1. Introduction
Large language models, such as GPT-2 [
1], have fundamentally transformed the field of natural language processing [
2]. These models exhibit a remarkable capacity to capture intricate linguistic patterns and structures [
3]. However, the precise nature of these learned representations remains an open question in computational linguistics and machine learning [
4]. Studying these representations is not merely an academic pursuit; it has profound implications for the design, interpretation, and application of language models across a broad spectrum of natural language processing tasks [
5].
Central to our investigation is the geometric analysis of token embedding spaces [
6]. These high-dimensional vector spaces, in which words or subwords are represented, form the foundation of a language model’s ability to process and generate text [
7]. Understanding the fractal properties of token embedding spaces in language models is crucial for advancing natural language processing and computational linguistics. Our research aims to uncover and characterize these properties within a large language model. We hypothesize that the fractal characteristics of the embedding space exhibit consistency across different vocabulary subsets, revealing fundamental structural features of language representation that persist across various scales. By analyzing these properties, we seek to provide insights into how language models encode and manipulate linguistic information.
Despite the importance of understanding the geometric structure of token embedding spaces, there remains a significant knowledge gap in characterizing their fractal properties within large language models like GPT-2. Previous studies have primarily focused on lower-dimensional embeddings or have not rigorously examined the stability of fractal dimensions across different subsets of embeddings. Furthermore, existing methodologies often lack the statistical rigor needed to validate the consistency of fractal characteristics in high-dimensional spaces. Our work addresses this gap by providing a theoretical and empirical framework for analyzing the fractal properties of token embedding spaces in large language models, introducing novel theorems, and leveraging advanced statistical techniques to ensure robustness and reliability in our findings.
The investigation of this hypothesis presents significant challenges due to the high dimensionality and complexity of embedding spaces [
8]. The traditional analytical methods often prove inadequate when they are applied to these vast, intricate structures, necessitating the development of novel approaches to uncover their underlying geometry [
9]. To address these challenges, we introduce a new theorem that formalizes the stability of the correlation dimension in token embedding subspaces. This theorem, which we will state and prove in
Section 4, provides a mathematical foundation for our analysis. It posits that the correlation dimension remains consistent within a small margin of error for sufficiently large random subsets of the embedding space. Our approach leverages the Grassberger–Procaccia algorithm for estimating correlation dimensions, providing a robust method for analyzing the fractal properties of these high-dimensional spaces.
The validation of our theoretical results is achieved through extensive empirical experiments using the GPT-2 model [
10]. We extract token embeddings using the Hugging Face Transformers library and compute the correlation dimension for multiple random vocabulary subsets. Our statistical analysis employs bootstrap sampling and confidence interval estimation to demonstrate the consistency of our findings across different subsets, thereby supporting the hypothesized fractal nature of the embedding space.
The results of our study contribute to a deeper understanding of the geometric properties of language models and may lead to new approaches in natural language processing and computational linguistics [
11]. By characterizing the fractal nature of token embedding spaces, we provide a novel perspective on the structure of learned language representations. This work opens avenues for future research into the fractal properties of other language models and potential applications in model compression, transfer learning, and linguistic theory [
12].
In this paper, the main contributions are as follows:
- •
We introduce a novel theorem (Theorem 4) that formalizes the stability of the correlation dimension in token embedding subspaces of GPT-2, providing a mathematical foundation for analyzing the fractal properties of these high-dimensional spaces;
- •
We develop and validate an empirical methodology combining the Grassberger–Procaccia algorithm for
estimation with bootstrap sampling for statistical consistency, specifically tailored to analyzing token embedding spaces;
- •
We conduct extensive experiments on GPT-2 models of varying sizes, embedding dimensions, and network depths, demonstrating the stability of the correlation dimension across different subsets and providing new insights into how
scales with model complexity;
- •
We present novel findings on the layer-wise progression of the correlation dimension within GPT-2 models, revealing distinct patterns of the evolution of
that contribute to our understanding of information processing in transformer-based architectures.
These contributions advance the current understanding of the geometric properties of language model representations and open new avenues for research in natural language processing and computational linguistics.
4. Method
4.1. Fractal Analysis of Token Embedding Spaces
The application of fractal geometry to token embedding spaces provides a novel approach to understanding the intricate structures within language models. We posit that the token embedding space of GPT-2 exhibits fractal properties that are consistent across different subsets of vocabulary, revealing fundamental structural characteristics of language representation. This subsection formalizes the concept of the fractal dimension in the context of token embeddings and introduces the correlation dimension as a computationally tractable proxy.
