
Prediction of Waste Generation Using Machine Learning: A Regional Study in Korea


Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area and Variable Description
2.2. Prediction Framework Structure
2.3. Model Configuration and Training
2.3.1. Machine Learning Models and Training Setup
2.3.2. Hyperparameter Tuning
- n_estimators ∈ {100, 300, 500}.
- max_depth ∈ {10, 20, 30, None}.
- min_samples_split ∈ {2, 5, 10}.
- min_samples_leaf ∈ {1, 2, 4}.
- max_features ∈ {“sqrt”, “log2”}.
- n_estimators = 300, max_depth = 20, min_samples_split = 5, min_samples_leaf = 2, max_features = “sqrt”, which provided a good trade-off between bias and variance.
- n_estimators ∈ {100, 300, 500}.
- max_depth ∈ {3, 5, 7, 10}.
- learning_rate ∈ {0.01, 0.05, 0.1}.
- subsample ∈ {0.6, 0.8, 1.0}.
- colsample_bytree ∈ {0.6, 0.8, 1.0}.
- gamma ∈ {0, 1, 5}.
- reg_alpha ∈ {0, 0.1, 1}.
- reg_lambda ∈ {1, 5, 10}.
- n_estimators = 300, max_depth = 7, learning_rate = 0.05, subsample = 0.8, colsample_bytree = 0.8, gamma = 1, reg_alpha = 0.1, reg_lambda = 5. These settings provided strong predictive accuracy while maintaining generalizability [5]. During tuning, the negative root mean squared error (neg-RMSE) was used as the scoring metric to evaluate performance across folds [3]. All model training and tuning procedures were implemented using the Scikit-learn and XGBoost Python(version 3.12.7) packages. Final models were retrained on the full training set using the optimal hyperparameter configurations before evaluation on the test set. This systematic tuning approach ensured fair model comparison and improved generalization, particularly when tested on administrative units with diverse population sizes and economic conditions [7].
