1. Background
Snort is a commonly used, signature-based network intrusion detection system (NIDS) [
1]. It is implemented in many network security systems. Typically, users install Snort sensors to detect intrusions in their networks. The sensors send the log data to a dedicated defense center for processing and aggregation. In the typical Snort architecture, the sensors and the defense center must be physically placed in the same local network.
One of the best examples of Snort’s implementation is in the Mata Garuda Project of the Indonesia Security Incident Response Team in the Internet Infrastructure coordination center (ID-SIRTII/CC) [
2,
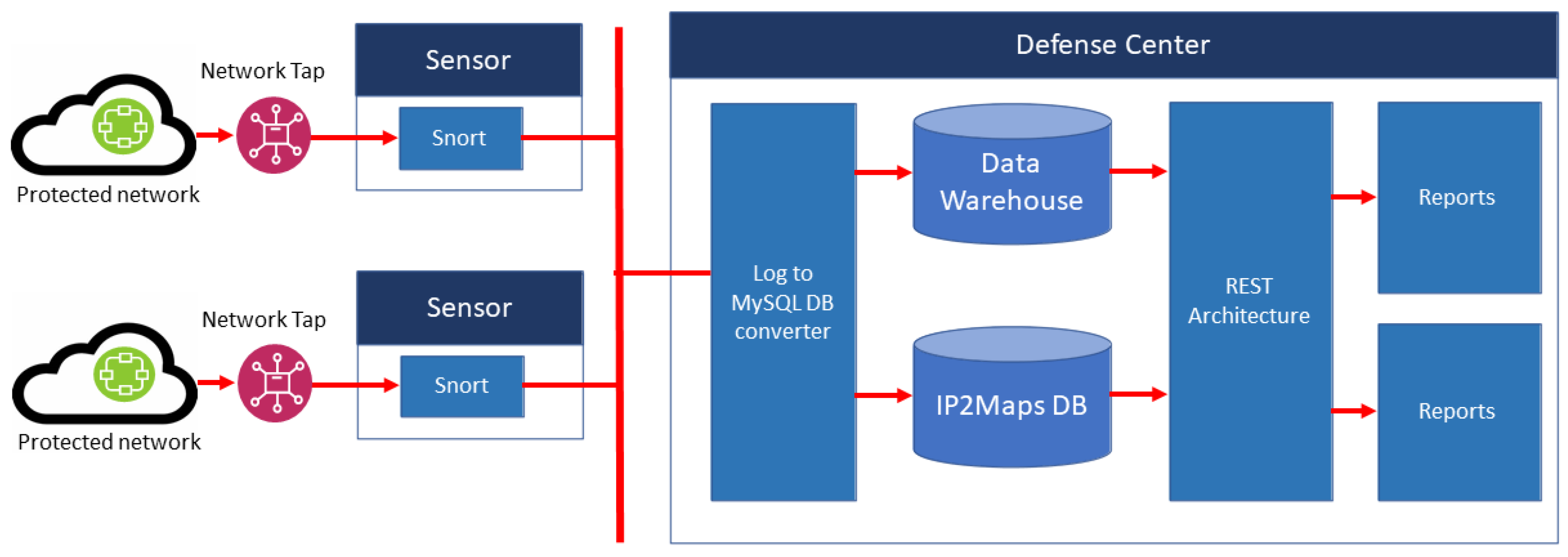
3]. We implemented the system on 12 ISP routers that handled the highest volumes of Indonesian Internet traffic in 2014. The intrusion detection, data aggregation sensors, and defense center were in the same networks. Each of the sensors had two interfaces: one for sniffing the packet and the other for sending the intrusion logs to the defense center each minute through a secure file transfer protocol (FTP). At the defense center, the data were aggregated based on various time units and enriched with IP geolocation to build attack maps and other security-related tools for analyses.
Figure 1 shows the topology of Mata Garuda implemented at the ID-SIRTII/CC.
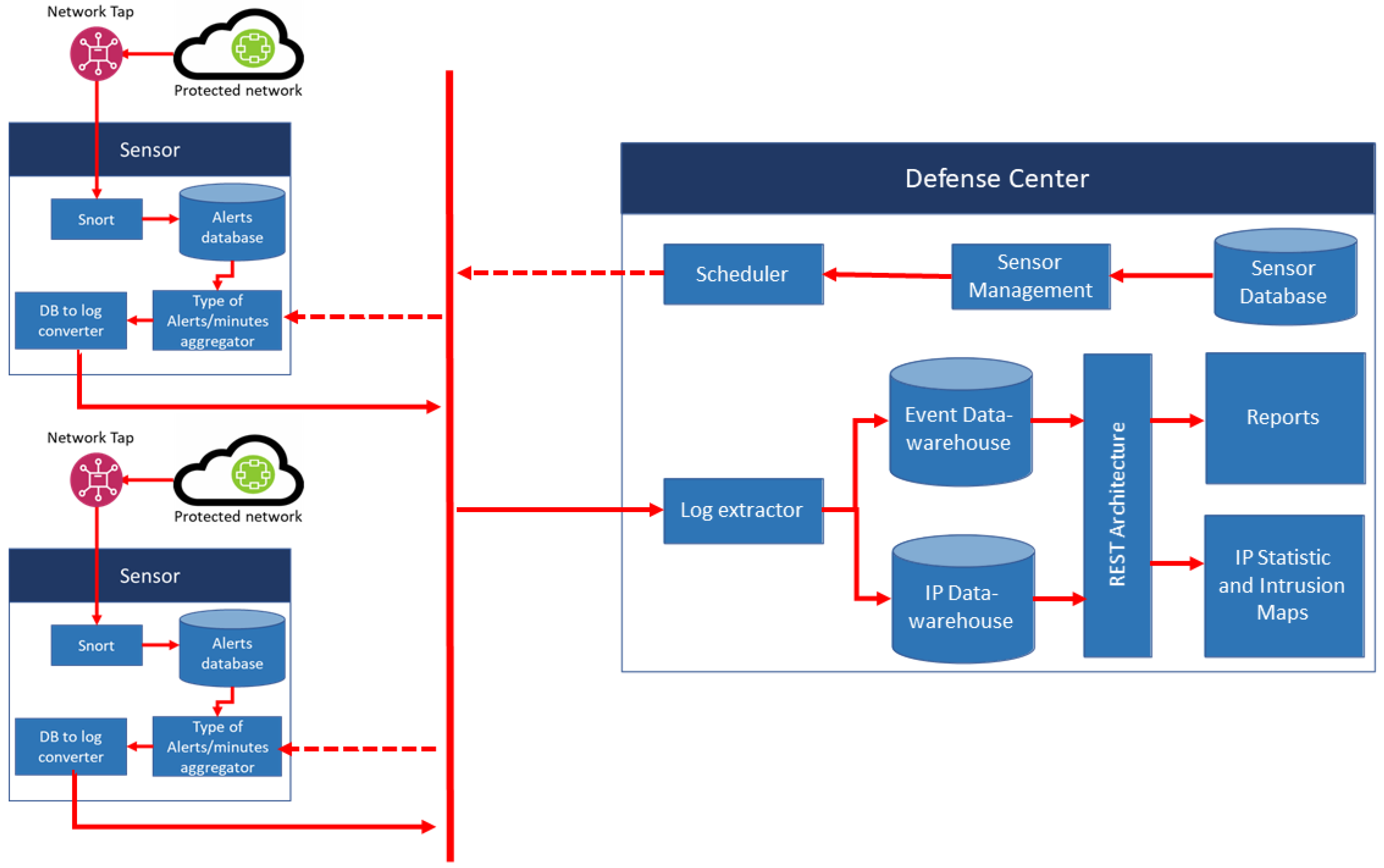
In early 2015, when we were implementing our system in a real gigabit network, we found that the system could only efficiently handle 4–5 million pieces of data per query. As the number of data grew exponentially, the data table also grew in size. Join queries in several large tables caused Mata Garuda to run slowly. Another problem was that the topology still only utilizes one Online Transaction Processing (OLTP) database server. The database server’s load was high, and one OLTP database could not handle the join queries, especially when generating reports. Then, we proposed a distributed database design [
2]. Each sensor has a database of attack logs and aggregates the data every minute. The defense center triggers the sensor to send their aggregated data and extract the information of alerts and source IP of attackers.
Figure 2 shows the overall system that significantly increased the computation time when generating monthly and annual reports (see
Table 1).
In early 2019, the rapid change in Internet technology in Indonesia, with cloud computing and big data technology, challenged us to develop a new version of Mata Garuda. The improved version of Mata Garuda had to be compatible with cloud technology and also had to be able to handle big data, which posed a challenge to the existing system due to the increasing number of sensor instances, followed by a rapid increase in the log data volume. Based on our works in [
3,
4], we successfully processed the Extract Transform Load (ETL) and data enrichment of Snort log files using big data and data mining in the Mata Garuda application. We carried out the data-mining method on geolocation data to determine the attack’s location in our proposed distributed system. We used the SQL-User Defined Table Generating Function (UDTF) feature in Hadoop to perform “join queries” between the source IP address and Geo2IP location table. The algorithm that we applied in the mining process was
