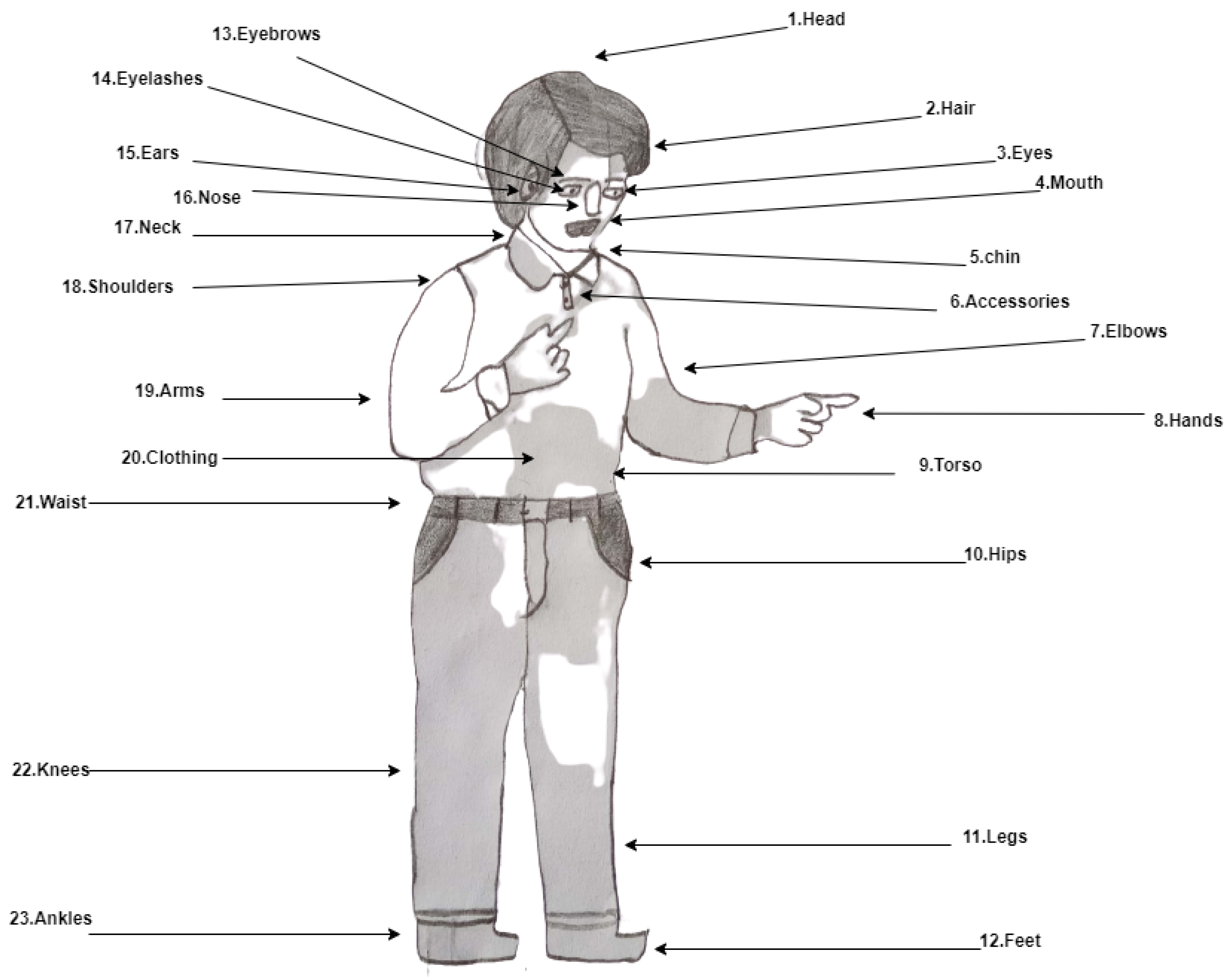
Figure 1.
Human figure drawing with 23 indicators.
Figure 1.
Human figure drawing with 23 indicators.
Figure 2.
Mouth indicator scores for DAP-IQ test.
Figure 2.
Mouth indicator scores for DAP-IQ test.
