
Revisiting Gradient Boosting-Based Approaches for Learning Imbalanced Data: A Case of Anomaly Detection on Power Grids



Abstract
:1. Introduction
- We benchmark several implementations of state-of-the-art gradient boosting ensembles for anomaly detection on power grids;
- We assess the performance of each gradient boosting ensemble under different imbalanced ratios ();
- We apply an oversampling strategy, namely the majority weighted minority oversampling technique (MWMOTE) [16], to overcome the imbalanced data issue.
2. Related Work
3. Methods
3.1. Oversampling Technique
| Algorithm 1: General procedure of majority weighted minority oversampling technique |
Preparation: Training samples, ; number of examples to generate, ; threshold, ; Procedure: 1. Calculate a set of filtered positive examples, 2. Calculate positive boundary of , U and negative boundary, V. 3. , determine the likelihood of picking x by assigning: and normalize those likelihoods. 4. Estimate clusters of using agglomerative clustering algorithm and threshold, 5. Generate by iteratively picking w.r.t. the likelihood , and update iteratively by performing , where is uniformly picked and is the cluster containing x. |
3.2. Gradient Boosting Ensembles
4. Experiment Settings and Results
4.1. Power Grid Data Set
4.2. Evaluation Metrics
4.3. Hyperparameters Search
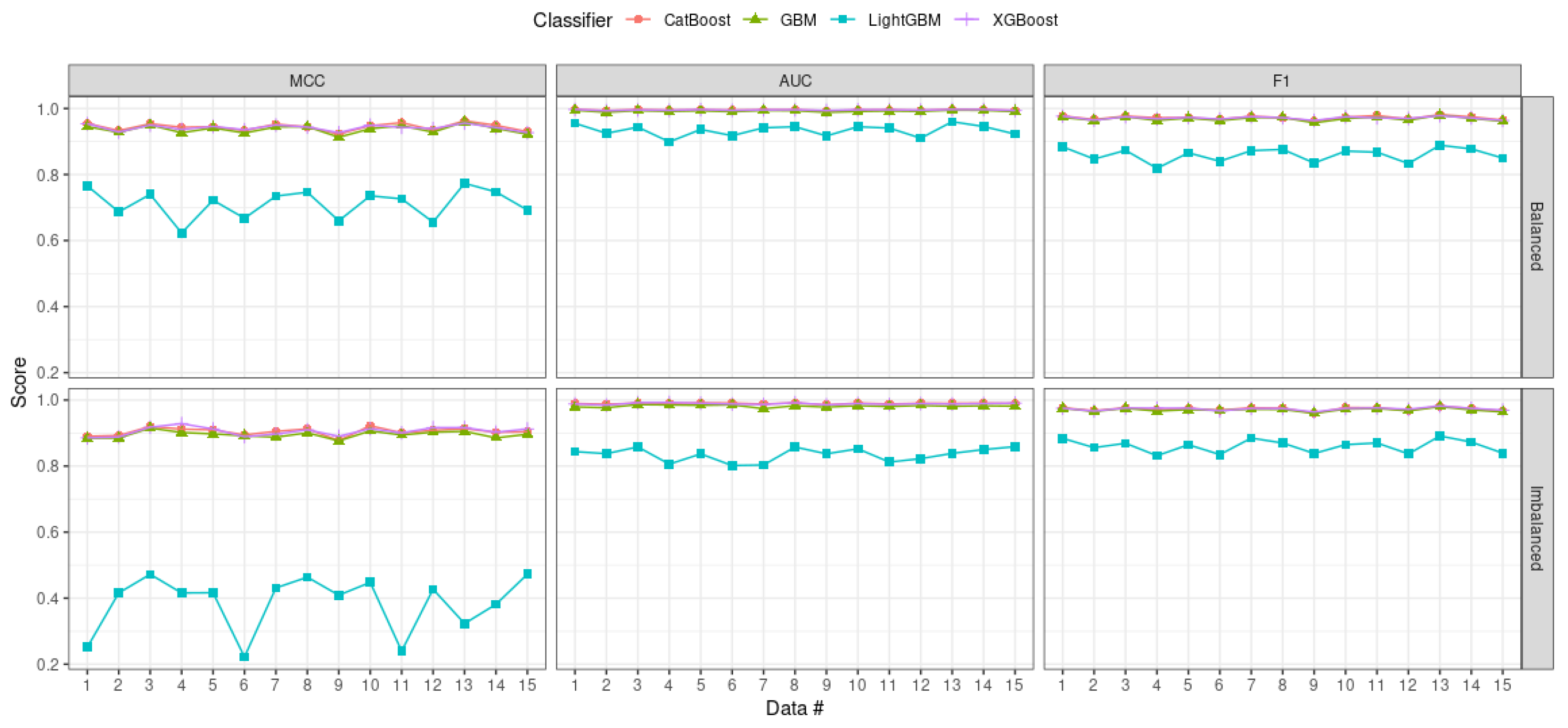
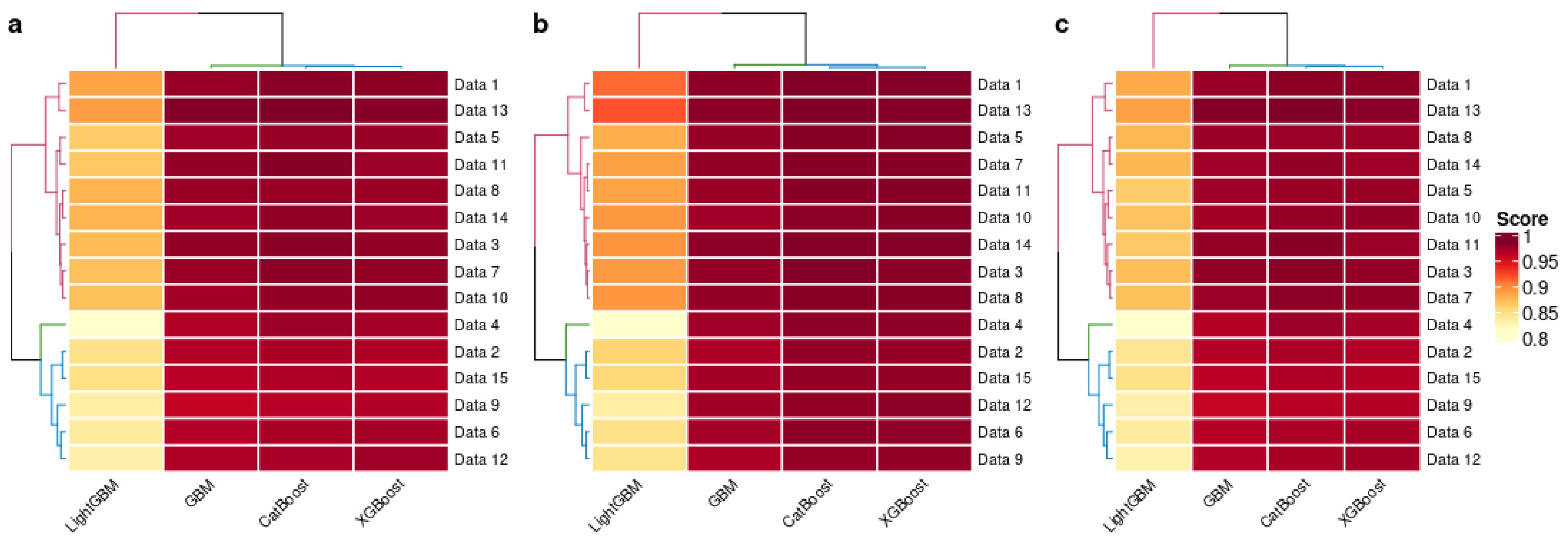
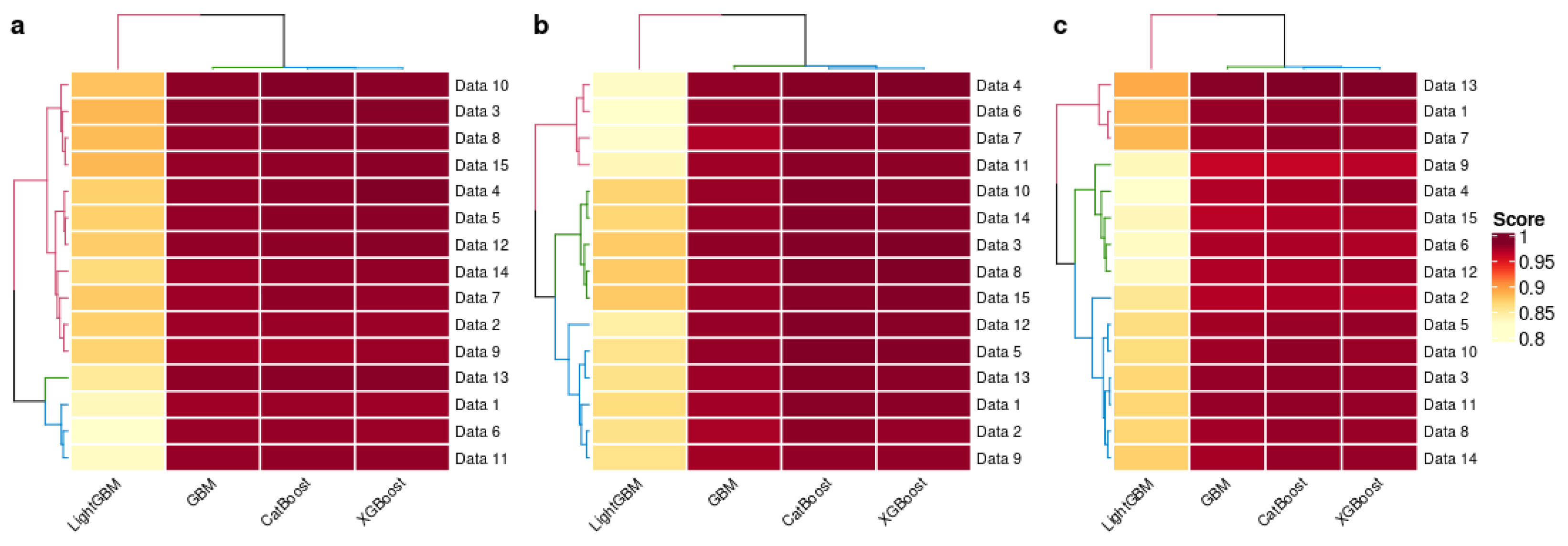
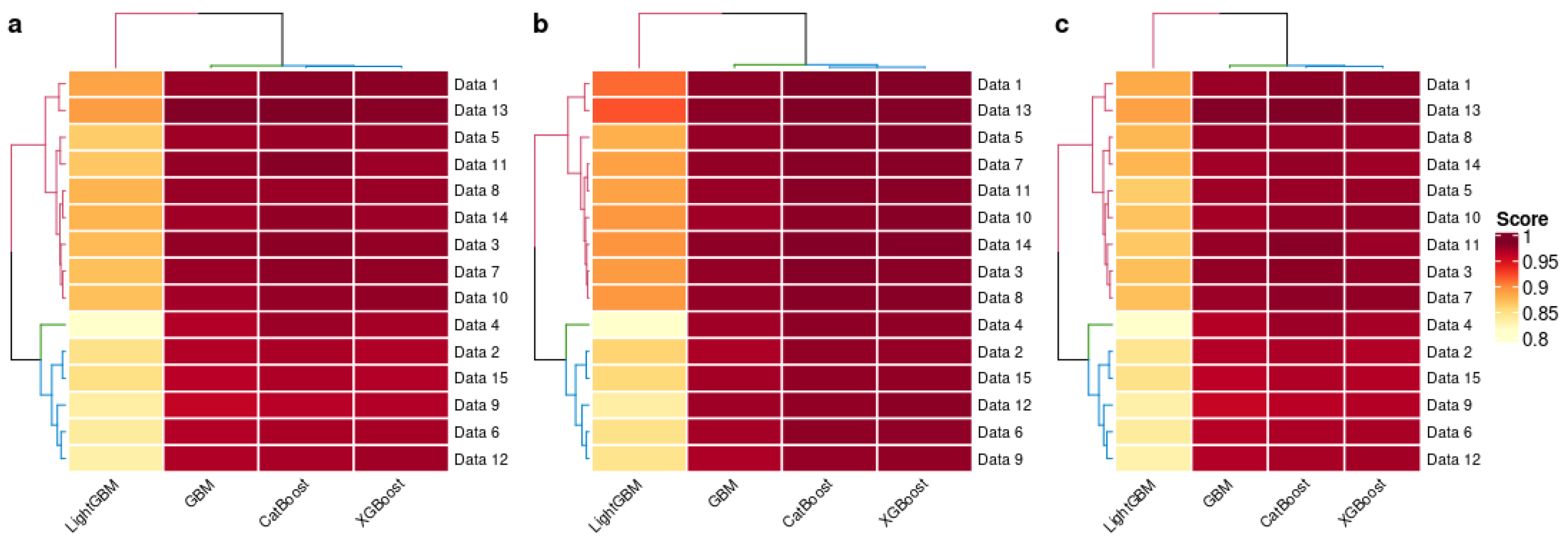
4.4. Result Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, Z.; Das, D.K.; Guo, W.; Wei, W. Does power grid infrastructure stimulate regional economic growth? Energy Policy 2021, 155, 112296. [Google Scholar] [CrossRef]
