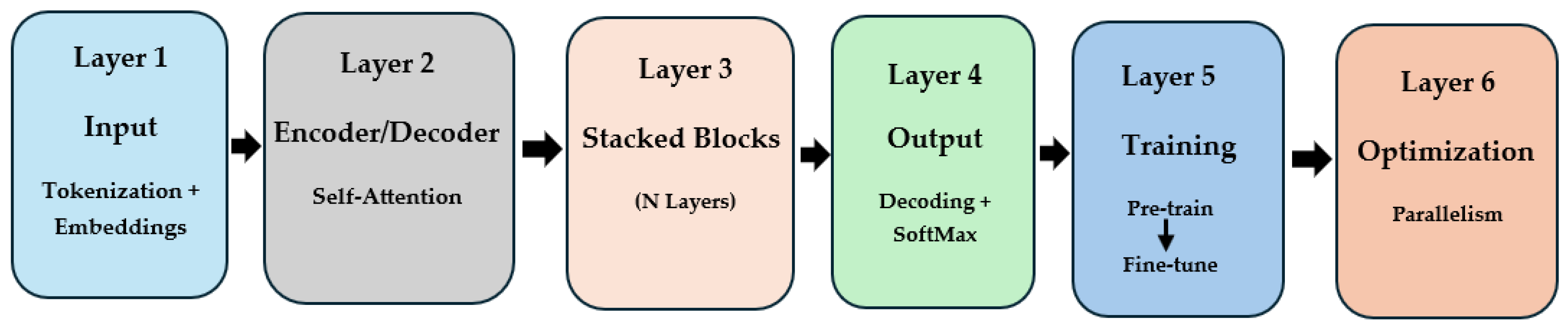
The increasing adoption of LLMs in cyber security reflects a notable shift in how modern threats are detected, understood, and mitigated. As cyber threats grow in scale, complexity, and subtlety, traditional systems often fall short in responding to evolving attack vectors, particularly those that leverage social engineering, code obfuscation, or multi-stage strategies. In contrast, LLMs and their fine-tuned derivatives have demonstrated a remarkable ability to understand, generate, and contextualize human language, making them uniquely suited for analysing unstructured data. This paper advances the existing literature by offering a holistic framework that categorizes LLM applications into six key cyber security domains, including vulnerability detection, anomaly detection, cyber threat intelligence, blockchain security, penetration testing, and digital forensics. These domains were selected based on the maturity of research, practical impact, and the demonstrated value of LLMs in addressing real-world cyber security challenges. Within each domain, this paper examines in depth how LLMs contribute to context-aware reasoning, automation, and adaptability to emerging threats (
Figure 3).
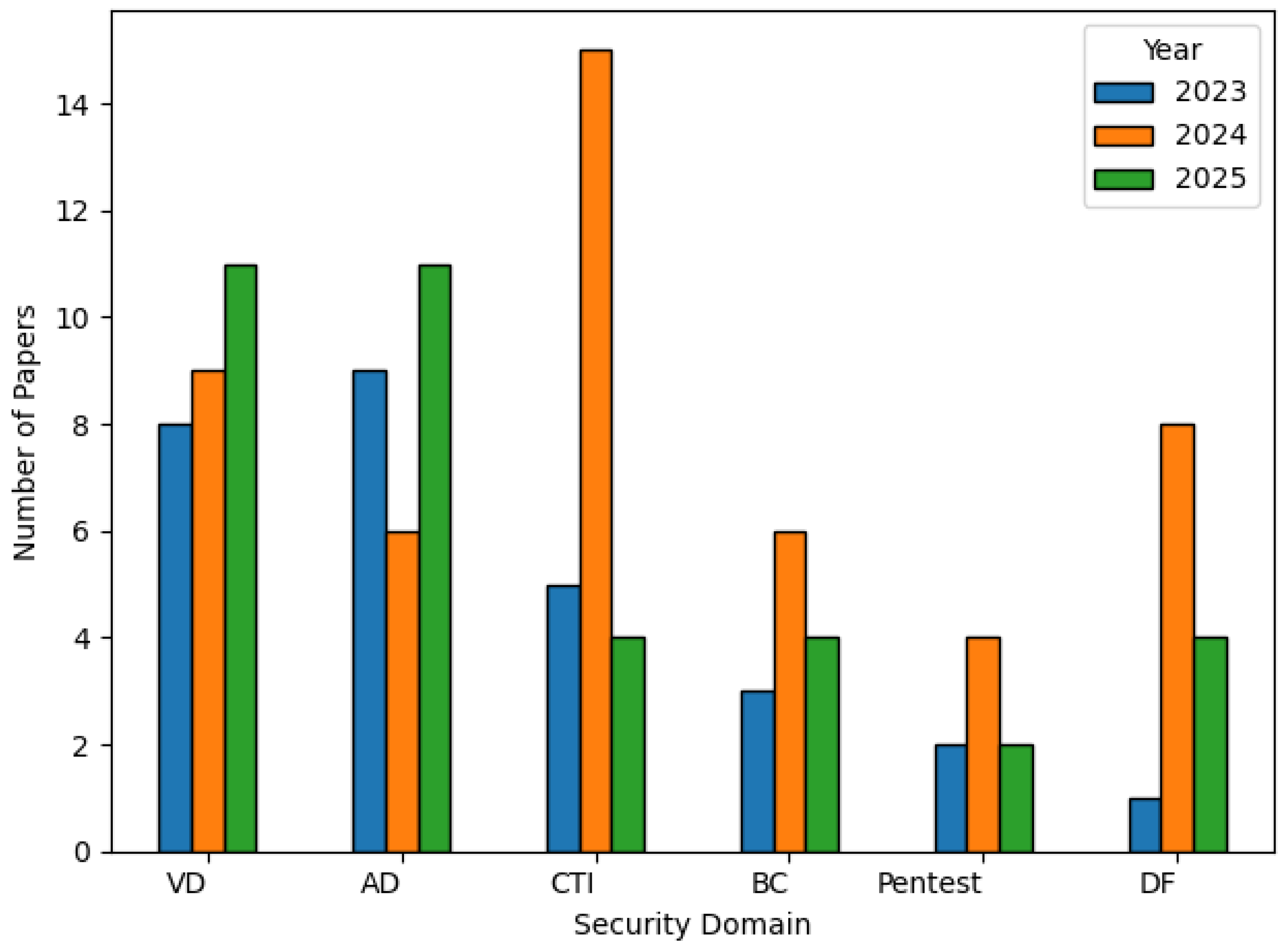
This categorization not only brings clarity to the fragmented landscape of LLM applications in cyber security but also serves as a structured lens through which researchers and practitioners can assess current capabilities and identify future opportunities. The chart, shown in
Figure 4, reinforces this categorization by illustrating the distribution of published research papers across the six identified domains from 2023 to 2025. Notably, vulnerability detection (VD) and anomaly detection (AD) exhibit steady growth, reflecting their foundational role in proactive cyber defence. Cyber threat intelligence (CTI) saw a dramatic spike in 2024, suggesting heightened research interest in leveraging LLMs for extracting actionable insights from threat data. In contrast, areas like penetration testing (Pentest) and blockchain security (BC) show relatively modest and consistent publication volumes, potentially indicating emerging research interest in these areas. Digital forensics (DF), while initially underexplored in 2023, witnessed significant attention in 2024, possibly driven by new investigative use cases and tools.
4.1. Vulnerability Detection
The application of LLMs in vulnerability detection has rapidly evolved into one of the most active and impactful areas of LLM-driven cyber security research. A wide range of studies reviewed by Zhang et al. [
42] have explored how LLMs can enhance traditional vulnerability detection techniques by improving automation, reducing false positives, and enabling the semantic understanding of code and configurations. The key to this evolution is the integration of LLMs into both static and dynamic analysis pipelines.
Several studies have demonstrated the use of LLMs to detect vulnerabilities directly from source code. Zhou et al. [
43,
44], and Tamberg and Bahsi [
