
No-Code Edge Artificial Intelligence Frameworks Comparison Using a Multi-Sensor Predictive Maintenance Dataset

 ,
,  ,
,  ,
,  and
and 
Abstract
1. Introduction
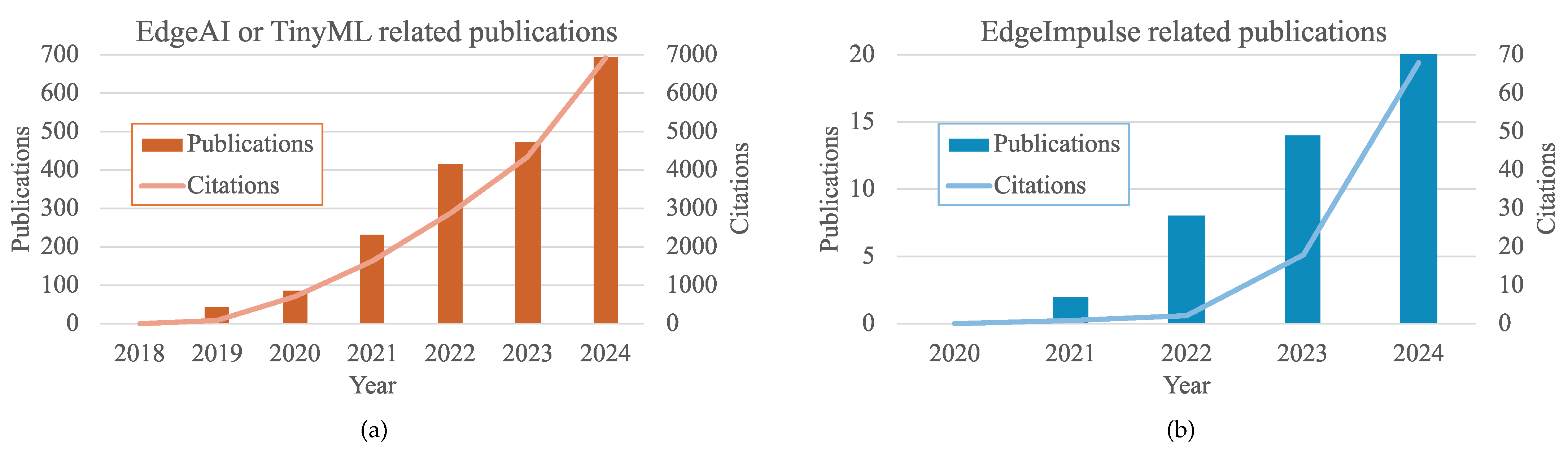
1.1. Edge AI
1.2. Multi-Attribute Decision Making (MADM)
1.3. MADM and Edge AI: Closest Related Works
1.4. Structure of This Work
- First, an introduction to Edge AI, PdM, and MADM is presented.
- Then, the study workflow is described. Each agent of the workflow is detailed, including the no-code Edge AI frameworks evaluated, the weight selection with the AHP method, the TOPSIS technique, the dataset used in the tests, and the custom solution previously developed for this dataset.
- The results of our study are presented next. This includes the performance metrics of the tests, the weights assigned by the experts with AHP, and the results of the TOPSIS comparisons.
- These results are then analyzed in Section 4.
- Finally, we present a conclusion where we point out the limitations of this study, some future improvements, and our prediction for the future of no-code Edge AI frameworks.
1.5. Contributions of This Work
- An overview of the state of the art in the currently available no-code Edge AI frameworks and what each one offers.
- A proposal on how to apply AHP-TOPSIS to compare these frameworks.
- An insight into the opinions of both academia and industry experts regarding no-code Edge AI frameworks, which was also used in the AHP-TOPSIS method.
- The performance results with two already validated tests, and how each frameworks compare with each other in these PdM scenarios.
- A comparison between these results and a custom solution.
- A discussion about the future of no-code Edge AI frameworks.