- Wei, R.; Kelly, T.P.; Hawkins, R.; Armengaud, E. Deis: Dependability engineering innovation for cyber-physical systems. In Federation of International Conferences on Software Technologies: Applications and Foundations; Springer: Berlin/Heidelberg, Germany, 2017; pp. 409–416. [Google Scholar]
- Irmak, E.; Erkek, İ. An overview of cyber-attack vectors on SCADA systems. In Proceedings of the 2018 6th International Symposium on Digital Forensic and Security (ISDFS), Antalya, Turkey, 22–25 March 2018; pp. 1–5. [Google Scholar]
- Li, Y.G.; Yang, G.H. Worst-case ϵ-stealthy false data injection attacks in cyber-physical systems. Inf. Sci. 2020, 515, 352–364. [Google Scholar] [CrossRef]
- Sengan, S.; Subramaniyaswamy, V.; Indragandhi, V.; Velayutham, P.; Ravi, L. Detection of false data cyber-attacks for the assessment of security in smart grid using deep learning. Comput. Electr. Eng. 2021, 93, 107211. [Google Scholar] [CrossRef]
- Pan, S.; Morris, T.; Adhikari, U. Classification of disturbances and cyber-attacks in power systems using heterogeneous time-synchronized data. IEEE Trans. Ind. Inform. 2015, 11, 650–662. [Google Scholar] [CrossRef]
- Pan, S.; Morris, T.; Adhikari, U. Developing a hybrid intrusion detection system using data mining for power systems. IEEE Trans. Smart Grid 2015, 6, 3104–3113. [Google Scholar] [CrossRef]
- Keshk, M.; Sitnikova, E.; Moustafa, N.; Hu, J.; Khalil, I. An integrated framework for privacy-preserving based anomaly detection for cyber-physical systems. IEEE Trans. Sustain. Comput. 2019, 6, 66–79. [Google Scholar] [CrossRef]
- Upadhyay, D.; Manero, J.; Zaman, M.; Sampalli, S. Intrusion detection in SCADA based power grids: Recursive feature elimination model with majority vote ensemble algorithm. IEEE Trans. Netw. Sci. Eng. 2021, 8, 2559–2574. [Google Scholar] [CrossRef]
