5.1. Test Function Minimization
The technical contribution is the crossing of the gradient (YogiPMN and DiffPNM) and coordinate descent optimization algorithms for an increase in drone detection quality in videos. In conditions of night and far distance, neural networks cannot attain the required detection quality. Such a feature affects the loss function, resulting in domains with vanishing and exploding gradients. The usual gradient-based approaches cannot handle minimization in such conditions. To solve this problem, we propose to reinforce the advanced positive–negative optimizers with the coordinate descent technique.
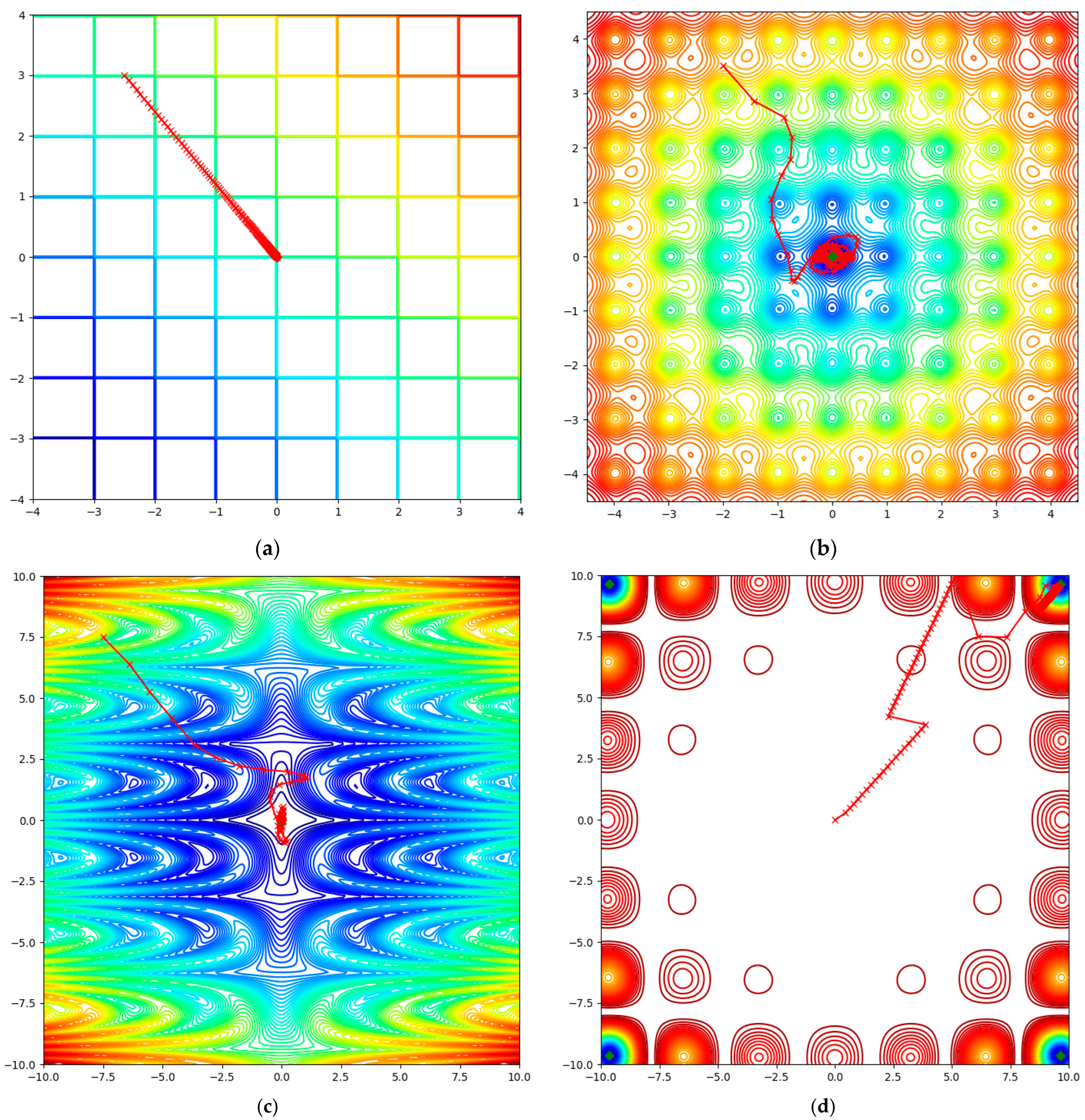
Before including the proposed YogiPNM and DiffPNM with coordinate descent in NNs, we examine the proposed optimization algorithms on test functions [
35], such as Plateau, Ackley, Pinter, and Carrom. The Plateau and Carrom functions contain domains with vanishing gradient problems. The Ackley and Pinter functions have subsets with exploding gradient problems. We set the default parameter for each optimization algorithm. The maximal number of epochs is 500. The global minimums of the Plateau, Ackley, Pinter, and Carrom test functions are 0, −3.3068, 0, and −24.15, respectively. The corresponding initial points are (−2.5, 3), (−2, 3.5), (−7.5, −7.5), and (0, 0). In
Figure 4, we show the minimization trajectory of the optimizer, which shows the smallest value compared to other approaches.