2. Materials and Methods
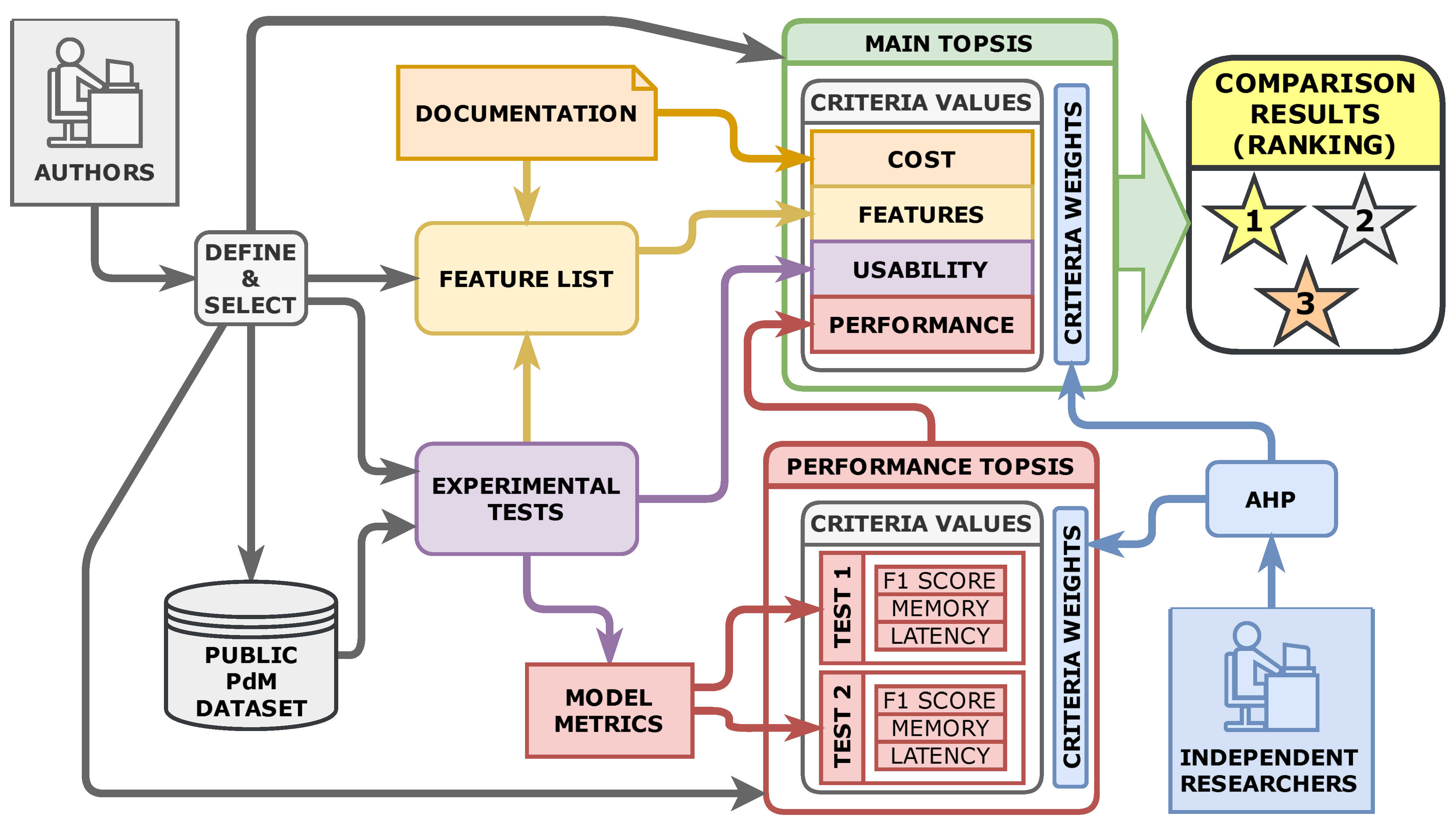
2.1. Workflow
2.2. No-Code Edge AI Frameworks
2.3. Multi-Sensor Public Dataset for PdM
2.4. Custom Solution Based on Tensorflow/Keras
- First, a public dataset was created in CSV format using a commercial sensing device.
- Then, a machine learning network that includes a recurring neural network (RNN) with one or two layers was defined.
- After that, several combinations of RNN for each sensor, with different sampling rates, were trained locally using a GPU.
- Subsequently, the different results were analyzed to choose the best network for their application.
- Finally, by using external tools from the vendor ST (ST-CUBE-AI), the selected network was deployed on a microcontroller. This was only tested on ST boards (ARM architecture).
- For the LIS2MSL magnetometer dataset at 100 Hz (Test 1 in our work), the best result metrics are as follows.
- −
- Model reference in the article: M4.
- −
- F1 weighted average (with holdout data): 1.00.
- −
- Memory: 21,624 bytes.
- −
- Latency (in ARM Cortex M4 80 Mhz): 3.85 ms.
- For the LSM6DSOX accelerometer at 6667 Hz (Test 2 in our work), the best result metrics are as follows.
- −
- Model reference in the article: A5.
- −
- F1 weighted average (with holdout data): 1.00.
- −
- Memory: 20,480 bytes.
- −
- Latency (in ARM Cortex M4 80 Mhz): 164.05 ms.
2.5. Proposed Experimental Test
- Creating a new classification project for three classes. If the target needs to be selected in this step, we will try to select a generic ARM Cortex M4 processor running at 80 MHz, or similar. By doing so, we can fairly compare the metrics with the custom solution developed previously.
- Dataset loading (magnetometer data for test 1, or accelerometer data for test 2). The preprocessing of the data is performed previously previously only if required, trying to use the tools included with the framework if any.
- Model configuration. We will accept all suggestions made from the tool, if any.
- Training models using all samples but the ones marked as recommended for holdout in the dataset. We will also accept all suggestions the tool makes for the selection of training parameters.
- Validation of the models with holdout data, if possible.
- Best model selection based on results with holdout data. Memory usage and inference time, when available, will also be considered.
- Generating code for deployment. This will be performed for a generic ARM Cortex M4 architecture when possible.
2.6. Feature List
2.7. TOPSIS Analysis
2.7.1. Selecting Criteria
2.7.2. Selecting Weights with AHP
- AHP for the main TOPSIS:
- −
- Goal: Determine the most suitable no-code Edge AI framework among all alternatives in a PdM scenario for the biomedical field.
- −
- Alternatives: All frameworks from Table 1.
- −
- Criteria: Cost, number of features (the feature list is provided), usability, and performance. It is explained that performance is a value obtained from the sub-criteria in the performance TOPSIS.
