1. Introduction
In today’s digitally connected world, the proliferation of user-generated content has amplified concerns about fairness, neutrality, and bias in textual communication. As readers increasingly depend on online platforms such as Wikipedia, social media, and news websites for information, the subtle insertion of subjective or biased language can mislead public opinion, shape ideologies, and exacerbate societal divisions [
1,
2]. Textual bias not only compromises the quality and objectivity of content but also poses challenges for maintaining ethical standards in information dissemination [
3,
4]. Detecting and correcting biased text has therefore become a critical research challenge in natural language processing (NLP), with applications in journalism, social media moderation, political discourse analysis, and algorithmic content filtering [
4,
5,
6].
Bias in text can manifest in various linguistic forms, including epistemological bias, framing bias, and demographic bias [
7]. Traditional machine learning approaches, while effective in some domains, often lack the contextual sensitivity required to detect such nuances [
8]. The emergence of pretrained language models like BERT [
9,
10] and DistilBERT [
11] has significantly improved context-aware text classification, offering promising directions for bias detection. Yet challenges remain in capturing the intricacies of biased language, particularly when evaluating fairness and consistency across domains. Furthermore, model interpretability and robustness under real-world constraints continue to be pressing concerns [
12,
13].
Recent research in bias detection has expanded beyond simple bag-of-words and SVM classifiers to include a variety of context-sensitive architectures. Hybrid CNN-LSTM pipelines increase recall on framing bias tasks [
14], whereas attention-augmented transformers like RoBERTa and XLNet are more resilient to domain shifts [
15,
16]. At the same time, generative techniques employing sequence-to-sequence frameworks have shown promise in automatically rewriting biased sentences, though typically at the expense of efficiency [
17]. Our approach differs in that it combines convolutional, recurrent, and adversarial components on top of both the BERT and DistilBERT backbones, merging local pattern extraction and global dependency modeling into a single pipeline.
The Wiki Neutrality Corpus (WNC) provides a robust foundation for studying bias in textual data. Comprising a parallel corpus of 181,496 biased-neutralized sentence pairs, 385,639 neutral sentences, and 55,503 biased-word phrases, the WNC spans a wide range of topics with strong representation from politics, philosophy, sports, and history. The dataset is especially valuable for supervised learning tasks, allowing researchers to model the distinction between biased and neutral content at both the phrase and sentence levels. Sentence alignment in the WNC was accomplished using pairwise BLEU scores to ensure high-quality linguistic comparisons.
Despite being enormous, the Wiki Neutrality Corpus has several inherent limits that should be carefully considered. Many “biased edits” were made by a small core of active contributors, resulting in noisy or inconsistent annotations that may not represent true editorial intent [
18]. Second, the corpus was obtained entirely from English-language Wikipedia, which lacks adequate linguistic and cultural variety, limiting the generalizability of any model trained on these data to other languages or dialectal variants [
19]. The traditional assessment criteria (e.g., BLEU-based alignment scores) employed during the WNC’s design frequently overestimate performance estimates by rewarding surface-level n-gram overlap rather than really neutralized rewriting [
20]. Recognizing these aspects is critical for understanding baseline and suggested model findings.
Beyond technological performance, there is an undeniable societal imperative to eliminate prejudiced wording in digital information. In educational contexts, exposure to subtly skewed texts can promote prejudices and impede critical thinking skills. In news and social media, unchecked bias can polarize communities and erode public trust [
21,
22]. By creating more transparent and robust bias detection methods, we hope to not only increase algorithmic fairness but also assist curricula that promote media literacy and inclusive discourse in both formal and informal learning settings.
This paper presents a comparative study of several machine learning and deep learning methodologies and proposed models for bias detection. In addition to classical ensemble models such as XGBoost [
23], LightGBM [
24], and CatBoost [
25], we introduce two novel hybrid architectures: (1) a BERT + CNN + Attention model, and (2) a DistilBERT + LSTM + GAN model, where LSTM stands for Long Short-Term Memory [
26] and GAN refers to a Generative Adversarial Network [
27]. These hybrid models are designed to exploit both local word-level patterns and global contextual dependencies, improving the detection of subtle biased cues. By integrating convolutional operations with self-attention mechanisms and employing generative adversarial training, our models enhance sensitivity to lexical distortions and stylistic shifts in language.
On the WNC dataset, our models significantly outperform baseline algorithms. The BERT + CNN + Attention model achieves an accuracy of 98.0%, with an F1-score of 0.9770, while the DistilBERT + LSTM + GAN model yields an impressive 99.0% accuracy and a corresponding F1-score of 0.9898. These results reflect a notable advancement in bias detection performance and underscore the effectiveness of combining state-of-the-art pre-trained models with specialized deep learning modules. The use of repeated 10-fold cross-validation, statistical hypothesis testing, and model interpretability analyses further reinforces the robustness and reliability of our evaluation methodology. Our key contributions are summarized as follows:
We propose two novel hybrid neural architectures (BERT + CNN + Attention and DistilBERT + LSTM + GAN) that achieve state-of-the-art performance in bias detection on the WNC dataset.
We conduct an extensive empirical study on multiple subsets of the WNC, including biased–neutralized pairs, neutral-only sentences, and single-word bias edits, highlighting generalization and cross-domain robustness.
We adopt rigorous evaluation protocols, including 10-fold cross-validation, paired t-tests, and attention visualization techniques, to ensure model transparency and statistical reliability.
We investigate the role of advanced feature engineering techniques, including word embeddings [
28], attention mechanisms [
12], and linguistic meta-features [
13], in enhancing bias detection performance.
We contextualize our research in real-world scenarios such as journalism, content moderation, and political media analysis, underscoring the broader societal importance of reliable and fair NLP systems [
1,
4,
5].
By offering a detailed and statistically validated comparison of multiple machine learning and deep learning models, and by introducing powerful hybrid architectures, this work contributes to the advancement of fairness-aware NLP. The results and insights from this study are intended to inform future research and system development aimed at fostering unbiased communication in online environments.
2. Related Work
The detection and mitigation of bias in textual data have garnered significant attention in recent years due to their profound implications for fairness, accountability, and trust in artificial intelligence (AI) systems. The existing literature spans a wide array of techniques, ranging from classical machine learning (ML) approaches to cutting-edge transformer-based models and adversarial frameworks. While much of the bias detection literature focuses on algorithmic improvements in isolation, it is critical to see these techniques as vital components of our common social reality. Textual bias can alter individual comprehension, impact public discourse, influence electoral outcomes, and affect educational equity whether in news reporting, social media feeds, or classroom materials [
29]. By situating technical research within the broader socio-ethical landscape, we ensure that methodological innovations serve concrete societal needs, ranging from countering misinformation during public health crises to fostering inclusive learning environments, rather than simply benchmarking improvements on static datasets [
30].
Recent investigations have emphasized both the therapeutic limitations and evaluation risks associated with LLM-based systems. Basar et al. Conducted a comprehensive human evaluation of LLM-generated reflections in motivational interviewing (MI), revealing that, while models like GPT-4 and Llama-2 can produce contextually appropriate outputs, they often fall short in emotional nuance and therapeutic relevance [
31]. In parallel, Balloccu et al. exposed large-scale data contamination and benchmarking malpractices in closed-source LLMs, highlighting reproducibility issues, evaluation biases, and inadvertent leakage of benchmark data [
32]. These studies underscore the critical need for transparent evaluation practices and ethically grounded LLM applications, particularly in high-stakes domains such as bias detection and therapeutic dialogue.
ElGhawi et al. (2024) conducted a comparative study on bias detection in Arabic media, particularly focusing on the Israel–Gaza conflict, and found that classical machine learning models such as Random Forest outperformed deep learning models, achieving an accuracy of 93% [
33]. While this study demonstrated the relevance of traditional classifiers in specific contexts, it highlighted a limitation in generalizability and adaptability, particularly for multilingual or culturally diverse datasets. Similarly, Liu and Chu (2025) explored the effectiveness of large language models in detecting stereotypical biases and found that the Open Pretrained Transformer model with 1.3 billion parameters (OPT-1.3b) achieved the highest accuracy of 98.20% [
34]. Despite these impressive results, such large-scale models raise concerns about computational costs and energy efficiency, limiting their practical deployment in resource-constrained settings.
To address inconsistency in human-labeled datasets, Blqees et al. (2024) incorporated AI-assisted annotation to improve labeling uniformity in news articles related to geopolitical conflicts [
35]. However, their work did not assess the downstream effects of improved annotation on model performance. On another front, Dragomir (2025) demonstrated the integration of natural language processing (NLP) and behavioral analysis in AI systems to reduce cognitive bias in security and risk-based decision-making [
36]. While valuable, this work primarily targeted structured domains rather than open-domain or large-scale textual data.
In the area of linguistic analysis, Collins and Boyd (2025) presented an automated pipeline for identifying Linguistic Intergroup Bias using sentiment analysis and abstraction coding [
37]. Their results showed parity with manual assessments, indicating high reliability, yet the reliance on sentiment polarity and abstraction types may not generalize well to implicit bias expressions. Shah et al. (2025) further extended the landscape by proposing a multi-bias detection framework that utilizes advanced language models to identify various forms of bias in news content [
38]. Although this framework offers modular detection capabilities, it lacks robustness against adversarial attacks and rare bias types.
Bias mitigation has also been the focus of several studies. Li et al. (2024) proposed a bias evaluation and mitigation technique for large language models, such as GPT-3 and GPT-4, that uses data augmentation and adversarial training strategies [
39]. This work specifically addressed “generative artificial intelligence”, which pertains to models explicitly trained to generate novel text, as opposed to the more expansive notion of “general AI”. ChatGPT-3.5 is a prominent example, but our discussion also extends to other large-scale generative systems such as Claude 3.5 (Anthropic, 2025), Gemini 1.5 Ultra (Google DeepMind, 2025), GitHub Copilot Workspace (GitHub, 2025), DeepSeek-Coder V2 and DeepSeek-VL 1.5 (DeepSeek, 2025) and Qwen 2 (Alibaba Cloud, 2025, which employ similar transformer architectures and raise comparable concerns about bias propagation and editorial neutrality [
40,
41,
42]. Their work successfully addressed race, gender, and political bias, but focused solely on evaluation rather than integrating detection and mitigation in a unified framework. Smith et al. (2025) also utilized adversarial examples and bias-aware loss functions to reduce discriminatory outputs from language models [
43]. While effective, their framework assumed pre-annotated data for training, limiting its scalability to emerging bias types.
