
Quantifying Post-Purchase Service Satisfaction: A Topic–Emotion Fusion Approach with Smartphone Data


Abstract
1. Introduction
- We present a comprehensive evaluation framework that integrates product reviews and Q and A data, addressing the limitations of single-indicator and survey-based methods.
- We introduce the ERNIE-LSTM Emotion Model (ELEM), a lightweight extension of the CFEE framework, optimized for real-world user reviews and more effective in detecting and filtering fake content.
- We apply Biterm Topic Modeling (BTM) to filtered reviews to extract latent service dimensions and construct a sentiment-weighted evaluation structure.
- Clustering analysis of Q and A content, combined with word frequency statistics, enables cross-corpus comparisons and reveals hidden service quality issues not captured by conventional approaches.
2. Literature Review
2.1. Text Features and Service Quality
2.2. Text Analytics in Service Evaluation
2.3. Multi-Source Data Convergence in Service Evaluation
2.4. Methodological Limitations and Conceptual Framework
3. Materials and Methods
3.1. Software and Tools
3.2. Data Collection
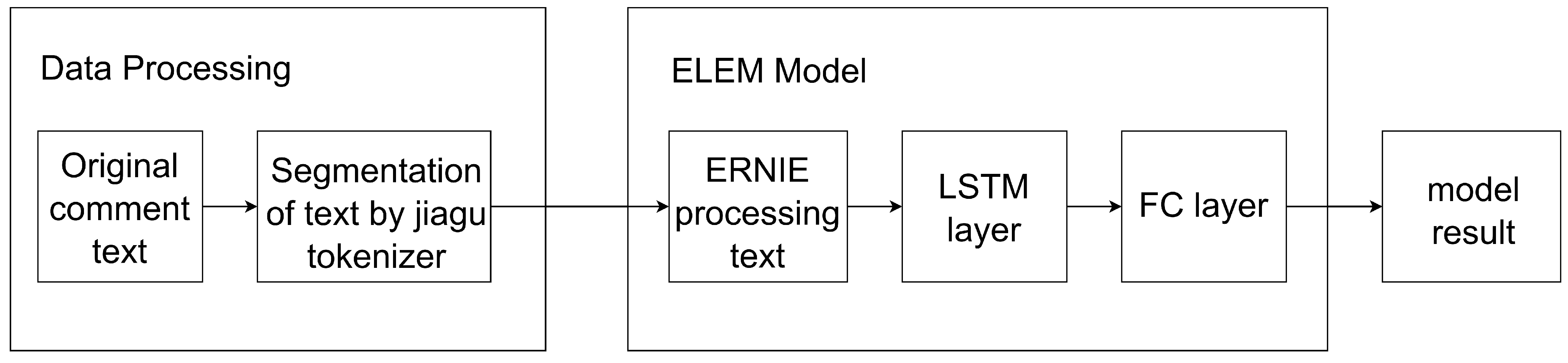
3.2.1. Fake Review Detection Model
- (1)
- Contextual Embedding Layer
- (2)
- Sequential Encoding Layer (LSTM)
- (3)
- Classification Layer
3.2.2. Pre-Processing of Data
3.3. Methods
3.3.1. Establish a Service Evaluation System