- AHP for the performance TOPSIS:
- −
- Goal: Determine the best-performing no-code edge AI framework when tested with two datasets coming from the same PdM scenario in terms of accuracy, memory size, and latency.
- −
- Alternatives: All frameworks from Table 1.
- −
- Criteria: Test 1 F1 score, Test 1 Memory, Test 1 Latency, Test 2 F1 score, Test 2 Memory, and Test 2 Latency. Each researcher is provided with information about what each criterion represents and the nature of Tests 1 and 2.
- First, we structured the decision hierarchy. In this case, we decided to assign weights using AHP to the main TOPSIS and the performance TOPSIS, as previously stated. This hierarchy is also described in Section 2.1. Therefore, two different AHP matrices were obtained for each researcher. The following steps must be repeated for each TOPSIS.
- For each k researcher participant, we constructed a pairwise comparison matrix . Given n attributes, we organized the pairwise comparison of all attributes with each other in a square matrix, where represents how attribute i is prioritized relative to attribute j on a scale of 1 to 9. These values were obtained from independent researchers during the interview process.Note that when (comparison of the importance of a criterion with itself). Also, .
- We computed the principal eigenvector (weights) for each :where is the largest eigenvalue of .
- The weights were normalized to achieve
- We searched for inconsistencies in the answers of the researchers. If the consistency ratio was greater than 10%, then we prompted the interviewee to review their answers. To verify consistency,where is the Consistency Index and is the Random Index, which are predefined for a matrix of size n. For example, for , . For , .
- We obtained the desired consolidated matrix C which is a combination of several decision matrices . We obtained three different C matricies for each AHP: using all participants , using only participants from the academic world , and using only participants from the industry . Since we used AHP for the weights of the performance TOPSIS and also for the weights of the main TOPSIS, this results in six different C matrices in total. Each C is obtained by using a geometric mean of elements of the selected :The C matrix also follows the same rules as matrices, so when , and .
2.7.3. Criteria Values
2.7.4. Calculation of TOPSIS Results
- Normalize the decision matrix:
- Calculate the weighted normalized decision matrix:
- Determine the positive ideal () and negative ideal () solutions:
- Calculate the separation measures:
- Finally, calculate the relative closeness to the ideal solution:
3. Results
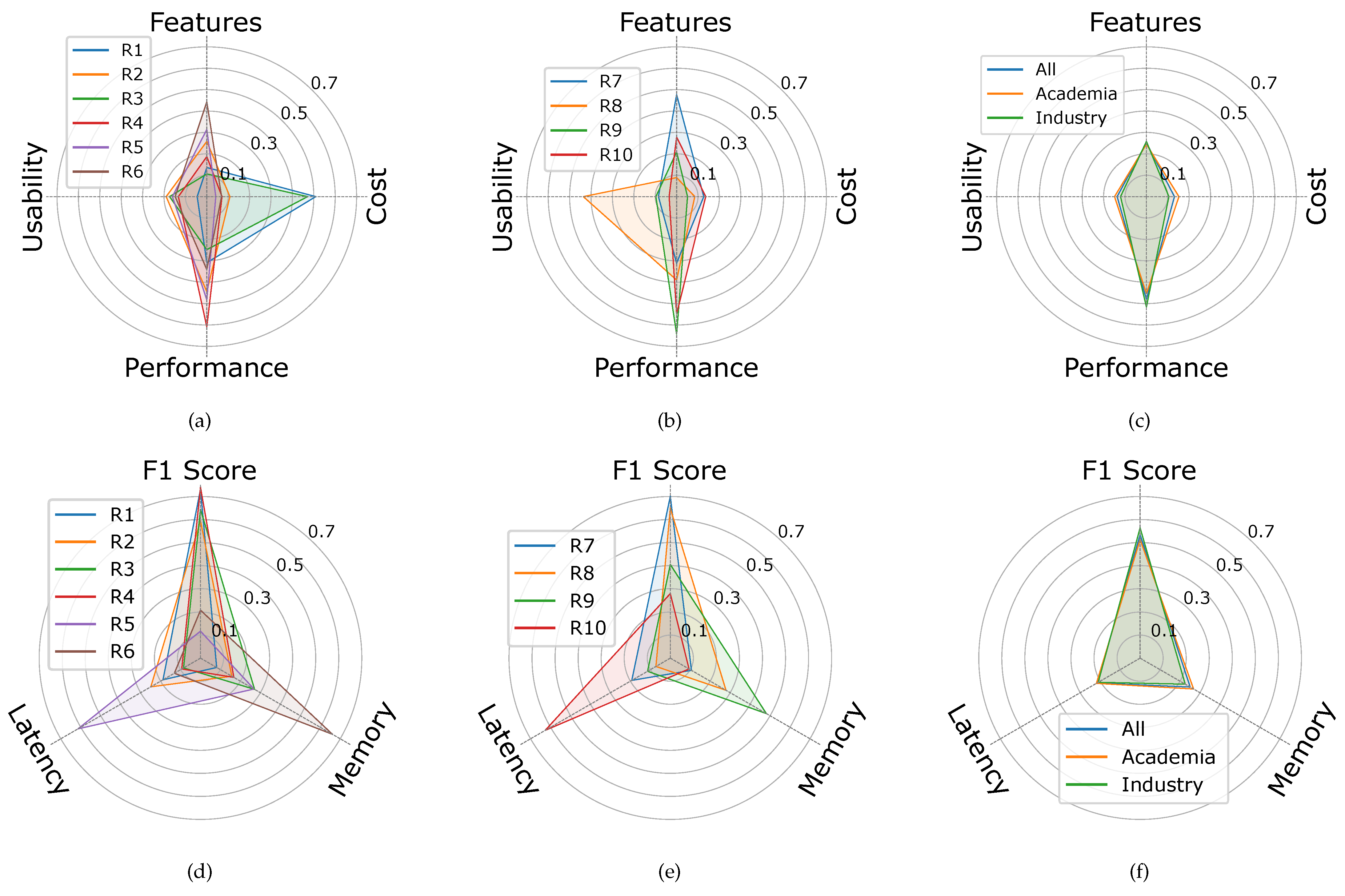
3.1. AHP Results (Assigned Weights)
3.2. Usability
- The DEEPCRAFT Studio requires an installation on a Windows PC. It has little flexibility when importing data since it requires a very specific format and does not include tools for this preparation. Some AI training knowledge is required to select the training settings. The latency estimation is given in cycles instead of in seconds. The paid version does not offer improvements to any of these limitations. The usability score was 4 for both the free and paid versions.