Definition 5 (Fractal dimension)
. For a set S in the token embedding space E, the fractal dimension
is defined as where
is the number of ϵ-sized boxes required to cover S. The fractal dimension provides a measure of the space-filling capacity of a set, reflecting its complexity across different scales. However, direct computation of
is often infeasible for high-dimensional spaces such as token embeddings. To address this challenge, we employ the correlation dimension
as a more tractable alternative. To estimate
, we employ the Grassberger–Procaccia algorithm (Algorithm 1), which offers a computationally efficient approach to approximating the correlation dimension.
| Algorithm 1 Grassberger–Procaccia algorithm for estimating
. |
- 1:
Compute the pairwise distances
for all the points in the dataset. - 2:
For a range of
values, compute the correlation sum:
. - 3:
Plot
against
. - 4:
Estimate
as the slope of the linear region in this plot.
|
The application of the Grassberger–Procaccia algorithm to GPT-2 token embeddings provides a crucial link between the geometric structure of the embedding space and the linguistic properties encoded by the model. The correlation dimension
serves as a quantitative measure of the complexity and intrinsic dimensionality of the token embedding space, directly reflecting the semantic and syntactic relationships between tokens. In GPT-2 embeddings, tokens that share similar meanings or grammatical functions are often situated closer together, forming clusters or manifolds that represent specific linguistic features. A higher correlation dimension indicates a more intricate embedding space where tokens are distributed in a manner that captures nuanced linguistic phenomena such as polysemy, synonymy, and syntactic variations. By analyzing
, we gain insights into how the language model organizes and represents linguistic information, revealing the richness and diversity of the language features captured by the embeddings. This connection allows us to interpret the fractal properties of the embedding space as manifestations of the underlying linguistic structures learned by GPT-2.
The Grassberger–Procaccia algorithm provides a practical method for estimating
, but its accuracy depends on the choice of the scaling region and the number of data points. To address these limitations, we introduce the following theorem on the convergence of the correlation sum estimator:
Theorem 3 (Convergence of the correlation sum estimator)
. Let
be a sample from a probability distribution with the correlation dimension
. Then, for a fixed value of
, in probability, where
is the true correlation sum. Proof. The proof follows from the law of large numbers for U-statistics. The left-hand side of Equation (
8) is a U-statistic of order 2, which converges in probability to its expected value,
, as
. □
This theorem ensures that our estimation procedure converges to the true correlation dimension as the sample size increases, providing a theoretical foundation for the application of fractal analysis to token embedding spaces.
4.2. Theorem on the Stability of the Correlation Dimension
We now present our main theoretical contribution, a novel theorem on the stability of the correlation dimension across subsets of the token embedding space.
Theorem 4 (Stability of the correlation dimension)
. Let E be the d-dimensional token embedding space of GPT-2. For any two random subsets
with
, the correlation dimension
satisfies where
is a small constant, and N is a sufficiently large number. Proof. Consider any subset
with
, where
n is sufficiently large. The estimate
converges to the true correlation dimension
as
:
Given any value of
, a sufficiently large value of
N exists such that for all
,
Now, consider two independent random subsets
with
. The independence of
and
implies that
Since each probability is greater than
, we have
According to the triangle inequality, it follows that
Since
can be made arbitrarily small by choosing a value of
N that is sufficiently large, this implies that for any value of
, a value of
N exists such that for all values of
, the difference in the correlation dimension estimates satisfies
□
In practical applications, the constants N and
in Theorem 4 can be determined based on the desired level of statistical confidence and the variance observed in preliminary experiments. Specifically, the value of N chosen should be large enough to ensure that the sample size
provides a reliable estimate of the correlation dimension
with acceptable variance. Empirically, we observed that a subset size of
embeddings yielded stable
estimates with low standard errors (e.g., less than 0.01). The parameter
represents the acceptable margin of error between the correlation dimensions of different subsets and can be set according to the precision required for the analysis. In our experiments, setting
to values less than 0.02 provided sufficient sensitivity to detect meaningful differences while maintaining the practical computational requirements. There are inherent upper bounds on
, as excessively large values would make it trivial to assert the stability. Therefore,
should be chosen to balance between sensitivity and practicality, ensuring that
reflects meaningful consistency across subsets. This theorem implies that the correlation dimension is a stable property of the GPT-2 token embedding space, invariant regardless of the specific subset of tokens chosen for the analysis.
4.3. Statistical Consistency and Bootstrap Sampling for the Theorem 4
To empirically validate Theorem 4 and assess the statistical consistency of our
estimates, we employ bootstrap sampling. This non-parametric approach allows us to estimate the sampling distribution of
and construct confidence intervals. The bootstrap method is particularly suitable for our analysis due to its ability to handle complex data structures and provide robust estimates of uncertainty.