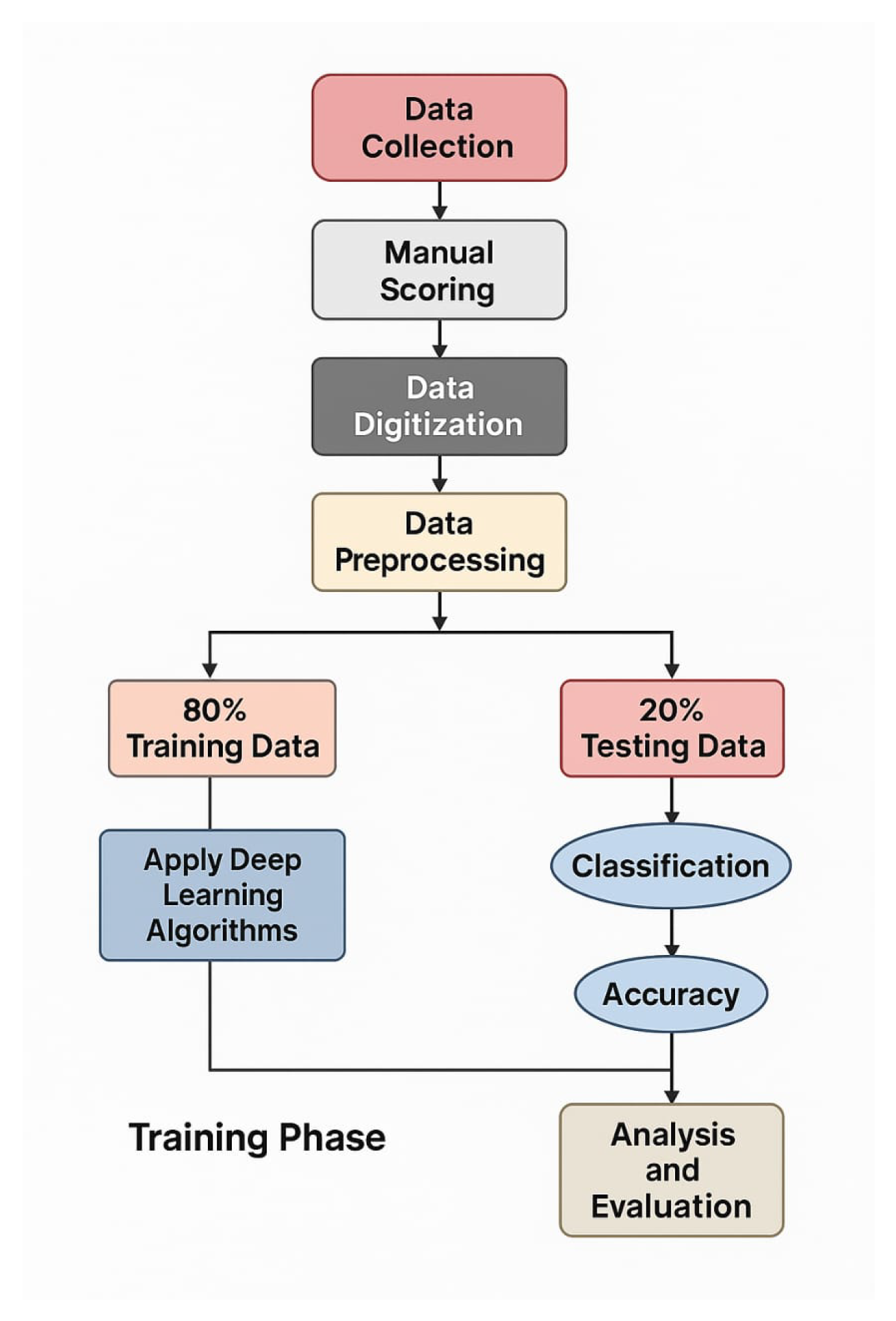
Figure 3.
Block Diagram of our Proposed Methodology.
Figure 3.
Block Diagram of our Proposed Methodology.
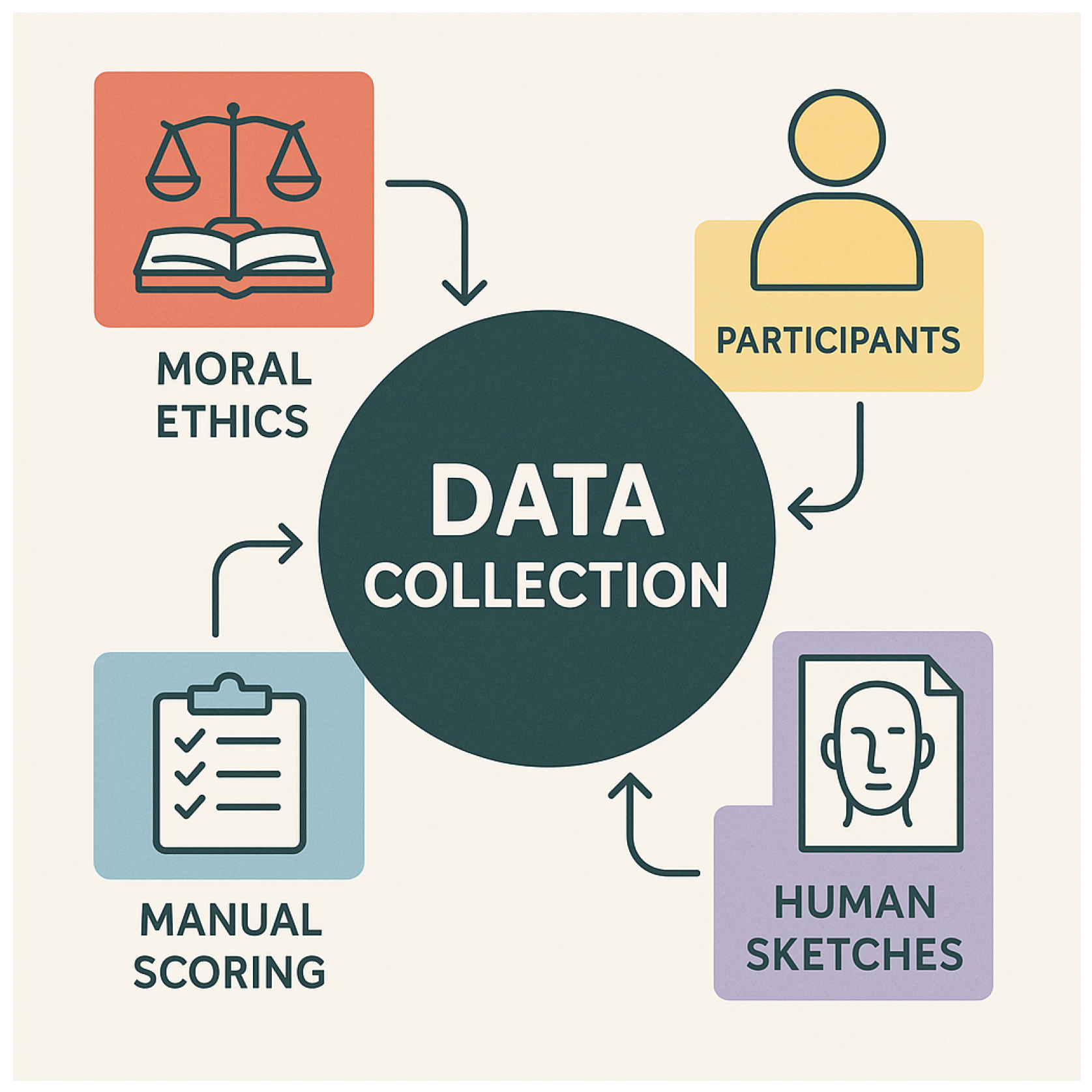
Figure 4.
