
An Efficient Multi-Scale Anchor Box Approach to Detect Partial Faces from a Video Sequence




Abstract
:1. Introduction
- i.
- We proposed a deep convolutional neural network for partial face detection using the anchor box selection strategy on the FDDB dataset;
- ii.
- We utilized the class existence probability of anchor proposals to classify the partial features of faces;
- iii.
- We considered eight anchor boxes and two scales to avoid extra computations. Anchor boxes sizes and scales were chosen from facial subparts and shapes;
- iv.
- The proposed method shows the balance performance between precision and detection speed;
- v.
- The proposed method examined the FDDB dataset with partial face examples, and the results were compared with the other state-of-the-art face detection methods.
2. Related Work
2.1. Handcrafted Face Detection Methods
2.2. Deep-Learning-Based Face Detectors
3. Methodology
3.1. Proposed Work
3.2. Anchor Box Selection Approach
4. Experimental Analysis
4.1. Dataset
4.2. Evaluation Matrices
4.3. Experimental Setup
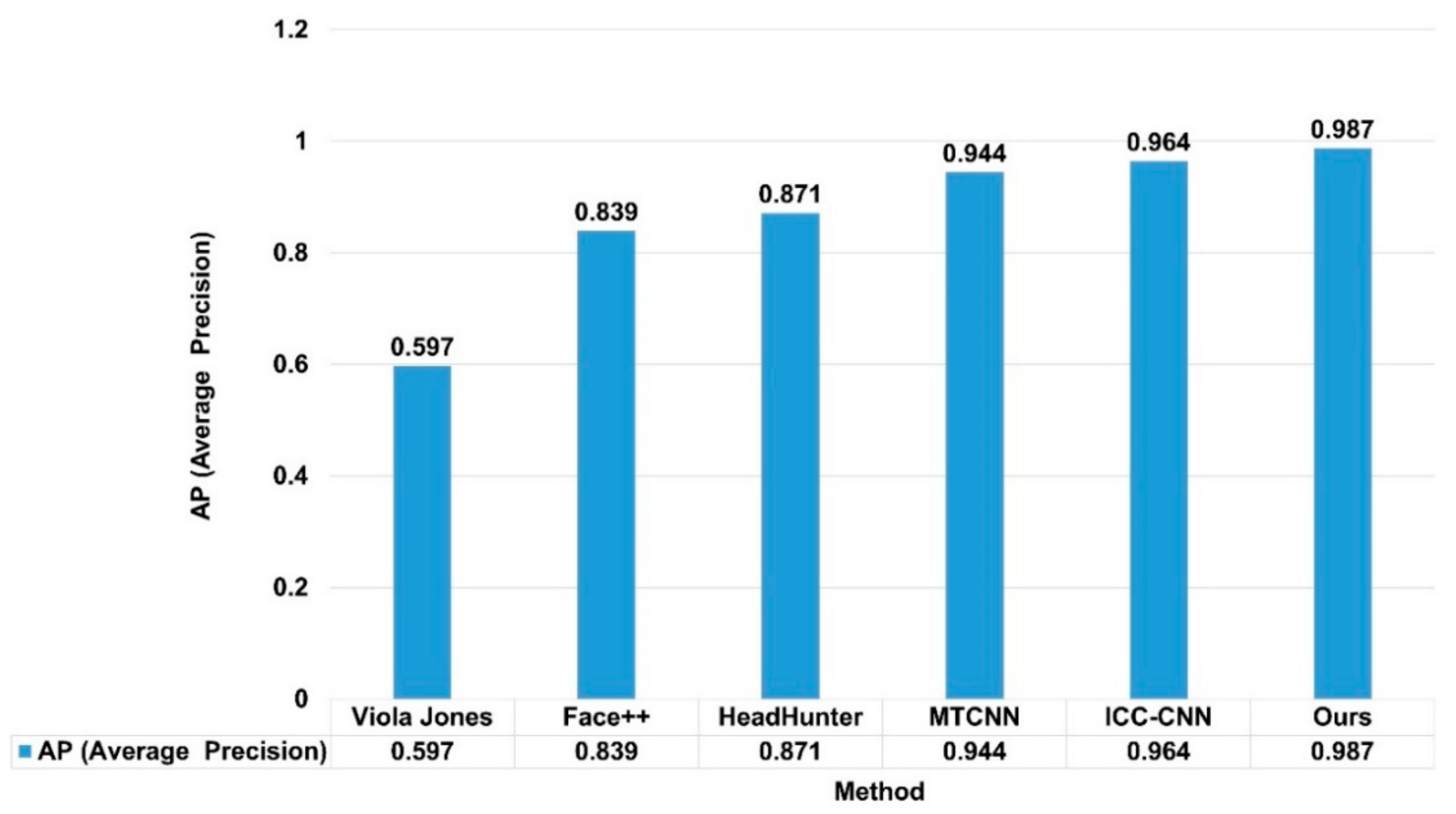
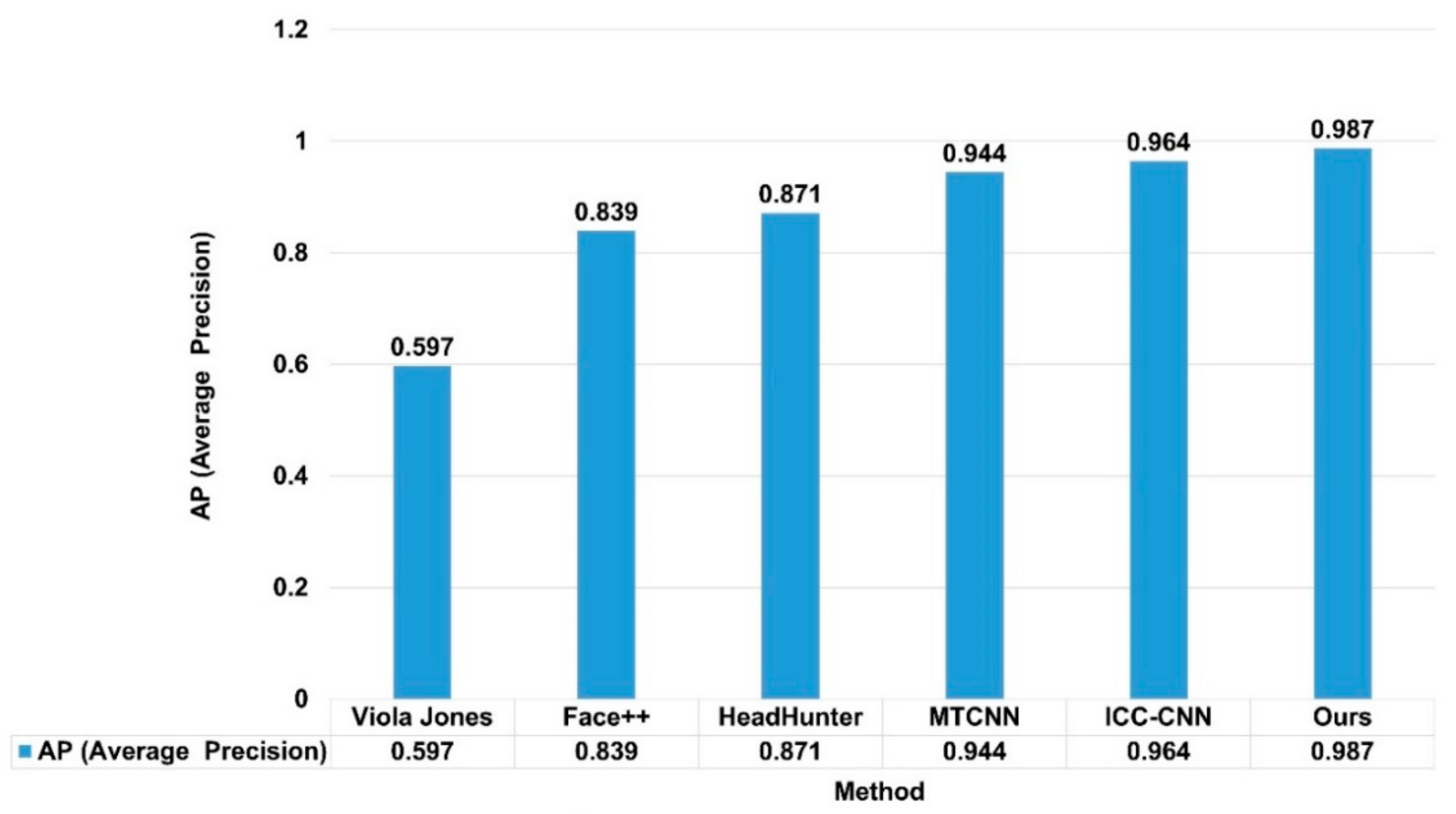
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Faster, R. Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L.S. Ssh: Single stage headless face detector. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4875–4884. [Google Scholar]
- Tang, X.; Du, D.K.; He, Z.; Liu, J. Pyramidbox: A context-assisted single shot face detector. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 797–813. [Google Scholar]
