
The Development of Small-Scale Language Models for Low-Resource Languages, with a Focus on Kazakh and Direct Preference Optimization



Abstract
1. Introduction
- Create a reliable Kazakh LLM. We train a 1.94B parameter model from scratch, with a tokenizer customized for Kazakh’s agglutinative structure.
- Advance data and methodology for low-resource settings.
- Developing a Kazakh Language Model:
- Data Collection and Preparation: Gather diverse, high-quality Kazakh textual data from reliable sources, ensuring coverage of various topics and writing styles to capture linguistic richness. This includes identifying and filtering out any non-Kazakh content deemed noise.
- Model Architecture and Training: We adopt the LLaMA (Large Language Model Meta AI) architecture due to its efficiency in autoregressive language modeling—specifically, its ability to achieve strong performance with relatively fewer parameters and lower memory requirements per token. These characteristics align well with our computational constraints. We train the model from scratch, adapting key architectural parameters—such as hidden size, number of layers, and attention heads—to better accommodate the morphological richness and syntactic flexibility of the Kazakh language.
- Performance Evaluation: Establish rigorous evaluation metrics (e.g., perplexity, fluency, linguistic accuracy) to systematically assess the model’s performance and guide iterative improvements.
- 2.
- Efficient Language Modeling:
- Instruction-Based Tuning: Curate and construct a high-quality instructional dataset, designed to represent a wide spectrum of tasks—ranging from general inquiries to specialized domain-specific queries—in Kazakh.
- Task-Specific Optimization: Apply state-of-the-art tuning methods, including DPO, to refine the model’s ability to follow task instructions, improve factual correctness, and reduce undesired outputs (e.g., hallucinations).
- Application and Utility: Demonstrate the model’s value in educational, professional, and digital contexts by testing its performance on real-world tasks, such as question answering, summarization, and interactive dialogue.
- 3.
- Advancing Low-Resource Language Modeling: While multilingual models offer partial solutions, their performance on low-resource languages remains suboptimal due to data scarcity, linguistic divergence, and insufficient specialization. To bridge this gap, we propose a holistic framework for building performant, culturally aligned models for low-resource settings, using Kazakh—a Turkic language spoken by over 13 million people but critically under-represented in NLP– as a case study. Our work addresses three systemic challenges: (i) the absence of curated, large-scale corpora and linguistically tailored preprocessing tools, (ii) the inefficiency of scaling multilingual models without targeted monolingual optimization, (iii) the computational and methodological barriers to reproducing alignment pipelines in resource-constrained environments. We introduce a suite of modular resources and a reproducible training methodology designed to empower researchers and practitioners, prioritizing transparency, computational efficiency, and linguistic specificity. By decoupling model performance from reliance on high-resource data and proprietary infrastructure, this framework advances the broader NLP community’s capacity to develop inclusive, equitable language technologies.
1.1. Literature Review
1.2. Limitations of Existing Approaches
- Data Imbalance and Morphological Complexity. Current LLMs (e.g., GPT, transformer-based models) are trained on datasets dominated by high-resource languages (e.g., English, Chinese), limiting their ability to capture Kazakh’s morphological, syntactic, and semantic intricacies. Addressing this requires curated Kazakh corpora and specialized training approaches sensitive to morphological features.
- Limited Crosslingual Generalization. Multilingual models struggle with linguistically distant languages. Pelofske et al. (2024) showed significant translation performance drops for Kazakh without explicit fine-tuning, highlighting the need for language-specific adaptation over generic multilingual approaches [6].
- Inadequate Evaluation Metrics. Conventional metrics (BLEU, METEOR) fail to assess Kazakh’s linguistic subtleties, necessitating linguistically informed evaluation frameworks.
- Insufficient Targeted Fine-Tuning. While Kamshat et al. (2024) demonstrated the value of Kazakh-specific fine-tuning, NLP research lacks models optimized for its unique linguistic and digital context. Enhanced, tailored fine-tuning methods remain underexplored [7].
- Safety–Performance Trade-offs. Adversarial training reduces vulnerabilities but degrades performance. For example, adversarial fine-tuning led to lower MT-Bench scores than smaller models like LLaMA-2-7b-chat [12], underscoring challenges in balancing safety and efficacy [6]. Challenges in Preference-Based Optimization Reinforcement Learning (RL) methods (e.g., PPO) demand significant resources and stable preference data. Direct Preference Optimization (DPO) simplifies alignment via maximum likelihood classification, offering stability and lower computational costs [13]. However, DPO faces sensitivity to distribution shifts and biases. Emerging variants (CPO, IPO, Online DPO) aim to address these issues but require further refinement.
