
Impacts of Missing Data Imputation on Resilience Evaluation for Water Distribution System


Abstract
1. Introduction
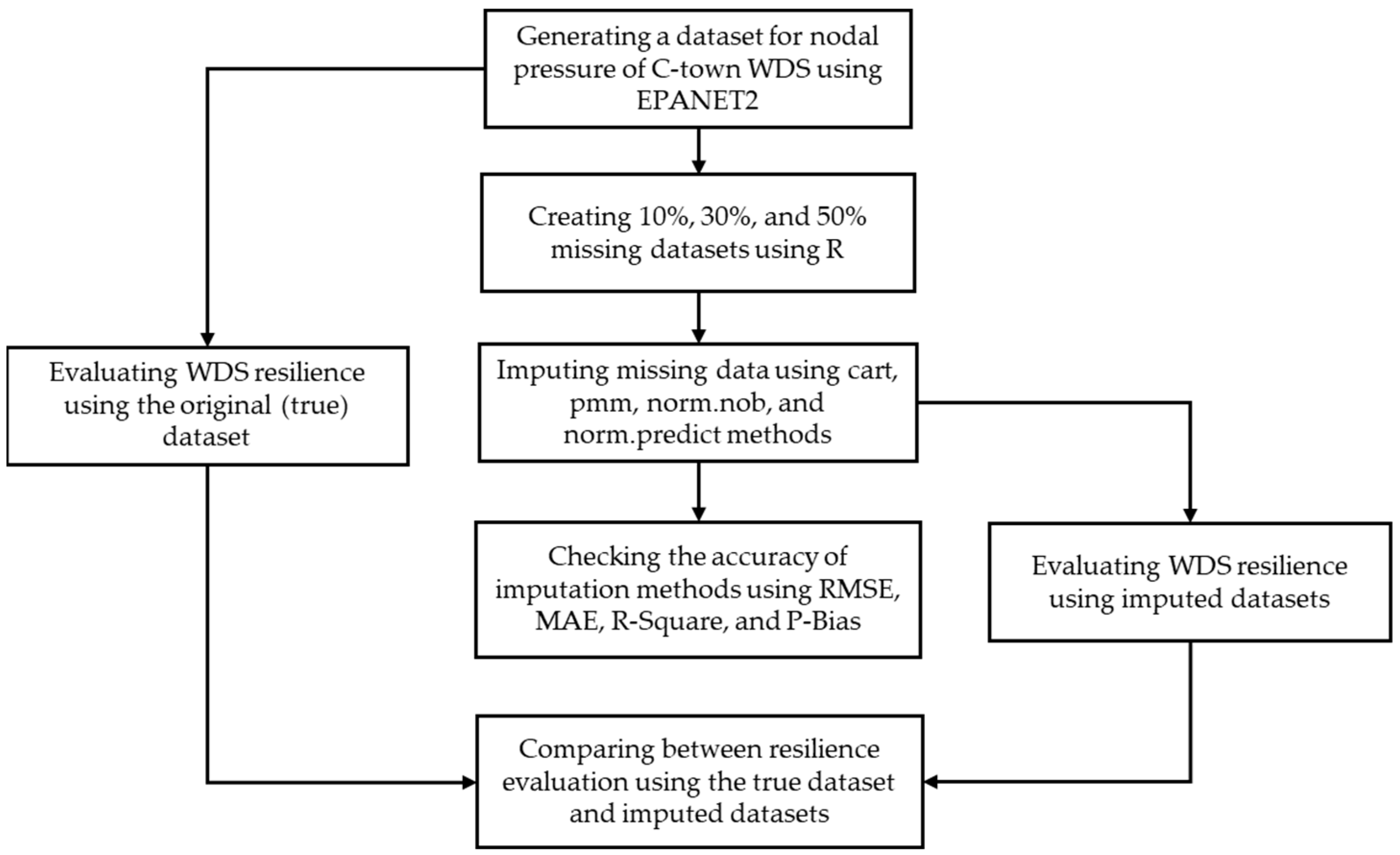
2. Methods
2.1. Creating the Datasets for Normal Operating Conditions
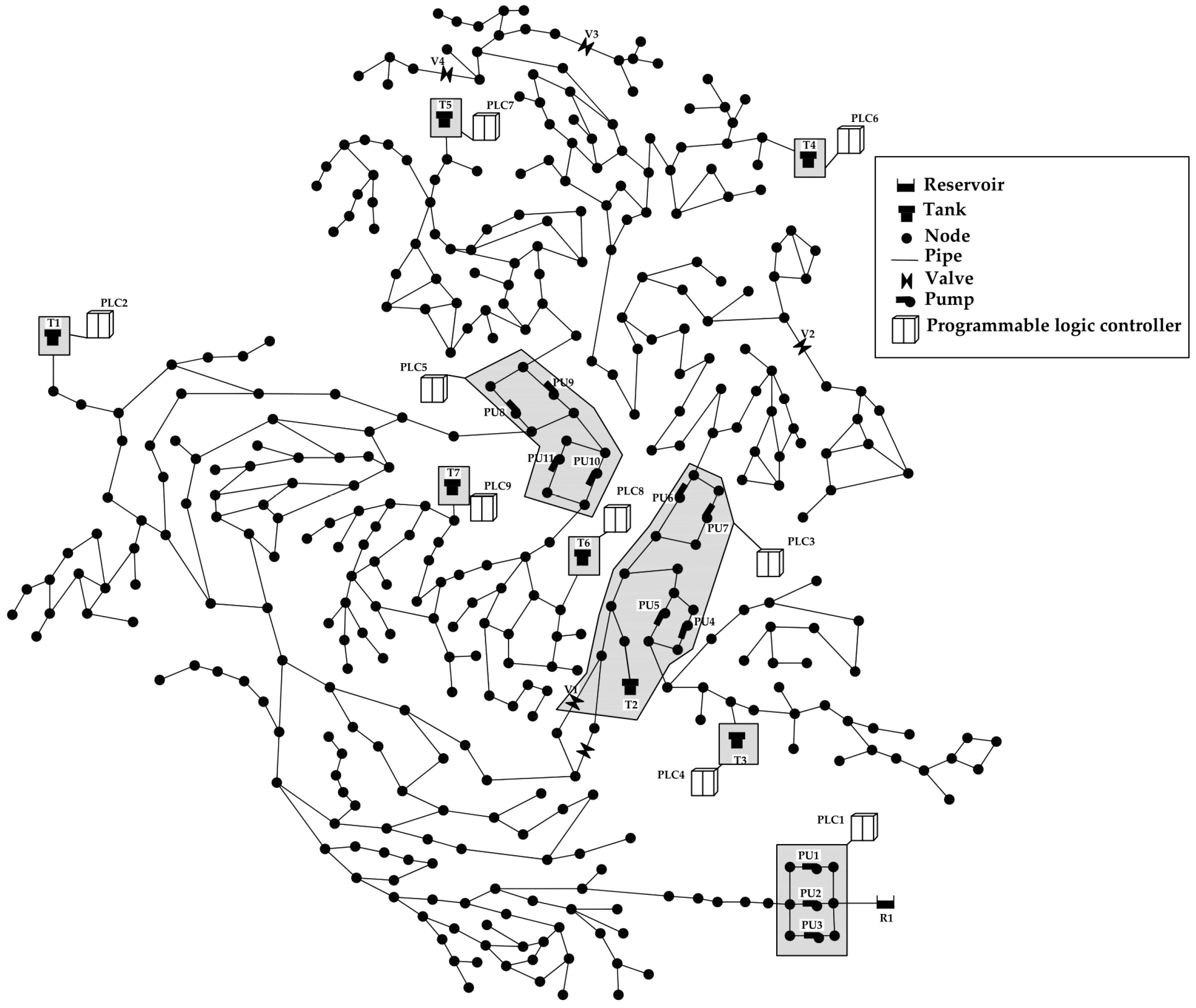
