1. Introduction
The growing global demand for mineral resources necessitates that exploration efforts maintain or enhance the rate of discovery of mineral deposits [
1,
2,
3], presenting numerous challenges to exploration activities. One such challenge is how to effectively integrate diverse datasets, including geochemical, geophysical, and geological structural data, for conducting prospecting surveys [
4,
5,
6,
7,
8,
9]. This endeavor necessitates interdisciplinary collaboration and the application of mathematical techniques. Subsequently, various statistical methods have been developed to address professional challenges across different fields. These include fractal and multifractal models [
10], univariate analysis [
11], multivariate analysis [
12], and geostatistics [
13]. So, which method is suitable for which data is also a problem we need to discuss, which often needs experts to prove through practice, so that the method we choose can reflect the problem we need to solve as much as possible.
The extensive data generated by geological studies encompass not only qualitative and quantitative data but also textual descriptions, geological videos, and more. The challenge lies in efficiently utilizing these data to enhance mineral exploration, an issue at the intersection of big data and geology. We propose that the integration of geology with data science can be achieved through cloud platforms, leveraging GIS spatiotemporal data models, and dynamically managing geological spatiotemporal big data models. Furthermore, we underscore the necessity of interdisciplinary collaboration by employing a range of data methodologies to address modeling challenges in geology, incorporating cloud computing and artificial intelligence into the analysis of geological big data to inform geological exploration.
In recent decades, multifractal methods have become a popular approach for locating geochemical anomalies. Among them, the C-A fractal method has been widely used in mineral prediction [
10], which is particularly useful for identifying geochemical anomalies. For the identification of deeper-level anomalies, the S-A method and singularity analysis method have shown advantages [
14,
15]. It is well known that supervised machine learning methods rely on well-defined mineralization types with good features in different geological environments to label geochemical indicators and sample classifications. The prediction of uncertain areas using supervised machine learning methods, which utilize large amounts of data and information, can be challenging, especially in different geological environments with different features and background values. In contrast, unsupervised machine learning techniques, such as cluster analysis, do not require sample classifications but require expert validation to determine the number and meaning of clusters [
16,
17,
18].
The purpose of this study is to incorporate multiple fractal singular results into the unsupervised learning algorithm of clustering principal components, in order to enhance the identification of abnormal geochemical indicators in the Taiwan Strait Basin. There are more than twenty geochemical indicators for oil and gas in the Taiwan Strait Basin. If we perform calculations on all indicators, it could lead to the incorporation of extensive and comprehensive data information. However, if there is redundant information in these data that may affect the calculation results, it is necessary to eliminate this useless information. In this study, unsupervised machine learning methods and comprehensive singularity analysis methods are used to identify abnormal geochemical indicators in the Taiwan Strait Basin. This strategy aims to identify unknown favorable areas that cannot be explained by the currently available surface indicators. The findings of this study strongly endorse the efficacy of abnormality detection in geochemical data and clustering principal component methods for mineral exploration in the Taiwan Strait Basin.
Oil and gas exploration in the Taiwan Strait Basin commenced in the late 20th century. Numerous organizations, including the Second Marine Geological Survey Brigade of the Ministry of Geology and Mineral Resources, the Guangzhou Marine Geological Survey Bureau, the State Oceanic Administration, the Chinese Academy of Geological Sciences, and various domestic and foreign oil companies, have conducted exploration activities in the region utilizing a range of techniques, such as gravity, magnetic, electrical, seismic, and geochemical surveys, leading to significant exploration accomplishments. The Guangzhou Marine Geological Survey Bureau has carried out extensive fundamental research in the area. The results from gravity, magnetic, seismic, and geological studies have identified three sets of promising hydrocarbon source rock series in the Taiwan Strait Basin, namely the Paleogene, Eocene, and Miocene. The reservoirs primarily comprise Paleogene and Eocene tidal sandstones, while the regional cap rocks are made up of Miocene and Quaternary mudstones. Previous studies on the Taiwan Strait Basin have predominantly focused on the tectonic and sedimentary evolution, with less emphasis on utilizing oil and gas indicators for prospecting analysis. This article presents a novel approach utilizing unsupervised machine learning-based singularity patterns to identify local variability and spatial structural information of anomalies in the Taiwan Strait Basin. The method, which combines spatial statistical analysis and singularity assessment, not only accounts for the spatial correlation and variability of field values but also effectively captures the local singularity of the field. This technique is employed to analyze geochemical data related to oil and gas indicators in the Taiwan Strait Basin, aiming to delineate the comprehensive anomaly zones of these indicators. The results offer valuable insights for oil and gas exploration and evaluation in the region. Conducting geochemical exploration for oil and gas in the Taiwan Strait Basin and investigating the response characteristics and distribution patterns of oil and gas indicators can provide direct evidence indicating the presence of deep oil and gas reservoirs. Geophysical and petroleum geological studies suggest that the Taiwan Strait possesses significant oil and gas potential, with oil and gas flows identified in the Jiulong River depression. To further assess the hydrocarbon potential of other structures, it is essential to conduct geochemical anomaly analyses to obtain direct evidence of oil and gas presence. Currently, CNOOC has undertaken drilling activities in the central and southern regions of the Taiwan Strait, leading to the discovery of several gas fields in the eastern area. These findings validate our analysis of the region and will support our future exploration efforts. In this study, we constructed the singularity pattern (LSP) based on unsupervised machine learning, as well as the hybrid models (PCA-LSP, CLA-PCA-LSP) that combine the singularity model with dimensionality reduction techniques. The effectiveness of these models in identifying geochemical anomalies in multiple indicators in the Taiwan Strait Basin was evaluated. These models include: (1) singularity index model; (2) the extraction of components and deep features of original indicator data using PCA and singularity index dimensionality reduction methods, respectively; (3) the selection of variables in the indicator dataset using the CLA method and the extraction of components and deep features of the indicator dataset using PCA and LSP, respectively.
