

Machine Learning Approaches for Predicting Risk of Cardiometabolic Disease among University Students

 , , , , , and
, , , , , and 
Abstract
1. Introduction
2. Literature Review
3. Dataset Description
3.1. Overview
3.2. Features
- Age: The age of an instance, typically measured in years;
- Height: The height in m;
- Weight: The weight in kg;
- MBF: The mass body fat in kg;
- BFP: The percentage of body fat;
- BMI: The body mass index, calculated by dividing the weight in kg by the square of the height in m;
- VFA: The visceral fat area, which is the fat surrounding the internal organs, in cm2;
- WC: The waist circumference measurement in cm;
- WHR: The waist-to-hip ratio, which is an indicator of the fat distribution in the body;
- FMI: The Fat Mass Index, which is similar to the BMI but focuses on the amount of body fat;
- C index: The Conicity Index, which is calculated using the waist and hip circumference;
- ABSI: A Body Shape Index, which is used to assess the risk of obesity-related diseases.
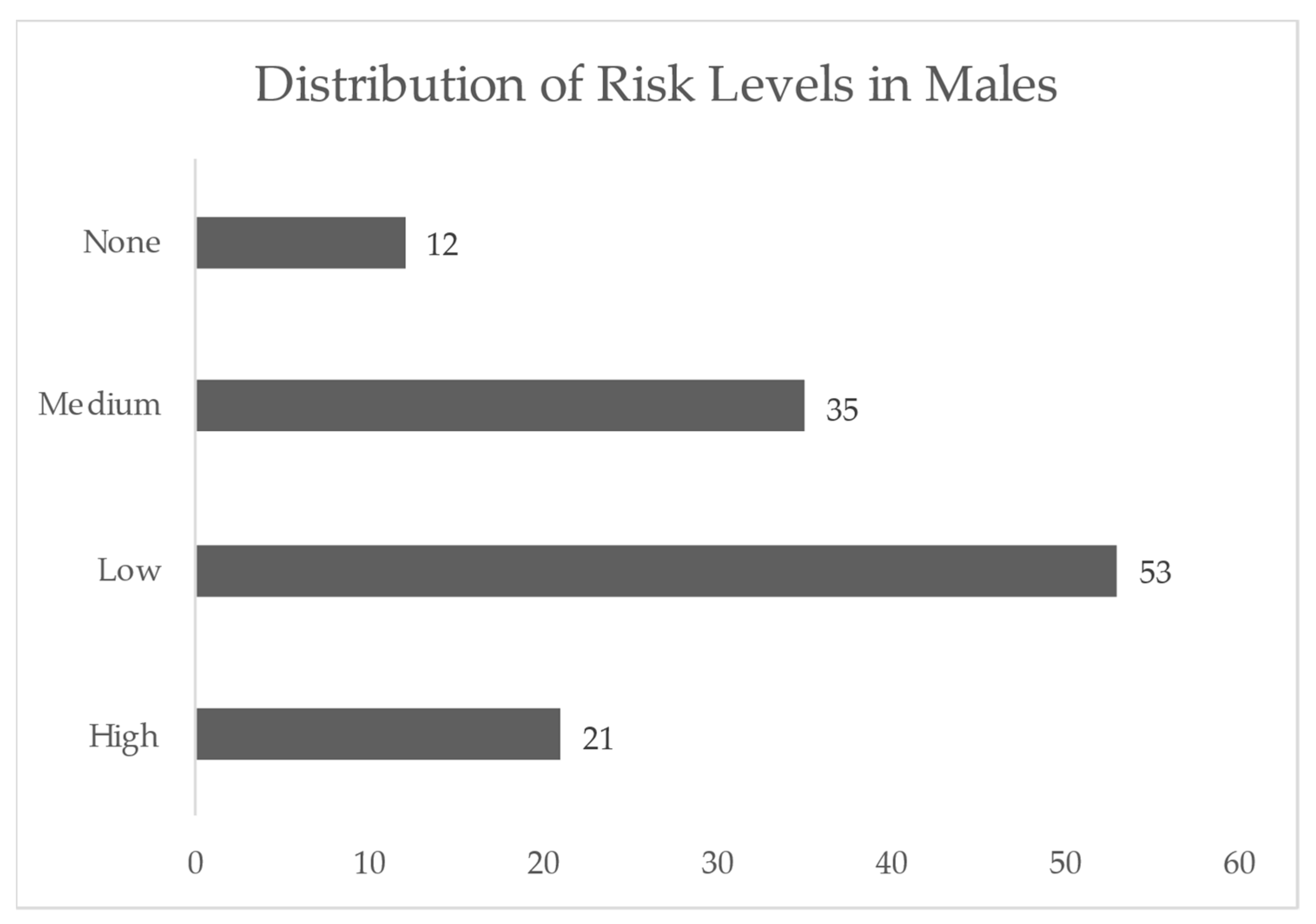
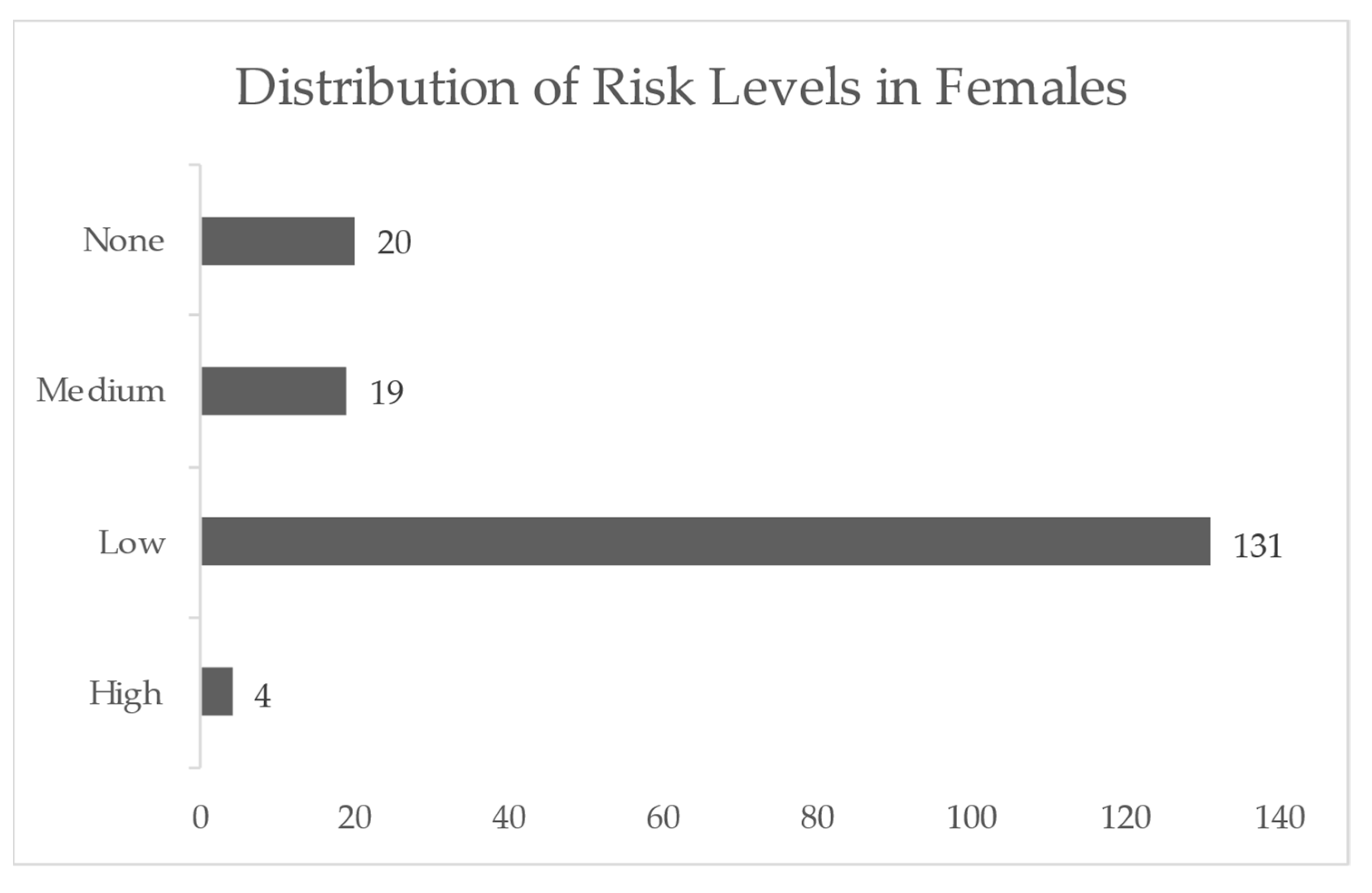
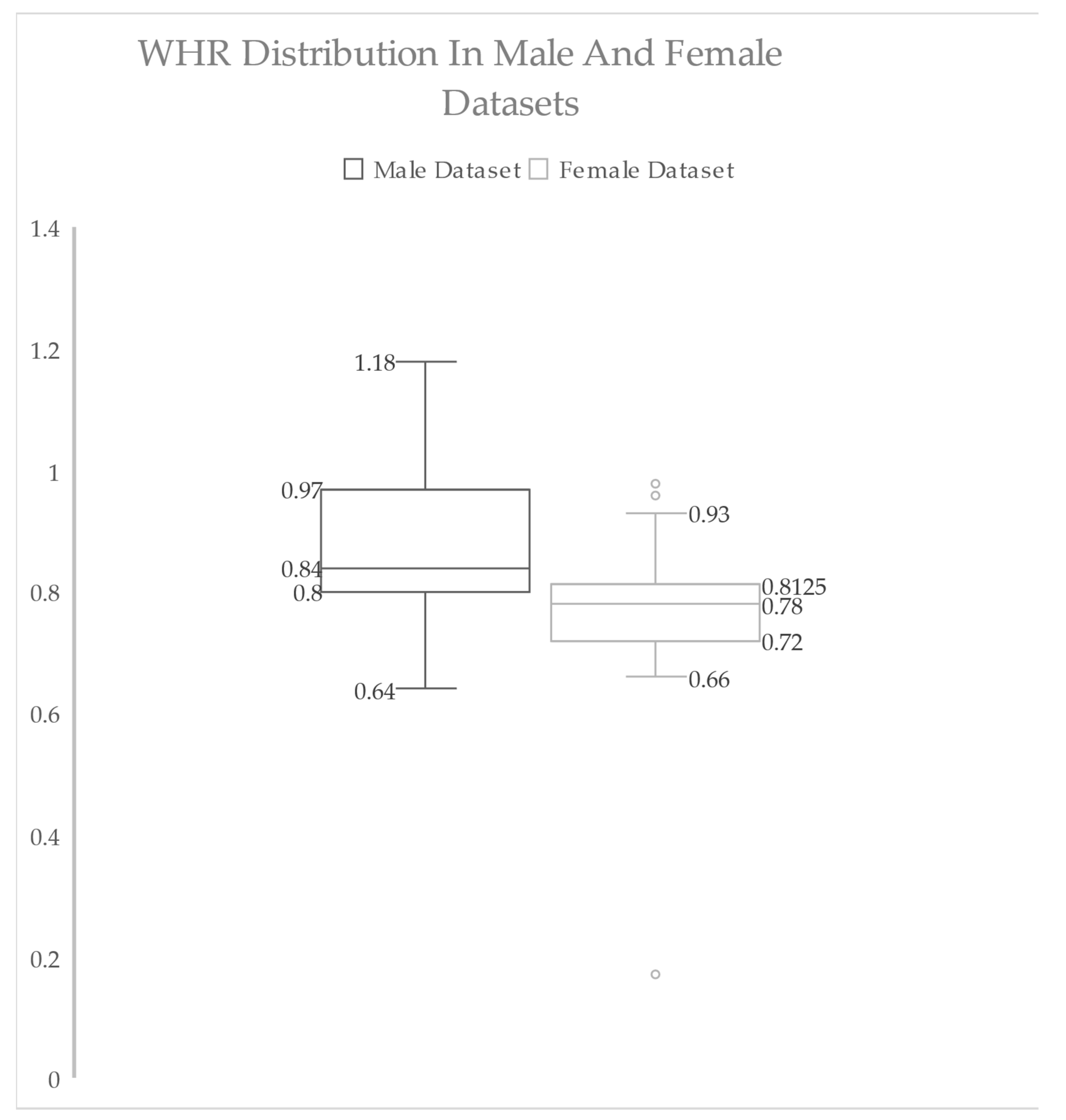
3.3. Overview of Statistics and Data Exploration Insights before Preprocessing
4. Methodology
4.1. Preprocessing Steps
4.1.1. Data Cleaning
4.1.2. Feature Engineering
4.1.3. Categorical Encoding
4.1.4. Overview of Statistics and Data Exploration Insights following Preprocessing
4.2. Machine Learning Algorithms
4.2.1. Logistic Regression
4.2.2. Random Forest
4.2.3. Support Vector Machine
4.2.4. K-Nearest Neighbors
4.2.5. Gradient Boosting
5. Experimental Results and Discussion
5.1. Evaluation Metrics
5.1.1. Accuracy
- TP (True Positive): The number of occurrences that are accurately identified as positive or falling within the positive category;
- TN (True Negative): A measure of how many instances were accurately identified as negative or falling under the category of negatives;
- FP (False Positive): The number of occurrences that are falsely predicted as positive when they really fall under the negative class (Type I error or false alarms);
- FN (False Negative): The number of cases that are falsely predicted as negative when they really fall within the positive class (Type II error or missed detections).