2.2. Introducing Missing Values into the Dataset with Data Missing Percentage
2.3. Imputing Missing Data Using Multiple Imputation Approaches
2.4. Checking the Accuracy of Imputation Methods
2.5. Evaluating the Resilience of the WDS with Imputed Data
3. Results and Discussion
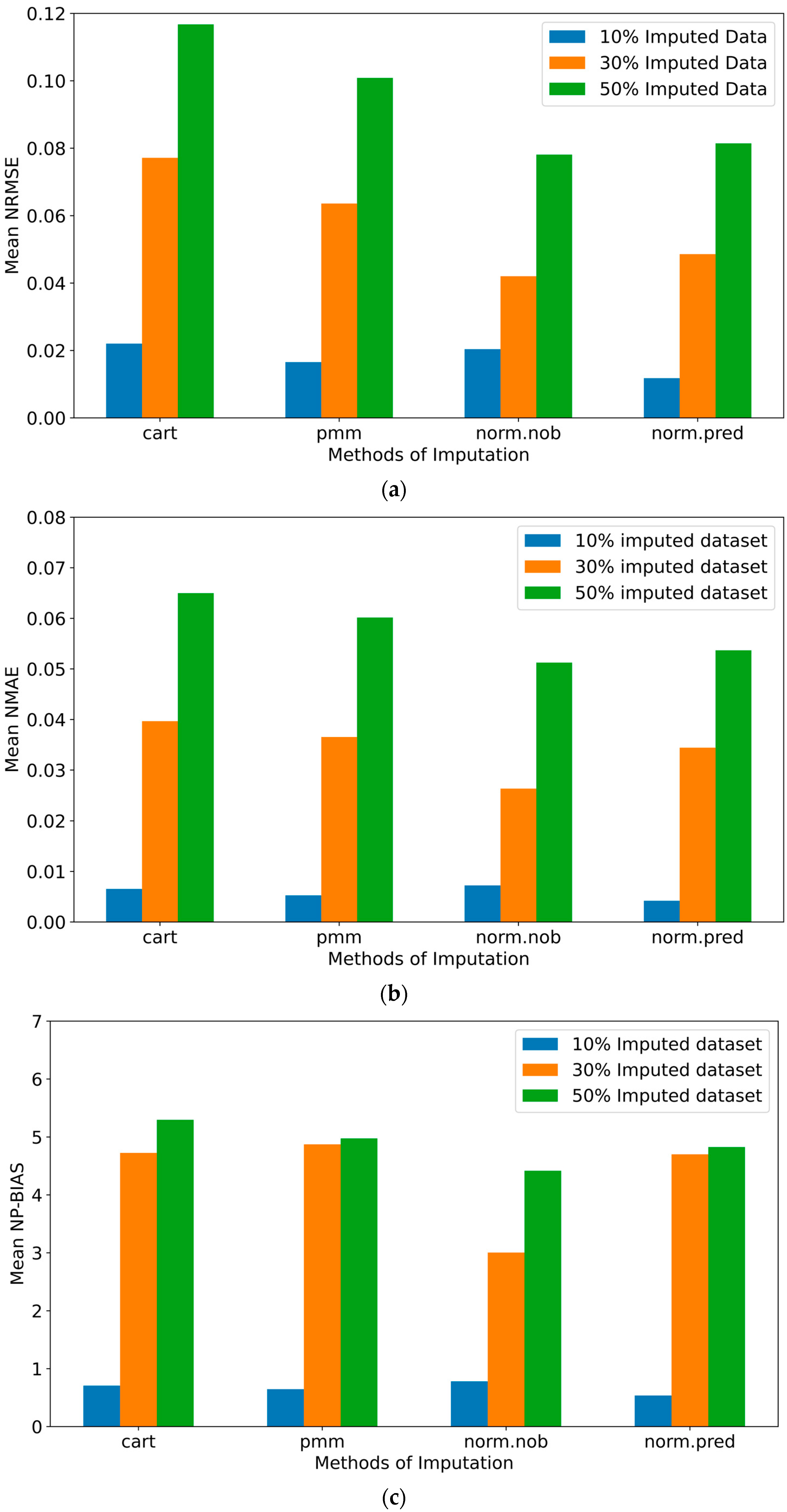
