1. Introduction
Volunteered geographic information (VGI) has expanded rapidly in recent years [
1]. Defined by Elwood et al., as “geographic information acquired and made available to others through the voluntary activity of individuals or groups” [
2], (p. 575), VGI is an outgrowth of recent technological trends. The early twenty-first century proliferation of Web-based collaborative and social media tools has yielded new opportunities for research. Recent Web 2.0 applications enable participants to take advantage of locative technologies such as global positioning systems to generate their own georeferenced content and data. A number of recent innovative projects have emerged to leverage participation in user-generated content to develop datasets that are reliable and accurate enough to support knowledge development and potentially serve as a tool to influence public policy decision-making processes [
3]. As an example of this movement, Web-based VGI applications that provide a collaborative platform for crowdsourced urban tree inventories have been launched in a number of American cities through partnership efforts between government entities, nonprofits, and businesses. These Web 2.0 technologies that allow user-generated content, use by non-experts, and interoperability present significant opportunities for citizens and policy practitioners to engage in collaborative data gathering activities, and the availability of data has spurred innovative new research [
2]. This paper examines the spatial distribution of tree mapping efforts and the richness of data contributed to VGI urban tree mapping applications in two study areas, Philadelphia, Pennsylvania and San Francisco, California, USA. This research contributes to recent interest in the implications of the democratization of data-gathering operations, and the use of data-driven computational approaches to influence policy decisions [
4,
5]. We specifically address how interpretations of urban forestry analysis and ecosystem services calculations may help to shape decision-making processes and approaches to community engagement, especially surrounding urban environmental amenities, and ultimately improve the environmental and social conditions of urban residents. Equity concerns ground the paper, as both unequal participation in and representation by urban forest VGI represent digital divide issues [
2], and given the many benefits provided by urban forests, if uneven representation results in uneven management, environmental injustice can ensue.
As a pressing matter of public policy, asymmetries in Internet access and the adoption of digital technology have been known for quite some time, and recent work suggests that, perhaps counterintuitively, significant portions of the urban population do not utilize the Internet at all, let alone Web 2.0 technologies. Broadband adoption (and therefore broadband use) is strongly correlated with socioeconomic markers and clusters of poverty [
6,
7], such as race, ethnicity, education, age, and income [
8,
9,
10,
11,
12]. Studies on the persistent inequality in broadband adoption serve as the motivation for policy interventions such as the federal broadband initiatives of the Obama Presidential Administration.
A prevailing assumption in any data model centered on public inputs is that the public be in a position to provide them. An increase in data availability has the potential to improve upon traditional sources of geographic information [
2,
13] and increase equitable participation [
14]; however, some caveats have been offered. In addition to issues raised about factors of data input, including the validity of crowdsourced data [
2,
15,
16,
17], a growing body of literature addresses the potential digital divide surrounding VGI technology [
1,
2,
14,
16,
18], and similar concerns have emerged about the challenges inherent in the adoption of VGI by policymakers [
19]. We expand previous theoretical explorations of the considerations influencing the quality and usefulness of VGI data for policymakers by empirically addressing potential information asymmetries in crowdsourced urban spatial data.
This paper is concerned with a specific example of VGI, namely local efforts at mapping urban forests in two major cities. A crucial aspect of evaluating VGI is their accuracy. How and whether VGI comport to reality is, of course, an important concern in their future. This paper leaves aside the question of whether VGI are providing an accurate representation of existing urban forests, and instead focuses on where and how VGI is collected. We assess the observations made by volunteers in order to probe where these observations are made and under what local conditions. For instance, to what extent do the physical attributes of place influence whether or not data are collected and therefore greater numbers of trees are mapped? In addition, in the case of tree maps, much of the information comes from anonymous, private contributors. Little can be said about the motivations of participants. That said, trees are rooted, as it were, in place. So it is possible to assess whether trees are more likely to be mapped in areas with varying sociodemographic characteristics. Our starting points, then, are the point locations of trees, how many of these are voluntarily provided to publicly accessible data gathering sites by various unknown private users, and where the highest concentrations of detailed data about species, size, and condition are located.
The paper begins by presenting an overview of tree point data in both study areas, then assesses whether sociodemographic and environmental indicators predict characteristics of data richness and densities of attributed trees. The results are used to explore theoretical challenges in the design of geotechnology applications, potential causes in discrepancies in the process of data gathering, and interpret quantitative modeling of urban environments. Given that one of the intended purposes of VGI tree applications is to influence decision-making processes surrounding urban environmental amenities, the conclusion discusses the potential for VGI to influence place-based policy decisions.
2. Literature Review: VGI, Planning, and Urban Forests
Along with the exponential growth in academic research on VGI, practicing planners and public officials have become interested in the potential to use VGI tools in attempts to make planning more participatory [
3,
20,
21,
22,
23], reflecting earlier and continuing interests in public participation geographic information systems (GIS) (PPGIS) [
22,
23]. The hopes and concerns surrounding VGI in the planning community are similar to those presented in academic discourse. Planners recognize that official data often does not include information about marginalized citizens and neighborhoods, resulting in their needs not being considered when making urban policy deliberations [
4]. VGI is seen as a potential remedy to this issue, but there remain concerns surrounding the barriers to participation in VGI creation that may result in further exclusion [
4,
5,
22,
24,
25].
The use of VGI applications to analyze the distribution of trees in urban areas by policy practitioners would rely upon both coverage of trees and richness of data to inform decision-making processes. Where tree representation is plentiful and data are rich, policy practitioners could take a greater interest in these areas [
1], so VGI has the potential to perpetuate and contribute to existing inequalities in investment of public funds and resources. In the example of Philly TreeMap, where empty tree pits are plotted separately, representation of tree pits may facilitate interest in future tree plantings. Furthermore, data on problem/hazardous trees, tree pests, and diseases potentially contribute to better tree management and care. On the other hand, policy practitioners’ inability to assess urban tree coverage in areas where representation is lacking could contribute to less urban greening activity and reduced quality of tree care in these neighborhoods. In both cities, the VGI tree mapping efforts focus upon street and park trees that are publicly managed. These concerns over uneven coverage and data richness influencing management decisions raise environmental justice concerns, given the many social and ecological benefits of urban forests.
Akin to issues in participatory planning at large, there remain questions as to the level that which VGI would be considered by actual decision-makers [
20,
21,
24]. Johnson and Seiber [
19] identify cost of the technology, questionable accuracy, and formality of non-expert data, and jurisdictional issues as three considerations for local governments to take into account. Despite these concerns, successful pilot studies of VGI as a participatory planning tool have been conducted in Finland, Norway [
20], and Ecuador [
21]. VGI urban forest inventories represent one of the many ways in which the technology could be used as a participatory planning tool in the United States.