- Persistent Systemic Issues. Models face data quality, bias, and adaptability limitations. Wang and Li (2025) emphasize that these shortcomings heighten misinformation risks in low-resource languages like Kazakh, where fact-checking infrastructure is weak, necessitating transparent, linguistically informed models [2].
1.3. Contributions of LLaMA-Based Kazakh Model
2. Materials and Methods: Building Small-Scale Kazakh LLaMA
2.1. Model Development
2.1.1. Data Collection and Preprocessing
- Kazakh news articles, to capture contemporary language usage and terminology.
- Kazakh literature, including classic and modern works to ensure the model understood literary forms and stylistic diversity.
- Academic dissertations and monographs, to introduce formal language structures and specialized terminology.
- Educational textbooks and Wikipedia dumps: The Kazakh Wikipedia dump (as of August 2024) was included to cover a broad range of topics and enhance the model’s general knowledge base [15].
- Mixed Kazakh–Russian texts, incorporated to reflect the real-world language use in Kazakhstan, where Kazakh and Russian are often used.
- Training: 1.37 B tokens, 127,701 unique tokens.
- Validation: 1.35 M tokens, 85,815 unique tokens.
2.1.2. Dataset for Supervised Fine-Tuning (SFT)
2.1.3. ChatTune-DPO: A Dataset for Direct Preference Optimization in Kazakh
2.1.4. A Synthetic Pseudo-DPO Dataset from the Instruction-Based Fine-Tuning
- 1.
- Generating Candidate Responses:
- ○
- For each query, five candidate responses were generated.
- ○
- Sampling parameters were varied, with top-p = 0.9 and temperature ranging from 0.5 to 1.0, with an increment of 0.1.
- 2.
- Selecting the Most Similar Response:
- ○
- Among the five generated candidates, the response most similar to the original dataset answer was selected.
- ○
- Similarity was measured using cosine similarity on embeddings extracted from the RoBERTa-Kaz-Large model (nur-dev/roberta-kaz-large).
- 3.
- Constructing the Pseudo-DPO Dataset:
- ○
- The most similar generated response was labeled as the rejected response.
- ○
- The original dataset answer was assigned as the accepted response.
2.2. Model Architecture
Key Aspects of Model Architecture
- Causal language modeling (CLM): The model was trained using the causal language modeling approach, where it learned to predict the next word in a sequence based on the context provided by the preceding words. This method was particularly well-suited for text generation tasks, enabling the model to produce coherent and contextually relevant Kazakh text [23].
- Parameter reduction and customization: We modified the standard LLaMA architecture to reduce the number of parameters to 1.94 billion. This reduction struck a balance between model complexity and computational feasibility, making it suitable for environments with limited resources. Additionally, we introduced specific customizations to better handle the morphological and syntactic nuances of the Kazakh language, which is highly agglutinative compared to more analytically structured languages like English. These customizations included adjustments in the embedding layers and attention mechanisms to accommodate the rich morphological variations inherent in Kazakh.
- Tokenizer customization: A specialized tokenizer was developed to effectively manage the unique characters and linguistic structures of the Kazakh language. This tokenizer ensured that the tokenization process preserved the linguistic integrity of the input text by correctly handling Kazakh-specific characters and affixes. By accurately segmenting words and morphemes, the tokenizer enhanced the model’s ability to understand and generate grammatically correct and meaningful text.
- ○
- Hidden and Intermediate Sizes: A hidden size of 2048 and an intermediate size of 5504 provided sufficient capacity to represent complex syntactic structures while keeping the model size manageable. This followed LLaMA’s approach of emphasizing dense layers (MLPs) in each transformer block, supporting a richer internal representation of language.
- ○
- Number of Layers and Attention Heads: With 32 transformer layers, each containing 32 total attention heads (8 key-value heads), the model maintained sufficient depth and multi-head parallelization to capture nuanced patterns in Kazakh text. These hyperparameters allowed for the handling of different semantic and syntactic aspects simultaneously during self-attention.
- ○
- Activation and Normalization: The SiLU (Sigmoid Linear Unit) activation function was used, in line with standard LLaMA configurations, along with RMS normalization for numerical stability. RMSNorm stabilizes gradients, which is especially beneficial for smaller or low-resource models.
- ○
- Positional Encoding and Long Context: The max_position_embeddings parameter was set to 8192 to support extended context windows, which was crucial for tasks such as document summarization and long-form question answering. A high rope-theta value ensured that larger contexts could be accommodated without the excessive distortion of positional signals, preserving coherence over longer sequences [24].
- ○
- Attention Dropout: This variable was set to 0.0 to prevent the loss of the vital signal, which was particularly important given the limited volume of high-quality Kazakh data. In larger datasets, a small attention dropout may serve as a regularization mechanism, but in this case, reducing it helped to retain essential features from each training step.