- Edge Impulse offered the best user experience, and the process could be completed even without reading the documentation. Therefore, the usability score was 9 (maximum) for both the free and paid versions.
- NanoEdgeAIStudio requires an installation on Windows or Linux. It runs locally and only has CPU training support, which could mean slower training time in some systems. Data formatting tools are included, but it is not clear how to use them to obtain the desired input format. The usability score was 6.
- The Neuton.AI data loading process was difficult, as it required a specific format and did not include data formatting tools to perform it. The training time for Test 2 was very long (more than 18 h). The metrics do not include latency estimations. The usability score was 5.
- SensEI AutoML asks for credit card information even for the trial version. It requires a desktop tool (available for Mac and Windows) and a compatible browser (only Chrome or Edge). External data import is difficult, since it only supports integer data, and the conversion from real numbers to integer numbers of the readings must be performed with external tools. Initially, the data import proceeded without any warnings. However, due to an incorrectly formatted timestamp, the build phase failed, failing to identify the specific issue, which we discovered through our own investigation. The training is easy to set up, and the tool provides automatic suggestions for all settings. We experienced some graphical bugs after training in the tables of results. Finally, latency estimations, although possible to obtain according to the documentation, seem to require specific physical hardware. Therefore, it is not an estimation, but a real test, and we think this is a limitation. For these reasons, the usability score was low: 2 for the Pro version and 3 for the Enterprise version (slightly higher since it is stated to include local training that should improve the experience in some cases).
- The SensiML workflow was perplexing because it suggests installing a required desktop application for successful data loading, yet the remaining steps must be completed online. We think this was not clearly stated in the documentation. Using the documentation as a guide and working with the website, we were able to conduct the tests smoothly. However, having only 1 h of training per month restricts its practicality for more than one or two test runs. The usability score was 4 for the free version and 5 for the Proto version (slightly higher since it is stated to include more training time).
3.3. Experimental Test Results and Performance TOPSIS
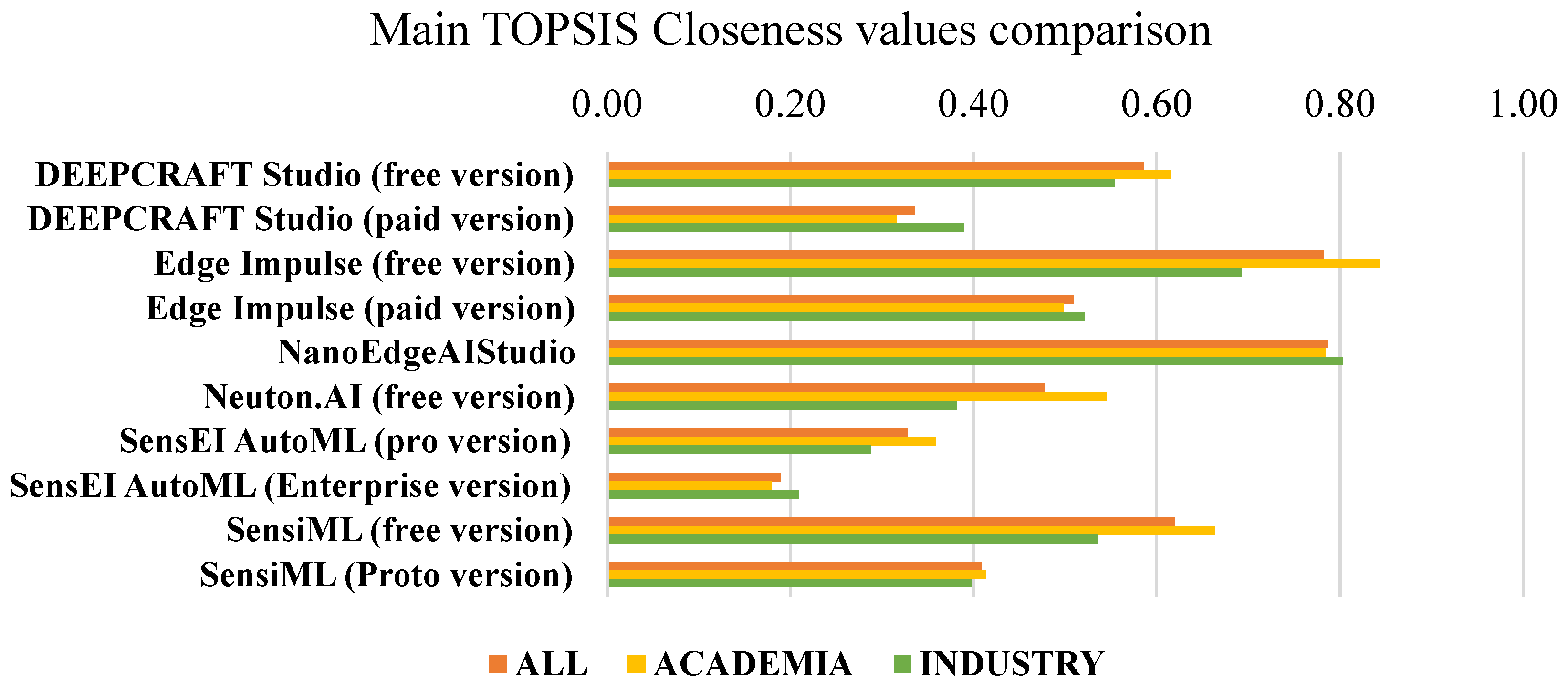
3.4. Main TOPSIS Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AHP | Analytic Hierarchy Process |
| CPU | Central Processing Unit |
| CSV | Comma-separated Values |
| EC | Edge Computing |
| Edge AI | Edge Artificial Intelligence |
| GPU | Graphics Processing Unit |
| GUI | Graphical User Interface |
| LLM | Large Language Model |
| MADM | Multi-attribute Decision Making |