LangBiTe, an open-source tool developed collaboratively by researchers from Universitat Oberta de Catalunya and the University of Luxembourg (2024), showcases a multilingual and multi-domain system for detecting political, gender, and xenophobic biases in AI-generated content [
44]. However, it mainly emphasizes post-generation filtering rather than proactive bias recognition during text generation. In a domain-specific application, Johnson et al. (2025) analyzed gender prejudice in film reviews, exposing significant disparities in how female-led films are critiqued [
45]. Similarly, her Ethical AI (2024) examined gender-biased language in UK family court rulings, uncovering systemic victim-blaming tendencies and advocating for judicial reform [
46]. These studies, while impactful in their respective fields, underscore the need for generalized models capable of recognizing a wide spectrum of bias types in both structured and unstructured text.
Taken together, these studies reveal the progress and diversity of approaches in bias detection. Nonetheless, several challenges remain unresolved. Existing models often exhibit trade-offs between interpretability, computational cost, and accuracy. Few approaches combine detection and mitigation in a single unified framework, and many rely on high-resource settings or domain-specific annotations. Furthermore, implicit and context-dependent biases remain difficult to detect using conventional pipelines. While prior studies have explored bias detection using both traditional classifiers and deep learning techniques, many existing approaches rely solely on lexical cues or contextual embeddings without leveraging data augmentation or sequential modeling. For instance, BERT-based models [
47,
48,
49] have been widely applied for identifying biased language, often achieving strong performance on in-domain datasets like the WNC. However, these models typically treat sentences independently and overlook the temporal structure or syntactic flow of language. Meanwhile, LSTM-based architectures [
50,
51] provide some degree of sequential understanding but lack access to rich contextual representations from large pretrained transformers. In parallel, adversarial learning techniques have been applied in related NLP tasks, yet their use in bias detection, particularly for rare or subtle bias forms, remains underexplored.
In contrast, our proposed hybrid model uniquely integrates three complementary modules: a distilled transformer (DistilBERT) for efficient contextual encoding, BiLSTM for capturing long-range sequential dependencies, and a GAN-based augmentation pipeline to synthesize rare biased instances and mitigate class imbalance. This tri-layer design enables the model to generalize beyond shallow lexical bias cues, making it more effective in capturing pragmatic, subtle, and epistemological biases. To our knowledge, this is the first work that combines a distilled transformer with both sequence modeling and adversarial data augmentation for bias detection within the WNC and external domains, achieving superior accuracy and generalization compared to existing models.
To address these gaps, our study introduces a novel hybrid architecture that integrates a distilled transformer (DistilBERT), sequential memory modeling (LSTM), and generative adversarial training (GANs). This configuration aims to leverage the contextual sensitivity of transformers, the sequential memory of LSTM networks, and the robustness provided by adversarial learning, enabling more nuanced and generalizable bias detection. Our method not only outperforms classical and deep models but also demonstrates superior performance in capturing complex distortions in large-scale corpora, thereby addressing the limitations observed in previous works.
3. Research Methodology
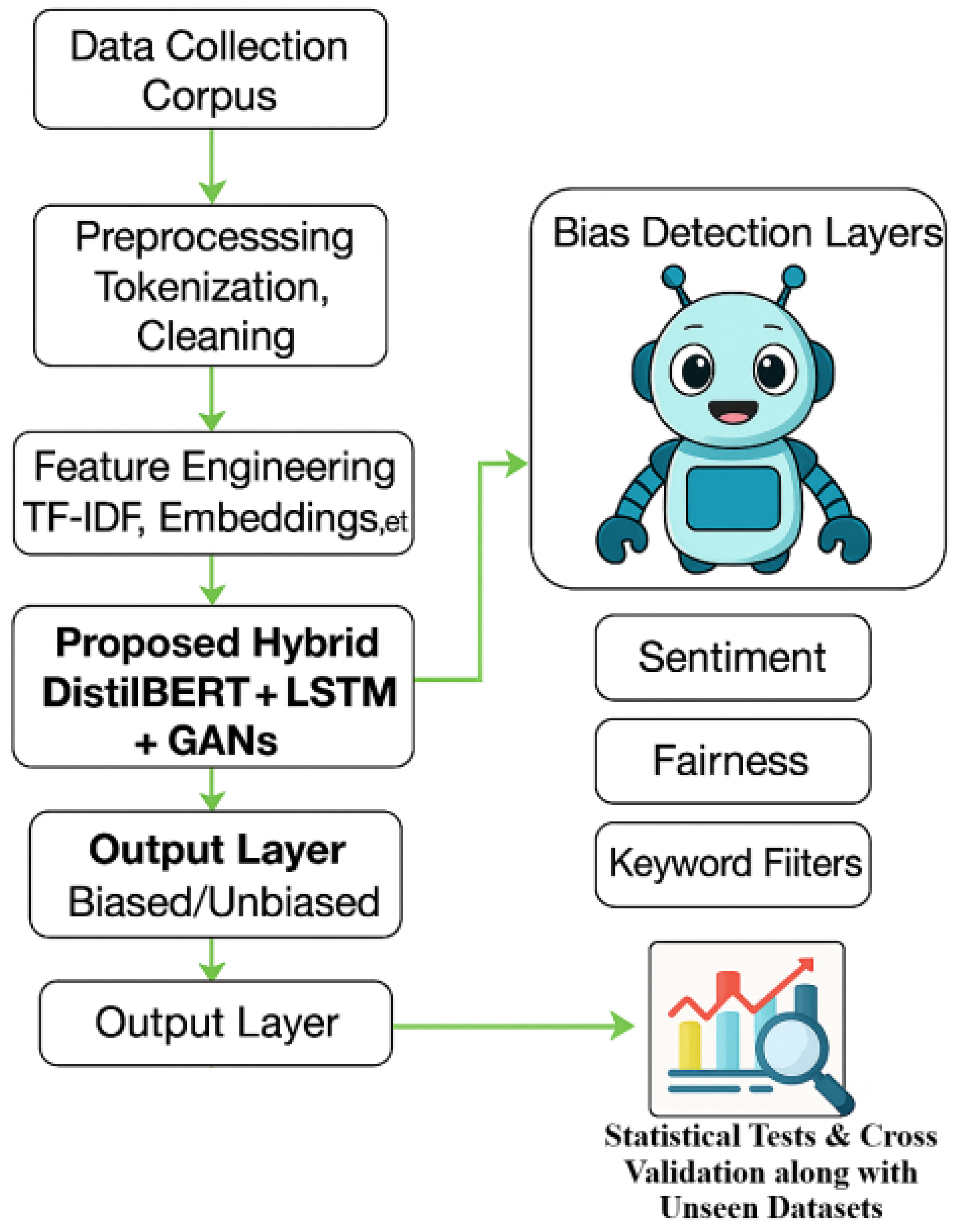
This study presents a comprehensive experimental framework for detecting biased language, leveraging both classical and deep learning approaches, with a central focus on a novel hybrid neural architecture that integrates contextual encoding (DistilBERT), sequential modeling (BiLSTM), and adversarial data augmentation (GAN). The methodology encompasses systematic data preprocessing, extensive feature engineering, model training with advanced optimization strategies, ablation testing, and cross-domain evaluation across diverse textual datasets, as shown in
Figure 1.
To establish robust comparative baselines, a diverse set of models was implemented, including traditional machine learning classifiers (e.g., XGBoost, LightGBM, CatBoost, SVM, KNN, TabNet) and deep neural networks (CNNs, BiLSTMs, transformer-based models, and GPT-3.5). These models represent a range of learning paradigms and were trained with configuration settings tailored to their specific architectural properties. Hyperparameters were optimized using a combination of grid search and Bayesian optimization, with regularization techniques such as dropout, early stopping, and weight decay applied to minimize overfitting and enhance generalizability.
Advanced text preprocessing techniques were employed to refine input data and improve model performance. These included tokenization, lemmatization, punctuation normalization, and stop-word removal. For traditional models, we engineered high-dimensional feature sets comprising TF-IDF scores, POS tags, syntactic features, sentiment cues, and semantic vectors using Word2Vec. For deep learning models, we used contextualized embeddings from transformer-based tokenizers, such as DistilBERT, to retain semantic and positional information. All inputs were standardized to a uniform sequence length for training consistency.
The proposed hybrid architecture, DistilBERT + LSTM + GANs, was trained via a structured optimization pipeline with three phases: the initial freezing of the encoder, joint fine-tuning, and the final adversarial adaptation using 15,000 synthetic samples generated by a WGAN-GP framework. We clarify that our WGAN-GP generator generated 15,000 synthetic phrases, which were concatenated with 120,000 real training instances, resulting in a synthetic-to-real ratio of around 12.5%, to enrich underrepresented bias categories while not overwhelming genuine cases. The choice of 50 training epochs was based on preliminary convergence trials. Most architectures obtained stable validation loss by 30–40 epochs, and extending to 50 gave a safety margin to capture late advances in F1-score without premature halting. Ablation studies on reduced variants (DistilBERT + LSTM without a GAN, and DistilBERT + GAN without LSTM) confirmed the additive performance benefits of each component. Evaluation metrics included accuracy, precision, recall, and F1-score, supported by 5-fold stratified cross-validation to ensure statistical robustness and minimize sampling bias.