Block diagram for data collection.
Figure 4.
Block diagram for data collection.
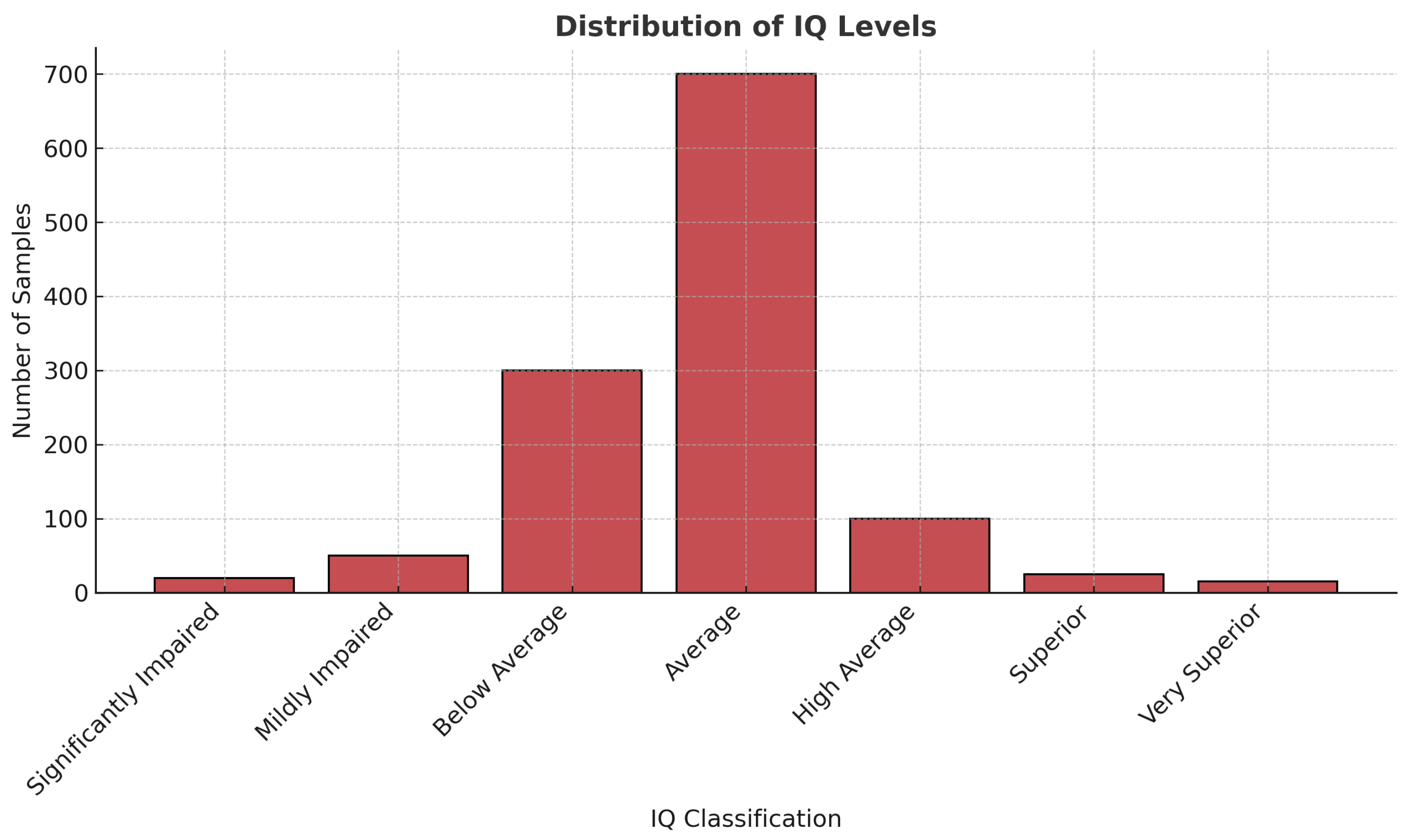
Figure 5.
DAP-IQ dataset distribution using a column graph.
Figure 5.
DAP-IQ dataset distribution using a column graph.