- ○
- Tie Word Embeddings: Weight tying was disabled, ensuring that the input and output embeddings remained separate. This allowed for greater flexibility in handling the subtleties of Kazakh vocabulary during both encoding and decoding.
2.3. Contrastive Loss and Entropy for Robust Preference Optimization
- Contrastive margin—prevented the model from lowering the log-probability of a preferred completion below that assigned by the reference model;
- Entropy/KL regularization—preserved distributional diversity and averted mode collapse [25].
2.3.1. Problem Setup
- 1.
- Contrastive-Like Penalty. To anchor the preferred completion, we addedi.e., the policy pays a cost whenever it pushes below the reference value. λ ≥ 0 tunes the strictness of this margin.
- 2.
- Entropy or KL Regularization. To keep from collapsing or drifting too far, an additional penalty is often placed on the policy’s distribution. The common choices are as follows:
- KL to Reference. Add for each prompt.
- Entropy. Add if exploration needs to be preserved.
where α, γ ≥ 0 and H denotes entropy. In large-scale LMs, the KL term is often preferred because it measures drift directly against the well-behaved reference distribution.
2.3.2. Combined Loss Formulation
- Preserves the relative ordering demanded by DPO;
- Locks the probability of preferred answers above a reference floor;
- Maintains healthy output entropy.
2.4. Training Setup
2.4.1. Data Preparation and Preprocessing for CLM
- Data Cleaning: The removal of HTML tags, normalization of URLs to a generic <link> token, and elimination of noise such as excessive punctuation and formatting artifacts like empty brackets and parentheses.
- Kazakh Text Filtering: Special attention was given to Kazakh texts to ensure richness in Kazakh content. Specific character filters were applied to discard lines that did not meet certain criteria, thereby improving the dataset’s linguistic integrity.
- Normalization: Ensuring consistent formatting and representation of the Kazakh script, addressing issues related to unique characters and diacritics that are essential in Kazakh.
2.4.2. Training Configuration
- Computational Resources: We utilized two NVIDIA A100 GPUs with 80 GB memory each, employing Distributed Data Parallel (DDP) to distribute the training process across the GPUs. This parallelism enhanced computational efficiency and reduced overall training time.
- Training Data: We employed a dataset of over 5.3 million examples covering various domains and text types to ensure comprehensive language learning and generalization capabilities.
- Optimization Algorithm: We implemented a cosine annealing with warm restarts scheduler for optimization, allowing cyclic learning rates. This approach improved convergence rates and helped prevent the model from getting trapped in local minima.
- Warm-up Steps: We incorporated 8000 warm-up steps to gradually increase the learning rate at the beginning of training. This strategy helped to stabilize the training process and improved the initial convergence rate by preventing sudden shocks to the network weights.
- Hyperparameters: The careful tuning of hyperparameters such as batch size, sequence length, and learning rates was conducted to achieve optimal training efficiency and model performance.
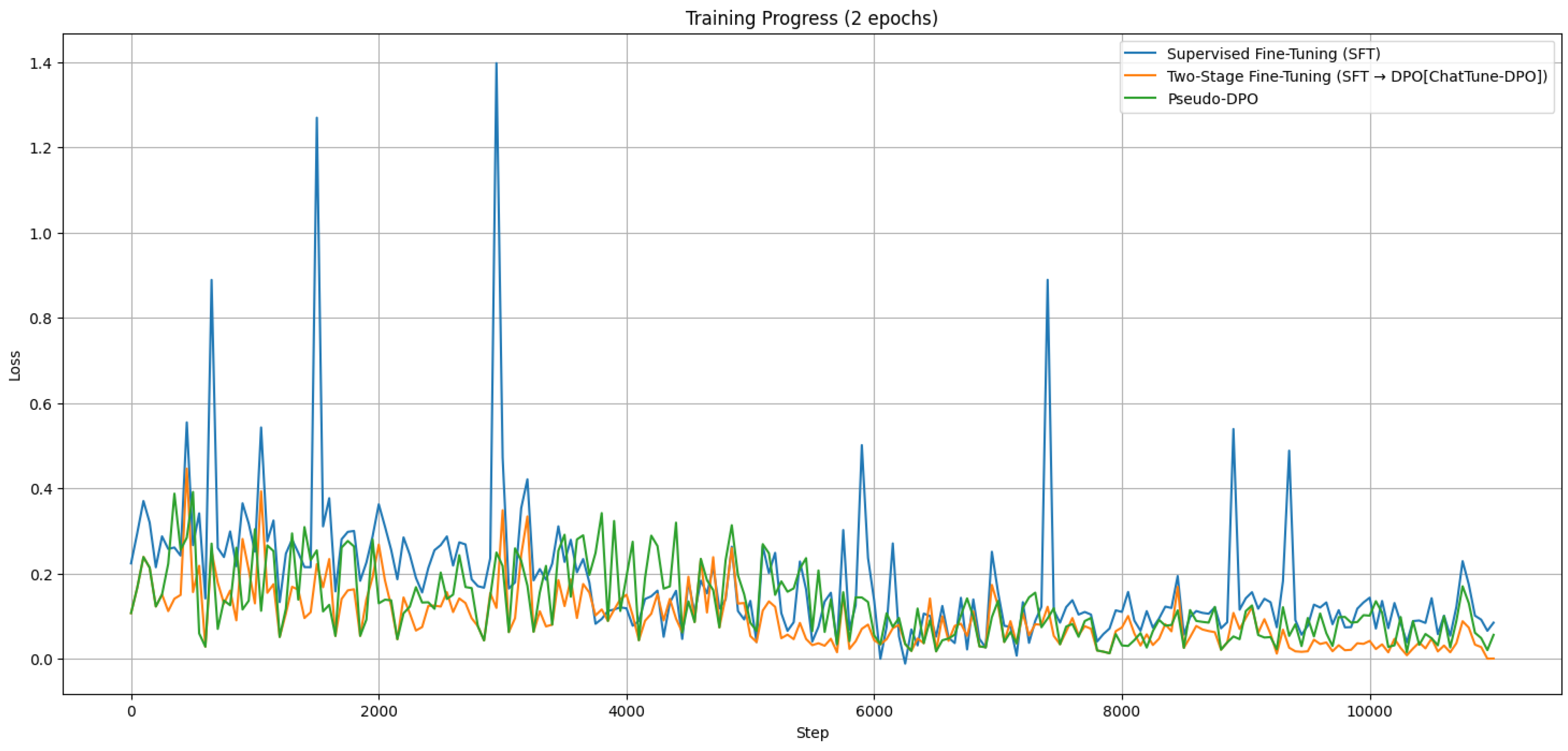