2.4. Evaluation Metrics and Visualization Strategy
3. Results
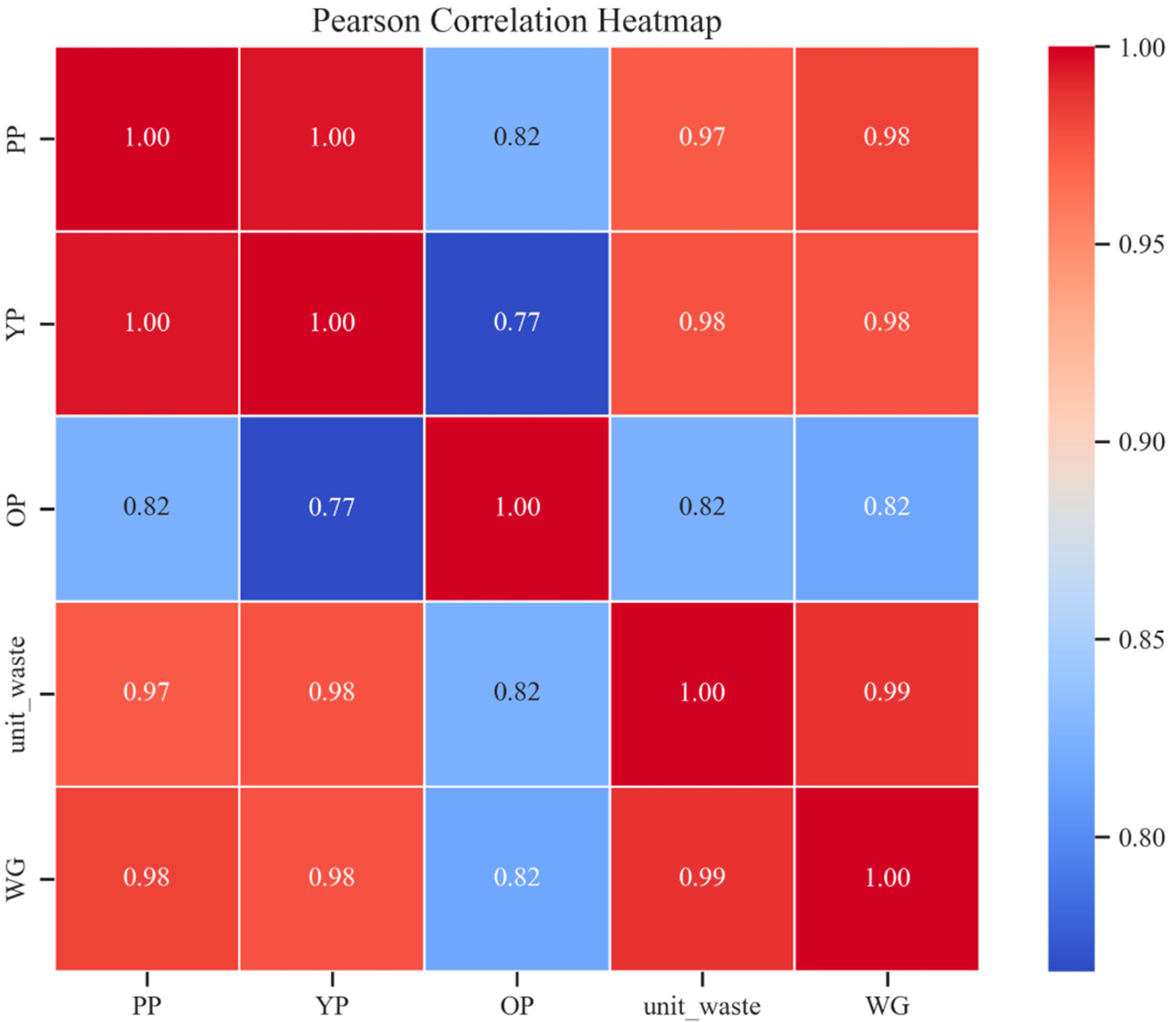
3.1. Correlation Analysis and Feature Interactions
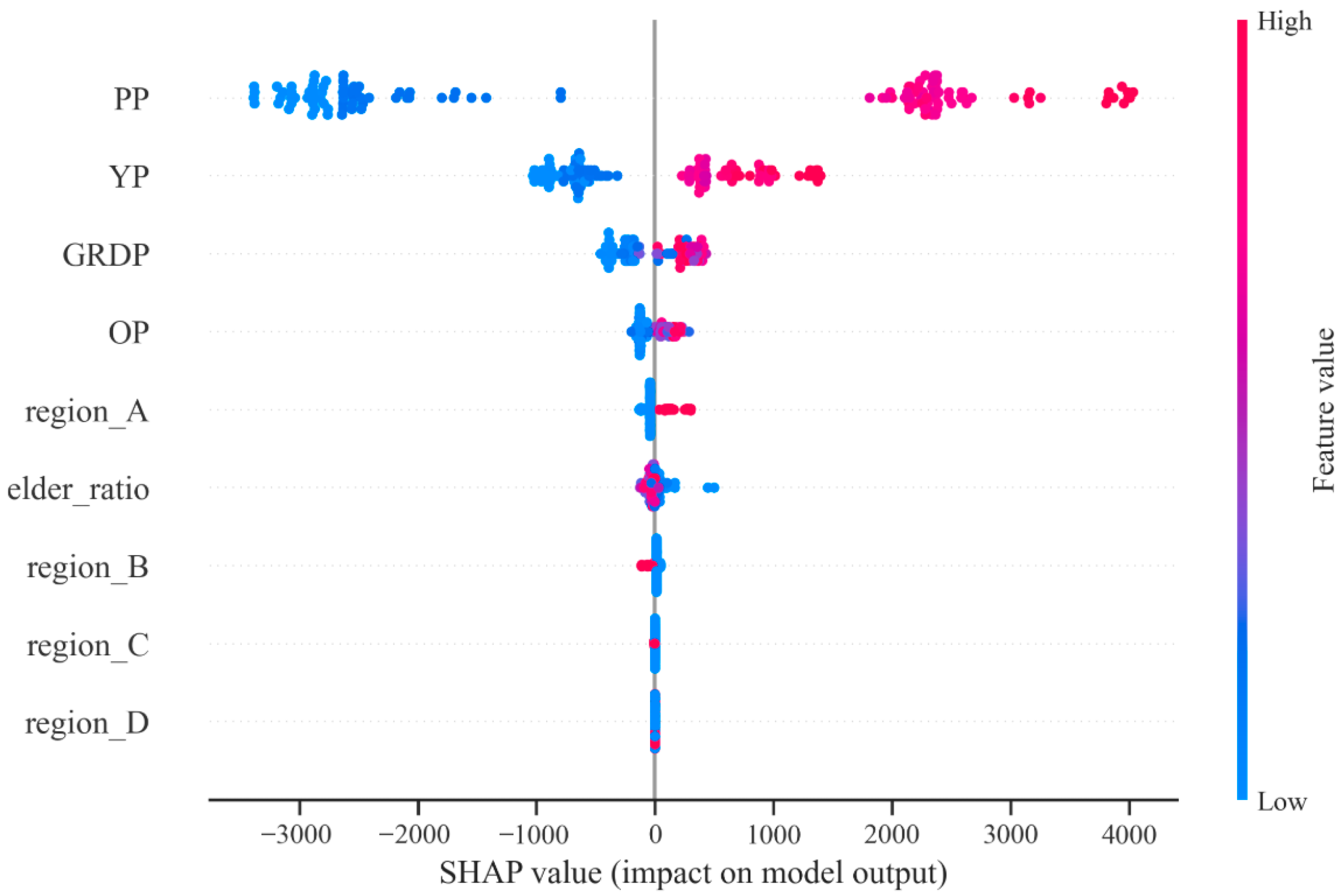
3.2. Feature Importance and Model Interpretation
3.3. Regional Forecast Performance
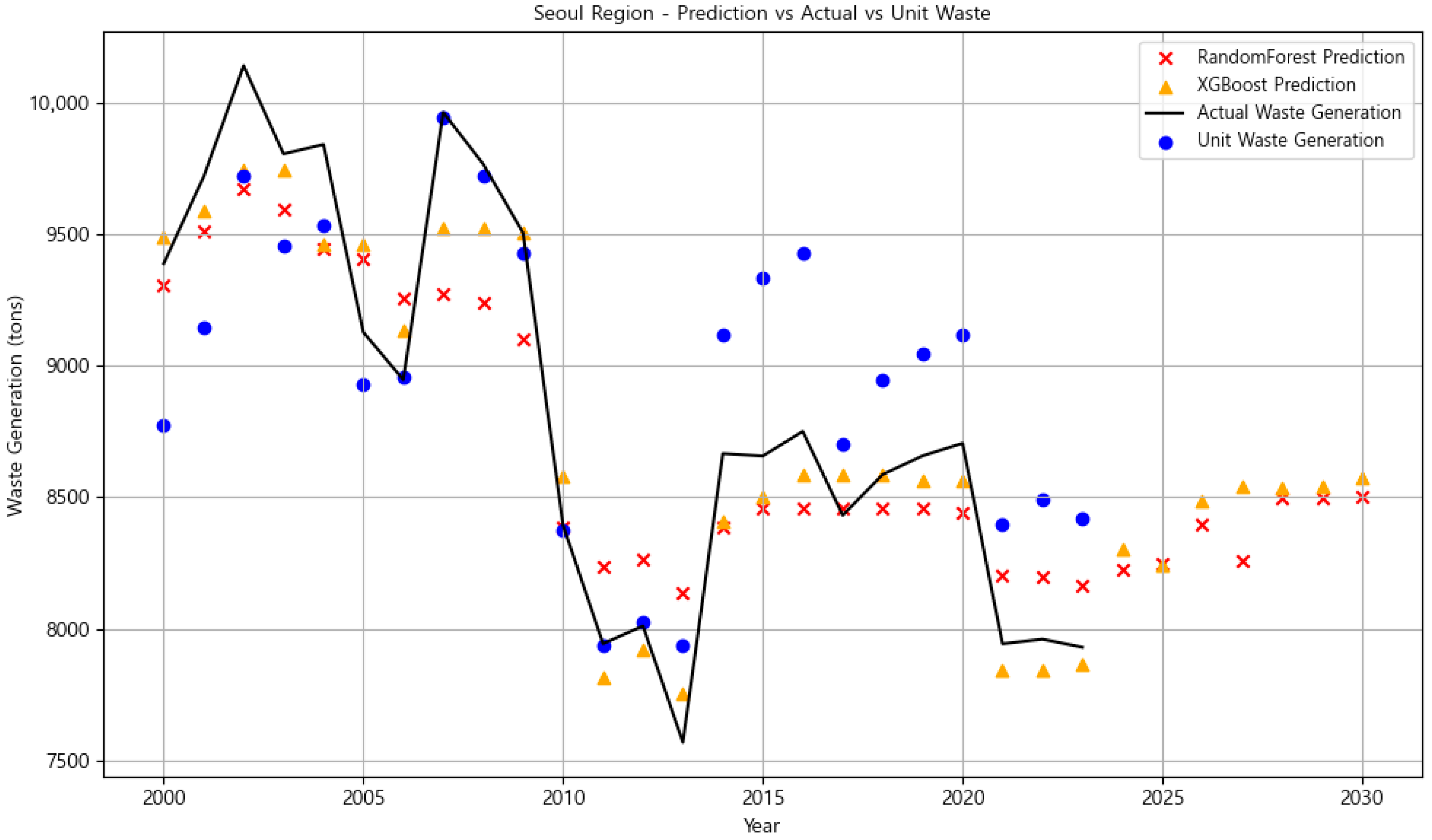
3.3.1. Seoul Region
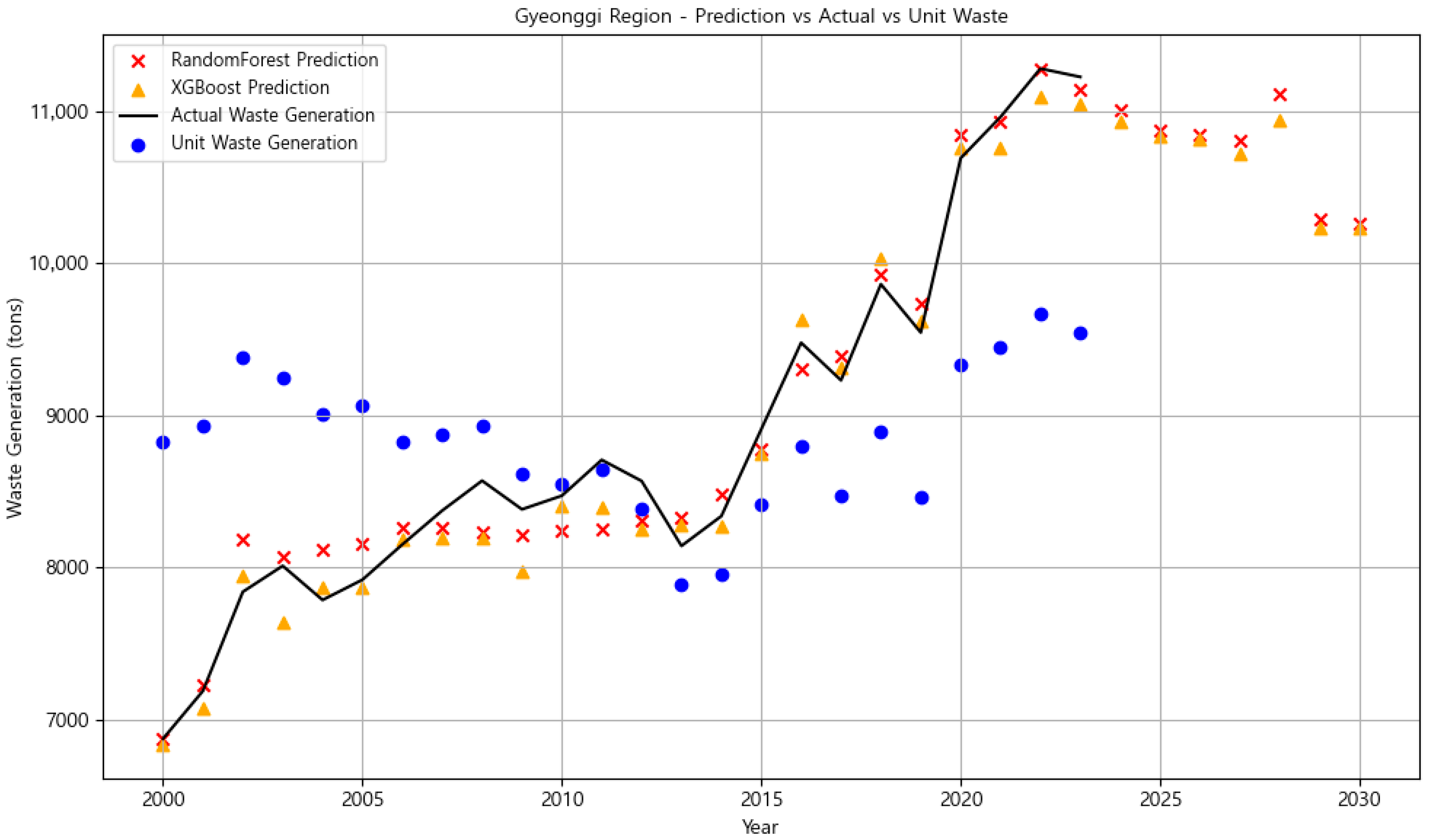
3.3.2. Gyeonggi Region
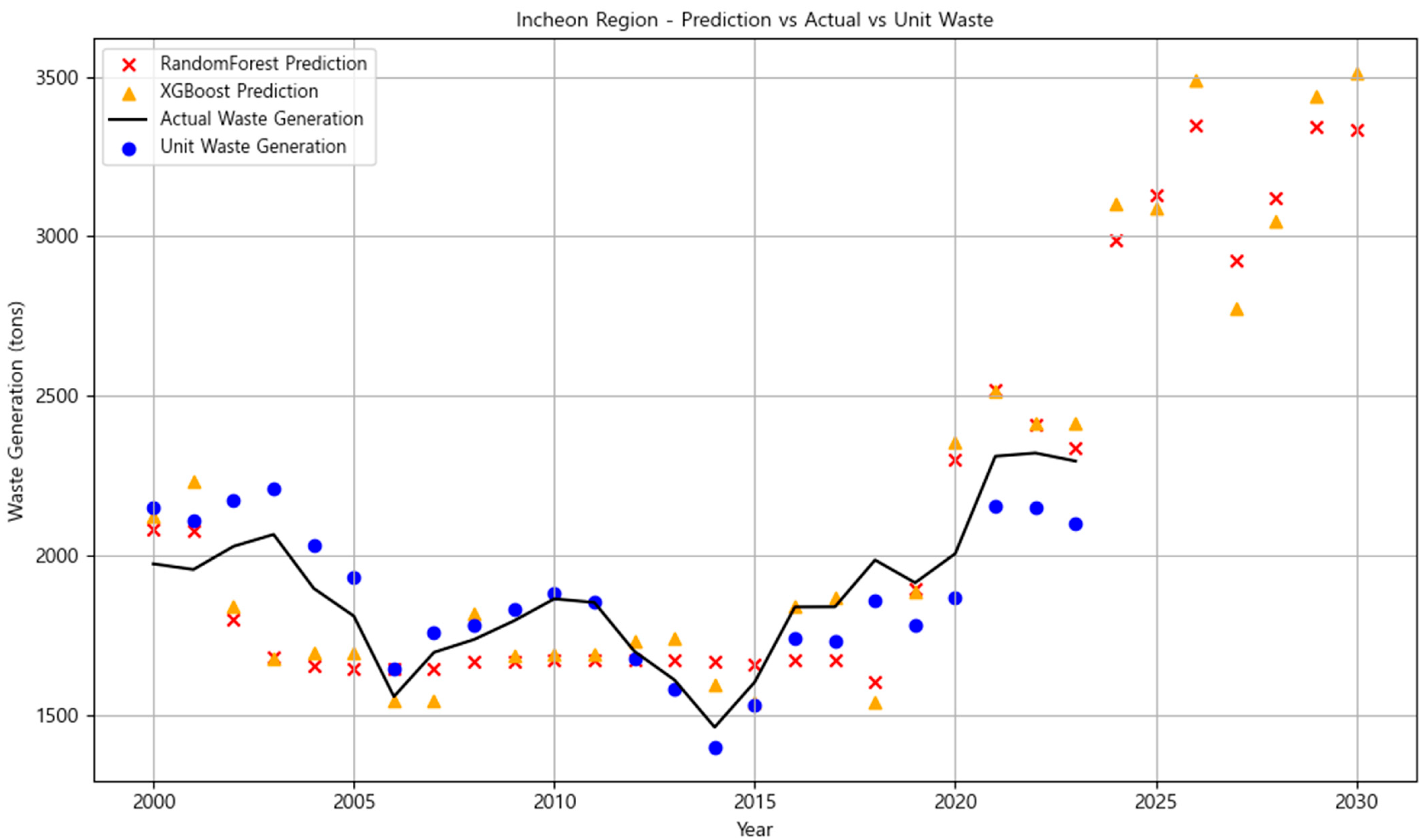
3.3.3. Incheon Region
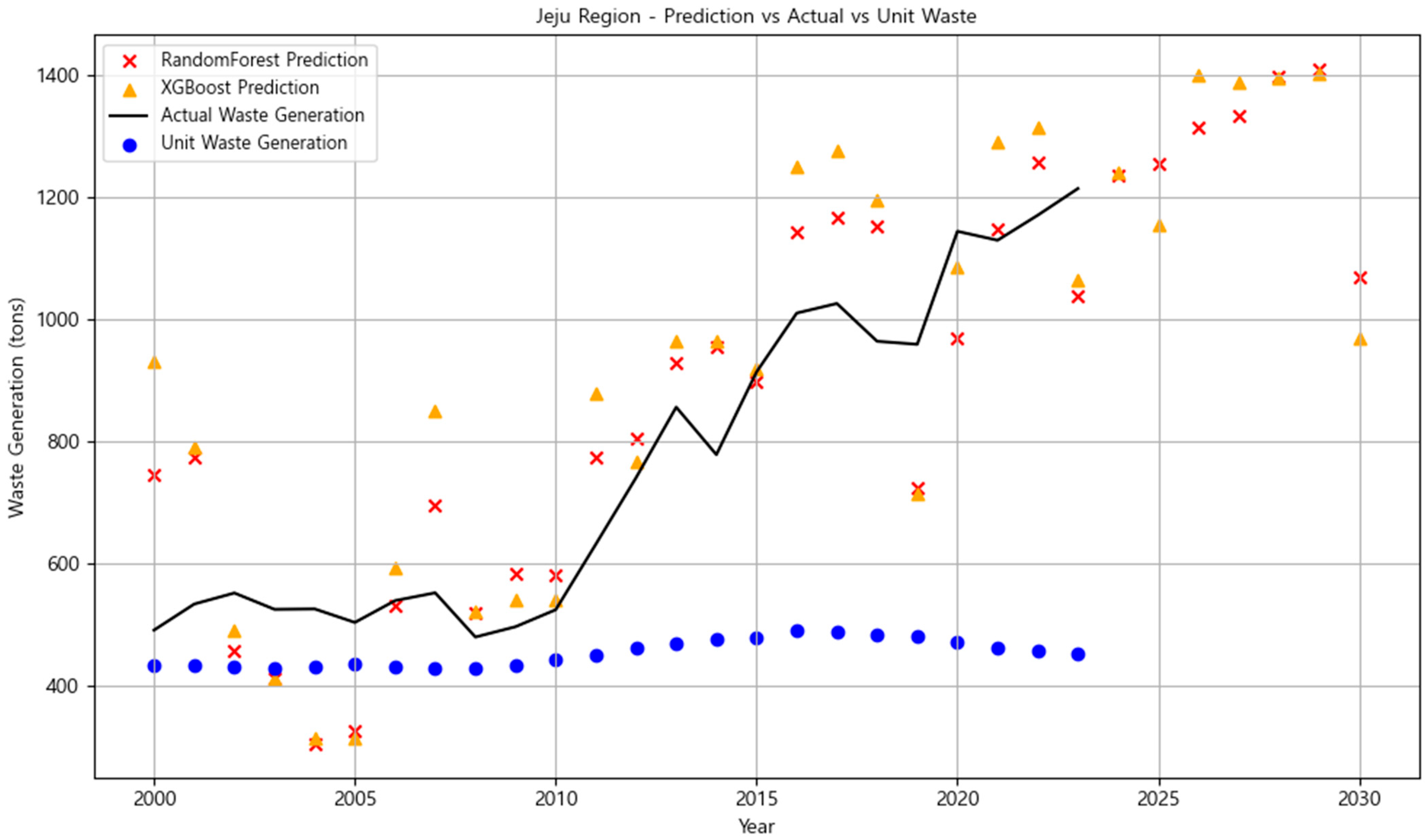
3.3.4. Jeju Region
3.4. Quantitative Regional Comparison
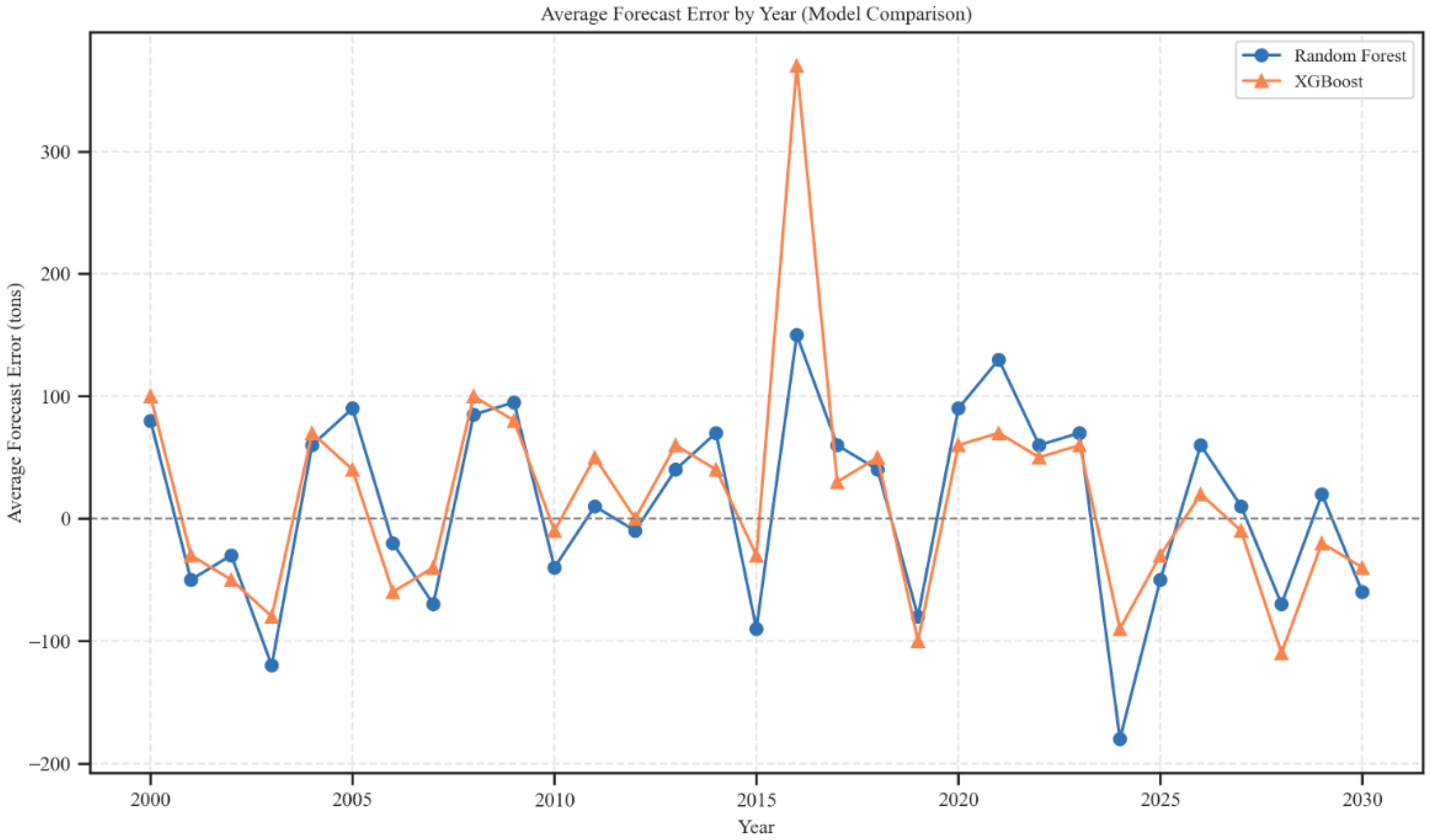
3.5. Temporal Forecast Errors
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kaza, S.; Yao, L.; Bhada-Tata, P.; Van Woerden, F. What a Waste 2.0: A Global Snapshot of Solid Waste Management to 2050; World Bank: Washington, DC, USA, 2018. [Google Scholar] [CrossRef]
