
Extraction of the Relations among Significant Pharmacological Entities in Russian-Language Reviews of Internet Users on Medications

 ,
,  , ,
, ,
Abstract
:1. Introduction
- The relation extraction method is proposed, in which the task of determining the presence of a relation is formulated using multi-context annotation: entities belonging to the same context are considered to be related. The method is based on a language model fine-tuned to classify entity pairs by the presence of relations.
- Several variations of the text representation used to present the entities under consideration to the language model are compared, and the optimal representation is shown to be the one that includes the text of target entities along with the whole review text, concatenated with special tokens;
- The method based on a language model trained on a large corpus of unlabeled Russian drug review texts and fine-tuned on an annotated corpus of Russian drug reviews is shown to be applicable to the task of determining the relations among pharmaceutically-relevant entities of the newly-created corpus. The accuracy estimations are obtained for this task for Russian language;
- The same proposed model, pre-trained on Russian drug reviews, is shown to achieve relation extraction results comparable to the state of the art on the DDI corpus.
2. Related Works
- cascade approach: sequential text analysis, where the tasks of named entity recognition and relation extraction are performed separately. At the first stage, named entities are extracted from the text, either by expert annotation or using a machine learning model [3,9,13,17,18]. At the second stage, the entities extracted are evaluated in terms of their possible relations [14,15,19,20]. This approach allows one to control the learning process of each model, which in turn gives the opportunity for a more thorough choice of methods and hyperparameters.
3. Materials and Methods
3.1. Datasets
- Medication—this group includes everything related to the mentions of drugs and drugs manufacturers, including: Drug name, Drug class, Drug form, Route (how to use the drug), Dosage, SourceInfoDrug (source of the consumer’s information about the drug) etc.;
- Disease—this group contains entities related to the diseases or reasons for using the drug (disease name, indications or symptoms), as well as mentions of the effects achieved (NegatedADE—the drug was inefficient, Worse—some deterioration was observed, BNE-POS—the condition improved) etc.
- ADR—mentions of occurring adverse reactions.
- 2nd context: “allergy” (Diseasename), “red spots” (Indication), “zyrtek” (Drugname), “the situation did not improve” (NegatedADE), “it seems to have gotten even worse” (Worse).
- 3d context: “allergy” (Diseasename), “red spots” (Indication), “doctor” (SourceInfoDrug), “On her recommendation” (SourceInfoDrug), “smecta” (Drugname), “the situation did not improve” (NegatedADE), “it seems to have gotten even worse” (Worse).
- 4th context: “allergy” (Diseasename), “red spots” (Indication), “doctor” (SourceInfoDrug), “On her recommendation” (SourceInfoDrug), “suprastin” (Drugname), “the situation did not improve” (NegatedADE), “it seems to have gotten even worse” (Worse), “Injected” (Route), “The redness seems to pass” (BNE-POS), ““swelling on the face still remains” (NegatedADE).
- 5th context: “allergy” (Diseasename), “red spots” (Indication), “doctor” (SourceInfoDrug), “prednisone” (Drugname), “Injected” (Route), “The redness seems to pass” (BNE-POS), ““swelling on the face still remains” (NegatedADE).