- Unnormalized Loss displayed a high degree of volatility with large fluctuations, making it difficult to assess the model’s learning progress and convergence.
- Normalized loss showed a much smoother and more controlled trajectory. In the validation phase, the normalized loss consistently exhibited less variance and stabilized more quickly, indicating better generalization and a more reliable training process.
2.5. Training Models for Instructional Response Generation
2.5.1. Chat Templates
- <|begin_of_text|><|start_header_id|>system<|end_header_id|>
- This is a system message.<|eot_id|><|start_header_id|>user<|end_header_id|>
- Hello! How are you?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
- I’m fine, thank you. How can I assist you today?<|eot_id|><|end_of_text|>
2.5.2. Evaluation Setup: Task-Specific Assessment
3. Results
- Supervised Fine-Tuning (SFT);
- Two-Stage Fine-Tuning (SFT → DPO [ChatTune-DPO]) over two epochs (each epoch included an SFT phase followed by DPO);
- Pseudo-DPO, with the same step count as SFT.
4. Discussion
4.1. Engineering Challenges and Solutions
- Handling mixed-language data: Mixed-language data in the training corpus, particularly Russian text interspersed in the corpus, posed a significant challenge to maintaining the model’s primary focus on Kazakh while retaining its capacity to process code-switched contexts. To resolve this, we developed a targeted cleaning pipeline to filter non-Kazakh content and applied domain-specific tokenization strategies optimized for Kazakh morphological complexity. These steps balanced strict linguistic specificity with controlled flexibility for mixed-language inputs.
- Optimizing model performance: Optimizing the model’s performance with a relatively small parameter size of 1.94 billion, especially when compared to larger models trained on high-resource languages, posed another challenge. We adopted innovative techniques such as modifying the LLaMA architecture to suit the specific linguistic features of Kazakh, reducing the parameter size to manage computational load, and employing a cosine annealing with restarts scheduler to enhance convergence rates during training.
- Managing hardware constraints: Training a large language model typically requires significant computational resources. With only two NVIDIA A100 GPUs (80 GB each) available, we needed to efficiently manage these resources to prevent bottlenecks and ensure smooth training. To overcome this, we utilized Distributed Data Parallel (DDP) to distribute the computational load across GPUs, maximizing GPU usage and minimizing training time. We also carefully planned the training phases, including 8000 warm-up steps, to stabilize the model’s learning process and avoid issues related to overfitting or hardware limitations.
4.2. Limitations
- Computational scale: Our experiments were limited to two A100-80 GB GPUs; larger context windows or deeper hyperparameter sweeps remain unexplored.
- Domain coverage: The training corpus, while diverse, is still skewed toward news and literary prose; highly technical sub-domains (e.g., legal or medical) are under-represented.
- Evaluation breadth: Automatic metrics target general language proficiency; human judgments of cultural adequacy and bias were only collected for a small pilot subset and are not reported here.