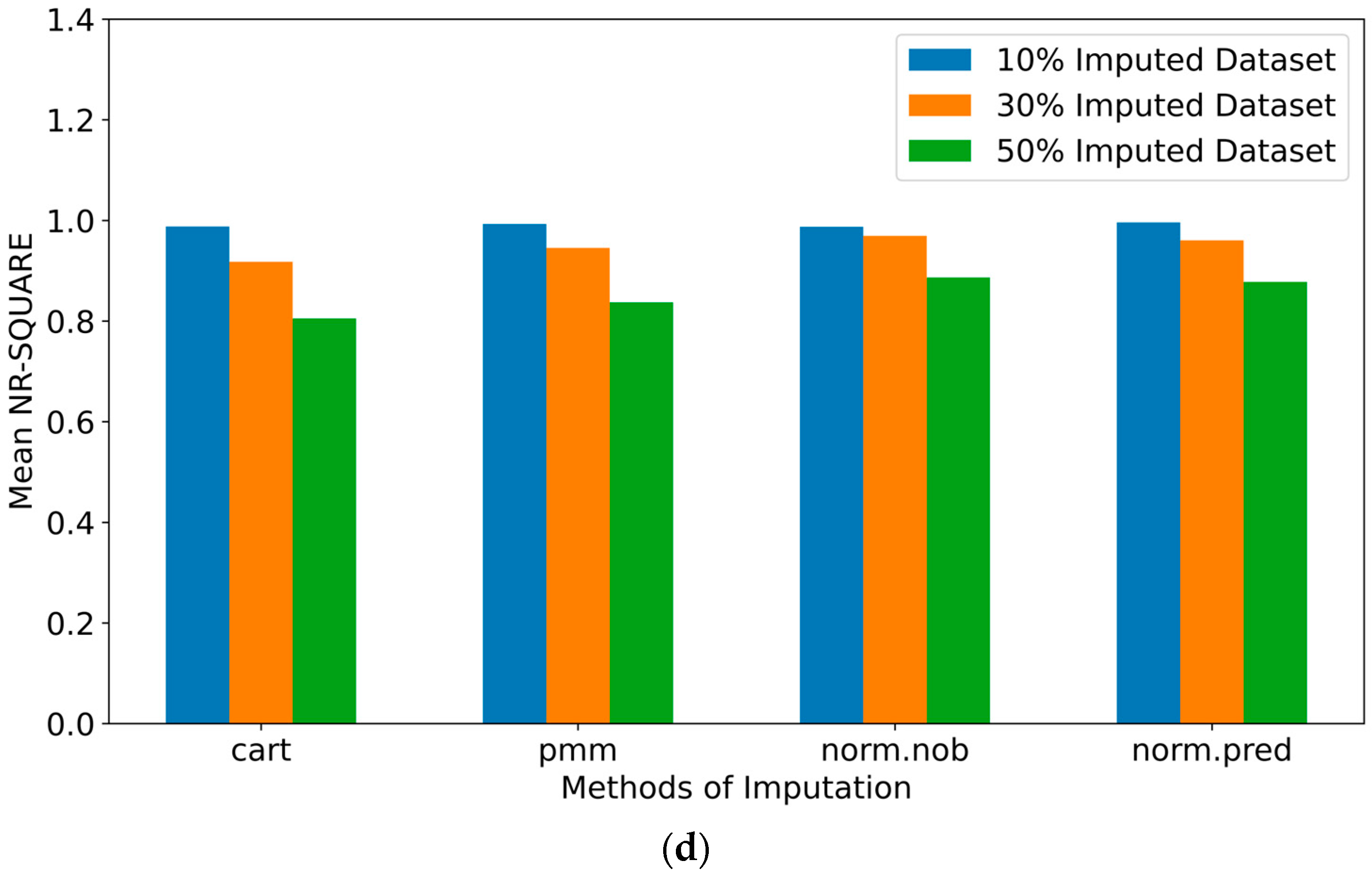
3.1. The Performance of Data Imputation Methods
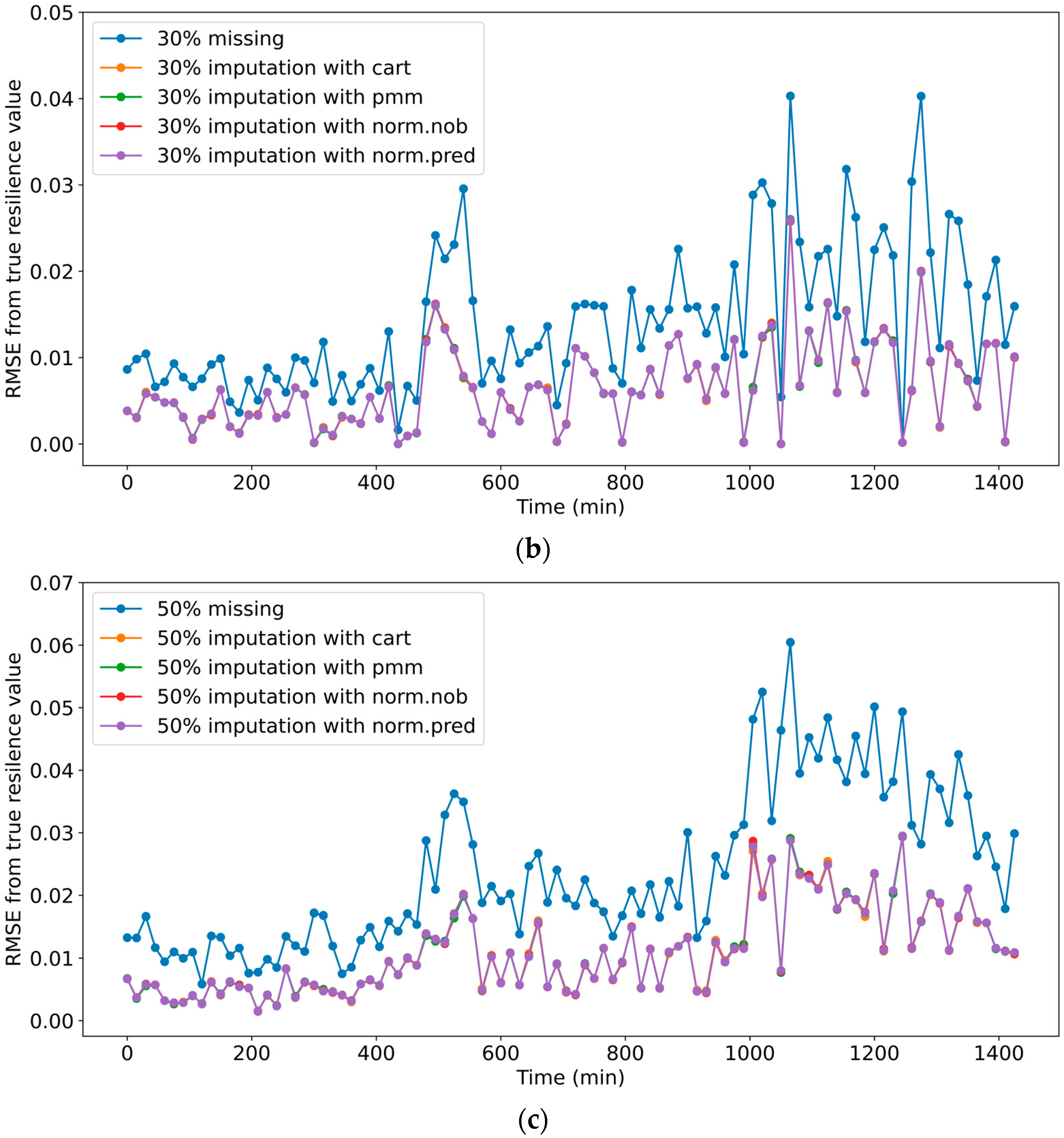
3.2. The Impacts of Imputed Data on Resilience Evaluation
4. Conclusions
- (1)
- The results showed differences in the performance of the imputation methods depending on the data missing percentages. Thus, rather than relying on a single imputation method, an ensemble set of multiple imputation methods is suggested in a decision-making framework for a more reliable imputation of missing data in a wide range of missing data percentages.