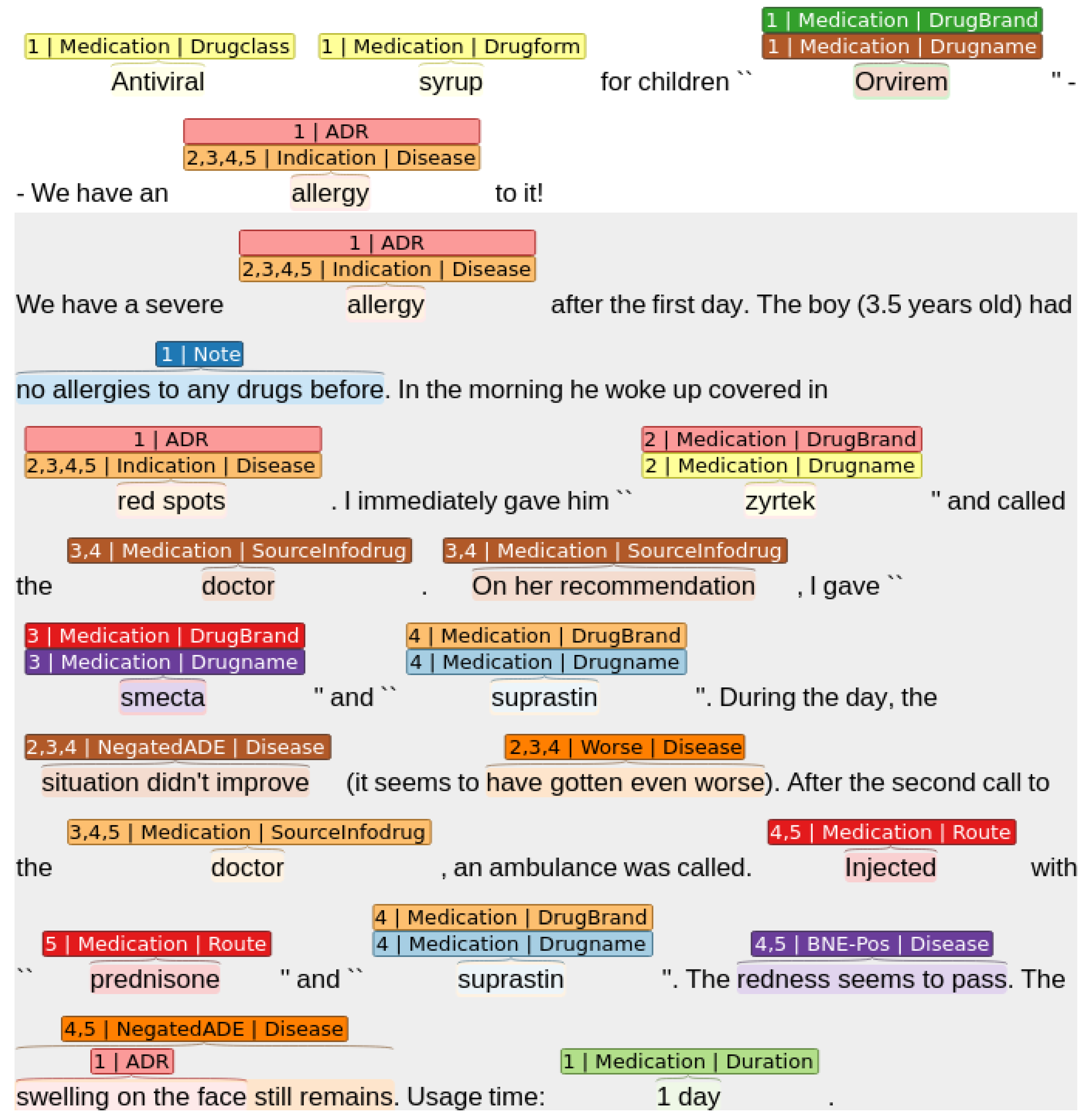
- ADR–Drugname—the relationship between the drug and its side effects;
- Drugname–SourceInfodrug—the relationship between the medication and the source of information about it (e.g., “was advised at the pharmacy”, “the doctor recommended it”);
- Drugname–Diseasename—the relationship between the drug and the disease;
- Diseasename–Indication—the connection between the illness and its symptoms (e.g., “cough”, “fever 39 degrees”).
- The first one includes 628 texts containing ADR and Drugname entity pairs. The experiments on this part are aimed at selecting the most effective combinations of the input feature representations and hyper-parameters of the methods used. The texts of the RDRS corpus that contain ADR and Drugname entities were divided into training and test parts, the composition of which is presented in Table 3.
