Text Mining in Big Data Analytics

 ,
, 
{kind=link}
Abstract
:1. Introduction
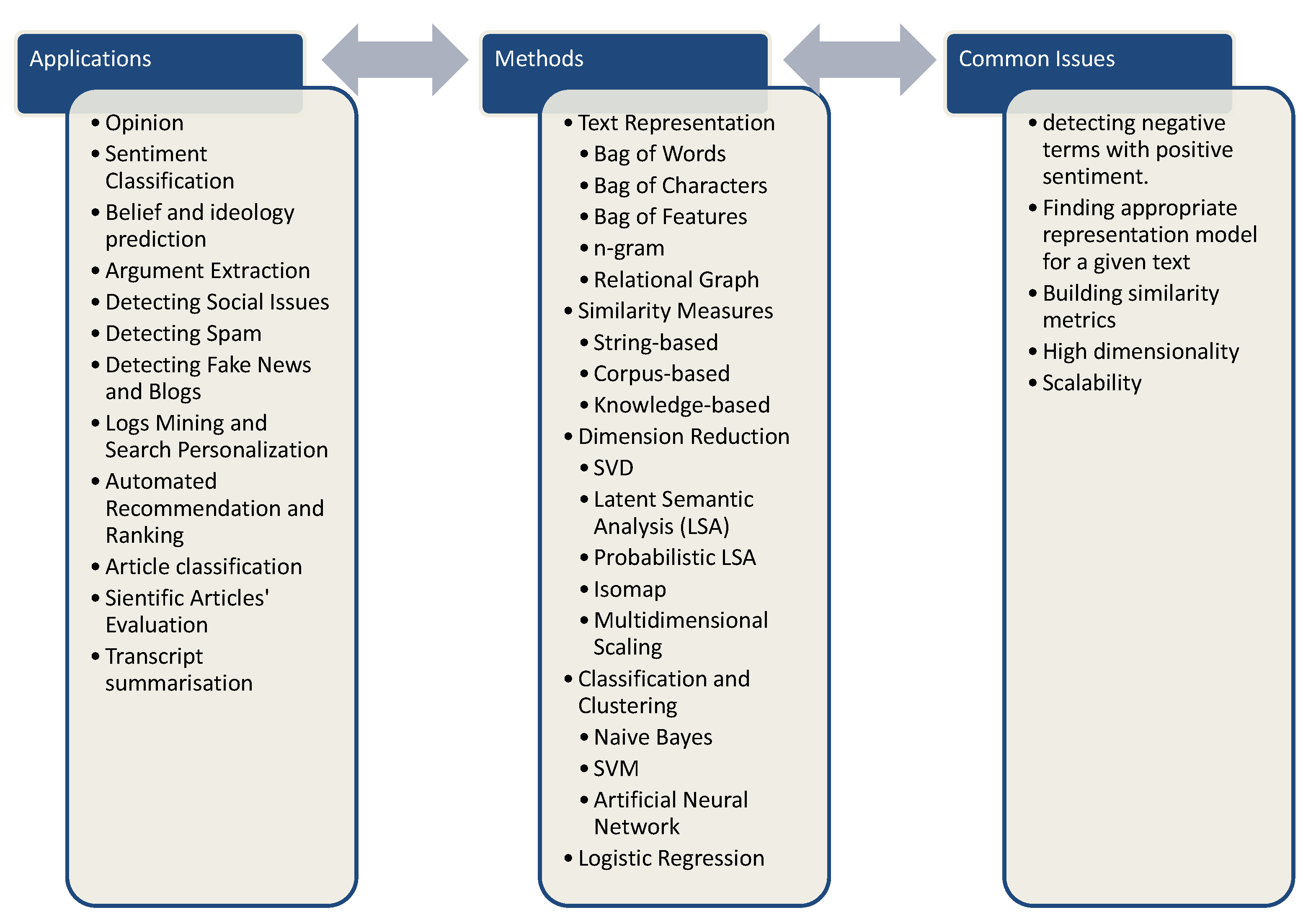
2. Text Mining in Transcripts and Speeches
2.1. Opinion Classification
- Determining text polarity to decide whether a given text is factual in nature (i.e., it unbiasedly describes a particular situation or event and refrains from providing a positive or a negative opinion on it) or not (i.e., it comments on its subject matter and expresses specific opinions on it), which amounts to the categorization of binary texts into subjective and objective [18,19].
2.2. Sentiment Classification
2.3. Functionality
2.4. Arguments Extraction
2.5. Methods
- A component for identifying speech events (e.g., “stated” and “according to”) and directing subjective expressions (e.g.,, “appalled” and “is sad”);
- A component that applies two classifiers to identify the words contained in phrases that express positive or negative sentiments [63].
2.6. Shortcomings
3. Blog Mining
4. Email Mining
5. Web Mining
6. Social Media
6.1. Twitter
6.2. Facebook
6.3. Other Social Media Platforms
7. Published Articles
8. Meeting Transcripts
9. Knowledge Extraction
- Extract concepts on terms describing genes and diseases from abstracts.
- Derive genes-disease annotation.
- Use similarity metrics to demonstrate the relevance between genes, which measures the terms shared between genes to identifies the possible relations.
- Summarize the resulting annotation network as a graph.
10. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Talabis, M.R.M.; McPherson, R.; Miyamoto, I.; Martin, J.L.; Kaye, D. Security and text mining. In Information Security Analytics; Talabis, M.R.M., McPherson, R., Miyamoto, I., Martin, J.L., Kaye, D., Eds.; Elsevier: Amsterdam, The Netherlands, 2015; pp. 123–150. [Google Scholar] [CrossRef]
- Hearst, M.A. Text Data Mining. In The Oxford Handbook of Computational Linguistics; Mitkov, R., Ed.; Oxford University Press: Oxford, UK, 2005; pp. 616–662. [Google Scholar] [CrossRef]
- Dumais, S. Using SVMs for text categorization, Microsoft research. IEEE Intell. Syst. Mag. 1998, 13, 18–28. [Google Scholar]
- Guduru, N. Text Mining with Support Vector Machines and Non-Negative Matrix Factorization Algorithms. Ph.D. Thesis, University of Rhodes Island, Rhodes Island, Greece, 2006. [Google Scholar]
- Bholat, D.; Hansen, S.; Santos, P.; Schonhardt-Bailey, C. CCBS Handbook No. 33, Text Mining For Central Banks; Bank of England: London, UK, 2015. [Google Scholar]
- OPEC Bulletin. Language Lessons, July–August 2019. Available online: https://www.opec.org/opec_web/static_files_project/media/downloads/publications/OB07_082019.pdf (accessed on 1 January 2020).
- Poole, K.T. Changing minds? Not in Congress! Public Choice 2007, 131, 435–451. [Google Scholar] [CrossRef]
- Yu, B.; Kaufmann, S.; Diermeier, D. Classifying party affiliation from political speech. J. Inf. Technol. Polit. 2008, 5, 33–48. [Google Scholar] [CrossRef]
- Esuli, A. A Bibliography on Sentiment Classification. 2006. Available online: http://liinwww.ira.uka.de/bibliography/Misc/Sentiment.html (accessed on 27 June 2019).
- Dave, K.; Lawrence, S.; Pennock, D.M. Mining the peanut gallery: Opinion extraction and semantic classification of product reviews. In Proceedings of the 12th international conference on World Wide Web (WWW2003), Budapest, Hungary, 20–24 May 2003; pp. 519–528. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’2004), Seattle, WA, USA, 22 August 2004; pp. 168–177. [Google Scholar] [CrossRef] [Green Version]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. In Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing (EMNLP’02), Philadelphia, PA, USA, 6–7 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 79–86. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, R.; Rajagopalan, S.; Srikant, R.; Xu, Y. Mining newsgroups using networks arising from social behavior. In Proceedings of the 12th International Conference on World Wide Web (WWW2003), Budapest, Hungary, 20 May 2003; pp. 529–535. [Google Scholar] [CrossRef]
- Kwon, N.; Zhou, L.; Hovy, E.; Shulman, S.W. Identifying and classifying subjective claims. In Proceedings of the 8th Annual International Conference on Digital Government Research: Bridging Disciplines & Domains, New York, NY, USA, 20–23 May 2007; Digital Government Society of North America: Philadelphia, PA, USA, 2006; pp. 76–81. [Google Scholar]
- Shulman, S.W. E-rulemaking: Issues in current research and practice. Int. J. Public Adm. 2015, 28, 621–641. [Google Scholar] [CrossRef] [Green Version]
- Thomas, M.; Pang, B.; Lee, L. Get out the vote: Determining support or opposition from Congressional floor-debate transcripts. In Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing (EMNLP’06), Sydney, Australia, 22–23 July 2006; Association for Computational Linguistics: Stroudsburg, PA, USA, 2006; pp. 327–335. [Google Scholar]
- Esuli, A.; Sebastiani, F. SENTIWORDNET: A Publicly Available Lexical Resource for Opinion Mining. In Proceedings of the Fifth International Conference on Language Resources and Evaluation (LREC’06), Genoa, Italy, 22 May 2006. [Google Scholar]
- Pang, B.; Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd Meeting of the Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 271–278. [Google Scholar] [CrossRef] [Green Version]
- Yu, H.; Hatzivassiloglou, V. Towards answering opinion questions: Separating facts from opinions and identifying the polarity of opinion sentences. In Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, Sapporo, Japan, 11 July 2003; pp. 129–136. [Google Scholar]
- Turney, P.D. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 417–424. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. In Proceedings of the 43rd Meeting of the Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005; pp. 115–124. [Google Scholar] [CrossRef]
- Wilson, T.; Wiebe, J.; Hwa, R. Just how mad are you? Finding strong and weak opinion clauses. In Proceedings of the 21st Conference of the American Association for Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; AAAI Press: Palo Alto, CA, USA, 2004; pp. 761–769. [Google Scholar]
- Baccianella, S.; Esuli, A.; Sebastiani, F. SENTIWORDNET 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In Proceedings of the International Conference on Language Resources and Evaluation, LREC, Valletta, Malta, 17–23 May 2010; pp. 2200–2204. [Google Scholar]
- Pang, B.; Lee, L. Opinion Mining and Sentiment Analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef] [Green Version]
- Wordnet. 2019. Available online: https://wordnet.princeton.edu/ (accessed on 28 June 2019).