We begin with the bootstrap estimator for the correlation dimension in Definition 4. The bootstrap procedure (Algorithm 2) for assessing the consistency of
estimates is implemented as follows:
| Algorithm 2 Bootstrap sampling for the consistency of
. |
- 1:
Given a subset S of token embeddings, compute
. - 2:
for
to B, do - 3:
Generate bootstrap sample
by sampling n points from S with replacement. - 4:
Compute
using the Grassberger–Procaccia algorithm. - 5:
end for - 6:
Compute the bootstrap mean
. - 7:
Compute the bootstrap standard error
. - 8:
Construct the 95% confidence interval:
.
|
The choice of the number of bootstrap replicates B is crucial for balancing computational efficiency with statistical accuracy. A larger value for B reduces the sampling error of the bootstrap estimates but increases the computational cost. In our analysis, we set
, which is a common choice that provides a good trade-off between accuracy and efficiency. To assess the sensitivity of our results to the choice of B, we conducted experiments with B values ranging from 500 to 2000. The estimated standard errors and confidence intervals showed negligible differences (less than a 0.001 change in the standard error) across this range, indicating that our results were robust to the specific choice of B. This sensitivity analysis supports the reliability of our bootstrap-based statistical inferences.
The theoretical justification for the consistency of this bootstrap procedure is provided by Theorem 2. This theorem ensures that the bootstrap distribution of
approximates the true sampling distribution of
, allowing us to make valid inferences about the stability of
across different subsets of the token embedding space.
To assess the practical implications of this theorem, we introduce the following corollary:
Corollary 1 (Confidence interval validity)
. Under the conditions of Theorem 2, the bootstrap confidence interval where
is the
quantile of the standard normal distribution and has a probability of asymptotically correct coverage of
. This corollary provides the theoretical foundation for the construction of the confidence intervals in our analysis, ensuring that our inferences about the stability of
across different subsets of the token embedding space are statistically valid.
In practice, we implement this bootstrap procedure using a large number of replicates (typically
) to ensure accurate estimation of the sampling distribution. The resulting confidence intervals allow us to quantify the uncertainty in our
estimates and assess the statistical significance of the differences observed across different subsets or model configurations.
Algorithm 3 outlines the overall research methodology employed in this study. This structured approach ensures a systematic investigation of the fractal properties of token embedding spaces across different configurations of GPT-2 models. By providing a clear sequence of steps, the algorithm facilitates reproducibility and allows other researchers to apply the same methodology to analyzing other language models.
| Algorithm 3 Overall research methodology. |
- 1:
Input: A pre-trained GPT-2 model of a selected size. - 2:
Extract the token embeddings from the model. - 3:
Generate multiple random subsets of token embeddings with varying sizes. - 4:
for each subset, do - 5:
Estimate the correlation dimension
using the Grassberger–Procaccia algorithm (Algorithm 1) - 6:
Perform bootstrap sampling to assess the statistical consistency (Algorithm 2). - 7:
end for - 8:
Analyze the impact of the model size, embedding dimension, and network layers on
. - 9:
Interpret the results and formulate conjectures based on your observations.
|
5. The Experimental Setup
Our experimental framework is designed to investigate the stability of the correlation dimension in GPT-2 token embedding subspaces across various model sizes and embedding dimensions. We employ the Hugging Face Transformers library to access pre-trained GPT-2 models of three distinct sizes: small (124 M parameters), medium (355 M parameters), and large (774 M parameters). This selection enables a comprehensive examination of how the complexity of the embedding space scales with model size, providing insights into the fractal properties of language representations across different model capacities.
For each model, we extract token embeddings from multiple layers, including the initial embedding layer and subsequent transformer layers. We utilize the Grassberger–Procaccia algorithm to estimate the correlation dimension (
) of these embedding spaces. The algorithm is implemented as follows:
where
is the correlation sum,
N is the number of points,
is the Heaviside step function, and
is the Euclidean distance between embeddings.
To ensure the robustness of our results, we implement a bootstrap sampling approach. For each model size and embedding dimension configuration, we generate multiple random subsets of token embeddings. The subset sizes are systematically varied between 100, 500, 1000, 5000, 10,000, and 20,000 tokens. This range allows us to investigate how the estimated correlation dimension converges as the sample size increases. We perform five independent trials for each configuration to assess the variability in our estimates and compute the confidence intervals. To quantify the uncertainty in our estimates, we calculate the mean and standard error of
across multiple trials for each configuration.
All experiments were conducted using PyTorch 2.1 and the Hugging Face Transformers library, version 4.31. We utilized an NVIDIA RTX 3090 GPU with 24 GB of VRAM to perform the computations. The Grassberger–Procaccia algorithm and the bootstrap procedures were implemented in Python, ensuring efficient computation of the correlation dimension estimates even for large subsets of token embeddings. The codebase was developed to leverage GPU acceleration where possible, particularly for pairwise distance calculations, to handle the computational demands of high-dimensional data. All the hyperparameters, such as the number of bootstrap replicates (), were selected based on preliminary experiments to balance computational efficiency with statistical accuracy.