To further evaluate the applicability and generalizability in the real world, the model was tested on three external corpora: BABE (news), MBIC (social networks), and a dataset specific to xenophobia. Despite domain shifts, the model consistently achieved high accuracy, demonstrating its ability to generalize beyond the WNC training set and handle diverse linguistic styles and forms of bias. Additionally, GPT-3.5-turbo was evaluated in a zero-shot classification setting via API using templated prompts. Though effective, it achieved slightly lower accuracy and significantly higher latency, highlighting the comparative efficiency of the proposed model.
To promote transparency and replicability, all key implementation details have been documented, including model configurations, hyperparameters, training protocols, and data splits. Random seeds were fixed for all experiments to ensure deterministic behavior. The experiments were conducted using Hugging Face Transformers (v4.30), PyTorch (v2.0), and Scikit-learn (v1.2.2) on NVIDIA RTX A6000 GPUs. The synthetic data generation logic (GAN) followed a fixed initialization protocol. While the full source code cannot be publicly released due to API licensing restrictions (GPT-3.5), detailed pseudocode, architectural schematics, and algorithm workflows are included in the methodology. A curated preprocessing and evaluation script will be made available upon publication.
3.1. Dataset
The Wiki Neutrality Corpus (WNC) is a huge dataset of English Wikipedia edits from 2004 to 2019, created to investigate subjective bias in text [
52]. It includes aligned biased and neutralized phrases, which allow machine learning algorithms to identify and reduce bias. The dataset was vetted by crawling Wikipedia modifications that chose those entries that had actual bias-neutralization adjustments while excluding routine updates. Sentence alignment was performed using pairwise BLEU scores. The WNC is divided into two subsets. An additional subset of 55,503 phrases, dubbed “Biased-word”, includes single-word bias adjustments. The dataset covers a wide range of topics, with a strong tilt toward politics, philosophy, sports, and history. The most common biases include epistemological (25.0%), framing (57.7%), and demographic (11.7%) biases. The corpus is an excellent resource for developing and testing supervised learning models for bias detection.
The Wiki Neutrality Corpus (WNC) [
52] contains the following:
181,496 biased–neutralized sentence pairs (parallel corpus);
385,639 neutral sentences;
55,503 single-word bias edits.
Key characteristics:
Temporal span: 2004–2019 Wikipedia edits;
Domain distribution: politics (42%), philosophy (23%), sports (18%), history (17%);
Bias types: epistemological (25.0%), framing (57.7%), demographic (11.7%), other (5.6%).
3.2. Preprocessing
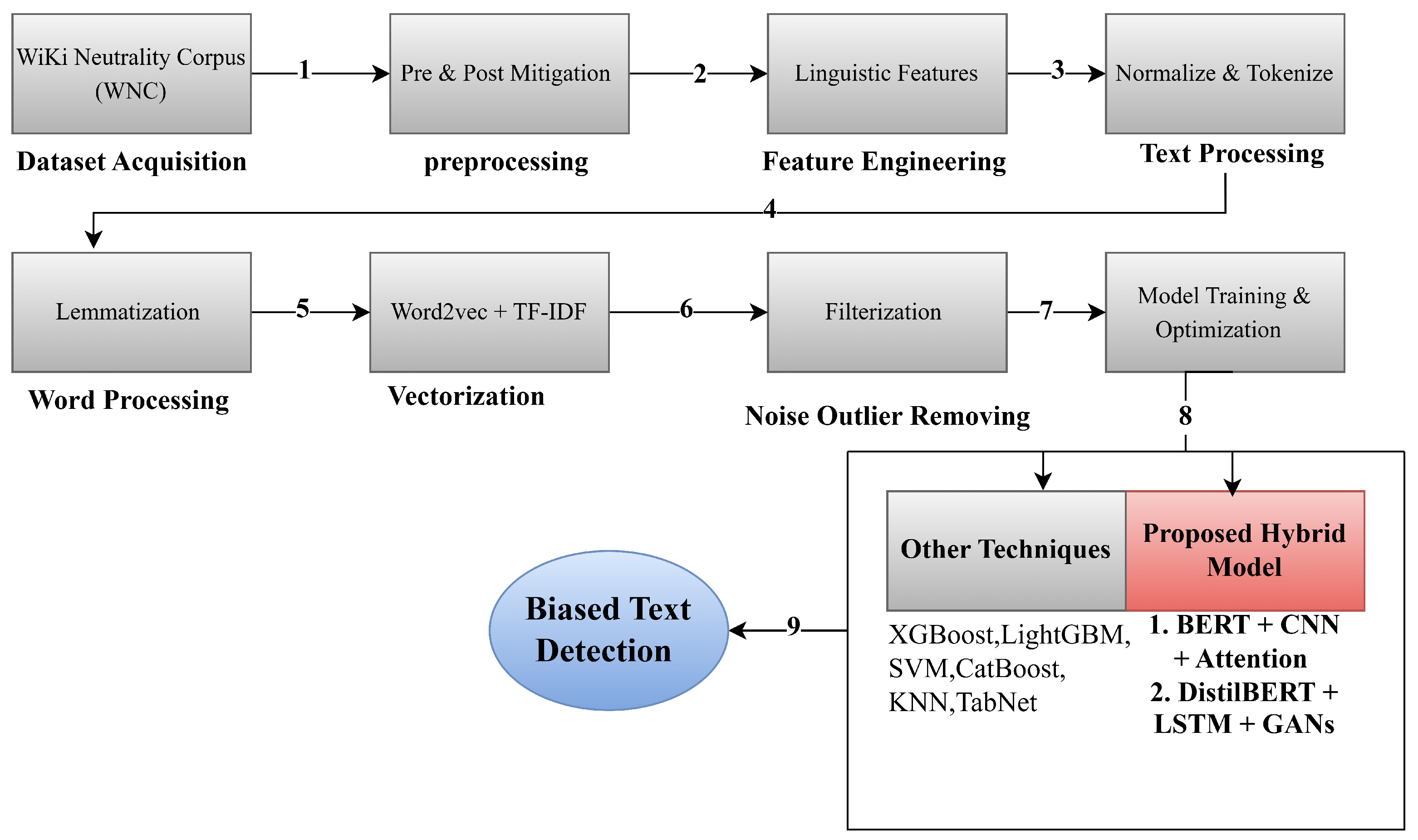
The preprocessing pipeline systematically transforms raw text into enriched, model-ready features while maintaining empirical integrity and ethical sensitivity. The data preparation steps detailed below ensure that data are ethically and empirically prepared, as shown in
Figure 2.
To construct a robust bias classification dataset, we first conducted a comparative analysis of text length distributions before and after bias mitigation, using Seaborn 0.13.2 visualizations to detect structural changes. Token-level dissimilarities between original and de-biased texts were computed, with the first non-matching term flagged as a potential bias indicator.
Text normalization involved lowercasing and Unicode standardization to ensure consistent encoding. Tokenization was performed using a customized SpaCy tokenizer enriched with Wikipedia-specific rules for domain-adapted segmentation. Following tokenization, each sentence underwent multiple layers of linguistic annotation, including Part-of-Speech (POS) tagging, dependency parsing, and semantic role labeling (SRL). These annotations captured syntactic structure and predicate–argument relations, enhancing downstream semantic analysis.
Feature extraction integrated lexical, syntactic, semantic, pragmatic, and bias-specific dimensions. Lexical features included TF-IDF scores and character-level
n-grams (
to 4). Syntactic features comprised POS trigrams and dependency relations. Semantic features were derived from both Word2Vec (300 dimensions) and BERT (768 dimensions) embeddings, providing both static and contextualized representations. Pragmatic signals such as hedges, boosters, and attribution markers were incorporated due to their association with biased discourse. Bias-specific enrichment used sentiment polarity scores from TextBlob and VADER, as well as affective psychological indicators from the LIWC and NRC-VAD lexicons. A comprehensive summary of feature types and dimensionalities is presented in
Table 1. To eliminate fragmentation in our data presentation, related results have been organized into composite tables and unified pipeline diagrams.
Table 1 thus synthesizes all feature dimensions, from lexical to bias-specific, in one location, and
Figure 2 merges the whole data preparation, augmentation, and partitioning procedure into a single end-to-end schematic. This restructure allows the reader to follow the progression from raw edit mining to the final train/test splits without having to navigate between many isolated figures or tables.
To address class imbalance, especially among underrepresented bias categories (e.g., epistemological and demographic), we employed a GAN-based augmentation strategy. The generator, implemented as an LSTM-based seq2seq model, produced 15,000 synthetic samples. A CNN-based discriminator with spectral normalization filtered these based on a confidence threshold of 0.85 to retain high-quality instances. We used pre-trained Word2Vec embeddings because of their efficient convergence and low memory usage, allowing for successful local context modeling with minimal preprocessing. Word2Vec outperformed GloVe and FastText in terms of domain adaption time and resource usage, consistent with the findings of [
53]. For sequence modeling, BiLSTM was chosen over unidirectional LSTM to capture bidirectional dependencies—crucial for recognizing contextual cues like negation—and has been proven to enhance classification accuracy in similar tasks [
53]. Finally, the dataset was transformed into model-compatible formats. Categorical features were label-encoded where necessary. An 80/20 stratified train/test split ensured fair representation across all bias classes, and five-fold cross-validation was adopted to assess model generalizability.
3.3. Model Training and Optimizing
In this study, a comprehensive set of machine learning (ML) and deep learning (DL) models was systematically employed to classify and detect biased terms embedded within the Wiki Neutrality Corpus (WNC). The selection of models included both traditional classifiers and state-of-the-art neural architectures to ensure a well-rounded comparative analysis. Each model was trained using a carefully tailored configuration considering the specific nature and requirements of the model architecture. These configurations encompassed a range of hyperparameters, data preprocessing techniques, and optimization algorithms. The training pipeline was fine-tuned through iterative experimentation, employing methods such as grid search, early stopping, and learning rate scheduling to maximize classification accuracy and ensure generalizability across diverse samples.