- Miller, G.A.; Beckwith, R.; Fellbaum, C.; Gross, D.; Miller, K.J. Introduction to WordNet: An On-line Lexical Database. Int. J. Lexicogr. 1990, 3, 235–244. [Google Scholar] [CrossRef] [Green Version]
- Rauh, C. Validating a sentiment dictionary for German political language—A workbench note. J. Inf. Technol. Polit. 2018, 15, 319–343. [Google Scholar] [CrossRef] [Green Version]
- Young, L.; Soroka, S. Affective news: The automated coding of sentiment in political texts. Polit. Commun. 2012, 29, 205–231. [Google Scholar] [CrossRef]
- Ceron, A.; Curini, L.; Iacus, S.M. iSA: A fast, scalable and accurate algorithm for sentiment analysis of social media content. Inf. Sci. 2016, 367–368, 105–124. [Google Scholar] [CrossRef]
- Hopkins, D.; King, G. A method of automated nonparametric content analysis for social science. Am. J. Polit. Sci. 2010, 54, 229–247. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, D.J.S.; Bermejo, P.H.D.S.; dos Santos, P.A. Can social media reveal the preferences of voters? A comparison between sentiment analysis and traditional opinion polls. J. Inf. Technol. Polit. 2017, 14, 34–45. [Google Scholar] [CrossRef]
- Van Atteveldt, W.; Kleinnijenhuis, J.; Ruigrok, N.; Schlobach, S. Good news or bad news? Conducting sentiment analysis on Dutch text to distinguish between positive and negative relations. J. Inf. Technol. Polit. 2008, 5, 73–94. [Google Scholar] [CrossRef]
- Klebanov, B.B.; Diermeier, D.; Beigman, E. Lexical cohesion analysis of political speech. Polit. Anal. 2008, 16, 447–463. [Google Scholar] [CrossRef]
- Acharya, A.; Crawford, N.; Maduabum, M. A Nation Divided: Classifying Presidential Speeches; Stanford Univesity: Stanford, CA, USA, 2016. [Google Scholar]
- Lakoff, G. Moral Politics: How Liberals and Conservatives Think, 2nd ed.; The University of Chicago Press: Chicago, IL, USA, 2002. [Google Scholar] [CrossRef]
- Lakoff, G.; Johnson, M. Metaphors We Live By; The Chicago University Press: Chicago, IL, USA, 1980. [Google Scholar]
- Miner, G.; Elder, J.; Fast, A.; Hill, T.; Nisbet, R.; Delen, D. Practical Text Mining and Statistical Analysis for Non-Structured Text Data; Academic Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Anurag, S.; Chatterjee, S.; Das, W.; Datta, D. Text Classification using Support Vector Machine. Int. J. Eng. Sci. Invent. 2015, 4, 33–37. [Google Scholar]
- Lu, Y.; Wang, H.; Zhai, C.; Roth, D. Unsupervised discovery of opposing opinion networks from forum discussions. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 2 November 2012; pp. 1642–1646. [Google Scholar]
- Kennedy, A.; Inkpen, D. Sentiment classification of movie reviews using contextual valence shifters. Comput. Intell. 2006, 22, 110–125. [Google Scholar] [CrossRef] [Green Version]
- Tripathy, A.; Agrawal, A.; Rath, S.K. Classification of sentiment reviews using n-gram machine learning approach. Expert Syst. Appl. 2016, 57, 117–126. [Google Scholar] [CrossRef]
- Joachims, T. Text categorization with Support Vector Machines: Learning with many relevant features. In Machine Learning: ECML-98; Nédellec, C., Rouveirol, C., Eds.; Lecture Notes in Computer Science (Lecture Notes in Artificial Intelligence); Springer: Berlin/Heidelberg, Germany, 1998; Volume 1398, pp. 137–142. [Google Scholar] [CrossRef] [Green Version]
- Sardianos, C.; Katakis, I.M.; Petasis, G.; Karkaletsis, V. Argument extraction from news. In Proceedings of the 2nd Workshop on Argumentation Mining, Denver, CO, USA, 4 June 2015; pp. 56–66. [Google Scholar] [CrossRef]
- Florou, E.; Konstantopoulos, S.; Koukourikos, A.; Karampiperis, P. Argument extraction for supporting public policy formulation. In Proceedings of the 7th Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities, Sofia, Bulgaria, 8 August 2013; pp. 49–54. [Google Scholar]
- Goudas, T.; Louizos, C.; Petasis, G.; Karkaletsis, V. Argument extraction from news, blogs, and social media. Int. J. Artif. Intell. Tools 2015, 24, 287–299. [Google Scholar] [CrossRef]
- Lippi, M.; Torroni, P. Argument Mining from Speech: Detecting Claims in Political Debates. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12 February 2016; pp. 2979–2985. [Google Scholar] [CrossRef]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Soumya, G.K.; Shibily, J. Text classification by augmenting Bag of Words (BOW) representation with co-occurrence feature. OSR J. Comput. Eng. 2014, 16, 34–38. [Google Scholar] [CrossRef]
- Giannakopoulos, G.; Mavridi, P.; Paliouras, G.; Papadakis, G.; Tserpes, K. Representation models for text classification: A comparative analysis over three web document types. In Proceedings of the 2nd International Conference on Web Intelligence, Mining and Semantics, Craiova, Romania, 13 June 2012; pp. 1–12. [Google Scholar] [CrossRef]
- Gomaa, W.H.; Fahmy, A.A. A survey of text similarity approaches. Int. J. Comput. Appl. 2013, 68, 13–18. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Vinodhini, G.; Chrasekaran, R.M. Sentiment Analysis and Opinion Mining: A Survey. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2012, 2, 282–292. [Google Scholar]
- Berger, A.L.; Brown, P.F.; Della Pietra, S.A.; Della Pietra, V.J.; Gillett, J.R.; Lafferty, J.D.; Mercer, R.L.; Printz, H.; Ureš, L. The Candide system for machine translation. In HLT ’94 Proceedings of the Workshop on Human Language Technology; Association for Computational Linguistics: Stroudsburg, PA, USA, 1994; pp. 157–162. [Google Scholar] [CrossRef] [Green Version]
- Diermeier, D.; Godbout, J.-F.; Yu, B.; Kaufmann, S. Language and ideology in Congress. In Proceedings of the Annual Meeting of the Midwest Political Science Association (MPSA’07), Chicago, IL, USA, 4 April 2007. [Google Scholar]
- Evans, M.; Wayne, M.; Cates, C.L.; Lin, J. Recounting the court? Toward a text-centered computational approach to understanding they dynamics of the judicial system. In Proceedings of the Annual Meeting of the Midwest Political Science Association, Chicago, IL, USA, 7 April 2005. [Google Scholar]
- Laver, M.; Benoit, K.; Garry, J. Extracting policy positions from political texts using words as data. Am. Polit. Sci. Rev. 2003, 97, 311–337. [Google Scholar] [CrossRef] [Green Version]
- Piryani, R.; Madhavi, D.; Singh, V.K. Analytical mapping of opinion mining and sentiment analysis research during 2000–2015. Inf. Process. Manag. 2017, 53, 122–150. [Google Scholar] [CrossRef]
- Riloff, E.; Wiebe, J. Learning extraction patterns for subjective expressions. In Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing (EMNLP-2003), Sapporo, Japan, 11–12 July 2003; Association for Computational Linguistics: Stroudsburg, PA, USA, 2003; pp. 105–112. [Google Scholar] [CrossRef]
- Riloff, E.; Wiebe, J. Exploiting subjectivity classification to improve information extraction. In Proceedings of the 20th National Conference on Artificial Intelligence, Pittsburgh, PA, USA, 9–13 July 2005; AAAI Press: Palo Alto, CA, USA, 2005; Volume 3, pp. 1106–1111. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning, Williams College, MA, USA, 28 June–1 July 2001; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001; pp. 282–289. [Google Scholar]
- Riloff, E. An empirical study of automated dictionary construction for information extraction in three domains. Artif. Intell. 1996, 85, 101–134. [Google Scholar] [CrossRef] [Green Version]
- Choi, Y.; Cardie, C.; Riloff, E.; Patwardhan, S. Identifying sources of opinions with conditional random fields and extraction patterns. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, Sydney, Australia, 22–23 July 2006; Association for Computational Linguistics: Stroudsburg, PA, USA, 2006; pp. 355–362. [Google Scholar] [CrossRef] [Green Version]