6. Results
6.1. Stability of the Correlation Dimension Across Subsets
Our initial experiments focused on validating the stability of the correlation dimension (
) across different subsets of the GPT-2 token embedding space. We analyzed the smallest GPT-2 model (124 M parameters) using multiple random subsets of 1000 token embeddings each. The results, presented in
Table 1, demonstrate remarkable consistency in the values of
estimated across different subsets.
The mean value of
across these subsets was 1.4176, with a standard error of 0.0066. To assess the stability of our estimates further, we performed a bootstrap analysis, which yielded a bootstrap mean
of 1.4109 and a bootstrap standard deviation of 0.0089. These results provide strong evidence supporting the stability of the correlation dimension in GPT-2 token embedding subspaces, as posited in Theorem 4.
6.2. Impact of the Model Size and the Embedding Dimension
We extended our analysis to investigating how the correlation dimension varied with the model size and the embedding dimension.
Table 2 presents the estimated correlation dimension (
) values for different GPT-2 model sizes and embedding dimensions using a subset size of 5000 tokens.
For the small and medium models, we observe a general trend of decreasing
values as the embedding dimension increases. This indicates that in these models, increasing the embedding dimension results in embeddings that occupy a lower intrinsic dimensionality relative to the ambient space. Specifically, the embeddings become more concentrated or constrained within certain regions of the high-dimensional space, reducing the correlation dimension measured. This behavior suggests that the models may not fully utilize the additional embedding dimensions to capture new variations, possibly due to limitations in their capacity or training procedures. Instead, the higher-dimensional embeddings might introduce redundancy, leading to more structured and less complex representations as measured by the correlation dimension.
In contrast, the large model exhibits different behavior, with the
values increasing up to the 256-dimensional embedding and then slightly decreasing for the 512-dimensional embedding. This non-monotonic relationship indicates that the large model’s capacity allows it to maintain more complex structures in higher-dimensional spaces, potentially capturing more nuanced language representations.
One possible explanation for the non-monotonic trend observed in the large model is the interplay between the model’s capacity and embedding dimensionality. As the embedding dimension increases, the model has more space to capture intricate semantic and syntactic relationships among tokens. However, beyond a certain dimensionality, these additional dimensions may introduce redundancy or noise, leading to saturation of or even a slight decrease in the correlation dimension. This could be due to the model’s optimization process favoring more efficient representations that minimize unnecessary complexity. Furthermore, larger models may employ mechanisms such as regularization and parameter sharing more effectively, resulting in embeddings that are both rich in information and organized in a way that reduces the overall fractal complexity. This phenomenon highlights the balance between capacity and efficiency in large language models, suggesting that there is an optimal embedding dimensionality for which the correlation dimension, and thus the complexity of the embedding space, is maximized.