Previous studies on the Taiwan Strait have primarily concentrated on fundamental basin analyses, employing traditional statistical methods to delineate anomalies. In contrast, this study utilizes unsupervised machine learning and singularity analysis to examine the Taiwan Strait, allowing for the identification of low, gentle, and weak anomaly areas that traditional methodologies cannot reveal. The significance of these identified anomaly areas has been corroborated through subsequent geophysical analyses.
2. Study Area and Data
2.1. Geological Setting
The Taiwan Strait Basin is a Cenozoic continental margin rift basin that developed within an intracontinental extensional setting. Subsequently, it became superimposed on a foreland basin and displays a structural configuration characterized by four depressions and two uplifts: the Jinjiang Depression, Hsinchu Depression, Jiulongjiang Depression, Taichung Depression, Pengbei Uplift, and Miaoli Uplift. The basin is intersected by three sets of faults oriented northeast (NE), northwest (NW), and nearly south–north (SN) (see
Figure 1). The western section of the Taiwan Strait Basin, known as the Taixi Basin, is situated in the northern part of the Taiwan Strait, with its western boundary defined by the coastal fault zone located east of the Zhejiang–Fujian Uplift. The eastern boundary is marked by the Quchi-Laocong Fault, which lies west of the Central Mountain Range in Taiwan. To the north, the basin is bordered by the Guanyin Uplift, separating it from the East China Sea Shelf, while to the south, it is delineated by the Penghu–Beigang Uplift, which separates it from the Pearl River Mouth Basin and the southwestern Taiwan Basin. The Taiwan Strait Basin encompasses an area of approximately 39,000 km
2.
The Jinjiang Depression is a narrow and elongated half-graben with east-dipping and west-overlapping faults. The strata thicken from west to east, and the sediment source is mainly from the west side of the Min-Zhe Uplift, transported from west to east. The sediment on the west side is coarser, while the sediment near the depositional center on the east side is finer. Therefore, the better reservoir rocks should be on the west side, while the source rocks should be on the east side. According to the analysis [
19] of the basin’s evolution and sedimentary patterns, there are shale deposits from the Paleogene syn-rift period, including lake and fan-delta sediments. These shales should be rich in organic matter due to the semi-closed environment, making them good source rocks for oil generation. The deep depression zone on the eastern margin of the basin is the oil generation center. Preliminary geochemical maturity simulations show that the Paleogene source rocks in the central part of the basin entered the mature stage in the Eocene, and the generated oil and gas can be accumulated in the sand layers of the Paleogene, with the shale of the Eocene as the main cap rock. Therefore, the Paleogene is the most prospective formation for oil and gas accumulation in this basin. Although the lower Eocene is mainly shale, the thin sand layers within it may also contain oil and gas [
20].
The Jinjiang Depression and Jiulongjiang Depression have similar petroleum geological conditions. In the central part of the Jiulongjiang Depression, lacustrine deposits of the Eocene/Oligocene have been encountered, and it is also possible that the Paleogene strata in the Jinjiang Depression contain good quality lacustrine source rocks. Based on seismic facies analysis, the Eocene formations are interpreted to represent delta plain to delta front environments, which may also contain fair to good quality source rocks [
19].
2.2. Geochemical Data
The data presented in this study were collected from the Jiulongjiang Depression and Jinjiang Depression within the Taiwan Strait Basin. The indicators utilized in the analysis include acid-extractable hydrocarbons, thermally released hydrocarbons, total aromatic hydrocarbons and their derivatives, weathered carbonates, and microorganisms. Acid-extractable hydrocarbons were analyzed using an Agilent 7890A gas chromatograph (Agilent Technologies, Santa Clara, CA, USA), employing the GBW(E)061164 nitrogen-based C1-C5 mixed gas standard for calibration. The results are expressed as the volume of each hydrocarbon component per unit mass of the sample, in μL/kg. The thermally released hydrocarbons were also analyzed using an Agilent 7890A gas chromatograph from Agilent Technologies, USA, with GBW(E)061164 nitrogen-based C1-C5 mixed gas standard substance. The results are expressed as the volume of each hydrocarbon component per unit mass of the sample, in μL/kg. The weathered carbonates were analyzed using a GXH-1050 infrared gas analyzer from Beijing Jufang Physical and Chemical Technology Research Institute (Beijing, China), with two high-precision temperature-controlled furnaces as auxiliary instruments, and GBW(E)0060856 nitrogen-based carbon dioxide gas standard substance. The main measurement was the volume percentage of carbon dioxide in the decomposed gas of the sample at 500–600 °C, which was used to measure the content of weathered carbonate components in the sample. ΔC represents weathered carbonates, with units of 10−2. The total amount of aromatic hydrocarbons and polycyclic aromatic hydrocarbons was analyzed using an LS55 fluorescence spectrophotometer from PE Corporation, Boston, MA, USA, with spectroscopically pure naphthalene as the standard substance. This measurement was mainly used to quantify the content of polycyclic aromatic hydrocarbons in the sample, with units of 10−6. The sediment soil samples for oil and gas microbiological detection were collected at a depth of 20 cm underwater. After being frozen and stored, they were transported to the laboratory for analysis. The MV value represents the abundance of original hydrocarbon microorganisms.