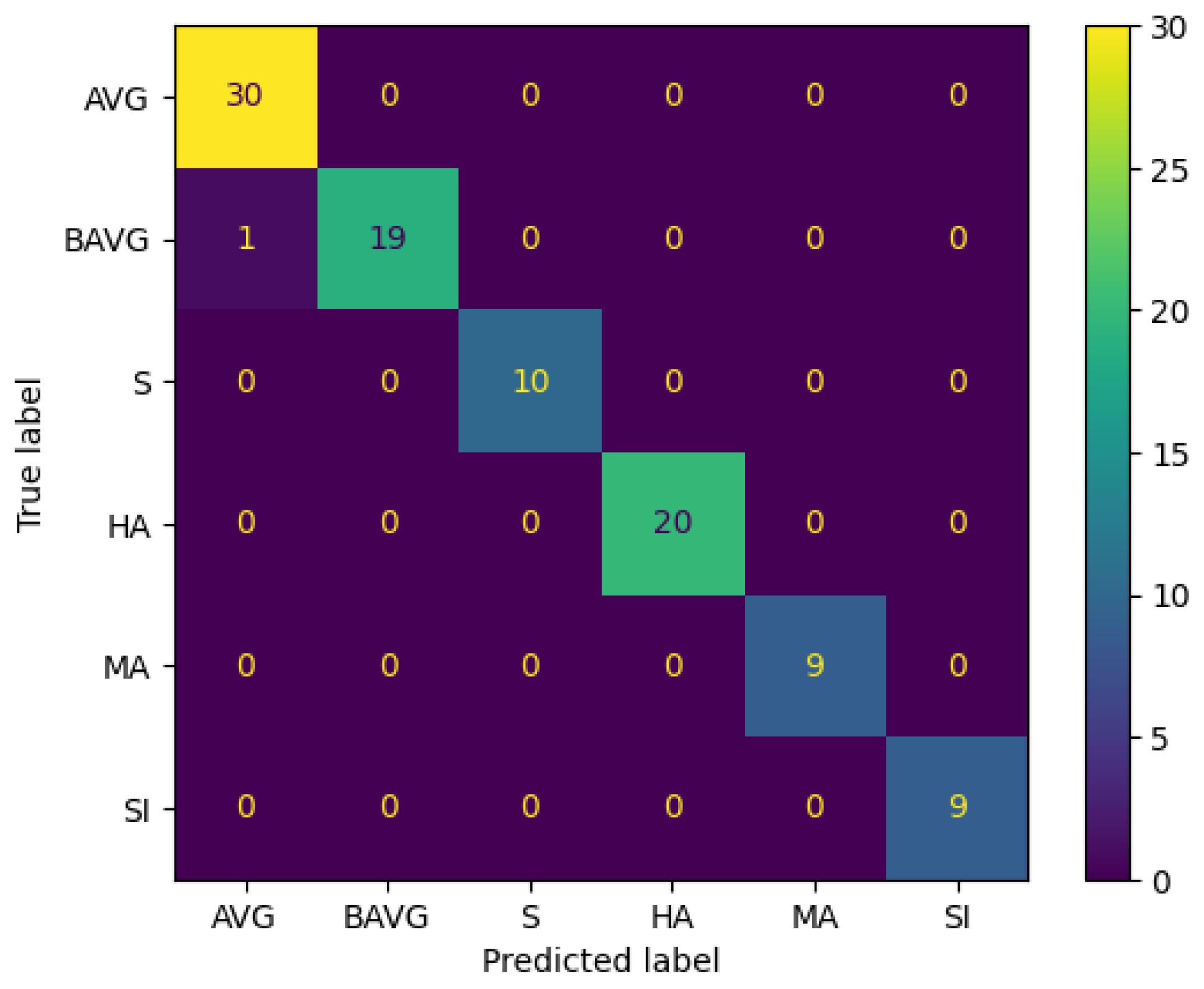
Figure 6.
Statistics of the human annotators and psychologist by kappa.
Figure 6.
Statistics of the human annotators and psychologist by kappa.
Table 1.
Intelligence quotient classes following the application of the data augmentation techniques.
Table 1.
Intelligence quotient classes following the application of the data augmentation techniques.
| Sr. | Classes | Frequency |
|---|
| 1 | Significantly Impaired | 66 |
| 2 | Mildly Impaired | 342 |
| 3 | Below Average | 1578 |
| 4 | Average | 4164 |
| 5 | High Average | 474 |
| 6 | Superior | 60 |
| 7 | Very Superior | 18 |
Table 2.
Hyperparameters and configurations of the MobileNet model.
Table 2.
Hyperparameters and configurations of the MobileNet model.
|
Component
|
Value/Setting
|
|---|
| Model Architecture |
|
Base Model
|
MobileNet (ImageNet weights)
|
|
Include Top
|
False
|
|
Input Shape
|
(224, 224, 3)
|
|
Pooling Layer
|
GlobalAveragePooling2D
|
|
Dense Layer
|
512 units, ReLU
|
|
Output Layer
|
7 units, Softmax
|
| Training Configuration |
|
Batch Size
|
32
|
|
Epochs
|
30
|
|
Optimizer
|
Adam
|
|
Loss Function
|
Categorical Crossentropy
|
|
Metrics
|
Accuracy
|
|
Trainable Base Model
|
False
|
| Data Augmentation |
| Rescale |
1./255
|
|
Rotation Range
|
20
|
|
Width Shift Range
|
0.1
|
|
Height Shift Range
|
0.1
|
|
Shear Range
|
0.1
|
|
Zoom Range
|
0.2
|
|
Horizontal Flip
|
True
|
|
Fill Mode
|
Nearest
|
| Evaluation Settings |
|
Batch Size (Evaluation)
|
1
|
|
Shuffle
|
False
|
|
Rescale (Evaluation)
|
1./255
|
|
Metric
|
Classification report (precision, recall, F1-score)
|
Table 3.