While our observations suggest a relationship between embedding dimensionality and the correlation dimension, we acknowledge that the current empirical evidence is limited. Future work should involve a systematic exploration of a wider range of embedding dimensions and model sizes to empirically validate the influence of dimensionality on the correlation dimension. This will help to confirm whether the non-monotonic trends observed, particularly in the large model, are consistent and generalizable across different architectures and datasets.
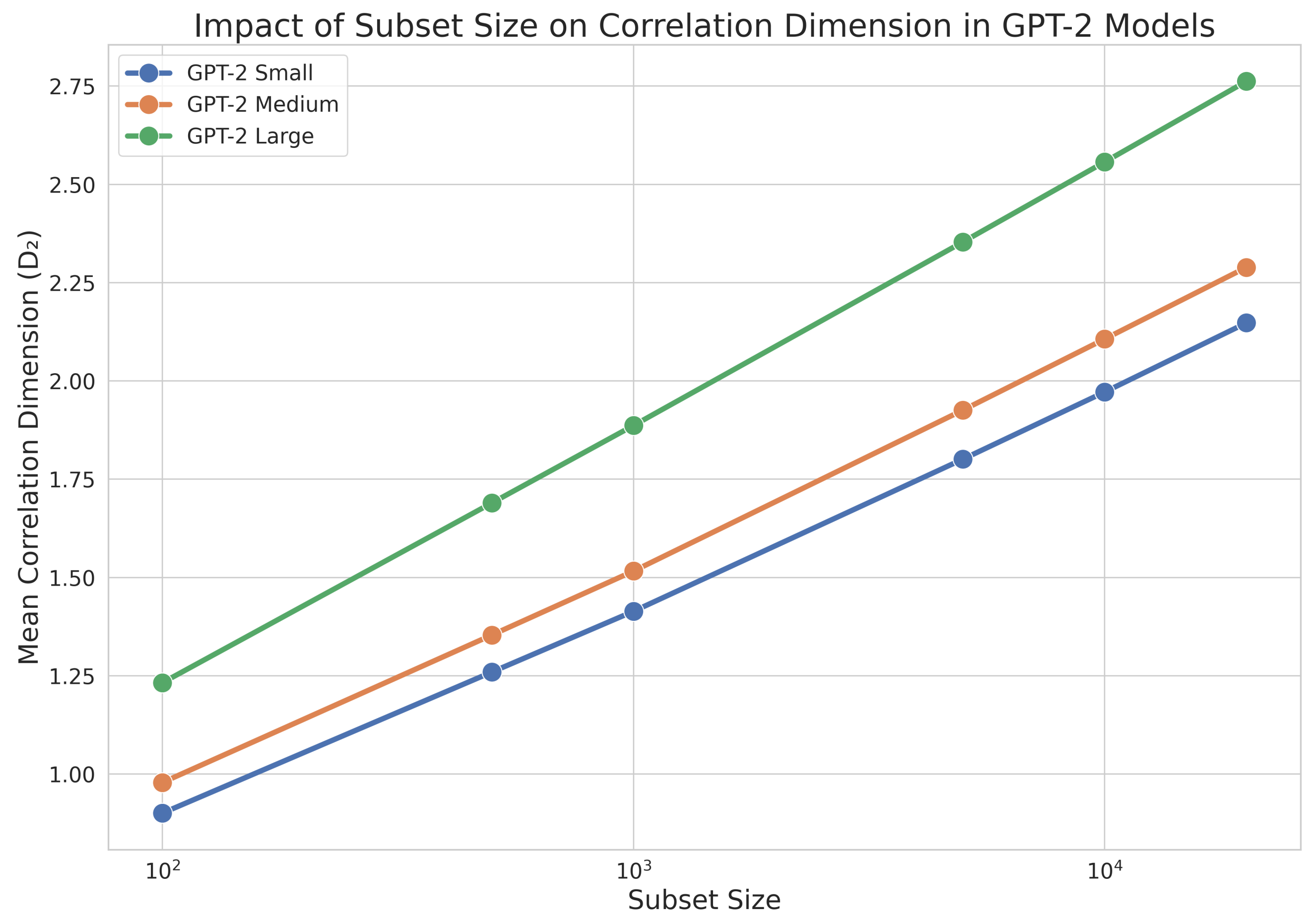
To investigate the impact of the subset size on the correlation dimension further, we examined how
changes with increasing subset sizes for different model sizes.
Figure 1 illustrates these findings.
In
Figure 1, we observe that the correlation dimension
increases with the subset size
n for all model sizes. This trend aligns with the theoretical expectation that as more data points are sampled from the embedding space, the estimated value of
converges to the true correlation dimension of the space, as established in Theorem 3. The diminishing rate of the increase in
with larger subset sizes indicates that the estimates approach stability, suggesting convergence to the true fractal dimension of the embedding space. Notably, the larger models exhibit faster convergence, as reflected by the smaller incremental increase in
with increasing
n, which may be attributed to their more complex and well-defined embedding spaces requiring fewer samples to accurately estimate
. This behavior underscores the importance of sufficient sample sizes in fractal analysis and validates the efficacy of the Grassberger–Procaccia algorithm in capturing the intrinsic dimensionality of high-dimensional embedding spaces.
To quantify the differences in the convergence behavior across model sizes, we computed the relative increase in
between consecutive subset sizes. For the largest jump from 10,000 to 20,000 tokens, we observed relative increases of 8.9%, 8.6%, and 8.0% for the small, medium, and large models, respectively. This decreasing trend in the relative increase supports the notion that larger models achieve faster convergence to their asymptotic
values.
These findings contribute to our understanding of how the fractal properties of token embedding spaces scale with the model size and the embedding dimension. The observed differences in behavior between model sizes suggest that the relationship between the model capacity and the complexity of learned representations is non-trivial and warrants further investigation.
