
Deep One-Directional Neural Semantic Siamese Network for High-Accuracy Fact Verification


Abstract
1. Introduction
- The development of the DOD–NSSN fact verification model with a modified architecture across four main layers: the encoding layer, alignment layer, matching layer, and output layer. The modifications include the introduction of Siamese MaLSTM to process two text inputs (claim and evidence) from two LSTM models at the early stage of sentence processing, enabling classification based on Manhattan distance to achieve high accuracy.
- The introduction of MFRS as an evaluative metric designed to enhance precision in fact verification classification.
2. Related Works
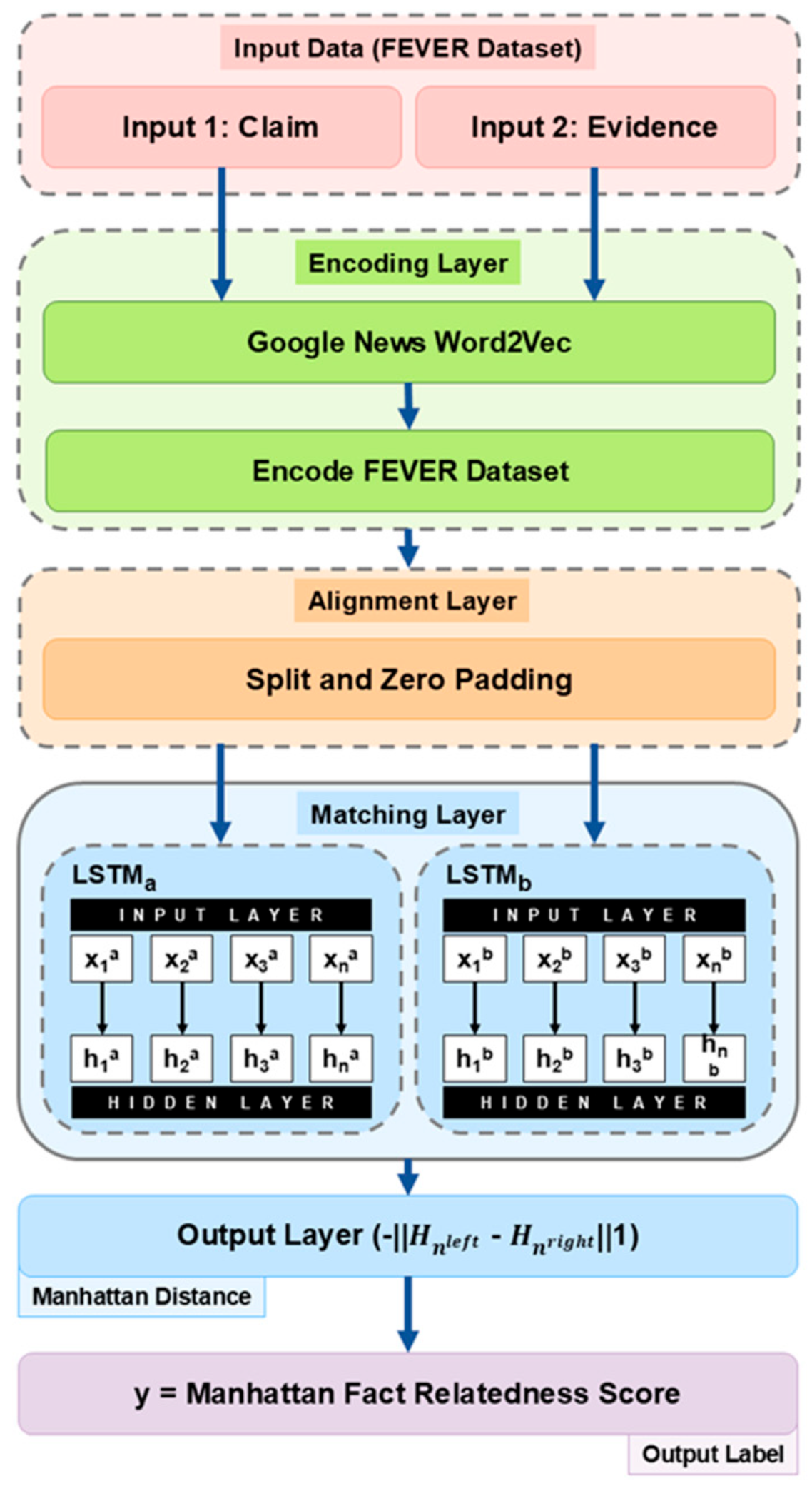
3. DOD–NSSN
| Algorithm 1: Pseudocode of DOD–NSSN. |
|
3.1. DOD–NSSN Preprocessing
- The dataset is processed and consists of two categories: sentence 1 (as the claim) and sentence 2 (as the evidence).
- Tokenizing sentences aims to split the text in each sentence into individual tokens or words. For example, the sentence “Coffee stunts growth in children.” After tokenization, it becomes [“Coffee”, “stunts”, “growth”, “in”, “children”, “.”].