- Synthetic-pair quality: Pseudo-DPO relies on embedding-based similarity; errors in the similarity heuristic could mis-label the “rejected” side, introducing noisy gradients. Improving pair-selection heuristics is left to future work.
- Code-switching generalization: While mixed Kazakh–Russian text was present in the corpus, a systematic evaluation of code-switched text generation and comprehension is pending.
4.3. Scientific Contributions
- Novel insights into training language models for low-resource languages: The study provides valuable insights into the specific challenges and strategies associated with training language models for low-resource languages like Kazakh. The use of a carefully curated dataset that includes diverse text types, combined with innovative data preprocessing and model customization techniques, underscores the importance of tailored approaches for different linguistic contexts.
- The development of new techniques for model fine-tuning: The instruction-based fine-tuning methodology developed for this model represents a novel approach in fine-tuning LLMs for specific tasks. By focusing on instruction-based datasets and utilizing supervised fine-tuning, the model demonstrates significant improvements in generating context-aware and relevant responses. This showcases the effectiveness of these techniques in enhancing model performance for specialized applications.
- Open-Source Dataset Contributions: A distinctive contribution of this study lies in the family of datasets we built and open-sourced, providing a valuable resource for the research community (Table 3).
5. Conclusions
- Focused Monolingual Training: Concentrating on Kazakh-specific morphological and syntactic structures yields more context-aligned outputs than general-purpose multilingual models that dilute low-resource data.
- Preference-Based Fine-Tuning: Integrating DPO—especially when enhanced by contrastive constraints and entropy regularization—addresses common weaknesses in preference ranking, aligns responses with human feedback, and reduces hallucinations.
- Feasibility Under Resource Constraints: Employing a moderate-scale model (1.94B parameters) on limited GPU resources demonstrates that advanced NLP performance is achievable without massive computational budgets.
6. Future Work
6.1. Dataset Expansion and Quality Control
- Richer Domain Coverage: Collect more specialized texts (e.g., legal, medical, technical) to refine domain-aware generation and comprehension.
- Language Diversity: Incorporate code-switching texts (Kazakh–Russian–English) and dialectal data to capture broader real-world usage.
- Continuous Curation: Systematically improve data cleanliness and representation of under-sampled linguistic features for more robust downstream performance.
6.2. Query Decomposition and Multi-Turn Reasoning
- Hierarchical Query Splitting: Investigate pipeline methods that decompose intricate questions into simpler sub-queries, particularly beneficial for educational or domain-specific scenarios.
6.3. Fine-Tuning for Retrieval-Augmented Generation (RAG)
- Dynamic Document Retrieval: Integrate a high-fidelity retrieval module for real-time access to external knowledge bases, improving factual correctness and reducing hallucinations.
- Domain-Specific RAG: Tailor RAG components to specialized fields (e.g., law or healthcare) by combining curated reference documents with the language model’s generative capabilities.
6.4. Deployment and Optimization for Edge Devices
- Parameter and Quantization Strategies: Explore 8-bit or 4-bit quantization to shrink model size while maintaining acceptable performance.
- Hardware-Specific Tuning: Optimize inference pipelines for edge accelerators (e.g., mobile GPUs, FPGAs), ensuring low-latency responses in resource-constrained environments.
- On-Device Caching and Compression: Implement token caching mechanisms and advanced compression to reduce computational overhead and enable real-time inference on lower-powered devices.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kozov, V.; Ivanova, B.; Shoylekova, K.; Andreeva, M. Analyzing the Impact of a Structured LLM Workshop in Different Education Levels. Appl. Sci. 2024, 14, 6280. [Google Scholar] [CrossRef]
- Wang, Q.; Li, H. On Continually Tracing Origins of LLM-Generated Text and Its Application in Detecting Cheating in Student Coursework. Big Data Cogn. Comput. 2025, 9, 50. [Google Scholar] [CrossRef]
- Huang, D.; Yan, C.; Li, Q.; Peng, X. From Large Language Models to Large Multimodal Models: A Literature Review. Appl. Sci. 2024, 14, 5068. [Google Scholar] [CrossRef]
- Kuznetsova, I.; Mukhamejanova, G.; Tuimebayev, Z.; Myrzaliyeva, S.; Aldasheva, K. Axiological Approach as a Factor of University Curriculum Language. XLinguae 2024, 17, 268–279. [Google Scholar] [CrossRef]
- Papageorgiou, E.; Chronis, C.; Varlamis, I.; Himeur, Y. A Survey on the Use of Large Language Models (LLMs) in Fake News. Future Internet 2024, 16, 298. [Google Scholar] [CrossRef]
- Pelofske, E.; Urias, V.; Liebrock, L.M. Automated Multi-Language to English Machine Translation Using Generative Pre-Trained Transformers. arXiv 2024, arXiv:2404.14680. [Google Scholar] [CrossRef]
- Kamshat, A.; Auyeskhan, U.; Zarina, N.; Alen, S. Integration AI Techniques in Low-Resource Language: The Case of Kazakh Language. In Proceedings of the 2024 IEEE AITU: Digital Generation, Astana, Kazakhstan, 3–4 April 2024; IEEE: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Li, Z.; Shi, Y.; Liu, Z.; Yang, F.; Liu, N.; Du, M. Quantifying multilingual performance of large language models across languages. arXiv 2024, arXiv:2404.11553v2. Available online: https://arxiv.org/html/2404.11553v2 (accessed on 25 August 2024).
