
AI-Generated Text Detector for Arabic Language Using Encoder-Based Transformer Architecture


Abstract
1. Introduction
1.1. Arabic Language Challenges
1.2. Arabic Diacritization Marks’ Background
1.3. Challenges for AI Detectors in Processing Arabic Texts with Diacritics
1.4. Large Language Models
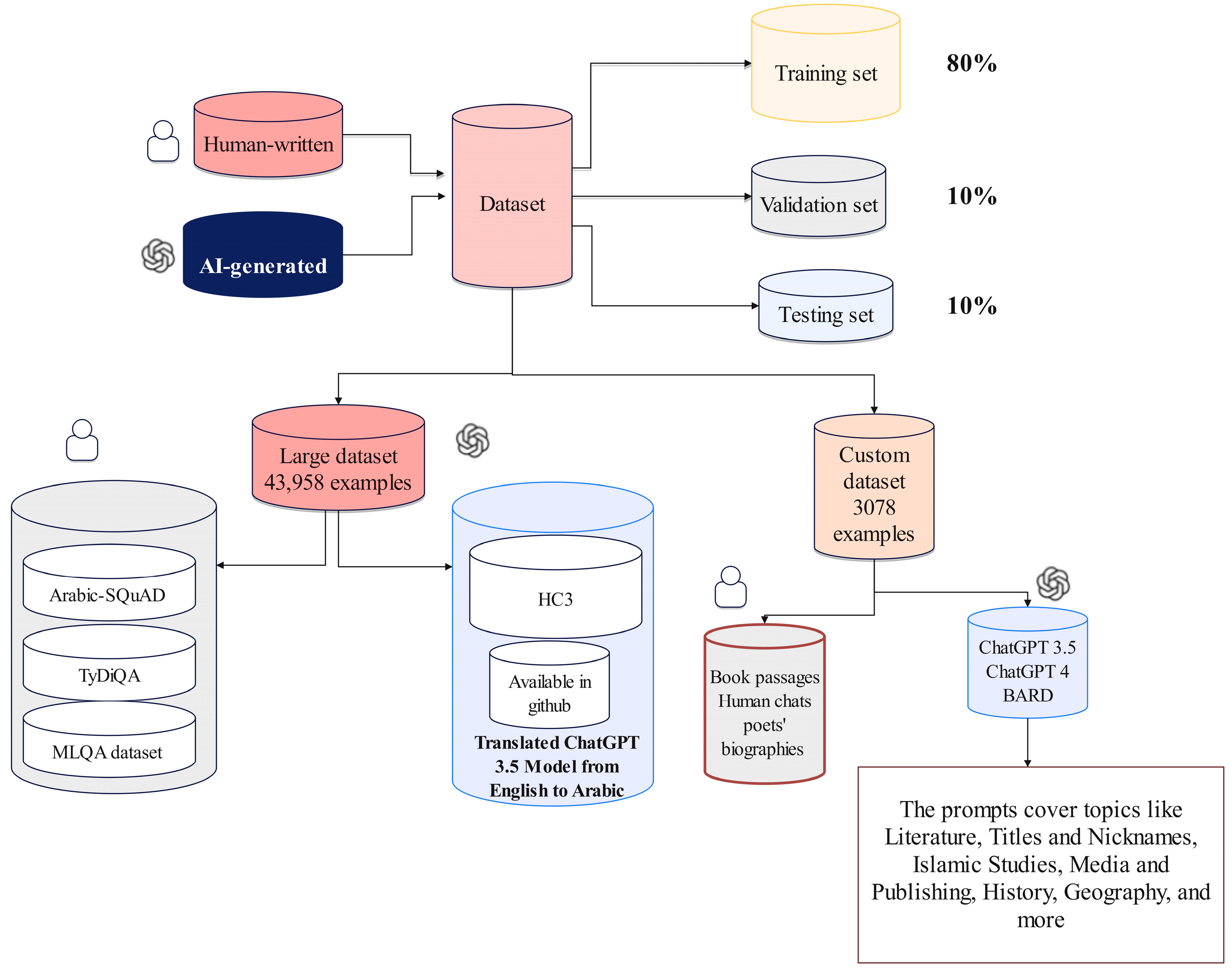
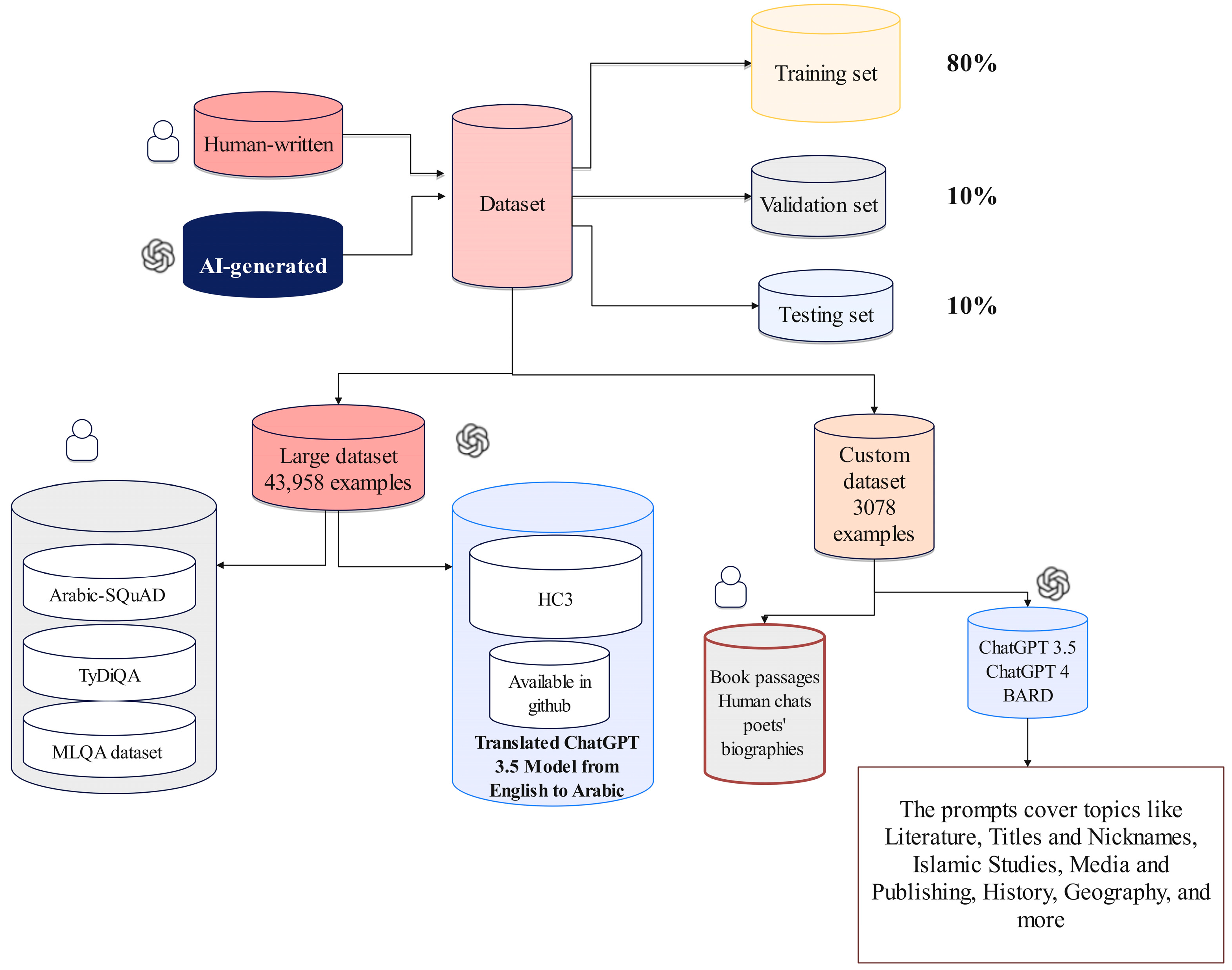
- Development of Two Arabic AI Classifier Models: We trained these models on a dataset comprising 35,166 examples, validated them on 4369 examples, and tested them on another set of 4369 examples. These examples include HWTs and AIGTs derived from the ChatGPT 3.5 Turbo model.
- Evaluation Using a Custom-Crafted Dataset: The models were further evaluated on our handcrafted dataset, which includes 2466 training examples, 306 validation examples, and 306 testing examples. This dataset encompasses a diverse range of HWTs from various sources and AIGTs generated by ChatGPT 3.5, ChatGPT 4, and BARD.
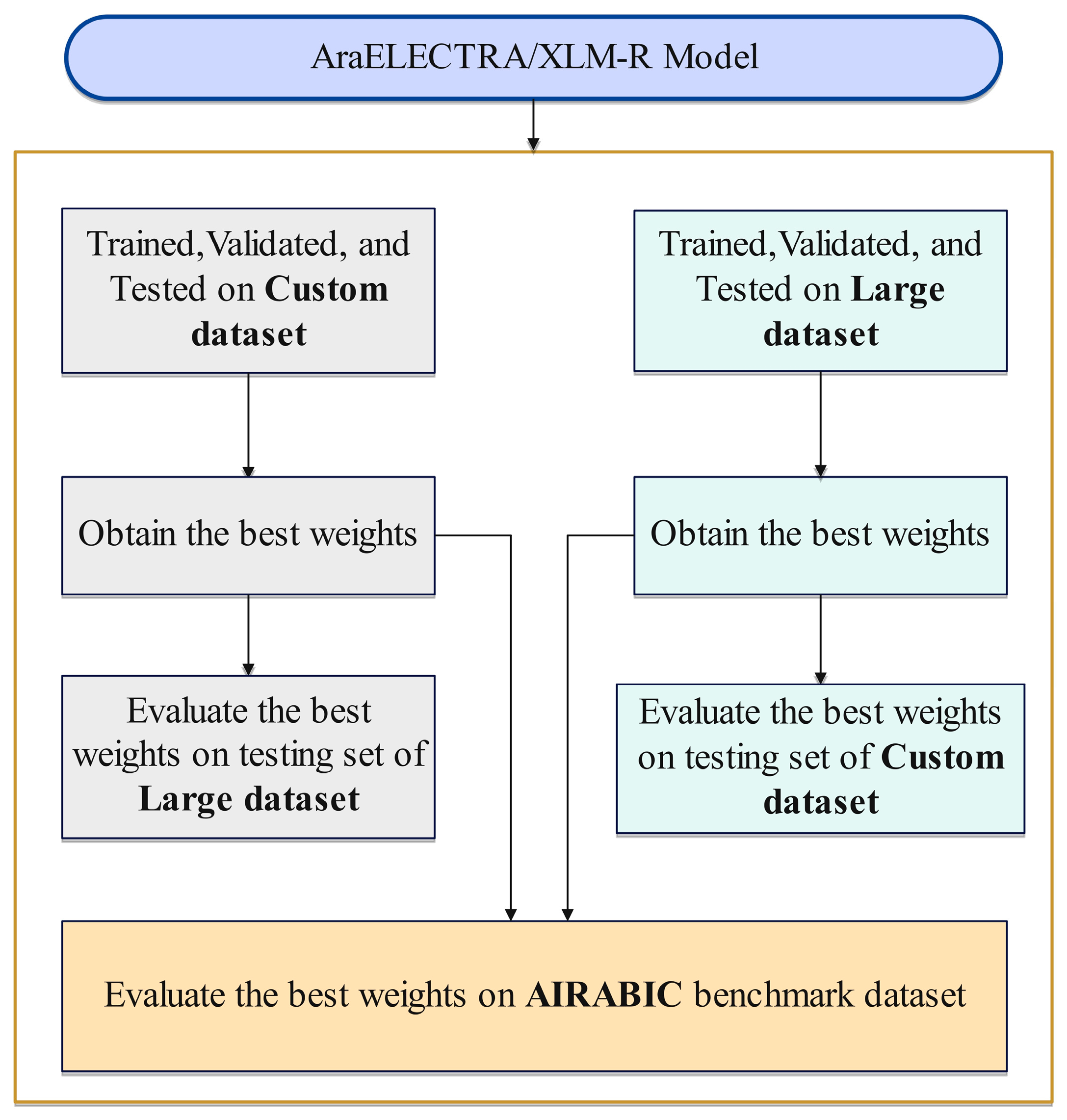
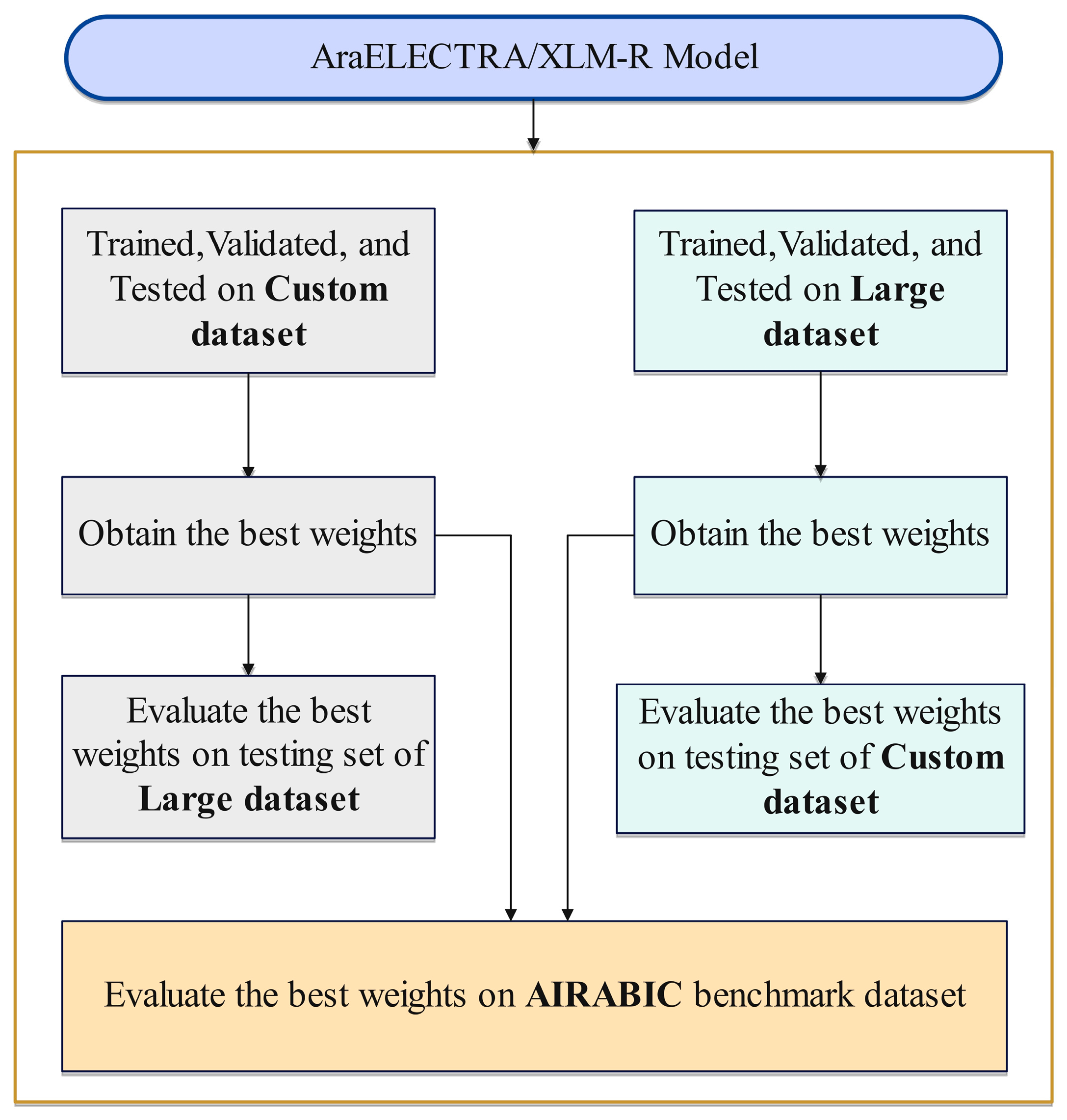
- Benchmarking Against AIRABIC Dataset: We employed the AIRABIC benchmark dataset to assess our models’ robustness and efficacy. This allowed us to measure our models’ performance and compare it with two prominent AI detectors, GPTZero and the OpenAI Text Classifier.
