
LeONet: A Hybrid Deep Learning Approach for High-Precision Code Clone Detection Using Abstract Syntax Tree Features

 ,
,  ,
,  , and
, and 
Abstract
1. Introduction
2. Literature Review
3. Methodology
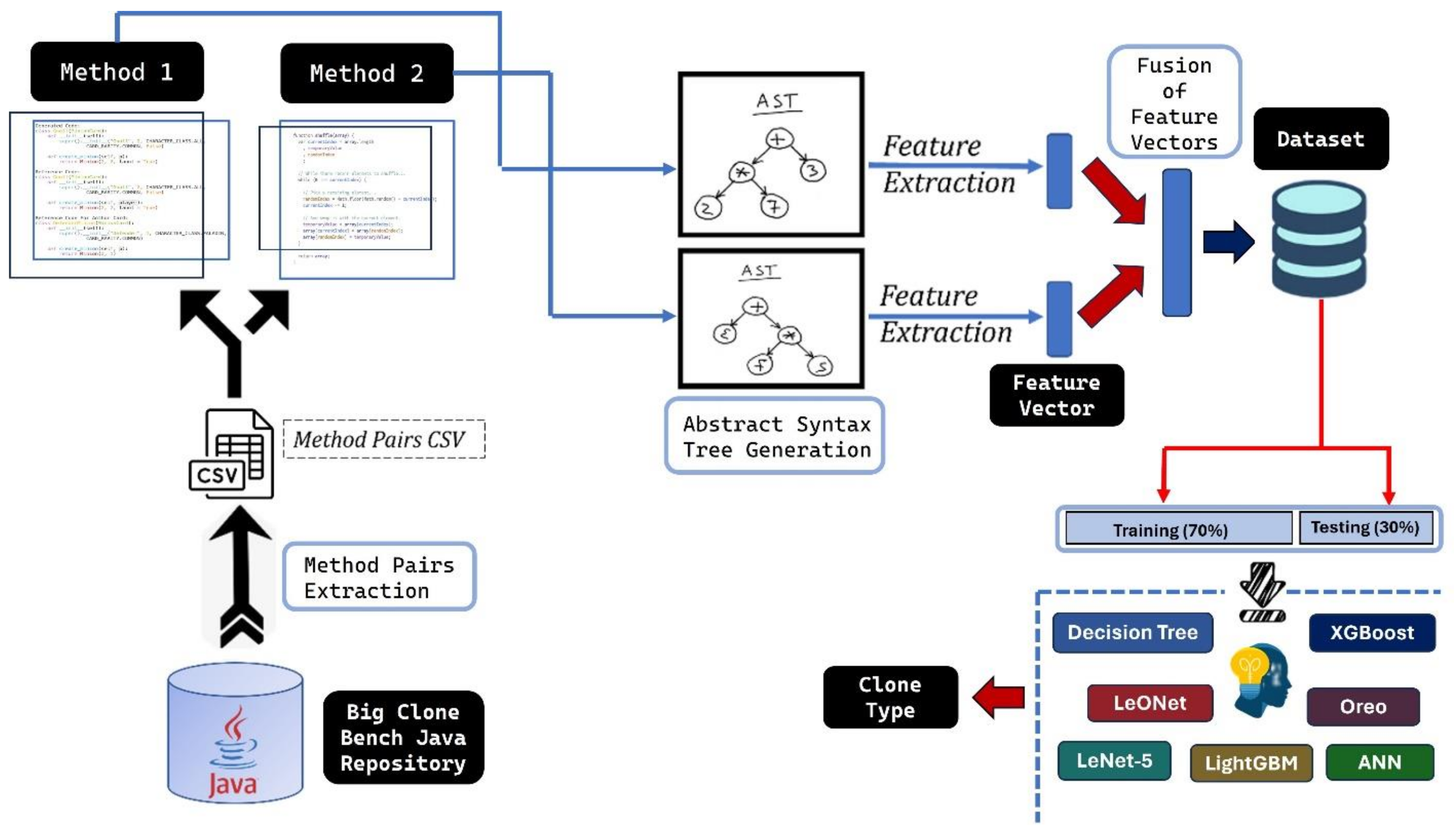
3.1. Research Design
3.1.1. BigCloneBench Java Repository
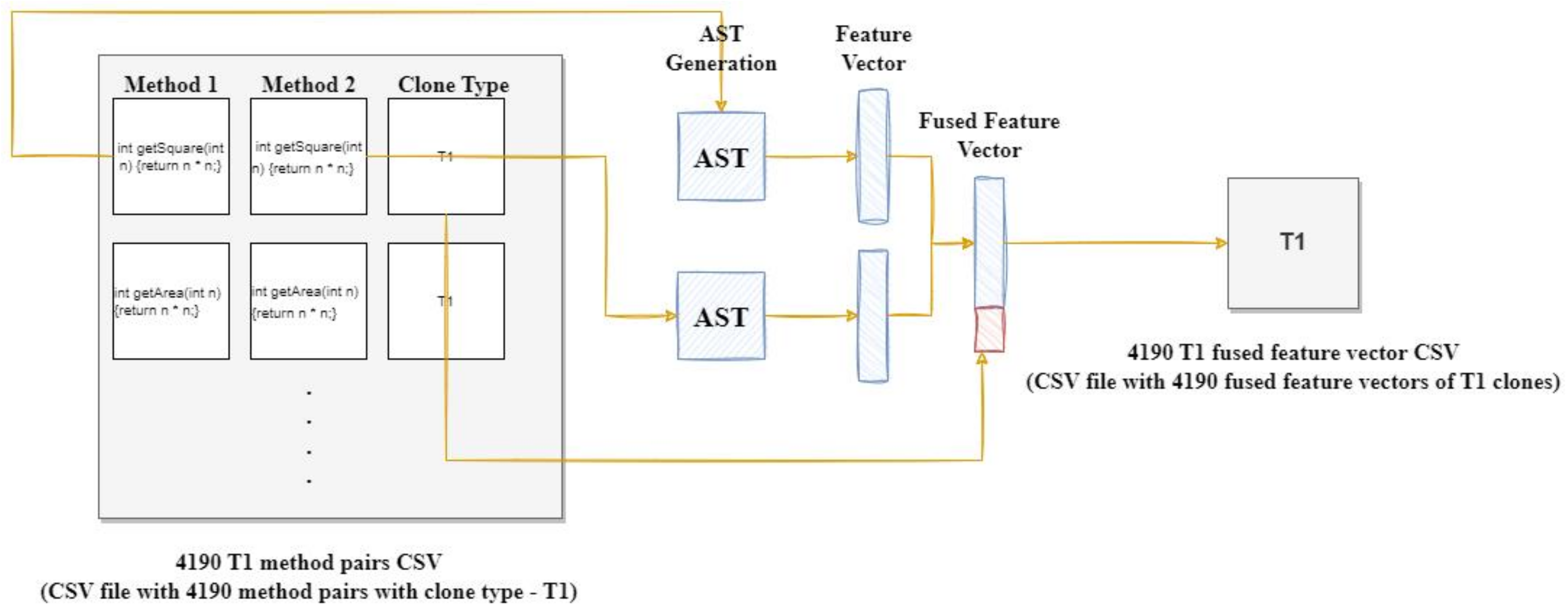
3.1.2. Method Pairs Extraction
3.1.3. AST Generation
3.1.4. Feature Extraction
3.1.5. Fusion of Feature Vectors
3.1.6. Dataset
3.1.7. Multiclass Classifier Model
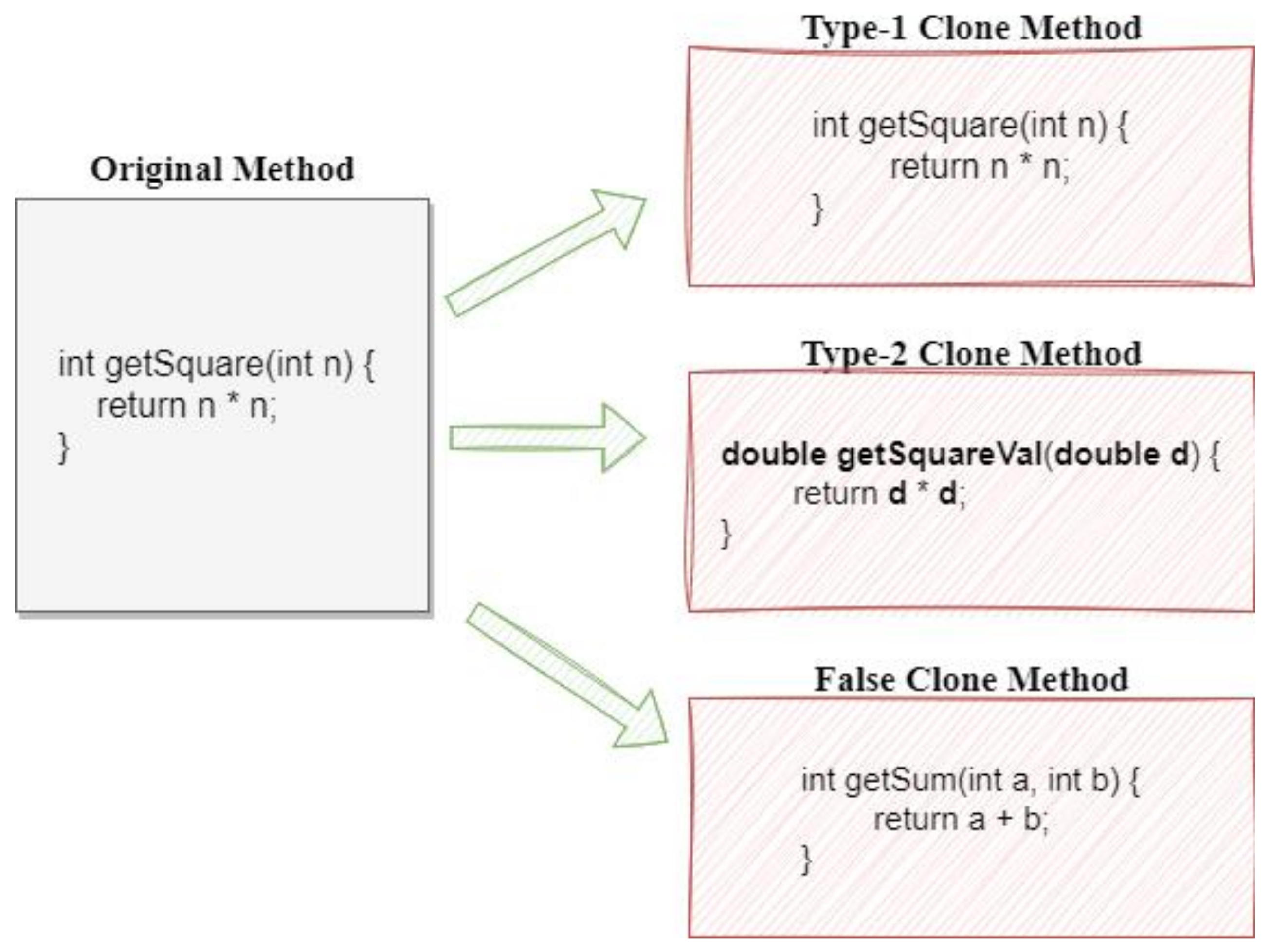
3.1.8. Clone Type
3.2. Proposed Hybrid DL Approach
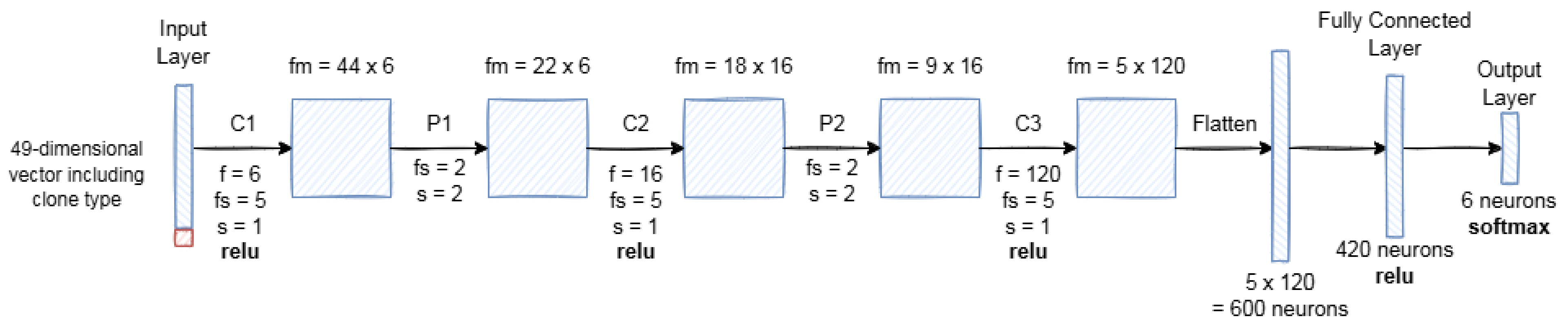
3.2.1. LetNet-5
3.2.2. Oreo
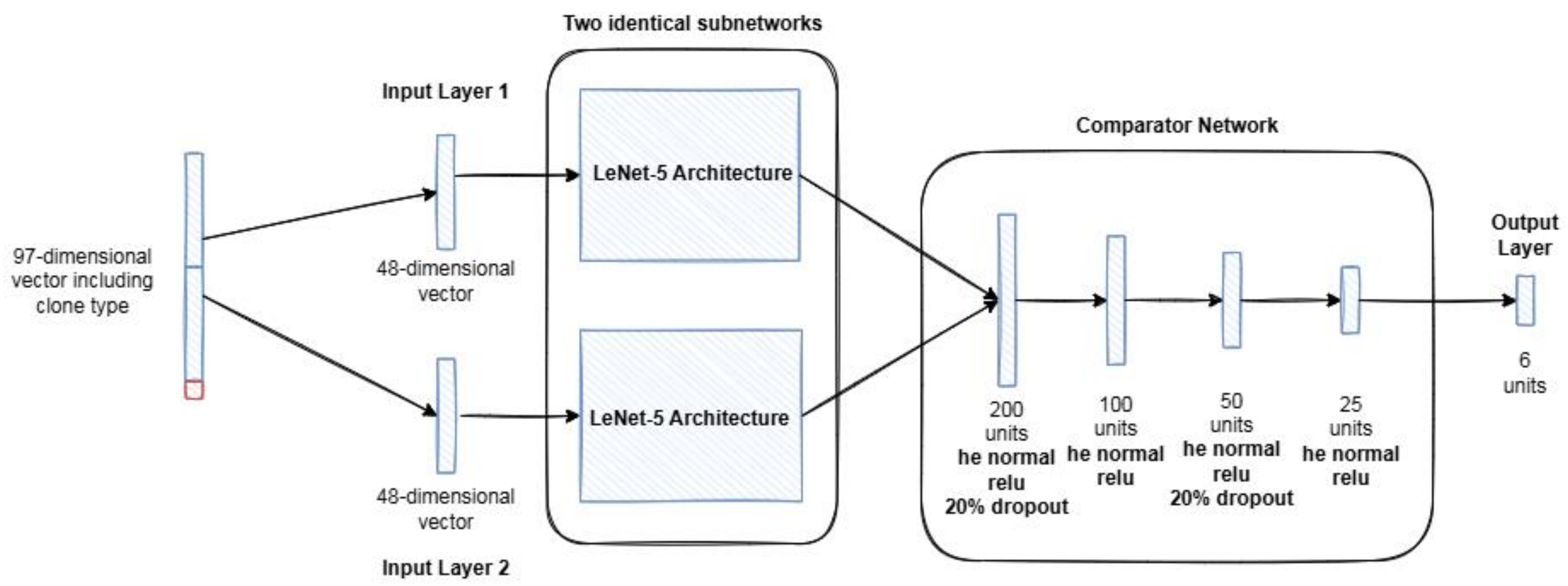
3.2.3. LeONet
4. Results and Discussion
4.1. Machine Configuration
4.2. Model Evaluation Metrics
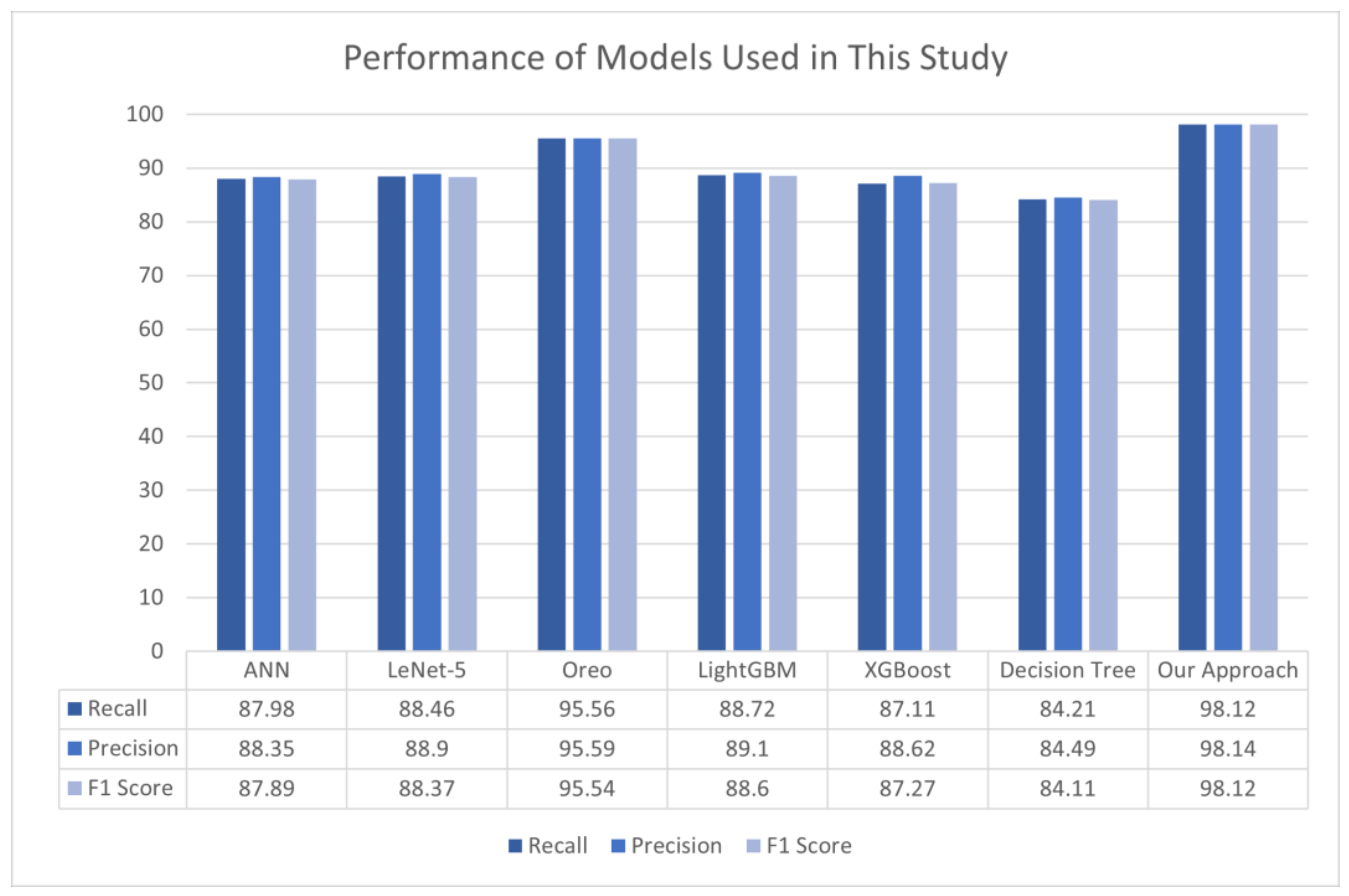
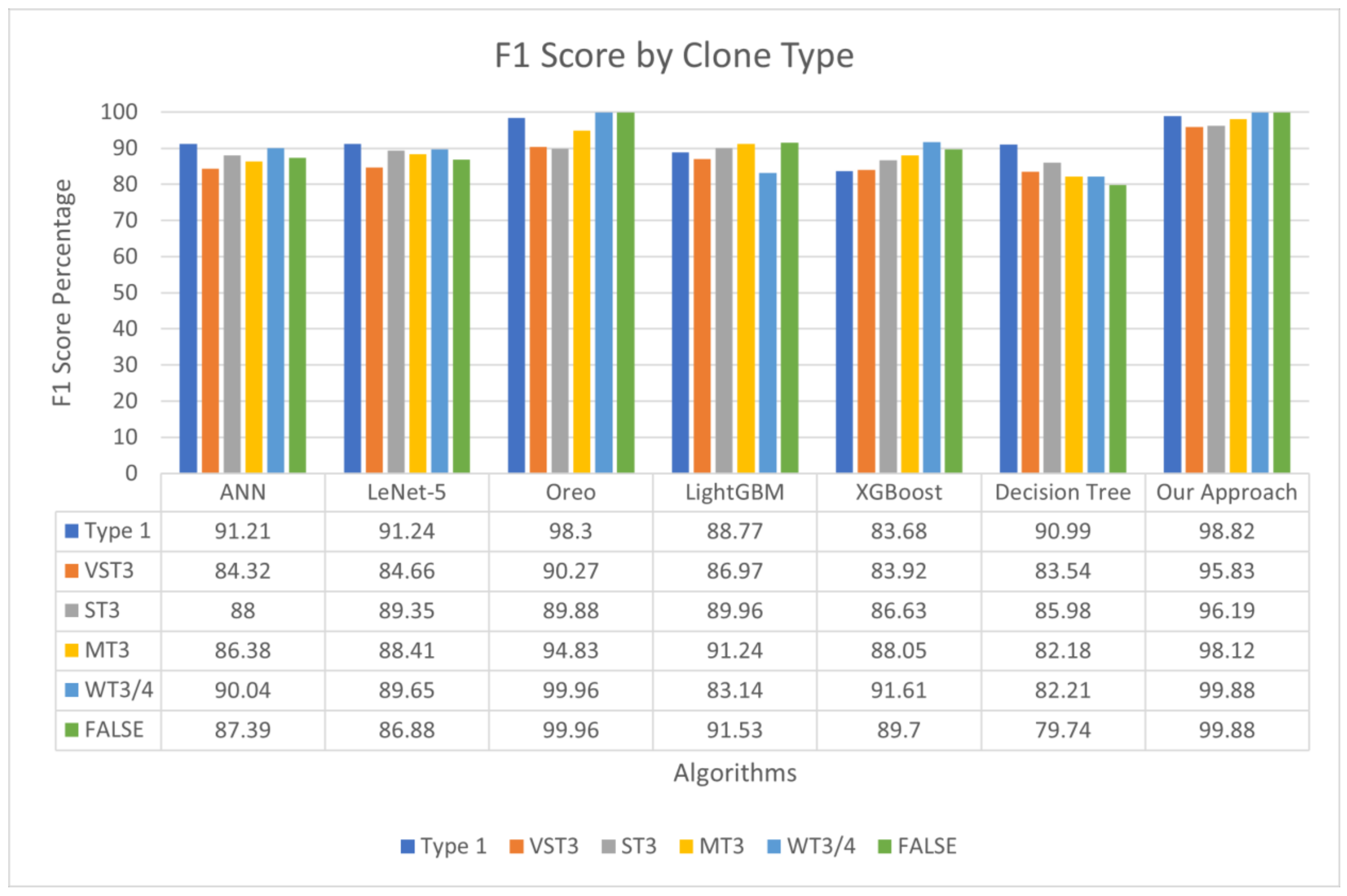
4.3. Performance Comparison of Several Algorithms Used in This Study to Detect Code Clones
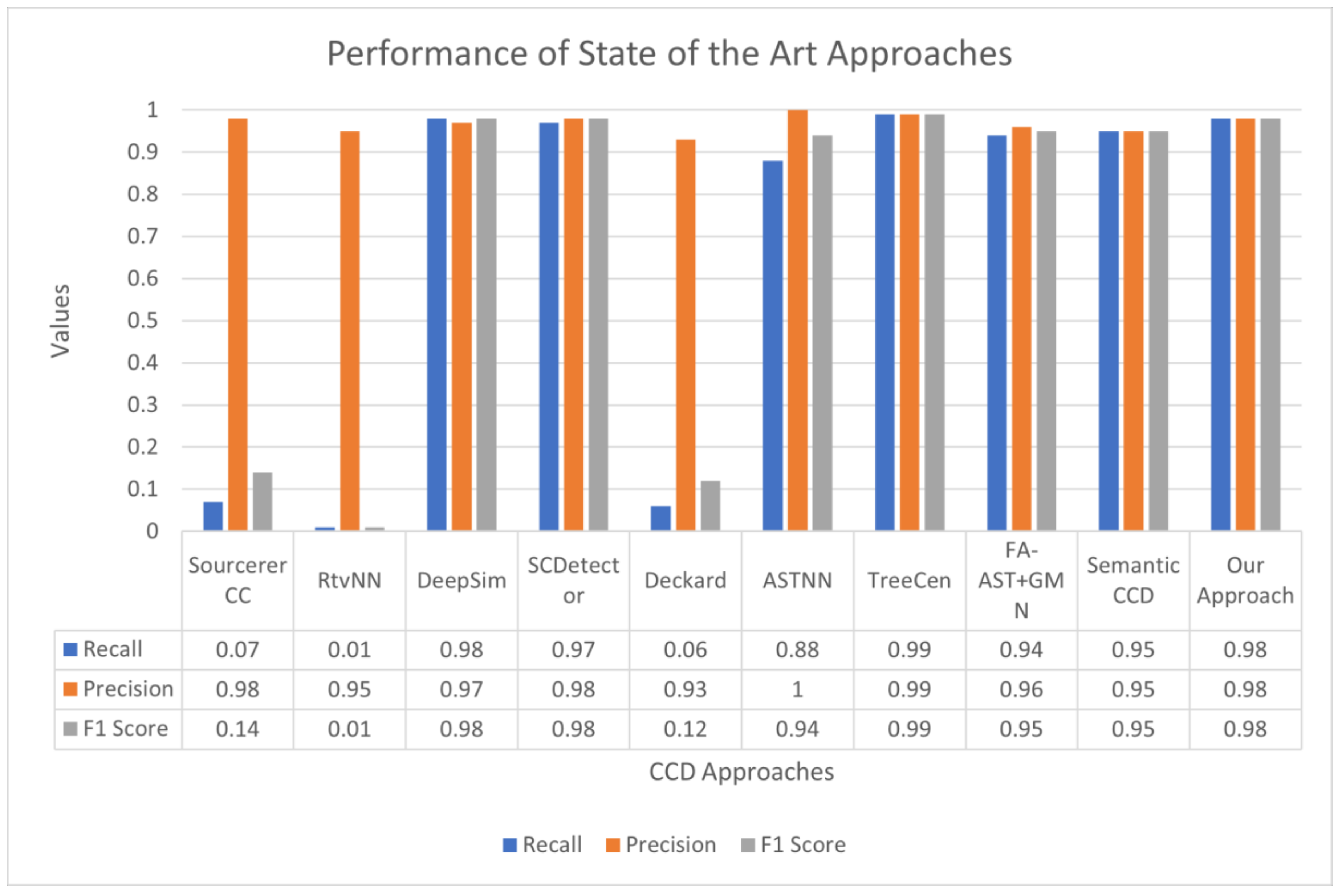
4.4. Performance Comparison of Several CCD Approaches Considered in Literature Review
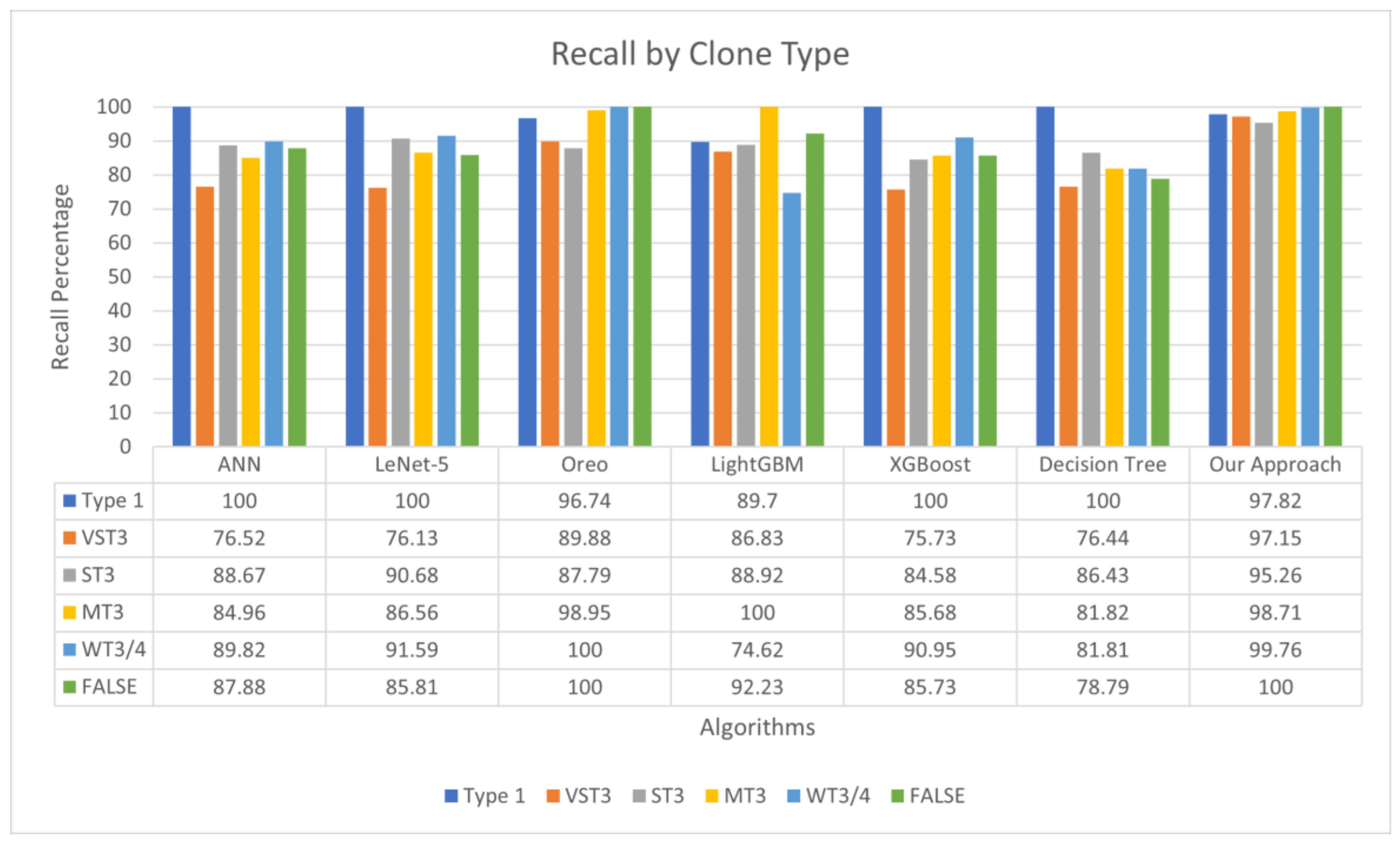
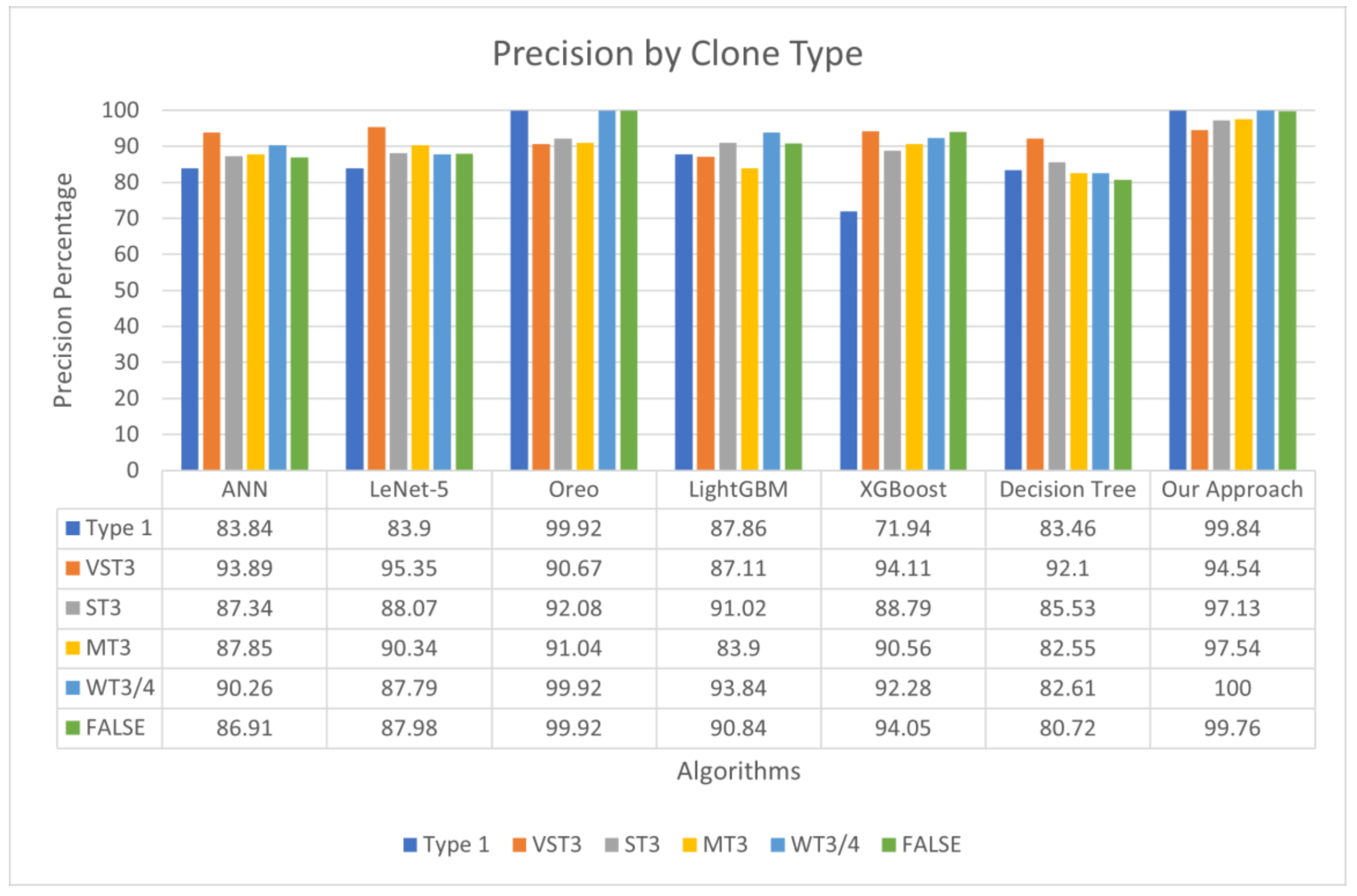
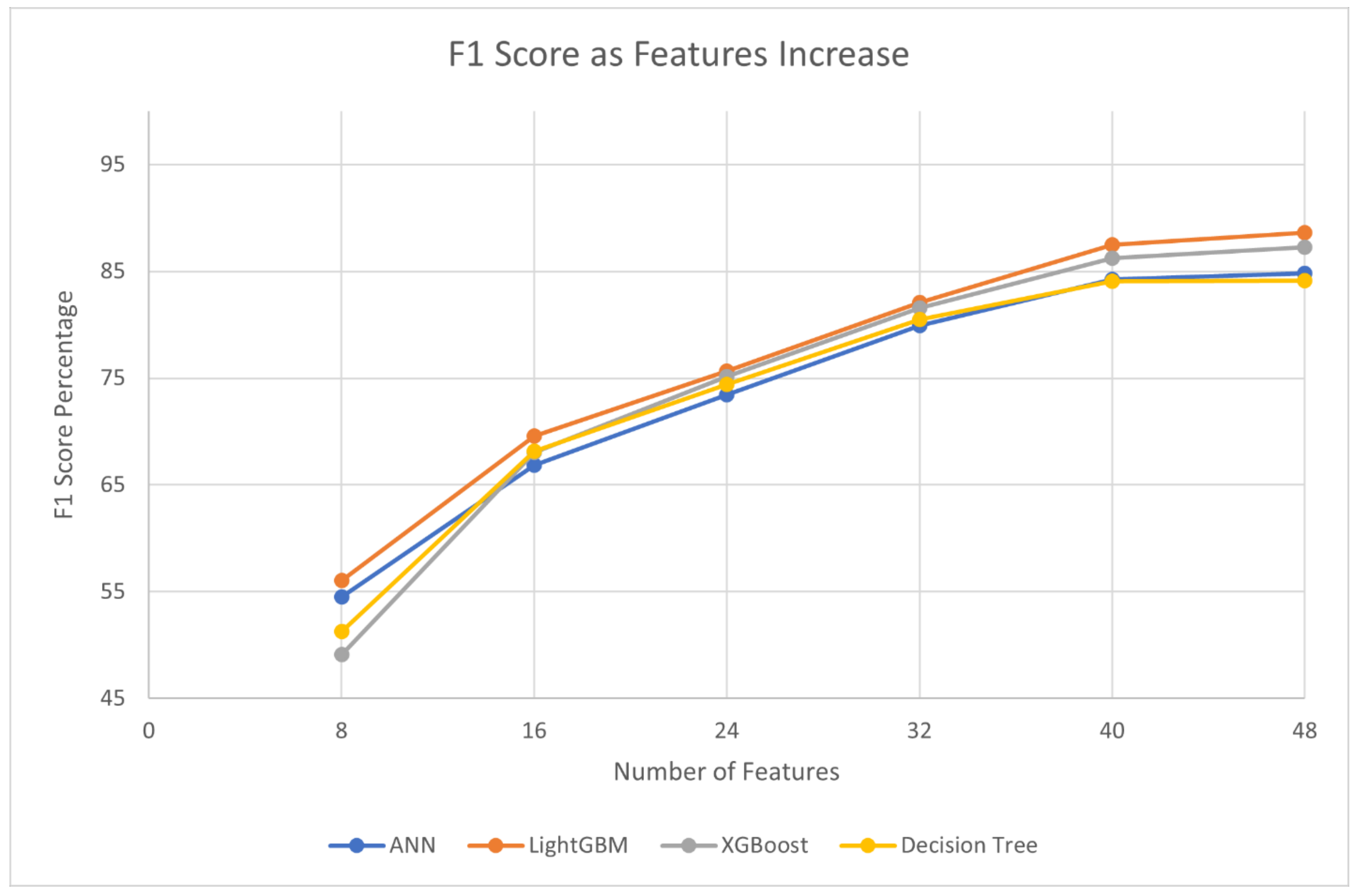
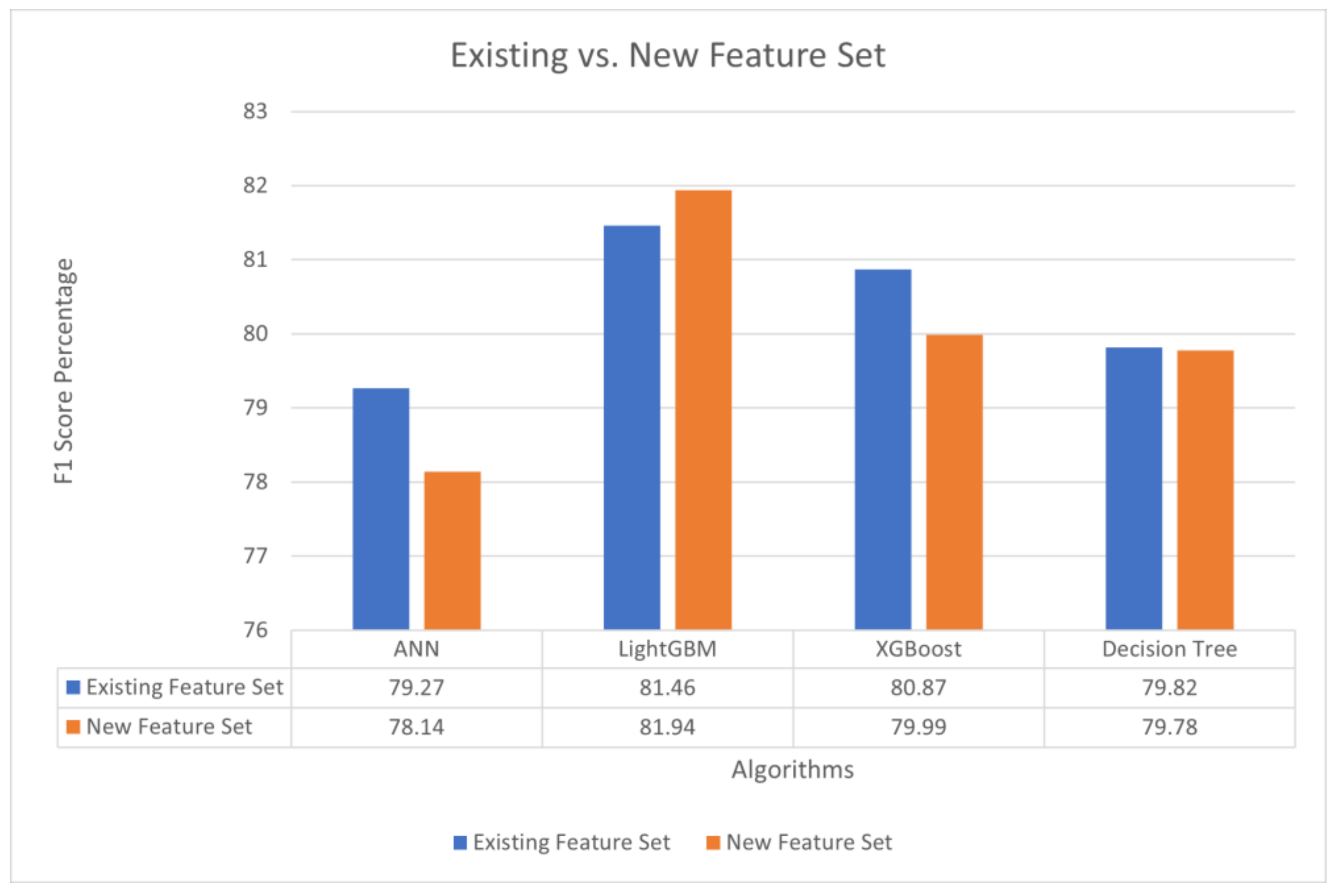
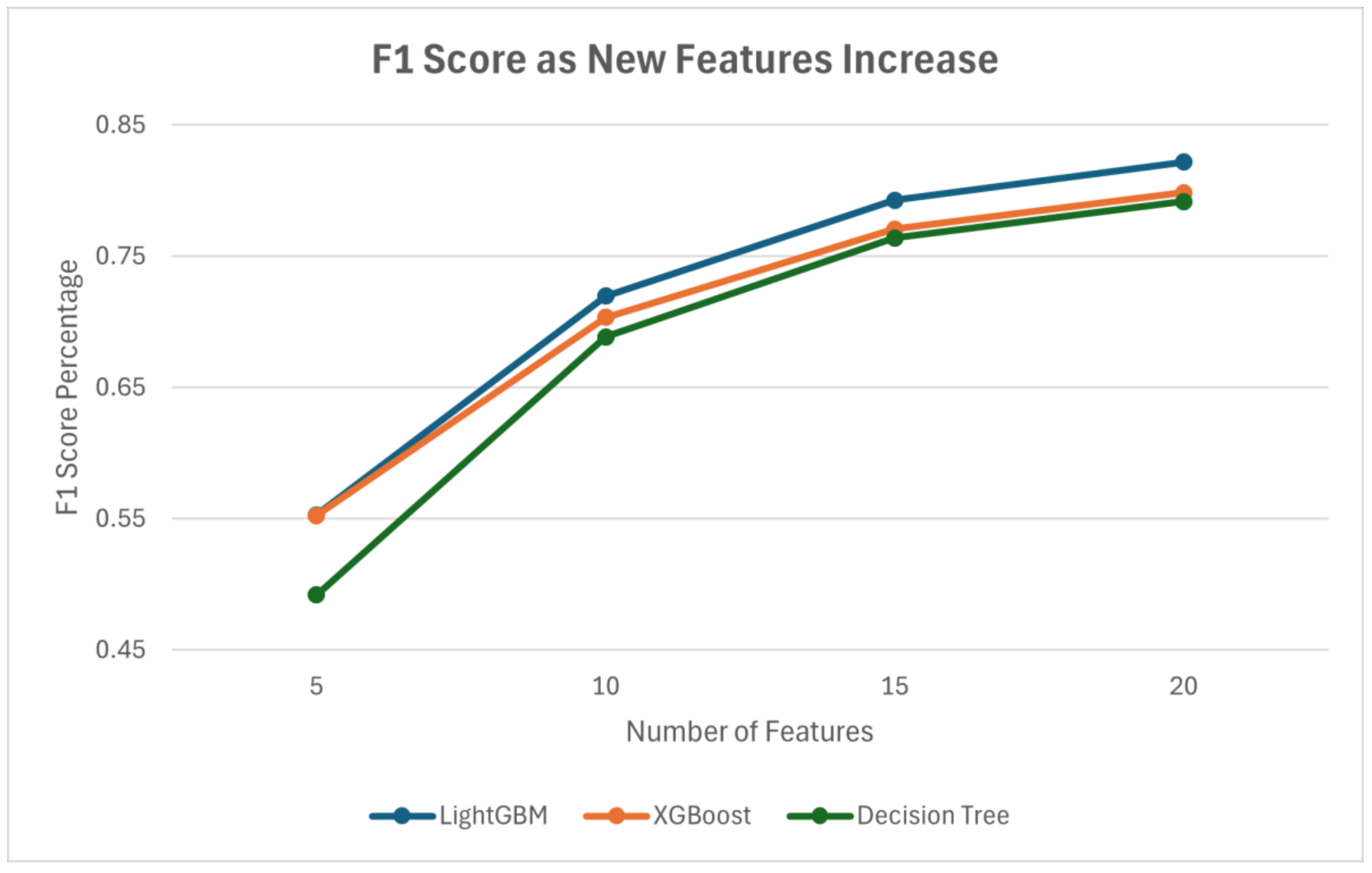
4.5. Results Obtained During Evaluation of Features in Classifying Code Clones
5. Limitations of This Study
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, M.; Bergman, L.; Lau, T.; Notkin, D. An ethnographic study of copy and paste programming practices in OOPL. In Proceedings of the 2004 International Symposium on Empirical Software Engineering (ISESE 2004), Redondo Beach, CA, USA, 19–20 August 2004; pp. 83–92. [Google Scholar]
- Ain, Q.U.; Butt, W.H.; Anwar, M.W.; Azam, F.; Maqbool, B. A systematic review on code clone detection. IEEE Access 2019, 7, 86121–86144. [Google Scholar] [CrossRef]
- Rattan, D.; Bhatia, R.; Singh, M. Software clone detection: A systematic review. Inf. Softw. Technol. 2013, 55, 1165–1199. [Google Scholar] [CrossRef]
- Roy, C.K.; Cordy, J.R. A survey on software clone detection research. Queen’s Sch. Comput. TR 2007, 541, 64–68. [Google Scholar]
- Monden, A.; Nakae, D.; Kamiya, T.; Sato, S.-I.; Matsumoto, K.-I. Software quality analysis by code clones in industrial legacy software. In Proceedings of the Eighth IEEE Symposium on Software Metrics, Ottawa, ON, Canada, 4–7 June 2002; pp. 87–94. [Google Scholar]
- Yamashita, A.; Counsell, S. Code smells as system-level indicators of maintainability: An empirical study. J. Syst. Softw. 2013, 86, 2639–2653. [Google Scholar] [CrossRef]