- The second part includes texts that contain multiple contexts. The total number of such texts is 908. Statistics on the types of relationships are presented in Table 4. This corpus is used to establish the current level of accuracy in determining the relationships between pharmacologically-significant entities in Russian-language review texts.
3.2. Methods
3.2.1. Deep Learning Methods
Language Models
- XLM-RoBERTa-base-sag—12 Transformer blocks, 768 hidden neurons, 8 Attention Heads, 125 millions of parameters, 2 epochs of additional training on Russian texts about medications;
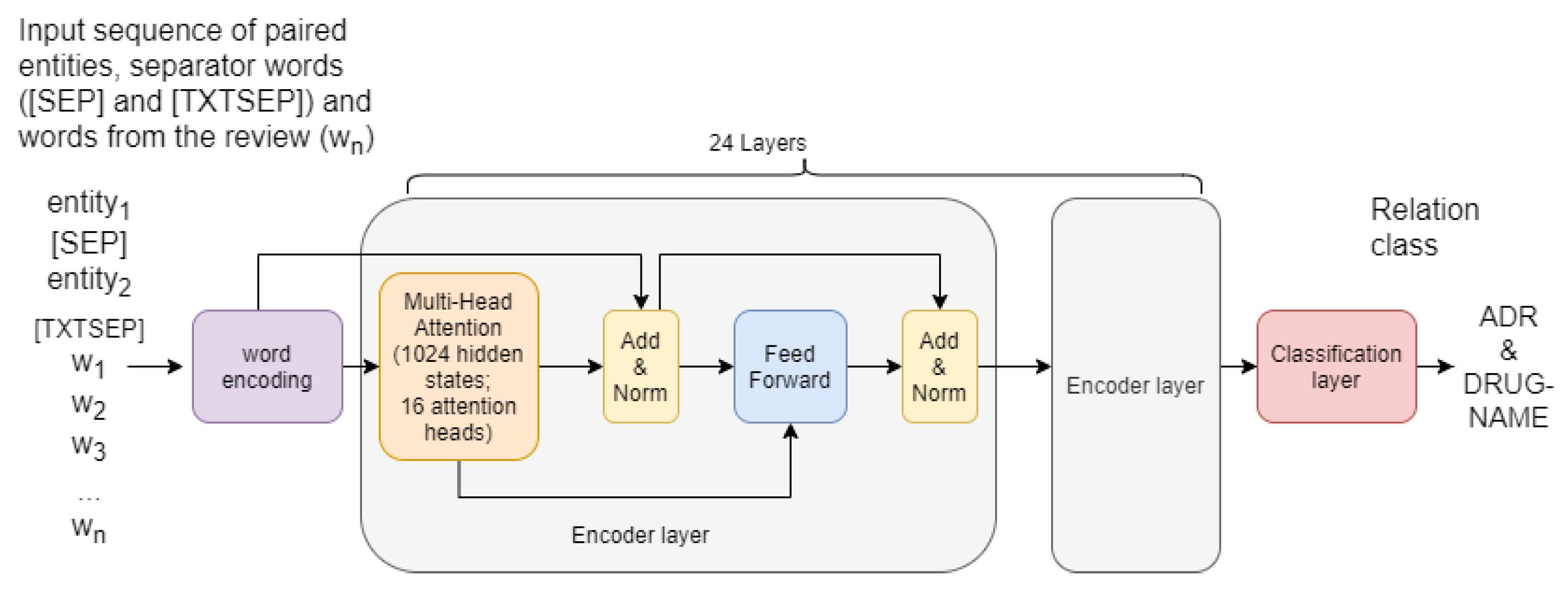
- XLM-RoBERTa-large-sag—24 Transformer blocks, 1024 hidden neurons, 16 Attention Heads, 355 millions of parameters, 1 epoch of additional training on Russian texts about medications;
Input Text Pre-Processing
- The whole text—the tokenized input text that the language model receives at its input is the whole drug review text, in which target entities are highlighted using special start and end tokens, e. g. [T_ADR] and [\T_ADR] for an entity of type ADR:<<[CLS]Antiviral syrup for children [T_DRUG]“Orvirem”[\T_DRUG] - We have an allergy to it! We have a severe allergy after the first day of taking it. Moreover, the boy (3.5 years old) had no allergies to any drugs before. In the morning he woke up covered in [T_ADR]red spots[\T_ADR]. I immediately gave him zyrtek…>>
- The text of target entities only—only the mentions of the target entities are used as the input text;
- The text of the target entities and the text between the mentions of the target entities;
- The text of the target entities concatenated with the whole text:[CLS]<<text of first target entity>>[SEP]<<text of second target entity>>[TXTSEP]<<whole text of the drug review>>.