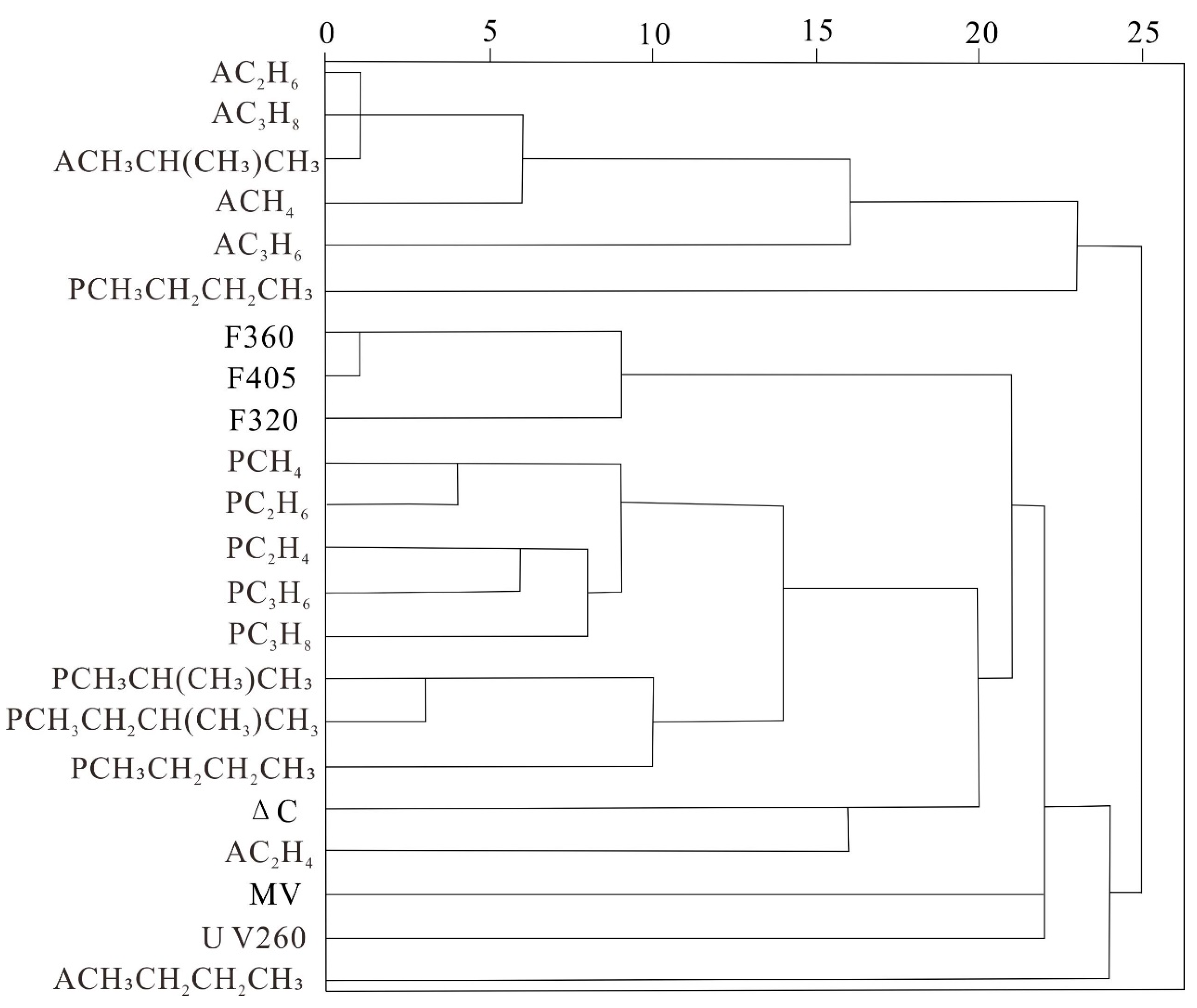
The indicators used in the study include: Acidolysis hydrocarbon methane (ACH4), Acidolysis hydrocarbon ethane (AC2H6), Acidolysis hydrocarbon ethylene (AC2H4), Acidolysis hydrocarbon propane (AC3H8), Acidolysis hydrocarbon isobutane (ACH₃CH(CH₃)CH₃), Acidolysis hydrocarbon propylene (AC3H6), Acidolysis hydrocarbon n-butane (ACH₃CH2CH2CH₃), Total polycyclic aromatic hydrocarbons 320 nm (320 nmF320), Total polycyclic aromatic hydrocarbons 360 nm (360 nmF360), Total polycyclic aromatic hydrocarbons 405 nm (405 nmF405), Pyrolyzed hydrocarbon methane (PCH4), Pyrolyzed hydrocarbon ethane (PC2H6), Pyrolyzed hydrocarbon ethylene (PC2H4), Pyrolyzed hydrocarbon propylene (PC3H6), Pyrolyzed hydrocarbon propane (PC3H8), Pyrolyzed hydrocarbon isobutane (PCH₃CH(CH₃)CH₃), Pyrolyzed hydrocarbon isopentane (PCH3CH2CH(CH3)CH3), Pyrolyzed hydrocarbon n-butane (PCH₃CH2CH2CH₃), Pyrolyzed hydrocarbon n-pentane (PCH₃CH2CH2CH₃), Erosion carbonate (ΔC), MV (exclusive hydrocarbon oxidizing bacteria content), and Total aromatics and their derivatives 260 nm (UV260).