5.1.2. Precision
5.1.3. Recall
5.1.4. F1-Score
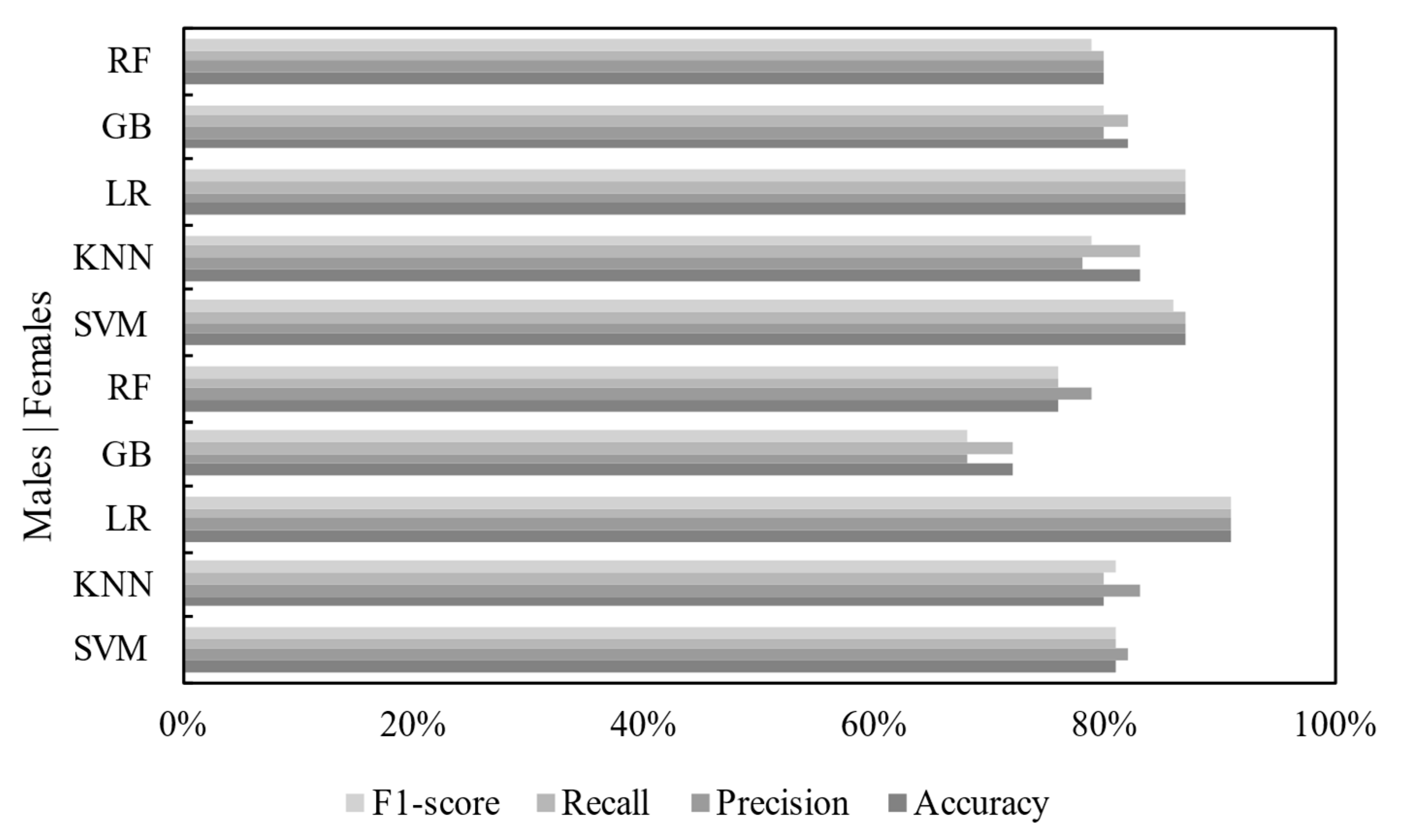
5.2. Model Performance Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Ahmad, A.; Elbadawi, N.E.; Osman, M.S.; Elmahdi, E.M. The Prevalence and Risk Factors of Obesity among Medical Students at Shaqra University, Saudi Arabia. Ann. Med. Health Sci. Res. 2020, 10, 903–906. [Google Scholar]
- Albaker, W.; El-Ashker, S.; Baraka, M.A.; El-Tanahi, N.; Ahsan, M.; Al-Hariri, M. Adiposity and Cardiometabolic Risk Assessment among University Students in Saudi Arabia. Sci. Prog. 2021, 104, 0036850421998532. [Google Scholar] [CrossRef]
- Atehortúa Labrador, A.M.; Gkontra, P.; Camacho, M.; Diaz, O.; Bulgheroni, M.; Simonetti, V.; Chadeau-Hyam, M.; Felix, J.F.; Sébert, S.P.; Lekadir, K. Cardiometabolic Risk Estimation Using Exposome Data and Machine Learning. Int. J. Med. Inform. 2023, 179, 105209. [Google Scholar] [CrossRef]
- Gerrits, N.; Elen, B.; Van Craenendonck, T.; Triantafyllidou, D.; Petropoulos, I.N.; Malik, R.A.; De Boever, P. Age and Sex Affect Deep Learning Prediction of Cardiometabolic Risk Factors from Retinal Images. Sci. Rep. 2020, 10, 9432. [Google Scholar] [CrossRef] [PubMed]
- Pang, X.; Forrest, C.B.; Lê-Scherban, F.; Masino, A.J. Prediction of Early Childhood Obesity with Machine Learning and Electronic Health Record Data. Int. J. Med. Inform. 2021, 150, 104454. [Google Scholar] [CrossRef] [PubMed]
- El-Ashker, S.; Pednekar, M.S.; Narake, S.S.; Albaker, W.; Al-Hariri, M. Blood Pressure and Cardio-Metabolic Risk Profile in Young Saudi Males in a University Setting. Medicina 2021, 57, 755. [Google Scholar] [CrossRef]
- Banerjee, A.; Chen, S.; Dashtban, M.; Pasea, L.; Thygesen, J.H.; Fatemifar, G.; Tyl, B.; Dyszynski, T.; Asselbergs, F.W.; Lund, L. Identifying Subtypes of Heart Failure with Machine Learning: External, Prognostic and Genetic Validation in Three Electronic Health Record Sources with 320,863 Individuals. medRxiv 2022, 2022–2026. [Google Scholar] [CrossRef]
- O’Sullivan, T.A.; Schmidt, K.A.; Kratz, M. Whole-Fat or Reduced-Fat Dairy Product Intake, Adiposity, and Cardiometabolic Health in Children: A Systematic Review. Adv. Nutr. 2020, 11, 928–950. [Google Scholar] [CrossRef]
- Arisaka, O.; Ichikawa, G.; Koyama, S.; Sairenchi, T. Childhood Obesity: Rapid Weight Gain in Early Childhood and Subsequent Cardiometabolic Risk. Clin. Pediatr. Endocrinol. 2020, 29, 135–142. [Google Scholar] [CrossRef]
- Tsai, T.-Y.; Hsu, P.-F.; Lin, C.-C.; Wang, Y.-J.; Ding, Y.-Z.; Liou, T.-L.; Wang, Y.-W.; Huang, S.-S.; Chan, W.-L.; Lin, S.-J. Factor Analysis for the Clustering of Cardiometabolic Risk Factors and Sedentary Behavior, a Cross-Sectional Study. PLoS ONE 2020, 15, e0242365. [Google Scholar] [CrossRef]
- Berkowitz, S.A.; Basu, S.; Venkataramani, A.; Reznor, G.; Fleegler, E.W.; Atlas, S.J. Association between Access to Social Service Resources and Cardiometabolic Risk Factors: A Machine Learning and Multilevel Modeling Analysis. BMJ Open 2019, 9, e025281. [Google Scholar] [CrossRef]
- Shang, X.; Li, Y.; Xu, H.; Zhang, Q.; Liu, A.; Du, S.; Guo, H.; Ma, G. Leading Dietary Determinants Identified Using Machine Learning Techniques and a Healthy Diet Score for Changes in Cardiometabolic Risk Factors in Children: A Longitudinal Analysis. Nutr. J. 2020, 19, 1–16. [Google Scholar] [CrossRef]
- Taghiyev, A.; Altun, A.A.; Caglar, S. A Hybrid Approach Based on Machine Learning to Identify the Causes of Obesity. J. Control Eng. Appl. Inform. 2020, 22, 56–66. [Google Scholar]
- Chatterjee, A.; Gerdes, M.W.; Martinez, S.G. Identification of Risk Factors Associated with Obesity and Overweight—A Machine Learning Overview. Sensors 2020, 20, 2734. [Google Scholar] [CrossRef] [PubMed]
- Ferdowsy, F.; Rahi, K.S.A.; Jabiullah, M.I.; Habib, M.T. A Machine Learning Approach for Obesity Risk Prediction. Curr. Res. Behav. Sci. 2021, 2, 100053. [Google Scholar] [CrossRef]
- Agrawal, S.; Klarqvist, M.D.R.; Diamant, N.; Stanley, T.L.; Ellinor, P.T.; Mehta, N.N.; Philippakis, A.; Ng, K.; Claussnitzer, M.; Grinspoon, S.K. Association of Machine Learning-Derived Measures of Body Fat Distribution with Cardiometabolic Diseases in >40,000 Individuals. medRxiv 2021, 2021–2025. [Google Scholar] [CrossRef]
