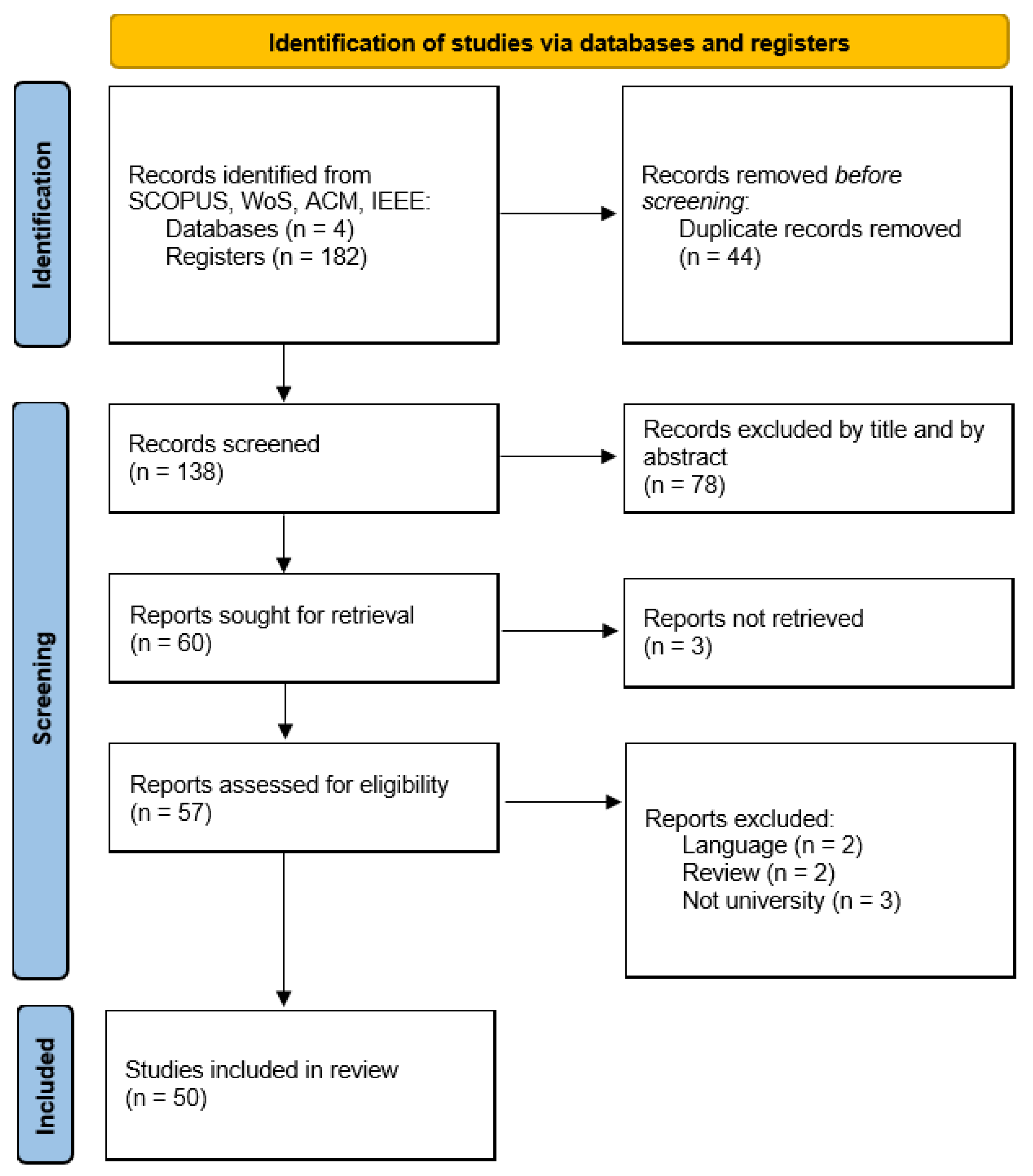
4.1.2. Bibliographic Analysis
In the bibliographic analysis, we divided the research question PQ1 (Where, how, and in what ways has LA been deployed in the studies produced?) into three parts: (1) where, (2) how, and (3) in what ways. The results obtained for each part are described next.