3. Methods
3.1. S-A
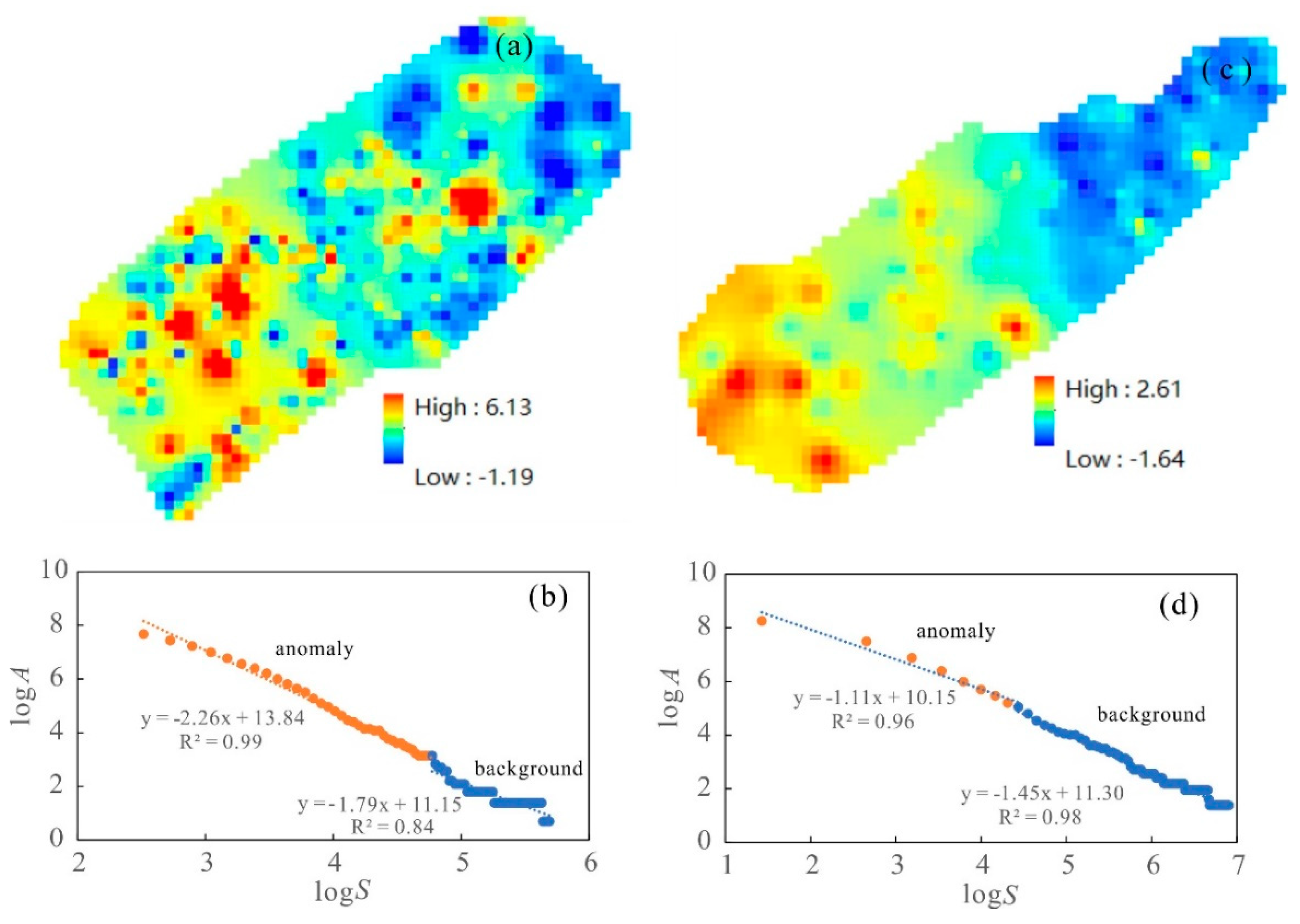
The S-A model is characterized by a power–law relationship expressed as:
where
S represents the energy spectral density. When the energy spectral density is set to a critical value
S0, A denotes the area where
S >
S0.