- After tokenization, the next step is to remove stopwords from the text. Stopwords are common words that do not provide much information about the context or meaning of the sentence. For example, the result of stopword removal using the previous sentence becomes [“Coffee”, “stunts”, “growth”, “children”, “.”].
- The next process is converting uppercase letters in the text to lowercase during preprocessing to avoid discrepancies in tokenizing the same words with different cases. For example, “Coffee” and “coffee” are considered the same word after converting the text to lowercase.
- The next step is removing non-alphanumeric characters such as punctuation and special symbols, which are often deleted from the text to maintain consistency. For example, the result of removing non-alphanumeric characters from the previous sentence becomes [“coffee”, “stunts”, “growth”, “children”].
- Finally, replace short forms with their full forms to ensure consistency and ease of text processing. For example, “don’t” can be replaced with “do not” for text consistency within the dataset.
3.2. DOD–NSSN Feature Extraction
3.3. DOD–NSSN Layers
3.3.1. Encoding Layer
3.3.2. Alignment Layer
3.3.3. Matching Layer
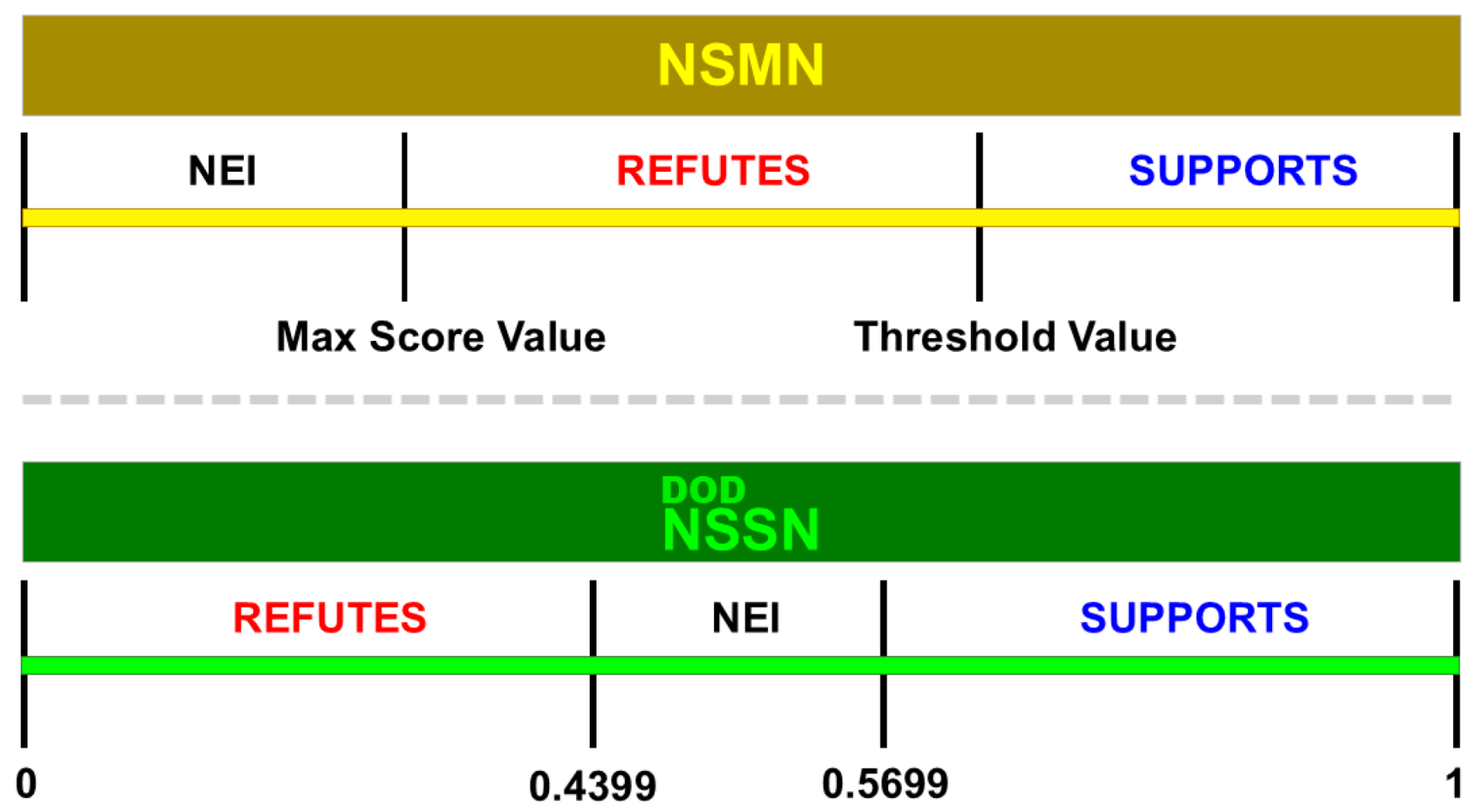
3.3.4. Output Layer
3.4. DOD–NSSN Implementation Environment
3.5. Dataset
3.6. Performance Evaluation Metrics
3.7. Dataset Testing Against DOD–NSSN
4. Results and Discussion
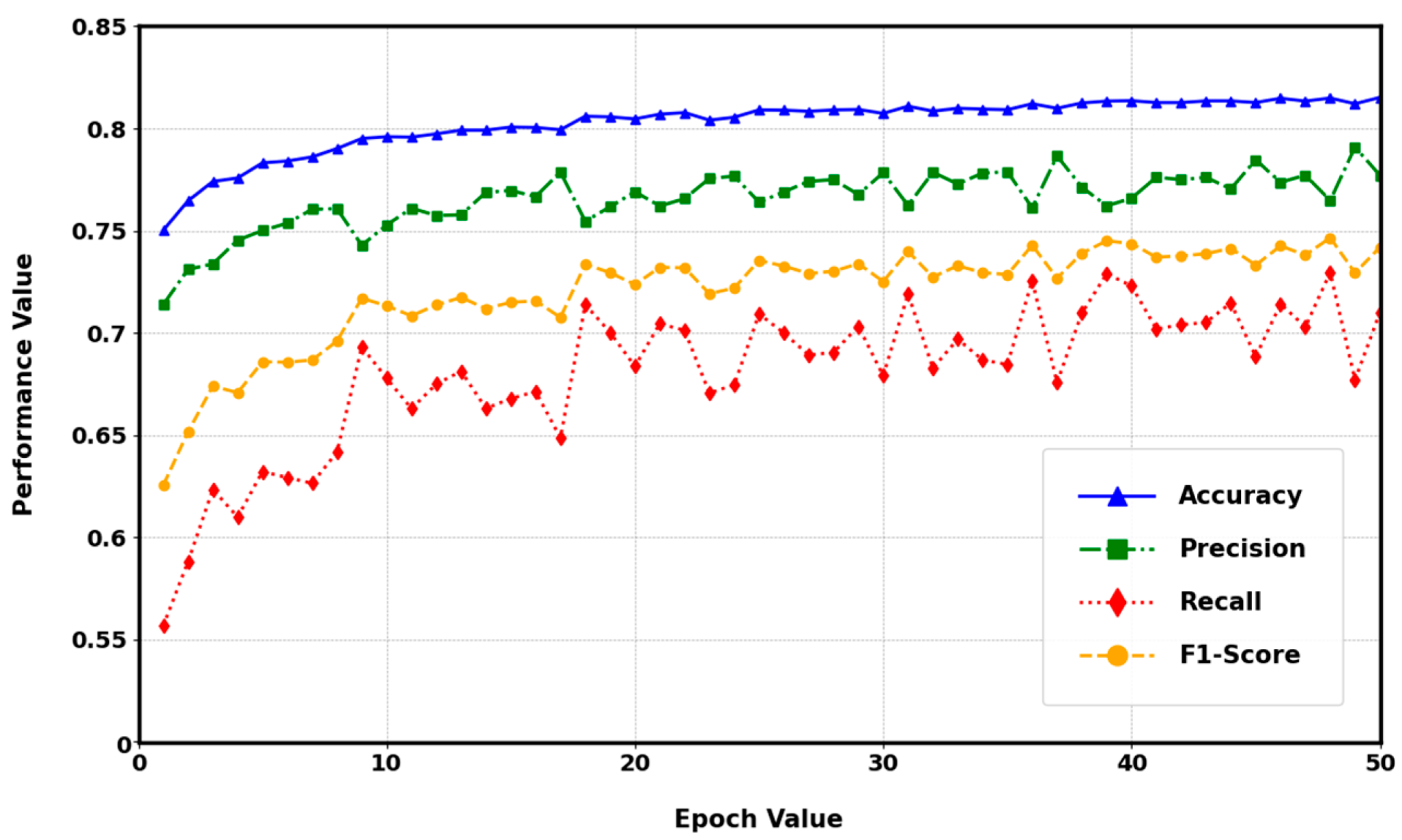
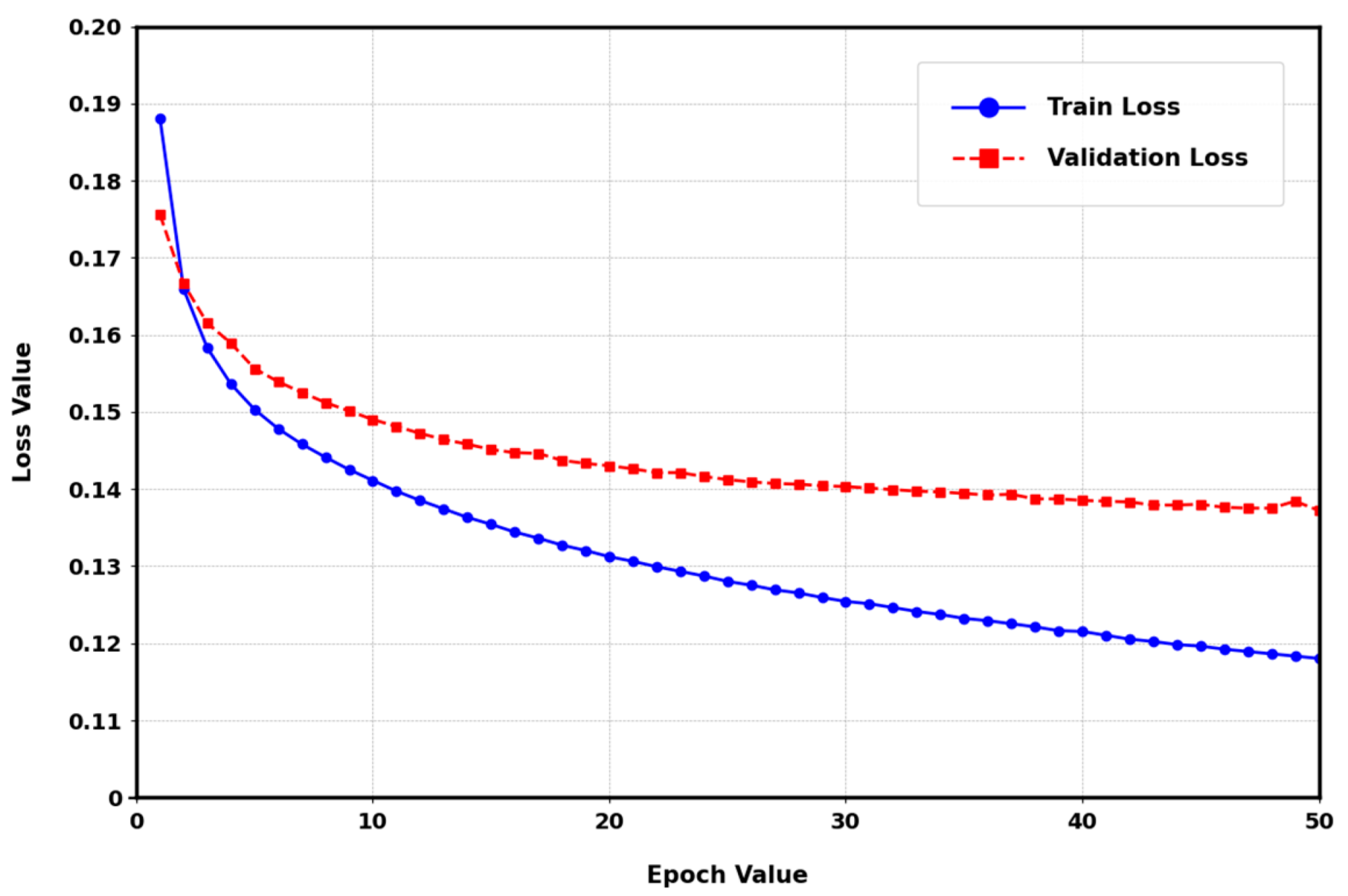
4.1. Results
4.2. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DOD–NSSN | Deep One Directional Neural Semantic Siamese Network |