- Wilson, T.; Wiebe, J.; Hoffmann, P. Recognizing contextual polarity in phrase-level sentiment analysis. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005; pp. 347–354. [Google Scholar] [CrossRef] [Green Version]
- Chesley, P.; Vincent, B.; Xu, L.; Srihari, R.K. Using verbs and adjectives to automatically classify blog sentiment. In AAAI Spring Symposium: Computational Approaches to Analyzing Weblogs (2006); AAAI: Menlo Park, CA, USA, 2006. [Google Scholar]
- Choi, Y.; Cardie, C. Adapting a polarity lexicon using integer linear programming for domain-specific sentiment classification. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; Association for Computational Linguistics: Stroudsburg, PA, USA, 2009; Volume 2, pp. 590–598. [Google Scholar]
- Jiang, L.; Yu, M.; Zhou, M.; Liu, X.; Zhao, T. Target-dependent twitter sentiment classification. In Proceedings of the 49th, Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; Volume 1, pp. 151–160. [Google Scholar]
- Tan, L.K.-W.; Na, J.-C.; Theng, Y.-L.; Chang, K. Sentence-Level Sentiment Polarity Classification Using a Linguistic Approach. In Digital Libraries: For Cultural Heritage, Knowledge Dissemination, and Future Creation; Xing, C., Crestani, F., Rauber, A., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 7008, pp. 77–87. [Google Scholar] [CrossRef]
- Fang, X.; Zhan, J. Sentiment analysis using product review data. J. Bigdata 2015, 2, 5. [Google Scholar] [CrossRef] [Green Version]
- Nockleby, J.T. Hate Speech. In Encyclopedia of the American Constitution, 2nd ed.; Levy, L.W., Karst, K.L., Winkler, A., Eds.; Macmillan: New York, NY, USA, 2000; pp. 1277–1279. [Google Scholar]
- Warner, W.; Hirschberg, J. Detecting Hate Speech on the World Wide Web. In Proceedings of the 2012 Workshop on Language in Social Media (LSM 2012), Montréal, QC, Canada, 7 June 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 19–26. [Google Scholar]
- Fiscus, J.G.; Ajot, J.; Garofolo, J.S. The Rich Transcription 2007 Meeting Recognition Evaluation. In Multimodal Technologies for Perception of Humans. RT 2007, CLEAR 2007. Lecture Notes in Computer Science; Stiefelhagen, R., Bowers, R., Fiscus, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; Volume 4625, pp. 373–389. [Google Scholar] [CrossRef]
- Camelin, N.; Béchet, F.; Damnati, G.; De Mori, R. Speech Mining in Noisy Audio Message Corpus. In Proceedings of the Interspeech 2007, Antwerp, Belgium, 27–31 August 2007; pp. 2401–2404. Available online: https://www.semanticscholar.org/paper/Speech-mining-in-noisy-audio-message-corpus-Camelin-Béchet/9d59c1f2d228fce67c5c6fac7f04cc1a2b29b532 (accessed on 15 January 2020).
- Hookway, N. Entering the blogosphere: Some strategies for using blogs in social research. Qual. Res. 2008, 8, 91–113. [Google Scholar] [CrossRef]
- Thompson, C. The Early Years. New York Magazine, 10 February 2006; 1. [Google Scholar]
- Tsai, F.S.; Chen, Y.; Chan, K.L. Probabilistic Techniques for Corporate Blog Mining. In PAKDD 2007: Emerging Technologies in Knowledge Discovery and Data Mining; Washio, T., Zhou, Z.-H., Huang, J.Z., Hu, X., Li, J., Xie, C., He, J., Zou, D., Li, K.-C., Freire, M.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 35–44. [Google Scholar] [CrossRef]
- Webb, L.M.; Wang, Y. Techniques for analyzing blogs and micro-blogs. In Advancing Research Methods with New Technologies; Sappleton, N., Ed.; IGI Global: Hershey, PA, USA, 2013; pp. 206–227. [Google Scholar] [CrossRef]
- Tsai, F.S. Dimensionality reduction techniques for blog visualization. Expert Syst. Appl. 2011, 38, 2766–2773. [Google Scholar] [CrossRef]
- Tsai, F.S. A tag-topic model for blog mining. Expert Syst. Appl. 2011, 38, 5330–5335. [Google Scholar] [CrossRef]
- Zafarani, R.; Abbasi, M.; Liu, H. Social Media Mining: An Introduction; Cambridge University Press: New York, NY, USA, 2014. [Google Scholar] [CrossRef] [Green Version]
- Berendt, B. Text mining for news and blogs analysis. In Encyclopedia of Machine Learning and Data Mining; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2017; pp. 1247–1255. [Google Scholar] [CrossRef]
- Barbier, G.; Liu, H. Data Mining in social media. In Social Network Data Analytics; Aggarwal, C.C., Ed.; Springer: Boston, MA, USA, 2011; pp. 327–352. [Google Scholar] [CrossRef]
- Kumar, S.; Zafarani, R.; Abbasi, M.; Barbier, G.; Liu, H. Convergence of influential bloggers for topic discovery in the blogosphere. In Advances in Social Computing. SBP 2010. Lecture Notes in Computer Science; Chai, S.K., Salerno, J., Mabry, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6007, pp. 406–412. [Google Scholar] [CrossRef]
- Leban, G.; Fortuna, B.; Brank, J.; Grobelnik, M. Event registry: Learning about world events from news. In WWW ’14 Companion Proceedings of the 23rd International Conference on World Wide Web; ACM: New York, NY, USA, 2014; pp. 107–110. [Google Scholar] [CrossRef]
- Tsai, F.S.; Chan, K.L. Dimensionality reduction techniques for data exploration. In Proceedings of the 2007 6th International Conference on Information, Communications and Signal Processing, Singapore, 10–13 December 2007; pp. 1568–1572. [Google Scholar] [CrossRef]
- Tsai, F.S.; Chan, K.L. Detecting Cyber Security Threats in Weblogs using Probabilistic Models. In PAISI 2007: Intelligence and Security Informatics; Yang, C.C., Zeng, D., Chau, M., Chang, K., Yang, Q., Cheng, X., Wang, J., Wang, F.-Y., Chen, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4430, pp. 46–57. [Google Scholar] [CrossRef]
- Liang, H.; Tsai, F.S.; Kdwee, A.T. Detecting novel business blogs. In Proceedings of the 7th International Conference on Information, Communications and Signal Processing, Macau, China, 8–10 December 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 651–655. [Google Scholar] [CrossRef]
- Tsai, F.S. A data-centric approach to feed search in blogs. Int. J. Web Eng. Technol. 2012, 7, 228–249. [Google Scholar] [CrossRef]
- Tsai, F.S. Blogger-Link-Topic Model for Blog Mining. In New Frontiers in Applied Data Mining. PAKDD 2011. Lecture Notes in Computer Science; Cao, L., Huang, J.Z., Bailey, J., Koh, Y.S., Luo, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 28–39. [Google Scholar] [CrossRef]
- Tsai, F.S. Dimensionality reduction framework for blog mining and visualisation. Int. J. Data Mining Model. Manag. 2012, 4, 267–285. [Google Scholar] [CrossRef]
- Seep, K.S.; Patil, N. A Multidimensional Approach to Blog Mining. In Progress in Intelligent Computing Techniques: Theory, Practice, and Applications; Sa, P., Sahoo, M., Murugappan, M., Wu, Y., Majhi, B., Eds.; Springer: Singapore, 2018; pp. 51–58. [Google Scholar] [CrossRef]
- Tsirakis, N.; Poulopoulos, V.; Tsantilas, P.; Varlamis, I. Large scale opinion mining for social, news and blog data. J. Syst. Softw. 2017, 127, 237–248. [Google Scholar] [CrossRef]
- Hussein, D.M.E.-D.M. A survey on sentiment analysis challenges. J. King Saud Univ. Eng. Sci. 2018, 30, 330–338. [Google Scholar] [CrossRef]
- Chen, M.-Y.; Chen, T.-H. Modeling public mood and emotion: Blog and news sentiment and socio-economic phenomena. Future Gener. Comput. Syst. 2019, 96, 692–699. [Google Scholar] [CrossRef]
- Tsai, F.S.; Chan, K.L. Blog Data Mining for Cyber Security Threats. In Data Mining for Business Applications; Cao, L., Yu, P.S., Zhang, C., Zhang, H., Eds.; Springer: Boston, MA, USA, 2009; pp. 169–182. [Google Scholar] [CrossRef]