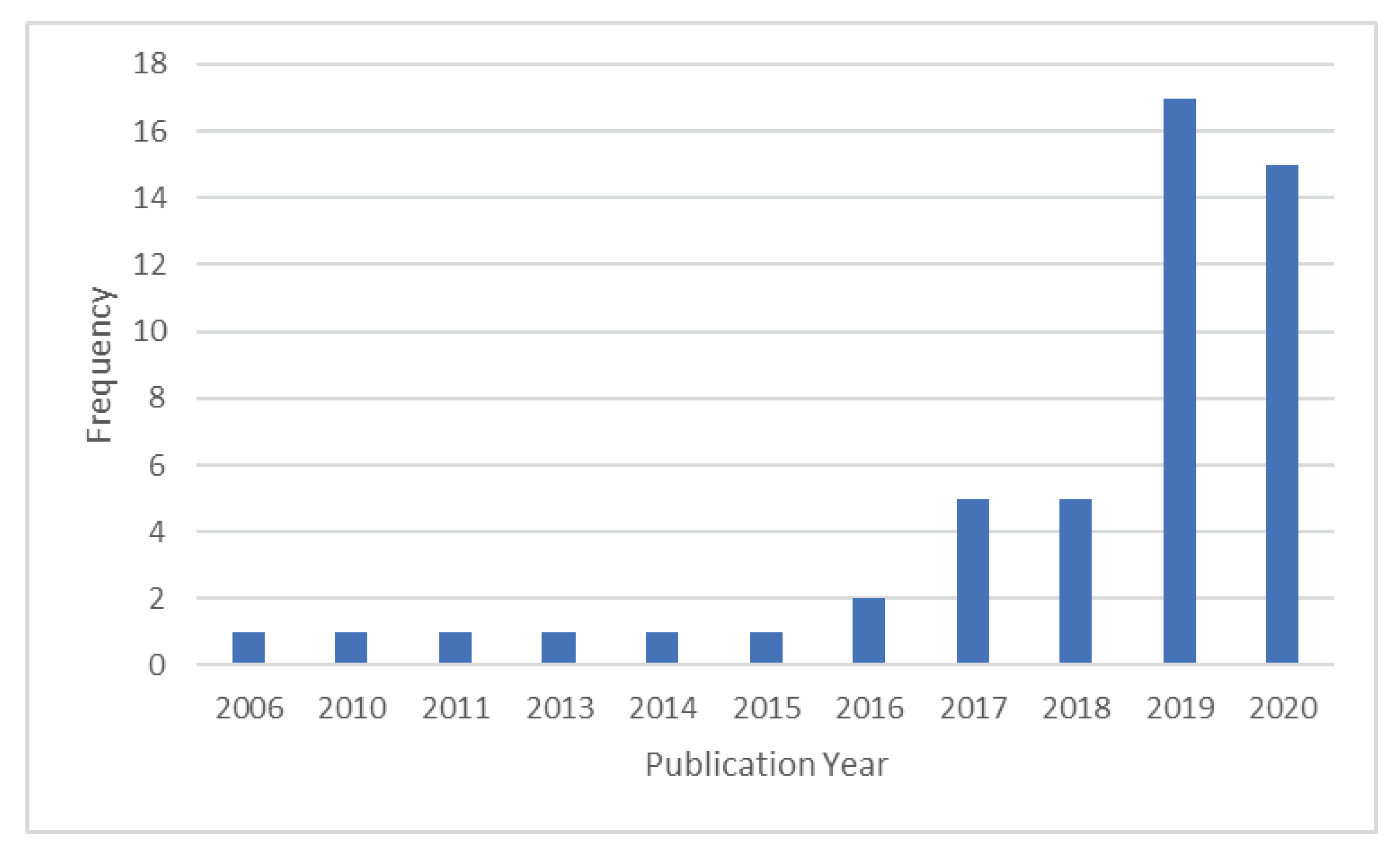
We start by analysing the university, course, disciplines, school year and number of students considered for the study, together with whether the class methodology included online teaching. Fifteen of the analysed studies were performed with online classes. These are the ones referred to in the following studies addressed in [
71,
72,
73,
74,
75,
76,
77,
78,
79,
80,
81,
82,
83,
84]. Additionally, the studies referred to in [
85,
86] include both traditional and online classes. We refer to the ones that explicitly state being conducted with, or including, online classes and assume that the remaining ones were performed in traditional classes.
The articles collected referred studies conducted in different countries and continents: Asia (sixteen studies with data retrieved from universities in ten different countries), Europe (thirteen studies with data from universities in six different countries), North America (ten studies with data obtained from universities in two different countries), South America (seven studies concerning data of universities from four different countries), Africa (the study in [
77] considers 496 records of data obtained from an online course of Management Informatics on the Abdelmalek Essaadi University, in Morocco), and Australia (the study published in [
78] was performed using data about online learning activities of an Australian university). Furthermore, the study described in [
87] does not state the university where it is performed, only revealing that it focuses on 16,000 grade records obtained from students. Finally, the study referred to in [
88] includes engineering courses of six different universities in five different countries of the European Union. These three studies are not considered as being conducted in any specific country.