- Guerrero, L.A.; Maas, G.; Hogland, W. Solid waste management challenges for cities in developing countries. Waste Manag. 2013, 33, 220–232. [Google Scholar] [CrossRef]
- Schratz, P.; Muenchow, J.; Iturritxa, E.; Richter, J.; Brenning, A. Performance evaluation and hyperparameter tuning of statistical and machine-learning models using spatial data. arXiv 2018, arXiv:1803.11266. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Tasic, A.; Jovanovic, L.; Bacanin, N.; Zivkovic, M.; Simic, V.; Popovic, M.; Antonijevic, M. Towards sustainable so-cieties: Convolutional neural networks optimized by modified crayfish optimization algorithm aided by AdaBoost and XGBoost for waste classification tasks. Appl. Soft Comput. 2025, 175, 113086. [Google Scholar] [CrossRef]
- Ranjbaran, G.; Recupero, D.R.; Roy, C.K.; Schneider, K.A. C-SHAP: A hybrid method for fast and efficient interpretability. Appl. Sci. 2025, 15, 672. [Google Scholar] [CrossRef]
- Fang, B.; Yu, J.; Chen, Z.; Osman, A.I.; Farghali, M.; Ihara, I.; Hamza, E.H.; Rooney, D.W.; Yap, P.-S. Artificial intelligence for waste management in smart cities: A review. Environ. Chem. Lett. 2023, 21, 1959–1989. [Google Scholar] [CrossRef]
- Kumar, R.; Verma, A.; Shome, A.; Sinha, R.; Sinha, S.; Jha, P.K.; Kumar, R.; Kumar, P.; Shubham, S.; Das, S.; et al. Impacts of plastic pollution on ecosystem services, sustainable development goals, and need to focus on circular economy and policy interventions. Sustainability 2021, 13, 9963. [Google Scholar] [CrossRef]