| NSMN | Neural Semantic Matching Network |
| Siamese MaLSTM | Siamese Manhattan Long Short-Term Memory |
| BiLSTM | Bidirectional Long Short-Term Memory |
| XL-Net | Generalized Autoregressive Pretraining for Language Understanding |
| BERT | Bidirectional Encoder Representations from Transformers |
| XLM | Cross-lingual Language Model Pretraining |
| RoBERTa | Robustly Optimized BERT Approach |
References
- Giachanou, A.; Ghanem, B.; Ríssola, E.A.; Rosso, P.; Crestani, F.; Oberski, D. The Impact of Psycholinguistic Patterns in Discriminating between Fake News Spreaders and Fact Checkers. Data Knowl. Eng. 2022, 138, 101960. [Google Scholar] [CrossRef]
- Nayoga, B.P.; Adipradana, R.; Suryadi, R.; Suhartono, D. Hoax Analyzer for Indonesian News Using Deep Learning Models. Procedia Comput. Sci. 2021, 179, 704–712. [Google Scholar] [CrossRef]
- Thorne, J.; Vlachos, A.; Christodoulopoulos, C.; Mittal, A. FEVER: A Large-Scale Dataset for Fact Extraction and VERification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 809–819. [Google Scholar] [CrossRef]
- Thorne, J.; Vlachos, A.; Cocarascu, O.; Christodoulopoulos, C.; Mittal, A. The Fact Extraction and VERification (FEVER) Shared Task. In Proceedings of the First Workshop on Fact Extraction and VERification (FEVER), Brussels, Belgium, 1 November 2018. [Google Scholar] [CrossRef]
- Nie, Y.; Chen, H.; Bansal, M. Combining Fact Extraction and Verification with Neural Semantic Matching Networks. Proc. AAAI Conf. Artif. Intell. 2019, 33, 6859–6866. [Google Scholar] [CrossRef]
- White, R. Evidence and Truth. Philos. Stud. 2023, 180, 1049–1057. [Google Scholar] [CrossRef]