Single-class accuracy for Mobile-Net model.
Table 3.
Single-class accuracy for Mobile-Net model.
| Classes | Accuracy |
|---|
| Below Average | 0.98% |
| Mildly Impaired | 0.91% |
| High Average | 0.99% |
| Very Superior | 0.51% |
| Superior | 0.66% |
| Average | 0.99% |
| Significantly Impaired | 0.84% |
Table 4.
Classification report for MobileNet without data augmentation: precision, recall, and F1-score for each class.
Table 4.
Classification report for MobileNet without data augmentation: precision, recall, and F1-score for each class.
| Class | Precision | Recall | F1-Score | Support |
|---|
| Mildly Impaired | 0.53 | 0.17 | 0.26 | 106 |
| Significantly Impaired | 0.83 | 0.17 | 0.28 | 117 |
| Superior | 0.76 | 0.27 | 0.40 | 126 |
| Average | 0.51 | 0.75 | 0.61 | 189 |
| Below Average | 0.48 | 0.81 | 0.61 | 139 |
| High Average | 0.29 | 0.56 | 0.38 | 108 |
| Very Superior | 0.77 | 0.47 | 0.58 | 109 |
| Accuracy | 0.49 | 894 |
| Macro Average | 0.60 | 0.46 | 0.45 | 894 |
| Weighted Average | 0.59 | 0.49 | 0.46 | 894 |
Table 5.
Experiment for precision, recall, and F1-score (MobileNet Model).
Table 5.
Experiment for precision, recall, and F1-score (MobileNet Model).
| Classes | Precision | Recall | f1-Score |
|---|
| Mildly Impaired | 0.79% | 0.90% | 0.84% |
| Significantly Impaired | 0.94% | 0.78% | 0.85% |
| Superior | 0.86% | 0.81% | 0.83% |
| Average | 0.88% | 0.85% | 0.87% |
| Below Average | 0.61 % | 1.00% | 0.76% |
| High Average | 0.83% | 0.44% | 0.58% |
| Very Superior | 0.96% | 0.79% | 0.846% |
Table 6.
Experiment for MobileNet-V2 model.
Table 6.
Experiment for MobileNet-V2 model.
| Training Accuracy | Training Loss | Test Accuracy | Test Loss |
|---|
| 98.68% | 0.03% | 89.0% | 0.3% |
Table 7.
Hyperparameters and configurations of the MobileNetV2 model.
Table 7.
Hyperparameters and configurations of the MobileNetV2 model.
|
Component
|
Value/Setting
|
|---|
| Model Architecture |
|
Base Model
|
MobileNetV2 (Pre-trained on ImageNet)
|
|
Include Top
|
False
|
|
Input Shape
|
(224, 224, 3)
|
|
Output Layer
|
Dense (7); Activation: Softmax
|
|
Pooling Layer
|
GlobalAveragePooling2D
|
|
Additional Dense Layer
|
Dense (512); Activation: ReLU
|
| Training Settings |
|
Batch Size
|
32
|
|
Epochs
|
30
|
|
Optimizer
|
Adam
|
|
Loss Function
|
Categorical Crossentropy
|
|
Metrics
|
Accuracy
|
|
Base Model Trainable
|
False (frozen)
|
| Data Augmentation Parameters |
|
Rescale
|
1./255
|
|
Rotation Range
|
20 degrees
|
|
Width Shift Range
|
0.1
|
|
Height Shift Range
|
0.1
|
|
Shear Range
|
0.1
|
|
Zoom Range
|
0.2
|
|
Horizontal Flip
|
True
|
|
Fill Mode
|
Nearest
|
| Evaluation Settings |
|
Evaluation Rescale
|
1./255
|
|
Shuffle
|
False
|
|
Evaluation Batch Size
|
1
|
|
Evaluation Metric
|
Classification report (precision, recall, F1-score)
|
Table 8.
Classification report for MobileNet V2 without data augmentation: precision, recall, and F1-score for each class.
Table 8.
Classification report for MobileNet V2 without data augmentation: precision, recall, and F1-score for each class.
| Class | Precision | Recall | F1-Score | Support |
|---|
| Mildly Impaired | 0.55 | 0.18 | 0.26 | 106 |
| Significantly Impaired | 0.83 | 0.17 | 0.28 | 117 |
| Superior | 0.60 | 0.30 | 0.40 | 126 |
| Average | 0.51 | 0.75 | 0.61 | 189 |
| Below Average | 0.48 | 0.81 | 0.70 | 139 |
| High Average | 0.29 | 0.56 | 0.38 | 108 |
| Very Superior | 0.77 | 0.47 | 0.58 | 109 |
| Accuracy | 0.56 | 894 |
| Macro Average | 0.60 | 0.46 | 0.45 | 894 |
| Weighted Average | 0.59 | 0.49 | 0.46 | 894 |
Table 9.