- Li, J.; Wang, Y.; Wang, C.; Tai, Y.; Qian, J.; Yang, J.; Wang, C.; Li, J.; Huang, F. DSFD: Dual shot face detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5060–5069. [Google Scholar]
- Zeng, D.; Liu, H.; Zhao, F.; Ge, S.; Shen, W.; Zhang, Z. Proposal pyramid networks for fast face detection. Inf. Sci. 2019, 495, 136–149. [Google Scholar] [CrossRef]
- Luo, J.; Liu, J.; Lin, J.; Wang, Z. A lightweight face detector by integrating the convolutional neural network with the image pyramid. Pattern Recognit. Lett. 2020, 133, 180–187. [Google Scholar] [CrossRef]
- Hou, S.; Fang, D.; Pan, Y.; Li, Y.; Yin, G. Hybrid Pyramid Convolutional Network for Multiscale Face Detection. Comput. Intell. Neurosci. 2021, 2021, 9963322. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Adouani, A.; Henia, W.M.B.; Lachiri, Z. Comparison of Haar-like, HOG and LBP approaches for face detection in video sequences. In Proceedings of the 2019 16th International Multi-Conference on Systems, Signals & Devices (SSD), Istanbul, Turkey, 21–24 March 2019; pp. 266–271. [Google Scholar]
- Roy, A.; Marcel, S. Haar local binary pattern feature for fast illumination invariant face detection. In Proceedings of the British Machine Vision Conference 2009, London, UK, 7–10 September 2009. number CONF. [Google Scholar]
- Hjelmås, E.; Low, B.K. Face detection: A survey. Comput. Vis. Image Underst. 2001, 83, 236–274. [Google Scholar] [CrossRef] [Green Version]
- Mathias, M.; Benenson, R.; Pedersoli, M.; Van Gool, L. Face detection without bells and whistles. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 720–735. [Google Scholar]
