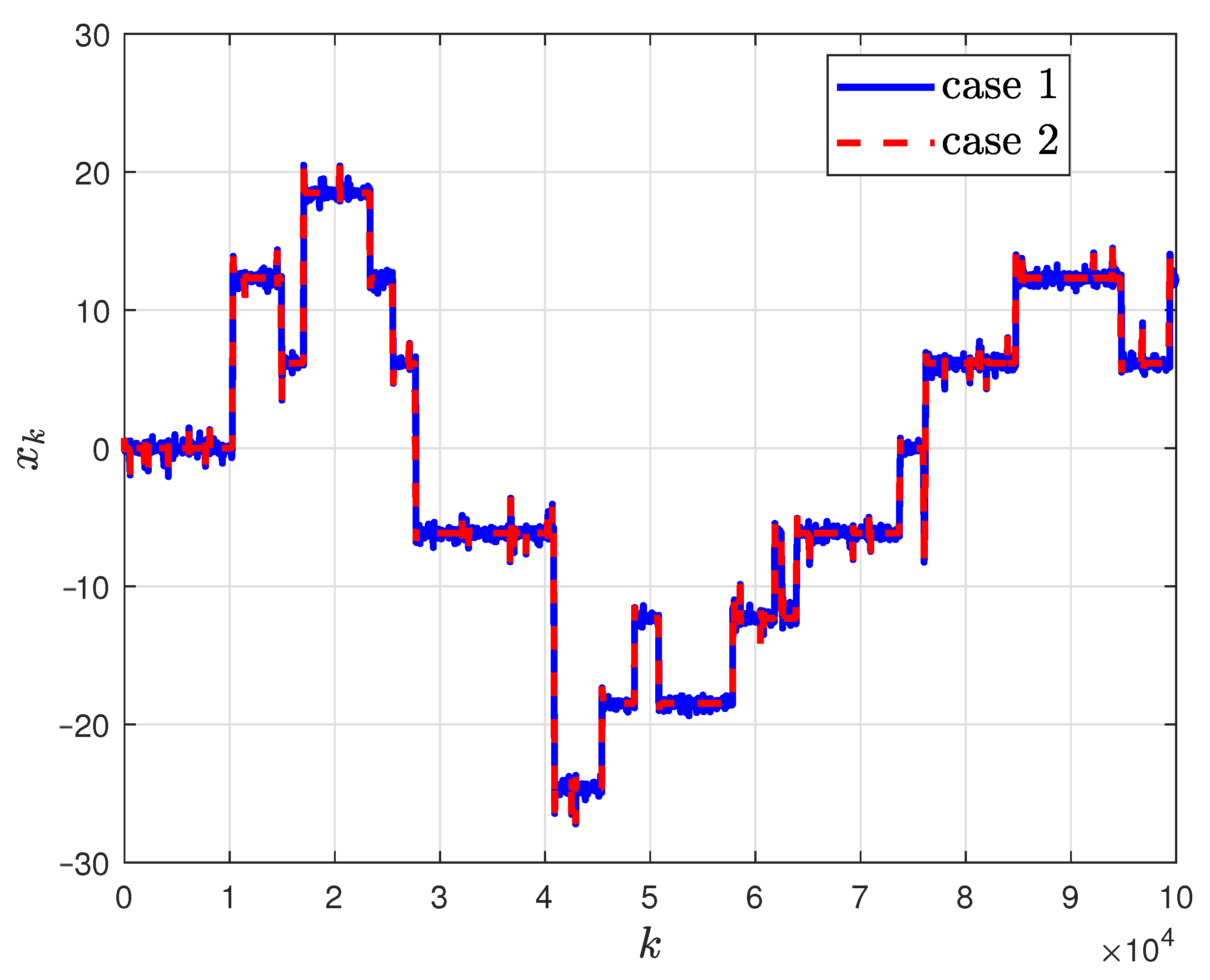
- The transition among different local minima always happens when the large jump arrives, and we have labeled some typical transition points in Figure 2, which shows the main contribution of large jumps for improving global search ability.