- Xu, Z.; Huang, G.; Weinberger, K.Q.; Zheng, A.X. Gradient boosted feature selection. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 522–531. [Google Scholar]
- Tama, B.A.; Lim, S. Ensemble learning for intrusion detection systems: A systematic mapping study and cross-benchmark evaluation. Comput. Sci. Rev. 2021, 39, 100357. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems; ACM: New York, NY, USA, 2017; pp. 3146–3154. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Advances in Neural Information Processing Systems; ACM: New York, NY, USA, 2018; pp. 6638–6648. [Google Scholar]
- Barua, S.; Islam, M.M.; Yao, X.; Murase, K. MWMOTE–majority weighted minority oversampling technique for imbalanced data set learning. IEEE Trans. Knowl. Data Eng. 2012, 26, 405–425. [Google Scholar] [CrossRef]
- Hink, R.C.B.; Beaver, J.M.; Buckner, M.A.; Morris, T.; Adhikari, U.; Pan, S. Machine learning for power system disturbance and cyber-attack discrimination. In Proceedings of the 2014 7th International Symposium on Resilient Control Systems (ISRCS), Denver, CO, USA, 19–21 August 2014; pp. 1–8. [Google Scholar]
- Keshk, M.; Moustafa, N.; Sitnikova, E.; Creech, G. Privacy preservation intrusion detection technique for SCADA systems. In Proceedings of the 2017 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 14–16 November 2017; pp. 1–6. [Google Scholar]
- Upadhyay, D.; Manero, J.; Zaman, M.; Sampalli, S. Gradient boosting feature selection with machine learning classifiers for intrusion detection on power grids. IEEE Trans. Netw. Serv. Manag. 2020, 18, 1104–1116. [Google Scholar] [CrossRef]