Single-class accuracy for MobileNet-V2 model.
Table 9.
Single-class accuracy for MobileNet-V2 model.
| Classes | Accuracy |
|---|
| Below Average | 0.98% |
| Mildly Impaired | 0.91% |
| High Average | 0.99% |
| Very Superior | 0.54% |
| Superior | 0.69% |
| Average | 0.99% |
| Significantly Impaired | 0.88% |
Table 10.
Experiment for the MobileNet-V2 model.
Table 10.
Experiment for the MobileNet-V2 model.
| Training Accuracy | Training Loss | Test Accuracy | Test Loss |
|---|
| 96.49% | 0.07% | 80.11% | 0.5% |
Table 11.
Experiment for precision, recall, and F1-score (MobileNet-V2).
Table 11.
Experiment for precision, recall, and F1-score (MobileNet-V2).
| Classes | Precision | Recall | F1-Score |
|---|
| Mildly Impaired | 0.68% | 0.43% | 0.53% |
| Significantly Impaired | 0.55% | 0.54% | 0.55% |
| Superior | 0.62% | 0.44% | 0.51% |
| Average | 0.44% | 0.90% | 0.59% |
| Below Average | 0.89 % | 0.46 % | 0.61% |
| High Average | 0.56% | 0.56% | 0.56% |
| Very Superior | 0.94% | 0.47% | 0.63% |
Table 12.
Hyperparameters and configurations of the Xception model.
Table 12.
Hyperparameters and configurations of the Xception model.
|
Component
|
Value/Setting
|
|---|
| Model Architecture |
|
Base Model
|
Xception (Pre-trained on ImageNet)
|
|
Include Top
|
False
|
|
Input Shape
|
(224, 224, 3)
|
|
Output Layer
|
Dense (7); Activation: Softmax
|
|
Pooling Layer
|
GlobalAveragePooling2D
|
|
Additional Dense Layer
|
Dense (512); Activation: ReLU
|
| Training Settings |
|
Batch Size
|
32
|
|
Epochs
|
30
|
|
Optimizer
|
Adam
|
|
Loss Function
|
Categorical Crossentropy
|
|
Metrics
|
Accuracy
|
|
Base Model Trainable
|
False (frozen)
|
| Data Augmentation Parameters |
|
Rescale
|
1./255
|
|
Rotation Range
|
20 degrees
|
|
Width Shift Range
|
0.1
|
|
Height Shift Range
|
0.1
|
|
Shear Range
|
0.1
|
|
Zoom Range
|
0.2
|
|
Horizontal Flip
|
True
|
|
Fill Mode
|
Nearest
|
|
Evaluation Rescale
|
1./255
|
|
Shuffle
|
False
|
|
Evaluation Batch Size
|
1
|
|
Evaluation Metric
|
Classification Report (Precision, Recall, F1-score)
|
Table 13.
Classification Report for Xception without data augmentation: precision, recall, F1-score for each class.
Table 13.
Classification Report for Xception without data augmentation: precision, recall, F1-score for each class.
| Class | Precision | Recall | F1-Score | Support |
|---|
| Mildly Impaired | 0.53 | 0.18 | 0.26 | 106 |
| Significantly Impaired | 0.83 | 0.17 | 0.28 | 117 |
| Superior | 0.60 | 0.27 | 0.40 | 126 |
| Average | 0.51 | 0.75 | 0.61 | 189 |
| Below Average | 0.48 | 0.81 | 0.61 | 139 |
| High Average | 0.29 | 0.56 | 0.38 | 108 |
| Very Superior | 0.77 | 0.47 | 0.58 | 109 |
| Accuracy | 0.60 | 894 |
| Macro Average | 0.60 | 0.46 | 0.45 | 894 |
| Weighted Average | 0.59 | 0.49 | 0.46 | 894 |
Table 14.
Single-class accuracy for the Xception Model.
Table 14.
Single-class accuracy for the Xception Model.
| Classes | Accuracy |
|---|
| Below Average | 0.98% |
| Mildly Impaired | 0.91% |
| High Average | 0.98% |
| Very Superior | 0.50% |
| Superior | 0.63% |
| Average | 0.99% |
| Significantly Impaired | 0.85% |
Table 15.
Experiment for the Xception model.
Table 15.
Experiment for the Xception model.
| Training Accuracy | Training Loss | Test Accuracy | Test Loss |
|---|
| 97.74% | 0.05% | 86.93% | 0.7% |
Table 16.
Experiment for precision, recall, and F1-score (Xception Model).
Table 16.
Experiment for precision, recall, and F1-score (Xception Model).
| Classes | Precision | Recall | F1-Score |
|---|
| Mildly Impaired | 0.51% | 0.95% | 0.66% |
| Significantly Impaired | 0.78% | 0.44% | 0.56% |
| Superior | 0.53% | 0.83% | 0.64% |
| Average | 0.79% | 0.51% | 0.62% |
| Below Average | 0.82% | 0.93% | 0.87% |
| High Average | 0.87% | 0.38% | 0.53% |
| Very Superior | 0.79% | 0.78% | 0.79% |
Table 17.
Hyperparameters and configurations of the InceptionV3 model.
Table 17.