By taking the logarithm of the aforementioned equation, we applied the least squares method to fit the relationship between (log A) and (log S) in a piecewise manner to determine the power index β across various spectral density ranges. In the (log A)–(log S) plot, all linear segments conform to the power–law relationship. Each segment corresponds to a distinct fractal relationship, with different segments representing varying fractal characteristics. The x-coordinate value at the intersection of each segment defines the threshold value for the fractal filter. Utilizing these thresholds, we are able to construct the background and anomaly filters, thereby facilitating the separation of background and anomalies by transforming them into the spatial domain using these filters.
3.2. LSP
The developed method of local singularity analysis can be used to delineate and quantify the degree of singularity of multiscale geochemical, geophysical, and other types of local anomalies. The principle is to decompose the field values defined within a small range into two components based on the scale scaling of the field (
) [
21]. There are two components related to the measurement scale unit of density (c) (such as units of g/
): one is the scale component
independent of the measurement scale unit, and the other is the density component with density characteristics. The measurement unit can be g/
, which can be called fractal density [
22]. The exponent α in the latter corresponds to the fractal dimension of space. The method of local singularity analysis actually measures the intensity or density of the field in fractal space to determine the fractal density c and the fractal dimension α. The difference between the fractal dimension and the normal Euclidean dimension
(for two-dimensional fields) represents the difference in spatial dimension between fractal density and normal density. When
is not an integer, the density is called fractal density, and as the measurement range decreases, such as when ε approaches 0, the density becomes infinitely large or infinitely small. When the density belongs to fractal density and
, as the measurement range decreases, such as when ε approaches 0, the density becomes infinitely large and exhibits nonlinear singular characteristics such as non-smoothness, instability, and non-convergence at that position. Conversely, when the density belongs to fractal density and
, as the measurement range decreases, such as when ε approaches 0, the density of the field approaches 0 and exhibits nonlinear singular characteristics such as high-order derivative non-existence, non-smoothness, instability, and non-convergence at that position. Only when
, the density is independent of the size of the measurement range. From the perspective of geochemical fields, regions with positive singularity (
) correspond to enrichment areas of elements, while regions with negative singularity (
) correspond to depletion areas of elements. Regions without singularity correspond to background fields, which generally occupy the majority of the range [
21,
23].
In a two-dimensional environment, the model for local singularity analysis is defined as follows:
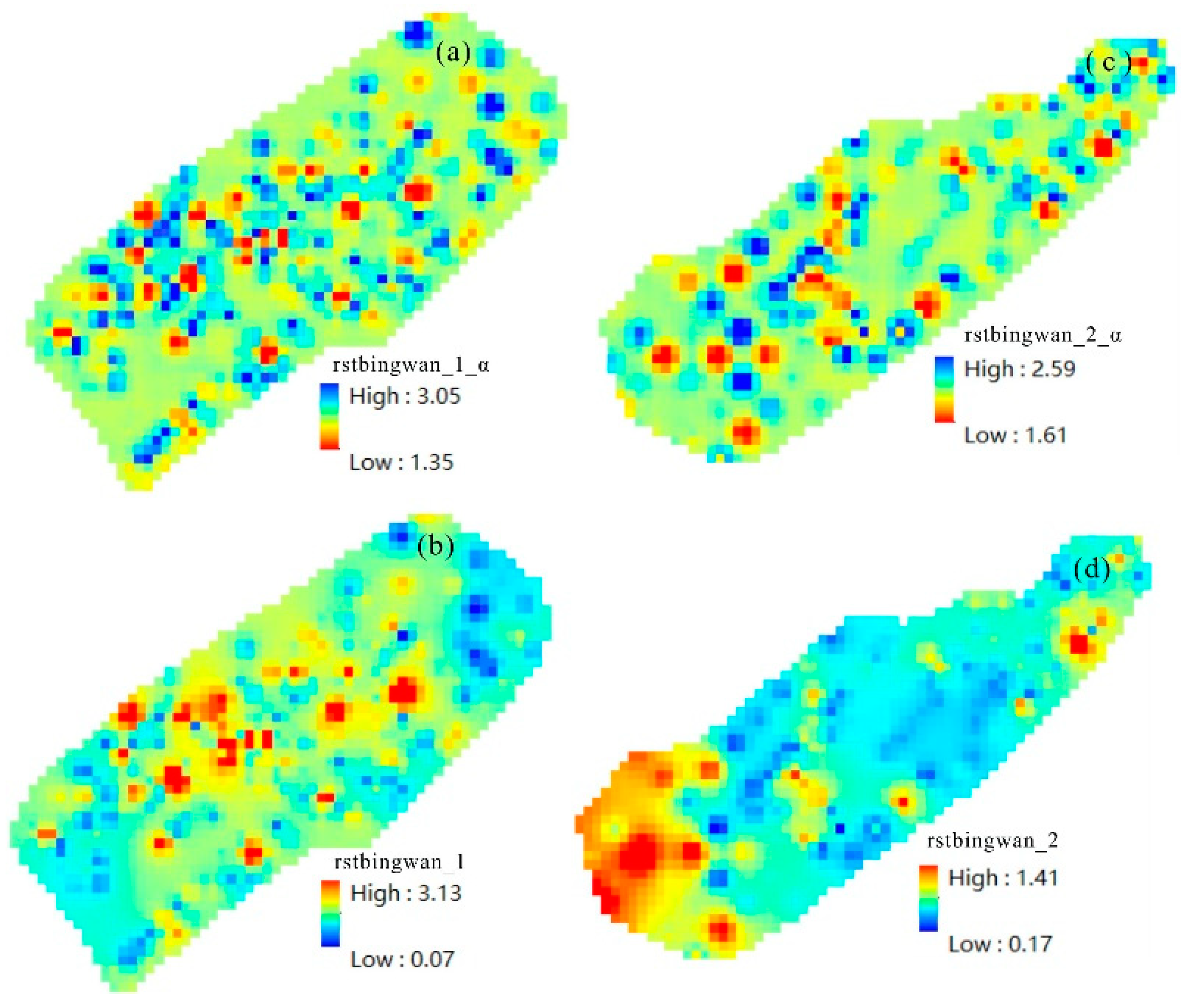
In the equation above, c represents a constant, while α denotes the singularity index. The calculation process for the singularity index is as follows:
First, we define a set of rectangular windows of size e centered on the sample point. Next, we plot the concentration of the indicator against the window size e across all rectangular windows
C(e) using a double logarithmic scale. Subsequently, we apply the least squares method to fit the data and determine the slope k of the double logarithmic plot, which is used to estimate the singularity index α, defined as (k + 2). Finally, by repeating these steps for all sample positions, we can obtain the spatial distribution of the singularity index.