- Thamrin, S.A.; Arsyad, D.S.; Kuswanto, H.; Lawi, A.; Nasir, S. Predicting Obesity in Adults Using Machine Learning Techniques: An Analysis of Indonesian Basic Health Research 2018. Front. Nutr. 2021, 8, 669155. [Google Scholar] [CrossRef] [PubMed]
- Safaei, M.; Sundararajan, E.A.; Driss, M.; Boulila, W.; Shapi’i, A. A Systematic Literature Review on Obesity: Understanding the Causes & Consequences of Obesity and Reviewing Various Machine Learning Approaches Used to Predict Obesity. Comput. Biol. Med. 2021, 136, 104754. [Google Scholar]
- Kerkadi, A.; Suleman, D.; Salah, L.A.; Lotfy, C.; Attieh, G.; Bawadi, H.; Shi, Z. Adiposity Indicators as Cardio-Metabolic Risk Predictors in Adults from Country with High Burden of Obesity. Diabetes Metab. Syndr. Obes. Targets Ther. 2020, 13, 175. [Google Scholar] [CrossRef] [PubMed]
- Gorgey, A.S.; Ennasr, A.N.; Farkas, G.J.; Gater, D.R., Jr. Anthropometric Prediction of Visceral Adiposity in Persons with Spinal Cord Injury. Top. Spinal Cord Inj. Rehabil. 2021, 27, 23–35. [Google Scholar] [CrossRef] [PubMed]
- Beck, D.; De Lange, A.-M.G.; Alnæs, D.; Maximov, I.I.; Pedersen, M.L.; Leinhard, O.D.; Linge, J.; Simon, R.; Richard, G.; Ulrichsen, K.M. Adipose Tissue Distribution from Body MRI Is Associated with Cross-Sectional and Longitudinal Brain Age in Adults. NeuroImage Clin. 2022, 33, 102949. [Google Scholar] [CrossRef]
- Sajid, M.R.; Almehmadi, B.A.; Sami, W.; Alzahrani, M.K.; Muhammad, N.; Chesneau, C.; Hanif, A.; Khan, A.A.; Shahbaz, A. Development of Nonlaboratory-Based Risk Prediction Models for Cardiovascular Diseases Using Conventional and Machine Learning Approaches. Int. J. Environ. Res. Public Health 2021, 18, 12586. [Google Scholar] [CrossRef]
- Guarneros-Nolasco, L.R.; Cruz-Ramos, N.A.; Alor-Hernández, G.; Rodríguez-Mazahua, L.; Sánchez-Cervantes, J.L. Identifying the Main Risk Factors for Cardiovascular Diseases Prediction Using Machine Learning Algorithms. Mathematics 2021, 9, 2537. [Google Scholar] [CrossRef]
- Reddy, K.V.V.; Elamvazuthi, I.; Aziz, A.A.; Paramasivam, S.; Chua, H.N.; Pranavanand, S. Heart Disease Risk Prediction Using Machine Learning Classifiers with Attribute Evaluators. Appl. Sci. 2021, 11, 8352. [Google Scholar] [CrossRef]
- Khennou, F.; Fahim, C.; Chaoui, H.; Chaoui, N.E.H. A Machine Learning Approach: Using Predictive Analytics to Identify and Analyze High Risks Patients with Heart Disease. Int. J. Mach. Learn. Comput. 2019, 9, 762–767. [Google Scholar] [CrossRef]
- Schober, P.; Vetter, T.R. Logistic Regression in Medical Research. Anesth. Analg. 2021, 132, 365. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.; Zhang, P.; Wang, Z.; Li, D. Prediction of Cardiovascular Diseases Based on Machine Learning. ASP Trans. Internet Things 2021, 1, 30–35. [Google Scholar] [CrossRef]
- Soofi, A.A.; Awan, A. Classification Techniques in Machine Learning: Applications and Issues. J. Basic Appl. Sci 2017, 13, 459–465. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient Boosting Machines, a Tutorial. Front. Neurorobotics 2013, 7, 21. [Google Scholar] [CrossRef]
- Ghosh, P.; Azam, S.; Jonkman, M.; Karim, A.; Shamrat, F.M.J.M.; Ignatious, E.; Shultana, S.; Beeravolu, A.R.; De Boer, F. Efficient Prediction of Cardiovascular Disease Using Machine Learning Algorithms with Relief and LASSO Feature Selection Techniques. IEEE Access 2021, 9, 19304–19326. [Google Scholar] [CrossRef]
- Gollapalli, M.; Alansari, A.; Alkhorasani, H.; Alsubaii, M.; Sakloua, R.; Alzahrani, R.; Al-Hariri, M.; Alfares, M.; AlKhafaji, D.; Al Argan, R.; et al. A Novel Stacking Ensemble for Detecting Three Types of Diabetes Mellitus Using a Saudi Arabian Dataset: Pre-Diabetes, T1DM, and T2DM. Comput. Biol. Med. 2022, 147, 105757. [Google Scholar] [CrossRef] [PubMed]
- Weng, S.F.; Reps, J.; Kai, J.; Garibaldi, J.M.; Qureshi, N. Can Machine-Learning Improve Cardiovascular Risk Prediction Using Routine Clinical Data? PLoS ONE 2017, 12, e0174944. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Authors (Year) | Aim | Models or Classifiers | Dataset Size and Source | Strength | Weakness | Performance Measurements |