- For different PAGDs where perturbations are added to different positions, different transitions can be viewed with the same perturbations, where we have also labeled in Figure 2.
- As labeled in Figure 1, the arrival time of two successive large jumps can be very close. Therefore, Assumption 1 only holds in the mean of expectation and we can try to design the arrival time of large jumps in the future.

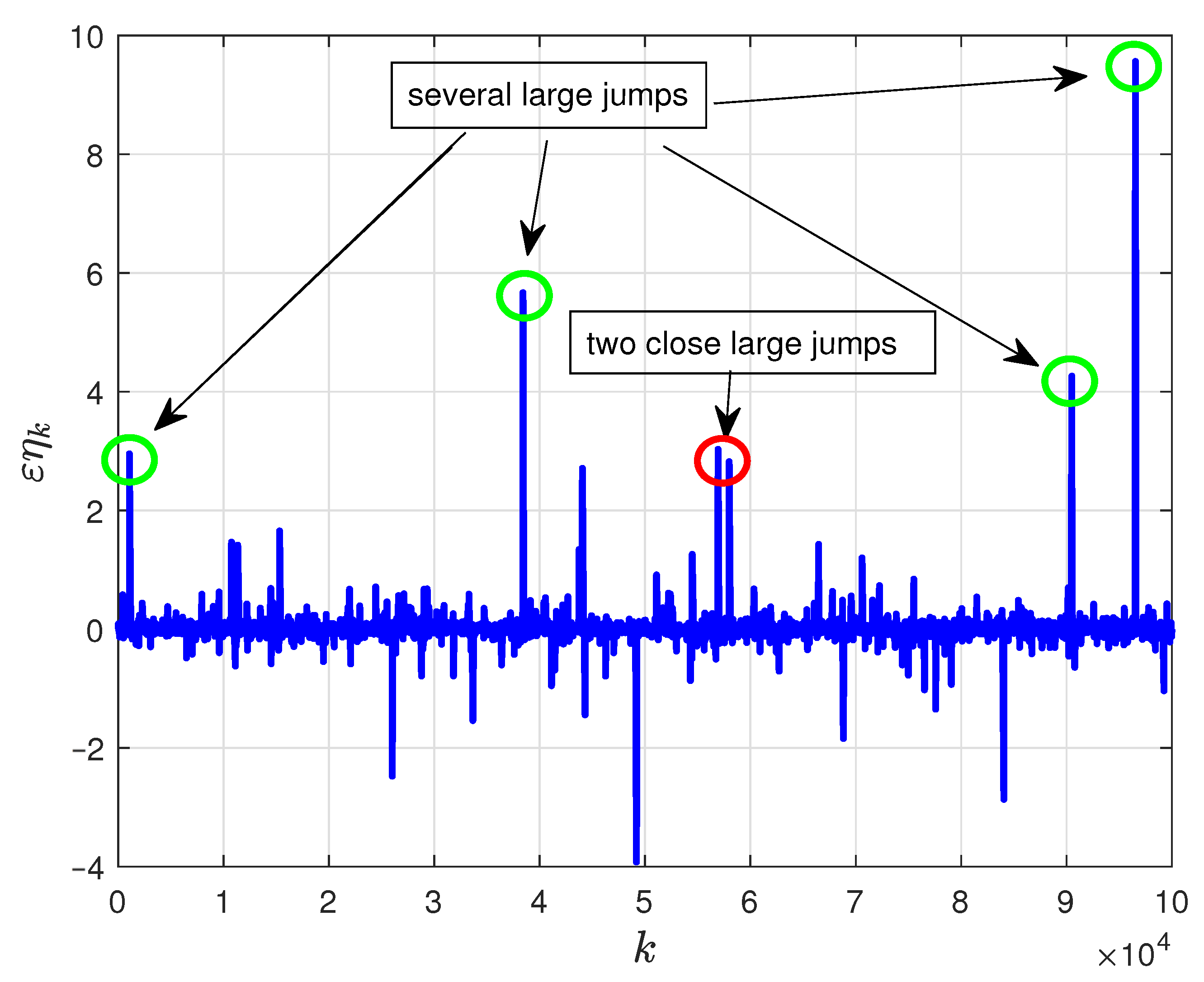
- Figure 3 shows the comparison of Lévy perturbations and truncated Lévy perturbations (red circles) with threshold . Moreover, it is found that transition among local minimum points always happens when the large jump arrives, and Markovian transition property can also be observed.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
7. Conclusions and Future Topics
- extend the results to PAGDs with adaptive Lévy index for better convergence performance;
- extend the results to the optimization algorithms driven by truncated Lévy perturbations;
- apply the proposed PAGDs in non-convex optimization problems such as neural networks training.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, Y.; Wei, Y.; Liang, S.; Wang, Y. Indirect model reference adaptive control for a class of fractional order systems. Commun. Nonlinear Sci. Numer. Simul. 2016, 39, 458–471. [Google Scholar] [CrossRef]
- Lewis, F.L.; Vrabie, D.; Syrmos, V.L. Optimal Control; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: New York, USA, 2004. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Qian, N. On the momentum term in gradient descent learning algorithms. Neural Netw. 1999, 12, 145–151. [Google Scholar] [CrossRef]
- Wilson, A.C.; Recht, B.; Jordan, M.I. A Lyapunov analysis of momentum methods in optimization. arXiv 2016, arXiv:1611.02635. [Google Scholar]
- Nesterov, Y.E. A method for solving the convex programming problem with convergence rate O (1/kˆ2). Dokl. Akad. Nauk SSSR 1983, 269, 543–547. [Google Scholar]
- Gill, P.E.; Murray, W. Quasi-Newton methods for unconstrained optimization. IMA J. Appl. Math. 1972, 9, 91–108. [Google Scholar] [CrossRef]
- An, W.; Wang, H.; Sun, Q.; Xu, J.; Dai, Q.; Zhang, L. A PID controller approach for stochastic optimization of deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8522–8531. [Google Scholar]
- Liu, L.; Liu, X.; Hsieh, C.J.; Tao, D. Stochastic second-order methods for non-convex optimization with inexact Hessian and gradient. arXiv 2018, arXiv:1809.09853. [Google Scholar]