k-means clustering, which allowed us to cluster GeoIP attacks. The UDTF reduced join table operation computation time from 3561 s to 0.08 s using join queries.
Figure 3 shows the architecture of the improved version of Mata Garuda, based on big data technology.
2. Related Works
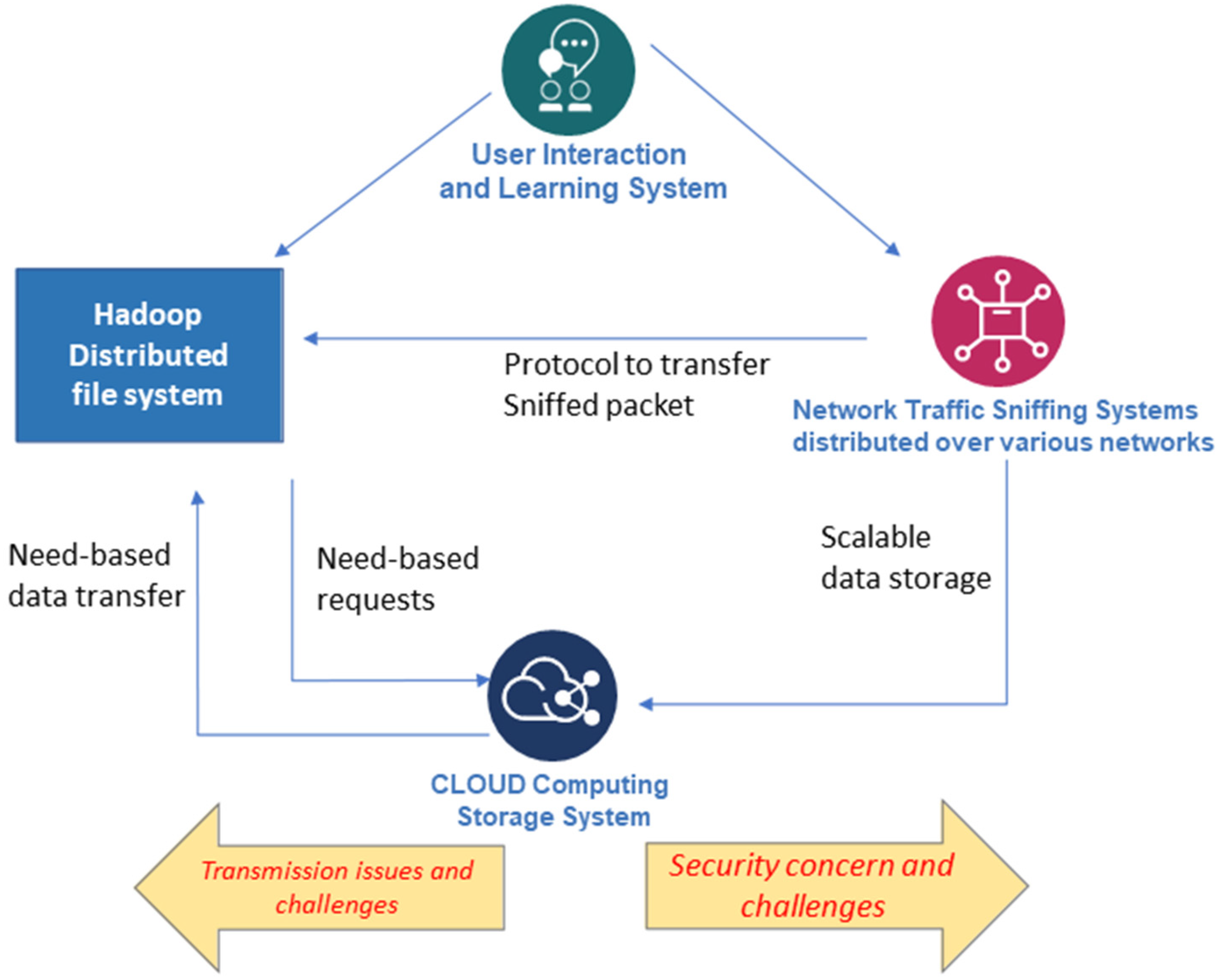
Recently, however, cloud technology has become more prevalent. In this technology, the servers and networks monitored by the administrator can be anywhere. Thus, the NIDS architecture configured by Mata Garuda cannot be used. The dynamic change in the cloud-based architecture requires ubiquitous sensor placement, lightweight sensor deployment, and the most reliable means of data transport to the defense center. Moreover, cloud technology significantly increases the volume, velocity, and variety of the data that must be processed at the defense center. This means that the defense center needs a big data platform.
The implementation of ubiquitous sensor placement and lightweight sensor deployment was first introduced by [
5]. The researchers implemented docker technology to auto-scald Snort IDS sensors placed on Software Defined Network (SDN). The systems consist of 3 components: (1) the Snort IDS sensor runs inside the docker container. It detects and drops abnormal traffic; (2) the application determines the number of agents to be deployed based on the type of abnormal traffic; (3) the container daemon controls the operation of the docker deployment based on the instruction from the application. Therefore, the Docker containers can be automatically scaled out or scaled down on demand. The researchers reported that their design could handle DDoS attacks with 2000 packets/s with only 50% CPU usage. The Docker container’s lightweight characteristics allow for the rapid application of Snort IDS and are also easy to manage.
The proof of concept of implementing big data tools to analyze the network security data was introduced by [
6]. The researchers used Apache Spark, a big-data processing tool, and its machine library, namely, MLlib, to analyze extensive network traffic. DARPA KDD’99 was used, a dataset containing approximately 4 GB of network traffic data in the form of tcpdump. This dataset was processed and stored using approximately 5 million network connections at DARPA. Each network connection record had 41 features, and was labeled as either regular traffic or malicious traffic. There were 22 types of attack mentioned, and these attacks were categorized into four groups such as Denial of Service (DoS), Port Scanning attack (Probe), unauthorized access to a remote machine (R2L), and unauthorized access to root superuser privileges (U2R attack). They also analyzed the NSL-KDD dataset. This was a reduced version of the KDD’99 dataset all of the duplicate instances were removed from the KDD’99 dataset.
