Correcting Bias in Crowdsourced Data to Map Bicycle Ridership of All Bicyclists


Abstract
1. Introduction
2. Materials and Methods
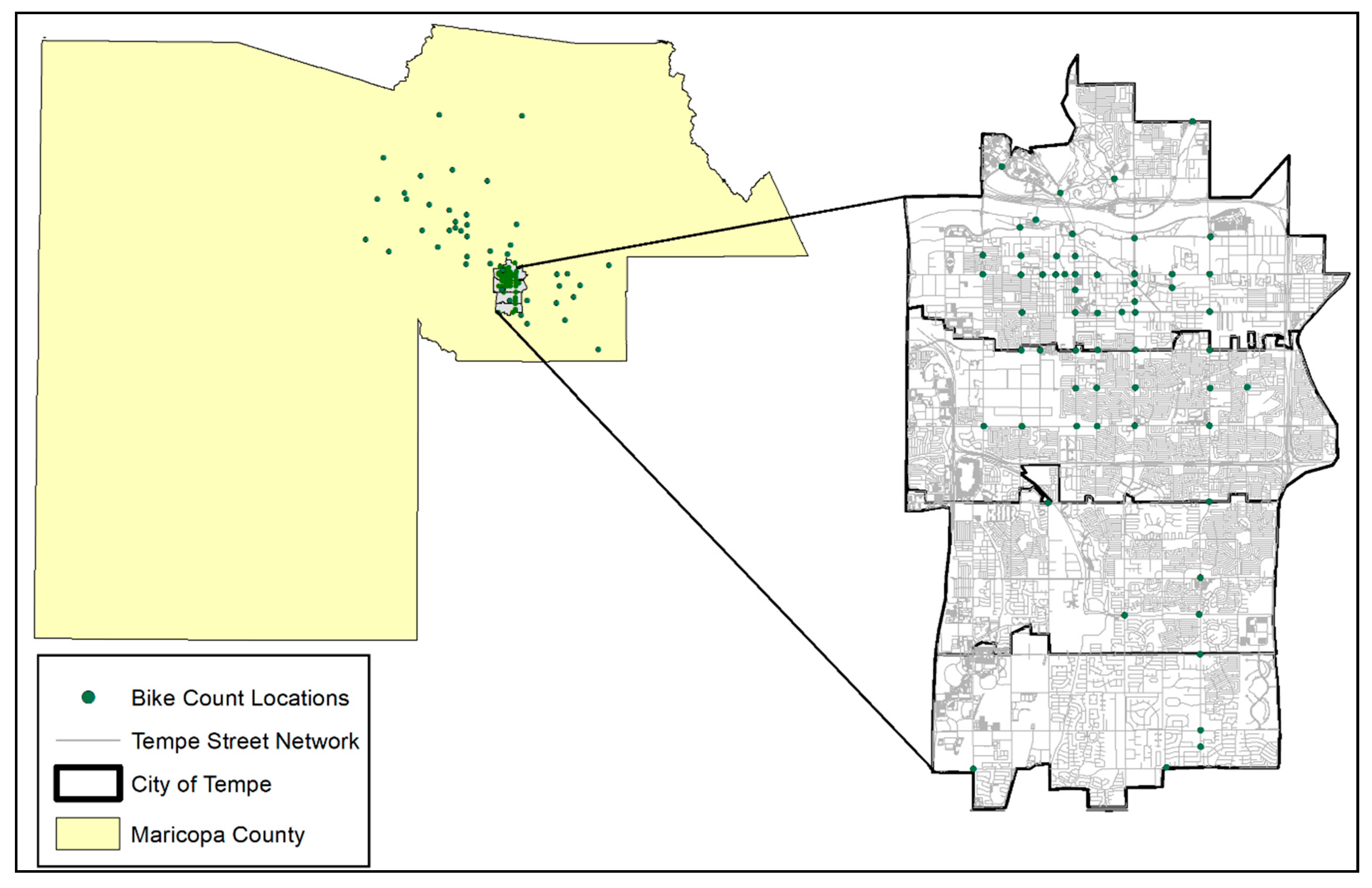
2.1. Study Area
2.2. Data Sources
2.2.1. Official Bicycle Counts
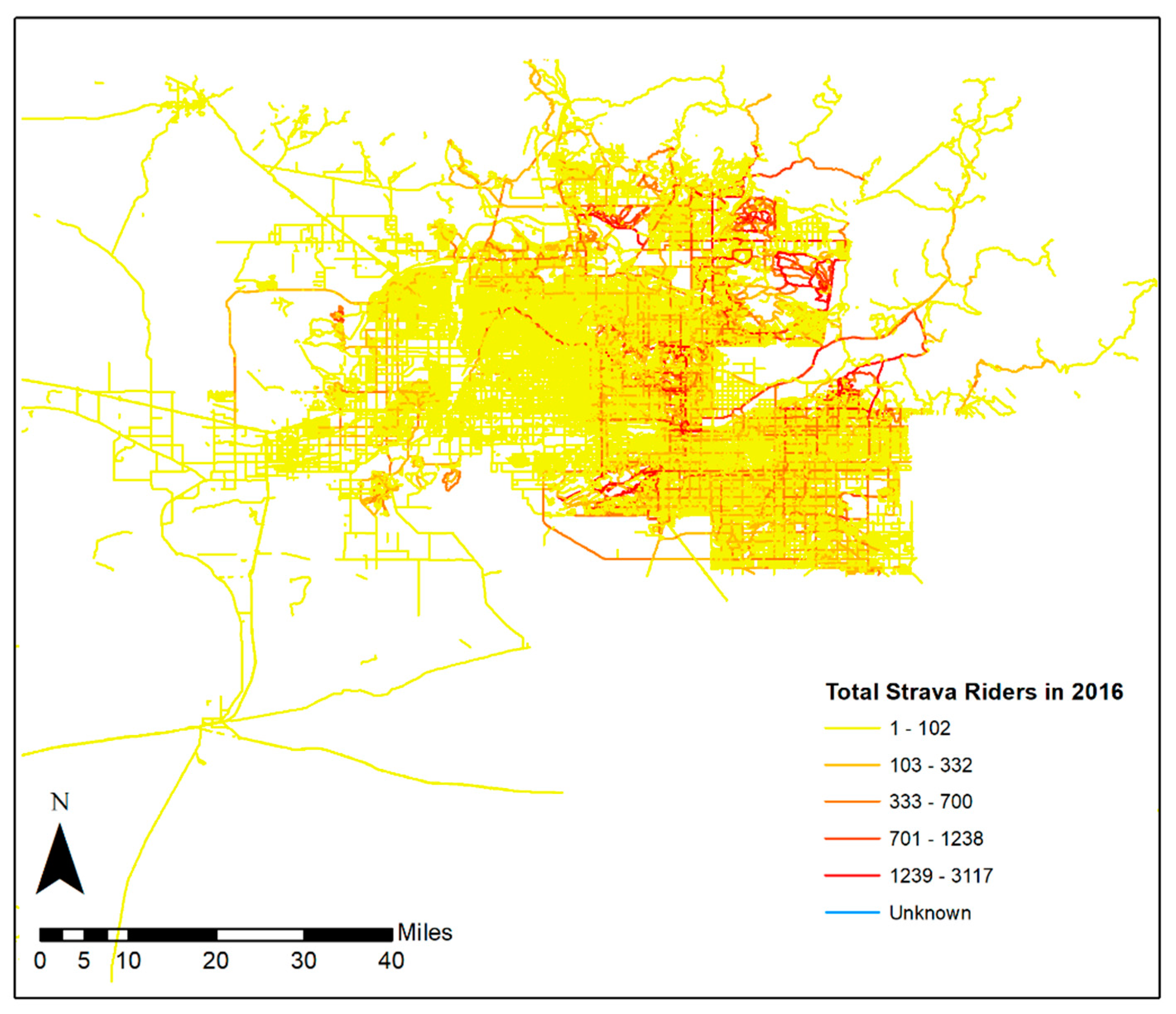
2.2.2. Crowdsourced Data from Fitness App