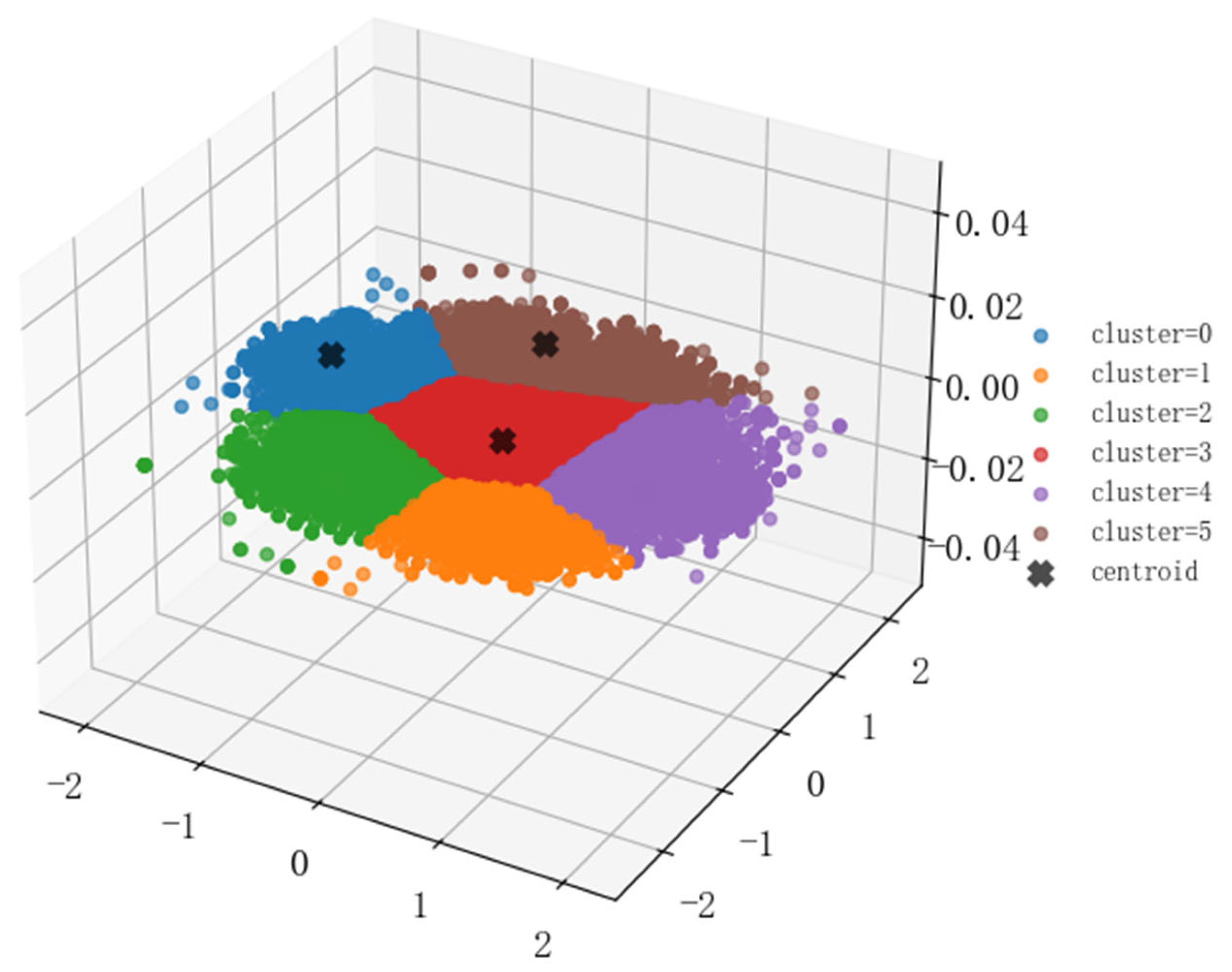
3.3.2. User Concern Profiling and Clustering Validation
3.3.3. The Analysis of the Q and A System
4. Results
4.1. Preliminary Analysis
4.2. Establishment Model
4.2.1. Extract Service Factors
- Imaging Capabilities and Hardware Innovations (8.6%)
- Core Performance and System Optimization (10.0%)
- User-Centric Design and Multifunctional Experience (70.8%)
- Consumer Decision-Making and Promotional Drivers (7.8%)
- Industrial Design and Ecosystem Balance (2.8%)
4.2.2. Model Evaluation Score
4.2.3. Generation and Analysis of User Portrait
4.3. Explore Potential Factors
5. Conclusions and Discussion
- (1)
- User-Centric Design and Multifunctional Experience (70.8%), emphasizing intuitive UI interactions, adaptive interfaces, and diversified usage scenarios;
- (2)
- Core Performance and System Optimization (10.0%), reflecting user priorities in processing speed, thermal stability, and smooth responsiveness;
- (3)
- Imaging Capabilities and Hardware Innovation (8.6%), focusing on camera clarity, night-mode quality, and sensor enhancements;
- (4)
- Promotional Incentives and Decision-Making Factors (7.8%), including price-performance perceptions, promotional effectiveness, and discount transparency;
- (5)
- Industrial Design and Ecosystem Integration (2.8%), incorporating users’ aesthetic preferences as well as issues related to software intrusion (e.g., pre-installed apps, ad overlays).