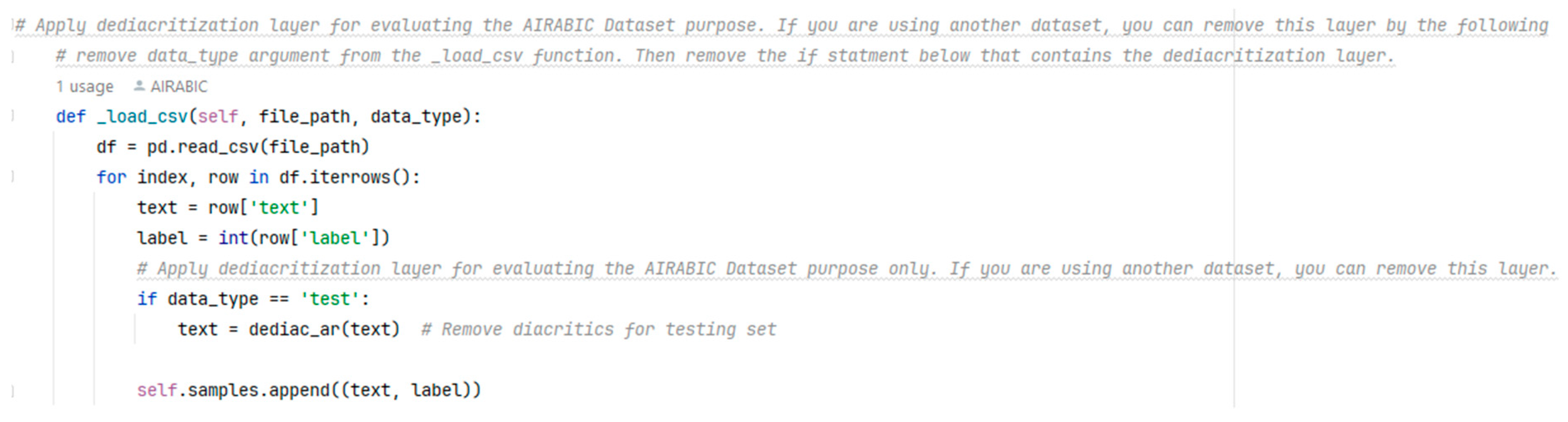
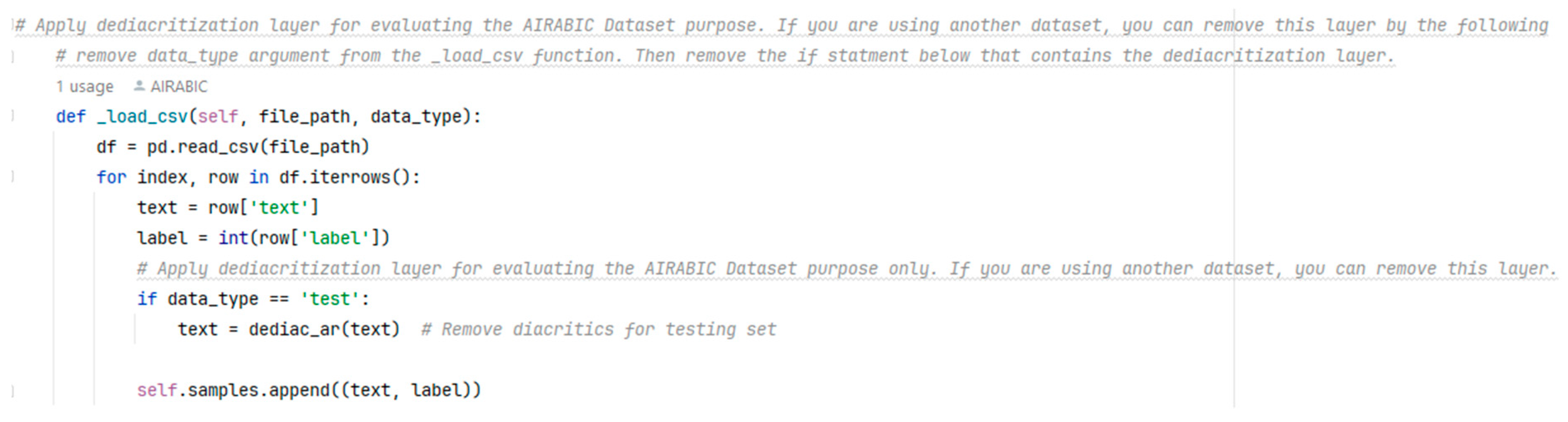
- Incorporation of the Dediacritization Layer: We incorporated a Dediacritization Layer in our architecture, aiming to enhance the classification performance of the proposed models, particularly for texts with diacritics.
- We conducted a detailed comparative analysis of the used pre-trained models emphasizing their performance across various datasets and under different hyperparameter configurations, thereby offering critical insights for enhancing language-specific AI text classifiers.
- ➢
- Section 2, Related Works, delves into the evolution of AIGT detection, focusing on developments before and after the emergence of ChatGPT. This section sets the stage for our research by highlighting the progress and remaining gaps in the field.
- ➢
- Section 3, Methodology, details the comprehensive approach taken in our study, including data collection and the architecture of our detector. Special attention is paid to the fine-tuning process, the innovative Dediacritization Layer, and the design of our evaluation pipeline. Additionally, this section outlines the experimental protocol and hyperparameter settings, emphasizing scheduler and learning rate optimizations to underscore the rigor of our research design.
- ➢
- Section 4, Results, offers an in-depth comparative analysis of our models against established benchmarks such as GPTZero and OpenAI Text Classifier. Through a series of tests on the AIRABIC benchmark dataset, we demonstrate the effectiveness of our fine-tuned AraELECTRA and XLM-R models. This section highlights the advancements our research contributes to the field and presents evidence of our models’ superior performance and efficiency.
- ➢
- Section 5, Discussion, provides insights gleaned from our findings, with an emphasis on the impact of dataset size and content variation. It also provides a comparative performance analysis of the XLM-R versus AraELECTRA models. The significant role of the Dediacritization Layer in enhancing classifier performance is examined in detail, showcasing the methodological innovations at the heart of our study.
- ➢
- Section 6, Conclusion and Future Work, summarizes the contributions of our research, outlines the potential for future work, and suggests directions for further research to build on the strong foundation laid by our study, aiming to inspire continued advancements in the field of Arabic AI detection.
2. Related Works