- Lee, K.-C.; Hsieh, C.-H.; Wei, L.-J.; Mao, C.-H.; Dai, J.-H.; Kuang, Y.-T. Sec-Buzzer: Cyber security emerging topic mining with open threat intelligence retrieval and timeline event annotation. Soft Comput. 2017, 21, 2883–2896. [Google Scholar] [CrossRef]
- Valsamidis, S.; Theodosiou, T.; Kazanidis, I.; Nikolaidis, M. A Framework for opinion mining in blogs for agriculture. Procedia Technol. 2013, 8, 264–274. [Google Scholar] [CrossRef] [Green Version]
- Kim, L.; Ju, J. Can media forecast technological progress? A text-mining approach to the on-line newspaper and blog’s representation of prospective industrial technologies. Inf. Process. Manag. 2019, 56, 1506–1525. [Google Scholar] [CrossRef]
- Beheshti-Kashi, S.; Lùtjen, M.; Thoben, K.-D. Social media analytics for decision support in fashion buying processes. In Artificial Intelligence for Fashion Industry in the Big Data Era, Springer Series in Fashion Business; Thomassey, S., Zeng, X., Eds.; Springer: Singapore, 2018; pp. 71–93. [Google Scholar] [CrossRef]
- Bhadoria, R.S.; Dixit, M.; Bansal, R.; Chauhan, A.S. Detecting and searching system for event on internet blog data using cluster mining algorithm. In Proceedings of the International Conference on Information Systems Design and Intelligent Applications 2012 (INDIA 2012), Visakhapatnam, India, 5–7 January 2012; Satapathy, S.C., Avadhani, P.S., Abraham, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 83–91. [Google Scholar] [CrossRef]
- Yuan, H.; Xu, H.; Qian, Y.; Li, Y. Make your travel smarter: Summarizing urban tourism information from massive blog data. Int. J. Inf. Manag. 2016, 36, 1306–1319. [Google Scholar] [CrossRef]
- Xu, H.; Yuan, H.; Ma, B.; Qian, Y. Where to go and what to play: Towards summarizing popular information from massive tourism blogs. J. Inf. Sci. 2019, 41, 830–854. [Google Scholar] [CrossRef]
- Evans, D.K.; Klavans, J.L.; McKeown, K.R. Columbia newsblaster: Multilingual news summarization on the web. In Proceedings of the Demonstration Papers at HLT-NAACL, Boston, MA, USA, 2–7 May 2004; Available online: https://www.aclweb.org/anthology/N04-3001 (accessed on 15 January 2020).
- Li, Z.; Tang, J.; Wang, X.; Liu, J.; Lu, H. Multimedia news summarization in search. ACM Trans. Intell. Syst. Technol. 2016, 7, 33. [Google Scholar] [CrossRef]
- Kouris, P.; Alexandridis, G.; Stafylopatis, A. Abstractive text summarization based on deep learning and semantic content generalization. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July 2019; pp. 5082–5092. [Google Scholar]
- Chen, Y.; Conroy, N.J.; Rubin, V.L. Misleading online content: Recognizing clickbait as false news. In Proceedings of the 2015 ACM on Workshop on Multimodal Deception Detection, Seattle, WA, USA, 1 August 2015; pp. 15–19. [Google Scholar]
- The Radicati Group, Inc. Email Statistics Report, 2019–2023–Executive Summary February. February 2019. Available online: https://www.radicati.com/wp/wp-content/uploads/2018/12/Email-Statistics-Report-2019-2023-Executive-Summary.pdf (accessed on 1 January 2020).
- Palmer, D.D. Text preprocessing. In Handbook of Natural Language Processing, 2nd ed.; Indurkhya, N., Damerau, F.J., Eds.; Chapman & Hall/CRC: London, UK, 2010; pp. 9–30. [Google Scholar]
- Katakis, I.; Tsoumakas, G.; Vlahavas, I. E-mail mining: Emerging techniques for E-Mail management. In Web Data Management Practices: Emerging Techniques and Technologies; Vakali, A., Pallis, G., Eds.; IGI Global: Hershey, PA, USA, 2007; pp. 220–243. [Google Scholar] [CrossRef]
- Laclavík, M.; Dlugolinský, Š.; Šeleng, M.; Kvassay, M.; Gatial, E.; Balogh, Z.; Hluchý, L. Email analysis and information extraction for enterprise benefit. Comput. Inform. 2011, 30, 57–87. [Google Scholar]
- Chen, F.; Deng, P.; Wan, J.; Zhang, D.; Vasilakos, A.V.; Rong, X. Data mining for the internet of things: literature review and challenges. Int. J. Distrib. Sens. Netw. 2015, 431047. [Google Scholar] [CrossRef] [Green Version]
- Wani, M.A.; Jabin, S. Big Data: Issues, challenges, and techniques in business intelligence. In Big Data Analytics. Advances in Intelligent Systems and Computing; Aggarwal, V., Bhatnagar, V., Mishra, D., Eds.; Springer: Singapore, 2018; pp. 613–628. [Google Scholar] [CrossRef]
- Klimt, B.; Yang, Y. Introducing the Enron corpus. In Proceedings of the CEAS 2004—First Conference on Email and Anti-Spam, Mountain View, CA, USA, 30–31 July 2004. [Google Scholar]
- Minkov, E.; Wang, R.C.; Cohen, W.W. Extracting personal names from emails: Applying named entity recognition to informal text. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005; pp. 443–450. [Google Scholar] [CrossRef] [Green Version]
- Androutsopoulos, I.; Koutsias, J.; Chrinos, K.V.; Paliouras, G.; Spyropoulos, C. An evaluation of naive Bayesian anti-spam filtering. In Proceedings of the 1th European Conference on Machine Learning in the New Information Age, Barcelona, Spain, 2 June 2000; pp. 9–17. [Google Scholar]
- Weerkamp, W.; Balog, K.; De Rijke, M. Using contextual information to improve search in email archives. In Proceedings of the 31th European Conference on IR Research on Advances in Information Retrieval, Toulouse, France, 6–9 April 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 400–411. [Google Scholar] [CrossRef] [Green Version]
- Tang, G.; Pei, J.; Luk, W.S. Email mining: Tasks, common techniques, and tools. Knowl. Inf. Syst. 2014, 41, 1–31. [Google Scholar] [CrossRef]
- Mujtaba, G.; Shuib, L.; Raj, R.G.; Majeed, N.; Al-Garadi, M.A. Email classification research trends: review and open issues. IEEE Access 2017, 5, 9044–9064. [Google Scholar] [CrossRef]
- Hangal, S.; Lam, M.S.; Heer, J. MUSE: Reviving memories using email archives. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; ACM: New York, NY, USA, 2011; pp. 75–84. [Google Scholar] [CrossRef]
- Liu, B. Sentiment Analysis and Opinion Mining; Morgan & Claypool Publishers: Williston, VT, USA, 2012. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Lee, I. A Hybrid Sentiment Analysis Framework for Large Email Data. In Proceedings of the 10th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Taipei, Taiwan, 24–27 November 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar] [CrossRef]
- Liu, S.; Lee, I. Discovering sentiment sequence within email data through trajectory representation. Expert Syst. Appl. 2018, 99, 1–11. [Google Scholar] [CrossRef]
- Wimmer, B. Business Espionage: Risk, Threats, and Countermeasures; Butterworth-Heinemann: Oxford, UK, 2015. [Google Scholar] [CrossRef]
- Chi, H.; Scarllet, C.; Prodanoff, Z.G.; Hubbard, D. Determining predisposition to insider threat activities by using text analysis. In Future Technologies Conference (FTC); IEEE: Piscataway, NJ, USA, 2016; pp. 985–990. [Google Scholar] [CrossRef]
- Soh, C.; Yu, S.; Narayanan, A.; Duraisamy, S.; Chen, L. Employee profiling via aspect-based sentiment and network for insider threats detection. Expert Syst. Appl. 2019, 351–361. [Google Scholar] [CrossRef]
- Cisco Talos Intelligence Group Report. 2019. Available online: https://www.talosintelligence.com/ (accessed on 1 January 2020).
- Osterman Research, Inc. Techniques for Dealing with Ransomware, Business Email Compromise and Spearphishing, An Osterman Research White Paper; Osterman Research, Inc.: Washington, DC, USA, 2017. [Google Scholar]
- Tretyakov, K. Machine Learning Techniques in Spam Filtering. In Data Mining Problem-Oriented Seminar; MTAT: Beauvallon, France, 2004; pp. 60–79. Available online: https://courses.cs.ut.ee/2004/dm-seminarspring/uploads/Main/P06.pdf (accessed on 1 January 2020).