|---|---|---|---|---|---|---|---|
| [18] | Safaei, M. et al. (2021) | Reviewing ML techniques used for obesity prediction; one study conducted for early childhood obesity | Random Forest, ID3, Naïve Bayes, Random Tree, J48, Bayes trained | A pediatric clinical decision support system called CHICA | Contributes to a concerning topic | The accuracy score was not that great compared to that of other papers reviewed in the same paper | 85% accuracy and 89% sensitivity |
| [16] | Agrawal, S. et al. (2021) | Exploring the clinical implications of how fat is distributed in the body | CNNs | MRI imaging data of 40,032 UK Biobank participants | Accuracy was near perfect | Does not mention the exact percentage of accuracy | Near perfection (number not mentioned) |
| [17] | Thamrin, S.A. et al. (2021) | Utilizing machine learning methods to predict obesity in adults | Logistic Regression, Classification and Regression Trees (CARTs), and Naïve Bayes | 634,709 respondents; was requested at the Institute of Health Research and Development of the Indonesian Ministry of Health | Used a novel approach with sophisticated ML techniques instead of using traditional prediction models | N/A | Accuracy of 0.798 |
| [7] | Banerjee, A. et al. (2022) | Identifying subtypes of heart failure with machine learning | Unsupervised ML methods (Kmeans, hierarchical, K-Medoids, and mixture model clustering) | 320,863 Clinical Practice Research Datalink, CPRD, and the Health Improvement Network | Large dataset size | The accuracy score, F1 score, and precision score were not mentioned | Good predictive accuracy, as authors claim |
| [10] | Tsai, T.-Y. et al. (2020) | Exploring the clustering pattern of CVD risk factors using exploratory factor analysis to investigate the underlying relationships between various CVD risk factors | N/A | 5606 from Taipei Veterans General Hospital Institutional | Reducing sedentary behavior and addressing multiple cardiometabolic risk factors to prevent cardiometabolic diseases | N/A | N/A |
| [11] | Berkowitz, S.A. et al. (2019) | Determining association between access to social service resources and cardiometabolic risk factors | Random Forest with multilevel modeling method | 123,355 participants from the National Health and Nutrition Examination Survey (NHANES) in the United States | Used multilevel modeling analysis to examine the association between access to social service resources and cardiometabolic risk factors, such as obesity, diabetes, and high blood pressure | Restricted access to social service resources | N/A |
| [12] | Shang, X. et al. (2020) | Urgently identifying leading dietary determinants for cardiometabolic risk (CMR) factors to prioritize interventions in children | Random Forest, gradient boost machine, and multiple linear regression model | 5676 children aged 6–13 years | Used multiple linear regression model | Machine learning methodology was not very precise or clear | N/A |
| [13] | Taghiyev, A. et al. (2020) | Using a machine learning model to identify the causes of obesity | Hybrid model, DT, and LR | 56 attributes and 500 instances | Compared the hybrid model with other classification models, such as DT and LR | N/A | Hybrid model achieved 91.4% accuracy, 90.4% recall, and 92.9% specificity |
| [15] | Ferdowsy, F. et al. (2021) | Using a machine learning model to predict obesity risks | KNN, LR, MLP, SVM, NB, ADA Boosting, DT, and Gradient Boosting | 1000 records | High accuracy | Small dataset compared to other papers | LR achieved 97.09% accuracy |
| [14] | Chatterjee, A. et al. (2020) | Using a machine learning approach to identify obesity risk factors in addition to presenting an overview | SVM, NB, DT, RF, and KNN | 500 records | High accuracy | Small dataset compared to other papers | SVM achieved 95% accuracy |
| [9] | Arisaka, O. et al. (2020) | Assessing the latest research on the relationship between early fast growth and future risks for obesity and cardiometabolic conditions | N/A | N/A | N/A | N/A | N/A |