| MCU | Microcontroller Unit |
| ML | Machine Learning |
| PdM | Predictive Maintenance |
| RNN | Recurrent Neural Network |
| TinyML | Tiny Machine Learning |
| TOPSIS | Technique for Order Performance by Similarity to the Ideal Solution |
References
- Rammer, C.; Fernández, G.P.; Czarnitzki, D. Artificial intelligence and industrial innovation: Evidence from German firm-level data. Res. Policy 2022, 51, 104555. [Google Scholar] [CrossRef]
- Jiang, P.; Sonne, C.; Li, W.; You, F.; You, S. Preventing the Immense Increase in the Life-Cycle Energy and Carbon Footprints of LLM-Powered Intelligent Chatbots. Engineering 2024, 40, 202–210. [Google Scholar] [CrossRef]
- Saso, K.; Hara-Azumi, Y. Revisiting Simple and Energy Efficient Embedded Processor Designs Toward the Edge Computing. IEEE Embed. Syst. Lett. 2020, 12, 45–49. [Google Scholar] [CrossRef]
- Nain, G.; Pattanaik, K.K.; Sharma, G.K. Towards Edge Computing in intelligent manufacturing: Past, present and future. J. Manuf. Syst. 2022, 62, 588–611. [Google Scholar] [CrossRef]
- Ghosh, A.M.; Grolinger, K. Edge-Cloud Computing for Internet of Things Data Analytics: Embedding Intelligence in the Edge With Deep Learning. IEEE Trans. Ind. Inform. 2021, 17, 2191–2200. [Google Scholar] [CrossRef]
- Google LLC. LiteRT for Microcontrollers. 2024. Available online: https://ai.google.dev/edge/litert/microcontrollers/overview (accessed on 16 May 2025).
- Scaife, A.D. Improve Predictive Maintenance through the application of artificial intelligence: A systematic review. Results Eng. 2024, 21, 101645. [Google Scholar] [CrossRef]
- Guthardt, T.; Kosiol, J.; Hohlfeld, O. Low-code vs. the developer: An empirical study on the developer experience and efficiency of a no-code platform. In Proceedings of the ACM/IEEE 27th International Conference on Model Driven Engineering Languages and Systems, Linz, Austria, 22–27 September 2024; pp. 856–865. [Google Scholar]
- Edge AI Foundation. Edge AI Foundation Webpage. 2025. Available online: https://www.edgeaifoundation.org/ (accessed on 16 May 2025).
- Silva, J.X.; Lopes, M.; Avelino, G.; Santos, P. Low-code and No-code Technologies Adoption: A Gray Literature Review. In Proceedings of the XIX Brazilian Symposium on Information Systems, Maceió, Brazil, 29 May–1 June 2023; SBSI ’23. pp. 388–395. [Google Scholar] [CrossRef]
- Monteiro, M.; Branco, B.C.; Silvestre, S.; Avelino, G.; Valente, M.T. NoCodeGPT: A No-Code Interface for Building Web Apps With Language Models. Softw. Pract. Exp. 2025; online version. [Google Scholar] [CrossRef]
- Sundberg, L.; Holmström, J. Teaching tip: Using no-code AI to teach machine learning in higher education. J. Inf. Syst. Educ. 2024, 35, 56–66. [Google Scholar] [CrossRef]
- Chow, M.; Ng, O. From technology adopters to creators: Leveraging AI-assisted vibe coding to transform clinical teaching and learning. Med. Teach. 2025, 1–3. [Google Scholar] [CrossRef] [PubMed]
- Edge Impulse. Edge Impulse—The Leading Platform for Embedded Machine Learning. 2025. Available online: https://edgeimpulse.com/ (accessed on 16 May 2025).