- (2)
- The investigation of the resilience evaluation highlighted that significant deviations from the true resilience values were produced in the evaluation using unimputed datasets, while the imputed datasets effectively contributed to reducing the deviations.
- (3)
- The evaluation using the unimputed datasets that included missing values suggested lower performances than the imputed datasets, as the missing data missing percentage increased.
- (4)
- Resilience evaluation using incomplete or inaccurately imputed datasets for the periods of high demand can produce significant deviations from true resilience values evaluated using true datasets.
- (5)
- The imputation of missing data can enhance the reliability of resilience-based decision-making by improving the results of a resilience evaluation.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shin, S.; Lee, S.; Judi, D.; Parvania, M.; Goharian, E.; Mcpherson, T.; Burian, S. A Systematic Review of Quantitative Resilience Measures for Water Infrastructure Systems. Water 2018, 10, 164. [Google Scholar] [CrossRef]
- Brown, C.; Boltz, F.; Freeman, S.; Tront, J.; Rodriguez, D. Resilience by Design: A Deep Uncertainty Approach for Water Systems in a Changing World. Water Secur. 2020, 9, 100051. [Google Scholar] [CrossRef]
- Schramm, E.; Felmeden, J. Towards More Resilient Water Infrastructures. In Resilient Cities 2; Springer: Dordrecht, The Netherlands, 2012; Volume 2, pp. 177–186. ISBN 978-94-007-4223-9. [Google Scholar]
- Pamidimukkala, A.; Kermanshachi, S.; Adepu, N.; Safapour, E. Resilience in Water Infrastructures: A Review of Challenges and Adoption Strategies. Sustainability 2021, 13, 2986. [Google Scholar] [CrossRef]
- Khatri, K.B. Current State and Future Direction for Building Resilient Water Resources and Infrastructure Systems. Eng 2022, 3, 175–195. [Google Scholar] [CrossRef]
- Hunaidi, O.; Chu, W.; Wang, A.; Guan, W. Detecting Leaks in Plastic Pipes. J. Am. Water Work. Assoc. 2000, 92, 82–94. [Google Scholar] [CrossRef]
- Islam, M.; Azam, S.; Shanmugam, B.; Mathur, D. A Review on Current Technologies and Future Direction of Water Leakage Detection in Water Distribution Network. IEEE Access 2022, 10, 107177–107201. [Google Scholar] [CrossRef]
- Gopi, C.; Vidyanandan, L. Sensor Network Infrastructure for AMI in Smart Grid. Procedia Technol. 2016, 24, 854–863. [Google Scholar] [CrossRef]
- Shuang, Q.; Liu, H.; Porse, E. Review of the Quantitative Resilience Methods in Water Distribution Networks. Water 2019, 11, 1189. [Google Scholar] [CrossRef]
- Krishnamurthi, R.; Kumar, A.; Gopinathan, D.; Nayyar, A.; Qureshi, B. An Overview of IoT Sensor Data Processing, Fusion, and Analysis Techniques. Sensors 2020, 20, 6076. [Google Scholar] [CrossRef]
- Clark, R.M.; Panguluri, S.; Nelson, T.D.; Wyman, R.P. Protecting Drinking Water Utilities from Cyberthreats. J. AWWA 2017, 109, 50–58. [Google Scholar] [CrossRef]
- Cahn, A. An Overview of Smart Water Networks. J. AWWA 2014, 106, 68–74. [Google Scholar] [CrossRef]
- Shin, S.; Lee, S.; Burian, S.; Judi, D.; Mcpherson, T. Evaluating Resilience of Water Distribution Networks to Operational Failures from Cyber-Physical Attacks. J. Environ. Eng. 2020, 146, 04020003. [Google Scholar] [CrossRef]
- Zanfei, A.; Menapace, A.; Brentan, B.M.; Righetti, M. How Does Missing Data Imputation Affect the Forecasting of Urban Water Demand? J. Water Resour. Plan. Manag. 2022, 148, 04022060. [Google Scholar] [CrossRef]
- Hernández-Pereira, E.M.; Álvarez-Estévez, D.; Moret-Bonillo, V. Automatic Classification of Respiratory Patterns Involving Missing Data Imputation Techniques. Biosyst. Eng. 2015, 138, 65–76. [Google Scholar] [CrossRef]