The San Francisco Urban Forest Map [
26] is an interactive Web-based map database of trees in San Francisco. The mission of the Urban Forest Map is “to build technology that improves information sharing, communicates the value of the urban forest, and engages communities in creating greener, more livable urban environments [
26]”. Implemented by Autodesk, Inc. (San Rafael, CA, USA), in May 2007, in partnership with local government entities and nonprofits, the project sets the ambitious goal of mapping every tree in San Francisco. After creating free accounts, users are able to enter and modify trees as points on a map with species, condition and planting site information. The option of modifying the contributions of other users, similar to Wikipedia, helps to lend validity to the contributions. The site allows for estimations of the monetary values of the environmental benefits of trees in terms of storm water retention and filtration, air pollution reduction, energy conservation and carbon dioxide removed from the atmosphere. PhillyTreeMap [
27] was launched in 2010 by Azavea, a Philadelphia-based software design and development firm, with funding from the United States Department of Agriculture (USDA). PhillyTreeMap has similar properties to the San Francisco Urban Forest Map, along with similar goals in documenting the City’s urban forest and publicizing the suite of benefits it offers. Both cities’ VGI tree maps now utilize Azavea’s Opentreemap software, along with more than thirty other cities, counties, and states, largely in the United States and Canada.
According to the San Francisco Urban Forest Map, the data gathered by the application can be used to help urban foresters to better manage trees, allow climatologists to study the effects of urban forests on climates, and allow researchers to learn about the role of trees in urban ecosystems, building upon previous analyses of San Francisco’s urban forest [
28]. Previous analyses of Philadelphia’s urban forest have been based on sampling performed in 1996 [
29] and using remotely sensed imagery to describe tree canopy cover [
30]. Although both of these methods are valuable to urban forest managers, VGI has the potential to improve urban forest managers’ ability to make informed decisions to maximize benefits and evaluate programs and policies by increasing the amount of available information [
31]. This is essential because, like many other cities, Philadelphia and San Francisco are pursuing aggressive tree planting campaigns.
3. Materials and Methods
3.1. Study Areas
The City and County of Philadelphia share boundaries, with a population of 1,560,297 residents, making it the largest city in Pennsylvania [
32]. In the mid- to late-twentieth century, Philadelphia experienced decline and abandonment when, in the wake of deindustrialization and other economic and social changes, businesses and middle class residents moved from urban areas to suburban locales. As a result, the city experienced an erosion of the tax base [
33]. While the trend of population loss has more recently reversed, the legacy of these processes is seen in the high concentrations of poverty in in the urban core of the city, and a high degree of economic inequality across the greater metropolitan area [
32,
34]. Philadelphia County is also racially diverse, with an African American population of approximately 44 percent, compared to the state of Pennsylvania average of 11 percent; and a Hispanic population of approximately 13 percent, compared to a state average of nearly 6 percent. Non-Hispanic whites make up approximately 37 percent of the population of Philadelphia County [
32]. The most recent estimate of Philadelphia’s urban forest using high resolution remotely sensed imagery found that 20 percent of the City was covered by tree canopy [
30].
The City and County of San Francisco share boundaries, with a population of 825,863 residents [
32]. Demographically, the area is very different to Philadelphia, with a much more affluent population (median household income (all values in US Dollars) of
$72,947 compared to
$36,947 in Philadelphia in 2012) and a higher level of educational attainment (51.4 percent of residents above the age of 25 with a bachelor’s degree or higher, compared to 22.6 percent in Philadelphia in 2012). While San Francisco is also racially diverse, the diversity is distributed differently in a large Asian population (32.6 percent), compared to the large African American population in Philadelphia. The demise of industry and waves of suburbanization also greatly reduced the population of San Francisco from the 1950s onward, but this trend reversed beginning in 1980, and San Francisco together with New York, formed the only two major American cities that had rebounded to their historic 1950 population levels by 2000 [
35]. This demographic and economic growth was spurred by San Francisco’s place at the leading edge of information technology and creativity, evidenced by its number one ranking in Richard Florida’s first creativity index [
35]. “The City” is also home to several participatory urban planning digital applications [
3] that might make residents more comfortable with urban forest VGI technologies. The most recent estimate of San Francisco’s urban forest using sampling plots found that 11.9 percent of the city was covered by tree canopy [
28].
These differences make Philadelphia and San Francisco compelling case studies for comparison. Namely, San Francisco County is fairly affluent and potentially not representative of the diversity found in the greater Bay Area. On the other hand, many parts of Philadelphia County are far less affluent, and more racially and ethnically diverse than the surrounding counties in the metropolitan area. Within the larger economy-wide changes over the latter half of the twentieth century that have shaped urban physical landscapes and human livelihoods—including the transition from manufacturing to a more high-tech economy that is focused on professional services [
36]—the two cities have fared differently. Philadelphia has a history of industrial decline, and now is working towards renewal, with higher education, healthcare and biotechnology, telecommunications, and financial services emerging as top industries. Contrarily, while San Francisco was also subject to these same economy-wide changes, proximity to Silicon Valley and emphasis on innovation and technology ventures has allowed the economy to revitalize much faster than in the case of Philadelphia.
3.2. Data
This analysis includes several types of data from multiple sources. Most important were the tree map data for both study locations, which was downloaded on October 2013. Other than the point location of the trees entered into the websites, several other important pieces of information were included in this dataset. The first of these was the contributor of the data point for each tree, which was used to determine the trees entered by individuals (considered VGI trees) and those entered by organizations such as city government agencies or urban forest groups (considered authoritative data and not VGI). Second, the different pieces of additional information entered for each tree (species, diameter at breast height, height, canopy height, condition, pit width, pit length, type of pit, canopy condition, presence or absence of power lines, presence or absence of sidewalk damage, additional comments, and photos) could assist in management of the trees for which they were provided. They were used here to create an index of the total number of additional data points per tree which was averaged to give a measure of data richness at the block group level for both all trees and VGI trees. It is important to note that the representation of VGI trees and the associated attributes do not necessarily mean that local residents were involved in data collection. While the trees entered by municipal agencies and community groups were removed from analysis, there are still no assurances that the individual names associated with VGI trees belong to those who live nearby. Unfortunately, the websites do not provide information on how the VGI data were collected, raising the possibility that organized mapping events and other citizen science strategies such as “bioblitzes” are driving the distribution of urban forest VGI. While we cannot be sure about where contributors come from, we can be sure of the locations that are represented, and for that reason we compare demographic and environmental variables to VGI data density and richness to assess the evenness of representation.