- Bhowmick, A.; Hazarika, S.M. Machine learning for E-Mail spam filtering: review, techniques and trends. arXiv 2016, arXiv:1606.01042v1. [Google Scholar]
- Dada, E.G.; Bassi, J.S.; Chiroma, H.; Abdulhamid, S.M.; Adetunmbi, A.O.; Ajibuwa, O.E. Machine learning for email spam filtering: Review, approaches and open research problems. Heliyon 2019, 5, e01802. [Google Scholar] [CrossRef] [Green Version]
- Bahgat, E.M.; Rady, S.; Gad, W.; Moawad, I.F. Efficient email classification approach based on semantic methods. Ain Shams Eng. J. 2018, 9, 3259–3269. [Google Scholar] [CrossRef]
- Almomani, A.; Wan, T.C.; Manasrah, A.; Altaher, A.; Baklizi, M.; Ramadass, S. An enhanced online phishing e-mail detection framework based on evolving connectionist system. Int. J. Innov. Comput. Inf. Control 2013, 9, 169–175. [Google Scholar]
- Chowdhury, M.U.; Abawajy, J.H.; Kelarev, A.V.; Hochin, T. Multilayer hybrid strategy for phishing email zero-day filtering. Concurr. Comput. Pract. Exp. 2016, 29, e3929. [Google Scholar] [CrossRef]
- Smadi, S.; Aslam, N.; Zhang, L. Detection of online phishing email using dynamic evolving neural network based on reinforcement learning. Decis. Support Syst. 2018, 107, 88–102. [Google Scholar] [CrossRef] [Green Version]
- Gök, A.; Waterworth, A.; Shapira, P. Use of web mining in studying innovation. Scientometrics 2015, 102, 653–671. [Google Scholar] [CrossRef] [Green Version]
- Waldherr, A.; Maier, D.; Miltner, P.; Günther, E. B Big Data, Big Noise: The Challenge of Finding Issue Networks on the Web. Soc. Sci. Comput. Rev. 2017, 35, 427–443. [Google Scholar] [CrossRef]
- Etzioni, O. The world wide web: Quagmire or gold mine. Commun. ACM 1996, 39, 65–68. [Google Scholar] [CrossRef]
- Cooley, R.; Mobasher, B.; Srivastava, J. Data preparation for mining World Wide Web browsing patterns. Knowl. Inf. Syst. 1999, 1, 5–32. [Google Scholar] [CrossRef]
- Markov, Z.; Larose, D.T. Data Mining the Web: Uncovering Patterns in Web Content, Structure and Usage; Wiley-Interscience: Hoboken, NJ, USA, 2007. [Google Scholar]
- Velásquez, J.D. Web mining and privacy concerns: Some important legal issues to be consider before applying any data and information extraction technique in web-based environments. Expert Syst. Appl. 2013, 40, 5228–5239. [Google Scholar] [CrossRef]
- Borges, J.; Levene, M. Data mining of user navigation patterns. In Web Usage Analysis and User Profiling. WebKDD 1999. Lecture Notes in Computer Science; Masand, B., Spiliopoulou, M., Eds.; Springer: Berlin/Heidelberg, Germany, 1999; pp. 92–112. [Google Scholar] [CrossRef]
- Madria, S.K.; Bhowmick, S.S.; Ng, W.K.; Lim, E.P. Research Issues in Web Data Mining. In DataWarehousing and Knowledge Discovery. DaWaK 1999. Lecture Notes in Computer Science; Mohania, M., Tjoa, A.M., Eds.; Springer: Berlin/Heidelberg, Germany, 1999; pp. 303–312. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Y.; Li, L. Web Mining and Social Networking; Springer: Boston, MA, USA, 2011. [Google Scholar] [CrossRef]
- Kanathey, K.; Thakur, R.S.; Jaloree, S. Ranking of web pages using aggregation of page rank and hits algorithm. Int. J. Adv. Stud. Comput. Sci. Eng. 2018, 7, 17–22. [Google Scholar]
- Facca, F.M.; Lanzi, P.L. Mining interesting knowledge from weblogs: A survey. Data Knowl. Eng. 2005, 53, 225–241. [Google Scholar] [CrossRef]
- Srivastava, J.; Cooley, R.; Deshpe, M.; Tan, P.-N. Web usage mining: Discovery and applications of usage patterns from web data. ACM SIGKDD Explor. Newsl. 2000, 1, 12–23. [Google Scholar] [CrossRef]
- Liu, H.; Keselj, V. Combined mining of web server logs and web contents for classifying user navigation patterns and predicting users’ future requests. Data Knowl. Eng. 2007, 61, 304–330. [Google Scholar] [CrossRef]
- Kohli, S.; Gupta, A. Fuzzy information retrieval in WWW: A survey. Int. J. Adv. Intell. Paradig. 2014, 6, 272–311. [Google Scholar] [CrossRef]
- Gupta, A.; Kohli, S. FORA: An OWO based framework for finding Outliers in Web Usage Mining. Inf. Fusion 2019, 48, 27–38. [Google Scholar] [CrossRef]
- Chola, V.; A Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. (CSUR) 2009, 41, 15. [Google Scholar] [CrossRef]
- Gupta, A.; Kohli, S. An analytical study of ordered weighted geometric averaging operator on Web data set as a MCDM problem. In Proceedings of the Fourth International Conference on Soft Computing for Problem Solving, Assam, India, 23 December 2014; Das, K., Deep, K., Pant, M., Bansal, J., Nagar, A., Eds.; Springer: New Delhi, India, 2014; pp. 585–597. [Google Scholar] [CrossRef]
- Gupta, A.; Kohli, S. OWA operator-based hybrid framework for outlier reduction in web mining. Int. J. Intell. Syst. 2016, 31, 947–962. [Google Scholar] [CrossRef]
- Iglesias, J.A.; Tiemblo, A.; Ledezma, A.; Sanchis, A. Web news mining in an evolving framework. Inf. Fusion 2016, 28, 90–98. [Google Scholar] [CrossRef]
- Za’in, C.; Pratama, M.; Lughofer, E.; Anavatti, S.G. Evolving type-2 web news mining. Appl. Soft Comput. 2017, 54, 200–220. [Google Scholar] [CrossRef]
- Kosala, R.; Blockeel, H. Web mining research: A survey. ACM SIGKDD Explor. Newsl. 2000, 2, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Dias, J.P.; Ferreira, H.S. Automating the extraction of static content and dynamic behaviour from e-commerce websites. Procedia Comput. Sci. 2017, 109, 297–304. [Google Scholar] [CrossRef]
- Zhou, J.; Cheng, C.; Kang, L.; Sun, R. Integration and Analysis of Agricultural Market Information Based on Web Mining. IFAC-PapersOnLine 2018, 51, 778–783. [Google Scholar] [CrossRef]
- Symantec Corporation Inc. Internet Security Threat Report. 2019. Available online: https://resource.elq.symantec.com/LP=6819?CID=70138000001QvI4AAK (accessed on 1 January 2020).