- Juergens, E.; Deissenboeck, F.; Hummel, B.; Wagner, S. Do code clones matter? In Proceedings of the 2009 IEEE 31st International Conference on Software Engineering, Vancouver, BC, Canada, 16–24 May 2009; pp. 485–495. [Google Scholar]
- Barbour, L.; Khomh, F.; Zou, Y. An empirical study of faults in late propagation clone genealogies. J. Softw. Evol. Process 2013, 25, 1139–1165. [Google Scholar] [CrossRef]
- Mondal, M.; Roy, C.K.; Schneider, K.A. An empirical study on clone stability. ACM SIGAPP Appl. Comput. Rev. 2012, 12, 20–36. [Google Scholar] [CrossRef]
- Mondal, M.; Roy, B.; Roy, C.K.; Schneider, K.A. An empirical study on bug propagation through code cloning. J. Syst. Softw. 2019, 158, 110407. [Google Scholar] [CrossRef]
- Zhang, H.; Sakurai, K. A survey of software clone detection from a security perspective. IEEE Access 2021, 9, 48157–48173. [Google Scholar] [CrossRef]
- Li, H.; Kwon, H.; Kwon, J.; Lee, H. CLORIFI: Software vulnerability discovery using code clone verification. Concurr. Comput. Pract. Exp. 2016, 28, 1900–1917. [Google Scholar] [CrossRef]
- Bellon, S.; Koschke, R.; Antoniol, G.; Krinke, J.; Merlo, E. Comparison and evaluation of clone detection tools. IEEE Trans. Softw. Eng. 2007, 33, 577–591. [Google Scholar] [CrossRef]
- Alhazami, E.A.; Sheneamer, A.M. Graph-of-code: Semantic clone detection using graph fingerprints. IEEE Trans. Softw. Eng. 2023, 49, 3972–3988. [Google Scholar] [CrossRef]
- Sheneamer, A.; Roy, S.; Kalita, J. An effective semantic code clone detection framework using pairwise feature fusion. IEEE Access 2021, 9, 133438–133452. [Google Scholar] [CrossRef]
- Sheneamer, A.; Kalita, J. Semantic clone detection using machine learning. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; pp. 1024–1028. [Google Scholar]
- Jo, Y.-B.; Lee, J.; Yoo, C.-J. Two-pass technique for clone detection and type classification using tree-based convolution neural network. Appl. Sci. 2021, 11, 6613. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Saini, V.; Farmahinifarahani, F.; Lu, Y.; Baldi, P.; Lopes, C.V. Oreo: Detection of clones in the twilight zone. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Lake Buena Vista, FL, USA, 4–9 November 2018; pp. 354–365. [Google Scholar]
- Kaur, M.; Rattan, D. A systematic literature review on the use of machine learning in code clone research. Comput. Sci. Rev. 2023, 47, 100528. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Sajnani, H.; Saini, V.; Svajlenko, J.; Roy, C.K.; Lopes, C.V. SourcererCC: Scaling code clone detection to big-code. In Proceedings of the 38th International Conference on Software Engineering, Austin, TX, USA, 14–22 May 2016; pp. 1157–1168. [Google Scholar]