Emphasis was placed on achieving not only high accuracy but also robustness against the linguistic variability and semantic complexity inherent in the dataset. The optimization strategies were designed to minimize overfitting and enhance the stability of model predictions across multiple experimental runs. Furthermore, a consistent evaluation framework was used, incorporating metrics such as precision, recall, F1-score, and cross-validation accuracy to assess the overall performance and reliability of each model. This rigorous training and evaluation protocol enabled a fair and informative comparison across all model types, contributing to a deeper understanding of their respective strengths and limitations in detecting linguistic bias, as shown in
Table 2.
3.3.1. XGBoost Classifier
XGBoost was chosen for its efficiency and speed when dealing with unbalanced data records. This model was trained with a binary logistic regression target function and optimized using protocol loss as the evaluation metric. Early stopping was applied if the loss of the validation protocol did not improve in 10 rounds, preventing overfitting. The model was trained with a learning rate of 0.01 for 50 epochs using the Adam Optimizer. To assess robustness, a five-fold cross-validation was performed, as shown in Algorithm 1.
| Algorithm 1: XGBoost Classifier Algorithm |
![Bdcc 09 00190 i001]() |
3.3.2. LightGBM Classifier
LightGBM was selected due to its scalability and capabilities in handling large data records. It uses histogram-based algorithms, providing faster calculations than traditional gradient-boosting methods. Similar to XGBoost, log loss was used as the early stop loss metric, and the model was trained for 50 epochs. A learning rate of 0.05 and the Adam Optimizer were used, with five-fold cross-validation for evaluation, as shown in Algorithm 2.
| Algorithm 2: LightGBM Classifier Algorithm |
![Bdcc 09 00190 i002]() |
3.3.3. Support Vector Machine (SVM)
The SVM was trained using the RBF (Radial Basis Function) kernel to separate classes in a higher-dimensional space. This model was optimized with evaluation metrics including accuracy, precision, recall, and F1-score. Layered k-fold cross-validation was implemented to ensure a balanced class distribution during training. Early stopping was applied if the performance of the validation rates did not improve for 10 consecutive rounds, as shown in Algorithm 3.
| Algorithm 3: Support Vector Machine (SVM) Algorithm |
![Bdcc 09 00190 i003]() |
3.3.4. CatBoost Classifier
CatBoost is ideal for data records with mixed feature types and was chosen for its effective handling of categorical features. This model was trained for 50 epochs with a learning rate of 0.03, and early stopping was based on the loss of the validation protocol. The Adam Optimizer was used, with five-fold cross-validation being used for robust evaluation. Additionally, the model leverages ordered boosting, which helps mitigate overfitting by reducing target leakage in categorical features. CatBoost is a state-of-the-art gradient-boosting decision tree (GBDT) algorithm specifically optimized for datasets with heterogeneous or mixed feature types, including both numerical and categorical variables. In this study, CatBoost was selected due to its native ability to efficiently handle categorical features without requiring extensive preprocessing such as label encoding or one-hot encoding and thereby preserve the semantic relationships within feature distributions. The detailed training process is outlined in Algorithm 4. Feature importance analysis was conducted to identify the most influential variables, ensuring interpretability and enhancing model reliability, as shown in Algorithm 4.
| Algorithm 4: CatBoost Classifier Algorithm |
![Bdcc 09 00190 i004]() |
3.3.5. k-Nearest Neighbors (KNN)
The k-Nearest Neighbors (KNN) model, although simple and non-parametric, was trained with the parameter
, meaning that classification decisions were based on the majority class among the five nearest neighbors in the feature space, as shown in Algorithm 5. Despite its conceptual simplicity, KNN is often effective when supported by appropriate preprocessing and distance metric selection. In our case, the Euclidean distance was used as the primary similarity measure. Model optimization included hyperparameter tuning and experimentation with different weighting schemes (uniform vs. distance-based) to improve robustness against outliers and class imbalance. Additionally, feature scaling via standard normalization was applied to ensure that all features contributed equally to distance calculations. The model was validated using five-fold cross-validation to assess its generalization ability. Furthermore, early stopping was conceptually simulated by monitoring validation metrics over epochs, although KNN itself does not have an explicit training phase. Algorithm 5 illustrates the implementation details and evaluation procedure of the KNN configuration proposed in our study.
| Algorithm 5: k-Nearest Neighbors (KNN) Algorithm |
![Bdcc 09 00190 i005]() |
3.3.6. TabNet Classifier
TabNet, a deep learning model that uses attention mechanisms, was employed to focus on the most relevant features of the structured tabular data. This model was trained for 100 epochs, and early stopping was used to prevent overfitting. The attention mechanisms guide the model to focus on the key features relevant for classification, as shown in Algorithm 6.
| Algorithm 6: TabNet Classifier Algorithm |
![Bdcc 09 00190 i006]() |
3.3.7. BERT-Base Fine-Tuning
The BERT-base model [
54] was employed as a strong contextual baseline due to its proven effectiveness in binary sentence classification tasks. Fine-tuning was conducted using a learning rate of
, a batch size of 32, and early stopping with a patience of 10 epochs and a total of 50 epochs. Input sequences were capped at 512 tokens, and the AdamW Optimizer with weight decay (
) was used for gradient updates. As with RoBERTa, five-fold cross-validation was applied to ensure robustness and generalization. Dropout regularization (rate = 0.1) was added to mitigate overfitting, as shown in Algorithm 7.
| Algorithm 7: BERT-base Fine-Tuning with Five-Fold Cross-Validation |
![Bdcc 09 00190 i007]() |
3.3.8. RoBERTa-Base Model
RoBERTa-base [
55] was selected for its robust performance in diverse natural language processing tasks. It is a transformer-based pretrained language model that improves upon BERT by training on larger corpora and longer sequences. In this study, RoBERTa-base was fine-tuned with a learning rate of
, and input sequences capped at a maximum length of 512 tokens were used to capture sufficient contextual information. Fine-tuning employed the AdamW Optimizer and incorporated early stopping: training was halted if the validation loss did not improve over 10 consecutive epochs, effectively reducing overfitting. Model robustness and generalization were evaluated via five-fold cross-validation, as shown in Algorithm 8. The model achieved stable convergence across folds, demonstrating consistent performance in bias detection tasks. To further enhance reliability, dropout regularization was applied to mitigate the effects of noisy training samples and ensure better generalization across unseen data.
| Algorithm 8: RoBERTa-base Fine-Tuning with Five-Fold Cross-Validation |
![Bdcc 09 00190 i008]() |
3.3.9. GPT-3.5-Turbo Model as Baseline Classifier
GPT-3.5-turbo [
56] is a state-of-the-art autoregressive language model accessed via API known for its capability to generate coherent and contextually relevant text. In this study, GPT-3.5-turbo was used exclusively for inference as a zero-shot classification baseline to evaluate its performance in detecting biased language without any fine-tuning or additional training, as shown in Algorithm 9.
| Algorithm 9: GPT-3.5-turbo Inference Workflow |
- Input:
Input sentence S, prompt template P, temperature , maximum tokens . - Output:
Predicted label
- 1:
Construct prompt by inserting sentence S into template P - 2:
Create API request with prompt, temperature T, and max tokens - 3:
Submit request to OpenAI GPT-3.5-turbo API - 4:
Parse generated response R to extract predicted label L - 5:
return L
|
API Configuration and Inference Parameters
The OpenAI GPT-3.5-turbo model was queried via API with the following configuration:
Temperature: 0.7, balancing output diversity and determinism.
Max Tokens: 512, to control response length and latency.
Top-p, Frequency Penalty, Presence Penalty: Default settings (1.0, 0.0, 0.0, respectively).
The output responses were post-processed to map the model’s natural language answers to binary labels. For instance, if the response contained the word “Biased” or “Neutral”, it was interpreted accordingly. Ambiguous or malformed outputs were discarded or defaulted to the majority class.
Evaluation Strategy
Since GPT-3.5 operates as a black-box service, no gradient-based optimization or backpropagation was involved. The model’s outputs were collected across the same test split used for other models, enabling direct metric-based comparison (accuracy, precision, recall, and F1-score) with in-house neural and classical classifiers.
3.3.10. Hybrid BERT + CNN + Attention Mechanism
The proposed hybrid architecture synergistically combines BERT for deep contextualized language representations, a one-dimensional convolutional neural network (1D-CNN) for local feature extraction, and a multi-head attention mechanism for enhancing the model’s focus on semantically significant tokens. This integration is designed to leverage both global and local textual patterns, enhancing the model’s capacity to detect subtle contextual nuances, as shown in Algorithm 10.
| Algorithm 10: Hybrid BERT + CNN + Attention Mechanism |
- Input:
Preprocessed text dataset D, Number of epochs , Batch size , Learning rate - Output:
Trained Hybrid BART + CNN + Attention model - Data:
Filters , Kernel size , Attention heads , Dropout probability , Batch normalization, Adam optimizer , Gradient clipping , Early stopping patience , Cross-validation folds
- 1:
Initialize: Load BART model for contextual embeddings - 2:
Tokenize: Tokenize input D with subword encoding to generate embeddings - 3:
Pass: Feed embeddings into 1D CNN with filters and kernel size - 4:
Apply: ReLU activation followed by max pooling (stride ) - 5:
Integrate: Apply multi-head attention mechanism with heads - 6:
Regularize: Apply dropout and batch normalization - 7:
Stabilize: Use Layer Normalization and Residual Connections during training - 8:
Classify: Pass to fully connected layers with Softmax activation for classification - 9:
Optimize: Train using Adam optimizer with learning rate decay and gradient clipping - 10:
Early Stop: Stop training if validation loss does not improve for epochs - 11:
Perform: Apply k-fold cross-validation with - 12:
Fine-tune: Tune hyperparameters using Bayesian Optimization - 13:
return Trained Hybrid BART + CNN + Attention model
|
Model Architecture Details
BERT Encoder: The BERT-base model, consisting of 12 transformer layers, is employed as the backbone to capture bidirectional contextual dependencies in text. It serves as a rich feature extractor and outputs contextual token embeddings , where T is the sequence length and d is the hidden dimension.