2.2.3. Explanatory Geographical Covariates
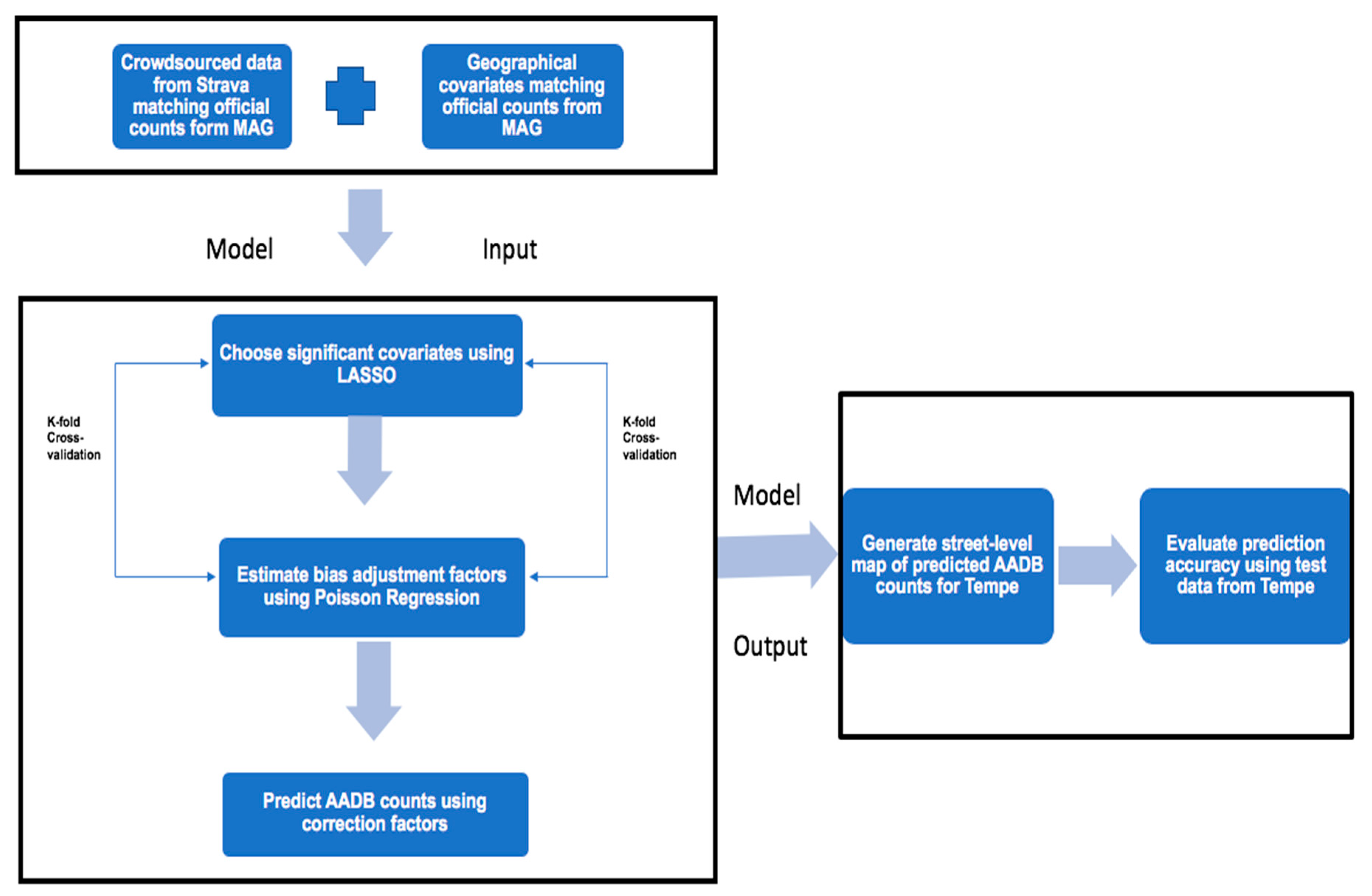
2.3. Model Design and Analysis
- (i)
- The relationship between the Strava ridership data and official counts across 44 locations in Maricopa County (train data) was quantified using ordinary least squares regression.