- Louk, M.H.L.; Tama, B.A. Exploring Ensemble-Based Class Imbalance Learners for Intrusion Detection in Industrial Control Networks. Big Data Cogn. Comput. 2021, 5, 72. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chicco, D.; Tötsch, N.; Jurman, G. The Matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation. BioData Min. 2021, 14, 13. [Google Scholar] [CrossRef] [PubMed]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Lang, M.; Binder, M.; Richter, J.; Schratz, P.; Pfisterer, F.; Coors, S.; Au, Q.; Casalicchio, G.; Kotthoff, L.; Bischl, B. mlr3: A modern object-oriented machine learning framework in R. J. Open Source Softw. 2019, 4, 1903. [Google Scholar] [CrossRef] [Green Version]
- Murtagh, F.; Legendre, P. Ward’s hierarchical agglomerative clustering method: Which algorithms implement Ward’s criterion? J. Classif. 2014, 31, 274–295. [Google Scholar] [CrossRef] [Green Version]
- Friedman, M. A comparison of alternative tests of significance for the problem of m rankings. Ann. Math. Stat. 1940, 11, 86–92. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Japkowicz, N.; Shah, M. Evaluating Learning Algorithms: A Classification Perspective; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Tama, B.A.; Lim, S. A comparative performance evaluation of classification algorithms for clinical decision support systems. Mathematics 2020, 8, 1814. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | ||||
|---|---|---|---|---|
| Data 1 | 4966 | 3866 | 1100 | 0.285 |
| Data 2 | 5069 | 3525 | 1544 | 0.438 |
| Data 3 | 5415 | 3811 | 1604 | 0.421 |
| Data 4 | 5202 | 3402 | 1800 | 0.529 |
| Data 5 | 5161 | 3680 | 1481 | 0.402 |
| Data 6 | 4967 | 3490 | 1477 | 0.423 |