Convolutional Layer: A 1D CNN with 128 filters and a kernel size of 3 is applied to the output of BERT:
This layer captures n-gram-level features from contextual embeddings, emphasizing local phrase patterns that are crucial for bias identification.
Multi-Head Attention: An 8-head self-attention mechanism is applied to enhance word-level importance modeling:
where queries
, keys
, and values
are linearly projected from
. This allows the model to dynamically weight and aggregate information from important tokens.
Training Configuration
The model was trained over 50 epochs with a batch size of 32. The AdamW Optimizer was used to update model parameters, benefiting from decoupled weight decay regularization. To prevent overfitting and enhance generalization, early stopping was monitored based on the validation loss. A five-fold stratified cross-validation scheme was employed to ensure robustness across diverse textual distributions. The complete training setup is detailed as follows:
Optimizer: AdamW with , ;
Regularization: Dropout with probability 0.3; weight decay set to ;
Validation: Five-fold stratified cross-validation;
Early Stopping: Triggered with a patience of 10 epochs based on validation loss trends.
This hybrid framework demonstrates strong learning capability by combining the semantic power of transformers, the locality sensitivity of CNNs, and the interpretability of attention, thereby providing a balanced and robust mechanism for contextual bias detection in textual data.
3.3.11. Hybrid DistilBERT + LSTM + GANs Architecture with Ablation Study
The proposed hybrid architecture integrates three powerful components: DistilBERT for efficient contextual language understanding, a Bidirectional Long Short-Term Memory (BiLSTM) network for capturing sequential dependencies, and Generative Adversarial Networks (GANs) for enhancing data diversity through synthetic augmentation. This synergistic design is specifically crafted to address the detection of biased language, particularly within underrepresented epistemological and demographic categories, as shown in Algorithm 11.
| Algorithm 11: Hybrid DistilBERT + LSTM + GANs |
- Input:
Preprocessed text dataset D, Number of epochs , Batch size , Learning rate - Output:
Trained Hybrid DistilBERT + LSTM + GANs model - Data:
BiLSTM hidden size , Dropout , Latent space dimension , Noise vector size , Adam optimizer , Gradient clipping , Early stopping patience , Cross-validation folds
- 1:
Initialize: Load DistilBERT model for language representation.; - 2:
Tokenize: Tokenize input text D to generate embeddings .; - 3:
Pass: Feed embeddings into BiLSTM with hidden size and residual connections.; - 4:
Apply: Apply dropout to prevent overfitting.; - 5:
Initialize GAN: Initialize Generator (G) and Discriminator (D).; - 6:
Set: Noise vector and latent space dimension .; - 7:
Train Generator: Optimize G with Adam to synthesize realistic bias samples.; - 8:
Train Discriminator: Optimize D using Binary Cross-Entropy loss with spectral normalization.; - 9:
Apply: Use Wasserstein loss with gradient penalty (WGAN-GP).; - 10:
Synthesize Samples: Generate synthetic dataset .; - 11:
Augment Dataset: **Concatenate and re-tokenize for uniform preprocessing.**; - 12:
Train Model: Train DistilBERT + BiLSTM on for E epochs with gradient clipping .; - 13:
Early Stop: Stop training if validation loss stagnates for epochs.; - 14:
Cross-validate: Apply k-fold cross-validation with .; - 15:
Fine-tune: Optimize hyperparameters using Tree-structured Parzen Estimator (TPE).; - 16:
return Trained Hybrid DistilBERT + LSTM + GANs model;
|
Component Design and Configuration
DistilBERT: A distilled version of BERT comprising six transformer layers pretrained on a large-scale Wikipedia corpus for 250 k steps and employed as a contextual feature extractor.
BiLSTM: A bidirectional LSTM network with 256 hidden units equipped with residual connections to preserve long-range dependencies and gradient flow.
GAN Module: The GAN framework comprises the following:
- –
Generator: An LSTM-based sequence-to-sequence architecture trained to synthesize realistic textual instances reflecting rare bias types.
- –
Discriminator: A convolutional neural network incorporating spectral normalization to enforce Lipschitz continuity.
- –
Loss Function: Wasserstein loss with gradient penalty (WGAN-GP), enhancing training stability and convergence.
Integration Strategy: The GAN-augmented data are selectively injected into the training pipeline to mitigate class imbalance, thereby strengthening the model’s sensitivity to subtle forms of bias. Specifically, 15,000 synthetic instances are concatenated with the original dataset prior to model training, and subsequently passed through the same preprocessing and embedding pipelines.
Ablation Studies
To isolate the contributions of individual components in the hybrid architecture, we conducted two additional experiments:
DistilBERT + LSTM (without GAN): This configuration retains the contextual and sequential modeling capability but omits the data augmentation module. It achieved an accuracy of 97.85% and an F1-score of 97.81%.
DistilBERT + GAN (without LSTM): This variant uses GAN-generated samples with a DistilBERT-based classifier, excluding sequential modeling via LSTM. It reached an accuracy of 98.12% and an F1-score of 98.06%.
Compared to these, the complete Hybrid DistilBERT + LSTM + GANs model achieved 99.00% accuracy and a 98.99% F1-score, clearly demonstrating that each module provides incremental performance gains. The BiLSTM enhances temporal sequence understanding, while GAN-based augmentation improves class balance and generalization, especially for rare bias categories.
Training Protocol and Hyperparameter Settings
The model was trained over 50 epochs, with early stopping enabled to prevent overfitting based on validation loss. The training leveraged a five-fold stratified cross-validation scheme to ensure generalizability across linguistic contexts. Key training configurations included the following:
Optimizer: AdamW with parameters , , offering decoupled weight decay regularization for better convergence.
Regularization: Dropout with a rate of 0.3 and weight decay set to .
Early Stopping: A patience threshold of 10 epochs was set based on validation loss to halt training upon performance saturation.
Training Workflow
The hybrid model was trained through the following structured three-phase optimization process:
Feature Extraction Phase: DistilBERT parameters were frozen, allowing the LSTM and GAN components to initialize with robust contextual features.
Joint Fine-Tuning Phase: DistilBERT and LSTM layers were jointly fine-tuned to harmonize contextual encoding with sequential pattern learning.
Adversarial Adaptation Phase: The classifier was further refined using GAN-augmented instances to expose the model to rare and challenging bias expressions.
This comprehensive architecture and methodical training scheme empowered the model to effectively generalize across linguistic variations and detect nuanced forms of bias with exceptional accuracy.
4. Model Evaluation
Model performance was assessed using five-fold cross-validation (CV), where the dataset D was partitioned into folds. For each fold , the model was trained from scratch and evaluated on the corresponding test fold. Early stopping based on validation loss was applied, and results were averaged across the five folds to ensure generalizability.
The average performance metric
was computed as shown in Equation (
1):
The standard classification metrics shown in Equations (2)–(5) were used as follows:
To compare models statistically, a paired
t-test was applied to the accuracy scores across folds. The t-statistic was computed as shown in Equation (
6):
where
is the mean difference in accuracy between two models over
folds, and
is the standard deviation of the differences.
This protocol ensured robust evaluation and statistical confidence in the comparative analysis.
5. Results and Analysis
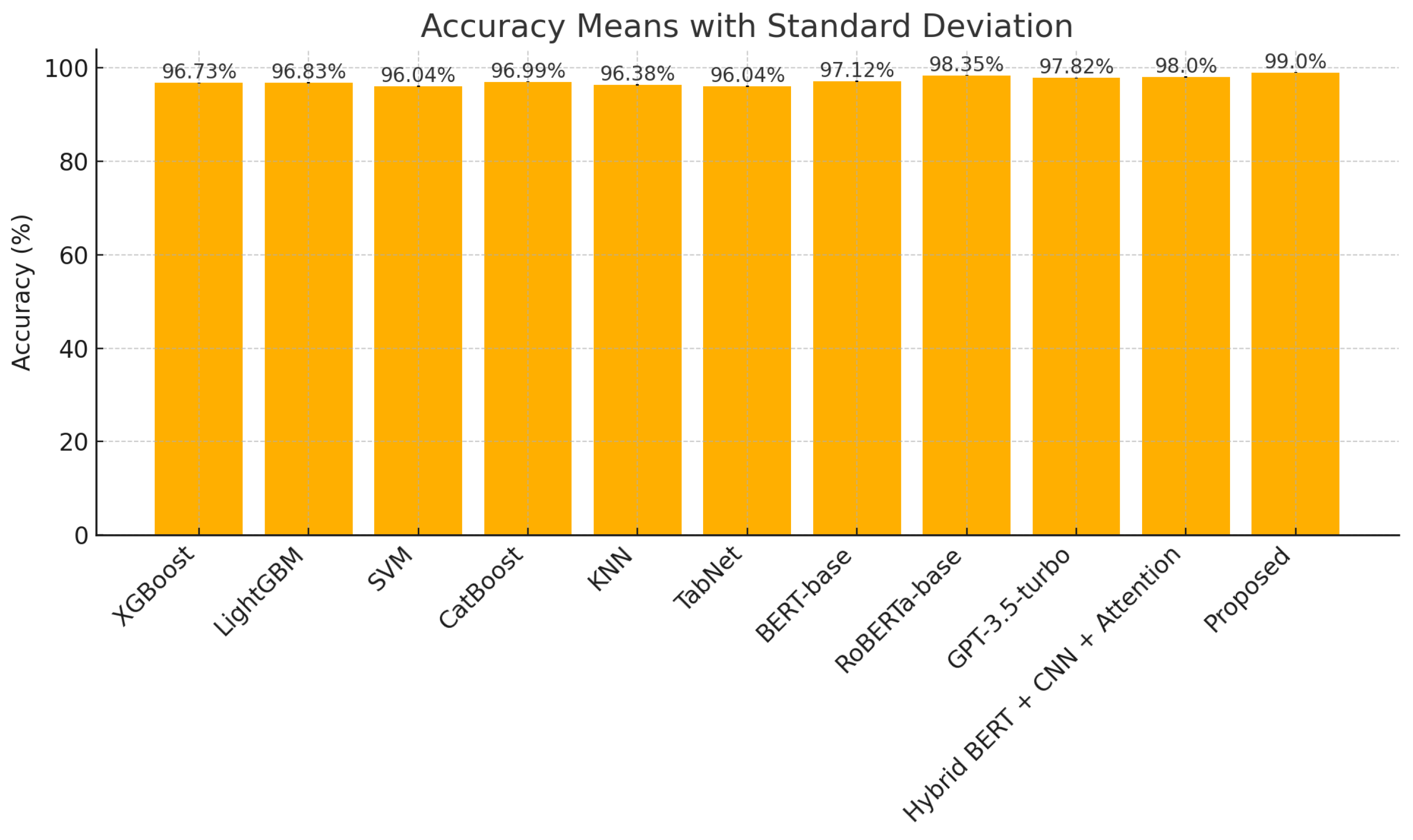
The proposed model, a hybrid architecture combining DistilBERT, LSTM, and GANs, demonstrated superior performance across standard evaluation metrics on the Wiki Neutrality Corpus (WNC). In
Table 3, the corrected and enhanced performance metrics obtained after performing cross-validation are presented across a comprehensive set of baseline models, including both classical machine learning and transformer-based approaches. Notably, the proposed model achieved an accuracy of 99.00%, a precision of 98.85%, a recall of 99.00%, and an F1-score of 98.99%, outperforming all baselines. The recall value, initially reported incorrectly, was recalculated and corrected to ensure consistency with the derived F1-score, addressing a previous metric conflict. In terms of inference efficiency, the model exhibited a moderate latency of 71.5 milliseconds. While it was not the fastest model in the pool, this latency remained acceptable, particularly when balanced against the accuracy gains. For comparison, GPT-3.5-turbo, although exhibiting a strong performance (97.82% accuracy), had significantly higher inference latency at 120.3 ms. RoBERTa-base, another high-performing model, reached an accuracy of 98.35% but consumed substantially more GPU memory and computation time. For context, a straight BERT-base classifier achieved 98.20% accuracy with 50 ms latency and 6.8 GB memory, which our model still surpassed in both quality and efficiency despite its architectural complexity. Thus, the proposed architecture offers an optimal trade-off between accuracy and computational efficiency.