- Kardeş-NLU: Transfer to Low-Resource Languages with the Help of a High-Resource Cousin—A Benchmark and Evaluation for Turkic Languages. Available online: https://aclanthology.org/2024.eacl-long.100 (accessed on 18 August 2024).
- Ataman, D.; Derin, M.O.; Ivanova, S.; Köksal, A.; Sälevä, J.; Zeyrek, D. Proceedings of the First Workshop on Natural Language Processing for Turkic Languages (SIGTURK 2024); Association for Computational Linguistics: Bangkok, Thailand, 2024. Available online: https://aclanthology.org/2024.sigturk-1 (accessed on 22 September 2024).
- Ding, B.; Qin, C.; Zhao, R.; Luo, T.; Li, X.; Chen, G.; Xia, W.; Hu, J.; Luu, A.T.; Joty, S. Data Augmentation Using Large Language Models: Data Perspectives, Learning Paradigms and Challenges. arXiv 2024, arXiv:2403.02990. [Google Scholar] [CrossRef]
- Jiang, F.; Xu, Z.; Niu, L.; Lin, B.Y.; Poovendran, R. ChatBug: A Common Vulnerability of Aligned LLMs Induced by Chat Templates. arXiv 2024, arXiv:2406.12935. [Google Scholar] [CrossRef]
- Rafailov, R.; Sharma, A.; Mitchell, E.; Ermon, S.; Manning, C.D.; Finn, C. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. arXiv 2023, arXiv:2305.18290. [Google Scholar]
- Farabi-Lab/Kazakh Text for Language Modeling—Normalized Dataset; Hugging Face, 2024. Available online: https://huggingface.co/datasets/farabi-lab/kaz-text-for-lm-normalized (accessed on 13 August 2024).
- Farabi-Lab/Kazakh Wikipedia Dumps Cleaned Dataset; Hugging Face, 2024. Available online: https://huggingface.co/datasets/farabi-lab/wiki_kk (accessed on 14 August 2024).
- Nurgali, K. llama-1.9B-kaz-instruct Hugging Face, 2025. Available online: https://huggingface.co/nur-dev/llama-1.9B-kaz-instruct (accessed on 9 February 2025).
- Farabi Lab/KazNU-Lib-OCR-for-LM Dataset; Hugging Face: 2024. Available online: https://huggingface.co/datasets/farabi-lab/kaznu-lib-ocr-for-lm (accessed on 19 January 2025).
- Lee, A.V.Y.; Teo, C.L.; Tan, S.C. Prompt Engineering for Knowledge Creation: Using Chain-of-Thought to Support Students’ Improvable Ideas. AI 2024, 5, 1446–1461. [Google Scholar] [CrossRef]
- Nurgali, K. ChatTune-DPO Hugging Face, 2025. Available online: https://huggingface.co/datasets/farabi-lab/user-feedback-dpo (accessed on 9 February 2025).
- Nurgali, K. Instruct-KZ-RL Hugging Face, 2025. Available online: https://huggingface.co/datasets/nur-dev/kaz-instruct-rl (accessed on 12 January 2025).
- Luo, J.; Luo, X.; Chen, X.; Xiao, Z.; Ju, W.; Zhang, M. Semi-supervised Fine-tuning for Large Language Models. arXiv 2024, arXiv:2410.14745. [Google Scholar] [CrossRef]
- Maree, M.; Shehada, W. Optimizing Curriculum Vitae Concordance: A Comparative Examination of Classical Machine Learning Algorithms and Large Language Model Architectures. AI 2024, 5, 1377–1390. [Google Scholar] [CrossRef]
- Nurgali, K. llama-1.9B-kaz; Hugging Face, 2025. Available online: https://huggingface.co/nur-dev/llama-1.9B-kaz (accessed on 10 February 2025).