| [3] | Atehortúa, A. et al. (2023) | Introducing a fair machine learning model that predicts the risks of acquiring cardiovascular disease (CVD) and type 2 diabetes (T2D) by utilizing easily accessible exposome factors | A novel, fair machine learning (ML) model | 5348 participants who were diagnosed with CVD and 1534 participants who were diagnosed with (T2D) | Novel approach, large dataset, and comparative analysis | Limited generalizability and model complexity | ROC-AUC values of 0.78 ± 0.01 and 0.77 ± 0.01 for CVD and T2D risk prediction, respectively |
| [2] | Albaker, W. et al. (2021) | Determining the prevalence of adiposity and the risk of cardiometabolic disease among Saudi university students | N/A | 310 subjects (with 127 males and 183 females), Imam Abdulrahman Bin Faisal University (IAU) | Assessment of adiposity and cardiometabolic risk among university students, emphasizing early prediction and prevention of obesity-related health issues | Limited sample size and potential generalizability limitations | N/A |
| [5] | Pang, X. et al. (2021) | Comparing machine learning models for predicting childhood obesity using EHR data up to age 2 and evaluating their performance in predicting obesity incidence up to 7 years of age | XGBoost, DT, SVM, LR, NN, GNB, and BNB | 860,510 patients with 11,194,579 healthcare encounters, Children’s Hospital of Philadelphia | Large dataset, comparison of multiple models | Data limitation and model performance | Using XGBoost: AUC: 0.81 Sensitivity: 80% Precision: 30.90% F1-score: 44.60% Accuracy: 66.14% Specificity: 63.27% |
| [4] | Gerrits, N. et al. (2020) | Examining the use of deep learning models trained on retinal images to predict cardiometabolic risk factors | MobileNet-V2 architecture | Retinal images from 3000 Qatari citizens, Qatar Biobank study | Large dataset, acceptable performance for several cardiometabolic risk factors | Limited generalizability | Age prediction: MAE of 2.78 years Sex prediction: AUC of 0.97 SBP prediction: MAE of 8.96 mmHg DBP prediction: MAE of 6.84 mmHg |
| [6] | EL-Ashker et al. (2021) | Investigating the metabolic risk factors and their association with blood pressure alteration in young Saudi males in a university setting | ROC and AUC curves and Logistic Regression | 284 male university students from the Eastern Province | Provides valuable insights into the cardiovascular health of young Saudi men in a university setting | The study only focuses on male university students in one region of Saudi Arabia, so the results may not be generalizable to other populations | ROC curve BMI (specificity = 0.806, sensitivity = 0.811) WC (sensitivity = 0.876, specificity = 0.746) WHR (sensitivity = 0.908 specificity = 0.092) WHtR (sensitivity = 0.811 specificity = 0.776) |
| [19] | Kerkadi et al. (2020) | Comparing different methods of assessing adiposity to identify risk of developing CM issues among Qatari adults | ROC and AUC curves | 558 healthy Qatari adults aged 20 to 50 years; data obtained from Qatar Biobank survey | Used a large sample size and compared different methods of assessing adiposity | Does not provide explicit information on the study’s results | TG (AUC = 0.556), HDL (AUC = 0.556), and TG/HDL (AUC = 0.581) HbA1c (AUC = 0.629), and VAT for Tyr (AUC = 0.626) |
| [20] | Gorgey et al. (2021) | Creating a formula that can predict visceral adiposity in people with spinal cord injury using anthropometric measurements | N/A | Men who had complete motor spinal cord injuries | Offers insights into the factors causing visceral adiposity in individuals with SCI; suggests a practical tool for healthcare providers to identify those at risk of central obesity-related health problems | Only analyzed data from a small group of men who had complete motor spinal cord injuries | N/A |