45] proposed approaches using LLMs to identify insecure coding patterns and semantic weaknesses, emphasizing the benefit of pretrained language models over traditional pattern-matching tools. Similarly, Mahyari [
46] and Mao et al. [
47] leveraged LLM models, like CodeBERT and GPT-3, for vulnerability classification tasks, showing that LLMs could generalize across different programming languages and vulnerability types with minimal retraining. Beyond classification, several researchers focused on vulnerability localization and explanation. For example, Cheshkov et al. [
48] designed a method to highlight precise code lines contributing to a vulnerability, while Purba et al. [
49] applied LLMs to reason about causality in code defects. These efforts represent a shift toward interpretable vulnerability detection, where models not only identify vulnerable code but also offer human-readable explanations.
Dozono et al. [
50] extended this evaluation across multiple programming languages, developing CODEGUARDIAN, a VSCode-integrated tool that enhances developers’ accuracy and speed in detecting vulnerabilities. Berabi et al. [
51] also proposed DeepCode AI Fix, a system that utilizes program analysis to focus LLMs’ attention on relevant code snippets, thereby improving the efficiency of vulnerability fixes. Similarly, Noever [
37] assessed GPT-4′s performance against traditional static analysers, like Snyk and Fortify, finding that GPT-4 identified approximately four times more vulnerabilities and provided viable fixes with a low false positive rate. Sheng et al. [
52] also proposed LProtector, an LLM-driven vulnerability detection system that leverages GPT-4o and Retrieval-Augmented Generation (RAG) to identify vulnerabilities in C/C++ codebases, outperforming State-of-the-Art baselines in F1 score.
LLMs have also been integrated into software development environments. Khare et al. [
53] and Jensen et al. [
54] demonstrated how developer-facing tools powered by LLMs could offer real-time feedback on insecure code during the writing process, bridging the gap between detection and secure development. Shestov et al. [
55] extended this by proposing LLM-assisted bug reporting systems that correlate vulnerabilities with developer comments and test results. Other works, like those by Li et al. [
56] and Kouliaridis et al. [
2], explored the fine-tuning of LLMs for vulnerability datasets, improving detection precision and recall. Guo et al. [
57] and Wang et al. [
58] focused on model robustness in the face of obfuscated or adversarial code, an important area given the tendency of attackers to hide exploit logic. At the infrastructure level, Bakhshandeh et al. [
59] and Mathews et al. [
60] showed how LLMs could identify misconfigurations in containerized environments and cloud infrastructures, extending vulnerability detection beyond traditional application code. LLMs were also utilized as virtual security response experts. Lin et al. [
61] demonstrated that LLMs could assist in vulnerability mitigation by retrieving relevant CVE and CWE data and suggesting remediation strategies. Kaheh et al. [
62] took this a step further, arguing that LLMs should not only answer queries but also perform actions, such as instructing a firewall to block a malicious IP.