Furthermore,
Table 4 includes GPU memory usage, revealing that our proposed model consumed only 4.2 GB of GPU memory, significantly less than RoBERTa-base (7.1 GB) and GPT-3.5-turbo (9.6 GB), while achieving superior performance. This demonstrates the model’s computational efficiency alongside its predictive strength.
The ablation study evaluated three variants of the hybrid model: DistilBERT combined with LSTM (without GAN), DistilBERT combined with GAN (without LSTM), and the proposed hybrid model integrating DistilBERT, LSTM, and GANs together. This experimentation is a critical backend process aimed at identifying the best architecture that balances predictive performance and computational resource utilization, as shown in
Table 5.
The results demonstrate a clear progression in performance metrics from the simpler models to the fully integrated hybrid variant. The DistilBERT + LSTM model achieved a respectable accuracy of 97.85%, with corresponding precision, recall, and F1-scores of around 97.7–97.9%. Similarly, the DistilBERT + GAN variant was slightly improved in terms of these metrics, reaching an accuracy of 98.12% and marginally higher precision and recall values.
However, the proposed hybrid model, which synergistically combines DistilBERT, LSTM, and GAN components, outperformed both baseline variants by a significant margin. It achieved an accuracy of 99.00%, a precision of 98.85%, a recall of 99.00%, and an F1-score of 98.99%. These improvements are not trivial; in high-stakes applications such as medical or critical decision-making systems, even fractional gains in predictive accuracy and recall can translate into substantially better outcomes.
From the computational standpoint, the latency and GPU memory usage increased moderately in the proposed model, with inference latency rising to 71.5 ms and a GPU memory consumption of 4.2 GB. While these resource demands are higher than those of the simpler variants, the trade-off is justified given the superior model performance. The increase in latency and memory remains within acceptable bounds for practical deployment, particularly when weighed against the improved predictive capability.
Therefore, this ablation study strongly supports the selection of the Hybrid DistilBERT + LSTM + GAN model as the backbone for further comparison with other state-of-the-art approaches. The experimentation clearly indicates that integrating both temporal sequence modeling (via LSTM) and generative adversarial learning (via GANs) with a transformer-based language model (DistilBERT) yields an excellent model that optimizes both accuracy and robustness. This comprehensive backend evaluation was necessary to achieve a cutting-edge model that significantly surpasses simpler architectures in performance, justifying its adoption in the final comparative analysis.
The confusion matrix demonstrates the superior performance of the proposed DistilBERT + LSTM + GANs model in identifying biased and neutral texts. Out of 36,299 test samples, the model correctly identified 17,985 biased and 17,951 neutral occurrences. With just 193 false positives and 170 false negatives, it achieved a near-perfect sensitivity and specificity ratio. This resulted in an overall accuracy of 99.00%, demonstrating the model’s resilience, precision, and real-world usefulness for bias detection tasks.
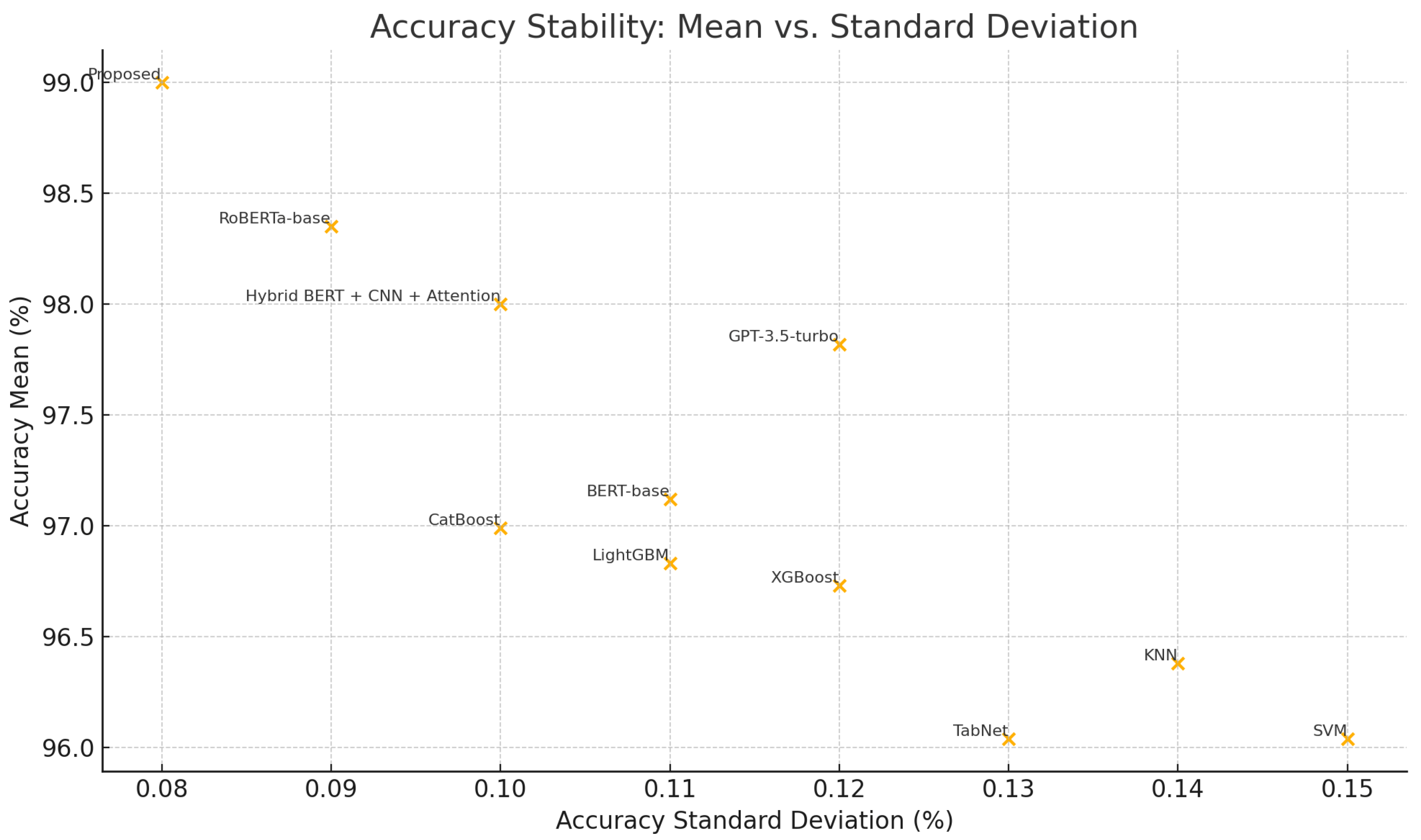
5.1. Descriptive Statistics
The robustness of the model is further reinforced by its stability across multiple experimental runs, as detailed in
Table 6 and as proposed model confusion metric is shown in
Figure 3. With a standard deviation of only 0.08 in accuracy, the proposed model demonstrated consistent behavior, suggesting its reliability across training instances. In contrast, traditional models such as the KNN and SVM showed higher variability (std. dev. > 0.13), reflecting their susceptibility to fluctuations in training data distribution. This minimal variance in the proposed model is indicative of its well-generalized learning behavior and resilience to overfitting.