2.1. Detection of AIGT Prior to ChatGPT
2.2. Detection of AIGT after ChatGPT
3. Methodology
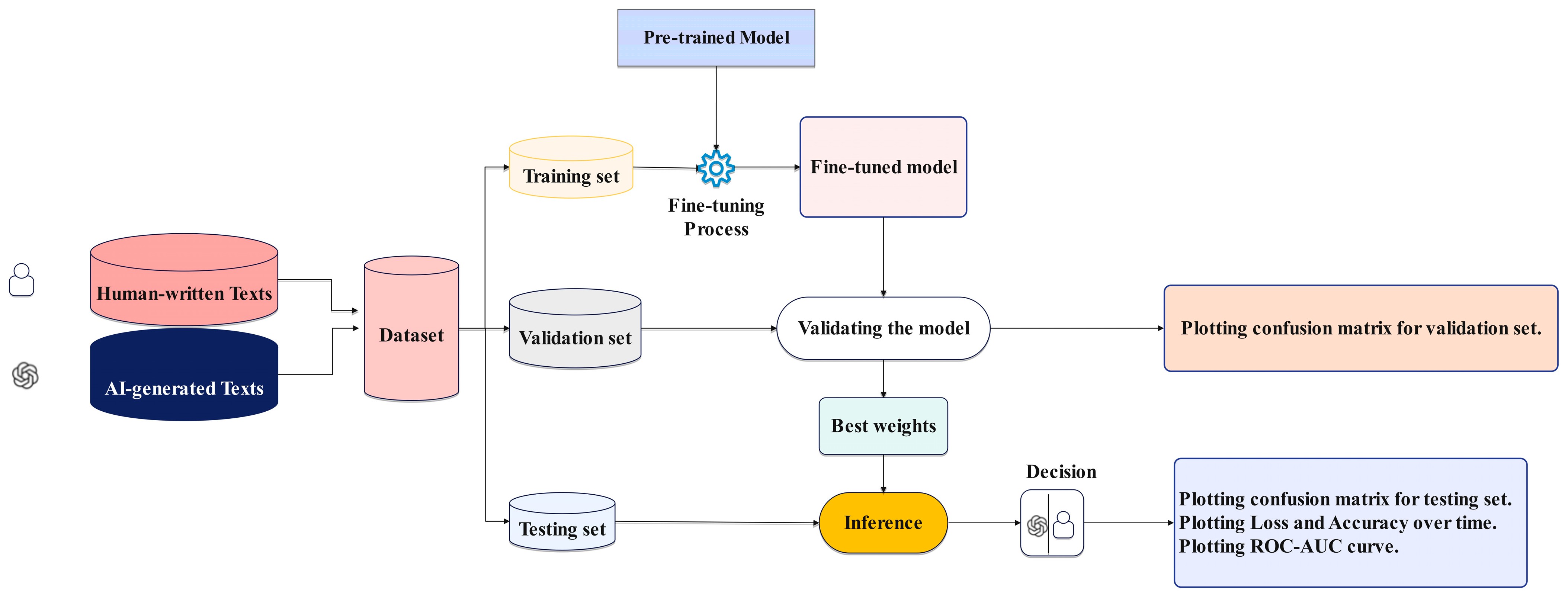
3.1. Data Collection
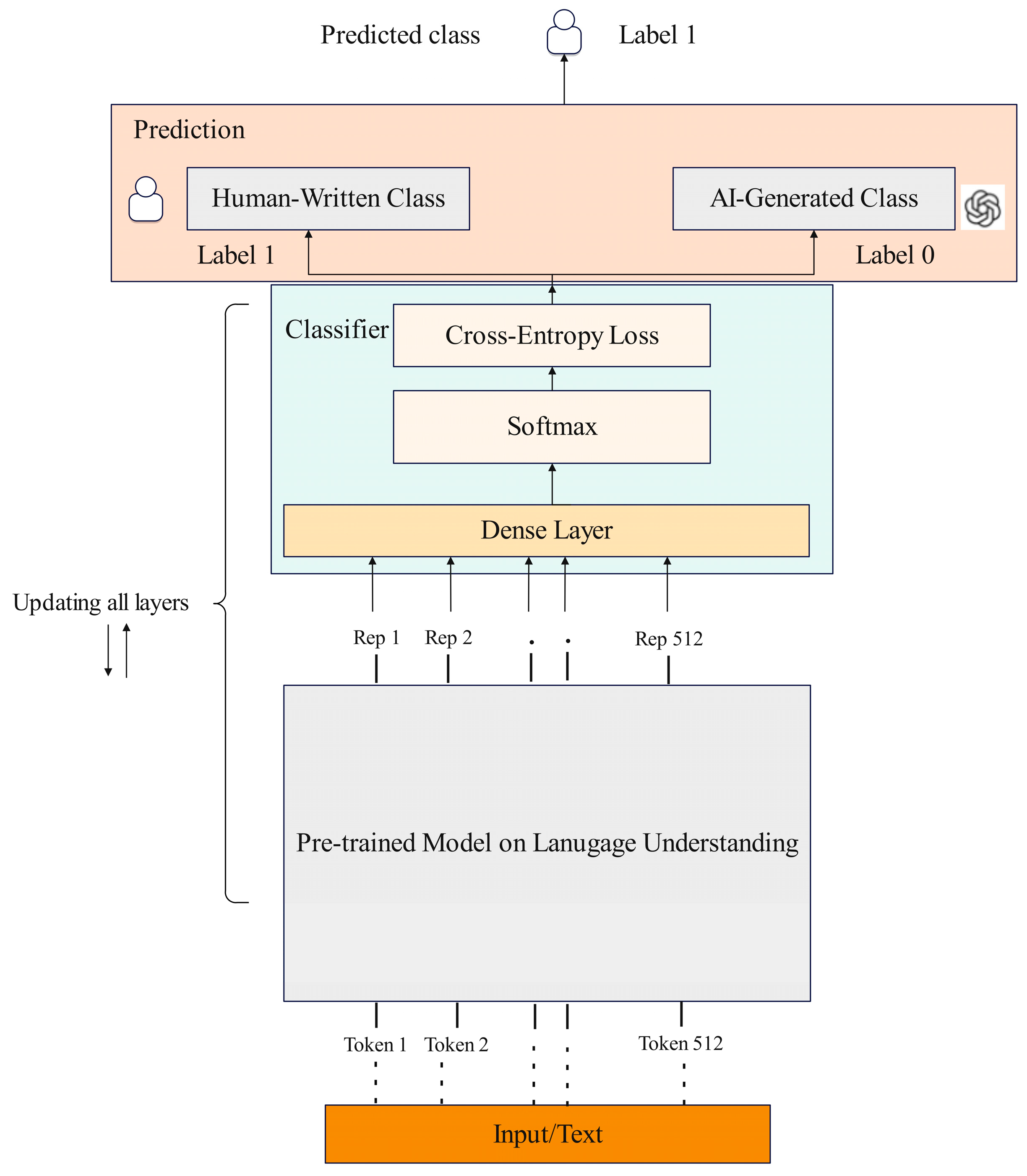
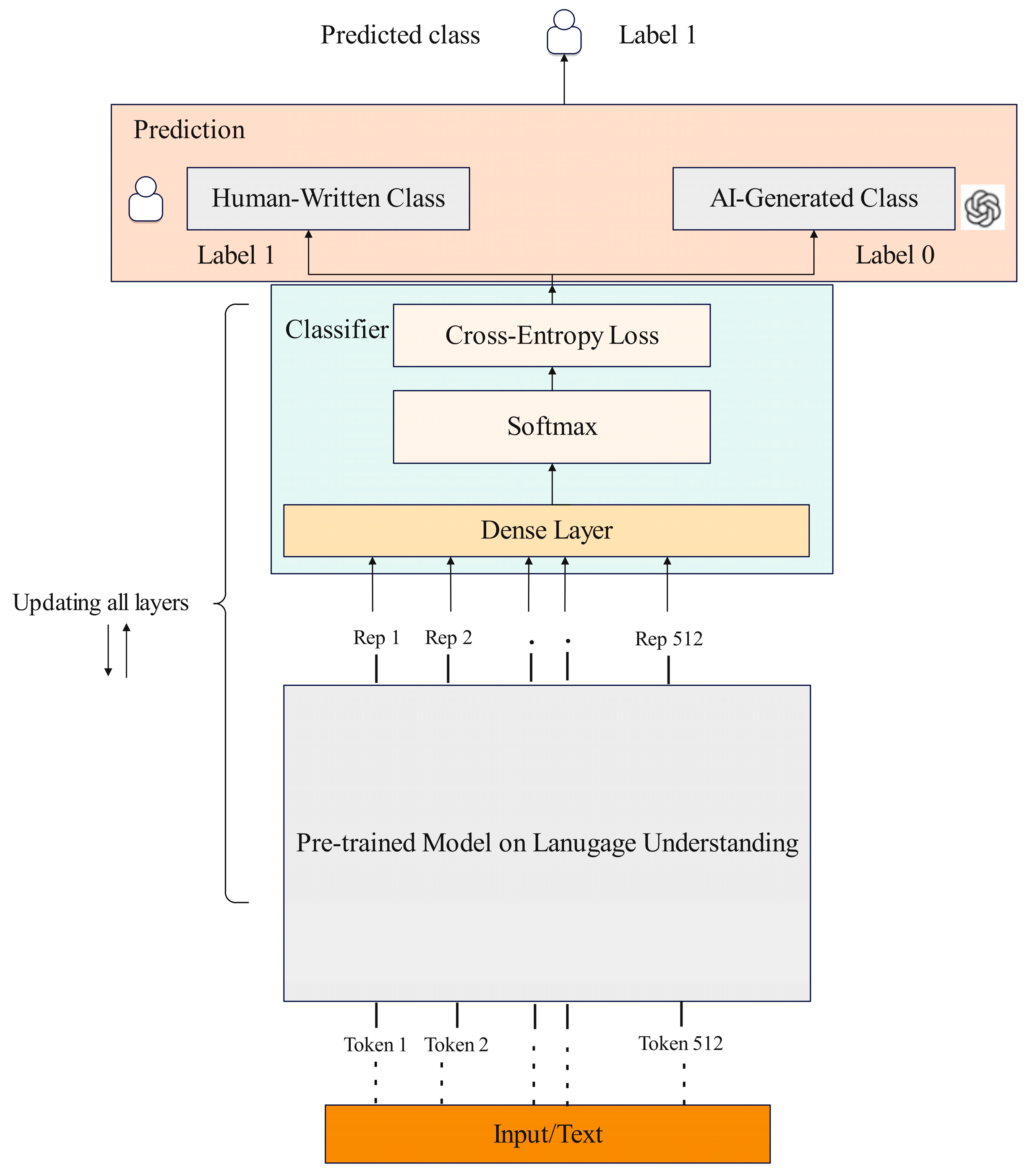
3.2. Detector Architecture
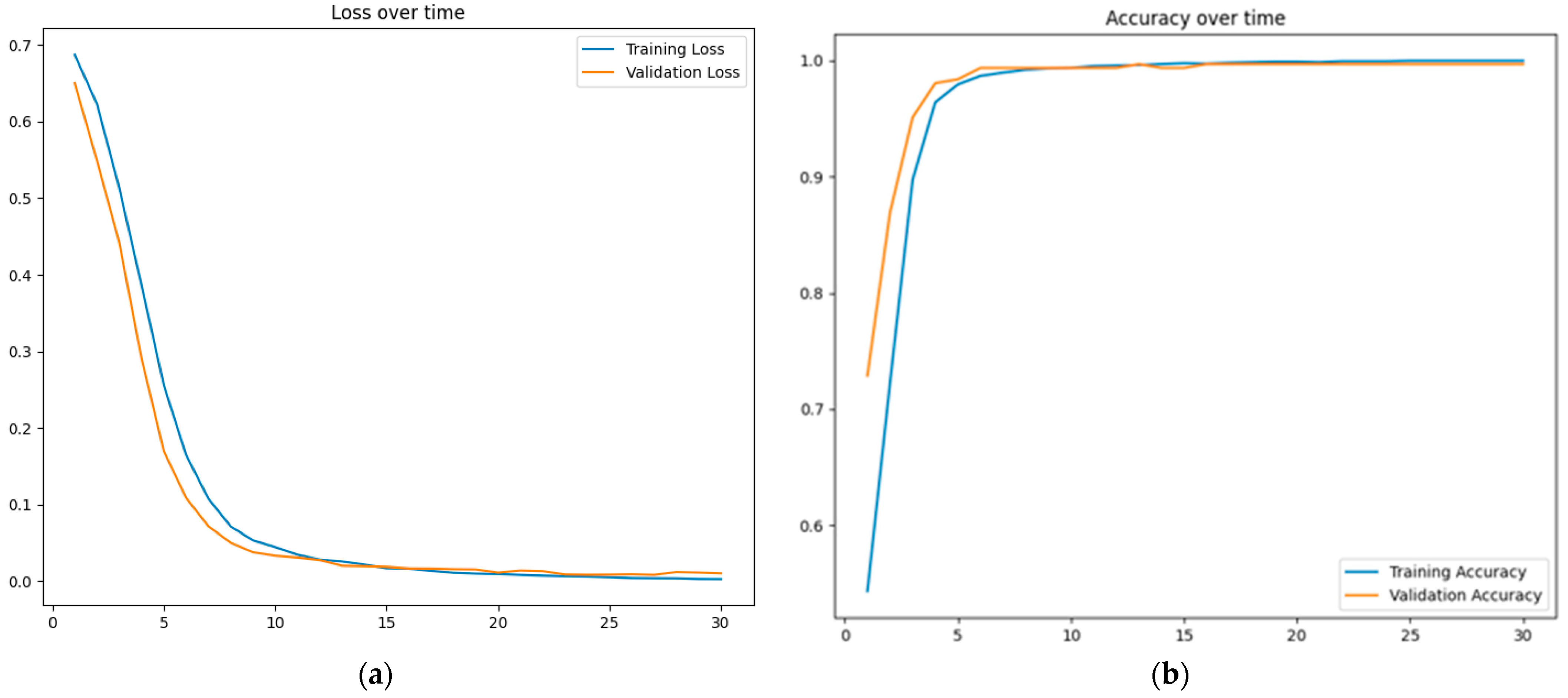
3.2.1. Fine-Tuning Process
3.2.2. Dediacritization Layer
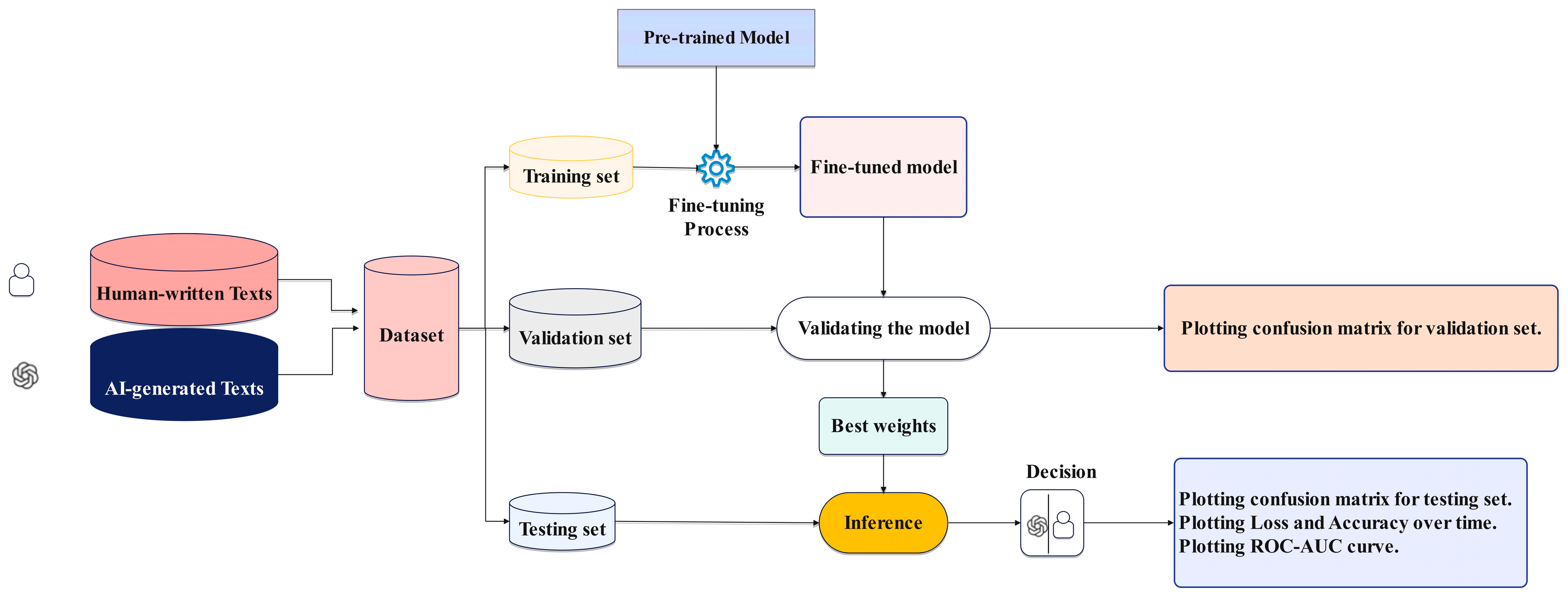
3.3. Pipeline Design
3.4. Experimental Evaluation Protocol
3.5. Hyperparameters
Scheduler and Learning Rate
4. Results
4.1. Our Best Models vs. GPTZero and OpenAI Text Classifier
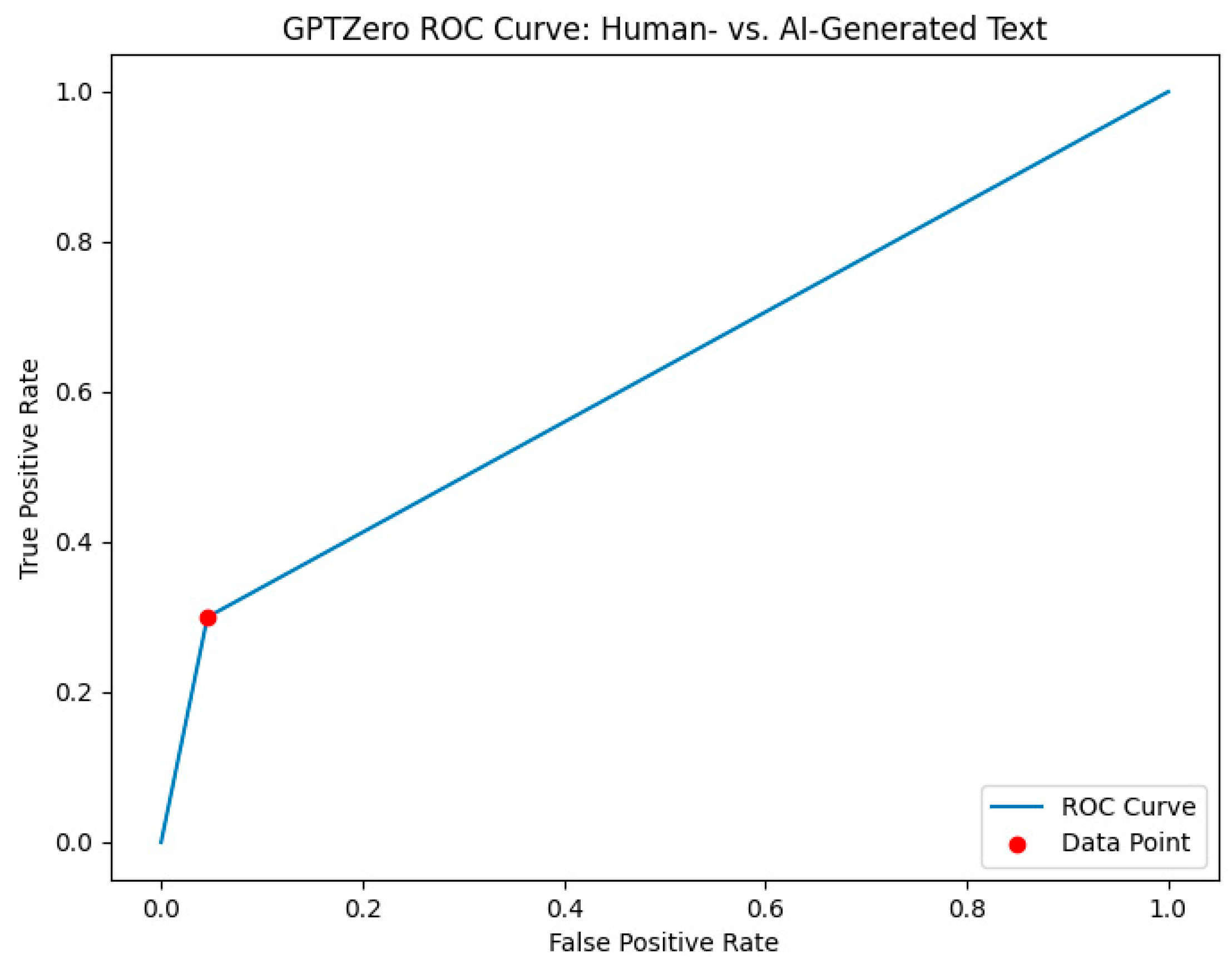
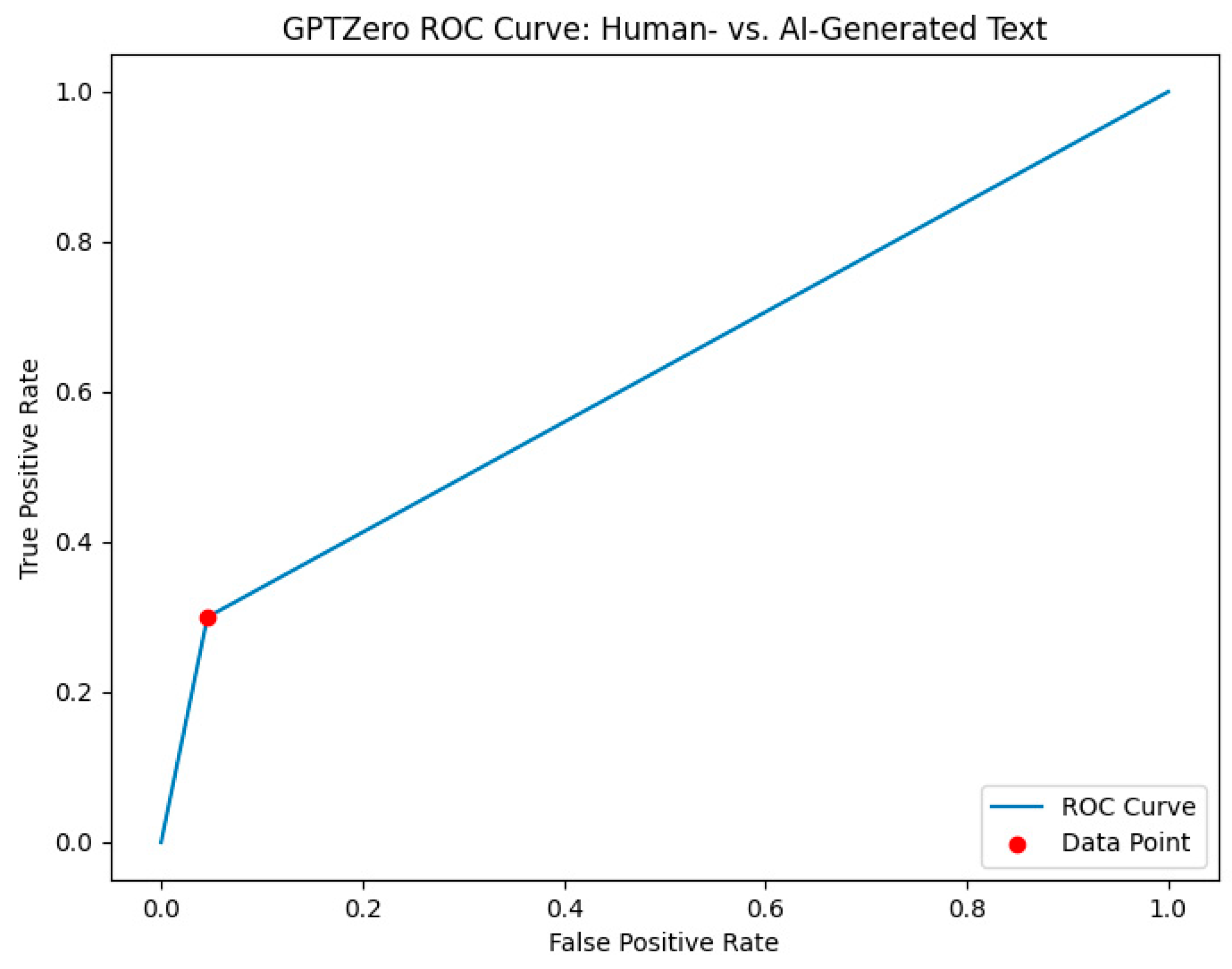
4.1.1. GPTZero against AIRABIC Benchmark Dataset
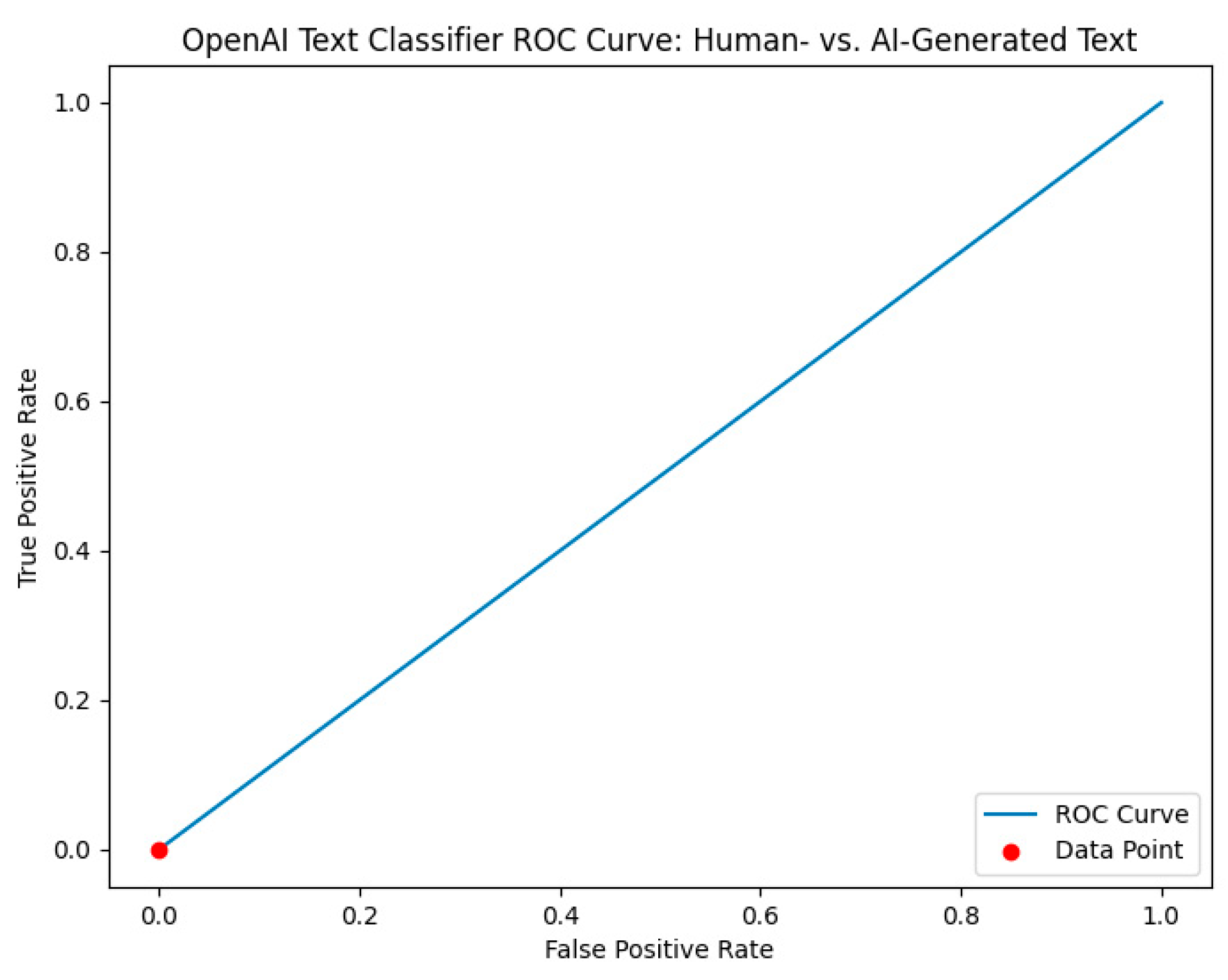
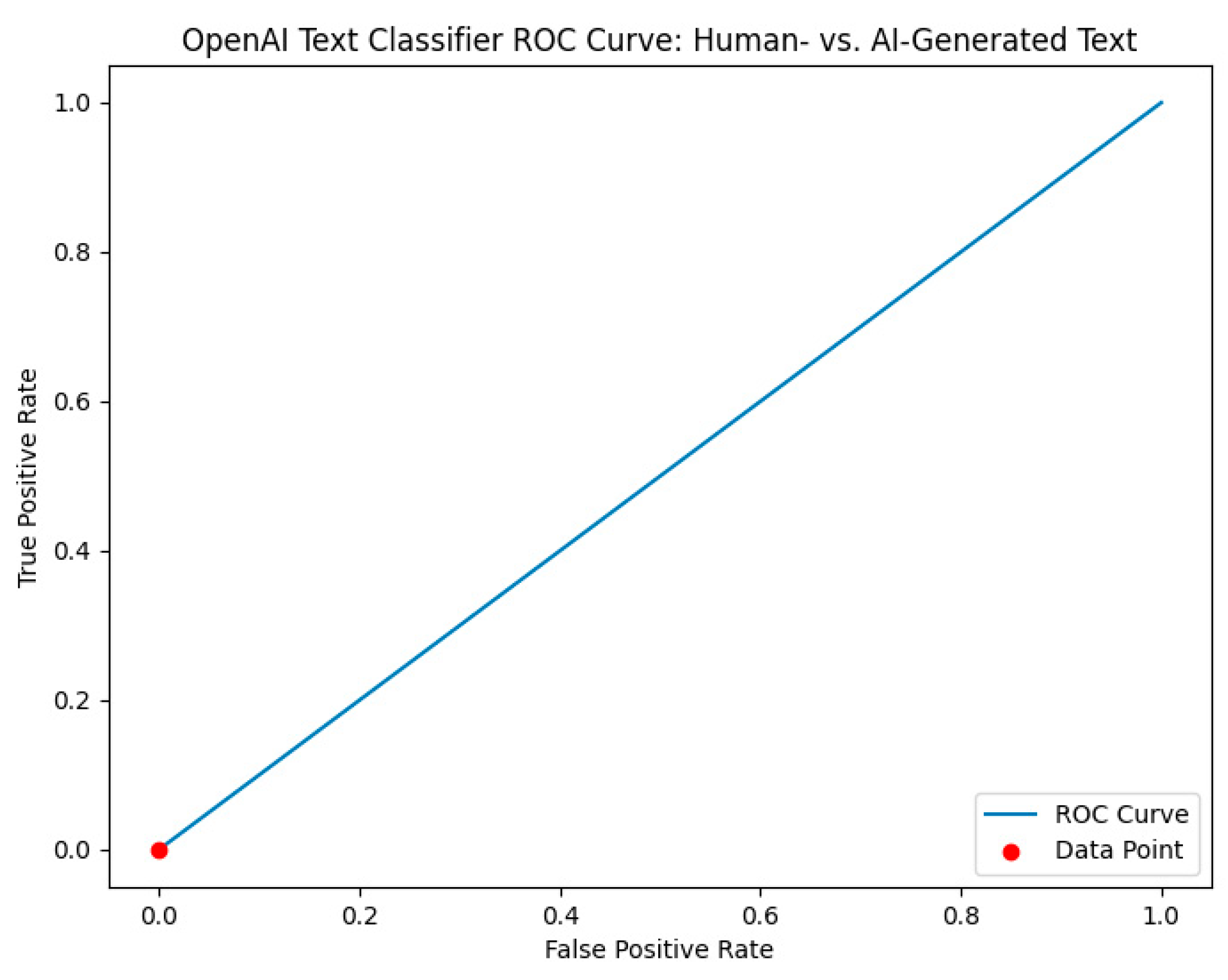
4.1.2. OpenAI Text Classifier against AIRABIC Benchmark Dataset
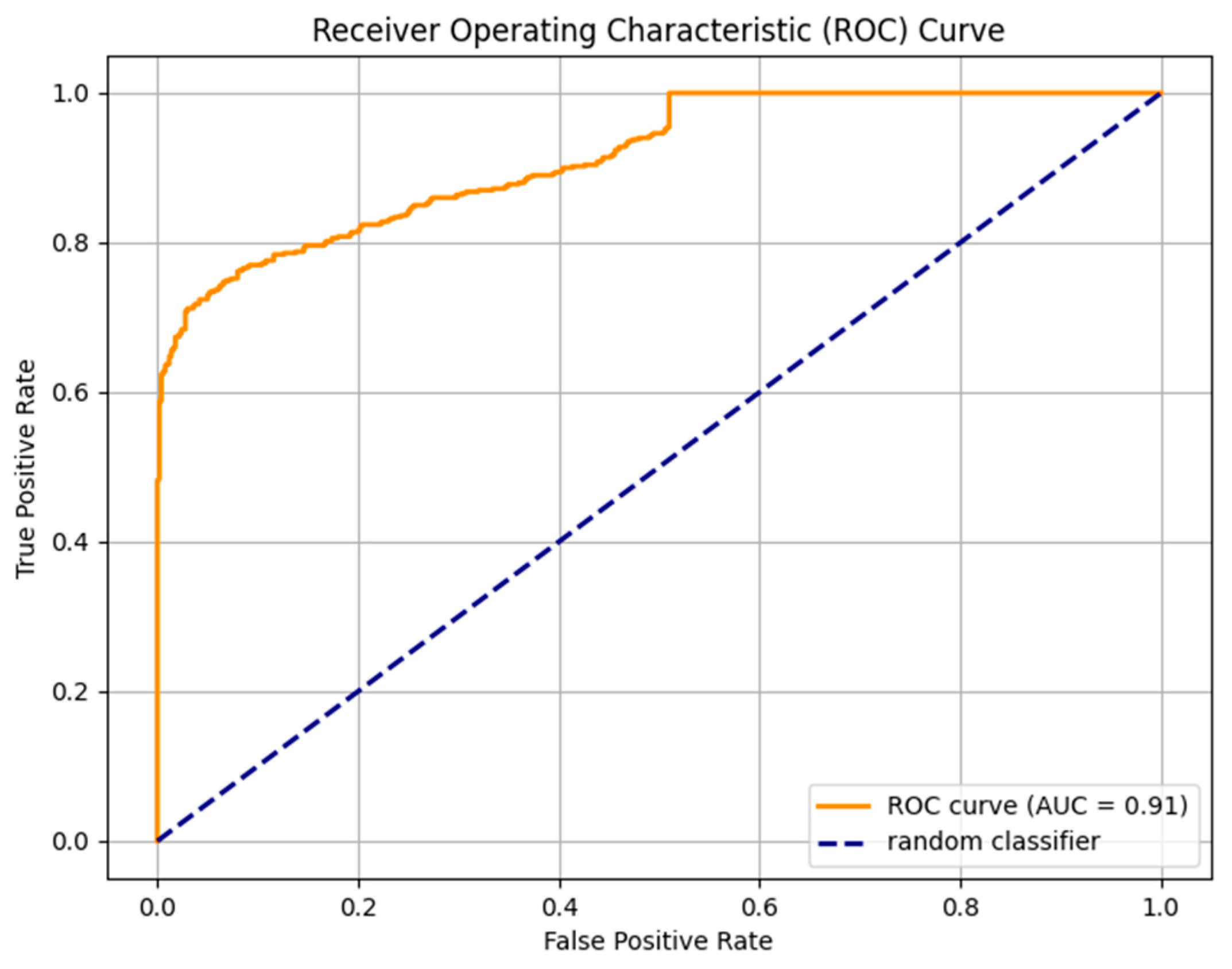
4.1.3. Fine-Tuned AraELECTRA Model against AIRABIC Benchmark Dataset
4.1.4. Fine-Tuned XLM-R Model against AIRABIC Benchmark Dataset
5. Discussion
5.1. Large Dataset vs. Custom Dataset Content Variation
5.2. XLM-R vs. AraELECTRA Performance
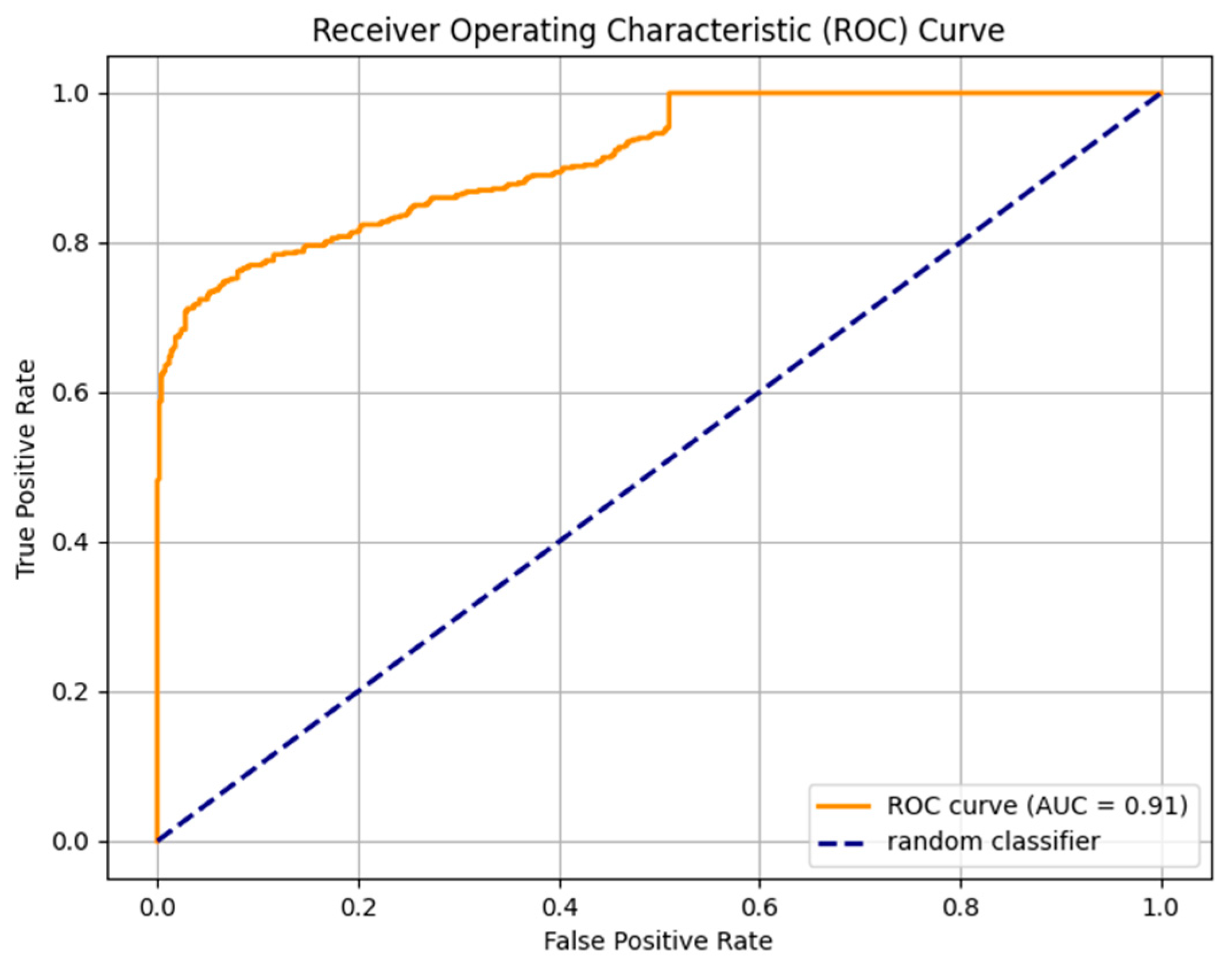
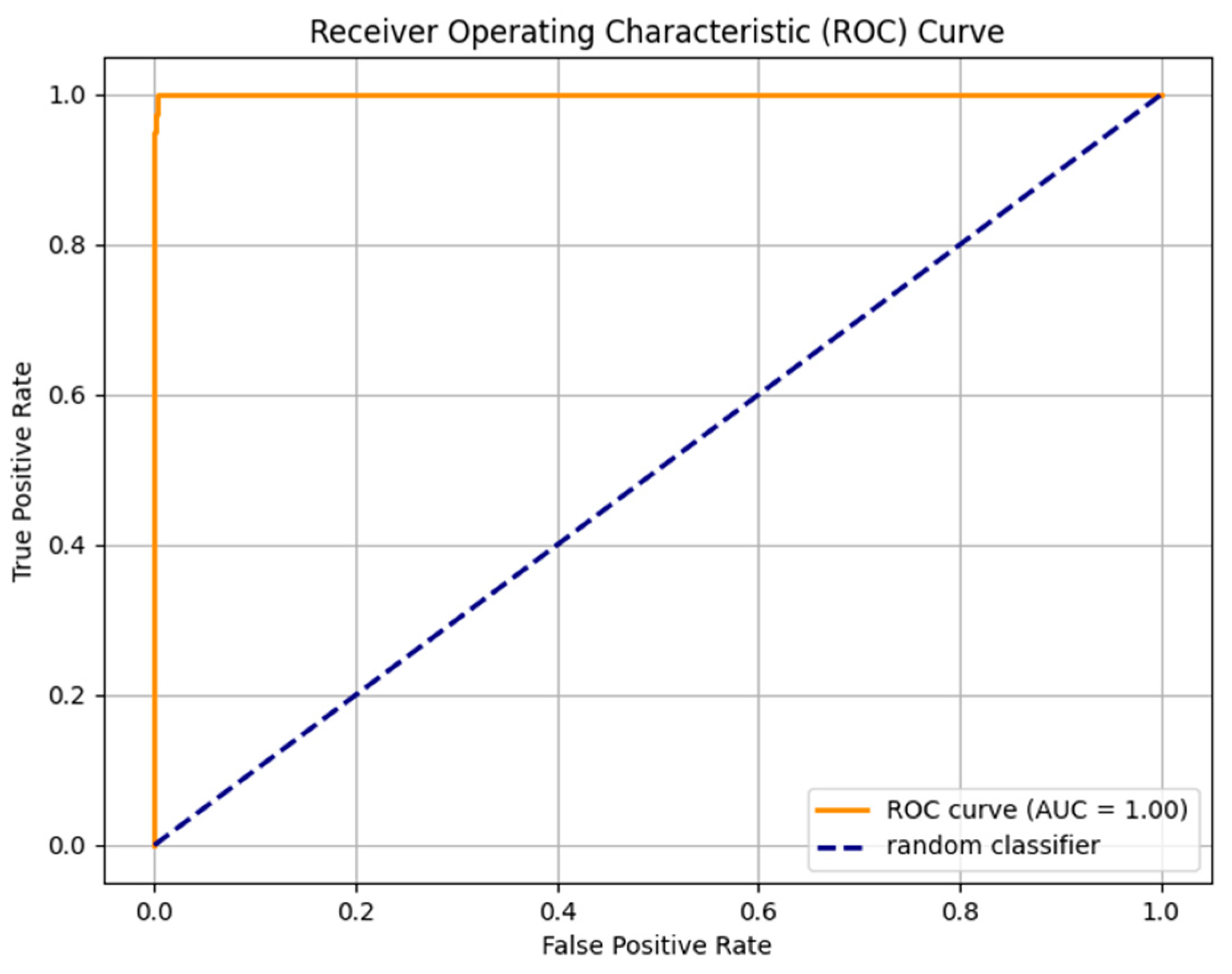
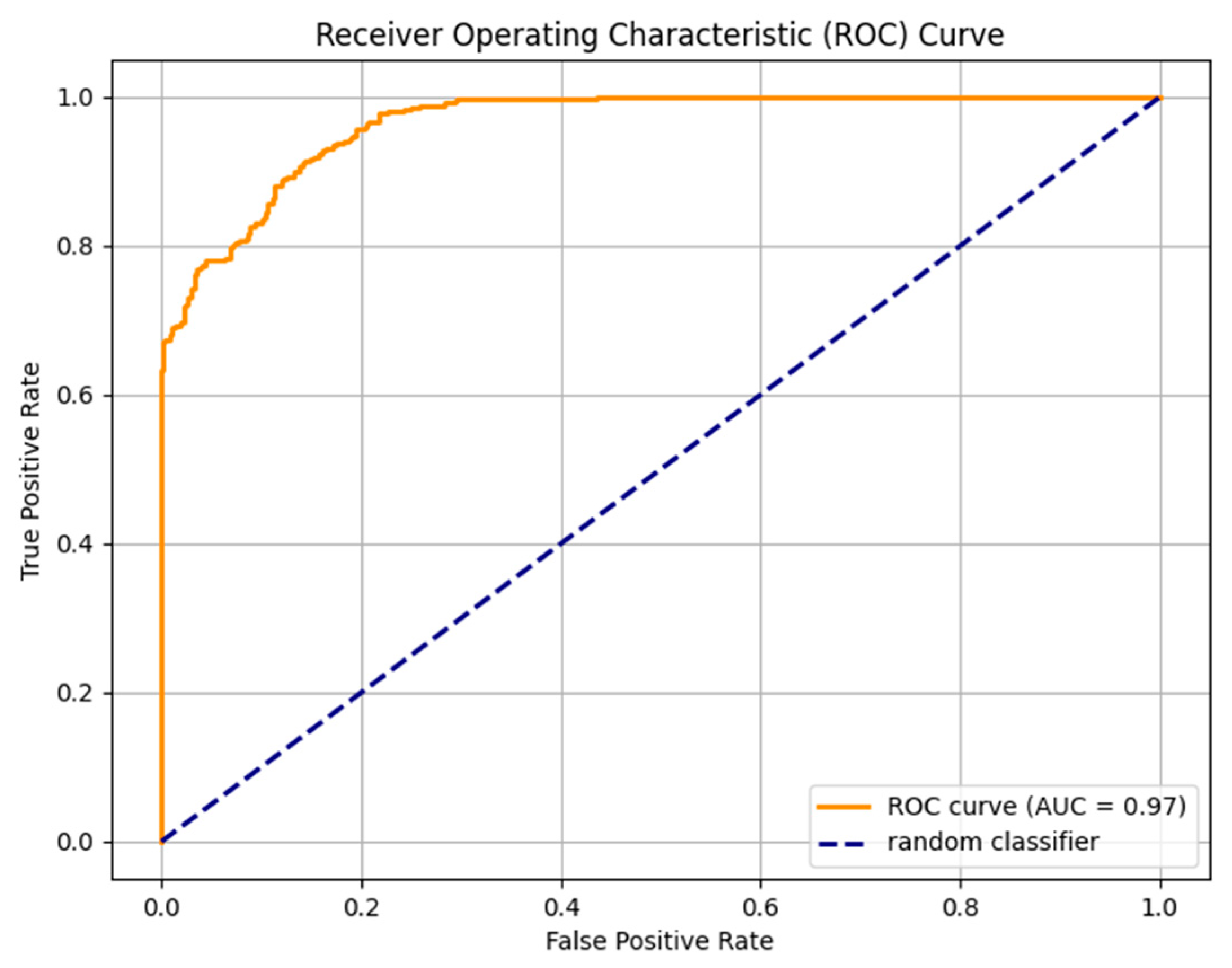
5.3. Improvement Contribution of Dediacritization Layer toward the Classifier
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ahmed, A.; Ali, N.; Alzubaidi, M.; Zaghouani, W.; Abd-alrazaq, A.A.; Househ, M. Freely available Arabic corpora: A scoping review. Comput. Methods Programs Biomed. Update 2022, 2, 100049. [Google Scholar] [CrossRef]
- UNESCO. World Arabic Language Day. Available online: https://www.unesco.org/en/world-arabic-language-day (accessed on 19 December 2023).
- Chemnad, K.; Othman, A. Advancements in Arabic Text-to-Speech Systems: A 22-Year Literature Review. IEEE Access 2023, 11, 30929–30954. [Google Scholar] [CrossRef]
- United Nations. Official Languages. Available online: https://www.un.org/en/our-work/official-languages (accessed on 25 December 2023).
- Obeid, O.; Zalmout, N.; Khalifa, S.; Taji, D.; Oudah, M.; Alhafni, B.; Inoue, G.; Eryani, F.; Erdmann, A.; Habash, N. CAMeL tools: An open source python toolkit for Arabic natural language processing. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 7022–7032. [Google Scholar]
- Farghaly, A.; Shaalan, K. Arabic natural language processing: Challenges and solutions. ACM Trans. Asian Lang. Inf. Process. (TALIP) 2009, 8, 1–22. [Google Scholar] [CrossRef]