- Rodríguez, R.; Pastorini, M.; Etcheverry, L.; Chreties, C.; Fossati, M.; Castro, A.; Gorgoglione, A. Water-Quality Data Imputation with a High Percentage of Missing Values: A Machine Learning Approach. Sustainability 2021, 13, 6318. [Google Scholar] [CrossRef]
- Zhang, K.; Zhou, F.; Wu, L.; Xie, N.; He, Z. Semantic Understanding and Prompt Engineering for Large-Scale Traffic Data Imputation. Inf. Fusion 2024, 102, 102038. [Google Scholar] [CrossRef]
- Gómez-Carracedo, M.P.; Andrade, J.M.; López-Mahía, P.; Muniategui, S.; Prada, D. A Practical Comparison of Single and Multiple Imputation Methods to Handle Complex Missing Data in Air Quality Datasets. Chemom. Intell. Lab. Syst. 2014, 134, 23–33. [Google Scholar] [CrossRef]
- Rahman, M.M.; Davis, D.N. Machine Learning-Based Missing Value Imputation Method for Clinical Datasets. In IAENG Transactions on Engineering Technologies: Special Volume of the World Congress on Engineering 2012; Yang, G.-C., Ao, S., Gelman, L., Eds.; Springer: Dordrecht, The Netherlands, 2013; pp. 245–257. ISBN 978-94-007-6190-2. [Google Scholar]
- Khan, S.I.; Hoque, A.S.M.L. SICE: An Improved Missing Data Imputation Technique. J. Big Data 2020, 7, 37. [Google Scholar] [CrossRef]
- Aguilera, H.; Guardiola-Albert, C.; Serrano-Hidalgo, C. Estimating Extremely Large Amounts of Missing Precipitation Data. J. Hydroinform. 2020, 22, 578–592. [Google Scholar] [CrossRef]
- Lin, W.-C.; Tsai, C.-F. Missing Value Imputation: A Review and Analysis of the Literature (2006–2017). Artif. Intell. Rev. 2020, 53, 1487–1509. [Google Scholar] [CrossRef]
- Pan, S.; Chen, S. Empirical Comparison of Imputation Methods for Multivariate Missing Data in Public Health. Int. J. Environ. Res. Public Health 2023, 20, 1524. [Google Scholar] [CrossRef]
- Little, R.J.A.; Rubin, D.B. Single Imputation Methods. In Statistical Analysis with Missing Data; Wiley Series in Probability and Statistics; John and Wiley and Sons: Hoboken, NJ, USA, 2014; pp. 59–74. ISBN 978-1-119-01356-3. [Google Scholar]
- Graham, J.W.; Van Horn, M.L.; Taylor, B.J. Dealing with the Problem of Having Too Many Variables in the Imputation Model. In Missing Data; Springer: New York, NY, USA, 2012; pp. 213–228. ISBN 978-1-4614-4017-8. [Google Scholar]
- Rubin, D. An Overview of Multiple Imputation. In Proceedings of the Survey Research Methods Section; American Statistical Association: Alexandria, VA, USA, 1988. [Google Scholar]
- Schafer, J.L.; Olsen, M.K. Multiple Imputation for Multivariate Missing-Data Problems: A Data Analyst’s Perspective. Multivar. Behav. Res. 1998, 33, 545–571. [Google Scholar] [CrossRef]
- Honaker, J.; King, G.; Blackwell, M. Amelia II: A Program for Missing Data. J. Stat. Softw. 2011, 45, 1–47. [Google Scholar] [CrossRef]
- Templ, M.; Kowarik, A.; Filzmoser, P. Iterative Stepwise Regression Imputation Using Standard and Robust Methods. Comput. Stat. Data Anal. 2011, 55, 2793–2806. [Google Scholar] [CrossRef]
- Harder, A.A.; Olbricht, G.R.; Ekuma, G.; Hier, D.B.; Obafemi-Ajayi, T. Multiple Imputation for Robust Cluster Analysis to Address Missingness in Medical Data. IEEE Access 2024, 12, 42974–42991. [Google Scholar] [CrossRef]
- Nguyen, Q.; Matthews, G.J. Filling the Gaps: A Multiple Imputation Approach to Estimating Aging Curves in Baseball. J. Sports Anal. 2024, 10, 77–85. [Google Scholar] [CrossRef]
- Ni, D.; Leonard, J.D.; Guin, A.; Feng, C. Multiple Imputation Scheme for Overcoming the Missing Values and Variability Issues in ITS Data. J. Transp. Eng. 2005, 131, 931–938. [Google Scholar] [CrossRef]