- (ii)
- Additional geographic data from multiple disparate sources (Table 1) were then aligned, controlling for variable multicollinearity, with ridership data from Strava, and a variable selection technique—LASSO—was used to identify the most significant geographical variables from all the listed variables in Table 1.
- (iii)
- A generalized linear model with a Poisson distribution was fitted using the observed AADB counts as a dependent variable and the Strava ridership data along with the geographical covariates selected by LASSO, which were outcomes of step (ii), at comparable spatial and temporal scales as independent variables. Using this model, we corrected the bias in the crowdsourced bicycle ridership data by age and ability across Maricopa County using a 10-fold cross-validation across the 44 locations.
- (iv)
- The coefficients of the model fitted in step (iii) were then used to explain the variation in the AADB counts and the bias-corrected predictions.
- (v)
- The best-fitted model from step (iii) was cross-validated, which is a technique used to test the model fit by holding out 10% of the data and training the model with 90% of the data in multiple iterations, and the model with least cross-validation error was used to predict the observed AADB at unknown locations and to create a street-level map of bias-corrected AADB counts in Tempe.
- (vi)
- Finally, the prediction accuracy of the model, shown in step (iii), was evaluated in Tempe across 60 locations where ground truth data for the AADB counts were available (test data).
2.3.1. Comparison of Official and Crowdsourced Bicyclist Counts
2.3.2. Variable Selection for Bias Correction Using LASSO
2.3.3. Estimating Bias-Corrected Bicycle Volumes from a Crowdsourced Fitness App and Geographical Covariates
- = the AADB counts at site i
- = vector of parameters for count site i
- = vector of the observed geographical covariates for count site i.
2.3.4. Predicting Ridership Using Poisson Model Coefficients
2.3.5. Mapping Predicted Bicyclist Counts
2.3.6. Bias Correction Model Prediction Accuracy
3. Results
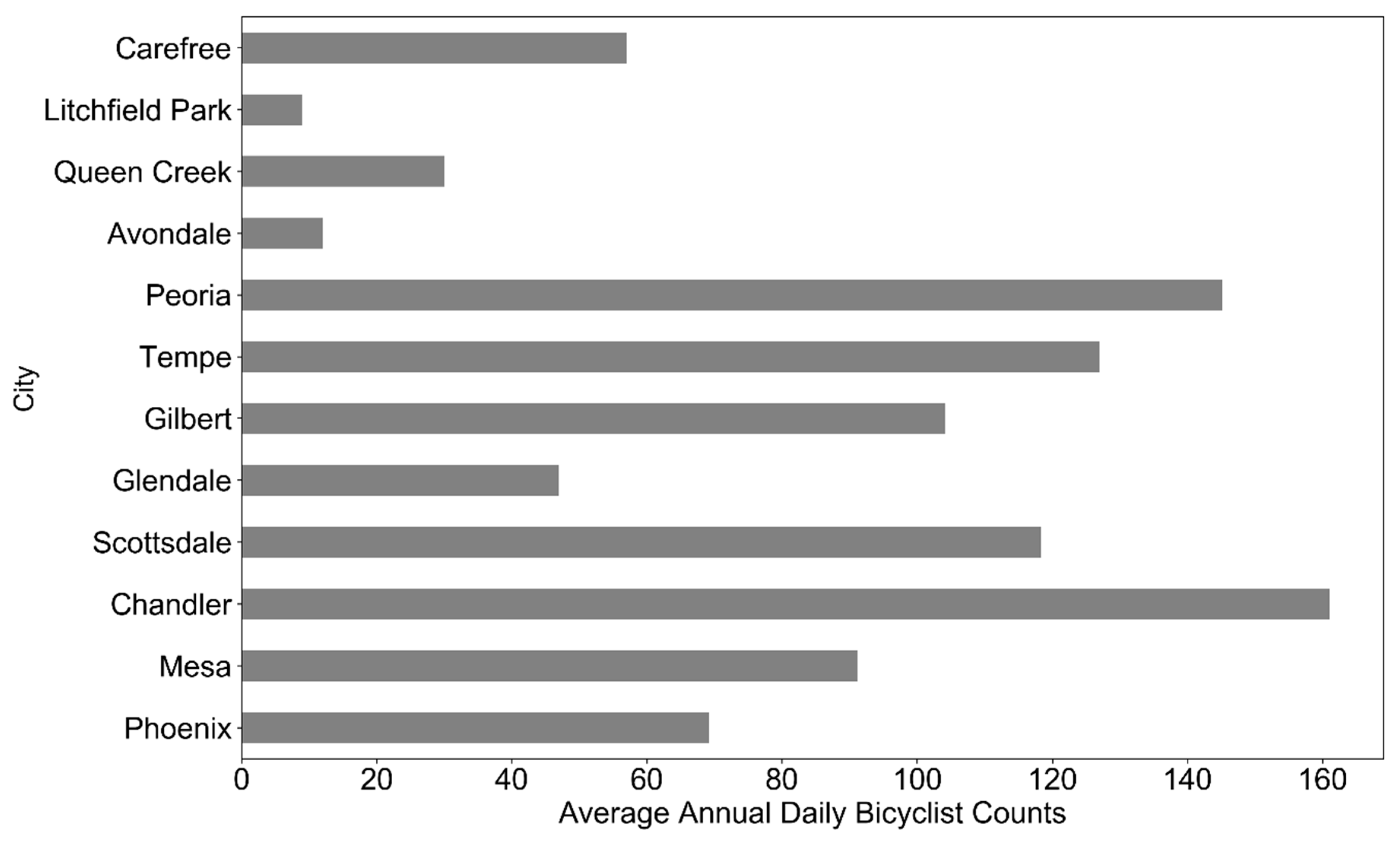
3.1. Strava and the MAG Count Comparisons
3.2. Variables Selected for Correcting Bias Using LASSO
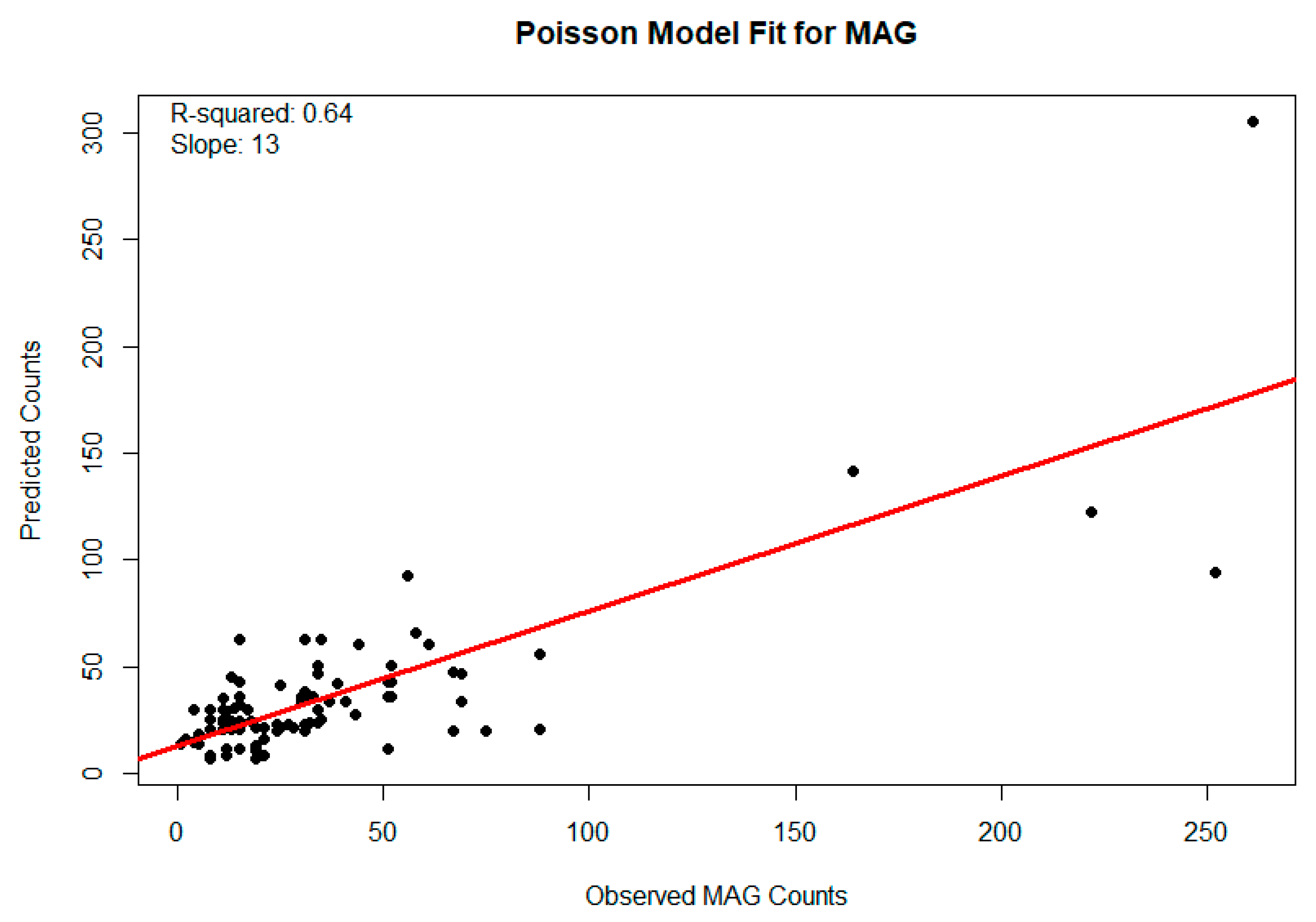
3.3. Poisson Model Results for Bias-Corrected Bicyclist Volumes
3.4. Predicted Ridership Estimates Using Poisson Model Coefficients
3.5. Mapping Predicted Ridership Volumes in Tempe
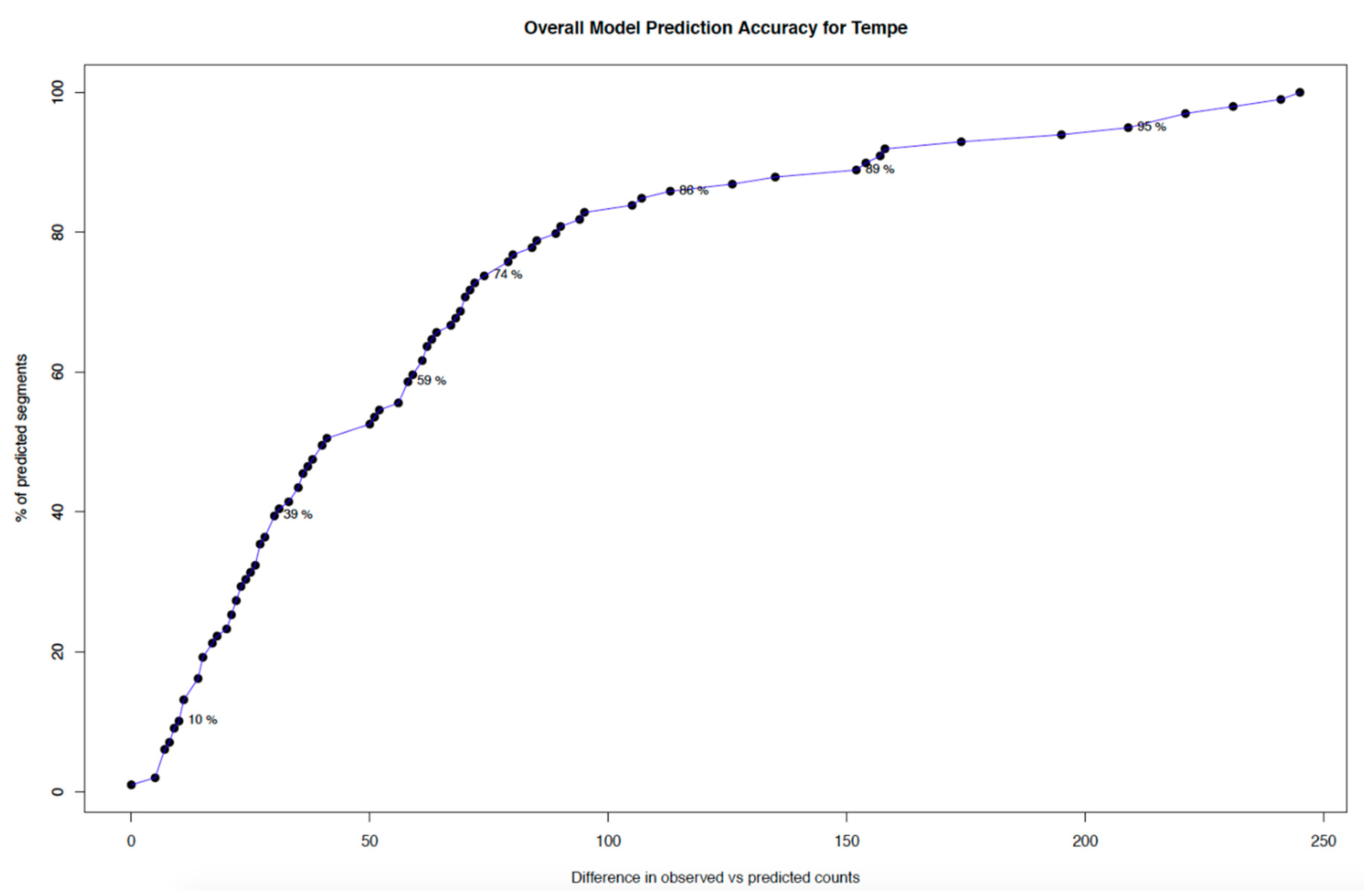
3.6. Prediction Accuracy of the Bias Correction Model in Tempe
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| MAG | Maricopa Association of Governments |
| TBAG | Tempe Bicycle Action Group |
| LASSO | Least absolute shrinkage and selection operator |
| PANDAS | Python data analysis library |
| AADB | Average annual daily bicyclists |
| VIF | Variance Inflation Factor |
References
- Sallis, J.F.; Floyd, M.F.; Rodríguez, D.A.; Saelens, B.E. Role of built environments in physical activity, obesity, and cardiovascular disease. Circulation 2012, 125, 729–737. [Google Scholar] [CrossRef]