- Yin, M.; Vaughan, J.W.; Wallach, H. Understanding the Effect of Accuracy on Trust in Machine Learning Models. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow Scotland, UK, 4–9 May 2019. [Google Scholar] [CrossRef]
- Ma, Z.; Li, J.; Song, Y.; Wu, X.; Chen, C. Network Intrusion Detection Method Based on FCWGAN and BiLSTM. Comput. Intell. Neurosci. 2022, 2022, 6591140. [Google Scholar] [CrossRef] [PubMed]
- Lakatos, R.; Pollner, P.; Hajdu, A.; Joó, T. Investigating the Performance of Retrieval-Augmented Generation and Domain-Specific Fine-Tuning for the Development of AI-Driven Knowledge-Based Systems. Mach. Learn. Knowl. Extr. 2025, 7, 15. [Google Scholar] [CrossRef]
- Ion, R.; Păiș, V.; Mititelu, V.B.; Irimia, E.; Mitrofan, M.; Badea, V.; Tufiș, D. Unsupervised Word Sense Disambiguation Using Transformer’s Attention Mechanism. Mach. Learn. Knowl. Extr. 2025, 7, 10. [Google Scholar] [CrossRef]
- Zengeya, T.; Fonou Dombeu, J.V.; Gwetu, M. A Centrality-Weighted Bidirectional Encoder Representation from Transformers Model for Enhanced Sequence Labeling in Key Phrase Extraction from Scientific Texts. Big Data Cogn. Comput. 2024, 8, 182. [Google Scholar] [CrossRef]
- Li, Q.; Zhou, W. Connecting the Dots Between Fact Verification and Fake News Detection. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; International Committee on Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1820–1825. [Google Scholar]
- Wang, Y.; Xia, C.; Si, C.; Yao, B.; Wang, T. Robust Reasoning Over Heterogeneous Textual Information for Fact Verification. IEEE Access 2020, 8, 157140–157150. [Google Scholar] [CrossRef]