Hyperparameters and configurations of the InceptionV3 model.
|
Component
|
Value/Setting
|
|---|
| Model Architecture |
|
Base Model
|
InceptionV3 (Pre-trained on ImageNet)
|
|
Include Top
|
False
|
|
Input Shape
|
(224, 224, 3)
|
|
Custom Layers
|
GlobalAveragePooling2D, Dense (1024, ReLU), Dense (7, Softmax)
|
| Training Settings |
|
Batch Size
|
32
|
|
Epochs
|
30
|
|
Optimizer
|
Adam
|
|
Loss Function
|
Categorical Crossentropy
|
|
Metrics
|
Accuracy
|
|
Trainable Layers
|
Only custom layers (base frozen)
|
|
Shuffle (training)
|
True
|
| Data Augmentation Parameters |
|
Rescale
|
1./255
|
|
Rotation Range
|
20 degrees
|
|
Width Shift Range
|
0.1
|
|
Height Shift Range
|
0.1
|
|
Shear Range
|
0.1
|
|
Zoom Range
|
0.2
|
|
Horizontal Flip
|
True
|
|
Fill Mode
|
Nearest
|
| Evaluation Settings |
|
Evaluation Rescale
|
1./255
|
|
Shuffle
|
False
|
|
Evaluation Batch Size
|
1
|
|
Classification Metric
|
Precision, recall, and F1-score (via the classification report)
|
Table 18.
Classification report for Inception V3 without data augmentation: precision, recall, and F1-score for each class.
Table 18.
Classification report for Inception V3 without data augmentation: precision, recall, and F1-score for each class.
| Class | Precision | Recall | F1-Score | Support |
|---|
| Mildly Impaired | 0.53 | 0.18 | 0.26 | 106 |
| Significantly Impaired | 0.83 | 0.17 | 0.28 | 117 |
| Superior | 0.61 | 0.27 | 0.40 | 126 |
| Average | 0.51 | 0.75 | 0.61 | 189 |
| Below Average | 0.50 | 0.81 | 0.61 | 139 |
| High Average | 0.29 | 0.56 | 0.38 | 108 |
| Very Superior | 0.77 | 0.47 | 0.58 | 109 |
| Accuracy | 0.43 | 894 |
| Macro Average | 0.60 | 0.46 | 0.45 | 894 |
| Weighted Average | 0.59 | 0.49 | 0.46 | 894 |
Table 19.
Single-class accuracy for the Inception-V3 model.
Table 19.
Single-class accuracy for the Inception-V3 model.
| Classes | Accuracy |
|---|
| Below Average | 0.98% |
| Mildly Impaired | 0.85% |
| High Average | 0.98% |
| Very Superior | 0.51% |
| Superior | 0.58% |
| Average | 0.99% |
| Significantly Impaired | 0.85% |
Table 20.
Experiment for the Inception-V3 model.
Table 20.
Experiment for the Inception-V3 model.
| Training Accuracy | Training Loss | Test Accuracy | Test Loss |
|---|
| 97.03% | 0.10% | 84.65% | 0.6% |
Table 21.
Experiment for precision, recall, and F1-score (Inception-V3).
Table 21.
Experiment for precision, recall, and F1-score (Inception-V3).
| Classes | Precision | Recall | F1-Score |
|---|
| Mildly Impaired | 0.66% | 0.70% | 0.68% |
| Significantly Impaired | 0.71% | 0.49% | 0.58% |
| Superior | 0.83% | 0.50% | 0.62% |
| Average | 0.71% | 0.84% | 0.77% |
| Below Average | 0.90% | 0.71% | 0.80% |
| High Average | 0.51% | 0.83% | 0.63% |
| Very Superior | 0.75% | 0.78% | 0.76% |
Table 22.
Hyperparameters and configurations of the custom CNN model.
Table 22.
Hyperparameters and configurations of the custom CNN model.
|
Component
|
Value/Setting
|
|---|
| Model Architecture |
|
Convolutional Layers
|
3 Conv layers (filters: 32, 64, 128)
|
|
Kernel Size
|
3 × 3
|
|
Activation Function
|
ReLU
|
|
Pooling Layers
|
MaxPooling2D after each Conv layer
|
|
Flatten Layer
|
Yes
|
|
Dense Layers
|
Dense (128), Dense (7)
|
|
Output Activation
|
Softmax
|
| Training Settings |
|
Input Shape
|
(224, 224, 3)
|
|
Batch Size
|
32
|
|
Epochs
|
30
|
|
Optimizer
|
Adam
|
|
Loss Function
|
Categorical Crossentropy
|
|
Metrics
|
Accuracy
|
|
Shuffle (training)
|
True
|
| Data Augmentation Parameters |
|
Rescale
|
1./255
|
|
Rotation Range
|
20 Degrees
|
|
Width Shift Range
|
0.1
|
|
Height Shift Range
|
0.1
|
|
Shear Range
|
0.1
|
|
Zoom Range
|
0.2
|
|
Horizontal Flip
|
True
|
|
Fill Mode
|
Nearest
|
| Evaluation Settings |
|
Evaluation Rescale
|
1./255
|
|
Shuffle
|
False
|
|
Evaluation Batch Size
|
1
|
|
Classification Metric
|
Precision, recall, and F1-score (via the classification report)
|
Table 23.
Classification report for CNN without data augmentation: precision, recall, and F1-score for each class.
Table 23.