- Daoud, A.O.; Elattar, H.; Abdelatif, G.; Morsy, K.M.; Peters, R.W.; Mostafa, M.K. Implications of the COVID-19 pandemic on the management of municipal solid waste and medical waste: A comparative review of selected countries. Biomass 2024, 4, 555–573. [Google Scholar] [CrossRef]
- Alsabt, R.; Alkhaldi, W.; Adenle, Y.A.; Alshuwaikhat, H.M. Optimizing Waste Management Strategies Through Artificial Intelligence and Machine Learning An Economic and Environmental Impact Study. Clean. Waste Syst 2024, 8, 100158. [Google Scholar] [CrossRef]
- Liu, X.; Zhi, W.; Akhundzada, A. Enhancing performance prediction of municipal solid waste generation: A strategic management. Front. Environ. Sci. 2025, 13, 1553121. [Google Scholar] [CrossRef]
- Mecheri, H.; Benamirouche, I.; Fass, F.; Ziou, D.; Kadri, N. Prediction of rare events in the operation of household equipment using co-evolving time series. arXiv 2023, arXiv:2312.09410. [Google Scholar] [CrossRef]
- Branco, P.; Torgo, L.; Ribeiro, R. A survey of predictive modelling under imbalanced distributions. arXiv 2015, arXiv:1505.01658. [Google Scholar] [CrossRef]
- Pohjankukka, J.; Pahikkala, T.; Nevalainen, P.; Heikkonen, J. Estimating the prediction performance of spatial models via spatial k-fold cross validation. arXiv 2020, arXiv:2005.14263. [Google Scholar] [CrossRef]
- KOSIS (Korean Statistical Information Service). Available online: https://kosis.kr (accessed on 5 January 2023).
- Local Statistical Yearbook. Statistics Korea. Available online: https://kostat.go.kr (accessed on 5 January 2023).
- Bank of Korea. Regional Gross Domestic Product Data. Available online: https://bok.or.kr (accessed on 5 January 2023).