- Li, H.; Lin, Z.; Shen, X.; Brandt, J.; Hua, G. A convolutional neural network cascade for face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5325–5334. [Google Scholar]
- Qin, H.; Yan, J.; Li, X.; Hu, X. Joint training of cascaded CNN for face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3456–3465. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Hao, Z.; Liu, Y.; Qin, H.; Yan, J.; Li, X.; Hu, X. Scale-aware face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6186–6195. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. From facial parts responses to face detection: A deep learning approach. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3676–3684. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M.M. To boost or not to boost? on the limits of boosted trees for object detection. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 3350–3355. [Google Scholar]
- Hu, P.; Ramanan, D. Finding tiny faces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 951–959. [Google Scholar]
- Shi, X.; Shan, S.; Kan, M.; Wu, S.; Chen, X. Real-time rotation-invariant face detection with progressive calibration networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2295–2303. [Google Scholar]
- Song, G.; Liu, Y.; Jiang, M.; Wang, Y.; Yan, J.; Leng, B. Beyond trade-off: Accelerate fcn-based face detector with higher accuracy. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7756–7764. [Google Scholar]
- Wang, H.; Li, Z.; Ji, X.; Wang, Y. Face r-cnn. arXiv 2017, arXiv:1706.01061 2017. [Google Scholar]