- White, M.; Tufano, M.; Vendome, C.; Poshyvanyk, D. Deep learning code fragments for code clone detection. In Proceedings of the 2016 31st IEEE/ACM International Conference on Automated Software Engineering (ASE), Singapore, 3–7 September 2016; pp. 87–98. [Google Scholar]
- Jiang, L.; Misherghi, G.; Su, Z.; Glondu, S. Deckard: Scalable and accurate tree-based detection of code clones. In Proceedings of the 29th International Conference on Software Engineering (ICSE'07), Minneapolis, MN, USA, 20–26 May 2007; pp. 96–105. [Google Scholar]
- Zhao, G.; Huang, J. DeepSim: Deep learning code functional similarity. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Lake Buena Vista, FL, USA, 4–9 November 2018; pp. 141–151. [Google Scholar]
- Wu, Y.; Zou, D.; Dou, S.; Yang, S.; Yang, W.; Cheng, F.; Hong, L.; Hai, J. SCDetector: Software functional clone detection based on semantic tokens analysis. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering, Virtual Event, 21–25 September 2020; pp. 821–833. [Google Scholar]
- Zhang, J.; Wang, X.; Zhang, H.; Sun, H.; Wang, K.; Liu, X. A novel neural source code representation based on abstract syntax tree. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 783–794. [Google Scholar]
- Hu, Y.; Zou, D.; Peng, J.; Wu, Y.; Shan, J.; Jin, H. TreeCen: Building tree graph for scalable semantic code clone detection. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, Rochester, MI, USA, 10–14 October 2022; pp. 1–12. [Google Scholar]
- Wang, W.; Li, G.; Ma, B.; Xia, X.; Jin, Z. Detecting code clones with graph neural network and flow-augmented abstract syntax tree. In Proceedings of the 2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER), London, ON, Canada, 18–21 February 2020; pp. 261–271. [Google Scholar]
- Svajlenko, J.; Islam, J.F.; Keivanloo, I.; Roy, C.K.; Mia, M.M. Towards a big data curated benchmark of inter-project code clones. In Proceedings of the 2014 IEEE International Conference on Software Maintenance and Evolution, Victoria, BC, Canada, 29 September–3 October 2014; pp. 476–480. [Google Scholar]
- Svajlenko, J.; Roy, C.K. Evaluating clone detection tools with BigCloneBench. In Proceedings of the 2015 IEEE International Conference on Software Maintenance and Evolution (ICSME), Bremen, Germany, 29 September–1 October 2015; pp. 131–140. [Google Scholar]
- Svajlenko, J.; Roy, C.K. BigCloneEval: A clone detection tool evaluation framework with BigCloneBench. In Proceedings of the 2016 IEEE International Conference on Software Maintenance and Evolution (ICSME), Raleigh, NC, USA, 2–7 October 2016; pp. 596–600. [Google Scholar]
- Li, L.; Feng, H.; Zhuang, W.; Meng, N.; Ryder, B. CCLearner: A deep learning-based clone detection approach. In Proceedings of the 2017 IEEE International Conference on Software Maintenance and Evolution (ICSME), Shanghai, China, 17–22 September 2017; pp. 249–260. [Google Scholar]