The Asian countries where most of the analysed studies have occurred are India and Thailand (three studies in each), and Indonesia and China (two studies in each). We have also analysed one study conducted in each of the following countries: Japan, Malaysia, Palestine, Pakistan, Philippines, and Turkey (for this study, Turkey is considered to belong to the Asian continent).
Three of the analysed studies were performed in Indian Universities. The study described in [
89] was performed considering the data of 240 undergraduate students from an unidentified university. The study referred to in [
81] uses postgraduate student data of the open and distance learning directorate of the University of North Bengal from 2006 until 2008. The work described in [
90] was conducted with data regarding 163 students enrolled in a Zoology course of the Dr Ambedkar Government College.
We found three works conducted in Thai universities. The study referred to in [
91] was conducted using the data of 811 students enrolled in the Mae Fah Luang University between 2009 and 2012, and the other two studies were performed in a business computer program of the University of Phayao. The first one is the work described in [
92], which used data of 2017 students enrolled between 2001 and 2019. Then, the study referred to in [
93] used data of 389 students enrolled in the university between 2012 and 2019. These two studies are complementary to one another and do not overlap since their objectives are different, as will be stated later in this work.
Two of the analysed studies were conducted in Indonesian Universities. The work referred to in [
94] considered data on 17,432 students enrolled between 2016 and 2018 in the Faculty of Social and Political Science of a private university in Jacarta. The study described in [
95] refers to data on 425 students enrolled in information systems and in informatics engineering courses in an East Java university between the years 2009 and 2015.
We found two works ( [
83] and [
72]) conducted with data retrieved from XuetangX, a Chinese Massive Online Open Course (MOOC) platform, which consists of 39 courses, 79,186 students, and 120,542 student enrolments in 39 courses in 2015. This is a publicly available EDM dataset that was used on the 2015 KDD CUP (data available at
http://moocdata.cn/challenges/kdd-cup-2015, accessed 13 October 2021).
The remaining six works analysed that took place on Asian universities are referred to next. The work described in [
85] used data on 1167 students enrolled in six consecutive semesters (from 2012–2013 to 2017–2018) in a digital signal processing discipline of a sophomore-level course with online and traditional classes taking place in the Engineering Faculty of Kumamoto University, Japan. Data regarding students enrolled between 2015 and 2016 in the courses of chemical engineering, electrical and electronic engineering, and mechanical engineering of the School of Engineering of Taylor’s University in Malaysia were used for the work described in [
96]. The study referred to in [
97] used data about students enrolled between 2010 and 2015 in five courses (architectural engineering, industrial automation, computer programming and database, office automation, and fashion design and dress making) of the Technical University of Palestine. The work described in [
98] was conducted using data of 128 students enrolled in the Spring term of 2016 in the first-year electrical engineering and computer science courses of the School of Electrical Engineering and Computer Science (SEECS) of the National University of Sciences and Technology (NSUT), Islamabad and Abasyn University, Pakistan. The study conducted in [
99] regards 3765 civil, electrical, electronics and communication, and mechanical engineering students that, between 2008 and 2015, were enrolled in maths and physics disciplines in the Technological University of the Philippines. In [
100], the study described concerns data on 127 students of the Department of Computer Education and Instructional Technology in Fırat University, Turkey.
The European country where most of the analysed studies occurred is Greece (four studies, all with data regarding the same university—Hellenic Open University) followed by Italy (three studies), Germany and Spain (two studies each), and Bulgaria and Scotland (one study each).
Four studies used data from Greek Hellenic Open University online classes. The study described in [
73] focused on data obtained from 453 students enrolled, in 2017–2018, in six sections of same module of the master’s in information systems. The remaining studies used data obtained from computer science students. The work in [
76] used the data of 492 students enrolled in the discipline of principles of software technology and the other two studies used data regarding students enrolled in the introduction to informatics discipline: the study in [
79] used data of 3882 students enrolled between 2008 and 2010, and the study described in [
71] used data of 1073 students enrolled in 2013–2014.
We found tree studies conducted with data from Italian universities. The study referred to in [
101] used data of 6000 students enrolled since 2009 in the department of education of Roma Tre university. In [
102], the authors used data regarding 561 undergraduate students enrolled in a first level three-year program of five degree-courses of an unidentified university. For the study published in [
103] the data were retrieved from 11,000 students enrolled in all the bachelor’s degree programs in University of Bari Aldo Moro in the school year of 2015–2016.
Two studies considered data from German universities. The first one [
104] occurred in the Karlsruhe Institute of Technology regarding data retrieved from 3176 students between the years 2007 and 2012. The second study [
105] considered data retrieved from 17,910 first year students enrolled in the winter term of 2010/2011 in bachelor’s, state examination, master’s or specific art and design degrees.