Other research related to Big Data implementation combined with ML in the NIDS system was reported [
7]. They developed a system called BigFlow. It has five main parts: the monitored agents, the messaging middleware, the stream-processing parts, the stream-learning parts, and the analytics. The agent sends the network event to the messaging middleware, which acts as a broker of events. Then, the event is streamed to the stream-processing line to extract 158 features from its bidirectional network flow. The stream-learning module processes the features from the captured flow in a 15 s time window to create an initial classification model. The stream learning module provides reliable classifications as it has a Verification module. At the same time, it provides updated machine learning models. According to the authors, BigFlow can maintain a high accuracy over a network traffic dataset spanning an entire year.
Conceptually similar work has been proposed [
8,
9,
10,
11,
12,
13]. The researchers extensively investigated the implementation of big data technology to improve NIDS performance, and they used well-known IDS datasets offline to conduct experiments. The dataset was divided into training and testing datasets. The training dataset was used to process various machine-learning algorithms implemented in the big-data environment to create a model that served as the rule of the detection engine for detecting intrusions. Then, the testing data were streamed to the detection engine and measured the performance of intrusion classification based on its accuracy, precision, and various other machine learning evaluation metrics.
In [
14], the researchers reported that the correlation of security events, the collection of data from diverse sources, and big data technologies were recommended when building an efficient intrusion detection system. The researchers reviewed 74 papers related to Big Data Cyber Security Analytics (BDCA) and identified 17 architectural tactics for BDCA based on the qualitative goals, i.e., performance, accuracy, scalability, reliability, security, and usability of BDCA systems. One example of the codified architectural tactics was data ingestion monitoring tactics. In some situations, the security event data could be generated and collected at speed beyond the DC’s capacity, which led the defense center to crash. Therefore, the DC must have a data ingestion monitor to control the distributed data collector agents.
The pioneering studies showed that the NIDS must support multiagents, data ingestion, and big data environments. These requirements increase the complexity of the entire NIDS platform. Our research focuses on addressing this complexity in the NIDS and its defense center in four ways:
We describe the architecture and components of our proposed design in detail;
We propose a novel Snort-based NIDS design for the cloud, which makes it scalable and easy to configure against intrusion in the cloud;
We implement messaging middleware framework to support data ingestion monitoring;
We propose a new design for the defense center to handle massive data using the advantages of big data technologies.