| Data 7 | 5236 | 3910 | 1326 | 0.339 |
| Data 8 | 5315 | 3771 | 1544 | 0.409 |
| Data 9 | 5340 | 3570 | 1770 | 0.496 |
| Data 10 | 5569 | 3921 | 1648 | 0.420 |
| Data 11 | 5251 | 3969 | 1282 | 0.323 |
| Data 12 | 5224 | 3453 | 1771 | 0.513 |
| Data 13 | 5271 | 4118 | 1153 | 0.280 |
| Data 14 | 5115 | 3762 | 1353 | 0.360 |
| Data 15 | 5276 | 3415 | 1861 | 0.545 |
| Scenario | Performance Metric | CatBoost | GBM | LightGBM | XGBoost |
|---|---|---|---|---|---|
| Imbalanced | MCC | 1.47 | 2.93 | 4.00 | 1.60 |
| AUC | 1.27 | 3.00 | 4.00 | 1.73 | |
| F1 | 1.40 | 2.87 | 4.00 | 1.73 | |
| Balanced | MCC | 1.40 | 2.67 | 4.00 | 1.93 |
| AUC | 1.53 | 3.00 | 4.00 | 1.47 | |
| F1 | 1.40 | 2.67 | 4.00 | 1.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Louk, M.H.L.; Tama, B.A. Revisiting Gradient Boosting-Based Approaches for Learning Imbalanced Data: A Case of Anomaly Detection on Power Grids. Big Data Cogn. Comput. 2022, 6, 41. https://doi.org/10.3390/bdcc6020041
Louk MHL, Tama BA. Revisiting Gradient Boosting-Based Approaches for Learning Imbalanced Data: A Case of Anomaly Detection on Power Grids. Big Data and Cognitive Computing. 2022; 6(2):41. https://doi.org/10.3390/bdcc6020041
Chicago/Turabian StyleLouk, Maya Hilda Lestari, and Bayu Adhi Tama. 2022. "Revisiting Gradient Boosting-Based Approaches for Learning Imbalanced Data: A Case of Anomaly Detection on Power Grids" Big Data and Cognitive Computing 6, no. 2: 41. https://doi.org/10.3390/bdcc6020041
APA StyleLouk, M. H. L., & Tama, B. A. (2022). Revisiting Gradient Boosting-Based Approaches for Learning Imbalanced Data: A Case of Anomaly Detection on Power Grids. Big Data and Cognitive Computing, 6(2), 41. https://doi.org/10.3390/bdcc6020041