- Darwish, K.; Habash, N.; Abbas, M.; Al-Khalifa, H.; Al-Natsheh, H.T.; Bouamor, H.; Bouzoubaa, K.; Cavalli-Sforza, V.; El-Beltagy, S.R.; El-Hajj, W. A panoramic survey of natural language processing in the Arab world. Commun. ACM 2021, 64, 72–81. [Google Scholar] [CrossRef]
- Habash, N.Y. Introduction to Arabic natural language processing. Synth. Lect. Hum. Lang. Technol. 2010, 3, 1–187. [Google Scholar]
- GPTZero. Available online: https://gptzero.me/ (accessed on 1 June 2023).
- OpenAI. Available online: https://beta.openai.com/ai-text-classifier (accessed on 1 June 2023).
- Alshammari, H.; El-Sayed, A. AIRABIC: Arabic Dataset for Performance Evaluation of AI Detectors. In Proceedings of the 2023 International Conference on Machine Learning and Applications (ICMLA), Jacksonville Riverfront, FL, USA, 15–17 December 2023; pp. 1–5. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S. Palm: Scaling language modeling with pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar]
- OpenAI. ChatGPT (Mar 14 Version) [Large Language Model]. Available online: https://chat.openai.com/chat (accessed on 14 March 2023).
- Trichopoulos, G.; Konstantakis, M.; Caridakis, G.; Katifori, A.; Koukouli, M. Crafting a Museum Guide Using ChatGPT4. Big Data Cogn. Comput. 2023, 7, 148. [Google Scholar] [CrossRef]
- Pegoraro, A.; Kumari, K.; Fereidooni, H.; Sadeghi, A.-R. To ChatGPT, or not to ChatGPT: That is the question! arXiv 2023, arXiv:2304.01487. [Google Scholar]
- Wölfel, M.; Shirzad, M.B.; Reich, A.; Anderer, K. Knowledge-Based and Generative-AI-Driven Pedagogical Conversational Agents: A Comparative Study of Grice’s Cooperative Principles and Trust. Big Data Cogn. Comput. 2023, 8, 2. [Google Scholar] [CrossRef]
- Hassani, H.; Silva, E.S. The role of ChatGPT in data science: How ai-assisted conversational interfaces are revolutionizing the field. Big Data Cogn. Comput. 2023, 7, 62. [Google Scholar] [CrossRef]
- Bard. Available online: https://bard.google.com/ (accessed on 30 January 2023).
- Sheng, E.; Chang, K.-W.; Natarajan, P.; Peng, N. Societal biases in language generation: Progress and challenges. arXiv 2021, arXiv:2105.04054. [Google Scholar]
- Weidinger, L.; Uesato, J.; Rauh, M.; Griffin, C.; Huang, P.-S.; Mellor, J.; Glaese, A.; Cheng, M.; Balle, B.; Kasirzadeh, A. Taxonomy of risks posed by language models. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, 21–24 June 2022; pp. 214–229. [Google Scholar]