- Jiang, Y.; Bordia, S.; Zhong, Z.; Dognin, C.; Singh, M.; Bansal, M. HOVER: A Dataset for Many-Hop Fact Extraction and Claim Verification. In Proceedings of the Findings of the Association for Computational Linguistics Findings of ACL: EMNLP 2020, Online, 16–20 November 2020; pp. 3441–3460. [Google Scholar] [CrossRef]
- Schuster, T.; Fisch, A.; Barzilay, R. Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Proceedings of the Conference; Online, 6–11 June 2021, pp. 624–643. [CrossRef]
- Atanasova, P.; Simonsen, J.G.; Lioma, C.; Augenstein, I. Fact Checking with Insufficient Evidence. Trans. Assoc. Comput. Linguist. 2022, 10, 746–763. [Google Scholar] [CrossRef]
- Gohourou, D.; Kuwabara, K. Knowledge Graph Extraction of Business Interactions from News Text for Business Networking Analysis. Mach. Learn. Knowl. Extr. 2024, 6, 126–142. [Google Scholar] [CrossRef]
- Chen, Z.; He, Z.; Liu, X.; Bian, J. Evaluating Semantic Relations in Neural Word Embeddings with Biomedical and General Domain Knowledge Bases. BMC Med. Inf. Decis. Mak. 2018, 18, 65. [Google Scholar] [CrossRef]
- Mitrov, G.; Stanoev, B.; Gievska, S.; Mirceva, G.; Zdravevski, E. Combining Semantic Matching, Word Embeddings, Transformers, and LLMs for Enhanced Document Ranking: Application in Systematic Reviews. Big Data Cogn. Comput. 2024, 8, 110. [Google Scholar] [CrossRef]
- Ellis, L. B2B Marketing News: New Influencer Marketing & Social Reports, LinkedIn’s B2B Engagement Study, & Google My Business Gets Messaging UK, 2021. Available online: https://www.toprankmarketing.com/blog/b2b-marketing-news-021921/ (accessed on 24 June 2025).