- Okoronkwo, C.; Ikerionwu, C.; Ramsurrun, V.; Seeam, A.; Esomonu, N.; Obodoagwu, V. Optimization of Waste Management Disposal Using Edge Impulse Studio on Tiny-Machine Learning (Tiny-ML). In Proceedings of the 2024 IEEE 5th International Conference on Electro-Computing Technologies for Humanity (NIGERCON), Ado Ekiti, Nigeria, 26–28 November 2024; pp. 1–5. [Google Scholar]
- Diab, M.S.; Rodriguez-Villegas, E. Performance evaluation of embedded image classification models using edge impulse for application on medical images. In Proceedings of the 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Glasgow, UK, 11–15 July 2022; pp. 2639–2642. [Google Scholar]
- Hwang, C.L.; Yoon, K.; Hwang, C.L.; Yoon, K. Methods for multiple attribute decision making. In Multiple Attribute Decision Making: Methods and Applications a State-of-the-Art Survey; Springer: Berlin/Heidelberg, Germany, 1981; pp. 58–191. [Google Scholar] [CrossRef]
- Zaidan, A.; Zaidan, B.; Hussain, M.; Haiqi, A.; Kiah, M.M.; Abdulnabi, M. Multi-criteria analysis for OS-EMR software selection problem: A comparative study. Decis. Support Syst. 2015, 78, 15–27. [Google Scholar] [CrossRef]
- Karim, R.; Karmaker, C.L. Machine selection by AHP and TOPSIS methods. Am. J. Ind. Eng. 2016, 4, 7–13. [Google Scholar]
- Sahoo, S.K.; Goswami, S.S. A comprehensive review of multiple criteria decision-making (MCDM) Methods: Advancements, applications, and future directions. Decis. Mak. Adv. 2023, 1, 25–48. [Google Scholar] [CrossRef]
- Sotoudeh-Anvari, A. The applications of MCDM methods in COVID-19 pandemic: A state of the art review. Appl. Soft Comput. 2022, 126, 109238. [Google Scholar] [CrossRef] [PubMed]
- Qin, Y.; Qi, Q.; Shi, P.; Lou, S.; Scott, P.J.; Jiang, X. Multi-attribute decision-making methods in additive manufacturing: The state of the art. Processes 2023, 11, 497. [Google Scholar] [CrossRef]
- Canpolat Şahin, M.; Kolukısa Tarhan, A. Evaluation and Selection of Hardware and AI Models for Edge Applications: A Method and A Case Study on UAVs. Appl. Sci. 2025, 15, 1026. [Google Scholar] [CrossRef]
- Aljohani, A. AI-Driven decision-making for personalized elderly care: A fuzzy MCDM-based framework for enhancing treatment recommendations. BMC Med. Inform. Decis. Mak. 2025, 25, 119. [Google Scholar] [CrossRef] [PubMed]
- Imagimob. Imagimob’s DEEPCRAFT™ Studio. 2025. Available online: https://www.imagimob.com/deepcraft/ (accessed on 16 May 2025).
- STMicroelectronics. NanoEdge AI Studio—Development Tool. 2025. Available online: https://www.st.com/en/development-tools/nanoedgeaistudio.html (accessed on 16 May 2025).
- Neuton AI. Neuton AI—Tiny Machine Learning Platform. 2025. Available online: https://neuton.ai (accessed on 16 May 2025).
- TDK Corporation. TDK Sensei—AutoML for Embedded AI. 2025. Available online: https://sensei.tdk.com/automl (accessed on 16 May 2025).
- SensiML Corporation. SensiML—AI Development Tools for Edge Devices. 2025. Available online: https://sensiml.com/ (accessed on 16 May 2025).
- Montes-Sánchez, J.; Uwate, Y.; Nishio, Y.; Jiménez-Fernández, A.; Vicente-Díaz, S. Peristaltic pump aging detection dataset. idUS (Depósito Investig. Univ. Sevilla) 2024. [Google Scholar] [CrossRef]
- Montes-Sánchez, J.M.; Uwate, Y.; Nishio, Y.; Vicente-Díaz, S.; Jiménez-Fernández, Á. Predictive Maintenance Edge Artificial Intelligence Application Study Using Recurrent Neural Networks for Early Aging Detection in Peristaltic Pumps. IEEE Trans. Reliab. 2024; early access. 1–15. [Google Scholar] [CrossRef]
- Goepel, K.D. Implementing the analytic hierarchy process as a standard method for multi-criteria decision making in corporate enterprises—A new AHP excel template with multiple inputs. In Proceedings of the International Symposium on the Analytic Hierarchy Process, Kuala Lumpur, Malaysia, 19–23 June 2013; Creative Decisions Foundation: Kuala Lumpur, Malaysia, 2013; Volume 2, pp. 1–10. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Name | Company | Platform | Cost of Paid Version | Limitations of Free Version |