Considering the results in
Figure 4 and
Table 1, we can infer that the proposed DiffPNM and YogiPNM with coordinate descent attain the global minimum of test functions, solving the vanishing and exploding gradient problems. We can see that the proposed DiffPNM and YogiPNM with coordinate descent give the best solutions for vanishing gradient and exploding gradient problems, respectively. Among SOTA optimizers, only AdamW considers the coordinate descent technique, unlike other known analogs.
The problem of vanishing and exploding gradients regularly occurs in the loss functions of modern NNs. Such issues are connected to drone detection problems, where night and far-distance conditions lead to exploding and vanishing gradient problems, respectively. For that reason, we suggest using a coordinate approach with gradient-based optimization. The proposed DiffPNM and YogiPNM with coordinate descent and SOTA approach AdamW attain the global minimum in the Plateau and Carrom test functions with a tiny gradient value, while other optimizers fail. In the case of exploding gradient, the proposed optimization algorithms demonstrate the smallest value of the Ackley and Pinter test functions. In the next subsection, we verify the quality of solving drone detection problems in visual datasets by Yolov11 and Yolov12 with the proposed optimizers.
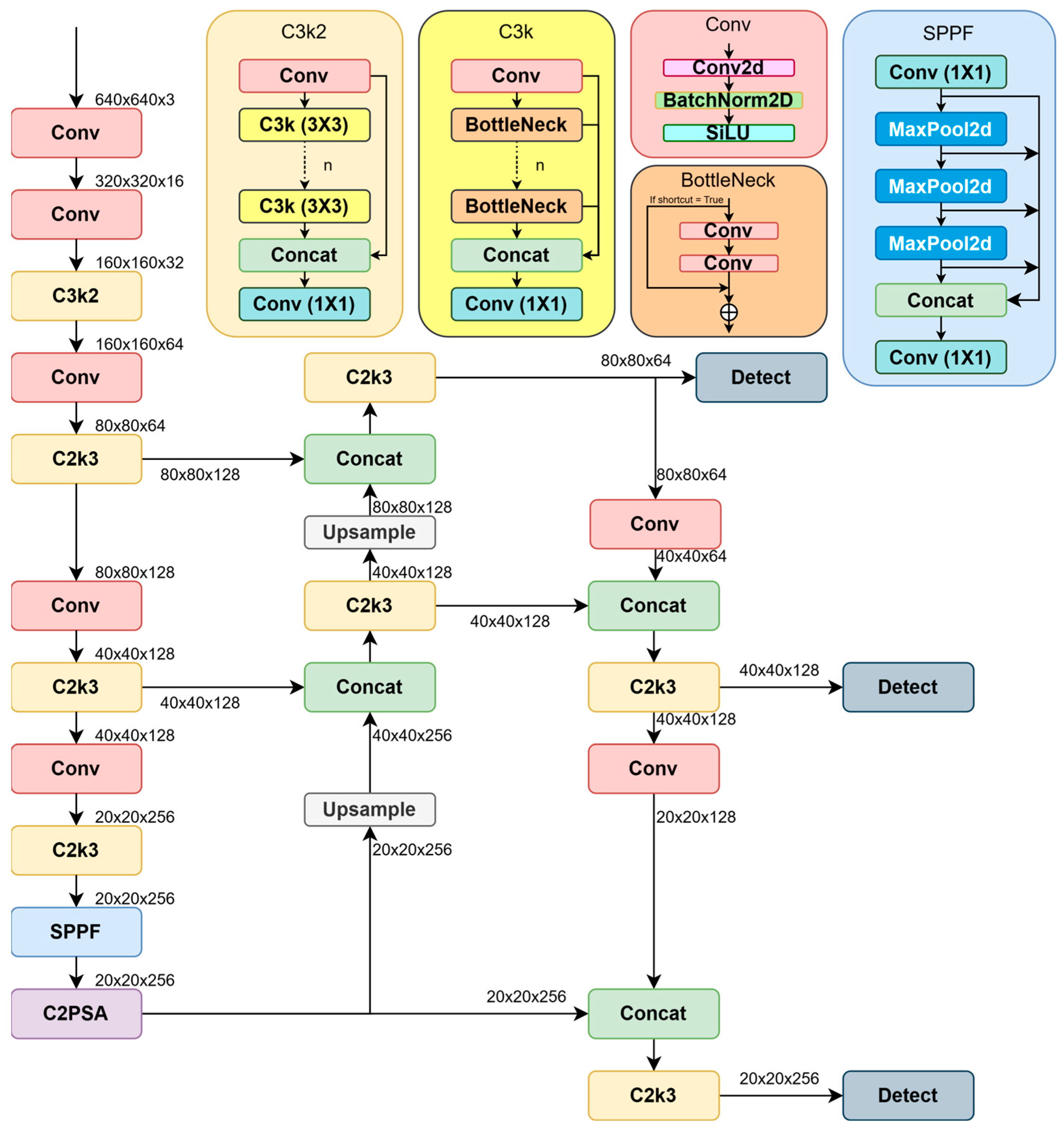
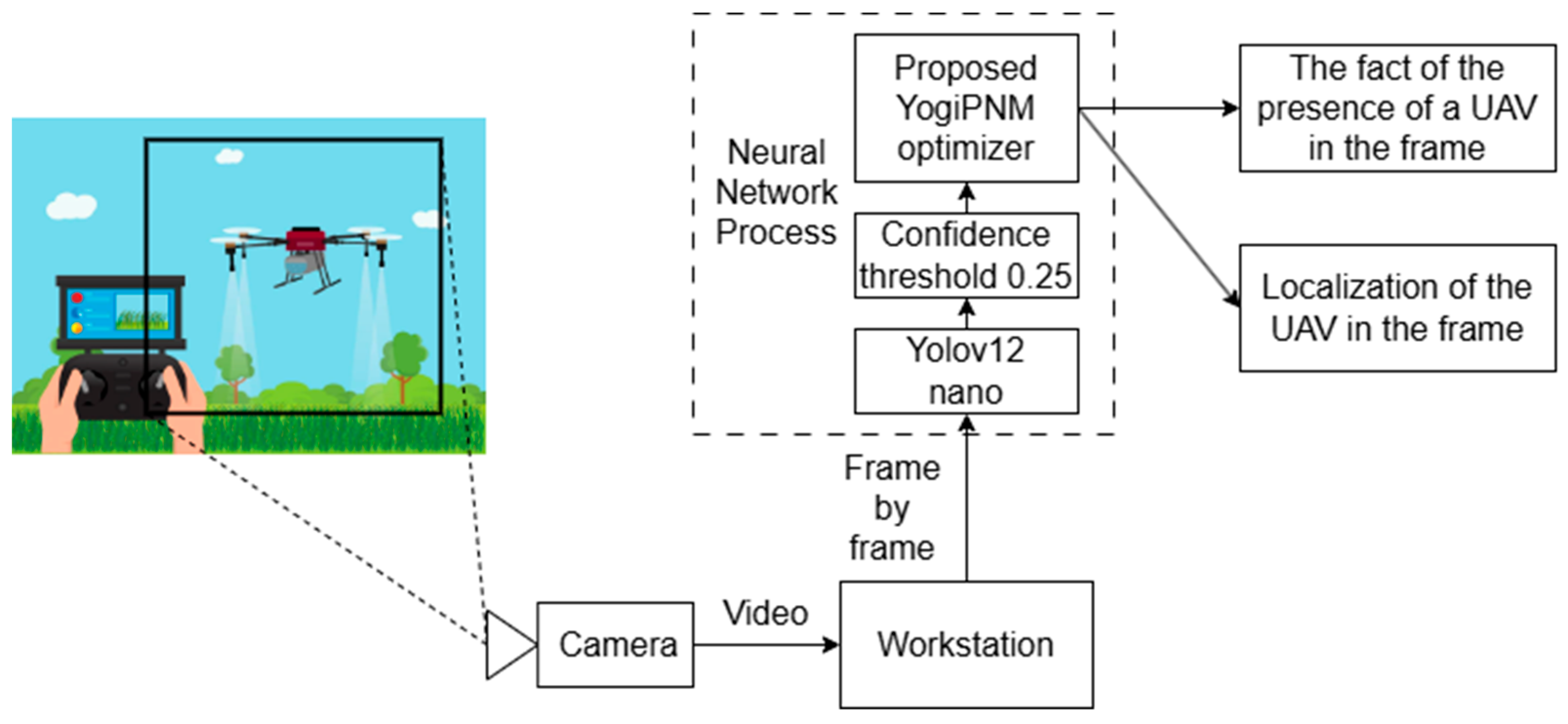
5.2. UAV Detection in Video Data
This section presents the experimental results obtained from the training process. The training is implemented on Yolov12 with positive–negative optimizers YogiPNM and DiffPNM. The open-source DroneDetectionDataset [