3.2.2. Other Machine Learning Methods
- Logistic regression [44]—a basic linear model for text classification using a logistic function to estimate the probability of an example to belong to a certain class;
- Support vector machine [45]—a linear model based on building a hyperplane that maximizes the margin between two classes;
- Multinomial Naive Bayes model [46]—a popular solution for baselines in such text analysis tasks as spam filtering or text classification. It performs text classification based on words’ or n-grams’ co-occurrence probability;
- Gradient Boosting [47]—a strong decision tree-based ensemble model, which iteratively “boosts” the result of each tree by building a next tree that should classify examples that the previous tree fails to classify correctly.
3.2.3. Dummy Models
- most frequent class labeling—every pair of entities is assigned to the most frequent class in the dataset (in case of extraction of ADR–DrugName relations in the RDRS dataset, thus classifier considers every pair to have a relation);
- uniform random labeling—labels are predicted randomly according to a uniform probability distribution, without taking into account any characteristics of the input dataset;
- stratified random labeling—labels are predicted randomly but from the distribution corresponding to that of the input data: the probability of an input example to belong to a class is proportional to the portion of examples of such class in the dataset.
4. Experiments
4.1. Accuracy Metric
4.2. Selection of the Model Features and Hyperparameters
- Fixed stratified split into training (80%) and testing (20%) sets; In order to avoid overfitting, entity pairs from each review all go either to the training set or to the testing set, but no review is split between the sets;
- Hyperparameters of the language model’s fine-tuning process are searched manually so that to maximize the accuracy (by the f1-macro metric) on the validation part of the training set, without taking into account the testing set;
- The language model involves early stopping and learning rate decay (Experiments show the positive effect of such techniques on the model accuracy);
4.3. An Estimation of Efficiency of Selected Methods
5. Results
5.1. Comparison of the Model Features and Hyperparameters
- maximum input length—512;
- early stopping—active;
- learning rate—0.00005;
- batch size—32;
- maximum epochs—10;
- learning rate decay—active;
- maximum input length— 512;
- early stopping—active;
- learning rate—0.00001;
- batch size—8 (there was not enough memory for bigger batch size with XLM-RoBERTa-large);
- maximum epochs—10;
- learning rate decay—active;
5.2. Estimation of the Relation Extraction Efficiency
5.3. Applying the Proposed Approach to the DDI Dataset
- Drug—used to annotate those human medicines known by a generic name;
- Brand—drugs described by a trade or brand name;
- Group—drug interaction descriptions often include groups of drugs, that were separated to “group” entity type;
- Drug_n— active substances that weren’t approved for human use, such as toxins or pesticides.
- Mechanism— this type is used to annotate DDIs that are described by their pharmacokinetic mechanism;
- Effect—this type is used to annotate DDIs describing an effect or a pharmacodynamic mechanism;
- Advice—This type is used when a recommendation or advice regarding a drug interaction is given;
- Int—This type is used when a DDI appears in the text without providing any additional information.