Two studies were performed with data obtained from Spanish universities. The work described in [
75] focused on data obtained from over 11,000 students enrolled in several online courses in the National Distance Education University. The study referred in [
106] considered data obtained from 323 students enrolled, from 2010 to 2018, in the computer sciences and information course of a public unidentified university.
We analysed two other studies performed with data from European universities. The study described in [
107] uses data on 252 students enrolled in a web programming course of an unidentified Bulgarian university. Finally, in [
108], the study describes the use of data on 141 students enrolled in the University of the West of Scotland in the first semester of 2016.
The North American country in which most of the analysed studies occurred is the United States of America (nine studies). The study described in [
109] entailed data on 25,224 students enrolled as freshmen between 1999 and 2006 in a public university. Then, in [
110], the authors used records on 272 students enrolled, between 2001 and 2007, in a maths major of a Mid-Eastern university. After that, the study in [
111] analysed data concerning students enrolled in aerospace engineering, biomedical engineering, chemical engineering, chemistry, civil engineering, computer science, electrical engineering, material science, mathematics, mechanical engineering, physics, and statistics courses in the University of Minnesota in the periods of Fall 2002 to Fall 2013 (10,245 students) and Fall 2002 to Spring 2015 (12,938 students). The study in [
112] considered 140 students enrolled in 2014 in a computer science course at Washington State University. There was also a study ([
113]) conducted with data collected from the Fall 2017 and Spring 2018 periods of the Virginia Commonwealth University (VCU) College of Engineering. There were two studies that used data from MOOC available from American universities: [
74] used data concerning a total of 1,117,411 students of three datasets obtained from the Massachusetts Institute of Technology (MIT), Harvard; and in [
84], the data considered regard 29,604 students enrolled in eleven public online classes from Stanford University. Finally, the study in [
114] was performed with data obtained from six unidentified universities, and the study described in [
115] used data obtained on 16,066 students enrolled on a public American university.
We have also analysed one study described in [
116], which analysed data retrieved from 200 students enrolled in several public universities in Mexico, but also 300 students enrolled in public universities in the same country.
The South American country in which most of the analysed studies occurred is Brazil (4 studies). We have also analysed one study each, conducted in Chile, Ecuador, and Peru (one study in each country).
Four studies occurred in Brazilian universities. The study referred in [
117] considered a total of 706 students enrolled in computer science and production engineering courses from 2004 to 2014 in Fluminense Federal University. In [
80], the study focused on two online classes on the discipline of family health that occurred in the Federal University of Maranhão: the class of 2010 (with 349 students), and the class of 2011 (with 753 students). The study described in [
86] regards two different classes of an introductory programming discipline occurring in several courses of the Federal University of Alagoas: an online class of 262 students enrolled in 2013, and a traditional class of 161 students enrolled in 2014. Finally, the study referred to in [
118] used data on 49 students enrolled in the discipline of differential and integral calculus I of the mathematics major of Universidade Estadual do Oeste do Paraná.
In the study described in [
2], the data consist of records on 3362 students enrolled between 2012 and 2016 in three bachelor courses of a Chilean university. Furthermore, in [
82], the authors used data regarding 2030 students enrolled from March 2014 to September 2018 in an online course of an unidentified university in Ecuador. Finally, the study described in [
119] used the data of 970 students enrolled in the Institute of Computing of the Professional School of Systems Engineering of the National University of San Agustín (UNSA), Peru.
For this part of the study, we focused on the main objectives of the analysed articles. Most of the studies aim at providing some prediction, such as, for example, [
73], where the authors wish to predict a set of 8 variables. Some studies aim at predicting student performance [
79,
91] or grades [
71,
90,
111] in order to improve it [
100].
However, the majority of the analysed studies aim at predicting student attrition (the reduction in numbers of students attending courses as time goes by, including dropout and desertion) in order to better understand [
88] the reasons and find the most important factors [
93,
110,
116] and causes [
74,
76,
81,
82,
89,
95,
102,
109,
115,
117,
118] of those results, with the objective of preventing [
75] or reducing [
76,
98,
99] those outcomes. In this context, some works analyse student attrition [
76,
109,
115], but we can also include in this group its underlying causes: student dropout [
72,
75,
76,
80,
81,
83,
88,
89,
93,
95,
97,
98,
99,
101,
102,
103,
104,
105,
110,
116,
118] and desertion [
82,
119] as well as students’ risk of failure [
78,
85,
86,
107,
113,
119] or retention [
74,
117] (
retention here means that students fail the discipline and need to be retained—e.g., in the following year—in order to complete it).
Furthermore, there are studies that evaluate and compare prediction models [
73,
77,
92,
94,
100,
108] in order to find the best suited ones for the problem at hand. There are also some approaches that aim at early prediction [
88] for the anticipation of dropout [
75] and risk of failure [
86,
107].