Recent research has increasingly focused on the application of LLMs for vulnerability detection and code security. Dolcetti et al. [
63] and Feng et al. [
64] explored enhancing LLM performance by integrating them with traditional techniques like testing, static analysis, and code graph structures, improving both detection and repair capabilities. Similarly, Lin and Mohaisen [
65] investigated the effectiveness of fine-tuned LLMs and general-purpose models, highlighting the role of dataset quality and token length in shaping model reliability. Torkamani et al. [
66] proposed CASEY, a triaging tool that accurately classifies CWEs and predicts severity levels, demonstrating practical utility in automating security assessments. In parallel, broader methodological and empirical advancements have surfaced. Ghosh et al. [
67] introduced CVE-LLM, embedding ontology-driven semantics from CVE and CWE databases to enhance context-aware vulnerability evaluations. Also, Sheng et al. [
7] provided a State-of-the-Art survey mapping out the LLM landscape in software security and identifying key challenges. Sovrano et al. [
39] also offered critical insight into LLM limitations by identifying the “lost-in-the-end” effect, where vulnerabilities near the input’s end are frequently missed, calling for smarter input management strategies.
Table 2 summarizes the contributions and limitations of recent LLM-based systems for vulnerability detection in ascending order per year of publication.
Although research on LLM-based vulnerability detection continues to advance, it also uncovers recurring challenges that limit practical deployment. Many systems, such as those proposed by Li et al. [
56] and Mahyari [
46], rely on fine-tuning LLMs with labelled datasets to enhance accuracy. However, this approach introduces bias risks and reduces performance on rare or unseen vulnerabilities. Several works, including those by Purba et al. [
49] and Wang et al. [
58], focus on enriching LLM reasoning or generalization through causality analysis or code embeddings but at the cost of scalability and compute intensity. A common strength across reviewed studies, such as those by Khare et al. [
53], Jensen et al. [
54], and Shestov et al. [
55], is integration with developer environments for real-time feedback and contextualized insights. However, these systems suffer from trust issues, hallucinations, or reliance on high-quality developer context. Additionally, limitations in generalizability across codebases or languages [
38,
45] and challenges in handling obfuscated or deeply nested code [
42,
43] highlight persistent gaps. Other studies aim to address these weaknesses by ensuring scalability, cross-language robustness, and enhanced resilience to code complexity, which is lacking in the current systems [
61,
62].
Several LLM-based tools show promising potential for production deployment. CODEGUARDIAN [
50], for example, is integrated into Visual Studio Code, enabling real-time vulnerability detection during coding, which is a valuable feature for secure software development pipelines. DeepCode AI Fix [
51] extends this by not only identifying but also suggesting fixes, making it suitable for continuous integration workflows. LProtector [
52] combines GPT-4o with RAG to effectively detect C/C++ vulnerabilities in large codebases, showing promise for enterprise-scale applications. These tools go beyond experimental use and are designed with real-world developer workflows in mind. Their architecture and integration features position them well for practical deployment; however, broader industry validation is still needed.
4.2. Anomaly Detection
Anomaly detection plays a crucial role in cyber security, and recent studies have increasingly leveraged LLMs to enhance this capability across various contexts, from system logs to email filtering and traffic inspection. A standout contribution in log-based anomaly detection is LogPrompt [
68], which utilizes LLMs to parse and semantically understand unstructured logs. It applies chain-of-thought reasoning and in-context learning to distinguish between normal and anomalous behaviour, thus moving beyond static rule sets. LEMUR [
69] further expands this field by employing entropy sampling for efficient log clustering and uses LLMs to differentiate between invariant tokens and parameters with high accuracy, greatly improving the effectiveness of template merging. In a practical cloud environment, ScaleAD [
70] offers an adaptive anomaly detection system where a Trie-based agent flags potential anomalies, and an LLM is queried to assess log semantics and assign confidence scores. Similarly, LogGPT [
71] introduces a full pipeline that preprocesses logs, crafts context-rich prompts, and parses LLM outputs for anomaly evaluation. These techniques allow the system to intelligently detect anomalies even in high-volume environments. Adding to the landscape, Han et al. [
72] improve GPT-2′s focus in log sequence analysis through a Top-K reward mechanism, which directs model attention to the most relevant tokens, thus enhancing detection precision.
Outside of logs, LLMs have been evaluated for their performance in phishing and spam detection. The Improved Phishing and Spam Detection Model (IPSDM) [
73] fine-tunes DistilBERT and RoBERTa for email filtering, showing LLMs’ promise in real-time protection against social engineering. Si et al. [
74] also highlight ChatGPT’s potential, outperforming BERT on low-resource Chinese datasets but showing limitations on large-scale English corpora. Nahmias et al. [
38] targeted spear-phishing detection with a unique approach using LLMs to generate contextual document vectors that reflect persuasion tactics, outperforming classical classifiers in recognizing malicious intent. Further, Heiding et al. [
75] examined the dual-use nature of LLMs in both crafting and detecting phishing emails. Their analysis demonstrates that models like GPT-4, Claude, and PaLM outperform humans in detection tasks, though they warn of adversarial misuse. An additional threat domain is covered by Vörös et al. [
76], who propose a student–teacher LLM approach for malicious URL detection via knowledge distillation, making the model suitable for lightweight deployments. Also, Guastalla et al. [
77] fine-tuned LLMs for DDoS detection on pcap-based and IoT datasets, adapting to real-world traffic complexities.