Demographic data and boundaries were downloaded from the 2010 United States Census. The choice of demographic variables for analysis is based on an existing precedent in environmental justice and similar equity examinations, especially those regarding urban forest distribution and the digital divide that have found race and class to be strong predictors of urban form and function [
5,
37,
38]. It includes: income (median household income), education (percentage of the population age 25 or above with a high school diploma), age (percentage of population over age 65), and ethnicity (percentage of African American, Latino, and Asian residents).
Environmental variables were also included in the model as predictors of VGI tree locations. The most important of these environmental variables is the estimation of tree canopy from high resolution remotely-sensed data for both locations, a 1-m land cover raster derived from Light Detection and Ranging (LiDAR) data [
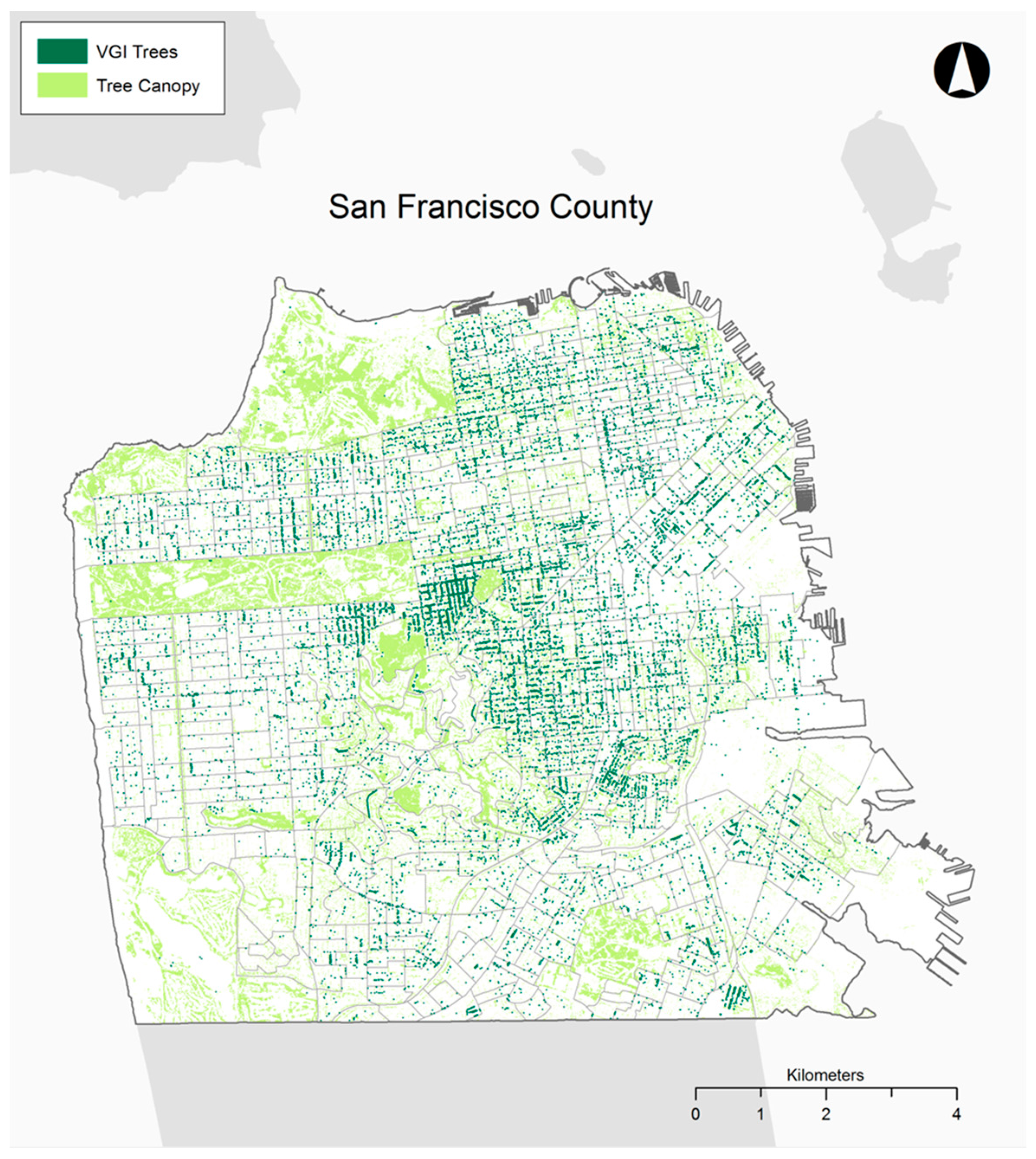
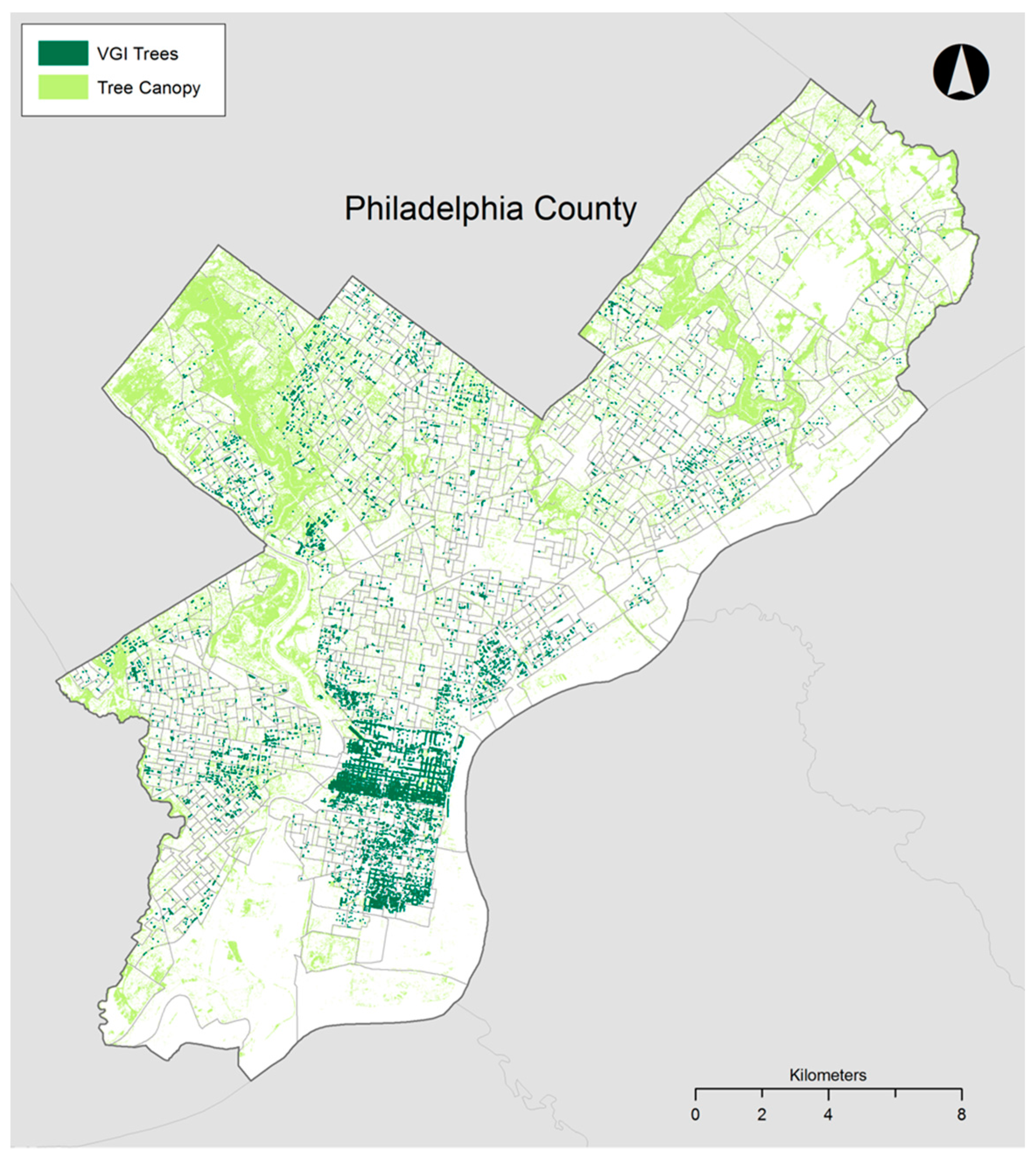
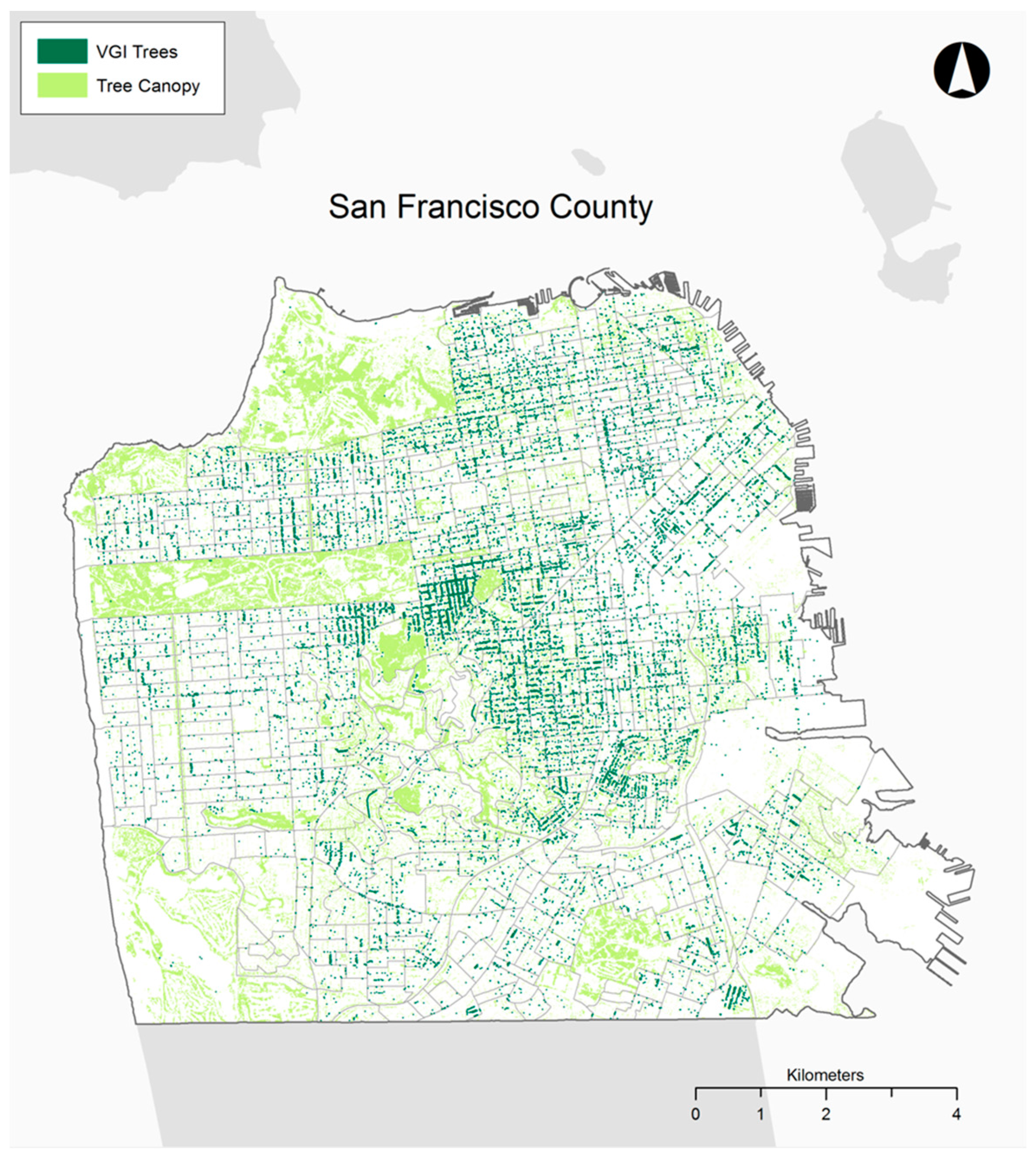
30] for Philadelphia in 2008, and a combination of 3-m, 1-meter, and 15.24-cm tree canopy rasters from 2010 derived from LiDAR data and aerial photography for San Francisco (unfortunately the data set does not include the percentage of coverage from each data source). Including the percentage of tree canopy per block group as an explanatory variable helps to remove the possibility that there are simply more VGI trees where there are more physical trees. This tree canopy coverage data, overlaid with the tree points downloaded from each location’s urban forest map, are shown in
Figure 1 and
Figure 2, for Philadelphia and San Francisco, respectively. Building footprint data were also obtained from the County Planning Department for both study sites (2007 data for Philadelphia and 2010 data for San Francisco) as an environmental variable, yielding the highest building elevation per block group. The two measures provide a control for density of local urban forests and for the density of the surrounding urban fabric. Other environmental variables such as mean slope, percent impervious surface cover, and population density were considered, but in line with previous research [
38,
39,
40], they were found to be highly correlated with the percentage of tree canopy and for this reason were not included in the analysis.