36], which contains 51,446 RGB images in the test sample, was used in the training process. The provided videos are sufficient to evaluate NNs for solving the drone detection problem. Based on testing the developed deep learning model in the simulation environment, the most important shortcomings of the proposed NN can be identified so that the drone detection performance does not degrade in real-world conditions. Future research can implement the proposed architectures in real-world cases. All images have a resolution of 640 × 480 pixels. These images show drones in different types, scales, sizes, positions, environments, and times of day, with bounding boxes in XML format. Training of Yolov12 with the YogiPNM optimizer on the DroneDetectionDataset was conducted using the Kaggle cloud service. The experiment utilized a 16 GB NVIDIA Tesla P100 graphics card, PyTorch 2.4.0 deep learning library, Ultralytics 8.3.94 library, Python 3.10.14, CUDA 12.3, and Ubuntu 22.04.3 LTS 64-bit operating system. A loss function similar to Yolov8 was used for training. It can be represented by the following formula:
where Loss
box is the bounded box loss, Loss
dfl is the distribution focal loss, Loss
cls is the class loss, and a, b, and c are the weighting coefficients of the entries of each loss function into the overall function. In this experiment, a = 7.5, b = 1.5, and c = 0.5, respectively. These values are the default values used in the Ultralytics library and have been used by other researchers in training [
14,
37]. During training, the DroneDetectionDataset containing 51,446 images in the training sample and 5375 images in the validation sample was used. The test sample consisted of real drone flight videos taken from open sources and manually labeled using the CVAT tool. The size of the images fed to the NN input was 640 × 480, but all images were scaled to 640 × 640 before processing. This image resolution allows for real-time computation while still being able to recognize small objects. During the experiment, Yolov12 nano-models pre-trained on the COCO image set were additionally pre-trained for five epochs on the DroneDetectionDataset. Various optimizers, such as SGD, AdamW, AdaBelief, Yogi, DiffGrad, YogiPNM, and DiffPNM, were used for comparative analysis. All NN architectures were trained with the same hyperparameters presented in