|---|---|---|---|---|---|
| [25] | DEEPCRAFT Studio (Imagimob) | Infineon | Local (Windows) with cloud training. | Quotation needed. | Limited training time to 3000 min/month. Limited license. |
| [14] | Edge Impulse | Qualcomm | Cloud | Quotation needed for Enterprise version. | Limited number of private projects. Limited compute resources. |
| [26] | NanoEdgeAIStudio | ST | Local (Windows, Linux) | Free | Commercial license included but only for STM32 microcontrollers. |
| [27] | Neuton.AI | Neuton.AI | Cloud | Free, but uses Google Cloud Platform which needs credits. | 100 h of training included. |
| [28] | SensEI AutoML | TDK | Cloud | USD 100/month | No free version but offers a 30-day trial. |
| [29] | SensiML | QuickLogic | Cloud | From USD 291 monthly | Limited cloud storage and training time. Only public datasets. Only demo outputs. |
| Price per Month ($) | Total Features | Data Handling | Network Training | Validation | Deployment | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Data Logger Included | CSV Data Support | Audio Data Support | Data Formatting Tools Included | Data Previewer and Analyzer | Allows Multiple Files for Each Class | Data Augmentation for All Data | Feature Extraction | Multi-Sensor Data Support | N-Class Classification Support | Custom Network Architecture Support | Unlimited Training Time | Cloud Training | Local Training | GPU Training | Suggests and Trains Network Variations | Holdout Validation Support | Memory Consumption Estimation | Inference Time Estimation | Generates Generic Code | Advanced Microcontroller Skills Not Required | Allows Commercial Use | |||
| DEEPCRAFT Studio (free version) | 0 | 15 | Y | Y | Y | N | Y | Y | N | Y | Y | Y | Y | N | Y | N | N | Y | Y | Y | Y | Y | N | N |
| DEEPCRAFT Studio (paid version) | (1) | 17 | Y | Y | Y | N | Y | Y | N | Y | Y | Y | Y | Y | Y | N | N | Y | Y | Y | Y | Y | N | Y |
| Edge Impulse (free version) | 0 | 18 | Y | Y | Y | Y | Y | Y | N | Y | Y | Y | Y | N | Y | N | Y | Y | Y | Y | Y | Y | N | Y |
| Edge Impulse (paid version) | (1) | 19 | Y | Y | Y | Y | Y | Y | N | Y | Y | Y | Y | Y | Y | N | Y | Y | Y | Y | Y | Y | N | Y |
| NanoEdgeAIStudio | 0 | 16 | Y | Y | Y | Y | Y | Y | N | N | Y | Y | N | Y | N | Y | N | Y | Y | Y | Y | Y | N | Y |
| Neuton.AI | 14 | N | Y | N | N | Y | Y | Y | Y | Y | Y | N | N | Y | N | Y | Y | Y | Y | N | Y | N | Y | |
| SensEI AutoML (pro version) | 100 | 16 | Y | Y | Y | N | Y | Y | N | Y | Y | Y | Y | Y | Y | N | Y | N | Y | Y | Y | Y | N | |
| SensEI AutoML (Enterprise version) | (1) | 19 | Y | Y | Y | N | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | N | Y | Y | Y | Y | Y | |
| SensiML (free version) | 0 | 17 | Y | Y | Y | Y | Y | Y | N | Y | Y | Y | Y | N | Y | N | Y | Y | Y | Y | Y | Y | N | N |
| SensiML (Proto version) | 291 | 19 | Y | Y | Y | Y | Y | Y | N | Y | Y | Y | Y | Y | Y | N | Y | Y | Y | Y | Y | Y | N | Y |
| Researcher ID | Sector | Academic Degree | Main Field of Application |
|---|---|---|---|
| R1 | Academia | PhD Computer Science | Medical and neuromorphic |
| R2 | Academia | PhD Computer Science | Medical |
| R3 | Academia | PhD Computer Science | Neuromorphic |
| R4 | Academia | PhD Computer Science | Wearables |
| R5 | Academia | PhD Computer Science | Wearables, IoT |
| R6 | Academia | PhD Computer Science | Medical |
| R7 | Industry | Msc Computer Science | Biomedical devices |
| R8 | Industry | Msc Computer Science | Biomedical devices |
| R9 | Industry | Msc Computer Science | Aeronautics |
| R10 | Industry | Bachelor Degree Computer Science | Elevators |
| Criteria | Unit | Value Source | Consolidated Weight | |||
|---|---|---|---|---|---|---|
| Main TOPSIS | Cost | USD/month | Documentation | 0.131 | 0.152 | 0.105 |
| Features | Integer | Feature list | 0.252 | 0.245 | 0.258 | |
| Usability | 1 to 9 scale | Mean of authors opinions | 0.137 | 0.149 | 0.121 | |
| Performance | Relative closeness | Performance TOPSIS | 0.480 | 0.453 | 0.516 | |