3.3. Methods
This paper assessed whether asymmetries exist in data gathered through participatory urban forest mapping. These effects are modeled in two ways. Firstly, using the point data for trees mapped through the efforts described above, VGI trees are modeled in Philadelphia and San Francisco. The points are aggregated to counts by United States Census Block Groups, which are the finest level of spatial aggregation to which the measures we use are available. These models provide a gauge of data density. Secondly, we assess whether there are asymmetries in data richness, measured by the number of attributes entered for each tree, aggregated to a mean index of data richness for VGI trees (VGI tree index) in each block group.
Our question is whether physical, environmental, and sociodemographic measures might predict where VGI trees are contributed and/or the richness of data contributions (the VGI tree index). Overall, the assumptions follow the aforementioned literature on technological adoption discussed in the introduction. Specifically, the hypotheses are: trees will be better represented in areas that are relatively affluent (using median household income as a measure), elderly residents (measured in percentage of residents over 65 years old) and lower educational levels (measured as percentage of block group residents over 25 without high a school diploma) will be negatively correlated with our measures of VGI data density and richness, and the percentage of minority racial and ethnic status (specifically of Latino, African American, and Asian populations) will have negative relationships with our dependent variables as well. The local density of the urban forest is controlled for (by including the percentage tree canopy by block group), which is hypothesized to have a positive effect on the density of volunteered tree observations. We also control for the density of local urban fabric by including maximum building height as a proxy measure, where a negative relationship with the density of urban forest VGI is hypothesized. Finally, the block groups comprising the major parks in each study location were omitted from the analyses, as these block groups contain a high percentage of tree canopy that is not intended as the target for VGI tree mapping efforts, which instead focus upon street trees. Removing major parks resulted in 1333 and 578 block groups in the analysis for Philadelphia and San Francisco, respectively.
As is often the case with count data, the distribution of tree counts in both cities, and the derivative measures calculated from them, were found to be dramatically skewed, with false truncations at zero [
41]. Typically count data have this pattern for which linear regression techniques are not generally viable options for examining correlations between these distributions and demographic and environmental neighborhood characteristics [
42]. The two cities were not entirely similar, however. In Philadelphia, general linear models were fit using Poisson distribution with log link, treating the different dependent variables (count of VGI trees and average VGI tree index) as count data. The independent variables (median household income, percentage of residents over 65 years old, percentage of residents over 25 without a high school diploma, percentage of Latino, African American and Asian residents, percentage tree canopy, and maximum building height) were also distributed in a non-normal fashion, requiring square root transformations to make them suitable for inclusion in regression analyses.
In San Francisco, the counts of VGI trees were modeled as above, fitting the data based on log-linked Poisson distributions using general linear models. The VGI tree index’s distribution was less skewed when root squared, allowing for ordinary least squares (OLS) regression analysis to be performed.
Given the spatial nature of the data analyzed, the independence of observations and error terms in the four regression models presented a concern. The spatial clustering expressed in Tobler’s first law of geography, where increased proximity leads to increased relatedness [
43], could lead to incorrect interpretations of model outcomes. Due to these concerns, tests were performed to detect spatial autocorrelation using the queen contiguity-based method to define the spatial weights matrix. The Moran’s I statistic revealed the presence of statistically significant positive spatial autocorrelation in three of four models, with the exception being the VGI tree index for San Francisco. This led to the construction of spatial autoregressive (SAR) models. Spatial error and spatial lag models are the two main options for incorporating spatial autocorrelation into regression equations [
37,
43,
44]. Spatial error models associate the autocorrelation with the error term, while spatial lag models associate it with the dependent variable. The choice between models was based upon the robust Lagrange multiplier statistic [
43], which was higher for the spatial lag in the three regression models exhibiting spatial autocorrelation issues, leading to its use here.
4. Results
The VGI data density and richness measures developed are shown in
Table 1. As of October 2013, the Phillytreemap dataset contained 56,406 trees, of which 2947 were considered VGI trees. The VGI tree index was higher for all trees than VGI trees (1.6 compared to 1.4). Out of 1333 block groups, 1031 had a tree entered and 680 had a VGI tree. This helps to explain the average percentage of all trees that were VGI trees of 23.3 at the block group level.
At the same time, the San Francisco Open Tree Map consisted of 88,121 trees, of which 24,376 were considered VGI trees. The VGI tree index was higher for all trees than VGI trees (2.2 compared to 1.8). Out of 578 block groups, only three contained no trees and only eight contained no VGI trees. The mean percentage of VGI trees at the block group level was 31.8.