- Colberg, S.R.; Sigal, R.J.; Fernhall, B.; Regensteiner, J.G.; Blissmer, B.J.; Rubin, R.R.; Chasan-Taber, L.; Albright, A.L.; Braun, B.; American College of Sports Medicine; et al. Exercise and type 2 diabetes: The American College of Sports Medicine and the American Diabetes Association: joint position statement executive summary. Diabetes Care 2010, 33, 2692–2696. [Google Scholar] [CrossRef] [PubMed]
- Kushi, L.H.; Doyle, C.; McCullough, M.; Rock, C.L.; Demark-Wahnefried, W.; Bandera, E.V.; Gapstur, S.; Patel, A.V.; Andrews, K.; Gansler, T.; et al. American Cancer Society guidelines on nutrition and physical activity for cancer prevention: Reducing the risk of cancer with healthy food choices and physical activity. CA Cancer J. Clin. 2012, 62, 30–67. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization (WHO). Global Recommendations on Physical Activity for Health: World Health Organization; World Health Organization (WHO): Geneve, Switzerland, 2010. [Google Scholar]
- Mansfield, T.J.; Gibson, J.M. Estimating Active Transportation Behaviors to Support Health Impact Assessment in the United States. Front. Public Health 2016, 4, 591. [Google Scholar] [CrossRef] [PubMed]
- Lyons, W.; Peckett, H.; Morse, L.; Khurana, M.; Nash, L. Metropolitan Area Transportation Planning for Healthy Communities; No. DOT-VNTSC-FHWA-13-01; John A. Volpe National Transportation Systems Center: Boston, MA, USA, 2012.