The following parts of this paper are organized as follows:
Section 2 contains the main idea of our proposed design.
Section 3 shows the detailed architecture and components of the proposed system. We experiment with the sensor deployment strategy, selecting the messaging protocol between sensors and the DC, and the building blocks of big data components. We conclude the work in
Section 4.
4. Result and Discussion
This research paper proposes a novel design for a cloud-based Snort NIDS using containers, the messaging middleware between sensors and the DC, and big data architecture implemented at the DC. Moreover, to the best of our knowledge, our proposed design is the first reported design, which implements a big data architecture, namely, Lambda architecture, in the defense center as part of a network security monitoring platform.
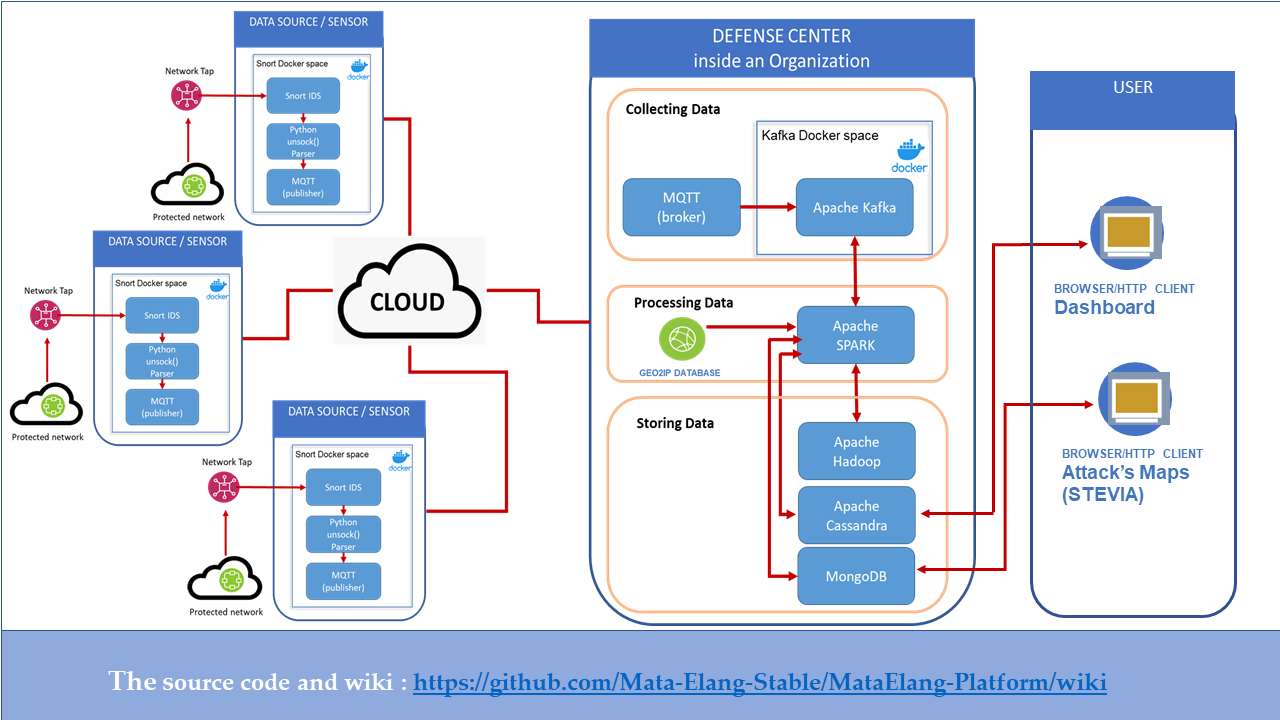
Our proposed design is composed of three main blocks: the Data Source or sensor, the DC, and the Dashboard and Visualization Service. The functional block diagram of our proposed design is shown in
Figure 6.
4.1. Data Source/Sensor
4.1.1. Building the Snort Using Docker Technology
Docker is an open-source platform used by development teams to effectively build, run, and distribute applications [
17]. Docker technology has two elements. The first element is the docker engine. This is a portable software packaging tool with a lightweight system that is run by a particular library, namely, libcontainer(). Using this library, Docker can manipulate namespaces, control groups, SELinux policies, network interfaces, and firewall rules. This feature allows independent containers to run within a single instance to avoid the overhead of starting virtual machines. The second element is the docker hub. This is a docker data-sharing application on a cloud service, automating the workflow. It makes the creation of new containers easy, enabling it to iterate applications and provide transparency in application updates.