- Kofman, P.; Sharpe, I.G. Using Multiple Imputation in the Analysis of Incomplete Observations in Finance. J. Financ. Econom. 2003, 1, 216–249. [Google Scholar] [CrossRef]
- Oriani, F.; Borghi, A.; Straubhaar, J.; Mariethoz, G.; Renard, P. Missing Data Simulation inside Flow Rate Time-Series Using Multiple-Point Statistics. Environ. Model. Softw. 2016, 86, 264–276. [Google Scholar] [CrossRef]
- Nieh, C.; Dorevitch, S.; Liu, L.C.; Jones, R.M. Evaluation of Imputation Methods for Microbial Surface Water Quality Studies. Environ. Sci. Process. Impacts 2014, 16, 1145–1153. [Google Scholar] [CrossRef]
- Evans, S.; Williams, G.P.; Jones, N.L.; Ames, D.P.; Nelson, E.J. Exploiting Earth Observation Data to Impute Groundwater Level Measurements with an Extreme Learning Machine. Remote Sens. 2020, 12, 2044. [Google Scholar] [CrossRef]
- Sarma, R.; Singh, S.K. A Comparative Study of Data-Driven Models for Groundwater Level Forecasting. Water Resour Manag. 2022, 36, 2741–2756. [Google Scholar] [CrossRef]
- Pournaras, E.; Taormina, R.; Thapa, M.; Galelli, S.; Palleti, V.; Kooij, R. Cascading Failures in Interconnected Power-to-Water Networks. ACM SIGMETRICS Perform. Eval. Rev. 2019, 47, 16–20. [Google Scholar] [CrossRef]
- Ostfeld, A.; Salomons, E.; Ormsbee, L.; Uber, J.G.; Bros, C.M.; Kalungi, P.; Burd, R.; Zazula-Coetzee, B.; Belrain, T.; Kang, D.; et al. Battle of the Water Calibration Networks. J. Water Resour. Plan. Manag. 2012, 138, 523–532. [Google Scholar] [CrossRef]
- Arunkumar, M.; Mariappan, V.N. Water Demand Analysis of Municipal Water Supply Using Epanet Software. Int. J. Appl. Bioeng. 2011, 5, 9–19. [Google Scholar]
- Taormina, R.; Galelli, S.; Tippenhauer, N.O.; Salomons, E.; Ostfeld, A. Characterizing Cyber-Physical Attacks on Water Distribution Systems. J. Water Resour. Plan. Manag. 2017, 143, 04017009. [Google Scholar] [CrossRef]
- Umar, N.; Gray, A. Comparing Single and Multiple Imputation Approaches for Missing Values in Univariate and Multivariate Water Level Data. Water 2023, 15, 1519. [Google Scholar] [CrossRef]
- Thurow, M.; Dumpert, F.; Ramosaj, B.; Pauly, M. Imputing Missings in Official Statistics for General Tasks—Our Vote for Distributional Accuracy. Stat. J. IAOS 2021, 37, 1379–1390. [Google Scholar] [CrossRef]
- Kaplan, D.; Yavuz, S. An Approach to Addressing Multiple Imputation Model Uncertainty Using Bayesian Model Averaging. Multivar. Behav. Res. 2020, 55, 553–567. [Google Scholar] [CrossRef]
- Zhang, Z. Multiple Imputation with Multivariate Imputation by Chained Equation (MICE) Package. Ann. Transl. Med. 2016, 4, 30. [Google Scholar] [CrossRef]
- Bartlett, J.W.; Seaman, S.R.; White, I.R.; Carpenter, J.R. Multiple Imputation of Covariates by Fully Conditional Specification: Accommodating the Substantive Model. Stat. Methods Med. Res. 2015, 24, 462–487. [Google Scholar] [CrossRef]
- Van Buuren, S.; Groothuis-Oudshoorn, K. Mice: Multivariate Imputation by Chained Equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar] [CrossRef]
- Burgette, L.F.; Reiter, J.P. Multiple Imputation for Missing Data via Sequential Regression Trees. Am. J. Epidemiol. 2010, 172, 1070–1076. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Taylor & Francis: New York, NY, USA, 2017; ISBN 9781315139470. [Google Scholar]
- Yang, S.; Kim, J.K. Predictive Mean Matching Imputation in Survey Sampling. arXiv 2018, arXiv:1703.10256. [Google Scholar]