| [21] | Beck et al. (2022) | Examining the correlation between adipose tissue distribution from body MRI and brain ages in middle-aged individuals | Bayesian multilevel modeling and XGBoost | 1062 brain MRI data from 790 participants with age range of 19–86; data obtained from NIPH’s Twin Study | Combined cross-sectional and longitudinal designs to explore link between adipose measures during follow-up and brain’s biological age; examined cross-sectional relationships between tissue-specific BAG, adipose tissue measures, and conventional anthropometric measures | Small sample size during follow-up, which reduces its statistical power; additionally, body MRI data were only collected during the follow-up examination, further limiting its power | N/A |
| [8] | O’Sullivan et al. (2020) | Conducting pediatric studies on whole-fat and reduced-fat dairy intake and adiposity, biomarkers of cardiometabolic disease risk, and glucose homeostasis; authors suggest that high-quality randomized controlled trials are needed to obtain better evidence on recommending reduced-fat dairy products for children | N/A | N/A | Provides a clear definition of whole-fat and reduced-fat dairy products and includes studies conducted in different countries | The limited literature in the field is not consistent with dietary guidelines recommending reduced-fat dairy products for children | N/A |
| [22] | Sajid et al. (2021) | Using ML-based RPMs for CVDs in LMICs using non-laboratory features; comparing their performance with that of conventional RPMs and determining the best models and feature order for predicting CVD status | ANN, SVM | Dataset based on case–control study conducted at the Punjab Institute of Cardiology, Pakistan; dataset includes 460 subjects aged between 30 and 76 years | Shows the importance of developing customized and region-specific RPMs for accurate risk estimates in new populations | The study focuses on only one LMIC, Pakistan, which may not be representative of other LMICs | N/A |
| [24] | Reddy K et al. (2021) | Using a machine learning model to predict heart disease risk using the Cleveland heart dataset; evaluates ten classifiers, proposing that an automated system using patient data and ML can achieve accurate predictions | Naïve Bayes, Bayesian network, Decision Table, Decision Tree, KNN, Random Forest, AdaBoostM1, Bagging, LR, and SMO | The Cleveland heart dataset comprising 303 patient records | The research improves the accuracy of one of the classifiers, IBk, by tuning the hyperparameter “k” to 9 with the chi-squared attribute set, achieving an 8.25% accuracy improvement | The study was conducted using only the Cleveland Heart dataset, which limits the generalizability of the findings to other populations or datasets | Acc (%): 86.468 Pre: 0.865 Sen: 0.865 AUC: 0.861 |
| [23] | Guarneros-Nolasco et al. (2021) | Analyzing 10 ML algorithms on 4 datasets for CVD prediction/diagnosis, identifying top 2/4 risk attributes, and determining main CVD risk factors with suggestions for improving diagnosis in regions with limited medical staff; ML has been shown to be effective/reliable in discerning patients with CVD | Decision Tree, Random Forest, Gradient Boosting, SVM, KNN, NB, and LR | The Cleveland dataset: containing 303 patient records, the Faisalabad Dataset containing 299 patients with heart failure (105 women and 194 men), and the South African Hearth dataset containing 462 records of patient data | It mentions all of the advantages and disadvantages and the performance of each classifier algorithm independently | N/A | Accuracy: 1-Cleveland (LR): 77.22% 2-Faisalabad (CatBoost Classifier): 76.28% 3-South African Hearth (Decision Tree Classifier): 72.51% |
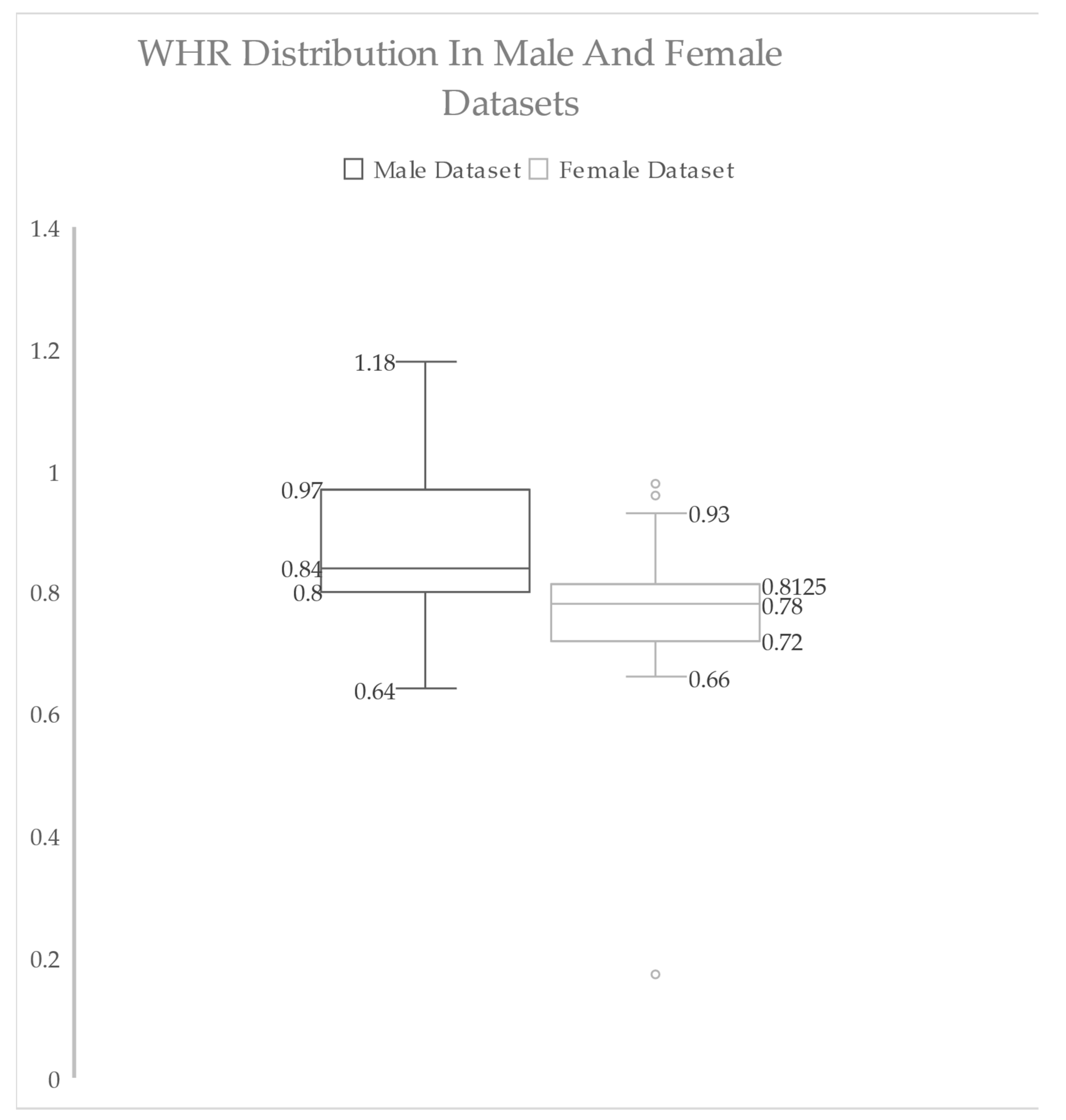
| Height (m) | Weight (kg) | MBF (kg) | BFP (%) | BMI | VFA (cm2) | WC (m) | WHR | FMI | |
|---|---|---|---|---|---|---|---|---|---|
| Mean | 1.70 | 82.96 | 25.27 | 27.15 | 28.46 | 118.83 | 0.95 | 0.88 | 8.65 |
| Median | 1.69 | 74.30 | 20.70 | 26.50 | 25.60 | 84.00 | 0.90 | 0.84 | 6.72 |
| Std. Dev. | 0.07 | 29.09 | 17.99 | 10.58 | 9.45 | 81.83 | 0.31 | 0.12 | 6.06 |
| Range | 0.40 | 118.80 | 77.40 | 47.00 | 44.50 | 378.00 | 1.65 | 0.54 | 29.42 |
| Minimum | 1.52 | 47.20 | 1.40 | 3.00 | 15.20 | 25.00 | 0.00 | 0.64 | 0.46 |
| Maximum | 1.92 | 166.00 | 78.80 | 50.00 | 59.70 | 403.00 | 1.65 | 1.18 | 29.87 |