- Wang, Y.; Ji, X.; Zhou, Z.; Wang, H.; Li, Z. Detecting faces using region-based fully convolutional networks. arXiv 2017, arXiv:1709.05256 2017. [Google Scholar]
- Zhang, C.; Xu, X.; Tu, D. Face detection using improved faster rcnn. arXiv 2018, arXiv:1802.02142 2018. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Advances in Neural Information Processing Systems; Curran Associates Inc.: New York, NY, USA, 2016; pp. 379–387. [Google Scholar]
- Tian, W.; Wang, Z.; Shen, H.; Deng, W.; Meng, Y.; Chen, B.; Zhang, X.; Zhao, Y.; Huang, X. Learning better features for face detection with feature fusion and segmentation supervision. arXiv 2018, arXiv:1811.08557 2018. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wang, J.; Yuan, Y.; Yu, G. Face attention network: An effective face detector for the occluded faces. arXiv 2017, arXiv:1711.07246. [Google Scholar]
- Zhang, J.; Wu, X.; Hoi, S.C.; Zhu, J. Feature agglomeration networks for single stage face detection. Neurocomputing 2020, 380, 180–189. [Google Scholar] [CrossRef] [Green Version]
- Chi, C.; Zhang, S.; Xing, J.; Lei, Z.; Li, S.Z.; Zou, X. Selective refinement network for high performance face detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8231–8238. [Google Scholar]
- Zhang, Y.; Xu, X.; Liu, X. Robust and high performance face detector. arXiv 2019, arXiv:1901.02350 2019. [Google Scholar]
- Hoang, T.M.; Nam, G.P.; Cho, J.; Kim, I.J. Deface: Deep efficient face network for small scale variations. IEEE Access 2020, 8, 142423–142433. [Google Scholar] [CrossRef]