- Zhuo, T.Y.; Huang, Y.; Chen, C.; Xing, Z. Exploring ai ethics of chatgpt: A diagnostic analysis. arXiv 2023, arXiv:2301.12867. [Google Scholar]
- Cotton, D.R.; Cotton, P.A.; Shipway, J.R. Chatting and cheating: Ensuring academic integrity in the era of ChatGPT. Innov. Educ. Teach. Int. 2023, 61, 228–239. [Google Scholar] [CrossRef]
- Gao, C.A.; Howard, F.M.; Markov, N.S.; Dyer, E.C.; Ramesh, S.; Luo, Y.; Pearson, A.T. Comparing scientific abstracts generated by ChatGPT to original abstracts using an artificial intelligence output detector, plagiarism detector, and blinded human reviewers. BioRxiv 2022. [Google Scholar] [CrossRef]
- Anderson, N.; Belavy, D.L.; Perle, S.M.; Hendricks, S.; Hespanhol, L.; Verhagen, E.; Memon, A.R. AI did not write this manuscript, or did it? Can we trick the AI text detector into generated texts? The potential future of ChatGPT and AI in Sports & Exercise Medicine manuscript generation. BMJ Open Sport Exerc. Med. 2023, 9, e001568. [Google Scholar] [PubMed]
- Kumar, S.; Balachandran, V.; Njoo, L.; Anastasopoulos, A.; Tsvetkov, Y. Language generation models can cause harm: So what can we do about it? An actionable survey. arXiv 2022, arXiv:2210.07700. [Google Scholar]
- Abramski, K.; Citraro, S.; Lombardi, L.; Rossetti, G.; Stella, M. Cognitive network science reveals bias in GPT-3, GPT-3.5 Turbo, and GPT-4 mirroring math anxiety in high-school students. Big Data Cogn. Comput. 2023, 7, 124. [Google Scholar]
- Taecharungroj, V. “What Can ChatGPT Do?” Analyzing Early Reactions to the Innovative AI Chatbot on Twitter. Big Data Cogn. Comput. 2023, 7, 35. [Google Scholar] [CrossRef]
- Zellers, R.; Holtzman, A.; Rashkin, H.; Bisk, Y.; Farhadi, A.; Roesner, F.; Choi, Y. Defending against neural fake news. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. work in progress. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 1 December 2023).
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Gehrmann, S.; Strobelt, H.; Rush, A.M. Gltr: Statistical detection and visualization of generated text. arXiv 2019, arXiv:1906.04043. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Adelani, D.I.; Mai, H.; Fang, F.; Nguyen, H.H.; Yamagishi, J.; Echizen, I. Generating sentiment-preserving fake online reviews using neural language models and their human-and machine-based detection. In Advanced Information Networking and Applications, Proceedings of the 34th International Conference on Advanced Information Networking and Applications (AINA-2020), Caserta, Italy, 15–17 April 2020; pp. 1341–1354.