3.3. PCA-LSP
Principal component analysis (PCA) is a widely utilized technique for dimensionality reduction that effectively retains the essential information and structure of data within a lower-dimensional space [
24,
25]. The primary objective of PCA is to transform a set of originally correlated variables (e.g., P indicators) into a new set of uncorrelated composite indicators. This transformation is accomplished through the linear combination of the original P indicators to generate new composite indicators.
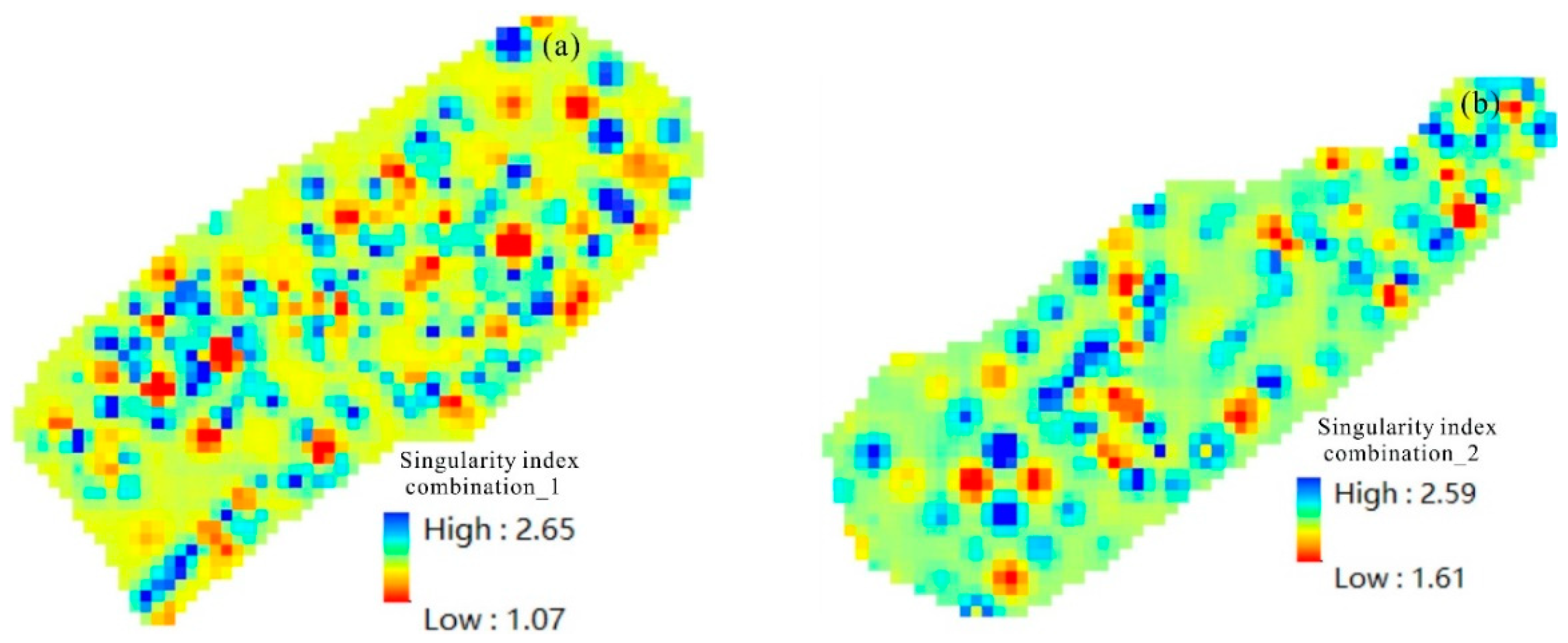
In this context, the variance of the first linear combination, denoted as Var(F1), is of particular interest. A greater Var(F1) signifies that the first principal component, F1, encapsulates more information. Consequently, F1 is selected as the linear combination that exhibits the highest variance. If F1 does not sufficiently represent the information contained in the original P indicators, the analysis proceeds to consider the second linear combination, F2. To ensure that F2 effectively captures distinct information, it is essential that the information represented by F1 does not overlap with that of F2. This requirement is mathematically expressed as Cov(F1, F2) = 0, with F2 being designated as the second principal component. This iterative process can be continued to derive additional principal components, including the third, fourth, and up to the Pth component. By combining PCA with singularity analysis, a joint model called PCA-LSP is established. In this study, a new method is proposed where PCA is applied to the original data first, followed by singularity analysis, with the aim of extracting comprehensive abnormal information from the indicators.