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. Tutorial and critical analysis of phishing websites methods. Comput. Sci. Rev. 2015, 17, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Yi, P.; Guan, Y.; Zou, F.; Yao, Y.; Wang, W.; Zhu, T. Web Phishing Detection Using a Deep Learning Framework. Wirel. Commun. Mob. Comput. 2018, 1–9. [Google Scholar] [CrossRef]
- Román, P.E.; Dell, R.F.; Velásquez, J.D.; Loyola, P.S. Identifying User Sessions from Web Server Logs with Integer Programming. Intell. Data Anal. 2014, 18, 43–61. [Google Scholar] [CrossRef] [Green Version]
- Apaolaza, A.; Vigo, M. Assisted pattern mining for discovering interactive behaviors on the web. Int. J. Hum.-Comput. Stud. 2019, 130, 196–208. [Google Scholar] [CrossRef]
- Slanzi, G.; Pizarro, G.; Velásquez, J.D. Biometric information fusion for web user navigation and preferences analysis: An overview. Inf. Fusion 2017, 38, 12–21. [Google Scholar] [CrossRef]
- Öztürk, N.; Ayvaz, S. Sentiment analysis on Twitter: A text mining approach to the Syrian refugee crisis. Telemat. Inf. 2018, 35, 136–147. [Google Scholar] [CrossRef]
- Irfan, R.; King, C.K.; Grages, D.; Ewen, S.; Khan, S.U.; Madani, S.A.; Kolodziej, J.; Wang, L.; Chen, D.; Rayes, A.; et al. A survey on text mining in social networks. Knowl. Eng. Rev. 2015, 30, 157–170. [Google Scholar] [CrossRef] [Green Version]
- Pak, A.; Paroubek, P. Twitter as a corpus for sentiment analysis and opinion mining. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10), Valletta, Malta, 17–23 May 2010; Calzolari, N., Choukri, K., Maegaard, B., Mariani, J., Odijk, J., Piperidis, S., Rosner, M., Tapias, D., Eds.; European Language Resources Association (ELRA): Luxembourg, 2010; pp. 1320–1326. [Google Scholar]
- Nisar, T.M.; Yeung, M. Twitter as a tool for forecasting stock market movements: A short-window event study. J. Financ. Data Sci. 2018, 4, 101–119. [Google Scholar] [CrossRef]
- Bollen, J.; Mao, H.; Zeng, X. Twitter mood predicts the stock market. J. Comput. Sci. 2011, 2, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Ruiz, E.J.; Hristidis, V.; Castillo, C.; Gionis, A.; Jaimes, A. Correlating financial time series with micro-blogging activity. In Proceedings of the Fifth ACM International Conference on Web Search and Data Mining, (WSDM’12), Seattle, WA, USA, 8–12 February 2012; ACM: New York, NY, USA, 2012; pp. 513–522. [Google Scholar] [CrossRef] [Green Version]
- Hagenau, M.; Liebmann, M.; Neumann, D. Automated news reading: Stock price prediction based on financial news using context-capturing features. Decis. Support Syst. 2013, 55, 685–697. [Google Scholar] [CrossRef]
- Zhang, L. Sentiment Analysis on Twitter with Stock Price and Significant Keyword Correlation; The University of Texas: Austin, TX, USA, 2013. [Google Scholar]
- Bing, L.; Chan, K.C.; Ou, C. Public sentiment analysis in Twitter data for prediction of a company’s stock price movements. In Proceedings of the 2014 IEEE 11th International Conference on e-Business Engineering, Guangzhou, China, 5–7 November 2014; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar] [CrossRef]
- Dickinson, B.; Hu, W. Sentiment analysis of investor opinions on twitter. Soc. Netw. 2015, 4, 62–71. [Google Scholar] [CrossRef] [Green Version]
- Das, S.; Behera, R.K.; Rath, S.K. Real-time sentiment analysis of Twitter streaming data for stock prediction. Procedia Comput. Sci. 2018, 132, 956–964. [Google Scholar] [CrossRef]
- Alkubaisi, G.A.A.J.; Kamaruddin, S.S.; Husni, H. Stock market classification model using sentiment analysis on twitter based on hybrid naive bayes classifiers. Comput. Inf. Sci. 2018, 11, 52–64. [Google Scholar] [CrossRef] [Green Version]
- Broadstock, D.C.; Zhang, D. Social-media and intraday stock returns: The pricing power of sentiment. Financ. Res. Lett. 2019, 116–123. [Google Scholar] [CrossRef]
- Alkhatib, M.; El Barachi, M.; Shaalan, K. An Arabic social media based framework for incidents and events monitoring in smart cities. J. Clean. Prod. 2019, 220, 771–785. [Google Scholar] [CrossRef]
- Gupta, B.; Sharma, S.; Chennamaneni, A. Twitter Sentiment Analysis: An Examination of Cybersecurity Attitudes and Behavior. In Proceedings of the 2016 Pre-ICIS SIGDSA/IFIP WG8.3 Symposium: Innovations in Data Analytics, Dublin, Ireland, 11 December 2016; p. 17. [Google Scholar]
- Philer, K.; Zhong, Y. Twitter sentiment analysis: Capturing sentiment from integrated resort tweets. Int. J. Hosp. Manag. 2016, 55, 16–24. [Google Scholar] [CrossRef]
- Lee, N.Y.; Kim, Y.; Sang, Y. How do journalists leverage Twitter? Expressive and consumptive use of Twitter. Soc. Sci. J. 2017, 54, 139–147. [Google Scholar] [CrossRef]
- Crannell, W.C.; Clark, E.; Jones, C.; James, T.A.; Moore, J. A pattern-matched Twitter analysis of US cancer-patient sentiments. J. Surg. Res. 2016, 206, 536–542. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Can, D.; Kazemzadeh, A.; Bar, F.; Narayanan, S. A system for real-time twitter sentiment analysis of 2012 US presidential election cycle. In Proceedings of the ACL 2012 System Demonstrations, Jeju Island, Korea, 8–14 July 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 115–120. [Google Scholar]
- Greco, F.; Polli, A. Emotional text mining: Customer profiling in brand management. Int. J. Inf. Manag. 2019. [Google Scholar] [CrossRef]
- Akundi, A.; Tseng, B.; Wu, J.; Smith, E.; Subbalakshmi, M.; Aguirre, F. Text mining to understand the influence of social media applications on smartphone supply chain. Procedia Comput. Sci. 2018, 140, 87–94. [Google Scholar] [CrossRef]
- Mansour, S. Social Media Analysis of User’s Responses to Terrorism Using Sentiment Analysis and Text Mining. Procedia Comput. Sci. 2018, 140, 95–103. [Google Scholar] [CrossRef]
- Reyes-Menendez, A.; Saura, J.R.; Alvarez-Alonso, C. Understanding #WorldEnvironmentDay user opinions in Twitter: A topic-based sentiment analysis approach. Int. J. Environ. Res. Public Health 2018, 15, 2537. [Google Scholar] [CrossRef] [Green Version]
- Al-Daihani, S.M.; Abrahams, A. A text mining analysis of academic libraries’ Tweets. J. Acad. Librariansh. 2016, 42, 135–143. [Google Scholar] [CrossRef]
- Center, P.R. Social Media Fact Sheet; Pew Research Center: Washington, DC, USA, 2017. [Google Scholar]
- Kim, J.; Hastak, M. Social network analysis: Characteristics of online social networks after a disaster. Int. J. Inf. Manag. 2018, 38, 86–96. [Google Scholar] [CrossRef]
- He, W.; Zha, S.; Li, L. Social media competitive analysis and text mining: A case study in the pizza industry. Int. J. Inf. Manag. 2013, 33, 464–472. [Google Scholar] [CrossRef]
- Salloum, S.A.; Mhamdi, C.; Al-Emran, M.; Shaalan, K. Analysis and classification of Arabic newspapers’ Facebook pages using text mining techniques. Int. J. Inf. Technol. Lang. Stud. 2017, 1, 8–17. [Google Scholar]
- Al-Daihani, S.M.; Abrahams, A. Analysis of academic libraries’ facebook posts: Text and data analytics. J. Acad. Librariansh. 2018, 44, 216–225. [Google Scholar] [CrossRef]
- Serna, A.; Gasparovic, S. Transport analysis approach based on big data and text mining analysis from social media. Transp. Res. Procedia 2018, 33, 291–298. [Google Scholar] [CrossRef]
- Sezgen, E.; Mason, K.J.; Mayer, R. Voice of airline passenger: A text mining approach to understand customer satisfaction. J. Air Transp. Manag. 2019, 77, 65–74. [Google Scholar] [CrossRef]
- Suresh, V.; Roohi, S.; Eirinaki, M. Aspect-based opinion mining and recommendation system for restaurant reviews. In Proceedings of the 8th ACM Conference on Recommender systems, Foster City, CA, USA, 1 October 2014; pp. 361–362. [Google Scholar] [CrossRef]
- Saha, S.; Santra, A.K. Restaurant rating based on textual feedback. In Proceedings of the 2017 International conference on Microelectronic Devices, Circuits and Systems (ICMDCS), Vellore, India, 10–12 August 2017. [Google Scholar] [CrossRef]
- Chen, M.-Y.; Liao, C.-H.; Hsieh, R.-P. Modeling public mood and emotion: Stock market trend prediction with anticipatory computing approach. Comput. Hum. Behav. 2019. [Google Scholar] [CrossRef]
- Liu, Y.; Qin, Z.; Li, P.; Wan, T. Stock volatility prediction using recurrent neural networks with sentiment analysis. In International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems; Benferhat, S., Tabia, K., Ali, M., Eds.; Springer: Cham, Switzerland, 2017; pp. 192–201. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Yeo, C.K.; Lau, C.T.; Lee, B.S. Leveraging social media news to predict stock index movement using RNN-boost. Data Knowl. Eng. 2018, 118, 14–24. [Google Scholar] [CrossRef]
- Liu, P.; Xia, X.; Li, A. Tweeting the financial market: Media effect in the era of Big Data. Pac. Basin Financ. J. 2018, 51, 267–290. [Google Scholar] [CrossRef]