- Uchendu, A.; Le, T.; Shu, K.; Lee, D. Authorship attribution for neural text generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 8384–8395. [Google Scholar]
- Keskar, N.S.; McCann, B.; Varshney, L.R.; Xiong, C.; Socher, R. Ctrl: A conditional transformer language model for controllable generation. arXiv 2019, arXiv:1909.05858. [Google Scholar]
- Lample, G.; Conneau, A. Cross-lingual language model pretraining. arXiv 2019, arXiv:1901.07291. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Dathathri, S.; Madotto, A.; Lan, J.; Hung, J.; Frank, E.; Molino, P.; Yosinski, J.; Liu, R. Plug and play language models: A simple approach to controlled text generation. arXiv 2019, arXiv:1912.02164. [Google Scholar]
- Ng, N.; Yee, K.; Baevski, A.; Ott, M.; Auli, M.; Edunov, S. Facebook FAIR’s WMT19 news translation task submission. arXiv 2019, arXiv:1907.06616. [Google Scholar]
- Fagni, T.; Falchi, F.; Gambini, M.; Martella, A.; Tesconi, M. TweepFake: About detecting deepfake tweets. PLoS ONE 2021, 16, e0251415. [Google Scholar] [CrossRef] [PubMed]
- Harrag, F.; Debbah, M.; Darwish, K.; Abdelali, A. Bert transformer model for detecting Arabic GPT2 auto-generated tweets. arXiv 2021, arXiv:2101.09345. [Google Scholar]
- Nguyen-Son, H.-Q.; Thao, T.; Hidano, S.; Gupta, I.; Kiyomoto, S. Machine translated text detection through text similarity with round-trip translation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 5792–5797. [Google Scholar]
- Antoun, W.; Baly, F.; Hajj, H. AraGPT2: Pre-trained transformer for Arabic language generation. arXiv 2020, arXiv:2012.15520. [Google Scholar]
- Clark, K.; Luong, M.-T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Jawahar, G.; Abdul-Mageed, M.; Lakshmanan, L.V. Automatic Detection of Entity-Manipulated Text using Factual Knowledge. arXiv 2022, arXiv:2203.10343. [Google Scholar]
- Guo, B.; Zhang, X.; Wang, Z.; Jiang, M.; Nie, J.; Ding, Y.; Yue, J.; Wu, Y. How close is chatgpt to human experts? comparison corpus, evaluation, and detection. arXiv 2023, arXiv:2301.07597. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. Squad: 100,000+ questions for machine comprehension of text. arXiv 2016, arXiv:1606.05250. [Google Scholar]
- Fan, A.; Jernite, Y.; Perez, E.; Grangier, D.; Weston, J.; Auli, M. ELI5: Long form question answering. arXiv 2019, arXiv:1907.09190. [Google Scholar]
- Kirchenbauer, J.; Geiping, J.; Wen, Y.; Katz, J.; Miers, I.; Goldstein, T. A watermark for large language models. arXiv 2023, arXiv:2301.10226. [Google Scholar]
- Fernandez, P.; Chaffin, A.; Tit, K.; Chappelier, V.; Furon, T. Three bricks to consolidate watermarks for large language models. arXiv 2023, arXiv:2308.00113. [Google Scholar]
- Christ, M.; Gunn, S.; Zamir, O. Undetectable Watermarks for Language Models. arXiv 2023, arXiv:2306.09194. [Google Scholar]
- Mitrović, S.; Andreoletti, D.; Ayoub, O. Chatgpt or human? detect and explain. explaining decisions of machine learning model for detecting short chatgpt-generated text. arXiv 2023, arXiv:2301.13852. [Google Scholar]
- Antoun, W.; Mouilleron, V.; Sagot, B.; Seddah, D. Towards a Robust Detection of Language Model Generated Text: Is ChatGPT that Easy to Detect? arXiv 2023, arXiv:2306.05871. [Google Scholar]
- De Bruyn, M.; Lotfi, E.; Buhmann, J.; Daelemans, W. MFAQ: A multilingual FAQ dataset. arXiv 2021, arXiv:2109.12870. [Google Scholar]
- Martin, L.; Muller, B.; Suárez, P.J.; Dupont, Y.; Romary, L.; de La Clergerie, É.V.; Seddah, D.; Sagot, B. CamemBERT: A tasty French language model. arXiv 2019, arXiv:1911.03894. [Google Scholar]
- Antoun, W.; Sagot, B.; Seddah, D. Data-Efficient French Language Modeling with CamemBERTa. arXiv 2023, arXiv:2306.01497. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Mozannar, H.; Hajal, K.E.; Maamary, E.; Hajj, H. Neural Arabic question answering. arXiv 2019, arXiv:1906.05394. [Google Scholar]
- Clark, J.H.; Choi, E.; Collins, M.; Garrette, D.; Kwiatkowski, T.; Nikolaev, V.; Palomaki, J. Tydi qa: A benchmark for information-seeking question answering in ty pologically di verse languages. Trans. Assoc. Comput. Linguist. 2020, 8, 454–470. [Google Scholar] [CrossRef]