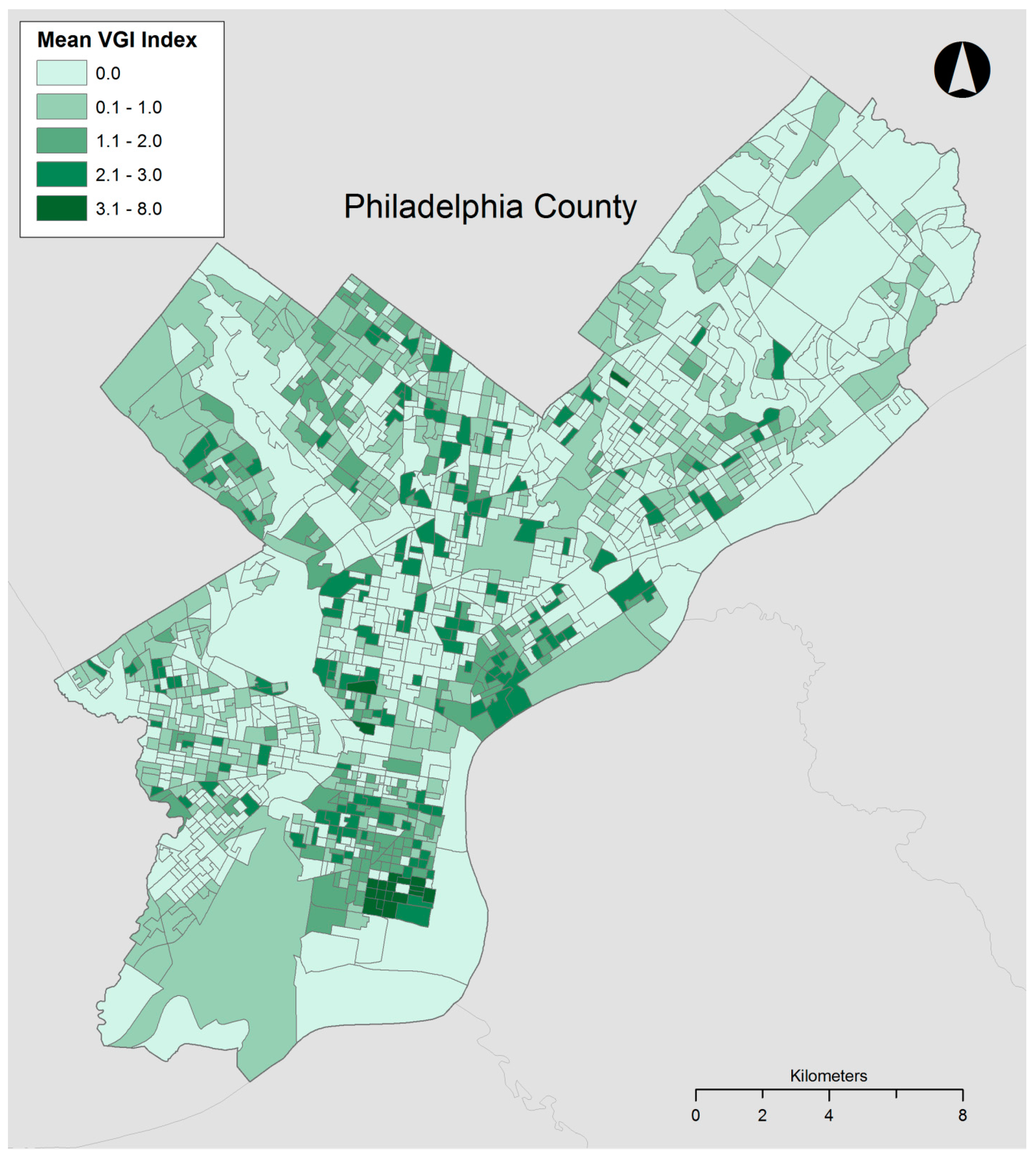
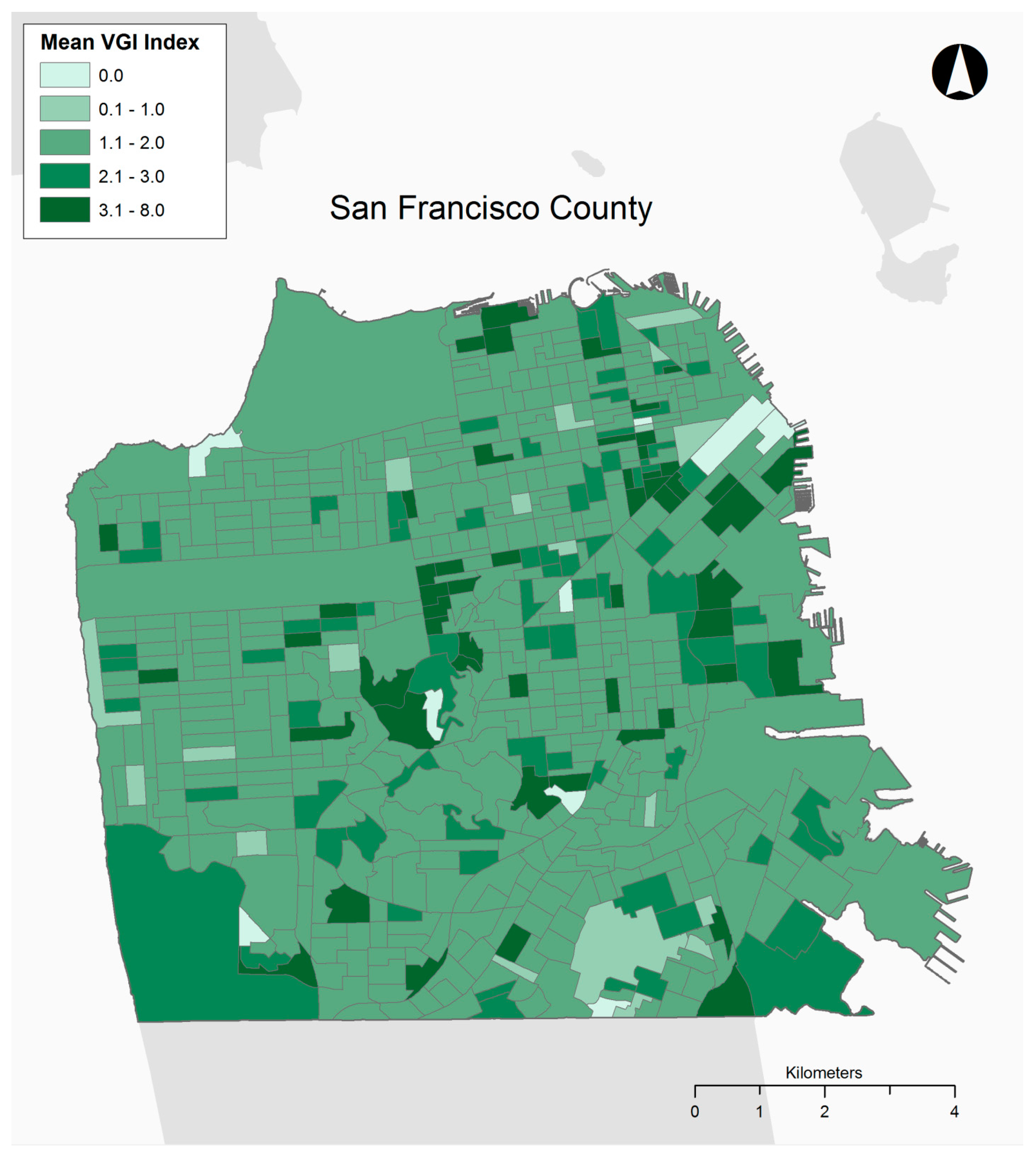
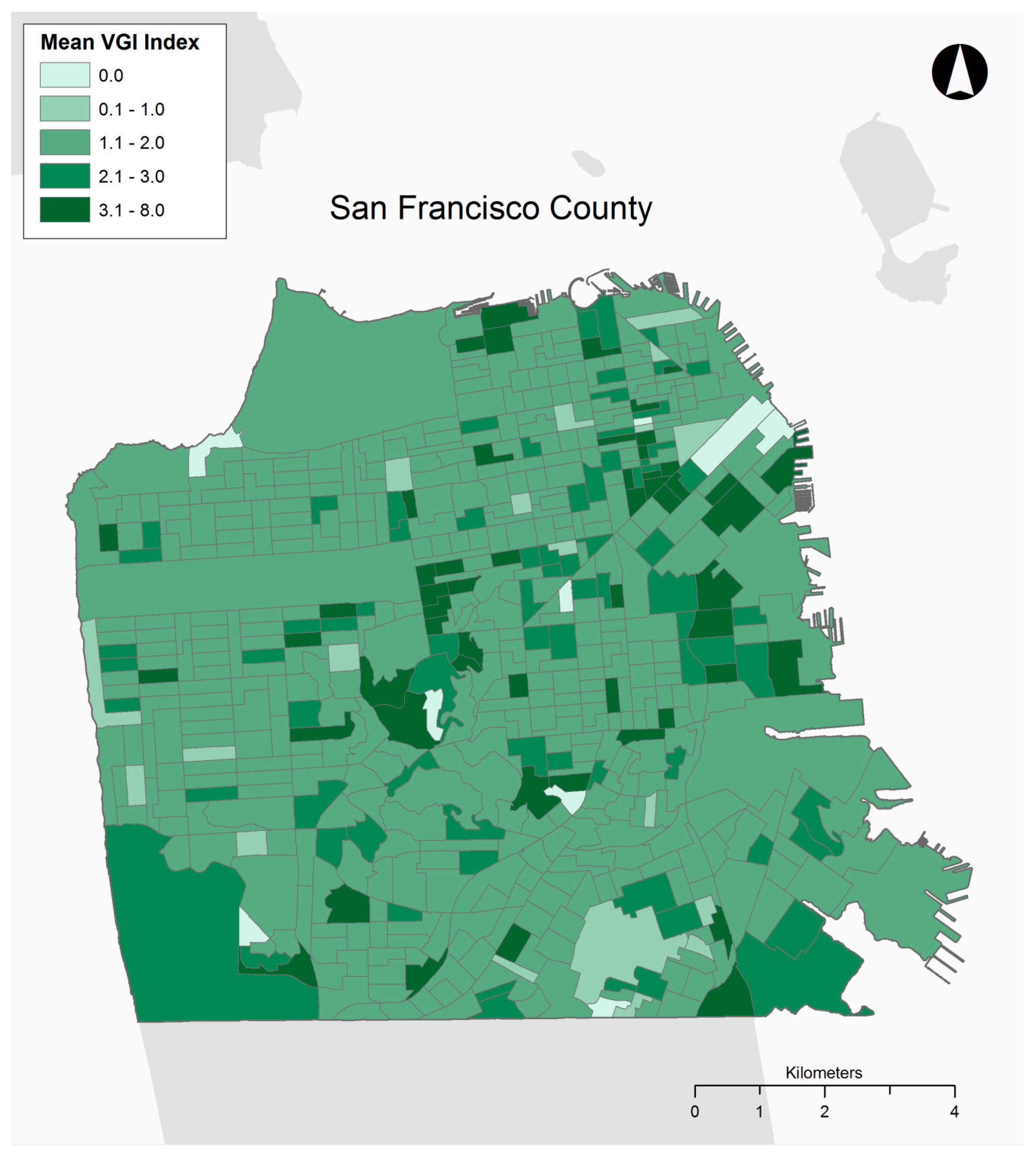
The raw numbers for the two study sites reveal disparities between the amount and type of contributions to each tree mapping website. San Francisco has a greater number of total trees and proportion of trees considered to be VGI contributed by citizens. The VGI tree index was greater for both all trees and VGI trees alone, revealing that San Francisco residents entered more trees and more information about them. This could be the result of the San Francisco website being active for three years longer than Philadelphia’s or it might be explained by other factors such as the level of promotion of the websites or preferences for urban trees. Finally, as shown in
Figure 3 and
Figure 4, representing the average VGI tree index per block group for Philadelphia and San Francisco, the data richness measure was also clustered spatially, suggesting that neighborhoods are contributing data differently in both locations.
The descriptive statistics for the explanatory variables in both locations are shown in
Table 2. The differences highlighted between the two cities previously are evidenced by the differences in income, education and ethnicity between them. Philadelphia’s tree canopy, at the block group level, was 3.5 percent greater than San Francisco’s, which serves to invalidate the concern that more trees were entered in San Francisco simply due to a greater number of trees. The greater variances in the percentage of African American and Latino residents in Philadelphia and Asian residents in San Francisco suggest that these demographic characteristics have bimodal distributions, evidencing a high level of spatial segregation.
The results from the Poisson regressions in Philadelphia are shown in
Table 3. First, all of the models were highly statistically significant, with extremely high chi squares. As the independent variables have all undergone square root transformations to approach normality, the following discussion will focus upon the signs that they carried in the regression rather than their magnitude. All of the explanatory variables were significant at the