Other research has extended LLM-based anomaly detection beyond logs and text into diverse data modalities. Alnegheimish et al. [
78] proposed sigllm, a zero-shot time series anomaly detector that converts numerical sequences into a textual form, enabling LLMs to forecast and flag anomalies without specific training. Gu et al. [
79] introduced AnomalyGPT, leveraging vision–language models like MiniGPT-4 for industrial defect detection using synthetic image–text pairs, eliminating manual thresholding. Elhafsi et al. [
80] also applied LLMs in robotic systems, identifying semantic inconsistencies in visual behaviours, while Li et al. [
81] demonstrated that LLMs can detect outliers in tabular data with zero-shot capabilities, which was further improved through fine-tuning for real-world contexts.
Guan et al. [
82] proposed a framework combining BERT and LLaMA models to detect anomalies in system records. By aligning semantic vectors from log messages, the model effectively captures anomalies without relying on traditional log parsing methods. Su et al. [
83] conducted a systematic literature review on the use of LLMs in forecasting and anomaly detection. The review highlights the potential of LLMs in these areas while also addressing challenges such as data requirements, generalizability, and computational resources. Ali and Kostakos [
84] integrated LLMs with traditional ML techniques and explainability tools, like SHAP, in a hybrid model called HuntGPT, which enriches anomaly detection through human-interpretable insights.
Recently, Liu et al. [
85] introduced CYLENS, an LLM-powered assistant that supports security analysts in interpreting anomalies, attributing threats, and suggesting mitigations by leveraging contextual memory and historical CTI through expert-style dialogues. Wang and Yang [
86] also proposed a federated LLM framework that performs anomaly detection across distributed and privacy-sensitive environments by processing multimodal data without centralizing it. Qian et al. [
87] focused on Android malware detection with LAMD, a multi-tiered system that integrates program slicing, control flow graphs, and LLM prompting to detect and explain malicious behaviour while also reducing hallucinations through consistency verification. Benabderrahmane et al. [
88] target stealthy APTs with APT-LLM, encoding low-level system traces into text and using LLMs to generate semantic embeddings, which are analysed via autoencoders to detect subtle deviations.
Additionally, Meguro and Chong [
89] proposed AdaPhish to advance phishing defence by automating phishing email analysis and anonymization using LLMs and vector databases, which serve both detection and organizational education. Another tool named SHIELD [
4] goes beyond detection by combining statistical and graph-based techniques with LLM-generated APT kill chain narratives, which provide security analysts with actionable and human-readable summaries for stealthy threat detection. In the same way, Akhtar et al. [
90] reviewed the LLM-log analysis landscape and identified major methodologies, like fine-tuning, RAG, and in-context learning, and outlined the trade-offs and practical challenges in real deployments. Walton et al. [
91] also introduced MSP, which enhances malware reverse engineering with structured LLM-driven summarization that categorizes threats and pinpoints specific malicious behaviours.
Table 3 provides a summary of the contributions and limitations of recent LLM-based systems for anomaly detection in ascending order per year of publication.
The reviewed literature demonstrates varied approaches to utilize LLMs in anomaly detection but also highlights common limitations. Several studies, such as those by Qi et al. [
71] and Liu et al. [
70], focus on LLM-based log analysis, emphasizing structured outputs and integration with existing systems. However, these approaches suffer from latency issues or reliance on prompt quality. Similarly, phishing and spam detection systems [
70,
73] showcase the effectiveness of LLMs in recognizing persuasive language but are hindered by risks of misuse, generalization gaps, or poor performance on novel formats. Other studies proposed solutions to address issues of real-time detection, cross-domain generalization, and reduced dependency on handcrafted prompts. For example, systems, like those by Gandhi et al. [
4] and Benabderrahmane et al. [
88], attempt to provide deeper semantic understanding through kill chain alignment or provenance embeddings; however, they still face challenges in computational overhead and interpretability. While many papers suggest innovative techniques, like federated learning [
86] or zero-shot detection [
81], their practical deployment remains limited.
4.3. Cyber Threat Intelligence (CTI)
The integration of LLMs into CTI has become a prominent area of study, as researchers assess how these models can assist with threat detection, analysis, and decision-making. Recent advances in CTI leverage LLMs to transform unstructured and distributed threat data into actionable insights. Mitra et al. [
92] proposed LocalIntel, a framework that synthesizes global threat databases, like CVE and CWE, with organization-specific knowledge, allowing for personalized, high-context intelligence summaries. Perrina et al. [
93] automate CTI report generation using LLMs to extract threat knowledge from unstructured sources, highlighting LLMs’ capability in structuring scattered data. Fayyazi and Yang [
94] also fine-tuned LLMs with structured threat ontologies, resulting in models that excel in producing precise, technique-specific threat narratives. Also, Schwartz et al. [
95] proposed LMCloudHunter, which translates OSINT into candidate detection rules for signature-based systems using LLMs, thus connecting high-level intelligence with operational defences.