- Lewis, P.; Oğuz, B.; Rinott, R.; Riedel, S.; Schwenk, H. MLQA: Evaluating cross-lingual extractive question answering. arXiv 2019, arXiv:1910.07475. [Google Scholar]
- Nguyen, T.T.; Hatua, A.; Sung, A.H. How to Detect AI-Generated Texts? In 2023 IEEE 14th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON); IEEE: Piscataway, NJ, USA, 2023. [Google Scholar]
- Zerrouki, T.; Balla, A. Tashkeela: Novel corpus of Arabic vocalized texts, data for auto-diacritization systems. Data Brief. 2017, 11, 147–151. [Google Scholar] [CrossRef]
- Shamela. Available online: https://shamela.ws/ (accessed on 3 August 2023).
- Aldiwan: Encyclopedia of Arabic Poetry. Available online: https://www.aldiwan.net/ (accessed on 1 October 2023).
- Antoun, W.; Baly, F.; Hajj, H. AraELECTRA: Pre-training text discriminators for Arabic language understanding. arXiv 2020, arXiv:2012.15516. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Custom Dataset AIGT | |||||||
|---|---|---|---|---|---|---|---|
| ChatGPT | BARD | ||||||
| Model 3.5 turpo | Model 4 | - | |||||
| 513 Prompts | 513 Prompts | 513 Prompts | |||||
| Topics | |||||||
| Literature | Titles and Nicknames | Islamic Studies | Media and Publishing | History | Geography | ||
| 71 prompts | 29 prompts | 100 prompts | 75 prompts | 106 prompts | 132 prompts | ||
| Custom Dataset HWT | ||
|---|---|---|
| Shamela Library | Aldiwan website | Tashkila dataset (diacritics-free) |
| 249 samples obtained from book passages | 240 samples obtained from poets’ biographies | 1050 samples, including book passages, human text chats, and lecture notes |
| Parameter | Value | Description |
|---|---|---|
| Seed | 1 | Used consistent random seed throughout all experiments. |
| Batch Size (Large Dataset) | 64 | Used for training, validation, and testing phases. |
| Batch Size (Custom Dataset) | 32 to 64 | Varied to find the optimal setting for model performance. |
| Epochs | 10 | Range considered: 30 to 8; results reported for 10 epochs. |
| Early Stopping Patience (<10 Epochs) | 3 to 4 | To prevent overfitting, applied for models trained for less than 10 epochs. |
| Early Stopping Patience (>10 Epochs) | 5 to 7 | Applied when training for more than 10 epochs to mitigate overfitting. |
| Initial Testing Batch Size | 8 | Initial size used during the inference phase. |
| Adjusted Testing Batch Size | 32 | Incremented to enhance performance and decrease loss. |
| Model | Trained on | Evaluated on | Precision | Recall | F1 Score | AUC-ROC | Loss |
|---|---|---|---|---|---|---|---|
| AraELECTRA | Custom Dataset | Validation set | 1.0 | 1.0 | 1.0 | 1.0 | 0.0002 |
| Testing set | 1.0 | 1.0 | 1.0 | 1.0 | 0.0006 | ||
| Large dataset | 0.9437 | 0.7333 | 0.8253 | 0.9525 | 0.8197 | ||
| AIRABIC without Dediacritization Layer | 0.7953 | 0.824 | 0.8094 | 0.9139 | 0.4267 | ||
| AIRABIC with Dediacritization Layer | 0.9900 | 1.0 | 0.9950 | 0.9998 | 0.0302 | ||
| Large Dataset | Validation set | 0.9968 | 0.9955 | 0.9961 | 0.9999 | 0.0138 | |
| Testing set | 0.9995 | 0.9927 | 0.9961 | 0.9999 | 0.0180 | ||
| Custom dataset | 0.9114 | 0.9411 | 0.9260 | 0.9698 | 0.4422 | ||
| AIRABIC without Dediacritization Layer | 0.6435 | 0.928 | 0.7600 | 0.7745 | 2.42 | ||
| AIRABIC with Dediacritization Layer | 0.8169 | 1.0 | 0.8992 | 0.9719 | 0.6587 | ||
| XLM-R | Custom Dataset | Validation set | 1.0 | 1.0 | 1.0 | 1.0 | 0.0003 |
| Testing set | 1.0 | 0.9608 | 0.98 | 0.9804 | 0.1426 | ||
| Large dataset | 0.9223 | 0.8753 | 0.8982 | 0.9476 | 0.6820 | ||
| AIRABIC without Dediacritization Layer | 1.0 | 0.634 | 0.7760 | 0.9652 | 1.372 | ||
| AIRABIC with Dediacritization Layer | 1.0 | 1.0 | 1.0 | 1.0 | 0.0001 | ||
| Large Dataset | Validation set | 0.9977 | 0.9977 | 0.9977 | 0.9997 | 0.0153 | |
| Testing set | 0.9977 | 0.9977 | 0.9977 | 0.9999 | 0.0151 | ||
| Custom dataset | 0.5 | 0.9738 | 0.6607 | 0.8223 | 4.4082 | ||
| AIRABIC without Dediacritization Layer | 0.5263 | 1.0 | 0.6896 | 0.7182 | 3.9560 | ||
| AIRABIC with Dediacritization Layer | 0.5470 | 1.0 | 0.7072 | 0.9042 | 3.5100 |
| GPTZero | Predicted: Human-Written | Predicted: Al-Generated | Performance Metrics | Value |