Other studies aim at developing some tool or framework to help students or tutors in the process of reducing dropout or increasing performance. For example, in [
2], the authors developed a modelling framework to maximise the effectiveness of retention efforts. In [
88], a tool was developed with the objective of supporting tutors on the process. Another example is the work described in [
98], where EDM is used to warn students of poor performance. In [
106], students are provided with recommended subjects based on historic data. In [
112], a tool identifies the urgency in student posts so that a tutor can prioritise the answers.
We also found that some of the analysed studies had very specific objectives. These include implementing retention strategies [
75] (
retention here means to convince students to not desert or drop out); identifying student satisfaction [
114]; recommending strategies to reduce attrition by reducing dropout [
76]; analysing students’ learning behaviour through the creation of a feature matrix for keeping information related to the local correlation of learning behaviour [
72]; analysing activity, polarity, and emotions of students and tutors to perform sentiment analysis to help in dropout prediction [
73]; monitoring the learning process and performing student profiling to support pedagogical actions to reduce dropout [
80]; predicting remedial actions [
87]; using data to improve courses [
96] and learning experiences [
96]; and exploring relationships between programming behaviour, student participation, and the outcomes obtained [
112].
As referred, EDM uses data mining techniques on educational data. In this section, we focus on this and analyse the dataset: target variable and features; the ML task considered and the ML algorithm used to solve it; the validation and evaluation processes performed, including the ML metrics and the baselines considered (if used); and also the ML results obtained.
The target variable is the information that we want to be able to predict with DM. Most of the analysed studies try to predict student status [
110,
116] to try to prevent attrition [
109], including desertion [
82] but, most of all, dropout [
2,
72,
74,
76,
79,
80,
81,
83,
88,
89,
91,
92,
93,
94,
95,
97,
98,
99,
101,
102,
103,
104,
105,
106,
115,
117,
118] as well as the students’ risk of failure [
75,
78,
85,
86,
108,
113,
119]. In some cases, the authors approached this by trying to predict the students’ performance or grades [
71,
73,
77,
88,
90,
100,
108,
111,
112]. However, there are also approaches where the target variable is the students’ satisfaction [
114], ranking [
107], or graduation rates [
96]. Some also tried to predict remedial actions to take if the student is at risk of failure [
87], or even the urgency in replying to students’ posts on the learning management system (LMS) forum [
84]. To perform the predictions, the authors took advantage of a set of information (features) that will be described next.
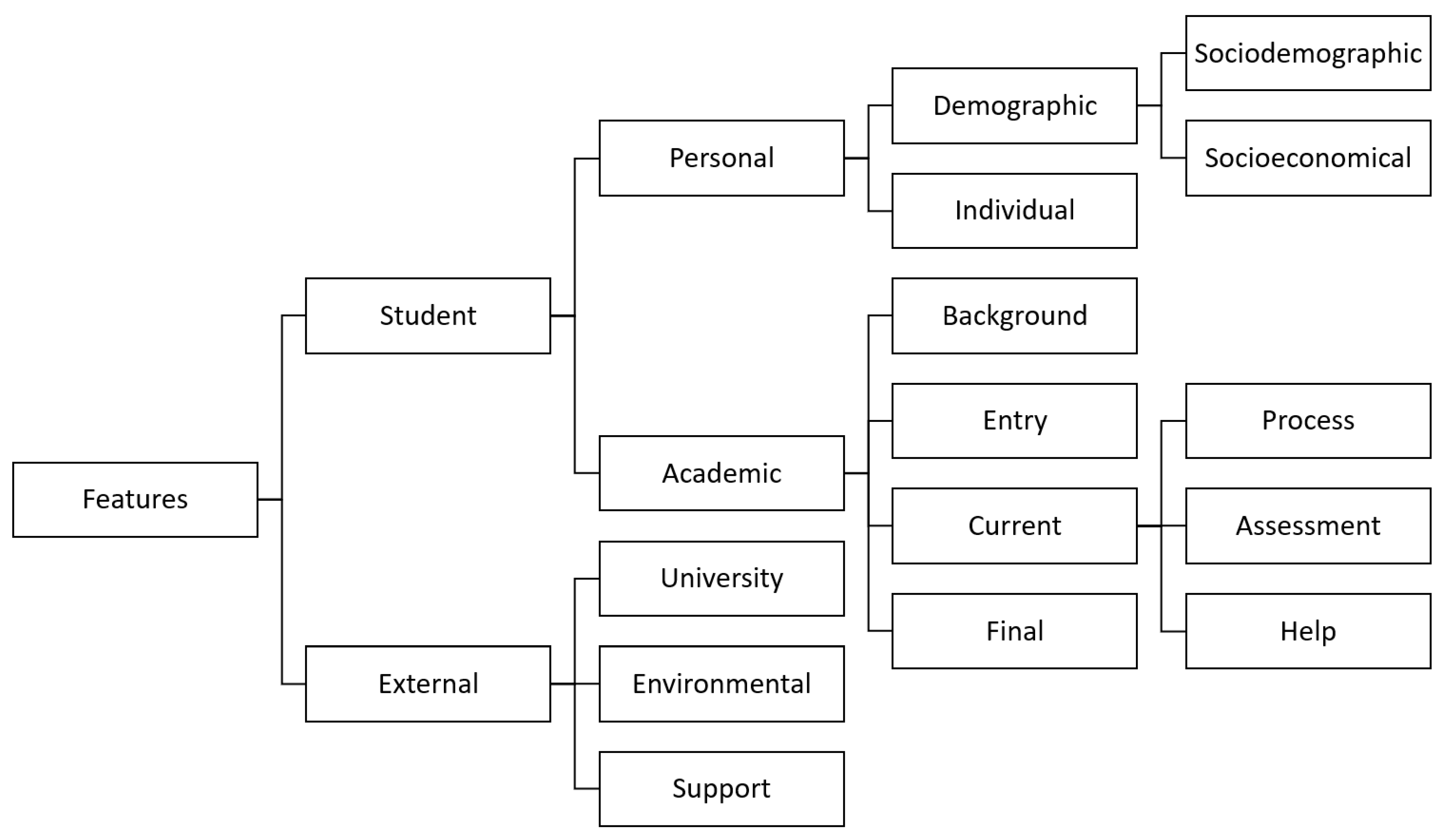
Apart from the study referred in [
114], where the authors used web scraping methods to extract information from reviews for the university and its competitors, the features considered in the analysed studies can be grouped into categories and subcategories that can be represented by the hierarchy depicted in