- Pan, L.; Chen, W.; Xiong, W.; Kan, M.-Y.; Wang, W.Y. Zero-Shot Fact Verification by Claim Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Online, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 476–483. [Google Scholar]
- Chen, Z.; Hui, S.C.; Zhuang, F.; Liao, L.; Jia, M.; Li, J.; Huang, H. A Syntactic Evidence Network Model for Fact Verification. Neural Netw. 2024, 178, 106424. [Google Scholar] [CrossRef]
- Liu, R.; Zhang, Y.; Yang, B.; Shi, Q.; Tian, L. Robust and Resource-Efficient Table-Based Fact Verification through Multi-Aspect Adversarial Contrastive Learning. Inf. Process. Manag. 2024, 61, 103853. [Google Scholar] [CrossRef]
- Chen, C.; Chen, W.; Zheng, J.; Luo, A.; Cai, F.; Zhang, Y. Input-Oriented Demonstration Learning for Hybrid Evidence Fact Verification. Expert. Syst. Appl. 2024, 246, 123191. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, R.; Guo, J.; Fan, Y.; Cheng, X. GERE: Generative Evidence Retrieval for Fact Verification; Association for Computing Machinery: New York, NY, USA, 2022; Volume 1, ISBN 9781450387323. [Google Scholar]
- Chen, Q.; Ling, Z.; Jiang, H.; Zhu, X.; Wei, S.; Inkpen, D. Enhanced LSTM for Natural Language Inference. In Proceedings of the ACL 2017—55th Annual Meeting of the Association for Computational Linguistics, Proceedings of the Conference (Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; Volume 1, pp. 1657–1668. [Google Scholar]
- Kowsher, M.; Tahabilder, A.; Islam Sanjid, M.Z.; Prottasha, N.J.; Uddin, M.S.; Hossain, M.A.; Kader Jilani, M.A. LSTM-ANN & BiLSTM-ANN: Hybrid Deep Learning Models for Enhanced Classification Accuracy. Procedia Comput. Sci. 2021, 193, 131–140. [Google Scholar] [CrossRef]
- Zhu, B.; Zhang, X.; Gu, M.; Deng, Y. Knowledge Enhanced Fact Checking and Verification. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3132–3143. [Google Scholar] [CrossRef]
- Gong, H.; Wang, C.; Huang, X. Double Graph Attention Network Reasoning Method Based on Filtering and Program-Like Evidence for Table-Based Fact Verification. IEEE Access 2023, 11, 86859–86871. [Google Scholar] [CrossRef]
- Chang, Y.-C.; Kruengkrai, C.; Yamagishi, J. XFEVER: Exploring Fact Verification across Languages. In Proceedings of the Proceedings of the 35th Conference on Computational Linguistics and Speech Processing (ROCLING 2023), Taipei City, Taiwan, 20–21 October 2023. [Google Scholar]
- Zhong, W.; Xu, J.; Tang, D.; Xu, Z.; Duan, N.; Zhou, M.; Wang, J.; Yin, J. Reasoning Over Semantic-Level Graph for Fact Checking. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Stella, M.; Kenett, Y.N. Knowledge Modelling and Learning through Cognitive Networks. Big Data Cogn. Comput. 2022, 6, 53. [Google Scholar] [CrossRef]
- Belaroussi, R. Subjective Assessment of a Built Environment by ChatGPT, Gemini and Grok: Comparison with Architecture, Engineering and Construction Expert Perception. Big Data Cogn. Comput. 2025, 9, 100. [Google Scholar] [CrossRef]
- Schuster, T.; Shah, D.; Yeo, Y.J.S.; Roberto Filizzola Ortiz, D.; Santus, E.; Barzilay, R. Towards Debiasing Fact Verification Models. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3417–3423. [Google Scholar]
- Thorne, J.; Vlachos, A.; Christodoulopoulos, C.; Mittal, A. Evaluating Adversarial Attacks against Multiple Fact Verification Systems. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 2944–2953. [Google Scholar]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. The Performance of LSTM and BiLSTM in Forecasting Time Series. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; Volume 2019, pp. 3285–3292. [Google Scholar] [CrossRef]