Other studies have focused on extracting CTI from unstructured text. For example, Clairoux-Trepanier et al. [
96] evaluated GPT-based LLMs for extracting key threat indicators, showing promise in identifying IOCs and attack tactics. Siracusano et al. [
97] introduced the aCTIon framework, combining LLMs with a parsing engine to export CTI in the STIX format, enabling integration with existing intelligence platforms. Hu et al. [
98] extended this idea using fine-tuned LLMs to build and populate knowledge graphs from raw CTI, improving the structured representation. Zhang et al. [
99] also proposed AttacKG, a full LLM-based pipeline that rewrites and summarizes CTI into attack graphs. Fieblinger et al. [
100] validated open-source LLMs for extracting entity–relation triples, confirming their role in enriching semantic CTI knowledge graphs.
Park and You [
101] proposed CTI-BERT, a domain-adapted BERT model trained on cyber security-specific corpora to enhance the extraction of structured threat intelligence from unstructured data. Gao et al. [
102] also presented ThreatKG, which uses LLMs to extract entities and relationships from CTI reports to construct and update a cyber threat knowledge graph, supporting continuous integration into analytic workflows. To address the challenge of limited labelled data, Sorokoletova et al. [
103] proposed 0-CTI, a versatile framework supporting both supervised and zero-shot learning for threat extraction and STIX alignment, ensuring standardized data communication. Wu et al. [
104] focused on verifying extracted intelligence, using LLMs to identify key claims in reports and validate them against a structured knowledge base, enhancing the credibility of threat intelligence. Fayyazi et al. [
105] demonstrated how integrating RAG with LLMs enriches and improves the accuracy of MITRE ATT&CK TTP summaries. Singla et al. [
106] also showed LLMs’ effectiveness in analysing software supply chain vulnerabilities and identifying causes and propagation paths. Zhang et al. [
107] tackled bug report deduplication by enhancing traditional similarity-based models with LLM-driven semantic insights, leading to more accurate identification of duplicate reports.
To support strategic defence reasoning, Jin et al. [
3] proposed Crimson, a system that aligns LLM outputs with MITRE ATT&CK tactics through a novel Retrieval-Aware Training (RAT) approach. This fine-tuning method significantly reduced hallucinations while improving alignment with expert knowledge. Similarly, Tseng et al. [
108] proposed an LLM-powered agent to automate SOC tasks, such as extracting CTI from reports and generating regular expressions for detection rules. Rajapaksha et al. [
109] also introduced a QA system using LLMs and RAG to support context-rich attack investigations. Shah and Parast [
110] applied GPT-4o with one-shot fine-tuning to automate CTI workflows, reducing manual effort while ensuring accuracy. Shafee et al. [
5] assessed LLM-driven chatbots for OSINT, showing their ability to classify threat content and extract entities. Alevizos and Dekker [
111] also proposed an AI-powered CTI pipeline that fosters collaboration between analysts and LLMs, enhancing both speed and precision in threat intelligence generation. Daniel et al. [
112] also evaluated LLMs’ ability to map Snort NIDS rules to MITRE ATT&CK techniques, highlighting their scalability and explainability. Similarly, Alturkistani et al. [
113] explored the significant role of LLMs in ICT education, highlighting their potential to enhance personalised learning, automate content generation, and support practical skill development.
Table 4 summarizes the contributions and limitations of recent LLM-based systems for CTI in ascending order per year of publication.
The reviewed studies highlight the growing role of LLMs in enhancing CTI through automation, semantic understanding, and integration with structured formats. Many studies, such as those by Perrina et al. [
93], Siracusano et al. [
97], and Zhang et al. [
99], employ LLMs to convert unstructured threat data into structured formats, like STIX or knowledge graphs, offering semantic depth and automation. However, these systems suffer from limitations like hallucinated outputs, parsing errors, and cumulative complexity across multi-stage pipelines. Similarly, RAG-based approaches, such as those by Jin et al. [
3] and Fayyazi et al. [
105], improve factual accuracy by grounding responses in external sources, but their performance heavily depends on the quality and structure of the retrieval corpus. Tools designed for operational use, such as those by Wu et al. [
104] and Rajapaksha et al. [
109], show promise in supporting SOC analysts through verification and context-aware reasoning; however, they struggle with latency and incomplete context. Furthermore, domain-specific models like CTI-BERT [
101] offer improved accuracy but lack generalizability. A common limitation across various studies, especially those by Hu et al. [
98] and Liu et al. [
85], is the difficulty in grounding LLM-generated outputs and managing conflicting or ambiguous intelligence, which poses risks to reliability and practical deployment.
4.4. Blockchain Security
Recent advancements in blockchain security have seen the integration of LLMs to enhance smart contract auditing and anomaly detection. Chen et al. [
115] conducted an empirical study assessing ChatGPT’s performance in identifying vulnerabilities within smart contracts. Their findings indicate that while ChatGPT exhibits high recall, its precision is limited, with performance varying across different vulnerability types. David et al. [
116] also explored the feasibility of employing LLMs, specifically GPT-4 and Claude, for smart contract security audits. Their research focused on optimizing prompt engineering and evaluating model performance using a dataset of 52 compromised DeFi smart contracts. The study revealed that LLMs correctly identified vulnerability types in 40% of cases but also demonstrated a high false positive rate, underscoring the continued necessity for manual auditors.