Table 2.
To determine the optimum value of the confidence threshold of the model, an experiment was conducted by testing NNs with different thresholds. The best threshold was determined by the values of the F1-score metric, as a metric combining precision and recall. The results are summarized in
Table 3. In this table, the rows represent the name of the model and optimizer, the columns indicate the confidence threshold value, and the table fields show the F1-score value for this model at the specified confidence threshold. The model works best at a confidence threshold of 0.25. This value will be used in testing in all subsequent experiments.
The metrics precision, recall, mean average precision (mAP) 50, and F1-score were chosen to evaluate the performance of the NN. Precision and recall are calculated using the following formulas:
where TP (true positives) denotes the number of targets detected correctly, FN (false negatives) is the number of targets detected as backgrounds, and FP (false positives) denotes the number of backgrounds detected as targets. F1-score is a harmonic average between precision and recall. This metric provides a comprehensive assessment of the number of errors of the first and second kind. F1-score can be represented by the following formula:
mAP is a metric that allows the accuracy of localization of the object frame compared to the reference frame to be estimated. mAP50 means that the metric will be calculated considering only frames with an intersection over union (IoU) value greater than 0.5 (50%) to be correct. IoU and mAP are represented by the following formulas:
where A and B are the reference and predicted bounding boxes, N is the number of detectable classes, and
is the average accuracy of each category.