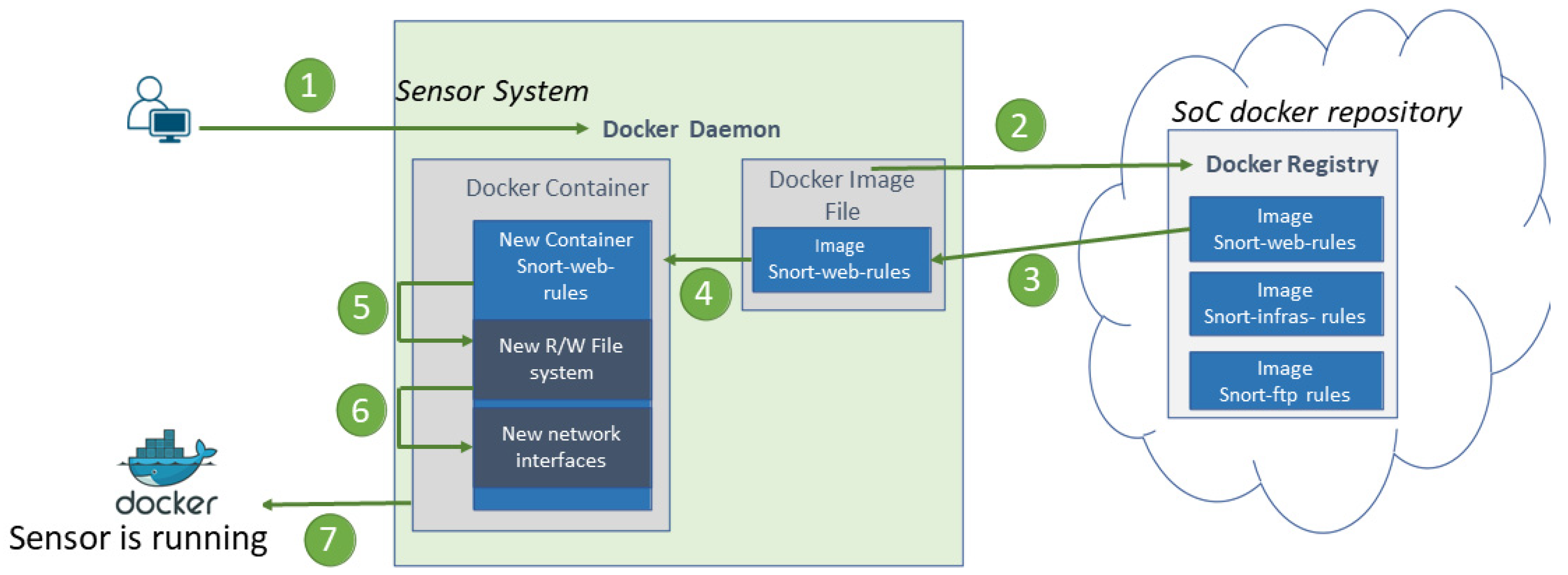
Moreover, Docker can shorten application development, testing, and production times. These advantages led us to base our Snort-based IDS sensor on docker technology [
18]. We saw that we could build the Snort-based NIDS and its dependencies into one docker image. Users can download this pre-configured sensor application without any further configuration; this can be as simple as issuing the Command-Line Interface (CLI) “docker run” (see
Figure 7). The sequence of installing and configuring the Snort sensor container is as follows:
Through CLI, execute the “docker run” command for the image sensor with web rules;
Obtain the image sensor with web rules from the docker registry;
Put the image on a file;
Create a new Snort Sensor container;
Create a new read and write file system for the newly created container;
Create a new network interface that will connect the container to the network;
Start the Snort Sensor container.
We tried four Linux distributions as the operating system of the Snort docker containers, i.e., Debian, Ubuntu Server, Alpine, and Mint. We experimented on each Linux distribution three times. We experimented with CPU Intel i5 as the host and 4 GB RAM and 500 GB HDD. As shown in
Table 2, our experiments indicated that the docker container with Alpine as its base image has a shorter build time and smaller sizes than the other Linux distributions, which may cause Alpine Linux [
19] to have a smaller memory usage footprint designed for containers.
4.1.2. The Data Flow from the Snort to the MQTT (Publisher)
As we previously explained, we used the Docker containers to make the sensor installation easier. We assigned a device ID to each sensor as its identifier. The data stream starts from the alert file generated by the Snort. Then, the Python’s library, called unsock() parses every line of the alert. The parser builds a data structure for messages. The MQTT (Publisher) sends messages to the MQTT (Broker).
Box 1 shows an example of a Snort alert sent by the MQTT (Publisher).
Box 1. Example of the Snort alert sent through the MQTT.
{
“src_mac”: “08:00:27:5b:df:e1”,
“dest_ip”: “173.194.70.94”,
“src_ip”: “10.0.2.16”,
“packet_info”: {
“len”: 40,
“ttl”: 128,
“offset”: 0,
“DF”: true,
“MF”: false
},
“protocol”: 6,
“classification”: 131072,
“dst_port”: 80,
“alert_msg”: “(http_inspect) INVALID CONTENT-LENGTH OR CHUNK SIZE”,
“priority”: 196608,
“timestamp”: “1523556223.279105”,
“sig_id”: 524288,
“src_port”: 49165,
“sig_gen”: 7864320,
“ip_type”: “IPv4”,
“sig_rev”: 131072,
“device_id”: “sensor-1”,
“dest_mac”: “52:54:00:12:35:02”
}
4.2. The Messaging Middleware Using MQTT
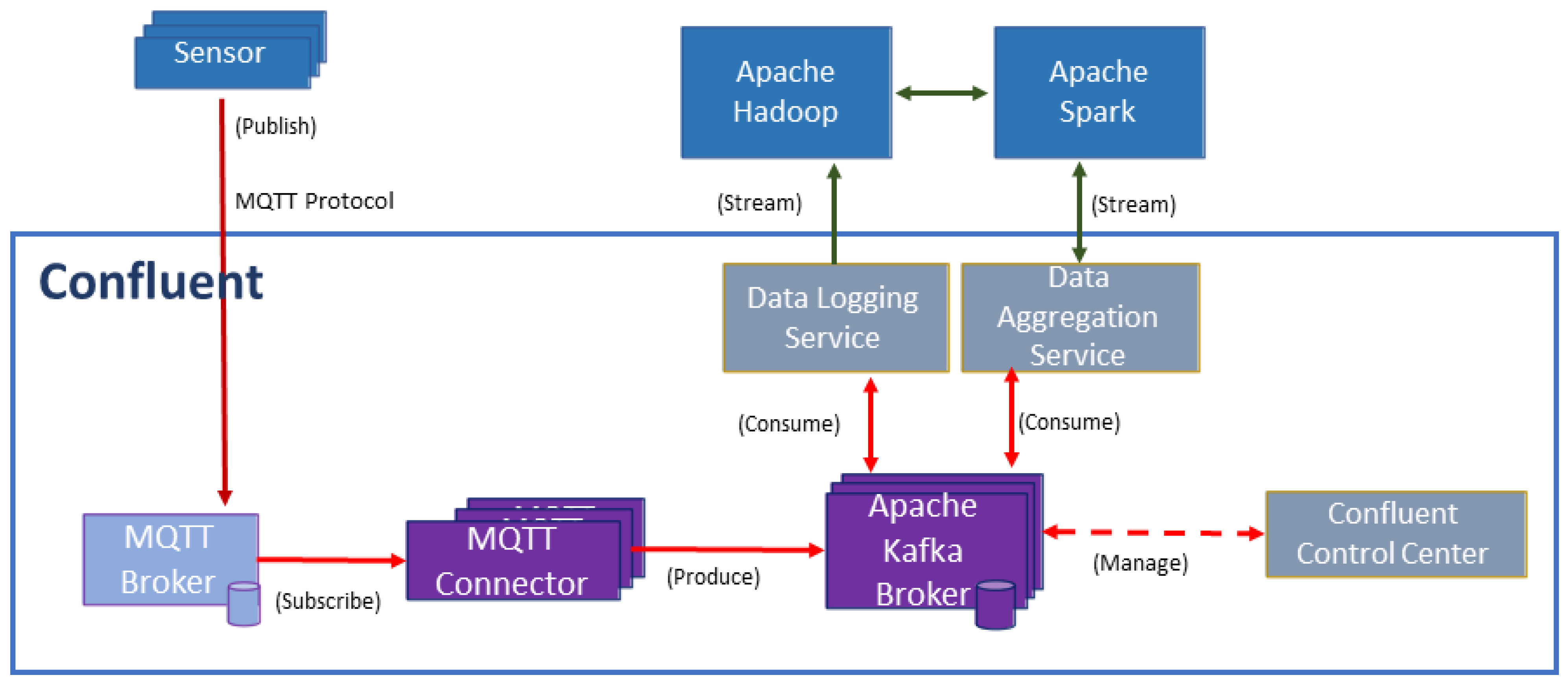
The messaging middleware has a hub and spoke architecture that makes it the central point of communication between all applications. It controls the transport method, the rule, and the data reformatting to ensure that the data will arrive at the receiving application precisely. For example, data sent by one application (Publisher) can be stored in a queue and then forwarded to the receiving application (Subscriber) when it becomes available for processing. The messaging middleware system is commonly implemented in an Internet of Things (IoT) architecture. Most IoT projects combine MQTT and Kafka for good performance and scalability. The high-level IoT architecture is shown in
Figure 8.