Gai et al. [
117] proposed BLOCKGPT, a dynamic, real-time approach to detecting anomalous blockchain transactions. By training a custom LLM from scratch, BLOCKGPT acts as an IDS, effectively identifying abnormal transactions without relying on predefined rules. In experiments, it successfully ranked 49 out of 124 attacks among the top three most abnormal transactions, showcasing its potential in real-time anomaly detection. Hu et al. [
118] proposed GPTLENS, an adversarial framework that enhances smart contract vulnerability detection by breaking the process into two stages: generation and discrimination. In this framework, the LLM serves dual roles as both AUDITOR and CRITIC, aiming to balance the detection of true vulnerabilities while minimizing false positives. The experimental results demonstrate that this two-stage approach yields significant improvements over conventional one-stage detection methods. Similarly, Sun et al. [
119] proposed GPTScan, a tool that combines GPT with static analysis to detect logic vulnerabilities in smart contracts. Unlike traditional tools that focus on fixed-control or data-flow patterns, GPTScan leverages GPT’s code understanding capabilities to identify a broader range of vulnerabilities. The evaluations on diverse datasets showed that GPTScan achieved high precision for token contracts and effectively detected ground-truth logic vulnerabilities, including some missed by human auditors. Hossain et al. [
120] combined LLMs with traditional ML models to detect vulnerabilities in smart contract code, achieving over 90% accuracy.
Yu et al. [
121] proposed Smart-LLaMA, a vulnerability detection framework leveraging domain-specific pretraining and explanation-guided fine-tuning to identify and explain smart contract flaws with improved accuracy. Similarly, Zaazaa and El Bakkali [
122] proposed SmartLLMSentry, which employs ChatGPT and in-context learning to detect Solidity-based vulnerabilities with over 90% precision. Also, Wei et al. [
123] proposed LLM-SmartAudit, a multi-agent conversational system that enhances auditing by outperforming traditional tools in identifying complex logical issues. He et al. [
124] conducted a comprehensive review on integrating LLMs in blockchain security tasks, covering smart contract auditing, anomaly detection, and vulnerability repair. Moreover, Ding et al. [
125] proposed SmartGuard, which uses LLMs to retrieve semantically similar code snippets and apply Chain-of-Thought prompting to improve smart contract vulnerability detection, achieving near-perfect recall. Ma et al. [
126] proposed iAudit, a two-stage LLM-based framework for smart contract auditing. The system employs a Detector to flag potential vulnerabilities and a Reasoner to provide contextual explanations, improving audit interpretability. However, its effectiveness is contingent on the quality and diversity of fine-tuning data. Similarly, Bu et al. [
127] introduced vulnerability detection in DApps by fine-tuning LLMs on a large dataset of real-world smart contracts. Their method excelled in identifying complex, non-machine-auditable issues, achieving high precision and recall. However, its robustness depends on the continual inclusion of diverse, evolving contract patterns.
Table 5 summarizes the contributions and limitations of recent LLM-based systems in blockchain security in ascending order per year of publication.
The reviewed studies highlight the growing interest in applying LLMs for smart contract auditing and blockchain security, with varying approaches in model architecture, data usage, and integration techniques. A common trend among various studies, such as those by Hu et al. [
118], Ma et al. [
126], and Zaazaa and El Bakkali [
126], is the adoption of multi-stage or fine-tuned frameworks aimed at improving vulnerability detection accuracy and interpretability. Other studies, including those by David et al. [
116] and Chen et al. [
115], focused on evaluating general-purpose LLMs, like GPT-4, revealing promising recall rates but also significant limitations in precision and high false positive rates. Real-time detection systems, like BLOCKGPT [
117] and Smart-LLaMA [
121], highlight the importance of domain-specific training; however, they suffer from a dependence on large, high-quality datasets. Similarly, systems like LLM-SmartAudit [
123] and the one studied by Hossain et al. [
120] explore hybrid architectures, though they introduce additional complexity and face challenges with generalization to evolving platforms. While tools like SmartGuard [
125] and GPTScan [
119] explore novel prompting or static analysis integration, their performance is constrained when multiple or subtle vulnerabilities exist. Generally, most systems demonstrate potential but struggle with generalizability, data dependency, scalability, or interpretability, highlighting the need for balanced, robust, and empirically validated solutions.
Several tools show growing readiness for real-world deployment, particularly in smart contract auditing. iAudit [
126] simulates a structured audit process using LLM-driven detection and reasoning, making it suitable for automated contract security assessments. SmartLLMSentry [
122] and Smart-LLaMA [
121] apply pretrained and fine-tuned LLMs to detect vulnerabilities in Solidity code, achieving high accuracy on real-world datasets. GPTScan [
119] and SmartGuard [
125] combine static analysis with LLM reasoning to uncover logic vulnerabilities often overlooked by traditional tools. While large-scale production deployments are not yet widely documented, these tools demonstrate strong potential for integration into blockchain security workflows.