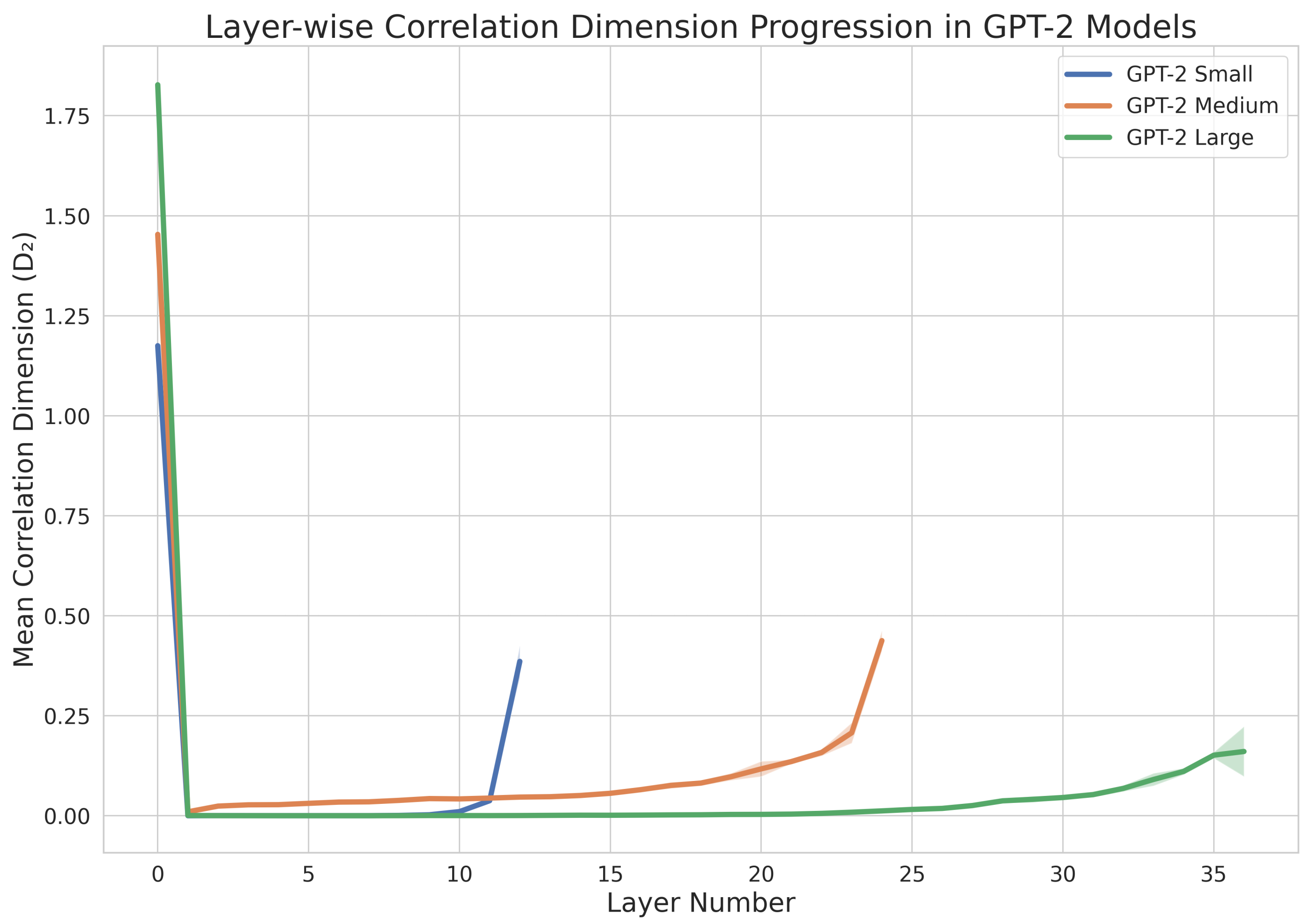
6.3. Layer-Wise Analysis of the Correlation Dimension
Our final set of experiments investigated how the correlation dimension changes across the different layers of the GPT-2 models.
Figure 2 illustrates the progression of the values of
through the network layers for the small, medium, and large GPT-2 models.
Figure 2 reveals that the correlation dimension
varies across the layers of the GPT-2 models, highlighting the transformation of the token representations as they propagate through the network. The initial decrease in
from the embedding layer to the first few layers suggests that the model initially reduces the complexity of the input representations, possibly by filtering out noise and redundant information. As we progress to deeper layers, the gradual increase in
indicates that the model constructs more complex features by combining simpler ones, thereby increasing the intrinsic dimensionality of the representations. This trend reflects the hierarchical nature of feature extraction in deep neural networks, where higher layers capture more abstract and complex patterns. The differences observed between model sizes, particularly the more gradual increase in
for the large model, suggest that larger models may develop richer hierarchical structures, allowing for more nuanced transformations of the embedding space.
These results reveal intriguing patterns in how the complexity of the token representations evolves through the network. For all three models, we observe a general trend of increasing
values from the initial layers to the final layers, suggesting that the complexity of the representation increases as information flows through the network. Interestingly, the embedding layer (layer 0) consistently shows the highest value of
across all the models, indicating that the initial embedding space has a rich, complex structure that is then processed and refined by subsequent layers.
The higher correlation dimension observed in the embedding layer can be attributed to the initial representation of the tokens before any transformation by the network. At this stage, the embeddings capture a wide range of raw lexical information, including various semantic and syntactic features, resulting in a highly complex and less structured space. As the input progresses through the layers, the model applies nonlinear transformations and attention mechanisms that refine and reorganize these embeddings. This process reduces redundancy and aligns the token representations in directions that are more meaningful for the specific tasks the model is trained on, effectively reducing the correlation dimension. The decrease in
in the initial layers followed by a gradual increase suggests that while the initial processing simplifies the representation, subsequent layers reintroduce complexity in a more task-specific manner. This reflects the model’s hierarchical feature extraction, where low-level features are combined into higher-level abstractions, leading to an evolution of the fractal properties of the embedding space.