Figure 5.
As presented in the figure, the features used in the analysed works can be split into two main categories: student data, and external data. Student data is the most-used category of data and can be split into data concerning personal and academic information.
Regarding personal information, the analysed studies take into account demographic data [
71,
84,
105,
119], such as the students’ age [
78,
79,
80,
81,
82,
86,
88,
94,
95,
103,
104,
108,
109,
115], but also sociodemographic data [
2], such as gender [
78,
79,
80,
81,
82,
86,
88,
94,
95,
98,
103,
104,
108,
109,
110,
114,
115], country of birth [
88,
104], race or ethnicity [
108,
109,
110,
115], regional origin or residence postal code [
80,
86,
89,
95,
108,
109,
115], marital status [
79,
80,
81,
86,
109,
115], number of children [
79], parents’ cohabitation status [
91], and social status [
81]. Socioeconomic variables are also included, and these encompass the family background [
2,
113,
116]; socioeconomic environment [
75,
97,
102,
113,
118]; information regarding the students’ parents (income [
89,
94,
108], educational level [
89,
91,
94], profession [
89], work hours and pressure [
89,
108], and if they can meet university expenses [
89]); students’ economic status [
78]; employment status (including type of employment and profession) [
79,
80,
81,
91,
108]; income [
81,
85]; and whether the student receives financial aid, has a student loan, or a grant [
109,
115].
The studies also account for personal [
102] data, such as personal information [
75,
93,
113], satisfaction [
89,
97,
108] and adaptation [
108], computer knowledge and usage at work [
79], average hours spent studying [
89,
98,
108,
109,
115], technology impact [
108], learning style [
108], health status [
98,
108], prior course knowledge [
108], psychological factors [
108], cognitive features [
91], and level of concentration [
109,
115]. The study presented in [
98] takes some different features into account: time management, self concept and appraisal, free time, independence, and whether the student often goes out. The study presented in [
89] considers yet another set of different features, as the existence of family problems, homesickness, change of goal, adjustment problems, and whether the student is enrolled in other universities.
The students’ academic data [
81] encompass career [
119] and administrative [
75,
101], including the students’ background data (data from previous academic experiences), entry-level data (the data that are recorded at the moment when the student enrols in the university), current status (data concerning the courses and subjects that the student is enrolled in at the moment), and also final status. This last category includes information on dropout [
2,
92], and final graduation result [
88,
104,
110] together with the date of this result [
80,
104,
106].
The background student data include, for example, data regarding the student’s path in high school or in previous university enrolments. These include the results obtained by the student [
82,
89,
91,
95,
103,
107,
108,
116], specifically in assessments, such as the Standardised Admission Test (SAT) [
2,
88,
109,
110,
113,
115], or the Test of English as a Foreign Language (TOEFL) [
109,
113].