- Zhou, Z.; He, Z.; Jia, Y.; Du, J.; Wang, L.; Chen, Z. Context prior-based with residual learning for face detection: A deep convolutional encoder–decoder network. Signal Processing Image Commun. 2020, 88, 115948. [Google Scholar] [CrossRef]
- Li, X.; Lai, S.; Qian, X. DBCFace: Towards Pure Convolutional Neural Network Face Detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 1. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Jain, V.; Learned-Miller, E. Fddb: A Benchmark for Face Detection in Unconstrained Settings; Technical Report, UMass Amherst Technical Report; University of Massachusetts: Amherst, MA, USA, 2010. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Zhang, Z.; Wang, H.; Li, Z.; Qiao, Y.; Liu, W. Detecting faces using inside cascaded contextual cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3171–3179. [Google Scholar]
- Ge, S.; Li, J.; Ye, Q.; Luo, Z. Detecting masked faces in the wild with lle-cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2682–2690. [Google Scholar]



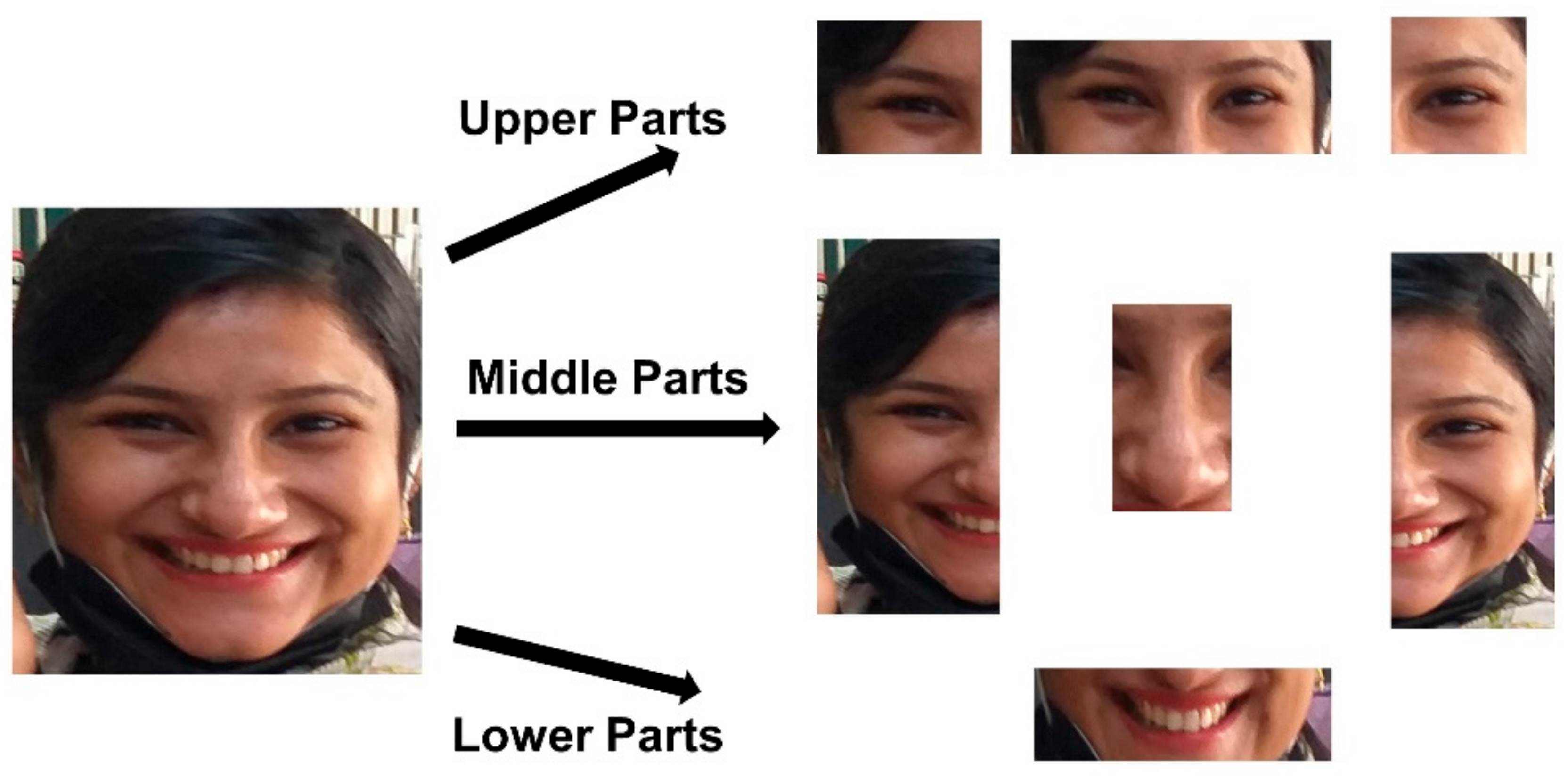




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
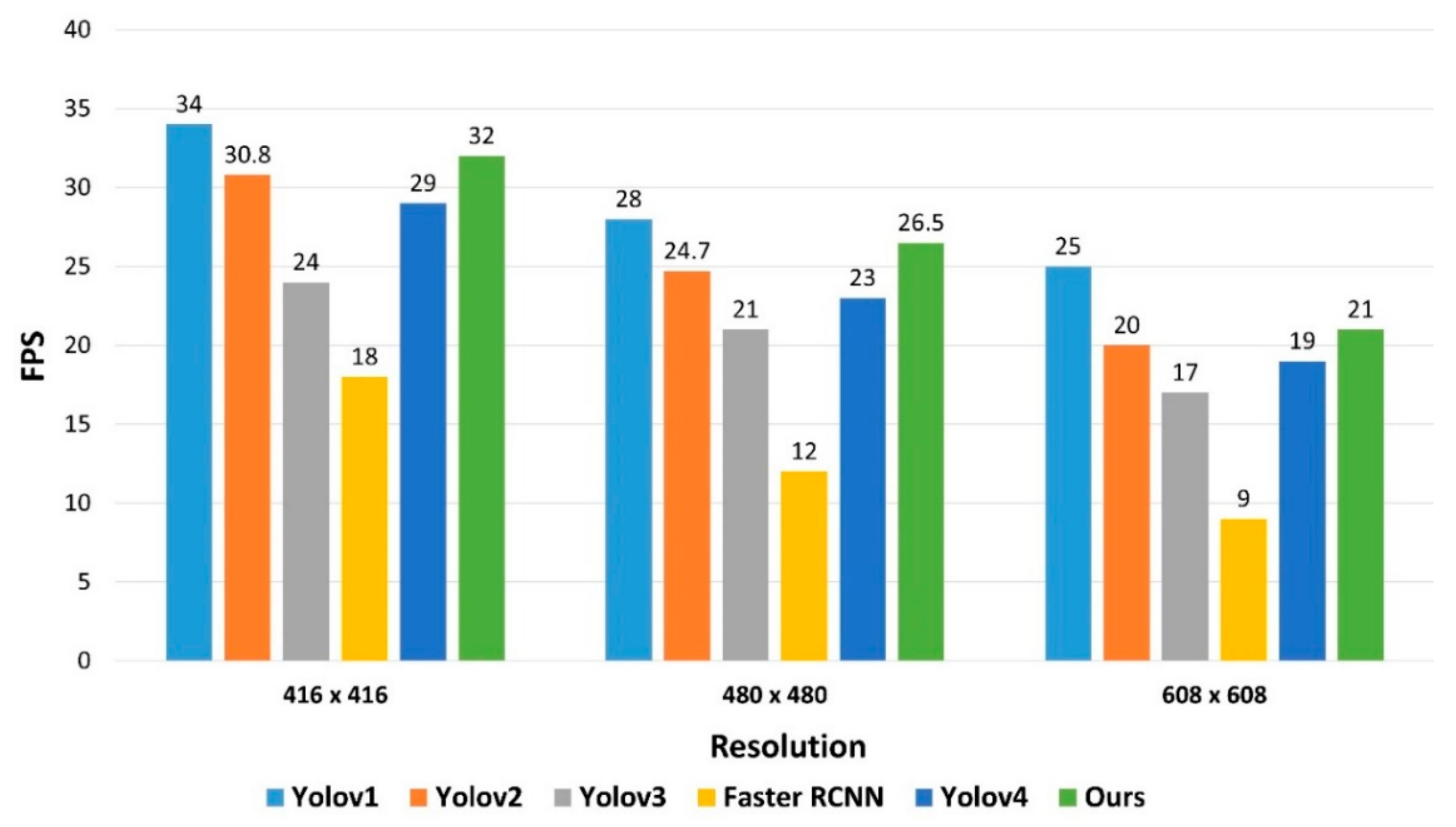
| Resolution | Method | Accuracy | Precision | Recall | F1-Score | Inference Time (ms) |
|---|---|---|---|---|---|---|
| 416 × 416 | Yolov1 | 71.4 | 80.2 | 83.4 | 81.77 | 29.41 |
| Yolov2 | 73.5 | 84.3 | 82.5 | 83.39 | 32.47 | |
| Yolov3 | 74.8 | 86.7 | 85.1 | 85.89 | 41.67 | |
| Faster RCNN | 79.45 | 90.6 | 91.8 | 91.20 | 55.56 | |
| Yolov4 | 79.6 | 91.2 | 88.4 | 89.78 | 34.48 | |
| Ours | 80.4 | 94.8 | 91.6 | 93.17 | 31.25 | |
| 480 × 480 | Yolov1 | 76.8 | 84.8 | 85.4 | 85.10 | 35.71 |
| Yolov2 | 78.9 | 88.7 | 86.2 | 87.43 | 40.49 | |