- Su, J.; Lu, Y.; Pan, S.; Murtadha, A.; Wen, B.; Liu, Y. RoFormer: Enhanced Transformer with Rotary Position Embedding. Computation and Language 2021. arXiv 2021, arXiv:2104.09864. [Google Scholar] [CrossRef]
- Feng, D.; Qin, B.; Huang, C.; Zhang, Z.; Lei, W. Towards Analyzing and Understanding the Limitations of DPO: A Theoretical Perspective. arXiv 2024, arXiv:2404.04626. [Google Scholar]
- AI Forever, Kazakh mGPT 1.3B, Hugging Face, 2024. Available online: https://huggingface.co/ai-forever/mGPT-1.3B-kazakh (accessed on 16 February 2025).
- ISSAI, LLama-3.1-KazLLM-1.0-8B, Hugging Face, 2024. Available online: https://huggingface.co/issai/LLama-3.1-KazLLM-1.0-8B (accessed on 16 February 2025).
- Kadyrbek, N. QThink-Task: A Task-Level Benchmark for Evaluating Kazakh Language Models; Hugging Face, 2025. Available online: https://huggingface.co/datasets/nur-dev/QThink-Task (accessed on 30 April 2025).
- Dam, S.K.; Hong, C.S.; Qiao, Y.; Zhang, C. A Complete Survey on LLM-based AI Chatbots. arXiv 2024, arXiv:2406.16937. [Google Scholar] [CrossRef]
- Kadyrbek, N. Raw Text for CLM V1 (Farabi-Lab/Raw-Text-for-Clm-V1); Hugging Face: 2024. Available online: https://huggingface.co/datasets/farabi-lab/raw-text-for-clm-v1 (accessed on 30 April 2025).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LLaMA-1.94B (Base Instruction) | LLaMA-1.94B (Base Instruction + ChatTune-DPO) | LLaMA-1.94B (Pseudo-DPO) | Kazakh mGPT 1.3B | Llama-3.1-8b-Instruct (by ISSAI) | |
|---|---|---|---|---|---|
| Accuracy (%) | 56.5 | 62.7 (61.1 *) | 61.3 (59.9 *) | 36.1 | 58.2 |
| Relevance | 58.1 | 65.1 (65.8 *) | 63.0 (64.95 *) | 39.3 | 60.6 |
| Coherence | 65.3 | 69.6 (66.9 *) | 66.9 (63.1 *) | 50.3 | 67.3 |
| Context-Awareness | 58.1 | 63.2 (61.7 *) | 60.9 (60.8 *) | 35.8 | 59.8 |
| Early Stopping | Functioning Properly | Functioning Properly | Functioning Properly | Issues with Long Contexts and Hallucination | Functioning Properly |
| Task Type | LLaMA-1.94B (SFT) | LLaMA-1.94B (ChatTune-DPO) | LLaMA-1.94B (Pseudo-DPO) | Llama-3.1-8B-instr | Kazakh mGPT 1.3B |
|---|---|---|---|---|---|
| Contextual Explanation | 54.0% | 59.5% | 57.8% | 56.1% | 34.2% |
| Fact Verification | 55.7% | 56.82% | 56.5% | 57.8% | 35.9% |
| Hypothetical Reasoning | 52.9% | 53.1% | 53.2% | 55.4% | 32.6% |