| Height (m) | Weight (kg) | MBF (kg) | BFP (%) | BMI | VFA (cm2) | WC (m) | WHR | FMI | |
|---|---|---|---|---|---|---|---|---|---|
| Mean | 1.57 | 56.16 | 17.24 | 29.46 | 22.73 | 54.65 | 0.71 | 0.77 | 6.98 |
| Median | 1.56 | 53.80 | 15.90 | 29.50 | 21.80 | 46.00 | 0.74 | 0.78 | 6.21 |
| Std. Dev. | 0.05 | 12.25 | 7.52 | 6.46 | 4.74 | 31.03 | 0.20 | 0.08 | 3.00 |
| Range | 0.25 | 59.90 | 36.10 | 31.50 | 21.60 | 140.00 | 1.05 | 0.79 | 13.98 |
| Minimum | 1.46 | 38.80 | 5.80 | 12.90 | 15.30 | 20.00 | 0.00 | 0.17 | 1.98 |
| Maximum | 1.71 | 98.70 | 41.90 | 44.40 | 36.90 | 160.00 | 1.05 | 0.96 | 15.97 |
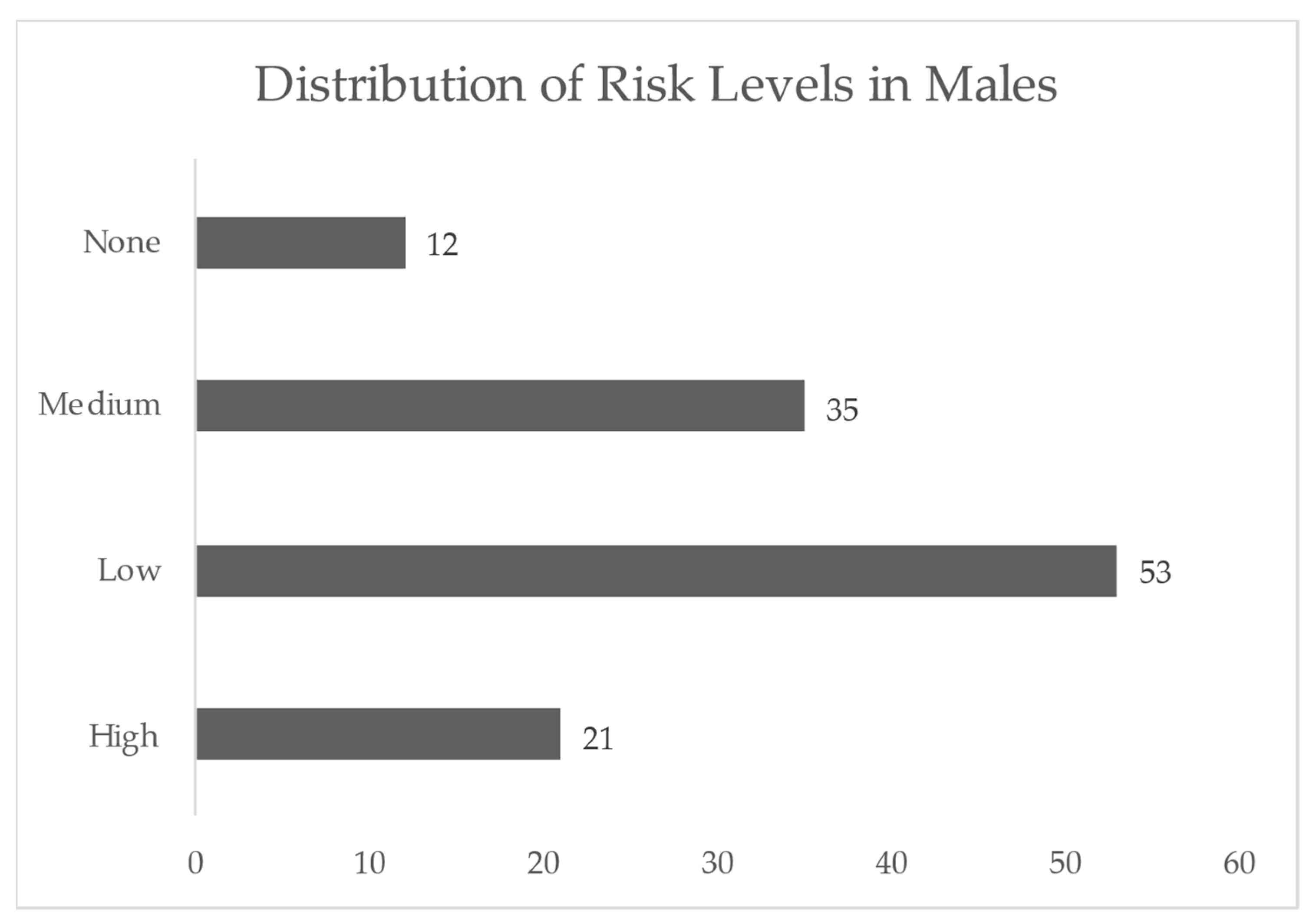
| Risk Level | Conicity Index Range |
|---|---|
| None | ≤1.20 |
| Low | 1.21–1.30 |
| Medium | 1.31–1.40 |
| High | ≥1.41 |
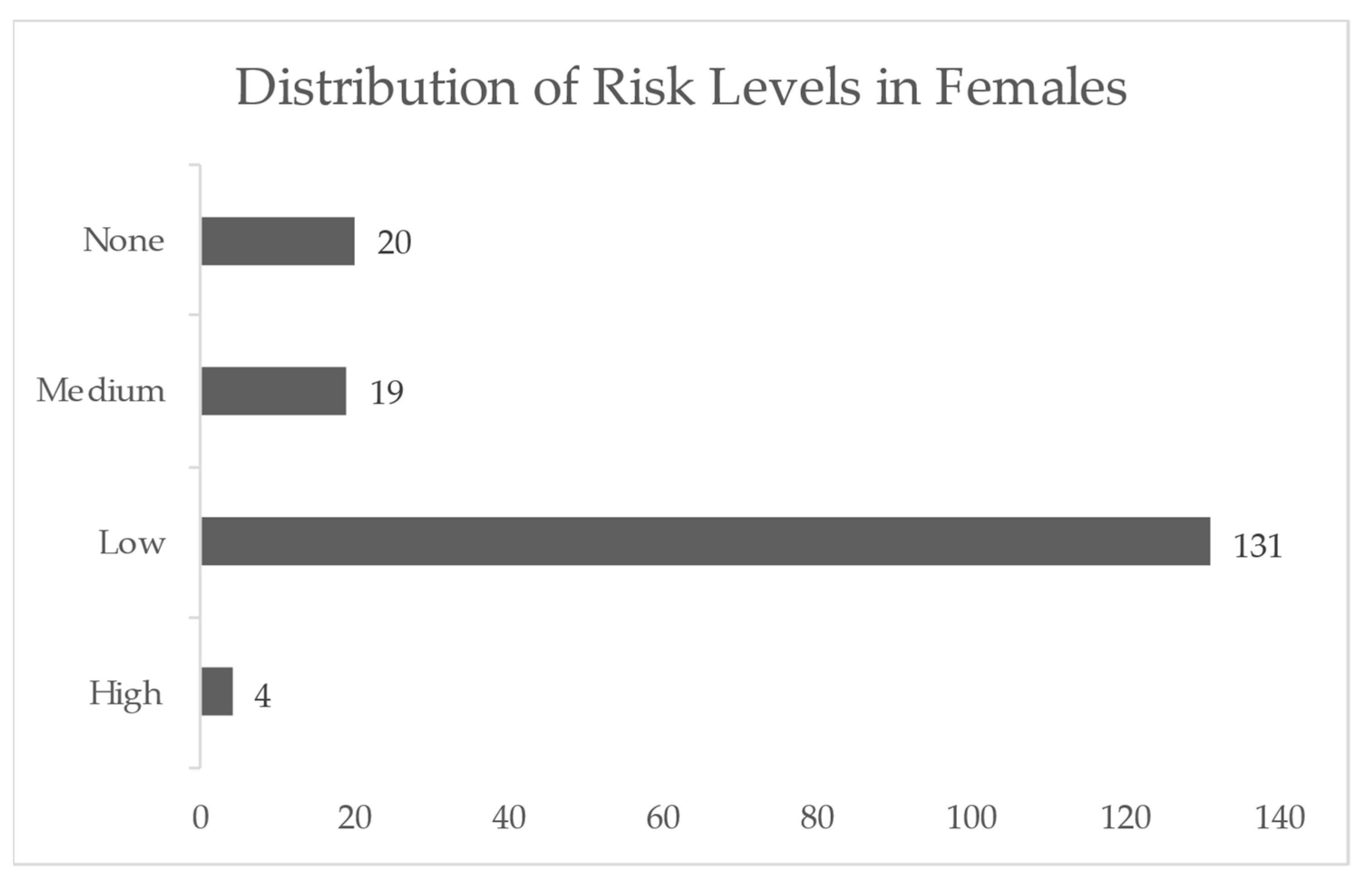
| Risk Level | Conicity Index Range |
|---|---|
| None | ≤1.15 |
| Low | 1.16–1.20 |
| Medium | 1.21–1.25 |
| High | ≥1.26 |
| Height (m) | Weight (kg) | MBF (kg) | BFP (%) | BMI | VFA (cm2) | WC (m) | WHR | FMI | |
|---|---|---|---|---|---|---|---|---|---|
| Mean | 1.71 | 83.47 | 25.55 | 27.18 | 28.61 | 118.83 | 0.99 | 0.88 | 8.74 |
| Median | 1.69 | 74.30 | 19.20 | 26.50 | 25.60 | 84.00 | 0.92 | 0.84 | 6.72 |
| Std. Dev. | 0.07 | 29.64 | 18.34 | 10.76 | 9.63 | 81.83 | 0.24 | 0.12 | 6.18 |
| Range | 0.40 | 118.80 | 77.40 | 47.00 | 44.50 | 378.00 | 0.98 | 0.54 | 29.42 |
| Minimum | 1.52 | 47.20 | 1.40 | 3.00 | 15.20 | 25.00 | 0.66 | 0.64 | 0.46 |
| Maximum | 1.92 | 166.00 | 78.80 | 50.00 | 59.70 | 403.00 | 1.65 | 1.18 | 29.87 |
| Height (m) | Weight (kg) | MBF (kg) | BFP (%) | BMI | VFA (cm2) | WC (m) | WHR | FMI | |
|---|---|---|---|---|---|---|---|---|---|
| Mean | 1.57 | 57.27 | 17.87 | 29.76 | 23.12 | 58.55 | 0.77 | 0.78 | 7.22 |
| Median | 1.57 | 54.15 | 15.95 | 29.70 | 22.10 | 47.00 | 0.75 | 0.78 | 6.53 |
| Std. Dev. | 0.05 | 13.23 | 8.29 | 6.90 | 5.19 | 36.25 | 0.10 | 0.08 | 3.32 |
| Range | 0.25 | 65.10 | 42.70 | 34.50 | 25.20 | 208.00 | 0.50 | 0.82 | 16.92 |
| Minimum | 1.46 | 35.70 | 5.10 | 12.90 | 14.70 | 20.00 | 0.62 | 0.17 | 1.98 |
| Maximum | 1.71 | 100.80 | 47.80 | 47.40 | 39.90 | 228.00 | 1.12 | 0.99 | 18.91 |
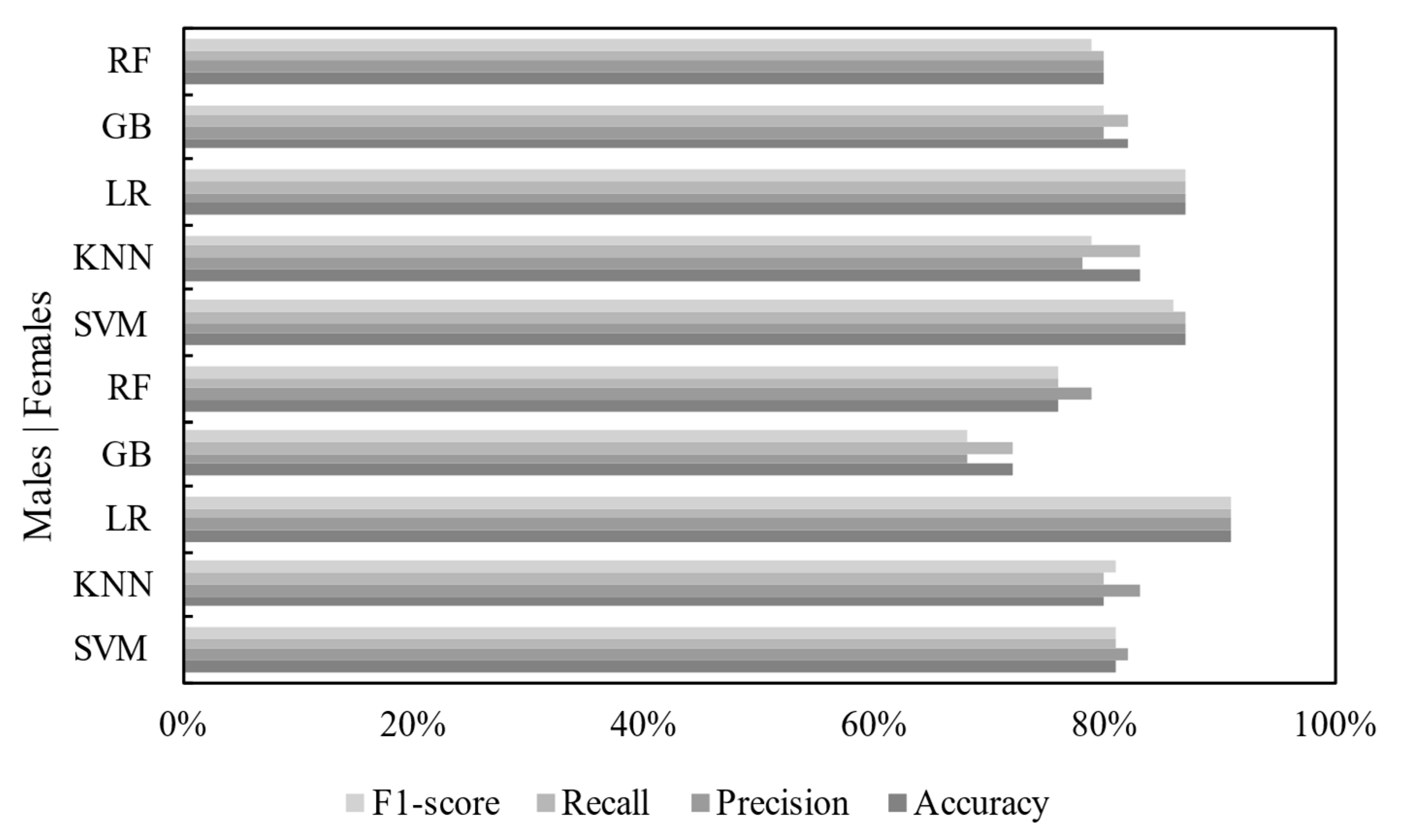
| Classifier | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Support Vector Machine | 81% | 82% | 81% | 81% |
| K-Nearest Neighbor | 80% | 83% | 80% | 81% |
| Logistic Regression | 91% | 91% | 91% | 91% |
| Gradient Boosting | 72% | 68% | 72% | 68% |
| Random Forest | 76% | 79% | 76% | 76% |
| Classifier | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Support Vector Machine | 87% | 87% | 87% | 86% |
| K-Nearest Neighbor | 83% | 78% | 83% | 79% |
| Logistic Regression | 87% | 87% | 87% | 87% |
| Gradient Boosting | 82% | 80% | 82% | 80% |
| Random Forest | 80% | 80% | 80% | 79% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Musleh, D.; Alkhwaja, A.; Alkhwaja, I.; Alghamdi, M.; Abahussain, H.; Albugami, M.; Alfawaz, F.; El-Ashker, S.; Al-Hariri, M. Machine Learning Approaches for Predicting Risk of Cardiometabolic Disease among University Students. Big Data Cogn. Comput. 2024, 8, 31. https://doi.org/10.3390/bdcc8030031
Musleh D, Alkhwaja A, Alkhwaja I, Alghamdi M, Abahussain H, Albugami M, Alfawaz F, El-Ashker S, Al-Hariri M. Machine Learning Approaches for Predicting Risk of Cardiometabolic Disease among University Students. Big Data and Cognitive Computing. 2024; 8(3):31. https://doi.org/10.3390/bdcc8030031
Chicago/Turabian StyleMusleh, Dhiaa, Ali Alkhwaja, Ibrahim Alkhwaja, Mohammed Alghamdi, Hussam Abahussain, Mohammed Albugami, Faisal Alfawaz, Said El-Ashker, and Mohammed Al-Hariri. 2024. "Machine Learning Approaches for Predicting Risk of Cardiometabolic Disease among University Students" Big Data and Cognitive Computing 8, no. 3: 31. https://doi.org/10.3390/bdcc8030031
APA StyleMusleh, D., Alkhwaja, A., Alkhwaja, I., Alghamdi, M., Abahussain, H., Albugami, M., Alfawaz, F., El-Ashker, S., & Al-Hariri, M. (2024). Machine Learning Approaches for Predicting Risk of Cardiometabolic Disease among University Students. Big Data and Cognitive Computing, 8(3), 31. https://doi.org/10.3390/bdcc8030031