MQTT Broker receives data from sensors (as Publisher) using MQTT protocols. Then, it sends the data to Apache Kafka Broker through the MQTT connector. Kafka Producer is an application that publishes data to a Kafka cluster made up of Kafka Brokers. Kafka Broker will be responsible for receiving and storing the data that a producer from MQTT Broker recently published. Then, Kafka Consumer consumes the data from Kafka Broker at specified offsets, timestamps, and positions. Each consumer can perform a specific task: write the messages to a Hadoop and stream the Spark engine’s data. A basic unit of data in Kafka is called a “message”. This contains the data and their metadata and the timestamps. These messages are organized into logical groupings called “topics,” on which Producers publish data. Typically, messages in a topic are distributed across different partitions in different Kafka Brokers. An Apache Kafka Broker can manage many partitions.
We experimented with comparing the performance of Apache Kafka with that of MQTT. In the experiment, the size of each piece of event data or message was 924 bytes. We increased the message rates from 1 to 1000 messages/s. Then, we found the best message rates according to their latency. The results, presented in
Table 3, show that MQTT has a higher message rate and lower latency than Apache Kafka. We used the MQTT for the IoT messaging protocol designed by researchers according to [
13,
14], a lightweight Publish/Subscribe protocol for connecting remote devices with minimal memory and bandwidth requirements. In MQTT, messages are stored until a receiving application connects and receives a queue message. The MQTT client can acknowledge the message when it receives it or when the client has completely processed the message. Once the message is acknowledged, the system removes it from the queue. The difference between Apache Kafka and MQTT is that Apache Kafka is not only designed as a broker. It is also a streaming platform that stores, reads, and analyzes streaming data. Consequently, the messages are still stored in the queue, even those sent to the target. In our experiment, we deleted all of the messages after the retention period.
4.3. The Defense Center
The Defense Center has three blocks: collecting and streaming, processing, and storing.
4.3.1. Collecting and Streaming Data
In the first stage of collecting data, the Kafka Broker does not directly receive the MQTT package when the package arrives at the machine that collects data blocks. We used Confluent’s Kafka-connect feature in the MQTT server and created a bridge class connector to bridge the MQTT server to the Kafka Broker. We chose the Confluent platform because of the simplicity with which it performs transformation tasks such as encoding, encrypting, and transforming data before the data go to any Kafka Broker partitions. We transformed the data into the Avro format (an encoded binary format) because Avro-format data have a higher level of security than JSON or ordinary text files. We had to define the Avro schema to read and parse the data at the receiver.
The MQTT (Broker) does not actively publish topics to other destination data but only serves destinations that subscribe to specific topics with the Broker. In our system development, only one topic was published/subscribed.
We chose Apache Spark to process data in the data-processing blocks because of its proven ability to effectively handle IDS data [
20]. However, to be more convincing during the selection of Apache Kafka for data ingestion, we experimented with the following specifications. We looked at 3 scenarios: sending 50 million, 100 million, and 150 million data sent simultaneously to a single Kafka Broker. Then, we analyzed the average message rates and the throughput. As seen in
Table 4, there was a significant decrease in the throughput rate when the messages reached 150 million. This result indicates that a single broker can process about 100 million messages, with a maximum message rate of 650,000 messages/s, and the maximum throughput was 172 MBps. If the number of messages that need to be processed is more than 150 million, we must scale up the Broker by adding more Apache Kafka Brokers.