| Summarization | 60.3% | 60.7% | 58.9% | 62.8% | 38.7% |
| Fill-in-the-Blank | 64.4% | 63.8% | 62.7% | 59.2% | 37.1% |
| Paraphrasing | 59.8% | 60.05% | 61.1% | 62.4% | 39.8% |
| Multiple-Choice Question | 57.8% | 56.9% | 57.0% | 58.6% | 36.5% |
| Error Detection | 55.2% | 56.6% | 56.32% | 57.08% | 31.5% |
| Counterfactual Analysis | 51.6% | 55.7% | 53.8% | 55.4% | 29.9% |
| Question Answering | 58.9% | 61.8% | 61.03% | 62.1% | 38.3% |
| Dataset | Size/Format | Purpose |
|---|---|---|
| Kazakh General Corpus [17,30] | 1.37 B tokens, balanced across news, literature, academia | Pre-training and linguistic preservation |
| ChatTune-DPO [19] | 52-user crowdsourced preference pairs | Human-verified alignment |
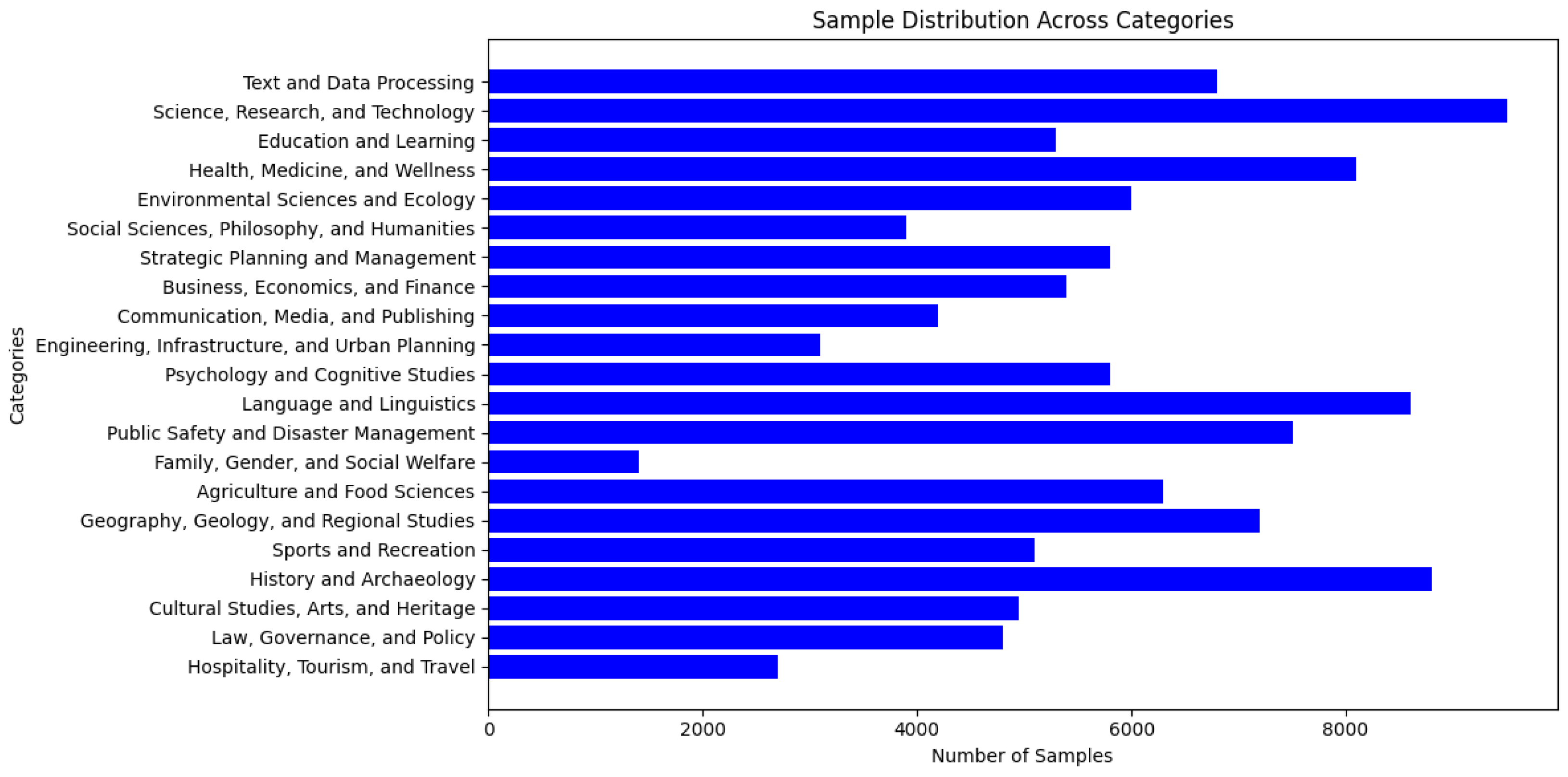
| QThink-Task [28] | Over 500 k samples, including 13 distinct task types, each labeled to enable fine-grained evaluation of reasoning, comprehension, and language understanding abilities | Instruction tuning, evaluation of reasoning and language skills, and advancing Kazakh NLP research |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kadyrbek, N.; Tuimebayev, Z.; Mansurova, M.; Viegas, V. The Development of Small-Scale Language Models for Low-Resource Languages, with a Focus on Kazakh and Direct Preference Optimization. Big Data Cogn. Comput. 2025, 9, 137. https://doi.org/10.3390/bdcc9050137
Kadyrbek N, Tuimebayev Z, Mansurova M, Viegas V. The Development of Small-Scale Language Models for Low-Resource Languages, with a Focus on Kazakh and Direct Preference Optimization. Big Data and Cognitive Computing. 2025; 9(5):137. https://doi.org/10.3390/bdcc9050137
Chicago/Turabian StyleKadyrbek, Nurgali, Zhanseit Tuimebayev, Madina Mansurova, and Vítor Viegas. 2025. "The Development of Small-Scale Language Models for Low-Resource Languages, with a Focus on Kazakh and Direct Preference Optimization" Big Data and Cognitive Computing 9, no. 5: 137. https://doi.org/10.3390/bdcc9050137
APA StyleKadyrbek, N., Tuimebayev, Z., Mansurova, M., & Viegas, V. (2025). The Development of Small-Scale Language Models for Low-Resource Languages, with a Focus on Kazakh and Direct Preference Optimization. Big Data and Cognitive Computing, 9(5), 137. https://doi.org/10.3390/bdcc9050137