- Kim, D.K. Enhancing code clone detection using control flow graphs. Int. J. Electr. Comput. Eng. 2019, 9, 3287–3296. [Google Scholar] [CrossRef]
- Zeng, J.; Ben, K.; Li, X.; Zhang, X. Fast code clone detection based on weighted recursive autoencoders. IEEE Access 2019, 7, 125062–125078. [Google Scholar] [CrossRef]
- Falleri, J.-R.; Morandat, F.; Blanc, X.; Martinez, M.; Monperrus, M. Fine-grained and accurate source code differencing. In Proceedings of the 29th ACM/IEEE International Conference on Automated Software Engineering, Vasteras, Sweden, 15–19 September 2014; pp. 313–324. [Google Scholar]
- Eclipse Foundation. Eclipse Java Development Tools (JDT). 2023. Available online: https://www.eclipse.org/jdt/ (accessed on 2 November 2022).
- JavaParser—Home. 2022. Available online: https://javaparser.org/ (accessed on 2 November 2022).
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- de Souza, J.V.A.; Oliveira, L.E.S.E.; Gumiel, Y.B.; Carvalho, D.R.; Moro, C.M.C. Exploiting Siamese neural networks on short text similarity tasks for multiple domains and languages. In Proceedings of the International Conference on Computational Processing of the Portuguese Language, Evora, Portugal, 2–4 March 2020; pp. 357–367. [Google Scholar]
- Ondrašovič, M.; Tarábek, P. Siamese visual object tracking: A survey. IEEE Access 2021, 9, 110149–110172. [Google Scholar] [CrossRef]
- Zhang, W.; Pang, J.; Chen, K.; Loy, C.C. Dense Siamese network for dense unsupervised learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 464–480. [Google Scholar]
- Qiao, Y.; Wu, Y.; Duo, F.; Lin, W.; Yang, J. Siamese neural networks for user identity linkage through web browsing. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 2741–2751. [Google Scholar] [CrossRef] [PubMed]
- Rao, Y.; Cheng, Y.; Xue, J.; Pu, J.; Wang, Q.; Jin, R.; Wang, Q. FPSiamRPN: Feature pyramid Siamese network with region proposal network for target tracking. IEEE Access 2020, 8, 176158–176169. [Google Scholar] [CrossRef]
- Yang, B.; Yan, J.; Lei, Z.; Li, S.Z. Convolutional channel features. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 82–90. [Google Scholar]
- Li, G.; Yu, Y. Visual saliency detection based on multiscale deep CNN features. IEEE Trans. Image Process. 2016, 25, 5012–5024. [Google Scholar] [CrossRef] [PubMed]
- Zaibi, A.; Ladgham, A.; Sakly, A. A lightweight model for traffic sign classification based on enhanced LeNet-5 network. J. Sens. 2021, 2021, 8870529. [Google Scholar] [CrossRef]
- Kumar, C.R.; Saranya, N.; Priyadharshini, M.; Gilchrist, D. Face recognition using CNN and Siamese network. Meas. Sens. 2023, 27, 100800. [Google Scholar] [CrossRef]