- Larsen, J.; Patterson, Z.; El-Geneidy, A. Build It. But Where? The Use of Geographic Information Systems in Identifying Locations for New Cycling Infrastructure. Int. J. Sustain. Transp. 2013, 7, 299–317. [Google Scholar] [CrossRef]
- Lovelace, R.; Goodman, A.; Aldred, R.; Berkoff, N.; Abbas, A.; Woodcock, J. The Propensity to Cycle Tool: An open source online system for sustainable transport planning. J. Transport Land Use 2017, 10, 505–528. [Google Scholar] [CrossRef]
- Ryus, P.; Ferguson, E.; Laustsen, K.M.; Schneider, R.J.; Proulx, F.R.; Hull, T.; Miranda-Moreno, L. National Academies of Sciences, Engineering, and Medicine; Transportation Research Board; National Cooperative Highway Research Program. In Methods and Technologies for Pedestrian and Bicycle Volume Data Collection; The National Academies Press: Washington, DC, USA, 2014. [Google Scholar]
- Griswold, J.B.; Medury, A.; Schneider, R.J.; Information, R. Pilot Models for Estimating Bicycle Intersection Volumes. Transp. Res. Rec. J. Transp. Res. Board 2011, 2247, 1–7. [Google Scholar] [CrossRef]
- Nordback, K.; Marshall, W.E.; Janson, B.N.; Stolz, E. Estimating annual average daily bicyclists: Error and accuracy. Transp. Res. Rec. J. Transp. Res. Board 2013, 2339, 90–97. [Google Scholar] [CrossRef]
- Griffin, G.; Nordback, K.; Götschi, T.; Stolz, E.; Kothuri, S. Monitoring Bicyclist and Pedestrian Travel and Behavior: Current Research and Practice. Transportation Research Circular E-C18. 2014. Available online: http://www.trb.org/Publications/Blurbs/170452.aspx (accessed on 31 May 2018).
- El Esawey, M.; Mosa, A.I.; Nasr, K. Estimation of daily bicycle traffic volumes using sparse data. Comput. Environ. Urban Syst. 2015, 54, 195–203. [Google Scholar] [CrossRef]
- Shen, L.; Stopher, P.R. Review of GPS Travel Survey and GPS Data-Processing Methods. Transp. Rev. 2014, 34, 316–334. [Google Scholar] [CrossRef]
- Griffin, G.P.; Jiao, J. Where does bicycling for health happen? Analysing volunteered geographic information through place and plexus. J. Transp. Health 2015, 2, 238–247. [Google Scholar] [CrossRef]
- Heesch, K.C.; Langdon, M. The usefulness of GPS bicycle tracking data for evaluating the impact of infrastructure change on cycling behaviour. Health Promot. J. Aust. 2016, 27, 222–229. [Google Scholar] [CrossRef]
- Bíl, M.; Andrášik, R.; Kubeček, J. How comfortable are your cycling tracks? A new method for objective bicycle vibration measurement. Transp. Res. Part C: Emerg. Technol. 2015, 56, 415–425. [Google Scholar] [CrossRef]
- Winters, M.; Brauer, M.; Setton, E.M.; Teschke, K. Built Environment Influences on Healthy Transportation Choices: Bicycling versus Driving. J. Urban Health 2010, 87, 969–993. [Google Scholar] [CrossRef]
- Nelson, T.A.; DenOuden, T.; Jestico, B.; Laberee, K.; Winters, M. BikeMaps.org: A Global Tool for Collision and Near Miss Mapping. Front. Public Health 2015, 3, 53. [Google Scholar] [CrossRef]
- Jestico, B.; Nelson, T.; Winters, M. Mapping ridership using crowdsourced cycling data. J. Geogr. 2016, 52, 90–97. [Google Scholar] [CrossRef]
- Strava.com. Strava Metro. Strava, April 2018. Available online: https://metro.strava.com/ (accessed on 28 April 2018).
- Lieske, S.N.; Leao, S.Z.; Conrow, L.; Pettit, C.J. Validating Mobile Phone Generated Bicycle Route Data in Support of Active Transportation. In Proceedings of the SOAC 2017—State of Australian Cities (SOAC) National Conference, Adelaide, South Australia, 28–30 November 2017. [Google Scholar]
- Feick, R.; Roche, S. Understanding the Value of VGI. In Crowdsourcing Geographic Knowledge; Sui, D., Elwood, S., Goodchild, M., Eds.; Springer: Dordrecht, The Netherlands, 2013; pp. 15–29. [Google Scholar]
- Solymosi, R.; Bowers, K.J.; Fujiyama, T. Crowdsourcing Subjective Perceptions of Neighbourhood Disorder: Interpreting Bias in Open Data. Br. J. Criminol. 2017, 58, 944–967. [Google Scholar] [CrossRef]
- Ton, D.; Duives, D.; Cats, O.; Hoogendoorn, S. Evaluating a data-driven approach for choice set identification using GPS bicycle route choice data from Amsterdam. Travel Behav. Soc. 2018, 13, 105–117. [Google Scholar] [CrossRef]
- Sun, Y.; Mobasheri, A. Utilizing Crowdsourced Data for Studies of Cycling and Air Pollution Exposure: A Case Study Using Strava Data. Int. J. Environ. Res. Public Health 2017, 14, 274. [Google Scholar] [CrossRef]
- Maricopa Association of Governments. MAG Bike Counts Initiative 2016. Available online: azmag.gov/Portals/0/Documents/BaP_2014-09-16_Item-07_MAG-Bicycles-Count-Project-Presentation.pdf?ver=2017-04-06-110803 (accessed on 6 April 2017).