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Segura-Bedmar, I.; Martínez, P. Pharmacovigilance through the development of text mining and natural language processing techniques. J. Biomed. Inform. 2015, 58, 288–291. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sboev, A.; Sboeva, S.; Gryaznov, A.; Evteeva, A.; Rybka, R.; Silin, M. A neural network algorithm for extracting pharmacological information from russian-language internet reviews on drugs. J. Phys. Conf. Ser. 2020, 1686, 012037. [Google Scholar] [CrossRef]
- Sboev, A.; Sboeva, S.; Moloshnikov, I.; Gryaznov, A.; Rybka, R.; Naumov, A.; Selivanov, A.; Rylkov, G.; Ilyin, V. An analysis of full-size Russian complexly NER labelled corpus of Internet user reviews on the drugs based on deep learning and language neural nets. arXiv 2021, arXiv:cs.CL/2105.00059. [Google Scholar]
- Oliveira, A.; Braga, H. Artificial Intelligence: Learning and Limitations. Wseas Trans. Adv. Eng. Educ. 2020, 17, 80–86. [Google Scholar] [CrossRef]
- Al-Haija, Q.A.; Jebril, N. A Systemic Study of Pattern Recognition System Using Feedback Neural Networks. Wseas Trans. Comput. 2020, 19, 115–121. [Google Scholar] [CrossRef]
- Ganesh, P.; Rawal, B.; Peter, A.; Giri, A. POS-Tagging based Neural Machine Translation System for European Languages using Transformers". Wseas Trans. Inf. Sci. Appl. 2021, 18, 26–33. [Google Scholar] [CrossRef]
- Xu, H.; Van Durme, B.; Murray, K. BERT, mBERT, or BiBERT? A Study on Contextualized Embeddings for Neural Machine Translation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 6663–6675. [Google Scholar]
- Ge, Z.; Sun, Y.; Smith, M. Authorship attribution using a neural network language model. In Proceedings of the AAAI Conference on Artificial Intelligence, Burlingame, CA, USA, 8–12 October 2016; Volume 30. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K. Deep contextualized word representations. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Volume 1. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Portelli, B.; Passabi, D.; Serra, G.; Santus, E.; Chersoni, E. Improving Adverse Drug Event Extraction with SpanBERT on Different Text Typologies. In Proceedings of the 5th International Workshop on Health Intelligence (W3PHIAI-21), Palo Alto, CA, USA, 8–9 February 2021. [Google Scholar]
- Yan, H.; Gui, T.; Dai, J.; Guo, Q.; Zhang, Z.; Qiu, X. A Unified Generative Framework for Various NER Subtasks. arXiv 2021, arXiv:2106.01223. [Google Scholar]
- Ge, S.; Wu, F.; Wu, C.; Qi, T.; Huang, Y.; Xie, X. FedNER: Privacy-Preserving Medical Named Entity Recognition with Federated Learning. Available online: https://arxiv.org/abs/2003.09288 (accessed on 30 October 2021).