p < 0.01 level for both models. The model explaining the count of VGI trees per block group showed mostly expected results, with median household income, percentage of residents over the age of 65, and maximum building elevation having positive effects. Percentage over 25 without high school diplomas, percentage of African American, Latino, and Asian residents, and tree canopy percentage all had negative effects. Finally, the model for the VGI tree index shows that median household income and percentage of residents over the age of 65 had positive effects, and percentage over 25 without high school diplomas, the percentage of Latino, African American, and Asian residents, the percentage of tree canopy, and the maximum building elevation all had negative effects.
Several patterns emerge when looking at these explanations of VGI urban forest contributions in Philadelphia. First, median household income is a positive influence in both models; Secondly, the percentage of tree canopy per block group is negative for all models, suggesting that Philadelphia residents are not necessarily documenting trees where they are more prevalent in the city. Finally, the results for the three minority population groups are negative across both models, suggesting that more trees are being contributed with greater levels of data richness in areas with fewer racialized minorities.
The results from the San Francisco regression models are shown in
Table 4, revealing that relationships between demographics and raw VGI tree count data are highly significant, with high chi-square tests. As the independent variables have all undergone square root transformations to normalize them, as was the case with the Philadelphia models above, their most salient aspects are the signs that they carried in the regression rather than their magnitudes. In the predictive model for the raw count of VGI trees, several hypothesized effects are evident. The density of observations is positively predicted by income, percent tree canopy, and density of the urban fabric. Additionally, the VGI count is negatively correlated with low levels of education, proportion of aged residents, and percent Latino. Unhypothesized effects are also present. The raw count of VGI trees is negatively correlated with percent Asian and positively correlated with percent black. The overall goodness of fit is statistically significant.