- Xiong, Y.-J.; Cheng, S.-Y.; Ren, J.-X.; Zhang, Y.-J. Attention-based multiple Siamese networks with primary representation guiding for offline signature verification. Int. J. Doc. Anal. Recognit. (IJDAR) 2024, 27, 195–208. [Google Scholar] [CrossRef]
- Zhou, W.; Liu, Y.; Wang, N.; Liang, D.; Peng, B. Efficient Siamese model for visual object tracking with attention-based fusion modules. Signal Image Video Process. 2024, 18, 1203–1212. [Google Scholar] [CrossRef]
- Han, S.; Nam, H.; Kang, J.; Kim, K.; Cho, S.; Lee, S. Code-Smash: Source-code vulnerability detection using Siamese and multi-level neural architecture. IEEE Access 2024, 12, 22784–22795. [Google Scholar] [CrossRef]
- Yahya, M.A.; Kim, D.-K. CLCD-I: Cross-language clone detection by using deep learning with InferCode. Computers 2023, 12, 12. [Google Scholar] [CrossRef]
- Yu, D.; Yang, Q.; Chen, X.; Chen, J.; Xu, Y. Graph-based code semantics learning for efficient semantic code clone detection. Inf. Softw. Technol. 2023, 156, 107130. [Google Scholar] [CrossRef]
- Tasci, M.; Istanbullu, A.; Kosunalp, S.; Iliev, T.; Stoyanov, I.; Beloev, I. An efficient classification of rice variety with quantized neural networks. Electronics 2023, 12, 2285. [Google Scholar] [CrossRef]
- An, Y.; Yang, C.; Zhang, S. A lightweight network architecture for traffic sign recognition based on enhanced LeNet-5 network. Front. Neurosci. 2024, 18, 1431033. [Google Scholar] [CrossRef] [PubMed]
- Srinivasarao, G.; Rajesh, V.; Saikumar, K.; Baza, M.; Srivastava, G.; Alsabaan, M. Cloud-based LeNet-5 CNN for MRI brain tumor diagnosis and recognition. Trait. Signal 2023, 40, 223–234. [Google Scholar] [CrossRef]
- Dhayalini, M.; Ponmozhi, B.R.A. Unravelling the mysteries of lung cancer: Harnessing the power of deep learning for detection and classification. In Proceedings of the 2024 International Conference on Recent Advances in Electrical, Electronics, Ubiquitous Communication, and Computational Intelligence (RAEEUCCI), Chennai, India, 16–17 January 2024; pp. 1–6. [Google Scholar]
- Sarmah, J.; Saini, M.L.; Kumar, A.; Chasta, V. Performance analysis of deep CNN, YOLO, and LeNet for handwritten digit classification. In Proceedings of the International Conference on Artificial Intelligence on Textile and Apparel, Milan, Italy, 15–17 November 2023; pp. 215–227. [Google Scholar]
- Li, B.; Ye, C.; Guan, S.; Zhou, H. Semantic code clone detection via event embedding tree and GAT network. In Proceedings of the 2020 IEEE 20th International Conference on Software Quality, Reliability and Security (QRS), Macau, China, 11–14 December 2020; pp. 382–393. [Google Scholar]
- Bisong, E. Introduction to Scikit-learn. In Building Machine Learning and Deep Learning Models on Google Cloud Platform; Apress: Berkeley, CA, USA, 2019; pp. 215–229. [Google Scholar]