- Imtiaz, Z.; Umer, M.; Ahmad, M.; Ullah, S.; Choi, G.S.; Mehmood, A. Duplicate Questions Pair Detection Using Siamese MaLSTM. IEEE Access 2020, 8, 21932–21942. [Google Scholar] [CrossRef]
- Carneiro, T.; Da Nobrega, R.V.M.; Nepomuceno, T.; Bian, G.B.; De Albuquerque, V.H.C.; Filho, P.P.R. Performance Analysis of Google Colaboratory as a Tool for Accelerating Deep Learning Applications. IEEE Access 2018, 6, 61677–61685. [Google Scholar] [CrossRef]
- Di Gennaro, G.; Buonanno, A.; Palmieri, F.A.N. Considerations about Learning Word2Vec. J. Supercomput. 2021, 77, 12320–12335. [Google Scholar] [CrossRef]
- Lombardo, G.; Tomaiuolo, M.; Mordonini, M.; Codeluppi, G.; Poggi, A. Mobility in Unsupervised Word Embeddings for Knowledge Extraction—The Scholars’ Trajectories across Research Topics. Future Internet 2022, 14, 25. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Type of Feature | Characteristic | NSMN [5] | BERT [29] | RoBERTa [28] | XLM [30] | XL-NET [31] | DOD–NSSN[Proposed] |
|---|---|---|---|---|---|---|---|---|
| 1 | Syntactic/textual | Fact verification Dataset | Y | Y | Y | Y | N | Y |
| Word embedding | Y | N | N | Y | Y | Y | ||
| 2 | Modelling | Development Model | Y | Y | Y | N | Y | Y |
| 3 | Verification features | Supports | Y | N | Y | Y | N | Y |
| Refutes | Y | Y | Y | Y | N | Y | ||
| Not enough info | Y | N | Y | Y | N | Y | ||
| Evidence | Y | Y | Y | Y | Y | Y | ||
| 4 | Human confidence value for the model | Accuracy > 70% | N | N | Y | Y | N | Y |
| 5 | Domain-specific fact verification words | Similarity vector | Y | Y | N | Y | N | Y |
| 6 | Content similarity feature | Relatedness score | Y | N | N | Y | Y | Y |
| Specific Hardware and Models | Configuration |
|---|---|
| Specific Hardware | |
| CPU model name | Tesla T4 |
| RAM | 16 GB |
| GPU | Amazon EC2 G4 |
| GPU Memory | 16 GB |
| Models Evaluation Parameter | |
| Epoch | 50 |
| Train Validation Ratio | 7:3 |
| Optimizer | Adam |
| Evaluation | Accuracy, Precision, Recall, F1-Score |
| Loss Evaluation Metric | mean_squared_error |
| Runtime Environment | |
| Development Platform | Google Colaboratory |
| Programming Language | Python 3.10 |
| Libraries & Versions | TensorFlow 2.12.0, NumPy 1.23.5, Gensim 4.3.1, Pandas 1.5.3, Scikit-learn 1.2.2, Matplotlib 3.7.x |
| Attributes | Description |
|---|---|
| id | Document Id |
| input1 | Contents of Claim |
| input2 | Content of Evidence |
| actual label | Actual Label of Claim |
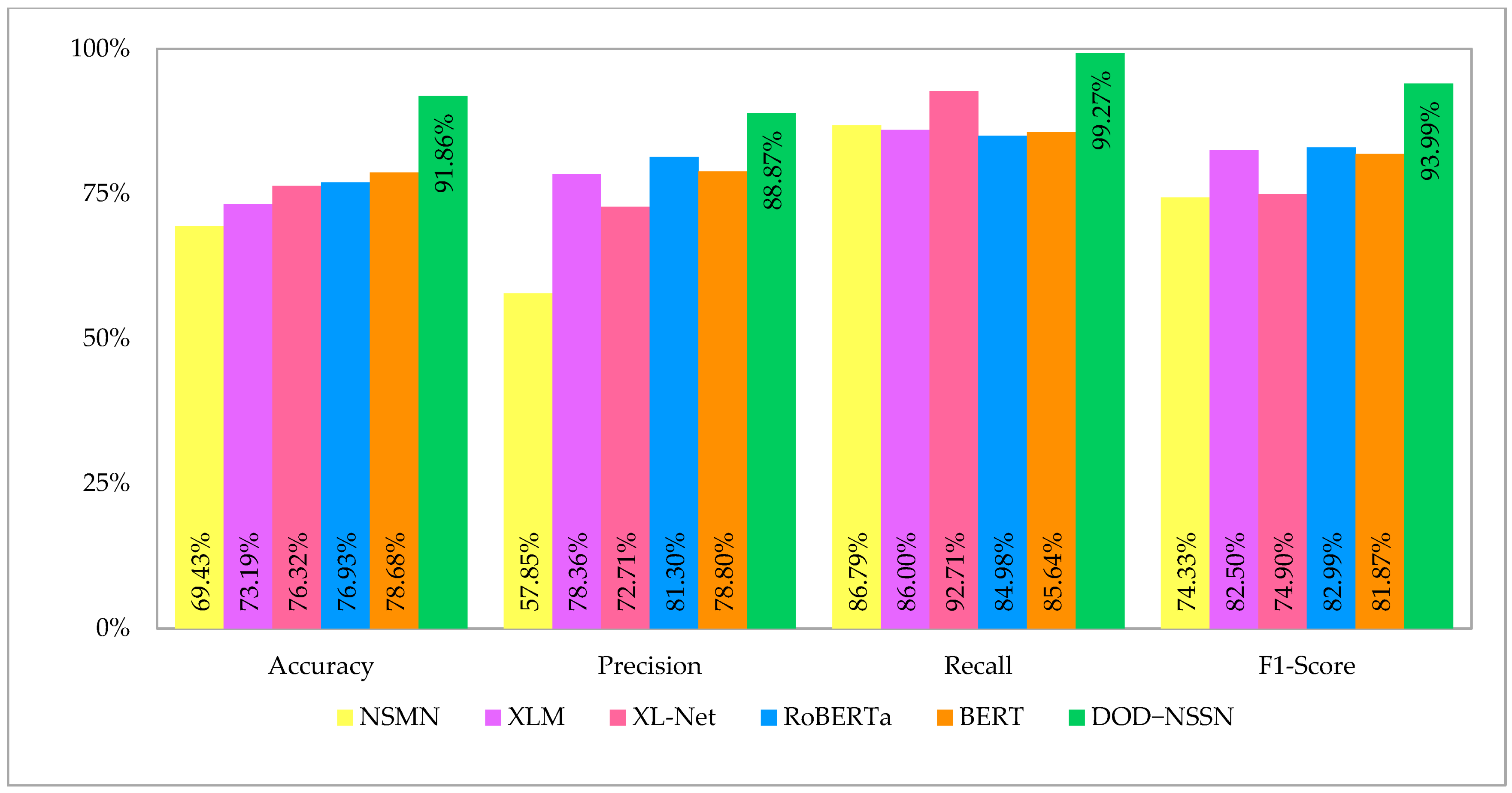
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| NSMN | 69.43% | 57.85% | 86.79% | 74.33% |
| XL-Net | 76.32% | 72.71% | 92.71% | 74.90% |
| BERT | 78.68% | 78.80% | 85.64% | 81.87% |
| XLM | 73.19% | 78.36% | 86.00% | 82.50% |
| RoBERTa | 76.93% | 81.30% | 84.98% | 82.99% |
| DOD–NSSN | 91.86% | 88.87% | 99.27% | 93.99% |
| No | Claim | Evidence | Actual Label | Predicted Label | Predicted Status |
|---|---|---|---|---|---|
| 1 | Dinosaurs lived around 100 million years ago. | Dinosaurs as well as most life was extinct about 65 million years ago | SUPPORTS | SUPPORTS | TRUE |
| 2 | Saltwater taffy candy imported in Australia | Saltwater taffy candy imported in Japan | REFUTES | SUPPORTS | FALSE |