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ELEM | ERNIE-LSTM-Emotion-Model |
| BTM | Biterm Topic Model |
| LDA | Latent Dirichlet Allocation |
| Q and A | Question and Answer System |
References
- Vakulenko, Y.; Shams, P.; Hellström, D.; Hjort, K. Online Retail Experience and Customer Satisfaction: The Mediating Role of Last Mile Delivery. Int. Rev. Retail. Distrib. Consum. Res. 2019, 29, 306–320. [Google Scholar] [CrossRef]
- Rita, P.; Oliveira, T.; Farisa, A. The Impact of E-Service Quality and Customer Satisfaction on Customer Behavior in Online Shopping. Heliyon 2019, 5, e02690. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Liu, D.; Liu, Y.; Zheng, Y.; Wang, B.; Zhou, Y. Research on User Generated Content in Q&A System and Online Comments Based on Text Mining. Alex. Eng. J. 2022, 61, 7659–7668. [Google Scholar] [CrossRef]
- Bao, J.; Yuan, Q. Research on the Impact of Systematic Clues of E-Commerce Platform on Consumers’ Purchase Intention under the Background of New Retail. China Bus. Mark. 2020, 33, 9. [Google Scholar]
- Li, D.; Yang, J.; Chen, J. Analysis of factors affecting consumer satisfaction of tea e-commerce–Based on the exploration and analysis of online reviews. For. Econ. 2019, 41, 70–77. [Google Scholar]
- Xu, X. Examining the Role of Emotion in Online Consumer Reviews of Various Attributes in the Surprise Box Shopping Model. Decis. Support Syst. 2020, 136, 113344. [Google Scholar] [CrossRef]
- Chen, T.; Samaranayake, P.; Cen, X.; Qi, M.; Lan, Y.-C. The Impact of Online Reviews on Consumers’ Purchasing Decisions: Evidence From an Eye-Tracking Study. Front. Psychol. 2022, 13, 865702. [Google Scholar] [CrossRef]
- Xu, X.; Wang, Y.; Zhu, Q.; Zhuang, Y. Time Matters: Investigating the Asymmetric Reflection of Online Reviews on Customer Satisfaction and Recommendation across Temporal Lenses. Int. J. Inf. Manag. 2024, 75, 102733. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, Y.; Luan, D. What factors influence consumers’ online purchasing decisions?—Customer perceived value drivers. Manag. Rev. 2017, 29, 136–146. [Google Scholar] [CrossRef]
- Lu, X.; Feng, Y. Value of word of mouth–an empirical study based on online restaurant reviews. Manag. World 2009, 26, 126–132+171. [Google Scholar] [CrossRef]
- Zheng, X. An Empirical Study of the Impact of Online Reviews on Online Consumers’ Purchasing Decisions. Unpublished. Master’s Thesis, Renmin University of China, Beijing, China, 2008. [Google Scholar]
- Zhou, X.; Wang, W.; Cai, H. Research on the perception of mountain tourism image based on text mining–Taking Yuntai Mountain scenic area as an example. J. Northwest Norm. Univ. Nat. Sci. 2023, 59, 37–43. [Google Scholar] [CrossRef]
- Liu, X.-X.; Chen, Z.-Y. Service Quality Evaluation and Service Improvement Using Online Reviews: A Framework Combining Deep Learning with a Hierarchical Service Quality Model. Electron. Commer. Res. Appl. 2022, 54, 101174. [Google Scholar] [CrossRef]
- Wang, Y.; Li, H.; Wu, Z. Attitude of the Chinese Public toward Off-Site Construction: A Text Mining Study. J. Clean. Prod. 2019, 238, 117926. [Google Scholar] [CrossRef]
- Sun, J.; Wang, G.; Cheng, X.; Fu, Y. Mining Affective Text to Improve Social Media Item Recommendation. Inf. Process. Manag. 2015, 51, 444–457. [Google Scholar] [CrossRef]
- Sun, B.-S.; Ao, C.-L.; Wang, J.-X.; Zhao, M.-Y. Evaluation of Ecotourism Satisfaction Based on Online Text Mining. Oper. Res. Manag. Sci. 2023, 31, 165. [Google Scholar]
- Cao, Y. Research on the Influencing Factors and Service Evaluation of Consumers’ Online Shopping Clothing Based on Online Reviews–Taking Pathfinder Enterprise as an Example. Unpublished. Master’s Thesis, Liaoning Technical University, Fuxin, China, 2022. [Google Scholar]