The large GPT-2 model shows a more gradual increase in the values of
across layers compared to the small and medium models. This suggests that larger models process information differently, potentially maintaining more complex representations throughout their deeper architecture. These findings contribute to our understanding of how information is processed and represented in different layers of transformer-based language models, suggesting that the fractal properties of these representations evolve throughout the network, with different patterns emerging based on the model size.
6.4. Implications for Practical Applications
The insights gained from our fractal analysis of GPT-2 token embedding spaces have significant implications for real-world natural language processing tasks. Understanding the fractal properties of and the stability of the correlation dimension of embedding spaces can inform the development of more efficient and effective language models. For instance, recognizing that the embedding space maintains consistent structural characteristics across different subsets suggests that model compression techniques could exploit this property to reduce the model size without compromising its performance. Additionally, the observed layer-wise progression of the correlation dimension provides a deeper understanding of how semantic and syntactic information is processed. This could enhance tasks such as text generation, machine translation, and sentiment analysis by informing layer-specific training or fine-tuning strategies. Moreover, our findings may contribute to improved interpretability of language models, aiding in identifying biases and facilitating more transparent AI systems. By aligning the fractal characteristics of embeddings with linguistic features, practitioners can develop models that capture the complexities of human language better, ultimately enhancing practical applications of GPT-2 in areas such as conversational agents, information retrieval, and language understanding.
For instance, in machine translation, understanding the fractal properties of the embedding spaces could lead to more effective alignment of semantic representations between languages, improving the quality of translation. In text classification tasks, insights into the intrinsic dimensionality of the embeddings may inform the feature selection or dimensionality reduction techniques, enhancing the model performance and computational efficiency. Additionally, recognizing the consistent structural characteristics of embeddings across different subsets could support developing more robust transfer learning approaches in which models trained on one task or domain could be adapted to others efficiently.
7. Conclusions
This study has presented a mathematical analysis of the fractal properties inherent in GPT-2 token embedding spaces, with a primary focus on the stability and behavior of the correlation dimension across varying model sizes, embedding dimensions, and network layers. Our findings provide substantial evidence supporting the fractal nature of these embedding spaces and elucidate how these properties scale with model complexity. The stability of the correlation dimension across different subsets of the embedding space, as demonstrated empirically and formalized in Theorem 4, suggests that this measure captures fundamental structural characteristics of the language representations learned by GPT-2 [
1].
Our work presents new theoretical and empirical results that enhance our understanding of the fractal properties in token embedding spaces. The introduction of Theorem 4 is a significant contribution that formalizes the stability of the correlation dimension in GPT-2 embeddings, a property not previously established in the literature. Additionally, our empirical methodology, combining the Grassberger–Procaccia algorithm with bootstrap sampling, is specifically adapted to high-dimensional embedding spaces, providing a robust framework for future studies.
While our current empirical evidence supports these observations, we recognize that more extensive experiments are necessary to fully substantiate these claims. Therefore, we identify this as an important area for future research. Specifically, we observed non-monotonic behavior of the correlation dimension in relation to the embedding dimensionality, particularly in larger models. This phenomenon can be formalized as follows:
Conjecture 1. Let
denote the correlation dimension of the embedding space for a model of size m with the embedding dimension d. Model sizes
exist such thatfor some range of d. The justification for this conjecture arises from the interplay between the model’s capacity and the utilization of embedding dimensions. In smaller models, increasing the embedding dimension may lead to redundancy and over-parameterization, causing the embeddings to occupy a lower intrinsic dimensionality relative to the ambient space. Conversely, larger models possess the capacity to effectively utilize additional dimensions to capture more complex linguistic patterns, resulting in an increase in the correlation dimension. Verifying this conjecture would have significant implications for the design of language models, suggesting that simply increasing the embedding dimensions may not uniformly enhance the complexity of representation unless this is accompanied by a proportional increase in the model capacity. This insight could inform strategies for model scaling and optimization, emphasizing the need for balanced growth in both the embedding and model size to achieve the desired representational properties. This conjecture captures the observed phenomenon that larger models can maintain more complex structures in higher-dimensional spaces, aligning with recent work on the geometric properties of embedding spaces [
32].