| Performance TOPSIS | Test 1 F1 score | Real number | Metrics from magnetometer experimental test | 0.267 | 0.257 | 0.282 |
| Test 1 Memory | Bytes | 0.126 | 0.134 | 0.113 | ||
| Test 1 Latency | ms | 0.108 | 0.110 | 0.105 | ||
| Test 2 F1 score | Real number | Metrics from accelerometer experimental test | 0.267 | 0.257 | 0.282 | |
| Test 2 Memory | Bytes | 0.126 | 0.134 | 0.113 | ||
| Test 2 Latency | ms | 0.108 | 0.110 | 0.105 | ||
| Weight (All) | Weight (Academia) | Weight (Industry) | DEEPCRAFT Studio | Edge Impulse | NanoEdgeAI Studio | Neuton.AI | SensEI AutoML | SensiML | Custom Solution * | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Test 1 | F1 score | 0.267 | 0.257 | 0.282 | 0.99 | 0.37 | 1.00 | 0.69 | 1.00 | 0.39 | 1.00 |
| Memory (Bytes) | 0.126 | 0.134 | 0.113 | 54,488 | 15,974 | 40,550 | 2500 | 37,417 | 3198 | 21,624 | |
| Latency (ms) | 0.108 | 0.113 | 0.105 | 17.42 | 11 | 6.1 | None | None | 0.09 | 3.85 | |
| Test 2 | F1 score | 0.267 | 0.257 | 0.282 | 0.45 | 0.97 | 0.99 | 0.51 | 0.78 | 0.51 | 1.00 |
| Memory (Bytes) | 0.126 | 0.134 | 0.113 | 12,164 | 17,920 | 17,510 | 2600 | 16,015 | 4140 | 20,480 | |
| Latency (ms) | 0.108 | 0.113 | 0.105 | 183.45 | 623.00 | 2.30 | None | None | 64.20 | 164.05 | |
| Closeness value | Using | 0.55 | 0.57 | 0.67 | 0.44 | 0.42 | 0.57 | ||||
| Using | 0.55 | 0.58 | 0.65 | 0.45 | 0.41 | 0.59 | |||||
| Using | 0.56 | 0.57 | 0.69 | 0.42 | 0.45 | 0.54 | |||||
| Rank position | Using | 4 | 2 | 1 | 5 | 6 | 3 | ||||
| Using | 4 | 3 | 1 | 5 | 6 | 2 | |||||
| Using | 3 | 2 | 1 | 6 | 5 | 4 | |||||
| DEEPCRAFT Studio (Free Version) | DEEPCRAFT Studio (Paid Version) | Edge Impulse (Free Version) | Edge Impulse (Paid Version) | NanoEdgeAIStudio | Neuton.AI | SensEI AutoML (Pro Version) | SensEI AutoML (Enterprise Version) | SensiML (Free Version) | SensiML (Proto Version) | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Cost | 0 | 300 * | 0 | 300 * | 0 | 0 ** | 100 | 300 * | 0 | 291 | |
| Features | 15 | 17 | 18 | 19 | 16 | 14 | 16 | 19 | 17 | 19 | |
| Usability | 4 | 4 | 9 | 9 | 6 | 5 | 2 | 3 | 4 | 5 | |
| Performance | All | 0.55 | 0.55 | 0.57 | 0.57 | 0.67 | 0.44 | 0.42 | 0.42 | 0.57 | 0.57 |
| Academia | 0.55 | 0.55 | 0.58 | 0.58 | 0.65 | 0.45 | 0.41 | 0.41 | 0.59 | 0.59 | |
| Industry | 0.56 | 0.56 | 0.57 | 0.57 | 0.69 | 0.42 | 0.45 | 0.45 | 0.54 | 0.54 | |
| All | 0.59 | 0.34 | 0.78 | 0.51 | 0.79 | 0.48 | 0.33 | 0.19 | 0.62 | 0.41 | |
| Academia | 0.61 | 0.32 | 0.84 | 0.50 | 0.78 | 0.55 | 0.36 | 0.18 | 0.66 | 0.41 | |
| Industry | 0.55 | 0.39 | 0.69 | 0.52 | 0.80 | 0.38 | 0.29 | 0.21 | 0.53 | 0.40 | |
| Rank position | All | 4 | 8 | 2 | 5 | 1 | 6 | 9 | 10 | 3 | 7 |
| Academia | 4 | 9 | 1 | 6 | 2 | 5 | 8 | 10 | 3 | 7 | |
| Industry | 3 | 7 | 2 | 5 | 1 | 8 | 9 | 10 | 4 | 6 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Montes-Sánchez, J.M.; Fernández-Cuevas, P.; Luna-Perejón, F.; Vicente-Diaz, S.; Jiménez-Fernández, Á. No-Code Edge Artificial Intelligence Frameworks Comparison Using a Multi-Sensor Predictive Maintenance Dataset. Big Data Cogn. Comput. 2025, 9, 145. https://doi.org/10.3390/bdcc9060145
Montes-Sánchez JM, Fernández-Cuevas P, Luna-Perejón F, Vicente-Diaz S, Jiménez-Fernández Á. No-Code Edge Artificial Intelligence Frameworks Comparison Using a Multi-Sensor Predictive Maintenance Dataset. Big Data and Cognitive Computing. 2025; 9(6):145. https://doi.org/10.3390/bdcc9060145
Chicago/Turabian StyleMontes-Sánchez, Juan M., Plácido Fernández-Cuevas, Francisco Luna-Perejón, Saturnino Vicente-Diaz, and Ángel Jiménez-Fernández. 2025. "No-Code Edge Artificial Intelligence Frameworks Comparison Using a Multi-Sensor Predictive Maintenance Dataset" Big Data and Cognitive Computing 9, no. 6: 145. https://doi.org/10.3390/bdcc9060145
APA StyleMontes-Sánchez, J. M., Fernández-Cuevas, P., Luna-Perejón, F., Vicente-Diaz, S., & Jiménez-Fernández, Á. (2025). No-Code Edge Artificial Intelligence Frameworks Comparison Using a Multi-Sensor Predictive Maintenance Dataset. Big Data and Cognitive Computing, 9(6), 145. https://doi.org/10.3390/bdcc9060145