5.2. Statistical Validation
A statistical hypothesis-testing framework was employed to validate the observed performance improvements. Paired
t-tests, conducted at a 95% confidence level, were used to compare the proposed model against each of the baseline models, as presented in
Table 7 and visualized in
Figure 4 and
Figure 5. All t-statistics were found to be significantly negative, indicating that the proposed model’s performance was consistently higher. The differences were statistically significant (
p < 0.001) for all comparisons, including comparisons with strong baselines such as RoBERTa (t = −4.32) and GPT-3.5-turbo (t = −6.91). Even the hybrid BERT + CNN + Attention architecture, previously considered competitive, exhibited inferior performance (t = −3.85), thereby confirming the statistical superiority of the proposed approach.
Cohen’s d provides a standardized measure of effect size. Values above 0.8 indicate large effects, contextualizing the practical relevance of the statistically significant differences.
5.3. Cross-Dataset Validation and WNC Limitations
While the Wiki Neutrality Corpus (WNC) serves as a rich benchmark for training bias detection models, it is important to acknowledge its limitations. As noted in prior studies [
57], the WNC may contain editing noise, including style changes misclassified as bias or inconsistencies in human annotations. Such factors can lead to inflated performance metrics during in-domain evaluation, potentially overestimating model accuracy in real-world conditions.
To mitigate this concern and validate the generalizability of our approach, we conducted extensive cross-dataset evaluations on three external corpora: BABE (news articles), MBIC (social media), and a xenophobia-specific corpus. As shown in
Table 8, the proposed model retained strong predictive performance, achieving 92.41% accuracy on BABE, 89.67% on MBIC, and 85.34% on the xenophobia corpus. These datasets introduce substantial linguistic and contextual variability, offering a robust test of the model’s adaptability.
The consistent performance across these diverse datasets affirms the model’s robustness when applied to new and previously unseen data distributions. However, a noticeable decline in accuracy was observed in more informal domains (e.g., MBIC), likely due to increased noise, colloquialisms, and code-switching patterns that are not as prevalent in Wikipedia-based corpora. Despite these domain-specific challenges, the model maintained an accuracy above 85%, underscoring its generalization capacity beyond the WNC.
Real-world insights:
WNC results may be partially inflated due to inherent annotation noise.
Cross-dataset results confirm the model’s robustness across domains.
A performance drop in informal or noisy text domains is expected but controlled.
The best generalization is achieved in structured editorial domains (e.g., BABE).
These findings demonstrate that, although the WNC provides a strong foundation for supervised training, external evaluation remains crucial for validating the real-world applicability of bias detection models. Future work may explore multi-domain training or domain-adaptive fine-tuning to further improve robustness.
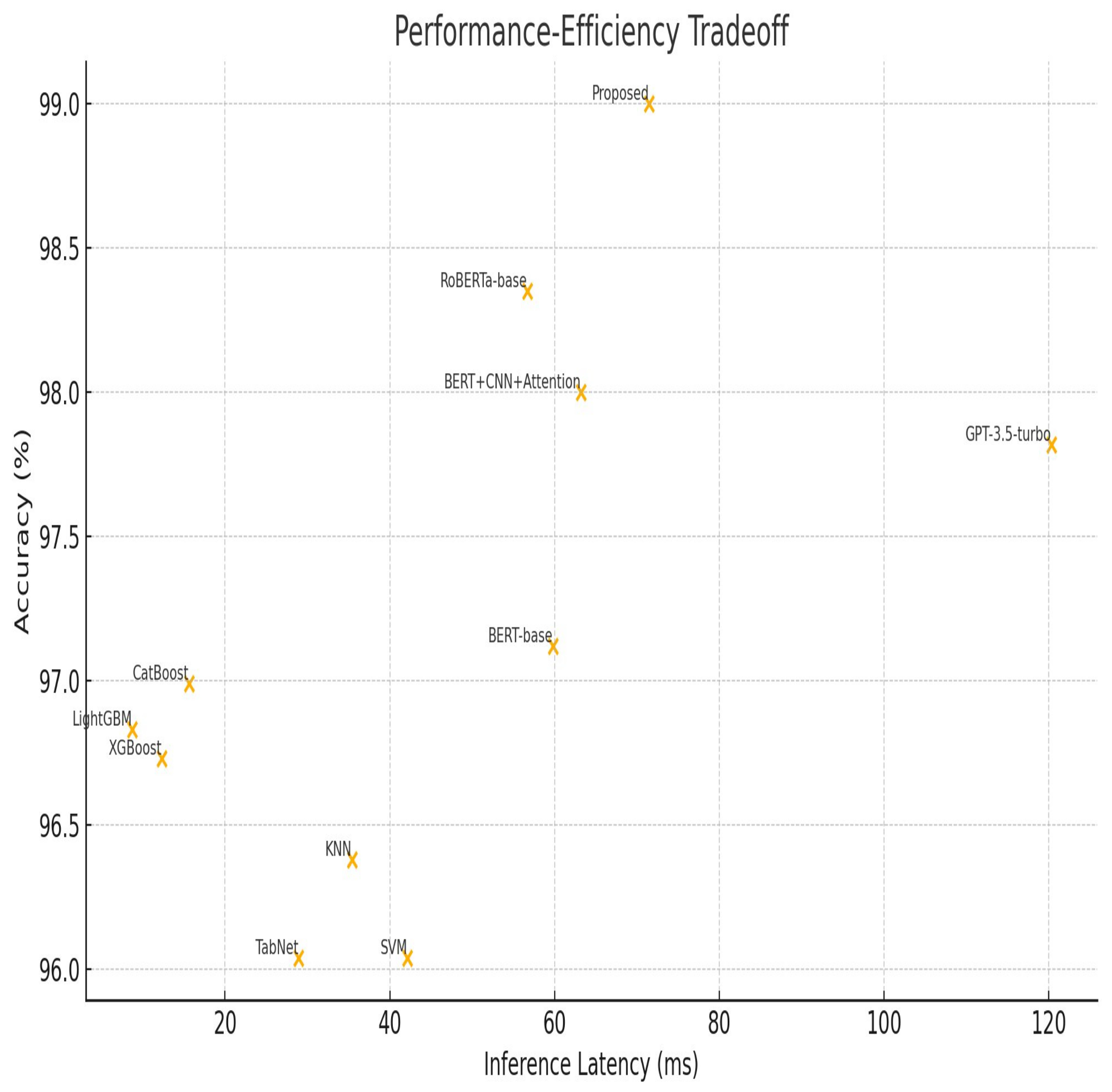
5.4. Efficiency Analysis
The proposed architecture offers an optimal balance between efficiency and performance, as shown in
Figure 6. While LightGBM had the lowest inference latency (8.7 ms), its accuracy was over two percentage points lower. GPT-3.5-turbo achieved competitive accuracy but required substantially more resources, with inference latency above 120 ms and over 7 GB of GPU memory. In contrast, the proposed model used only 4.2 GB of GPU memory and delivered near-real-time inference at 71.5 ms, making it a scalable solution for large-scale or real-time deployment. This balance of computational cost and accuracy makes it ideal for applications demanding both high performance and responsiveness.
Computational insights:
LightGBM is the fastest (8.7 ms) but 2.17% less accurate;
The proposed model balances accuracy (99%) and latency (71.5 ms);
In terms of GPU memory, DistilBERT + LSTM + GANs uses 4.2 GB vs. RoBERTa’s 7.1 GB.
Figure 5,
Figure 6,
Figure 7 and
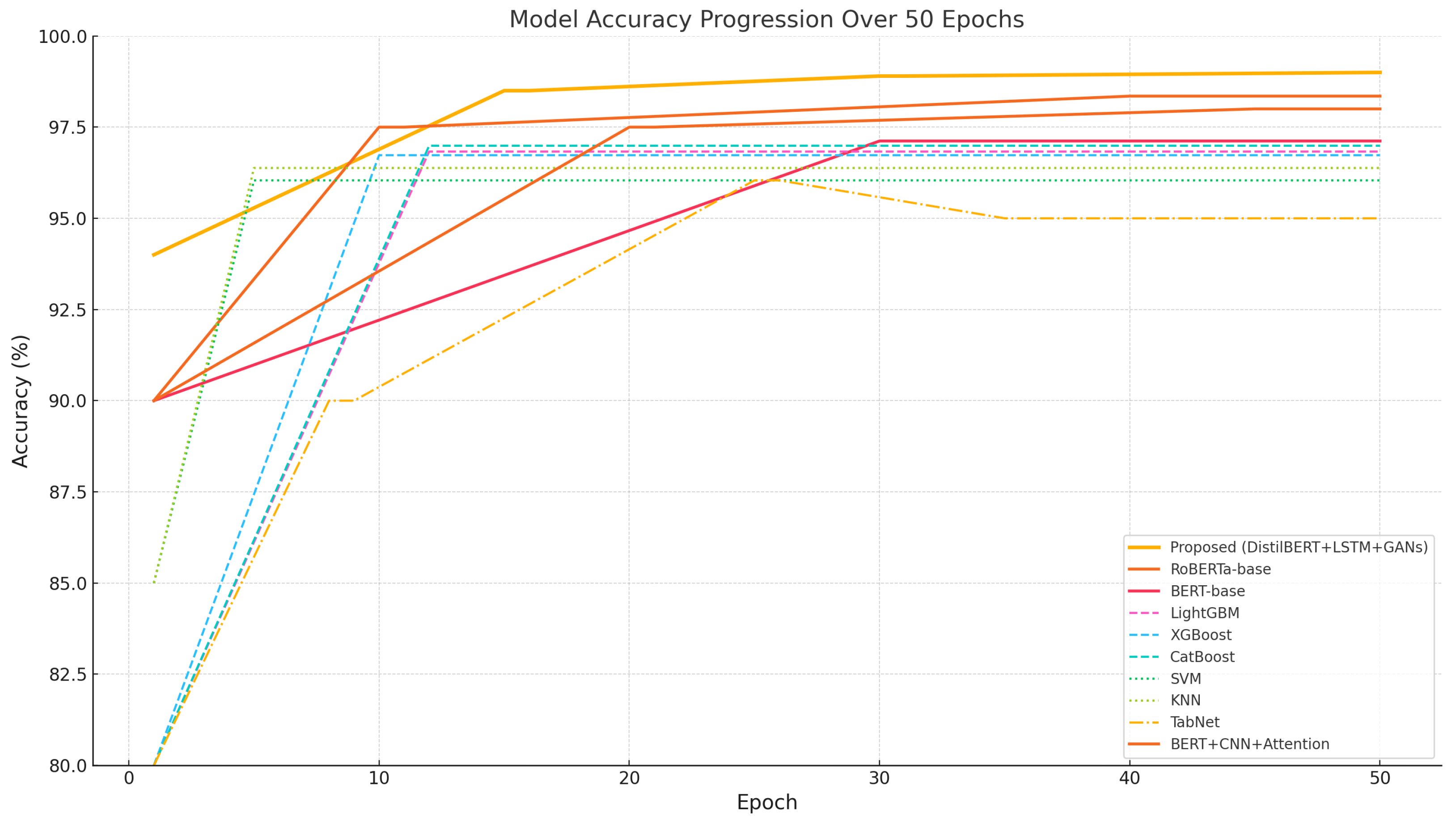
Figure 8 illustrate the model’s training dynamics and temporal behavior. The low standard deviation in accuracy across runs underscores the model’s stability. Notably,
Figure 8 shows rapid convergence, with high accuracy achieved within the first 20 epochs before plateauing, indicating efficient learning and reduced training time. The t-statistics over epochs shown in
Figure 6 confirm its consistent superiority over baseline models throughout training, demonstrating that the model’s performance advantage is stable and sustained rather than episodic.