- Prashanth, L.; Bhatnagar, S.; Bhavsar, N.; Fu, M.C.; Marcus, S. Random directions stochastic approximation with deterministic perturbations. IEEE Trans. Autom. Control. 2019, 65, 2450–2465. [Google Scholar] [CrossRef]
- Stariolo, D.A. The Langevin and Fokker-Planck equations in the framework of a generalized statistical mechanics. Phys. Lett. A 1994, 185, 262–264. [Google Scholar] [CrossRef]
- Kalmykov, Y.P.; Coffey, W.; Waldron, J. Exact analytic solution for the correlation time of a Brownian particle in a double-well potential from the Langevin equation. J. Chem. Phys. 1996, 105, 2112–2118. [Google Scholar] [CrossRef]
- Visscher, P.B. Escape rate for a Brownian particle in a potential well. Phys. Rev. B 1976, 13, 3272. [Google Scholar] [CrossRef]
- Jin, C.; Ge, R.; Netrapalli, P.; Kakade, S.M.; Jordan, M.I. How to escape saddle points efficiently. In Proceedings of the International Conference on Machine Learning PMLR, Sydney, Australia, 6–11 August 2017; pp. 1724–1732. [Google Scholar]
- Staib, M.; Reddi, S.; Kale, S.; Kumar, S.; Sra, S. Escaping saddle points with adaptive gradient methods. In Proceedings of the International Conference on Machine Learning PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 5956–5965. [Google Scholar]
- Mantegna, R.N. Fast, accurate algorithm for numerical simulation of Lévy stable stochastic processes. Phys. Rev. E 1994, 49, 4677. [Google Scholar] [CrossRef] [PubMed]
- Imkeller, P.; Pavlyukevich, I. Lévy flights: Transitions and meta-stability. J. Phys. A Math. Gen. 2006, 39, L237. [Google Scholar] [CrossRef]
- Pavlyukevich, I. Lévy flights, non-local search and simulated annealing. J. Comput. Phys. 2007, 226, 1830–1844. [Google Scholar] [CrossRef]
- Imkeller, P.; Pavlyukevich, I.; Wetzel, T. The hierarchy of exit times of Lévy-driven Langevin equations. Eur. Phys. J. Spec. Top. 2010, 191, 211–222. [Google Scholar] [CrossRef]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of COMPSTAT’2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Shamir, O.; Zhang, T. Stochastic gradient descent for non-smooth optimization: Convergence results and optimal averaging schemes. In Proceedings of the International Conference on Machine Learning, Miami, FL, USA, 4–7 December 2013; pp. 71–79. [Google Scholar]
- Simsekli, U.; Sagun, L.; Gurbuzbalaban, M. A tail-index analysis of stochastic gradient noise in deep neural networks. arXiv 2019, arXiv:1901.06053. [Google Scholar]