- Wu, S.; He, Y. Enriching pre-trained language model with entity information for relation classification. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2361–2364. [Google Scholar]
- Giorgi, J.; Wang, X.; Sahar, N.; Shin, W.Y.; Bader, G.D.; Wang, B. End-to-end named entity recognition and relation extraction using pre-trained language models. arXiv 2019, arXiv:1912.13415. [Google Scholar]
- Eberts, M.; Ulges, A. Span-Based Joint Entity and Relation Extraction with Transformer Pre-Training. In ECAI 2020; IOS Press: Amsterdam, Netherlands, 2020; pp. 2006–2013. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2019, 36, 1234–1240. [Google Scholar] [CrossRef]
- Gu, Y.; Tinn, R.; Cheng, H.; Lucas, M.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. arXiv 2020, arXiv:2007.15779. [Google Scholar] [CrossRef]
- Gordeev, D.; Davletov, A.; Rey, A.; Akzhigitova, G.; Geymbukh, G. Relation extraction dataset for the russian language. In Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialog” [Komp’iuternaia Lingvistika i Intellektual’nye Tehnologii: Trudy Mezhdunarodnoj Konferentsii “Dialog”]; Russian State University For The Humanities: Moscow, Russia, 2020. [Google Scholar]
- Naseem, U.; Dunn, A.G.; Khushi, M.; Kim, J. Benchmarking for biomedical natural language processing tasks with a domain specific albert. arXiv 2021, arXiv:2107.04374. [Google Scholar]
- Ju, M.; Nguyen, N.T.; Miwa, M.; Ananiadou, S. An ensemble of neural models for nested adverse drug events and medication extraction with subwords. J. Am. Med. Inform. Assoc. 2020, 27, 22–30. [Google Scholar] [CrossRef]
- Joshi, M.; Chen, D.; Liu, Y.; Weld, D.S.; Zettlemoyer, L.; Levy, O. Spanbert: Improving pre-training by representing and predicting spans. Trans. Assoc. Comput. Linguist. 2020, 8, 64–77. [Google Scholar] [CrossRef]
- Wang, J.; Lu, W. Two Are Better than One: Joint Entity and Relation Extraction with Table-Sequence Encoders. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1706–1721. [Google Scholar]
- Patrick, J.; Li, M. High accuracy information extraction of medication information from clinical notes: 2009 i2b2 medication extraction challenge. J. Am. Med. Inform. Assoc. 2010, 17, 524–527. [Google Scholar] [CrossRef] [Green Version]
- Anick, P.; Hong, P.; Xue, N.; Anick, D. I2B2 2010 challenge: Machine learning for information extraction from patient records. In Proceedings of the 2010 i2b2/VA Workshop on Challenges in Natural Language Processing for Clinical Data, Boston, MA, USA, 12 November 2010. [Google Scholar]
- Henry, S.; Buchan, K.; Filannino, M.; Stubbs, A.; Uzuner, O. 2018 n2c2 shared task on adverse drug events and medication extraction in electronic health records. J. Am. Med. Inform. Assoc. 2019, 27, 3–12. [Google Scholar] [CrossRef]
- Herrero-Zazo, M.; Segura-Bedmar, I.; Martínez, P.; Declerck, T. The DDI corpus: An annotated corpus with pharmacological substances and drug–drug interactions. J. Biomed. Inform. 2013, 46, 914–920. [Google Scholar] [CrossRef] [Green Version]
- Asada, M.; Miwa, M.; Sasaki, Y. Using Drug Descriptions and Molecular Structures for Drug-Drug Interaction Extraction from Literature. Bioinformatics 2020, 37, 1739–1746. [Google Scholar] [CrossRef]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: Pretrained Language Model for Scientific Text. arXiv 2019, arXiv:1903.10676. [Google Scholar]
- Gurulingappa, H.; Rajput, A.M.; Roberts, A.; Fluck, J.; Hofmann-Apitius, M.; Toldo, L. Development of a benchmark corpus to support the automatic extraction of drug-related adverse effects from medical case reports. J. Biomed. Inform. 2012, 45, 885–892. [Google Scholar] [CrossRef]
- Bruches, E.; Pauls, A.; Batura, T.; Isachenko, V. Entity Recognition and Relation Extraction from Scientific and Technical Texts in Russian. In Proceedings of the 2020 Science and Artificial Intelligence Conference (SAI Ence), Novosibirsk, Russia, 14–15 November 2020; pp. 41–45. [Google Scholar]
- Ivanin, V.; Artemova, E.; Batura, T.; Ivanov, V.; Sarkisyan, V.; Tutubalina, E.; Smurov, I. Rurebus-2020 shared task: Russian relation extraction for business. In Computational Linguistics and Intellectual Technologies; Russian State University for the Humanities: Moscow, Russia, 2020; pp. 416–431. [Google Scholar]
- Bondarenko, I.; Berezin, S.; Pauls, A.; Batura, T.; Rubtsova, Y.; Tuchinov, B. Using Few-Shot Learning Techniques for Named Entity Recognition and Relation Extraction. In Proceedings of the 2020 Science and Artificial Intelligence Conference (SAI Ence), Novosibirsk, Russia, 14–15 November 2020; pp. 58–65. [Google Scholar]
- Loukachevitch, N.; Artemova, E.; Batura, T.; Braslavski, P.; Denisov, I.; Ivanov, V.; Manandhar, S.; Pugachev, A.; Tutubalina, E. NEREL: A Russian Dataset with Nested Named Entities and Relations. arXiv 2021, arXiv:2108.13112. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Kudo, T.; Richardson, J. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv 2018, arXiv:1808.06226. [Google Scholar]
- Sboev, A.; Selivanov, A.; Rybka, R.; Moloshnikov, I.; Rylkov, G. Evaluation of Machine Learning Methods for Relation Extraction Between Drug Adverse Effects and Medications in Russian Texts of Internet User Reviews. Available online: https://pos.sissa.it/410/006/pdf (accessed on 30 October 2021).