The other model analyzing predictors of VGI data richness (VGI tree index)—that was fit using OLS regression—is more ambiguous, with a very modest r2 score of 0.2. In both cases, a great deal of variance in the dependent variables is unaccounted for by the model. Beyond this, the OLS model testing data richness found more modest results. A positive relationship with income and tree canopy percentage, and a negative relationship with all three racial/ethnic categories, where the explanatory variables achieved statistical significance at p < 0.05, were revealed.
The general pattern among both models generated from the San Francisco dataset is that VGI has a strong, positive relationship with income, tree canopy, and density of the urban fabric. Quite unlike Philadelphia, percent African American is a positive predictor of VGI contributions and the richness of their data. For raw VGI counts, VGI appears to have a negative relationship with education and age, but the relationships lose their significance when predicting VGI data richness. The relationship between VGI and either percent Asian and percent Latino is ambiguous.
The results of the SAR models are shown in
Table 5. As discussed previously, all of the models with the exception of the VGI tree index for San Francisco had positive and significant test statistics for spatial autocorrelation (Moran’s I), which led to the construction of spatial lag models. In comparison with the general linear models (GLM) models, the Aikake’s information criterion decreased for all three models, suggesting that the SAR models improved results and incorrect interpretations might be drawn from examining only the GLM results. The only explanatory variable that was significant across the three models was median household income, the positive sign associated with this predictor suggests that environmental injustices may be present if more urban forest VGI data density and richness is higher in more affluent areas. The percentage of Latino residents has a statistically significant negative relationship with VGI data density in Philadelphia, once again suggesting the presence of environmental injustice. Finally, as with the GLM models, the percentage of tree canopy per block group in Philadelphia has a negative relationship with urban forest data density and richness.
5. Discussion
This research serves as an initial exploration of the potential strengths and weaknesses of VGI as a collaborative urban planning tool. Through an examination of the spatial distribution and the data richness of volunteered data generated by tree mapping efforts in Philadelphia and San Francisco, our analyses conclude that sociodemographic and environmental indicators are predictive of characteristics of both densities of attributed trees and data richness. Contributing to the recent call for research on the implications of the democratization of data gathering operations through crowdsourcing [
5], these findings suggest potential differentials in digital literacy and citizenship by neighborhood type, raising concerns about a potential digital divide in the utilization of VGI tree mapping applications.
Minorities that were more spatially segregated (African Americans and Latinos in Philadelphia, Asians in San Francisco) were less likely to have urban forest VGI contributed in their neighborhoods, raising concerns about both the accessibility of this technology and possible negative implications if it is used by policy practitioners to manage urban forests. When accounting for spatial autocorrelation, median household income was still a positive predictor of urban forest VGI data density and richness, even when controlling for urban tree canopy. Environmental justice researchers, arguing that access to amenities such as urban forests is an integral component of environmental justice along with earlier foci on hazards and disamenities, have documented the relationships between affluence, whiteness and increased urban tree canopy coverage for many years [
37,
38,
45,
46,
47]. A recent study of seven major U.S. cities (including Philadelphia) [
48] found a positive relationship between income and urban tree canopy in each city. Such results suggest that less affluent neighborhoods have fewer trees both on the ground and in VGI representations. In the extreme case, VGI has the potential to deepen rather than ameliorate differentials in place-based resources devoted to certain locales through policy decisions if neighborhoods where a large portion of trees are unrepresented are neglected due to their lack of representation in urban forest VGI datasets. The uneven representation in VGI coverage extends beyond urban forests [
1,
14,
16], and may reinforce inequalities in representation from traditional data sources, where marginalized groups and areas are not always counted [
1,
2,
4,
21,
49]. While there are concerns around privacy and surveillance by both the state and capital with the growing amount of digital traces generated through VGI and other sources [
1,
2,
17], documenting the presence and condition of urban trees seems to provide a positive increase in legibility. Despite the democratizing rhetoric around VGI and other Web 2.0 technologies [
14], this research highlights their potential to reinforce rather than break down barriers in terms of representation and potential negative urban environmental consequences.
While this research has highlighted potential strengths and weaknesses of VGI, limitations and opportunities for further research include the following. The urban forest VGI data are a rich source of often unavailable data for policy practitioners [
31], and can reduce some of the costs [
50] associated with municipal field surveys, however, the question remains as to whether they actually being used. Interviews with local governments and urban forest stewardship groups could help to answer this important question. Furthermore, qualitative research could help in understanding the usefulness of urban forest VGI to managers and practitioners, and incorporate practitioner priorities in the design of future platforms to ensure that the most important data are being collected, allowing VGI to act as a supplement or even a replacement for traditional field and remotely sensed data.
While the TreeMap data allow for the distinction between authoritative and VGI tree inputs to the websites, who is actually entering the data, and why, is not yet fully understood. Qualitative research with contributors could help in understanding the motivations behind VGI participation. In light of this limitation, future research may examine VGI longitudinally to determine what type of neighborhoods are early adopters, which lag, and what are the correlates of each. Furthermore, the differences in both data distribution and the effects of demographic and environmental factors between the two locations make clear the need to examine how and why VGI is generated differentially, rather than drawing geographic generalizations. These heterogeneous results regarding urban forest VGI which highlight the importance of local analysis are similar to those regarding London’s Open Street Map found by Haklay et al. [
51]. The many other cities that have implemented the Open Tree Map platform should be investigated to see how patterns of urban forest VGI representation vary across sites and how such spatial variations can be explained by local dynamics and histories. Additionally, designers of geotechnology applications should seek to find ways to make technology accessible and perhaps incentivize use.
Geospatial Web 2.0 applications will continue to proliferate in coming years, presenting substantial opportunities for collaborative data gathering, innovative research, and improved policymaking; however, asymmetries in the quantity and quality of the data may undermine their effectiveness. The predictors of the uneven production of the spatial data in VGI applications appear to reflect previous research on, and may be interpreted as yet another expression of, the digital divide. We hope that this initial exploration of the potential of urban forest VGI as a collaborative urban planning tool will help to increase digital citizenship, improve urban forest management, and promote awareness of this powerful new technology. To be clear, despite the concerns expressed regarding the spatial distribution of contributions to urban forest VGI maps and their richness in Philadelphia and San Francisco, this paper is not a condemnation of tree mapping websites, their creators and contributors, or VGI in general. Rather, attention is called to the need to ensure that these technologies are employed and utilized in manners that increase equality. There is great potential to increase data richness and the equity of coverage if care is taken. To borrow Eric Darier’s paraphrase of Foucault “not everything is bad, but everything is dangerous [
52] (p. 603).”



{kind=link}
{kind=link}
{kind=link}
{kind=link}