Another set of important information regards the data recorded at the entry of the university. This includes the entry type [
2,
75,
78,
89,
91,
108,
109,
110,
115], the preferences stated about the area [
94,
103], type of degree [
103], the study [
98] and more specifically the bachelor [
2] or major [
109,
110,
115] program, the enrolment date or year [
86,
92,
95,
104,
113], data regarding the enrolment and coexistence [
75,
116], the entry grade [
113], data recorded on transfer transcripts [
113], data regarding the first term [
109,
110,
115] or semester [
97], number of University Educational Credits (UECs) in the first year [
103,
106] or in total [
94], the attendance type (full or partial time) [
78], and whether the student is a new student at the university [
79].
The information that was accounted for in the current academic data can be, in its turn, divided into process, assessment, and help. The process data concern data obtained during the student’s frequency of the study program; the assessment regards data obtained during evaluations; and the help data concern the help that was provided to the student and whether it was accepted or not. This last one includes participation in tutorials offered [
2], and in tutoring and advice programs [
116].
The process data concern the data obtained during the process of frequenting the program and includes students’ achievements and performance [
2,
71,
75,
82,
87,
91,
116], interaction with the university’s LMS [
71,
72,
73,
74,
75,
76,
77,
83,
84,
85,
86,
93,
107,
108,
113], lecture attendance [
90,
91,
93,
94,
113] and participation [
113], degree [
82,
85,
87,
88,
89,
92,
105,
106,
109,
115,
118] and subjects [
81,
82,
85,
88,
92,
106,
118] the student is enrolled in, study progression data [
104], discipline precedence [
117], lecture programme [
95], final grades obtained in maths and physics [
99], syllabus of the course [
89] and, more specifically, the students’ programming log [
112].
The assessment data include examination data [
104], assessment or test grades [
73,
76,
77,
86,
88,
90,
91,
94,
106,
107,
111,
112,
113], the score in each subject [
88,
92], students’ performance [
97], and homework grade [
94]. They also include data regarding course grades [
113] that, in some cases, can be measured by the grade point average (GPA) [
92,
94,
100,
109,
110,
113,
115], or the graduate record examinations (GRE) [
113].
Finally, the external data can be split into three subcategories: data regarding the university, environmental data, and data concerning the support offered. University data include information about its infrastructure [
89,
116], services [
116], institutional factors [
108], campus location [
89,
108], the students’ proximity to college [
98], data regarding the college campus [
85,
109,
115], and also the existence of extension activities [
90]. Environmental data include the cultural and educational environments [
102], but also information regarding the campus environment and whether extracurricular activities and entertainment are provided by the university [
89]. The support data regard the support given to the student by the community [
98], the family [
108], and the university [
98,
108], which also includes the teacher/student relationship [
89].
The information regarding the features used in each of the analysed studies is presented in
Table A3 in
Appendix A.
Table A4 presents this information grouped into three main categories: student personal data, student academic data, and external data.
As presented in the table, most of the studies use student personal and academic data, with the following exceptions:
Use only student academic data [
72,
73,
74,
76,
77,
81,
83,
87,
92,
96,
100,
101,
106,
107,
111,
112,
117].
Use student academic data together with external data [
90].
Use student personal data together with external data [
102,
114].
As for the ML task, in the analysed studies, we found works that used both unsupervised and supervised learning techniques. The unsupervised learning techniques found were clustering and mining of association rules. As for the supervised learning approaches, there were some studies that worked with regression, but the majority used classification.
The study described in [
88] used the clustering algorithm k-means together with principal component analysis (PCA). The authors divided the dataset into train and test sets for validation, and measured the model’s accuracy for evaluation. However, this study also used classification techniques, which will be referred to later in this work. Another study that used clustering is [
102], where the authors used Bayesian profile regression.
There are also cases where the approach consists of mining association rules. This is the approach in [
76,
78,
97,
113], where an implementation of the repeated incremental pruning to produce error reduction (RIPPER) algorithm in Java (JRip) was used to solve the problem.
In [
73], the authors used both regression and classification. For regression, the authors used additive regression. The classification techniques will be referred to later in this work. The validation occurs with 10F-CV by measuring the models’ mean absolute error (MAE). In [
100], the authors used neural networks (NNs), support vector machines (SVMs) and extreme learning machine (ELM) algorithms in a 5F-CV setup to measure the root mean squared (RMS) error,
, and the coefficient of variation (COV). The study described in [
77] considered a regression task and used the following algorithms: multilayer perceptron (MLP), Bayes net and deep NNs. The model validation occurs by considering different samples of the dataset for training, validation and testing. The metrics computed were accuracy, Cohen’s kappa, MAE, relative mean squared error (RMSE), root average error (RAE), and root relative squared error (RRSE). The work described in [
79,
84,
112] considered regression with the linear regression (LiR) algorithm. The study described in [
71] used semi-supervised regression with the COREG framework, together with K-nearest neighbours (KNN), LiR, gradient boosting, and MLP. This study uses cross validation (specifically 5F-CV) to evaluate the models used, through the calculation of the following metrics: MSE and MAE.