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar]
- Caruana, R.; Lawrence, S.; Giles, L. Overfitting in neural nets: Backpropagation, conjugate gradient, and early stopping. Adv. Neural Inf. Process. Syst. 2000, 13, 402–408. [Google Scholar]
- Sahoo, K.S.; Tripathy, B.K.; Naik, K.; Ramasubbareddy, S.; Balusamy, B.; Khari, M.; Burgos, D. An evolutionary SVM model for DDOS attack detection in software defined networks. IEEE Access 2020, 8, 132502–132513. [Google Scholar] [CrossRef]
- Chun, P.J.; Izumi, S.; Yamane, T. Automatic detection method of cracks from concrete surface imagery using two-step light gradient boosting machine. Comput.-Aided Civil Infrastruct. Eng. 2021, 36, 61–72. [Google Scholar] [CrossRef]
- Xu, F.; Pan, Z.; Xia, R. E-commerce product review sentiment classification based on a naïve Bayes continuous learning framework. Inf. Process. Manag. 2020, 57, 102221. [Google Scholar] [CrossRef]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013; Volume 398. [Google Scholar]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Rish, I. An empirical study of the naive Bayes classifier. In Proceedings of the IJCAI 2001 workshop on empirical methods in artificial intelligence, Seattle, WA, USA, 4 August 2001; Volume 3, pp. 41–46. [Google Scholar]
- Mason, L.; Baxter, J.; Bartlett, P.; Frean, M. Boosting algorithms as gradient descent in function space. In Proceedings of the NIPS, Denver, CO, USA, 29 November–4 December 1999; Volume 12, pp. 512–518. [Google Scholar]
- Kuratov, Y.; Arkhipov, M. Adaptation of deep bidirectional multilingual transformers for Russian language. In Komp’juternaja Lingvistika i Intellektual’nye Tehnologii; Russian State University For The Humanities: Moscow, Russia, 2019; pp. 333–339. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 8026–8037. [Google Scholar]
- Rajapakse, T.C. Simple Transformers. 2019. Available online: https://github.com/ThilinaRajapakse/simpletransformers (accessed on 30 October 2021).