- Krinke, J.; Ragkhitwetsagul, C. BigCloneBench considered harmful for machine learning. In Proceedings of the 2022 IEEE 16th International Workshop on Software Clones (IWSC), Limassol, Cyprus, 2 October 2022; pp. 1–7. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Feature | Representation | No | Feature | Representation |
|---|---|---|---|---|---|
| 1 | Lines count | Whole number | 25 | Primitive types count | Whole number |
| 2 | Assignments count | Whole number | 26 | Simple names count | Whole number |
| 3 | Selection statements count | Whole number | 27 | Simple types count | Whole number |
| 4 | Iteration statements count | Whole number | 28 | Wildcard types count | Whole number |
| 5 | Synchronized statements count | Whole number | 29 | Postfix expressions count | Whole number |
| 6 | Return statements count | Whole number | 30 | Variable declaration fragments Count | Whole number |
| 7 | Switch case statements count | Whole number | 31 | Reference types count | Whole number |
| 8 | Try statements count | Whole number | 32 | Void types count | Whole number |
| 9 | Single variable declarations count | Whole number | 33 | Binary expressions count | Whole number |
| 10 | Variable declarations count | Whole number | 34 | Double literal expressions count | Whole number |
| 11 | Variable declaration statements count | Whole number | 35 | Integer literal expressions count | Whole number |
| 12 | Expression statements count | Whole number | 36 | Long literal expressions count | Whole number |
| 13 | Type declaration statements count | Whole number | 37 | Literal string value expressions count | Whole number |
| 14 | Type parameters count | Whole number | 38 | Unary expressions count | Whole number |
| 15 | Class instance creations count | Whole number | 39 | Type bounds count | Whole number |
| 16 | Array creations count | Whole number | 40 | Boxed types count | Whole number |
| 17 | Cast expressions count | Whole number | 41 | Array creation levels count | Whole number |
| 18 | Constructor invocations count | Whole number | 42 | Poly expressions count | Whole number |
| 19 | Field declarations count | Whole number | 43 | Standalone expressions count | Whole number |
| 20 | Super method invocations count | Whole number | 44 | Elided type arguments count | Whole number |
| 21 | Infix expressions count | Whole number | 45 | Qualified expression names count | Whole number |
| 22 | Method invocations count | Whole number | 46 | Simple expression names count | Whole number |
| 23 | Method refs count | Whole number | 47 | Primary expressions count | Whole number |
| 24 | Parenthesized expressions count | Whole number | 48 | Literal expressions count | Whole number |