|---|---|---|---|---|
| Actual: Human-written | 150 (TP) | 350 (FN) | Sensitivity | 30% |
| Specificity | 95% | |||
| Actual: Al-generated | 23 (FP) | 477 (TN) | Precision | 86.7% |
| Accuracy | 62.7% | |||
| F1-Score | 44.5% |
| OpenAI Text Classifier | Predicted: Human-Written | Predicted: Al-Generated | Performance Metrics | Value |
|---|---|---|---|---|
| Actual: Human-written | 0 (TP) | 500 (FN) | Sensitivity | 0% |
| Specificity | 100% | |||
| Actual: Al-generated | 0 (FP) | 500 (TN) | Precision | 0% |
| Accuracy | 50% | |||
| F1-Score | 0% |
| AraELECTRA Model | Predicted: Human-Written | Predicted: Al-Generated | Performance Metrics | Value |
|---|---|---|---|---|
| Actual: Human-written | 412 (TP) | 88 (FN) | Sensitivity | 82% |
| Specificity | 79% | |||
| Actual: Al-generated | 106 (FP) | 394 (TN) | Precision | 79% |
| Accuracy | 81% | |||
| F1-Score | 82% |
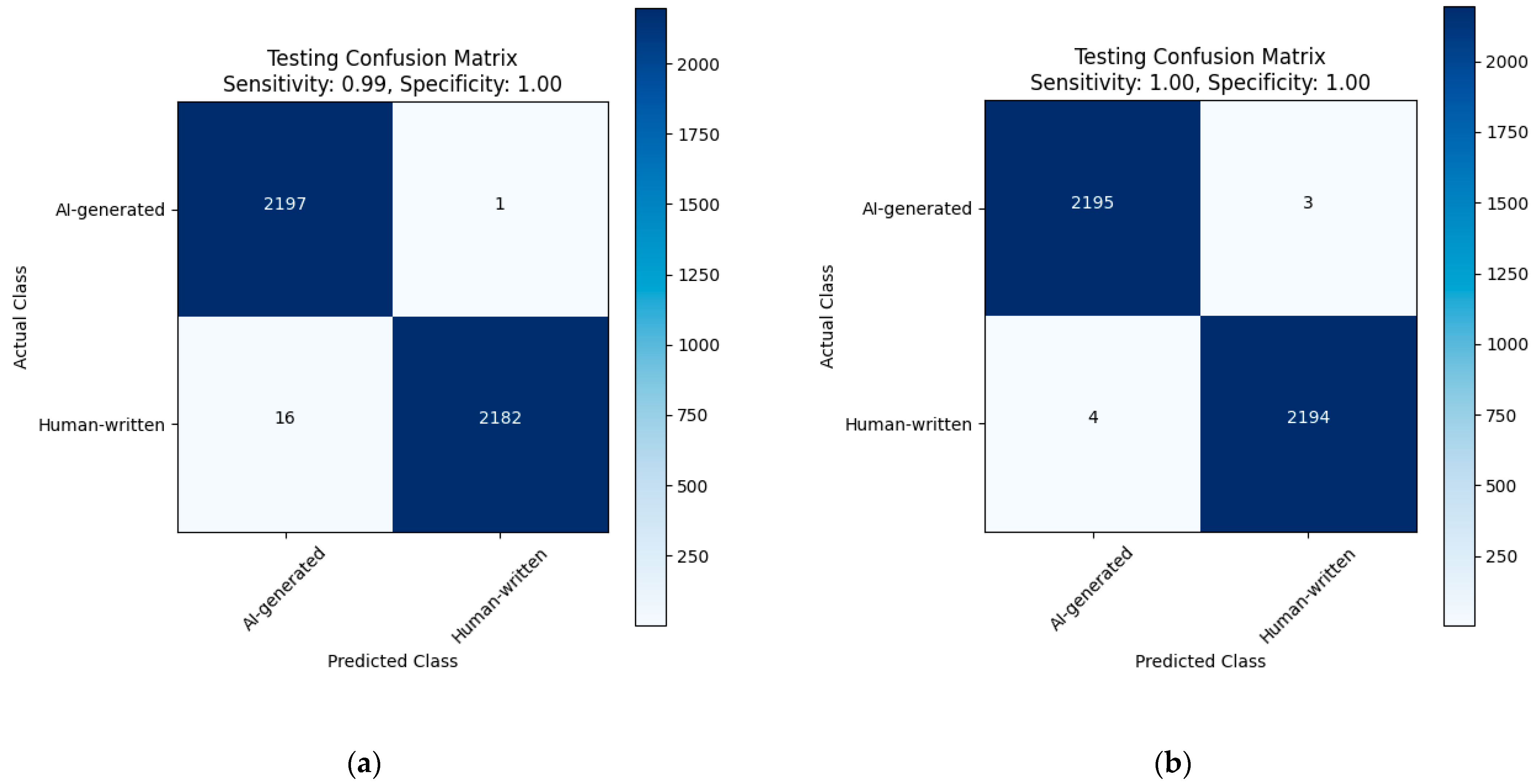
| AraELECTRA Model | Predicted: Human-Written | Predicted: Al-Generated | Performance Metrics | Value |
|---|---|---|---|---|
| Actual: Human-written | 500 (TP) | 0 (FN) | Sensitivity | 100% |
| Specificity | 99% | |||
| Actual: Al-generated | 5 (FP) | 495 (TN) | Precision | 99% |
| Accuracy | 99% | |||
| F1-Score | 99% |
| XLM-R Model | Predicted: Human-Written | Predicted: Al-Generated | Performance Metrics | Value |
|---|---|---|---|---|
| Actual: Human-written | 317 (TP) | 183 (FN) | Sensitivity | 63% |
| Specificity | 100% | |||
| Actual: Al-generated | 0 (FP) | 500 (TN) | Precision | 100% |
| Accuracy | 81% | |||
| F1-Score | 77% |
| XLM-R Model | Predicted: Human-Written | Predicted: Al-Generated | Performance Metrics | Value |
|---|---|---|---|---|
| Actual: Human-written | 500 (TP) | 0 (FN) | Sensitivity | 100% |
| Specificity | 100% | |||
| Actual: Al-generated | 0 (FP) | 500 (TN) | Precision | 100% |
| Accuracy | 100% | |||
| F1-Score | 100% |
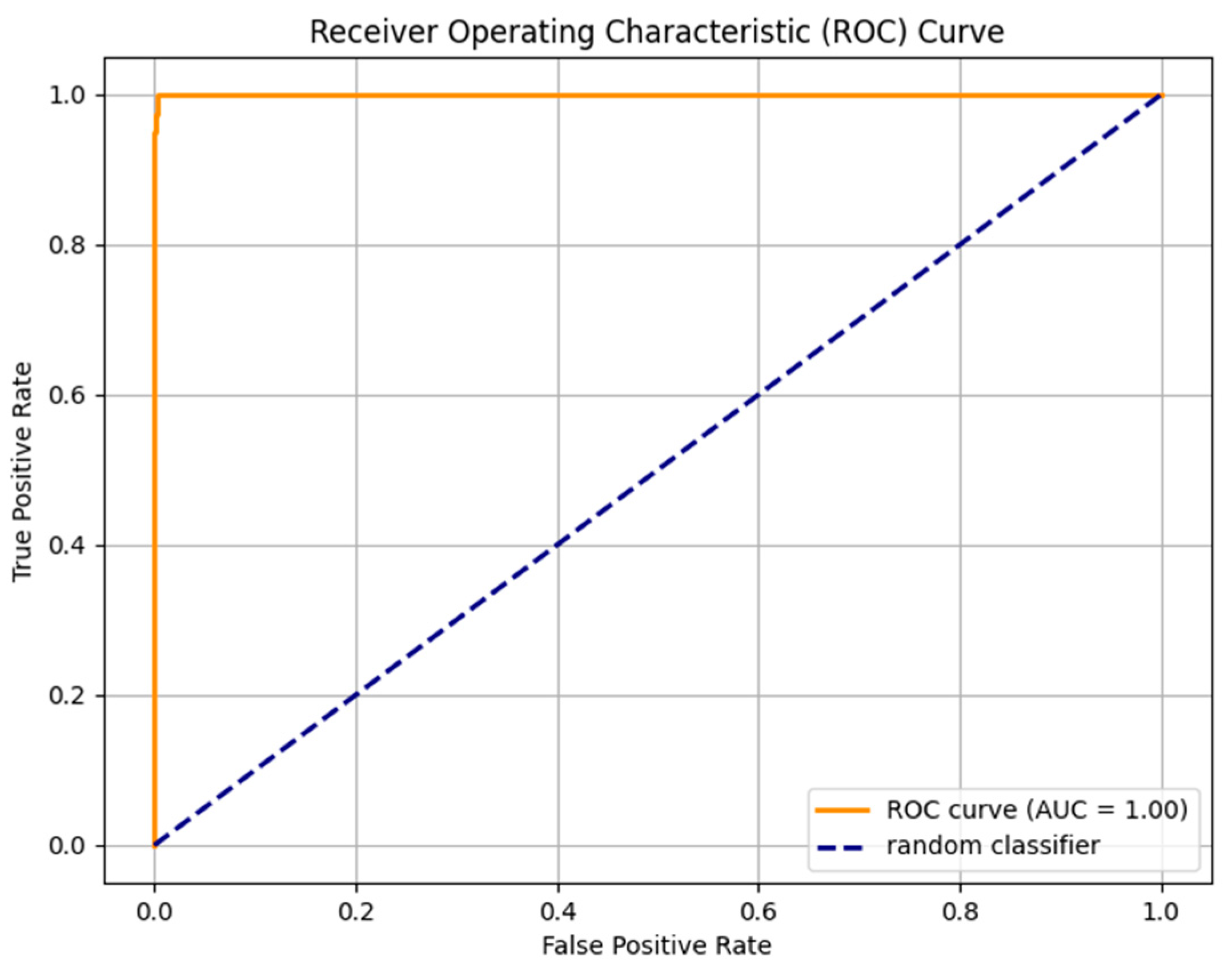
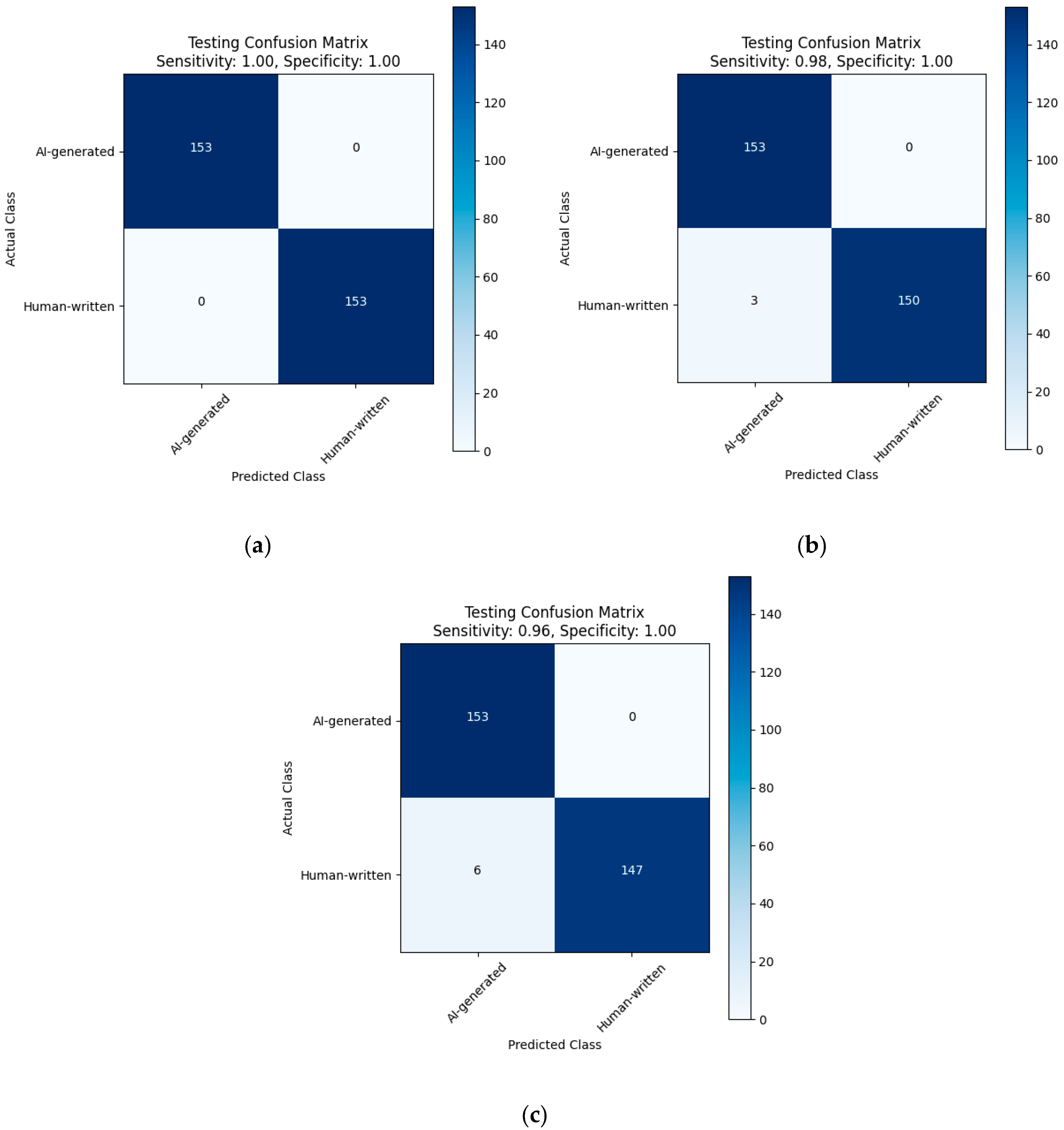
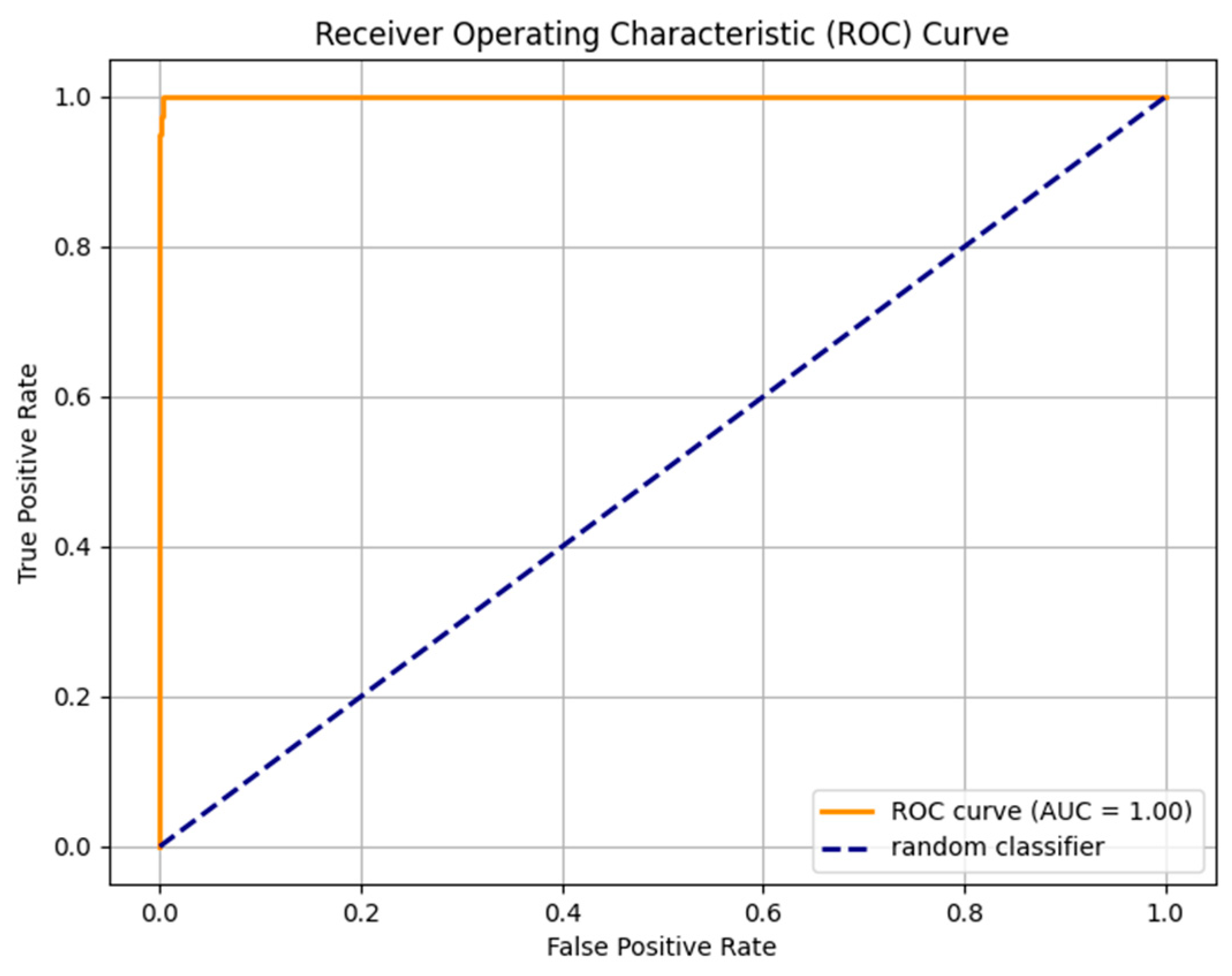
| Without Dediacritization Layer | With Dediacritization Layer |
|---|---|
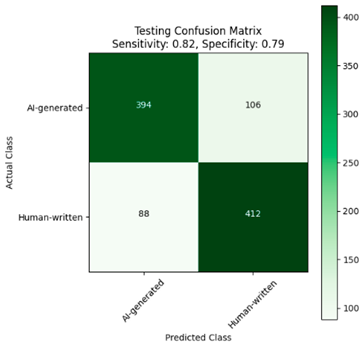 | 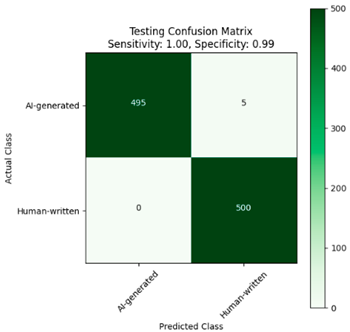 |
| (a) | (b) |
| Fine-tuned AraELECTRA model trained on the custom dataset. (a) Without Dediacritization Layer. (b) With Dediacritization Layer. | |
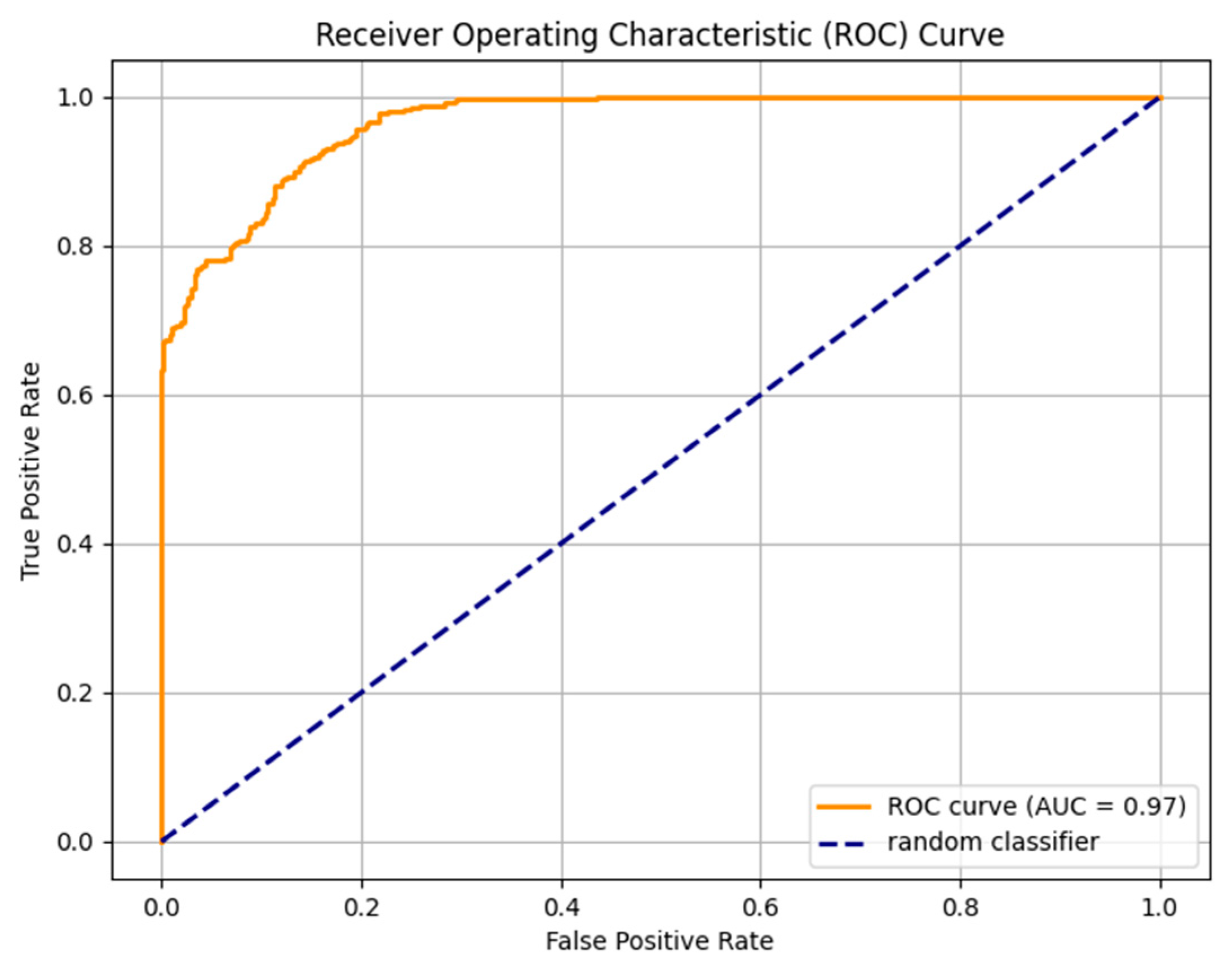
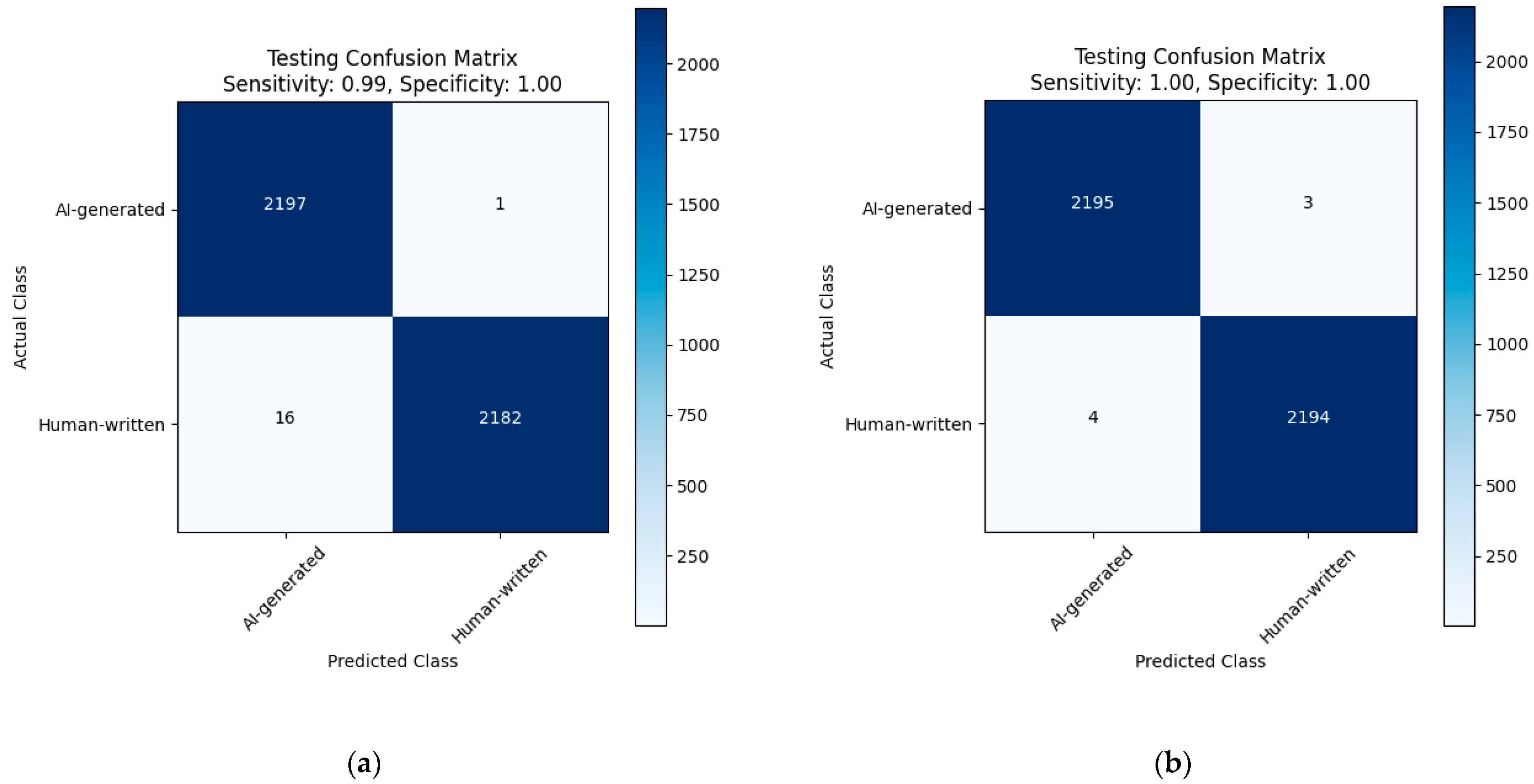
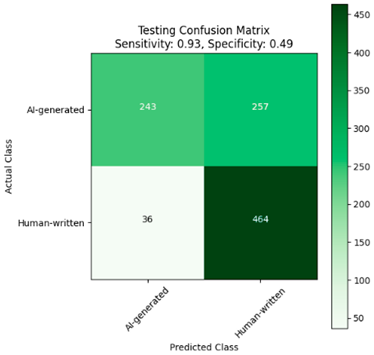 |  |
| (a) | (b) |
| Fine-tuned AraELECTRA model trained on the large dataset. (a) Without Dediacritization Layer. (b) With Dediacritization Layer. | |
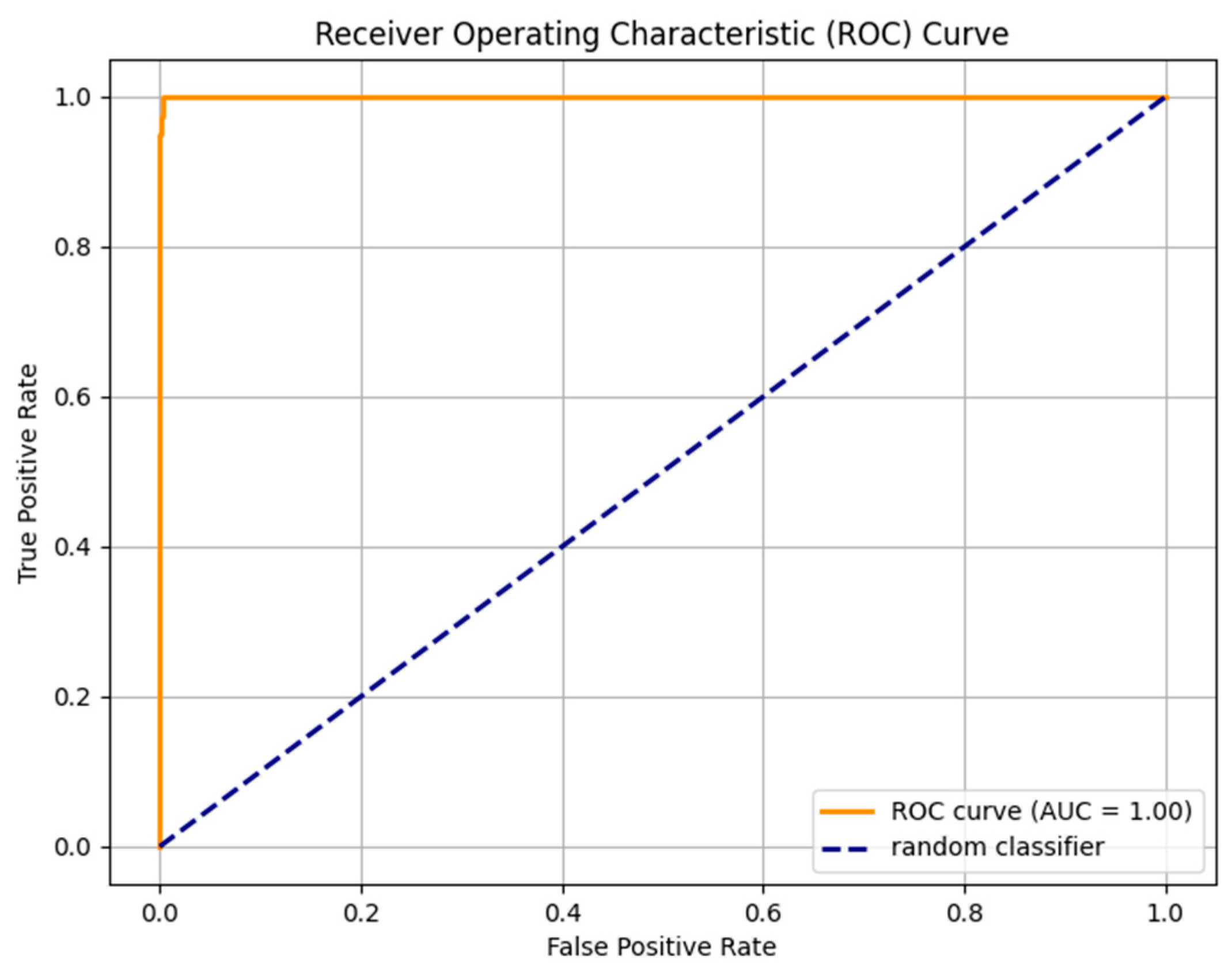
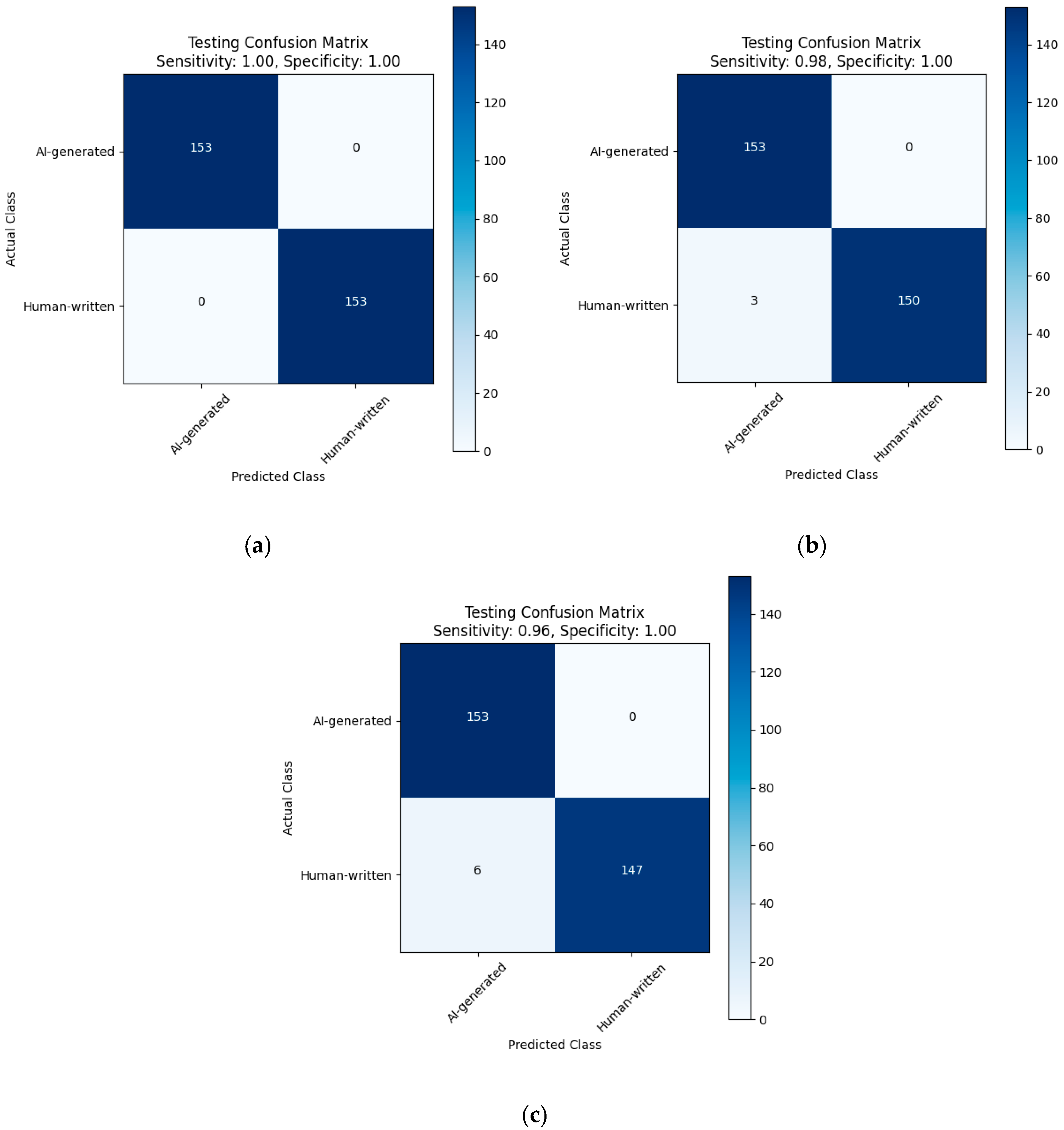
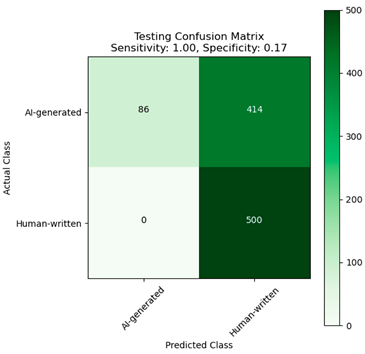
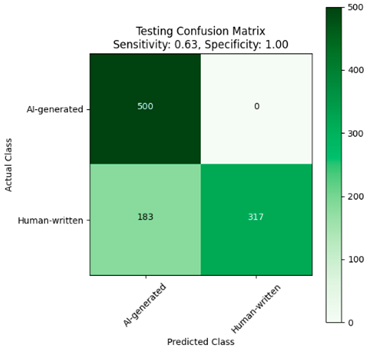 |  |
| (a) | (b) |
| Fine-tuned XLM-R model trained on the custom dataset. (a) Without Dediacritization Layer. (b) With Dediacritization Layer. | |
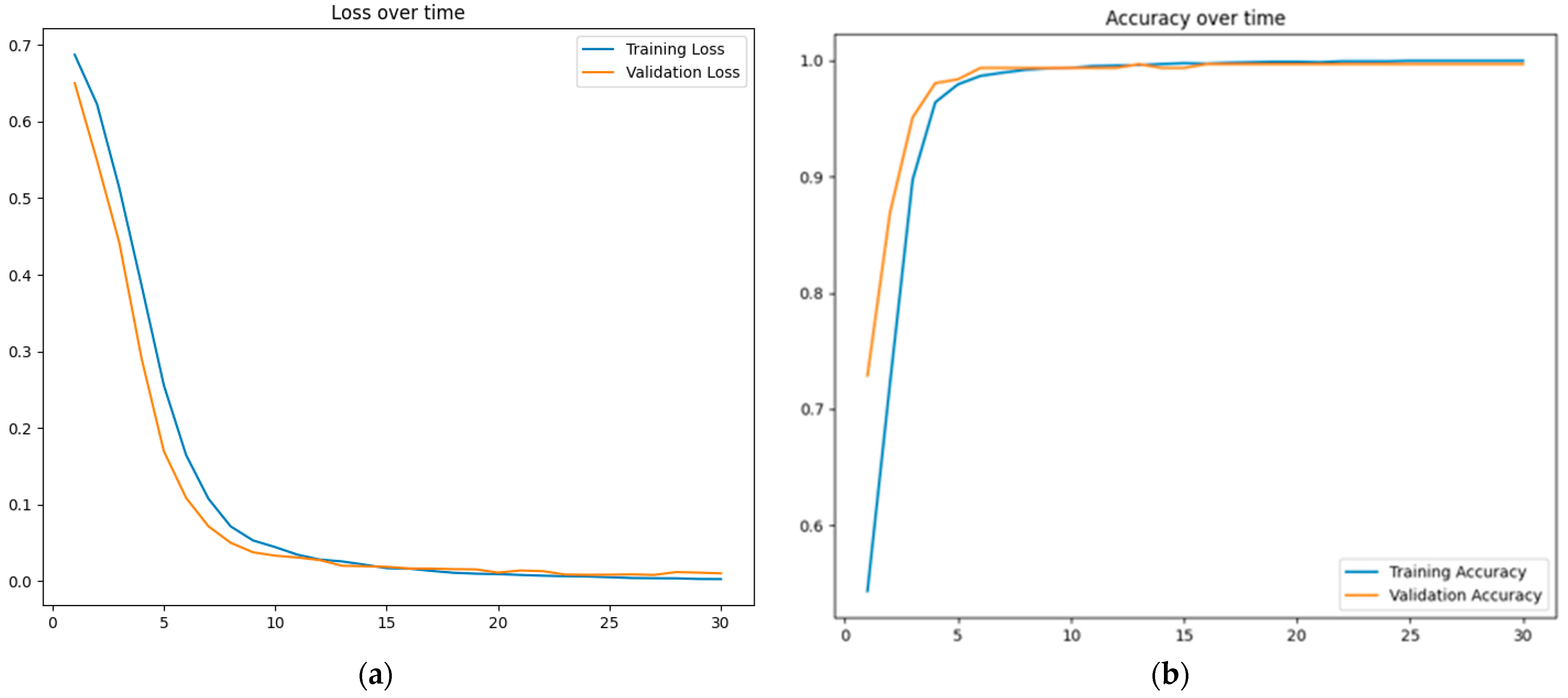
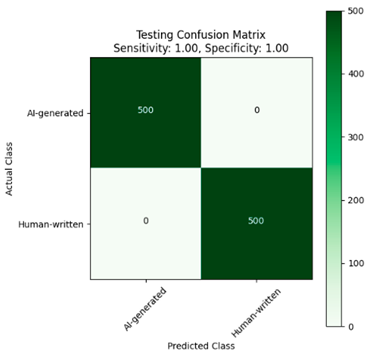
 |  |
| (a) | (b) |
| Fine-tuned XLM-R model trained on the large dataset. (a) Without Dediacritization Layer. (b) With Dediacritization Layer. | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alshammari, H.; El-Sayed, A.; Elleithy, K. AI-Generated Text Detector for Arabic Language Using Encoder-Based Transformer Architecture. Big Data Cogn. Comput. 2024, 8, 32. https://doi.org/10.3390/bdcc8030032
Alshammari H, El-Sayed A, Elleithy K. AI-Generated Text Detector for Arabic Language Using Encoder-Based Transformer Architecture. Big Data and Cognitive Computing. 2024; 8(3):32. https://doi.org/10.3390/bdcc8030032
Chicago/Turabian StyleAlshammari, Hamed, Ahmed El-Sayed, and Khaled Elleithy. 2024. "AI-Generated Text Detector for Arabic Language Using Encoder-Based Transformer Architecture" Big Data and Cognitive Computing 8, no. 3: 32. https://doi.org/10.3390/bdcc8030032
APA StyleAlshammari, H., El-Sayed, A., & Elleithy, K. (2024). AI-Generated Text Detector for Arabic Language Using Encoder-Based Transformer Architecture. Big Data and Cognitive Computing, 8(3), 32. https://doi.org/10.3390/bdcc8030032