- US Census Bureau Geography. Cartographic Boundary Shapefiles—Counties. 1 September 2012. Available online: https://www.census.gov/geo/maps-data/data/cbf/cbf_counties.html (accessed on 6 April 2018).
- City of Tempe. Tempe Transportation Master Plan. 2015. Available online: http://www.tempe.gov/home/showdocument?id=30317 (accessed on 20 April 2018).
- Saelens, B.E.; Sallis, J.F.; Frank, L.D. Environmental correlates of walking and cycling: Findings from the transportation, urban design, and planning literatures. Ann. Behav. Med. 2003, 25, 80–91. [Google Scholar] [CrossRef]
- Moudon, A.V.; Lee, C.; Cheadle, A.D.; Collier, C.W.; Johnson, D.; Schmid, T.L.; Weather, R.D. Cycling and the built environment, a US perspective. Transp. Res. Part D Transp. Environ. 2005, 10, 245–261. [Google Scholar] [CrossRef]
- Winters, M.; Teschke, K.; Grant, M.; Setton, E.M.; Brauer, M. How far out of the way will we travel?: Built environment influences on route selection for bicycle and car travel. Transp. Res. Rec. J. Transp. Res. Board 2010, 2190, 1–10. [Google Scholar] [CrossRef]
- Sallis, J.F.; Conway, T.L.; Dillon, L.I.; Frank, L.D.; Adams, M.A.; Cain, K.L.; Saelens, B.E. Environmental and Demographic Correlates of Bicycling. Prev. Med. 2013, 57, 456–460. [Google Scholar] [CrossRef]
- Nehme, E.K.; Pérez, A.; Ranjit, N.; Amick, B.C., III; Kohl, H.W., III. Sociodemographic factors, population density, and bicycling for transportation in the United States. J. Phys. Act. Health 2016, 13, 36–43. [Google Scholar] [CrossRef]
- Hankey, S.; Lindsey, G.; Wang, X.; Borah, J.; Hoff, K.; Utecht, B.; Xu, Z. Estimating use of non-motorized infrastructure: Models of bicycle and pedestrian traffic in Minneapolis, MN. Landsc. Urban Plan. 2012, 107, 307–316. [Google Scholar] [CrossRef]
- Plaut, P.O. Non-motorized commuting in the US. Transp. Res. Part D Transp. Environ. 2005, 10, 347–356. [Google Scholar] [CrossRef]
- Sallis, J.F.; Saelens, B.E.; Frank, L.D.; Conway, T.L.; Slymen, D.J.; Cain, K.L.; Chapman, J.E.; Kerr, J. Neighborhood Built Environment and Income: Examining Multiple Health Outcomes. Soc. Sci. Med. 2009, 68, 1285–1293. [Google Scholar] [CrossRef]
- Strauss, J.; Miranda-Moreno, L.F. Spatial modeling of bicycle activity at signalized intersections. J. Transp. Land Use 2013, 6, 47. [Google Scholar] [CrossRef]
- Piatkowski, D.P.; Marshall, W.E. Not all prospective bicyclists are created equal: The role of attitudes, socio-demographics, and the built environment in bicycle commuting. Travel Behav. Soc. 2015, 2, 166–173. [Google Scholar] [CrossRef]
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.E.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.B.; Grout, J.; Corlay, S.; et al. Jupyter Notebooks—A publishing format for reproducible computational workflows. In Positioning and Power in Academic Publishing: Players, Agents and Agendas; IOS Press: Amsterdam, The Netherlands, 2016; pp. 87–90. [Google Scholar]
- Python Software Foundation. Python Language Reference, Version 3.5. Available online: http://www.python.org (accessed on 31 May 2019).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. Available online: http://www.R-project.org (accessed on 31 May 2019).
- McKinney, W. Python for Data Analysis: Data Wrangling with Pandas, NumPy, and Ipython; O’Reilly Media Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Crawley, M.J. Statistics: An Introduction Using R; Wiley: Hoboken, NJ, USA, 2005; ISBN 0 470.02298. [Google Scholar]
- Jordahl, K. GeoPandas: Python Tools for Geographic Data. Geopandas, 2014. Available online: https://github.com/geopandas/geopandas (accessed on 31 May 2019).