| No | Feature | Example |
|---|---|---|
| 1 | Postfix expressions count | x++; (x++ is a postfix expression) |
| 2 | Variable declaration fragments count | int x = 10, y = 20, z = 30; (x, y, and z are variable declaration fragments) |
| 3 | Reference types count | Map<String, Integer> map = new HashMap<>(); (Map<String, Integer> is a reference type) |
| 4 | Void types count | void method() (The void type indicates that the method does not return a value) |
| 5 | Binary expressions count | boolean result = (a > 0 && b < 10); (a > 0 && b < 10 is a binary expression) |
| 6 | Double literal expressions count | double pi = 3.14; (3.14 is a double literal expression) |
| 7 | Integer literal expressions count | int count = 42; (42 is an integer literal expression) |
| 8 | Long literal expressions count | long value = 123456789L; (123456789L is a long literal expression) |
| 9 | Literal string value expressions count | String response = “Success”: + statusCode; (“Success”: is a literal string value expression) |
| 10 | Unary expressions count | boolean result = !flag; (!flag is a unary expression) |
| 11 | Type bounds count | class Container<T extends Comparable<T>> (the bound Comparable<T> specifies that T must implement Comparable<T>) |
| 12 | Boxed types count | Integer x = 5; (the type Integer is the boxed type) |
| 13 | Array creation levels count | int[][] grid = new int [3][4]; (2D array creation with 2 levels) |
| 14 | Poly expressions count | int result = x + (y > 10? 5:3); (The expression y > 10? 5:3 is a poly expression within the addition x + (y > 10? 5:3)) |
| 15 | Standalone expressions count | if (a > b) System.out.println(“A is greater”); (the entire if statement is a standalone expression) |
| 16 | Elided type arguments count | exampleMethod();, obj.exampleMethod();, obj<>.exampleMethod(); |
| 17 | Qualified expression names count | java.util.Date today = new java.util.Date(); (java.util.Date is a qualified expression name) |
| 18 | Simple expression names count | int result = a + (b * (c − d)); (a, b, c, and d are simple expression names) |
| 19 | Primary expressions count | int max = Math.max(a, b); (Math.max is a primary expression) |
| 20 | Literal expressions count | boolean flag = false; (false is a literal expression—Boolean literal) |
| Feature | Original Method | T1 Clone Method | T2 Clone Method |
|---|---|---|---|
| Lines count | 3 | 3 | 3 |
| Return statements count | 1 | 1 | 1 |
| Single variable declarations count | 1 | 1 | 1 |
| Variable declarations count | 1 | 1 | 1 |
| Infix expressions count | 1 | 1 | 1 |
| Primitive types count | 2 | 2 | 2 |
| Simple names count | 5 | 5 | 5 |
| Binary expressions count | 1 | 1 | 1 |