4.5. Penetration Testing
The integration of LLMs into penetration testing has seen significant advancements through recent research. Deng et al. [
128] introduced PentestGPT, an automated framework that utilizes LLMs to perform tasks such as tool usage, output interpretation, and suggesting subsequent actions. Despite its modular design aimed at mitigating context loss, the study highlighted challenges in maintaining a comprehensive understanding throughout the testing process. Building upon this, Isozaki et al. [
40] developed a benchmark to evaluate LLMs like GPT-4o and Llama 3.1-405B in automated penetration testing. Their findings indicate that while these models show promise, they currently fall short in executing end-to-end penetration tests without human intervention, particularly in areas like enumeration, exploitation, and privilege escalation.
Exploring the offensive capabilities of LLMs, Fang et al. [
129] demonstrated that GPT-4 could autonomously exploit 87% of tested one-day vulnerabilities when provided with CVE descriptions, outperforming other models and traditional tools. However, the model’s effectiveness significantly decreased without detailed descriptions, exploiting only 7% of vulnerabilities. In the reconnaissance phase, Temara [
130] examined ChatGPT’s ability to gather information such as IP addresses and network topology, aiding in penetration test planning. While the tool provided valuable insights, the study emphasized the need for further validation of the accuracy and reliability of the data obtained. Deng et al. [
131] evaluated PentestGPT, demonstrating a 228.6% increase in task completion compared to GPT-3.5. The modular design improved automation for penetration testing sub-tasks, though challenges with context-maintenance and complex scenarios persist.
Happe et al. [
41] proposed a fully automated privilege escalation tool to evaluate LLMs in ethical hacking, revealing that GPT-4-turbo exploited 33–83% of tested vulnerabilities, outperforming GPT-3.5 and LLaMA3. The study also explored how factors like context length and in-context learning impact performance. Happe and Cito [
132] also developed an AI sparring partner using GPT-3.5 to analyse machine states, recommend concrete attack vectors, and automatically execute them in virtual environments. Bianou et al. [
133] proposed PENTEST-AI, a multi-agent LLM-based framework that automates penetration testing by coordinating agents through the MITRE ATT&CK framework. While it improves test coverage and task distribution, its reliance on predefined attack patterns limits adaptability to emerging threats.
Table 6 summarizes the contributions and limitations of recent LLM-based systems in penetration testing in ascending order per year of publication.
The reviewed studies highlight the growing interest in applying LLMs to automate and enhance penetration testing; however, they also reveal common challenges and diverging strategies. Several studies, such as those by Deng et al. [
126,
130] and Bianou et al. [
133], proposed modular or multi-agent frameworks, demonstrating improved task decomposition and alignment with frameworks like MITRE ATT&CK. However, these systems face difficulties in handling complex scenarios or adapting to novel threats due to their reliance on predefined patterns or limited context retention. Other studies, such as those by Temara [
130] and Fang et al. [
129], examined specific capabilities of LLMs, such as reconnaissance or exploiting known vulnerabilities, but their findings highlight a dependency on structured input and the need for better validation mechanisms. Studies by Happe and Cito [
132] and Happe et al. [
41] also explored the use of LLMs as supportive tools for human testers; however, they emphasized concerns around ethical deployment and the models’ inability to manage errors and maintain focus during tasks. Isozaki et al. [
40] also proposed benchmarks to evaluate LLM performance, but their findings confirm that human oversight remains crucial for end-to-end testing. Generally, while these approaches show promise, limitations persist in scalability, reliability, and context management across tasks.
4.6. Digital Forensics
LLMs have shown significant promise in enhancing the efficiency and accuracy of digital forensics by automating complex tasks such as evidence search, anomaly detection, and report generation. Many studies have investigated their effectiveness in addressing traditional challenges in forensic investigations, with promising results in areas like ransomware triage, synthetic dataset generation, and cyber incident analysis. Yin et al. [
134] provided an overview of how LLMs are transforming digital forensics, emphasizing their capabilities and limitations while highlighting the need for forensic experts to understand LLMs to maximize their potential in various forensic tasks. Similarly, Scanlon et al. [
1] evaluated ChatGPT’s impact on digital forensics, identifying low-risk applications, like evidence searching and anomaly detection, but also noting challenges related to data privacy and accuracy. Wickramasekara et al. [
135] also explored the integration of LLMs into forensic investigations, highlighting their potential to improve efficiency and overcome technical and judicial barriers, though emphasizing the need for appropriate constraints to fully realize their benefits.
Bin Oh et al. [
136] proposed volGPT, an LLM-based approach designed to enhance memory forensics, specifically in triaging ransomware processes. Their research demonstrates high accuracy and efficiency in identifying ransomware-related processes from memory dumps, providing more detailed explanations during triage than traditional methods. Similarly, Voigt et al. [
137] combined LLMs with GUI automation tools to generate realistic background activity for synthetic forensic datasets. This innovation addresses the challenge of creating realistic “wear-and-tear” artefacts in synthetic disk images, improving forensic education and training. In addition, Michelet and Breitinger [
138] explore the use of local LLMs to assist in writing digital forensic reports, demonstrating that while LLMs can aid in generating content, human oversight remains essential for accuracy and completeness, highlighting their limitations in complex tasks like proofreading. Bhandarkar et al. [
139] evaluated the vulnerabilities of traditional DFIR pipelines in addressing the threats posed by Neural Text Generators (NTGs) like LLMs. Their study introduced a co-authorship text attack, CS-ACT, revealing significant weaknesses in current methodologies and emphasizing the need for advanced strategies in source attribution. Loumachi et al. [
140] also proposed GenDFIR, a framework that integrates LLMs with RAG for enhancing cyber incident timeline analysis. By structuring incident data into a knowledge base and enabling semantic enrichment through LLMs, GenDFIR automates timeline analysis and improves threat detection.