The covariance matrix is constructed from the covariances of multiple random variables. Let the dataset consist of n samples, each containing d features, which can be represented as an n times d matrix X. If the mean of each feature is denoted as u, the covariance matrix E can be calculated using the following formula:
where (X − u) represents the centering of each sample by subtracting the mean u. Consequently, each element of the covariance matrix corresponds to the covariance between the respective features.
3.4. CLA-PCA-LSP
Cluster analysis (CLA) has proven effective in extracting and distinguishing elements closely associated with mineralization events [
26,
27,
28,
29]. The fundamental principle of CLA is to identify the internal structure and patterns within the dataset, thereby enhancing the understanding of its composition and characteristics. By iteratively grouping variables that exhibit high correlations, CLA can identify key indicator variables [
26,
28]. This method is classified as unsupervised learning, and the relationships between variables can be visualized using a dendrogram. Variables are assigned to distinct clusters based on an appropriate similarity threshold, which is typically determined by correlation coefficients.
In this study, we employed a hybrid approach that integrates cluster analysis, principal component analysis, and singularity analysis to identify anomalous characteristics of oil and gas indicators in the study area. Following the grouping obtained from cluster analysis, the principal component analysis was performed on the indicators to derive comprehensive results. Subsequently, the singularity analysis was utilized to define the range of combined anomalies. For the r-type clustering analysis of the indicators, we applied the (1—Pearson r) distance metric along with the complete linkage hierarchical clustering method.