The order of the tasks in this structured streaming process is as follows. First, Spark will stream the topic defined when the job is executed on the Apache Kafka Broker. Then, the schema retrieved via the Confluent schema registry API deserializes Avro messages. The streaming process includes the following steps:
Deserialization of the Avro data with a pre-existing registry schema;
Conversion of the data into a data frame using the map function;
Execution of the aggregation process from the existing data frame using the Reduce function;
Storage of the data in Apache Hadoop.
4.3.2. Processing Data
In the data-preprocessing phase, the previously collected data are sorted and aggregated for further processing. The data stored in Apache Hadoop are retrieved and processed in Apache Spark using batch processing. The log-data-processing performed in Apache Spark consists of a timestamp and time-zone adjustments for sensors that use Unix Epoch as the format of the timestamp data sent by the sensor. The aggregation is performed in the following time units: second, minute, hour, day, month, and year. Additionally, we enriched the aggregation data with the Geo2IP database through Apache Spark. The aggregated data are shown in
Table 5.
4.4. Dashboard and Visualization Services
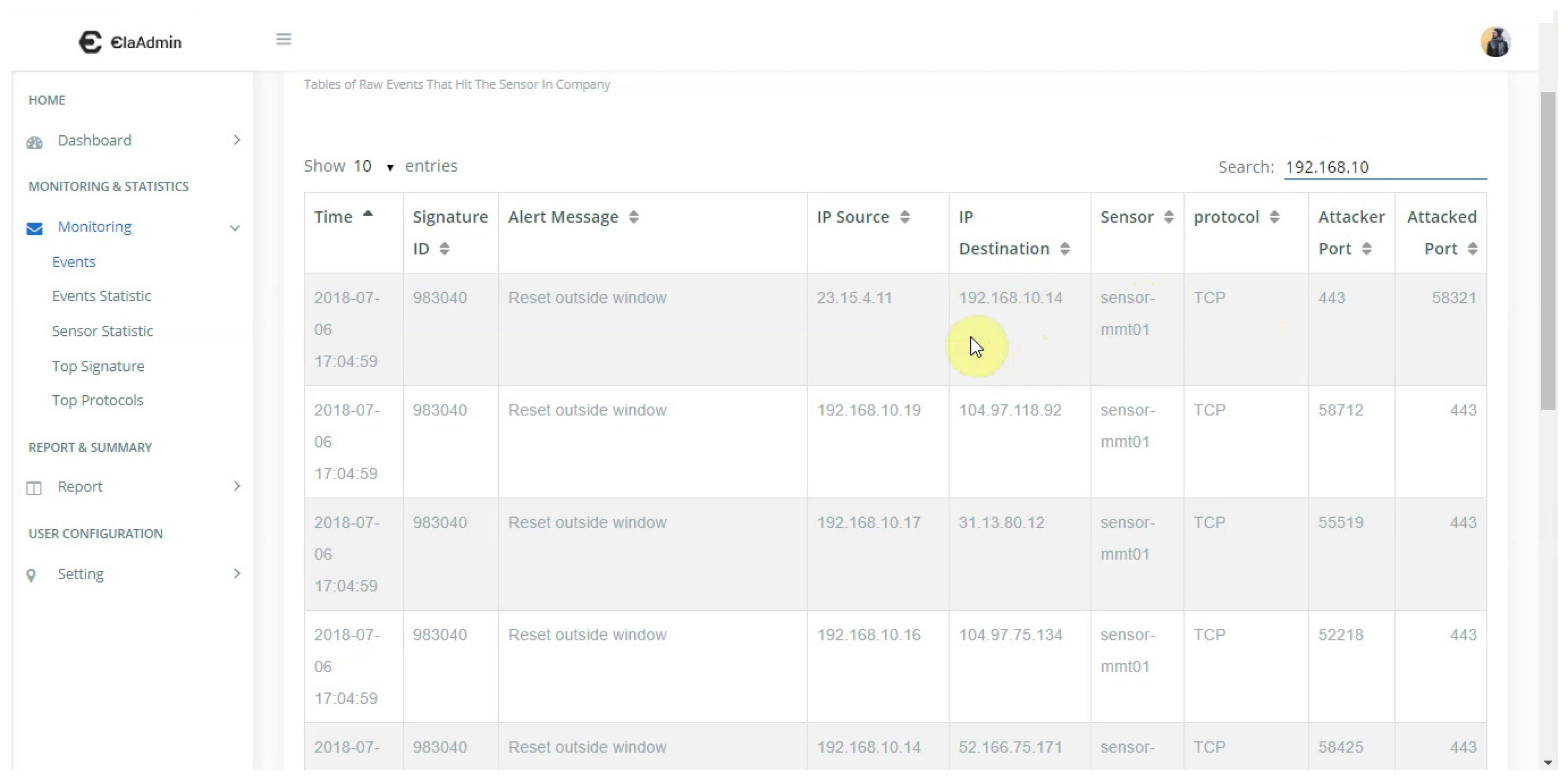
We build a service, namely, Kaspa Service, with web technology, using Python Flask to display the statistics in graphs and charts. KaspaService consists of two primary services: a backend and a frontend. It allows users to monitor and control the activity of the sensors they have installed.
Users can access all of the information sent by the sensors that the defense center has processed through a web browser using their previously set username and password. The information available on the dashboard page includes the sensor statistics; the daily, weekly, and monthly attack data; and a page for sensor management. We used [
21,
22] to design our dashboards, and
Figure 9 shows examples of our dashboards. We provided two main menus on the left side: (1) Monitoring & Statistics and (2) Report & Summary. The IDS metrics that we used are as follows:
Top 20 Alarming Signatures (ordering, highest count);
Top 20 Alerts by Date Metric (ordering, highest count);
Alerts by Source IP (aggregation, grouping);
Alerts by Date;
Alerts by Destination IP (aggregation, grouping);
Alerts Categorized by Severity (aggregation, grouping);
Number of Alerts by Signature (aggregation, grouping);
Alerts by Source Port (aggregation, grouping);
Alerts by Destination Port (aggregation, grouping); and
Source IP by Country (aggregation, count, sort).