| Standalone expressions count | 3 | 3 | 3 |
| Elided type arguments count | 3 | 3 | 3 |
| Simple expression names count | 2 | 2 | 2 |
| Layer | Filters | Kernal Size/Pool Size | Stride | Size of Feature Map | Activation Function |
|---|---|---|---|---|---|
| Input | - | - | - | 48 | - |
| Convolutional 1 | 6 | 5 | 1 | 44 × 6 | relu |
| Pooling 1 | - | 2 | 2 | 22 × 6 | - |
| Convolutional 2 | 16 | 5 | 1 | 18 × 16 | relu |
| Pooling 2 | - | 2 | 2 | 9 × 16 | - |
| Convolutional 3 | 120 | 5 | 1 | 5 × 120 | relu |
| Flatten | - | - | - | 5 × 120 = 600 | - |
| Fully Connected 1 | - | - | - | 420 | relu |
| Output | - | - | - | 6 | softmax |
| Layer | Units | Kernel Initializer | Activation Function |
|---|---|---|---|
| Dense | 200 | he normal | relu |
| Dropout (20%) | - | - | - |
| Dense | 200 | he normal | relu |
| Dense | 200 | he normal | relu |
| Dropout (20%) | - | - | - |
| Dense | 200 | he normal | relu |
| Layer | Units | Kernel Initializer | Activation Function |
|---|---|---|---|
| Dense | 200 | he normal | relu |
| Dropout (20%) | - | - | - |
| Dense | 100 | he normal | relu |
| Dense | 50 | he normal | relu |
| Dropout (20%) | - | - | - |
| Dense | 25 | he normal | relu |
| No | Models | Dataset Used | No | Models | Dataset Used |
|---|---|---|---|---|---|
| 1 | ANN | Distance dataset | 5 | XGBoost | Distance dataset |
| 2 | LeNet-5 | Distance dataset | 6 | Decision Tree | Distance dataset |
| 3 | Oreo | Linear dataset | 7 | LeONet | Linear dataset |
| 4 | LightGBM | Distance dataset |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vijayanandan, T.; Banujan, K.; Induranga, A.; Kumara, B.T.G.S.; Koswattage, K. LeONet: A Hybrid Deep Learning Approach for High-Precision Code Clone Detection Using Abstract Syntax Tree Features. Big Data Cogn. Comput. 2025, 9, 187. https://doi.org/10.3390/bdcc9070187
Vijayanandan T, Banujan K, Induranga A, Kumara BTGS, Koswattage K. LeONet: A Hybrid Deep Learning Approach for High-Precision Code Clone Detection Using Abstract Syntax Tree Features. Big Data and Cognitive Computing. 2025; 9(7):187. https://doi.org/10.3390/bdcc9070187
Chicago/Turabian StyleVijayanandan, Thanoshan, Kuhaneswaran Banujan, Ashan Induranga, Banage T. G. S. Kumara, and Kaveenga Koswattage. 2025. "LeONet: A Hybrid Deep Learning Approach for High-Precision Code Clone Detection Using Abstract Syntax Tree Features" Big Data and Cognitive Computing 9, no. 7: 187. https://doi.org/10.3390/bdcc9070187
APA StyleVijayanandan, T., Banujan, K., Induranga, A., Kumara, B. T. G. S., & Koswattage, K. (2025). LeONet: A Hybrid Deep Learning Approach for High-Precision Code Clone Detection Using Abstract Syntax Tree Features. Big Data and Cognitive Computing, 9(7), 187. https://doi.org/10.3390/bdcc9070187