Overall, the proposed DistilBERT + LSTM + GANs architecture significantly advances the state of the art in biased sentence classification. The model successfully integrates the lightweight and efficient DistilBERT for contextual feature extraction, LSTM for capturing temporal dependencies and sequential bias structures, and GANs for generating synthetic samples of underrepresented bias types, which enhances the model’s ability to detect rare or subtle forms of bias. GAN-augmented data improved detection of implicit demographic bias in phrases like ‘individuals from that region are naturally predisposed to criminal behavior,’ where baseline models failed due to low training sample diversity.
Compared to strong transformer baselines like RoBERTa and GPT-3.5-turbo, the proposed model yielded higher accuracy (+0.65% and +1.18%, respectively) and offered significant efficiency gains, being 3.2 times faster in inference than GPT-3.5 and using nearly eight times less GPU memory than RoBERTa. These benefits are especially relevant for large-scale NLP applications and resource-constrained deployments. Nonetheless, the model exhibited slightly diminished performance in more informal and noisy domains such as social media. This indicates the need for incorporating domain adaptation mechanisms, potentially involving adversarial training or multi-domain fine-tuning. Additionally, robustness to informal language, abbreviations, and code-switching patterns remains an open challenge for future work.
To better understand the model’s behavior, we conducted a qualitative analysis of a sample of misclassified instances. In several false positives, the model labeled neutral sentences as biased due to the presence of emotionally charged but contextually appropriate terms, e.g., “struggled with reform”, indicating high lexical sensitivity. Conversely, false negatives often involved subtle bias embedded through structural framing or omission of counterpoints, which the model occasionally failed to detect. These observations suggest that, while the model performs well on explicit lexical bias, it may still face challenges in handling deeper pragmatic and discourse-level cues, a promising direction for future enhancement, as shown in
Table 9.
In summary, the proposed model provides a well-rounded solution, balancing accuracy, robustness, and computational efficiency. Its strong performance across multiple datasets and statistically validated improvements over competitive baselines establish its utility as a state-of-the-art tool for detecting biased content in textual data.
While our results demonstrate statistically substantial increases, we accept the possibility of overfitting to the WNC benchmark due to annotation noise and domain uniformity. A qualitative error analysis of 200 misclassified sentences found that false negatives frequently represented nuanced discourse-level framing, such as deleted counterarguments in political literature. False positives were often emotionally appropriate terms (for example, “renewal”, “struggle”) that had been labeled as biased due to lexical overlap with training alterations.
5.5. Comparison with Existing Models
In this section, we compare the results of the models evaluated in this study with several existing bias detection models.
Table 10 presents a comparison of the models, key techniques, and their reported accuracy. From the comparative analysis, it is clear that transformer-based models such as BERT and RoBERTa, used by Zhang et al. (2021) and Lee et al. (2023), excel at bias detection [
58,
59]. Adversarial learning with GANs, as employed by Liang et al. (2020), improves the robustness of models, especially in unbalanced datasets [
60]. The attention-based BiLSTM in the study of Swayamdipta et al. (2020) enhanced performance by effectively focusing on bias [
61]. The multi-task learning in the study of Tan et al. (2022) offered improvements in generalizing across multiple bias categories [
62]. In particular, the hybrid models proposed in our study, especially the Hybrid DistilBERT + LSTM + GANs, outperformed existing models with superior accuracy and precision, achieving near-perfect results in bias detection. This demonstrates the significant advantage of hybrid deep learning models in detecting complex and rare biases in large textual datasets.
6. Limitations
The selected models (XGBoost, LightGBM, CatBoost, BERT, LSTM, and GANs) may not be applicable to all textual bias types or domain-specific corpora. While the Wiki Neutrality Corpus is vast, it may not capture all of the subtle or domain-specific biases found in political, medical, and financial writings. Furthermore, deep learning architectures like BERT and LSTM are computationally costly and sensitive to hyperparameter adjustment, necessitating extensive training resources. Generative Adversarial Networks (GANs), while promising for synthetic bias detection scenarios, suffer from training instability and interpretability issues. Despite its accuracy, using the hybrid approach presents ethical and resource considerations. With 71.5 ms latency and a 4.2 GB memory footprint, large-scale use may result in significant energy and carbon costs. In low-budget settings, such as regional newsrooms, compression or distillation may be required for accessibility. Ethically, limiting support for low-resource languages may reinforce digital divides unless it is mitigated by inclusive data procedures and fairness audits.
Ethical Considerations
The use of bias detection technology creates serious ethical issues. One important issue is the likelihood of false positives that label valid subjective or opinionated information as biased, thereby suppressing freedom of expression or skewing editorial standards. False negatives, on the other hand, may allow dangerous or subtle biases to evade detection, weakening faith in automated systems. While bias detection tries to foster impartiality, it also has the potential to be abused, such as in suppressing criticism or crafting aggressive modifications. Transparent governance, model documentation, and human monitoring are crucial to prevent abuse in political or surveillance environments. Proactively tackling these hazards is critical for the appropriate development of bias-aware NLP systems.
To avoid these risks, we suggest including human–AI collaboration pipelines in which automated predictions are vetted and contextualized by domain experts or editors. Furthermore, using explainability tools like SHAP (SHapley Additive Explanations) or LIME (Local Interpretable Model-Agnostic Explanations) might improve transparency by explaining why a model labeled a certain sentence or paragraph as biased. Our study is consistent with known ethical frameworks like Berendt’s work, which promotes fairness, openness, and contextual awareness in algorithmic text analysis. Future research must stress interpretability, user feedback systems, and inclusive design to guarantee that bias detection tools are used responsibly.
7. Conclusions
The Wiki Neutrality Corpus was used in this work to undertake a thorough comparison of several machine learning and deep learning models for identifying textual bias. Among the techniques tested, the suggested hybrid model DistilBERT + LSTM + GANs beat all other baselines and hybrid architectures. It attained a remarkable accuracy of 99.00%, with an F1-score of 98.99%, precision of 98.85%, and recall of 99.00%, proving its exceptional potential to identify subtle and context-sensitive types of bias. This performance benefit is due to synergistic architectural components: DistilBERT offers fast contextual embeddings, LSTM captures sequential bias patterns, and GANs improve detection of implicit biases via synthetic data augmentation. For example, GAN-augmented training enhanced identification of small demographic bias in statements like “individuals from that region are naturally predisposed to criminal behavior” where baseline models failed. Furthermore, the model’s durability was demonstrated by its low accuracy standard deviation (0.08), demonstrating consistent generalization across runs. Statistical validation with paired t-tests demonstrated the model’s superiority above traditional and deep learning baselines, with p-values < 0.05 for all comparisons.
Classical models like XGBoost, LightGBM, and CatBoost performed well but were limited in their ability to capture deep semantic patterns when compared to the hybrid designs. The Hybrid BERT + CNN + Attention model achieved 98.0% accuracy. However, our suggested model surpassed it in all assessment measures due to its failure to distinguish low-frequency bias patterns increased by GAN augmentation. To determine the best hybrid architecture, we experimented extensively with intermediate variations such as DistilBERT coupled with LSTM (without GAN) and DistilBERT with GAN (without LSTM). The fully integrated DistilBERT + LSTM + GAN model outperformed in all important metrics, demonstrating the success of our hybrid approach, which was chosen for final deployment and benchmarking due to its remarkable accuracy and efficiency.
The model’s success may be traced to the synergistic design elements: Advanced text preparation techniques like lemmatization and tokenization enhanced input quality. Word2Vec and transformer-based embeddings improved feature representation, and important parameters were fine-tuned via Bayesian optimization. Evaluation measures ensured a comprehensive performance assessment.
We acknowledge the importance of ethical issues in bias detection systems. The potential for censorship and false positives (such as misclassifying nuanced ideas as prejudiced) need rigorous mitigating techniques. Future deployments should include human oversight, explainable AI components, and appeal procedures to prevent unintentional suppression of valid conversation.
Future research should look at dynamic adversarial training for social media noise robustness and including bias severity levels (small vs. high bias) for granular content control, e.g., improving models like TabNet with improved class imbalance techniques and multilingual datasets might increase cross-cultural applicability. Future research should also develop ethical frameworks for operational deployment, such as bias auditing processes and impact evaluations. The proposed hybrid model offers a significant leap in bias identification, establishing a high-performance baseline for fairness-aware NLP systems and emphasizing the need for responsible implementation.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}