| Yolov3 | 79.8 | 90.3 | 88.7 | 89.49 | 47.62 | |
| Faster RCNN | 84.96 | 94.3 | 92.2 | 93.24 | 83.33 | |
| Yolov4 | 85.3 | 94.9 | 95.3 | 95.10 | 43.48 | |
| Ours | 86.7 | 97.2 | 94.8 | 95.99 | 37.74 | |
| 608 × 608 | Yolov1 | 80.1 | 88.9 | 86.5 | 87.68 | 40.00 |
| Yolov2 | 86.3 | 90.7 | 89.8 | 90.25 | 50.00 | |
| Yolov3 | 89.4 | 93.2 | 91.3 | 92.24 | 58.82 | |
| Faster RCNN | 92.4 | 97.2 | 92.3 | 94.69 | 111.11 | |
| Yolov4 | 93.7 | 96.1 | 95.2 | 95.65 | 52.63 | |
| Ours | 94.8 | 98.7 | 97.8 | 98.25 | 47.62 |
| IoU | 0.4 | 0.5 | 0.6 |
| Ours | 98.7 | 98.1 | 95.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garg, D.; Jain, P.; Kotecha, K.; Goel, P.; Varadarajan, V. An Efficient Multi-Scale Anchor Box Approach to Detect Partial Faces from a Video Sequence. Big Data Cogn. Comput. 2022, 6, 9. https://doi.org/10.3390/bdcc6010009
Garg D, Jain P, Kotecha K, Goel P, Varadarajan V. An Efficient Multi-Scale Anchor Box Approach to Detect Partial Faces from a Video Sequence. Big Data and Cognitive Computing. 2022; 6(1):9. https://doi.org/10.3390/bdcc6010009
Chicago/Turabian StyleGarg, Dweepna, Priyanka Jain, Ketan Kotecha, Parth Goel, and Vijayakumar Varadarajan. 2022. "An Efficient Multi-Scale Anchor Box Approach to Detect Partial Faces from a Video Sequence" Big Data and Cognitive Computing 6, no. 1: 9. https://doi.org/10.3390/bdcc6010009
APA StyleGarg, D., Jain, P., Kotecha, K., Goel, P., & Varadarajan, V. (2022). An Efficient Multi-Scale Anchor Box Approach to Detect Partial Faces from a Video Sequence. Big Data and Cognitive Computing, 6(1), 9. https://doi.org/10.3390/bdcc6010009