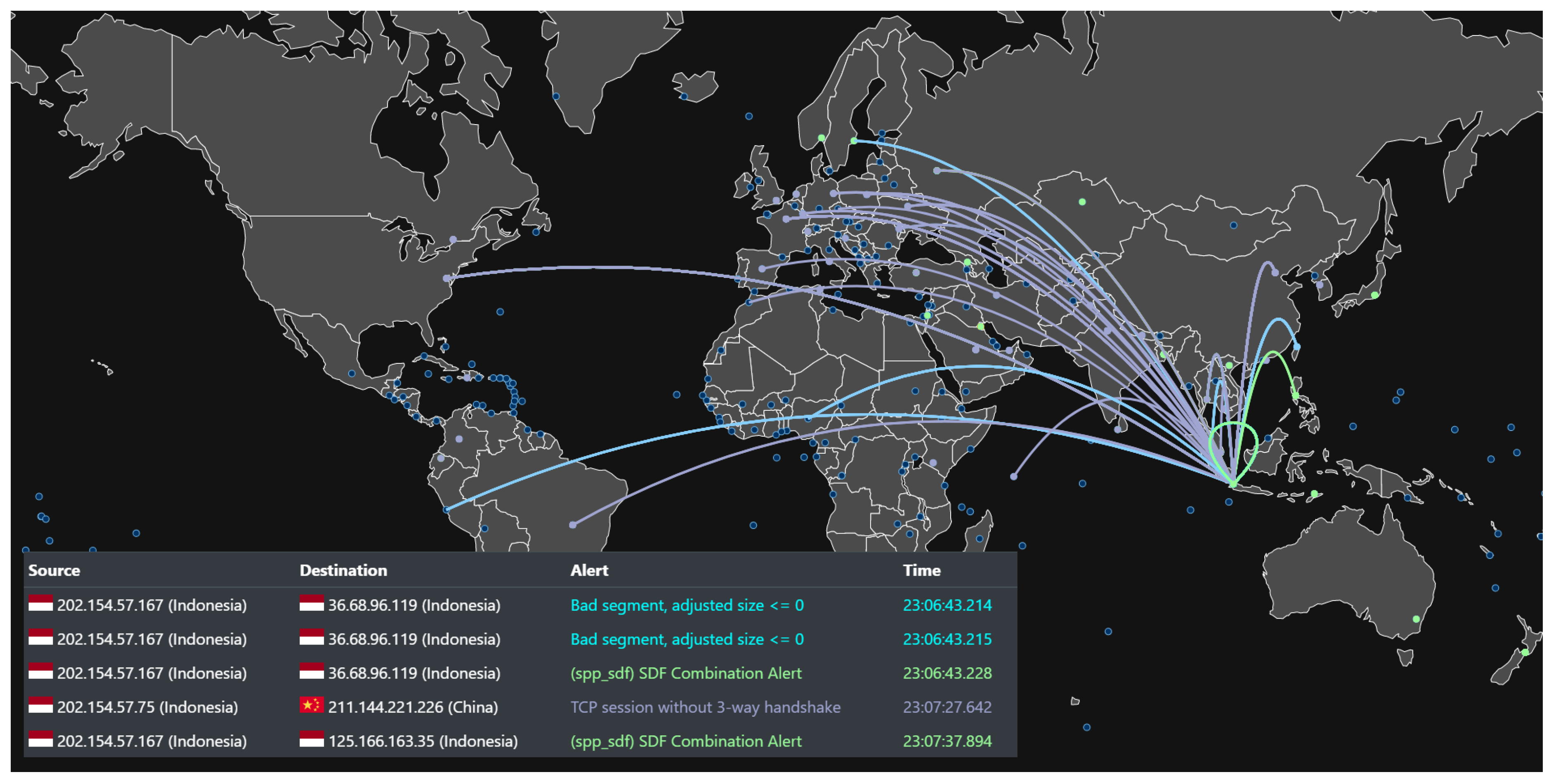
We used the D3-geo module of D3.js as a web application (STEVIA) to visualize the attack maps on the user’s dashboard. As explained previously, MongoDB receives data from Apache Spark through the change stream feature then notifies the web application to generate the maps.
Figure 10 shows the attack maps on the user’s browser.
5. Conclusions
The rapid change in Internet technology with cloud computing and big data technology challenged us to develop a new platform for a network intrusion detection system (NIDS). The cloud-based NIDS platform requires sensors that act as multi-agents, messaging middleware, and big data environments.
The change in the installation method and configuration of the Snort sensor enables it to act as an agent that is distributed over the cloud using Docker technology. The use of Docker can significantly reduce the sensor development and configuration time on the user side. We created our Docker image based on Alpine Linux distributions for the minimum image file size and build time.
Our experiment shows that the MQTT protocol has lightweight and latency qualities for communication between the sensors and the defense center. We used the following big data technologies inside the defense center: Apache Kafka, Hadoop, Spark, Mongo DB, Cassandra DB, and Rest API. Data ingestion by Apache Kafka was observed in our experiment. The experiments showed that Apache Kafka has a maximum message rate of 650,000 messages/sec and a maximum throughput of 172 MBps for streaming data into Spark and Hadoop.
In summary, based on our novel design, we successfully developed a cloud-based Snort NIDS and found the optimum method of message delivery from the sensor to the defense center. We also succeeded in developing the dashboard, and the attack maps to display the attack statistics and visualize the attacks. Our design is the first to implement a big data architecture, namely, the Lambda architecture, at the defense center as part of a network security-monitoring platform. We provide the detailed architecture of our system in
Appendix A.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}