- Darko, A.P.; Liang, D. Modeling Customer Satisfaction through Online Reviews: A FlowSort Group Decision Model under Probabilistic Linguistic Settings. Expert Syst. Appl. 2022, 195, 116649. [Google Scholar] [CrossRef]
- Kumar, A.; Chakraborty, S.; Bala, P.K. Text Mining Approach to Explore Determinants of Grocery Mobile App Satisfaction Using Online Customer Reviews. J. Retail. Consum. Serv. 2023, 73, 103363. [Google Scholar] [CrossRef]
- Zhao, X.; Huang, Z. A Method for Exploring Consumer Satisfaction Factors Using Online Reviews: A Study on Anti-Cold Drugs. J. Retail. Consum. Serv. 2024, 81, 103895. [Google Scholar] [CrossRef]
- Park, J. Combined Text-Mining/DEA Method for Measuring Level of Customer Satisfaction from Online Reviews. Expert Syst. Appl. 2023, 232, 120767. [Google Scholar] [CrossRef]
- Li, J.; Dong, W.; Ren, J. The Effects of User- and Marketer-Generated Content on Customer Satisfaction: A Textual Analysis Approach. Electron. Commer. Res. Appl. 2024, 65, 101407. [Google Scholar] [CrossRef]
- Aldunate, Á.; Maldonado, S.; Vairetti, C.; Armelini, G. Understanding Customer Satisfaction via Deep Learning and Natural Language Processing. Expert Syst. Appl. 2022, 209, 118309. [Google Scholar] [CrossRef]
- Park, J.Y.; Mistur, E.; Kim, D.; Mo, Y.; Hoefer, R. Toward Human-Centric Urban Infrastructure: Text Mining for Social Media Data to Identify the Public Perception of COVID-19 Policy in Transportation Hubs. Sustain. Cities Soc. 2022, 76, 103524. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Jiang, F.; Yao, H.; Huang, M.; Ma, Q. An Analysis and Risk Forecasting of Inland Ship Collision Based on Text Mining. J. Transp. Inf. Saf. 2018, 36, 8–18. [Google Scholar]
- Xu, X. What Are Customers Commenting on, and How Is Their Satisfaction Affected? Examining Online Reviews in the on-Demand Food Service Context. Decis. Support Syst. 2021, 142, 113467. [Google Scholar] [CrossRef]
- Shi, Y. Enhanced Customer Requirement Classification for Product Design Using Big Data and Improved Kano Model. Adv. Eng. Inform. 2021, 49, 101340. [Google Scholar] [CrossRef]
- Gu, Y.; Zheng, K.; Hu, Y.; Song, Y.; Liu, D. Support for Cross-Domain Methods of Identifying Fake Comments of Chinese. Data Anal. Knowl. Discov. 2024, 8, 84–98. [Google Scholar]
- Deng, X.; Li, J.-M.; Zeng, H.-J.; Chen, J.-Y.; Zhao, J.-F. Research on Computation Methods of AHP Wight Vector and Its Applications. Math. Pract. Theory 2012, 42, 93–100. [Google Scholar]
- Fei, P.; Lin, H.; Yang, L.; Xu, B.; Gulizige, A. A Multi-Perspective Fusion Framework for Constructing User Portraits. Comput. Sci. 2018, 45, 179–182. [Google Scholar]
- Yan, X.; Guo, J.; Lan, Y.; Cheng, X. A Biterm Topic Model for Short Texts. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 1445–1456. [Google Scholar]
- Wang, Y.; Hu, Y. Hotspot detection in microblog public opinion based on BTM. J. Intell. 2016, 35, 119–124+140. [Google Scholar]
- Liu, B. Sentiment Analysis: Mining Opinions, Sentiments, and Emotions; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Wang, Y.; Zhang, W.; Tang, Z. Research on user clustering method based on the sentiment analysis of e-commerce reviews. Mod. Inf. Technol. 2023, 7, 24–27+33. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database Name | Number of Comments | Remarks |
|---|---|---|
| Textrank keyword dataset | 8337 | JD.com |
| Mobile phone market model review dataset | 4016 | JD.com |
| False comment dataset | 8240 | JD.com |
| QandA comment dataset | 542 (Question) + 3252 (Answer) | Question + Answer in JD.com |