In [
114], the approach considered is sentiment analysis. In this case, the algorithm used is valence aware dictionary for sentiment reasoning (VADER). The study in [
107] used the analytic hierarchy process (AHP) together with the best–worst method (BWM).
As for the approaches that used classification, the analysed ones used different algorithms, validation techniques, and evaluation metrics. We describe this in detail in the following paragraphs.
The algorithm used in more studies is decision trees (DTs), which is used in 26 of the analysed studies [
74,
75,
76,
78,
81,
82,
86,
89,
90,
91,
92,
93,
94,
95,
97,
98,
99,
103,
104,
108,
109,
113,
115,
116,
118,
119]. Two algorithms are used in nine studies each: Naive Bayes (NB) [
74,
76,
78,
86,
91,
92,
94,
95,
98], and artificial neural networks (ANNs) [
85,
86,
91,
92,
98,
108,
109,
115,
119]. Logistic regression (LR) was used in seven of the analysed studies [
80,
83,
98,
103,
104,
109,
115]. Two algorithms were used in six studies: random forests (RF) [
2,
74,
76,
83,
95,
105], and SVM [
73,
83,
86,
88,
108,
115]. The KNN algorithm was used in five studies [
73,
74,
76,
91,
94]. The algorithm sequential minimal optimisation (SMO) was used in three studies [
76,
78,
79] and, also in three studies, the authors used the ensemble of classifiers gradient boosting [
84,
94,
95]. There are two algorithms that were used twice in the different studies analysed: convolutional neural networks (CNNs) [
72,
101], and MLP [
76,
88]. The following algorithms were used only once in the analysed studies: boosted decision trees [
2], Bayes net [
76], radial basis function (RBF) [
79], the ensembles AdaBoost and LogiBoost [
79], PAIRS3 [
87], multi-view multi-instance (MVMI) and multi-view Gaussian process (MVGP) [
113], and ensemble of linear discriminant analysis (E-LDA) [
114].
The most used validation is cross validation [
82,
92,
109]. Specifically, in two studies, the validation is made through 5F-CV [
93,
118], 10F-CV [
2,
72,
73,
76,
78,
83,
89,
91,
93,
94,
95,
97,
99,
103,
104,
105,
108,
115] was used 18 times, 15-FCV [
93] and LOO-CV [
93] were used once each. Besides that, there are seven studies in which the data were split into train and test sets [
74,
81,
84,
85,
87,
88,
111,
119], and also two where the split was made into train, validation and test sets [
77,
101].
Concerning the metrics used to evaluate classification models, the most used metrics are those that used the confusion matrix: in 23 studies, the authors measured accuracy [
42,
72,
74,
76,
85,
87,
88,
92,
93,
94,
95,
97,
98,
99,
101,
103,
104,
106,
107,
108,
109,
115,
119], 17 studies considered precision [
42,
72,
78,
82,
83,
84,
85,
86,
89,
92,
94,
95,
97,
101,
104,
108,
119], 14 used recall [
42,
72,
78,
82,
83,
84,
86,
89,
92,
94,
95,
97,
101,
108], 12 used some F measure [
42,
72,
78,
82,
83,
84,
85,
89,
97,
101,
106,
108], 7 used sensitivity (true positive rate) [
82,
85,
89,
103,
104,
113,
119], 4 used specificity (true negative rate) [
89,
103,
104,
113], 2 used the false positive rate [
82,
89], and 1 used the false negative rate [
89]. Besides that, there are 10 studies that considered the receiving operation characteristic (ROC), by using the ROC itself [
75,
89,
104], or the area under the curve (AUC) [
76,
78,
82,
99,
103,
105,
113]. Other metrics that were also used are Quini values [
2], observed uplift [
2], Cohen’s kappa [
78,
104,
113], Matthews correlation coefficient (MCC) [
82], and precision recall curve (PRC) area [
82].
Only three works reported using baselines in the model evaluation. The study presented in [
2] used a random model as the baseline. The study presented in [
72] used several baseline models: classification and regression trees (CART), NB, LDA, LR, SVM, RF, and gradient boosting decision trees (GBDT). Finally, the work described in [
101] used Bayesian networks as the baseline.
In summary, most of the analysed studies tried to predict student status to try to prevent attrition, desertion and, more importantly, dropout or risk of failure. Regarding the data used for such predictions, student data (personal and academic information) is the most-used category of data. In what concerns the ML task used for the prediction, most of the analysed studies used classification techniques, with several different classification algorithms. The most-used validation technique is cross validation, and the most frequent evaluation metrics are those based on the confusion matrix.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