- Zhang, X.; Shi, J.; Wang, D.; Fang, B. Exploiting investors social network for stock prediction in China’s market. J. Comput. Sci. 2018, 28, 294–303. [Google Scholar] [CrossRef] [Green Version]
- Pejic-Bach, M.; Bertoncel, T.; Meško, M.; Krstic, Ž. Text mining of industry 4.0 job advertisements. Int. J. Inf. Manag. 2019. [Google Scholar] [CrossRef]
- Moro, S.; Cortez, P.; Rita, P. Business intelligence in banking: A literature analysis from 2002 to 2013 using text mining and latent Dirichlet allocation. Expert Syst. Appl. 2015, 42, 1314–1324. [Google Scholar] [CrossRef] [Green Version]
- Amado, A.; Cortez, P.; Rita, P.; Moro, S. Research trends on Big Data in Marketing: A text mining and topic modeling based literature analysis. Eur. Res. Manag. Bus. Econ. 2018, 24, 1–7. [Google Scholar] [CrossRef]
- Moro, S.; Pires, G.; Rita, P.; Cortez, P. A text mining and topic modelling perspective of ethnic marketing research. J. Bus. Res. 2019, 103, 275–285. [Google Scholar] [CrossRef] [Green Version]
- Cortez, P.; Moro, S.; Rita, P.; King, D.; Hall, J. Insights from a text mining survey on Expert Systems research from 2000 to 2016. Expert Syst. 2018, 35, e12280. [Google Scholar] [CrossRef] [Green Version]
- Moro, S.; Rita, P. Brand strategies in social media in hospitality and tourism. Int. J. Contemp. Hosp. Manag. 2018, 30, 343–364. [Google Scholar] [CrossRef] [Green Version]
- Guerreiro, J.; Rita, P.; Trigueiros, D. A text mining-based review of cause-related marketing literature. J. Bus. Ethics 2016, 139, 111–128. [Google Scholar] [CrossRef]
- Loureiro, S.M.C.; Guerreiro, J.; Eloy, S.; Langaro, D.; Panchapakesan, P. Understanding the use of virtual reality in marketing: A text mining-based review. J. Bus. Res. 2019, 100, 514–530. [Google Scholar] [CrossRef]
- Galati, F.; Bigliardi, B. Industry 4.0: Emerging themes and future research avenues using a text mining approach. Comput. Ind. 2019, 109, 100–113. [Google Scholar] [CrossRef]
- Guan, J.; Manikas, A.S.; Boyd, L.H. The at 55: A content-driven review and analysis. Int. J. Prod. Res. 2017, 57, 4667–4675. [Google Scholar] [CrossRef] [Green Version]
- Demeter, K.; Szász, L.; Kö, A. A text mining based overview of inventory research in the ISIR special issues 1994-2016. Int. J. Prod. Econ. 2018, 209, 134–146. [Google Scholar] [CrossRef]
- Grubert, E. Implicit prioritization in life cycle assessment: Text mining and detecting metapatterns in the literature. Int. J. Life Cycle Assess. 2016, 22, 148–158. [Google Scholar] [CrossRef]
- Yang, D.; Kleissl, J.; Gueymard, C.A.; Pedro, H.T.C.; Coimbra, C.F.M. History and trends in solar irradiance and PV power forecasting: A preliminary assessment and review using text mining. Sol. Energy 2018, 168, 60–101. [Google Scholar] [CrossRef]
- Moro, S.; Rita, P.; Cortez, P. A text mining approach to analyzing Annals literature. Ann. Tour. Res. 2017, 66, 208–210. [Google Scholar] [CrossRef] [Green Version]
- Contiero, B.; Cozzi, G.; Karpf, L.; Gottardo, F. Pain in Pig Production: Text Mining Analysis of the Scientific Literature. J. Agric. Environ. Ethics 2019, 32, 401–412. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.-H.; Ding, Y.; Zhao, W.; Huang, Y.-H.; Perkins, R.; Zou, W.; Chen, J.J. Text mining for identifying topics in the literatures about adolescent substance use and depression. BMC Public Health 2016, 16. [Google Scholar] [CrossRef] [Green Version]
- Balan, P.F.; Gerits, A.; Vuffel, W. A practical application of text mining to literature on cognitive rehabilitation and enhancement through neurostimulation. Front. Syst. Neurosci. 2014, 8, 182. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, A.S.; Rodríguez, M.S.; Matthiesen, R. Review and literature mining on proteostasis factors and cancer. In Proteostasis. Methods in Molecular Biology; Matthiesen, R., Ed.; Humana Press: New York, NY, USA, 2016; pp. 71–84. [Google Scholar] [CrossRef]
- Karami, A.; Ghasemi, M.; Sen, S.; Moraes, M.F.; Shah, V. Exploring diseases and syndromes in neurology case reports from 1955 to 2017 with text mining. Comput. Biol. Med. 2019, 109, 322–332. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kayal, S.; Afzal, Z.; Tsatsaronis, G.; Doornenbal, M.; Katrenko, S.; Gregory, M. A framework to automatically extract funding information from text. In Proceedings of the International Conference on Machine Learning, Optimization, and Data Science, Volterra, Italy, 13 September 2018; pp. 317–328. [Google Scholar]
- Yousif, A.; Niu, Z.; Nyamawe, A.S.; Hu, Y. Improving citation sentiment and purpose classification using hybrid deep neural network model. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics, Cairo, Egypt, 26–28 October 2018; pp. 327–336. [Google Scholar]
- Sag, M. The new legal landscape for text mining and machine learning. J. Copyr. Soc. USA 2019, 66. [Google Scholar] [CrossRef]
- Directive (EU) 2019/790 of the European Parliament and of the Council of 17 April 2019 on Copyright in the Digital Single Market. Available online: https://eur-lex.europa.eu/eli/dir/2019/790/oj (accessed on 1 January 2020).
- Sheeba, J.; Vivekanan, K. Improved keyword and keyphrase extraction from meeting transcripts. Int. J. Comput. Appl. 2012, 52, 11–15. [Google Scholar]
- Liu, F.; Liu, F.; Liu, Y. A supervised framework for keyword extraction from meeting transcripts. IEEE Trans. Audio Speech Lang. Process. 2010, 19, 538–548. [Google Scholar] [CrossRef]
- Liu, F.; Pennell, D.; Liu, F.; Liu, Y. Unsupervised approaches for automatic keyword extraction using meeting transcripts. In NAACL’09 Proceedings of Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2009; pp. 620–628. [Google Scholar]
- Song, H.-J.; Go, J.; Park, S.-B.; Park, S.-Y. A just-in-time keyword extraction from meeting transcripts. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; Association for Computational Linguistics: Atlanta, GA, USA, 2013; pp. 888–896. [Google Scholar]
- Song, H.-J.; Go, J.; Park, S.-B.; Park, S.-Y.; Kim, K.Y. A just-in-time keyword extraction from meeting transcripts using temporal and participant information. J. Intell. Inf. Syst. 2017, 48, 117–140. [Google Scholar] [CrossRef]
- Xie, S.; Liu, Y. Improving supervised learning for meeting summarization using sampling and regression. Comput. Speech Lang. 2010, 24, 495–514. [Google Scholar] [CrossRef]
- Sharp, B.; Chibelushi, C. Text segmentation of spoken meeting transcripts. Int. J. Speech Technol. 2008, 11, 157. [Google Scholar] [CrossRef]
- Amancio, D.R.; Altmann, E.G.; Oliveira, O.N., Jr.; Costa, L.F. Comparing intermittency and network measurements of words and their dependence on authorship. New J. Phys. 2011, 13, 123024. [Google Scholar] [CrossRef]
- Amancio, D.R.; Oliveira, O.N., Jr.; Costa, L.F. Identification of literary movements using complex networks to represent texts. New J. Phys. 2012, 14, 043029. [Google Scholar] [CrossRef]
- Amancio, D.R. A complex network approach to stylometry. PLoS ONE 2015, 10, e0136076. [Google Scholar] [CrossRef]
- Wang, T.; Brede, M.; Ianni, A.; Mentzakis, E. Characterizing dynamic communication in online eating disorder communities: A multiplex network approach. Appl. Netw. Sci. 2019, 4. [Google Scholar] [CrossRef] [Green Version]
- Nuzzo, A.; Mulas, F.; Gabetta, M.; Arbustini, E.; Zupan, B.; Larizza, C.; Bellazzi, R. Text mining approaches for automated literature knowledge extraction and representation. Stud. Health Technol. Inform. 2010, 160, 954–958. [Google Scholar] [CrossRef] [PubMed]
- Gentzkow, M.; Kelly, B.T.; Taddy, M. Text As Data. NBER Work. Pap. 2017. [Google Scholar] [CrossRef] [Green Version]
- Lau, R.; Xia, Y. Latent text mining for cybercrime forensics. Int. J. Future Comput. Commun. 2013, 2, 368–371. [Google Scholar] [CrossRef]
- Suh-Lee, C.; Ju-Yeon, J.; Yoohwan, K. Text mining for security threat detection discovering hidden information in unstructured log messages. In Proceedings of the 2016 IEEE Conference on Communications and Network Security (CNS), Philadelphia, PA, USA, 17–19 October 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar] [CrossRef]
- Noel, S. Text Mining for Modeling Cyberattacks. In Computational Analysis and Understanding of Natural Languages: Principles, Methods and Applications; Venkat, N., Gudivada, C.R., Eds.; Elsevier: Amsterdam, The Netherlands, 2018; Chapter 14; pp. 463–515. [Google Scholar] [CrossRef]
- Dong, F.; Yuan, S.; Ou, H.; Liu, L. New Cyber Threat Discovery from Darknet Marketplaces. In Proceedings of the IEEE Conference on Big Data and Analytics (ICBDA), Shanghai, China, 21–22 November 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar] [CrossRef]
- Kaplan, J.; Sharma, S.; Weinberg, A. Meeting the Cybersecurity Challenge. Available online: https://www.mckinsey.com/business-functions/digital-mckinsey/our-insights/meeting-the-cybersecurity-challenge (accessed on 1 January 2020).