| Component | Setting |
|---|---|
| Encoder | ERNIE (768-dimensional) |
| LSTM | 1-layer, 128 hidden units |
| Classifier | Fully Connected Layer |
| Loss Function | Binary Cross-Entropy |
| Optimizer | Adam |
| Learning Rate | 3 × 10−5 |
| Batch Size | 16 |
| Epochs | 10 |
| Max Sequence Length | 64 tokens |
| Model | P | R | F1 | Amount of Data |
|---|---|---|---|---|
| ERNIE + FC | 84.23% | 84.27% | 84.26% | 1296 |
| CFEE [28] | 83.51% | 83.39% | 83.44% | 1296 |
| ELEM | 84.77% | 84.86% | 84.81% | 1296 |
| Rule | |
|---|---|
| 1. Emoji and normal expressions; | 6. Go to comments that are empty; |
| 2. Punctuation; | 7. To repeat single, one-word comments; |
| 3. Spaces; | 8. Uncompressed paragraphs; |
| 4. Repeated comments; | 9. Invalid reviews, including: “default positive review”, “cashback”, “This user did not fill in the evaluation.”; |
| 5. Useless comments, such as comments with numbers instead of text; | 10. Short sentences are comments whose length is less than 1. |
| Emotional Word Types | Number of Emotional Words |
|---|---|
| Positive emotional words | 227 |
| Negative emotional words | 53 |
| Evaluating Indicator | Numerical Value | Interpretation |
|---|---|---|
| Contour coefficient | 0.40 | Moderate intra-cluster cohesion |
| CH index | 14,088.01 | Strong inter-cluster differentiation |
| DB index | 0.78 | Low inter-cluster similarity |
| Evaluating Indicator | Numerical Value | Interpretation |
|---|---|---|
| Contour coefficient | 0.38 | Moderate intra-cluster cohesion |
| CH index | 388.14 | Moderate inter-cluster differentiation |
| DB index | 0.76 | Low inter-cluster similarity |
| Topic | Keyword | Interpreted Topic |
|---|---|---|
| topic0 | photo, good, smooth, clear, feel, battery, charging, speed, life, very good, very fast, cost-effective, appearance, effect, running, screen, worth, received, beautiful, capacity | Comprehensive Performance and Design Experience |
| topic1 | time, good, screen, standby, memory, old man, dad, a period, cost-effective, like, buy to, battery, feeling, value, New Year, satisfied, beautiful, old man, worth, enough | Budget-Friendly Models for Elderly Users |
| topic2 | feel, screen, fingerprint, one-handed, 21, ratio, body, grip, thin, 21pro, 219, white, comfortable, nice, camera, photo, appearance, back cover, really, panel | Ergonomics and Aesthetic Design |
| topic3 | smooth, photo, good, feel, system, okay, battery, effect, time, signal, experience, good, mode, endurance, optimization, charging, small screen, not too, standby, function | System Smoothness and Battery Optimization |
| topic4 | nice, system, price, cost-effective, smooth, speed, first time, feel, pixel, daily, no problem, satisfied, battery, get, price, no shame, flagship, very quickly, people-friendly, worried | Entry-Level Flagship Value Experience |
| topic5 | photo, like, nice, effect, special, speed, very good, smooth, satisfied, feel, good-looking, running, color, really, time, hope, very soon, clear, national products, cost-effective | Imaging Performance and Color Calibration |
| topic6 | photo, screen, hope, system, like, a little, good, feel, price, really, experience, image, appearance, support, performance, consumers, indeed, in line with, especially, appearance | Consumer Expectation Alignment |
| topic7 | screen, system, price point, nice, photo, charging, endurance, back cover, $1000, processor, telephoto, camera, very good, price, battery, gaming, metal, curved, super, workmanship | High-End Imaging and Gaming Performance |
| topic8 | good, like, price, elderly, gift, discount, really, special, quality, self-operated, activities, good, buy, New Year, good-looking, give, delivery, very good, cost-effective, very quickly | Holiday Promotions and Gifting Scenarios |