- raj Kanakarajan, K.; Kundumani, B.; Sankarasubbu, M. BioELECTRA: Pretrained Biomedical text Encoder using Discriminators. In Proceedings of the 20th Workshop on Biomedical Language Processing, Online, 11 June 2021; pp. 143–154. [Google Scholar]

{kind=link}
{kind=link}
| Contexts Count | 1 | 2 | 3 | >3 |
|---|---|---|---|---|
| Texts Count | 682 | 559 | 218 | 131 |
| Average Mentions Count | Average Tokens Count | |
|---|---|---|
| Main context | 19.9 | 38.9 |
| Other contexts | 3.7 | 6.6 |
| Number of | Train | Test |
|---|---|---|
| Texts | 502 | 126 |
| Sentences | 4016 | 1008 |
| Words | 82,425 | 20,961 |
| “ADR” type entities | 1461 | 356 |
| “Drugname” type entities | 1416 | 368 |
| Relations | 3444 | 845 |
| Avg. numbers of relations per text | 6.9 | 6.7 |
| Relation | ADR & Drugname | Drugname & Diseasename | Drugname & SourceInfoDrug | Diseasename & Indication | ||||
|---|---|---|---|---|---|---|---|---|
| Classes | pos. | neg. | pos. | neg. | pos. | neg. | pos. | neg. |
| Relations count | 1913 | 917 | 4277 | 2153 | 2700 | 1232 | 2588 | 701 |
| Text fraction | 0.273 | 0.204 | 0.634 | 0.514 | 0.598 | 0.457 | 0.416 | 0.148 |
| Text Representation | LM-Base | LM-Large |
|---|---|---|
| Text of target entities only | 0.75 | 0.76 |
| Whole text with highlighting target entities | 0.78 | 0.82 |
| Text of target entities and text between them | 0.81 | 0.80 |
| Text of target entities and the whole text | 0.91 | 0.95 |
| Methods | ADR– Drugname | Drugname– Diseasename | Drugname– Source Info Drug | Diseasename– Indication | ||||
|---|---|---|---|---|---|---|---|---|
| pos | neg | pos | neg | pos | neg | pos | neg | |
| Proposed model | 92.7 | 91.1 | 89.9 | 76.2 | 92.9 | 82.7 | 87.1 | 31 |
| 91.9 | 83.05 | 87.8 | 59 | |||||
| RuBERT | 88.8 | 76.2 | 86.1 | 66.2 | 89.4 | 72.6 | 85.7 | 27.7 |
| 82.5 | 76.15 | 81 | 56.7 | |||||
| Linear SVM | 72.8 | 45.0 | 75.6 | 44.9 | 77.9 | 45.2 | 83.2 | 24.4 |
| 58.9 | 60.25 | 61.55 | 53.8 | |||||
| Multinomial Naive Bayes | 66.3 | 33.8 | 68.8 | 26.1 | 73.4 | 14.3 | 80.2 | 5.4 |
| 50.05 | 47.45 | 43.85 | 42.8 | |||||
| Stratified Random Labeling | 66.5 | 31.8 | 66.5 | 33.3 | 69.8 | 32.9 | 77.8 | 22.0 |
| 49.15 | 49.9 | 51.35 | 49.9 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sboev, A.; Selivanov, A.; Moloshnikov, I.; Rybka, R.; Gryaznov, A.; Sboeva, S.; Rylkov, G. Extraction of the Relations among Significant Pharmacological Entities in Russian-Language Reviews of Internet Users on Medications. Big Data Cogn. Comput. 2022, 6, 10. https://doi.org/10.3390/bdcc6010010
Sboev A, Selivanov A, Moloshnikov I, Rybka R, Gryaznov A, Sboeva S, Rylkov G. Extraction of the Relations among Significant Pharmacological Entities in Russian-Language Reviews of Internet Users on Medications. Big Data and Cognitive Computing. 2022; 6(1):10. https://doi.org/10.3390/bdcc6010010
Chicago/Turabian StyleSboev, Alexander, Anton Selivanov, Ivan Moloshnikov, Roman Rybka, Artem Gryaznov, Sanna Sboeva, and Gleb Rylkov. 2022. "Extraction of the Relations among Significant Pharmacological Entities in Russian-Language Reviews of Internet Users on Medications" Big Data and Cognitive Computing 6, no. 1: 10. https://doi.org/10.3390/bdcc6010010
APA StyleSboev, A., Selivanov, A., Moloshnikov, I., Rybka, R., Gryaznov, A., Sboeva, S., & Rylkov, G. (2022). Extraction of the Relations among Significant Pharmacological Entities in Russian-Language Reviews of Internet Users on Medications. Big Data and Cognitive Computing, 6(1), 10. https://doi.org/10.3390/bdcc6010010