- Lu, W.; Huo, W.; Gulina, H.; Pan, C. Development of machine learning multi-city model for municipal solid waste generation prediction. Front. Environ. Sci. Eng. 2022, 16, 123. [Google Scholar] [CrossRef]
- Latif, S.D.; Hazrin, N.A.; Younes, M.K.; Ahmed, A.N.; Elshafie, A. Evaluating different machine learning models for predicting municipal solid waste generation: A case study of Malaysia. Environ. Dev. Sustain. 2023, 26, 12489–12512. [Google Scholar] [CrossRef]
- Kontokosta, C.E.; Hong, B.; Johnson, N.E.; Starobin, D. Using machine learning and small area estimation to predict building-level municipal solid waste generation in cities. Comput. Environ. Urban Syst. 2018, 70, 151–162. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A Comparative Analysis of Gradient Boosting Algorithms. Information 2020, 11, 193. [Google Scholar] [CrossRef]
- Ibrahim, K.; Savage, D.A.; Schnirel, A.; Intrevado, P.; Interian, Y. ContamiNet: Detecting contamination in municipal solid waste. arXiv 2019, arXiv:1911.04583. [Google Scholar] [CrossRef]
- Nam, Y.; Eom, Y.-H. Percolation analysis of spatiotemporal distribution of population in Seoul and Helsinki. arXiv 2024, arXiv:2408.08504. [Google Scholar] [CrossRef]
- Choi, H.; Kim, J.; Yu, D.; Jun, B. Population concentration in high-complexity regions within city during the heat wave. arXiv 2024, arXiv:2407.09795. [Google Scholar] [CrossRef]
- Mudannayake, O.; Rathnayake, D.; Herath, J.D.; Fernando, D.K.; Fernando, M. Exploring Machine Learning and Deep Learning Approaches for Multi-Step Forecasting in Municipal Solid Waste Generation. IEEE Access 2022, 10, 10. [Google Scholar] [CrossRef]
- Imran, M.; Ahmad, S.; Kim, D.H. Quantum GIS Based Descriptive and Predictive Data Analysis for Effective Planning of Waste Management. IEEE Access 2020, 8, 123456–123470. [Google Scholar] [CrossRef]
- Jayaraman, V.; Lakshminarayanan, A.R.; Parthasarathy, S.; Suganthy, A. Forecasting the Municipal Solid Waste Using GSO-XGBoost Model. Intell. Autom. Soft Comput. 2023, 37, 301–320. [Google Scholar] [CrossRef]
- Zhang, C.; Dong, H.; Geng, Y.; Liang, H.; Liu, X. Machine learning based prediction for China’s municipal solid waste under the shared socioeconomic pathways. J. Environ. Manag. 2022, 312, 114918. [Google Scholar] [CrossRef] [PubMed]
- Guo, R.; Liu, H.M.; Sun, H.H.; Wang, D.; Yu, H. Forecasting of municipal solid waste generation in China based on an optimized grey multiple regression model. J. Mater. Cycles Waste Manag. 2022, 24, 2314–2327. [Google Scholar] [CrossRef]
- Hoy, Z.X.; Woon, K.S.; Chin, W.C.; Hashim, H.; Fan, Y.V. Forecasting heterogeneous municipal solid waste generation via Bayesian-optimised neural network with ensemble learning. Comput. Chem. Eng. 2022, 166, 107946. [Google Scholar] [CrossRef]
- Liu, J.; Hu, M.; Xu, X. The role of prediction stability in municipal infrastructure under uncertainty. Sustain. Cities Soc. 2021, 69, 102829. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | R2 (95%CI) | RMSE | MAPE (%) |
|---|---|---|---|
| Random Forest | 0.9855 [0.9780–0.9987] | 500.35 | 3.88 |
| XGBoost | 0.9784 [0.9629–0.9892] | 609.84 | 4.28 |
| Region | Model | R2 | RMSE | MAPE (%) |
|---|---|---|---|---|
| Seoul | Random Forest | 0.8019 [0.7226–0.8531] | 299.48 | 2.86 |
| XGBoost | 0.9181 [0.8592–0.9486] | 192.61 | 1.70 | |
| Gyeonggi | Random Forest | 0.9721 [0.9695–0.9846] | 217.49 | 1.95 |
| XGBoost | 0.9752 [0.9540–0.9870] | 205.35 | 1.82 | |
| Incheon | Random Forest | 0.8934 [0.7676–0.9399] | 181.01 | 7.34 |
| XGBoost | 0.8546 [0.7437–0.9142] | 211.39 | 7.75 | |
| Jeju | Random Forest | 0.8148 [0.7680–0.8827] | 137.60 | 15.89 |
| XGBoost | 0.6773 [0.4872–0.8091] | 181.65 | 20.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.-S.; Shin, D.-C. Prediction of Waste Generation Using Machine Learning: A Regional Study in Korea. Urban Sci. 2025, 9, 297. https://doi.org/10.3390/urbansci9080297
Lee J-S, Shin D-C. Prediction of Waste Generation Using Machine Learning: A Regional Study in Korea. Urban Science. 2025; 9(8):297. https://doi.org/10.3390/urbansci9080297
Chicago/Turabian StyleLee, Jae-Sang, and Dong-Chul Shin. 2025. "Prediction of Waste Generation Using Machine Learning: A Regional Study in Korea" Urban Science 9, no. 8: 297. https://doi.org/10.3390/urbansci9080297
APA StyleLee, J.-S., & Shin, D.-C. (2025). Prediction of Waste Generation Using Machine Learning: A Regional Study in Korea. Urban Science, 9(8), 297. https://doi.org/10.3390/urbansci9080297