| topic9 | screen, smooth, photo, good, feel, good-looking, appearance, clear, battery, performance, effect, cost-effective, enhancement, camera, very good, touch, processor, 20, first, owned | Display Quality and Performance Upgrade |
| topic10 | photo, clear, effect, good, screen, running, feel, function, speed, smooth, sound quality, recommended, cost-effective, very good, battery, buy, endurance, performance, appearance, worthwhile | All-in-One Multimedia Device |
| topic11 | good, speed, endurance, very, fast, video, running, play-games, elderly, enough, charge, feel, games, okay, good, battery, smooth, price, ability, like, cost-effective | Gaming and Video Battery Life |
| topic12 | time, standby, battery, speed, running, charging, endurance, range, very fast, very good, photo, durable, a period, no problem, okay, smooth, effect, power, capacity, satisfactory | Basic Battery Life and Charging Efficiency |
| topic13 | fingerprint, ultrasonic, unlock, nice, motor, system, wide-area, experience, really, configuration, white, good, panel, boost, hope, comfortable, vibration, recognition, 21pro, 20pro | Biometric Recognition and Interaction Innovation |
| topic14 | good, cost-effective, charging, hope, a little, less than, battery, price, feel, support, feeling, new, satisfied, brand, smooth, parents, system, order, screen, experience | Balancing Cost-Effectiveness and Pain Points |
| topic15 | body, feel, design, benefits, thin, support, system, weight, performance, appearance, experience, camera, Ads, charging, screen, smooth, feel, run, settings, signal | Industrial Design and Ad Intrusions |
| topic16 | screen, support, inches, video, camera, every day, pixels, performance, smooth, photography, brings, photo, clear, feel, effect, great, rear, offers, display, finesse | Display and Photography Professional Upgrade |
| Emotional Short Sentence Rule | Examples of Emotional Short Sentences | Quantity | Emotional Short Sentence Rule | Examples of Emotional Short Sentences | Quantity |
|---|---|---|---|---|---|
| n + a | Speed + very fast | 1669 | v + n | Like + feel | 2598 |
| a + n | Not bad + fuselage | 2277 | d + v + n | Special + thank you + express delivery | 171 |
| n + d + a | Appearance + really + good-looking | 159 | d + a + n | Not too good + nice + music | 116 |
| n + d + d + a | Rear cover + excessive + slight + smooth | 2 |
| Topics | Category | Topic Category Content | Weight |
|---|---|---|---|
| topic4, topic7, topic13, topic16 | 0 | Imaging Capabilities and Hardware Innovations | 8.6% |
| topic3, topic5, topic9, topic12 | 1 | Core Performance and System Optimization | 10.0% |
| topic0, topic1, topic2, topic10, topic11 | 2 | User-Centric Design and Multifunctional Experience | 70.8% |
| topic6, topic8, topic14 | 3 | Consumer Decision-Making and Promotional Drivers | 7.8% |
| topic15 | 4 | Industrial Design and Software Ecosystem Balance | 2.8% |
| Product Number | Product Name | The Emotional Value |
|---|---|---|
| 1 | HUAWEI’s flagship mobile phone Mate 60 Pro 12 GB + 512 G | 1.548 |
| 2 | Xiaomi (MI)Redmi Note 11 5G Tianji 810 33W Pro fast charging 5000 mAh battery 8 GB + 256 GB. | 1.543 |
| Topic Category Content | Stores | Obtain Score |
|---|---|---|
| Imaging Capabilities and Hardware Innovations | HUAWEI | 0.028458 |
| Xiaomi | 0.055214 | |
| Core Performance and System Optimization | HUAWEI | 0.011942 |
| Xiaomi | 0.000636 | |
| User-Centric Design and Multifunctional Experience | HUAWEI | 0.073285 |
| Xiaomi | 0.061326 | |