- Aiken, M.; Mahon, C.; Haughton, C.; O’Neill, L.; O’Carroll, E. A consideration of the social impact of cybercrime: Examples from hacking, piracy, and child abuse material online. Contemp. Soc. Sci. 2015, 11, 373–391. [Google Scholar] [CrossRef]
- Ponemon Institute. 2017 Cost of Data Breach Study: Global Overview (Research Report). Ponemon Institute. 2017. Available online: https://www.ibm.com/downloads/cas/ZYKLN2E3 (accessed on 1 January 2020).
- EC Horizon 2020, Secure Societies—Protecting Freedom and Security of Europe and Its Citizens. Available online: https://ec.europa.eu/programmes/horizon2020/en/h2020-section/secure-societies-%E2%80%93-protecting-freedom-and-security-europe-and-its-citizens (accessed on 1 January 2020).
- Bayerl, P.S.; Akhgar, B.; Brewster, B.; Domdouzis, K.; Gibson, H. Social media and its role for LEAs. In Cyber Crime and Cyber Terrorism Investigator’s Handbook; Akhgar, B., Staniforth, A., Bosco, F., Eds.; Elsevier: Amsterdam, The Netherlands, 2014; pp. 197–220. [Google Scholar] [CrossRef]
- Donalds, C.; Osei-Bryson, K.-M. Toward a cybercrime classification ontology: A knowledge-based approach. Comput. Hum. Behav. 2019, 92, 403–418. [Google Scholar] [CrossRef]
- Hicks, C. An ontological approach to misinformation: Quickly finding relevant information. In Proceedings of the 50th Hawaii International Conference on System Sciences, (HICSS 2017), Waikoloa Village, HI, USA, 4–7 January 2017; pp. 1–8. [Google Scholar]
- Yu, F.; Liu, Q.; Wu, S.; Wang, L.; Tan, T. Attention-based convolutional approach for misinformation identification from massive and noisy microblog posts. Comput. Secur. 2019, 83, 106–121. [Google Scholar] [CrossRef]
- Zhang, C.; Gupta, A.; Kauten, C.; Deokar, A.V.; Qin, X. Detecting fake news for reducing misinformation risks using analytics approaches. Eur. J. Oper. Res. 2019, 279, 1036–1052. [Google Scholar] [CrossRef]
- Shelke, S.; Attar, V. Source detection of rumor in social network—A review. Online Soc. Netw. Media 2019, 9, 30–42. [Google Scholar] [CrossRef]
- Bondielli, A.; Marcelloni, F. A Survey on fake news and rumour detection techniques. Inf. Sci. 2019, 497, 38–55. [Google Scholar] [CrossRef]
- European Data Protection Supervisor. Meeting the Challenges of Big Data: A Call for Transparency, User Control, Data Protection by Design and Accountability, Opinion 7/2015. 2015. Available online: https://edps.europa.eu/sites/edp/files/publication/15-11-19_big_data_en.pdf (accessed on 1 January 2020).
- Truyens, M.; van Eecke, P. Legal aspects of text mining. Comput. Law Secur. Rev. 2014, 30, 153–170. [Google Scholar] [CrossRef]
- Fatima, R.; Yasin, A.; Liu, L.; Wang, J.; Afzal, W.; Yasin, A. Sharing information online rationally: An observation of user privacy concerns and awareness using serious game. J. Inf. Secur. Appl. 2019, 48, 102351. [Google Scholar] [CrossRef]
- Chilton, P.A. Analysing Political Discourse: Theory and Practice; Routledge: London, UK, 2004. [Google Scholar]
- Ludwig, S.A. MapReduce-based fuzzy c-means clustering algorithm: Implementation and scalability. Int. J. Mach. Learn. Cybern. 2015, 6, 923–934. [Google Scholar] [CrossRef]
- Kontopoulos, I.; Giannakopoulos, G.; Varlamis, I. Distributing n-gram graphs for classification. Eur. Conf. Adv. Databases Inf. Syst. 2017, 3–11. [Google Scholar] [CrossRef]
- Paul, M.J.; Sarker, A.; Brownstein, J.S.; Nikfarjam, A.; Scotch, M.; Smith, K.L.; Gonzalez, G. Social media mining for public health monitoring and surveillance. In Pacific Symposium on Biocomputing 2016, (PSB 2016); World Scientific Publishing Co.: Singapore, 2016; pp. 468–479. [Google Scholar] [CrossRef] [Green Version]
- Jordan, S.E.; Hovet, S.E.; Fung, I.C.-H.; Liang, H.; Fu, K.-W.; Tse, Z.T.H. Using Twitter for public health surveillance from monitoring and prediction to public response. Data 2018, 4, 6. [Google Scholar] [CrossRef] [Green Version]
- Lucini, F.R.; Fogliatto, F.S.; da Silveira, G.J.C.; Neyeloff, J.L.; Anzanello, M.J.; Kuchenbecker, R.S.; Schaan, B.D. Text mining approach to predict hospital admissions using early medical records from the emergency department. Int. J. Med Inform. 2017, 100, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Metsker, O.; Bolgova, E.; Yakovlev, A.; Funkner, A.; Kovalchuk, S. Pattern-based mining in electronic health records for complex clinical process analysis. Procedia Comput. Sci. 2017, 119, 197–206. [Google Scholar] [CrossRef]
- Leong, C.K.; Lee, Y.H.; Mak, W.K. Mining sentiments in SMS texts for teaching evaluation. Expert Syst. Appl. 2012, 39, 2584–2589. [Google Scholar] [CrossRef]
- He, W. Examining students’ online interaction in a live video streaming environment using data mining and text mining. Comput. Hum. Behav. 2013, 29, 90–102. [Google Scholar] [CrossRef]
- Rodrigues, M.W.; Isotani, S.; Zárate, L.E. Educational data mining: A review of evaluation process in the e-learning. Telemat. Inform. 2018, 35, 1701–1717. [Google Scholar] [CrossRef]
- Ferreira-Mello, R.; André, M.; Pinheiro, A.; Costa, E.; Romero, C. Text mining in education. WIREs Data Min. Knowl. Discov. 2019, e1332. [Google Scholar] [CrossRef]
- Zaeem, R.; Manoharan, M.; Yang, Y.; Barber, K.S. Modeling and analysis of identity threat behaviors through text mining of identity theft stories. Comput. Secur. 2017, 65, 50–63. [Google Scholar] [CrossRef]
- Das, P.; Das, A.K. Graph-based clustering of extracted paraphrases for labelling crime reports. Knowl. Based Syst. 2019, 179, 55–76. [Google Scholar] [CrossRef]
- Amrit, C.; Paauw, T.; Aly, R.; Lavric, M. Identifying child abuse through text mining and machine learning. Expert Syst. Appl. 2017, 88, 402–418. [Google Scholar] [CrossRef]
- Esser, D.E.; Williams, B.J. Tracing poverty and inequality in international development discourses: An algorithmic and visual analysis of agencies’ annual reports and occasional white papers, 1978–2010. J. Soc. Policy 2014, 43, 173–200. [Google Scholar] [CrossRef]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassani, H.; Beneki, C.; Unger, S.; Mazinani, M.T.; Yeganegi, M.R. Text Mining in Big Data Analytics. Big Data Cogn. Comput. 2020, 4, 1. https://doi.org/10.3390/bdcc4010001
Hassani H, Beneki C, Unger S, Mazinani MT, Yeganegi MR. Text Mining in Big Data Analytics. Big Data and Cognitive Computing. 2020; 4(1):1. https://doi.org/10.3390/bdcc4010001
Chicago/Turabian StyleHassani, Hossein, Christina Beneki, Stephan Unger, Maedeh Taj Mazinani, and Mohammad Reza Yeganegi. 2020. "Text Mining in Big Data Analytics" Big Data and Cognitive Computing 4, no. 1: 1. https://doi.org/10.3390/bdcc4010001
APA StyleHassani, H., Beneki, C., Unger, S., Mazinani, M. T., & Yeganegi, M. R. (2020). Text Mining in Big Data Analytics. Big Data and Cognitive Computing, 4(1), 1. https://doi.org/10.3390/bdcc4010001