5. Conclusions
This study investigates the application of nonlinear theory and methods, and unsupervised machine learning algorithms for data processing and anomaly delineation of geochemical indicators in the Taiwan Strait Basin. Local singularity principle (LSP), combined with principal component analysis (PCA) and clustering analysis, was used to comprehensively analyze the geochemical indicators and identify anomalies. The following conclusions are drawn:
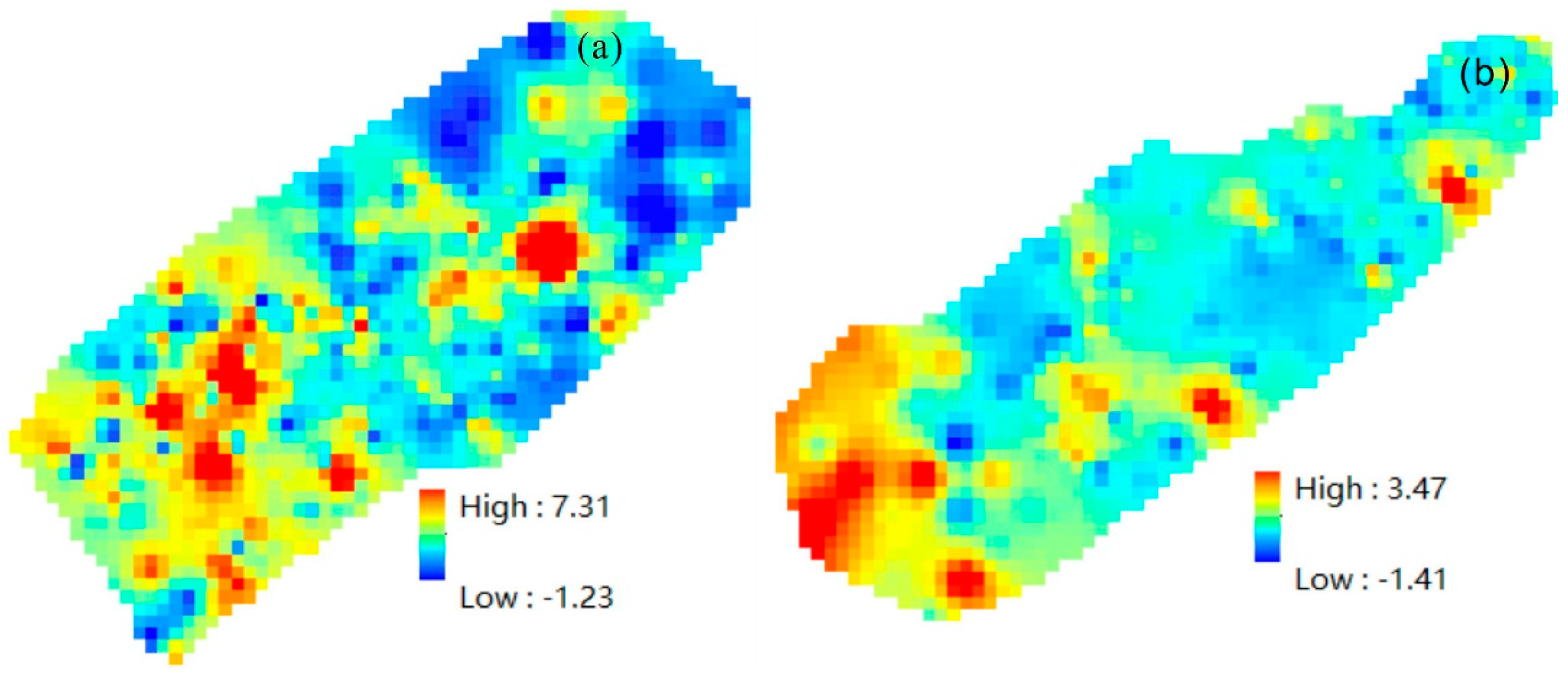
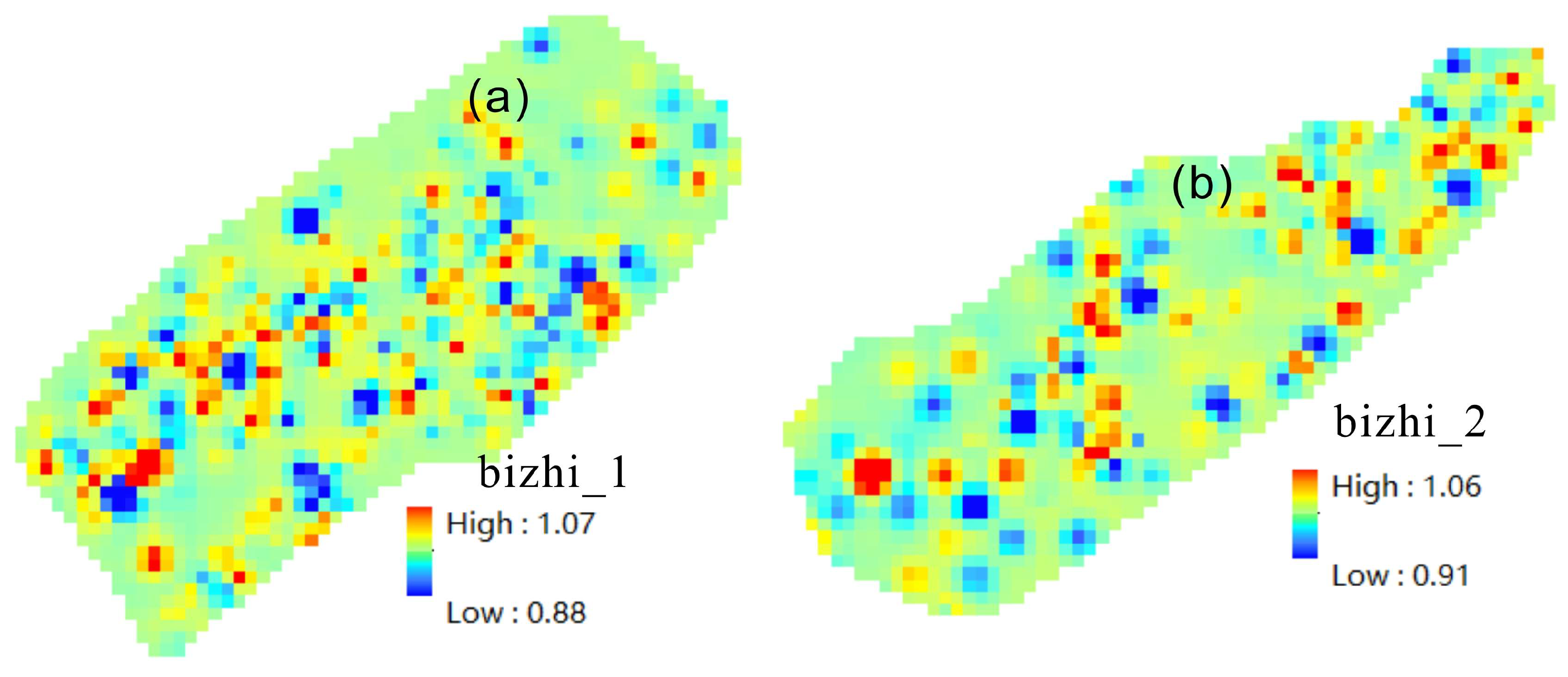
The local singularity principle and the generalized self-similarity principle were applied to extract geochemical information of oil and gas indicators in the Taiwan Strait Basin, highlighting key techniques such as identifying weak anomalies, decomposing complex anomalies, and integrating spatial information. The combination of local singularity principle and the S-A method delineates composite anomalies that not only reflect the spatial relationship with known oil and gas reservoir distributions but also reveal multiple composite anomalies in unknown areas. Although these anomalies exhibit different characteristics and diversities in terms of intensity and size, they exhibit self-similarity in the frequency domain.
The use of unsupervised machine learning algorithms for extracting all oil and gas indicators improves model performance and reduces the complexity of multiple calculations. For the Jiulongjiang Depression and Jinjiang Depression study areas, a clustering analysis was applied to extract indicators, followed by a principal component analysis and the calculation of their singularity index to select favorable oil and gas indicators for exploration analysis, thereby improving the efficiency of anomaly delineation calculations.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}