| 3 | China gets war reparation funds from Japan after World War II | - | NEI | REFUTES | FALSE |
| 4 | Mortal Kombat X (2015) on PC have a local multiplayer | Mortal Kombat X (2015) does have local multiplayer on PC. | SUPPORTS | SUPPORTS | TRUE |
| 5 | Mao Zedong killed over 50 million people during his reign | - | NEI | NEI | TRUE |
| 6 | Fresher chicken eggs have darker yellow yolks | As eggs age, the yolk may become flatter and less round due to the thinning of the albumen, the egg white | REFUTES | NEI | FALSE |
| 7 | RBI governer Urjit Patel is Brother-in-law of Mukesh Ambani | RBI Governor Urjit Patel Mukesh Ambani’s brother-in-law is a hoax | REFUTES | REFUTES | TRUE |
| 8 | CMI students have access to every mathematician’s house in the world 24/7 | - | NEI | NEI | TRUE |
| 9 | Amrita University hosting ACM ICPC World Finals 2019 | In 2019, Amrita University in India was selected to host the world finals of the competition. | SUPPORTS | SUPPORTS | TRUE |
| 10 | 4 ppm tds safe for drinking water | 15 ppm tds safe for drinking water most likely to give you mercy | REFUTES | REFUTES | TRUE |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| NSMN | 0.0011% | 0.0001% | 0.0008% | 0.0001% |
| XL-Net | 0.0010% | 0.0011% | 0.0006% | 0.0011% |
| BERT | 0.0010% | 0.0010% | 0.0008% | 0.0009% |
| XLM | 0.0011% | 0.0010% | 0.0008% | 0.0009% |
| RoBERTa | 0.0010% | 0.0009% | 0.0009% | 0.0009% |
| DOD–NSSN | 0.0006% | 0.0008% | 0.0002% | 0.0006% |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| t-Test | ||||
| NSMN | 8.2026 | 9.8631 | 14.7618 | 8.2719 |
| XL-Net | 5.6829 | 5.1382 | 7.7594 | 8.0320 |
| BERT | 5.5454 | 4.2369 | 5.7347 | 5.0994 |
| XLM | 6.8276 | 3.3417 | 15.6962 | 4.8343 |
| RoBERTa | 6.2817 | 3.1850 | 6.0124 | 4.6282 |
| p-Value | ||||
| NSMN | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| XL-Net | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| BERT | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| XLM | 0.0000 | 0.0008 | 0.0000 | 0.0000 |
| RoBERTa | 0.0000 | 0.0015 | 0.0000 | 0.0000 |
| Topic | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Sports | 97.75% | 96.76% | 95.60% | 96.95% |
| Government | 97.13% | 97.24% | 92.71% | 96.12% |
| Political | 97.49% | 95.95% | 95.11% | 96.67% |
| Health | 82.50% | 98.36% | 96.00% | 96.19% |
| Industry | 98.37% | 98.60% | 98.30% | 97.79% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naseer, M.; Windiatmaja, J.H.; Asvial, M.; Sari, R.F. Deep One-Directional Neural Semantic Siamese Network for High-Accuracy Fact Verification. Big Data Cogn. Comput. 2025, 9, 172. https://doi.org/10.3390/bdcc9070172
Naseer M, Windiatmaja JH, Asvial M, Sari RF. Deep One-Directional Neural Semantic Siamese Network for High-Accuracy Fact Verification. Big Data and Cognitive Computing. 2025; 9(7):172. https://doi.org/10.3390/bdcc9070172
Chicago/Turabian StyleNaseer, Muchammad, Jauzak Hussaini Windiatmaja, Muhamad Asvial, and Riri Fitri Sari. 2025. "Deep One-Directional Neural Semantic Siamese Network for High-Accuracy Fact Verification" Big Data and Cognitive Computing 9, no. 7: 172. https://doi.org/10.3390/bdcc9070172
APA StyleNaseer, M., Windiatmaja, J. H., Asvial, M., & Sari, R. F. (2025). Deep One-Directional Neural Semantic Siamese Network for High-Accuracy Fact Verification. Big Data and Cognitive Computing, 9(7), 172. https://doi.org/10.3390/bdcc9070172