| Consumer Decision-Making and Promotional Drivers | HUAWEI | 0.005092 |
| Xiaomi | 0.000000 | |
| Industrial Design and Software Ecosystem Balance | HUAWEI | 0.012937 |
| Xiaomi | 0.000000 |
| User Clustering | Clustering Attention |
|---|---|
| 0 | ‘0’: 8800, ‘1’: 1064, ‘2’: 1032, ‘3’: 7430, ‘4’: 521 |
| 1 | ‘0’: 9930, ‘1’: 9100, ‘2’: 1055, ‘3’: 7680, ‘4’: 372 |
| 2 | ‘0’: 5800, ‘1’: 1276, ‘2’: 1109, ‘3’: 1039, ‘4’: 722 |
| 3 | ‘0’: 1622, ‘1’: 1764, ‘2’: 1843, ‘3’: 1845, ‘4’: 987 |
| 4 | ‘0’: 2221, ‘1’: 2266, ‘2’: 2288, ‘3’: 1142, ‘4’: 490 |
| 5 | ‘0’: 1641, ‘1’: 2362, ‘2’: 2449, ‘3’: 1329, ‘4’: 783 |
| Category | Number | The Ratio of Categories to Total Questions | The Problem’s Average Word Frequency | Average Answers | The Average Word Frequency of Answers |
|---|---|---|---|---|---|
| 0 | 66 | 13% | 12.26 | 3.36 | 34.11 |
| 1 | 150 | 29% | 13.61 | 2.75 | 29.46 |
| 2 | 63 | 12% | 14.03 | 2.11 | 19.00 |
| 3 | 94 | 18% | 10.53 | 3.05 | 33.79 |
| 4 | 70 | 14% | 10.73 | 2.17 | 17.86 |
| 5 | 68 | 13% | 12.78 | 1.91 | 22.91 |
| Categories of Q and A Systems | Ultra-High Frequency Words | Sub-High-Frequency Words (Only the First Four Are Listed) |
|---|---|---|
| 0 | -- | (‘pixel’, 9), (‘earphone’, 8), (‘cosmetics’, 8), (‘normal product’, 7) |
| 1 | -- | (‘15’, 15), (‘batteries’, 14), (‘screen’, 9) |
| 2 | -- | (‘system’, 13), (‘whether or not’, 9), (‘support’, 7) |
| 3 | (‘charge’, 26) | (‘memory’, 10), (‘device-heating’, 10), (‘endurance’, 10), (‘king’, 8) |
| 4 | (‘function’, 16), (‘support’, 16), (‘NFC’, 11) | (‘4G’, 7), (‘open’, 6), (‘5g’, 6), (‘displayed, 6) |
| 5 | (‘photograph’, 21) | (‘video’, 9), (‘screen’, 9), (‘effect’, 8), (‘beautiful’, 8) |
| Category of Comments | UHF Words (Only the First Four Are Listed) | Sub-High Frequency Words (Only the First Four Are Listed) |
|---|---|---|
| 0 | (‘standbytime’, 1160), (‘phone’, 566), (‘charge’, 467), (‘endurance’, 426) | (‘two-days’, 60), (‘one-charge’, 58), (‘moreandmore’, 57), (‘character’, 53) |
| 1 | (‘screen’, 2159), (‘soundscape’, 1517), (‘nice’, 457), (‘clearer’, 314) | (‘luminance’, 53), (‘last’, 52), (‘endurance’, 52), (‘motor’, 51) |
| 2 | (‘appearance’, 2021), (‘contour’, 1591), (‘beautiful’, 636), (‘phone’, 619) | (‘blue’, 61), (‘high-end’, 60), (‘endurance’, 59), (‘character’, 59) |
| 3 | (‘phone’, 2168), (‘nice’, 1038), (‘smoothly’, 605), (‘quality-priceratio’, 596) | (‘game’, 75), (‘mom’, 75), (‘AD’, 73), (‘processingunit’, 70) |
| 4 | (‘photograph’, 2674), (‘effect’, 2001), (‘phone’, 785), (‘clearer’, 659) | (‘improvement’, 64), (‘camerashot’, 63), (‘shopping’, 62), (‘wish’, 61) |
| 5 | (‘speed’, 1967), (‘running’, 1722), (‘very-fast’, 825), (‘phone’, 821) | (‘very-big’, 60), (‘configure’, 60), (‘batteries’, 59), (‘statistics’, 59) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, P.; Li, H.; Mo, X. Quantifying Post-Purchase Service Satisfaction: A Topic–Emotion Fusion Approach with Smartphone Data. Big Data Cogn. Comput. 2025, 9, 125. https://doi.org/10.3390/bdcc9050125
Guo P, Li H, Mo X. Quantifying Post-Purchase Service Satisfaction: A Topic–Emotion Fusion Approach with Smartphone Data. Big Data and Cognitive Computing. 2025; 9(5):125. https://doi.org/10.3390/bdcc9050125
Chicago/Turabian StyleGuo, Peijun, Huan Li, and Xinyue Mo. 2025. "Quantifying Post-Purchase Service Satisfaction: A Topic–Emotion Fusion Approach with Smartphone Data" Big Data and Cognitive Computing 9, no. 5: 125. https://doi.org/10.3390/bdcc9050125
APA StyleGuo, P., Li, H., & Mo, X. (2025). Quantifying Post-Purchase Service Satisfaction: A Topic–Emotion Fusion Approach with Smartphone Data. Big Data and Cognitive Computing, 9(5), 125. https://doi.org/10.3390/bdcc9050125