It is important to note that the large GPT-2 model exhibited different behavior from that of the small and medium models, which can be partially attributed to differences in the volume of the training data and the model’s capacity to learn from them. The large model was trained on a more extensive dataset, enabling it to capture a wider array of linguistic patterns and nuances. This increased exposure allowed the model to utilize higher embedding dimensions more effectively, as evidenced by the non-monotonic trends observed in the correlation dimension. The larger volume of data contributes to the model’s ability to maintain complex structures within the embedding space, leading to the differences in the fractal properties observed. Recognizing the impact of the volume of training data on embedding complexity underscores the importance of considering both the model capacity and the dataset size when analyzing and designing language models. Future research should explore how variations in the training data influence the fractal characteristics of embedding spaces across different model architectures and sizes.
The layer-wise analysis of the progression of the correlation dimension through GPT-2 networks provided novel insights into the evolution of the token representation complexity during language processing. We observed a consistent pattern of an increasing correlation dimension from the initial to the final layers, with the embedding layer exhibiting the highest complexity. This pattern can be formalized as follows:
Conjecture 2. Let
denote the correlation dimension of the l-th layer in a GPT-2 model with L layers. Then,and The justification for this conjecture is based on the hierarchical processing of the information in transformer models. The initial embedding layer captures a wide array of lexical information, leading to a high correlation dimension. As information propagates through the network, layers apply transformations that initially reduce the redundancy and simplify the representations, resulting in a decrease in
. Subsequent layers progressively integrate and refine the information, increasing the complexity of the representations and thereby increasing
. Verifying this conjecture would enhance our understanding of how transformer models process and encode linguistic information in different layers, potentially guiding the development of more efficient architectures and informing techniques for layer-specific training or pruning. This underscores the importance of considering the dynamic evolution of the representational complexity within deep networks, which could lead to improved performance on various NLP tasks through targeted architectural modifications. This conjecture offers a new perspective on the information flow in transformer-based models, contributing to ongoing discourse on the interpretability and functional organization of deep language models [
21].
Our work extends the application of fractal analysis in natural language processing [
13] to the domain of large language models, demonstrating the utility of geometric approaches in understanding the intrinsic properties of learned representations. The methodological framework developed in this study, combining theoretical analysis with empirical validation through bootstrap sampling, provides a robust foundation for future investigations into the geometric properties of embedding spaces in other language models and architectures.
While our analysis included three GPT-2 model sizes (small, medium, and large), we acknowledge the limitations of not incorporating more extreme cases such as GPT-2 XL (with 1.5 B parameters) or GPT-3 due to computational resource constraints and the lack of open-source availability of GPT-3. The inclusion of GPT-2 XL would require significant GPU memory and computational power beyond our current capabilities, and GPT-3’s proprietary nature precludes direct experimentation with it. Despite these limitations, the trends observed suggest that larger models may exhibit even more pronounced fractal properties. Therefore, future work will aim to overcome these challenges by utilizing high-performance computing resources or alternative methods to analyze these larger models, providing a more comprehensive understanding of how scaling impacts the correlation dimension in transformer-based language models.
While varying the token subset size enhanced the robustness of our analysis, we acknowledge that the methodology for selecting the tokens may have influenced the correlation dimension estimates. Specifically, exploring whether certain token types, such as rare versus common tokens, disproportionately affect the correlation dimension could yield deeper insights into the structural properties of the embedding space. Preliminary observations suggest that rare tokens, which often carry more specific semantic or contextual information, might contribute differently to the fractal characteristics of the embedding space compared to high-frequency tokens. Incorporating token frequency and other linguistic attributes as variables into future analyses could refine our understanding of how specific linguistic features impact the geometric properties of language models.
Despite the strengths of our approach, there are limitations associated with using the Grassberger–Procaccia algorithm and bootstrap methods in high-dimensional spaces. The computational complexity of the Grassberger–Procaccia algorithm increases quadratically with the number of data points, making it computationally intensive for large datasets. Additionally, the curse of dimensionality poses challenges as distance measures become less discriminative in high-dimensional spaces, potentially affecting the accuracy of the correlation dimension estimates. The bootstrap method, while useful for estimating confidence intervals, also adds computational overhead due to the need for multiple resampling iterations. Future research could explore more efficient algorithms for estimating the fractal dimensions in high-dimensional data, such as methods that reduce the computational complexity or that are specifically designed for high-dimensional embedding spaces. Furthermore, developing theoretical advances to mitigate the effects of the curse of dimensionality on distance calculations could enhance the reliability of fractal analysis in this context.
Future research directions could explore the relationship between the fractal properties of embedding spaces and model performance on specific NLP tasks. Extending this analysis to other transformer-based architectures and larger models would further our understanding of how the fractal properties scale with model size and complexity. Finally, exploring the linguistic properties of token subsets that yield exceptionally high or low correlation dimensions could provide new perspectives on the nature of language representation in neural networks, potentially leading to formal characterization of the relationship between linguistic features and the geometric properties of embedding spaces.





{kind=link}
{kind=link}