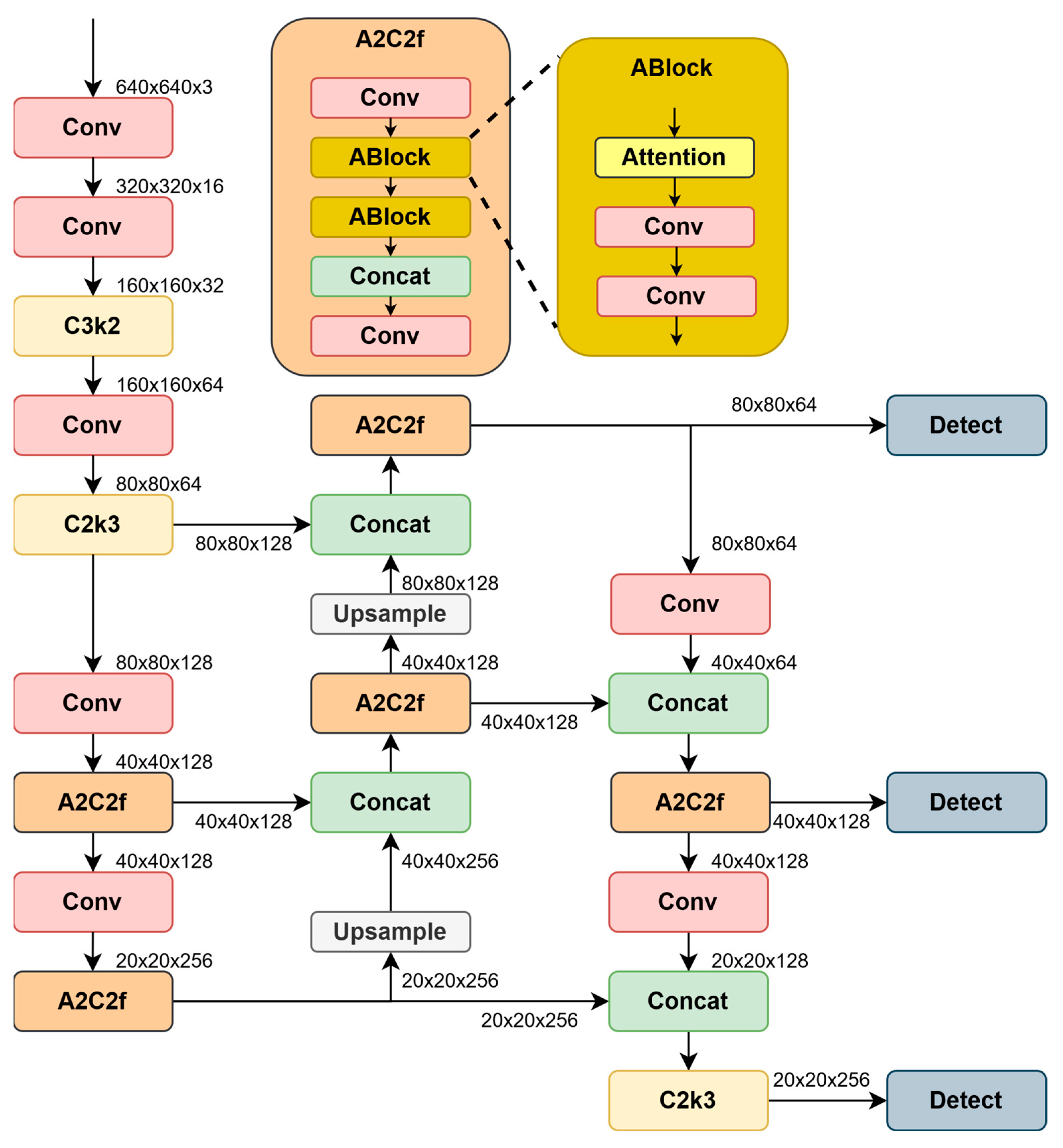
Experiments were conducted to train different combinations to determine the best combination of model and optimizers. A total of two architectures were chosen: Yolov11, as the state-of-the-art version of Yolo, based on CNN, and Yolov12, as the first architecture based on a self-attention mechanism. The following optimizers were chosen: SGD, AdamW, AdaBelief, DiffGrad, Yogi, YogiPNM, and DiffPNM [
32]. The metrics precision, recall, mAP50, and F1 were chosen to evaluate the accuracy of model recognition. All metrics were computed from the results of processing two hand-marked videos of real drone flights. The images from these videos were not involved in the training and validation process. Simulation results from the first video are presented in
Table 4.