- Tzen, B.; Liang, T.; Raginsky, M. Local optimality and generalization guarantees for the langevin algorithm via empirical metastability. In Proceedings of the Conference on Learning Theory PMLR, Stockholm, Sweden, 6–9 July 2018; pp. 857–875. [Google Scholar]
- Zhang, Y.; Liang, P.; Charikar, M. A hitting time analysis of stochastic gradient langevin dynamics. In Proceedings of the Conference on Learning Theory PMLR, Amsterdam, The Netherlands, 7–10 June 2017; pp. 1980–2022. [Google Scholar]
- Nguyen, T.H.; Simsekli, U.; Richard, G. Non-asymptotic analysis of Fractional Langevin Monte Carlo for non-convex optimization. In Proceedings of the International Conference on Machine Learning PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 4810–4819. [Google Scholar]
- Simsekli, U.; Zhu, L.; Teh, Y.W.; Gurbuzbalaban, M. Fractional underdamped langevin dynamics: Retargeting sgd with momentum under heavy-tailed gradient noise. In Proceedings of the International Conference on Machine Learning PMLR, Virtual, 13–18 June 2020; pp. 8970–8980. [Google Scholar]
- Cheng, X.; Chatterji, N.S.; Bartlett, P.L.; Jordan, M.I. Underdamped Langevin MCMC: A non-asymptotic analysis. arXiv 2017, arXiv:1707.03663. [Google Scholar]
- Li, Q.; Tai, C.; Weinan, E. Dynamics of stochastic gradient algorithms. arXiv 2015, arXiv:1511.06251. [Google Scholar]
- Samoradnitsky, G. Stable Non-Gaussian Random Processes: Stochastic Models with Infinite Variance; Routledge: New York, NY, USA, 2017. [Google Scholar]
- Meerschaert, M.M.; Sikorskii, A. Stochastic Models for Fractional Calculus; Walter de Gruyter: Berlin, Germany, 2011; Volume 43. [Google Scholar]
- Ye, H.; Gao, J.; Ding, Y. A generalized Gronwall inequality and its application to a fractional differential equation. J. Math. Anal. Appl. 2007, 328, 1075–1081. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Wu, Z.; Lu, Y.; Chen, Y.; Wang, Y. Accelerated Gradient Descent Driven by Lévy Perturbations. Fractal Fract. 2024, 8, 170. https://doi.org/10.3390/fractalfract8030170
Chen Y, Wu Z, Lu Y, Chen Y, Wang Y. Accelerated Gradient Descent Driven by Lévy Perturbations. Fractal and Fractional. 2024; 8(3):170. https://doi.org/10.3390/fractalfract8030170
Chicago/Turabian StyleChen, Yuquan, Zhenlong Wu, Yixiang Lu, Yangquan Chen, and Yong Wang. 2024. "Accelerated Gradient Descent Driven by Lévy Perturbations" Fractal and Fractional 8, no. 3: 170. https://doi.org/10.3390/fractalfract8030170
APA StyleChen, Y., Wu, Z., Lu, Y., Chen, Y., & Wang, Y. (2024). Accelerated Gradient Descent Driven by Lévy Perturbations. Fractal and Fractional, 8(3), 170. https://doi.org/10.3390/fractalfract8030170