Similarly, Zhou et al. [
141] presented an LLM-driven approach that constructs Forensic Intelligence Graphs (FIGs) from mobile device data, achieving over 90% coverage in identifying evidence entities and their relationships. Also, Kim et al. [
142] evaluated the application of LLMs, like GPT-4o, Gemini 1.5, and Claude 3.5, in analysing mobile messenger communications, demonstrating improved precision and recall in interpreting ambiguous language within real crime scene data. Sharma [
143] proposed ForensicLLM, a locally fine-tuned model based on LLaMA-3.1-8B, which outperformed its base model in forensic Q&A tasks and showed high accuracy in source attribution. Xu et al. [
144] conducted a tutorial exploring the potential of LLMs in automating digital investigations, emphasizing their role in evidence analysis and knowledge graph reconstruction. On the other hand, Cho et al. [
145] discussed the broader implications of LLM integration in digital forensics, emphasizing the need for transparency, accountability, and standardization to fully realize their benefits.
Table 7 summarizes the contributions and limitations of recent LLM-based systems in digital forensics in ascending order per year of publication.
The reviewed studies demonstrate increasing interest in applying LLMs to digital forensics while also exposing key limitations. Several studies focus on task-specific applications, such as ransomware triage [
136], mobile message analysis [
142], and forensic report writing [
138]. Other studies, such as those by Scanlon et al. [
1] and Yin et al. [
134], take a broader view, evaluating the overall impact and limitations of LLMs across digital forensic tasks. Common themes include the need for human oversight due to LLM hallucinations and errors [
1,
138], limited generalizability to diverse datasets [
141], and challenges in prompt engineering and model selection [
142]. While tools like GenDFIR [
140] and ForensicLLM [
143] show promise in enhancing timeline analysis and Q&A tasks, respectively, their effectiveness is constrained by scalability and training data limitations. Furthermore, the lack of standardization, transparency, and ethical controls is a recurring concern [
135,
145]. Generally, while LLMs offer promising potential in digital forensics, robust validation, domain adaptation, and expert supervision remain essential for reliable deployment.
Table 8 offers a comprehensive overview of popular LLMs and their applicability across the six cyber security domains that this paper is focusing on. It highlights the versatility and evolution of these models over time, showcasing their strengths and limitations in specific areas. While many models demonstrate utility in tasks like vulnerability detection and threat intelligence, fewer are readily equipped for niche applications, such as blockchain security and digital forensics. This variation reflects the need for task-specific fine-tuning and the integration of domain-relevant datasets to fully unlock each model’s potential. All the models listed in the table can be applied; however, their effectiveness in these specialized areas is generally limited without fine-tuning. These models are not explicitly designed for such tasks, so they require adaptation using domain-specific datasets and objectives. With proper fine-tuning and contextual alignment, they can support targeted functions, such as anomaly detection, smart contract analysis, threat pattern recognition, and forensic data interpretation, though their performance may still vary depending on the complexity of the task.
Across the six surveyed domains mentioned earlier, LLMs have introduced capabilities that extend well beyond the scope of traditional rule-based or statistical approaches. Numerous empirical studies show measurable gains in key performance metrics. For instance, LProtector [
52] achieved State-of-the-Art F1 scores on C/C++ vulnerability detection, and AnomalyGPT [
79] demonstrated superior detection of industrial defects compared to classical thresholds. Similarly, Nahmias et al. [
38] reported that contextual vectors derived from LLMs outperformed traditional classifiers in spear-phishing detection. These results suggest that when applied with targeted domain knowledge, LLMs can meaningfully improve detection accuracy, reduce false positives, and deliver more context-aware security insights.
However, these advantages come with critical limitations. A consistent challenge across domains is the limited robustness of LLMs under adversarial, ambiguous, or high-stakes operational conditions. Studies, such as the one by Sovrano et al. [
39], highlight position-based bias in LLM outputs, while Happe et al. [
132] showed that GPT-4-turbo struggles with privilege escalation tasks requiring multi-step reasoning. In CTI, tools like LMCloudHunter [
95] and 0-CTI [
103] improve automation but rely heavily on high-quality retrieval sources or STIX formats, which can break in noisy environments. Meanwhile, systems like PentestGPT [
128,
131] perform well in isolated tasks but still require human oversight for complex logic flows. These empirical findings highlight that while LLMs bring substantial innovations, they are not universally applicable nor fully reliable as stand-alone systems. Critical deployment risks, such as hallucination, cost, latency, and explainability, persist across all domains. Therefore, despite their promising trajectory, LLMs must be deployed within hybrid architectures that retain deterministic safeguards and enable human-in-the-loop oversight.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}