Looking at the results shown in
Table 4, we can see that Yolov11 shows the best performance in recall (10), mAP50 (13), and F1-score (11). Among the Yolov11 models, the highest precision (9) and F1-score of 76.7% and 49.9% were obtained by training with the YogiPNM optimizer. AdamW and Yogi ranked second in these metrics, respectively. Training with DiffPNM improved recall by seven percentage points over the default AdamW. The Yolov12 architecture achieved the highest precision value when using the Yogi optimizer, but the value of the recall metric for this model is the lowest, indicating a high number of erroneous detections.
Figure 5 and
Figure 6 show examples of image recognition using Yolov11 and Yolov12 with YogiPNM. These images show that Yolov11 fails to recognize a UAV against a dark background but recognizes a drone standing on the ground with a high degree of confidence. Yolov12 recognizes the drone against the background of trees.
Combining the information from
Table 4 and
Figure 5 and
Figure 6, we can conclude that Yolov12 models create more frames and recognize the drone more often, but it also increases the number of false detections of other objects like UAVs. Yolov11 allows fewer erroneous detections, but it misses many frames with the presence of a drone without recognizing it. The results obtained from the processing of the second video are presented in
Table 5.
Analyzing the results presented in
Table 5, we can conclude that the Yolov12 model with the YogiPNM optimizer was the best at processing the second video. The precision, recall, mAP50, and F1-score were 97.1%, 96.1%, 96.8%, and 96.6%, respectively. In second place is Yolov12 with DiffPNM. In third place is Yolov12 with the DiffGrad optimizer. Using the state-of-the-art optimization method improved precision by 3.1%, recall by 3%, mAP50 by 2.6%, and F1-score by 3.1 percentage points. For the Yolov11 model, the best optimizer was AdamW for recall and mAP50 metrics and AdaBelief for precision and F1-score. The NN based on the self-attention mechanism achieved a result that exceeded the best results of Yolov11 by 1.4–1.9 percentage points.
Comparing
Figure 7 and
Figure 8, it can be seen that both models perform well in recognizing the drone against a contrasting background. It can also be seen that Yolov11 shows more confidence in distinguishing the UAV in the bounding box.
Additionally, we demonstrate the solving of the drone detection problem on night-time datasets. We show the results of drone detection and accuracy assessment in
Figure 9 and
Figure 10 and
Table 6, respectively.
In the case of the R-CNN model, the proposed optimization algorithm DiffPNM demonstrates the highest quality of drone detection. YogiPNM gives the second-highest result in neural network training and drone detection. We can see that the proposed optimizers attain higher results than known analogs. In the case of Yolov11, the best average result belongs to YogiPNM. The optimizers DiffGrad and AdaBelief also demonstrate a high quality of drone detection problem-solving. Yolov12 attains the best results in solving the drone detection problem by using YogiPNM and DiffPNM approaches. The remaining SOTA optimizers either show lower-quality results or experience the anomalies in precision, recall, and F1-score.
Next, we examine our drone detection method in visual datasets containing far-distance conditions. We show the results of drone detection and accuracy assessment in
Figure 11 and
Figure 12 and
Table 7, respectively.
In the case of the R-CNN model, the proposed DiffPNM demonstrates the highest average result of drone detection. YogiPNM gives the second-best drone detection quality results. Among SOTA optimizers, SGD shows the best results in solving the drone detection problem. We can see that the proposed optimizers attain higher results than known analogs. In the case of Yolov11, the best average result belongs to YogiPNM. The optimizers DiffGrad and AdaBelief also demonstrate a high quality of drone detection problem-solving. Yolov12 attains the best results in solving the drone detection problem by using YogiPNM and DiffPNM approaches. The remaining SOTA optimizers either show lower-quality results or experience the anomalies in precision, recall, and F1-score.
The main advantage of the Yolo architecture over other architectures for solving the detection problem is the ability to work in real time. Yolov12 has five architecture sizes: nano, small, medium, large, and extra-large.
Table 8 was constructed to evaluate the feasibility of using larger architectures for real-time image processing. It shows the model name, size, number of parameters, and FPS.
Thus, for real-time video processing at 60 fps, all models except extra-large can be used. The proposed Yolov12 model achieves high performance in the task of UAV recognition in the video stream; however, the result can be improved by using larger Yolo models such as Yolov12s, Yolov12m, or Yolov12l. The peculiarity of the proposed models Yolov11 and Yolov12 is the use of optimization algorithms with positive–negative momentum estimation and coordinate descent. Unlike models using optimization of SOTA algorithms, our development achieves high accuracy of object detection in fewer epochs, and as a result, the occurrence of overfitting for calculating convergence on a global scale with minimal feature loss.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}