- Seyyed Nezhad Golkhatmi, N.; Farzandi, M. Enhancing Rainfall Data Consistency and Completeness: A Spatiotemporal Quality Control Approach and Missing Data Reconstruction Using MICE on Large Precipitation Datasets. Water Resour. Manag. 2024, 38, 815–833. [Google Scholar] [CrossRef]
- Kim, H.-R.; Soh, H.Y.; Kwak, M.-T.; Han, S.-H. Machine Learning and Multiple Imputation Approach to Predict Chlorophyll-a Concentration in the Coastal Zone of Korea. Water 2022, 14, 1862. [Google Scholar] [CrossRef]
- Jadhav, A.; Pramod, D.; Ramanathan, K. Comparison of Performance of Data Imputation Methods for Numeric Dataset. Appl. Artif. Intell. 2019, 33, 913–933. [Google Scholar] [CrossRef]
- Loh, W.S.; Ling, L.; Chin, R.J.; Lai, S.H.; Loo, K.K.; Seah, C.S. A Comparative Analysis of Missing Data Imputation Techniques on Sedimentation Data. Ain Shams Eng. J. 2024, 15, 102717. [Google Scholar] [CrossRef]
- Todini, E. Looped Water Distribution Networks Design Using a Resilience Index Based Heuristic Approach. Urban Water 2000, 2, 115–122. [Google Scholar] [CrossRef]
- Ding, Y.; Street, W.N.; Tong, L.; Wang, S. An Ensemble Method for Data Imputation. In Proceedings of the 2019 IEEE International Conference on Healthcare Informatics (ICHI), Xi’an, China, 10–13 June 2019; pp. 1–3. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Imputation Method | 10% Imputation | 30% Imputation | 50% Imputation | Rank by Mean | Rank by Mode |
|---|---|---|---|---|---|
| cart | 4 | 4 | 4 | 4.0 | 4 |
| pmm | 2 | 3 | 3 | 2.7 | 3 |
| norm.nob | 3 | 1 | 1 | 1.7 | 1 |
| norm.pred | 1 | 2 | 2 | 1.7 | 2 |
| Alternative Hypothesis: | Wt = 0.8122 | Kendall Chi-Squared = 12.18 | p-value = 0.00678 | ||
| Imputation Method | 10% Imputation | 30% Imputation | 50% Imputation | Rank by Mean | Rank by Mode |
|---|---|---|---|---|---|
| cart | 3 | 4 | 4 | 3.7 | 4 |
| pmm | 2 | 3 | 3 | 2.7 | 3 |
| norm.nob | 4 | 1 | 1 | 2.0 | 1 |
| norm.pred | 1 | 2 | 2 | 1.7 | 2 |
| Alternative Hypothesis: | Wt = 0.616 | Kendall Chi-Squared = 9.24 | p-value = 0.02626 | ||
| Imputation Method | 10% Imputation | 30% Imputation | 50% Imputation | Rank by Mean | Rank by Mode |
|---|---|---|---|---|---|
| cart | 4 | 3 | 4 | 3.7 | 4 |
| pmm | 2 | 4 | 3 | 3.0 | 3 |
| norm.nob | 3 | 1 | 1 | 1.7 | 1 |
| norm.pred | 1 | 2 | 2 | 1.7 | 2 |
| Alternative Hypothesis: | Wt = 0.7306 | Kendall Chi-Squared = 10.96 | p-value = 0.01195 | ||
| Imputation Method | 10% Imputation | 30% Imputation | 50% Imputation | Rank by Mean | Rank by Mode |
|---|---|---|---|---|---|
| cart | 3 | 4 | 4 | 3.7 | 4 |
| pmm | 2 | 3 | 3 | 2.7 | 3 |
| norm.nob | 4 | 1 | 1 | 2.0 | 1 |
| norm.pred | 1 | 2 | 2 | 1.7 | 2 |
| Alternative Hypothesis: | Wt = 0.616 | Kendall Chi-Squared = 9.24 | p-value = 0.02626 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghimire, A.B.; Magar, B.A.; Parajuli, U.; Shin, S. Impacts of Missing Data Imputation on Resilience Evaluation for Water Distribution System. Urban Sci. 2024, 8, 177. https://doi.org/10.3390/urbansci8040177
Ghimire AB, Magar BA, Parajuli U, Shin S. Impacts of Missing Data Imputation on Resilience Evaluation for Water Distribution System. Urban Science. 2024; 8(4):177. https://doi.org/10.3390/urbansci8040177
Chicago/Turabian StyleGhimire, Amrit Babu, Binod Ale Magar, Utsav Parajuli, and Sangmin Shin. 2024. "Impacts of Missing Data Imputation on Resilience Evaluation for Water Distribution System" Urban Science 8, no. 4: 177. https://doi.org/10.3390/urbansci8040177
APA StyleGhimire, A. B., Magar, B. A., Parajuli, U., & Shin, S. (2024). Impacts of Missing Data Imputation on Resilience Evaluation for Water Distribution System. Urban Science, 8(4), 177. https://doi.org/10.3390/urbansci8040177