Classification report for CNN without data augmentation: precision, recall, and F1-score for each class.
| Class | Precision | Recall | F1-Score | Support |
|---|
| Mildly Impaired | 0.51 | 0.18 | 0.26 | 106 |
| Significantly Impaired | 0.53 | 0.17 | 0.28 | 117 |
| Superior | 0.60 | 0.27 | 0.40 | 126 |
| Average | 0.51 | 0.75 | 0.61 | 189 |
| Below Average | 0.48 | 0.81 | 0.61 | 139 |
| High Average | 0.30 | 0.56 | 0.38 | 108 |
| Very Superior | 0.77 | 0.47 | 0.58 | 109 |
| Accuracy | 0.46 | 894 |
| Macro Average | 0.60 | 0.46 | 0.45 | 894 |
| Weighted Average | 0.59 | 0.49 | 0.46 | 894 |
Table 24.
Single-class accuracy for the CNN model.
Table 24.
Single-class accuracy for the CNN model.
| Classes | Accuracy |
|---|
| Below Average | 0.89% |
| Mildly Impaired | 0.98% |
| High Average | 0.99% |
| Very Superior | 0.62% |
| Superior | 0.66% |
| Average | 0.99% |
| Significantly Impaired | 0.83% |
Table 25.
Experiment for the CNN model.
Table 25.
Experiment for the CNN model.
| Training Accuracy | Training Loss | Test Accuracy | Test Loss |
|---|
| 92.86% | 0.22% | 93.75% | 0.9% |
Table 26.
Experiment for precision, recall, and F1-score(CNN model).
Table 26.
Experiment for precision, recall, and F1-score(CNN model).
| Classes | Precision | Recall | F1-Score |
|---|
| Mildly Impaired | 0.87% | 0.70% | 0.78% |
| Superior | 0.44% | 0.69% | 0.54% |
| Average | 0.87% | 0.70% | 0.78% |
| Below Average | 0.83% | 1.00% | 0.93% |
| High Average | 0.52% | 0.33% | 0.40% |
| Significantly Impaired | 1.00% | 0.19% | 0.32% |
| Very Superior | 0.46% | 0.43% | 0.44% |
Table 27.
Comparison of our proposed models based on Test Accuracy and evaluation metrics.
Table 27.
Comparison of our proposed models based on Test Accuracy and evaluation metrics.
|
Model
|
Test Accuracy
|
Avg. Precision
|
Avg. Recall
|
Avg. F1-Score
|
|---|
|
Mobile-Net
|
89.00%
|
0.70
|
0.62
|
0.60
|
|
Xception
|
86.93%
|
0.73
|
0.65
|
0.63
|
|
Mobile-Net-V2
|
80.11%
|
0.71
|
0.60
|
0.58
|
|
Inception-V3
|
84.65%
|
0.75
|
0.66
|
0.65
|
|
CNN (Custom)
|
93.75%
|
0.72
|
0.64
|
0.62
|
Table 28.
K-Fold cross-validation report (Mobile-Net).
Table 28.
K-Fold cross-validation report (Mobile-Net).
| Folds | Training Accuracy | Test Accuracy |
|---|
| 1 | 91.07% | 89.58% |
| 2 | 90.48% | 87.05% |
| 3 | 95.41% | 93.72% |
| 4 | 91.27% | 89.67% |
| 5 | 93.27% | 89.27% |
Table 29.
K-Fold cross-validation report (Xception Model).
Table 29.
K-Fold cross-validation report (Xception Model).
| Folds | Training Accuracy | Test Accuracy |
|---|
| 1 | 95.74% | 94.64% |
| 2 | 92.27% | 90.17% |
| 3 | 94.18% | 95.96% |
| 4 | 95.19% | 92.19% |
| 5 | 92.28% | 86.54% |
Table 30.
K-Fold cross-validation report (InceptionResNetV2).
Table 30.
K-Fold cross-validation report (InceptionResNetV2).
| Folds | Training Accuracy | Test Accuracy |
|---|
| 1 | 83.42% | 81.25% |
| 2 | 97.98% | 92.85% |
| 3 | 89.48% | 86.09% |
| 4 | 65.43% | 91.92% |
| 5 | 95.63% | 91.92% |
Table 31.
K-Fold cross-validation report (CNN).
Table 31.
K-Fold cross-validation report (CNN).
| Folds | Training Accuracy | Test Accuracy |
|---|
| 1 | 84.42% | 83.03% |
| 2 | 91.93% | 87.94% |
| 3 | 71.25% | 73.09% |
| 4 | 82.73% | 85.20% |
| 5 | 81.31% | 82.51% |
Table 32.
K-Fold cross-validation report (Inception-V3).
Table 32.
K-Fold cross-validation report (Inception-V3).
| Folds | Training Accuracy | Test Accuracy |
|---|
| 1 | 76.70% | 76.78% |
| 2 | 89.58% | 86.16% |
| 3 | 83.89% | 84.72% |
| 4 | 94.40% | 92.37% |
| 5 | 47.76% | 46.18% |
Table 33.
Average accuracies of K-Fold cross-validation.
Table 33.
Average accuracies of K-Fold cross-validation.
| Models | Training Accuracy | Test Accuracy |
|---|
| Mobile-Net | 91.98% | 90.15% |
| Xception | 93.93% | 82.03% |
| InceptionResNetV2 | 86.39% | 83.87% |
| CNN | 82.34% | 82.35% |
| Inception-V3 | 78.47% | 77.25% |








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}