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Meinshausen, N.; Bühlmann, P. Stability selection. J. R. Stat. Soc. Ser. B (Methodol.) 2010, 72, 417–473. [Google Scholar] [CrossRef]
- Dobson, A.J.; Barnett, A.G. An Introduction to Generalized Linear Models; CRC Press: Boca Raton, FL, USA, 2008; ISBN 9781138741515. [Google Scholar]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence (IJCAI’95), Montreal, QC, Canada, 20–25 August 1995; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1995; Volume 2. [Google Scholar]
- Hamann, C.; Peek-Asa, C. On-road bicycle facilities and bicycle crashes in Iowa, 2007–2010. Accid. Anal. Prev. 2013, 56, 103–109. [Google Scholar] [CrossRef]
- Fithian, W.; Elith, J.; Hastie, T.; Keith, D.A. Bias correction in species distribution models: pooling survey and collection data for multiple species. Methods Ecol. Evol. 2015, 6, 424–438. [Google Scholar] [CrossRef]
- Huang, L.; Stinchcomb, D.G.; Pickle, L.W.; Dill, J.; Berrigan, D. Identifying Clusters of Active Transportation Using Spatial Scan Statistics. Am. J. Prev. Med. 2009, 37, 157–166. [Google Scholar] [CrossRef][Green Version]
- Reis, R.S.; Hino, A.A.; Parra, D.C.; Hallal, P.C.; Brownson, R.C.; Hino, A.A. Bicycling and Walking for Transportation in Three Brazilian Cities. Am. J. Prev. Med. 2013, 44, e9–e17. [Google Scholar] [CrossRef]
- Chen, P.; Shen, Q. Built environment effects on cyclist injury severity in automobile-involved bicycle crashes. Anal. Prev. 2016, 86, 239–246. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Measure | Source | Year | Resolution | Relevance |
|---|---|---|---|---|---|
| Crowdsourced Fitness App | Bicyclist count across street segments grouped by location and timestamp | Strava Metro | 2016 | Street Segment | Crowdsourced cycling data help predict categories of cycling volumes in urban environments [15,20]. |
| Built Environment |
|
| 2016 | Street Segment | Built environment has a significant influence on active transportation choices [1,18,30,31]. Improving traffic promotes bicycling [32]. |
| Demographics |
| Maricopa Association of Governments Open Data Portal | 2010 | AZ Census Block Group | Densely populated areas have higher number of cyclists [33,34]. Ethnicity variations affect bicycle ridership levels [35]. |
| Land Use Mix |
| Maricopa Association of Governments Land Use Data | 2016 | Street Segment | Nearness to residential areas and green open spaces has shown positive associations with an increase in physical activity [1,36]. |
| Socio-Economic |
| Maricopa Association of Governments Open Data Portal | 2010 | AZ Census Block Group | Areas with lower income levels tend to bike more [10,37,38]. |
| Commute Patterns |
| Maricopa Association of Governments Open Data Portal | 2010 | AZ Census Block Group | Frequent bicycle commuters are more likely to have a higher level of education [39]. |
| Covariates | LASSO Scores |
|---|---|
| Distance to residential areas | 1.00 |
| Distance to green spaces | 1.00 |
| % white population | 1.00 |
| Median household income | 1.00 |
| Average segment speed limit | 0.98 |
| Strava counts | 0.96 |
| Average daily traffic volume | 0.59 |
| % veterans population | 0.43 |
| Population density | 0.4 |
| % population who commute with bicycles | 0.05 |
| Distance to commercial areas | 0.02 |
| Median age | 0 |
| % Population with at least high school education | 0 |
| Count month | 0 |
| Count day | 0 |
| Dependent Variable: AADB Counts from MAG | |||||
|---|---|---|---|---|---|
| Explanatory Variables () | Estimate(log) () | Std. Error | p-Value | 95% CI | |
| Lower | Upper | ||||
| Strava counts | 0.17 | 0.01 | <0.001 | 0.15 | 0.18 |
| Average segment speed limit | −0.09 | 0.01 | <0.001 | −0.11 | −0.08 |
| Distance to residential areas | −0.51 | 0.01 | <0.001 | −0.59 | −0.43 |
| Distance to green spaces | −0.74 | 0.07 | <0.001 | −0.88 | −0.59 |
| Median household income | −0.09 | 0.01 | <0.001 | −0.01 | −0.08 |
| % white residents | 0.11 | 0.01 | <0.001 | 0.09 | 0.14 |
| Intercept | 3.78 | 0.08 | <0.001 | 3.63 | 3.92 |
| Variables () | Scale (per unit) | Change Factor () | Change in Observed Bicyclist Counts (y) (all other Variables Held Constant at Their Mean) |
|---|---|---|---|
| Intercept | - | 43 | - |
| Strava riders | 1 rider | 1.18 | 18% increase |
| Distance to residential areas | 1 mile | 0.6 | 40% decrease |
| Distance to green spaces | 1 mile | 0.48 | 52% decrease |
| Average segment speed limit | 10 mph | 0.91 | 9% decrease |
| Median household income | $10,000 | 0.91 | 9% decrease |
| % white population | 10% | 1.12 | 12% increase |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roy, A.; Nelson, T.A.; Fotheringham, A.S.; Winters, M. Correcting Bias in Crowdsourced Data to Map Bicycle Ridership of All Bicyclists. Urban Sci. 2019, 3, 62. https://doi.org/10.3390/urbansci3020062
Roy A, Nelson TA, Fotheringham AS, Winters M. Correcting Bias in Crowdsourced Data to Map Bicycle Ridership of All Bicyclists. Urban Science. 2019; 3(2):62. https://doi.org/10.3390/urbansci3020062
Chicago/Turabian StyleRoy, Avipsa, Trisalyn A. Nelson, A. Stewart Fotheringham, and Meghan Winters. 2019. "Correcting Bias in Crowdsourced Data to Map Bicycle Ridership of All Bicyclists" Urban Science 3, no. 2: 62. https://doi.org/10.3390/urbansci3020062
APA StyleRoy, A., Nelson, T. A., Fotheringham, A. S., & Winters, M. (2019). Correcting Bias in Crowdsourced Data to Map Bicycle Ridership of All Bicyclists. Urban Science, 3(2), 62. https://doi.org/10.3390/urbansci3020062